
1. परिचय
Document AI, दस्तावेज़ों को समझने में मदद करने वाला एक समाधान है. यह दस्तावेज़ों, ईमेल वगैरह जैसे अनस्ट्रक्चर्ड डेटा को लेता है. इसके बाद, यह डेटा को समझने, उसका विश्लेषण करने, और उसे इस्तेमाल करने में मदद करता है.
Document AI Workbench की मदद से, दस्तावेज़ों को ज़्यादा सटीक तरीके से प्रोसेस किया जा सकता है. इसके लिए, आपको अपने ट्रेनिंग डेटा का इस्तेमाल करके, पूरी तरह से पसंद के मुताबिक बनाए गए मॉडल बनाने होंगे.
इस लैब में, आपको कस्टम दस्तावेज़ से जानकारी निकालने वाला प्रोसेसर बनाना है. साथ ही, डेटासेट इंपोर्ट करना है, उदाहरण के तौर पर दिए गए दस्तावेज़ों को लेबल करना है, और प्रोसेसर को ट्रेन करना है.
इस लैब में इस्तेमाल किया गया दस्तावेज़ डेटासेट, Kaggle पर मौजूद फ़र्ज़ी W-2 (अमेरिका का टैक्स फ़ॉर्म) डेटासेट से लिया गया है. यह CC0: Public Domain License के तहत उपलब्ध है.
ज़रूरी शर्तें
यह कोडलैब, Document AI के अन्य कोडलैब में दिए गए कॉन्टेंट पर आधारित है.
हमारा सुझाव है कि आगे बढ़ने से पहले, इन कोडलैब को पूरा कर लें.
- Document AI (Python) की मदद से ऑप्टिकल कैरेक्टर रिकग्निशन (ओसीआर)
- Document AI की मदद से फ़ॉर्म पार्स करना (Python)
- Document AI (Python) के साथ खास प्रोसेसर
- Python की मदद से Document AI प्रोसेसर मैनेज करना
- Document AI: ह्यूमन इन द लूप
- Document AI: Uptraining
आपको क्या सीखने को मिलेगा
- कस्टम दस्तावेज़ एक्सट्रैक्टर प्रोसेसर बनाएं.
- एनोटेशन टूल का इस्तेमाल करके, Document AI के ट्रेनिंग डेटा को लेबल करें.
- मॉडल के नए वर्शन को ट्रेन करें.
- नए मॉडल वर्शन की सटीकता का आकलन करें.
आपको इन चीज़ों की ज़रूरत होगी
2. सेट अप करना
इस कोडलैब में यह माना गया है कि आपने कोडलैब के बारे में बुनियादी जानकारी में दिए गए, Document AI सेटअप करने के चरण पूरे कर लिए हैं.
आगे बढ़ने से पहले, कृपया यह तरीका अपनाएं:
3. प्रोसेसर बनाना
इस लैब के लिए, आपको सबसे पहले कस्टम दस्तावेज़ एक्सट्रैक्टर प्रोसेसर बनाना होगा.
- कंसोल में, Document AI की खास जानकारी पेज पर जाएं.
- कस्टम प्रोसेसर बनाएं पर क्लिक करें. इसके बाद, कस्टम दस्तावेज़ एक्सट्रैक्टर चुनें.
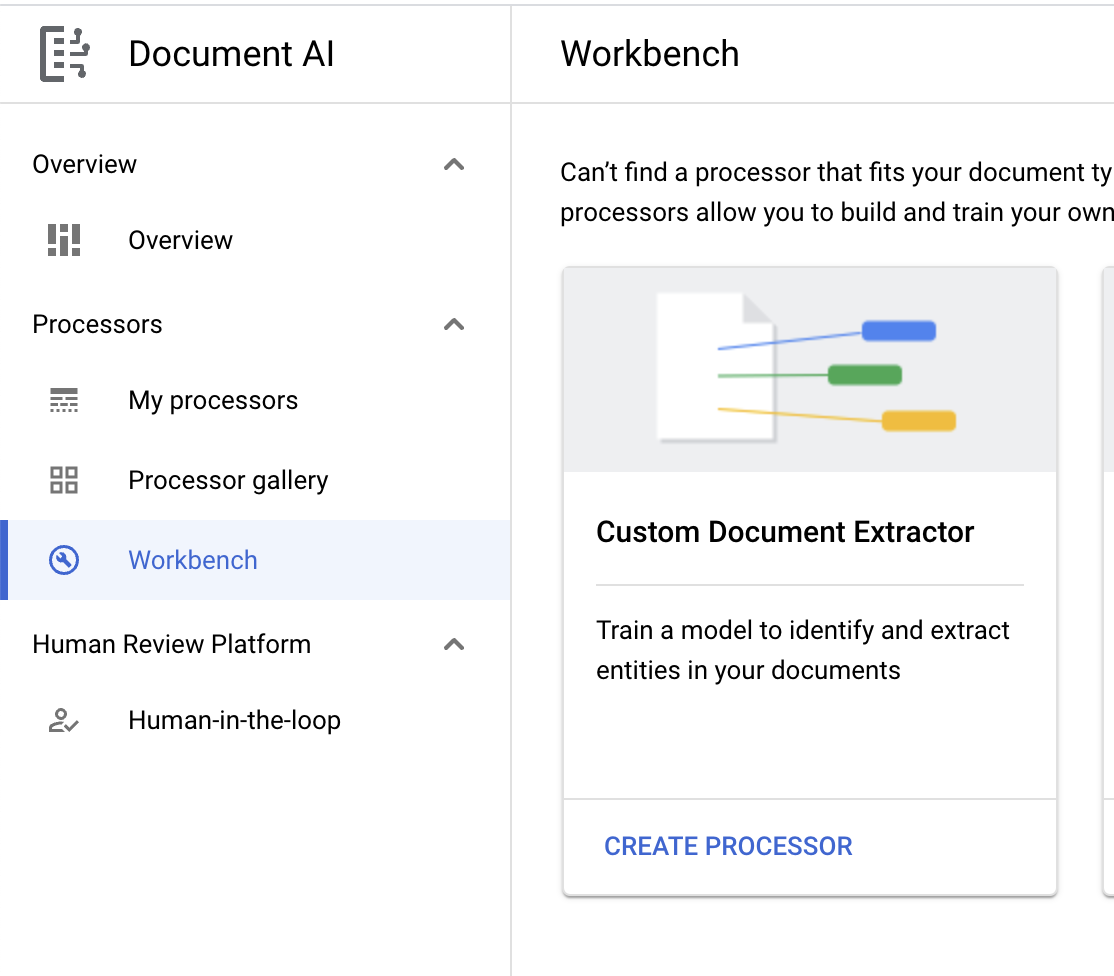
- इसे
codelab-custom-extractorनाम दें. इसके अलावा, कोई ऐसा नाम भी दिया जा सकता है जो आपको याद रहे. इसके बाद, सूची में से सबसे मिलता-जुलता क्षेत्र चुनें.
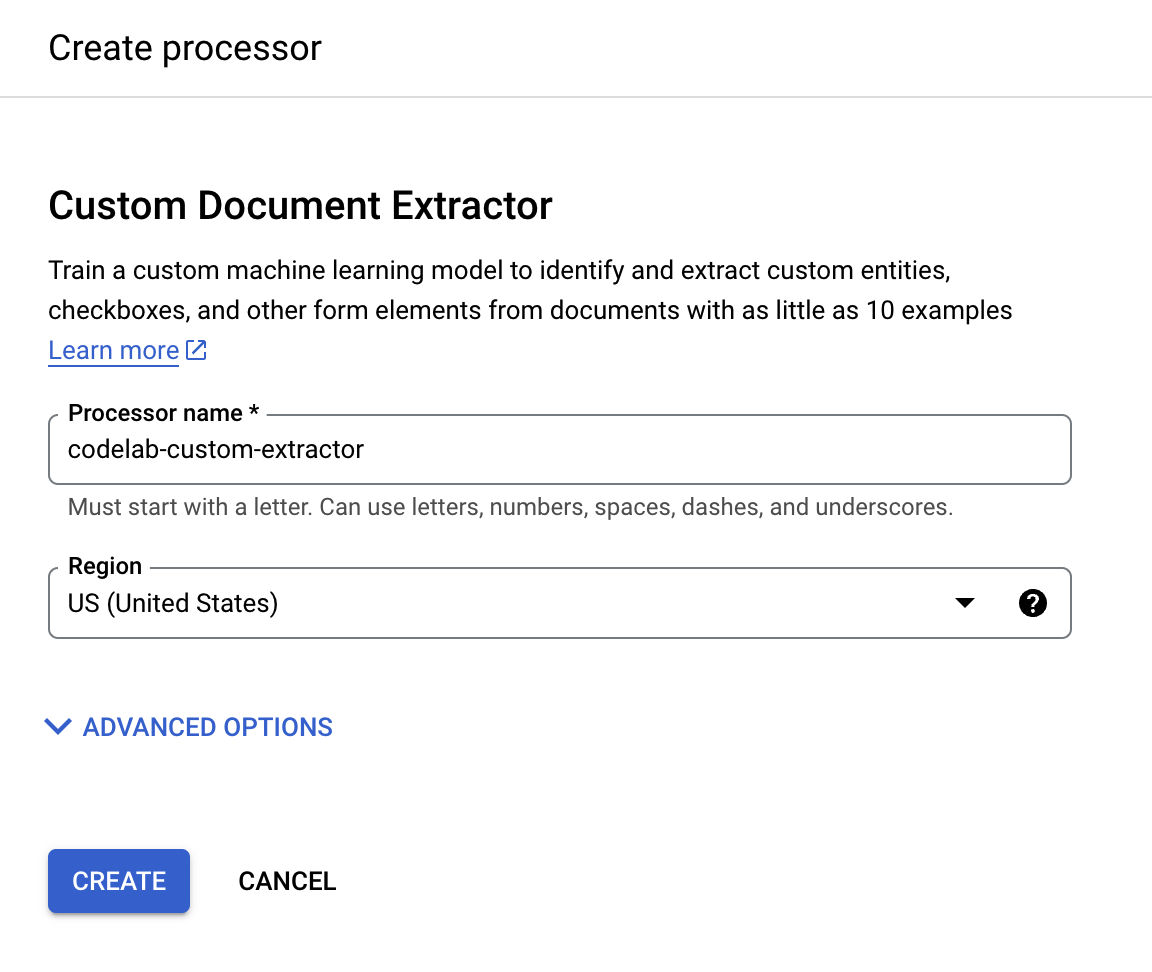
- प्रोसेसर बनाने के लिए, बनाएं पर क्लिक करें. इसके बाद, आपको प्रोसेसर की खास जानकारी देने वाला पेज दिखेगा.
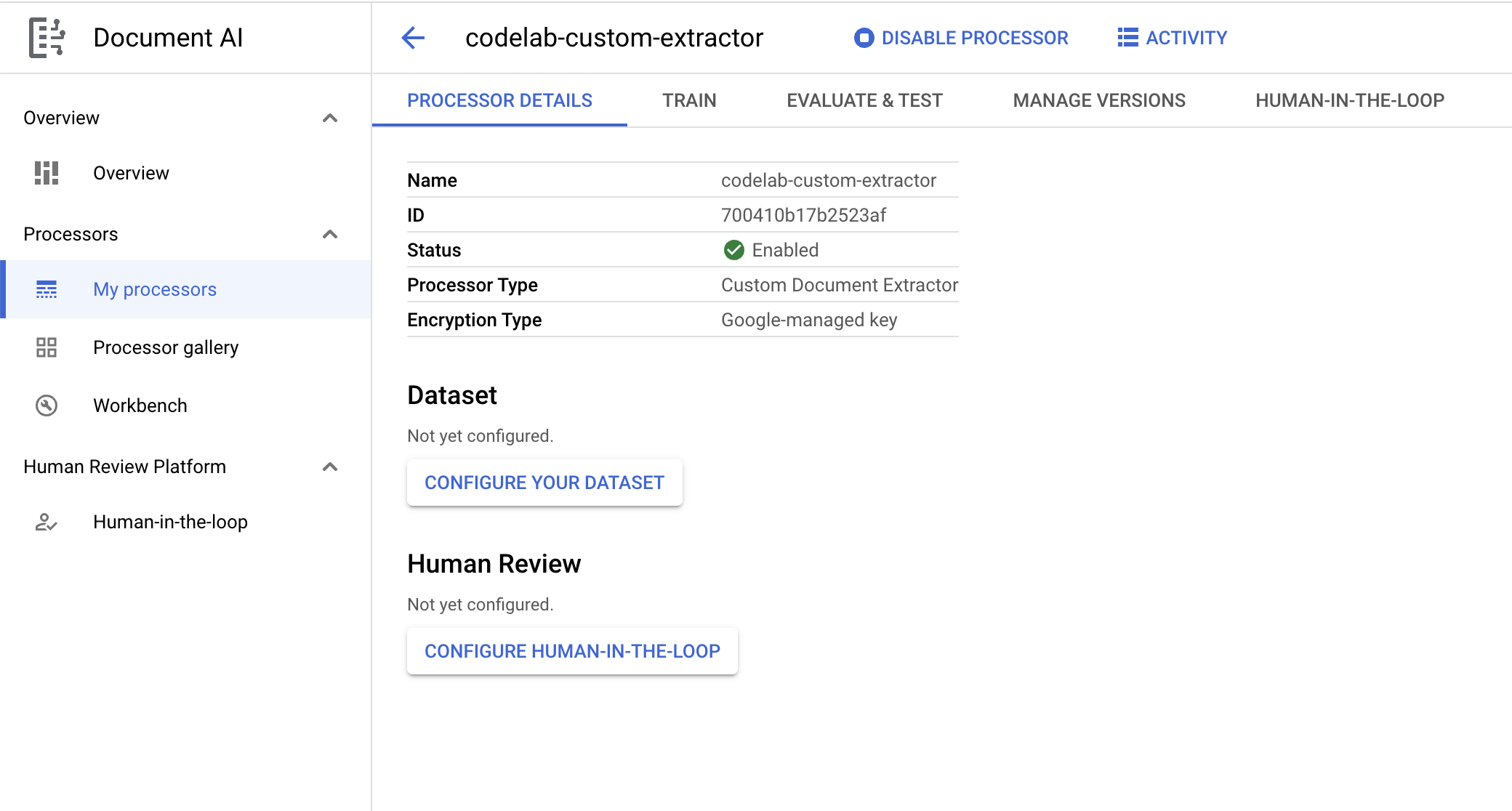
4. डेटासेट बनाना
अपने प्रोसेसर को ट्रेन करने के लिए, हमें ट्रेनिंग और टेस्टिंग डेटा वाला एक डेटासेट बनाना होगा. इससे प्रोसेसर को उन इकाइयों की पहचान करने में मदद मिलेगी जिन्हें हमें निकालना है.
- प्रोसेसर की खास जानकारी वाले पेज पर, अपना डेटासेट कॉन्फ़िगर करें पर क्लिक करें.
- अब आपको डेटासेट कॉन्फ़िगर करें पेज पर होना चाहिए. अगर आपको ट्रेनिंग के दस्तावेज़ और लेबल सेव करने के लिए, अपना बकेट तय करना है, तो ऐडवांस विकल्प दिखाएं पर क्लिक करें. अगर आपको ऐसा नहीं करना है, तो जारी रखें पर क्लिक करें.
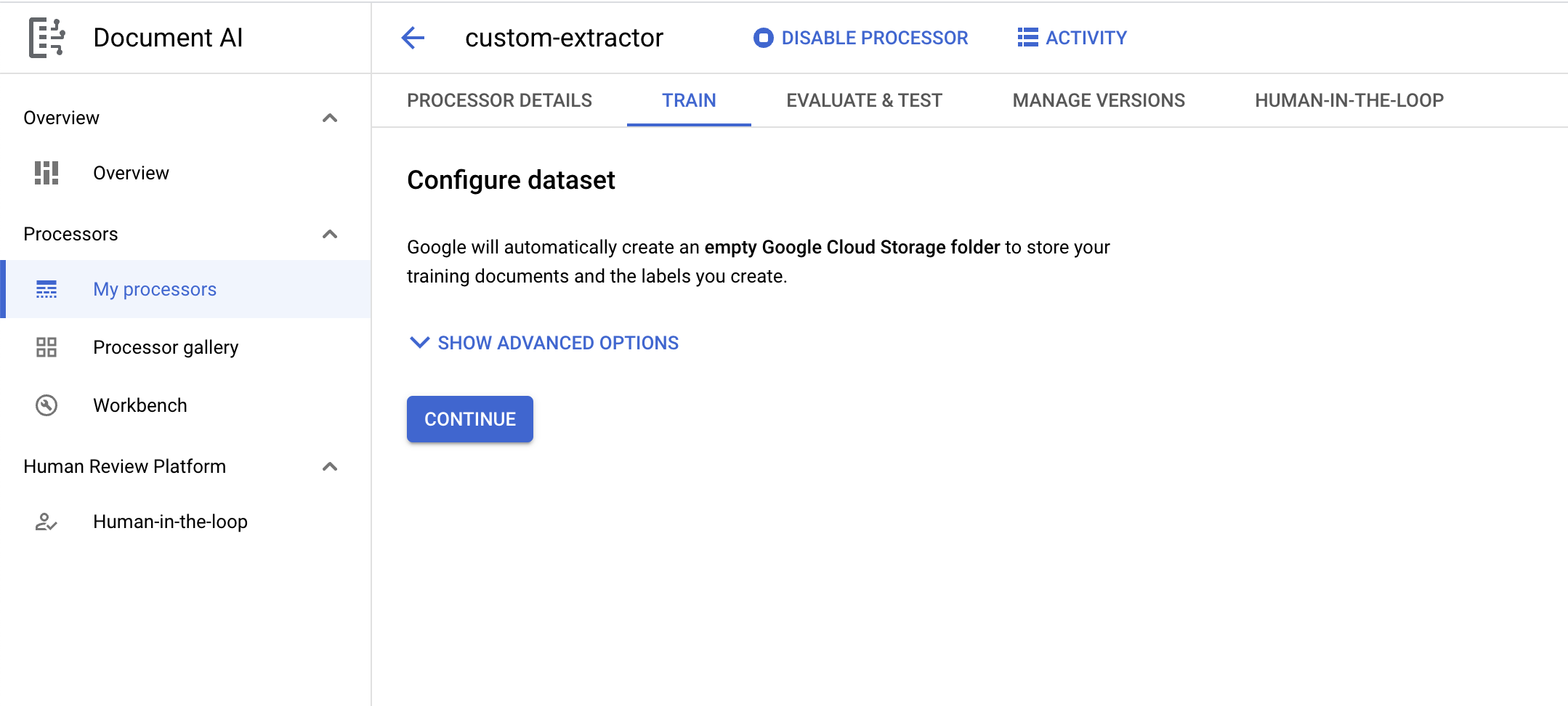
- डेटासेट बनने तक इंतज़ार करें. इसके बाद, आपको ट्रेनिंग पेज पर भेज दिया जाएगा.
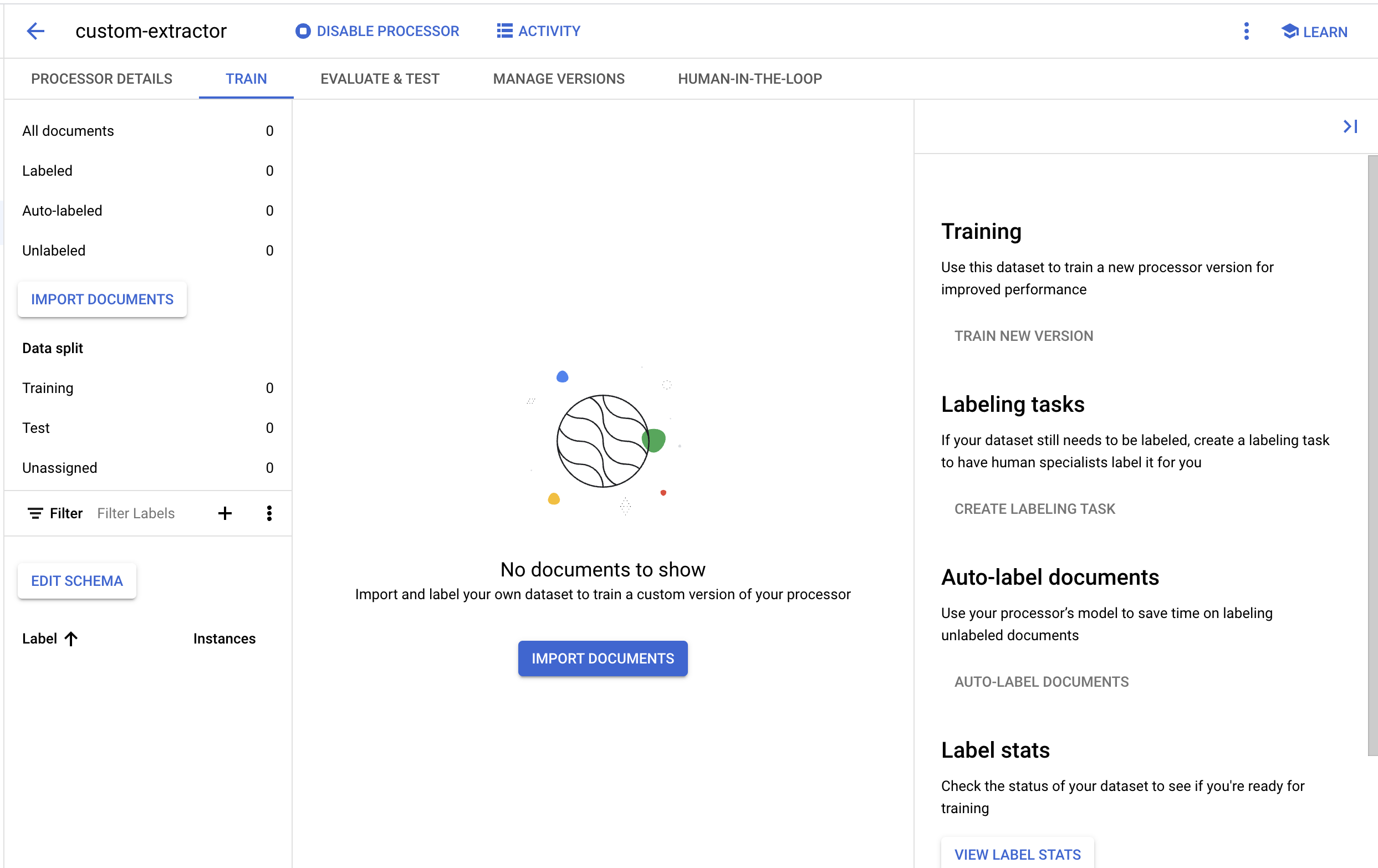
5. टेस्ट के लिए कोई दस्तावेज़ इंपोर्ट करना
अब, अपने डेटासेट में W2 का एक सैंपल PDF इंपोर्ट करते हैं.
- दस्तावेज़ इंपोर्ट करें पर क्लिक करें
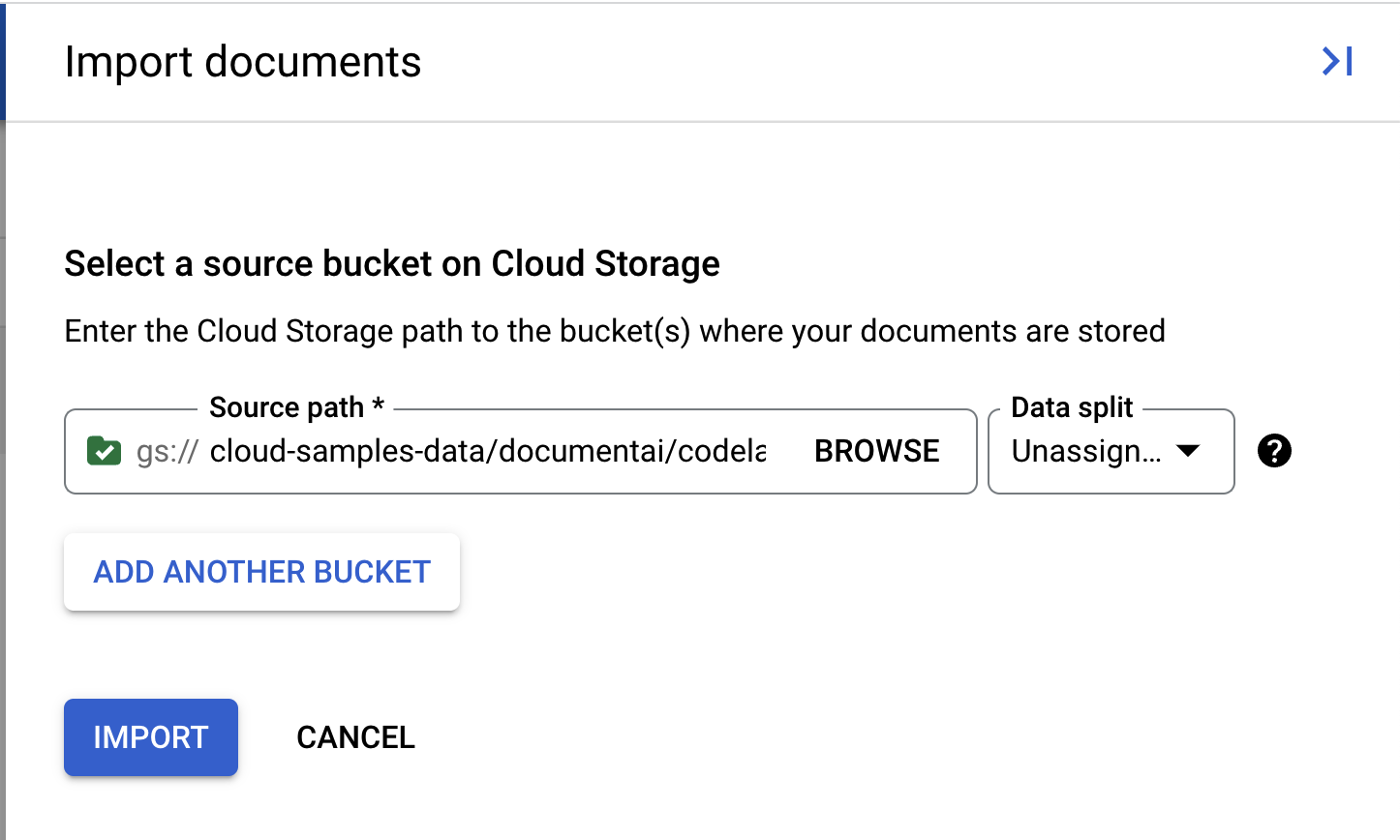
- इस लैब में इस्तेमाल करने के लिए, हमारे पास एक सैंपल PDF है. नीचे दिए गए लिंक को कॉपी करें और उसे सोर्स पाथ बॉक्स में चिपकाएं. फ़िलहाल, "डेटा स्प्लिट" को "Unassigned" के तौर पर छोड़ दें. अन्य सभी बॉक्स से सही का निशान हटाएं. इंपोर्ट करें पर क्लिक करें.
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs
- दस्तावेज़ इंपोर्ट होने का इंतज़ार करें. इसमें एक मिनट से भी कम समय लगेगा.
- इंपोर्ट पूरा होने के बाद, आपको ट्रेनिंग पेज पर दस्तावेज़ दिखेगा.
6. लेबल बनाना
हम एक नया प्रोसेसर टाइप बना रहे हैं. इसलिए, हमें कस्टम लेबल बनाने होंगे, ताकि Document AI को यह पता चल सके कि हमें कौनसे फ़ील्ड से डेटा निकालना है.
- सबसे नीचे बाएं कोने में मौजूद, स्कीमा में बदलाव करें पर क्लिक करें.
- अब आपको स्कीमा मैनेजमेंट कंसोल में होना चाहिए.
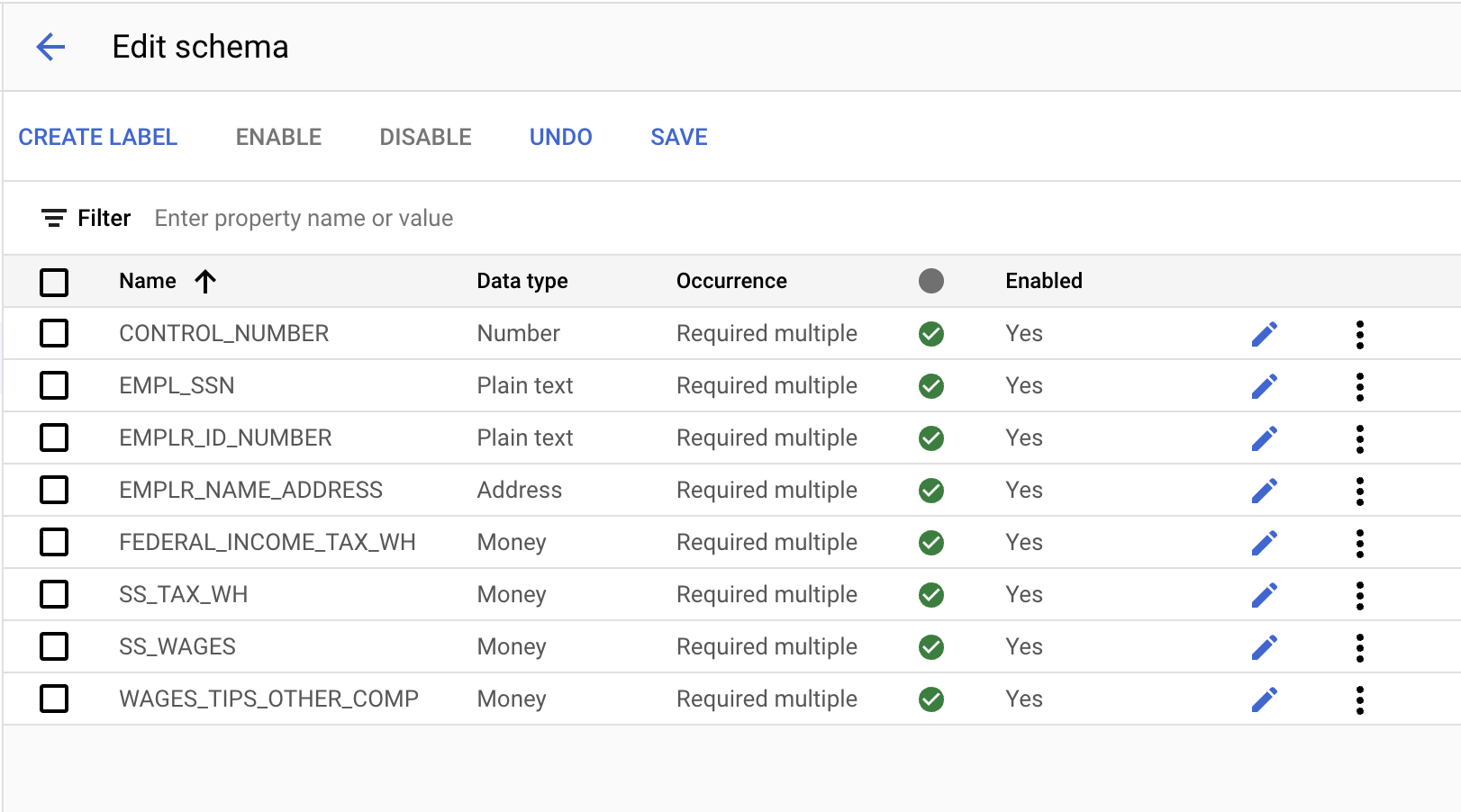
- लेबल बनाएं बटन का इस्तेमाल करके, ये लेबल बनाएं.
नाम | डेटा किस तरह का है | Occurrence |
| नंबर | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
| सादा टेक्स्ट | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
| सादा टेक्स्ट | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
| पता | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
| पैसे | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
| पैसे | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
| पैसे | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
| पैसे | एक से ज़्यादा बार इस्तेमाल करना ज़रूरी है |
- सेट अप पूरा होने के बाद, कंसोल ऐसा दिखेगा. बदलाव करने के बाद, सेव करें पर क्लिक करें.
- ट्रेनिंग पेज पर वापस जाने के लिए, बैक ऐरो पर क्लिक करें. ध्यान दें कि हमने जो लेबल बनाए हैं वे सबसे नीचे बाईं ओर दिख रहे हैं.
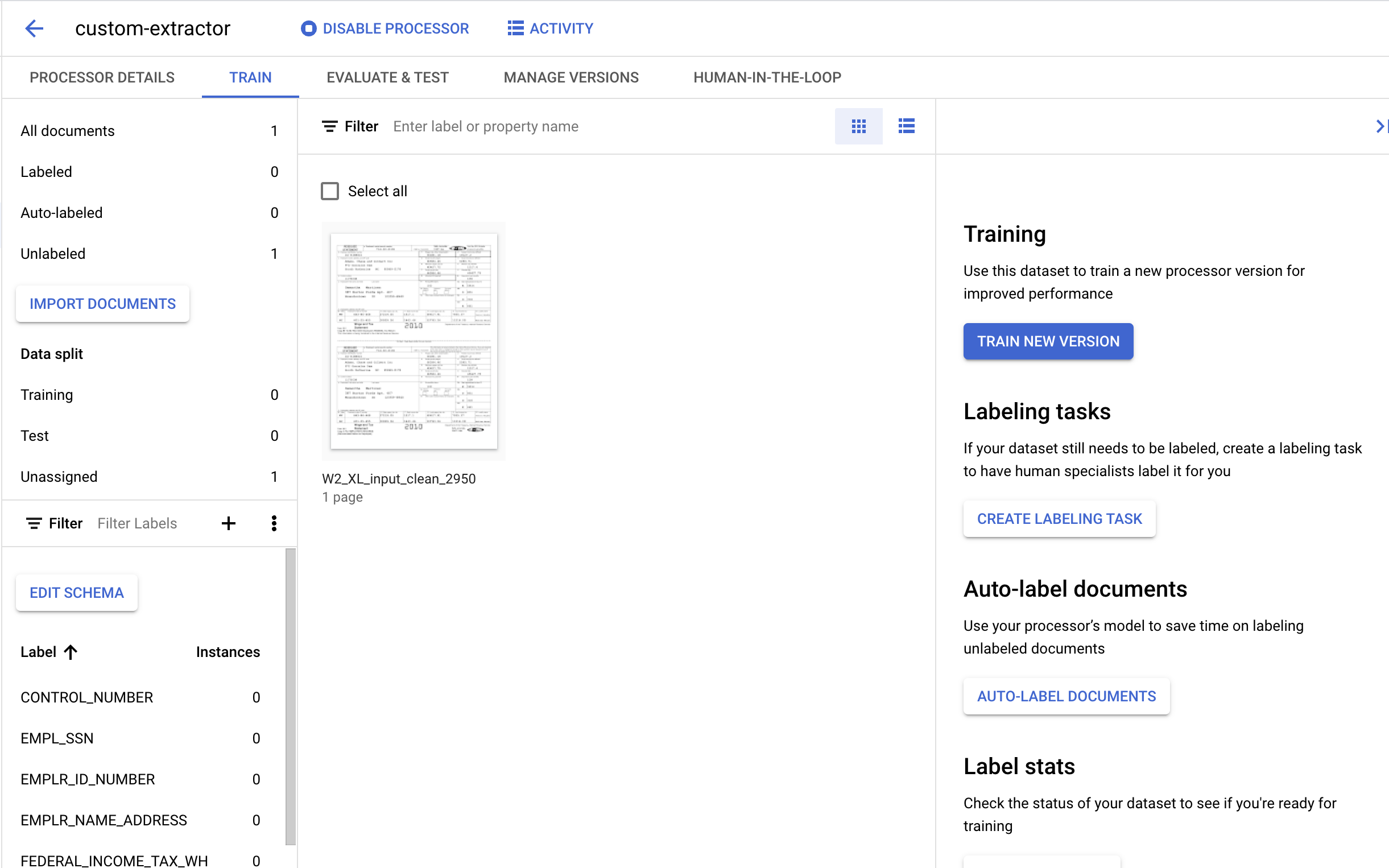
7. टेस्ट के लिए दस्तावेज़ को लेबल करना
इसके बाद, हम उन इकाइयों के लिए टेक्स्ट एलिमेंट और लेबल की पहचान करेंगे जिन्हें हमें एक्सट्रैक्ट करना है. इन लेबल का इस्तेमाल, हमारे मॉडल को इस खास दस्तावेज़ के स्ट्रक्चर को पार्स करने और सही टाइप की पहचान करने के लिए ट्रेन करने के लिए किया जाएगा.
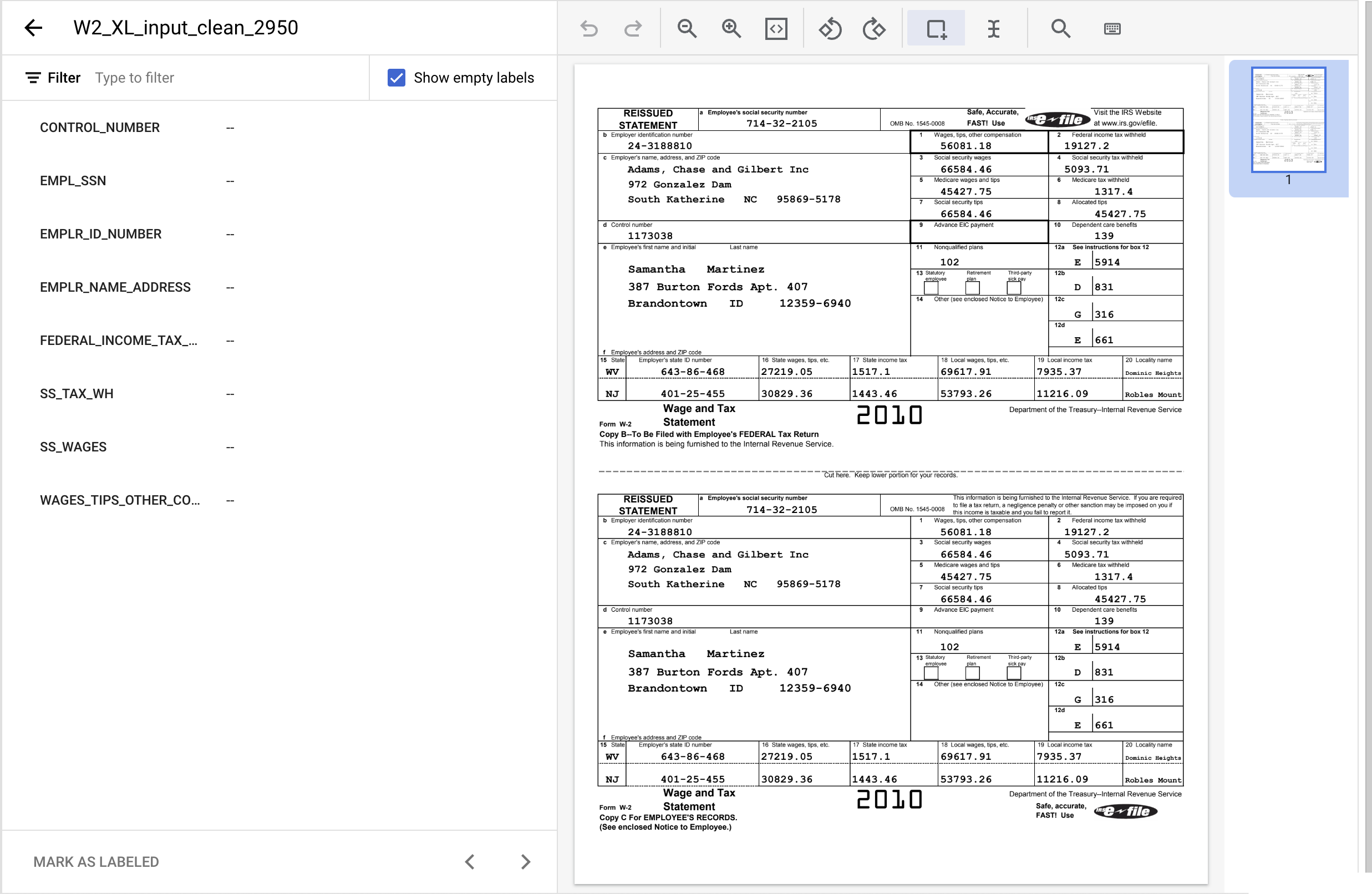
- लेबलिंग कंसोल में जाने के लिए, उस दस्तावेज़ पर दो बार क्लिक करें जिसे हमने पहले इंपोर्ट किया था. यह कुछ ऐसा नज़र आना चाहिए.
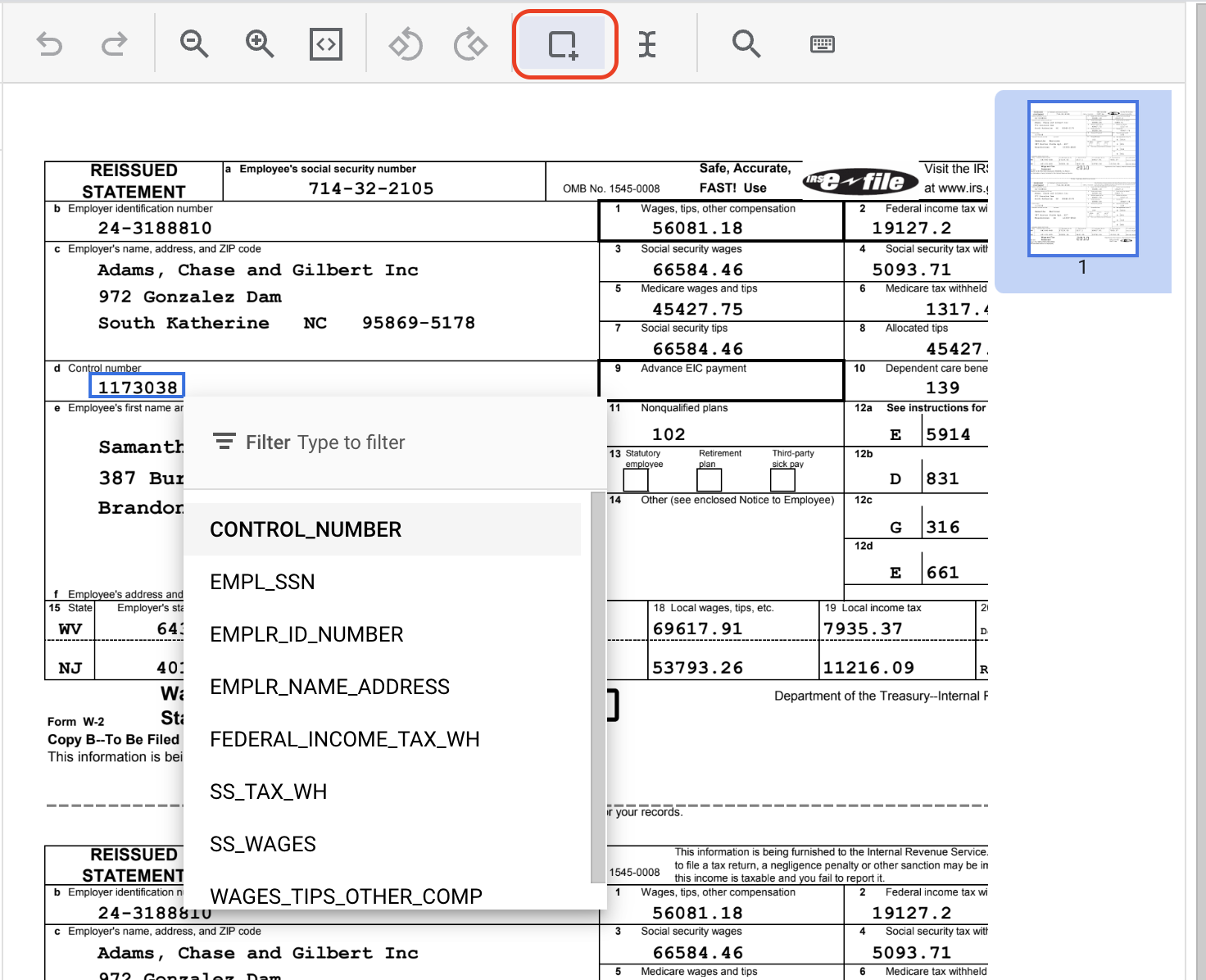
- "बाउंडिंग बॉक्स" टूल पर क्लिक करें. इसके बाद, "1173038" टेक्स्ट को हाइलाइट करें और
CONTROL_NUMBERलेबल असाइन करें. लेबल के नाम खोजने के लिए, टेक्स्ट फ़िल्टर का इस्तेमाल किया जा सकता है.
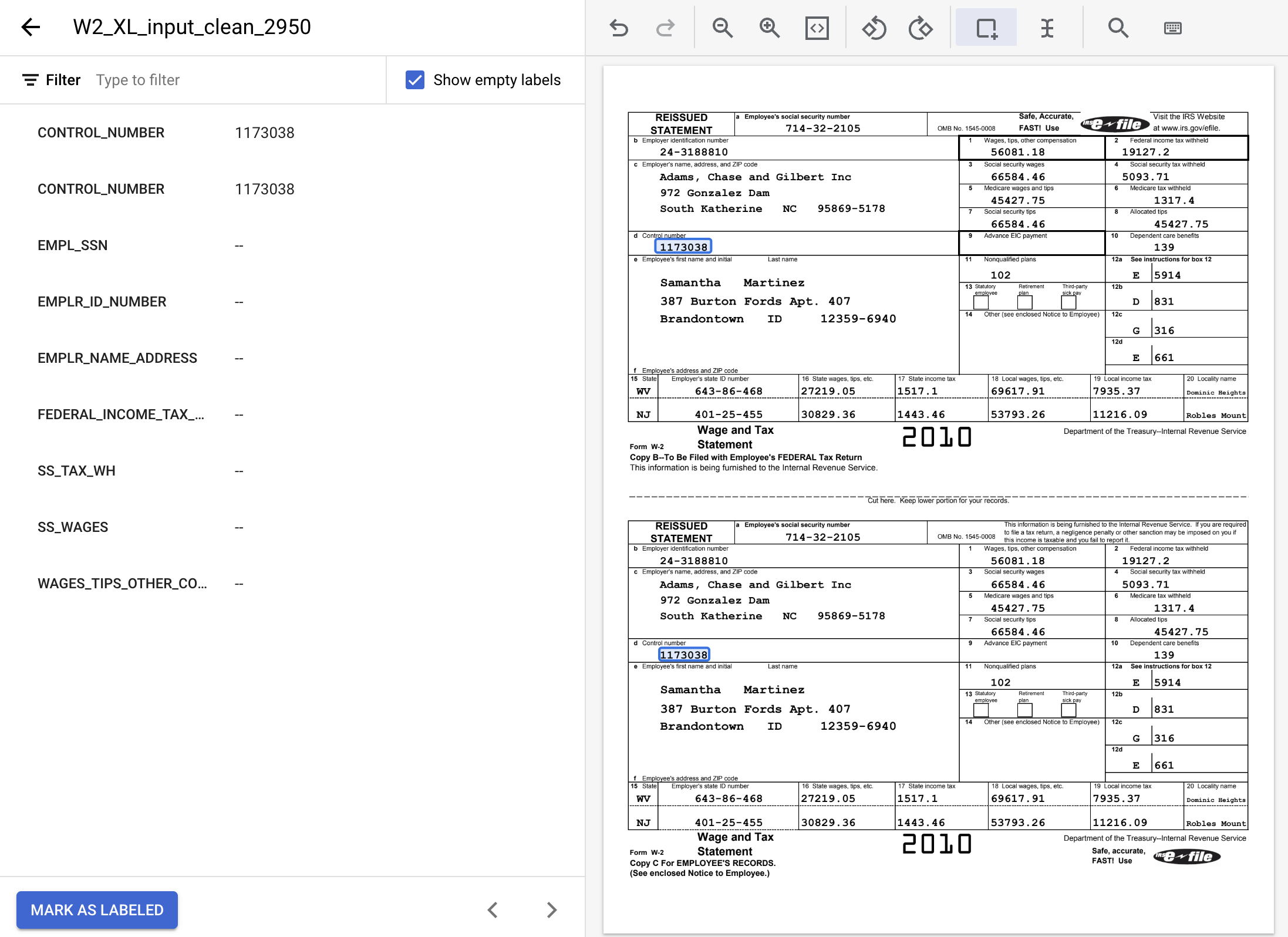
CONTROL_NUMBERके दूसरे इंस्टेंस के लिए भी ऐसा करें. लेबल करने के बाद, यह ऐसा दिखना चाहिए.
- नीचे दी गई टेक्स्ट वैल्यू के सभी उदाहरणों को हाइलाइट करें और सही लेबल असाइन करें.
लेबल का नाम | टेक्स्ट |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
- लेबल किया गया दस्तावेज़ पूरा होने पर ऐसा दिखना चाहिए. ध्यान दें, दस्तावेज़ में मौजूद बाउंडिंग बॉक्स या बाईं ओर मौजूद मेन्यू में लेबल के नाम/वैल्यू पर क्लिक करके, इन लेबल में बदलाव किया जा सकता है. लेबलिंग पूरी होने के बाद, 'लेबल किया गया' के तौर पर मार्क करें पर क्लिक करें. इसके बाद, डेटासेट मैनेजमेंट कंसोल पर वापस जाएं.
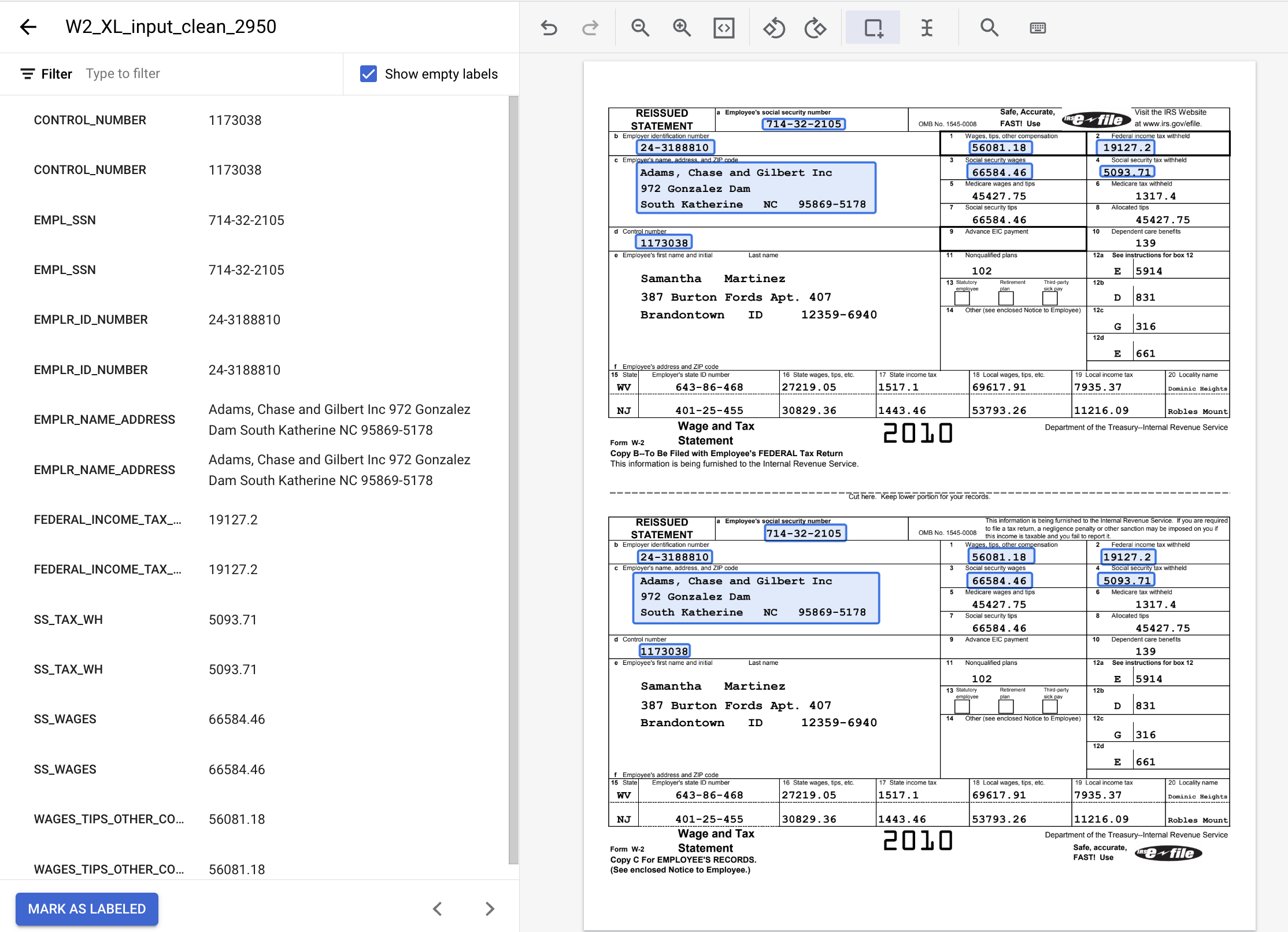
8. दस्तावेज़ को ट्रेनिंग सेट में असाइन करना
अब आपको डेटासेट मैनेजमेंट कंसोल पर वापस ले जाया जाएगा. ध्यान दें कि लेबल किए गए और लेबल नहीं किए गए दस्तावेज़ों की संख्या और हर लेबल के हिसाब से इंस्टेंस की संख्या बदल गई है.
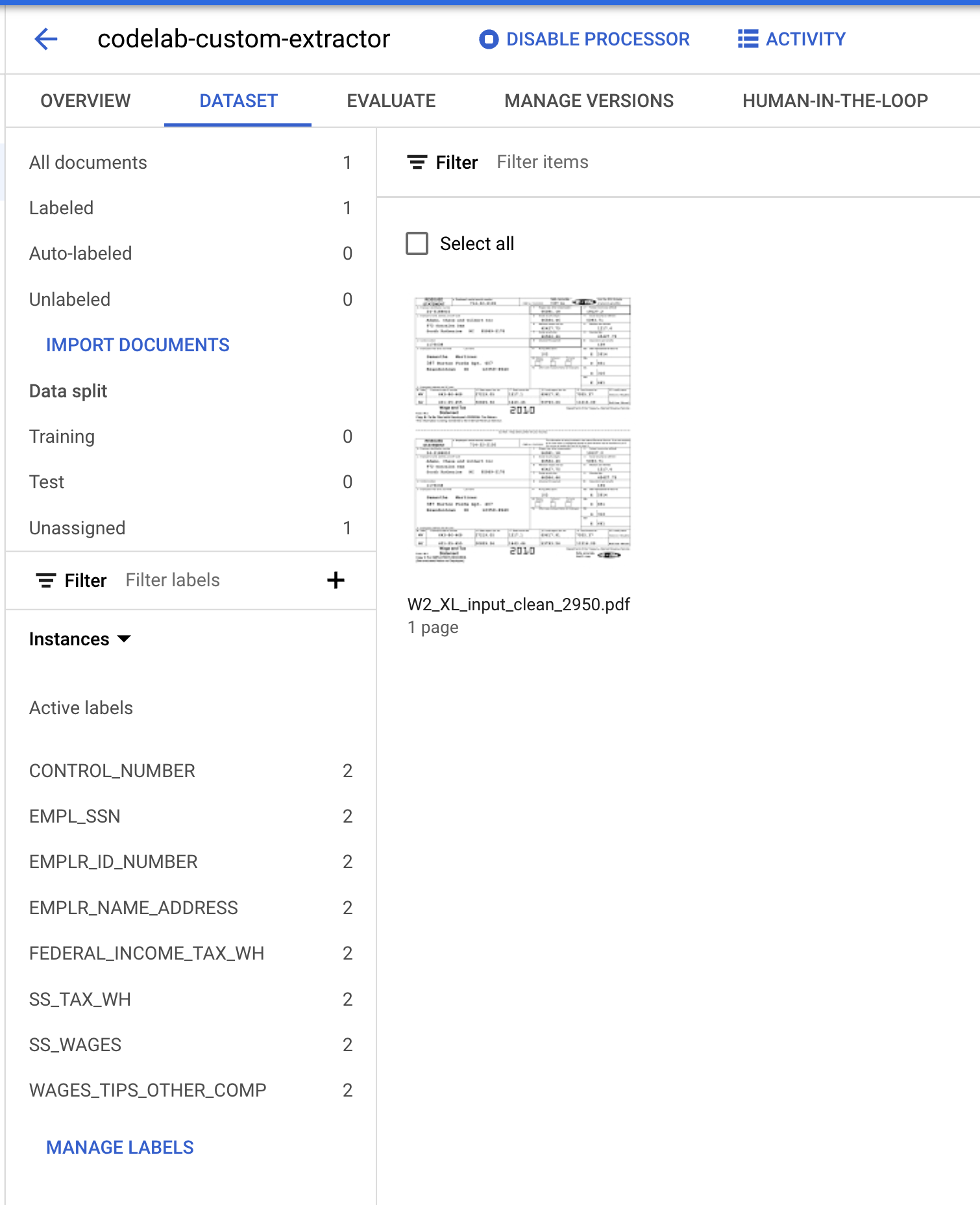
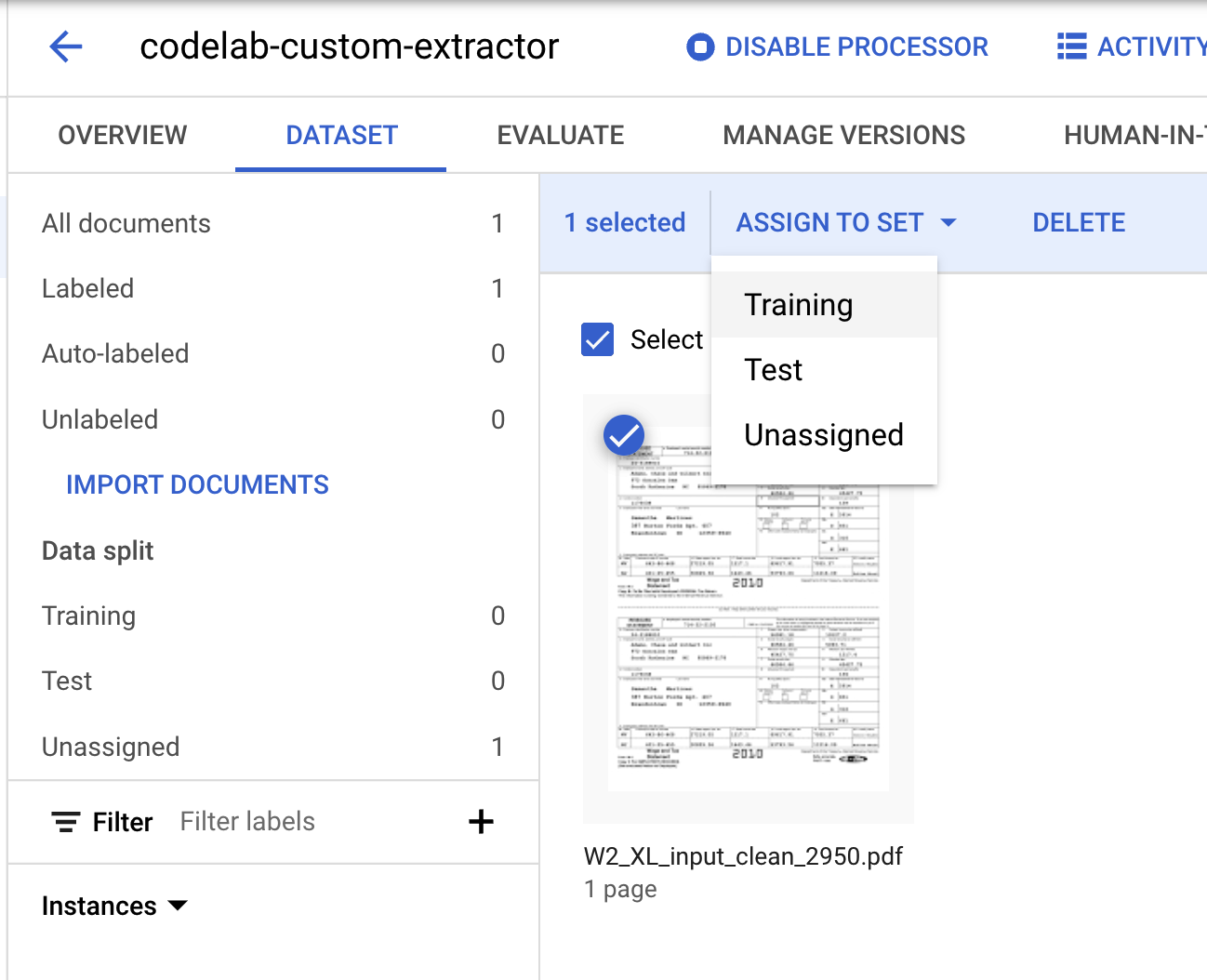
- हमें इस दस्तावेज़ को "ट्रेनिंग" या "टेस्ट" सेट में से किसी एक को असाइन करना होगा. दस्तावेज़ पर क्लिक करें. इसके बाद, सेट को असाइन करें पर क्लिक करें. इसके बाद, ट्रेनिंग पर क्लिक करें.
- ध्यान दें कि डेटा स्प्लिट के नंबर बदल गए हैं.
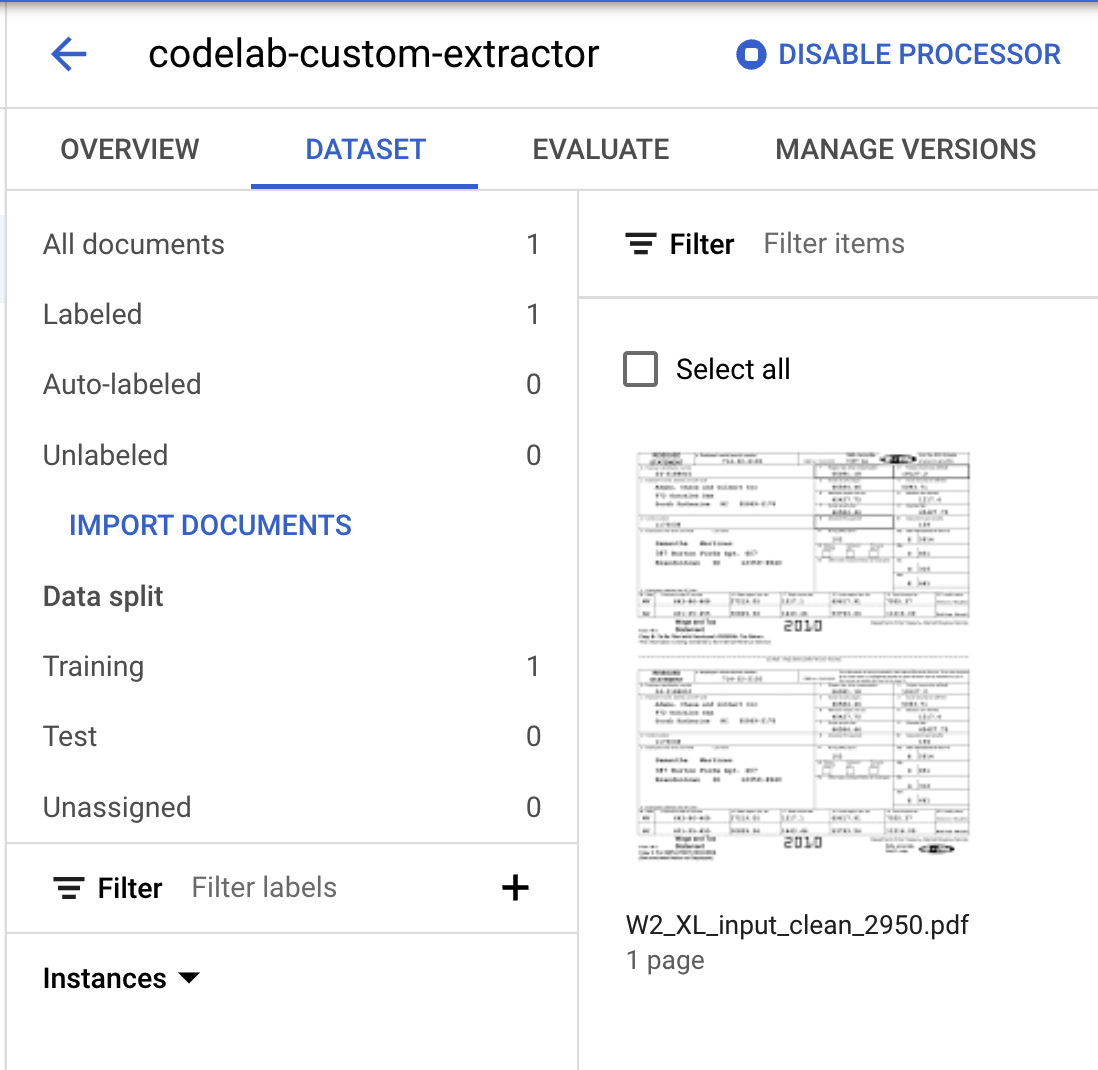
9. पहले से लेबल किया गया डेटा इंपोर्ट करना
Document AI के कस्टम प्रोसेसर के लिए, ट्रेनिंग और टेस्ट सेट, दोनों में कम से कम 10 दस्तावेज़ होने चाहिए. साथ ही, हर सेट में हर लेबल के 10 इंस्टेंस होने चाहिए.
बेहतर परफ़ॉर्मेंस के लिए, हमारा सुझाव है कि हर सेट में कम से कम 50 दस्तावेज़ हों. साथ ही, हर लेबल के 50 इंस्टेंस हों. आम तौर पर, ट्रेनिंग के लिए ज़्यादा डेटा का इस्तेमाल करने से, मॉडल ज़्यादा सटीक नतीजे देता है.
सभी दस्तावेज़ों को मैन्युअल तरीके से लेबल करने में काफ़ी समय लगेगा. इसलिए, हमारे पास पहले से लेबल किए गए कुछ दस्तावेज़ हैं. इस लैब के लिए, इन्हें इंपोर्ट किया जा सकता है.
Document.json फ़ॉर्मैट में, पहले से लेबल की गई दस्तावेज़ फ़ाइलें इंपोर्ट की जा सकती हैं. ये नतीजे, प्रोसेसर को कॉल करके और ह्यूमन इन द लूप (एचआईटीएल) का इस्तेमाल करके, सटीक होने की पुष्टि करके पाए जा सकते हैं.
aside negative
ध्यान दें: पहले से लेबल किया गया डेटा इंपोर्ट करते समय, यह बेहद ज़रूरी है कि मॉडल को ट्रेन करने से पहले, एनोटेशन की मैन्युअल तरीके से समीक्षा कर ली जाए.
- दस्तावेज़ इंपोर्ट करें पर क्लिक करें.
- Cloud Storage के इस पाथ को कॉपी/चिपकाएं और इसे ट्रेनिंग सेट को असाइन करें.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- एक और फ़ोल्डर जोड़ें पर क्लिक करें. इसके बाद, नीचे दिए गए Cloud Storage पाथ को कॉपी/चिपकाएं और इसे Test सेट को असाइन करें.
cloud-samples-data/documentai/codelabs/custom/extractor/test
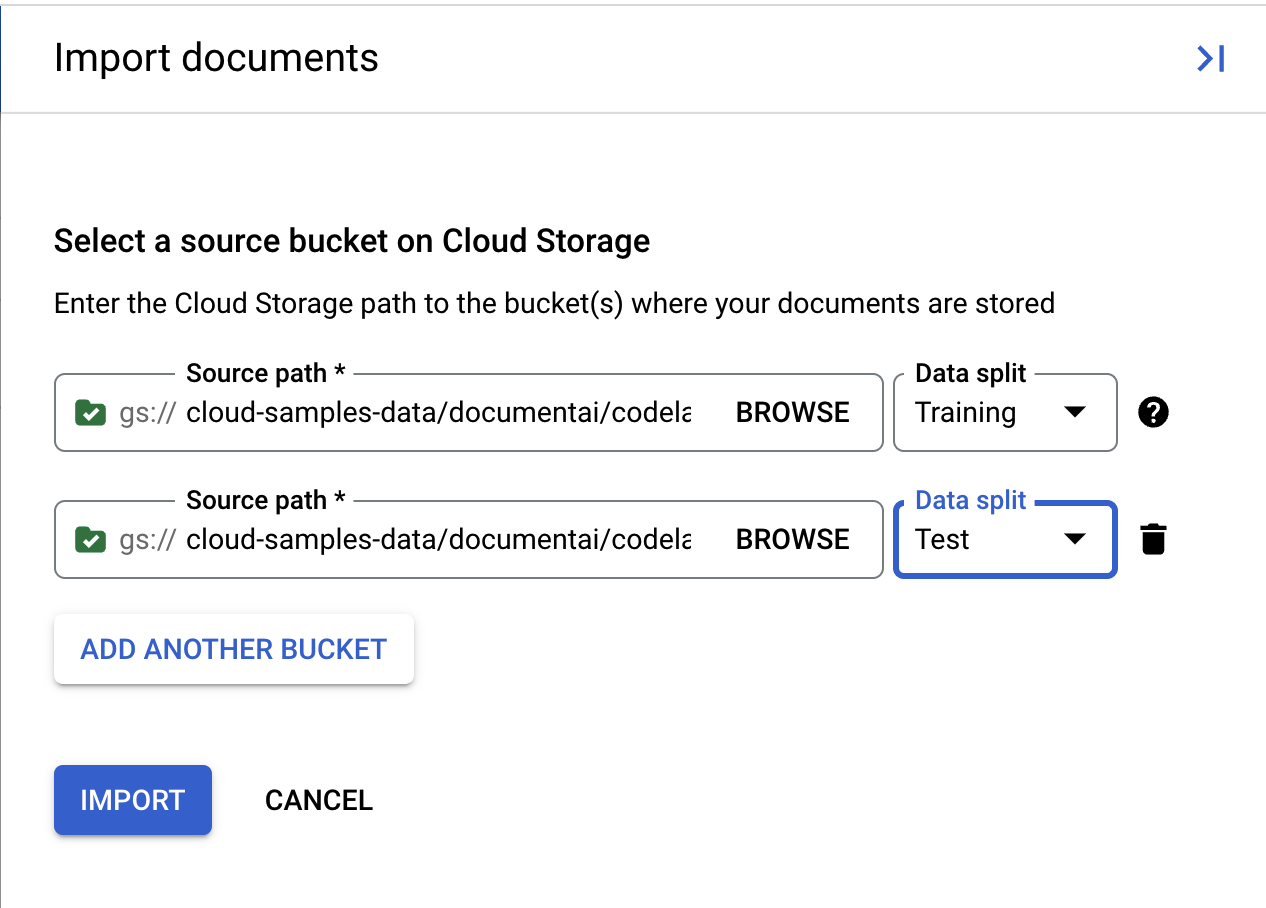
- इंपोर्ट करें पर क्लिक करें और दस्तावेज़ों के इंपोर्ट होने का इंतज़ार करें. इस बार, पिछली बार की तुलना में ज़्यादा समय लगेगा, क्योंकि प्रोसेस करने के लिए ज़्यादा दस्तावेज़ हैं. इसमें करीब छह मिनट लगेंगे. इस पेज को अभी छोड़ा जा सकता है. अपडेट के लिए इसे कुछ समय बाद फिर देखें.
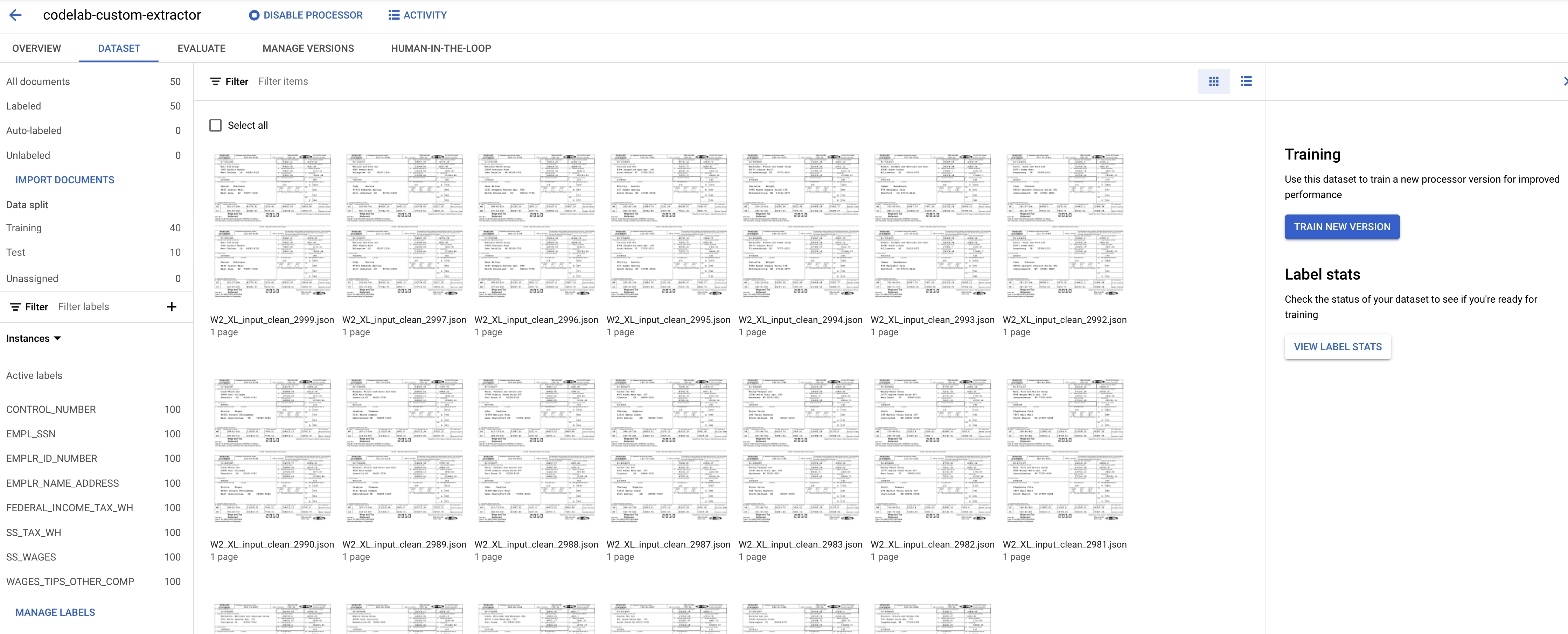
- प्रोफ़ाइल बनाने के बाद, आपको ट्रेनिंग पेज पर दस्तावेज़ दिखेंगे.
10. मॉडल को ट्रेनिंग देना
अब हम कस्टम दस्तावेज़ एक्सट्रैक्टर को ट्रेनिंग देने के लिए तैयार हैं.
- नया वर्शन ट्रेन करें पर क्लिक करें
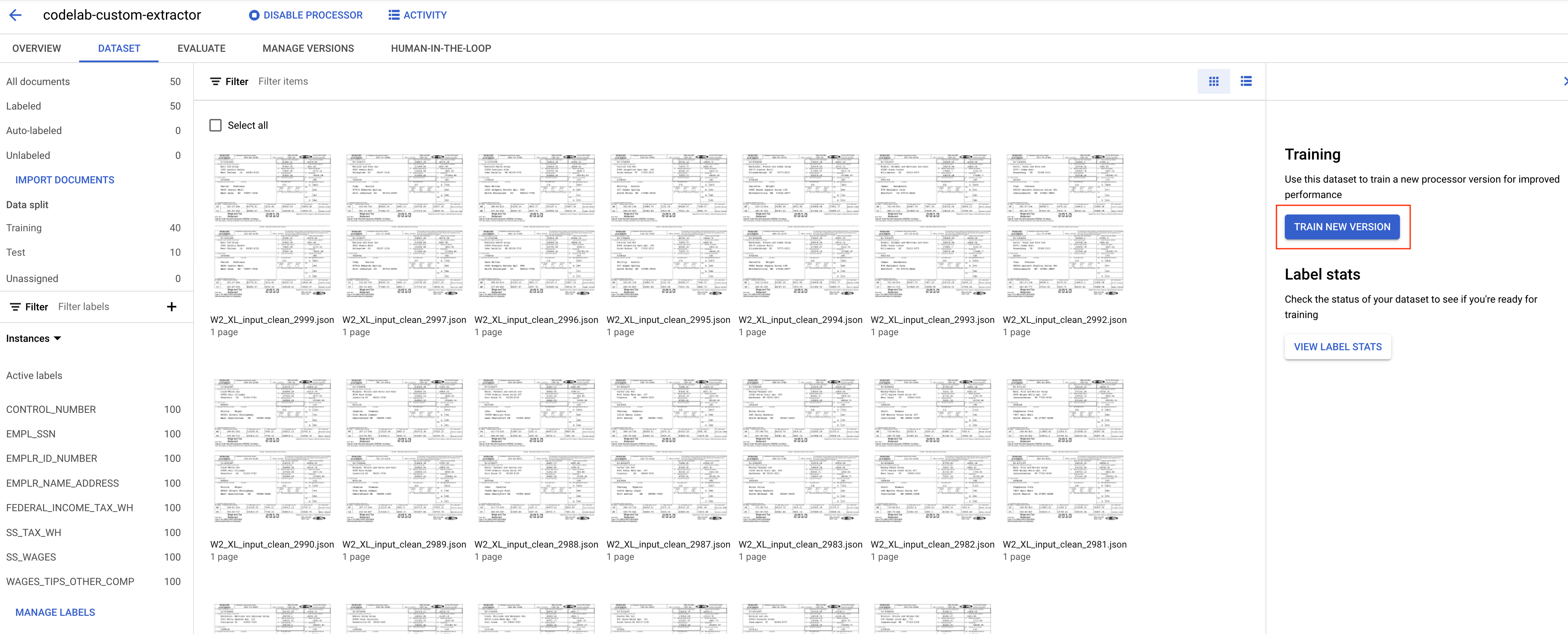
- अपने वर्शन को ऐसा नाम दें जो आपको याद रहे. जैसे,
codelab-custom-1. "ट्रेनिंग का तरीका" के लिए, "शुरुआत से ट्रेन करें" चुनें.
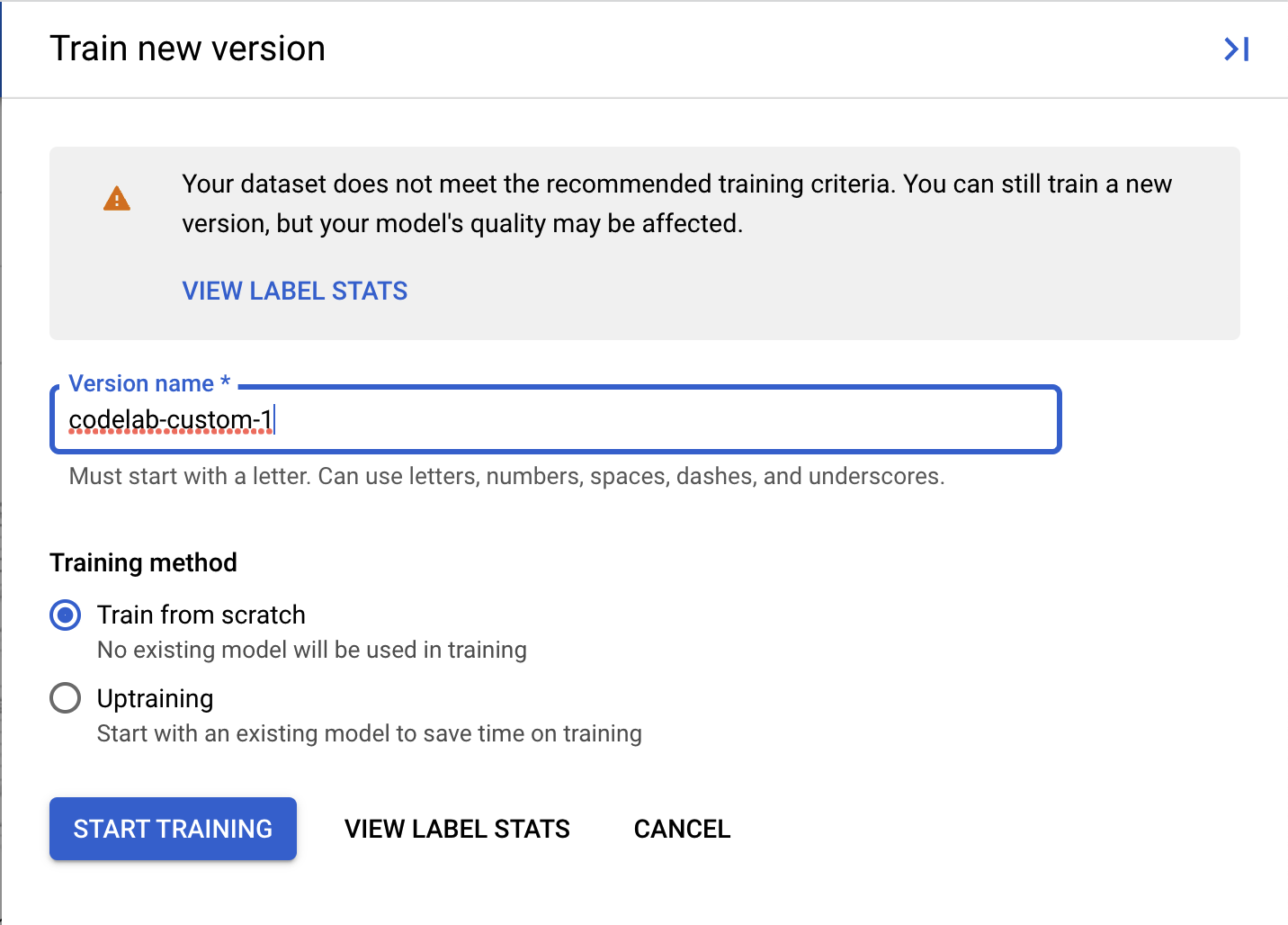
- (ज़रूरी नहीं) अपने डेटासेट में मौजूद लेबल के बारे में मेट्रिक देखने के लिए, लेबल के आंकड़े देखें को भी चुना जा सकता है.
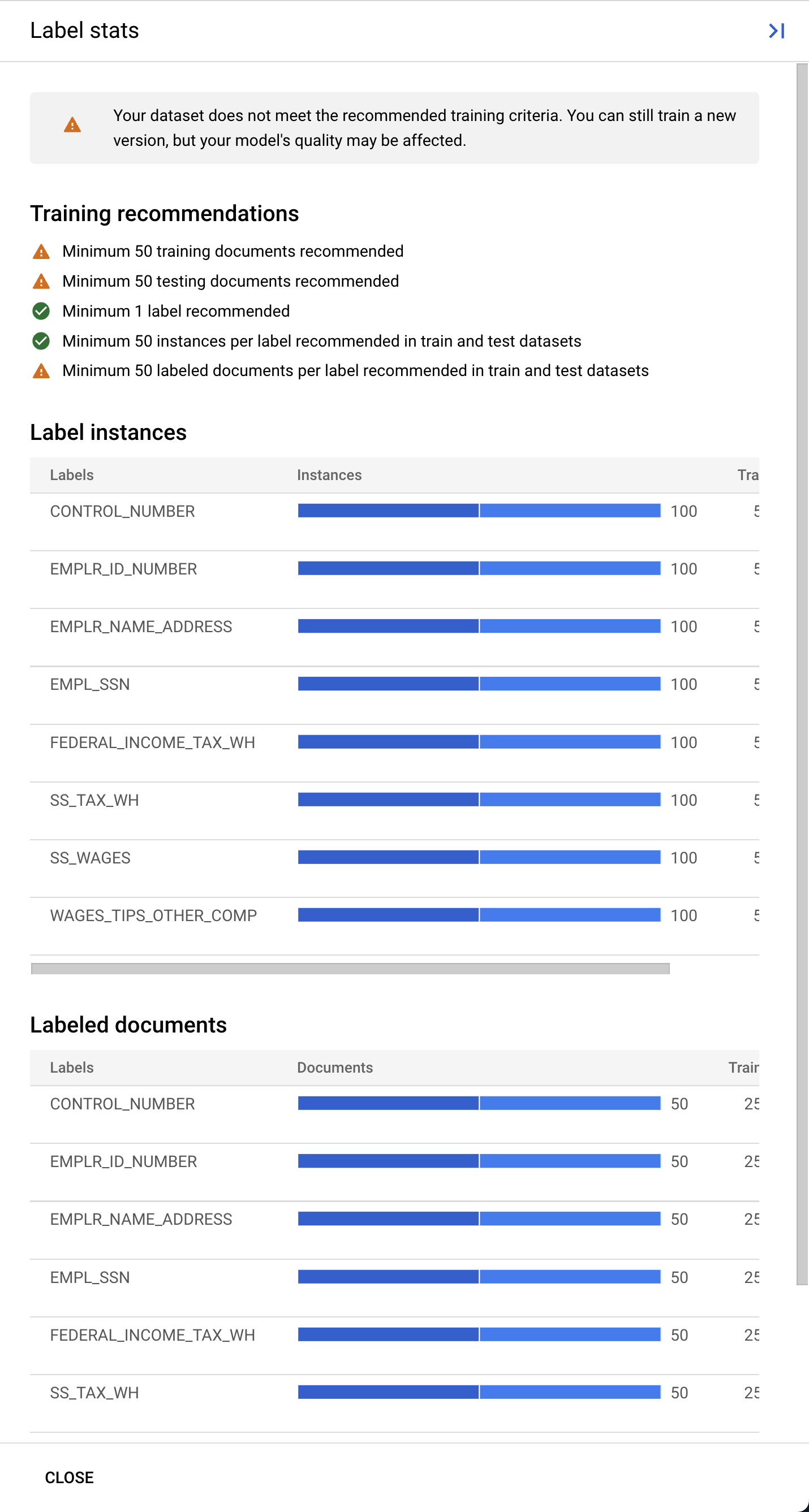
- ट्रेनिंग की प्रोसेस शुरू करने के लिए, ट्रेनिंग शुरू करें पर क्लिक करें. आपको डेटासेट मैनेजमेंट पेज पर रीडायरेक्ट कर दिया जाएगा. दाईं ओर ट्रेनिंग का स्टेटस देखा जा सकता है. ट्रेनिंग पूरी होने में कुछ घंटे लगेंगे. इस पेज को बंद करके, बाद में इस पर वापस आया जा सकता है.
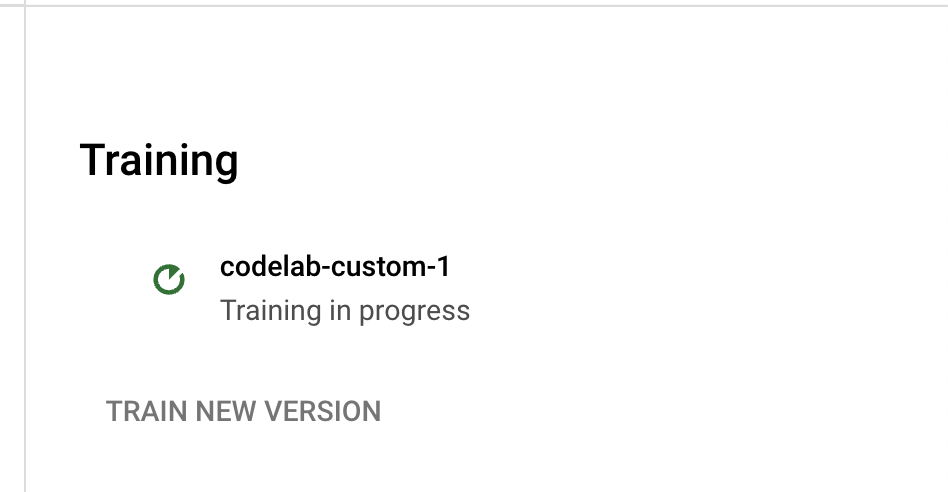
- वर्शन के नाम पर क्लिक करने से, आपको वर्शन मैनेज करें पेज पर भेज दिया जाएगा. इस पेज पर, वर्शन आईडी और ट्रेनिंग जॉब की मौजूदा स्थिति दिखती है.
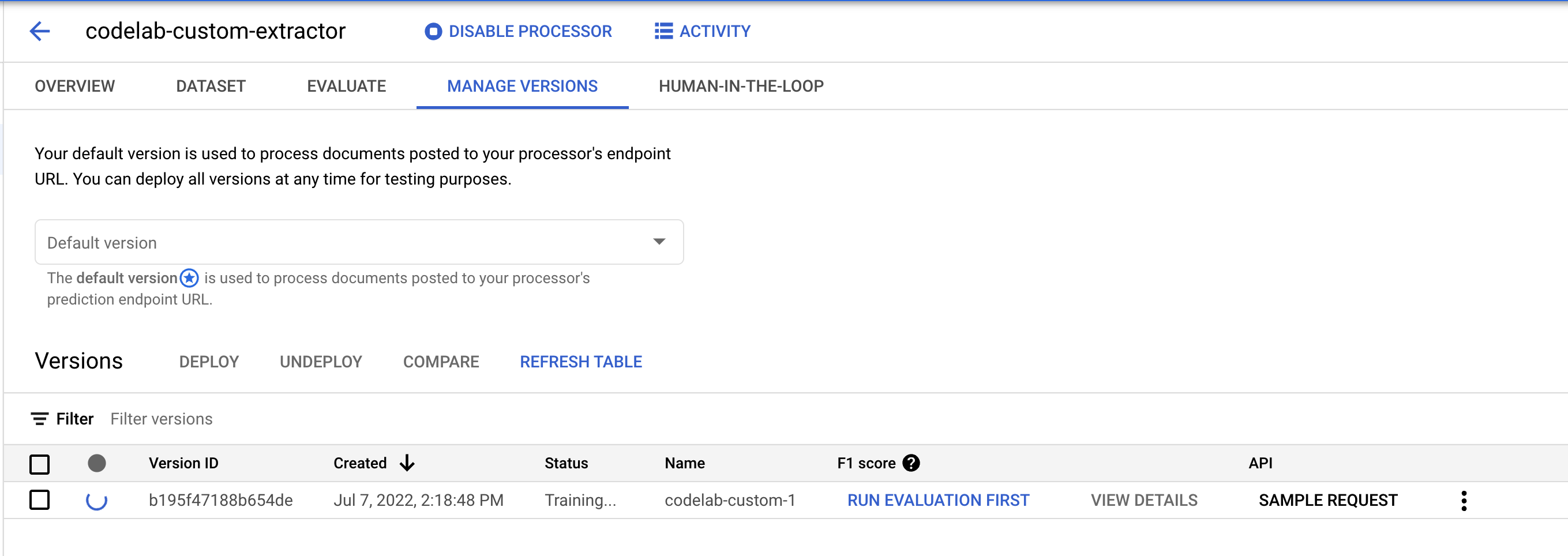
11. मॉडल के नए वर्शन को टेस्ट करना
ट्रेनिंग का काम पूरा होने के बाद (मेरे टेस्ट में इसे पूरा होने में करीब एक घंटा लगा), अब नए मॉडल वर्शन को आज़माया जा सकता है. साथ ही, इसका इस्तेमाल अनुमान लगाने के लिए किया जा सकता है.
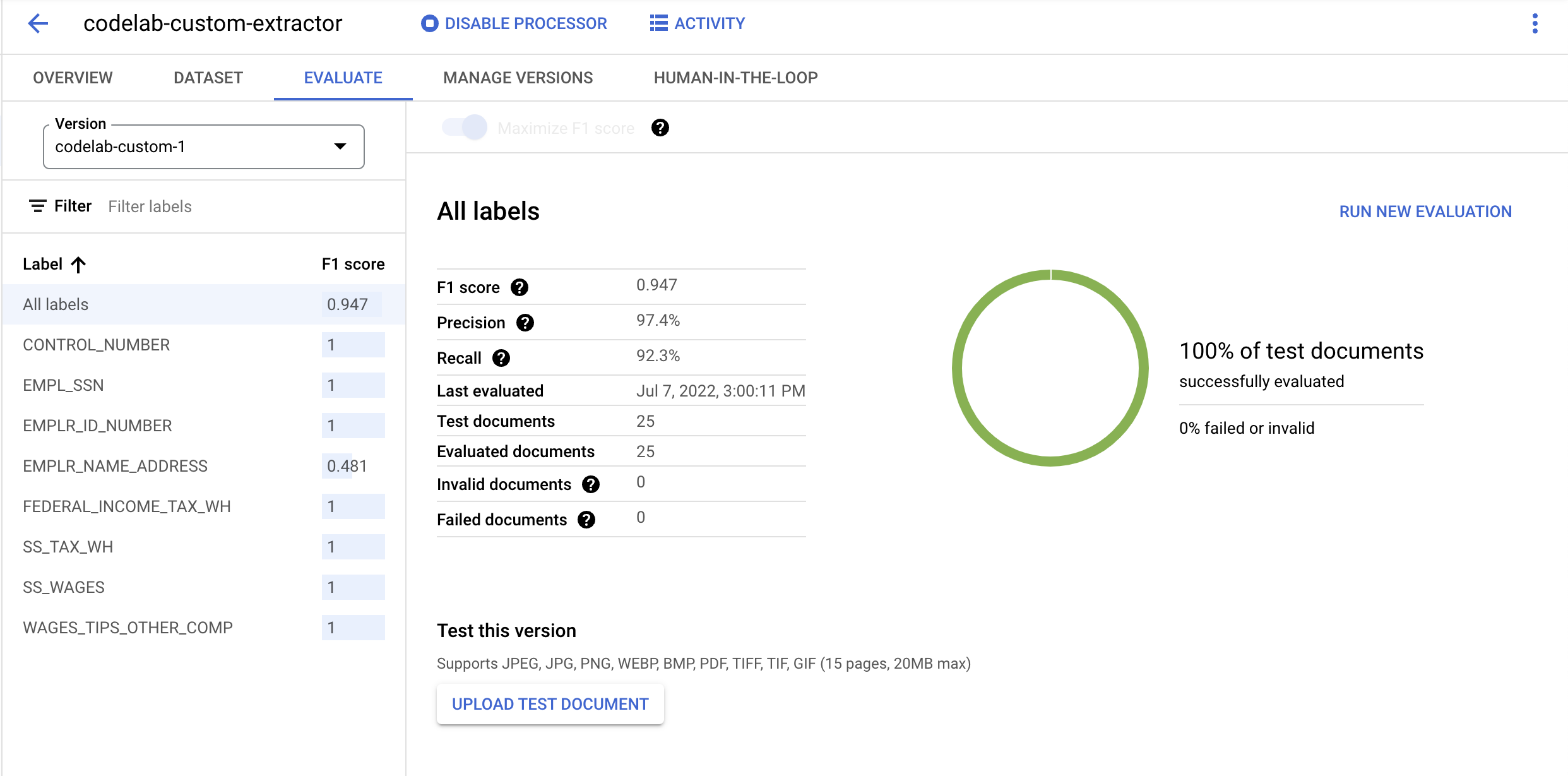
- वर्शन मैनेज करें पेज पर जाएं. यहां आपको मौजूदा स्टेटस और F1 स्कोर दिखेगा.
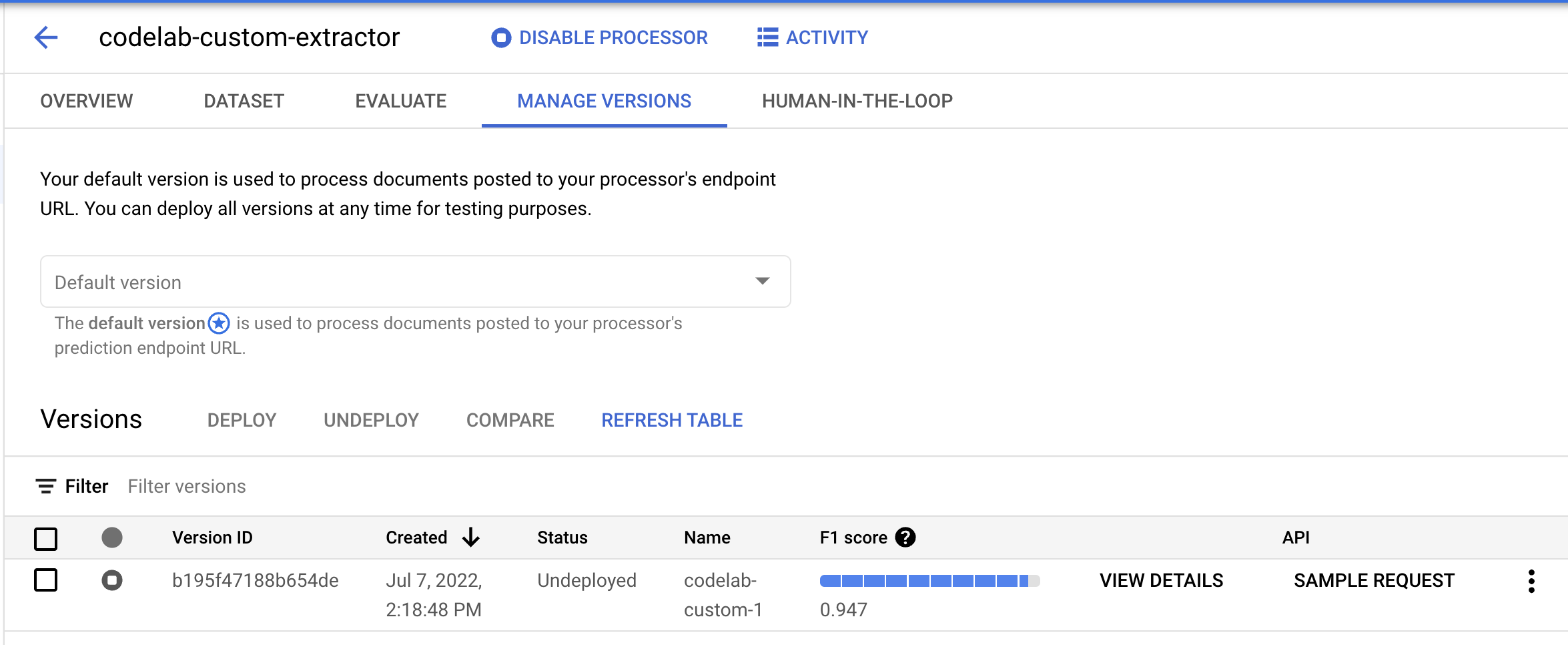
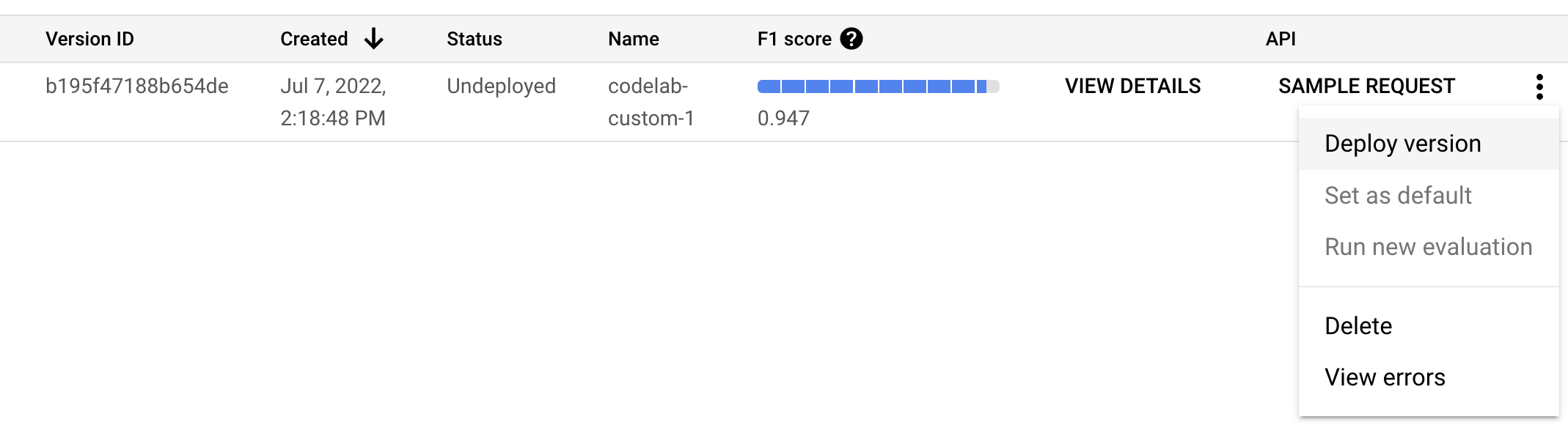
- इस मॉडल वर्शन को इस्तेमाल करने से पहले, हमें इसे डिप्लॉय करना होगा. दाईं ओर मौजूद वर्टिकल बिंदुओं पर क्लिक करें और Deploy Version को चुनें.
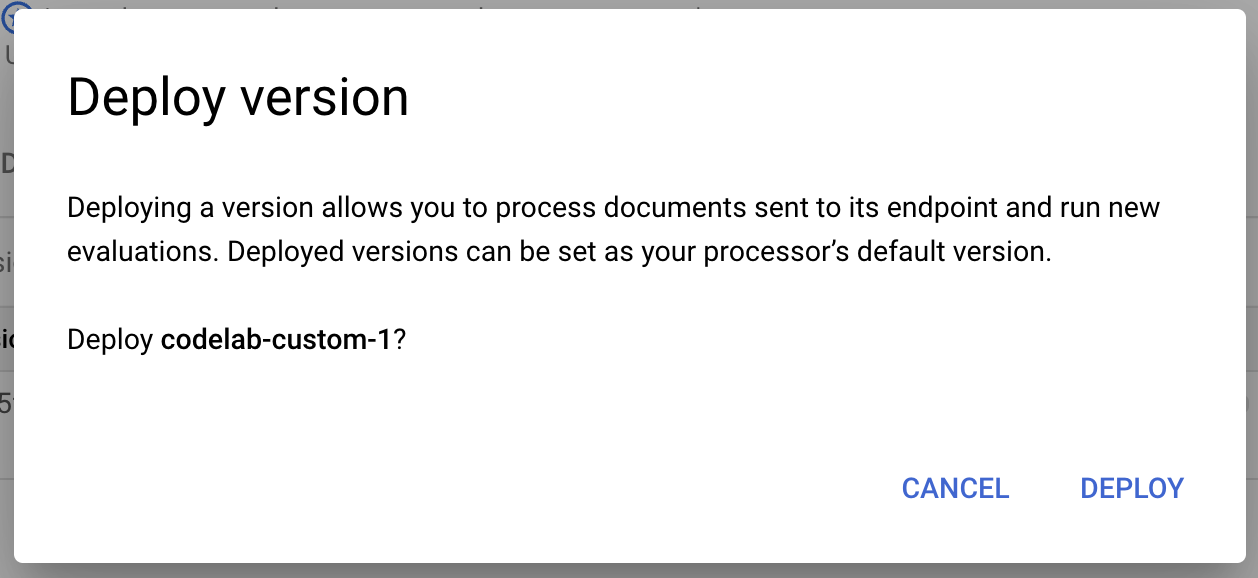
- वर्शन के डिप्लॉय होने का इंतज़ार करते समय, पॉप-अप विंडो में डिप्लॉय करें को चुनें. इस प्रोसेस को पूरा होने में कुछ मिनट लगेंगे. इसे डिप्लॉय करने के बाद, इस वर्शन को डिफ़ॉल्ट वर्शन के तौर पर भी सेट किया जा सकता है.
- डेटा डिप्लॉय होने के बाद, जांच करें टैब पर जाएं. इस पेज पर, आपको पूरे दस्तावेज़ के साथ-साथ अलग-अलग लेबल के लिए, F1 स्कोर, सटीक होने की दर, और रिकॉल करने की दर जैसी इवैलुएशन मेट्रिक दिखेंगी. इन मेट्रिक के बारे में ज़्यादा जानने के लिए, AutoML का दस्तावेज़ पढ़ें.
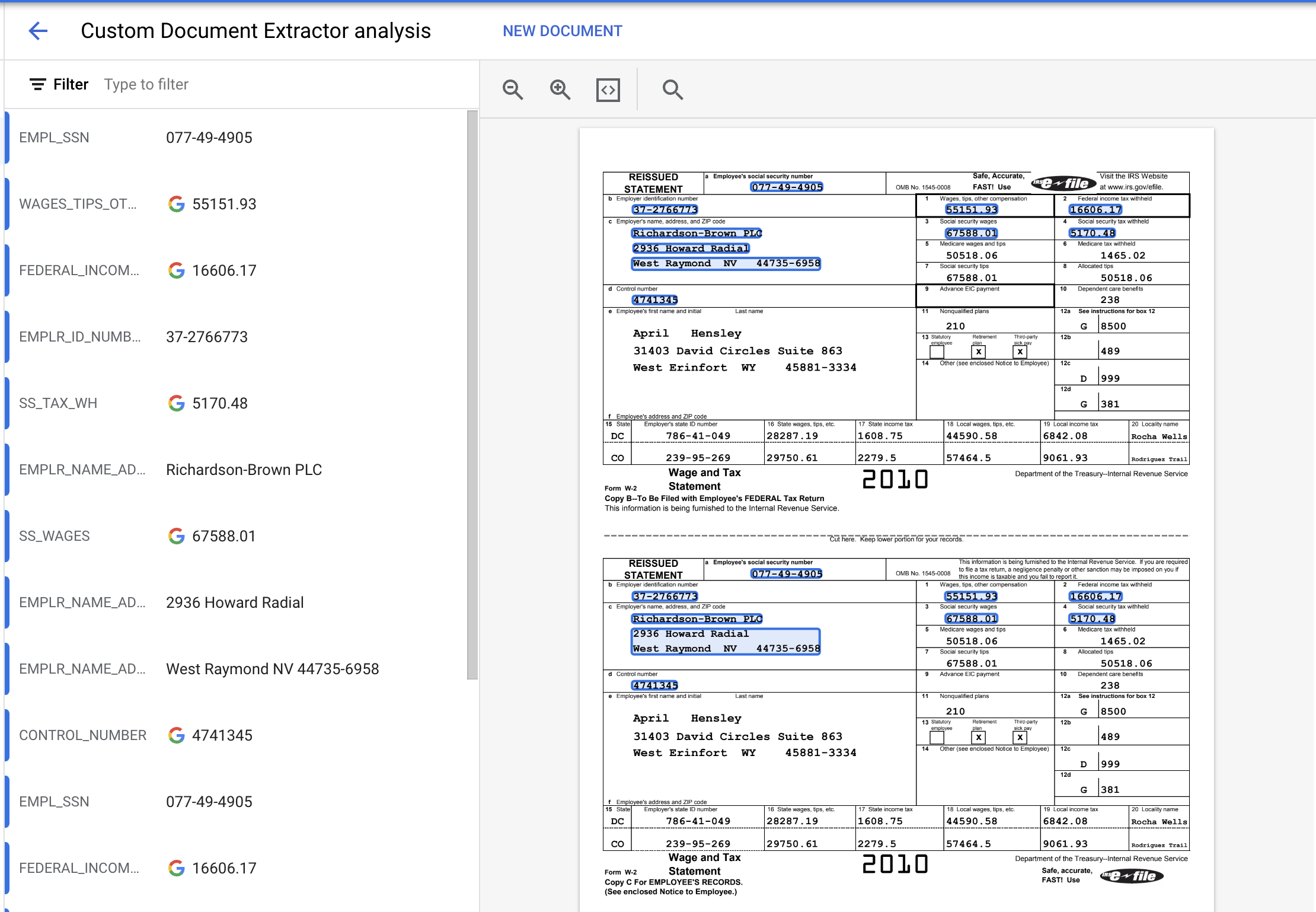
- यहां लिंक की गई PDF फ़ाइल डाउनलोड करें. यह W2 का एक सैंपल है, जिसे ट्रेनिंग या टेस्ट सेट में शामिल नहीं किया गया था.
- जांच के लिए दस्तावेज़ अपलोड करें पर क्लिक करें और PDF फ़ाइल चुनें.
- निकाली गई इकाइयां कुछ इस तरह दिखनी चाहिए.
12. ज़रूरी नहीं: इंपोर्ट किए गए नए दस्तावेज़ों को अपने-आप लेबल करने की सुविधा
ट्रेन किए गए प्रोसेसर वर्शन को डिप्लॉय करने के बाद, नए दस्तावेज़ इंपोर्ट करते समय लेबलिंग में लगने वाला समय बचाने के लिए, अपने-आप लेबल लगने की सुविधा का इस्तेमाल किया जा सकता है.
- ट्रेन करें पेज पर, दस्तावेज़ इंपोर्ट करें पर क्लिक करें.
- के इस पाथ को कॉपी करके चिपकाएं. इस डायरेक्ट्री में, बिना लेबल वाले पांच W2 PDF हैं. डेटा स्प्लिट ड्रॉपडाउन सूची से, ट्रेनिंग चुनें.
cloud-samples-data/documentai/Custom/W2/AutoLabel - अपने-आप लेबल लगने की सुविधा सेक्शन में जाकर, अपने-आप लेबल लगने की सुविधा के साथ इंपोर्ट करें चेकबॉक्स को चुनें.
- दस्तावेज़ों को लेबल करने के लिए, प्रोसेसर का कोई मौजूदा वर्शन चुनें.
- उदाहरण के लिए:
2af620b2fd4d1fcf
- इंपोर्ट करें पर क्लिक करें और दस्तावेज़ों के इंपोर्ट होने का इंतज़ार करें. इस पेज को बंद करके, बाद में इस पर वापस आया जा सकता है.
- प्रोसेस पूरी होने के बाद, दस्तावेज़ अपने-आप लेबल किए गए सेक्शन में, ट्रेन करें पेज पर दिखते हैं.
- लेबल किए गए दस्तावेज़ों के तौर पर मार्क किए बिना, ट्रेनिंग या टेस्टिंग के लिए अपने-आप लेबल किए गए दस्तावेज़ों का इस्तेमाल नहीं किया जा सकता. अपने-आप लेबल किए गए दस्तावेज़ देखने के लिए, अपने-आप लेबल किए गए सेक्शन पर जाएं.
- लेबलिंग कंसोल में जाने के लिए, पहला दस्तावेज़ चुनें.
- लेबल, बाउंडिंग बॉक्स, और वैल्यू की पुष्टि करें, ताकि यह पक्का किया जा सके कि वे सही हैं. छोड़ी गई किसी भी वैल्यू को लेबल करें.
- जब काम पूरा हो जाए, तब 'लेबल किया गया' के तौर पर मार्क करें को चुनें.
- अपने-आप लेबल किए गए हर दस्तावेज़ के लिए, लेबल की पुष्टि करने की प्रोसेस दोहराएं. इसके बाद, ट्रेनिंग के लिए डेटा का इस्तेमाल करने के लिए, ट्रेन करें पेज पर वापस जाएं.
13. नतीजा
बधाई हो, आपने Document AI का इस्तेमाल करके, कस्टम दस्तावेज़ एक्सट्रैक्टर प्रोसेसर को ट्रेन कर लिया है. अब इस प्रोसेसर का इस्तेमाल करके, इस फ़ॉर्मैट में मौजूद दस्तावेज़ों को पार्स किया जा सकता है. ठीक उसी तरह जैसे किसी स्पेशलाइज़्ड प्रोसेसर का इस्तेमाल किया जाता है.
प्रोसेसिंग के रिस्पॉन्स को मैनेज करने का तरीका जानने के लिए, स्पेशलाइज़्ड प्रोसेसर कोडलैब देखें.
सफ़ाई
इस ट्यूटोरियल में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए:
- Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- प्रोजेक्ट की सूची में, अपना प्रोजेक्ट चुनें. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
संसाधन
- Document AI Workbench से जुड़े दस्तावेज़
- द फ़्यूचर ऑफ़ डॉक्यूमेंट्स - YouTube प्लेलिस्ट
- Document AI से जुड़े दस्तावेज़
- Document AI Python क्लाइंट लाइब्रेरी
- Document AI के सैंपल
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 2.0 जेनेरिक लाइसेंस के तहत लाइसेंस मिला है.