
1. מבוא
Document AI הוא פתרון להבנת מסמכים שמקבל נתונים לא מובנים, כמו מסמכים, אימיילים וכו', והופך את הנתונים לקלים יותר להבנה, לניתוח ולשימוש.
בעזרת Document AI Workbench, אתם יכולים ליצור מודלים בהתאמה אישית מלאה באמצעות נתוני האימון שלכם, וכך להשיג רמת דיוק גבוהה יותר בעיבוד מסמכים.
בשיעור ה-Lab הזה תיצרו מעבד מותאם אישית לחילוץ מסמכים, תייבאו מערך נתונים, תתייגו מסמכים לדוגמה ותאמנו את המעבד.
מערך הנתונים של המסמכים שבו נעשה שימוש בשיעור ה-Lab הזה הוא מתוך מערך הנתונים Fake W-2 (US Tax Form) ב-Kaggle עם רישיון CC0: Public Domain.
דרישות מוקדמות
ה-Codelab הזה מבוסס על תוכן שמוצג ב-Codelabs אחרים של Document AI.
מומלץ להשלים את ה-Codelabs הבאים לפני שממשיכים.
- זיהוי תווים אופטי (OCR) באמצעות Document AI (Python)
- ניתוח טפסים באמצעות Document AI (Python)
- מעבדים ייעודיים עם Document AI (Python)
- ניהול מעבדים של Document AI באמצעות Python
- Document AI: האדם שבתהליך
- Document AI: Uptraining
מה תלמדו
- יוצרים מעבד Custom Document Extractor.
- מתייגים נתוני אימון של Document AI באמצעות כלי ההערות.
- מאמנים גרסה חדשה של המודל.
- בודקים את רמת הדיוק של גרסת המודל החדשה.
מה תצטרכו
2. תהליך ההגדרה
ב-Codelab הזה מניחים שהשלמתם את שלבי ההגדרה של Document AI שמפורטים ב-Codelab המבואי.
לפני שממשיכים, צריך לבצע את הפעולות הבאות:
3. יצירת מעבד
כדי להשתמש בשיעור ה-Lab הזה, צריך קודם ליצור מעבד Custom Document Extractor.
- במסוף, עוברים לדף סקירת AI של Document AI.
- לוחצים על Create Custom Processor (יצירת מעבד בהתאמה אישית) ובוחרים באפשרות Custom Document Extractor (מחולץ מסמכים בהתאמה אישית).
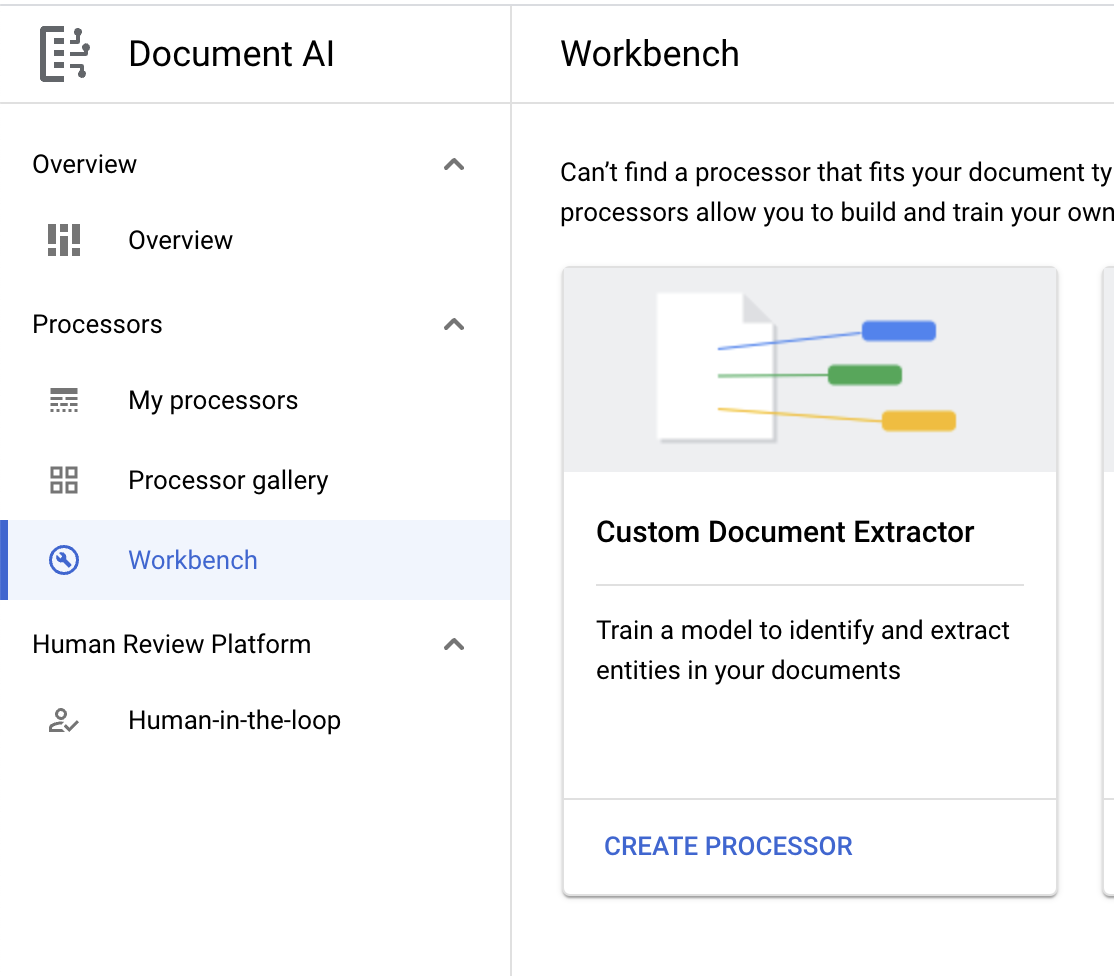
- נותנים לו את השם
codelab-custom-extractor(או שם אחר שתזכרו) ובוחרים את האזור הכי קרוב ברשימה.
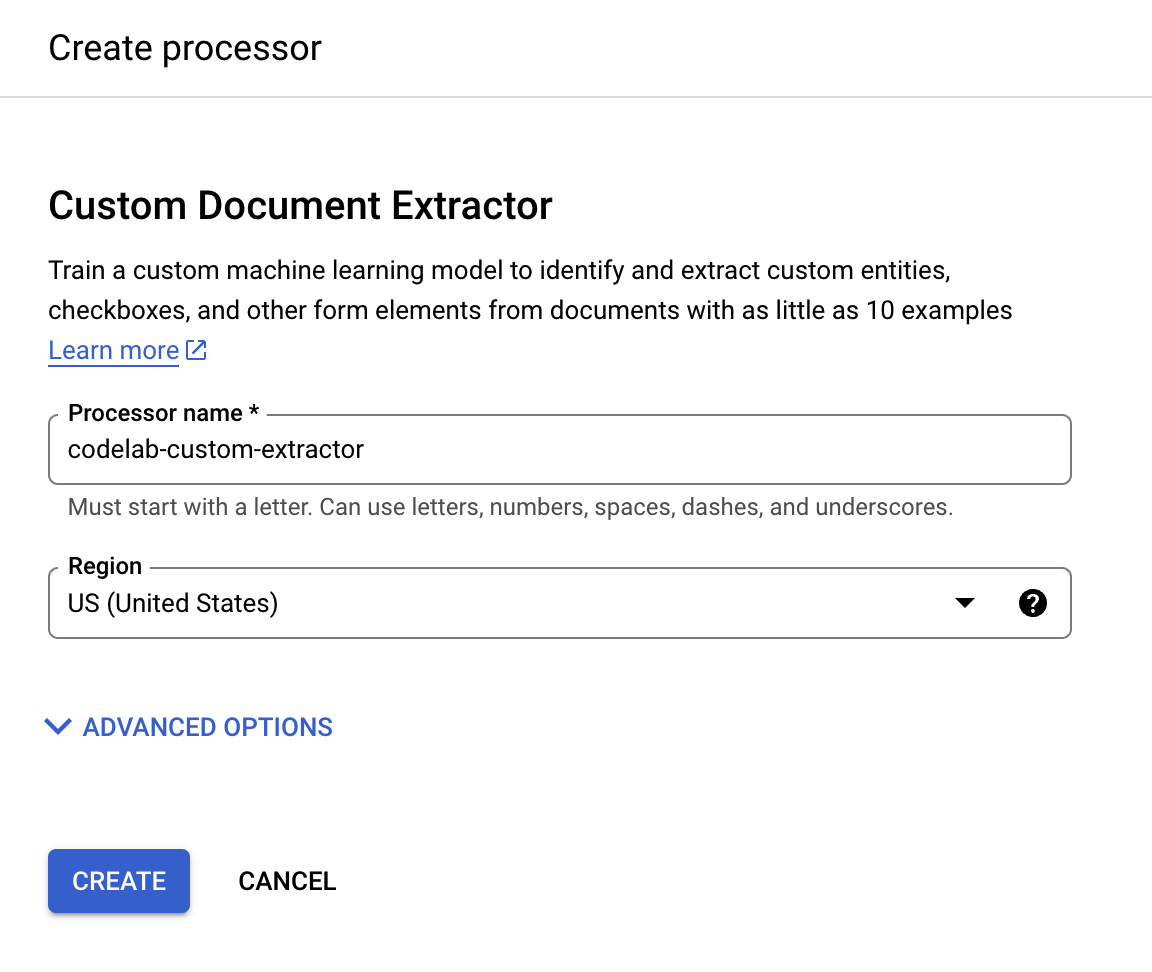
- לוחצים על יצירה כדי ליצור את המעבד. אחרי כן יוצג הדף 'סקירה כללית של מעבד המידע'.
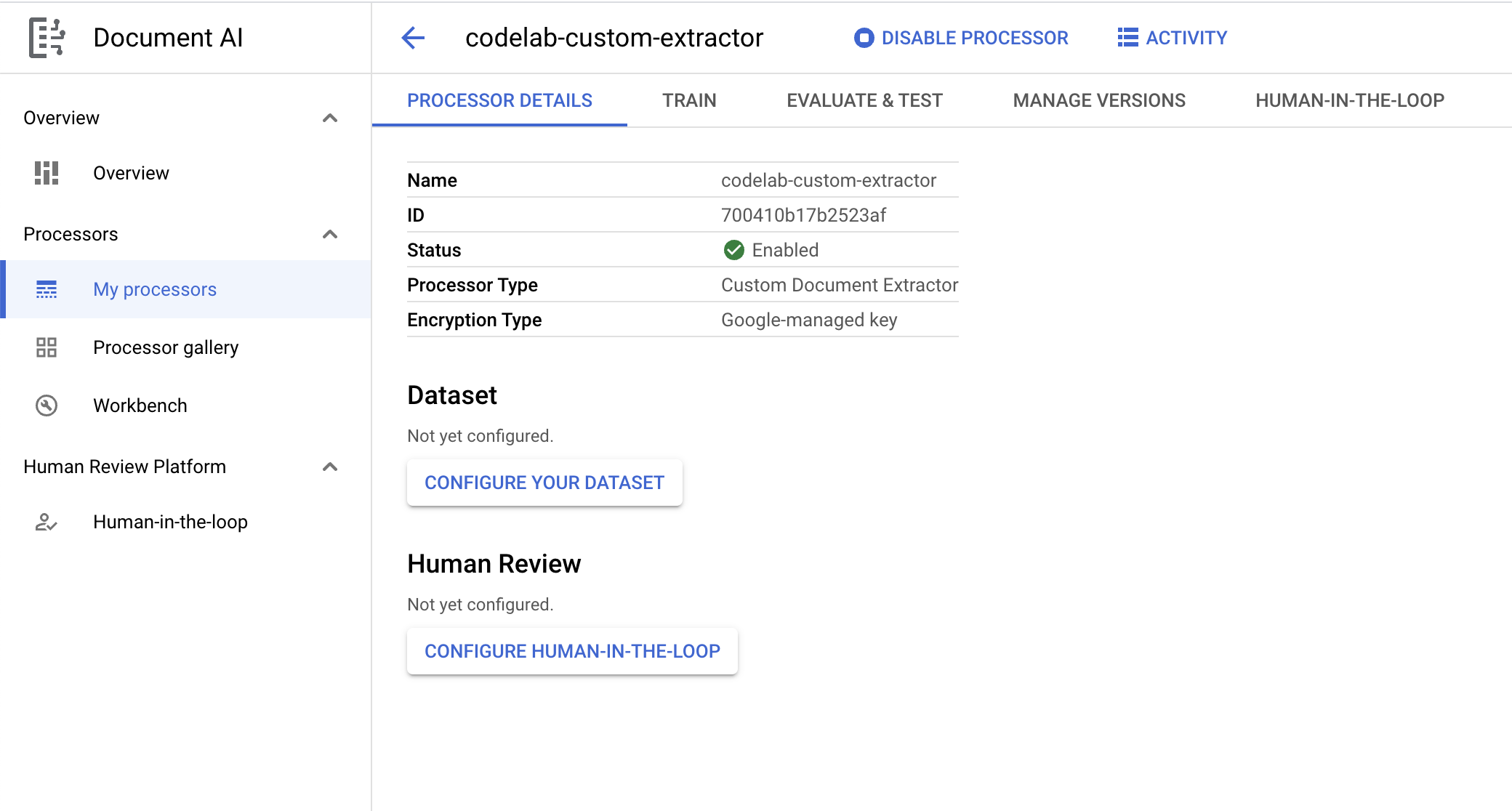
4. יצירת קבוצת נתונים
כדי לאמן את המעבד, נצטרך ליצור מערך נתונים עם נתוני אימון ובדיקה שיעזרו למעבד לזהות את הישויות שאנחנו רוצים לחלץ.
- בדף 'סקירה כללית של המעבד', לוחצים על הגדרת מערך הנתונים.
- עכשיו אמור להיפתח הדף Configure Dataset. אם רוצים לציין קטגוריה משלכם לאחסון מסמכי האימון והתוויות, לוחצים על הצגת אפשרויות מתקדמות. אחרת, פשוט לוחצים על המשך.
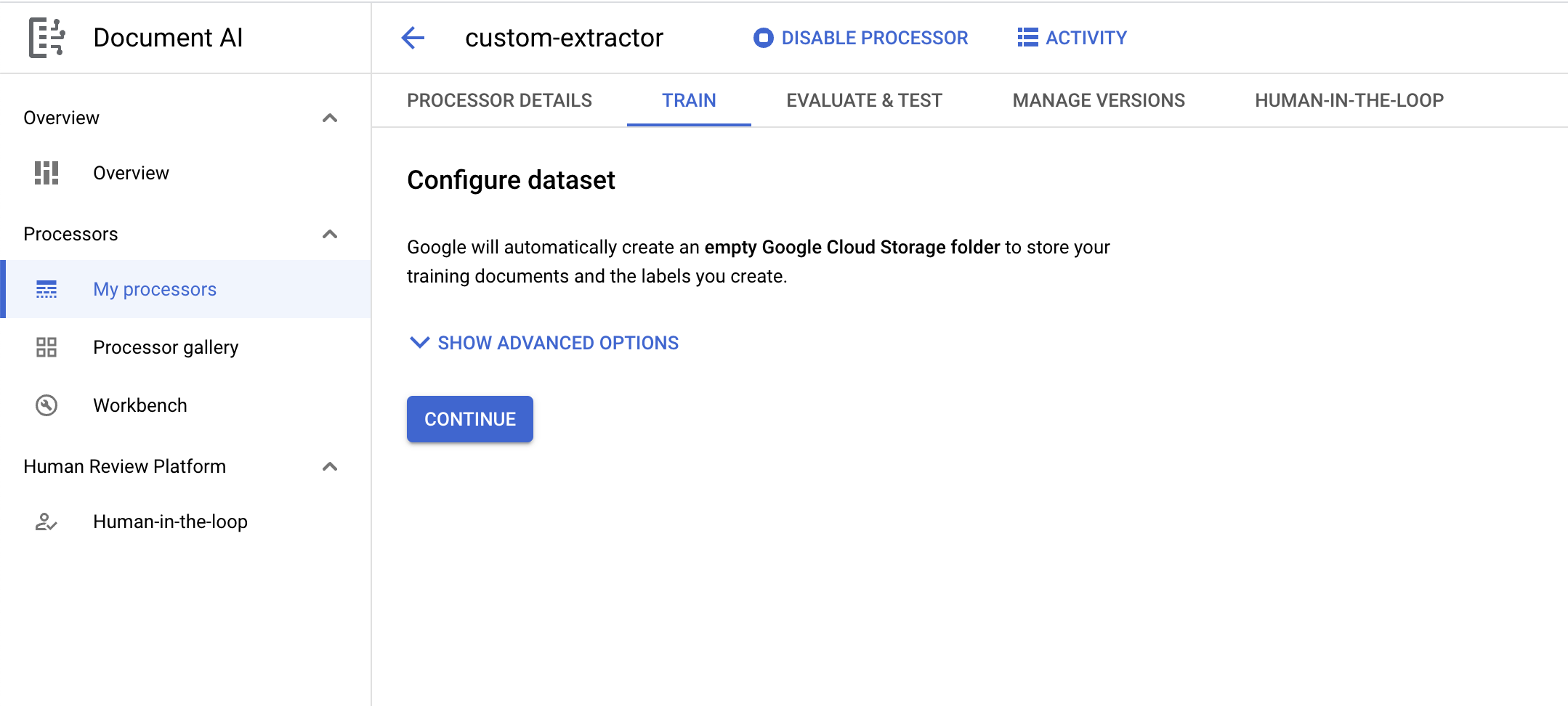
- מחכים עד שמערך הנתונים נוצר, ואז אמורים להיות מועברים לדף Training (אימון).
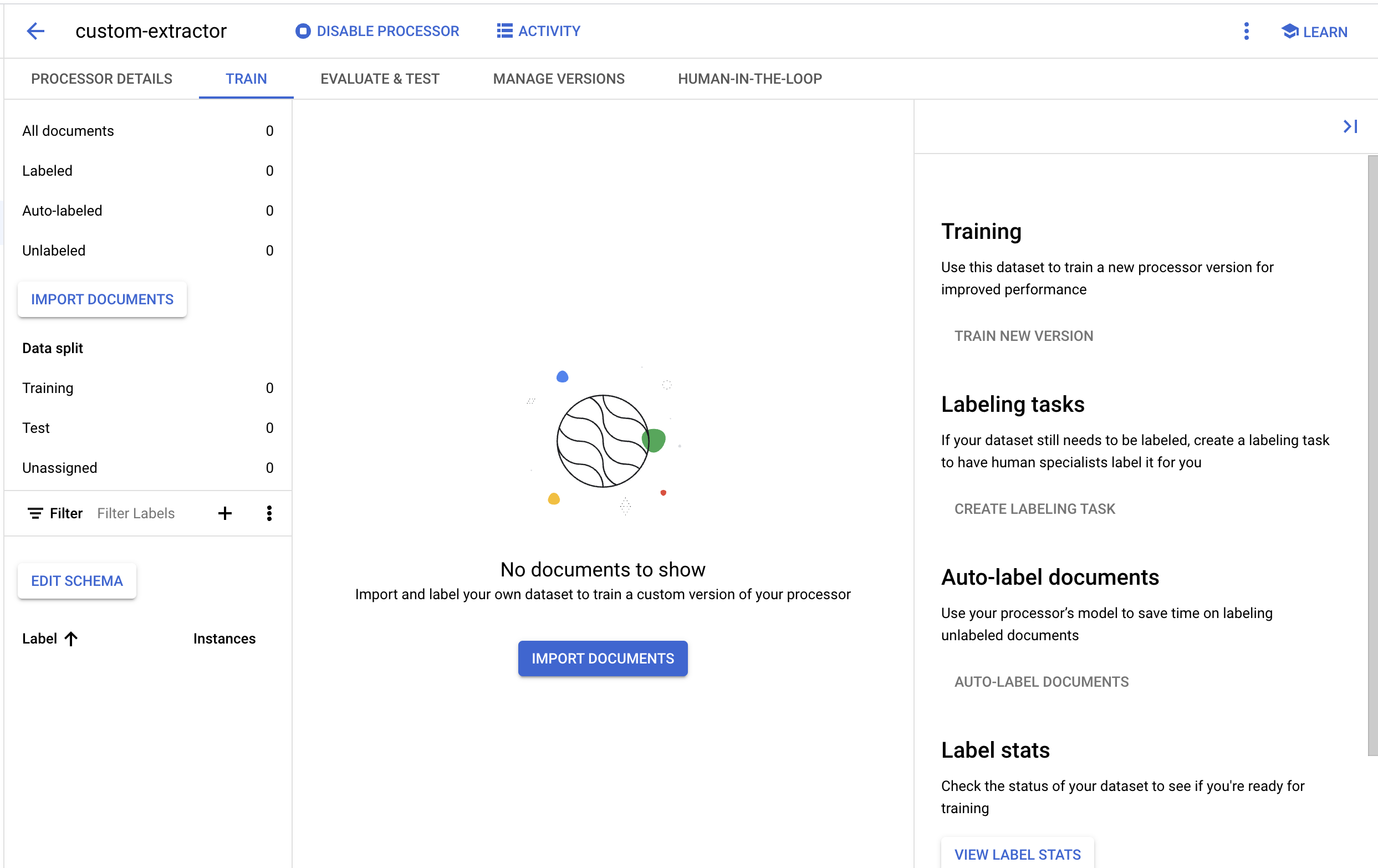
5. ייבוא מסמך בדיקה
עכשיו נייבא קובץ PDF לדוגמה של טופס W2 למערך הנתונים שלנו.
- לוחצים על ייבוא מסמכים.
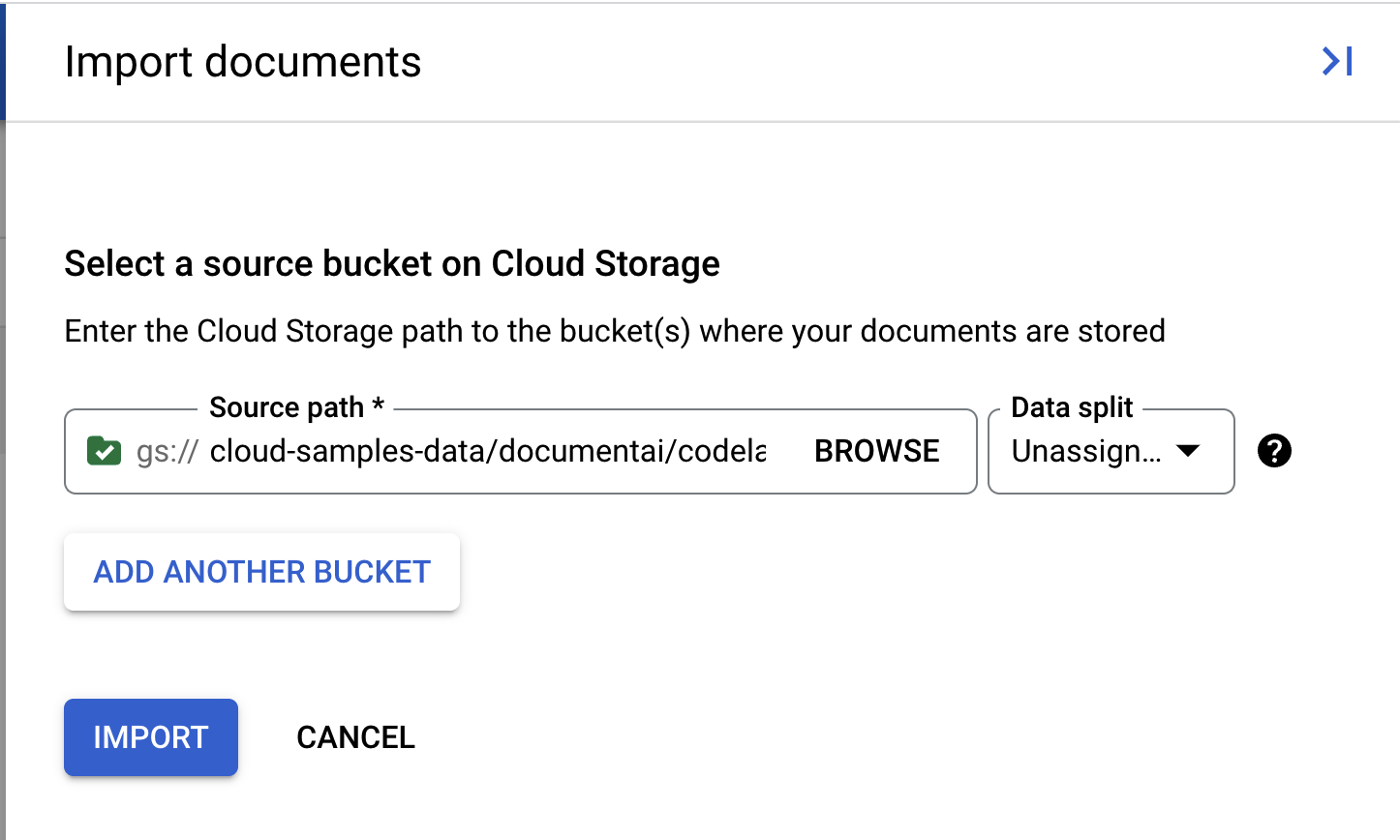
- יש לנו קובץ PDF לדוגמה שתוכלו להשתמש בו בשיעור ה-Lab הזה. מעתיקים את הקישור הבא ומדביקים אותו בתיבה Source Path (נתיב המקור). בינתיים, משאירים את האפשרות 'פיצול נתונים' כ-'לא הוקצה'. משאירים את כל שאר התיבות לא מסומנות. לוחצים על ייבוא.
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs
- ממתינים לייבוא המסמך. התהליך יימשך פחות מדקה.
- כשהייבוא מסתיים, המסמך אמור להופיע בדף אימון.
6. יצירת תוויות
מכיוון שאנחנו יוצרים סוג חדש של מעבד, נצטרך ליצור תוויות בהתאמה אישית כדי לציין ל-Document AI אילו שדות אנחנו רוצים לחלץ.
- לוחצים על עריכת סכימה בפינה הימנית התחתונה.
- עכשיו אתם אמורים להיות במסוף לניהול סכימות.
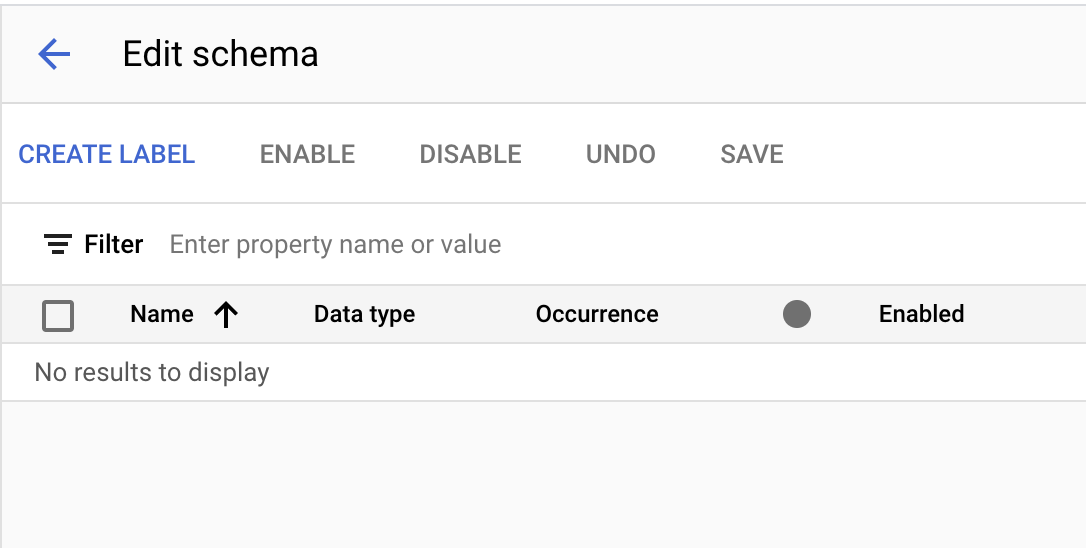
- יוצרים את התוויות הבאות באמצעות הלחצן יצירת תווית.
שם | סוג הנתונים | מופע |
| מספר | כמה צריך |
| טקסט פשוט | כמה צריך |
| טקסט פשוט | כמה צריך |
| כתובת | כמה צריך |
| כסף | כמה צריך |
| כסף | כמה צריך |
| כסף | כמה צריך |
| כסף | כמה צריך |
- בסיום התהליך, המסך ב-Console אמור להיראות כך. בסיום, לוחצים על שמירה.
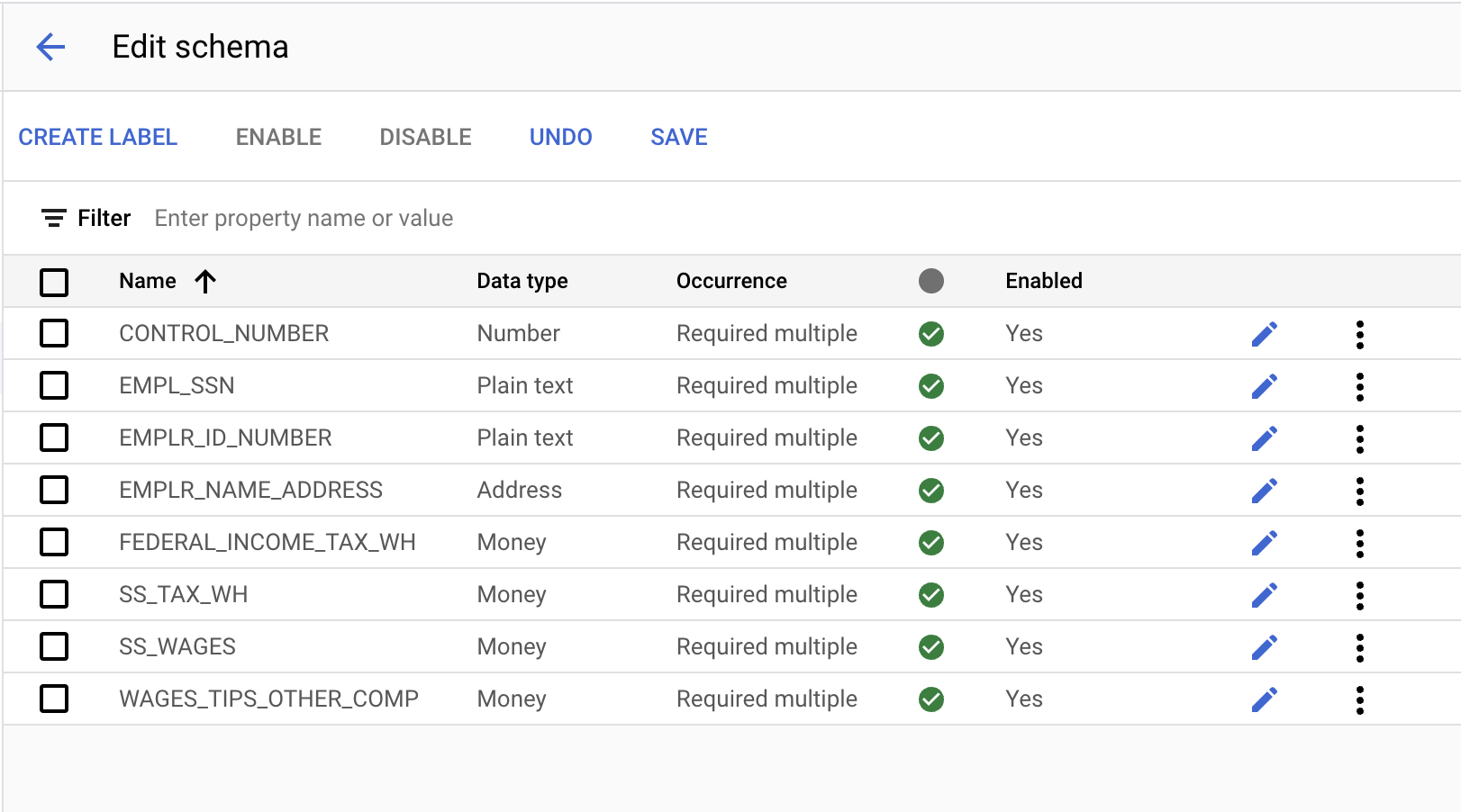
- לוחצים על חץ החזרה כדי לחזור לדף הדרכה. שימו לב שהתוויות שיצרנו מופיעות בפינה הימנית התחתונה.
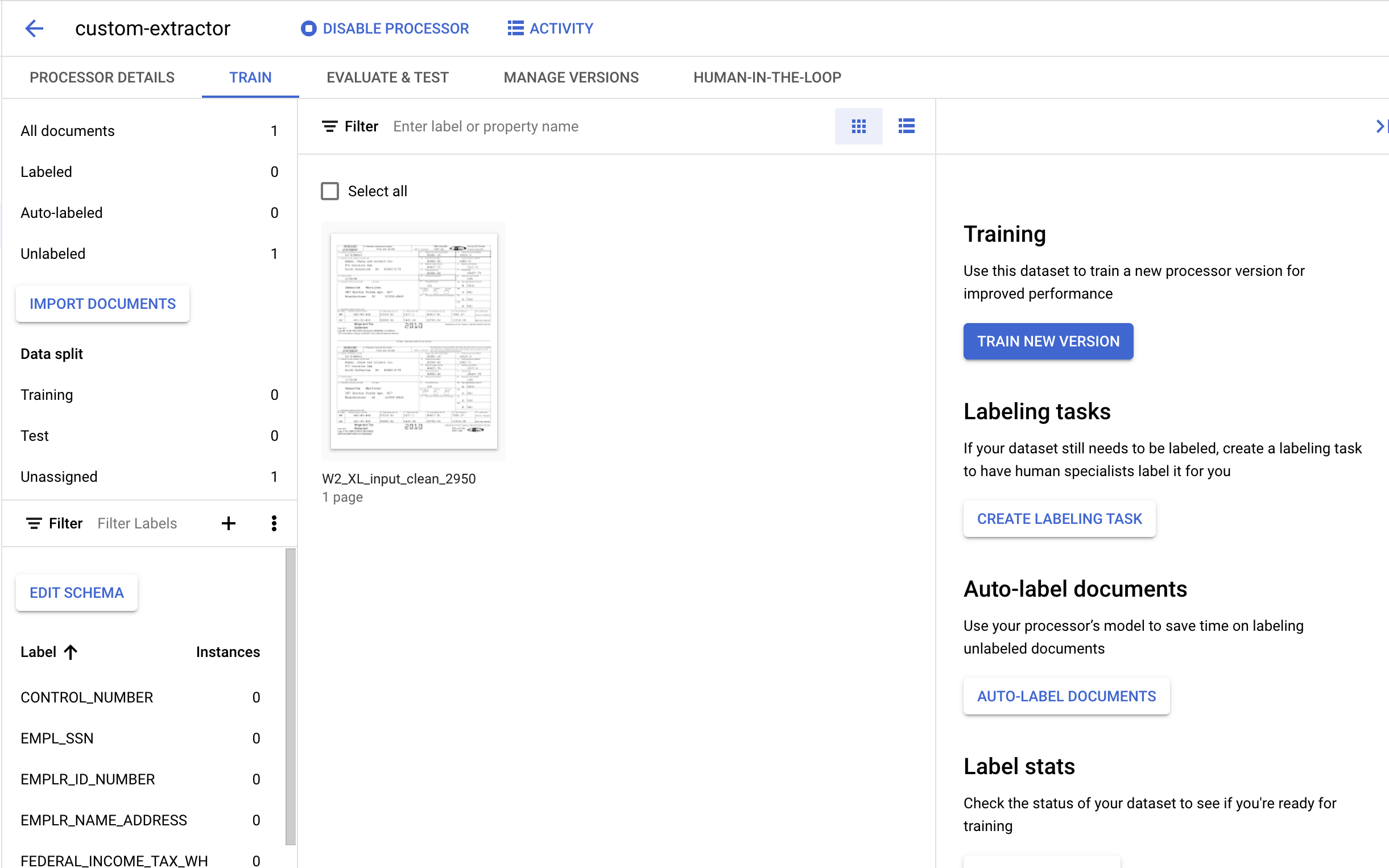
7. הוספת תוויות למסמך הבדיקה
בשלב הבא נזהה רכיבי טקסט ותוויות של הישויות שאנחנו רוצים לחלץ. התוויות האלה ישמשו לאימון המודל שלנו כדי לנתח את מבנה המסמך הספציפי הזה ולזהות את הסוגים הנכונים.
- לוחצים לחיצה כפולה על המסמך שייבאנו קודם כדי להיכנס למסוף התיוג. הוא אמור להיראות כך.
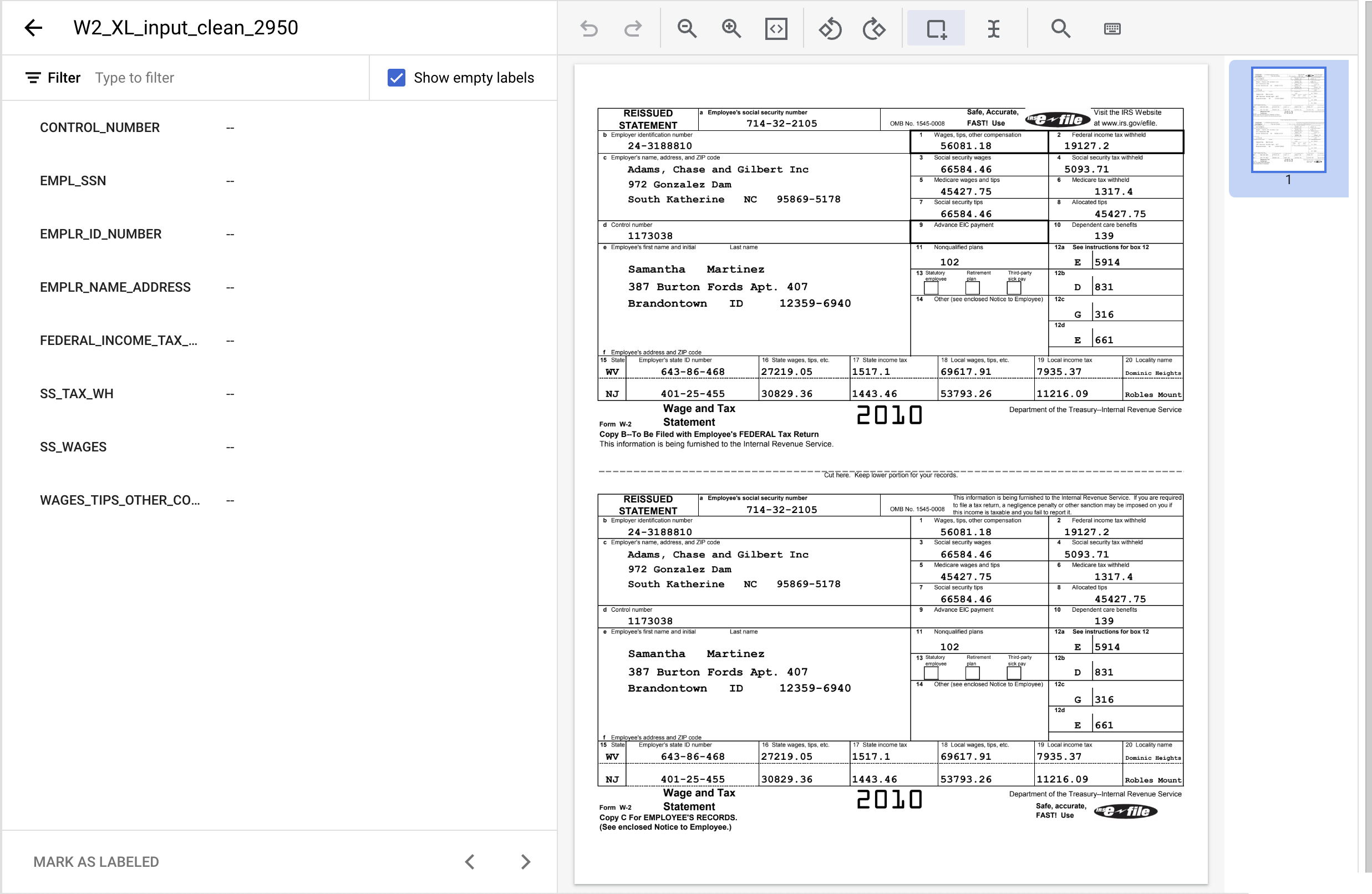
- לוחצים על הכלי 'תיבת תוחמת', מסמנים את הטקסט '1173038' ומקצים את התווית
CONTROL_NUMBER. אפשר להשתמש במסנן הטקסט כדי לחפש שמות של תוויות.
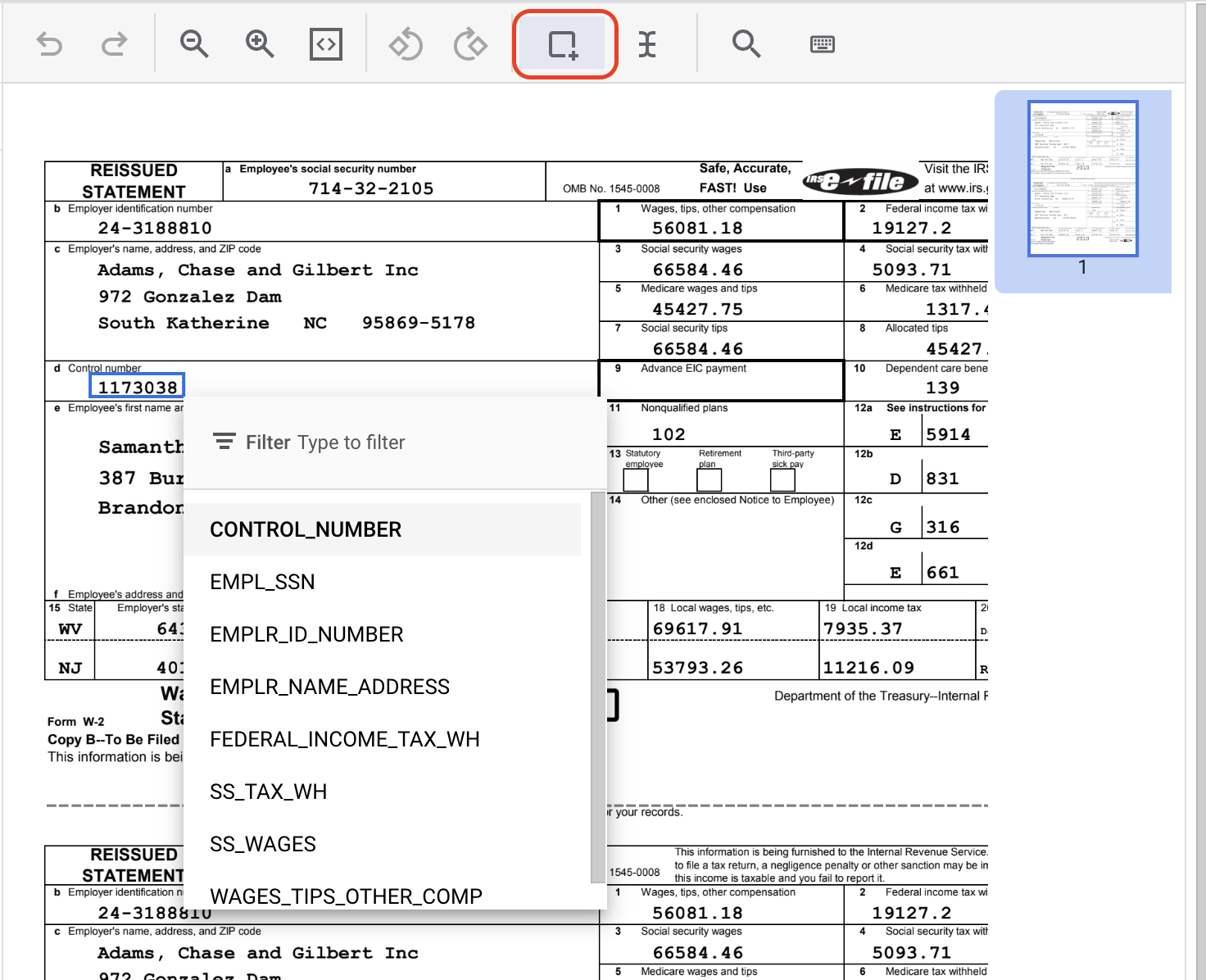
- משלימים את התיוג של המופע השני של
CONTROL_NUMBER. אחרי התיוג, הוא אמור להיראות כך:
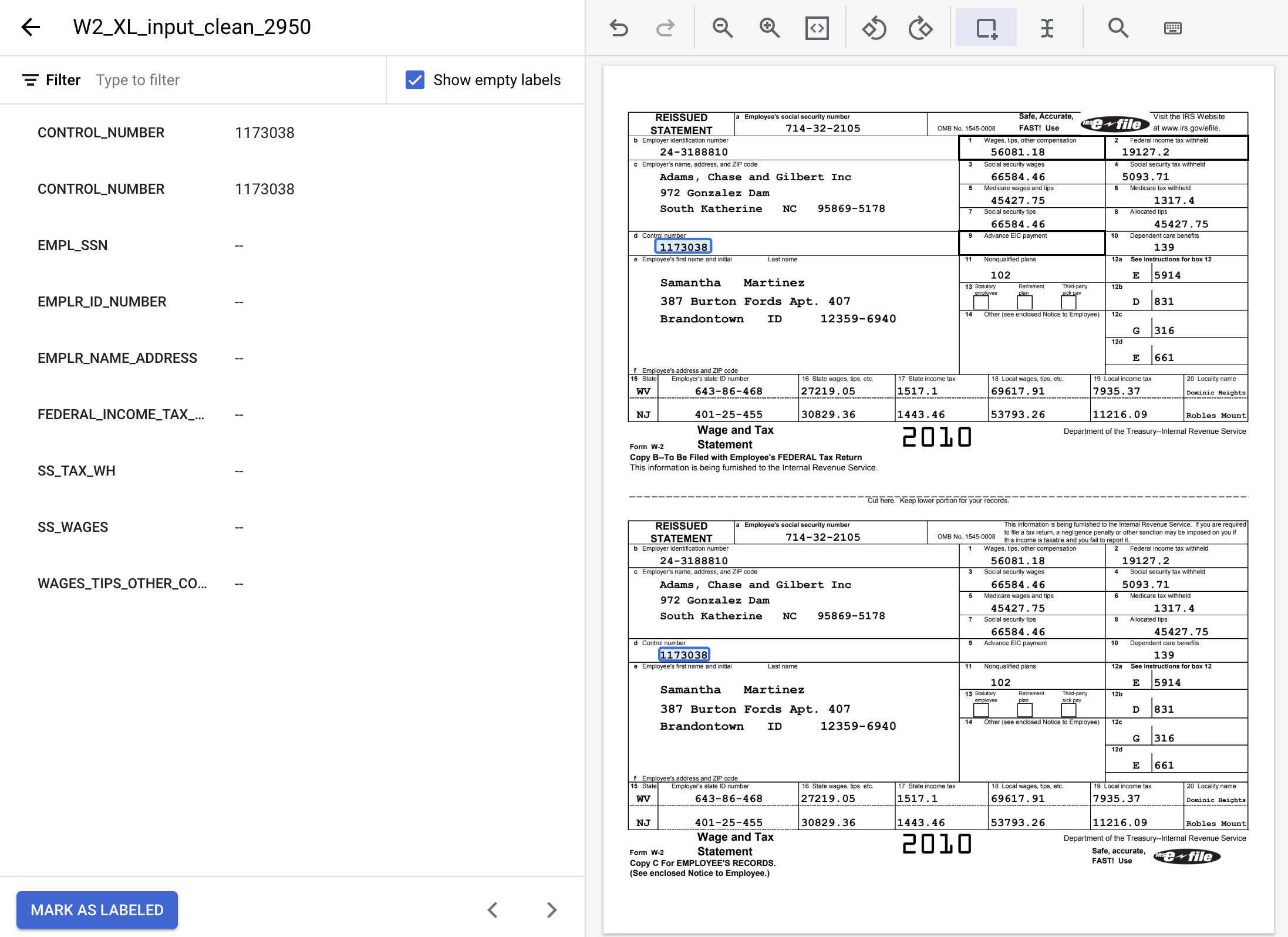
- מדגישים את כל המופעים של ערכי הטקסט הבאים ומקצים את התוויות המתאימות.
שם התווית | טקסט |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
- כך צריך להיראות המסמך המתויג בסיום התהליך. הערה: אפשר לבצע שינויים בתוויות האלה בלחיצה על תיבה תוחמת (bounding box) במסמך או על השם או הערך של התווית בתפריט צד. בסיום התיוג, לוחצים על סימון כ'תויג' וחוזרים למסוף לניהול מערך הנתונים.
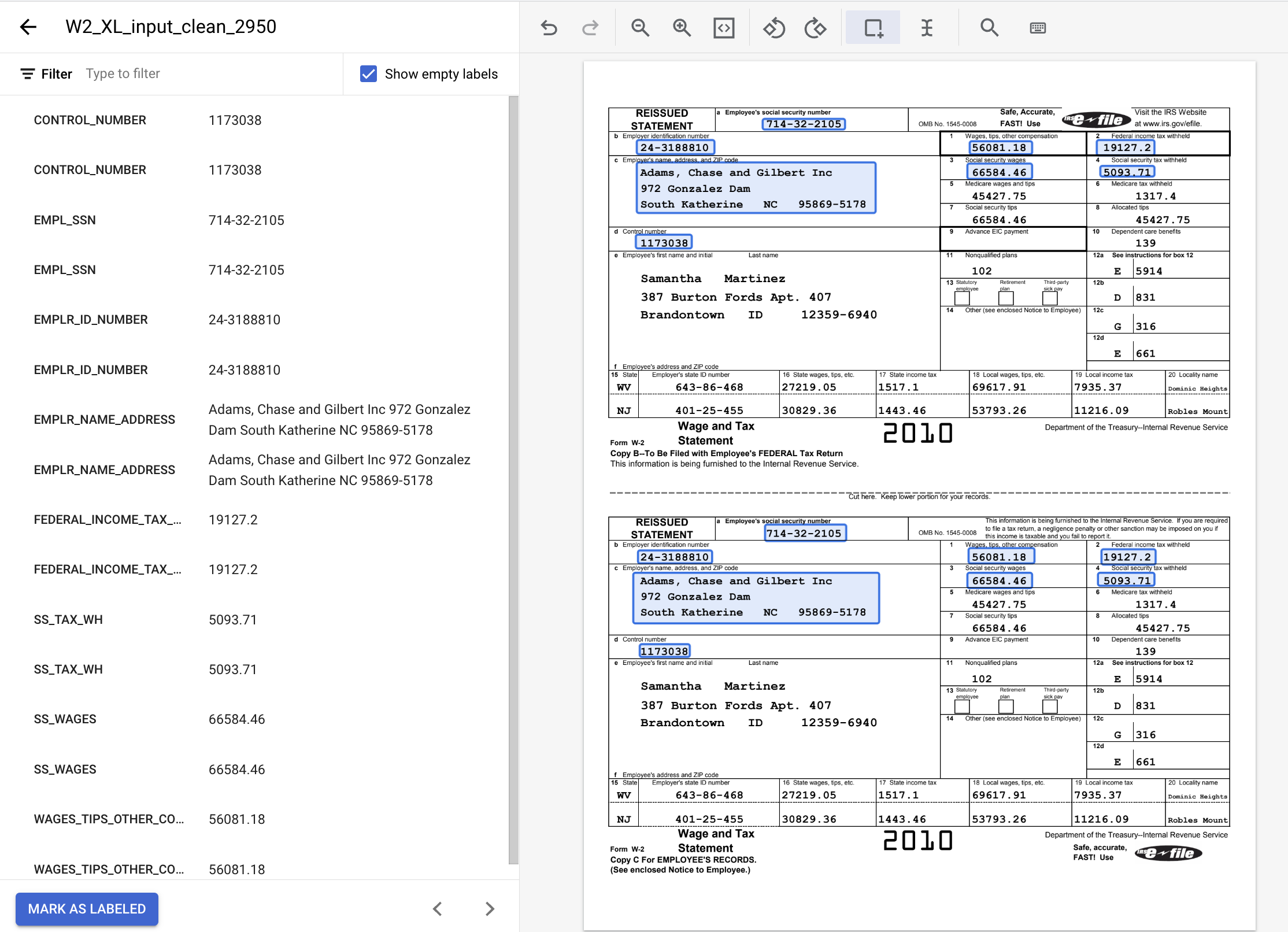
8. הקצאת מסמך לקבוצת נתונים לאימון
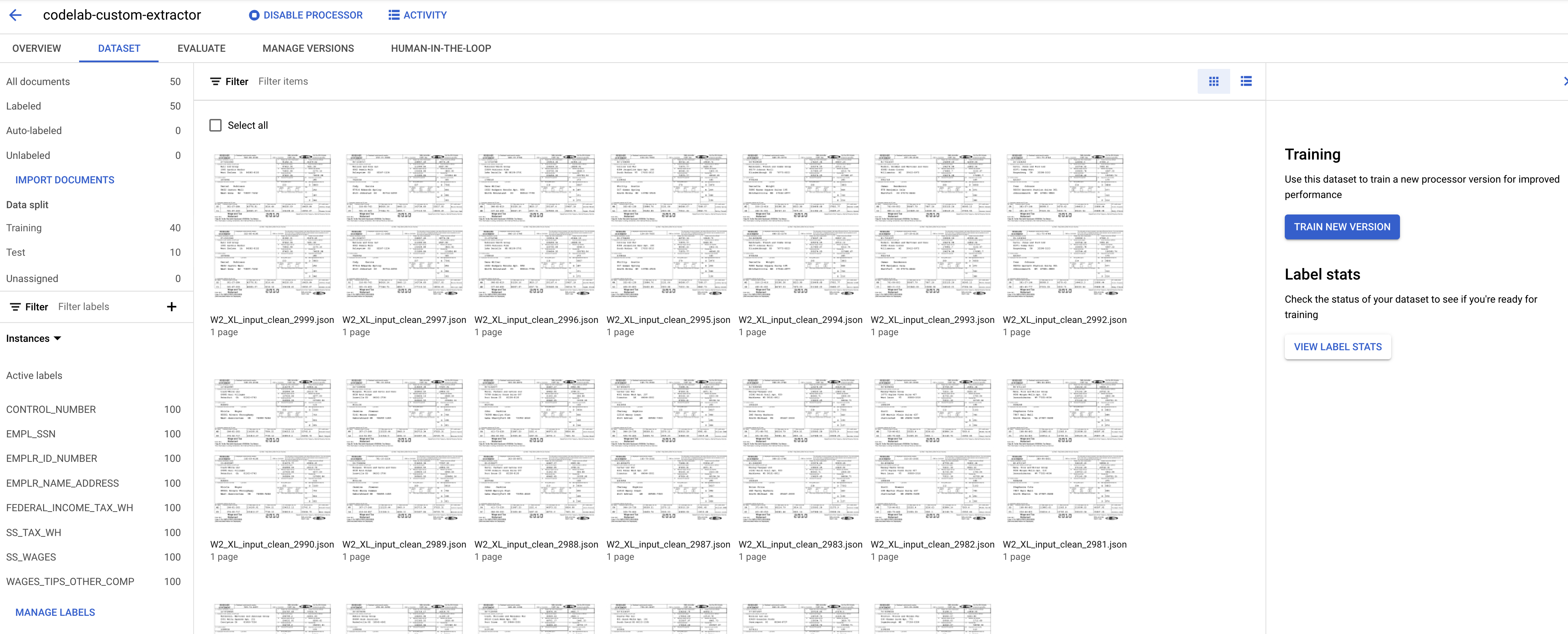
עכשיו אתם אמורים לחזור למסוף לניהול מערכי נתונים. שימו לב שמספר המסמכים עם התווית ומספר המסמכים ללא התווית, ומספר המקרים לכל תווית השתנו.
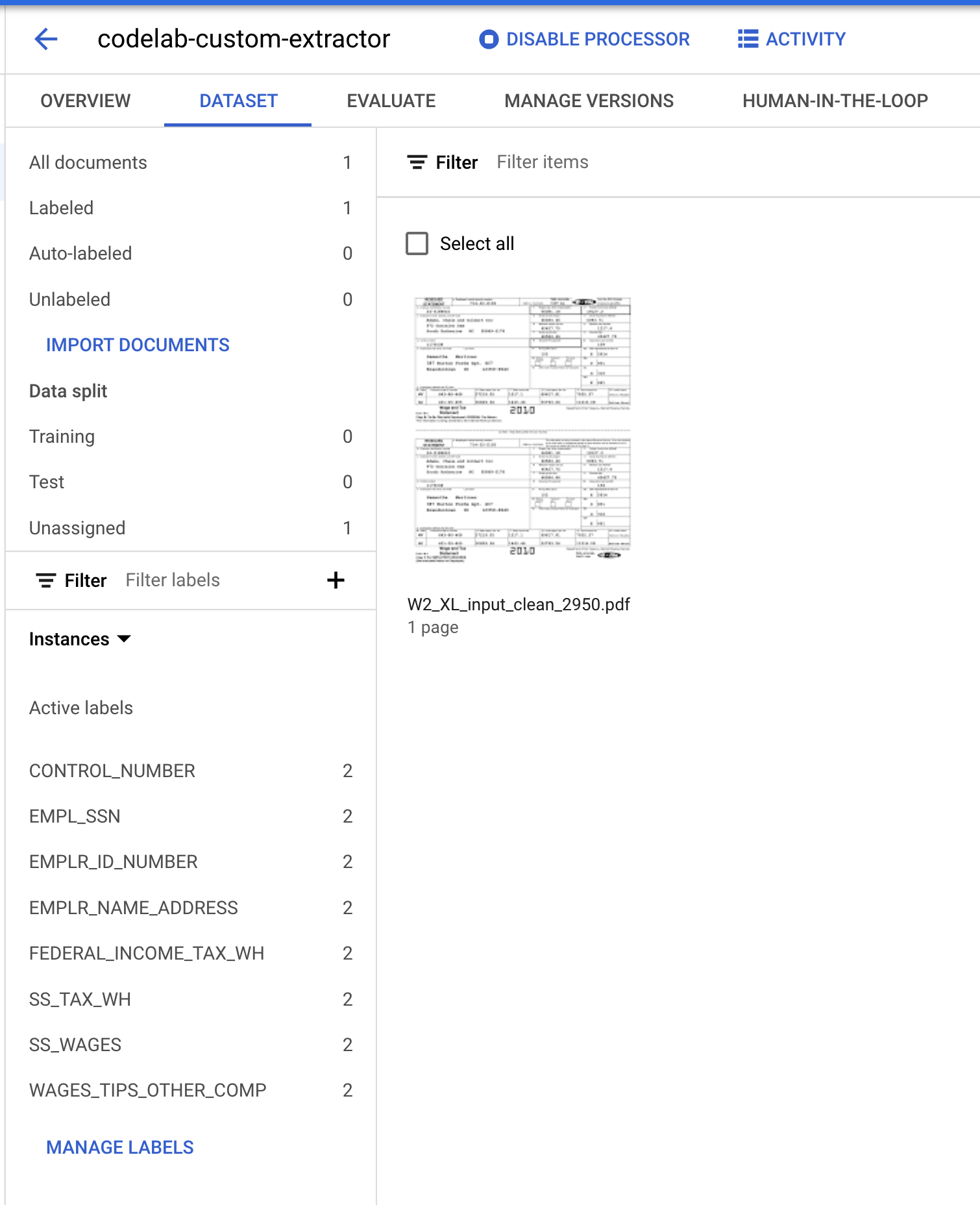
- אנחנו צריכים להקצות את המסמך הזה לקבוצה 'אימון' או לקבוצה 'בדיקה'. לוחצים על המסמך, לוחצים על הקצאה לקבוצה ואז לוחצים על אימון.
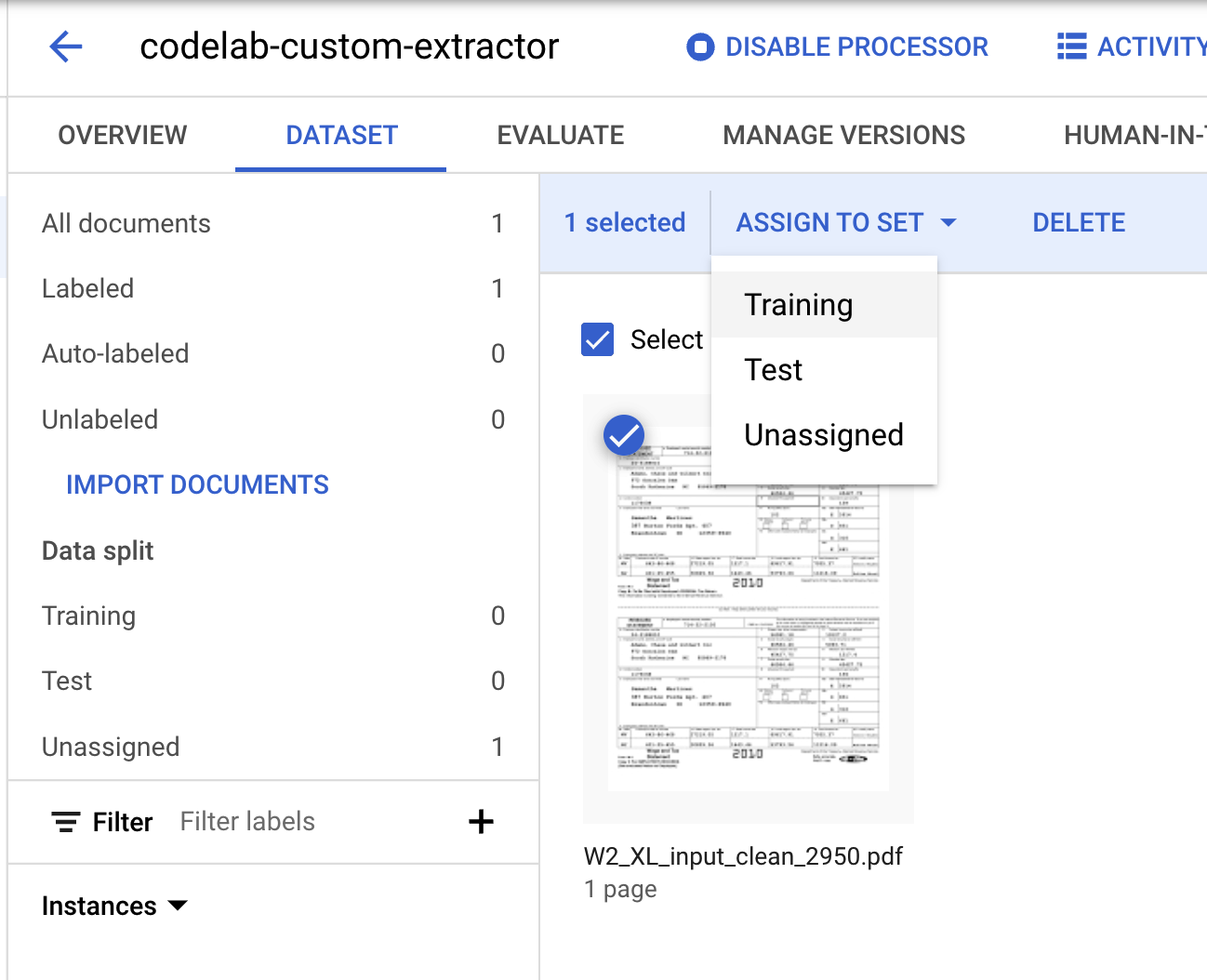
- שימו לב שהמספרים של חלוקת הנתונים השתנו.
9. ייבוא נתונים שכבר סומנו
מעבדים מותאמים אישית של Document AI דורשים מינימום של 10 מסמכים גם בקבוצות האימון וגם בקבוצות הבדיקה, וגם 10 מקרים של כל תווית בכל קבוצה.
כדי לקבל את הביצועים הכי טובים, מומלץ לכלול בכל קבוצה לפחות 50 מסמכים עם 50 מקרים של כל תווית. בדרך כלל, ככל שיש יותר נתוני אימון, כך הדיוק גבוה יותר.
ייקח הרבה זמן לסמן ידנית את כל המסמכים בתווית, לכן יש לנו כמה מסמכים שכבר סומנו בתווית שאפשר לייבא לשיעור ה-Lab הזה.
אפשר לייבא קבצים של מסמכים עם תוויות מוכנות מראש בפורמט Document.json. אלה יכולות להיות תוצאות של קריאה למעבד ואימות הדיוק באמצעות האדם שבתהליך (HITL).
הערת aside שלילית
הערה: כשמייבאים נתונים עם תוויות מוכנות מראש, מומלץ מאוד לבדוק ידנית את ההערות לפני שמבצעים אימון של המודל.
- לוחצים על ייבוא מסמכים.
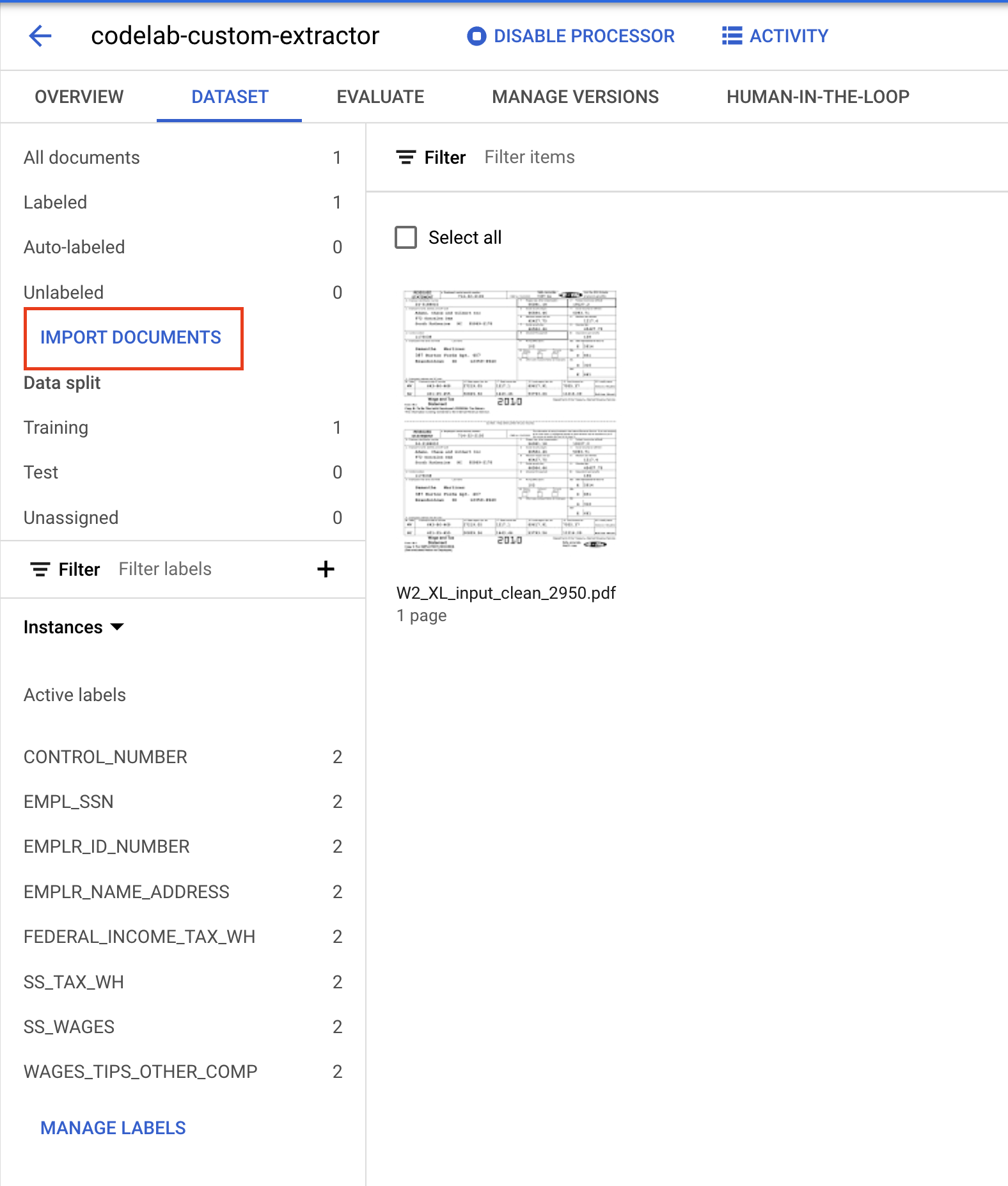
- מעתיקים ומדביקים את הנתיב הבא ב-Cloud Storage ומקצים אותו לקבוצת האימון.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- לוחצים על הוספת תיקייה נוספת. אחר כך מעתיקים ומדביקים את הנתיב הבא ב-Cloud Storage ומקצים אותו לקבוצת Test.
cloud-samples-data/documentai/codelabs/custom/extractor/test
- לוחצים על ייבוא וממתינים עד שהמסמכים יובאו. הפעם התהליך ייקח יותר זמן כי יש יותר מסמכים לעיבוד. התהליך יימשך כ-6 דקות. אפשר לצאת מהדף ולחזור אליו מאוחר יותר.
- אחרי שההעלאה תסתיים, המסמכים אמורים להופיע בדף אימון.
10. אימון המודל
עכשיו אפשר להתחיל לאמן את הכלי לחילוץ מסמכים בהתאמה אישית.
- לוחצים על אימון גרסה חדשה.
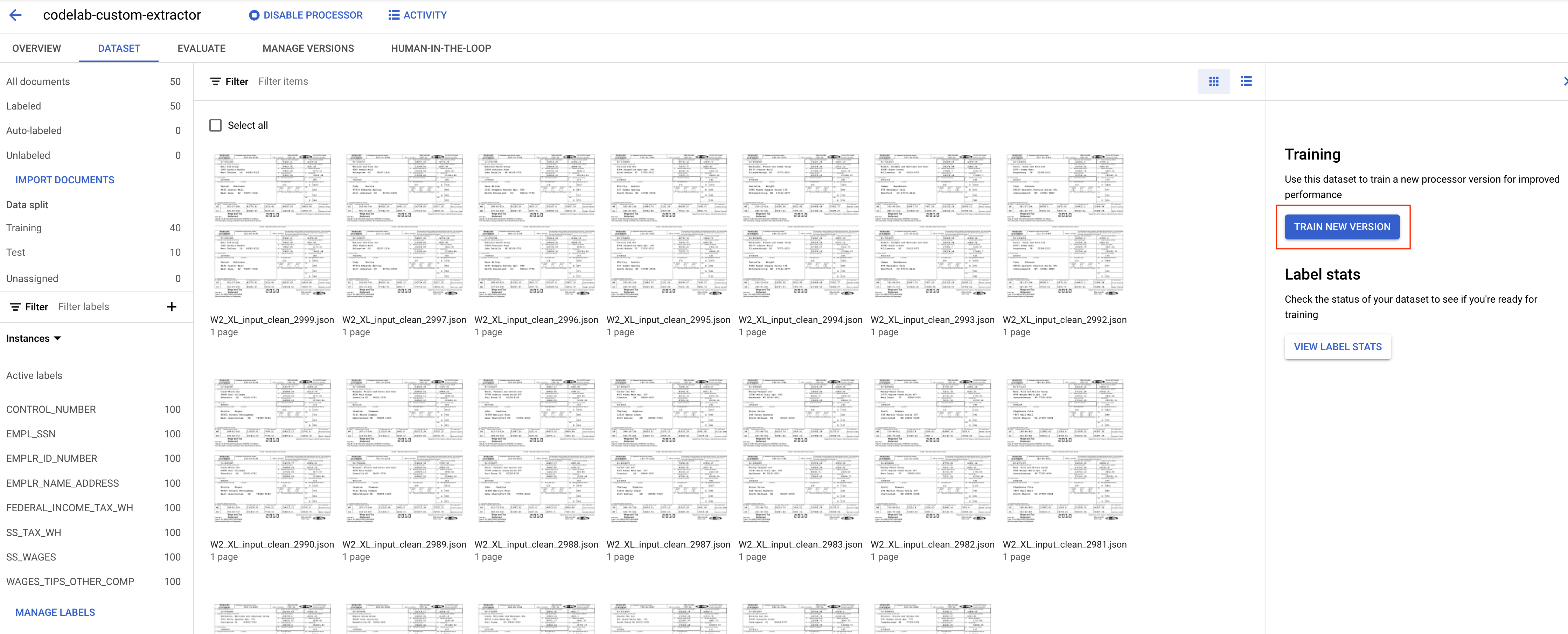
- נותנים לגרסה שם שקל לזכור, למשל
codelab-custom-1. בקטע 'שיטת אימון', בוחרים באפשרות 'אימון מאפס'.
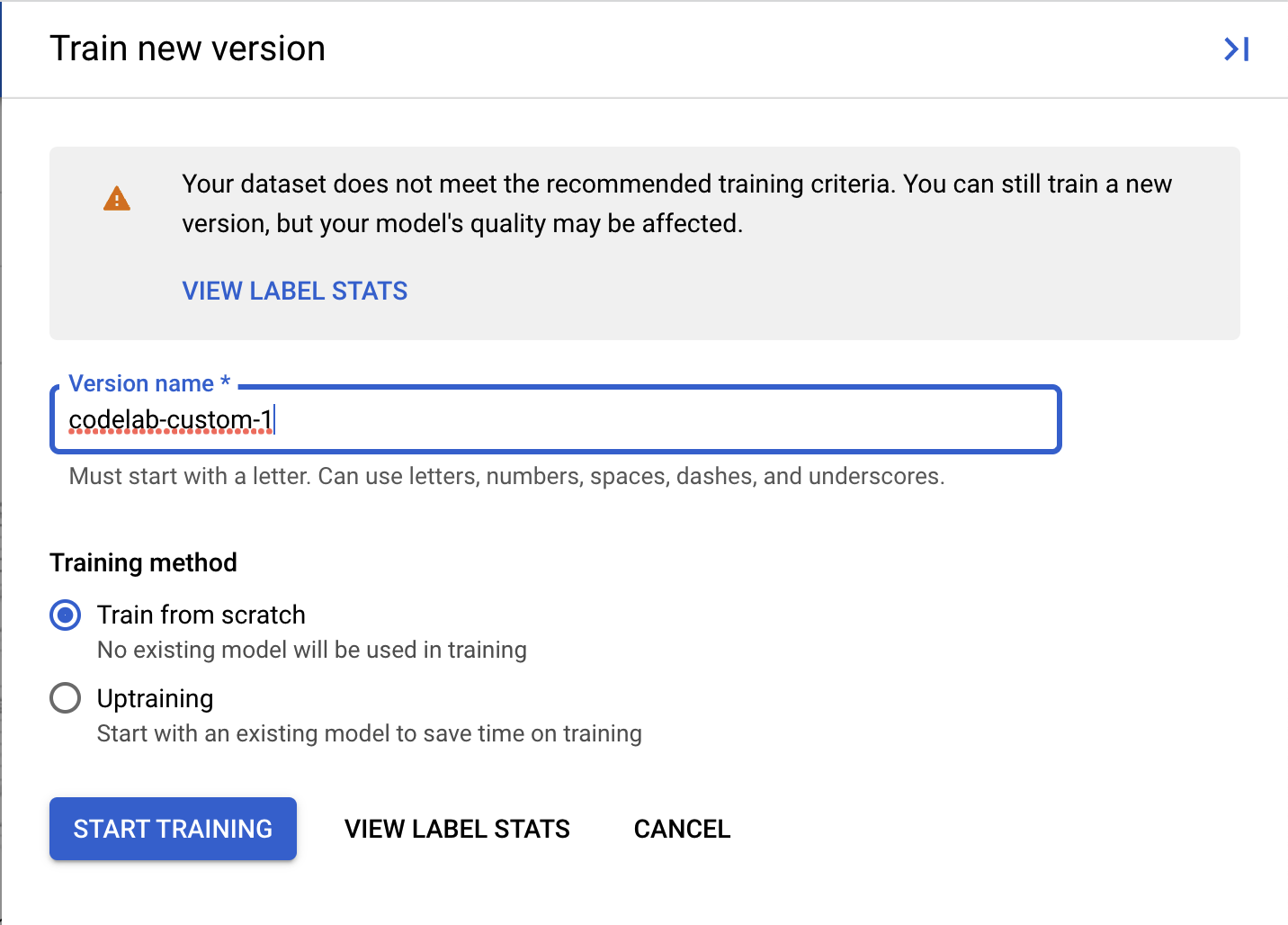
- (אופציונלי) אפשר גם ללחוץ על הצגת נתונים סטטיסטיים של התוויות כדי לראות מדדים לגבי התוויות במערך הנתונים.
- כדי להתחיל בתהליך ההדרכה, לוחצים על Start Training (התחלת ההדרכה). המערכת אמורה להפנות אתכם לדף 'ניהול מערכי נתונים'. הסטטוס של ההדרכה מוצג בצד שמאל. תהליך האימון יימשך כמה שעות. אפשר לצאת מהדף הזה ולחזור אליו מאוחר יותר.
- אם תלחצו על שם הגרסה, תועברו לדף ניהול גרסאות, שבו מוצגים מזהה הגרסה והסטטוס הנוכחי של משימת האימון.
11. בדיקת הגרסה החדשה של המודל
אחרי שמשימת האימון מסתיימת (בתהליך הבדיקה שלי זה לקח כשעה), אפשר לבדוק את הגרסה החדשה של המודל ולהתחיל להשתמש בה לחיזויים.
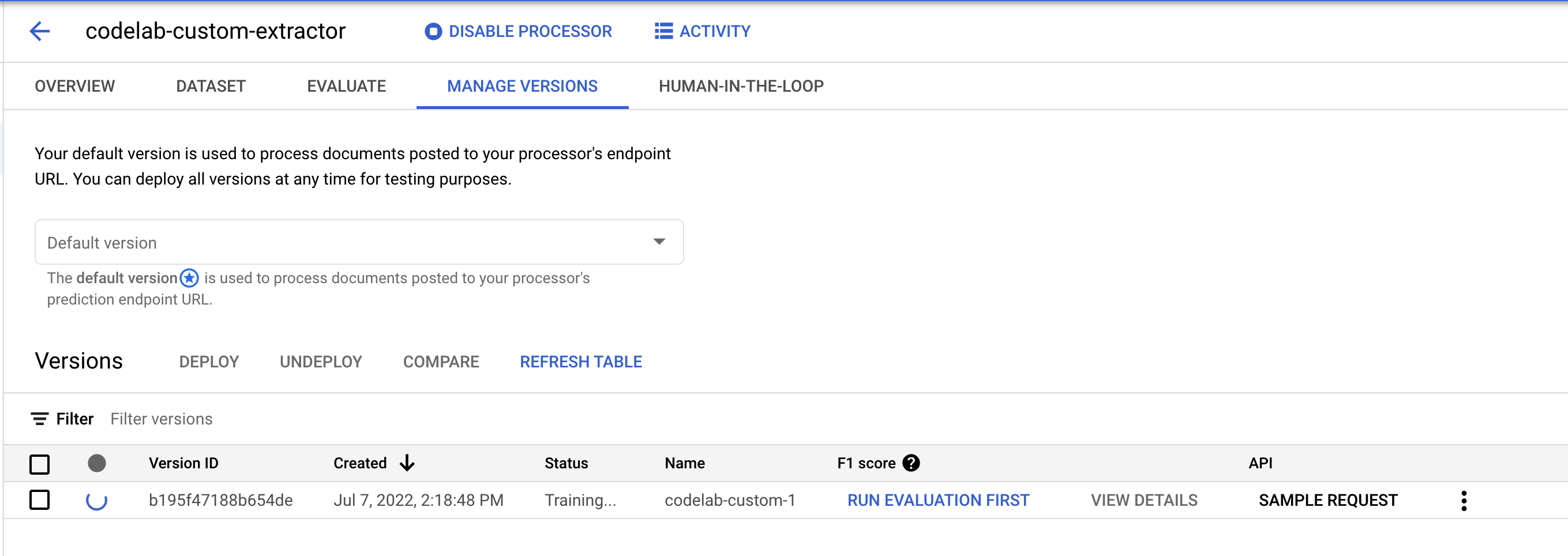
- עוברים לדף ניהול גרסאות. כאן אפשר לראות את הסטטוס הנוכחי ואת ציון ה-F1.
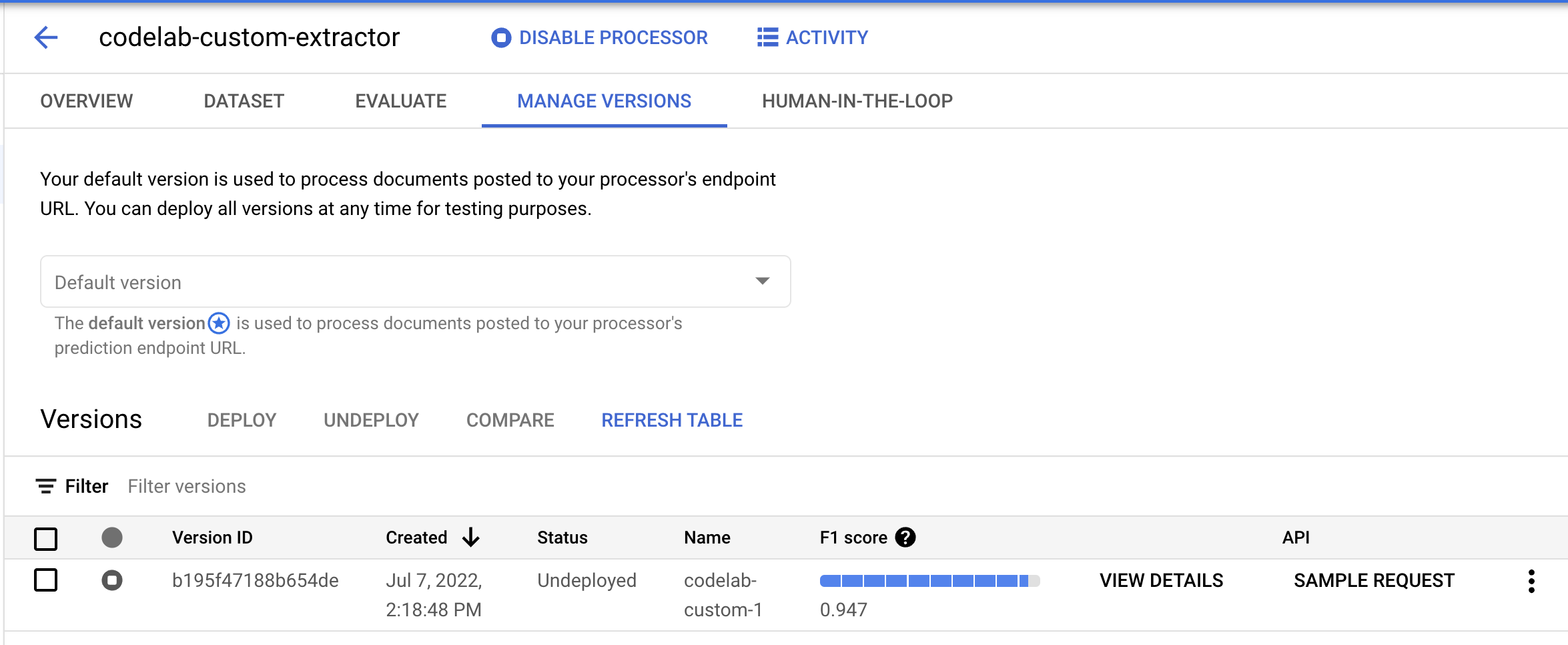
- נצטרך לפרוס את גרסת המודל הזו לפני שנוכל להשתמש בה. לוחצים על הנקודות האנכיות בצד שמאל ובוחרים באפשרות פריסת הגרסה.
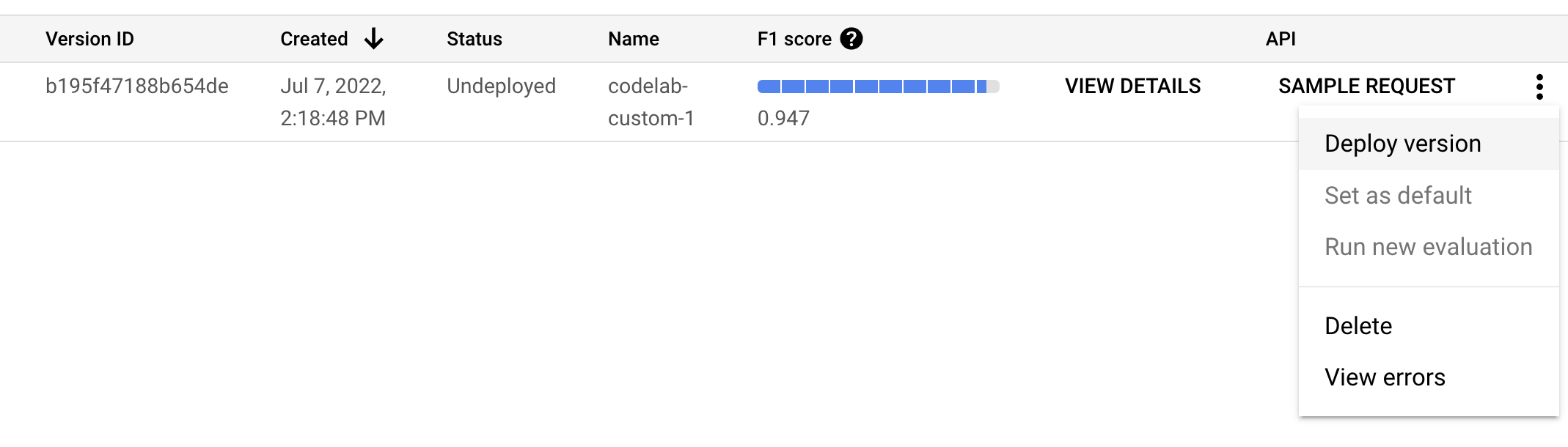
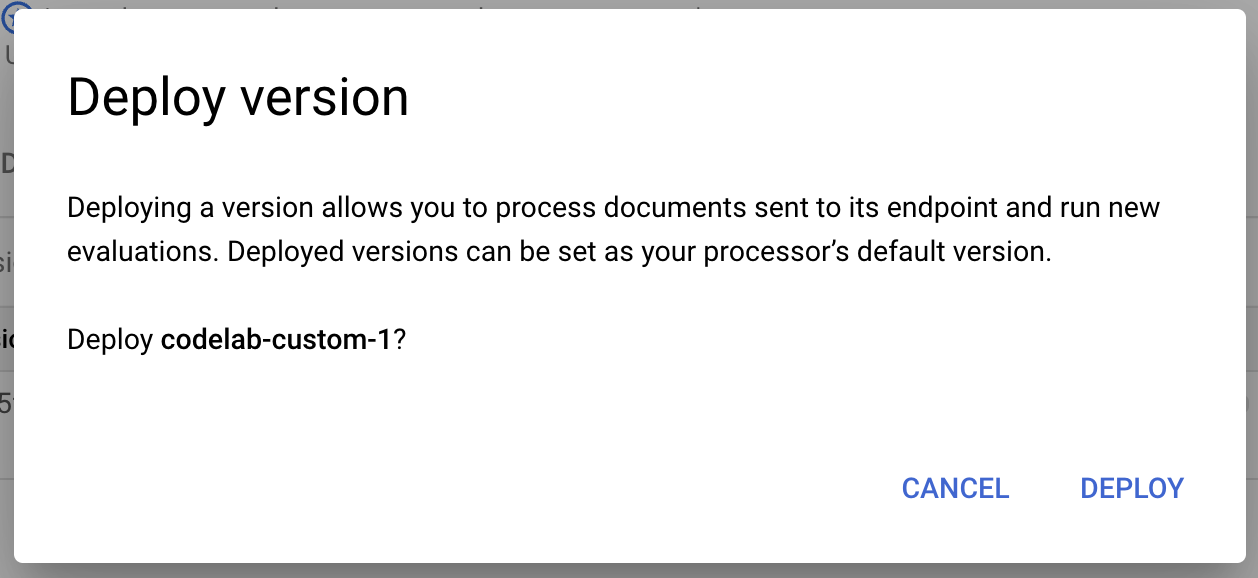
- בחלון הקופץ, לוחצים על פריסה ומחכים עד שהגרסה תיפרס. הפעולה תימשך כמה דקות. אחרי הפריסה, אפשר גם להגדיר את הגרסה הזו כגרסת ברירת המחדל.
- אחרי שהפריסה מסתיימת, עוברים לכרטיסייה הערכה. בדף הזה אפשר לראות מדדי הערכה, כולל ציון F1, דיוק והחזרה של מסמך מלא ושל תוויות נפרדות. מידע נוסף על המדדים האלה זמין במסמכי התיעוד של AutoML.
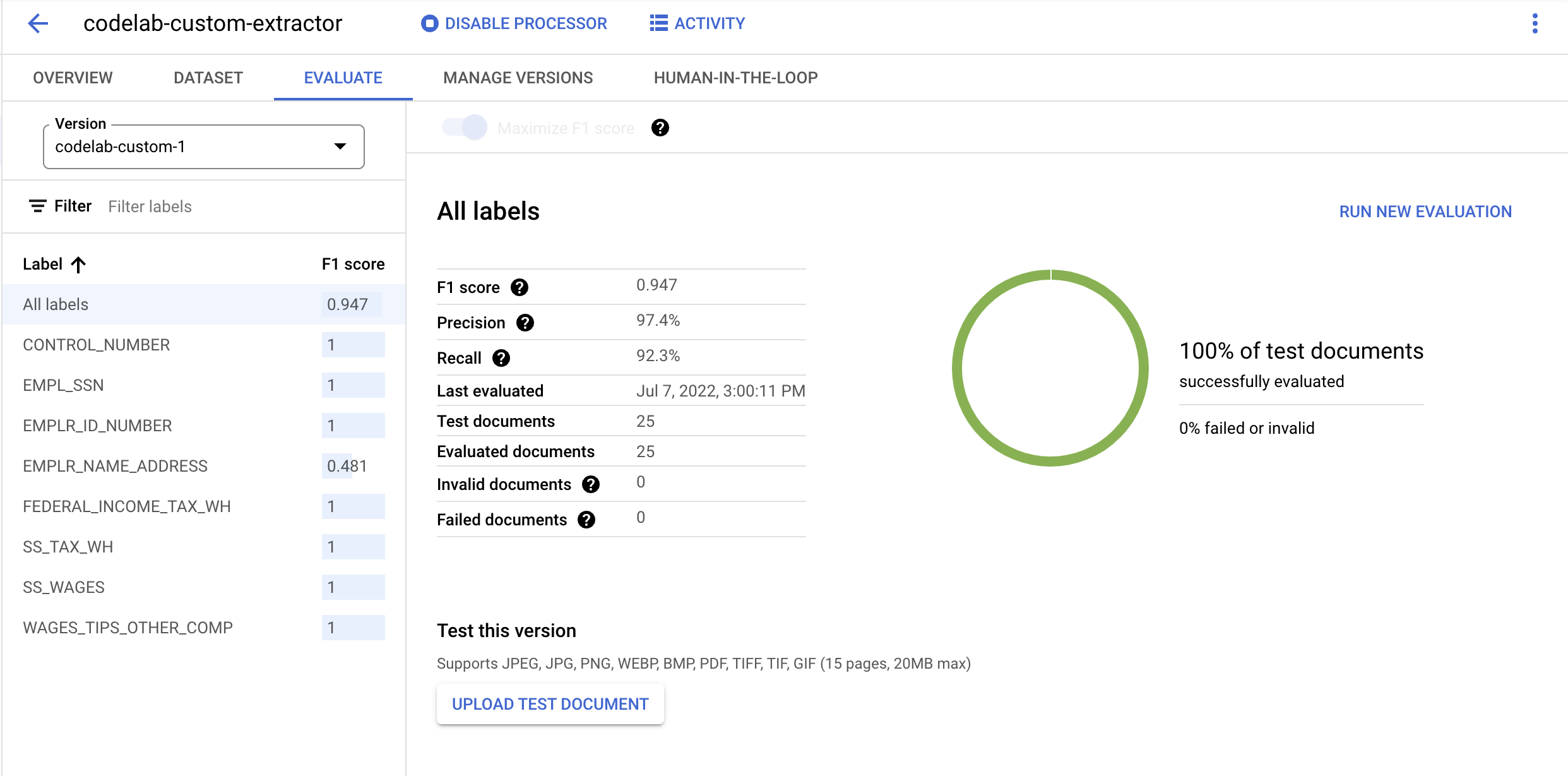
- מורידים את קובץ ה-PDF שמקושר למטה. זוהי דוגמה לטופס W2 שלא נכלל בסט האימונים או בקבוצת נתונים לבדיקה.
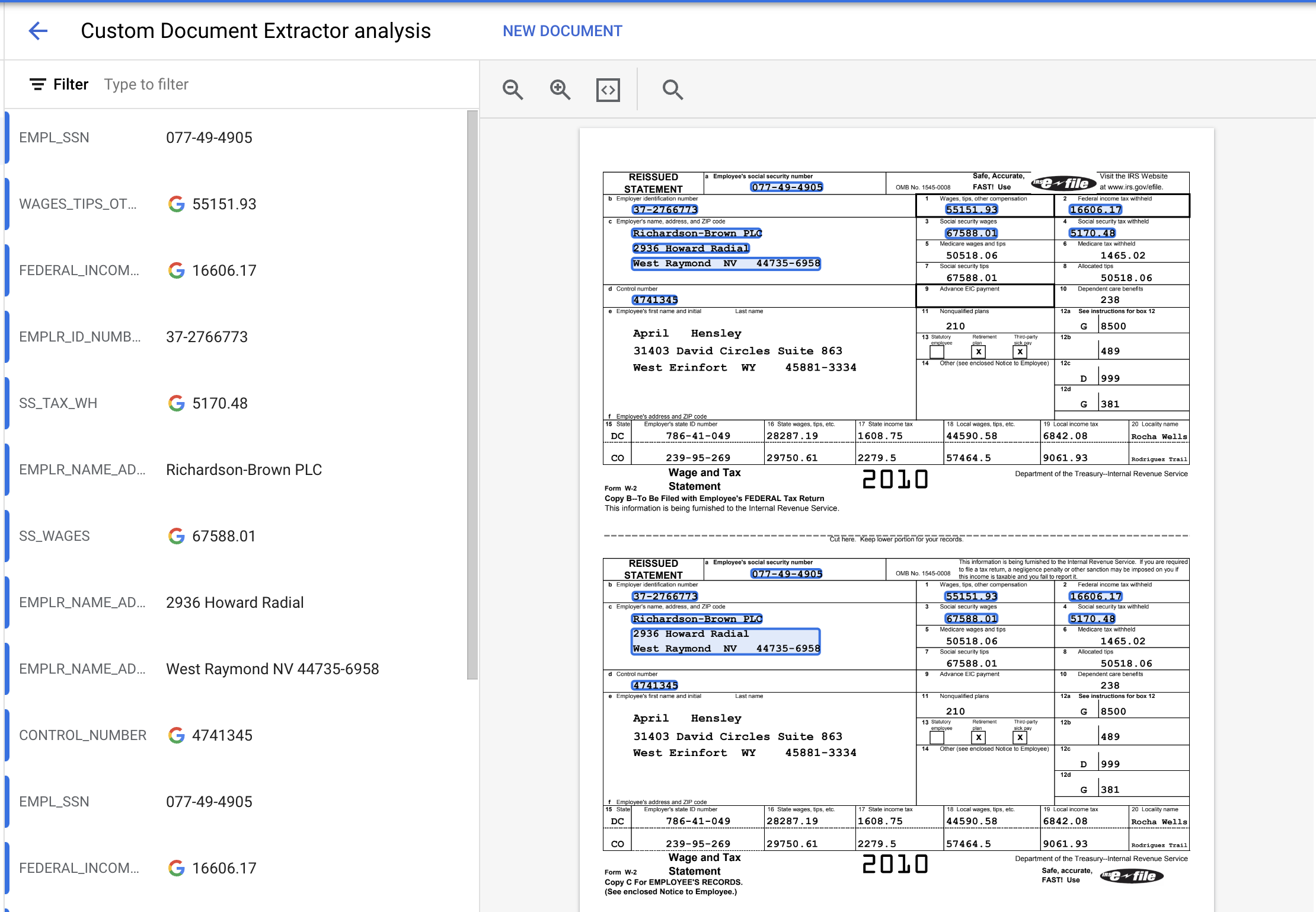
- לוחצים על העלאת מסמך בדיקה ובוחרים את קובץ ה-PDF.
- הישות שחולצה אמורה להיראות כך.
12. אופציונלי: סימון אוטומטי של מסמכים חדשים שיובאו
אחרי פריסת גרסה מאומנת של מעבד, אפשר להשתמש בתיוג אוטומטי כדי לחסוך זמן בתיוג כשמייבאים מסמכים חדשים.
- בדף Train (אימון), לוחצים על Import Documents (ייבוא מסמכים).
- מעתיקים ומדביקים את הנתיב הבא: . בספרייה הזו יש 5 קובצי PDF של W2 ללא תוויות. ברשימה הנפתחת פיצול נתונים, בוחרים באפשרות אימון.
cloud-samples-data/documentai/Custom/W2/AutoLabel - בקטע הוספת תוויות אוטומטית, מסמנים את התיבה ייבוא עם הוספת תוויות אוטומטית.
- בוחרים גרסה קיימת של מעבד כדי לתייג את המסמכים.
- לדוגמה:
2af620b2fd4d1fcf
- לוחצים על ייבוא וממתינים עד שהמסמכים יובאו. אפשר לצאת מהדף הזה ולחזור אליו מאוחר יותר.
- כשהפעולה מסתיימת, המסמכים מופיעים בדף Train בקטע Auto-labeled.
- אי אפשר להשתמש במסמכים עם תוויות אוטומטיות לאימון או לבדיקה בלי לסמן אותם ככאלה שסומנו. כדי לראות את המסמכים עם התוויות האוטומטיות, עוברים לקטע Auto-labeled.
- בוחרים את המסמך הראשון כדי להיכנס למסוף התיוג.
- בודקים את התוויות, תיבות התוחמות והערכים כדי לוודא שהם נכונים. מציינים תווית לכל הערכים שהושמטו.
- כשמסיימים, בוחרים באפשרות סימון כ'סומן בתווית'.
- חוזרים על אימות התוויות לכל מסמך שסומן אוטומטית, ואז חוזרים לדף אימון כדי להשתמש בנתונים לאימון.
13. סיכום
אנחנו שמחים לבשר לך שהשתמשת בהצלחה ב-Document AI כדי לאמן מעבד לחילוץ מסמכים בהתאמה אישית. עכשיו אפשר להשתמש במעבד הזה כדי לנתח מסמכים בפורמט הזה, בדיוק כמו שמשתמשים בכל מעבד ייעודי.
ב-Codelab בנושא מעבדים ייעודיים מוסבר איך לטפל בתגובת העיבוד.
ניקוי
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה:
- במסוף Cloud, נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט ולוחצים על Delete (מחיקה).
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
מקורות מידע
- תיעוד של Document AI Workbench
- העתיד של מסמכים – פלייליסט ב-YouTube
- מסמכי תיעוד בנושא Document AI
- ספריית לקוח Python של Document AI
- דוגמאות לשימוש ב-Document AI
רישיון
עבודה זו מורשית תחת רישיון Creative Commons שמותנה בייחוס 2.0 כללי.