
1. Introducción
| Kubeflow es un kit de herramientas de aprendizaje automático para Kubernetes. El objetivo de este proyecto es que las implementaciones de flujos de trabajo de aprendizaje automático (AA) en Kubernetes sean simples, portátiles y escalables. El objetivo es proporcionar una forma directa de implementar sistemas de código abierto de primer nivel para AA en diversas infraestructuras. |
| Un flujo de trabajo de aprendizaje automático puede incluir muchos pasos con dependencias entre sí, desde la preparación y el análisis de datos hasta el entrenamiento, la evaluación, la implementación y mucho más. Es difícil componer y hacer un seguimiento de estos procesos de forma ad hoc (por ejemplo, en un conjunto de notebooks o secuencias de comandos), y aspectos como la auditoría y la reproducibilidad se vuelven cada vez más problemáticos.Kubeflow Pipelines (KFP) ayuda a resolver estos problemas, ya que proporciona una forma de implementar canalizaciones de aprendizaje automático repetibles y sólidas, junto con la supervisión, la auditoría, el seguimiento de versiones y la reproducibilidad. Cloud AI Pipelines facilita la configuración de una instalación de KFP. |


Qué compilarás
En este codelab, compilarás una app web que resuma los problemas de GitHub con Kubeflow Pipelines para entrenar y entregar un modelo. Se basa en un ejemplo del repositorio de ejemplos de Kubeflow. Cuando termine, su infraestructura contendrá lo siguiente:
- Un clúster de Google Kubernetes Engine (GKE) con Kubeflow Pipelines instalado (a través de Cloud AI Pipelines)
- Es una canalización que entrena un modelo de Tensor2Tensor en GPUs.
- Un contenedor de entrega que proporciona predicciones a partir del modelo entrenado
- Una IU que interpreta las predicciones para proporcionar resúmenes de los problemas de GitHub
- Notebook que crea una canalización desde cero con el SDK de Kubeflow Pipelines (KFP)
Qué aprenderás
La canalización que compilarás entrena un modelo de Tensor2Tensor con datos de problemas de GitHub, y aprende a predecir los títulos de los problemas a partir de sus cuerpos. Luego, exporta el modelo entrenado y lo implementa con TensorFlow Serving. El paso final de la canalización inicia una app web que interactúa con la instancia de TF-Serving para obtener predicciones del modelo.
- Cómo instalar Kubeflow Pipelines en un clúster de GKE
- Cómo compilar y ejecutar flujos de trabajo de AA con Kubeflow Pipelines
- Cómo definir y ejecutar canalizaciones desde un notebook de AI Platform
Requisitos
- Será útil tener conocimientos básicos de Kubernetes, pero no es obligatorio.
- Un proyecto de GCP activo para el que tienes permisos de propietario
- (Opcional) Una cuenta de GitHub
- Acceso a Google Cloud Shell, disponible en Google Cloud Platform (GCP) Console
2. Configuración
Cloud Shell
Visita GCP Console en el navegador y accede con las credenciales de tu proyecto:
Si es necesario, haz clic en "Seleccionar un proyecto" para trabajar con tu proyecto de codelab.

Luego, haz clic en el ícono "Activar Cloud Shell" en la parte superior derecha de la consola para iniciar un Cloud Shell.

Cuando inicies Cloud Shell, te indicará el nombre del proyecto que está configurado para usar. Verifica que este parámetro de configuración sea correcto.
Para encontrar el ID de tu proyecto, visita el panel principal de GCP Console. Si la pantalla está vacía, haz clic en "Sí" en el mensaje para crear un panel.

Luego, en la terminal de Cloud Shell, ejecuta estos comandos si es necesario para configurar gcloud de modo que use el proyecto correcto:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
Crea un bucket de almacenamiento
Crea un bucket de Cloud Storage para almacenar los archivos de la canalización. Deberás usar un ID único a nivel global, por lo que es conveniente definir un nombre de bucket que incluya el ID de tu proyecto. Crea el bucket con el comando gsutil mb (crear bucket):
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
Como alternativa, puedes crear un bucket a través de GCP Console.
Opcional**: Crea un token de GitHub**
En este codelab, se llama a la API de GitHub para recuperar datos disponibles públicamente. Para evitar el límite de frecuencia, especialmente en eventos en los que se envía una gran cantidad de solicitudes anonimizadas a las APIs de GitHub, configura un token de acceso sin permisos. El objetivo es simplemente autorizarlo como un individuo, en lugar de como un usuario anónimo.
- Navega a https://github.com/settings/tokens y genera un token nuevo sin permisos.
- Guárdalo en un lugar seguro. Si la pierdes, deberás borrarla y crear una nueva.
Si omites este paso, el lab seguirá funcionando, pero tendrás menos opciones para generar datos de entrada y probar tu modelo.
Opcional: Fija los paneles útiles
En GCP Console, fija los paneles de Kubernetes Engine y Storage para acceder a ellos con mayor facilidad.
Crea una instalación de AI Platform Pipelines (Kubeflow Pipelines alojado)
Sigue las instrucciones de las secciones "Antes de comenzar" y "Configura tu instancia" aquí para configurar una instancia de GKE con KFP instalado. Asegúrate de marcar la casilla Permitir el acceso a las siguientes APIs de Cloud, como se indica en la documentación. (Si no lo haces, la canalización de ejemplo no se ejecutará correctamente). Deja el espacio de nombres de instalación como default.
Deberás elegir una zona que admita las Nvidia K80. Puedes usar us-central1-a o us-central1-c como valores predeterminados.
Una vez que se complete la instalación, anota el nombre del clúster y la zona de GKE que se indican para tu instalación en el panel de AI Pipelines y, para mayor comodidad, establece variables de entorno en estos valores.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
Configura kubectl para usar las credenciales de tu nuevo clúster de GKE
Después de crear el clúster de GKE, configura kubectl para que use las credenciales del clúster nuevo. Para ello, ejecuta el siguiente comando en Cloud Shell:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
Como alternativa, haz clic en el nombre del clúster en el panel de AI Pipelines para visitar su página de GKE y, luego, haz clic en "Conectar" en la parte superior de la página. En la ventana emergente, pega el comando en Cloud Shell.
Esto configura tu contexto de kubectl para que puedas interactuar con tu clúster. Para verificar la configuración, ejecuta el siguiente comando:
kubectl get nodes -o wide
Deberías ver los nodos enumerados con el estado "Ready" y otra información sobre la antigüedad, la versión, la dirección IP externa, la imagen del SO, la versión del kernel y el tiempo de ejecución del contenedor del nodo.
Configura el clúster para instalar el controlador de Nvidia en los grupos de nodos habilitados para GPU
A continuación, aplicaremos un daemonset al clúster, que instalará el controlador de Nvidia en cualquier nodo del clúster habilitado para GPU:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Luego, ejecuta el siguiente comando, que otorga a los componentes de KFP permiso para crear recursos nuevos de Kubernetes:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
Crea un grupo de nodos de GPU
Luego, configuraremos un grupo de nodos de GPU con un tamaño de 1:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3. Ejecuta una canalización desde el panel de canalizaciones
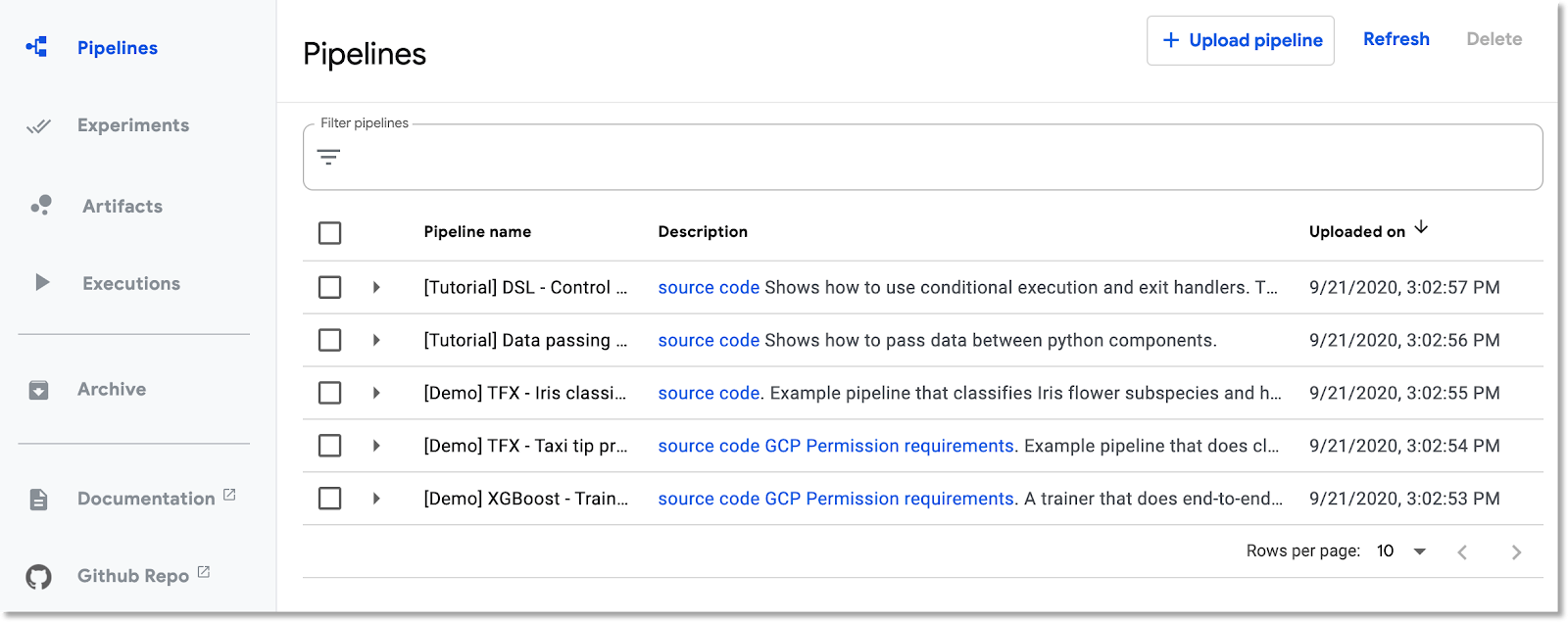
Abre el panel de canalizaciones
En la consola de Cloud, visita el panel de canalizaciones si aún no estás allí. A continuación, haz clic en "ABRIR PANEL DE CANALIZACIONES" para tu instalación y, luego, en Canalizaciones en la barra de menú de la izquierda. Si recibes un error de carga, actualiza la pestaña. Deberías ver una página nueva como esta:
Descripción de la canalización
La canalización que ejecutarás tiene varios pasos (consulta el Apéndice de este codelab para obtener más detalles):
- Se copia un punto de control del modelo existente en tu bucket.
- Se entrena un modelo de Tensor2Tensor con datos procesados previamente.
- El entrenamiento comienza desde el punto de control del modelo existente que se copió en el primer paso y, luego, se entrena durante unos cientos de pasos más. (Entrenarlo por completo durante el codelab llevaría demasiado tiempo).
- Cuando finaliza el entrenamiento, el paso de la canalización exporta el modelo en un formato adecuado para la entrega con TensorFlow Serving.
- Se implementa una instancia de TensorFlow Serving con ese modelo.
- Se inicia una app web para interactuar con el modelo publicado y recuperar predicciones.
Descarga y compila la canalización
En esta sección, veremos cómo compilar una definición de canalización. Lo primero que debemos hacer es instalar el SDK de KFP. Ejecuta lo siguiente en Cloud Shell:
pip3 install -U kfp
Para descargar el archivo de definición de la canalización, ejecuta este comando desde Cloud Shell:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
Luego, compila el archivo de definición de la canalización ejecutándolo de la siguiente manera:
python3 gh_summ_hosted_kfp.py
Verás el archivo gh_summ_hosted_kfp.py.tar.gz como resultado.
Sube la canalización compilada
En la IU web de Kubeflow Pipelines, haz clic en Upload pipeline y selecciona Import by URL. Copia y pega la siguiente URL, que apunta a la misma canalización que acabas de compilar. (Subir un archivo desde Cloud Shell requiere algunos pasos adicionales, por lo que tomaremos un atajo).
Asigna un nombre a la canalización (p.ej., gh_summ).

Ejecuta la canalización
Haz clic en la canalización subida en la lista (esto te permite ver el grafo estático de la canalización) y, luego, en Create experiment para crear un nuevo Experiment con la canalización. Un experimento es una forma de agrupar ejecuciones relacionadas semánticamente.

Asigna un nombre al experimento (p.ej., el mismo nombre que el de la canalización, gh_summ) y, luego, haz clic en Siguiente para crearlo.

Aparecerá una página en la que podrás ingresar los parámetros de una ejecución y comenzar.
Es posible que desees ejecutar los siguientes comandos en Cloud Shell para completar los parámetros.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
El nombre de la ejecución se completará automáticamente, pero puedes asignarle otro nombre si lo deseas.
Luego, completa tres campos de parámetros:
project- (opcional)
github-token working-dir
Para working-dir, ingresa alguna ruta en el bucket de GCS que creaste. Incluye el prefijo “gs://”. En el campo github-token, ingresa el token que generaste de forma opcional anteriormente o deja la cadena de marcador de posición tal como está si no generaste un token.

Después de completar los campos, haz clic en Start y, luego, en la ejecución que aparece en la lista para ver sus detalles. Mientras se ejecuta un paso de la canalización, puedes hacer clic en él para obtener más información, incluidos los registros del pod. (También puedes ver los registros de un paso de la canalización a través del vínculo a sus registros de Cloud Logging (Stackdriver), incluso si se desmanteló el nodo del clúster).

Cómo ver la definición de la canalización
Mientras se ejecuta la canalización, es posible que desees analizar con más detalle cómo se arma y qué hace. Encontrarás más detalles en la sección Apéndice del codelab.
Cómo ver la información del entrenamiento del modelo en TensorBoard
Una vez que se complete el paso de entrenamiento, selecciona la pestaña Visualizaciones y haz clic en el botón azul Iniciar TensorBoard. Luego, cuando esté listo, haz clic en Abrir TensorBoard.
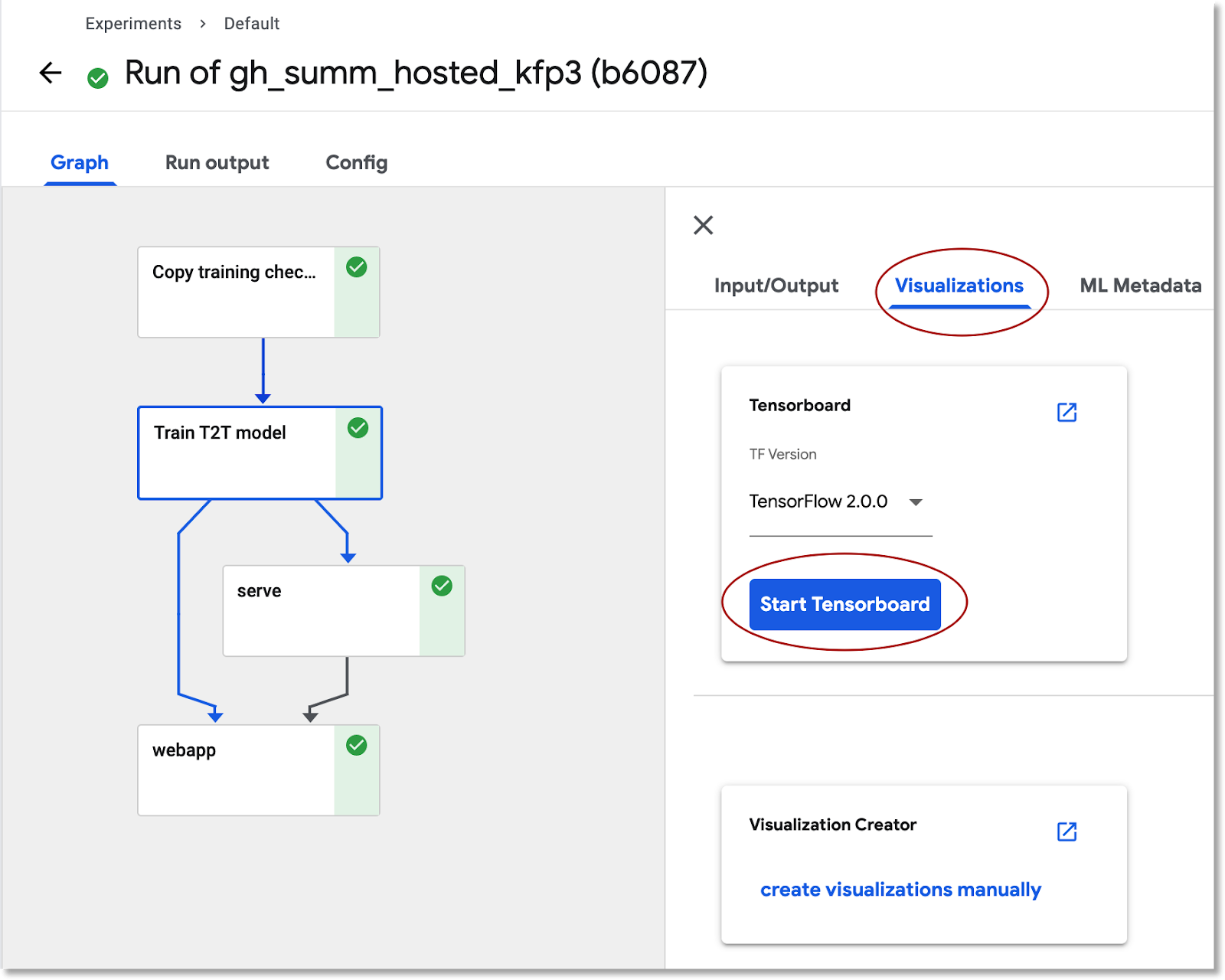
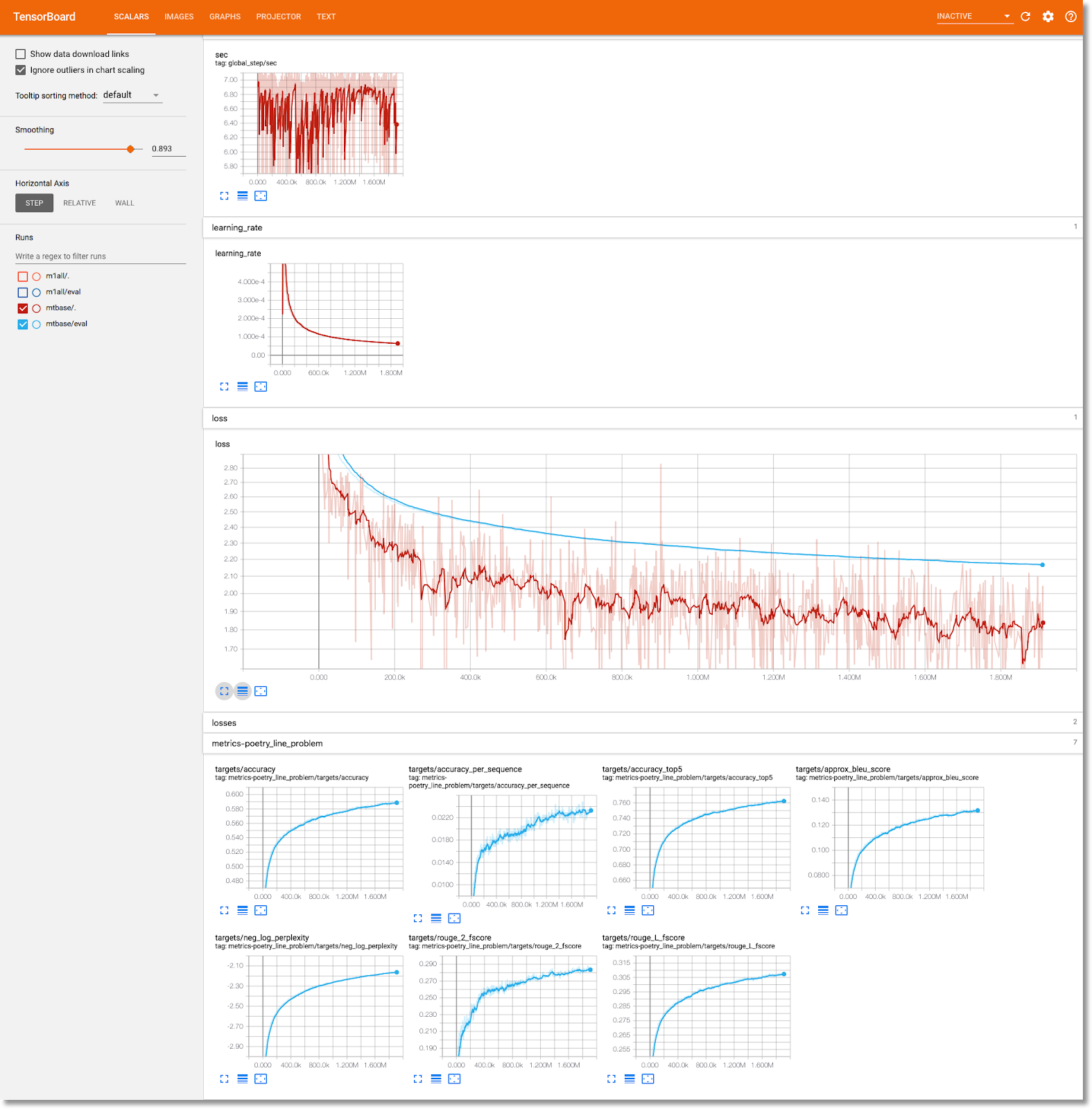
Explora el panel de artefactos y ejecuciones
Kubeflow Pipelines registra automáticamente los metadatos sobre los pasos de la canalización a medida que se ejecuta. Se registra la información de Artifact y Execution. Haz clic en estas entradas en la barra de navegación izquierda del panel para explorar más.

En el caso de los artefactos, puedes ver un panel de descripción general y un panel del Explorador de linaje.


Abre la app web creada por la canalización y haz algunas predicciones
El último paso de la canalización implementa una app web que proporciona una IU para consultar el modelo entrenado (entregado a través de TF Serving) y realizar predicciones.
Una vez que se complete la canalización, conéctate a la app web a través de la redirección de puertos a su servicio (redireccionamos puertos porque, para este codelab, el servicio de la app web no está configurado para tener un extremo externo).
Para encontrar el nombre del servicio, ejecuta este comando en Cloud Shell:
kubectl get services
Busca un nombre de servicio como este: ghsumm-*-webappsvc en la lista.
Luego, en Cloud Shell, reenvía el puerto a ese servicio de la siguiente manera, cambiando el siguiente comando para usar el nombre de tu webappsvc:
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
Una vez que se ejecute el reenvío de puertos, haz clic en el ícono de "vista previa" que se encuentra sobre el panel de Cloud Shell y, en el menú desplegable, haz clic en "Vista previa en el puerto 8080".

Deberías ver una página como esta en una pestaña nueva:

Haz clic en el botón Propagar problema aleatorio para recuperar un bloque de texto. Haz clic en Generar título para llamar al modelo entrenado y mostrar una predicción.

Si los parámetros de tu canalización incluían un token de GitHub válido, puedes intentar ingresar una URL de GitHub en el segundo campo y, luego, hacer clic en "Generar título". Si no configuraste un token de GitHub válido, usa solo el campo "Populate Random Issue".
4. Ejecuta una canalización desde un notebook de AI Platform
También puedes definir y ejecutar Kubeflow Pipelines de forma interactiva desde un notebook de Jupyter con el SDK de KFP. AI Platform Notebooks, que usaremos para este codelab, facilita mucho este proceso.
Crea una instancia de notebook
Crearemos una instancia de notebook desde Cloud Shell con su API. (Como alternativa, puedes crear un notebook a través de la consola de Cloud. Consulta la documentación para obtener más información).
Establece las siguientes variables de entorno en Cloud Shell:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
Luego, desde Cloud Shell, ejecuta el comando para crear la instancia de notebook:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
La primera vez que ejecutes este comando, es posible que se te solicite que habilites la API de notebooks para tu proyecto. Si es así, responde “y”.
Después de unos minutos, el servidor de notebooks estará en funcionamiento. Puedes ver tus instancias de Notebooks en la lista de la consola de Cloud.

Sube el notebook del codelab
Después de crear la instancia de notebook, haz clic en este vínculo para subir el notebook de Jupyter del codelab. Selecciona la instancia de notebook que deseas usar. El notebook se abrirá automáticamente.
Ejecuta el notebook
Sigue las instrucciones del notebook durante el resto del lab. Ten en cuenta que, en la parte de "Configuración" del notebook, deberás completar tus propios valores antes de ejecutar el resto del notebook.
(Si usas tu propio proyecto, no olvides volver y completar la sección "Haz una limpieza" de este lab).
5. Limpia
No es necesario que lo hagas si usas una cuenta temporal de codelab, pero es posible que desees quitar la instalación de Pipelines y el notebook si usas tu propio proyecto.
Desactiva el clúster de GKE de Pipelines
Puedes borrar el clúster de Pipelines desde la consola de Cloud. (Tienes la opción de borrar solo la instalación de Pipelines si deseas volver a usar el clúster de GKE).
Borra la instancia de AI Notebook
Si ejecutaste la parte de "Notebook" del codelab, puedes BORRAR o DETENER la instancia de notebook desde la consola de Cloud.
Opcional: Quita el token de GitHub
Navega a https://github.com/settings/tokens y quita el token generado.
6. Apéndices
Un vistazo al código
Cómo definir la canalización
La canalización que se usa en este codelab se define aquí.
Veamos cómo se define y cómo se definen sus componentes (pasos). Cubriremos algunos aspectos destacados, pero consulta la documentación para obtener más detalles.
Los pasos de Kubeflow Pipeline se basan en contenedores. Cuando compilas una canalización, puedes usar componentes prediseñados, con imágenes de contenedor ya compiladas, o bien compilar tus propios componentes. Para este codelab, creamos nuestro propio objeto.
Cuatro de los pasos de la canalización se definen a partir de componentes reutilizables, a los que se accede a través de sus archivos de definición de componentes. En el primer fragmento de código, accedemos a estos archivos de definición de componentes a través de su URL y usamos estas definiciones para crear "operaciones" que usaremos para crear un paso de canalización.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
A continuación, se muestra una de las definiciones de componentes, para la operación de entrenamiento, en formato YAML. Puedes ver que se definen sus entradas, salidas, imagen de contenedor y argumentos de entrypoint del contenedor.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
También puedes definir un paso de la canalización a través del constructor dsl.ContainerOp, como veremos a continuación.
A continuación, se muestra la mayor parte de la definición de la canalización. Definimos las entradas de la canalización (y sus valores predeterminados). Luego, definimos los pasos de la canalización. Para la mayoría, usamos la "operación" definida anteriormente, pero también definimos un paso "serve" intercalado a través de ContainerOp, especificando la imagen del contenedor y los argumentos del punto de entrada directamente.
Puedes ver que los pasos train, log_model y serve acceden a los resultados de los pasos anteriores como entradas. Puedes obtener más información sobre cómo se especifica aquí.
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
Ten en cuenta que requerimos que el paso "train" se ejecute en un nodo del clúster que tenga al menos 1 GPU disponible.
train.set_gpu_limit(1)
El último paso de la canalización, que también se define de forma intercalada, es condicional. Se ejecutará después de que finalice el paso “serve”, solo si el resultado del paso de entrenamiento launch_server es la cadena “true”. Se inicia la "app web de predicción" que usamos para solicitar resúmenes de problemas del modelo T2T entrenado.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
Las definiciones de imágenes de contenedor de componentes
En la documentación de Kubeflow Pipelines, se describen algunas prácticas recomendadas para compilar tus propios componentes. Como parte de este proceso, deberás definir y compilar una imagen de contenedor. Puedes ver los pasos del componente de la canalización de este codelab aquí. Las definiciones de Dockerfile se encuentran en los subdirectorios containers, p.ej., aquí.
Usa VMs interrumpibles con GPUs para el entrenamiento
Las VMs interrumpibles son instancias de VM de Compute Engine que duran un máximo de 24 horas y no proporcionan garantías de disponibilidad. El precio de las VM interrumpibles es más bajo que el de las VM estándar de Compute Engine.
Con Google Kubernetes Engine (GKE), es fácil configurar un clúster o un grupo de nodos que use VMs interrumpibles. Puedes configurar un grupo de nodos de este tipo con GPUs conectadas a las instancias interrumpibles. Estos nodos funcionan de la misma manera que los nodos normales habilitados para GPU, pero las GPU persisten solo durante la vida útil de la instancia.
Para configurar un grupo de nodos interrumpibles habilitado para GPU para tu clúster, ejecuta un comando similar al siguiente, edita el siguiente comando con el nombre y la zona de tu clúster, y ajusta el tipo y el recuento de aceleradores según tus requisitos. De manera opcional, puedes definir el grupo de nodos para que se ajuste automáticamente según las cargas de trabajo actuales.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
También puedes configurar un grupo de nodos a través de la consola de Cloud.
Cómo definir una canalización de Kubeflow que usa los nodos de GKE interrumpibles
Si ejecutas Kubeflow en GKE, ahora es fácil definir y ejecutar Kubeflow Pipelines en los que uno o más pasos de la canalización (componentes) se ejecutan en nodos interrumpibles, lo que reduce el costo de ejecutar un trabajo. Para que el uso de VMs interrumpibles arroje resultados correctos, los pasos que identifiques como interrumpibles deben ser idempotentes (es decir, si ejecutas un paso varias veces, tendrá el mismo resultado) o deben crear puntos de control del trabajo para que el paso pueda continuar donde lo dejó si se interrumpe.
Cuando defines una canalización de Kubeflow, puedes indicar que un paso determinado se debe ejecutar en un nodo interrumpible. Para ello, modifica la operación de la siguiente manera:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
Consulta la documentación para obtener más detalles.
Presumiblemente, también querrás reintentar el paso varias veces si se interrumpe el nodo. Puedes hacerlo de la siguiente manera. Aquí especificamos 5 reintentos.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
Intenta editar la canalización de Kubeflow que usamos en este codelab para ejecutar el paso de entrenamiento en una VM interrumpible.
Cambia la siguiente línea en la especificación de la canalización para usar también un grupo de nodos interrumpible (asegúrate de haber creado uno como se indicó anteriormente) y volver a intentarlo 5 veces:
train.set_gpu_limit(1)
Luego, vuelve a compilar la canalización, sube la versión nueva (asígnale un nombre nuevo) y, luego, ejecuta la versión nueva de la canalización.