
1. はじめに
Document AI は、ドキュメントやメールなどの非構造化データを理解、分析、利用しやすくするドキュメント理解ソリューションです。
Document AI Workbench では、独自のトレーニング データを使用して完全にカスタマイズされたモデルを作成し、より精度の高いドキュメント処理を行うことができます。
このラボでは、カスタム ドキュメント抽出プロセッサを作成して、データセットをインポートし、サンプル ドキュメントにラベルを付けてプロセッサをトレーニングします。
このラボでは、CC0 パブリック ドメイン ライセンスに基づいて Kaggle の Fake W-2 (US Tax Form) Dataset をドキュメント データセットとして使用しています。
前提条件
この Codelab は、Document AI の他の Codelab の内容に基づいて作成されています。
このラボを始める前に、次の Codelab を完了しておくことをおすすめします。
- Document AI(Python)を使用した光学式文字認識(OCR)
- Document AI(Python)を使用したフォーム解析
- Document AI(Python)を使用した特殊プロセッサ
- Python による Document AI プロセッサの管理
- Document AI: 人間参加型
- Document AI: アップトレーニング
学習内容
- カスタム ドキュメント エクストラクタのプロセッサを作成する。
- アノテーション ツールを使用して、Document AI トレーニング データにラベルを付ける。
- 新しいモデル バージョンをトレーニングする。
- 新しいモデル バージョンの精度を評価する。
必要なもの
2. 設定する
この Codelab は、入門編の Codelabにある Document AI の設定手順を完了していることを前提としています
先に進む前に、次のステップを完了してください。
3. プロセッサを作成する
まず、このラボで使用するカスタム ドキュメント エクストラクタのプロセッサを作成します。
- コンソールで、Document AI の概要ページに移動します。
- [カスタム プロセッサを作成] をクリックして、[カスタム ドキュメント エクストラクタ] を選択します。
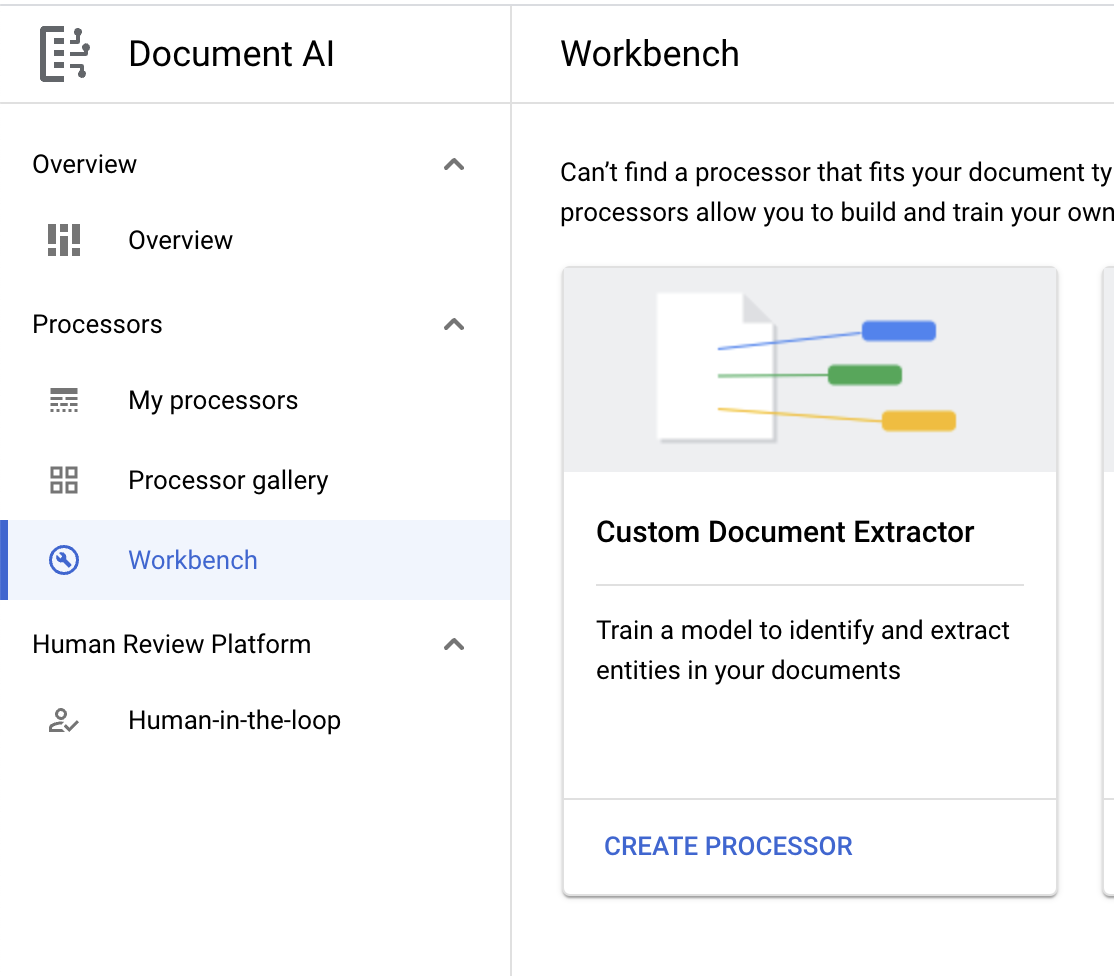
codelab-custom-extractor(または覚えている名前)を付けて、最も近いリージョンをリストから選択します。
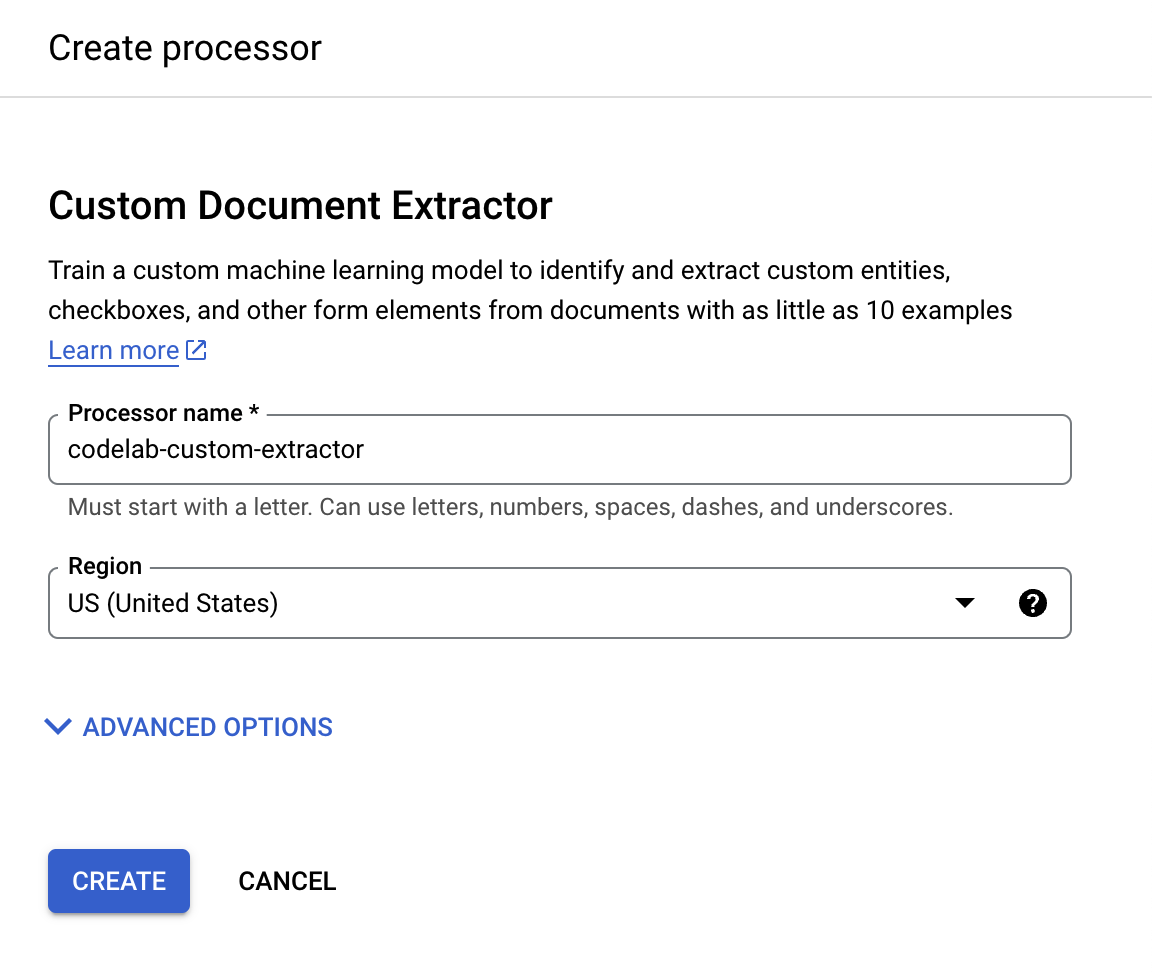
- [作成] をクリックして、プロセッサを作成します。プロセッサの概要ページが表示されます。
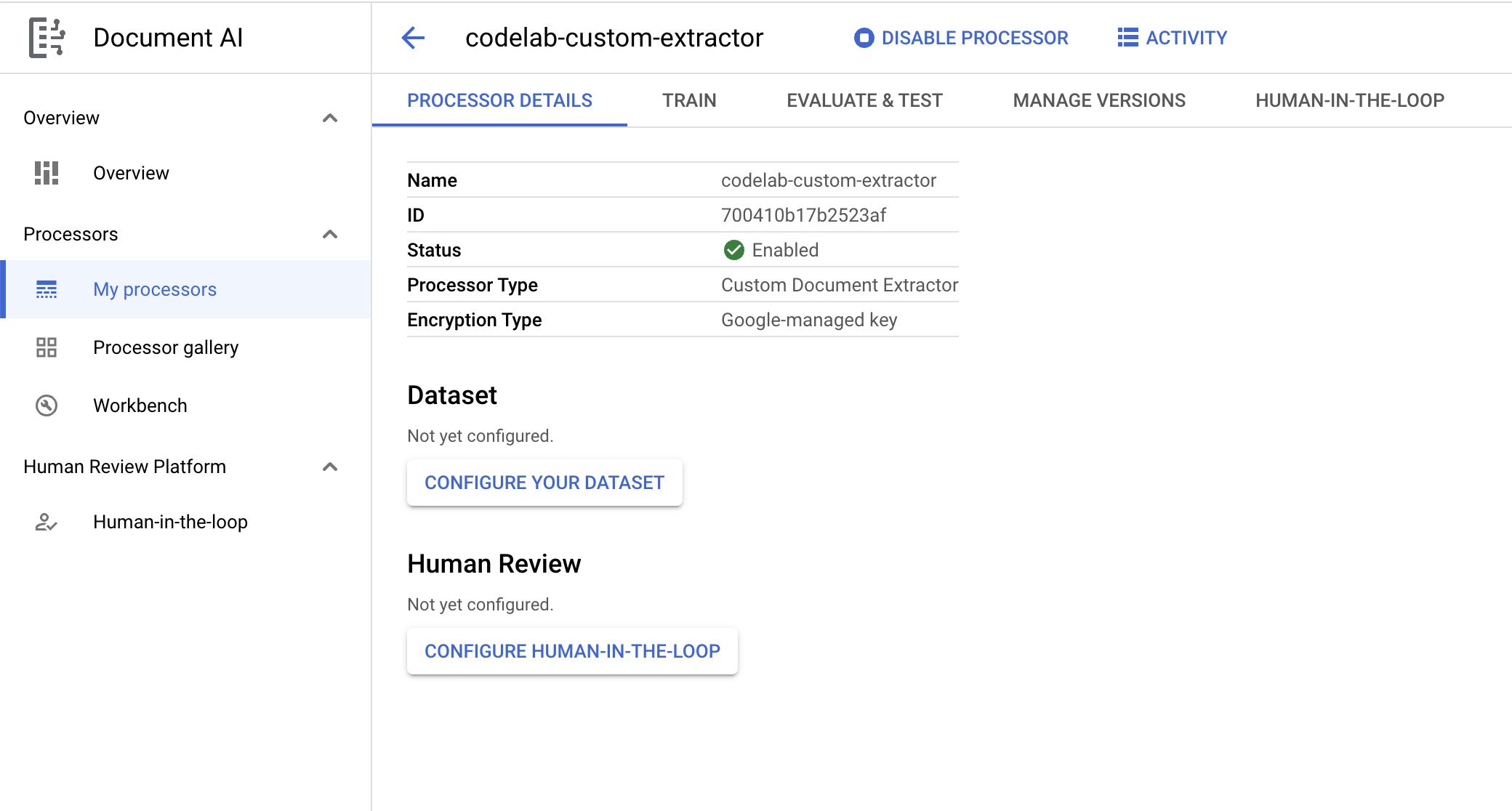
4. データセットを作成する
プロセッサをトレーニングするために、トレーニング データとテストデータを含むデータセットを作成します。このデータセットを使用して、抽出してほしいエンティティをプロセッサに学習させます。
- [プロセッサの概要] ページで、[データセットを構成する] をクリックします。
- [データセットの構成] ページが表示されます。トレーニング ドキュメントとラベルを保存する独自のバケットを指定する場合は、[詳細設定を表示] をクリックします。それ以外の場合は、[続行] をクリックします。
- データセットが作成されるまで待ちます。作成されると、[トレーニング] ページに移動します。
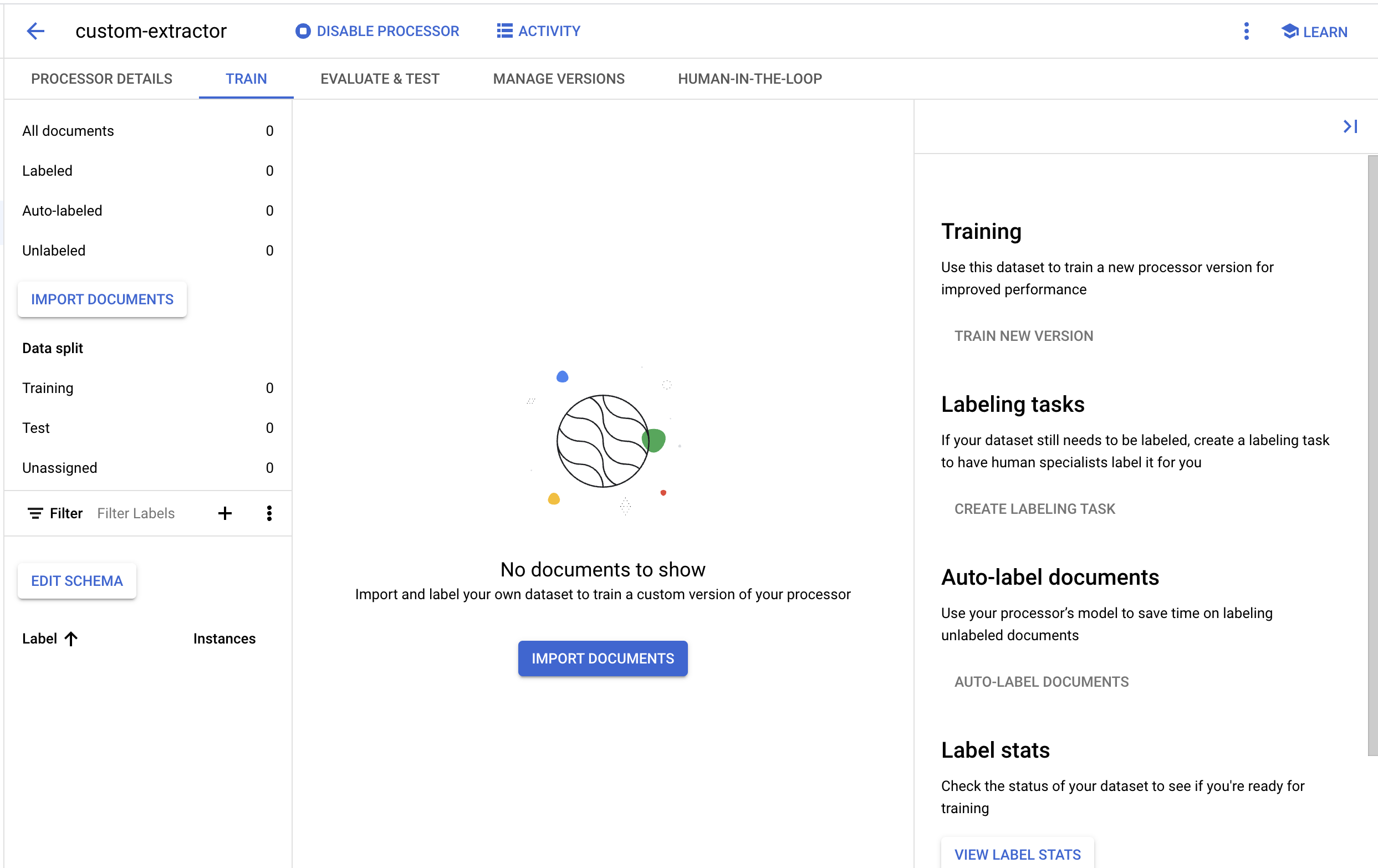
5. テスト ドキュメントをインポートする
次に、サンプルの W2 pdf をデータセットにインポートします。
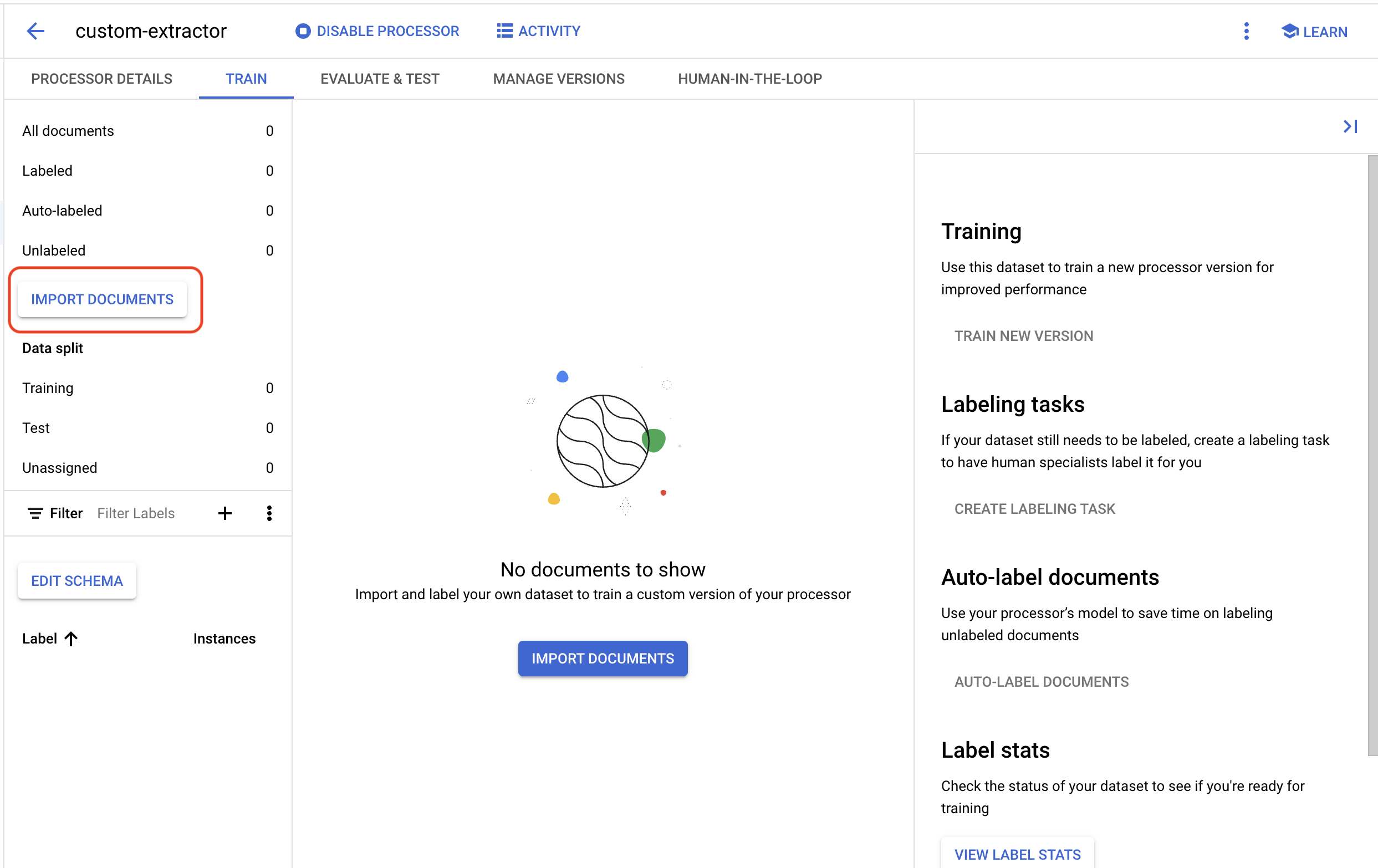
- [ドキュメントのインポート] をクリックします。
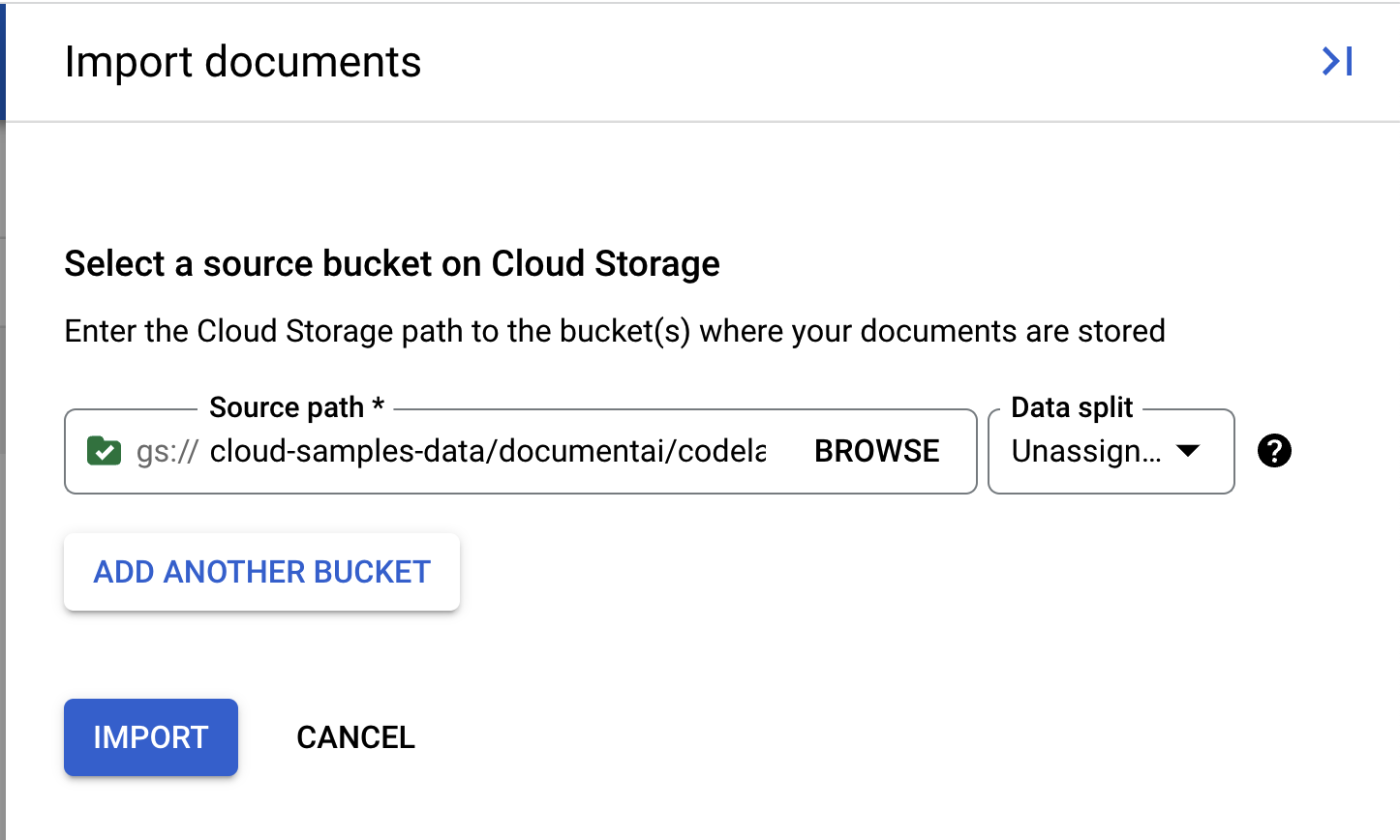
- このラボで使用するサンプル PDF が用意されています。次のリンクをコピーして [転送元のパス] ボックスに貼り付けます。[データ分割] は「未割り当て」のままにしておきます。他のチェックボックスはすべてオフにします。[インポート] をクリックします。
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs
- ドキュメントがインポートされるまで待ちます。1 分ほどで完了します。
- インポートが完了すると、[トレーニング] ページにドキュメントが表示されます。
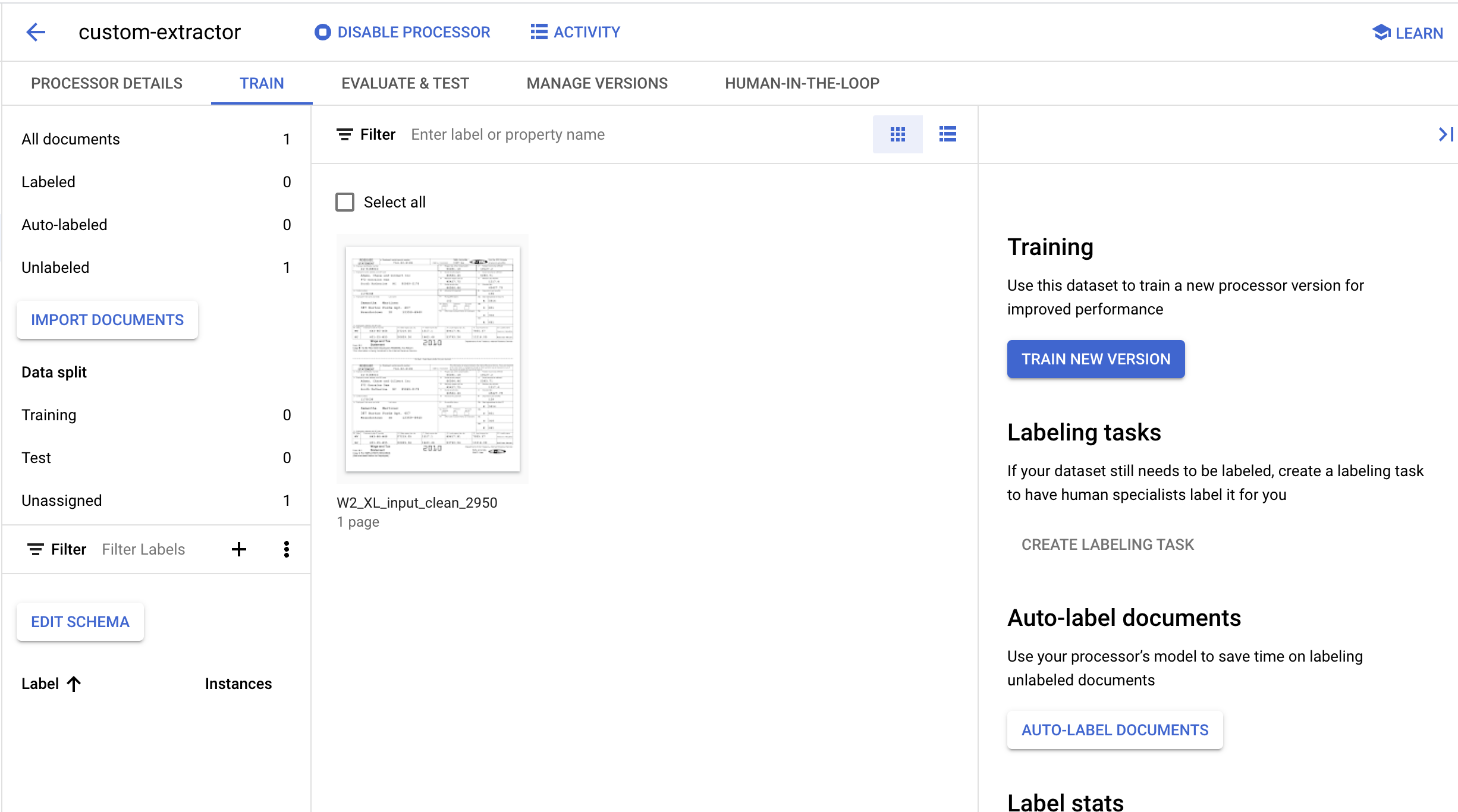
6. ラベルを作成する
ここでは新しいプロセッサ タイプを作成しているので、抽出対象のフィールドを Document AI に教えるため、カスタムラベルを作成する必要があります。
- 左下隅にある [スキーマを編集] をクリックします。
- スキーマ管理コンソールが表示されます。
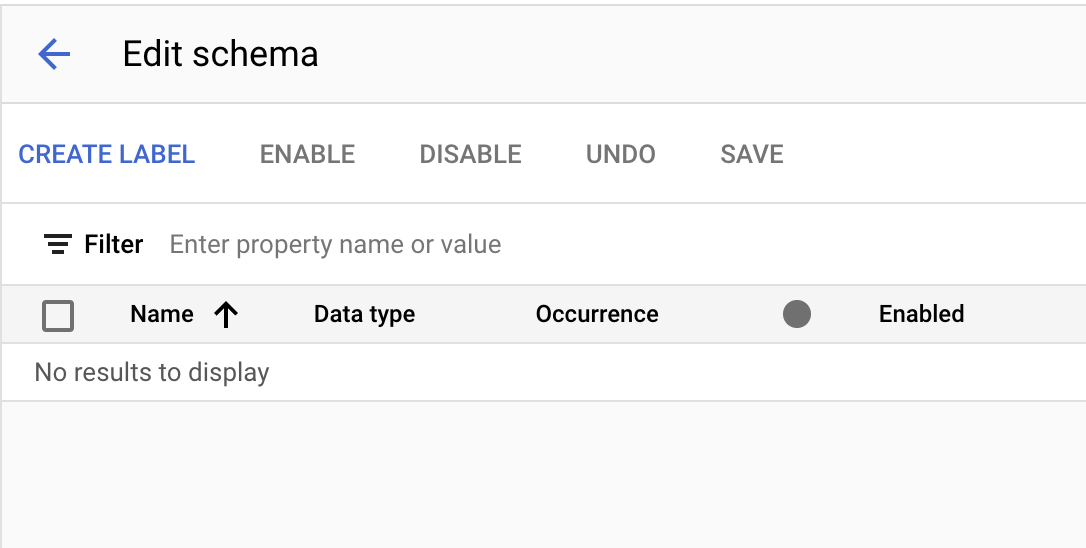
- [ラベルを作成] ボタンを使用して、次のラベルを作成します。
名前 | データ型 | オカレンス |
| 数値 | 複数回必要 |
| 書式なしテキスト | 複数回必要 |
| 書式なしテキスト | 複数回必要 |
| 住所 | 複数回必要 |
| 金額 | 複数回必要 |
| 金額 | 複数回必要 |
| 金額 | 複数回必要 |
| 金額 | 複数回必要 |
- 完了すると、コンソールは次のようになります。完了したら [保存] をクリックします
- 戻る矢印をクリックして [トレーニング] ページに戻ります。いま作成したラベルが左下に表示されています。
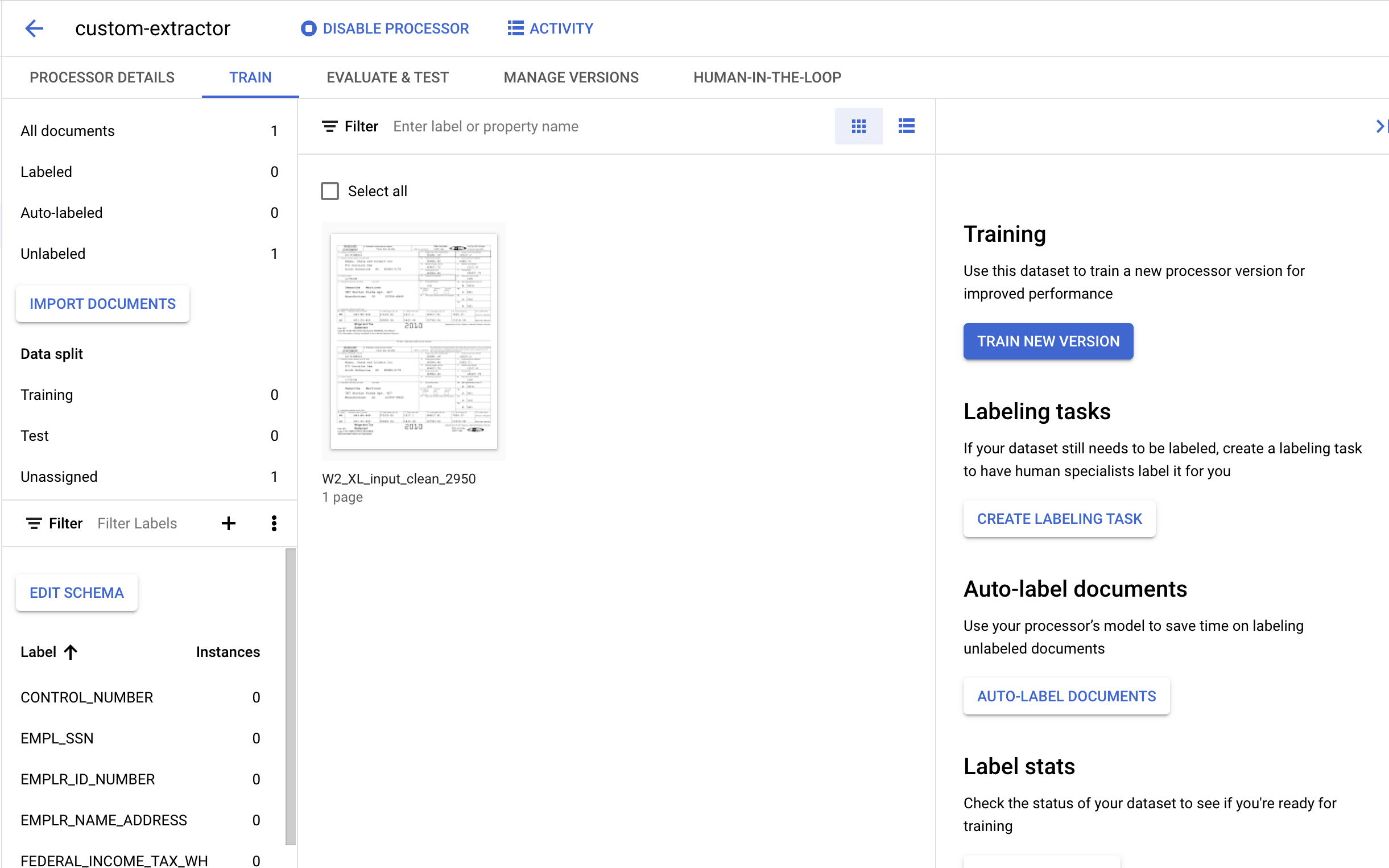
7. テスト ドキュメントにラベルを付ける
次に、抽出したいエンティティのテキスト要素とラベルを指定します。このラベルは、特定のドキュメント構造を解析して正しいタイプを識別するモデルのトレーニングで使用します。
- 前にインポートしたドキュメントをダブルクリックして、ラベリング コンソールに切り替えます。次のようになります。
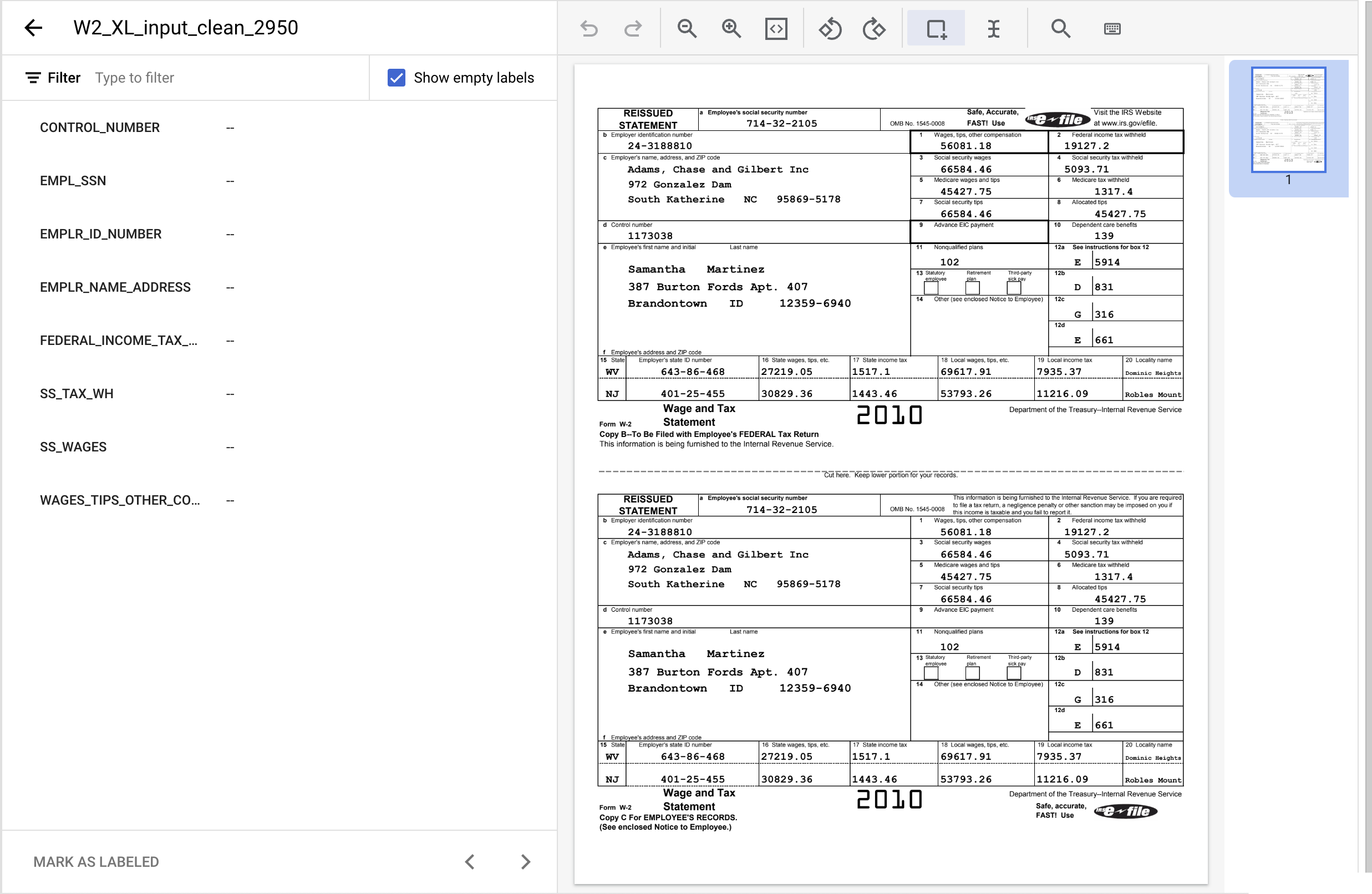
- 境界ボックスツールをクリックして「1173038」というテキストをハイライト表示し、ラベル
CONTROL_NUMBERを割り当てます。テキスト フィルタでラベル名を検索することもできます。
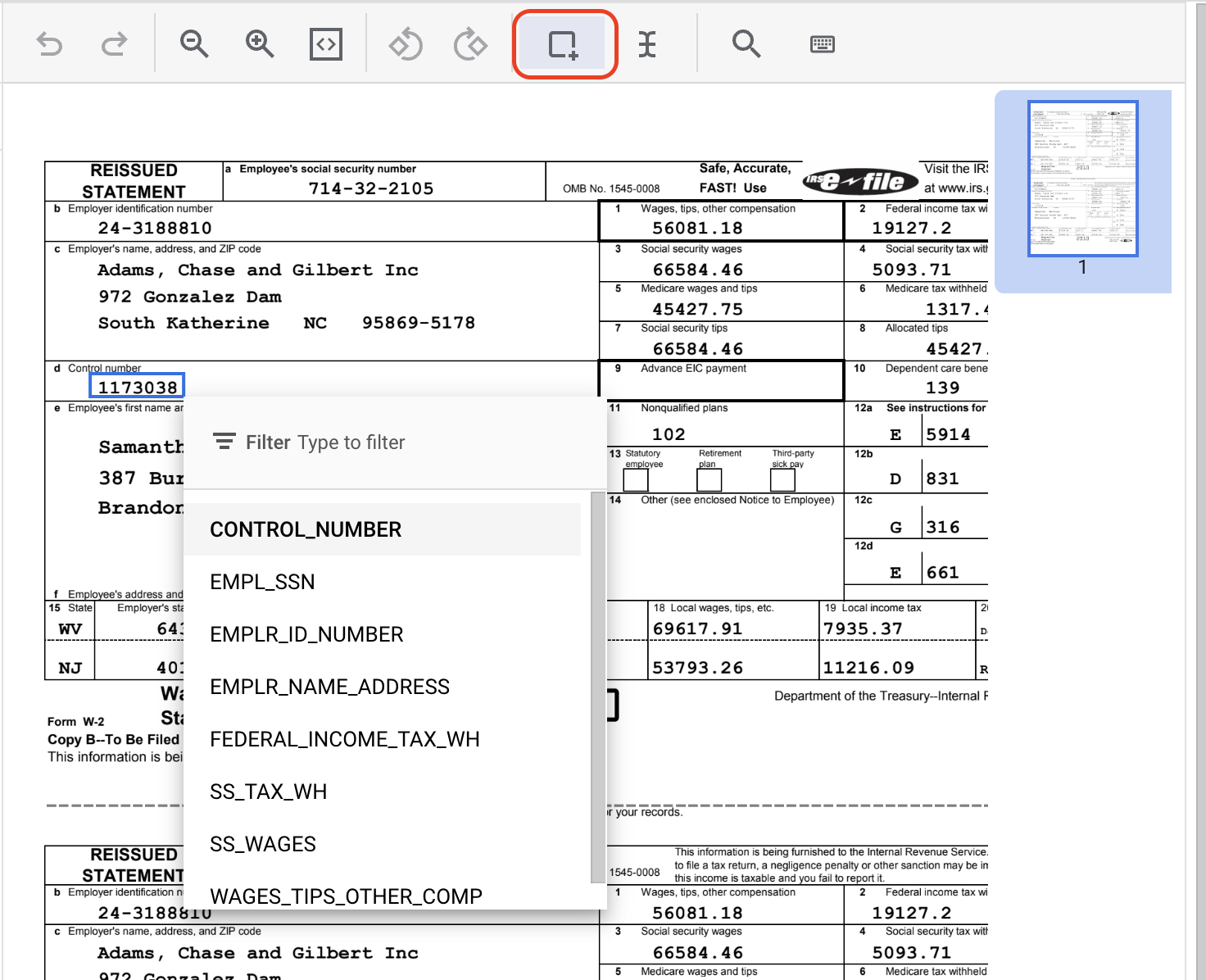
CONTROL_NUMBERの他のインスタンスにも同じ操作を行います。ラベル付けが完了すると、次のようになります。
- 次のテキスト値を持つインスタンスをすべてハイライト表示し、適切なラベルを割り当てます。
ラベル名 | テキスト |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
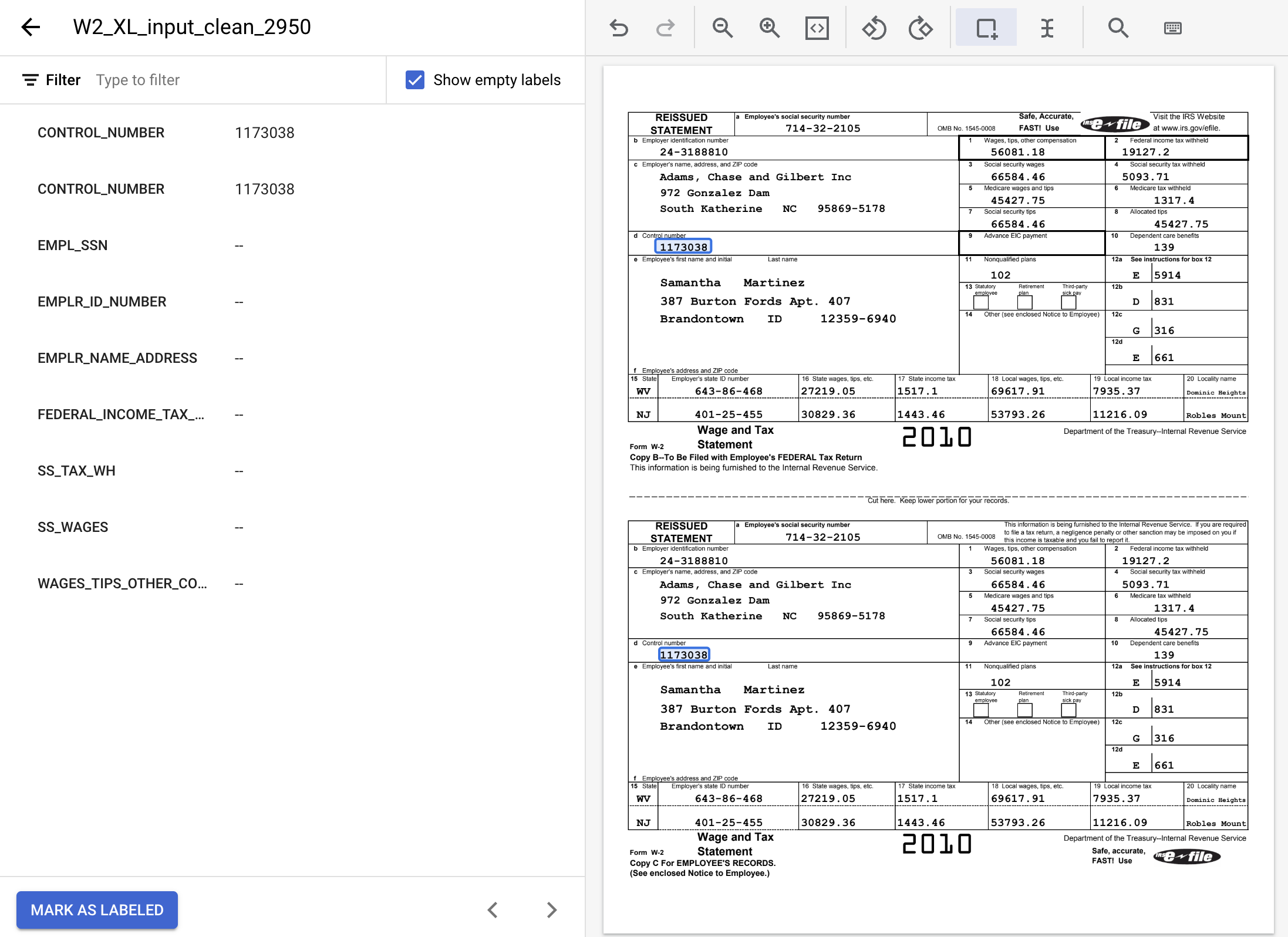
- 完了後のラベル付きドキュメントは次のようになります。ラベルを調整するには、ドキュメントの境界ボックスをクリックするか、左側のサイドメニューでラベル名 / 値をクリックします。ラベル付けが完了したら [ラベル付きとしてマーク] をクリックします。データセット管理コンソールに戻ります。
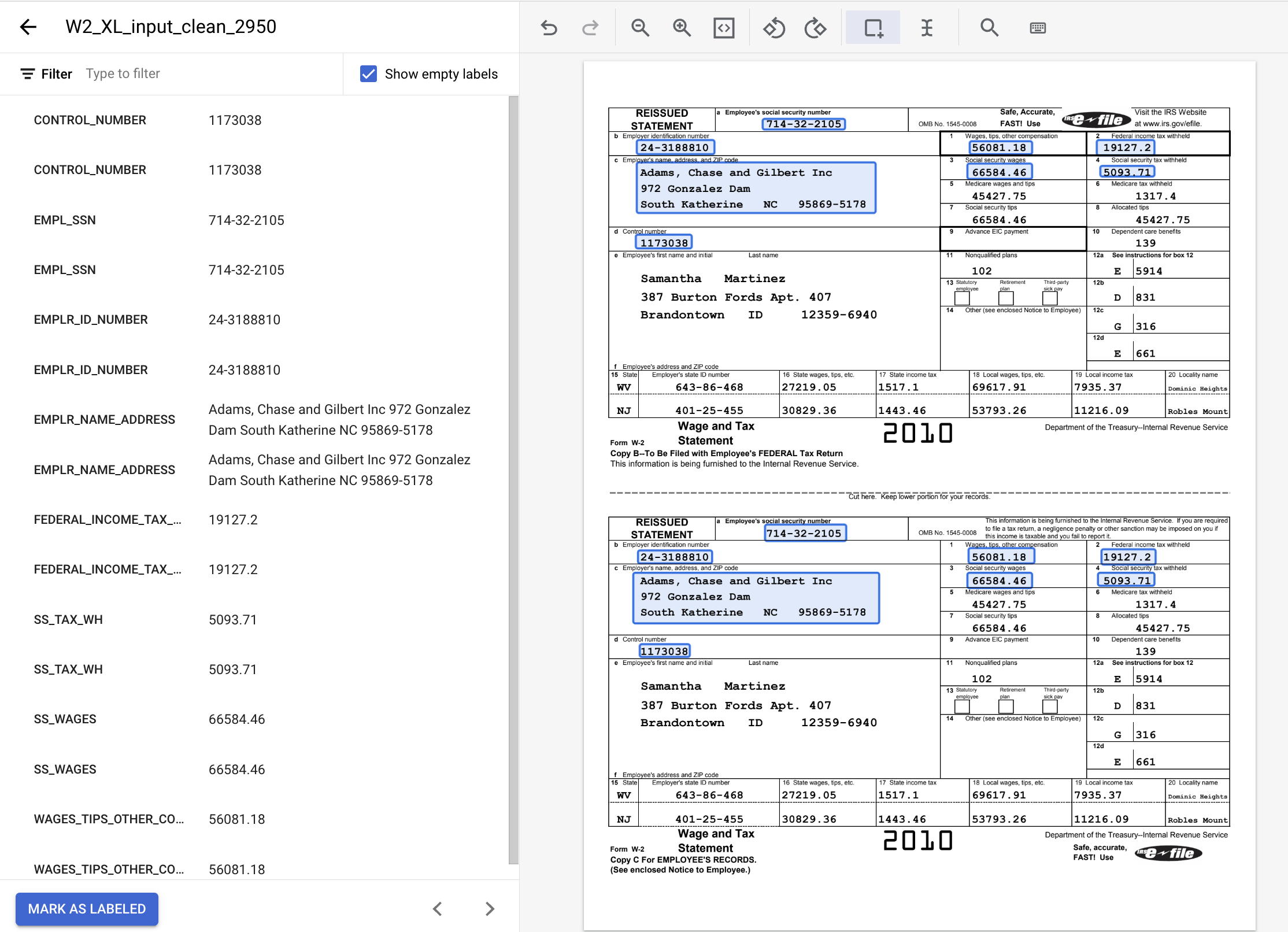
8. ドキュメントをトレーニング セットに割り当てる
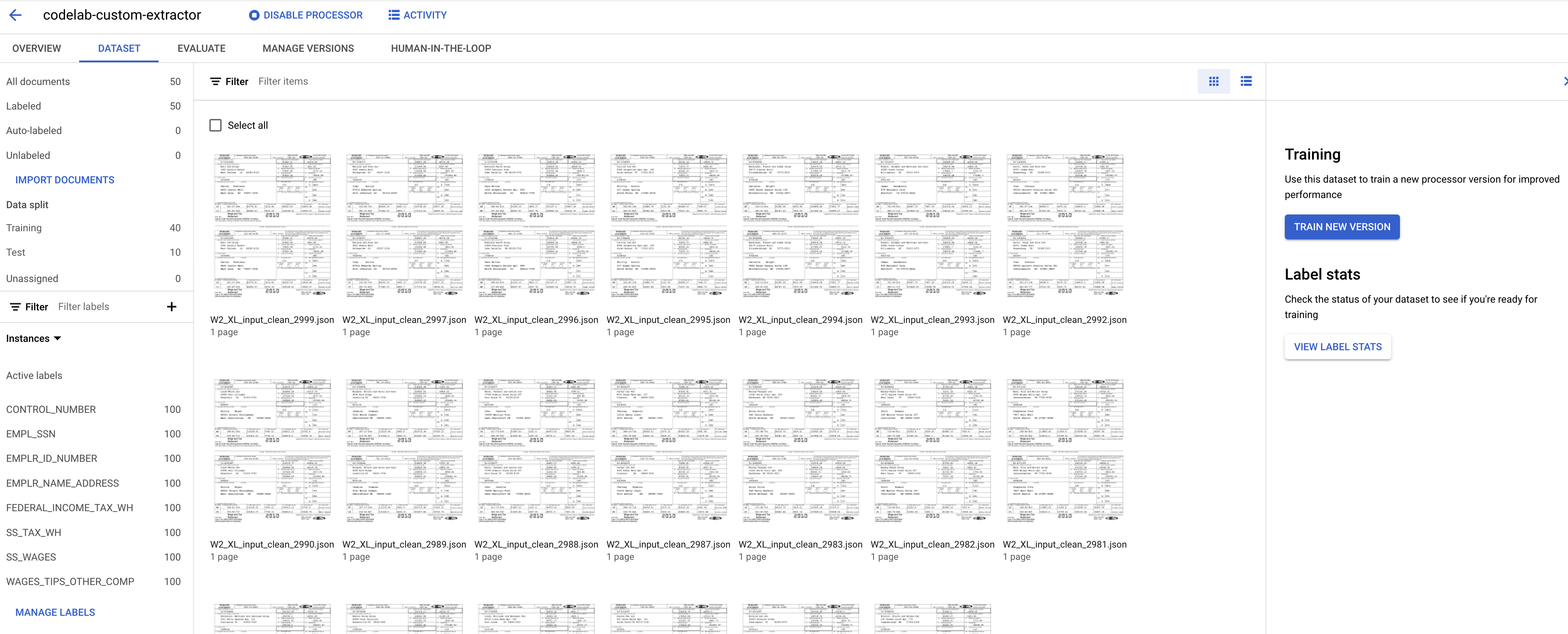
データセット管理コンソールに戻りました。ラベル付きのドキュメントとラベルなしのドキュメントの数、ラベルごとのインスタンス数を見てください。値が変わっているはずです。
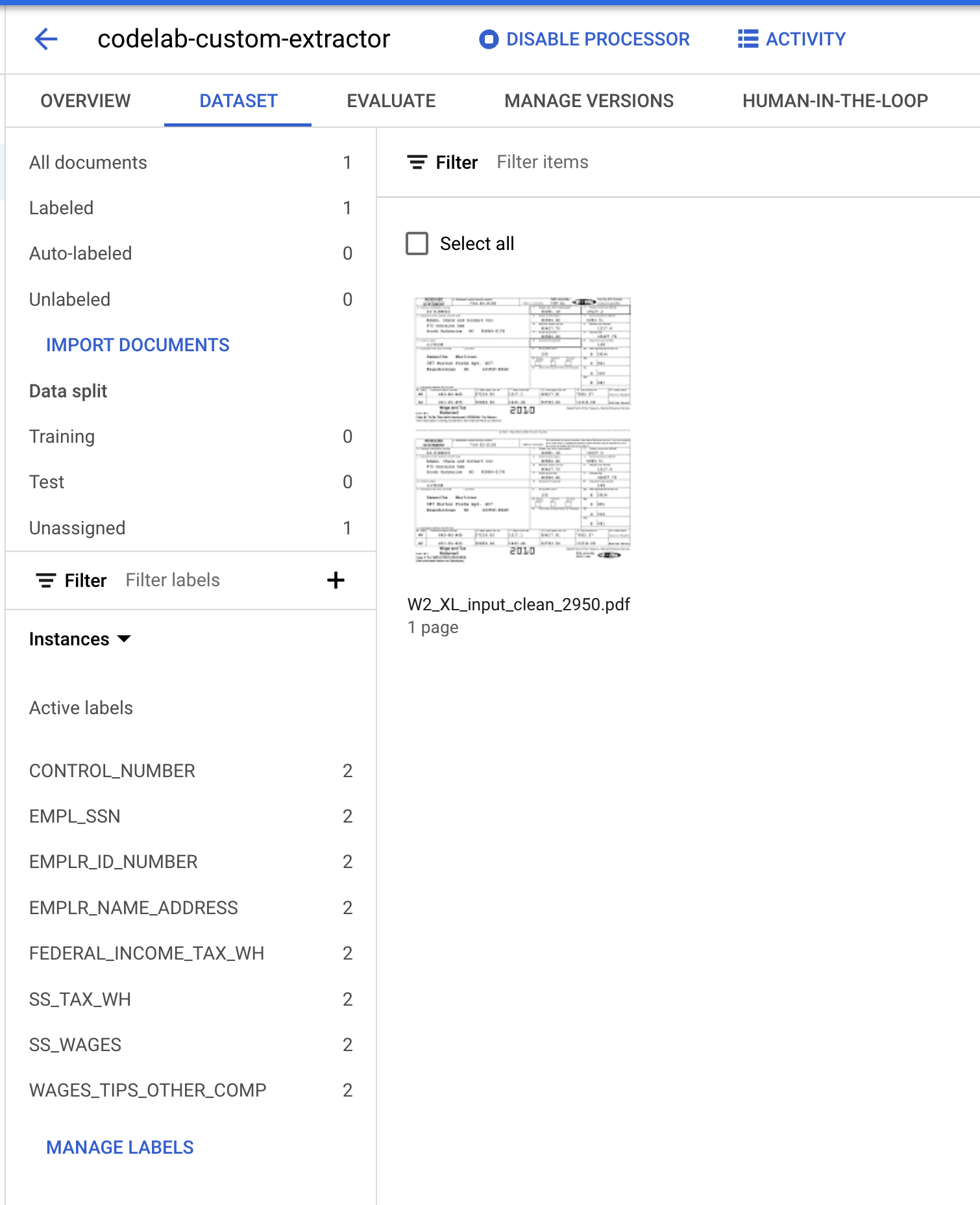
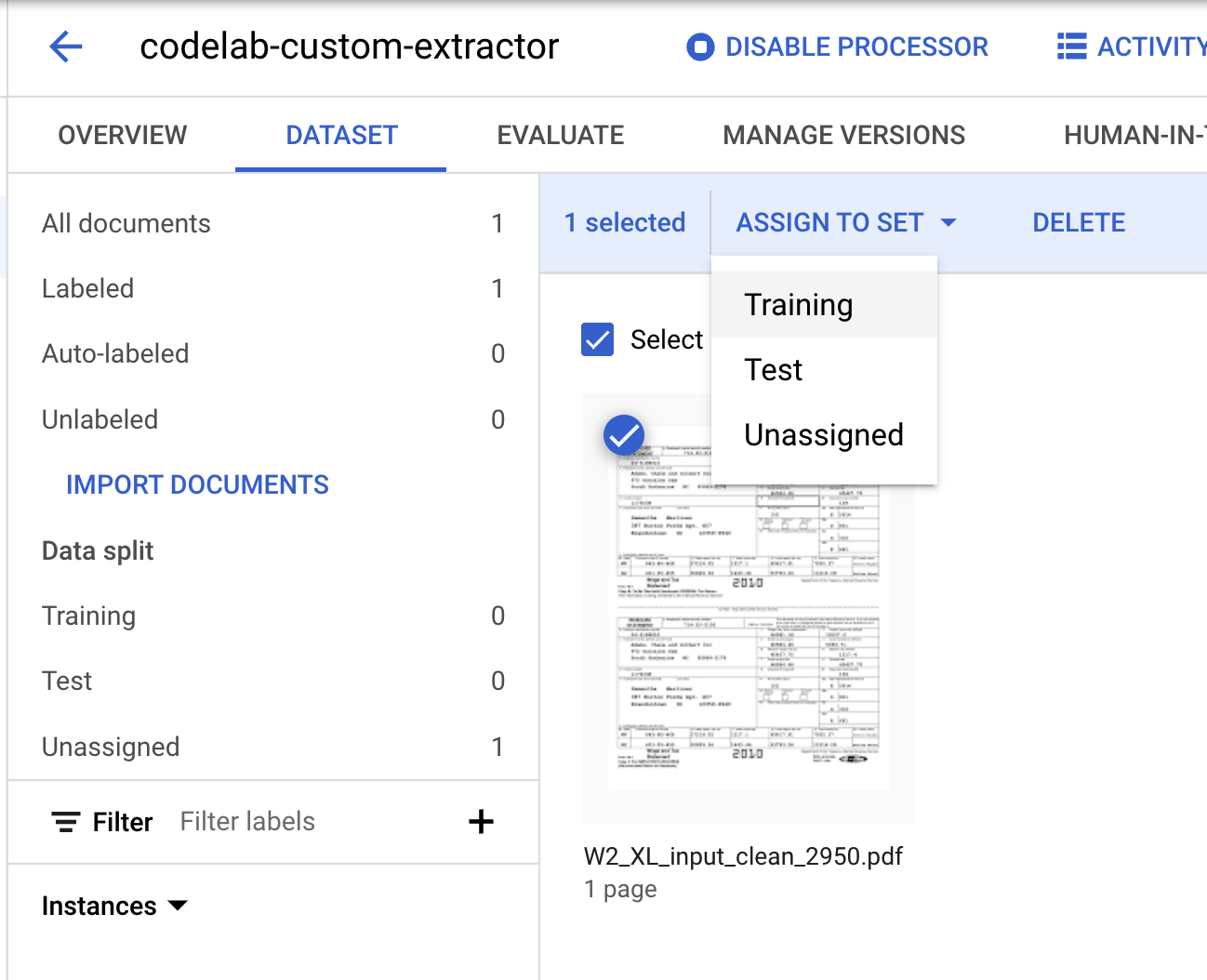
- このドキュメントをトレーニング セットかテストセットのいずれかに割り当てる必要があります。ドキュメントをクリックして [セットに割り当て] をクリックし、[トレーニング] をクリックします。
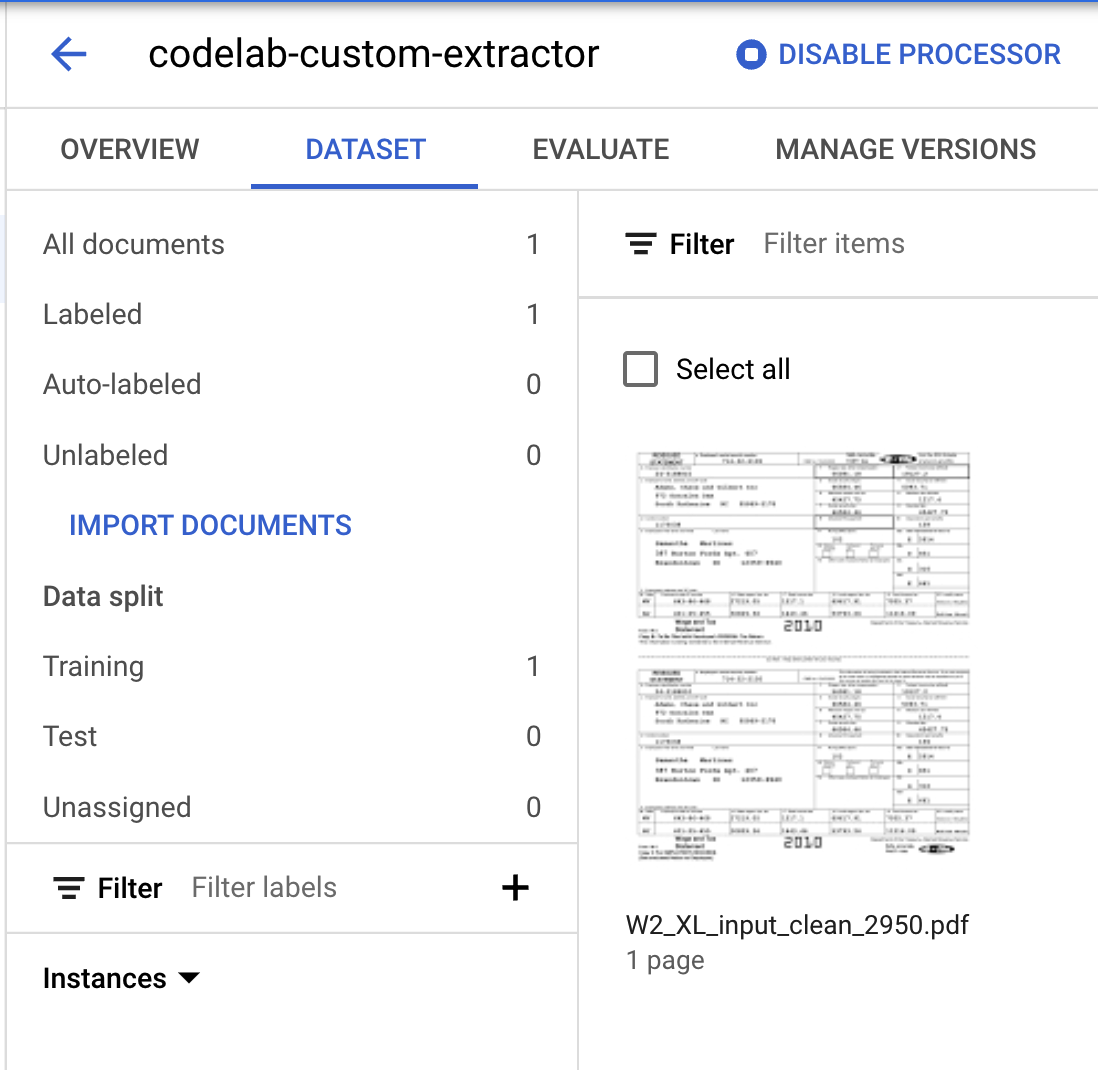
- データ分割の数字が変更されています。
9. 事前にラベル付けされたデータをインポートする
Document AI カスタム プロセッサでは、トレーニング セットとテストセットの両方で少なくとも 10 個のドキュメントと、各セットのラベルごとに 10 個のインスタンスが必要です。
最適なパフォーマンスを得るには、各セットに 50 個以上のドキュメントと、各ラベルに 50 個のインスタンスを含めることをおすすめします。一般に、トレーニング データが多いほど精度が高くなります。
すべてのドキュメントに手動でラベルを付けると時間がかかるので、このラボでは、すでにラベルの付いているドキュメントをいくつかインポートすることにします。
事前にラベル付けしたドキュメント ファイルは Document.json 形式でインポートできます。この中には、プロセッサを呼び出して人間参加型(HITL)で精度を検証した結果が含まれている場合があります。
ネガティブな結果は除く
注: 事前にラベル付けされたデータをインポートする場合は、モデルのトレーニングを行う前に、アノテーションを実際に確認することを強くおすすめします。
- [ドキュメントのインポート] をクリックします。
- 次の Cloud Storage パスをコピーして貼り付け、トレーニング セットに割り当てます。
cloud-samples-data/documentai/codelabs/custom/extractor/training
- [別のフォルダを追加] をクリックします。次の Cloud Storage パスをコピーして貼り付け、テストセットに割り当てます。
cloud-samples-data/documentai/codelabs/custom/extractor/test
- [インポート] をクリックして、ドキュメントがインポートされるのを待ちます。処理するドキュメントの数が多いため、前回よりも処理に時間がかかります。この処理には約 6 分かかります。このページを離れて、後で戻ってくることもできます。
- 完了すると、[トレーニング] ページにドキュメントが表示されます。
10. モデルをトレーニングする
これで、カスタム ドキュメント エクストラクタのトレーニングを開始する準備ができました。
- [新しいバージョンをトレーニング] をクリックします。
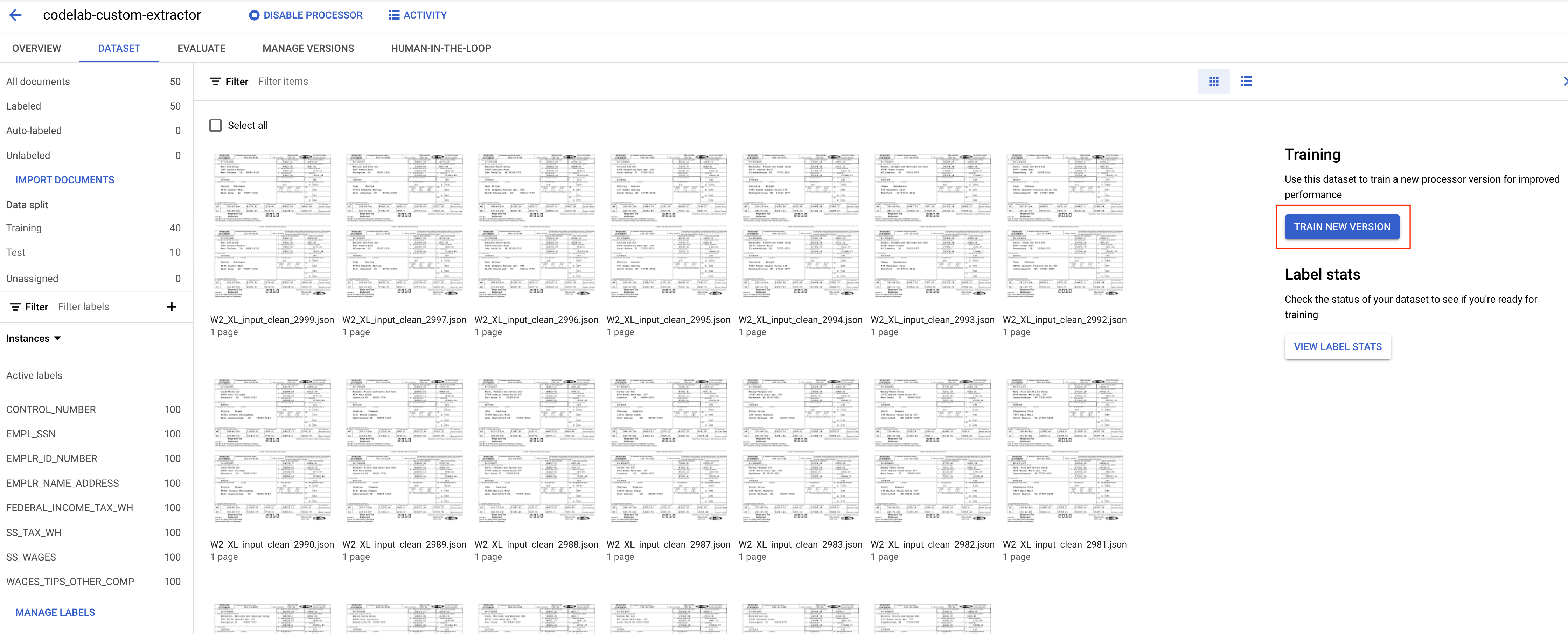
- バージョンに名前を付けます。
codelab-custom-1のように覚えやすいものにします。[トレーニング方法] で [Train from scratch] を選択します。
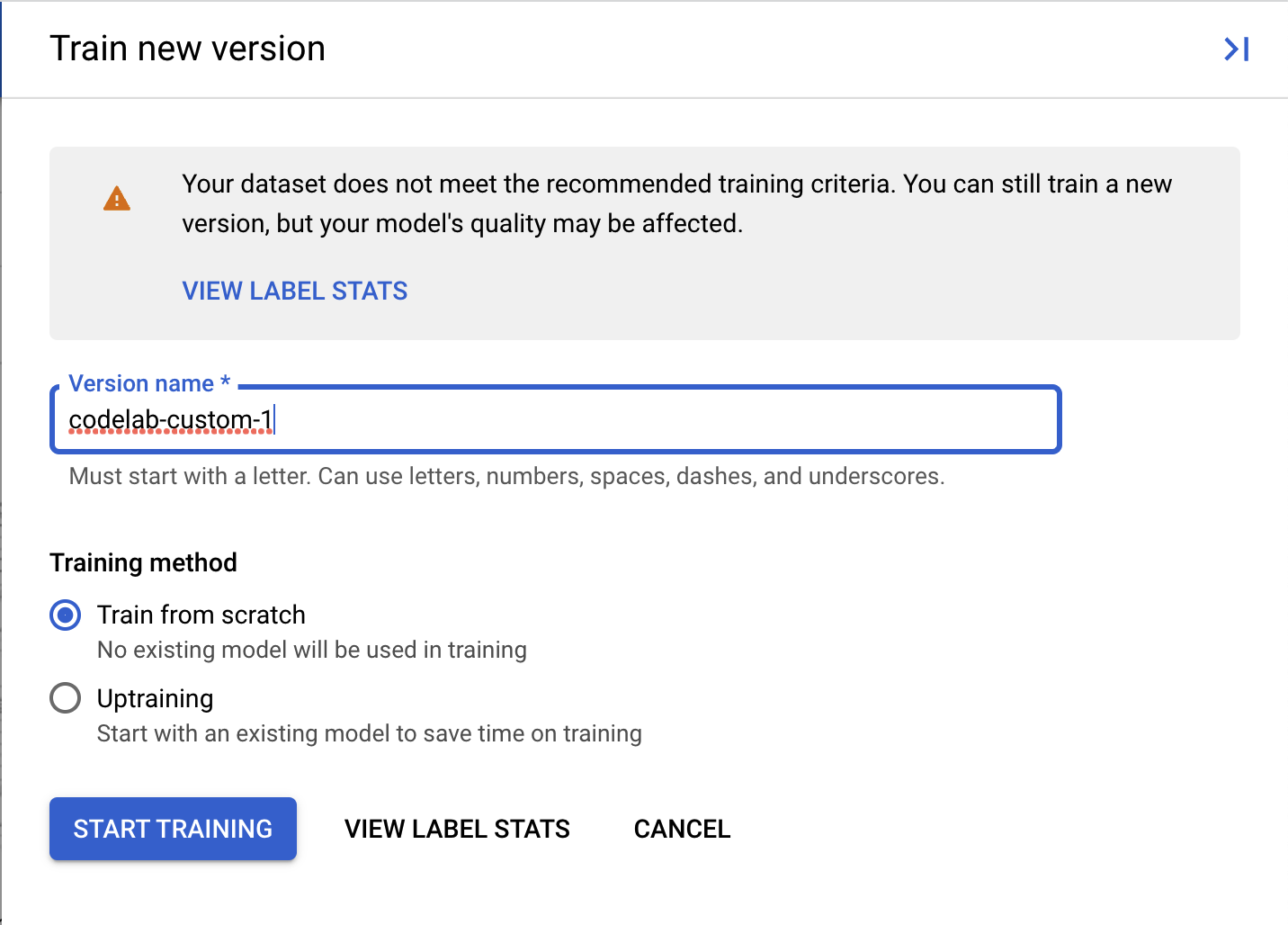
- (省略可)[ラベルの統計データを表示] を選択して、データセット内のラベルに関する指標を確認することもできます。
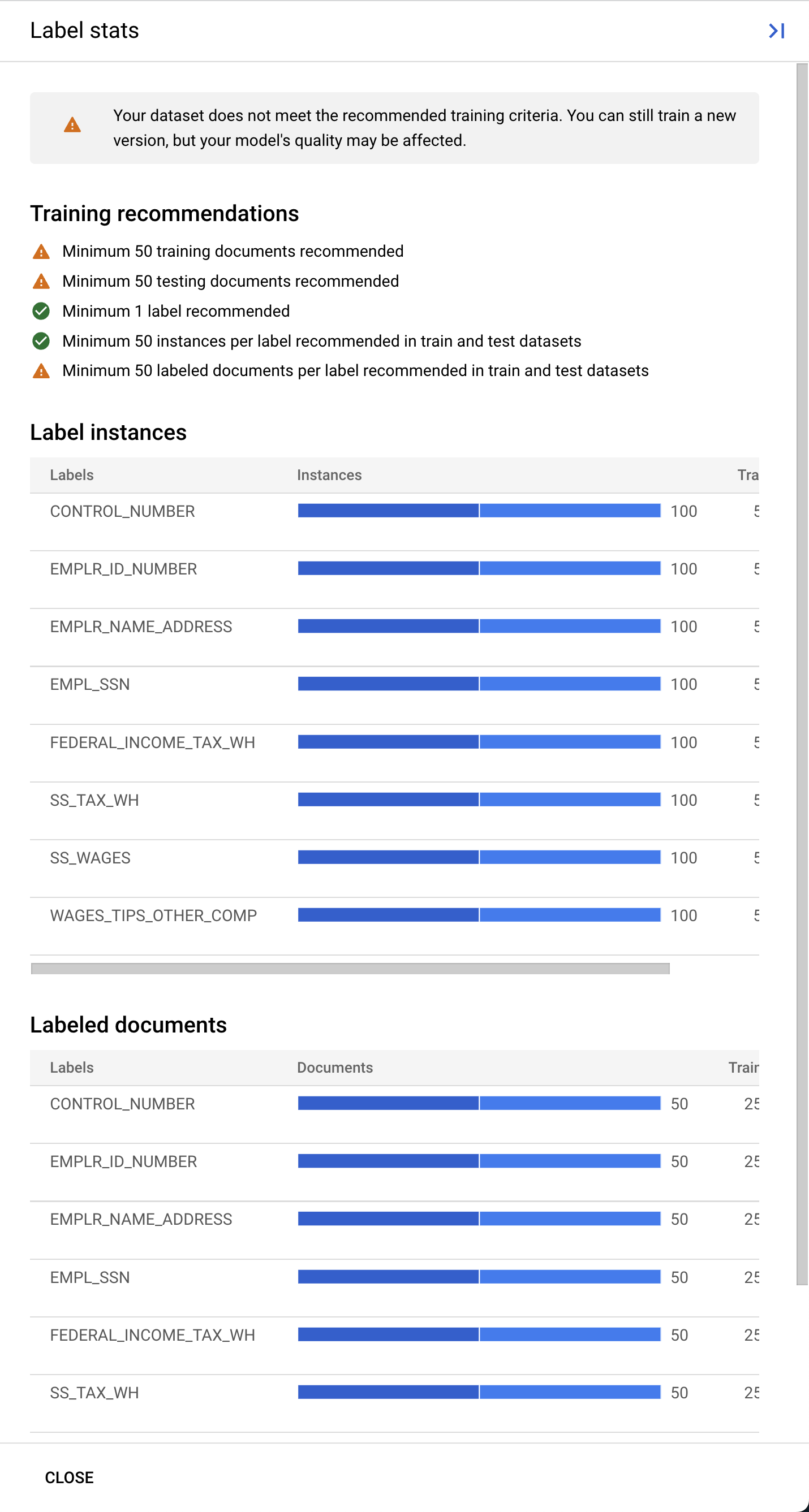
- [トレーニングを開始] をクリックして、トレーニング プロセスを開始します。データセット管理ページにリダイレクトされます。右側にトレーニングのステータスが表示されます。トレーニングには数時間かかります。このページを離れて、後で戻ってくることもできます。
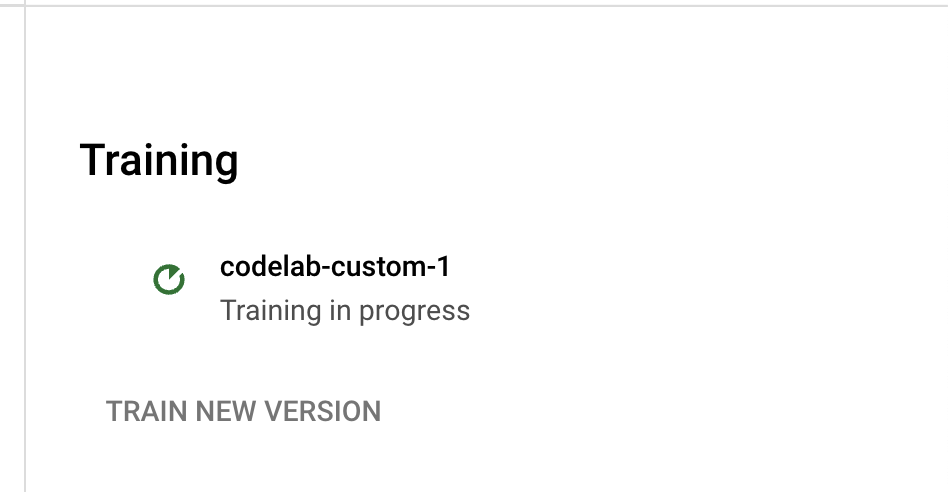
- バージョン名をクリックすると、[バージョンの管理] ページに移動します。このページには、トレーニング ジョブのバージョン ID と現在のステータスが表示されます。
11. 新しいモデル バージョンをテストする
トレーニング ジョブが完了したので(こちらのテストでは 1 時間ほどかかりました)、新しいモデル バージョンをテストし、そのモデルを使って予測を取得できます。
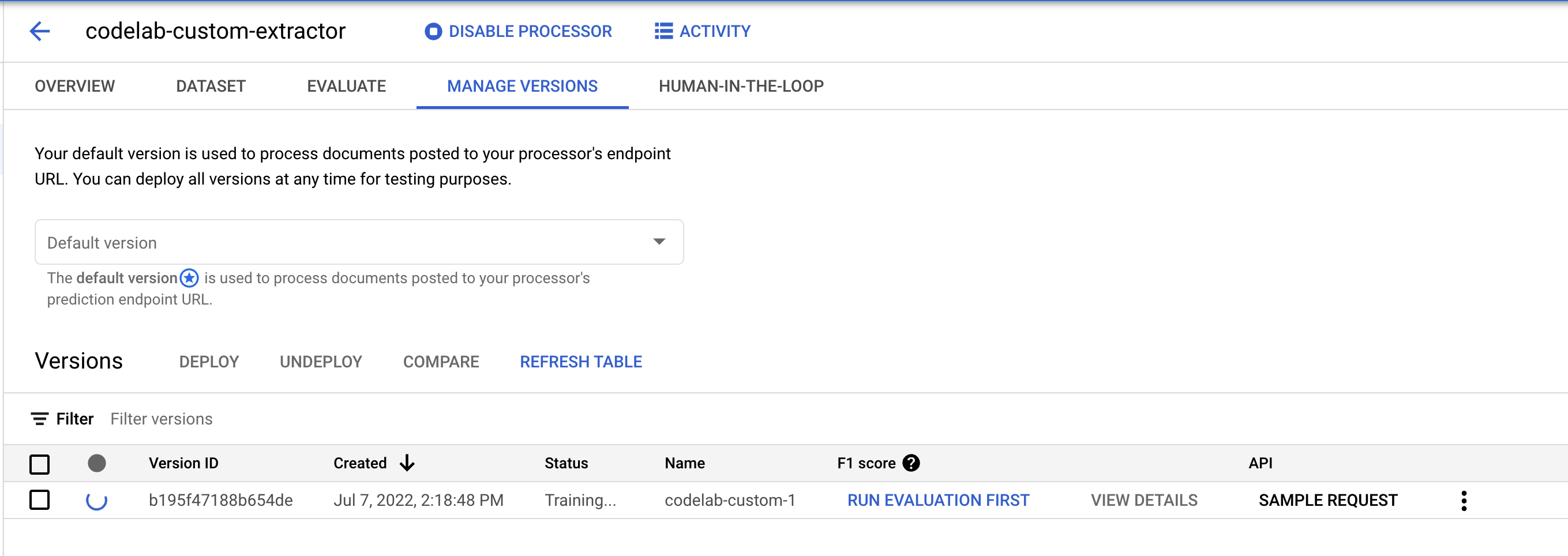
- [バージョンの管理] ページに移動します。ここには、現在のステータスと F1 スコアが表示されています。
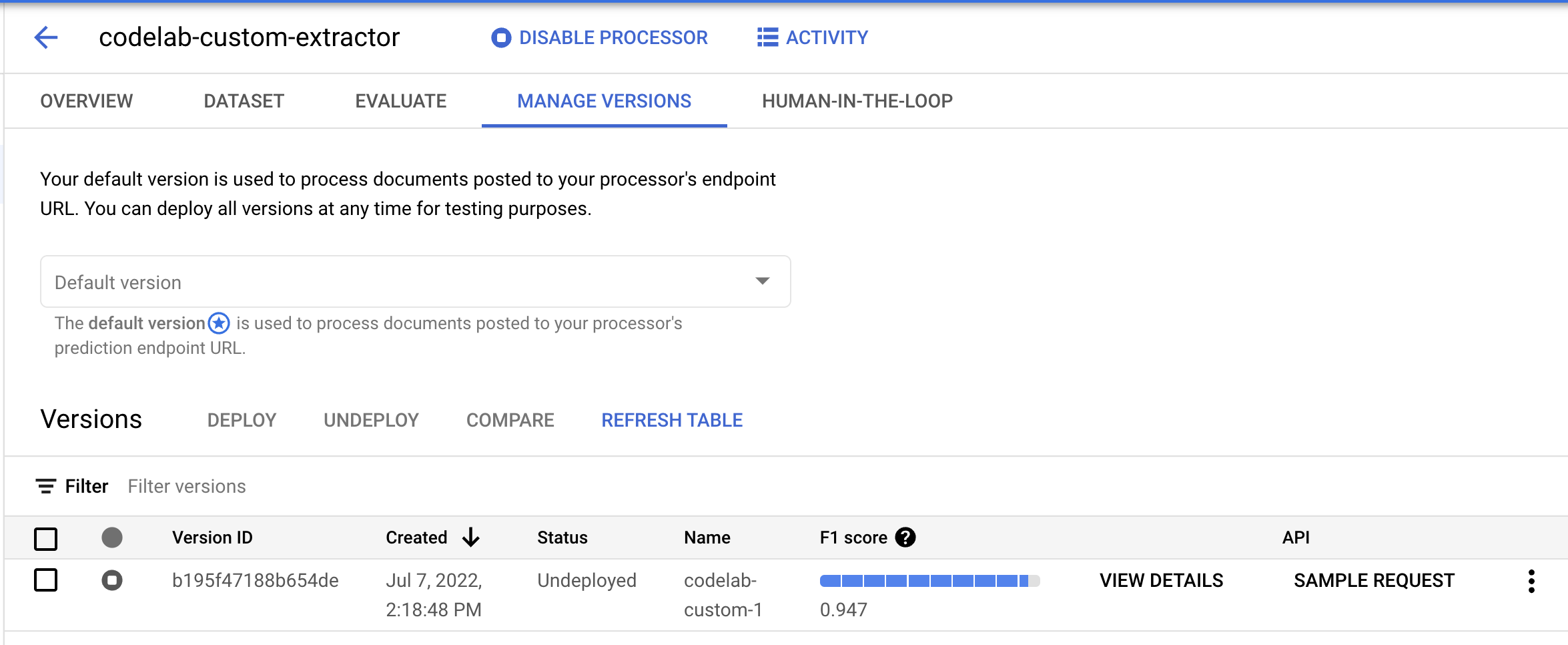
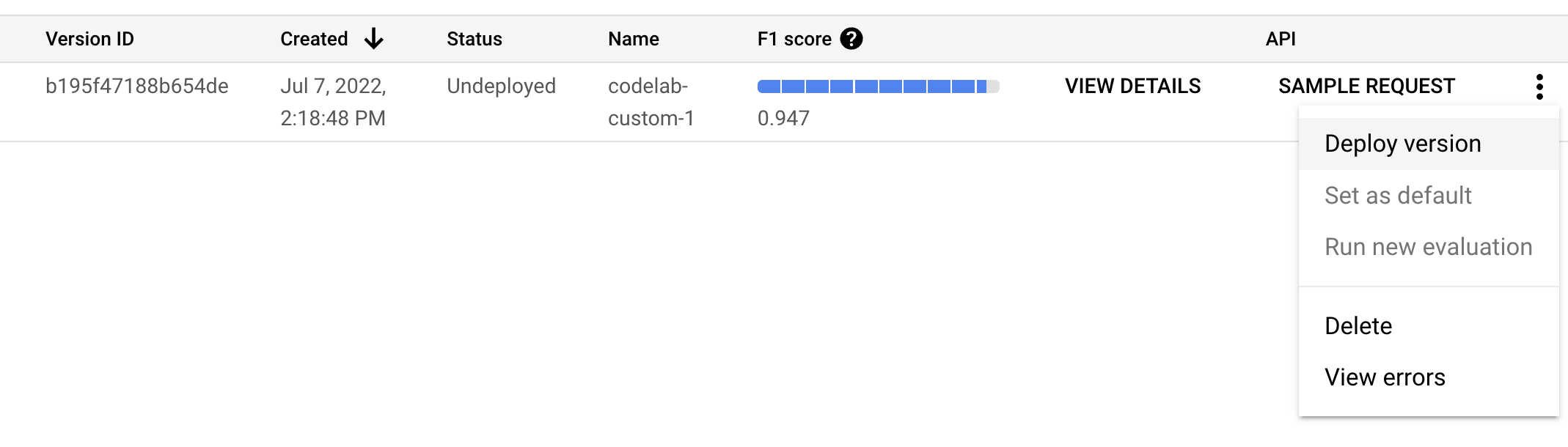
- このモデル バージョンを使用する前にデプロイする必要があります。右側の縦のドットをクリックして、[バージョンをデプロイ] を選択します。
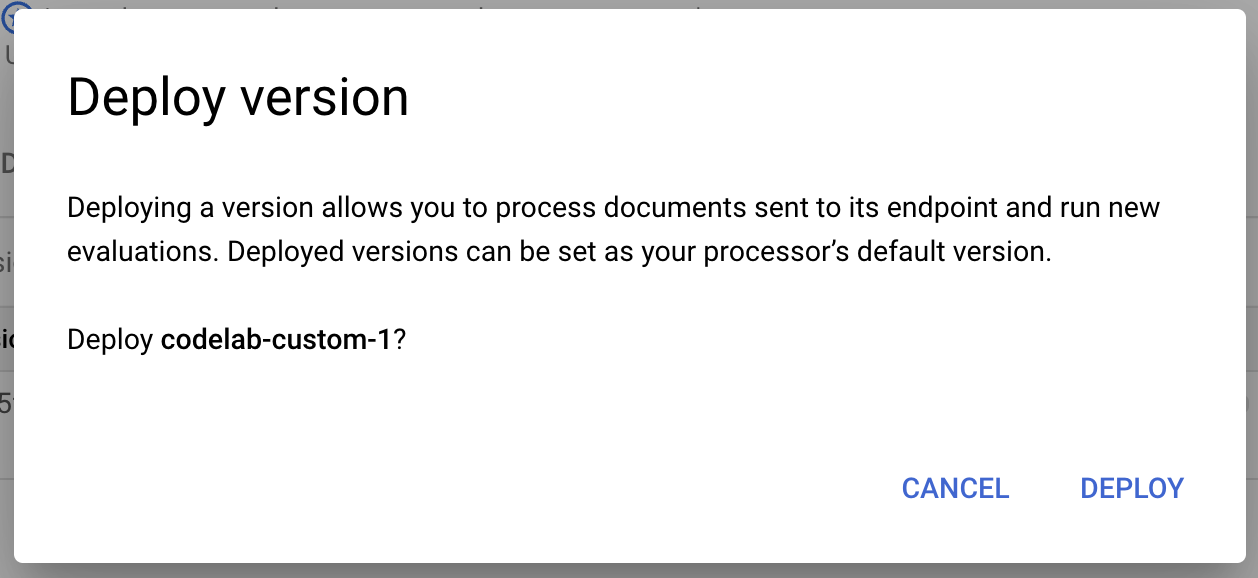
- ポップアップ ウィンドウから [デプロイ] を選択します。バージョンがデプロイされるまで待ちます。完了するまでに数分かかります。デプロイされたら、このバージョンをデフォルト バージョンに設定できます。
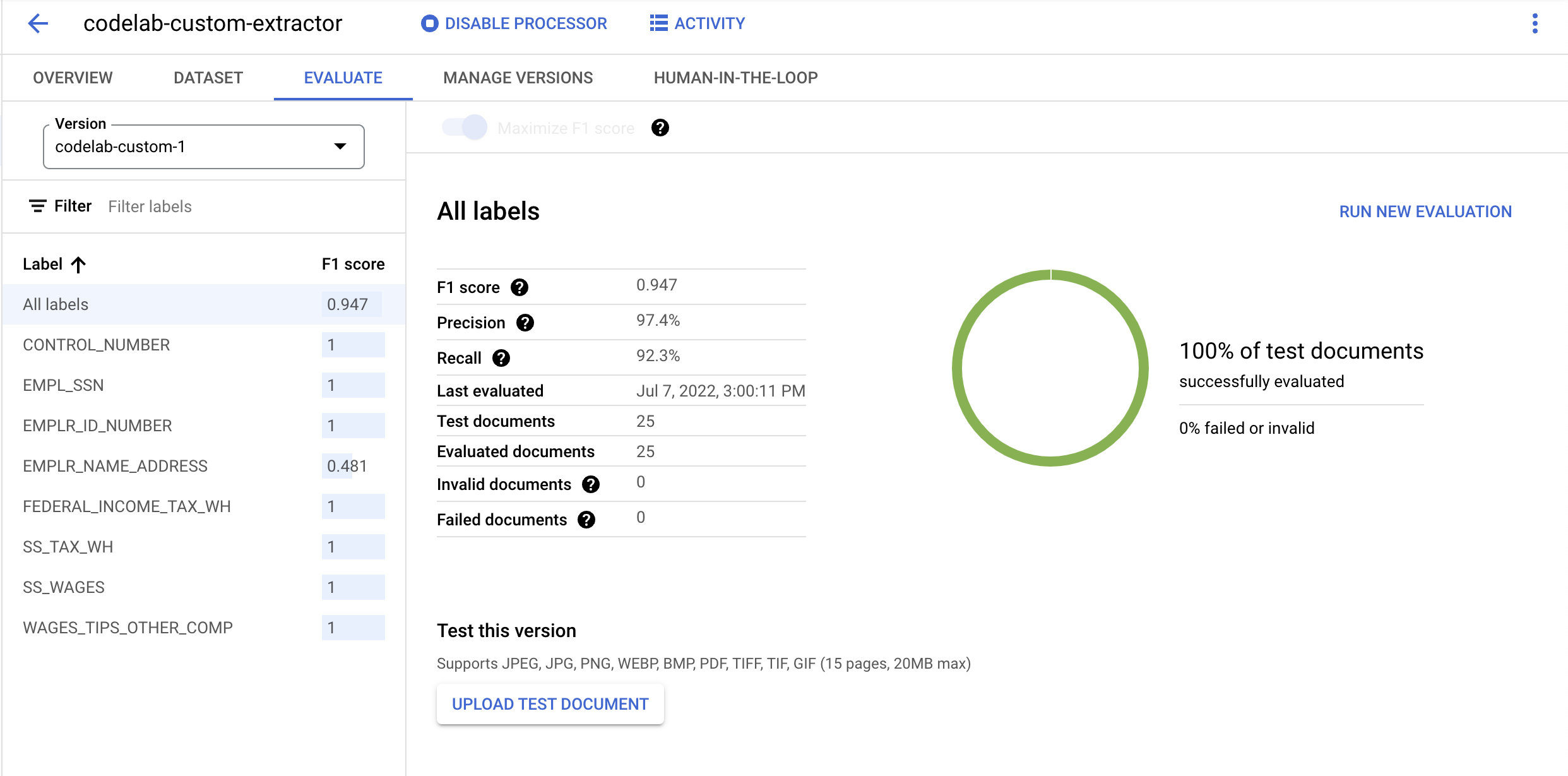
- デプロイが完了したら、[評価] タブに移動します。このページでは、ドキュメント全体の F1 スコア、適合率、再現率などの評価指標と、個々のラベルを確認できます。これらの指標の詳細については、AutoML のドキュメントをご覧ください。
- 次のリンク先から PDF ファイルをダウンロードします。これは、トレーニング セットまたはテストセットに含まれていない W2 のサンプルです。
- [テスト ドキュメントをアップロード] をクリックして、PDF ファイルを選択します。
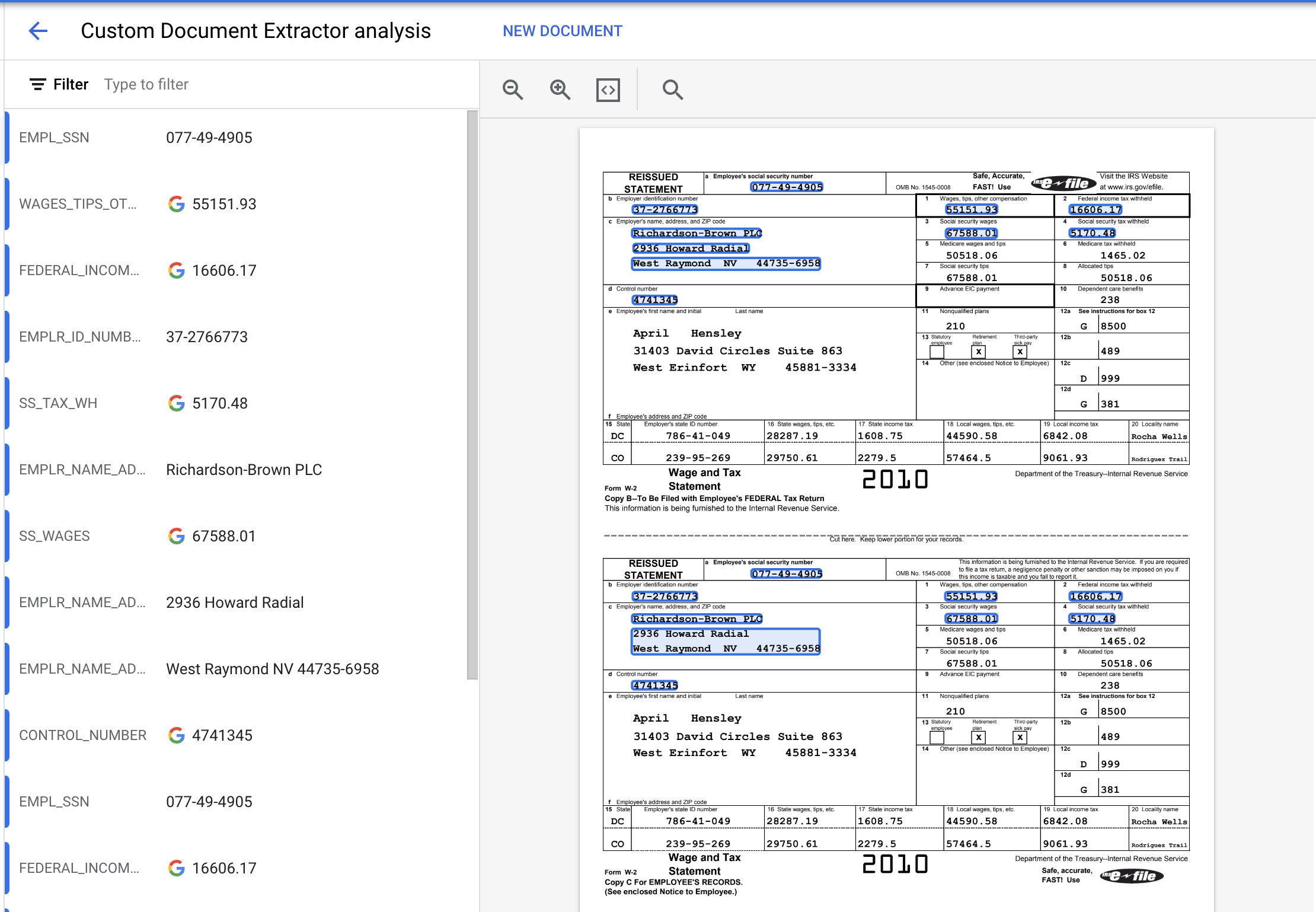
- 抽出されたエンティティは次のようになります。
12. 省略可: 新しくインポートしたドキュメントに自動的にラベルを付ける
トレーニング済みのプロセッサ バージョンをデプロイした後、自動ラベル付けを使用すると、新しいドキュメントをインポートしたときのラベル付けの時間を短縮できます。
- [トレーニング] タブで、[ドキュメントのインポート] をクリックします。
- 次の のパスをコピーして貼り付けます。このディレクトリには、ラベルのない W2 の PDF が 5 つ含まれています。[データ分割] プルダウン リストから [トレーニング] を選択します。
cloud-samples-data/documentai/Custom/W2/AutoLabel - [自動ラベル付け] セクションで、[自動ラベル付けを使用したインポート] チェックボックスをオンにします。
- ドキュメントのラベル付けを行う既存のプロセッサ バージョンを選択します。
- 例:
2af620b2fd4d1fcf
- [インポート] をクリックして、ドキュメントがインポートされるのを待ちます。このページを離れて、後で戻ってくることもできます。
- 完了すると、ドキュメントは [トレーニング] ページの [自動的にラベル付け] セクションに表示されます。
- ラベル付きとマークしないと、トレーニングやテストで自動ラベル付けのドキュメントを使用できません。[自動的にラベル付け] セクションに移動して、自動的にラベル付けされたドキュメントを表示します。
- 最初のドキュメントを選択して、ラベル付けのコンソールを開きます。
- ラベル、境界ボックス、値が正しいことを確認します。除外されている値にラベルを付けます。
- 完了したら、[ラベル付きとしてマーク] を選択します。
- 自動的にラベル付けされたドキュメントごとにラベルを確認します。その後、[トレーニング] ページに戻り、そのデータをトレーニングに使用します。
13. まとめ
お疲れさまでした。ここでは、Document AI を使用してカスタム ドキュメント エクストラクタのプロセッサをトレーニングしました。専用プロセッサと同じように、このプロセッサを使ってこの形式のドキュメントを解析することができます。
プロセッサのレスポンスを処理する方法については、専用プロセッサの Codelab をご覧ください。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにする手順は次のとおりです。
- Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストでプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
リソース
- Document AI Workbench のドキュメント
- ドキュメントの将来 - YouTube 再生リスト
- Document AI のドキュメント
- Document AI Python クライアント ライブラリ
- Document AI のサンプル
ライセンス
この作業はクリエイティブ・コモンズの表示 2.0 汎用ライセンスにより使用許諾されています。