
1. Introduction
Document AI est une solution de reconnaissance de documents qui exploite des données non structurées, telles que des documents et des e-mails, et en facilite la compréhension, l'analyse et l'utilisation.
Document AI Workbench vous permet d'améliorer la précision du traitement des documents en créant des modèles entièrement personnalisés à l'aide de vos propres données d'entraînement.
Dans cet atelier, vous allez créer un processeur d'extraction de document personnalisé, importer un ensemble de données, étiqueter des exemples de document et entraîner le processeur.
L'ensemble de données de document utilisé dans cet atelier provient d'un faux W-2 (formulaire fiscal américain), disponible sur Kaggle, et dispose d'une licence CC0 : domaine public.
Prérequis
Cet atelier s'appuie sur le contenu présenté dans d'autres ateliers de programmation Document AI.
Nous vous recommandons d'effectuer les ateliers de programmation suivants avant de continuer.
- Reconnaissance optique des caractères (ROC) avec Document AI et Python
- Analyse de formulaire avec Document AI et Python
- Outils de traitement spécialisés avec Document AI et Python
- Gérer les processeurs Document AI avec Python
- Document AI : human-in-the-loop (avec intervention humaine)
- Document AI : surentraînement
Points abordés
- Créer un processeur d'extraction de document personnalisé
- Étiqueter les données d'entraînement Document AI à l'aide d'un outil d'annotation
- Entraîner une nouvelle version du modèle
- Évaluer la justesse de la nouvelle version du modèle
Ce dont vous aurez besoin
2. Préparation
Cet atelier de programmation suppose que vous avez effectué les étapes de configuration de Document AI présentées dans l'atelier de programmation d'introduction.
Veuillez effectuer les étapes suivantes avant de continuer :
3. Créer un processeur
Vous devez d'abord créer un processeur d'extraction de document personnalisé que vous allez utiliser pour cet atelier.
- Dans la console, accédez à la page Présentation de Document AI.

- Cliquez sur Créer un processeur personnalisé, puis sélectionnez Extracteur de document personnalisé.

- Donnez-lui le nom
codelab-custom-extractor(ou un autre nom facile à mémoriser), puis sélectionnez la région la plus proche sur la liste.

- Cliquez sur Créer pour créer le processeur. Vous devriez alors voir la page de présentation du processeur.

4. Créer un ensemble de donnée
Pour entraîner notre processeur, nous devons créer un ensemble de données avec des données d'entraînement et de test pour que le processeur puisse identifier les entités que nous voulons extraire.
- Sur la page "Présentation du processeur", cliquez sur Configurer votre ensemble de données.
- La page Configurer l'ensemble de données s'affiche. Si vous souhaitez spécifier votre propre bucket pour stocker les documents et les libellés d'entraînement, cliquez sur Afficher les options avancées. Sinon, cliquez simplement sur Continuer.

- Attendez que l'ensemble de données soit créé. Vous serez ensuite redirigé vers la page Entraînement.

5. Importer un document de test
Importons maintenant un exemple de W2 au format PDF dans notre ensemble de données.
- Cliquez sur Importer des documents

- Vous avez la possibilité d'utiliser un exemple de PDF que nous avons mis à votre disposition pour cet atelier. Copiez et collez le lien suivant dans la zone Chemin source. Conservez "Non attribué" dans la zone "Répartition des données" pour le moment. Ne cochez pas les autres cases. Cliquez sur Importer.
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs

- Attendez que le document soit importé. Cela devrait prendre moins d'une minute.
- Une fois l'importation terminée, vous devriez voir le document sur la page Entraînement.
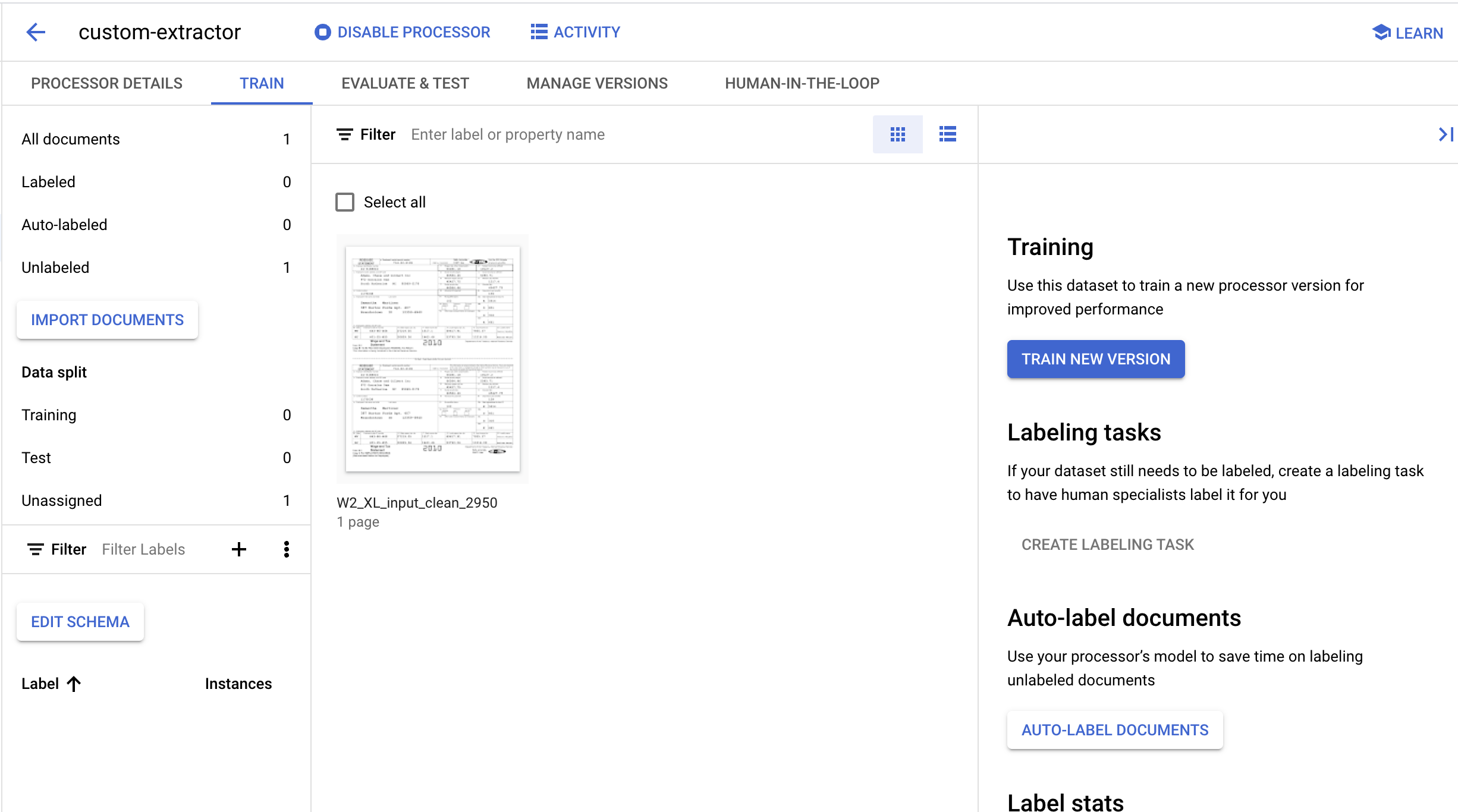
6. Créer des étiquettes
Puisque nous créons un nouveau type de processeur, nous devons créer des étiquettes personnalisées pour indiquer à Document AI les champs à extraire.
- Cliquez sur Modifier le schéma en bas à gauche.

- Vous devriez à présent vous trouver dans la console de gestion des schémas.

- Créez les libellés suivants à l'aide du bouton Créer un libellé.
Nom | Type de données | Occurrence |
| Nombre | Obligatoire multiple |
| Texte brut | Obligatoire multiple |
| Texte brut | Obligatoire multiple |
| Adresse | Obligatoire multiple |
| Valeur monétaire | Obligatoire multiple |
| Valeur monétaire | Obligatoire multiple |
| Valeur monétaire | Obligatoire multiple |
| Valeur monétaire | Obligatoire multiple |
- Une fois l'opération terminée, la console doit ressembler à ceci. Lorsque vous avez terminé, cliquez sur Enregistrer.

- Cliquez sur la flèche de retour pour revenir à la page Entraînement. Les étiquettes que nous avons créées sont affichées en bas à gauche.

7. Étiqueter le document de test
Nous allons ensuite identifier les étiquettes et les éléments de texte pour les entités que nous souhaitons extraire. Ces étiquettes seront utilisées pour entraîner notre modèle à analyser cette structure de document spécifique et identifier les types corrects.
- Double-cliquez sur le document que nous avons importé précédemment pour accéder à la console d'étiquetage. L'aperçu devrait ressembler à ceci.

- Cliquez sur l'outil "Cadre de délimitation", puis mettez le texte "1173038" en surbrillance et attribuez l'étiquette
CONTROL_NUMBER. Vous pouvez utiliser le filtre "Texte" pour rechercher des noms d'étiquettes.

- Procédez de la même façon pour l'autre instance de
CONTROL_NUMBER. Une fois l'étiquetage terminé, la page devrait ressembler à ceci.

- Mettez en surbrillance toutes les instances des valeurs de texte suivantes et attribuez les étiquettes appropriées.
Nom de l'étiquette | Texte |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
- Une fois l'opération terminée, le document étiqueté devrait ressembler à ceci. Vous pouvez ajuster ces étiquettes en cliquant sur le cadre de délimitation dans le document ou sur la valeur/le nom de l'étiquette dans le menu de gauche. Une fois l'étiquetage terminé, cliquez sur Marquer comme étiqueté, puis revenez à la console de gestion des ensembles de données.
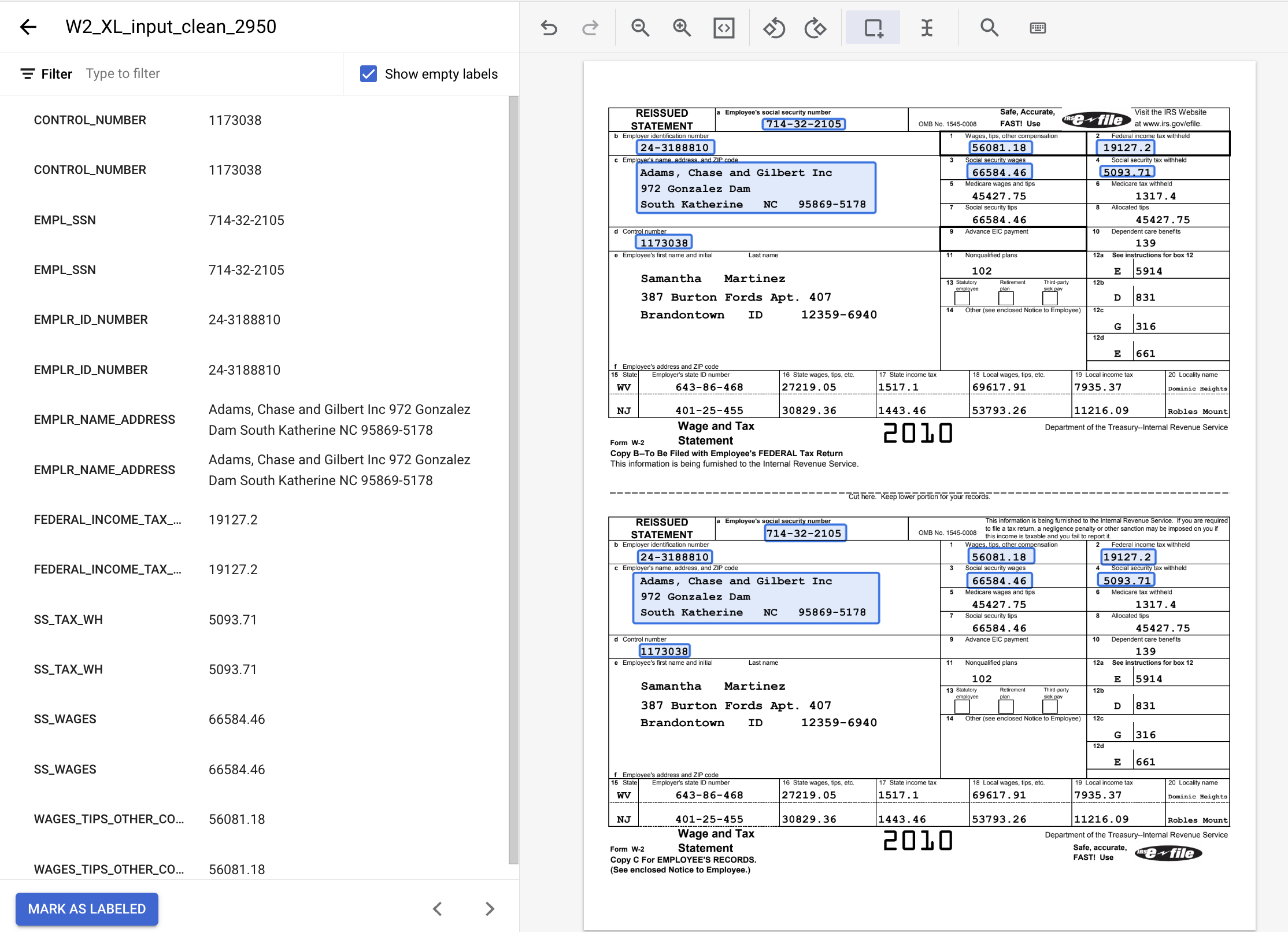
8. Attribuer le document à un ensemble d'entraînement
Vous devriez maintenant être de retour dans la console de gestion des ensemble données. Notez que le nombre de documents étiquetés et non étiquetés, et le nombre d'instances par étiquette a changé.

- Nous devons attribuer ce document à l'ensemble "Entraînement" ou "Test". Cliquez sur le document, puis sur Attribuer pour définir et sélectionnez Entraînement.

- Notez que les nombres dans la zone "Répartitions des données" ont changé.

9. Importer des données préalablement étiquetées
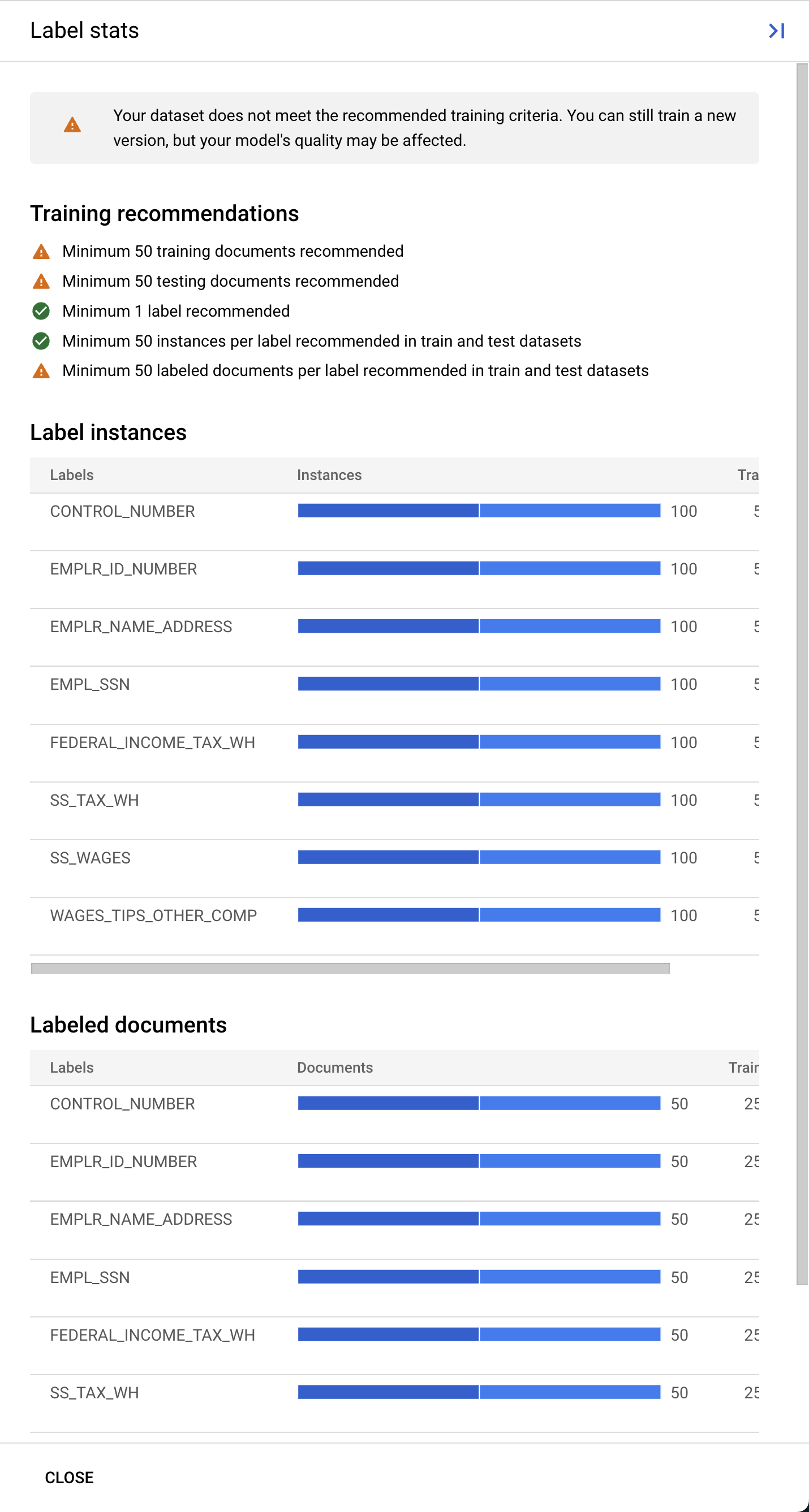
Les processeurs personnalisés de Document AI nécessitent au moins 10 documents dans les ensembles d'entraînement et de test, ainsi que 10 instances de chaque étiquette dans chaque ensemble.
Pour des performances optimales, nous vous recommandons d'avoir au moins 50 documents dans chaque ensemble, avec 50 instances de chaque étiquette. Généralement, plus la quantité de données d'entraînement est élevée, plus la précision est élevée.
Étiqueter manuellement tous les documents prend beaucoup de temps. Nous avons donc mis à votre disposition des documents préalablement étiquetés que vous pouvez importer pour cet atelier.
Vous pouvez importer les fichiers des documents préalablement étiquetés au format Document.json. Ils peuvent résulter de l'appel d'un processeur et de la vérification de la justesse à l'aide de human-in-the-loop (avec intervention humaine, HITL).
aside negative
REMARQUE : Lorsque vous importez les données préalablement étiquetées, il est fortement recommandé d'examiner manuellement les annotations avant qu'un modèle ne soit entraîné.
- Cliquez sur Importer des documents.

- Copiez et collez le chemin d'accès Cloud Storage suivant et attribuez-le à l'ensemble Entraînement.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- Cliquez sur Ajouter un autre dossier. Copiez et collez ensuite le chemin d'accès Cloud Storage suivant et attribuez-le à l'ensemble Test.
cloud-samples-data/documentai/codelabs/custom/extractor/test

- Cliquez sur Importer et attendez que les documents soient importés. L'importation nécessitera plus de temps que précédemment, car il y a davantage de documents à traiter. Cette opération devrait prendre environ six minutes. Vous pouvez quitter cette page et y revenir plus tard.
- Une fois l'opération terminée, vous devriez voir les documents sur la page Entraînement.

10. Entraîner le modèle
Nous sommes maintenant prêts à entraîner notre extracteur de document personnalisé.
- Cliquez sur Entraîner une nouvelle version.

- Attribuez un nom à votre version, tel que
codelab-custom-1. Pour "Méthode d'entraînement", sélectionnez "Entraînement à partir de zéro".
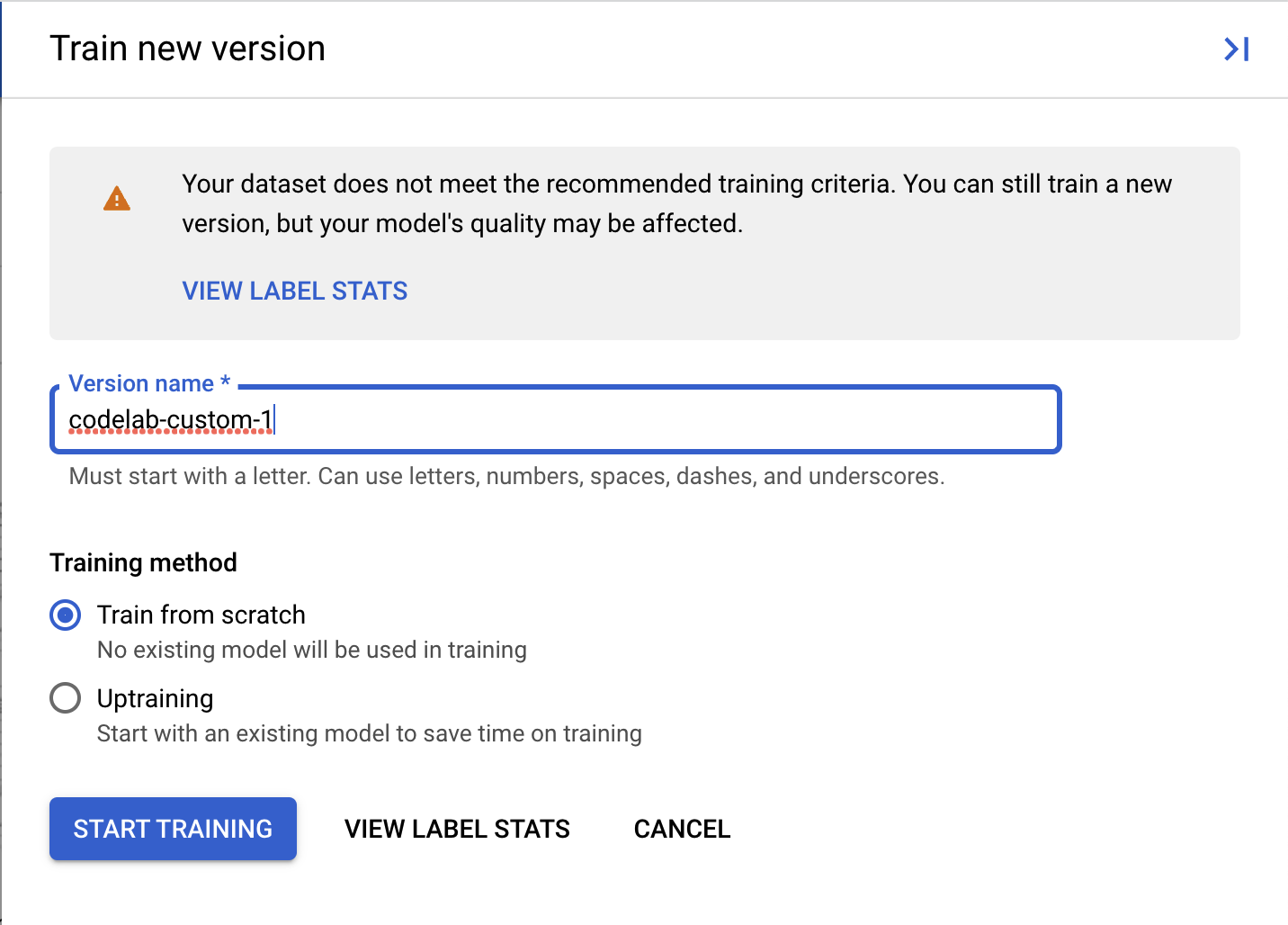
- (Facultatif) Vous pouvez également sélectionner Afficher les métriques relatives aux étiquettes pour afficher les métriques sur les étiquettes de votre ensemble de données.
- Cliquez sur Démarrer l'entraînement pour commencer le processus d'entraînement. Vous devriez être redirigé vers la page de gestion des ensembles de données. Vous pouvez consulter l'état de l'entraînement sur la droite. L'entraînement prendra quelques heures. Vous pouvez quitter cette page et y revenir plus tard.
- Si vous cliquez sur le nom de la version, vous serez redirigé vers la page Gérer les versions, qui indique l'ID de version et l'état actuel du job d'entraînement.

11. Tester la nouvelle version du modèle
Une fois le job d'entraînement terminé (au bout d'une heure environ pendant mes tests), vous pouvez tester la nouvelle version du modèle et commencer à l'utiliser pour obtenir des prédictions.
- Accédez à la page Gérer les versions. Vous pouvez voir l'état actuel et le score F1.
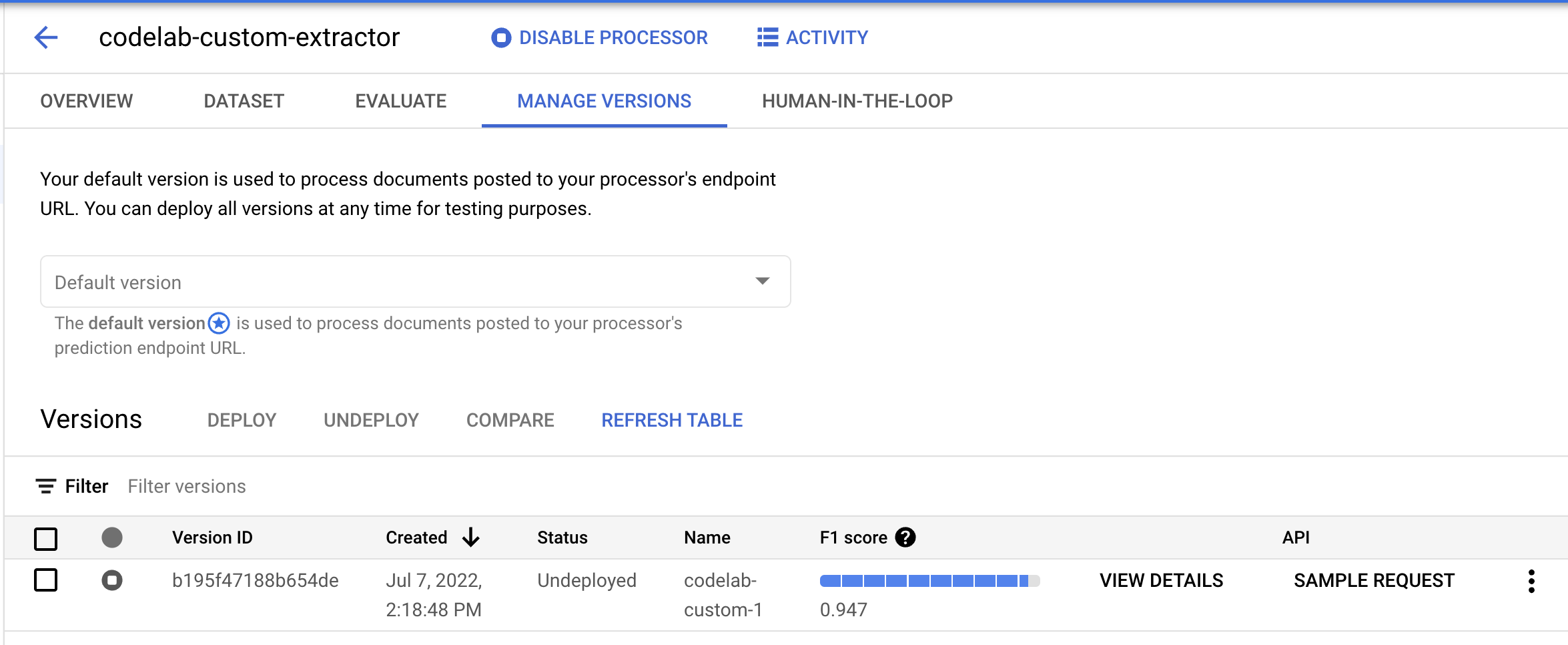
- Vous devrez déployer cette version du modèle avant de pouvoir l'utiliser. Cliquez sur les trois points verticaux à droite et sélectionnez Déployer la version.

- Sélectionnez Déployer dans la fenêtre pop-up, puis attendez que la version soit déployée. Cette opération prend quelques minutes. Une fois le déploiement terminé, vous pouvez également définir cette version comme celle par défaut.

- Après le déploiement, accédez à l'onglet Évaluation. Sur cette page, vous pouvez consulter les métriques d'évaluation, y compris le score F1, la précision et le rappel du document complet, ainsi que des étiquettes individuelles. Pour en savoir plus sur ces métriques, consultez la documentation AutoML.

- Téléchargez le fichier PDF en lien ci-dessous. Il s'agit d'un exemple de formulaire W2 qui n'était pas inclus dans l'entraînement ou l'ensemble de test.
- Cliquez sur Importer un document de test et sélectionnez le fichier PDF.
- Les entités extraites devraient ressembler à ceci.

12. Facultatif : Étiqueter automatiquement les nouveaux documents importés
Après avoir déployé une version de processeur entraînée, vous pouvez utiliser l'étiquetage automatique pour gagner du temps sur l'étiquetage lorsque vous importez de nouveaux documents.
- Sur la page Entraînement, cliquez sur Importer des documents.
- Copiez et collez le chemin d'accès suivant. Ce répertoire contient 5 PDF W2 sans étiquette. Dans la liste déroulante Répartition des données, sélectionnez Entraînement.
cloud-samples-data/documentai/Custom/W2/AutoLabel - Dans la section Étiquetage automatique, cochez la case Importer avec l'étiquetage automatique.
- Sélectionnez une version existante du processeur pour étiqueter les documents.
- Par exemple :
2af620b2fd4d1fcf
- Cliquez sur Importer et attendez que les documents soient importés. Vous pouvez quitter cette page et y revenir plus tard.
- Une fois l'opération terminée, les documents s'affichent sur la page Entraînement de la section Étiquette automatique.
- Vous ne pouvez pas utiliser de documents étiquetés automatiquement pour l'entraînement ou les tests sans les marquer comme étiquetés. Accédez à la section Étiquette automatique pour afficher les documents étiquetés automatiquement.
- Sélectionnez le premier document pour accéder à la console d'étiquetage.
- Vérifiez que les étiquettes, les cadres de délimitation et les valeurs sont corrects. Attribuez une étiquette aux valeurs omises.
- Lorsque vous avez terminé, sélectionnez Marquer comme étiqueté.
- Répétez la validation des étiquettes pour chaque document étiqueté automatiquement, puis revenez à la page Entraînement pour utiliser les données pour l'entraînement.
13. Conclusion
Félicitations, vous avez utilisé Document AI pour entraîner un processeur d'extraction de document personnalisé. Vous pouvez désormais utiliser ce processeur pour analyser des documents dans ce format, exactement comme vous le feriez avec tout processeur spécialisé.
Vous pouvez consulter l'atelier de programmation sur les processeurs spécialisés pour découvrir comment gérer la réponse de traitement.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez votre projet, puis cliquez sur "Supprimer".
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur "Arrêter" pour supprimer le projet.
Ressources
- Documentation sur Document AI Workbench
- The Future of Documents - YouTube Playlist
- Documentation Document AI
- Bibliothèque cliente Python Document AI
- Exemples Document AI
Licence
Ce document est publié sous une licence Creative Commons Attribution 2.0 Generic.