
1. Wprowadzenie
Ostatnia aktualizacja: 14.07.2022
Dostrzegalność aplikacji
Obserwacja i ciągłe profilowanie
Obserwowalność to termin używany do opisania atrybutu systemu. System z możliwością obserwacji umożliwia zespołom aktywne debugowanie systemu. W tym kontekście 3 filary dostrzegalności – logi, dane i logi czasu – są podstawowymi narzędziami do instrumentacji systemu w celu uzyskania dostrzegalności.
Oprócz 3 filarów obserwacji kolejnym kluczowym komponentem jest ciągłe profilowanie, które zwiększa liczbę użytkowników w branży. Cloud Profiler to jedna z pierwszych usług tego typu. Zapewnia ona prosty interfejs do szczegółowego analizowania danych o wydajności w stosach wywołań aplikacji.
Te ćwiczenia z programowania to część 2 serii. Omawiają one instrumentowanie agenta profilowania ciągłego. Część 1 obejmuje śledzenie rozproszone za pomocą OpenTelemetry i Cloud Trace. Dowiesz się z niej, jak lepiej identyfikować wąskie gardła mikroserwisów.
Co utworzysz
W tym ćwiczeniu skonfigurujesz agenta ciągłego programu profilującego w usłudze serwera „aplikacji Szekspira” (czyli Shakesapp), która działa w klastrze Google Kubernetes Engine. Architektura Shakesapp jest opisana poniżej:

- Narzędzie Loadgen wysyła do klienta ciąg zapytania w protokole HTTP.
- Klienci przekazują zapytanie z generatora obciążenia do serwera w gRPC.
- Serwer akceptuje zapytanie od klienta, pobiera wszystkie dzieła Szekspira w formacie tekstowym z Google Cloud Storage, wyszukuje wiersze zawierające zapytanie i zwraca klientowi numer wiersza, który pasuje do zapytania.
W części 1 stwierdziliśmy, że wąskie gardło występuje gdzieś w usłudze serwera, ale nie udało nam się ustalić dokładnej przyczyny.
Czego się nauczysz
- Jak osadzić agenta profilera
- Jak analizować wąskie gardła w Cloud Profiler
Z tych ćwiczeń z programowania dowiesz się, jak instrumentować agenta profilowania ciągłego w aplikacji.
Czego potrzebujesz
- Podstawowa znajomość języka Go
- Podstawowa znajomość Kubernetes
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform ( console.cloud.google.com) i utwórz nowy projekt.
Jeśli masz już projekt, kliknij menu wyboru projektu w lewym górnym rogu konsoli:
i w wyświetlonym oknie kliknij przycisk „NOWY PROJEKT”, aby utworzyć nowy projekt:
Jeśli nie masz jeszcze projektu, powinien wyświetlić się taki dialog, w którym możesz utworzyć pierwszy projekt:
W kolejnym oknie dialogowym tworzenia projektu możesz wpisać szczegóły nowego projektu:
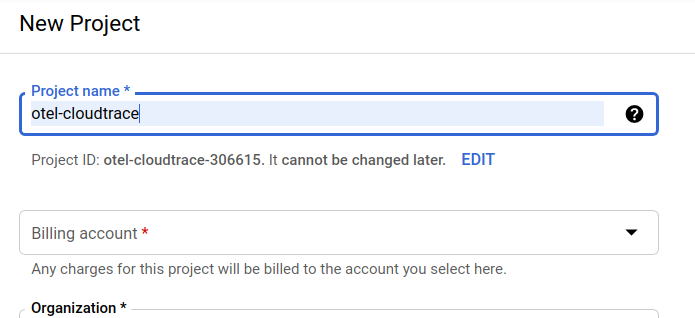
Zapamiętaj identyfikator projektu, który jest unikalną nazwą we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tych ćwiczeń z programowania będzie on nazywany PROJECT_ID.
Następnie, jeśli jeszcze tego nie zrobisz, musisz włączyć płatności w Konsoli deweloperów, aby korzystać z zasobów Google Cloud, i włączyć Cloud Trace API.
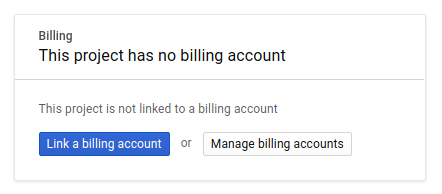
Wykonanie tego samouczka nie powinno kosztować więcej niż kilka dolarów, ale może okazać się droższe, jeśli zdecydujesz się wykorzystać więcej zasobów lub pozostawisz je uruchomione (patrz sekcja „Czyszczenie” na końcu tego dokumentu). Ceny Google Cloud Trace, Google Kubernetes Engine i Google Artifact Registry są podane w oficjalnej dokumentacji.
- Cennik pakietu operacyjnego Google Cloud | Operations Suite
- Cennik | Dokumentacja Kubernetes Engine
- Cennik Artifact Registry | Dokumentacja Artifact Registry
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD, co powinno sprawić, że ten samouczek będzie całkowicie bezpłatny.
Konfiguracja Google Cloud Shell
Z Google Cloud i Google Cloud Trace można korzystać zdalnie na laptopie, ale w tym module użyjemy Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Oznacza to, że do ukończenia tego ćwiczenia potrzebujesz tylko przeglądarki (działa ona na Chromebooku).
Aby aktywować Cloud Shell w konsoli Cloud, kliknij Aktywuj Cloud Shell  (udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).
(udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).
Po połączeniu z Cloud Shell zobaczysz, że uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu PROJECT_ID.
gcloud auth list
Wynik polecenia
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Wynik polecenia
[core] project = <PROJECT_ID>
Jeśli z jakiegoś powodu projekt nie jest ustawiony, po prostu wydaj to polecenie:
gcloud config set project <PROJECT_ID>
Szukasz urządzenia PROJECT_ID? Sprawdź, jakiego identyfikatora użyto w krokach konfiguracji, lub wyszukaj go w panelu konsoli Cloud:
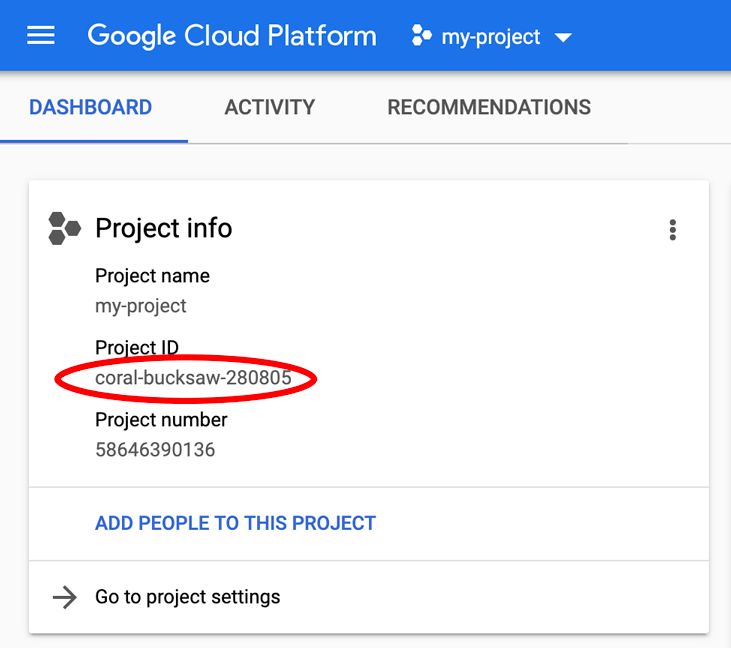
Cloud Shell domyślnie ustawia też niektóre zmienne środowiskowe, które mogą być przydatne podczas wykonywania kolejnych poleceń.
echo $GOOGLE_CLOUD_PROJECT
Wynik polecenia
<PROJECT_ID>
Na koniec ustaw domyślną strefę i konfigurację projektu.
gcloud config set compute/zone us-central1-f
Możesz wybrać różne strefy. Więcej informacji znajdziesz w artykule Regiony i strefy.
Przejdź do konfiguracji języka
W tym ćwiczeniu używamy języka Go we wszystkich kodach źródłowych. Uruchom to polecenie w Cloud Shell i sprawdź, czy wersja Go to 1.17 lub nowsza.
go version
Wynik polecenia
go version go1.18.3 linux/amd64
Konfigurowanie klastra Google Kubernetes
W tym module nauczysz się uruchamiać klaster mikroserwisów w Google Kubernetes Engine (GKE). W tym laboratorium wykonasz te czynności:
- Pobieranie projektu podstawowego do Cloud Shell
- Tworzenie mikroserwisów w kontenerach
- Przesyłanie kontenerów do Google Artifact Registry (GAR)
- Wdrażanie kontenerów w GKE
- Modyfikowanie kodu źródłowego usług na potrzeby instrumentacji śledzenia
- Przejdź do kroku 2
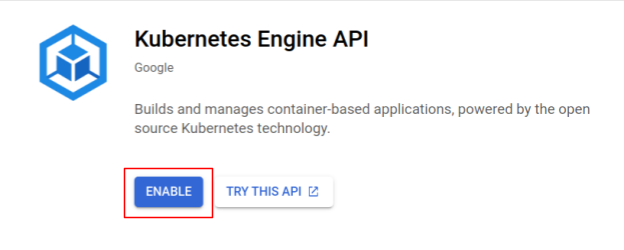
Włącz Kubernetes Engine
Najpierw skonfigurujemy klaster Kubernetes, w którym Shakesapp będzie działać w GKE, więc musimy włączyć GKE. Otwórz menu „Kubernetes Engine” i kliknij przycisk WŁĄCZ.
Teraz możesz utworzyć klaster Kubernetes.
Utwórz klaster Kubernetes
Aby utworzyć klaster Kubernetes, uruchom w Cloud Shell to polecenie: Sprawdź, czy wartość strefy znajduje się w regionie, którego użyjesz do utworzenia repozytorium Artifact Registry. Zmień wartość strefy us-central1-f, jeśli region repozytorium nie obejmuje tej strefy.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
Wynik polecenia
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
Konfigurowanie Artifact Registry i Skaffold
Mamy już klaster Kubernetes gotowy do wdrożenia. Następnie przygotowujemy rejestr kontenerów do przesyłania i wdrażania kontenerów. W tych krokach musimy skonfigurować Artifact Registry (GAR) i skaffold, aby z nich korzystać.
Konfiguracja Artifact Registry
Przejdź do menu „Artifact Registry” i kliknij przycisk WŁĄCZ.

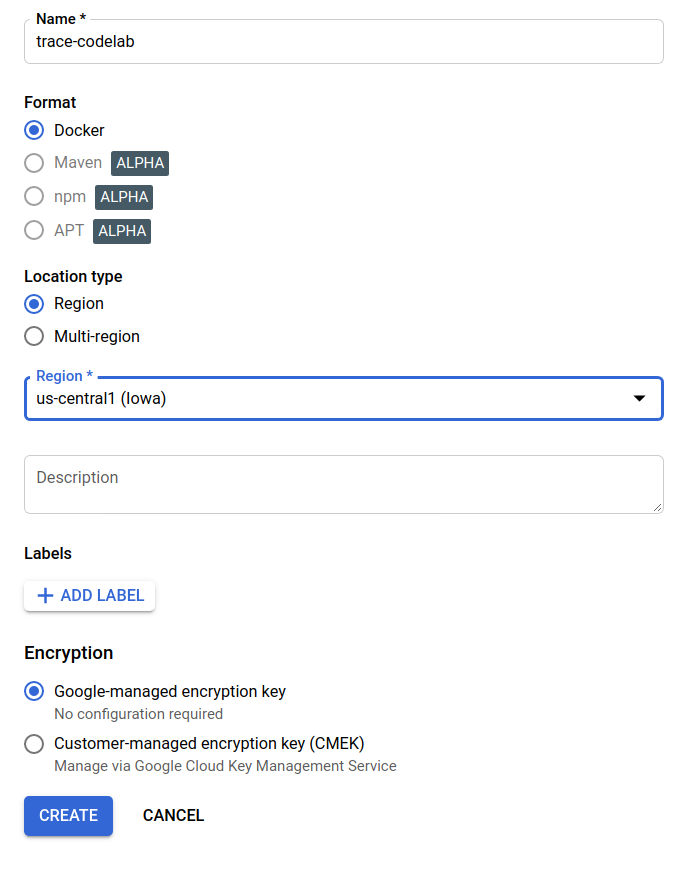
Po chwili zobaczysz przeglądarkę repozytorium GAR. Kliknij przycisk „UTWÓRZ REPOZYTORIUM” i wpisz nazwę repozytorium.
W tym laboratorium nadam nowemu repozytorium nazwę trace-codelab. Format artefaktu to „Docker”, a typ lokalizacji to „Region”. Wybierz region zbliżony do tego, który został ustawiony jako domyślna strefa Google Compute Engine. W tym przykładzie powyżej wybrano „us-central1-f”, więc tutaj wybieramy „us-central1 (Iowa)”. Następnie kliknij przycisk „UTWÓRZ”.
W przeglądarce repozytorium zobaczysz teraz „trace-codelab”.
Później wrócimy tutaj, aby sprawdzić ścieżkę rejestru.
Konfiguracja Skaffold
Skaffold to przydatne narzędzie podczas tworzenia mikroserwisów działających w Kubernetes. Za pomocą kilku poleceń obsługuje przepływ pracy związany z tworzeniem, przesyłaniem i wdrażaniem kontenerów aplikacji. Skaffold domyślnie używa Docker Registry jako rejestru kontenerów, więc musisz skonfigurować Skaffold, aby rozpoznawał GAR podczas przesyłania kontenerów.
Ponownie otwórz Cloud Shell i sprawdź, czy narzędzie Skaffold jest zainstalowane. (Cloud Shell domyślnie instaluje Skaffold w środowisku). Uruchom to polecenie i sprawdź wersję Skaffold.
skaffold version
Wynik polecenia
v1.38.0
Teraz możesz zarejestrować domyślne repozytorium, z którego będzie korzystać narzędzie Skaffold. Aby uzyskać ścieżkę rejestru, przejdź do panelu Artifact Registry i kliknij nazwę repozytorium, które zostało skonfigurowane w poprzednim kroku.
U góry strony zobaczysz wtedy elementy menu nawigacyjnego. Kliknij ikonę  , aby skopiować ścieżkę rejestru do schowka.
, aby skopiować ścieżkę rejestru do schowka.
Po kliknięciu przycisku kopiowania u dołu przeglądarki pojawi się okno z komunikatem podobnym do tego:
Skopiowano „us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab”
Wróć do Cloud Shell. Uruchom polecenie skaffold config set default-repo z wartością skopiowaną z panelu.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
Wynik polecenia
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
Musisz też skonfigurować rejestr w konfiguracji Dockera. Uruchom to polecenie:
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
Wynik polecenia
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
Możesz teraz przejść do następnego kroku, czyli skonfigurowania kontenera Kubernetes w GKE.
Podsumowanie
W tym kroku skonfigurujesz środowisko do ćwiczeń z programowania:
- Konfigurowanie Cloud Shell
- Utworzono repozytorium Artifact Registry dla rejestru kontenerów.
- Konfigurowanie narzędzia Skaffold do korzystania z repozytorium kontenerów
- utworzyć klaster Kubernetes, w którym będą działać mikroserwisy z tego laboratorium;
Dalsze czynności
W następnym kroku zinstrumentujesz agenta ciągłego profilowania w usłudze serwera.
3. Tworzenie, wypychanie i wdrażanie mikroserwisów
Pobieranie materiałów do ćwiczeń z programowania
W poprzednim kroku skonfigurowaliśmy wszystkie wymagania wstępne dotyczące tego ćwiczenia. Teraz możesz uruchomić na nich całe mikroserwisy. Materiały do ćwiczeń są hostowane w GitHubie, więc pobierz je do środowiska Cloud Shell za pomocą tego polecenia git:
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
Struktura katalogów projektu jest następująca:
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- manifests: pliki manifestu Kubernetes
- proto: definicja proto komunikacji między klientem a serwerem
- src: katalogi z kodem źródłowym poszczególnych usług;
- skaffold.yaml: plik konfiguracyjny Skaffold
W tym ćwiczeniu zaktualizujesz kod źródłowy znajdujący się w folderze step4. Zmiany od początku możesz też sprawdzić w kodzie źródłowym w folderach step[1-6]. (Część 1 obejmuje kroki 0–4, a część 2 – kroki 5 i 6).
Uruchom polecenie Skaffold
Teraz możesz utworzyć, przesłać i wdrożyć całą zawartość w utworzonym właśnie klastrze Kubernetes. Może się wydawać, że to wiele kroków, ale w rzeczywistości skaffold robi wszystko za Ciebie. Wypróbujmy to za pomocą tego polecenia:
cd step4 skaffold dev
Po uruchomieniu polecenia zobaczysz dane wyjściowe dziennika docker build i będziesz mieć pewność, że zostały one przesłane do rejestru.
Wynik polecenia
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
Po przesłaniu wszystkich kontenerów usług wdrożenia Kubernetes uruchamiają się automatycznie.
Wynik polecenia
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
Po wdrożeniu w każdym kontenerze zobaczysz rzeczywiste dzienniki aplikacji emitowane do stdout, np. w ten sposób:
Wynik polecenia
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
Pamiętaj, że w tym momencie chcesz zobaczyć wszystkie wiadomości z serwera. OK, teraz możesz zacząć instrumentować aplikację za pomocą OpenTelemetry, aby śledzić rozproszone usługi.
Zanim zaczniesz instrumentować usługę, wyłącz klaster, naciskając Ctrl+C.
Wynik polecenia
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
Podsumowanie
Na tym etapie przygotowujesz materiały do ćwiczeń w swoim środowisku i sprawdzasz, czy skaffold działa zgodnie z oczekiwaniami.
Dalsze czynności
W następnym kroku zmodyfikujesz kod źródłowy usługi loadgen, aby instrumentować informacje o śledzeniu.
4. Instrumentacja agenta Cloud Profiler
Koncepcja profilowania ciągłego
Zanim wyjaśnimy koncepcję ciągłego profilowania, musimy najpierw zrozumieć, czym jest profilowanie. Profilowanie to jeden ze sposobów dynamicznej analizy aplikacji (dynamiczna analiza programu), który jest zwykle przeprowadzany podczas tworzenia aplikacji w procesie testowania obciążenia itp. Jest to jednorazowe działanie służące do pomiaru wskaźników systemu, takich jak wykorzystanie procesora i pamięci, w określonym czasie. Po zebraniu danych profilu programiści analizują je poza kodem.
Ciągłe profilowanie to rozszerzone podejście do normalnego profilowania: okresowo uruchamia ono krótkie profile okien w długo działającej aplikacji i zbiera wiele danych profilu. Następnie automatycznie generuje analizę statystyczną na podstawie określonego atrybutu aplikacji, takiego jak numer wersji, strefa wdrożenia, czas pomiaru itp. Więcej informacji o tym pojęciu znajdziesz w naszej dokumentacji.
Ponieważ celem jest działająca aplikacja, można okresowo zbierać dane profilu i wysyłać je do backendu, który przetwarza statystyki. Jest to agent Cloud Profiler, który wkrótce umieścisz w usłudze serwera.
Umieszczanie agenta Cloud Profiler
Otwórz edytor Cloud Shell, klikając przycisk  w prawym górnym rogu Cloud Shell. Otwórz
w prawym górnym rogu Cloud Shell. Otwórz step4/src/server/main.go w eksploratorze w panelu po lewej stronie i znajdź funkcję główną.
step4/src/server/main.go
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
healthpb.RegisterHealthServer(srv, svc)
if err := srv.Serve(lis); err != nil {
log.Fatalf("error serving server: %v", err)
}
}
W funkcji main zobaczysz kod konfiguracji OpenTelemetry i gRPC, który został utworzony w części 1 ćwiczenia. Teraz dodasz tutaj instrumentację agenta Cloud Profiler. Podobnie jak w przypadku funkcji initTracer(), możesz napisać funkcję o nazwie initProfiler(), aby zwiększyć czytelność.
step4/src/server/main.go
import (
...
"cloud.google.com/go/profiler" // step5. add profiler package
"cloud.google.com/go/storage"
...
)
// step5: add Profiler initializer
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.0.0",
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Przyjrzyjmy się bliżej opcjom określonym w obiekcie profiler.Config{}.
- Usługa: nazwa usługi, którą możesz wybrać i włączyć w panelu profilera.
- ServiceVersion: nazwa wersji usługi. Na podstawie tej wartości możesz porównywać zbiory danych profili.
- NoHeapProfiling: wyłącza profilowanie zużycia pamięci.
- NoAllocProfiling: wyłącza alokację pamięci
- NoGoroutineProfiling: wyłącza profilowanie gorutyn.
- NoCPUProfiling: wyłącza profilowanie procesora.
W tym ćwiczeniu z programowania włączymy tylko profilowanie procesora.
Teraz wystarczy wywołać tę funkcję w funkcji main. W bloku importu zaimportuj pakiet Cloud Profiler.
step4/src/server/main.go
func main() {
...
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
// step5. start profiler
go initProfiler()
// step5. end
svc := NewServerService()
// step2: add interceptor
...
}
Pamiętaj, że wywołujesz funkcję initProfiler() ze słowem kluczowym go. Ponieważ profiler.Start() blokuje, musisz uruchomić go w innej procedurze goroutine. Teraz można go zbudować. Przed wdrożeniem uruchom go mod tidy.
go mod tidy
Teraz wdróż klaster z nową usługą serwera.
skaffold dev
Wyświetlenie wykresu płomieniowego w Cloud Profiler zwykle zajmuje kilka minut. Wpisz „profiler” w polu wyszukiwania u góry i kliknij ikonę Profilera.

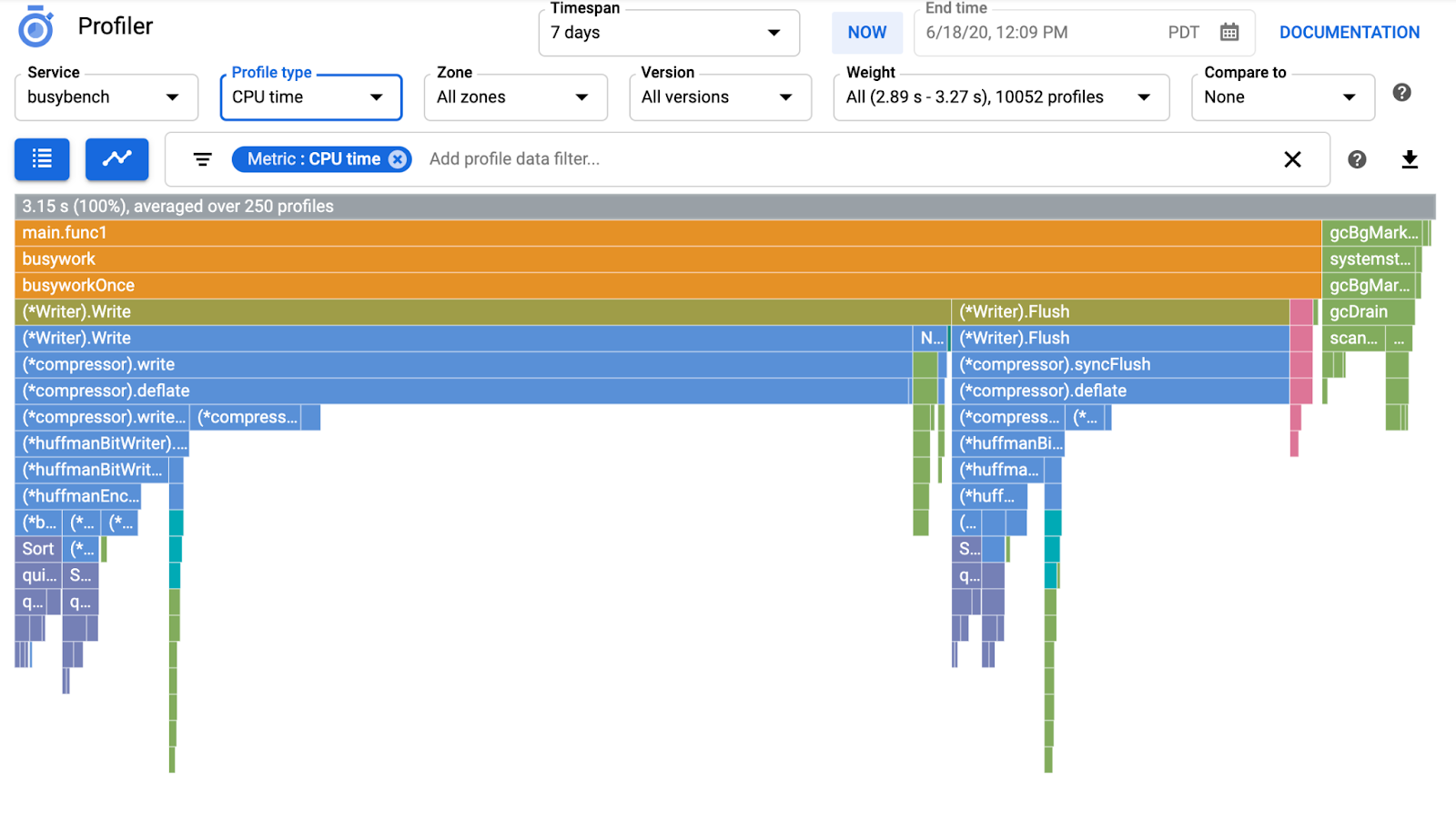
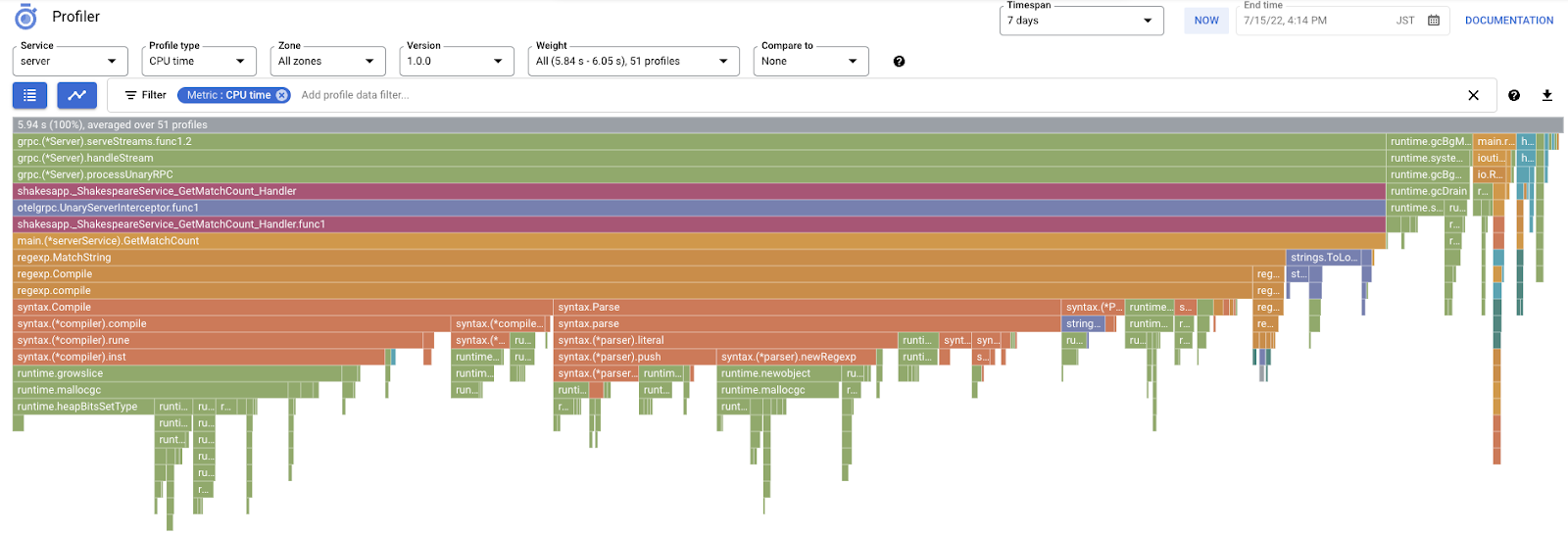
Następnie zobaczysz ten wykres płomieniowy.
Podsumowanie
W tym kroku osadzisz agenta Cloud Profiler w usłudze serwera i potwierdzisz, że generuje on wykres płomieniowy.
Dalsze czynności
W następnym kroku za pomocą wykresu płomieniowego zbadamy przyczynę wąskiego gardła w aplikacji.
5. Analizowanie wykresu płomieniowego Cloud Profiler
Co to jest wykres płomieniowy?
Wykres płomieniowy to jeden ze sposobów wizualizacji danych profilu. Szczegółowe wyjaśnienie znajdziesz w naszym dokumencie, ale oto krótkie podsumowanie:
- Każdy słupek przedstawia wywołanie metody lub funkcji w aplikacji.
- Kierunek pionowy to stos wywołań, który rośnie od góry do dołu.
- Kierunek poziomy to wykorzystanie zasobów – im dłuższy, tym gorszy.
W związku z tym przyjrzyjmy się uzyskanemu wykresowi płomieniowemu.
Analizowanie wykresu płomieniowego
W poprzedniej sekcji dowiedzieliśmy się, że każdy pasek na wykresie płomieniowym reprezentuje wywołanie funkcji lub metody, a jego długość oznacza wykorzystanie zasobów w tej funkcji lub metodzie. Wykres płomieniowy Cloud Profiler sortuje paski w kolejności malejącej lub według długości od lewej do prawej, więc możesz zacząć od lewego górnego rogu wykresu.
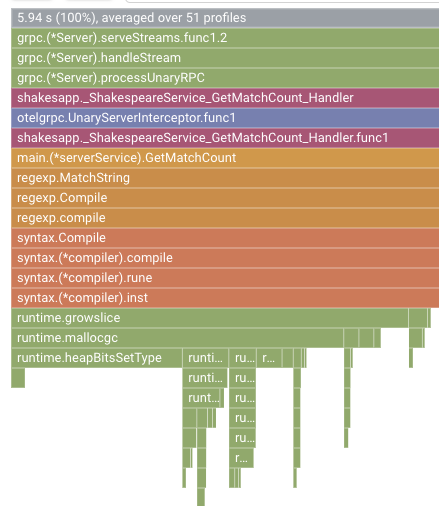
W naszym przypadku wyraźnie widać, że najwięcej czasu procesora zużywa funkcja grpc.(*Server).serveStreams.func1.2. Analizując stos wywołań od góry do dołu, widzimy, że najwięcej czasu spędza ona w funkcji main.(*serverService).GetMatchCount, która jest obsługą serwera gRPC w usłudze serwera.
W sekcji GetMatchCount zobaczysz serię funkcji regexp: regexp.MatchString i regexp.Compile. Pochodzą one ze standardowego pakietu, co oznacza, że zostały dokładnie przetestowane pod wieloma względami, w tym pod kątem wydajności. Wynik pokazuje jednak, że wykorzystanie czasu procesora jest wysokie w przypadku regexp.MatchString i regexp.Compile. Biorąc pod uwagę te fakty, można założyć, że użycie symbolu regexp.MatchString ma związek z problemami z wydajnością. Przyjrzyjmy się więc kodowi źródłowemu, w którym używana jest ta funkcja.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line, query := strings.ToLower(line), strings.ToLower(req.Query)
isMatch, err := regexp.MatchString(query, line)
if err != nil {
return resp, err
}
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
To miejsce, w którym wywoływana jest funkcja regexp.MatchString. Czytając kod źródłowy, możesz zauważyć, że funkcja jest wywoływana w zagnieżdżonej pętli for. Dlatego użycie tej funkcji może być nieprawidłowe. Sprawdźmy dokumentację GoDoc dla pakietu regexp.

Zgodnie z dokumentem funkcja regexp.MatchString kompiluje wzorzec wyrażenia regularnego przy każdym wywołaniu. Przyczyna dużego zużycia zasobów jest więc następująca.
Podsumowanie
W tym kroku założyliśmy przyczynę zużycia zasobów, analizując wykres płomieniowy.
Dalsze czynności
W następnym kroku zaktualizujesz kod źródłowy usługi serwera i potwierdzisz zmianę z wersji 1.0.0.
6. Aktualizowanie kodu źródłowego i porównywanie wykresów płomieniowych
Aktualizowanie kodu źródłowego
W poprzednim kroku założyliśmy, że użycie regexp.MatchString ma związek z dużym zużyciem zasobów. Rozwiążmy ten problem. Otwórz kod i nieco zmień tę część.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
// step6. considered the process carefully and naively tuned up by extracting
// regexp pattern compile process out of for loop.
query := strings.ToLower(req.Query)
re := regexp.MustCompile(query)
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line = strings.ToLower(line)
isMatch := re.MatchString(line)
// step6. done replacing regexp with strings
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Jak widać, proces kompilacji wzorca wyrażenia regularnego został wyodrębniony z funkcji regexp.MatchString i przeniesiony poza zagnieżdżoną pętlę for.
Przed wdrożeniem tego kodu zaktualizuj ciąg wersji w funkcji initProfiler().
step4/src/server/main.go
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.1.0", // step6. update version
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Zobaczmy teraz, jak to działa. Wdróż klaster za pomocą polecenia skaffold.
skaffold dev
Po pewnym czasie załaduj ponownie pulpit Cloud Profiler i sprawdź, jak wygląda.
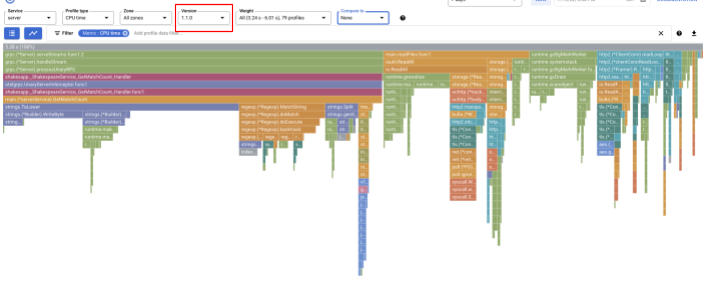
Zmień wersję na "1.1.0", aby wyświetlać tylko profile z wersji 1.1.0. Jak widać, długość paska GetMatchCount zmniejszyła się, a współczynnik wykorzystania czasu procesora (czyli długość paska) zmalał.

Możesz nie tylko przeglądać wykres płomieniowy pojedynczej wersji, ale też porównywać różnice między dwiema wersjami.

Zmień wartość na liście „Porównaj z” na „Wersja”, a wartość „Porównywana wersja” na „1.0.0”, czyli pierwotną wersję.
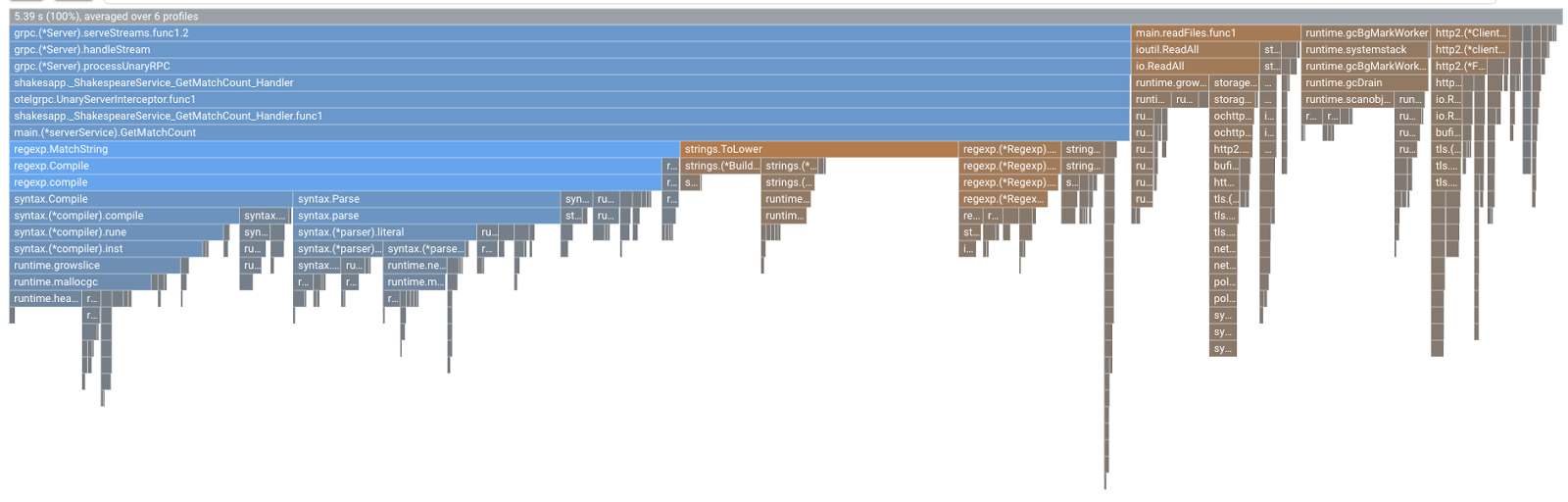
Zobaczysz wykres płomieniowy tego typu. Kształt wykresu jest taki sam jak w przypadku wersji 1.1.0, ale kolorystyka jest inna. W trybie porównania kolor oznacza:
- Niebieski: zmniejszona wartość (zużycie zasobów)
- Pomarańczowy: uzyskana wartość (zużycie zasobów)
- Szary: neutralny
Przyjrzyjmy się bliżej funkcji na podstawie legendy. Klikając słupek, który chcesz powiększyć, możesz wyświetlić więcej szczegółów w ramach stosu. Kliknij pasek main.(*serverService).GetMatchCount. Gdy najedziesz kursorem na słupek, zobaczysz szczegóły porównania.
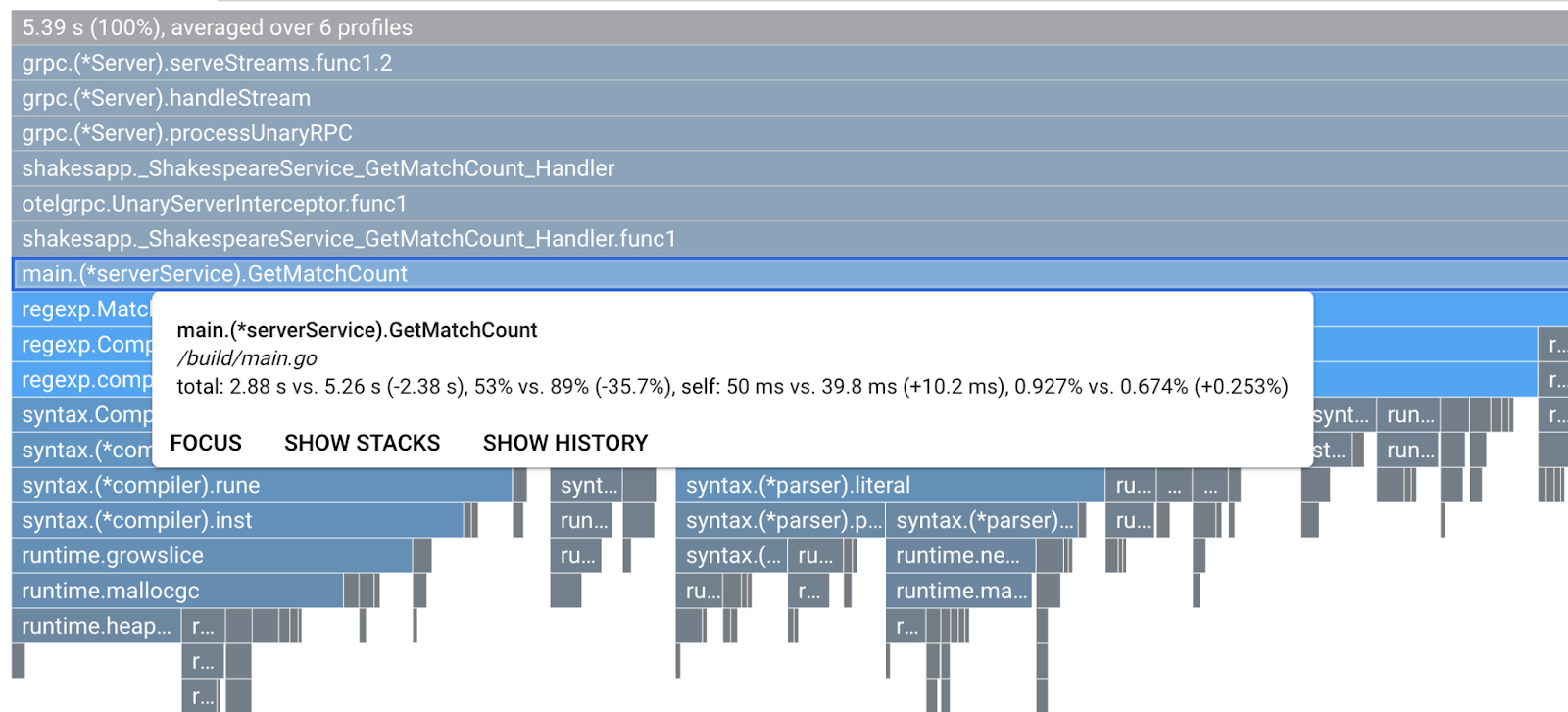
Wynika z niego, że łączny czas pracy procesora zmniejszył się z 5,26 s do 2,88 s (łączny czas to 10 s – okno próbkowania). To ogromna poprawa.
Na podstawie analizy danych profilu możesz teraz zwiększyć wydajność aplikacji.
Podsumowanie
W tym kroku wprowadzisz zmianę w usłudze serwera i potwierdzisz poprawę w trybie porównania Cloud Profiler.
Dalsze czynności
W następnym kroku zaktualizujesz kod źródłowy usługi serwera i potwierdzisz zmianę z wersji 1.0.0.
7. Dodatkowy krok: potwierdź poprawę w kaskadzie śledzenia
Różnica między śledzeniem rozproszonym a profilowaniem ciągłym
W części 1 tego laboratorium potwierdziliśmy, że możesz określić usługę, która jest wąskim gardłem na ścieżce żądania w mikroserwisach, ale nie możesz określić dokładnej przyczyny tego wąskiego gardła w konkretnej usłudze. W tej części 2 laboratorium dowiedziałeś się, że ciągłe profilowanie umożliwia identyfikowanie wąskich gardeł w pojedynczej usłudze na podstawie stosów wywołań.
W tym kroku przeanalizujemy wykres kaskadowy z rozproszonego śledzenia (Cloud Trace) i zobaczymy różnicę w porównaniu z profilowaniem ciągłym.
Ten wykres wodospadowy to jeden ze śladów z zapytaniem „love”. Trwa to łącznie około 6,7 s (6700 ms).
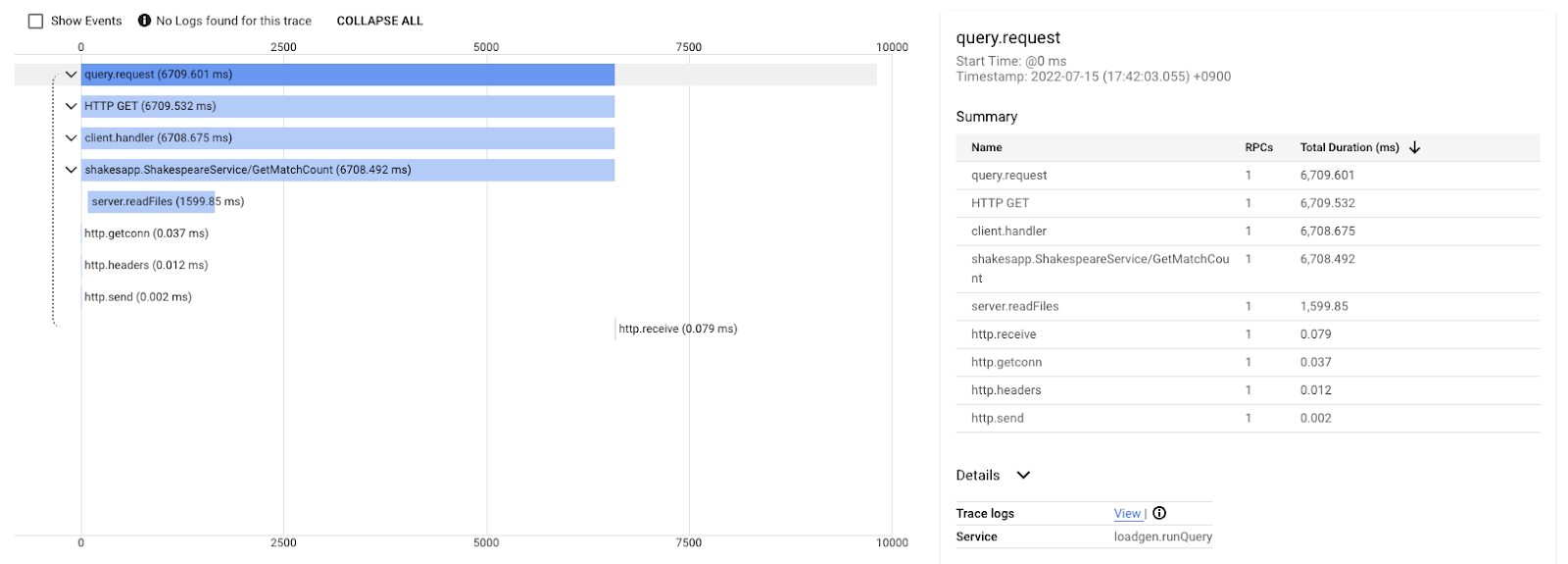
To jest wynik po ulepszeniu w przypadku tego samego zapytania. Jak widać, całkowite opóźnienie wynosi teraz 1,5 s (1500 ms), co jest ogromną poprawą w porównaniu z poprzednią implementacją.
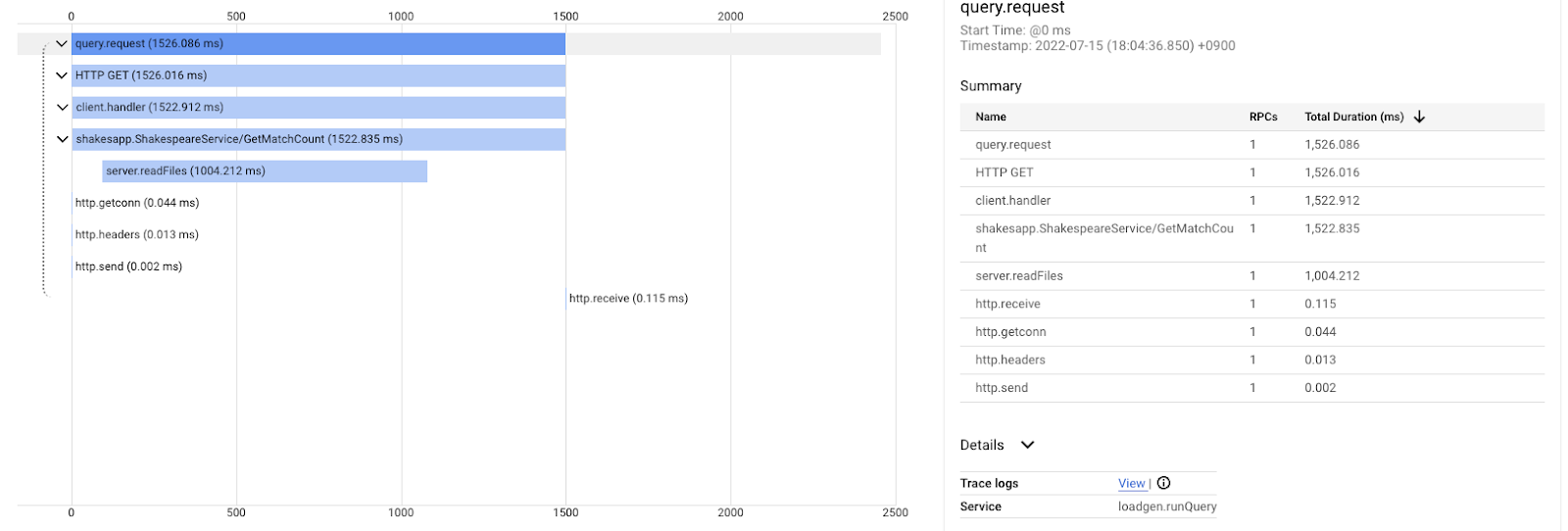
Ważne jest to, że na wykresie kaskadowym rozproszonego śledzenia informacje o stosie wywołań są niedostępne, chyba że instrumentujesz zakresy w każdym miejscu. Śledzenie rozproszone koncentruje się na opóźnieniach w usługach, a profilowanie ciągłe – na zasobach komputera (CPU, pamięć, wątki systemu operacyjnego) pojedynczej usługi.
Z innej strony ślad rozproszony jest oparty na zdarzeniach, a profil ciągły ma charakter statystyczny. Każdy ślad ma inny wykres opóźnienia, a do uzyskania trendu zmian opóźnienia potrzebny jest inny format, np. rozkład.
Podsumowanie
W tym kroku sprawdzisz różnicę między śledzeniem rozproszonym a profilowaniem ciągłym.
8. Gratulacje
Udało Ci się utworzyć rozproszone logi czasu za pomocą OpenTelemetry i potwierdzić opóźnienia żądań w mikrousłudze w Cloud Trace.
W przypadku rozbudowanych ćwiczeń możesz samodzielnie wypróbować te tematy.
- Obecna implementacja wysyła wszystkie zakresy wygenerowane przez kontrolę stanu. (
grpc.health.v1.Health/Check) Jak odfiltrować te zakresy z Cloud Trace? Podpowiedź znajdziesz tutaj. - Koreluj dzienniki zdarzeń z zakresami i sprawdź, jak to działa w Google Cloud Trace i Google Cloud Logging. Podpowiedź znajdziesz tutaj.
- Zastąp niektóre usługi usługami w innym języku i spróbuj je instrumentować za pomocą OpenTelemetry w tym języku.
Jeśli po tym chcesz dowiedzieć się więcej o profilerze, przejdź do części 2. W takim przypadku możesz pominąć sekcję zwalniania miejsca poniżej.
Czyszczenie danych
Po ukończeniu tego samouczka zatrzymaj klaster Kubernetes i usuń projekt, aby uniknąć nieoczekiwanych opłat za Google Kubernetes Engine, Google Cloud Trace i Google Artifact Registry.
Najpierw usuń klaster. Jeśli klaster jest uruchomiony za pomocą polecenia skaffold dev, wystarczy nacisnąć Ctrl-C. Jeśli klaster jest uruchomiony za pomocą skaffold run, uruchom to polecenie:
skaffold delete
Wynik polecenia
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
Po usunięciu klastra w panelu menu wybierz „IAM i administracja” > „Ustawienia”, a następnie kliknij przycisk „WYŁĄCZ”.
Następnie w formularzu w oknie wpisz identyfikator projektu (nie nazwę projektu) i potwierdź wyłączenie.