
1. Genel Bakış
Bu laboratuvarda, Keras ve TensorFlow 2 ile sıfırdan kendi evrişimli sinir ağlarınızı oluşturmayı, eğitmeyi ve ayarlamayı öğreneceksiniz. Bu işlem artık TPU'ların gücüyle dakikalar içinde yapılabiliyor. Ayrıca, çok basit aktarımlı öğrenmeden Squeezenet gibi modern evrişimli mimarilere kadar çeşitli yaklaşımları da keşfedeceksiniz. Bu laboratuvarda, sinir ağlarıyla ilgili teorik açıklamalar yer alır ve derin öğrenme hakkında bilgi edinmek isteyen geliştiriciler için iyi bir başlangıç noktasıdır.
Derin öğrenme makalelerini okumak zor ve kafa karıştırıcı olabilir. Gelin, modern evrişimli nöral ağ mimarilerine yakından bakalım.

Neler öğreneceksiniz?
- Özel modellerinizi daha hızlı oluşturmak için Keras ve Tensor İşleme Birimleri'ni (TPU'lar) kullanabilirsiniz.
- Eğitim verilerini verimli bir şekilde yüklemek için tf.data.Dataset API'yi ve TFRecord biçimini kullanın.
- Kendi modellerinizi oluşturmak yerine transfer öğrenimini kullanarak hile yapmak 😈
- Keras sıralı ve işlevsel model stillerini kullanmak için.
- Softmax katmanı ve çapraz entropi kaybı içeren kendi Keras sınıflandırıcınızı oluşturmak için.
- Modelinizi iyi bir seçimle evrişimli katmanlarla hassas şekilde ayarlamak için.
- Modüller, küresel ortalama havuzlama vb. gibi modern evrişimli ağ mimarisi fikirlerini keşfetmek için
- Squeezenet mimarisini kullanarak basit bir modern evrişimli sinir ağı oluşturmak için.
Geri bildirim
Bu kod laboratuvarında yanlış bir şey görürseniz lütfen bize bildirin. Geri bildirimler GitHub sorunları [geri bildirim bağlantısı] üzerinden gönderilebilir.
2. Google Colaboratory hızlı başlangıç
Bu laboratuvarda Google Collaboratory kullanılır ve sizin tarafınızda herhangi bir kurulum yapılması gerekmez. Uygulamayı Chromebook'ta çalıştırabilirsiniz. Lütfen aşağıdaki dosyayı açın ve Colab not defterlerini tanımak için hücreleri çalıştırın.
TPU arka ucu seçme

Colab menüsünde Çalışma zamanı > Çalışma zamanı türünü değiştir'i ve ardından TPU'yu seçin. Bu kod laboratuvarında, donanım hızlandırmalı eğitim için desteklenen güçlü bir TPU (Tensor İşleme Birimi) kullanacaksınız. Çalışma zamanına bağlantı ilk yürütmede otomatik olarak gerçekleşir veya sağ üst köşedeki "Bağlan" düğmesini kullanabilirsiniz.
Not defteri yürütme
Bir hücreyi tıklayıp Üst Karakter+ENTER tuşlarını kullanarak hücreleri teker teker çalıştırın. Ayrıca Çalışma zamanı > Tümünü çalıştır seçeneğini kullanarak not defterinin tamamını çalıştırabilirsiniz.
İçindekiler

Tüm not defterlerinde içindekiler tablosu bulunur. Sol taraftaki siyah oku kullanarak açabilirsiniz.
Gizli hücreler

Bazı hücrelerde yalnızca başlık gösterilir. Bu, Colab'e özgü bir not defteri özelliğidir. İçindeki kodu görmek için bunları çift tıklayabilirsiniz ancak genellikle çok ilginç değildir. Genellikle destek veya görselleştirme işlevleri. İçindeki işlevlerin tanımlanması için bu hücreleri çalıştırmanız gerekir.
Kimlik doğrulama

Colab, yetkili bir hesapla kimliğinizi doğruladığınız sürece özel Google Cloud Storage paketlerinize erişebilir. Yukarıdaki kod snippet'i bir kimlik doğrulama sürecini tetikleyecektir.
3. [INFO] Tensor İşleme Birimleri (TPU'lar) nedir?
Özet

Keras'ta TPU üzerinde model eğitme (TPU yoksa GPU veya CPU'ya geri dönme) kodu:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Bugün, etkileşimli hızlarda (eğitim çalıştırması başına dakika) bir çiçek sınıflandırıcı oluşturmak ve optimize etmek için TPU'ları kullanacağız.

Neden TPU'lar?
Modern GPU'lar, programlanabilir "çekirdekler" etrafında düzenlenir. Bu çekirdekler, 3D oluşturma, derin öğrenme ve fiziksel simülasyon gibi çeşitli görevleri yerine getirmelerini sağlayan çok esnek bir mimaridir. TPU'lar ise klasik bir vektör işlemcisini özel bir matris çarpma birimiyle eşleştirir ve büyük matris çarpımlarının baskın olduğu tüm görevlerde (ör. sinir ağları) üstün performans gösterir.

Resim: Bir matris çarpımı olarak yoğun bir nöral ağ katmanı. Nöral ağda aynı anda işlenen sekiz görüntülük bir toplu işlem. Bir resmin tüm piksel değerlerinin ağırlıklı toplamını gerçekten yaptığını doğrulamak için lütfen bir satır x sütun çarpımı yapın. Evrişimli katmanlar, biraz daha karmaşık olsa da matris çarpımları olarak da gösterilebilir ( 1. bölümdeki açıklama).
Donanım
MXU ve VPU
TPU v2 çekirdeği, matris çarpımlarını çalıştıran bir Matris Çarpma Birimi (MXU) ve etkinleştirme, softmax vb. gibi diğer tüm görevler için bir Vektör İşleme Birimi'nden (VPU) oluşur. VPU, float32 ve int32 hesaplamalarını işler. Diğer yandan MXU, karma hassasiyetli 16-32 bit kayan nokta biçiminde çalışır.

Karma kesinlikli kayan nokta ve bfloat16
MXU, bfloat16 girişlerini ve float32 çıkışlarını kullanarak matris çarpımlarını hesaplar. Ara biriktirmeler, float32 hassasiyetinde gerçekleştirilir.

Nöral ağ eğitimi genellikle azaltılmış kayan nokta duyarlılığının neden olduğu gürültüye karşı dirençlidir. Gürültünün, optimize edicinin yakınlaşmasına yardımcı olduğu durumlar da vardır. Hesaplamaları hızlandırmak için geleneksel olarak 16 bit kayan nokta duyarlılığı kullanılmıştır ancak float16 ve float32 biçimlerinin aralıkları çok farklıdır. Hassasiyeti float32'den float16'ya düşürmek genellikle taşma ve eksik akışa neden olur. Çözümler mevcuttur ancak genellikle float16'nın çalışması için ek çalışma gerekir.
Bu nedenle Google, TPU'larda bfloat16 biçimini kullanıma sundu. bfloat16, float32 ile tam olarak aynı üs bitlerine ve aralığa sahip, kısaltılmış bir float32'dir. Bu durum, TPU'ların bfloat16 girişleri ve float32 çıkışlarıyla karma duyarlılıkta matris çarpımlarını hesaplamasıyla birleştiğinde, genellikle duyarlılığın azaltılmasının performans kazançlarından yararlanmak için kodda değişiklik yapılması gerekmediği anlamına gelir.
Sistolik dizi
MXU, veri öğelerinin bir donanım hesaplama birimleri dizisinden aktığı "sistolik dizi" adı verilen bir mimari kullanarak donanımda matris çarpımlarını uygular. (Tıpta "sistolik", kalp kasılmaları ve kan akışı anlamına gelir. Burada ise veri akışı anlamında kullanılmıştır.)
Matris çarpımının temel öğesi, bir matristeki satır ile diğer matristeki sütun arasındaki nokta çarpımıdır (bu bölümün üst kısmındaki resmi inceleyin). Y=X*W matris çarpımı için sonucun bir öğesi şu şekilde olur:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Bir GPU'da bu nokta çarpımı bir GPU "çekirdeğine" programlanır ve ardından sonuç matrisinin her değerini aynı anda hesaplamak için paralel olarak mümkün olduğunca çok "çekirdekte" yürütülür. Ortaya çıkan matris 128x128 boyutunda olursa 128x128=16 bin "çekirdek" gerekir. Bu da genellikle mümkün değildir. En büyük GPU'larda yaklaşık 4.000 çekirdek bulunur. Diğer yandan TPU, MXU'daki işlem birimleri için en az miktarda donanım kullanır: yalnızca bfloat16 x bfloat16 => float32 çarpma-toplama birimi. Bu birimler o kadar küçüktür ki bir TPU, 128x128 MXU'da 16.000 birim uygulayabilir ve bu matris çarpımını tek seferde işleyebilir.

Resim: MXU sistolik dizisi. İşlem öğeleri, çarpma-toplama birimleridir. Bir matrisin değerleri diziye yüklenir (kırmızı noktalar). Diğer matrisin değerleri diziden akar (gri noktalar). Dikey çizgiler, değerleri yukarı doğru yayar. Yatay çizgiler, kısmi toplamları yayar. Veriler diziden geçerken sağ tarafta matris çarpımı sonucunu aldığınızı doğrulama işlemi kullanıcıya bırakılmıştır.
Buna ek olarak, skaler çarpımlar bir MXU'da hesaplanırken ara toplamlar yalnızca bitişik işlem birimleri arasında akar. Bu değerlerin bellekte veya bir kayıt dosyasında saklanması ve alınması gerekmez. Sonuç olarak, TPU sistolik dizi mimarisi, matris çarpımları hesaplanırken GPU'ya kıyasla önemli bir yoğunluk ve güç avantajının yanı sıra göz ardı edilemeyecek bir hız avantajına sahiptir.
Cloud TPU
Google Cloud Platform'da bir "Cloud TPU v2" istediğinizde, PCI'ye bağlı bir TPU kartı olan bir sanal makine (VM) elde edersiniz. TPU kartında dört adet çift çekirdekli TPU çipi bulunur. Her TPU çekirdeğinde bir VPU (Vektör İşleme Birimi) ve 128x128 MXU (MatriX Çarpma Birimi) bulunur. Bu "Cloud TPU" daha sonra genellikle ağ üzerinden bunu isteyen sanal makineye bağlanır. Dolayısıyla, resmin tamamı şu şekilde görünür:

Resim: Ağa bağlı "Cloud TPU" hızlandırıcıya sahip sanal makineniz. "Cloud TPU"nun kendisi, üzerinde dört çift çekirdekli TPU çipi bulunan, PCI ile bağlı bir TPU kartı olan bir sanal makineden oluşur.
TPU pod'ları
Google'ın veri merkezlerinde TPU'lar, yüksek performanslı bilgi işlem (HPC) ara bağlantısına bağlanır. Bu bağlantı, TPU'ların tek bir çok büyük hızlandırıcı gibi görünmesini sağlayabilir. Google bunlara kapsül adını verir ve 512 TPU v2 çekirdeği veya 2.048 TPU v3 çekirdeği içerebilirler.

Resim: TPU v3 kapsülü. HPC ara bağlantısı üzerinden bağlanmış TPU kartları ve rafları.
Eğitim sırasında, tümünü azaltma algoritması kullanılarak TPU çekirdekleri arasında gradyanlar değiştirilir ( Tümünü azaltma algoritmasıyla ilgili iyi bir açıklama için burayı tıklayın). Eğitilen model, büyük toplu iş boyutlarında eğitim yaparak donanımdan yararlanabilir.

Resim: Google TPU'nun 2 boyutlu toroidal örgü HPC ağında all-reduce algoritması kullanılarak eğitim sırasında gradyanların senkronizasyonu.
Yazılım
Büyük grup boyutu eğitimi
TPU'lar için ideal grup boyutu, TPU çekirdeği başına 128 veri öğesidir ancak donanım, TPU çekirdeği başına 8 veri öğesiyle de iyi bir kullanım gösterebilir. Bir Cloud TPU'nun 8 çekirdeği olduğunu unutmayın.
Bu kod laboratuvarında Keras API'yi kullanacağız. Keras'ta belirttiğiniz grup boyutu, tüm TPU için genel grup boyutudur. Gruplarınız otomatik olarak 8'e bölünür ve TPU'nun 8 çekirdeğinde çalıştırılır.

Ek performans ipuçları için TPU Performans Kılavuzu'na bakın. Çok büyük toplu boyutlar için bazı modellerde özel dikkat gerekebilir. Daha fazla bilgi için LARSOptimizer'a bakın.
Perde arkası: XLA
TensorFlow programları, hesaplama grafiklerini tanımlar. TPU, Python kodunu doğrudan çalıştırmaz. Tensorflow programınız tarafından tanımlanan hesaplama grafiğini çalıştırır. Arka planda, XLA (Hızlandırılmış Doğrusal Cebir derleyicisi) adlı bir derleyici, hesaplama düğümlerinin TensorFlow grafiğini TPU makine diline dönüştürür. Bu derleyici, kodunuzda ve bellek düzeninizde birçok gelişmiş optimizasyon da gerçekleştirir. Derleme, iş TPU'ya gönderilirken otomatik olarak gerçekleşir. XLA'yı derleme zincirinize açıkça dahil etmeniz gerekmez.

Resim: Tensorflow programınız tarafından tanımlanan hesaplama grafiğinin TPU'da çalıştırılması için önce XLA (hızlandırılmış doğrusal cebir derleyicisi) gösterimine çevrilir, ardından XLA tarafından TPU makine koduna derlenir.
Keras'ta TPU'ları kullanma
Tensorflow 2.1'den itibaren TPU'lar Keras API üzerinden desteklenir. Keras desteği, TPU'larda ve TPU kapsüllerinde çalışır. TPU, GPU ve CPU'da çalışan bir örneği aşağıda bulabilirsiniz:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Bu kod snippet'inde:
TPUClusterResolver().connect(), ağdaki TPU'yu bulur. Çoğu Google Cloud sisteminde (AI Platform işleri, Colaboratory, Kubeflow, "ctpu up" yardımcı programı aracılığıyla oluşturulan Deep Learning VM'leri) parametre olmadan çalışır. Bu sistemler, TPU_NAME ortam değişkeni sayesinde TPU'larının nerede olduğunu bilir. TPU'yu manuel olarak oluşturursanız TPU_NAME ortam değişkenini kullandığınız sanal makinede ayarlayın veyaTPUClusterResolverişlevini açık parametrelerle çağırın:TPUClusterResolver(tp_uname, zone, project)TPUStrategy, dağıtımı ve "all-reduce" gradyan senkronizasyon algoritmasını uygulayan kısımdır.- Strateji, bir kapsam aracılığıyla uygulanır. Model, strategy scope() içinde tanımlanmalıdır.
tpu_model.fitişlevi, TPU eğitimi için giriş olarak bir tf.data.Dataset nesnesi bekler.
Sık kullanılan TPU taşıma görevleri
- TensorFlow modeline veri yüklemenin birçok yolu olsa da TPU'larda
tf.data.DatasetAPI'sinin kullanılması gerekir. - TPU'lar çok hızlıdır ve bunlar üzerinde çalışırken veri alımı genellikle darboğaz haline gelir. TPU Performans Kılavuzu'nda, veri darboğazlarını tespit etmek için kullanabileceğiniz araçlar ve diğer performans ipuçları yer almaktadır.
- int8 veya int16 sayıları int32 olarak kabul edilir. TPU, 32 bit'ten daha az bit üzerinde çalışan tam sayı donanımına sahip değildir.
- Bazı TensorFlow işlemleri desteklenmez. Listeyi burada bulabilirsiniz. Bu sınırlamanın yalnızca eğitim kodu (yani modelinizdeki ileri ve geri geçiş) için geçerli olduğunu belirtmek isteriz. CPU'da yürütüleceği için veri girişi ardışık düzeninizde tüm TensorFlow işlemlerini kullanmaya devam edebilirsiniz.
tf.py_func, TPU'da desteklenmez.
4. Veriler yükleniyor






Çiçek resimlerinden oluşan bir veri kümesiyle çalışacağız. Amaç, bu çiçekleri 5 farklı türde sınıflandırmayı öğrenmektir. Veri yükleme işlemi tf.data.Dataset API kullanılarak gerçekleştirilir. Öncelikle API'yi tanıyalım.
Uygulamalı
Lütfen aşağıdaki not defterini açın, hücreleri çalıştırın (Shift-ENTER) ve "ÇALIŞMA GEREKLİ" etiketini gördüğünüz her yerde talimatları uygulayın.

Fun with tf.data.Dataset (playground).ipynb
Ek bilgiler
"Çiçekler" veri kümesi hakkında
Veri kümesi 5 klasör halinde düzenlenir. Her klasörde tek bir türden çiçekler bulunur. Klasörler ayçiçeği, papatya, karahindiba, lale ve gül olarak adlandırılıyor. Veriler, Google Cloud Storage'daki herkese açık bir pakette barındırılır. Alıntı:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Neden tf.data.Dataset?
Keras ve TensorFlow, tüm eğitim ve değerlendirme işlevlerinde veri kümelerini kabul eder. Bir veri kümesine veri yüklediğinizde API, sinir ağı eğitim verileri için yararlı olan tüm yaygın işlevleri sunar:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
Performans ipuçlarını ve veri kümesiyle ilgili en iyi uygulamaları bu makalede bulabilirsiniz. Referans belgelerini burada bulabilirsiniz.
tf.data.Dataset basics
Veriler genellikle birden fazla dosya halinde gelir. Burada resimler gösterilmektedir. Aşağıdaki işlevi çağırarak dosya adlarından oluşan bir veri kümesi oluşturabilirsiniz:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Ardından, her dosya adına bir işlev "eşlersiniz". Bu işlev genellikle dosyayı yükleyip bellekteki gerçek verilere dönüştürür:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
Veri kümesi üzerinde yineleme yapmak için:
for data in my_dataset:
print(data)
Demet veri kümeleri
Denetimli öğrenmede, eğitim veri kümesi genellikle eğitim verileri ve doğru yanıtlardan oluşan çiftlerden oluşur. Buna izin vermek için kod çözme işlevi demetler döndürebilir. Daha sonra, demetlerden oluşan bir veri kümeniz olur ve bu veri kümesi üzerinde yineleme yaptığınızda demetler döndürülür. Döndürülen değerler, modeliniz tarafından kullanılmaya hazır Tensorflow tensörleridir. Ham değerleri görmek için .numpy() işlevini kullanabilirsiniz:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Sonuç:Görüntüleri tek tek yüklemek yavaştır.
Bu veri kümesinde iterasyon yaptığınızda saniyede 1-2 görüntü yükleyebildiğinizi görürsünüz. Bu çok yavaş! Eğitim için kullanacağımız donanım hızlandırıcılar bu oranın çok üzerinde bir hıza dayanabilir. Bunu nasıl yapacağımızı görmek için sonraki bölüme geçin.
Çözüm
Çözüm not defterini burada bulabilirsiniz. Takılırsanız bu özelliği kullanabilirsiniz.
Fun with tf.data.Dataset (solution).ipynb
İşlediğimiz konular
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Demet veri kümeleri
- 😀 Veri kümelerinde yineleme
Lütfen bu kontrol listesini zihninizde gözden geçirin.
5. Verileri hızlı yükleme
Bu laboratuvarda kullanacağımız Tensor İşleme Birimi (TPU) donanım hızlandırıcıları çok hızlıdır. Genellikle bu modelleri meşgul edecek kadar hızlı veri sağlamak zorlu bir görevdir. Google Cloud Storage (GCS), çok yüksek gönderim hacmini destekleyebilir ancak tüm bulut depolama sistemlerinde olduğu gibi bağlantı başlatmak için ağda gidiş geliş gerekir. Bu nedenle, verilerimizin binlerce ayrı dosya olarak saklanması ideal değildir. Bu dosyaları daha az sayıda dosyada gruplandıracağız ve tf.data.Dataset'in gücünü kullanarak birden fazla dosyayı paralel olarak okuyacağız.
Read-through
Resim dosyalarını yükleyen, bunları ortak bir boyuta yeniden boyutlandıran ve ardından 16 TFRecord dosyasına depolayan kod aşağıdaki not defterinde yer almaktadır. Lütfen hızlıca okuyun. TFRecord biçiminde düzgün şekilde biçimlendirilmiş veriler, codelab'in geri kalanı için sağlanacağından bu işlemi yürütmek gerekli değildir.
Flower pictures to TFRecords.ipynb
Optimum GCS işleme hızı için ideal veri düzeni
TFRecord dosya biçimi
Tensorflow'un veri depolamak için tercih ettiği dosya biçimi, protobuf tabanlı TFRecord biçimidir. Diğer serileştirme biçimleri de kullanılabilir ancak TFRecord dosyalarından doğrudan veri kümesi yüklemek için şunu yazabilirsiniz:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
En iyi performans için aynı anda birden fazla TFRecord dosyasından okumak üzere aşağıdaki daha karmaşık kodu kullanmanız önerilir. Bu kod, N dosyayı paralel olarak okur ve okuma hızı için veri sırasını dikkate almaz.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
TFRecord yardımcı kısa bilgileri
TFRecord'larda üç tür veri depolanabilir: bayt dizeleri (bayt listesi), 64 bit tam sayılar ve 32 bit kayan sayılar. Bunlar her zaman liste olarak depolanır. Tek bir veri öğesi, boyutu 1 olan bir liste olur. Verileri TFRecord'lara depolamak için aşağıdaki yardımcı işlevleri kullanabilirsiniz.
bayt dizeleri yazma
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
tam sayıları yazma
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
yazı kaydırma
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
Yukarıdaki yardımcıları kullanarak TFRecord yazma
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
TFRecord'lardan veri okumak için öncelikle depoladığınız kayıtların düzenini bildirmeniz gerekir. Bildirimde, adlandırılmış alanlara sabit uzunluklu liste veya değişken uzunluklu liste olarak erişebilirsiniz:
TFRecord'lardan okuma
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Faydalı kod snippet'leri:
tek veri öğelerini okuma
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
sabit boyutlu öğe listelerini okuma
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
değişken sayıda veri öğesi okuma
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
VarLenFeature, seyrek bir vektör döndürür ve TFRecord'un kodu çözüldükten sonra ek bir adım gerekir:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
TFRecord'larda isteğe bağlı alanlar da olabilir. Bir alanı okurken varsayılan değer belirtirseniz alan eksikse hata yerine varsayılan değer döndürülür.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
İşlediğimiz konular
- 🤔 GCS'den hızlı erişim için veri dosyalarını parçalama
- 😓 TFRecord'ları yazma (Söz dizimini unuttunuz mu? Sorun değil, bu sayfayı yardımcı kısa bilgiler olarak işaretleyin)
- 🤔 TFRecordDataset kullanarak TFRecord'lardan bir veri kümesi yükleme
Lütfen bu kontrol listesini zihninizde gözden geçirin.
6. [INFO] Nöral ağ sınıflandırıcı 101
Özet
Bir sonraki paragraftaki kalın harflerle yazılmış tüm terimleri biliyorsanız bir sonraki alıştırmaya geçebilirsiniz. Derin öğrenmeye yeni başlıyorsanız hoş geldiniz. Lütfen okumaya devam edin.
Keras, katman dizisi olarak oluşturulan modeller için Sequential API'yi sunar. Örneğin, üç yoğun katman kullanan bir görüntü sınıflandırıcı, Keras'ta şu şekilde yazılabilir:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Yoğun nöral ağ
Bu, görüntüleri sınıflandırmak için kullanılan en basit nöral ağdır. Katmanlar halinde düzenlenmiş "nöronlardan" oluşur. İlk katman, giriş verilerini işler ve çıkışlarını diğer katmanlara aktarır. Her nöron önceki katmandaki tüm nöronlara bağlı olduğundan bu katmana "yoğun" adı verilir.

Tüm piksellerinin RGB değerlerini uzun bir vektör haline getirip giriş olarak kullanarak bu tür bir ağa resim besleyebilirsiniz. Bu, görüntü tanıma için en iyi teknik olmasa da daha sonra iyileştirilecektir.
Nöronlar, etkinleştirmeler, RELU
Bir "nöron", tüm girişlerinin ağırlıklı toplamını hesaplar, "bias" adı verilen bir değer ekler ve sonucu "aktivasyon işlevi" olarak adlandırılan bir işlev aracılığıyla besler. Ağırlıklar ve önyargı ilk başta bilinmez. Bu ağırlıklar rastgele başlatılır ve nöral ağın çok sayıda bilinen veri üzerinde eğitilmesiyle "öğrenilir".

En popüler etkinleştirme işlevine Doğrusal Birimi Düzeltilmiş (Rectified Linear Unit) anlamına gelen RELU adı verilir. Yukarıdaki grafikte de görebileceğiniz gibi, bu çok basit bir fonksiyondur.
Softmax etkinleştirme
Çiçekleri 5 kategoriye (gül, lale, karahindiba, papatya, ayçiçeği) ayırdığımız için yukarıdaki ağ 5 nöronlu bir katmanla sona eriyor. Ara katmanlardaki nöronlar, klasik RELU etkinleştirme işlevi kullanılarak etkinleştirilir. Ancak son katmanda, bu çiçeğin gül, lale vb. olma olasılığını temsil eden 0 ile 1 arasındaki sayıları hesaplamak istiyoruz. Bunun için "softmax" adlı bir etkinleştirme işlevini kullanacağız.
Bir vektöre softmax uygulamak için her öğenin üstel değeri alınır ve ardından vektör normalleştirilir. Genellikle değerlerin toplamı 1 olacak ve olasılık olarak yorumlanabilecek şekilde L1 normu (mutlak değerlerin toplamı) kullanılır.


Çapraz entropi kaybı (Cross-entropy loss)
Sinir ağımız artık giriş resimlerinden tahminler ürettiğine göre, bu tahminlerin ne kadar iyi olduğunu (yani ağın bize söyledikleri ile doğru cevaplar arasındaki mesafeyi) ölçmemiz gerekiyor. Bu mesafeye genellikle "etiketler" adı verilir. Veri kümesindeki tüm resimler için doğru etiketlere sahip olduğumuzu unutmayın.
Herhangi bir mesafe işe yarar ancak sınıflandırma sorunları için "çapraz entropi mesafesi" olarak adlandırılan mesafe en etkili olanıdır. Buna hata veya "kayıp" işlevimiz diyeceğiz:

Gradyan inişi
Nöral ağı "eğitmek" aslında çapraz entropi kayıp fonksiyonunu en aza indirmek için ağırlıkları ve önyargıları ayarlamak üzere eğitim resimlerini ve etiketlerini kullanmak anlamına gelir. İşleyiş şekli şöyledir:
Çapraz entropi, ağırlıkların, önyargıların, eğitim görüntüsünün piksellerinin ve bilinen sınıfının bir fonksiyonudur.
Çapraz entropinin tüm ağırlıklar ve tüm sapmalarla ilgili kısmi türevlerini hesaplarsak belirli bir resim, etiket ve ağırlıkların ve sapmaların mevcut değeri için hesaplanan bir "gradyan" elde ederiz. Milyonlarca ağırlık ve önyargı olabileceği için gradyanı hesaplamanın çok fazla iş gerektireceğini unutmayın. Neyse ki Tensorflow bunu bizim için yapar. Bir gradyanın matematiksel özelliği "yukarı"yı göstermesidir. Çapraz entropinin düşük olduğu yere gitmek istediğimiz için ters yönde ilerliyoruz. Ağırlıkları ve önyargıları gradyanın bir kısmı kadar güncelleriz. Ardından, eğitim döngüsünde bir sonraki eğitim resimleri ve etiket gruplarını kullanarak aynı işlemi tekrar tekrar yaparız. Bu işlemin, çapraz entropinin minimum olduğu bir noktada birleşeceği umulur ancak bu minimum değerin benzersiz olacağı garanti edilmez.

Mini toplu işleme ve momentum
Gradyanınızı yalnızca bir örnek resim üzerinde hesaplayıp ağırlıkları ve önyargıları hemen güncelleyebilirsiniz. Ancak bunu örneğin 128 resimlik bir grup üzerinde yapmak, farklı örnek resimlerin getirdiği kısıtlamaları daha iyi temsil eden bir gradyan sağlar ve bu nedenle çözüme daha hızlı ulaşma olasılığı daha yüksektir. Mini toplu işin boyutu ayarlanabilir bir parametredir.
Bazen "stokastik gradyan inişi" olarak da adlandırılan bu tekniğin daha pratik bir faydası vardır: Gruplarla çalışmak, daha büyük matrislerle çalışmak anlamına da gelir ve bunlar genellikle GPU'larda ve TPU'larda optimize edilmesi daha kolaydır.
Ancak yakınsama yine de biraz kaotik olabilir ve gradyan vektörü tamamen sıfırsa durabilir. Bu, minimum bir değer bulduğumuz anlamına mı geliyor? Her zaman değil Bir gradyan bileşeni, minimum veya maksimumda sıfır olabilir. Milyonlarca öğeden oluşan bir gradyan vektöründe, tüm öğeler sıfırsa her sıfırın bir minimuma ve hiçbirinin bir maksimum noktaya karşılık gelme olasılığı oldukça düşüktür. Çok boyutlu bir uzayda eyer noktaları oldukça yaygındır ve bu noktalarda durmak istemeyiz.

Resim: Eyer noktası. Eğim 0'dır ancak tüm yönlerde minimum değildir. (Resim ilişkilendirmesi Wikimedia: Nicoguaro - Own work, CC BY 3.0)
Çözüm, optimizasyon algoritmasına biraz ivme kazandırmaktır. Böylece algoritma, durmadan eyer noktalarını geçebilir.
Sözlük
Grup veya mini grup: Eğitim her zaman eğitim verisi grupları ve etiketleri üzerinde gerçekleştirilir. Bu sayede algoritmanın yakınlaşmasına yardımcı olursunuz. "Toplu iş" boyutu genellikle veri tensörlerinin ilk boyutudur. Örneğin, [100, 192, 192, 3] şeklindeki bir tensör, piksel başına üç değer (RGB) içeren 192x192 piksellik 100 resim içerir.
Çapraz entropi kaybı: Sınıflandırıcılarda sıklıkla kullanılan özel bir kayıp işlevi.
Yoğun katman: Her nöronun önceki katmandaki tüm nöronlara bağlı olduğu bir nöron katmanı.
Özellikler: Nöral ağın girişlerine bazen "özellikler" denir. İyi tahminler elde etmek için bir veri kümesinin hangi bölümlerinin (veya bölüm kombinasyonlarının) bir nöral ağa besleneceğini belirleme sanatına "özellik mühendisliği" adı verilir.
Etiketler: Denetimli sınıflandırma sorununda "sınıflar" veya doğru yanıtlar için kullanılan başka bir ad
Öğrenme hızı: Ağırlıkların ve yanlılıkların eğitim döngüsünün her yinelemesinde güncellendiği gradyanın kesri.
logits: Bir nöron katmanının, etkinleştirme işlevi uygulanmadan önceki çıkışlarına "logits" adı verilir. Bu terim, bir zamanlar en popüler etkinleştirme işlevi olan "sigmoid işlevi" olarak da bilinen "lojistik işlev"den gelir. "Neuron outputs before logistic function" (Lojistik işlevden önceki nöron çıkışları) ifadesi "logits" (logitler) olarak kısaltıldı.
kayıp (loss): Nöral ağ çıkışlarını doğru cevaplarla karşılaştıran hata işlevi
Nöron: Girişlerinin ağırlıklı toplamını hesaplar, bir önyargı ekler ve sonucu bir etkinleştirme işlevinden geçirir.
One-hot kodlama: 5 sınıftan 3. sınıf, 5 öğeli bir vektör olarak kodlanır. 3. öğe 1 olmak üzere diğer tüm öğeler sıfırdır.
relu: doğrultulmuş doğrusal birim. Nöronlar için popüler bir etkinleştirme işlevi.
sigmoid: Bir zamanlar popüler olan ve özel durumlarda hâlâ kullanışlı olan başka bir etkinleştirme işlevi.
softmax: Bir vektör üzerinde işlem yapan, en büyük bileşen ile diğer tüm bileşenler arasındaki farkı artıran ve aynı zamanda vektörü olasılık vektörü olarak yorumlanabilmesi için toplamı 1 olacak şekilde normalleştiren özel bir etkinleştirme işlevi. Sınıflandırıcılarda son adım olarak kullanılır.
tensor: "Tensor", matrise benzer ancak rastgele sayıda boyuta sahiptir. 1 boyutlu tensörler vektördür. 2 boyutlu tensör bir matristir. Daha sonra 3, 4, 5 veya daha fazla boyuta sahip tensörleriniz olabilir.
7. Transfer Öğrenimi
Resim sınıflandırma sorununda yoğun katmanlar muhtemelen yeterli olmayacaktır. Evrişimli katmanlar ve bunları düzenlemenin birçok yolu hakkında bilgi edinmemiz gerekiyor.
Ancak kısayol da kullanabiliriz. Tamamen eğitilmiş evrişimli nöral ağları indirebilirsiniz. Son katmanlarını (softmax sınıflandırma başlığı) kesip kendi katmanınızla değiştirmeniz mümkündür. Eğitilmiş tüm ağırlıklar ve önyargılar olduğu gibi kalır, yalnızca eklediğiniz softmax katmanını yeniden eğitirsiniz. Bu tekniğe aktarımlı öğrenme adı verilir ve sinir ağının önceden eğitildiği veri kümesi sizinkine "yeterince yakın" olduğu sürece bu teknik inanılmaz bir şekilde çalışır.
Uygulamalı
Lütfen aşağıdaki not defterini açın, hücreleri çalıştırın (Shift-ENTER) ve "ÇALIŞMA GEREKLİ" etiketini gördüğünüz her yerde talimatları uygulayın.
Keras Flowers transfer learning (playground).ipynb
Ek bilgiler
Transfer öğrenimi sayesinde hem en iyi araştırmacılar tarafından geliştirilen gelişmiş konvolüsyonel nöral ağ mimarilerinden hem de büyük bir görüntü veri kümesi üzerinde önceden eğitilmiş modellerden yararlanabilirsiniz. Bizim durumumuzda, çiçeklere yeterince yakın olan, birçok bitki ve dış mekan sahnesi içeren bir görüntü veritabanı olan ImageNet üzerinde eğitilmiş bir ağdan transfer öğrenimi yapacağız.

Resim: Önceden eğitilmiş karmaşık bir evrişimli nöral ağı kara kutu olarak kullanma ve yalnızca sınıflandırma başlığını yeniden eğitme. Buna transfer öğrenimi denir. Evrişimli katmanların bu karmaşık düzenlemelerinin nasıl çalıştığını daha sonra göreceğiz. Şu an için bu sorun başka bir kullanıcıyı etkiliyor.
Keras'ta transfer öğrenimi
Keras'ta, tf.keras.applications.* koleksiyonundan önceden eğitilmiş bir modeli başlatabilirsiniz. Örneğin, MobileNet V2, boyut olarak makul kalırken çok iyi bir evrişimli mimaridir. include_top=False seçeneğini belirleyerek, kendi softmax katmanınızı ekleyebilmeniz için önceden eğitilmiş modeli son softmax katmanı olmadan alırsınız:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
pretrained_model.trainable = False ayarına da dikkat edin. Yalnızca softmax katmanınızı eğitmeniz için önceden eğitilmiş modelin ağırlıklarını ve yanlılıklarını dondurur. Bu işlem genellikle nispeten az ağırlık içerir ve çok büyük bir veri kümesi gerektirmeden hızlı bir şekilde yapılabilir. Ancak çok fazla veriniz varsa aktarımlı öğrenme, pretrained_model.trainable = True ile daha da iyi sonuçlar verebilir. Önceden eğitilmiş ağırlıklar daha sonra mükemmel başlangıç değerleri sağlar ve yine de eğitilerek sorununuzla daha iyi eşleşecek şekilde ayarlanabilir.
Son olarak, yoğun softmax katmanınızdan önce eklenen Flatten() katmanına dikkat edin. Yoğun katmanlar, düz veri vektörleri üzerinde çalışır ancak önceden eğitilmiş modelin bunu döndürüp döndürmediğini bilmiyoruz. Bu nedenle eğriyi düzleştirmemiz gerekiyor. Bir sonraki bölümde, evrişimli mimarileri incelerken evrişimli katmanlar tarafından döndürülen veri biçimini açıklayacağız.
Bu yaklaşımla yaklaşık% 75 doğruluk elde edebilirsiniz.
Çözüm
Çözüm not defterini burada bulabilirsiniz. Takılırsanız bu özelliği kullanabilirsiniz.
Keras Flowers transfer learning (solution).ipynb
İşlediğimiz konular
- 🤔 Keras'ta sınıflandırıcı nasıl yazılır?
- 🤓 softmax son katmanı ve çapraz entropi kaybı ile yapılandırılmış
- 😈 Transfer learning
- 🤔 İlk modelinizi eğitme
- 🧐 Eğitim sırasında kaybı ve doğruluğu
Lütfen bu kontrol listesini zihninizde gözden geçirin.
8. [INFO] Evrişimli nöral ağlar
Özet
Bir sonraki paragraftaki kalın harflerle yazılmış tüm terimleri biliyorsanız bir sonraki alıştırmaya geçebilirsiniz. Evrişimli sinir ağlarını kullanmaya yeni başlıyorsanız lütfen okumaya devam edin.

Resim: Her biri 4x4x3=48 öğrenilebilir ağırlıktan oluşan iki ardışık filtreyle bir resmi filtreleme.
Basit bir evrişimli nöral ağın Keras'taki görünümü:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
Evrişimli nöral ağlara giriş
Bir evrişimli ağ katmanında, bir "nöron" yalnızca görüntünün küçük bir bölgesinde, hemen üstündeki piksellerin ağırlıklı toplamını yapar. Normal bir yoğun katmandaki nöron gibi bir önyargı ekler ve toplamı bir etkinleştirme işlevi aracılığıyla besler. Bu işlem daha sonra aynı ağırlıklar kullanılarak tüm görüntüde tekrarlanır. Yoğun katmanlarda her nöronun kendi ağırlıkları olduğunu unutmayın. Burada, ağırlıkların tek bir "yama"sı, görüntünün üzerinde her iki yönde de kayar ("evrişim"). Çıkışta, resimdeki piksel sayısı kadar değer bulunur (ancak kenarlarda biraz dolgu gerekir). 4x4x3=48 ağırlıklı bir filtre kullanılarak yapılan bir filtreleme işlemidir.
Ancak 48 ağırlık yeterli olmayacaktır. Daha fazla serbestlik derecesi eklemek için aynı işlemi yeni bir ağırlık grubuyla tekrarlıyoruz. Bu işlem, yeni bir filtre çıkışı grubu oluşturur. Giriş görüntüsündeki R, G, B kanallarına benzer şekilde, buna "çıkış kanalı" diyelim.

İki (veya daha fazla) ağırlık kümesi, yeni bir boyut eklenerek tek bir tensör olarak toplanabilir. Bu, bir evrişimli katmanın ağırlık tensörünün genel şeklini verir. Giriş ve çıkış kanallarının sayısı parametre olduğundan, evrişimli katmanları üst üste ve zincirleme yerleştirmeye başlayabiliriz.
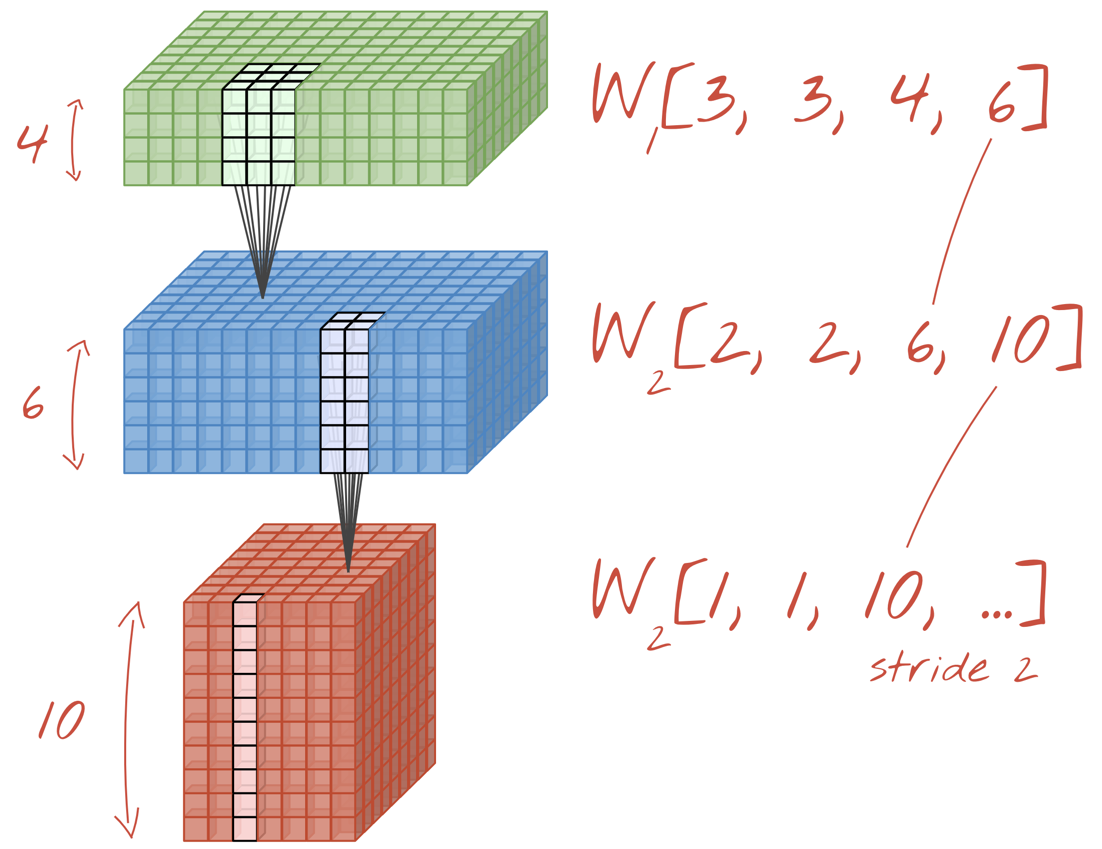
Resim: Evrişimli bir nöral ağ, veri "küplerini" başka veri "küplerine" dönüştürüyor.
Adımlı evrişimler, maksimum havuzlama
Evrişimleri 2 veya 3 adımlık bir adımla gerçekleştirerek elde edilen veri küpünü yatay boyutlarında da küçültebiliriz. Bunu yapmanın iki yaygın yolu vardır:
- Adımlı evrişim: Yukarıdaki gibi kayan bir filtre ancak adımı >1'dir.
- Maksimum havuzlama: MAX işlemini uygulayan bir kayan pencere (genellikle 2x2 yamalarda, her 2 pikselde bir tekrarlanır)

Resim: Hesaplama penceresinin 3 piksel kaydırılması, daha az çıktı değeriyle sonuçlanır. Adımlı evrişimler veya maksimum havuzlama (2 adımlık bir adımla kayan 2x2 pencerede maksimum) veri küpünü yatay boyutlarda küçültmenin bir yoludur.
Convolutional classifier
Son olarak, son veri küpünü düzleştirip yoğun ve softmax etkinleştirilmiş bir katmandan geçirerek bir sınıflandırma başlığı ekliyoruz. Tipik bir evrişimli sınıflandırıcı şu şekilde görünebilir:

Görsel: Evrişimli ve softmax katmanlarını kullanan bir görüntü sınıflandırıcı. 3x3 ve 1x1 filtreler kullanılır. Maksimum havuz katmanları, 2x2 veri noktası gruplarının maksimum değerini alır. Sınıflandırma başlığı, softmax etkinleştirmeli yoğun bir katmanla uygulanır.
Keras'ta
Yukarıda gösterilen evrişimli yığın, Keras'ta şu şekilde yazılabilir:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. Özel evrişimli ağınız
Uygulamalı
Sıfırdan bir konvolüsyonel sinir ağı oluşturalım ve eğitelim. TPU kullanarak çok hızlı yineleme yapabiliriz. Lütfen aşağıdaki not defterini açın, hücreleri çalıştırın (Shift-ENTER) ve "ÇALIŞMA GEREKLİ" etiketini gördüğünüz her yerde talimatları uygulayın.
Keras_Flowers_TPU (playground).ipynb
Hedef, aktarım öğrenimi modelinin% 75 doğruluk oranını aşmaktır. Bu model, milyonlarca resimden oluşan bir veri kümesi üzerinde önceden eğitildiği için avantajlıydı. Bizim veri kümemizde ise yalnızca 3.670 resim var. En azından bu fiyatı karşılayabilir misiniz?
Ek bilgiler
Kaç katlı ve ne kadar büyük?
Katman boyutlarını seçmek bilimden çok sanata benzer. Çok az ve çok fazla parametre (ağırlıklar ve yanlılıklar) arasında doğru dengeyi bulmanız gerekir. Ağırlık sayısı çok az olduğunda sinir ağı, çiçek şekillerinin karmaşıklığını temsil edemez. Çok fazla olduğunda ise "aşırı uyum" (overfitting) eğilimi gösterebilir. Yani eğitim resimlerinde uzmanlaşır ve genelleme yapamaz. Çok fazla parametre olduğunda modelin eğitimi de yavaşlar. Keras'ta model.summary() işlevi, modelinizin yapısını ve parametre sayısını gösterir:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
Birkaç ipucu:
- Birden fazla katmana sahip olmak, "derin" nöral ağları etkili kılar. Bu basit çiçek tanıma sorunu için 5 ila 10 kat mantıklıdır.
- Küçük filtreler kullanın. Genellikle 3x3 filtreler her yerde iyi sonuç verir.
- 1x1 filtreler de kullanılabilir ve ucuzdur. Bunlar aslında hiçbir şeyi "filtrelemez", yalnızca kanalların doğrusal kombinasyonlarını hesaplar. Bunları gerçek filtrelerle değiştirin. ("1x1 evrişimler" hakkında daha fazla bilgiyi sonraki bölümde bulabilirsiniz.)
- Bunun gibi bir sınıflandırma sorununda, maksimum havuzlama katmanlarıyla (veya adımı > 1 olan sarmalarla) sık sık alt örnekleme yapın. Çiçeğin nerede olduğu değil, gül veya karahindiba olup olmadığı önemli olduğundan x ve y bilgilerinin kaybolması önemli değildir ve daha küçük alanları filtrelemek daha ucuzdur.
- Filtre sayısı genellikle ağın sonunda sınıf sayısına benzer (Neden? Aşağıdaki "global ortalama havuz oluşturma" ipucuna bakın). Yüzlerce sınıfa sınıflandırma yapıyorsanız filtre sayısını ardışık katmanlarda kademeli olarak artırın. 5 sınıflı çiçek veri setinde yalnızca 5 filtreyle filtreleme yapmak yeterli olmaz. Çoğu katmanda aynı filtre sayısını (ör. 32) kullanabilir ve sonlara doğru bu sayıyı azaltabilirsiniz.
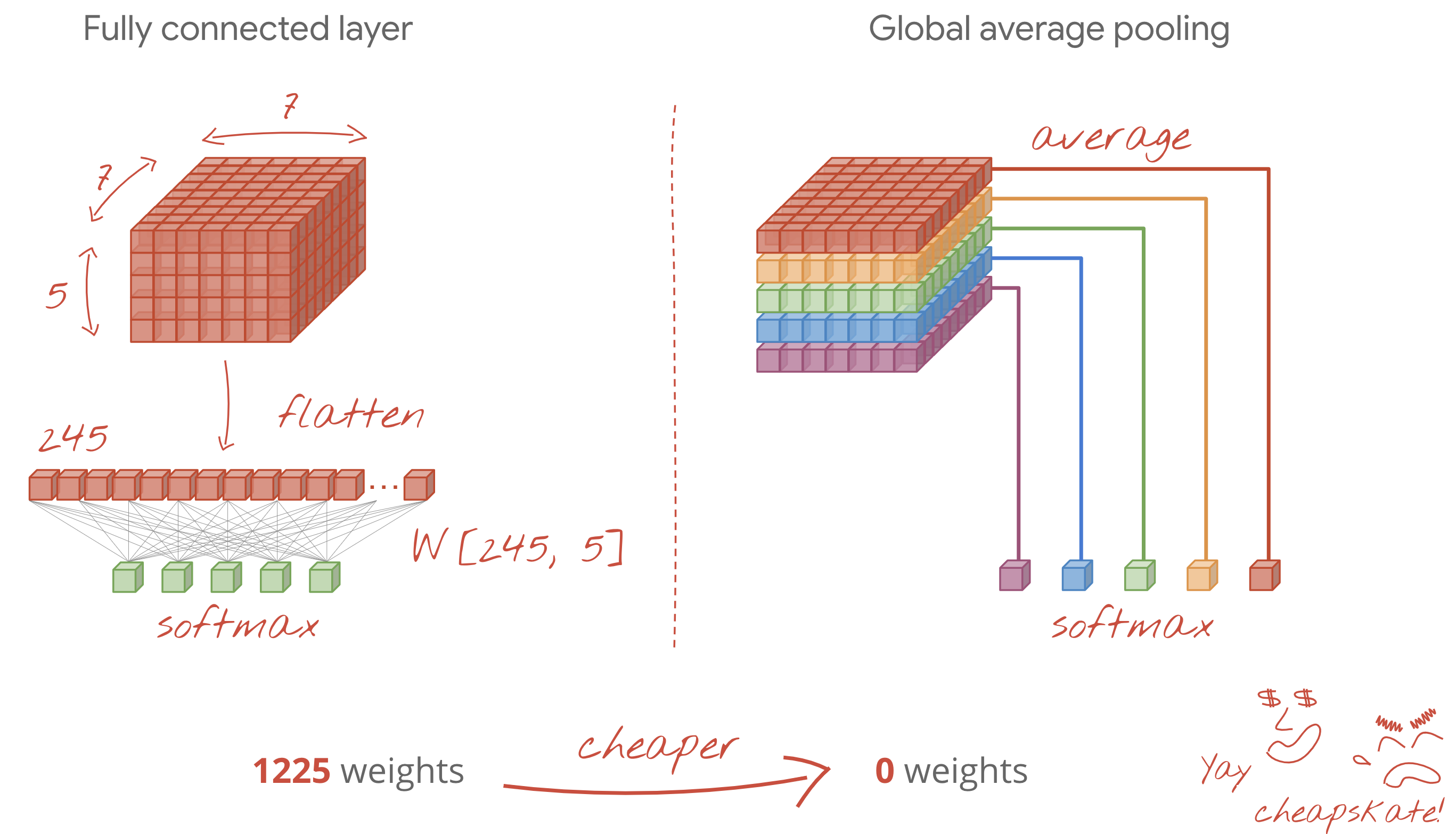
- Son yoğun katmanlar pahalıdır. Bu katmanlar, tüm evrişimli katmanların toplamından daha fazla ağırlığa sahip olabilir. Örneğin, son veri küpünden 24x24x10 veri noktası gibi çok makul bir çıkış olsa bile 100 nöronlu yoğun bir katman 24x24x10x100=576.000 ağırlığa mal olur. Dikkatli olmaya çalışın veya global ortalama havuzlamayı deneyin (aşağıya bakın).
Global ortalama havuzlama
Evrişimli sinir ağının sonunda pahalı bir yoğun katman kullanmak yerine, gelen veri "küpünü" sınıf sayınız kadar parçaya bölebilir, değerlerinin ortalamasını alabilir ve bunları bir softmax etkinleştirme işlevinden geçirebilirsiniz. Sınıflandırma başlığını bu şekilde oluşturmak 0 ağırlık maliyetine sahiptir. Keras'ta söz dizimi tf.keras.layers.GlobalAveragePooling2D(). şeklindedir.
Çözüm
Çözüm not defterini burada bulabilirsiniz. Takılırsanız bu özelliği kullanabilirsiniz.
Keras_Flowers_TPU (solution).ipynb
İşlediğimiz konular
- 🤔 Evrişimli katmanlarla oynandı
- 🤓 Maksimum havuz oluşturma, adımlar, genel ortalama havuz oluşturma ile denemeler yapıldı.
- 😀 TPU'da gerçek dünyadaki bir model üzerinde hızlı bir şekilde yineleme yapma
Lütfen bu kontrol listesini zihninizde gözden geçirin.
10. [INFO] Modern convolutional architectures
Özet

Resim: Bir evrişimli "modül". Bu noktada en iyi seçenek nedir? Maksimum havuz katmanını 1x1 boyutunda bir evrişimli katman mı yoksa farklı bir katman kombinasyonu mu takip etmeli? Hepsini deneyin, sonuçları birleştirin ve ağın karar vermesine izin verin. Sağda: Bu tür modüllerin kullanıldığı " inception" evrişimli mimarisi.
Keras'ta, veri akışının dallanabileceği modeller oluşturmak için "işlevsel" model stilini kullanmanız gerekir. Örnek:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
Diğer ucuz numaralar
Küçük 3x3 filtreler

Bu resimde, art arda uygulanan iki 3x3 filtresinin sonucu gösterilmektedir. Sonuca hangi veri noktalarının katkıda bulunduğunu belirlemeye çalışın: Bu iki ardışık 3x3 filtresi, 5x5 bölgenin bir kombinasyonunu hesaplar. Bu, 5x5 filtresinin hesaplayacağı kombinasyonla tam olarak aynı olmasa da iki ardışık 3x3 filtresi tek bir 5x5 filtresinden daha ucuz olduğundan denemeye değer.
1x1 evrişimler?

Matematiksel olarak, "1x1" evrişimi, sabit bir sayıyla çarpma işlemidir ve çok kullanışlı bir kavram değildir. Ancak evrişimli sinir ağlarında filtrenin yalnızca 2 boyutlu bir görüntüye değil, bir veri küpüne uygulandığını unutmayın. Bu nedenle, "1x1" filtresi, 1x1 veri sütununun ağırlıklı toplamını hesaplar (bkz. resim) ve filtreyi veriler üzerinde kaydırdığınızda giriş kanallarının doğrusal bir kombinasyonunu elde edersiniz. Bu aslında faydalı. Kanalları, tek tek filtreleme işlemlerinin sonuçları olarak düşünürseniz (ör. "sivri kulaklar" için bir filtre, "bıyıklar" için başka bir filtre ve "çekik gözler" için üçüncü bir filtre), "1x1" evrişimli katman bu özelliklerin olası doğrusal kombinasyonlarını hesaplar. Bu, "kedi" ararken faydalı olabilir. Ayrıca, 1x1 katmanlar daha az ağırlık kullanır.
11. Squeezenet
Bu fikirleri bir araya getirmenin basit bir yolu "Squeezenet" makalesinde gösterilmiştir. Yazarlar, yalnızca 1x1 ve 3x3 evrişimli katmanların kullanıldığı çok basit bir evrişimli modül tasarımı öneriyor.

Resim: "Ateş modüllerine" dayalı SqueezeNet mimarisi. Gelen verileri dikey boyutta "sıkıştıran" 1x1 katmanıyla başlayıp verilerin derinliğini tekrar "genişleten" iki paralel 1x1 ve 3x3 evrişimli katmanla devam eder.
Uygulamalı
Önceki not defterinizde çalışmaya devam edin ve SqueezeNet'ten ilham alan bir evrişimli sinir ağı oluşturun. Model kodunu Keras "işlevsel stili" olarak değiştirmeniz gerekir.
Keras_Flowers_TPU (playground).ipynb
Ek bilgiler
Bu alıştırmada, bir SqueezeNet modülü için yardımcı işlev tanımlamak faydalı olacaktır:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
Bu seferki hedef% 80 doğruluk oranına ulaşmak.
Deneyebilecekleriniz
Tek bir evrişimli katmanla başlayın, ardından "fire_modules" ile devam edin ve MaxPooling2D(pool_size=2) katmanlarıyla dönüşümlü olarak kullanın. Ağda 2 ila 4 maksimum havuz oluşturma katmanı ve maksimum havuz oluşturma katmanları arasında 1, 2 veya 3 ardışık ateşleme modülüyle denemeler yapabilirsiniz.
Ateş modüllerinde "sıkıştırma" parametresi genellikle "genişletme" parametresinden daha küçük olmalıdır. Bu parametreler aslında filtre sayısıdır. Genellikle 8 ila 196 arasında olabilir. Filtre sayısının ağ üzerinden kademeli olarak arttığı mimariler veya tüm ateşleme modüllerinin aynı sayıda filtreye sahip olduğu basit mimarilerle denemeler yapabilirsiniz.
Örnek:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
Bu noktada, denemelerinizin iyi gitmediğini ve% 80 doğruluk hedefinin uzak olduğunu fark edebilirsiniz. Birkaç ucuz numara daha yapmanın zamanı geldi.
Toplu Normalleştirme (Batch Normalization)
Toplu normalleştirme, yaşadığınız yakınsama sorunlarına yardımcı olur. Bu teknikle ilgili ayrıntılı açıklamalar bir sonraki atölye çalışmasında yapılacak. Şimdilik lütfen bu tekniği, ağınızdaki her evrişimli katmandan sonra bu satırı ekleyerek kara kutu "sihirli" yardımcı olarak kullanın. fire_module işlevinizin içindeki katmanlar da buna dahildir:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
Veri setimiz küçük olduğundan momentum parametresi, varsayılan değeri olan 0,99'dan 0,9'a düşürülmelidir. Şimdilik bu ayrıntıyı göz ardı edebilirsiniz.
Veri artırma
Verileri, doygunluk değişikliklerinin soldan sağa çevrilmesi gibi kolay dönüşümlerle artırarak birkaç puan daha kazanabilirsiniz:


Bu işlem, tf.data.Dataset API ile Tensorflow'da çok kolay bir şekilde yapılabilir. Verileriniz için yeni bir dönüşüm işlevi tanımlayın:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
Ardından, son veri dönüşümünüzde kullanın (hücre "training and validation datasets", işlev "get_batched_dataset"):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
Veri artırmayı isteğe bağlı hale getirmeyi ve yalnızca eğitim veri kümesinin artırıldığından emin olmak için gerekli kodu eklemeyi unutmayın. Doğrulama veri kümesini artırmanın bir anlamı yoktur.
35 dönemde% 80 doğruluk elde edebilirsiniz.
Çözüm
Çözüm not defterini burada bulabilirsiniz. Takılırsanız bu özelliği kullanabilirsiniz.
Keras_Flowers_TPU_squeezenet.ipynb
İşlediğimiz konular
- 🤔 Keras "functional style" modelleri
- 🤓 Squeezenet mimarisi
- 🤓 tf.data.datset ile veri artırma
Lütfen bu kontrol listesini zihninizde gözden geçirin.
12. Xception ince ayarı
Ayrılabilir evrişimler
Son zamanlarda, evrişimli katmanları uygulamanın farklı bir yolu olan derinlik ayrılabilir evrişimler popülerlik kazanmaktadır. Bu terimin biraz uzun olduğunun farkındayız ancak kavram oldukça basittir. Tensorflow ve Keras'ta tf.keras.layers.SeparableConv2D olarak uygulanır.
Ayrılabilir sarmalama da görüntüde filtre çalıştırır ancak giriş görüntüsünün her kanalı için farklı bir ağırlık kümesi kullanır. Bunu, filtrelenmiş kanalların ağırlıklı toplamıyla sonuçlanan bir dizi skaler çarpım olan "1x1 convolution" izler. Her seferinde yeni ağırlıklarla, gerektiği kadar ağırlıklı kanal yeniden birleşimi hesaplanır.

Resim: Ayrılabilir kıvrımlar. 1. Aşama: Her kanal için ayrı bir filtre içeren kıvrımlar. 2. aşama: Kanalların doğrusal rekombinasyonları. İstenen çıkış kanalı sayısına ulaşılana kadar yeni bir ağırlık grubuyla tekrarlanır. 1. aşama da her seferinde yeni ağırlıklarla tekrarlanabilir ancak pratikte bu durum nadiren görülür.
Ayrılabilir evrişimler, en yeni evrişimli ağ mimarilerinde (MobileNetV2, Xception, EfficientNet) kullanılır. Bu arada, daha önce aktarımlı öğrenme için MobileNetV2'yi kullanıyordunuz.
Normal evrişimlerden daha ucuzdur ve pratikte aynı derecede etkili olduğu bulunmuştur. Yukarıda gösterilen örnek için ağırlık sayısı şöyledir:
Evrişimli katman: 4 x 4 x 3 x 5 = 240
Ayrılabilir evrişimli katman: 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
Her bir evrişimli katman ölçeği stilini benzer şekilde uygulamak için gereken çarpma sayısını hesaplamak okuyucuya bırakılmıştır. Ayrılabilir sarmalar daha küçüktür ve hesaplama açısından çok daha etkilidir.
Uygulamalı
"Transfer learning" (Transfer öğrenimi) playground not defterinden yeniden başlayın ancak bu kez önceden eğitilmiş model olarak Xception'ı seçin. Xception yalnızca ayrılabilir sarmalar kullanır. Tüm ağırlıkları eğitilebilir bırakın. Önceden eğitilmiş katmanları olduğu gibi kullanmak yerine, önceden eğitilmiş ağırlıkları verilerimiz üzerinde ince ayarlayacağız.
Keras Flowers transfer learning (playground).ipynb
Hedef: %95'ten fazla doğruluk (Evet, gerçekten mümkün!)
Bu son alıştırma olduğundan biraz daha fazla kod ve veri bilimi çalışması gerektirir.
İnce ayar hakkında ek bilgiler
Xception, tf.keras.application.* içindeki standart önceden eğitilmiş modellerde kullanılabilir. Bu sefer tüm ağırlıkları eğitilebilir bırakmayı unutmayın.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
Bir modeli ince ayar yaparken iyi sonuçlar elde etmek için öğrenme hızına dikkat etmeniz ve kampanya gelişim dönemine sahip bir öğrenme hızı planı kullanmanız gerekir. Aşağıdaki gibi:

Standart bir öğrenme hızıyla başlamak, modelin önceden eğitilmiş ağırlıklarını bozacaktır. Aşamalı olarak başlatma, model verilerinize bağlanana ve bunları mantıklı bir şekilde değiştirene kadar bu öğeleri korur. Artış aşamasından sonra sabit veya üstel olarak azalan bir öğrenme hızıyla devam edebilirsiniz.
Keras'ta öğrenme oranı, her dönem için uygun öğrenme oranını hesaplayabileceğiniz bir geri çağırma yoluyla belirtilir. Keras, her dönem için doğru öğrenme hızını optimize ediciye iletir.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
Çözüm
Çözüm not defterini burada bulabilirsiniz. Takılırsanız bu özelliği kullanabilirsiniz.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
İşlediğimiz konular
- 🤔 Derinliğe göre ayrılabilen evrişim
- 🤓 Öğrenme hızı planları
- 😈 Önceden eğitilmiş bir modele ince ayar yapma
Lütfen bu kontrol listesini zihninizde gözden geçirin.
13. Tebrikler!
İlk modern evrişimli nöral ağınızı oluşturdunuz ve TPU'lar sayesinde yalnızca birkaç dakika içinde art arda eğitim çalıştırmaları yaparak% 90'ın üzerinde doğrulukla eğittiniz.
TPU'ların uygulamadaki yeri
TPU'lar ve GPU'lar, Google Cloud'un Vertex AI'ında kullanılabilir:
Son olarak, geri bildirimlerinizi öğrenmekten memnuniyet duyarız. Bu laboratuvarda yanlış bir şey görürseniz veya iyileştirilmesi gerektiğini düşünürseniz lütfen bize bildirin. Geri bildirimler GitHub sorunları [geri bildirim bağlantısı] üzerinden gönderilebilir.

|
|

