
1. Introduzione
Ultimo aggiornamento: 14/07/2022
Osservabilità dell'applicazione
Osservabilità e Continuous Profiler
Osservabilità è il termine utilizzato per descrivere un attributo di un sistema. Un sistema con osservabilità consente ai team di eseguire il debug attivo del sistema. In questo contesto, i tre pilastri dell'osservabilità (log, metriche e tracce) sono gli strumenti fondamentali per acquisire l'osservabilità del sistema.
Oltre ai tre pilastri dell'osservabilità, il profiling continuo è un altro componente chiave per l'osservabilità e sta ampliando la base utenti del settore. Cloud Profiler è uno degli strumenti di profilazione e fornisce un'interfaccia semplice per analizzare in dettaglio le metriche delle prestazioni negli stack di chiamate delle applicazioni.
Questo codelab è la seconda parte della serie e tratta l'instrumentazione di un agente di profilazione continua. La parte 1 tratta il tracciamento distribuito con OpenTelemetry e Cloud Trace e ti aiuterà a identificare meglio il collo di bottiglia dei microservizi.
Cosa creerai
In questo codelab, strumenterai l'agente di profilazione continua nel servizio server dell'applicazione "Shakespeare" (nota anche come Shakesapp) in esecuzione su un cluster Google Kubernetes Engine. L'architettura di Shakesapp è descritta di seguito:

- Loadgen invia una stringa di query al client in HTTP
- I client passano la query da loadgen al server in gRPC
- Il server accetta la query dal client, recupera tutte le opere di Shakespeare in formato di testo da Google Cloud Storage, cerca le righe che contengono la query e restituisce al client il numero della riga corrispondente
Nella parte 1, hai scoperto che il collo di bottiglia si trova da qualche parte nel servizio server, ma non sei riuscito a identificare la causa esatta.
Cosa imparerai a fare
- Come incorporare l'agente Profiler
- Come analizzare il collo di bottiglia su Cloud Profiler
Questo codelab spiega come instrumentare un agente di profilazione continua nella tua applicazione.
Che cosa ti serve
- Conoscenza di base di Go
- Conoscenza di base di Kubernetes
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud Platform ( console.cloud.google.com) e crea un nuovo progetto.
Se hai già un progetto, fai clic sul menu a discesa per la selezione dei progetti in alto a sinistra nella console:
e fai clic sul pulsante "NUOVO PROGETTO" nella finestra di dialogo risultante per creare un nuovo progetto:
Se non hai ancora un progetto, dovresti visualizzare una finestra di dialogo come questa per creare il primo:
La finestra di dialogo successiva per la creazione del progetto ti consente di inserire i dettagli del nuovo progetto:
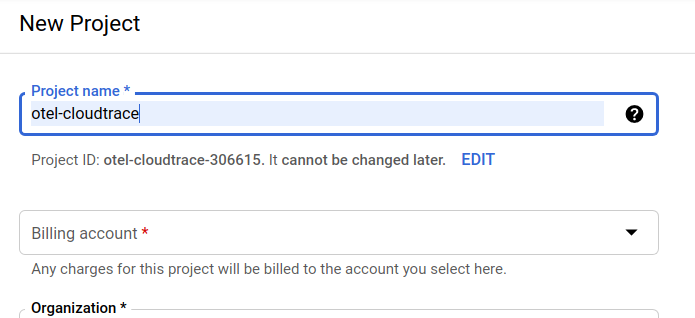
Ricorda l'ID progetto, che è un nome univoco tra tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, ci dispiace). In questo codelab verrà indicato come PROJECT_ID.
Successivamente, se non l'hai ancora fatto, devi abilitare la fatturazione in Developers Console per utilizzare le risorse Google Cloud e abilitare l'API Cloud Trace.
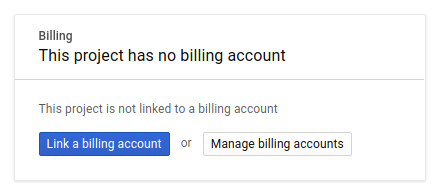
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione (vedi la sezione "Pulizia" alla fine di questo documento). I prezzi di Google Cloud Trace, Google Kubernetes Engine e Google Artifact Registry sono indicati nella documentazione ufficiale.
- Prezzi della suite operativa di Google Cloud | Operations Suite
- Prezzi | Documentazione di Kubernetes Engine
- Prezzi di Artifact Registry | Documentazione di Artifact Registry
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$, che dovrebbe rendere questo codelab completamente senza costi.
Configurazione di Google Cloud Shell
Anche se Google Cloud e Google Cloud Trace possono essere gestiti da remoto dal tuo laptop, in questo codelab utilizzeremo Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Ciò significa che per questo codelab ti servirà solo un browser (sì, funziona su Chromebook).
Per attivare Cloud Shell dalla console Cloud, fai clic su Attiva Cloud Shell  (bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).
(bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo PROJECT_ID.
gcloud auth list
Output comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
Se per qualche motivo il progetto non è impostato, esegui questo comando:
gcloud config set project <PROJECT_ID>
Stai cercando PROJECT_ID? Controlla l'ID che hai utilizzato nei passaggi di configurazione o cercalo nella dashboard della console Cloud:
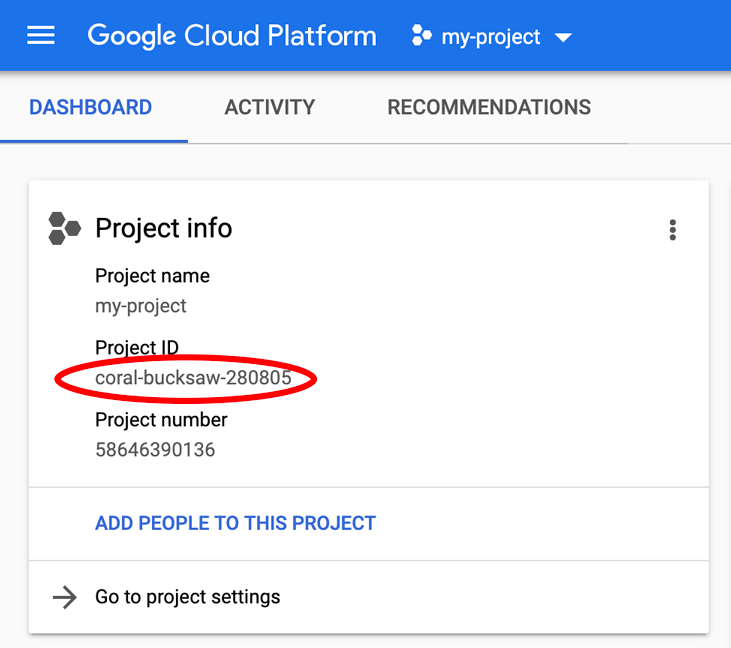
Cloud Shell imposta anche alcune variabili di ambiente per impostazione predefinita, che potrebbero essere utili quando esegui i comandi futuri.
echo $GOOGLE_CLOUD_PROJECT
Output comando
<PROJECT_ID>
Infine, imposta la zona e la configurazione del progetto predefinite.
gcloud config set compute/zone us-central1-f
Puoi scegliere una serie di zone diverse. Per saperne di più, consulta Regioni e zone.
Configurazione della lingua Go
In questo codelab, utilizziamo Go per tutto il codice sorgente. Esegui questo comando su Cloud Shell e verifica se la versione di Go è 1.17 o successive.
go version
Output comando
go version go1.18.3 linux/amd64
Configura un cluster Google Kubernetes
In questo codelab, eseguirai un cluster di microservizi su Google Kubernetes Engine (GKE). La procedura di questo codelab è la seguente:
- Scarica il progetto di base in Cloud Shell
- Creare microservizi in container
- Carica i container in Google Artifact Registry (GAR)
- Esegui il deployment dei container su GKE
- Modificare il codice sorgente dei servizi per l'instrumentazione delle tracce
- Vai al passaggio 2
Abilita Kubernetes Engine
Innanzitutto, configuriamo un cluster Kubernetes in cui Shakesapp viene eseguito su GKE, quindi dobbiamo abilitare GKE. Vai al menu "Kubernetes Engine" e premi il pulsante ATTIVA.
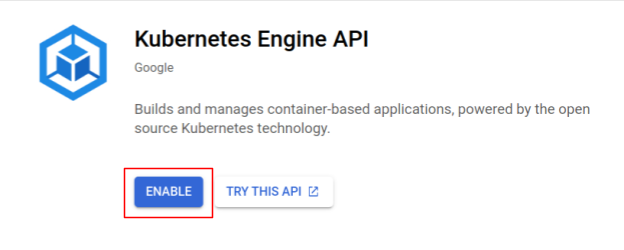
Ora puoi creare un cluster Kubernetes.
Crea un cluster Kubernetes
In Cloud Shell, esegui questo comando per creare un cluster Kubernetes. Conferma che il valore della zona rientra nella regione che utilizzerai per la creazione del repository Artifact Registry. Modifica il valore della zona us-central1-f se la regione del repository non copre la zona.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
Output comando
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
Configurazione di Artifact Registry e Skaffold
Ora abbiamo un cluster Kubernetes pronto per il deployment. Successivamente, ci prepariamo per un container registry per il push e il deployment dei container. Per questi passaggi, dobbiamo configurare un registro Artifact Registry (GAR) e Skaffold per utilizzarlo.
Configurazione di Artifact Registry
Vai al menu di "Artifact Registry" e premi il pulsante ATTIVA.

Dopo qualche istante, vedrai il browser del repository di GAR. Fai clic sul pulsante "CREA REPOSITORY" e inserisci il nome del repository.
In questo codelab, il nuovo repository viene chiamato trace-codelab. Il formato dell'artefatto è "Docker" e il tipo di località è "Regione". Scegli la regione più vicina a quella impostata per la zona predefinita di Google Compute Engine. Ad esempio, nell'esempio precedente è stato scelto "us-central1-f", quindi qui scegliamo "us-central1 (Iowa)". Poi fai clic sul pulsante "CREA".
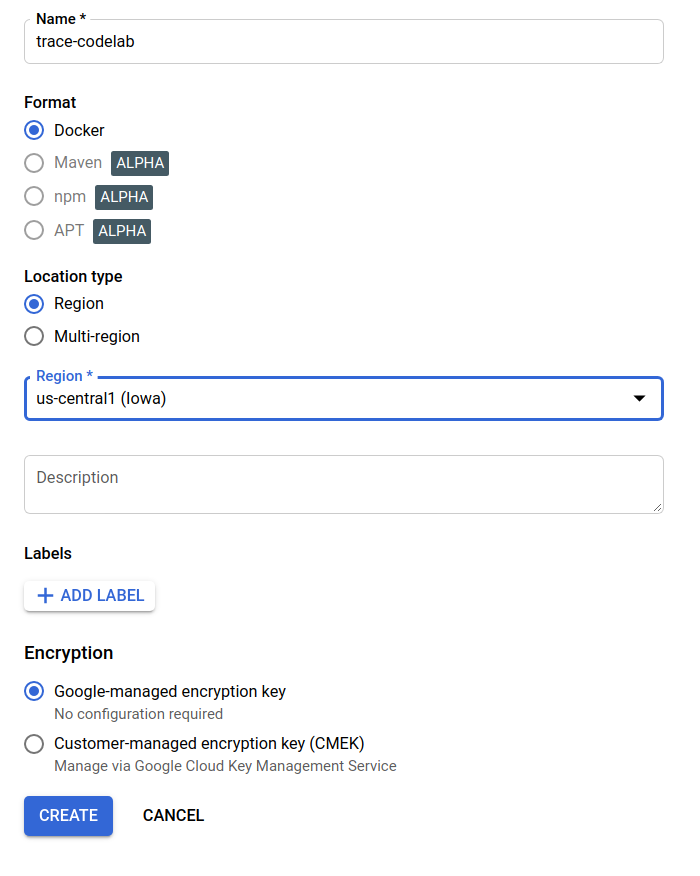
Ora vedi "trace-codelab" nel browser del repository.
Torneremo qui più tardi per controllare il percorso del registro.
Configurazione di Skaffold
Skaffold è uno strumento utile quando lavori alla creazione di microservizi eseguiti su Kubernetes. Gestisce il flusso di lavoro di creazione, push e deployment dei container delle applicazioni con un piccolo insieme di comandi. Per impostazione predefinita, Skaffold utilizza Docker Registry come registro dei container, quindi devi configurare Skaffold in modo che riconosca GAR quando esegui il push dei container.
Riapri Cloud Shell e verifica se Skaffold è installato. Cloud Shell installa Skaffold nell'ambiente per impostazione predefinita. Esegui questo comando e visualizza la versione di Skaffold.
skaffold version
Output comando
v1.38.0
Ora puoi registrare il repository predefinito da utilizzare per Skaffold. Per ottenere il percorso del registro, vai alla dashboard di Artifact Registry e fai clic sul nome del repository che hai appena configurato nel passaggio precedente.
Poi vedrai le tracce di breadcrumb nella parte superiore della pagina. Fai clic sull'icona  per copiare il percorso del registro negli appunti.
per copiare il percorso del registro negli appunti.
Se fai clic sul pulsante di copia, nella parte inferiore del browser viene visualizzata la finestra di dialogo con il messaggio:
"us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab" è stato copiato
Torna a Cloud Shell. Esegui il comando skaffold config set default-repo con il valore che hai appena copiato dalla dashboard.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
Output comando
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
Inoltre, devi configurare il registro nella configurazione Docker. Esegui questo comando:
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
Output comando
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
Ora puoi procedere al passaggio successivo per configurare un container Kubernetes su GKE.
Riepilogo
In questo passaggio, configurerai l'ambiente del codelab:
- Configura Cloud Shell
- È stato creato un repository Artifact Registry per il registro dei container
- Configura Skaffold per utilizzare Container Registry
- Creazione di un cluster Kubernetes in cui vengono eseguiti i microservizi del codelab
Avanti
Nel passaggio successivo, strumenterai l'agente di profilazione continua nel servizio server.
3. Crea, esegui il push e il deployment dei microservizi
Scarica il materiale del codelab
Nel passaggio precedente, abbiamo configurato tutti i prerequisiti per questo codelab. Ora puoi eseguire microservizi completi. Il materiale del codelab è ospitato su GitHub, quindi scaricalo nell'ambiente Cloud Shell con il seguente comando git.
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
La struttura delle directory del progetto è la seguente:
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- manifests: file manifest Kubernetes
- proto: definizione del protocollo per la comunicazione tra client e server
- src: directory per il codice sorgente di ciascun servizio
- skaffold.yaml: file di configurazione per Skaffold
In questo codelab, aggiornerai il codice sorgente che si trova nella cartella step4. Puoi anche fare riferimento al codice sorgente nelle cartelle step[1-6] per le modifiche dall'inizio. La parte 1 copre i passaggi da 0 a 4, mentre la parte 2 copre i passaggi 5 e 6.
Esegui il comando skaffold
Infine, puoi creare, eseguire il push e il deployment dell'intero contenuto nel cluster Kubernetes che hai appena creato. Sembra che contenga più passaggi, ma in realtà Skaffold fa tutto per te. Proviamo con il seguente comando:
cd step4 skaffold dev
Non appena esegui il comando, visualizzi l'output del log di docker build e puoi confermare che sono stati inviati correttamente al registro.
Output comando
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
Dopo il push di tutti i container di servizio, i deployment Kubernetes vengono avviati automaticamente.
Output comando
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
Dopo il deployment, vedrai i log dell'applicazione effettivi emessi in stdout in ogni container nel seguente modo:
Output comando
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
Tieni presente che a questo punto vuoi visualizzare tutti i messaggi del server. Ok, ora puoi iniziare a instrumentare la tua applicazione con OpenTelemetry per il tracciamento distribuito dei servizi.
Prima di iniziare a instrumentare il servizio, arresta il cluster con Ctrl+C.
Output comando
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
Riepilogo
In questo passaggio, hai preparato il materiale del codelab nel tuo ambiente e hai verificato che Skaffold venga eseguito come previsto.
Avanti
Nel passaggio successivo, modificherai il codice sorgente del servizio loadgen per instrumentare le informazioni di traccia.
4. Strumentazione dell'agente Cloud Profiler
Concetto di profilazione continua
Prima di spiegare il concetto di profilazione continua, dobbiamo capire cos'è la profilazione. La profilazione è uno dei modi per analizzare l'applicazione in modo dinamico (analisi dinamica del programma) e viene solitamente eseguita durante lo sviluppo dell'applicazione nel processo di test di carico e così via. Si tratta di un'attività di acquisizione singola per misurare le metriche di sistema, come l'utilizzo di CPU e memoria, durante il periodo specifico. Dopo aver raccolto i dati del profilo, gli sviluppatori li analizzano al di fuori del codice.
La profilazione continua è l'approccio esteso della profilazione normale: esegue profili di finestre brevi sull'applicazione in esecuzione a lungo termine periodicamente e raccoglie una serie di dati del profilo. Poi genera automaticamente l'analisi statistica in base a un determinato attributo dell'applicazione, come il numero di versione, la zona di deployment, il tempo di misurazione e così via. Per ulteriori dettagli sul concetto, consulta la nostra documentazione.
Poiché il target è un'applicazione in esecuzione, esiste un modo per raccogliere periodicamente i dati del profilo e inviarli a un backend che post-elabora i dati statistici. Si tratta dell'agente Cloud Profiler che incorporerai presto nel servizio server.
Incorpora l'agente Cloud Profiler
Apri l'editor di Cloud Shell premendo il pulsante  in alto a destra di Cloud Shell. Apri
in alto a destra di Cloud Shell. Apri step4/src/server/main.go dall'explorer nel riquadro a sinistra e trova la funzione principale.
step4/src/server/main.go
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
healthpb.RegisterHealthServer(srv, svc)
if err := srv.Serve(lis); err != nil {
log.Fatalf("error serving server: %v", err)
}
}
Nella funzione main, vedi del codice di configurazione per OpenTelemetry e gRPC, che è stato eseguito nella parte 1 del codelab. Ora aggiungi la strumentazione per l'agente Cloud Profiler qui. Come abbiamo fatto per initTracer(), puoi scrivere una funzione chiamata initProfiler() per una maggiore leggibilità.
step4/src/server/main.go
import (
...
"cloud.google.com/go/profiler" // step5. add profiler package
"cloud.google.com/go/storage"
...
)
// step5: add Profiler initializer
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.0.0",
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Esaminiamo da vicino le opzioni specificate nell'oggetto profiler.Config{}.
- Servizio: il nome del servizio che puoi selezionare e attivare nella dashboard del profiler
- ServiceVersion: il nome della versione del servizio. Puoi confrontare i set di dati dei profili in base a questo valore.
- NoHeapProfiling: disattiva la profilazione del consumo di memoria
- NoAllocProfiling: disattiva la profilazione dell'allocazione della memoria
- NoGoroutineProfiling: disattiva la profilazione delle goroutine
- NoCPUProfiling: disattiva la profilazione della CPU
In questo codelab, attiviamo solo la profilazione della CPU.
Ora devi solo chiamare questa funzione nella funzione main. Assicurati di importare il pacchetto Cloud Profiler nel blocco di importazione.
step4/src/server/main.go
func main() {
...
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
// step5. start profiler
go initProfiler()
// step5. end
svc := NewServerService()
// step2: add interceptor
...
}
Tieni presente che stai chiamando la funzione initProfiler() con la parola chiave go. Poiché profiler.Start() blocca, devi eseguirlo in un'altra goroutine. Ora è pronto per la creazione. Assicurati di eseguire go mod tidy prima del deployment.
go mod tidy
Ora esegui il deployment del cluster con il nuovo servizio server.
skaffold dev
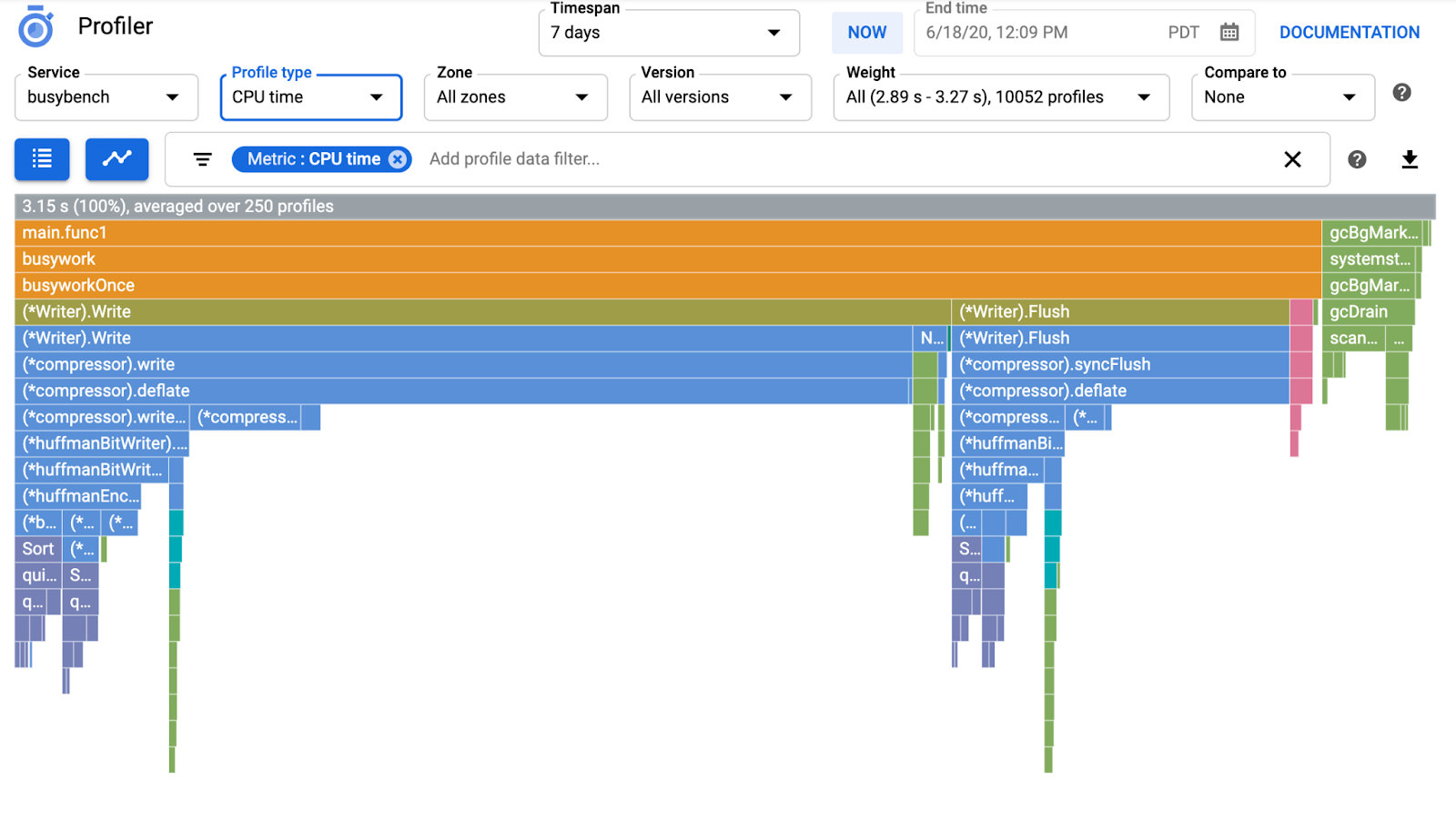
In genere, sono necessari un paio di minuti per visualizzare il grafico a fiamma in Cloud Profiler. Digita "profiler" nella casella di ricerca in alto e fai clic sull'icona di Profiler.

Verrà visualizzato il seguente grafico a fiamma.
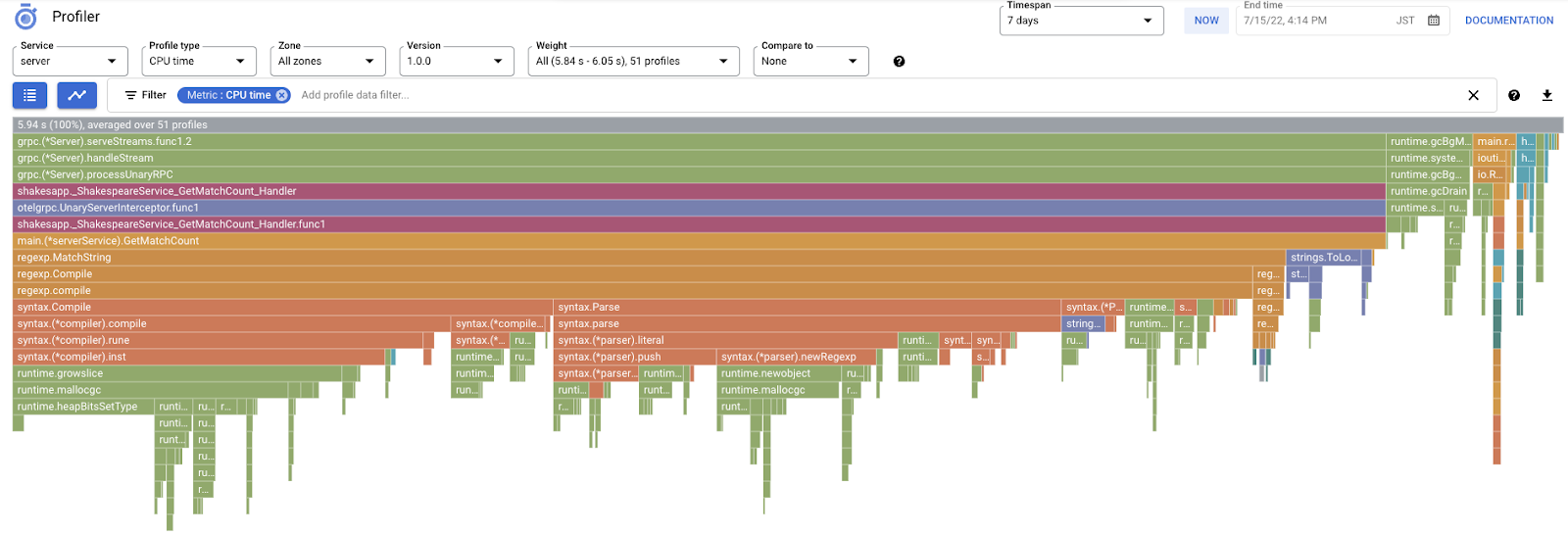
Riepilogo
In questo passaggio, hai incorporato l'agente Cloud Profiler nel servizio server e hai verificato che generi il grafico a fiamma.
Avanti
Nel passaggio successivo, analizzerai la causa del collo di bottiglia nell'applicazione con il grafico a fiamme.
5. Analizzare il grafico a fiamme di Cloud Profiler
Che cos'è il grafico a fiamme?
Flame Graph è uno dei modi per visualizzare i dati del profilo. Per una spiegazione dettagliata, consulta il nostro documento, ma il breve riepilogo è il seguente:
- Ogni barra esprime la chiamata al metodo/alla funzione nell'applicazione
- La direzione verticale è lo stack di chiamate, che cresce dall'alto verso il basso
- La direzione orizzontale indica l'utilizzo delle risorse: più è lunga, peggiore è.
Detto questo, esaminiamo il grafico a fiamme ottenuto.
Analizzare il grafico a fiamme
Nella sezione precedente hai appreso che ogni barra del grafico a fiamme esprime la chiamata di funzione/metodo e la sua lunghezza indica l'utilizzo delle risorse nella funzione/nel metodo. Il grafico a fiamme di Cloud Profiler ordina la barra in ordine decrescente o la lunghezza da sinistra a destra, quindi puoi iniziare a esaminare prima la parte in alto a sinistra del grafico.
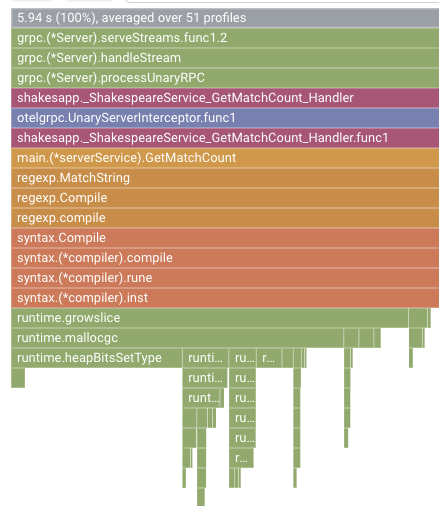
Nel nostro caso, è esplicito che grpc.(*Server).serveStreams.func1.2 consuma la maggior parte del tempo della CPU e, esaminando lo stack di chiamate dall'alto verso il basso, la maggior parte del tempo viene spesa in main.(*serverService).GetMatchCount, che è il gestore del server gRPC nel servizio server.
In GetMatchCount, vedrai una serie di funzioni regexp: regexp.MatchString e regexp.Compile. Provengono dal pacchetto standard, ovvero devono essere testati a fondo da molti punti di vista, incluso il rendimento. Tuttavia, il risultato mostra che l'utilizzo delle risorse di tempo della CPU è elevato in regexp.MatchString e regexp.Compile. Dati questi fatti, si presume che l'utilizzo di regexp.MatchString abbia a che fare con problemi di rendimento. Quindi, leggiamo il codice sorgente in cui viene utilizzata la funzione.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line, query := strings.ToLower(line), strings.ToLower(req.Query)
isMatch, err := regexp.MatchString(query, line)
if err != nil {
return resp, err
}
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Questo è il luogo in cui viene chiamato regexp.MatchString. Leggendo il codice sorgente, potresti notare che la funzione viene chiamata all'interno del ciclo for nidificato. Pertanto, l'utilizzo di questa funzione potrebbe essere errato. Cerchiamo la documentazione GoDoc di regexp.

Secondo il documento, regexp.MatchString compila il pattern dell'espressione regolare in ogni chiamata. Quindi, la causa del consumo elevato di risorse è la seguente.
Riepilogo
In questo passaggio, hai formulato un'ipotesi sulla causa del consumo di risorse analizzando il grafico a fiamma.
Avanti
Nel passaggio successivo, aggiornerai il codice sorgente del servizio server e confermerai la modifica dalla versione 1.0.0.
6. Aggiorna il codice sorgente e confronta i grafici a fiamma
Aggiornare il codice sorgente
Nel passaggio precedente, hai ipotizzato che l'utilizzo di regexp.MatchString abbia a che fare con il consumo elevato di risorse. Quindi risolviamo il problema. Apri il codice e modifica leggermente quella parte.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
// step6. considered the process carefully and naively tuned up by extracting
// regexp pattern compile process out of for loop.
query := strings.ToLower(req.Query)
re := regexp.MustCompile(query)
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line = strings.ToLower(line)
isMatch := re.MatchString(line)
// step6. done replacing regexp with strings
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
Come vedi, ora il processo di compilazione del pattern regexp viene estratto da regexp.MatchString e spostato fuori dal ciclo for nidificato.
Prima di eseguire il deployment di questo codice, assicurati di aggiornare la stringa della versione nella funzione initProfiler().
step4/src/server/main.go
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.1.0", // step6. update version
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
Vediamo come funziona. Esegui il deployment del cluster con il comando skaffold.
skaffold dev
Dopo un po' di tempo, ricarica la dashboard di Cloud Profiler e vedi come appare.
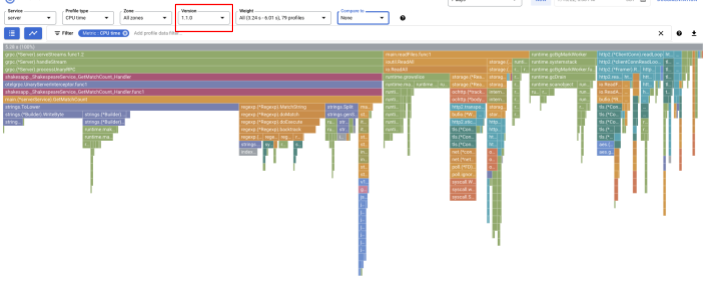
Assicurati di impostare la versione su "1.1.0" in modo da visualizzare solo i profili della versione 1.1.0. Come puoi notare, la lunghezza della barra di GetMatchCount è diminuita e il rapporto di utilizzo del tempo della CPU (ovvero la barra è diventata più corta).

Non solo puoi esaminare il grafico a fiamma di una singola versione, ma puoi anche confrontare le differenze tra due versioni.

Modifica il valore dell'elenco a discesa "Confronta con" in "Versione" e il valore di "Versione confrontata" in "1.0.0", la versione originale.
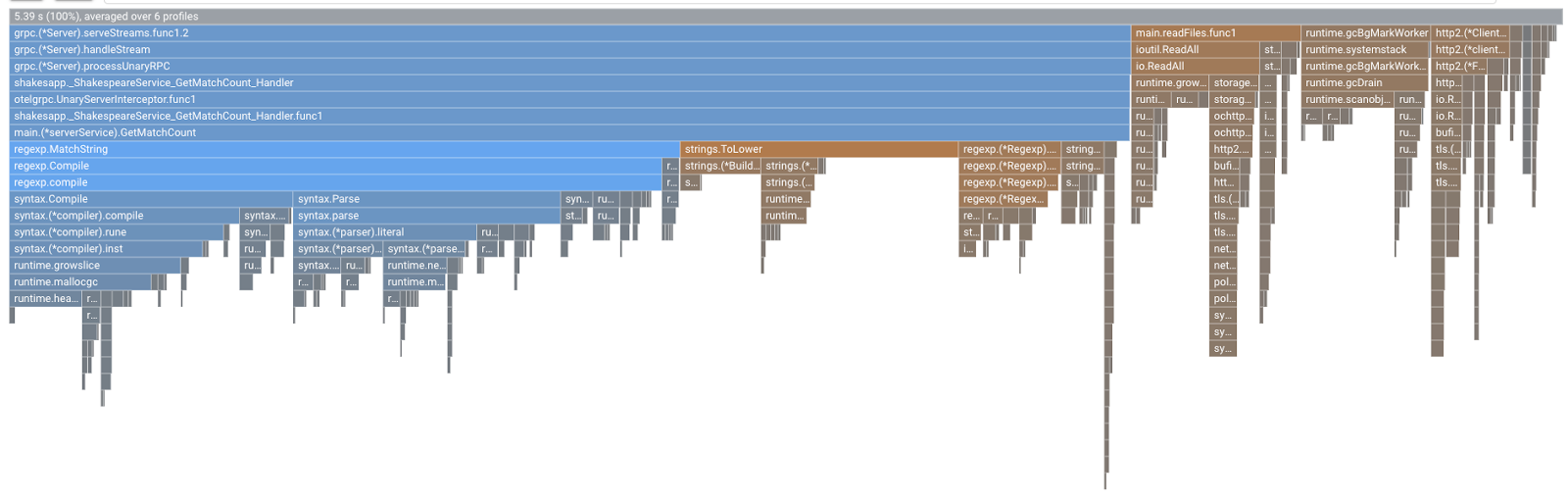
Vedrai questo tipo di grafico a fiamme. La forma del grafico è la stessa della versione 1.1.0, ma la colorazione è diversa. In modalità di confronto, il significato del colore è:
- Blu: il valore (consumo di risorse) ridotto
- Arancione: il valore (consumo di risorse) ottenuto
- Grigio: neutro
Data la legenda, diamo un'occhiata più da vicino alla funzione. Se fai clic sulla barra che vuoi ingrandire, puoi visualizzare ulteriori dettagli all'interno della pila. Fai clic sulla barra main.(*serverService).GetMatchCount. Inoltre, passando il mouse sopra la barra, vedrai i dettagli del confronto.
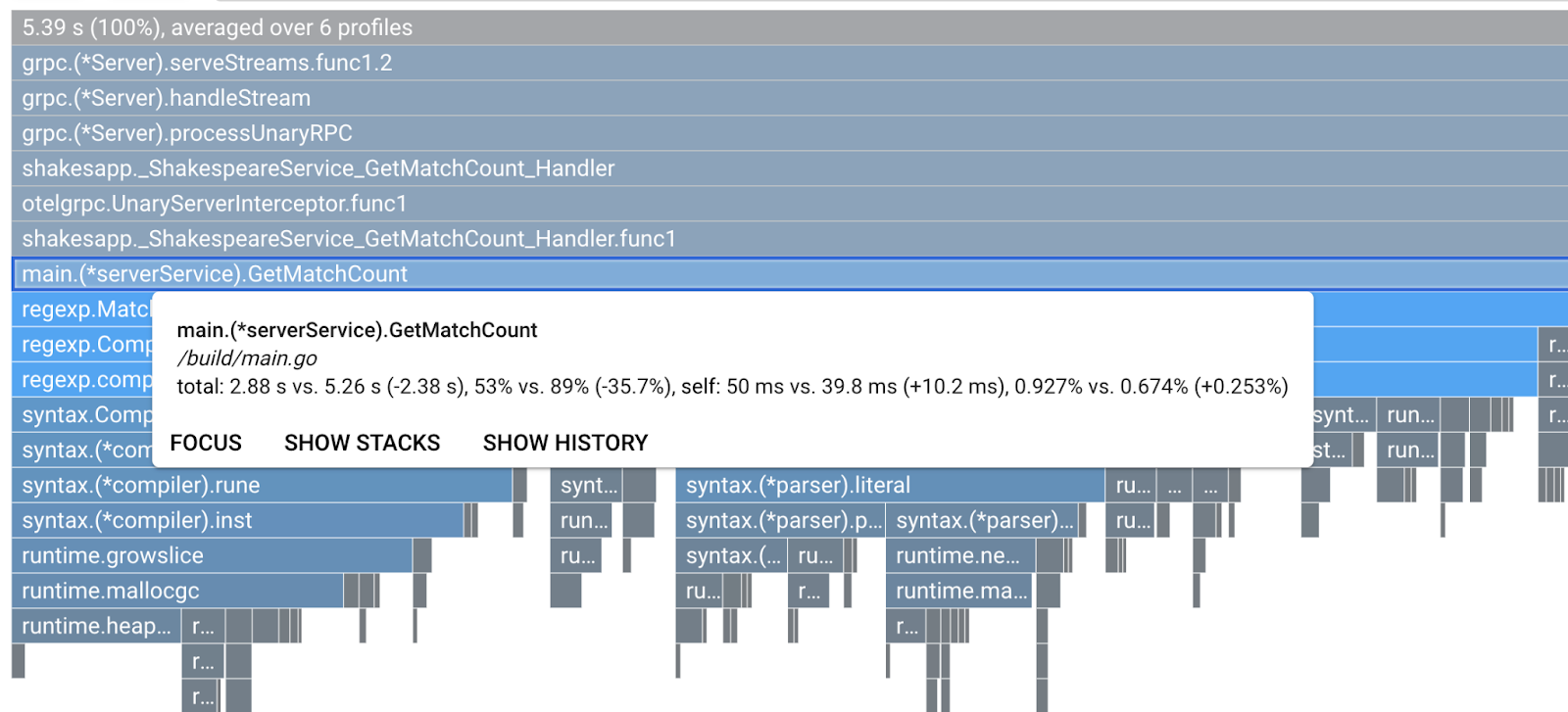
Indica che il tempo di CPU totale è ridotto da 5,26 secondi a 2,88 secondi (il totale è 10 secondi = finestra di campionamento). È un grande miglioramento.
Ora puoi migliorare le prestazioni dell'applicazione dall'analisi dei dati del profilo.
Riepilogo
In questo passaggio, hai apportato una modifica nel servizio server e hai confermato il miglioramento nella modalità di confronto di Cloud Profiler.
Avanti
Nel passaggio successivo, aggiornerai il codice sorgente del servizio server e confermerai la modifica dalla versione 1.0.0.
7. Passaggio aggiuntivo: conferma il miglioramento nella cascata di traccia
Differenza tra traccia distribuita e profilazione continua
Nella parte 1 del codelab, hai verificato di poter individuare il servizio collo di bottiglia tra i microservizi per un percorso di richiesta e di non poter individuare la causa esatta del collo di bottiglia nel servizio specifico. In questo codelab della seconda parte, hai imparato che la profilazione continua ti consente di identificare il collo di bottiglia all'interno del singolo servizio dagli stack di chiamate.
In questo passaggio, esaminiamo il grafico a cascata della traccia distribuita (Cloud Trace) e vediamo la differenza rispetto alla profilazione continua.
Questo grafico a cascata è una delle tracce con la query "love". Richiede circa 6,7 secondi (6700 ms) in totale.
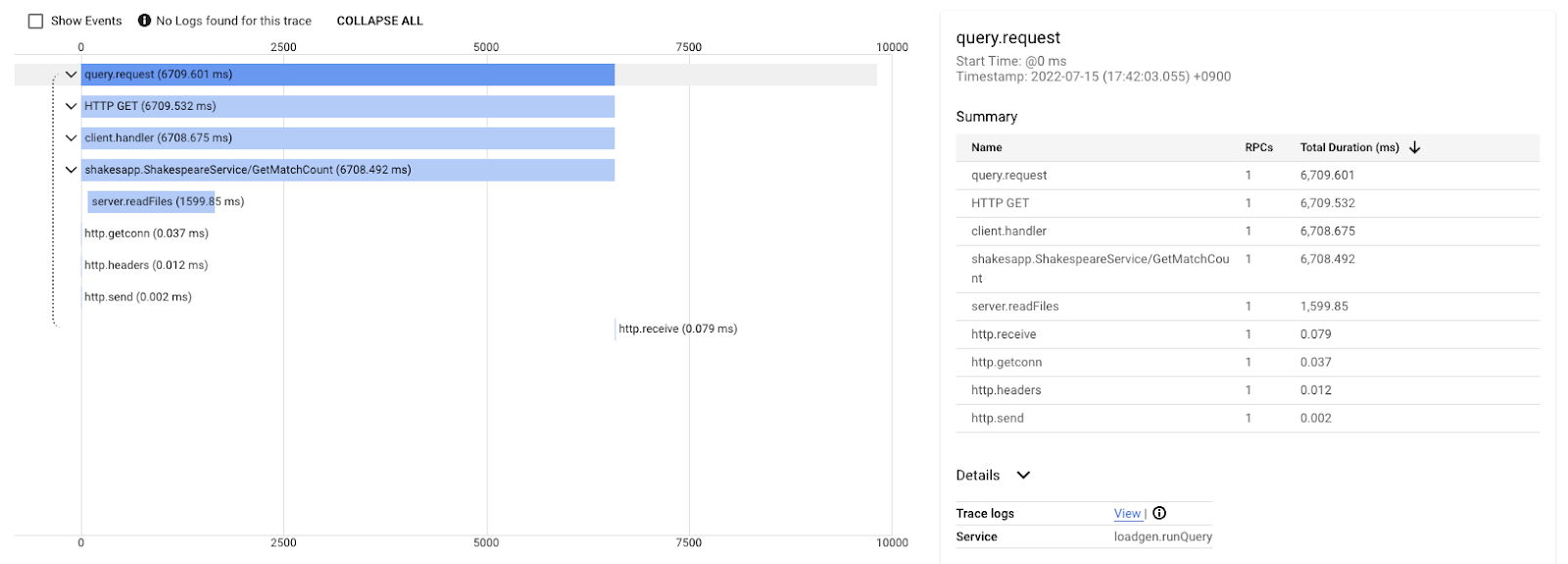
E questo è il risultato dopo il miglioramento per la stessa query. Come puoi notare, la latenza totale è ora di 1,5 secondi (1500 ms), un miglioramento enorme rispetto all'implementazione precedente.
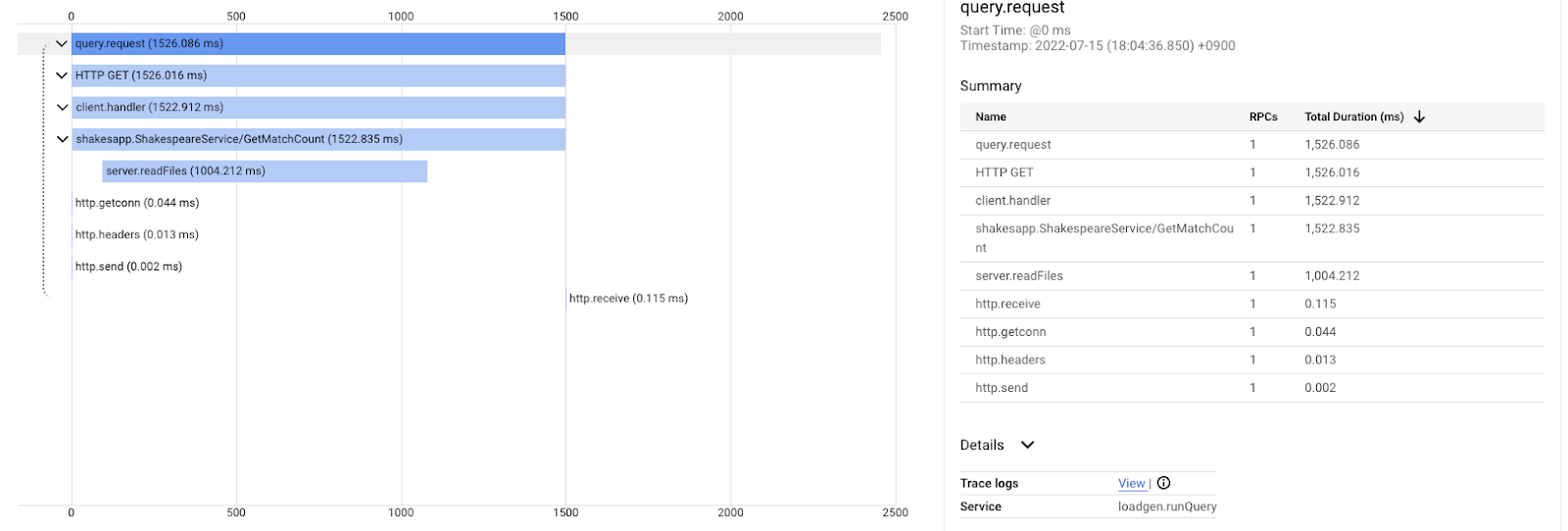
Il punto importante qui è che nel grafico a cascata della traccia distribuita, le informazioni sullo stack di chiamate non sono disponibili a meno che tu non strumentalizzi gli span ovunque. Inoltre, le tracce distribuite si concentrano solo sulla latenza tra i servizi, mentre la profilazione continua si concentra sulle risorse del computer (CPU, memoria, thread del sistema operativo) di un singolo servizio.
In un altro aspetto, la traccia distribuita è la base degli eventi, mentre il profilo continuo è statistico. Ogni traccia ha un grafico di latenza diverso e hai bisogno di un formato diverso, ad esempio la distribuzione, per ottenere la tendenza delle variazioni di latenza.
Riepilogo
In questo passaggio hai verificato la differenza tra la traccia distribuita e la profilazione continua.
8. Complimenti
Hai creato correttamente tracce distribuite con OpenTelemetry e hai confermato le latenze delle richieste nel microservizio su Google Cloud Trace.
Per esercizi più lunghi, puoi provare i seguenti argomenti da solo.
- L'implementazione attuale invia tutti gli span generati dal controllo di integrità. (
grpc.health.v1.Health/Check) Come si filtrano questi intervalli da Cloud Trace? Il suggerimento è disponibile qui. - Metti in correlazione i log eventi con gli intervalli e scopri come funziona su Google Cloud Trace e Google Cloud Logging. Il suggerimento è disponibile qui.
- Sostituisci un servizio con quello in un'altra lingua e prova a instrumentarlo con OpenTelemetry per quella lingua.
Inoltre, se vuoi saperne di più sul Profiler, passa alla parte 2. In questo caso, puoi saltare la sezione di pulizia riportata di seguito.
Pulizia
Al termine di questo codelab, arresta il cluster Kubernetes e assicurati di eliminare il progetto in modo da non ricevere addebiti imprevisti su Google Kubernetes Engine, Google Cloud Trace e Google Artifact Registry.
Innanzitutto, elimina il cluster. Se esegui il cluster con skaffold dev, devi solo premere Ctrl+C. Se esegui il cluster con skaffold run, esegui questo comando:
skaffold delete
Output comando
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
Dopo aver eliminato il cluster, seleziona "IAM e amministrazione" > "Impostazioni" dal riquadro del menu, quindi fai clic sul pulsante "CHIUDI".
Poi inserisci l'ID progetto (non il nome del progetto) nel modulo della finestra di dialogo e conferma l'arresto.