
1. Wprowadzenie
Document AI to rozwiązanie do analizy dokumentów, które przetwarza dane nieustrukturyzowane, takie jak dokumenty, e-maile itp., i ułatwia ich zrozumienie, analizowanie i wykorzystywanie.
Dzięki Document AI Workbench możesz zwiększyć dokładność przetwarzania dokumentów, tworząc w pełni dostosowane modele z użyciem własnych danych treningowych.
W tym module utworzysz niestandardowy procesor do wyodrębniania dokumentów, zaimportujesz zbiór danych, oznaczysz etykietami przykładowe dokumenty i wytrenujesz procesor.
Zbiór danych dokumentów użyty w tym module pochodzi ze zbioru Fake W-2 (US Tax Form) w Kaggle i jest dostępny na licencji CC0 (domena publiczna).
Wymagania wstępne
To ćwiczenie opiera się na treściach przedstawionych w innych ćwiczeniach Document AI.
Zanim przejdziesz dalej, zalecamy wykonanie tych ćwiczeń z programowania.
- Optyczne rozpoznawanie znaków (OCR) za pomocą Document AI (Python)
- Analizowanie formularzy za pomocą Document AI (Python)
- Specjalistyczne procesory z Document AI (Python)
- Zarządzanie procesorami Document AI za pomocą Pythona
- Document AI: weryfikacja przez człowieka
- Document AI: uptraining
Czego się nauczysz
- utworzyć niestandardowy procesor do wyodrębniania dokumentów;
- Oznaczanie danych treningowych Document AI etykietami za pomocą narzędzia do adnotacji.
- Wytrenuj nową wersję modelu.
- ocenić dokładność nowej wersji modelu,
Czego potrzebujesz
2. Przygotowania
W tym ćwiczeniu zakłada się, że masz już za sobą kroki konfiguracji Document AI wymienione w ćwiczeniu wprowadzającym.
Zanim przejdziesz dalej, wykonaj te czynności:
3. Tworzenie procesora
Aby wykonać to ćwiczenie, musisz najpierw utworzyć procesor niestandardowego ekstraktora danych z dokumentów.
- W konsoli otwórz stronę Document AI – przegląd.
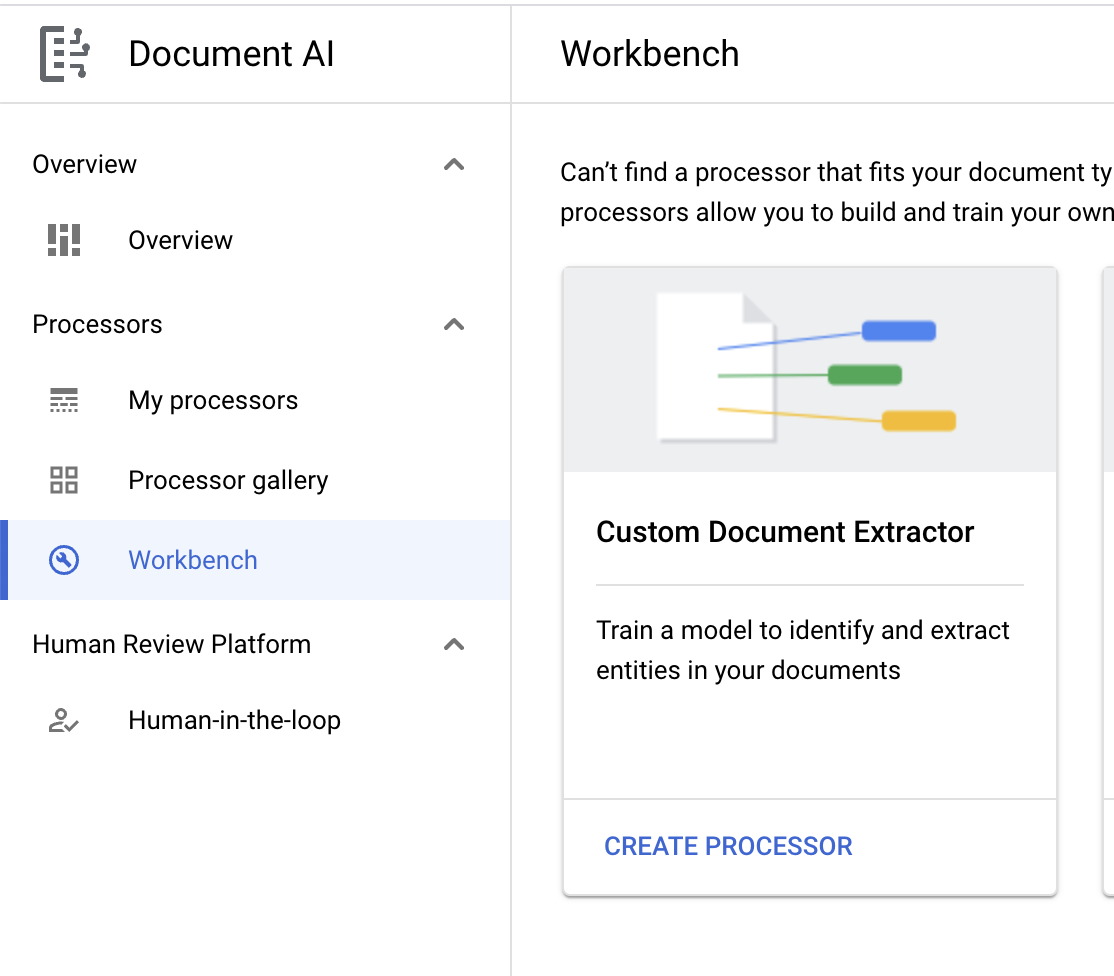
- Kliknij Utwórz procesor niestandardowy i wybierz Niestandardowy ekstraktor danych z dokumentów.
- Nadaj mu nazwę
codelab-custom-extractor(lub inną, którą będziesz pamiętać) i wybierz z listy region, który znajduje się najbliżej Ciebie.
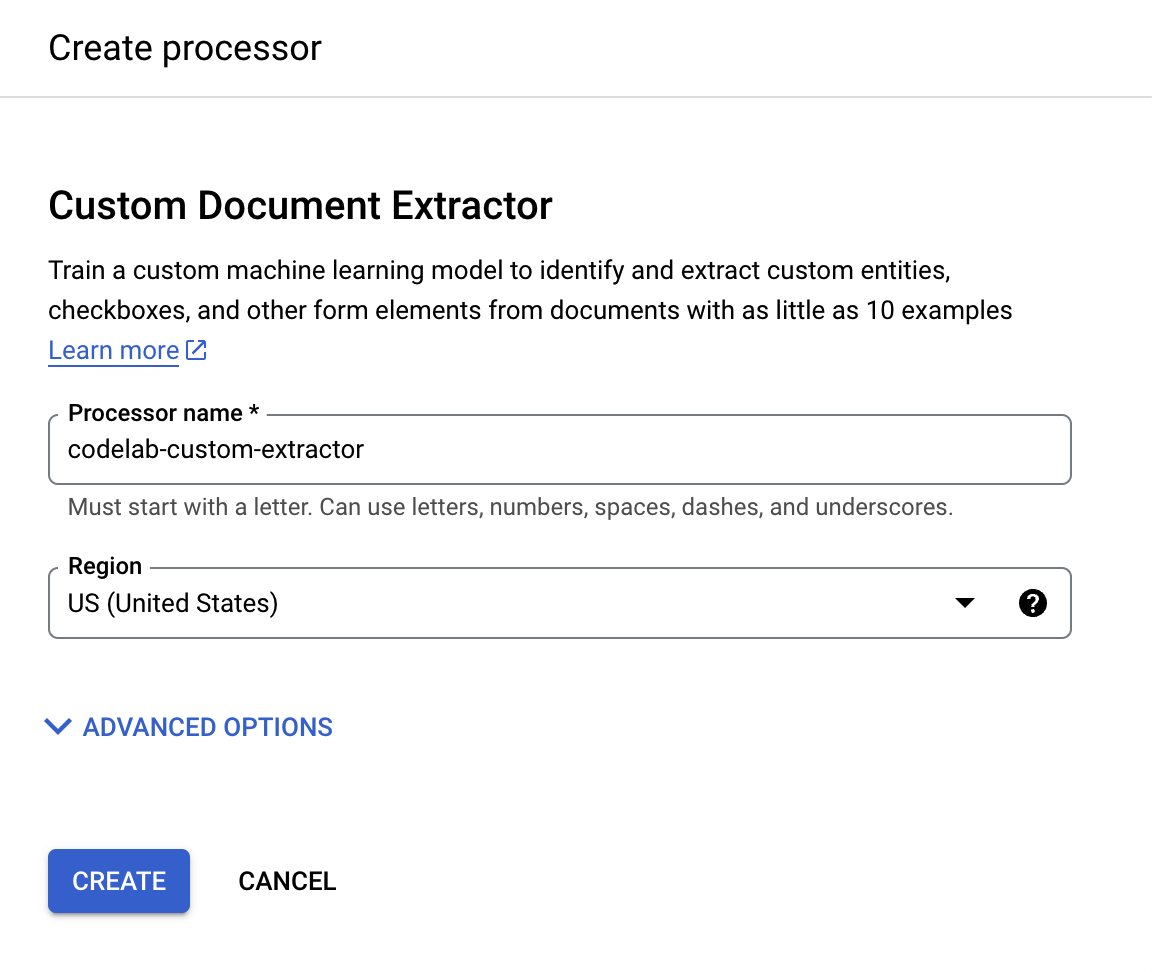
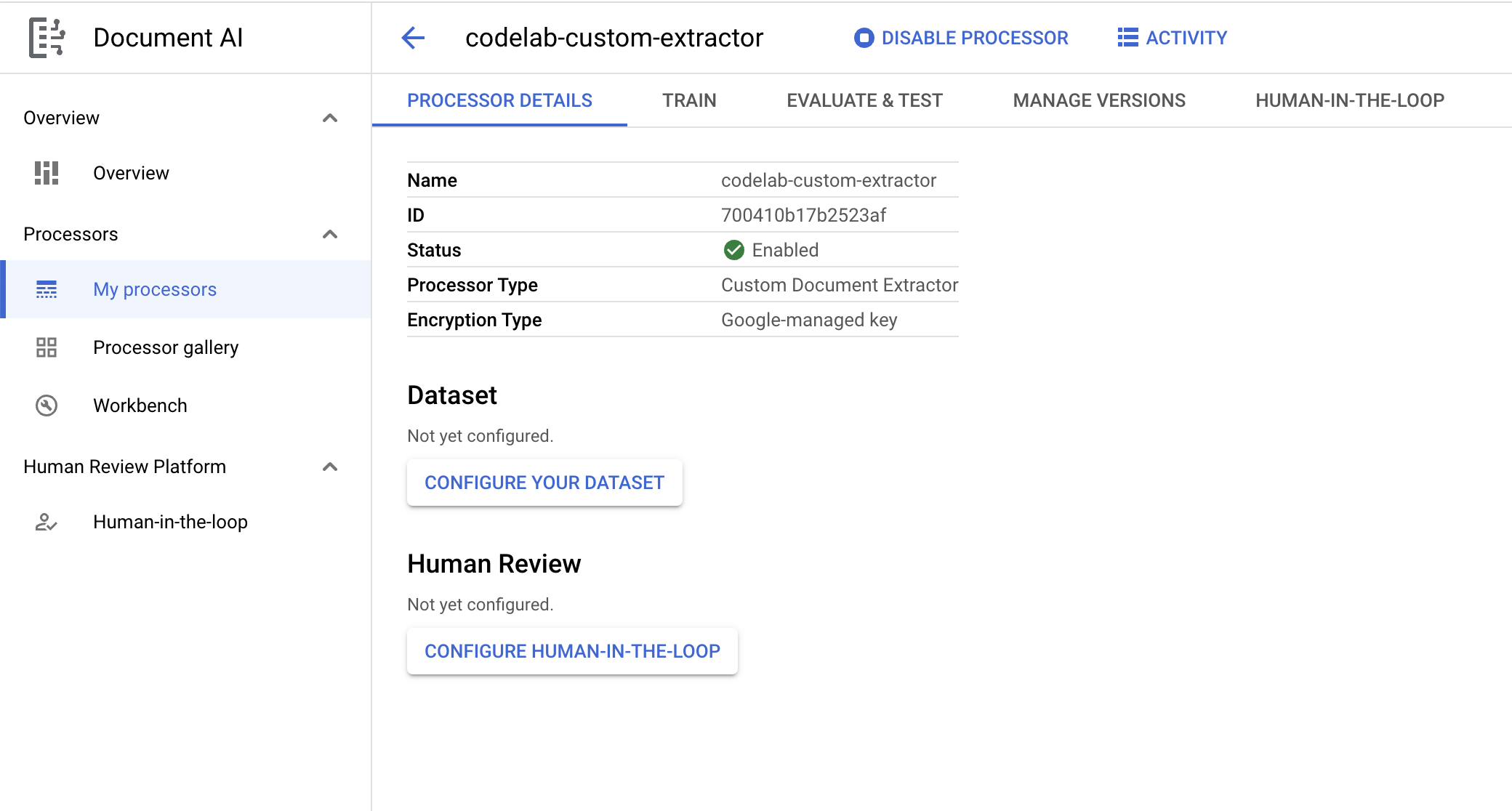
- Kliknij Utwórz, aby utworzyć procesor. Powinna wyświetlić się strona Przegląd procesora.
4. Tworzenie zbioru danych
Aby wytrenować nasz procesor, musimy utworzyć zbiór danych z danymi treningowymi i testowymi, dzięki czemu procesor nauczy się identyfikować encje, które chcemy wyodrębniać.
- Na stronie Omówienie procesora kliknij Skonfiguruj zbiór danych.
- Powinna wyświetlić się strona Skonfiguruj zbiór danych. Jeśli chcesz określić własny kosz na dokumenty do trenowania i etykiety, kliknij Pokaż opcje zaawansowane. W przeciwnym razie kliknij Dalej.
- Poczekaj na utworzenie zbioru danych. Następnie powinna otworzyć się strona Trenowanie.
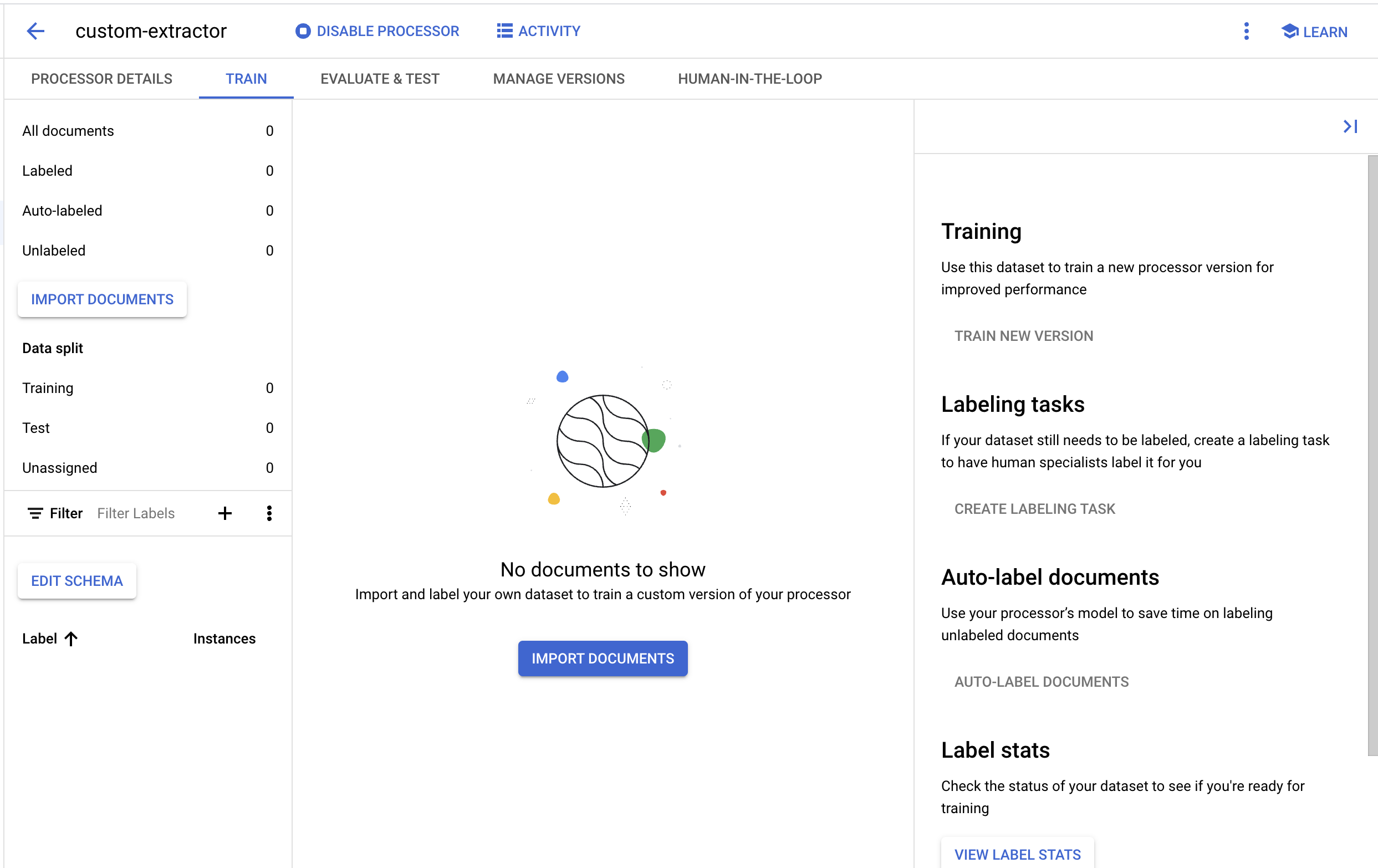
5. Importowanie dokumentu testowego
Teraz zaimportujmy do zbioru danych przykładowy plik PDF z formularzem W-2.
- Kliknij Importuj dokumenty.
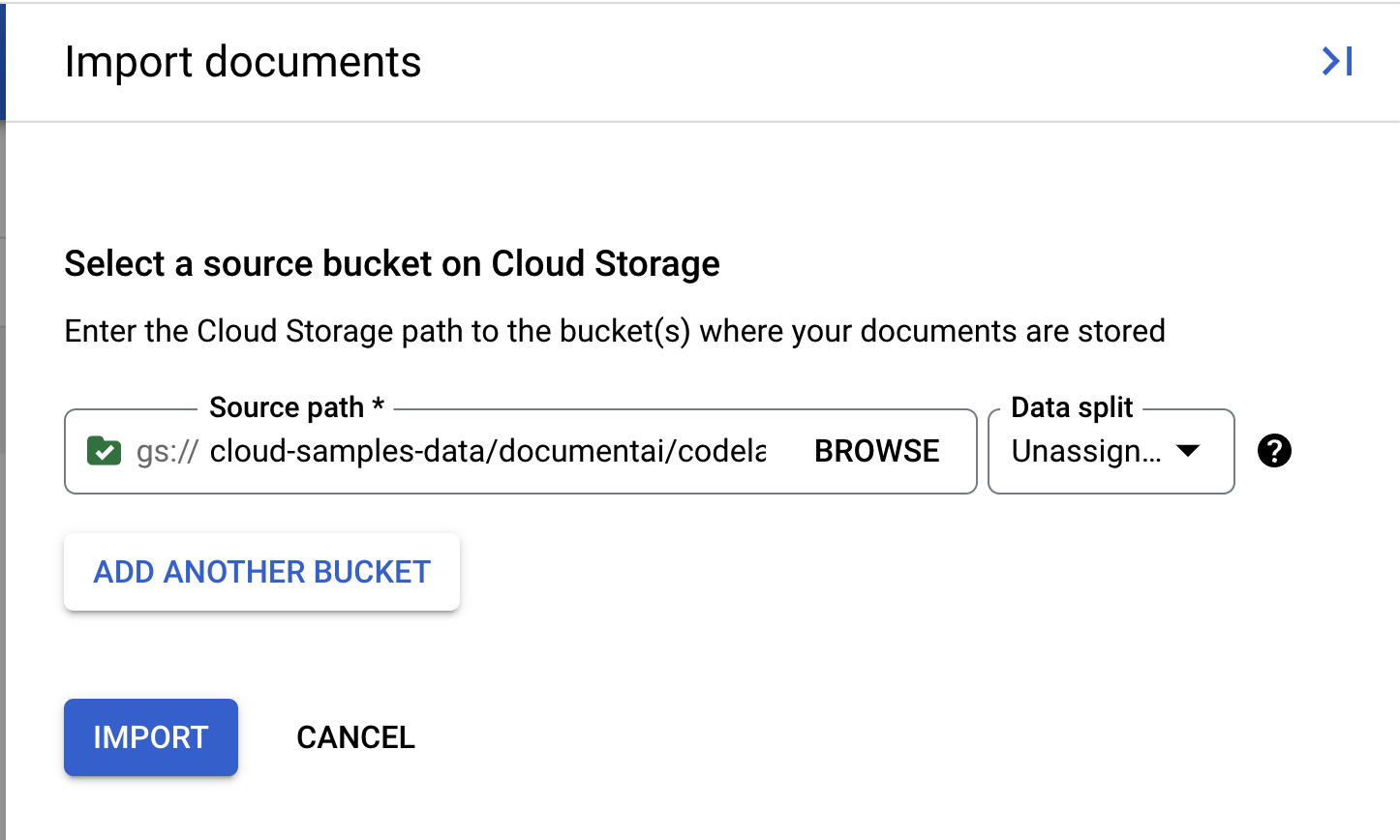
- Przygotowaliśmy przykładowy plik PDF, którego możesz użyć w tym module. Skopiuj ten link i wklej go w polu Ścieżka źródła. Na razie pozostaw w polu „Podział danych” wartość „Nieprzypisane”. Pozostałe pola pozostaw niezaznaczone. Kliknij Importuj.
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs
- Poczekaj na zaimportowanie dokumentu. Powinno to zająć mniej niż minutę.
- Po zakończeniu importowania dokument powinien pojawić się na stronie Trenowanie.
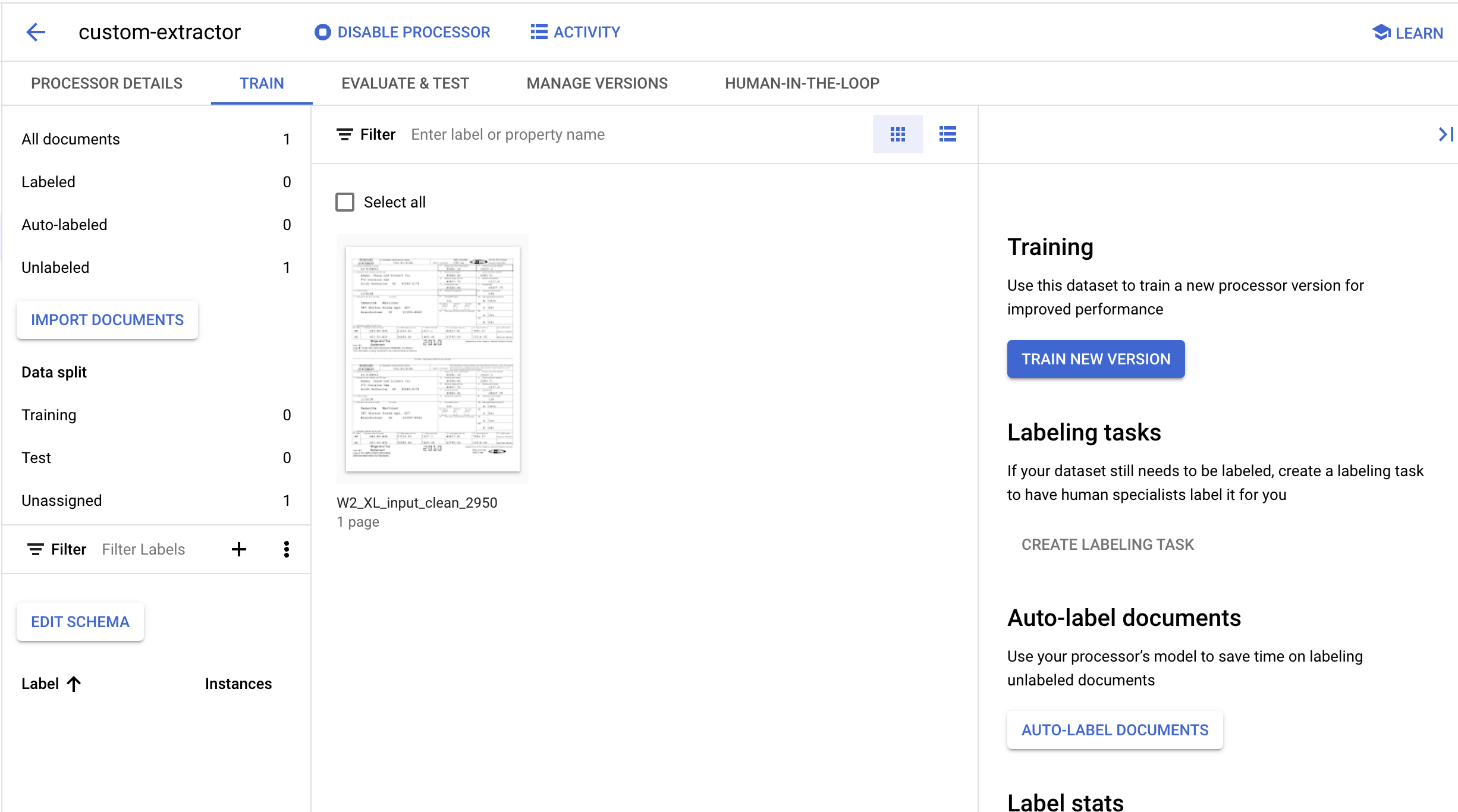
6. Tworzenie etykiet
Ponieważ tworzymy nowy typ procesora, musimy utworzyć niestandardowe etykiety, aby poinformować Document AI, które pola chcemy wyodrębnić.
- W lewym dolnym rogu kliknij Edytuj schemat.
- Powinna teraz otworzyć się konsola Zarządzanie schematami.
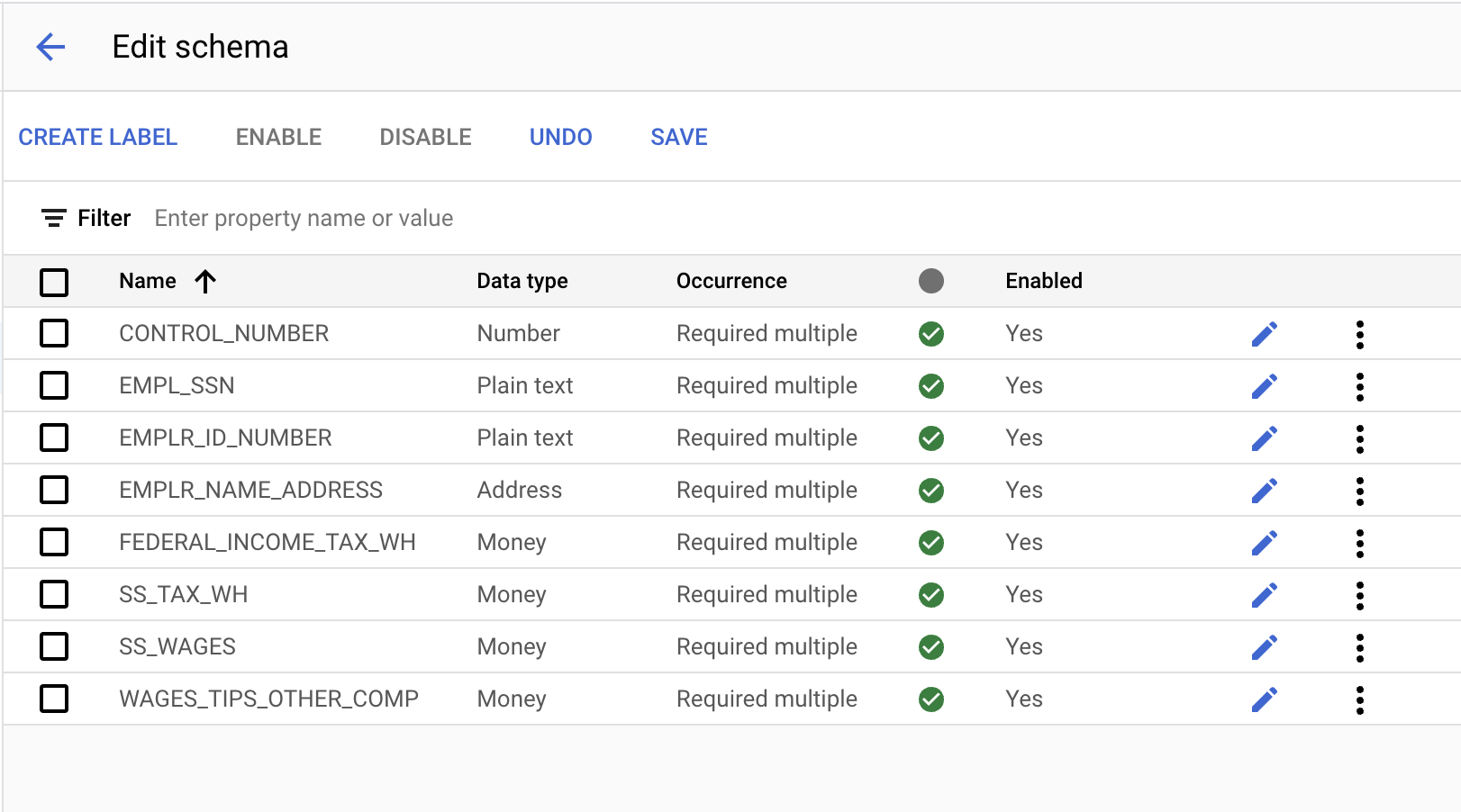
- Utwórz te etykiety, klikając przycisk Utwórz etykietę.
Nazwa | Typ danych | Wystąpienie |
| Liczba | Wymagana wiele razy |
| Zwykły tekst | Wymagana wiele razy |
| Zwykły tekst | Wymagana wiele razy |
| Adres | Wymagana wiele razy |
| Pieniądze | Wymagana wiele razy |
| Pieniądze | Wymagana wiele razy |
| Pieniądze | Wymagana wiele razy |
| Pieniądze | Wymagana wiele razy |
- Po zakończeniu konsola powinna wyglądać tak: Gdy skończysz, kliknij Zapisz.
- Kliknij strzałkę wstecz, aby wrócić na stronę Trenowanie. Zauważ, że utworzone przez nas etykiety pojawiają się w lewym dolnym rogu.
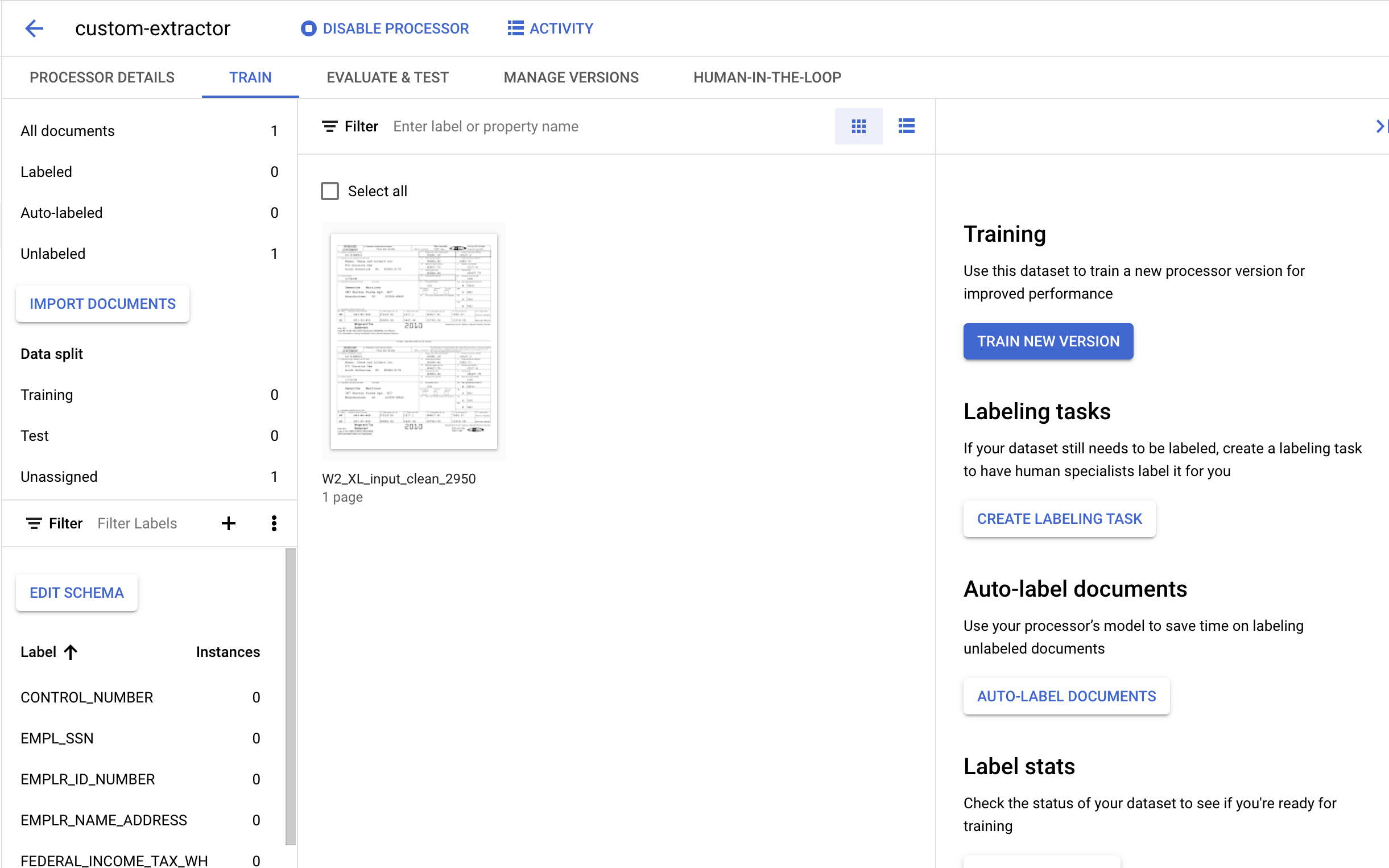
7. Oznaczanie dokumentu testowego etykietami
Następnie zidentyfikujemy elementy tekstowe i etykiety dla encji, które chcemy wyodrębnić. Te etykiety zostaną użyte do wytrenowania modelu, aby analizował on tę konkretną strukturę dokumentu i identyfikował prawidłowe typy.
- Kliknij dwukrotnie dokument zaimportowany wcześniej, aby przejść do konsoli do dodawania etykiet. Powinien on wyglądać mniej więcej tak.
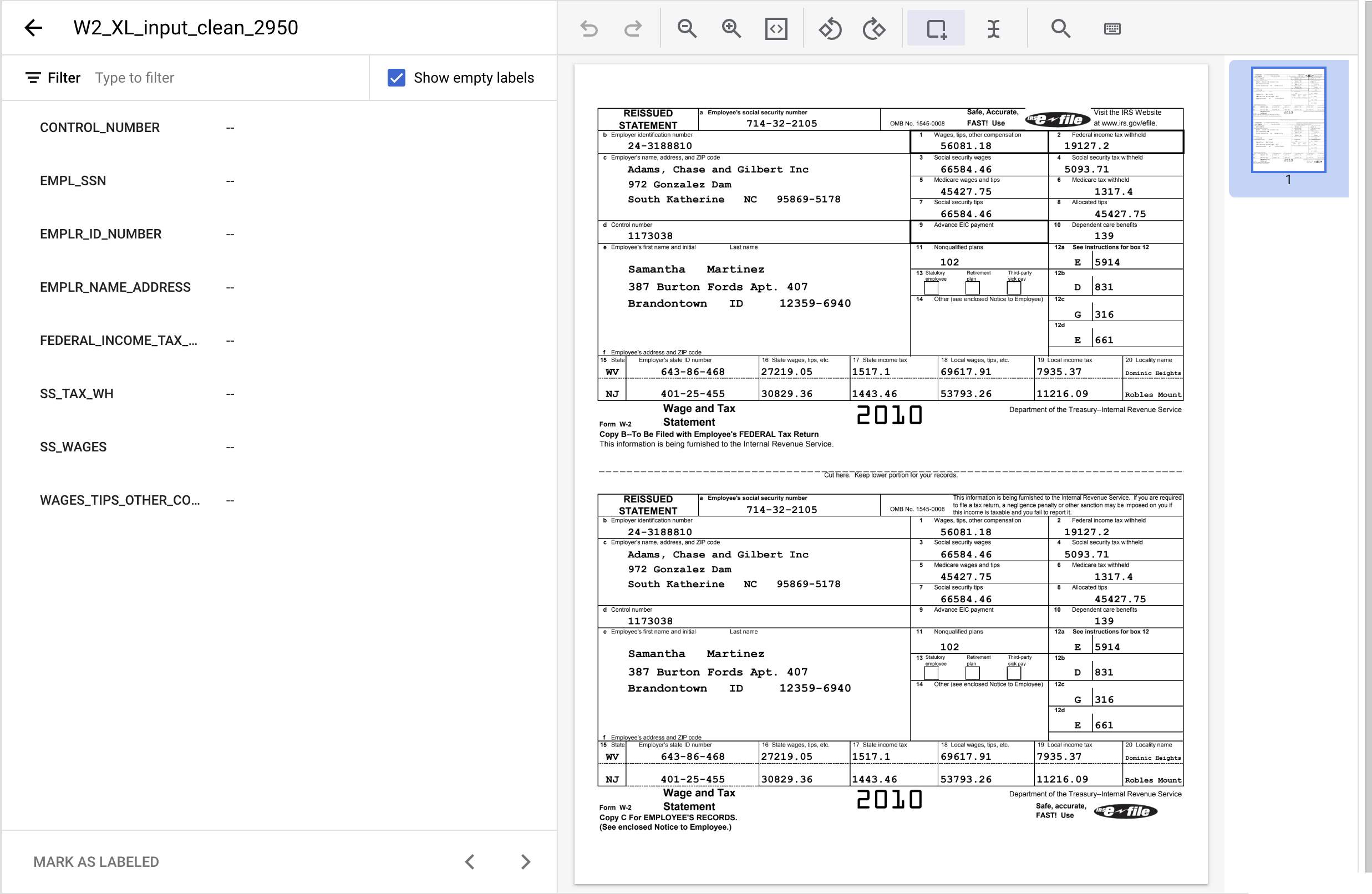
- Kliknij narzędzie „Bounding Box”, a następnie zaznacz tekst „1173038” i przypisz mu etykietę
CONTROL_NUMBER. Aby wyszukać nazwy etykiet, możesz użyć filtra tekstowego.
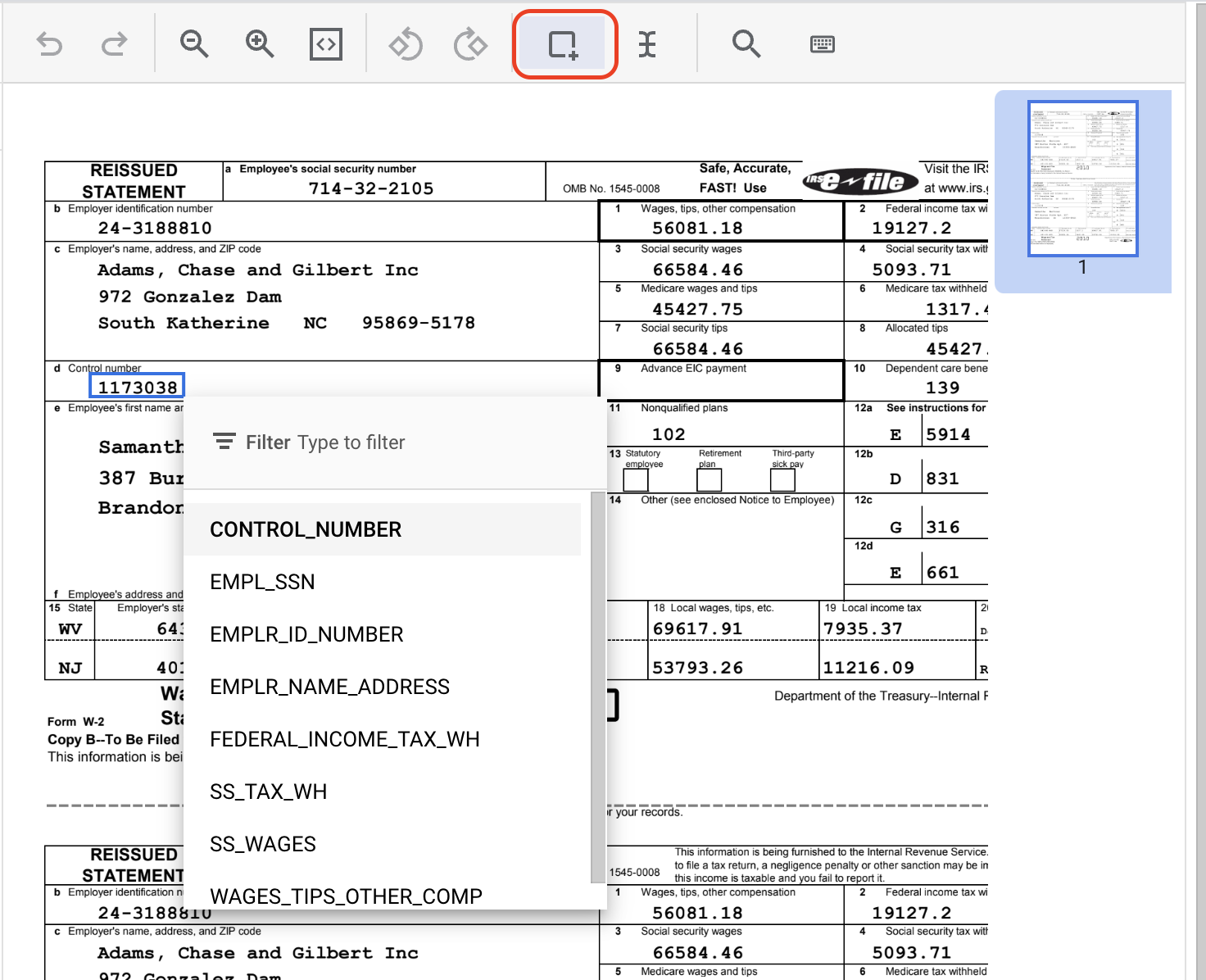
- Uzupełnij pozostałe wystąpienie symbolu
CONTROL_NUMBER. Po oznaczeniu powinno wyglądać tak:
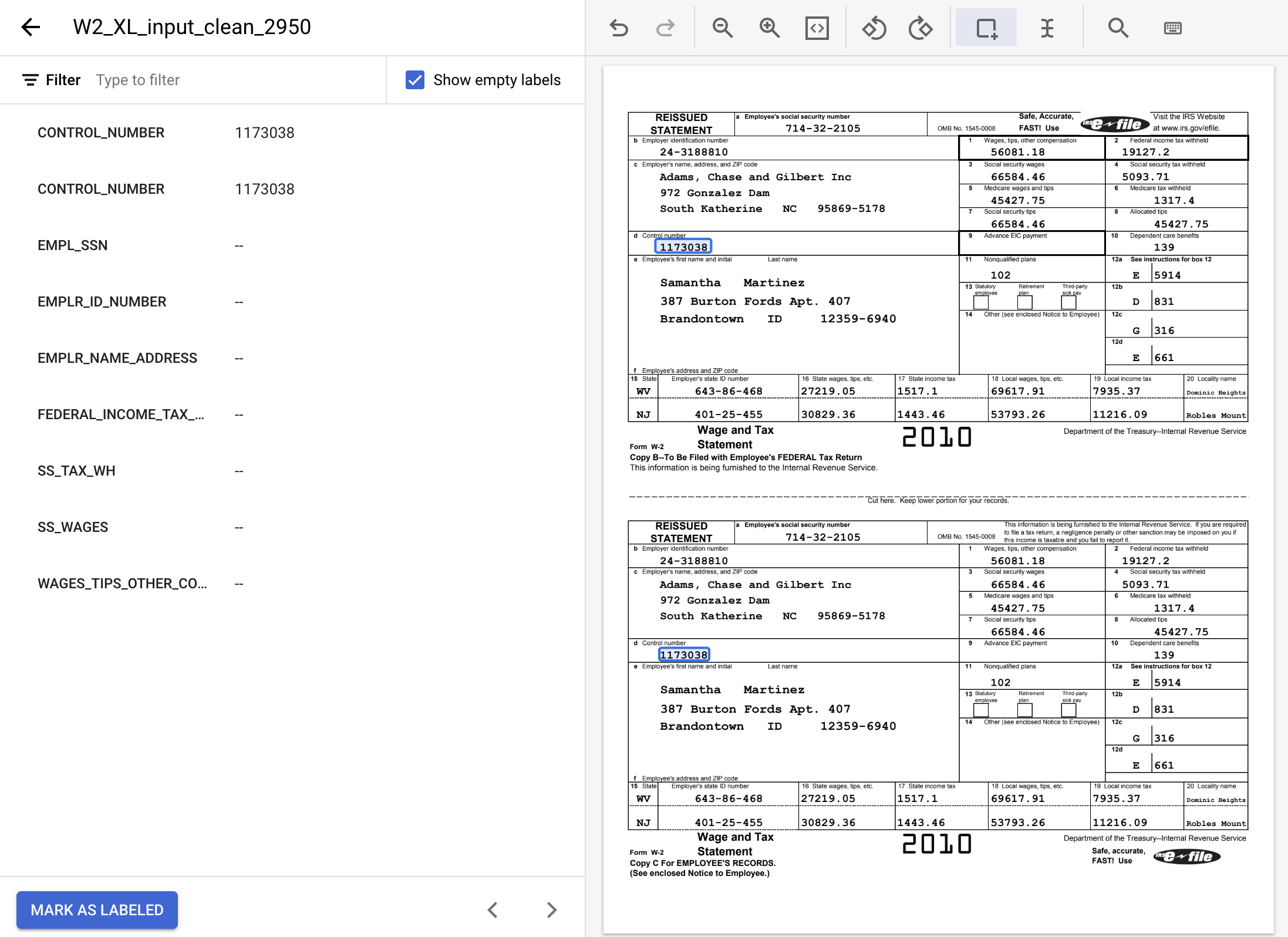
- Zaznacz wszystkie wystąpienia tych wartości tekstowych i przypisz odpowiednie etykiety.
Nazwa etykiety | Text |
| 24-3188810 |
| 19127.2 |
| 5093,71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
- Po zakończeniu pracy dokument opatrzony etykietami powinien wyglądać następująco. Pamiętaj, że możesz dostosować te etykiety, klikając ramkę ograniczającą w dokumencie lub nazwę/wartość etykiety w bocznym menu po lewej stronie. Gdy skończysz dodawać etykiety, kliknij Oznacz jako oznaczony etykietami, a następnie wróć do konsoli zarządzania zbiorem danych.
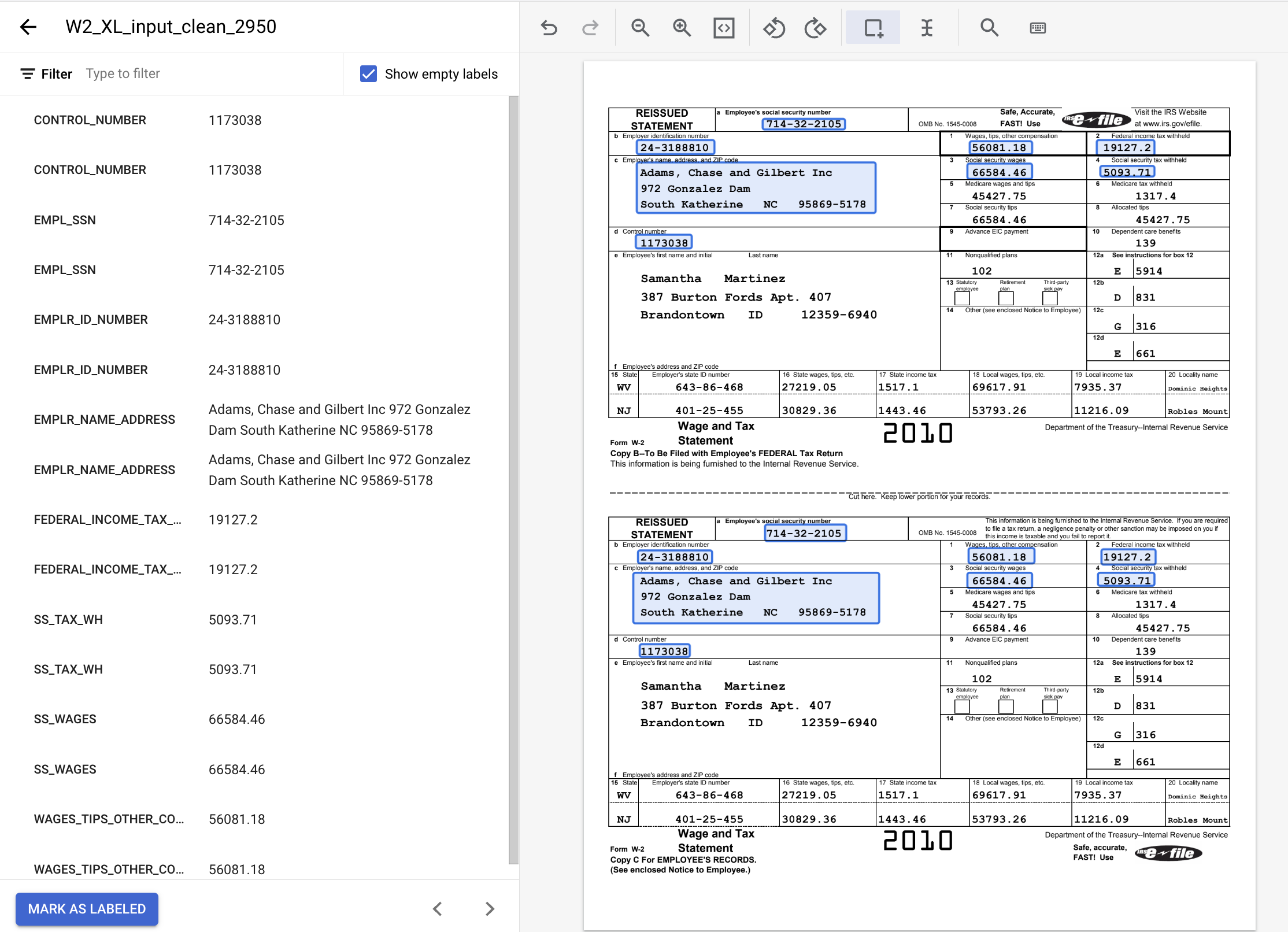
8. Przypisywanie dokumentu do zbioru treningowego
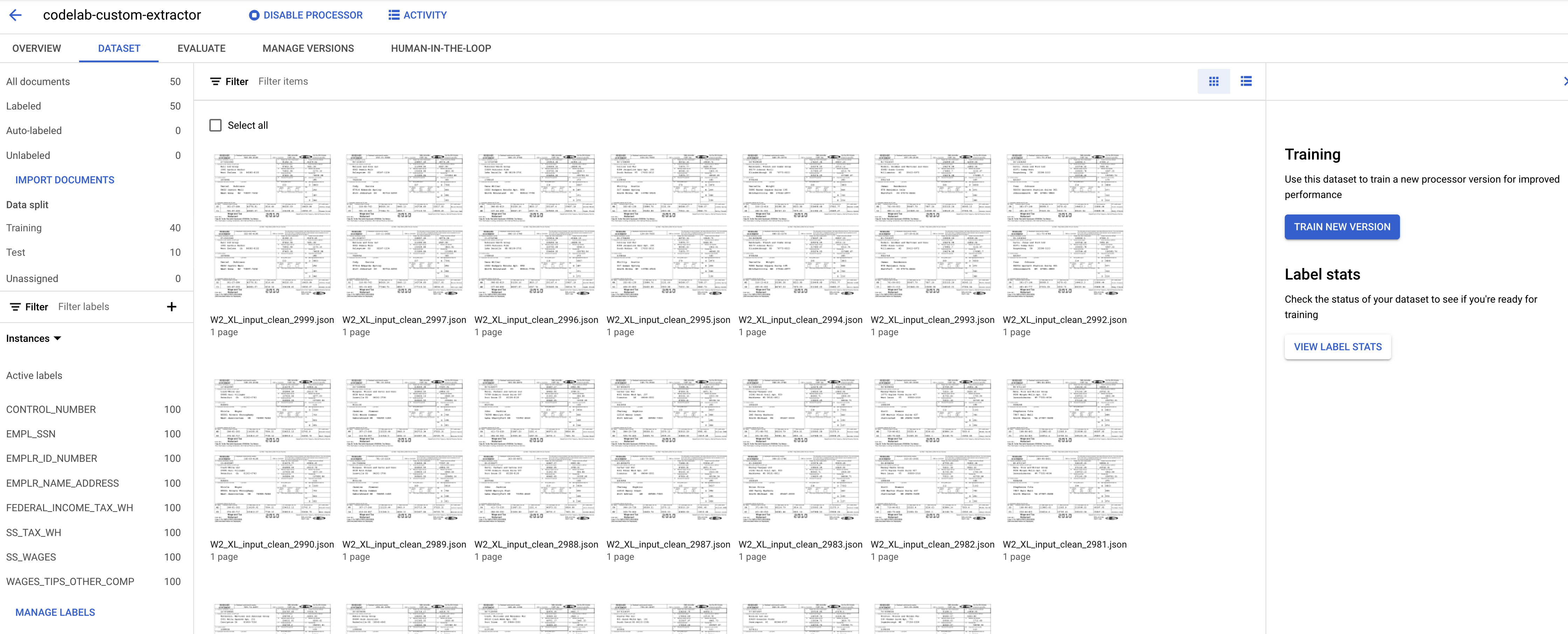
Powinna się teraz otworzyć konsola zarządzania zbiorem danych. Zwróć uwagę, że zmieniła się liczba dokumentów z etykietami i bez etykiet oraz liczba wystąpień poszczególnych etykiet.
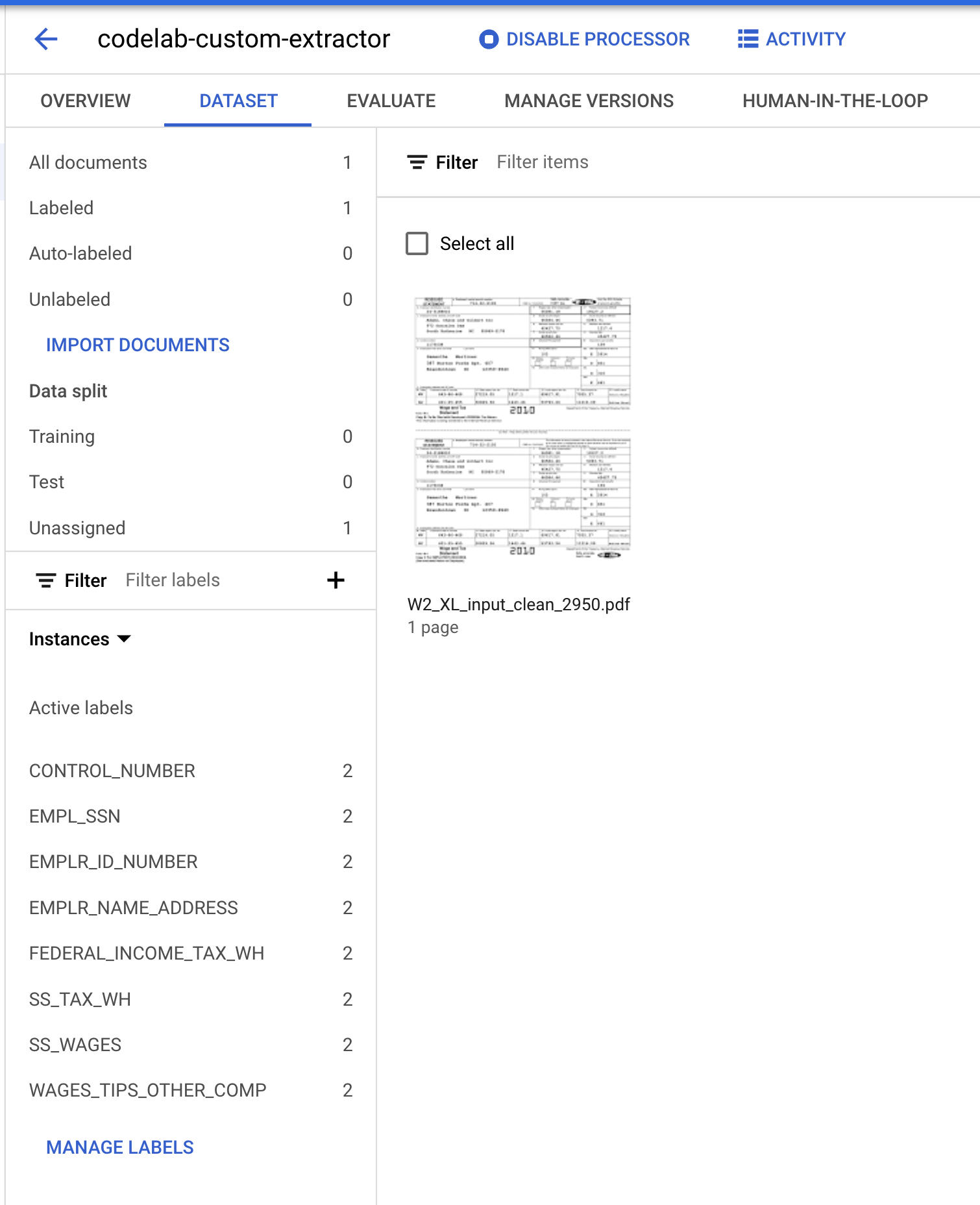
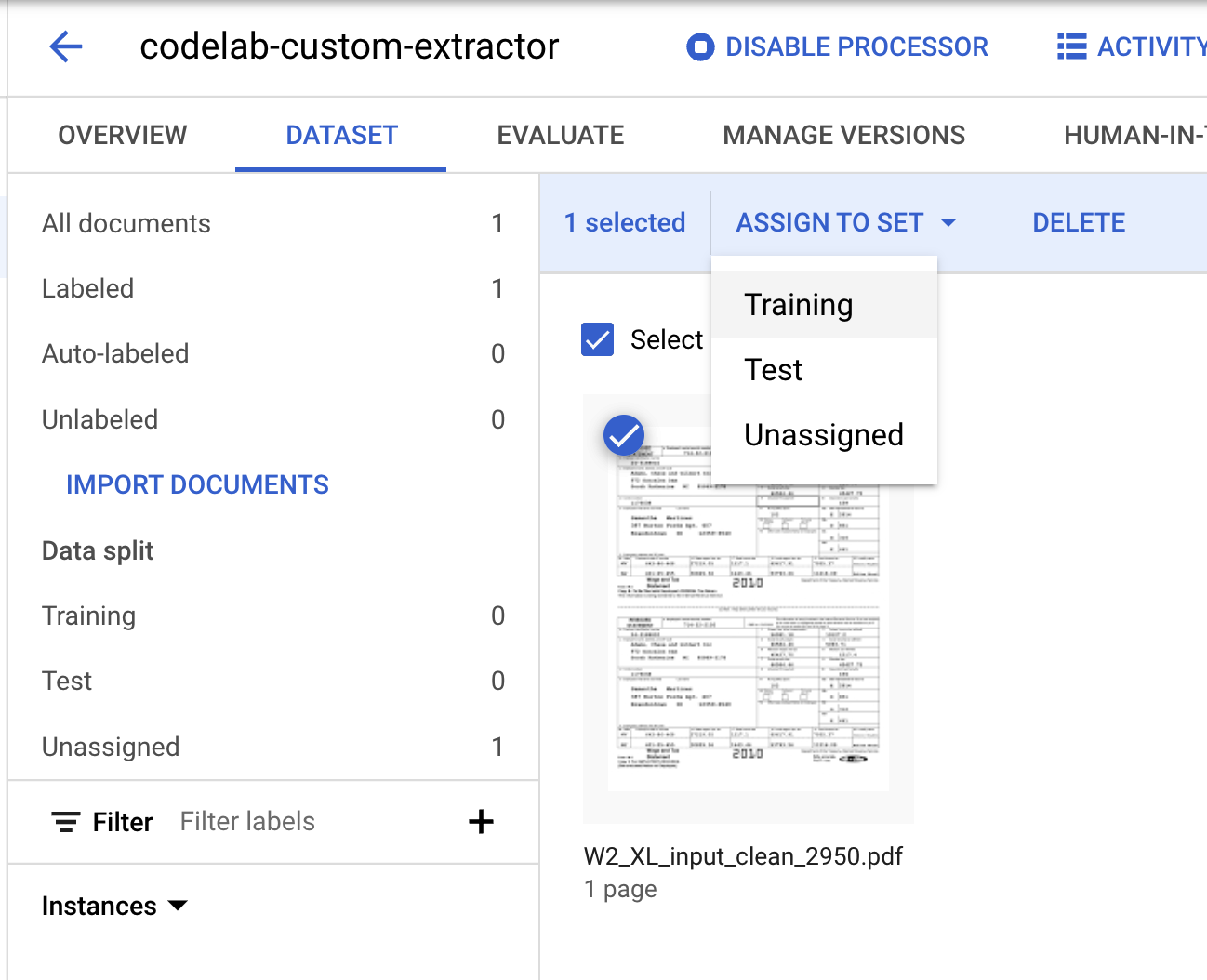
- Musimy przypisać ten dokument do zbioru „Treningowy” lub „Testowy”. Kliknij dokument, a potem kolejno Przypisz do zestawu i Trening.
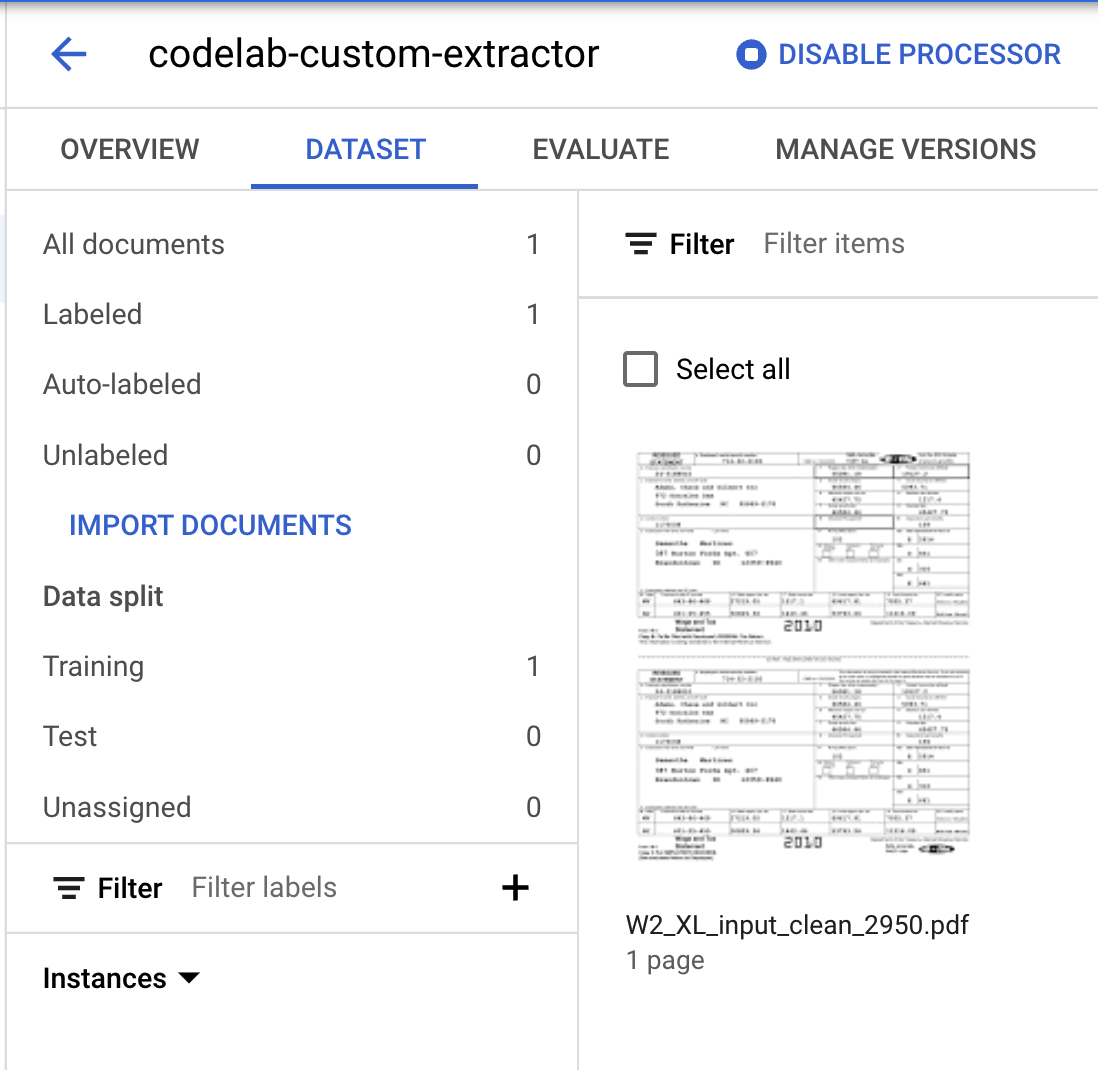
- Zwróć uwagę, że liczby w sekcji Podział danych uległy zmianie.
9. Importowanie wstępnie oznaczonych danych
Niestandardowe procesory Document AI wymagają co najmniej po 10 dokumentów w zbiorach treningowych i testowych oraz po 10 wystąpień każdej etykiety w każdym zbiorze.
Dla uzyskania największej skuteczności zalecamy dodanie do każdego zbioru co najmniej 50 dokumentów oraz 50 wystąpień każdej etykiety. Więcej danych treningowych zwykle oznacza większą dokładność.
Ręczne oznaczanie etykietami wszystkich dokumentów zajmie dużo czasu, dlatego mamy wstępnie oznaczone dokumenty, które możesz zaimportować na potrzeby tego modułu.
Możesz importować wstępnie oznaczone etykietami pliki dokumentów w formacie Document.json. Mogą to być wyniki wywołania procesora i sprawdzenia dokładności za pomocą procesu z udziałem człowieka.
Konflikt między elementem kierowania i wykluczającym elementem kierowania, które róż
UWAGA: podczas importowania wstępnie oznaczonych danych zdecydowanie zalecamy ręczne sprawdzenie adnotacji przed wytrenowaniem modelu.
- Kliknij Importuj dokumenty.
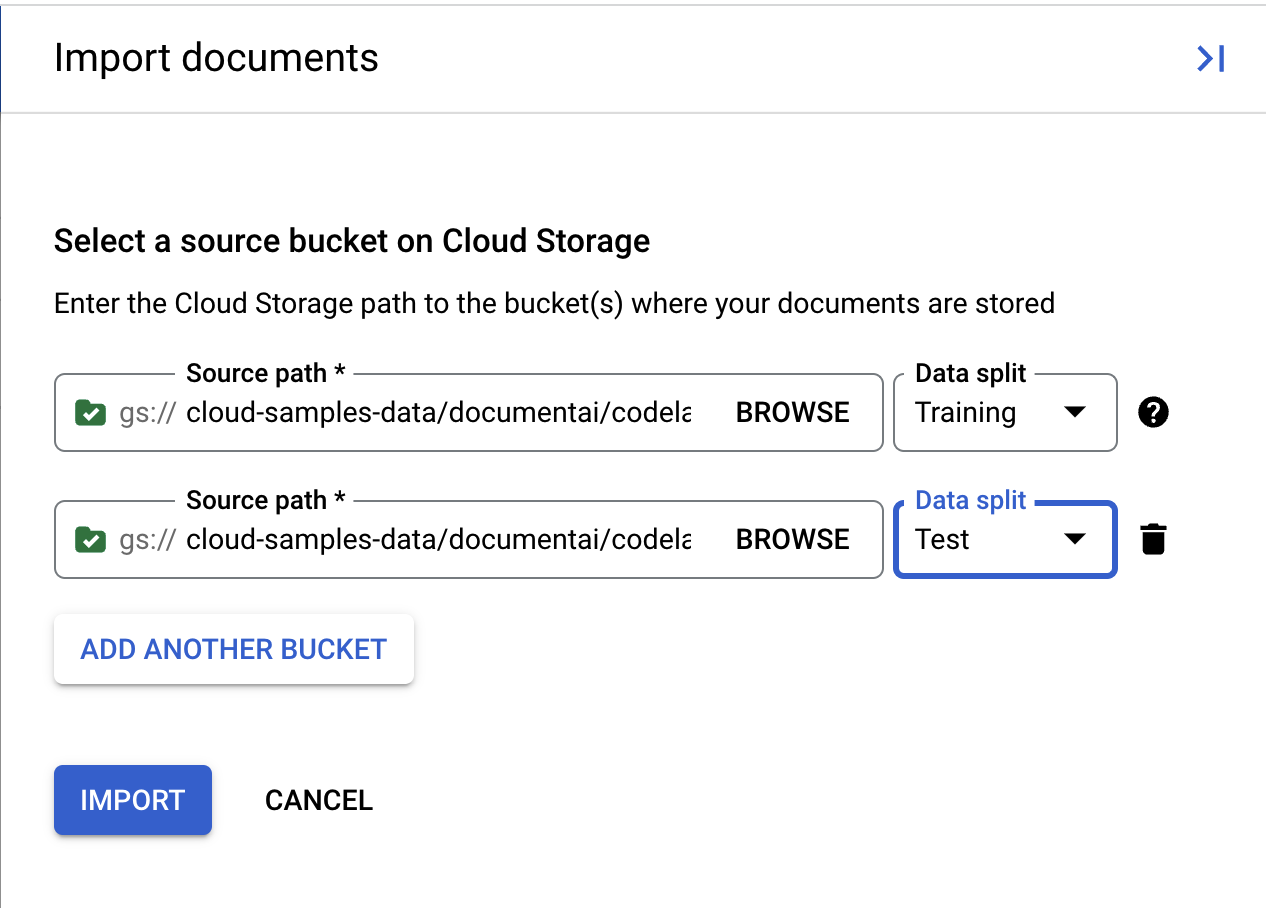
- Skopiuj i wklej tę ścieżkę Cloud Storage i przypisz ją do zbioru Trenowanie.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- Kliknij Dodaj kolejny folder. Następnie skopiuj i wklej tę ścieżkę Cloud Storage i przypisz ją do zbioru Test.
cloud-samples-data/documentai/codelabs/custom/extractor/test
- Kliknij Importuj i poczekaj na zaimportowanie dokumentów. Potrwa to dłużej niż ostatnim razem, ponieważ do przetworzenia jest więcej dokumentów. Powinno to zająć około 6 minut. Możesz opuścić tę stronę i wrócić na nią później.
- Gdy proces się zakończy, dokumenty powinny pojawić się na stronie Trenowanie.
10. Trenowanie modelu
Możemy teraz rozpocząć trenowanie narzędzia Custom Document Extractor.
- Kliknij Wytrenuj nową wersję.
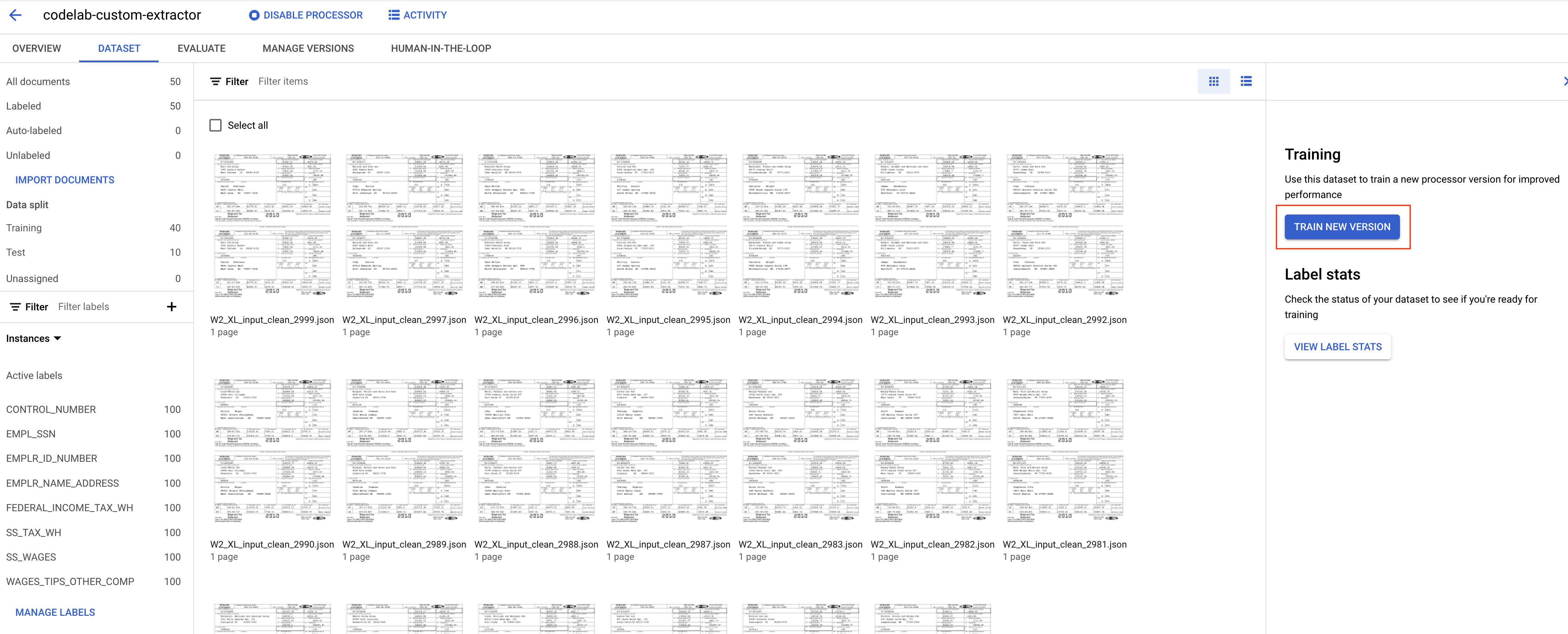
- Nadaj wersji nazwę, którą łatwo zapamiętasz, np.
codelab-custom-1. W sekcji „Metoda trenowania” wybierz „Trenuj od zera”.
- (Opcjonalnie) Możesz też kliknąć Wyświetl statystykę etykiet, aby zobaczyć dane o etykietach w zbiorze danych.
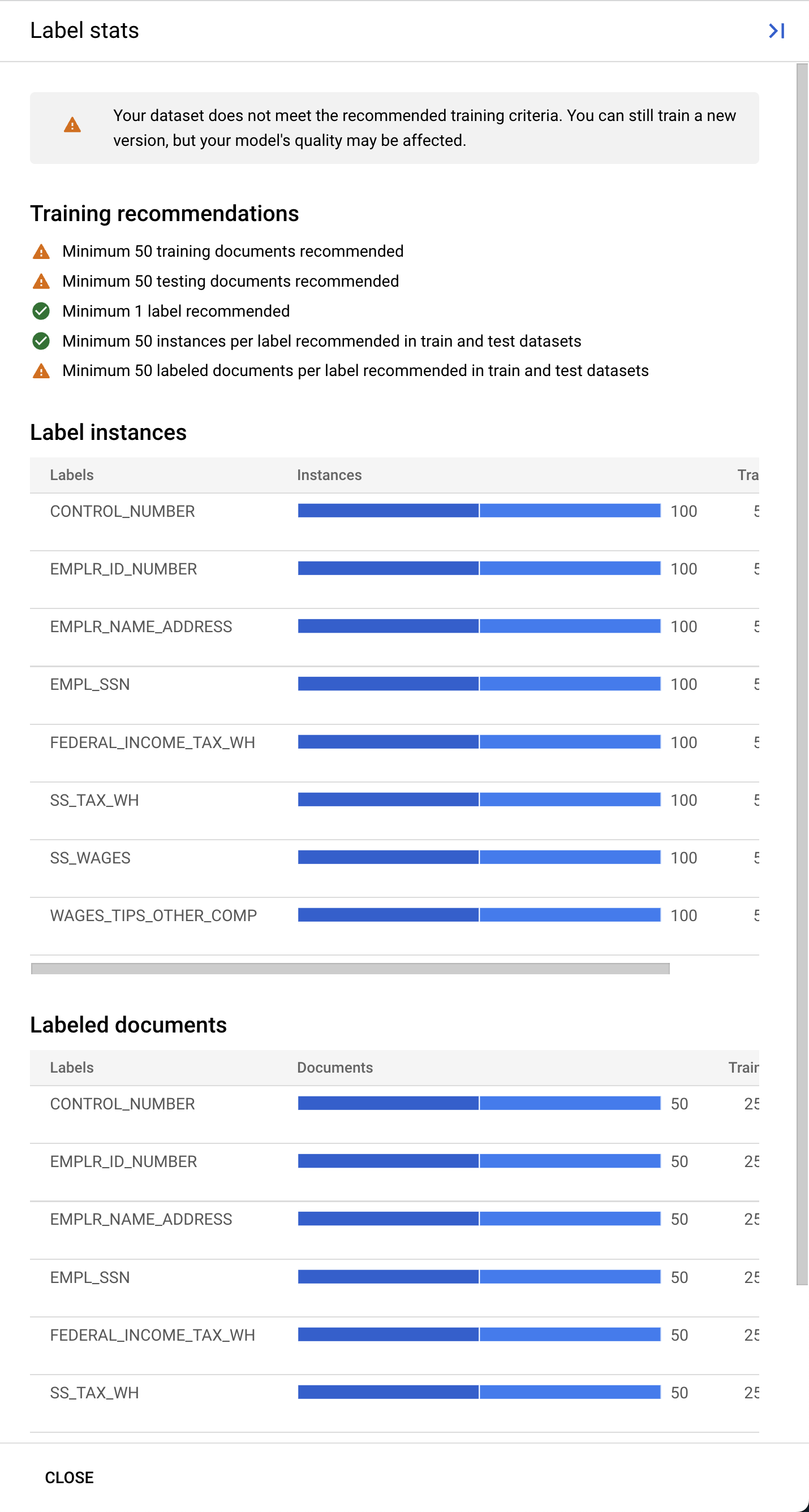
- Aby rozpocząć proces trenowania, kliknij Rozpocznij trenowanie. Powinno nastąpić przekierowanie na stronę Zarządzanie zbiorami danych. Stan trenowania możesz sprawdzić po prawej stronie. Trenowanie potrwa kilka godzin. Możesz opuścić tę stronę i wrócić na nią później.
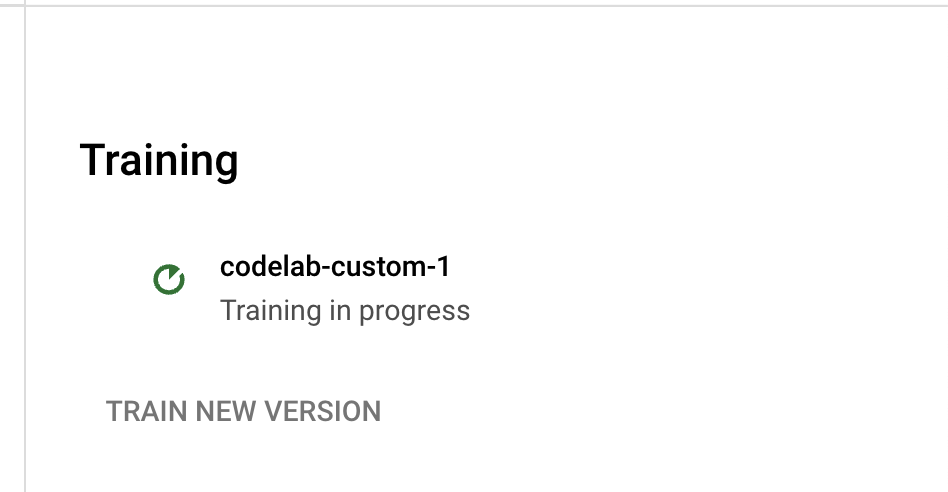
- Jeśli klikniesz nazwę wersji, otworzy się strona Zarządzaj wersjami, na której znajdziesz identyfikator wersji i bieżący stan zadania trenowania.
11. Testowanie nowej wersji modelu
Po zakończeniu zadania trenowania (w moich testach trwało to około godziny) możesz przetestować nową wersję modelu i zacząć używać jej do prognozowania.
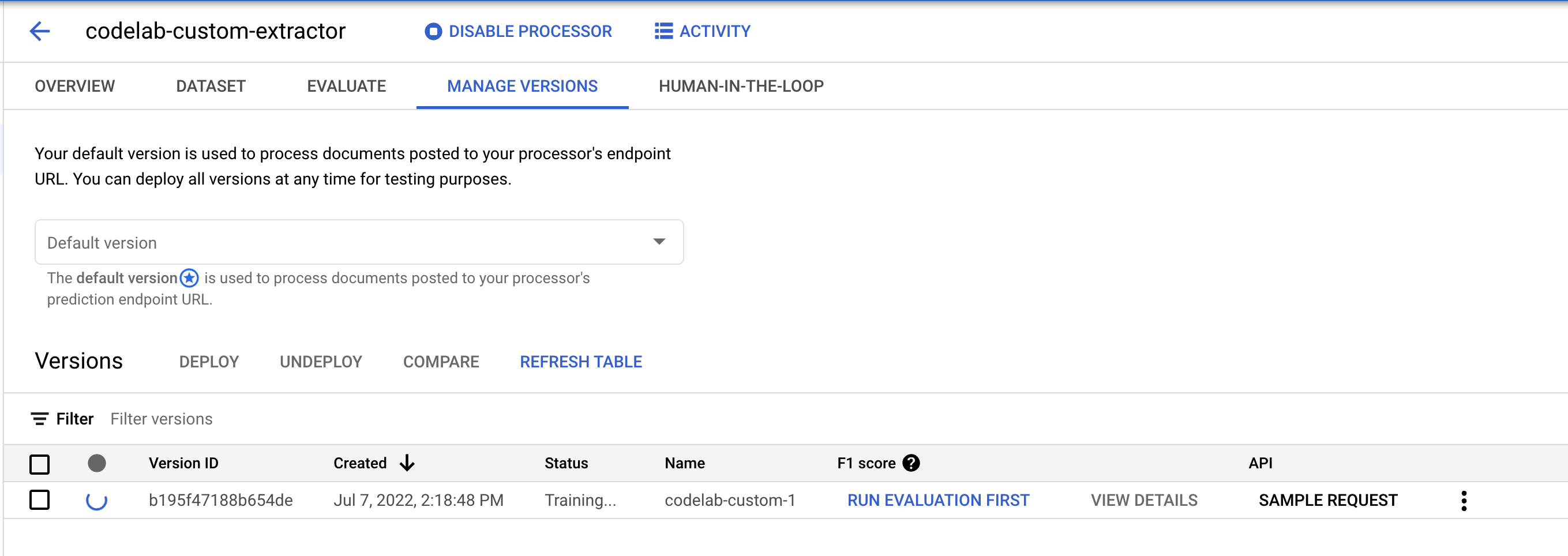
- Otwórz stronę Zarządzanie wersjami. Tutaj możesz sprawdzić aktualny stan i wynik F1.
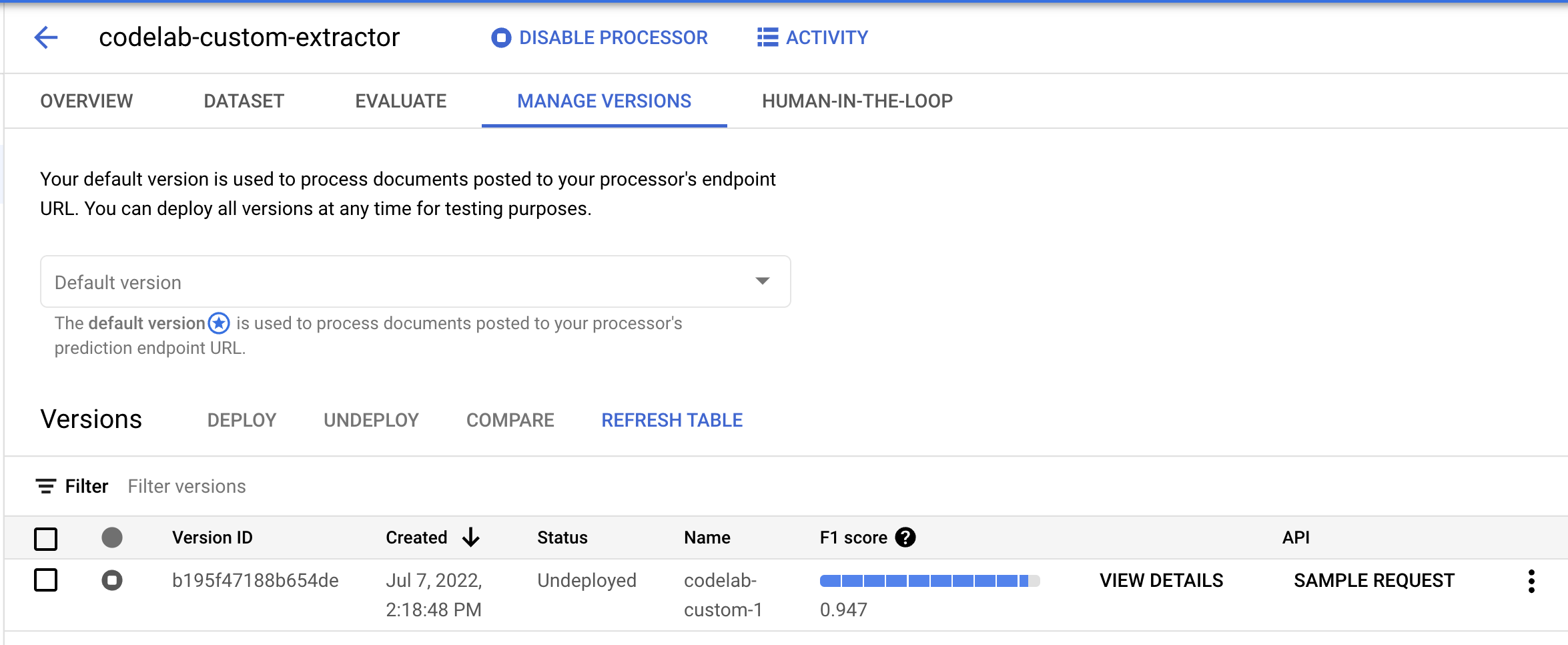
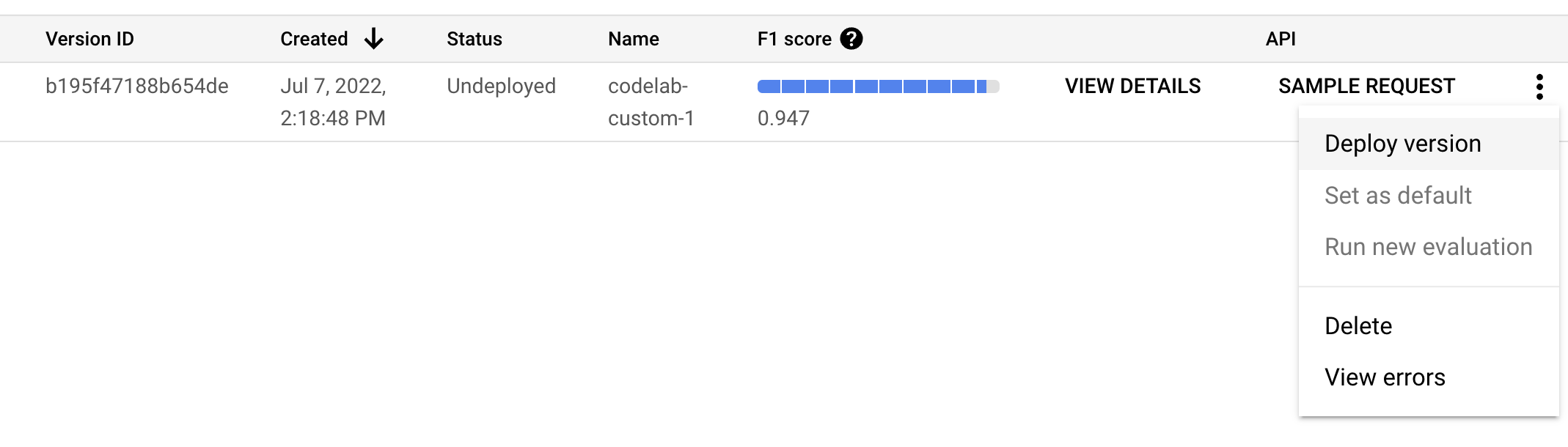
- Aby można było używać tej wersji modelu, musimy ją wdrożyć. Kliknij pionowe kropki po prawej stronie i wybierz Wdróż wersję.
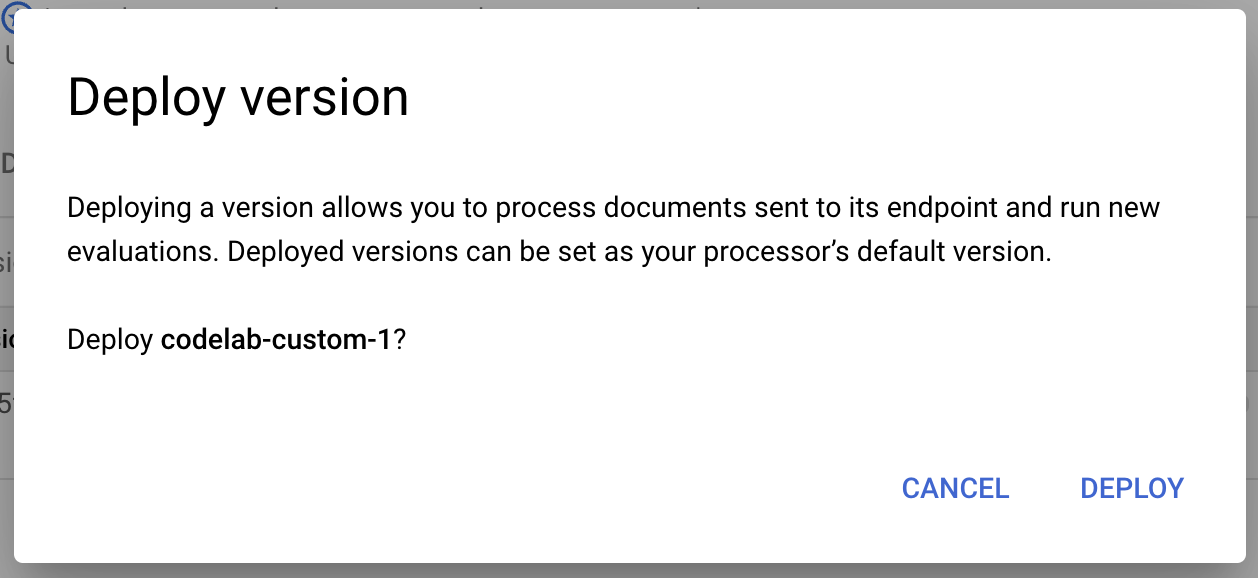
- W wyskakującym okienku kliknij Wdróż i poczekaj, aż wersja zostanie wdrożona. Ich wykonanie może potrwać kilka minut. Po wdrożeniu możesz też ustawić tę wersję jako wersję domyślną.
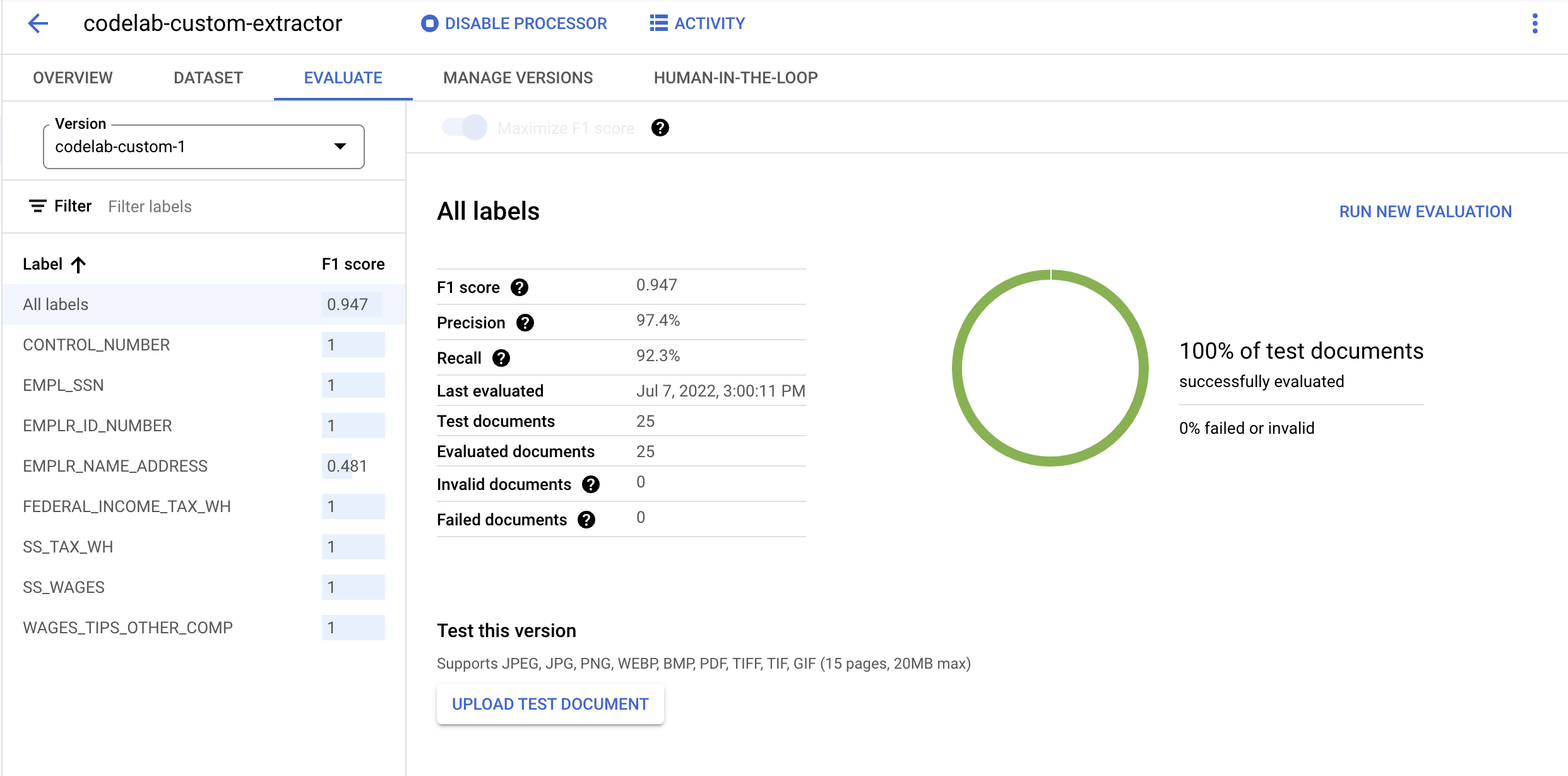
- Po zakończeniu wdrażania otwórz kartę Ocena. Na tej stronie możesz wyświetlić wskaźniki oceny, w tym wynik F1, precyzję i czułość dla całego dokumentu oraz dla poszczególnych etykiet. Więcej informacji o tych danych znajdziesz w dokumentacji AutoML.
- Pobierz plik PDF, do którego link znajdziesz poniżej. Jest to przykładowy formularz W2, który nie został uwzględniony w zbiorze treningowym ani testowym.
- Kliknij Prześlij dokument testowy i wybierz plik PDF.
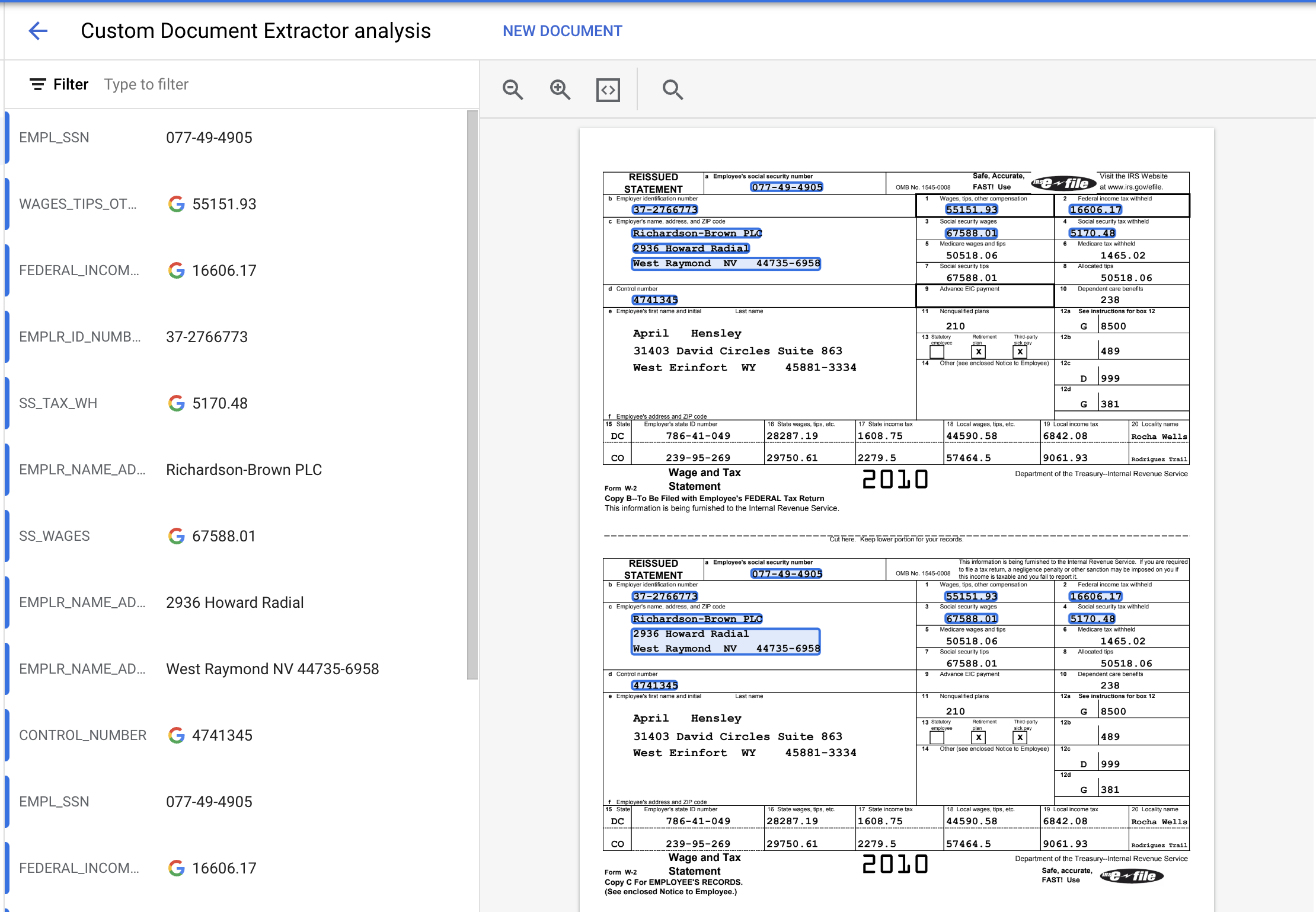
- Wyodrębnione jednostki powinny wyglądać mniej więcej tak:
12. Opcjonalnie: automatyczne dodawanie etykiet do nowo importowanych dokumentów
Po wdrożeniu wytrenowanej wersji procesora możesz skorzystać z automatycznego dodawania etykiet, aby zaoszczędzić czas przy oznaczaniu etykietami podczas importowania nowych dokumentów.
- Na stronie Trenowanie kliknij Importuj dokumenty.
- Skopiuj i wklej tę ścieżkę . Katalog ten zawiera 5 formularzy PDF W-2 bez etykiet. Na liście Podział danych wybierz Trenowanie.
cloud-samples-data/documentai/Custom/W2/AutoLabel - W sekcji Automatyczne dodawanie etykiet zaznacz pole wyboru Import z automatycznym oznaczaniem etykietami.
- Wybierz istniejącą wersję procesora, aby oznaczyć dokumenty etykietami.
- Na przykład:
2af620b2fd4d1fcf
- Kliknij Importuj i poczekaj na zaimportowanie dokumentów. Możesz opuścić tę stronę i wrócić na nią później.
- Gdy proces się zakończy, dokumenty pojawią się na stronie Trenowanie w sekcji Automatycznie oznaczone etykietami.
- Dokumentów automatycznie oznaczonych etykietami nie można używać do trenowania lub testowania, jeśli nie są oznaczone jako dokumenty z etykietami. Aby wyświetlić dokumenty automatycznie oznaczone etykietami, przejdź do sekcji Automatycznie oznaczone etykietami.
- Wybierz pierwszy dokument, aby przejść do konsoli do dodawania etykiet.
- Sprawdź, czy etykiety, ramki ograniczające i wartości są prawidłowe. Dodaj etykiety do wszystkich pominiętych wartości.
- Gdy skończysz, kliknij Oznacz jako oznaczony etykietami.
- Powtórz weryfikację etykiet dla każdego dokumentu automatycznie oznaczonego etykietami, a następnie wróć na stronę Trenowanie, aby wykorzystać dane do trenowania.
13. Podsumowanie
Gratulacje! Udało Ci się wytrenować niestandardowy procesor do wyodrębniania dokumentów za pomocą Document AI. Teraz możesz używać tego procesora do analizowania dokumentów w tym formacie tak samo jak w przypadku każdego procesora specjalistycznego.
Aby dowiedzieć się, jak obsługiwać odpowiedź przetwarzania, zapoznaj się z samouczkiem dotyczącym procesorów specjalistycznych.
Czyszczenie
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym samouczku:
- W Cloud Console otwórz stronę Zarządzanie zasobami.
- Na liście projektów wybierz projekt, a następnie kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
Materiały
- Dokumentacja Document AI Workbench
- Przyszłość dokumentów – playlista w YouTube
- Dokumentacja Document AI
- Biblioteka klienta Document AI w Pythonie
- Przykłady Document AI
Licencja
To zadanie jest licencjonowane na podstawie ogólnej licencji Creative Commons Attribution 2.0.