
1. 简介
在此 Codelab 中,您将学习如何通过将向量搜索与 Vertex AI 嵌入相结合来使用 Cloud SQL for MySQL Vertex AI 集成。

前提条件
- 对 Google Cloud 控制台有基本的了解
- 具备命令行界面和 Cloud Shell 方面的基本技能
学习内容
- 如何部署 Cloud SQL for PostgreSQL 实例
- 如何创建数据库并启用 Cloud SQL AI 集成
- 如何将数据加载到数据库中
- 如何使用 Cloud SQL Studio
- 如何在 Cloud SQL 中使用 Vertex AI 嵌入模型
- 如何使用 Vertex AI Studio
- 如何使用 Vertex AI 生成式模型丰富结果
- 如何使用向量索引提升性能
所需条件
- Google Cloud 账号和 Google Cloud 项目
- 支持 Google Cloud 控制台和 Cloud Shell 的网络浏览器,例如 Chrome
2. 设置和要求
项目设置
- 登录 Google Cloud 控制台。如果您还没有 Gmail 或 Google Workspace 账号,则必须创建一个。
请改用个人账号,而非工作账号或学校账号。
- 创建新项目或重复使用现有项目。如需在 Google Cloud 控制台中创建新项目,请在标题中点击“选择项目”按钮,系统随即会打开一个弹出式窗口。

在“选择项目”窗口中,按“新建项目”按钮,系统随即会打开一个用于创建新项目的对话框。
在对话框中,输入您偏好的项目名称,然后选择位置。
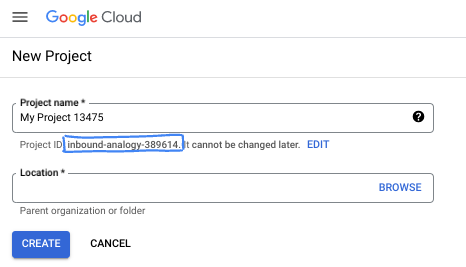
- 项目名称是此项目参与者的显示名称。Google API 不会使用项目名称,并且您可以随时更改项目名称。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Google Cloud 控制台会自动生成一个唯一 ID,但您可以自定义该 ID。如果您不喜欢生成的 ID,可以生成另一个随机 ID,也可以提供自己的 ID 来检查其可用性。在大多数 Codelab 中,您都需要引用项目 ID,该 ID 通常用占位符 PROJECT_ID 标识。
- 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
启用结算功能
您可以通过以下两种方式启用结算功能。您可以使用个人结算账号,也可以按照以下步骤兑换积分。
兑换 Google Cloud 赠金(可选)
如需运行此研讨会,您需要拥有一个有一定信用额度的结算账号。使用本 Codelab 顶部横幅中的积分开始学习。如果您已关联结算账号,则可以跳过此步骤。
设置个人结算账号
如果您使用 Google Cloud 积分设置了结算,则可以跳过此步骤。
如需设置个人结算账号,请点击此处在 Cloud 控制台中启用结算功能。
注意事项:
- 完成本实验的 Cloud 资源费用应低于 3 美元。
- 您可以按照本实验末尾的步骤删除资源,以避免产生更多费用。
- 新用户符合参与 $300 USD 免费试用计划的条件。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:
或者,您也可以按 G 键,然后按 S 键。如果您位于 Google Cloud 控制台中,或者使用此链接,此序列将激活 Cloud Shell。
预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
3. 准备工作
启用 API
如需使用 Cloud SQL、Compute Engine、网络服务和 Vertex AI,您需要在 Google Cloud 项目中启用它们各自的 API。
在 Cloud Shell 终端中,确保项目 ID 已设置:
gcloud config set project [YOUR-PROJECT-ID]
设置环境变量 PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
启用所有必要的服务:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
预期输出
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API 简介
- Cloud SQL Admin API (
sqladmin.googleapis.com) 可让您以编程方式创建、配置和管理 Cloud SQL 实例。它为 Google 的全托管式关系型数据库服务(支持 MySQL、PostgreSQL 和 SQL Server)提供控制平面,负责处理预配、备份、高可用性和扩缩等任务。 - 借助 Compute Engine API (
compute.googleapis.com),您可以创建和管理虚拟机 (VM)、永久性磁盘和网络设置。它提供运行工作负载所需的核心基础设施即服务 (IaaS) 基础,并为许多托管服务托管底层基础架构。 - 借助 Cloud Resource Manager API (
cloudresourcemanager.googleapis.com),您可以以编程方式管理 Google Cloud 云项目的元数据和配置。借助它,您可以整理资源、处理 Identity and Access Management (IAM) 政策,以及验证项目层次结构中的权限。 - 借助 Service Networking API (
servicenetworking.googleapis.com),您可以自动设置虚拟私有云 (VPC) 网络与 Google 的受管服务之间的专用连接。您必须为 AlloyDB 等服务建立专用 IP 访问通道,以便它们能够与其他资源安全地通信。 - Vertex AI API (
aiplatform.googleapis.com) 可让您的应用构建、部署和扩缩机器学习模型。它为所有 Google Cloud AI 服务提供统一的界面,包括访问生成式 AI 模型(如 Gemini)和自定义模型训练。
4. 创建 Cloud SQL 实例
创建 Cloud SQL 实例,并启用数据库与 Vertex AI 的集成。
创建数据库密码
为默认数据库用户定义密码。您可以自行定义密码,也可以使用随机函数生成密码:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
请注意生成的密码值:
echo $CLOUDSQL_PASSWORD
创建 Cloud SQL for MySQL 实例
您可以在创建实例时启用 cloudsql_vector 标志。矢量支持目前适用于 MySQL 8.0 R20241208.01_00 或更高版本
在 Cloud Shell 会话中,执行以下命令:
gcloud sql instances create my-cloudsql-instance \
--database-version=MYSQL_8_4 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--enable-google-ml-integration \
--edition=ENTERPRISE \
--root-password=$CLOUDSQL_PASSWORD
我们可以通过从 Cloud Shell 执行命令来验证连接
gcloud sql connect my-cloudsql-instance --user=root
运行该命令,并在系统准备好连接时在提示中输入密码。
预期输出:
$gcloud sql connect my-cloudsql-instance --user=root Allowlisting your IP for incoming connection for 5 minutes...done. Connecting to database with SQL user [root].Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 71 Server version: 8.4.4-google (Google) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
暂时使用 Ctrl+D 键盘快捷键或执行 exit 命令退出 MySQL 会话
exit
启用“Vertex AI 集成”
向内部 Cloud SQL 服务账号授予必要的权限,以便能够使用 Vertex AI 集成。
查找 Cloud SQL 内部服务账号电子邮件地址,并将其导出为变量。
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
向 Cloud SQL 服务账号授予对 Vertex AI 的访问权限:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
如需详细了解实例创建和配置,请点击此处参阅 Cloud SQL 文档。
5. 准备数据库
现在,我们需要创建数据库并启用向量支持。
创建数据库
创建一个名为 quickstart_db 的数据库。为此,我们可以使用不同的选项,例如命令行数据库客户端(如 MySQL 的 mysql)、SDK 或 Cloud SQL Studio。我们将使用 SDK (gcloud) 创建数据库。
在 Cloud Shell 中执行命令以创建数据库
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
6. 加载数据
现在,我们需要在数据库中创建对象并加载数据。我们将使用虚构的 Cymbal 商店数据。数据以 SQL(用于架构)和 CSV 格式(用于数据)提供。
Cloud Shell 将成为我们连接到数据库、创建所有对象和加载数据的主要环境。
首先,我们需要将 Cloud Shell 公共 IP 添加到 Cloud SQL 实例的授权网络列表中。在 Cloud Shell 中,执行以下命令:
gcloud sql instances patch my-cloudsql-instance --authorized-networks=$(curl ifconfig.me)
如果会话丢失、重置或您使用其他工具,请再次导出 CLOUDSQL_PASSWORD 变量:
export CLOUDSQL_PASSWORD=...your password defined for the instance...
现在,我们可以在数据库中创建所有必需的对象。为此,我们将使用 MySQL mysql 实用程序与 curl 实用程序相结合,后者可从公共来源获取数据。
在 Cloud Shell 中,执行以下命令:
export INSTANCE_IP=$(gcloud sql instances describe my-cloudsql-instance --format="value(ipAddresses.ipAddress)")
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_mysql_schema.sql | mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
我们在上一个命令中具体做了什么?我们连接到数据库并执行了下载的 SQL 代码,该代码创建了表、索引和序列。
下一步是加载 cymbal_products 数据。我们使用相同的 curl 和 mysql 实用程序。
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_products.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_products FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
然后,我们继续处理 cymbal_stores。
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_stores.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_stores FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
并使用 cymbal_inventory 完成,其中包含每家商店中每种产品的数量。
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_inventory.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_inventory FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
如果您有自己的示例数据,并且您的 CSV 文件与 Cloud 控制台中提供的 Cloud SQL 导入工具兼容,则可以使用这些数据和文件,而不是使用此处介绍的方法。
7. 创建嵌入
下一步是使用 Google Vertex AI 中的 textembedding-005 模型为产品说明构建嵌入,并将它们存储在 cymbal_products 表的新列中。
为了存储向量数据,我们需要在 Cloud SQL 实例中启用向量功能。在 Cloud Shell 中执行以下命令:
gcloud sql instances patch my-cloudsql-instance \
--database-flags=cloudsql_vector=on
连接到数据库:
mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
并使用嵌入函数在 cymbal_products 表中创建一个新列 embedding。新列将包含基于 product_description 列中的文本生成的向量嵌入。
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) using varbinary;
UPDATE cymbal_products SET embedding = mysql.ml_embedding('text-embedding-005', product_description);
为 2,000 行数据生成向量嵌入通常需要不到 5 分钟,但有时可能需要稍长的时间,而且通常会更快完成。
8. 运行相似度搜索
现在,我们可以使用相似度搜索来运行搜索,该搜索基于为说明计算的向量值以及我们使用同一嵌入模型为请求生成的向量值。
您可以通过同一命令行界面或 Cloud SQL Studio 执行 SQL 查询。任何多行复杂查询最好在 Cloud SQL Studio 中进行管理。
创建用户
我们需要一个可以使用 Cloud SQL Studio 的新用户。我们将创建一个内置类型的用户 student,并使用与根用户相同的密码。
在 Cloud Shell 中,执行以下命令:
gcloud sql users create student --instance=my-cloudsql-instance --password=$CLOUDSQL_PASSWORD --host=%
启动 Cloud SQL Studio
在控制台中,点击我们之前创建的 Cloud SQL 实例。
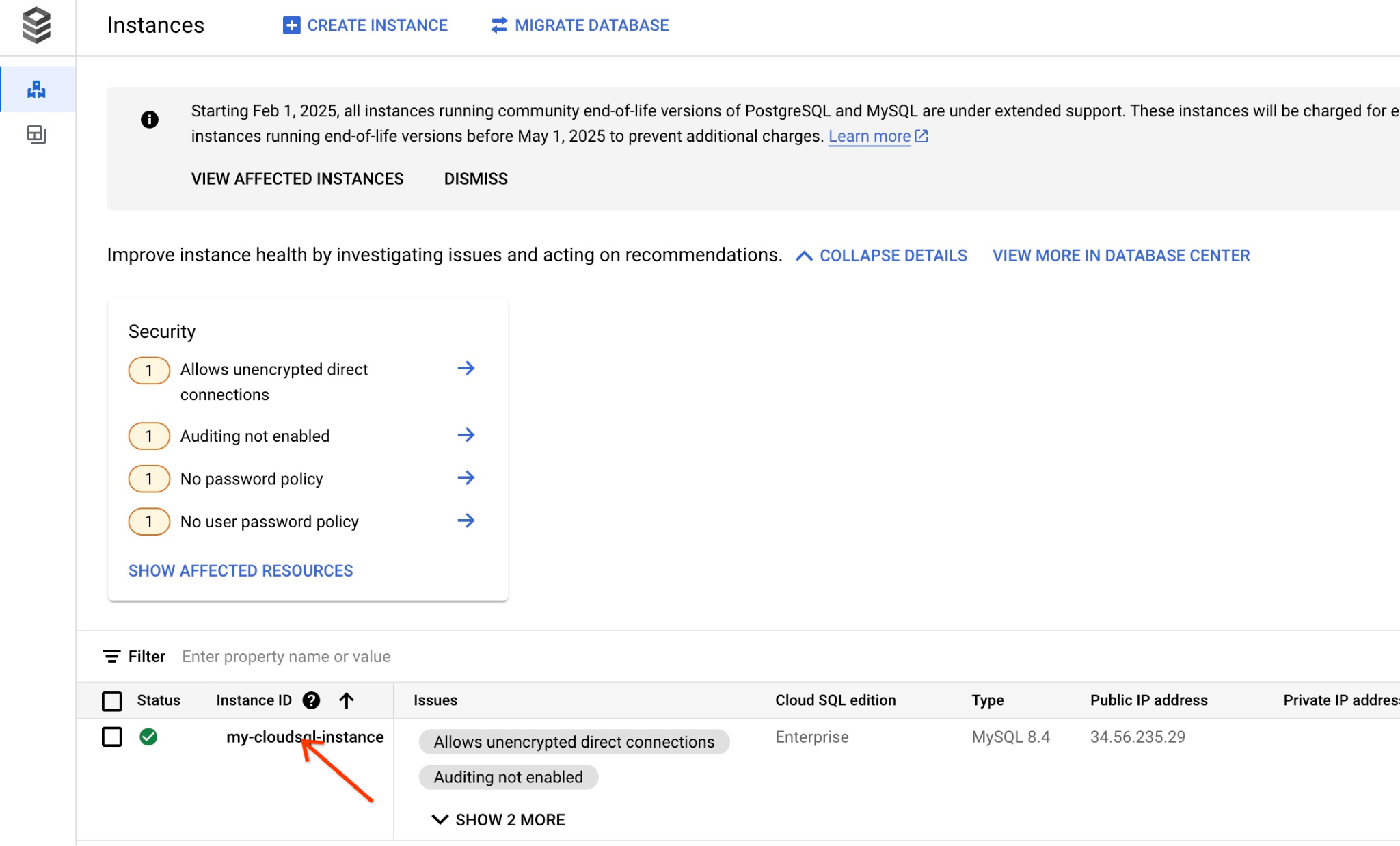
当右侧面板打开时,我们可以看到 Cloud SQL Studio。点击此标签页。
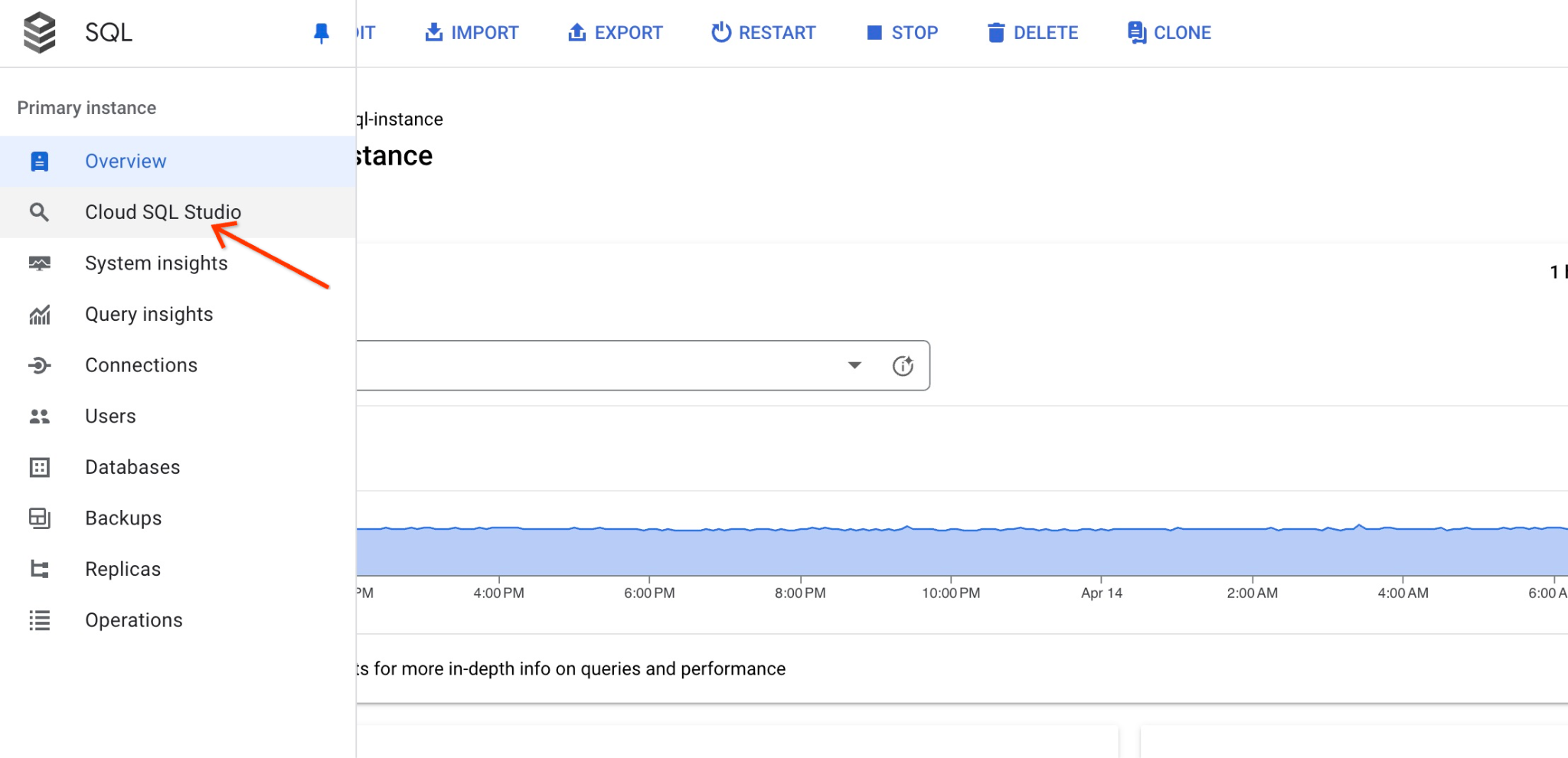
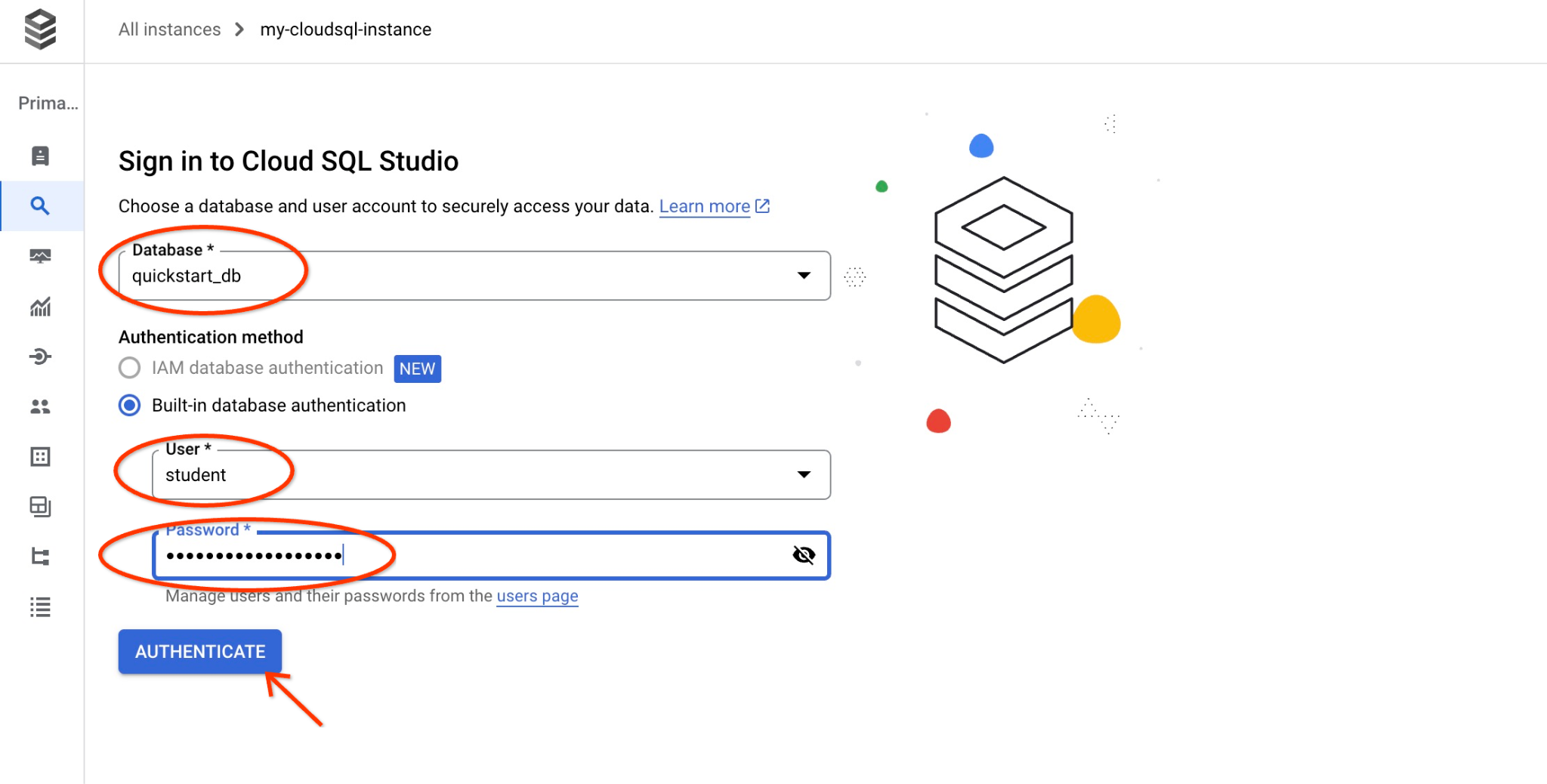
系统会打开一个对话框,供您提供数据库名称和凭据:
- 数据库:quickstart_db
- 用户:student
- 密码:您为用户记录的密码
然后点击“AUTHENTICATE”按钮。
系统随即会打开下一个窗口,您可以在其中点击右侧的“编辑器”标签页以打开 SQL 编辑器。
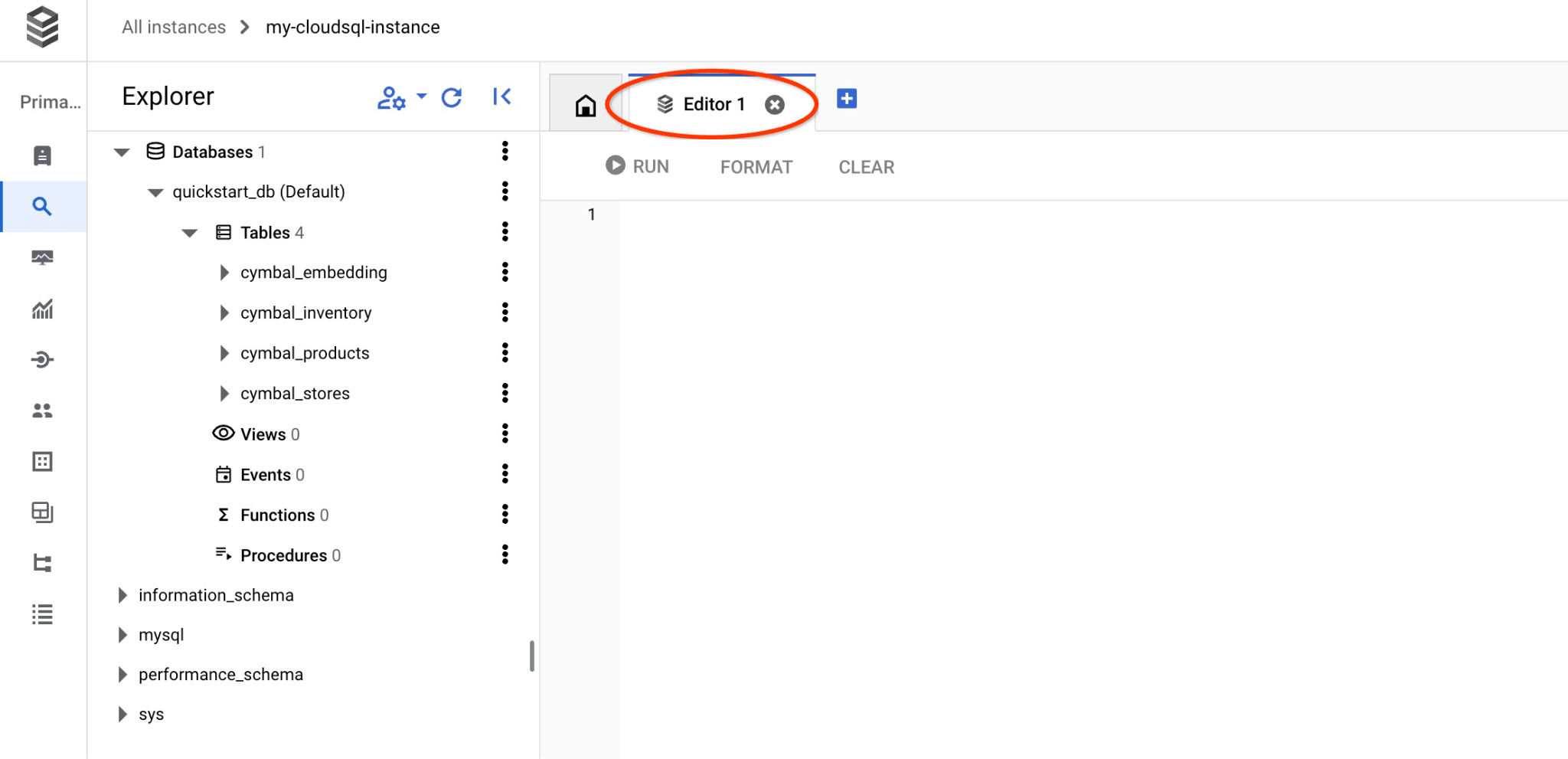
现在,我们已准备好运行查询。
运行查询
运行查询,获取与客户请求最相关的可用产品列表。我们将传递给 Vertex AI 以获取向量值的请求听起来像“这里适合种植哪种果树?”
运行使用 cosine_distance 进行 KNN(精确)向量搜索的查询
以下是您可以运行的查询,用于使用 cosine_distance 函数选择最适合我们请求的前 5 项:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cosine_distance(cp.embedding ,@query_vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
将查询复制并粘贴到 Cloud SQL Studio 编辑器中,然后按“运行”按钮,或者将其粘贴到连接到 quickstart_db 数据库的命令行会话中。
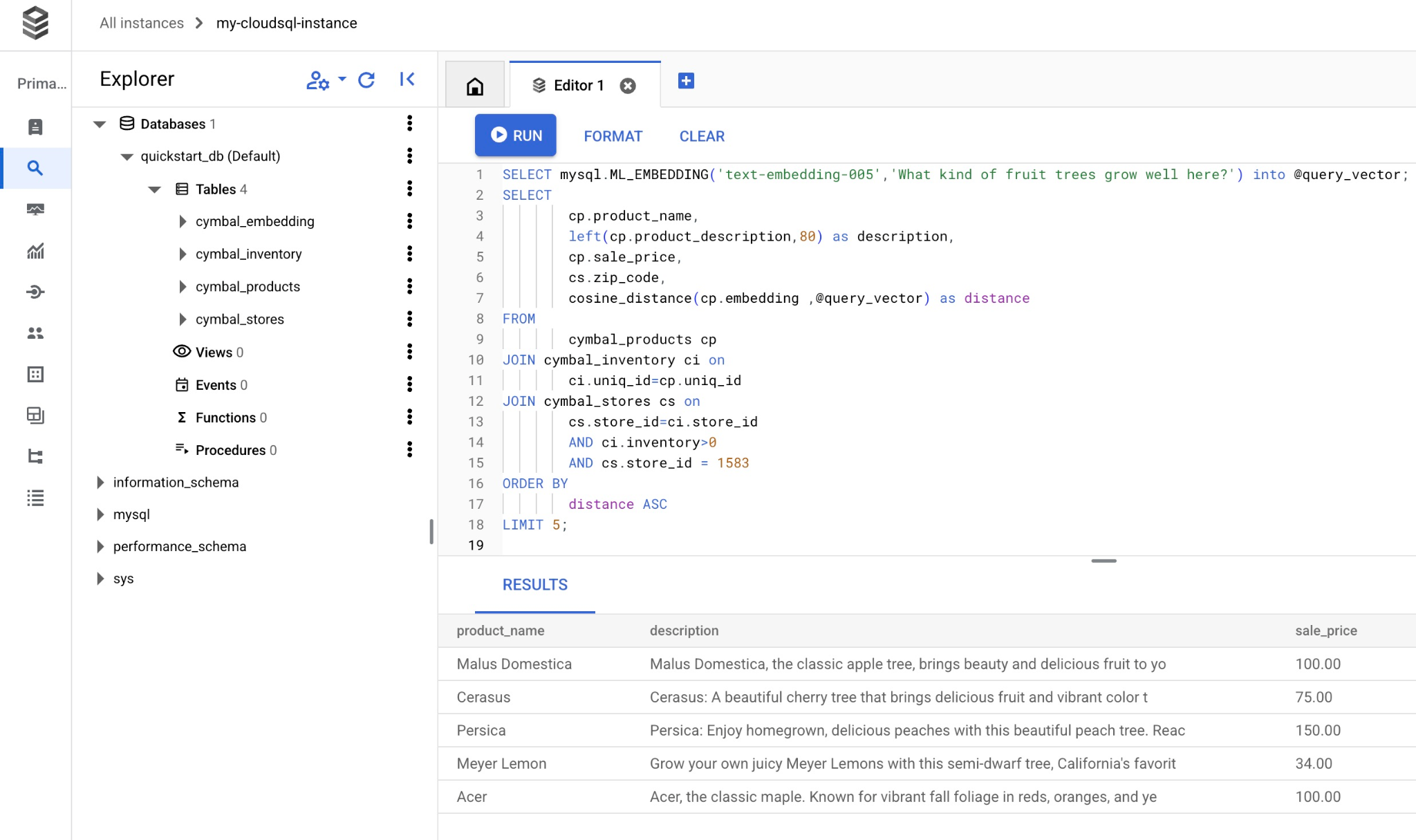
以下是根据查询选择的商品列表。
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set (0.13 sec)
使用 cosine_distance 函数时,查询执行时间为 0.13 秒。
运行使用 approx_distance 的查询,以进行 KNN(精确)向量搜索
现在,我们运行相同的查询,但使用基于 approx_distance 函数的 KNN 搜索。如果我们没有嵌入的 ANN 索引,系统会在后台自动恢复为精确搜索:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
以下是查询返回的商品列表。
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set, 1 warning (0.12 sec)
查询执行仅用了 0.12 秒。我们获得了与 cosine_distance 函数相同的结果。
9. 使用检索到的数据改进 LLM 回答
我们可以使用已执行查询的结果来改进生成式 AI LLM 对客户端应用的回答,并使用提供的查询结果作为提示的一部分,为 Vertex AI 生成式基础语言模型准备有意义的输出。
为此,我们需要生成一个包含向量搜索结果的 JSON,然后将生成的 JSON 添加到 Vertex AI 中 LLM 模型的提示中,以创建有意义的输出。在第一步中,我们生成 JSON,然后在 Vertex AI Studio 中对其进行测试,最后一步中,我们将其纳入可在应用中使用的 SQL 语句中。
以 JSON 格式生成输出
修改查询以生成 JSON 格式的输出,并仅返回一行以传递给 Vertex AI
以下是使用 ANN 搜索的查询示例:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1)
SELECT json_arrayagg(json_object('product_name',product_name,'description',description,'sale_price',sale_price,'zip_code',zip_code,'product_id',product_id)) FROM trees;
以下是输出中预期的 JSON:
[{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}]
在 Vertex AI Studio 中运行提示
我们可以使用生成的 JSON,将其作为提示的一部分提供给 Vertex AI Studio 中的生成式 AI 文本模型
在 Cloud 控制台中打开 Vertex AI Studio 提示。
它可能会要求您启用其他 API,但您可以忽略该请求。我们不需要任何其他 API 即可完成实验。
在 Studio 中输入提示。
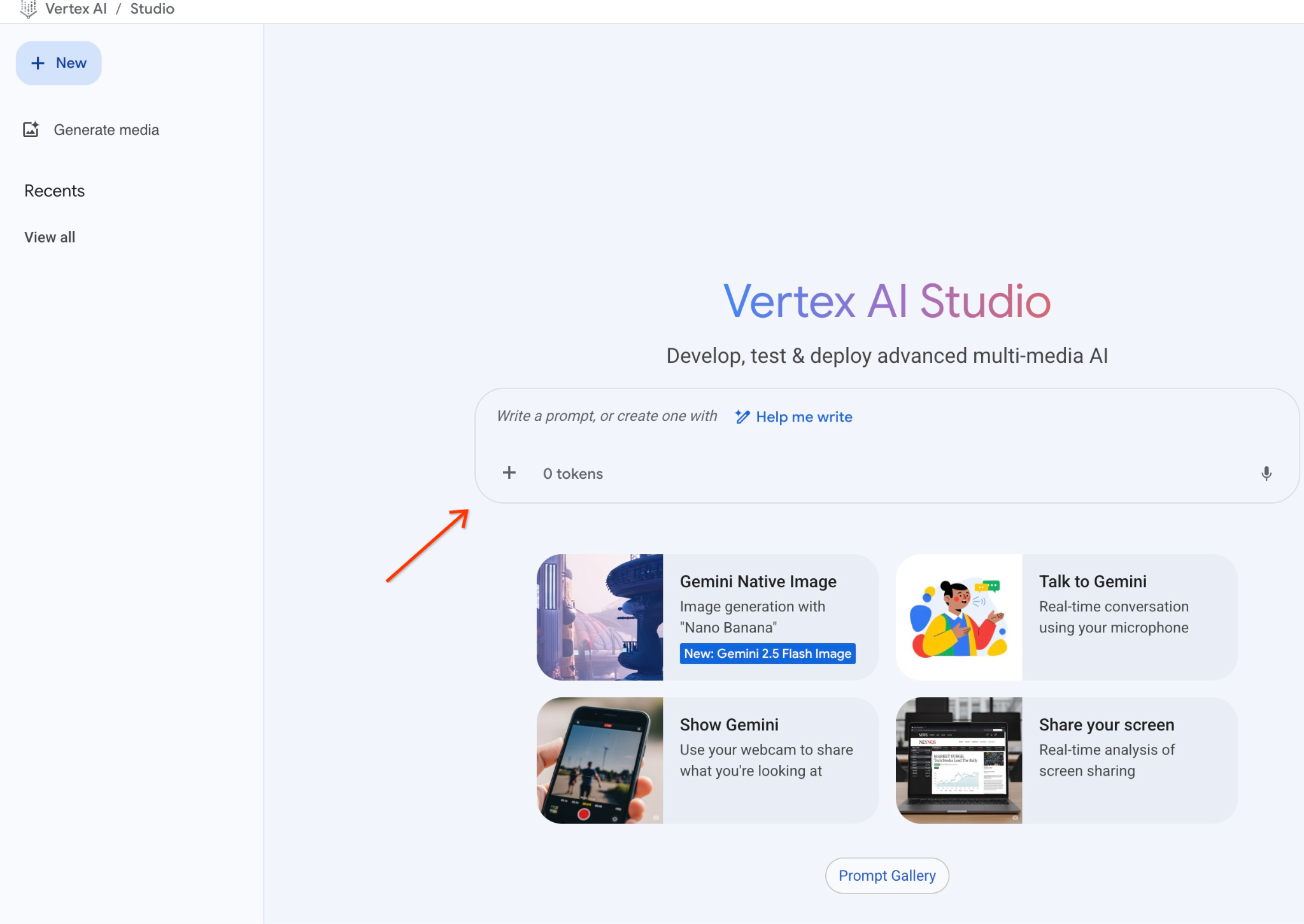
我们将使用以下提示:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
以下是我们将 JSON 占位符替换为查询响应后的样子:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
以下是我们使用 JSON 值和 gemini-2.5-flash 模型运行提示时的结果:
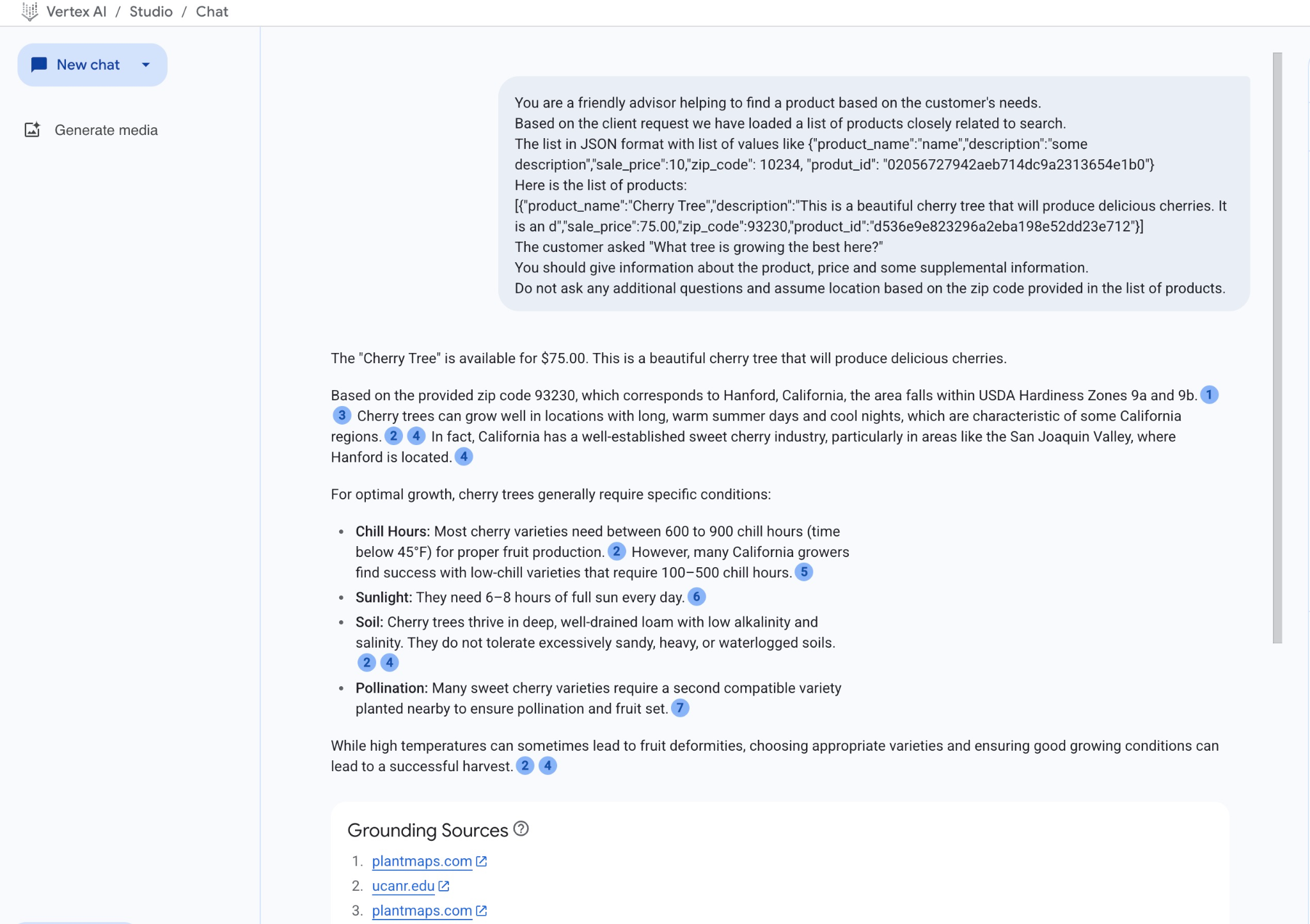
在此示例中,我们从模型中获得的回答是根据语义搜索结果和所提及邮政编码中最匹配的产品得出的。
在 SQL 中运行提示
我们还可以将 Cloud SQL AI 集成与 Vertex AI 搭配使用,直接在数据库中使用 SQL 从生成式模型获取类似回答。
现在,我们可以使用子查询中的生成结果(包含 JSON 结果),通过 SQL 将其作为提示的一部分提供给生成式 AI 文本模型。
在 mysql 或 Cloud SQL Studio 会话中,针对数据库运行查询
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1),
prompt AS (
SELECT
CONCAT( 'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:', json_arrayagg(json_object('product_name',trees.product_name,'description',trees.description,'sale_price',trees.sale_price,'zip_code',trees.zip_code,'product_id',trees.product_id)) , 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information') AS prompt_text
FROM
trees),
response AS (
SELECT
mysql.ML_PREDICT_ROW('publishers/google/models/gemini-2.0-flash-001:generateContent',
json_object('contents',
json_object('role',
'user',
'parts',
json_array(
json_object('text',
prompt_text))))) AS resp
FROM
prompt)
SELECT
JSON_EXTRACT(resp, '$.candidates[0].content.parts[0].text')
FROM
response;
以下是输出示例。您的输出结果可能会因模型版本和参数而异:
"Okay, I see you're looking for fruit trees that grow well in your area. Based on the available product, the **Malus Domestica** (Apple Tree) is a great option to consider!\n\n* **Product:** Malus Domestica (Apple Tree)\n* **Description:** This classic apple tree grows to about 30 feet tall and provides beautiful seasonal color with green leaves in summer and fiery colors in the fall. It's known for its strength and provides good shade. Most importantly, it produces delicious apples!\n* **Price:** \\$100.00\n* **Growing Zones:** This particular apple tree is well-suited for USDA zones 4-8. Since your zip code is 93230, you are likely in USDA zone 9a or 9b. While this specific tree is rated for zones 4-8, with proper care and variety selection, apple trees can still thrive in slightly warmer climates. You may need to provide extra care during heat waves.\n\n**Recommendation:** I would recommend investigating varieties of Malus Domestica suited to slightly warmer climates or contacting a local nursery/arborist to verify if it is a good fit for your local climate conditions.\n"
输出以 Markdown 格式提供。
10. 创建最近邻索引
我们的数据集相对较小,响应时间主要取决于与 AI 模型的互动。但当您有数百万个向量时,向量搜索可能会占用我们响应时间的一大部分,并给系统带来高负载。为了改进这一点,我们可以基于向量构建索引。
创建 ScaNN 索引
我们将尝试使用 ScANN 索引类型进行测试。
为了为嵌入列构建索引,我们需要为嵌入列定义距离度量。您可以在该文档中详细了解这些参数。
CREATE VECTOR INDEX cymbal_products_embedding_idx ON cymbal_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE;
比较回答
现在,我们可以再次运行矢量搜索查询并查看结果
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
预期输出:
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | product_name | description | sale_price | zip_code | distance | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 | | Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 | | Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 | | Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 | | Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ 5 rows in set (0.08 sec)
我们可以看到,执行时间仅略有不同,但对于如此小的数据集,这是意料之中的。对于包含数百万个向量的大型数据集,效果会更加明显。
我们可以使用 EXPLAIN 命令查看执行计划:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
EXPLAIN ANALYZE SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
执行计划(摘录):
...
-> Nested loop inner join (cost=443 rows=5) (actual time=1.14..1.18 rows=5 loops=1)
-> Vector index scan on cp (cost=441 rows=5) (actual time=1.1..1.1 rows=5 loops=1)
-> Single-row index lookup on cp using PRIMARY (uniq_id=cp.uniq_id) (cost=0.25 rows=1) (actual time=0.0152..0.0152 rows=1 loops=5)
...
我们可以看到,它在 cp(cymbal_products 表的别名)上使用了向量索引扫描。
您可以尝试使用自己的数据或测试不同的搜索查询,了解 MySQL 中的语义搜索功能。
11. 清理环境
删除 Cloud SQL 实例
完成实验后销毁 Cloud SQL 实例
如果您已断开连接且之前的所有设置都已丢失,请在 Cloud Shell 中定义项目和环境变量:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
删除实例:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
预期的控制台输出:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. 恭喜
恭喜您完成此 Codelab。
Google Cloud 学习路线
本实验是“利用 Google Cloud 构建可用于生产用途的 AI”学习路线的组成部分。
- 探索完整课程,弥合从原型设计到生产的差距。
- 使用 #
#ProductionReadyAI主题标签分享您的进度。
所学内容
- 如何部署 Cloud SQL for PostgreSQL 实例
- 如何创建数据库并启用 Cloud SQL AI 集成
- 如何将数据加载到数据库中
- 如何使用 Cloud SQL Studio
- 如何在 Cloud SQL 中使用 Vertex AI 嵌入模型
- 如何使用 Vertex AI Studio
- 如何使用 Vertex AI 生成式模型丰富结果
- 如何使用向量索引提升性能
13. 调查问卷
输出如下: