
1. परिचय
इस कोडलैब में, आपको Cloud SQL for MySQL के साथ Vertex AI इंटिग्रेशन का इस्तेमाल करने का तरीका बताया जाएगा. इसके लिए, वेक्टर सर्च को Vertex AI एम्बेडिंग के साथ जोड़ा जाएगा.

ज़रूरी शर्तें
- Google Cloud और Console की बुनियादी जानकारी
- कमांड लाइन इंटरफ़ेस और Cloud Shell में बुनियादी कौशल
आपको क्या सीखने को मिलेगा
- PostgreSQL के लिए Cloud SQL इंस्टेंस को डिप्लॉय करने का तरीका
- डेटाबेस बनाने और Cloud SQL AI इंटिग्रेशन को चालू करने का तरीका
- डेटाबेस में डेटा लोड करने का तरीका
- Cloud SQL Studio का इस्तेमाल कैसे करें
- Cloud SQL में Vertex AI एम्बेडिंग मॉडल का इस्तेमाल कैसे करें
- Vertex AI Studio का इस्तेमाल कैसे करें
- Vertex AI जनरेटिव मॉडल का इस्तेमाल करके, नतीजे को बेहतर बनाने का तरीका
- वेक्टर इंडेक्स का इस्तेमाल करके परफ़ॉर्मेंस को बेहतर बनाने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- Google Cloud Console और Cloud Shell के साथ काम करने वाला वेब ब्राउज़र, जैसे कि Chrome
2. सेटअप और ज़रूरी शर्तें
प्रोजेक्ट सेटअप करना
- Google Cloud Console में साइन इन करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
- कोई नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. Google Cloud Console में नया प्रोजेक्ट बनाने के लिए, हेडर में मौजूद 'कोई प्रोजेक्ट चुनें' बटन पर क्लिक करें. इससे एक पॉप-अप विंडो खुलेगी.

'कोई प्रोजेक्ट चुनें' विंडो में, 'नया प्रोजेक्ट' बटन दबाएं. इससे नए प्रोजेक्ट के लिए एक डायलॉग बॉक्स खुलेगा.
डायलॉग बॉक्स में, प्रोजेक्ट का पसंदीदा नाम डालें और जगह चुनें.
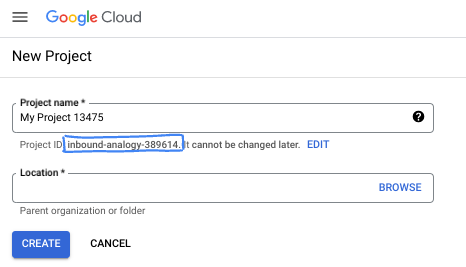
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. प्रोजेक्ट के नाम का इस्तेमाल Google API नहीं करते हैं. इसे कभी भी बदला जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Google Cloud Console, अपने-आप एक यूनीक आईडी जनरेट करता है. हालांकि, इसे अपनी पसंद के मुताबिक बनाया जा सकता है. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा आईडी जनरेट करें. इसके अलावा, अपनी पसंद का आईडी डालकर भी देखा जा सकता है कि वह उपलब्ध है या नहीं. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी का रेफ़रंस देना होगा. इसे आम तौर पर, PROJECT_ID प्लेसहोल्डर से पहचाना जाता है.
- आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
बिलिंग चालू करें
बिलिंग चालू करने के लिए, आपके पास दो विकल्प हैं. आप अपने निजी बिलिंग खाते का इस्तेमाल कर सकते हैं या यहां दिए गए तरीके से क्रेडिट रिडीम कर सकते हैं.
Google Cloud क्रेडिट रिडीम करना (ज़रूरी नहीं है)
इस वर्कशॉप को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, क्लाउड संसाधनों पर 3 डॉलर से कम खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, संसाधनों को मिटाने का तरीका जानने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करें.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त क्रेडिट का इस्तेमाल कर सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसके अलावा, G और फिर S दबाकर भी यह सुविधा ऐक्सेस की जा सकती है. इस क्रम से, Cloud Shell चालू हो जाएगा. इसके लिए, आपको Google Cloud Console में होना चाहिए या इस लिंक का इस्तेमाल करना होगा.
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. शुरू करने से पहले
एपीआई चालू करना
Cloud SQL, Compute Engine, नेटवर्किंग सेवाएं, और Vertex AI का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में इनसे जुड़े एपीआई चालू करने होंगे.
Cloud Shell टर्मिनल में, पक्का करें कि आपका प्रोजेक्ट आईडी सेट अप हो:
gcloud config set project [YOUR-PROJECT-ID]
PROJECT_ID एनवायरमेंट वैरिएबल सेट करें:
PROJECT_ID=$(gcloud config get-value project)
ज़रूरी सभी सेवाएं चालू करें:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
अनुमानित आउटपुट
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
एपीआई के बारे में जानकारी
- Cloud SQL Admin API (
sqladmin.googleapis.com) की मदद से, Cloud SQL इंस्टेंस को प्रोग्राम के हिसाब से बनाया, कॉन्फ़िगर किया, और मैनेज किया जा सकता है. यह Google की पूरी तरह से मैनेज की गई रिलेशनल डेटाबेस सेवा के लिए कंट्रोल प्लेन उपलब्ध कराता है. यह MySQL, PostgreSQL, और SQL Server के साथ काम करता है. यह सेवा, प्रोविज़निंग, बैकअप, ज़्यादा अपटाइम, और स्केलिंग जैसे टास्क मैनेज करती है. - Compute Engine API (
compute.googleapis.com) की मदद से, वर्चुअल मशीनें (वीएम), परसिस्टेंट डिस्क, और नेटवर्क सेटिंग बनाई और मैनेज की जा सकती हैं. यह मुख्य Infrastructure-as-a-Service (IaaS) फ़ाउंडेशन उपलब्ध कराता है. इसकी मदद से, अपने वर्कलोड चलाए जा सकते हैं. साथ ही, मैनेज की जाने वाली कई सेवाओं के लिए बुनियादी इंफ़्रास्ट्रक्चर को होस्ट किया जा सकता है. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) की मदद से, Google Cloud प्रोजेक्ट के मेटाडेटा और कॉन्फ़िगरेशन को प्रोग्राम के हिसाब से मैनेज किया जा सकता है. इससे आपको संसाधनों को व्यवस्थित करने, पहचान और ऐक्सेस मैनेजमेंट (IAM) नीतियों को मैनेज करने, और प्रोजेक्ट के क्रम में अनुमतियों की पुष्टि करने में मदद मिलती है. - Service Networking API (
servicenetworking.googleapis.com) की मदद से, वर्चुअल प्राइवेट क्लाउड (वीपीसी) नेटवर्क और Google की मैनेज की गई सेवाओं के बीच, निजी कनेक्टिविटी को अपने-आप सेटअप किया जा सकता है. AlloyDB जैसी सेवाओं के लिए, प्राइवेट आईपी ऐक्सेस सेट अप करना ज़रूरी है. इससे वे आपके अन्य संसाधनों के साथ सुरक्षित तरीके से कम्यूनिकेट कर सकती हैं. - Vertex AI API (
aiplatform.googleapis.com) की मदद से, आपके ऐप्लिकेशन मशीन लर्निंग मॉडल बना सकते हैं, उन्हें डिप्लॉय कर सकते हैं, और बड़े पैमाने पर उपलब्ध करा सकते हैं. यह Google Cloud की सभी एआई सेवाओं के लिए, एक जैसा इंटरफ़ेस उपलब्ध कराता है. इसमें जनरेटिव एआई मॉडल (जैसे, Gemini) का ऐक्सेस और कस्टम मॉडल ट्रेनिंग शामिल है.
4. Cloud SQL इंस्टेंस बनाना
Vertex AI के साथ डेटाबेस इंटिग्रेशन वाला Cloud SQL इंस्टेंस बनाएं.
डेटाबेस का पासवर्ड बनाना
डिफ़ॉल्ट डेटाबेस उपयोगकर्ता के लिए पासवर्ड तय करें. आपके पास अपना पासवर्ड तय करने या पासवर्ड जनरेट करने के लिए, रैंडम फ़ंक्शन का इस्तेमाल करने का विकल्प होता है:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
पासवर्ड के लिए जनरेट की गई वैल्यू नोट करें:
echo $CLOUDSQL_PASSWORD
Cloud SQL for MySQL इंस्टेंस बनाना
क्लाउड एसक्यूएल इंस्टेंस बनाते समय, cloudsql_vector फ़्लैग को चालू किया जा सकता है. फ़िलहाल, वेक्टर की सुविधा MySQL 8.0 R20241208.01_00 या इसके बाद के वर्शन के लिए उपलब्ध है
Cloud Shell सेशन में यह कमांड चलाएं:
gcloud sql instances create my-cloudsql-instance \
--database-version=MYSQL_8_4 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--enable-google-ml-integration \
--edition=ENTERPRISE \
--root-password=$CLOUDSQL_PASSWORD
Cloud Shell से कनेक्ट करके, हम अपने कनेक्शन की पुष्टि कर सकते हैं
gcloud sql connect my-cloudsql-instance --user=root
कमांड चलाएं और कनेक्ट करने के लिए तैयार होने पर, प्रॉम्प्ट में अपना पासवर्ड डालें.
अनुमानित आउटपुट:
$gcloud sql connect my-cloudsql-instance --user=root Allowlisting your IP for incoming connection for 5 minutes...done. Connecting to database with SQL user [root].Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 71 Server version: 8.4.4-google (Google) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
ctrl+d कीबोर्ड शॉर्टकट का इस्तेमाल करके या exit कमांड चलाकर, फ़िलहाल mysql सेशन से बाहर निकलें
exit
Vertex AI इंटिग्रेशन चालू करना
Vertex AI इंटिग्रेशन का इस्तेमाल करने के लिए, इंटरनल Cloud SQL सेवा खाते को ज़रूरी अनुमतियां दें.
Cloud SQL के इंटरनल सेवा खाते का ईमेल पता ढूंढता है और उसे वैरिएबल के तौर पर एक्सपोर्ट करता है.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Cloud SQL सेवा खाते को Vertex AI का ऐक्सेस दें:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Cloud SQL के दस्तावेज़ में, इंस्टेंस बनाने और उसे कॉन्फ़िगर करने के बारे में ज़्यादा जानें. इसके लिए, यहां जाएं.
5. डेटाबेस तैयार करना
अब हमें एक डेटाबेस बनाना होगा और वेक्टर सपोर्ट चालू करना होगा.
डेटाबेस बनाना
quickstart_db नाम का डेटाबेस बनाएं. इसके लिए, हमारे पास अलग-अलग विकल्प हैं. जैसे, कमांड लाइन डेटाबेस क्लाइंट (जैसे, MySQL के लिए mysql), SDK या Cloud SQL Studio. हम डेटाबेस बनाने के लिए, एसडीके (gcloud) का इस्तेमाल करेंगे.
डेटाबेस बनाने के लिए, Cloud Shell में यह कमांड चलाएं
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
6. डेटा लोड करें
अब हमें डेटाबेस में ऑब्जेक्ट बनाने और डेटा लोड करने की ज़रूरत है. हम काल्पनिक Cymbal Store के डेटा का इस्तेमाल करने जा रहे हैं. डेटा, SQL (स्कीमा के लिए) और CSV फ़ॉर्मैट (डेटा के लिए) में उपलब्ध है.
Cloud Shell, डेटाबेस से कनेक्ट करने, सभी ऑब्जेक्ट बनाने, और डेटा लोड करने के लिए हमारा मुख्य एनवायरमेंट होगा.
सबसे पहले, हमें अपने Cloud SQL इंस्टेंस के लिए, अनुमति वाले नेटवर्क की सूची में Cloud Shell का सार्वजनिक आईपी पता जोड़ना होगा. Cloud Shell में यह कमांड चलाएं:
gcloud sql instances patch my-cloudsql-instance --authorized-networks=$(curl ifconfig.me)
अगर आपका सेशन खत्म हो गया है, रीसेट हो गया है या किसी दूसरे टूल से काम किया जा रहा है, तो CLOUDSQL_PASSWORD वैरिएबल को फिर से एक्सपोर्ट करें:
export CLOUDSQL_PASSWORD=...your password defined for the instance...
अब हम अपने डेटाबेस में सभी ज़रूरी ऑब्जेक्ट बना सकते हैं. इसके लिए, हम MySQL की mysql यूटिलिटी का इस्तेमाल करेंगे. साथ ही, curl यूटिलिटी का इस्तेमाल करेंगे, जो सार्वजनिक सोर्स से डेटा हासिल करती है.
Cloud Shell में यह कमांड चलाएं:
export INSTANCE_IP=$(gcloud sql instances describe my-cloudsql-instance --format="value(ipAddresses.ipAddress)")
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_mysql_schema.sql | mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
हमने पिछले निर्देश में क्या किया था? हमने अपने डेटाबेस से कनेक्ट करके, डाउनलोड किए गए SQL कोड को लागू किया. इससे टेबल, इंडेक्स, और सीक्वेंस बनाए गए.
अगला चरण, cymbal_products डेटा लोड करना है. हम curl और mysql यूटिलिटी का इस्तेमाल करते हैं.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_products.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_products FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
इसके बाद, हम cymbal_stores के साथ आगे बढ़ते हैं.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_stores.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_stores FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
साथ ही, cymbal_inventory एट्रिब्यूट की वैल्यू के तौर पर, हर स्टोर में मौजूद हर प्रॉडक्ट की संख्या की जानकारी दें.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_inventory.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_inventory FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
अगर आपके पास अपना सैंपल डेटा है और Cloud Console से उपलब्ध Cloud SQL इंपोर्ट टूल के साथ काम करने वाली CSV फ़ाइलें हैं, तो दिखाई गई प्रोसेस के बजाय इनका इस्तेमाल किया जा सकता है.
7. Create Embeddings
अगला चरण, Google Vertex AI के textembedding-005 मॉडल का इस्तेमाल करके, हमारे प्रॉडक्ट के ब्यौरों के लिए एम्बेडिंग बनाना है. साथ ही, उन्हें cymbal_products टेबल के नए कॉलम में सेव करना है.
वेक्टर डेटा को सेव करने के लिए, हमें अपने Cloud SQL इंस्टेंस में वेक्टर फ़ंक्शन चालू करना होगा. Cloud Shell में यह कमांड चलाएं:
gcloud sql instances patch my-cloudsql-instance \
--database-flags=cloudsql_vector=on
डेटाबेस से कनेक्ट करें:
mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
साथ ही, एम्बेडिंग फ़ंक्शन का इस्तेमाल करके, cymbal_products टेबल में एक नया कॉलम embedding बनाएं. इस नए कॉलम में, product_description कॉलम में मौजूद टेक्स्ट के आधार पर वेक्टर एम्बेडिंग शामिल होंगी.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) using varbinary;
UPDATE cymbal_products SET embedding = mysql.ml_embedding('text-embedding-005', product_description);
आम तौर पर, 2,000 लाइनों के लिए वेक्टर एम्बेडिंग जनरेट करने में पांच मिनट से कम समय लगता है. हालांकि, कभी-कभी इसमें थोड़ा ज़्यादा समय लग सकता है. साथ ही, अक्सर यह प्रोसेस बहुत कम समय में पूरी हो जाती है.
8. मिलते-जुलते प्रॉडक्ट खोजने की सुविधा का इस्तेमाल करना
अब हम समानता के आधार पर खोज करने की सुविधा का इस्तेमाल करके खोज कर सकते हैं. इसके लिए, हम ब्यौरों के लिए कैलकुलेट की गई वेक्टर वैल्यू और उसी एम्बेडिंग मॉडल का इस्तेमाल करके, अपने अनुरोध के लिए जनरेट की गई वेक्टर वैल्यू का इस्तेमाल करते हैं.
एसक्यूएल क्वेरी को उसी कमांड लाइन इंटरफ़ेस से चलाया जा सकता है. इसके अलावा, Cloud SQL Studio से भी चलाया जा सकता है. एक से ज़्यादा लाइनों वाली और मुश्किल क्वेरी को Cloud SQL Studio में मैनेज करना बेहतर होता है.
उपयोगकर्ता बनाना
हमें एक ऐसे नए उपयोगकर्ता की ज़रूरत है जो Cloud SQL Studio का इस्तेमाल कर सके. हम एक बिल्ट-इन टाइप का छात्र उपयोगकर्ता बनाएंगे. इसके लिए, हम वही पासवर्ड इस्तेमाल करेंगे जो हमने रूट उपयोगकर्ता के लिए इस्तेमाल किया था.
Cloud Shell में यह कमांड चलाएं:
gcloud sql users create student --instance=my-cloudsql-instance --password=$CLOUDSQL_PASSWORD --host=%
Cloud SQL Studio शुरू करना
कंसोल में, उस Cloud SQL इंस्टेंस पर क्लिक करें जिसे हमने पहले बनाया था.
जब यह दाईं ओर के पैनल में खुला होता है, तब हमें Cloud SQL Studio दिखता है. इस पर क्लिक करें.
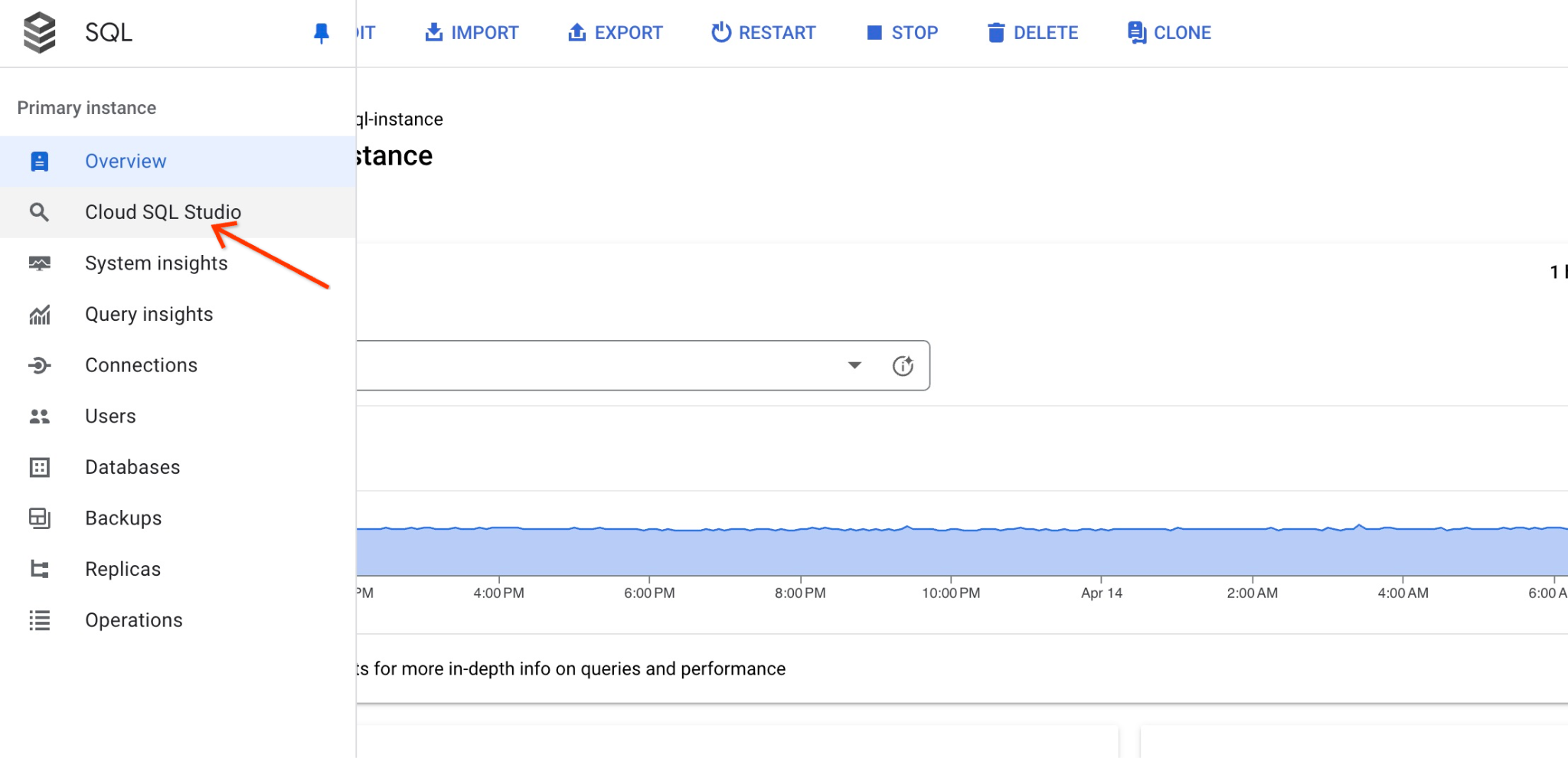
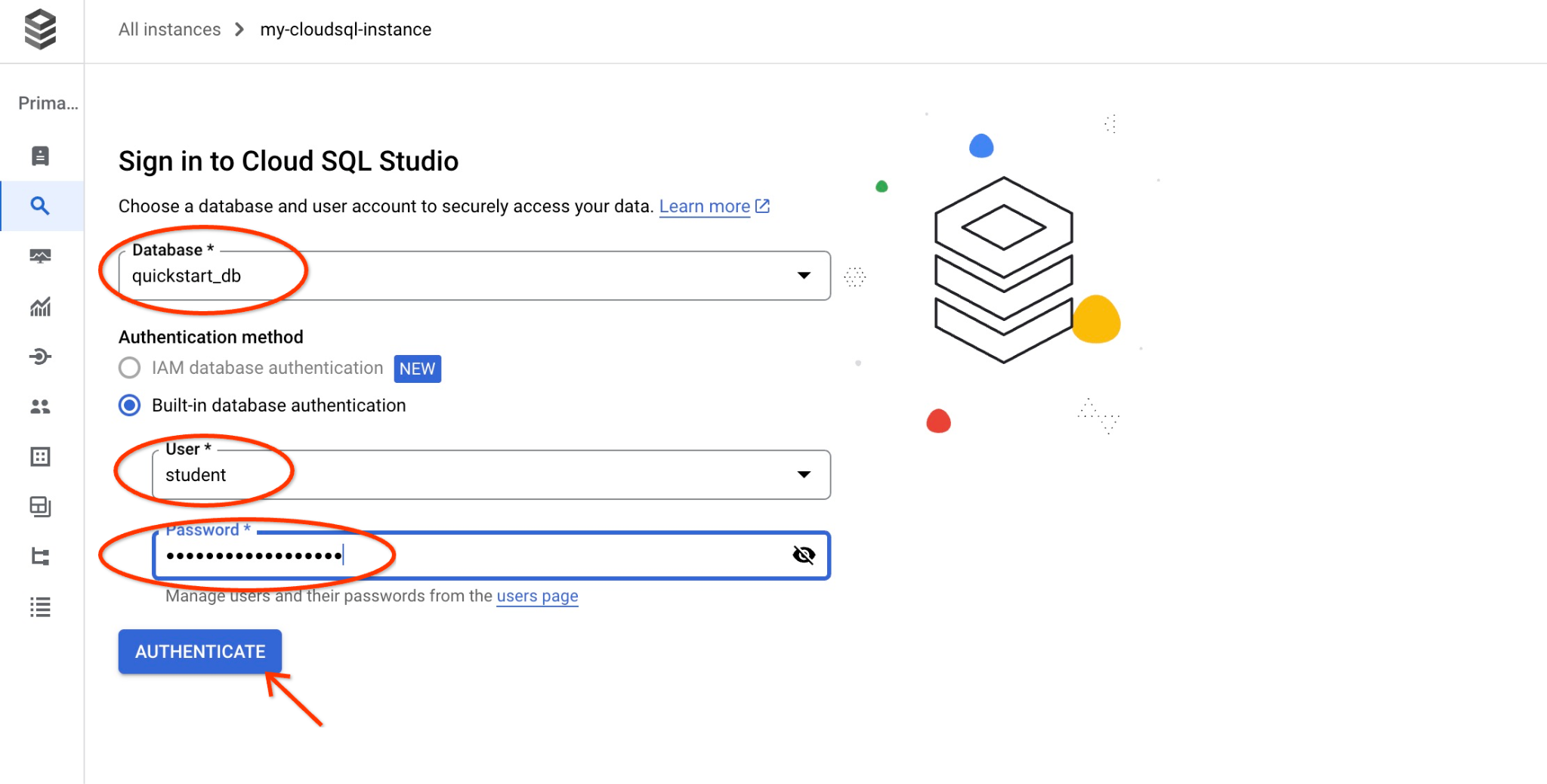
इससे एक डायलॉग बॉक्स खुलेगा. इसमें आपको डेटाबेस का नाम और अपने क्रेडेंशियल देने होंगे:
- डेटाबेस: quickstart_db
- उपयोगकर्ता: छात्र-छात्रा
- पासवर्ड: उपयोगकर्ता के लिए नोट किया गया पासवर्ड
इसके बाद, "पुष्टि करें" बटन पर क्लिक करें.
इससे अगली विंडो खुलेगी. इसमें, SQL एडिटर खोलने के लिए, दाईं ओर मौजूद "एडिटर" टैब पर क्लिक करें.
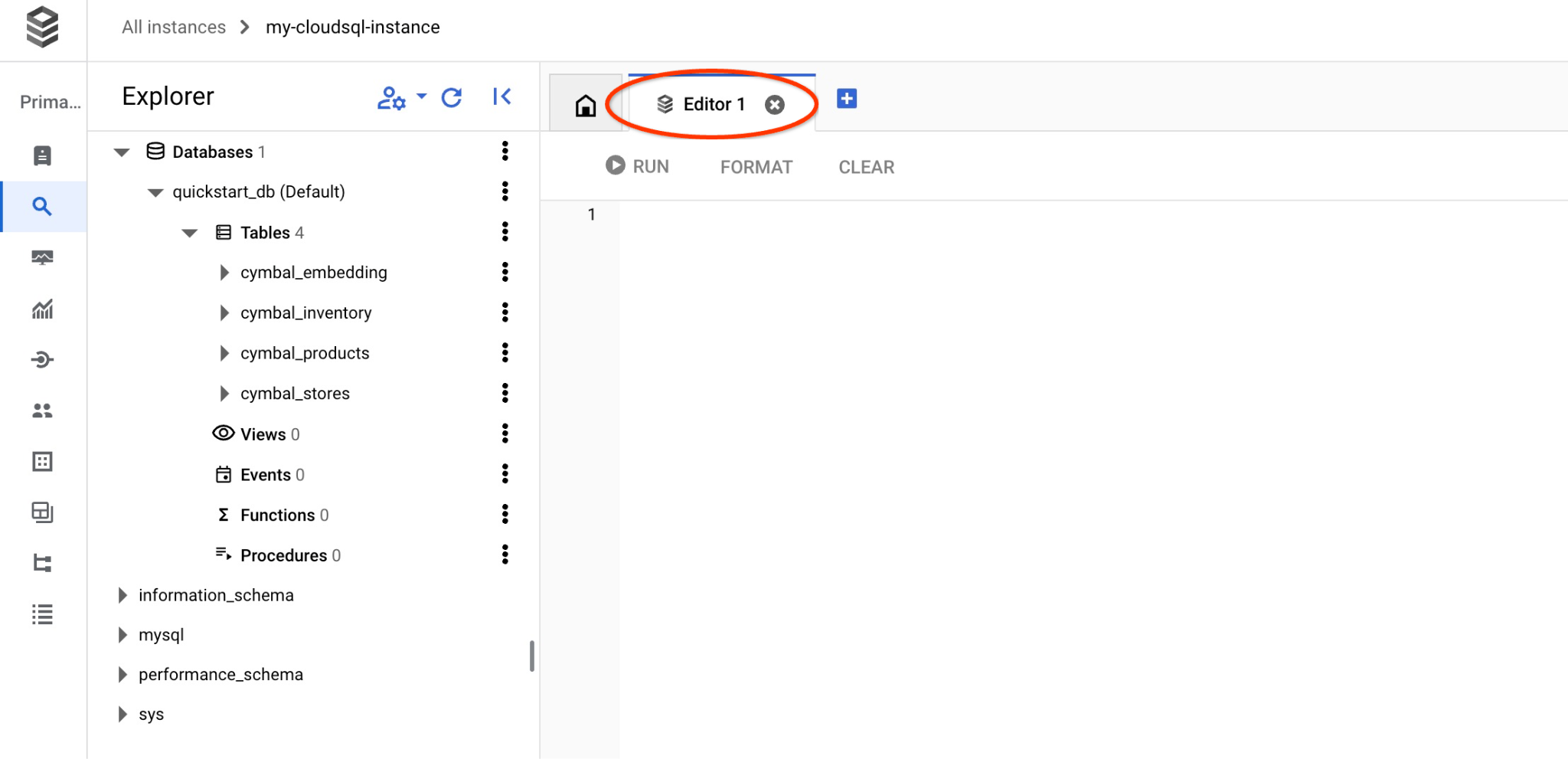
अब हम अपनी क्वेरी चलाने के लिए तैयार हैं.
क्वेरी चलाएं
क्लाइंट के अनुरोध से मिलते-जुलते उपलब्ध प्रॉडक्ट की सूची पाने के लिए, क्वेरी चलाएं. वेक्टर वैल्यू पाने के लिए, हम Vertex AI को यह अनुरोध भेजेंगे: "यहां किस तरह के फलों के पेड़ अच्छी तरह से बढ़ते हैं?"
केएनएन (एग्ज़ैक्ट) वेक्टर सर्च के लिए, cosine_distance के साथ क्वेरी चलाना
यहां दी गई क्वेरी को चलाकर, cosine_distance फ़ंक्शन का इस्तेमाल करके, हमारे अनुरोध के लिए सबसे सही पांच आइटम चुने जा सकते हैं:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cosine_distance(cp.embedding ,@query_vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
क्वेरी को Cloud SQL Studio एडिटर में कॉपी करके चिपकाएं. इसके बाद, "चलाएं" बटन दबाएं. इसके अलावा, इसे quickstart_db डेटाबेस से कनेक्ट करने वाले कमांड-लाइन सेशन में भी चिपकाया जा सकता है.
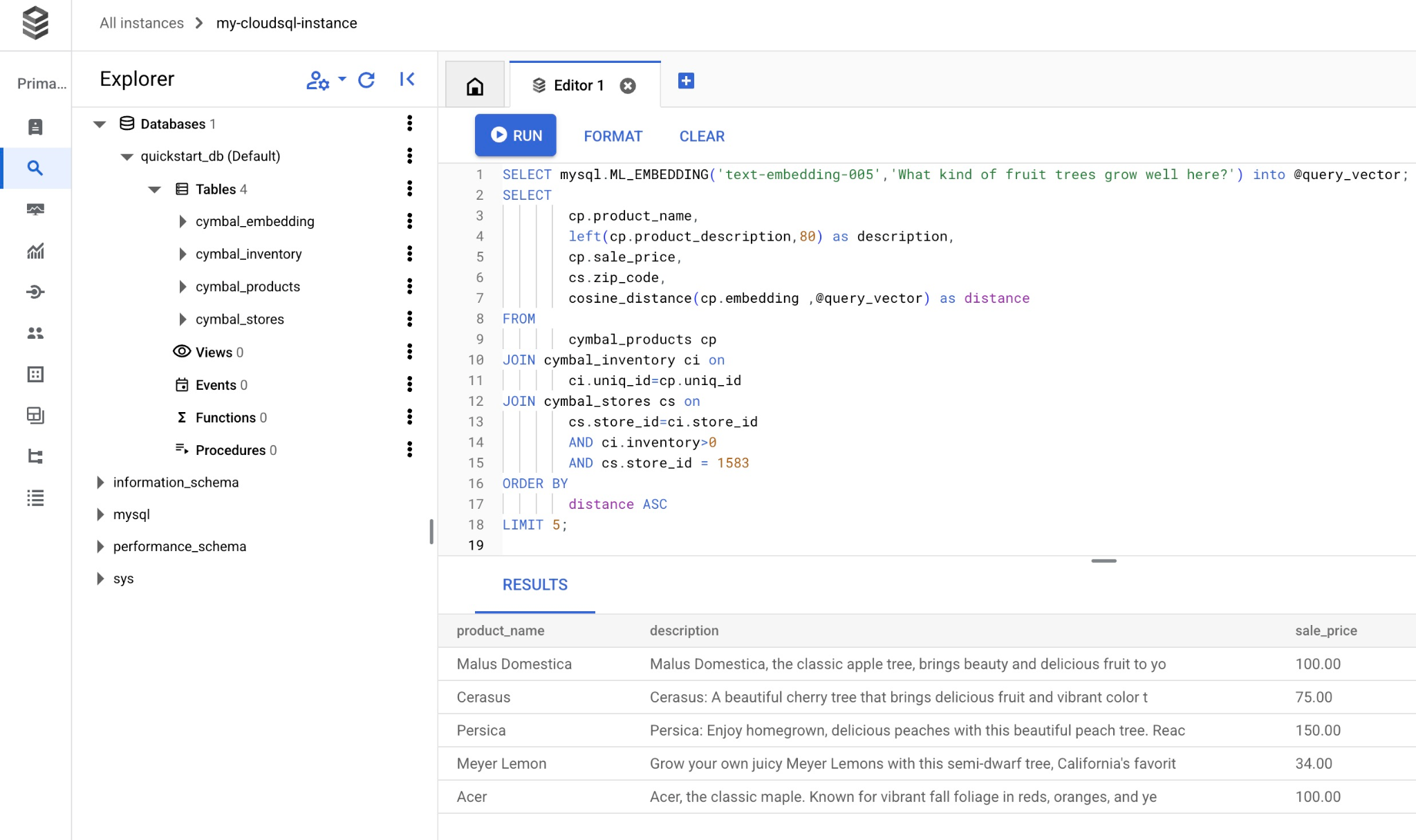
यहां क्वेरी से मेल खाने वाले चुने गए प्रॉडक्ट की सूची दी गई है.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set (0.13 sec)
cosine_distance फ़ंक्शन का इस्तेमाल करके क्वेरी को पूरा होने में 0.13 सेकंड लगे.
केएनएन (एग्ज़ैक्ट) वेक्टर सर्च के लिए, approx_distance के साथ क्वेरी चलाना
अब हम उसी क्वेरी को चलाते हैं. हालांकि, इसमें approx_distance फ़ंक्शन का इस्तेमाल करके केएनएन सर्च का इस्तेमाल किया जाता है. अगर हमारे पास एम्बेडिंग के लिए कोई एएनएन इंडेक्स नहीं है, तो यह बैकग्राउंड में सटीक खोज पर अपने-आप वापस आ जाता है:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
यहां क्वेरी के ज़रिए लौटाए गए प्रॉडक्ट की सूची दी गई है.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set, 1 warning (0.12 sec)
क्वेरी को पूरा होने में सिर्फ़ 0.12 सेकंड लगे. हमें cosine_distance फ़ंक्शन के लिए मिले नतीजों जैसे ही नतीजे मिले.
9. फ़ेच किए गए डेटा का इस्तेमाल करके एलएलएम के जवाब को बेहतर बनाना
हम क्वेरी के नतीजे का इस्तेमाल करके, क्लाइंट ऐप्लिकेशन के लिए Gen AI LLM के जवाब को बेहतर बना सकते हैं. साथ ही, क्वेरी के नतीजों को प्रॉम्प्ट के तौर पर इस्तेमाल करके, Vertex AI के जनरेटिव फ़ाउंडेशन लैंग्वेज मॉडल के लिए काम का आउटपुट तैयार कर सकते हैं.
इसके लिए, हमें वेक्टर सर्च से मिले नतीजों के साथ एक JSON जनरेट करना होगा. इसके बाद, उस जनरेट किए गए JSON का इस्तेमाल, Vertex AI में एलएलएम मॉडल के लिए प्रॉम्प्ट में जोड़कर करना होगा, ताकि काम का आउटपुट बनाया जा सके. पहले चरण में, हम JSON जनरेट करते हैं. इसके बाद, हम इसे Vertex AI Studio में टेस्ट करते हैं. आखिरी चरण में, हम इसे एसक्यूएल स्टेटमेंट में शामिल करते हैं, जिसका इस्तेमाल किसी ऐप्लिकेशन में किया जा सकता है.
JSON फ़ॉर्मैट में आउटपुट जनरेट करना
क्वेरी में बदलाव करके, JSON फ़ॉर्मैट में आउटपुट जनरेट करें. साथ ही, Vertex AI को सिर्फ़ एक लाइन का डेटा भेजें
एएनएन सर्च का इस्तेमाल करके क्वेरी का उदाहरण यहां दिया गया है:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1)
SELECT json_arrayagg(json_object('product_name',product_name,'description',description,'sale_price',sale_price,'zip_code',zip_code,'product_id',product_id)) FROM trees;
यहां आउटपुट में अनुमानित JSON दिया गया है:
[{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}]
Vertex AI Studio में प्रॉम्प्ट चलाएं
हम जनरेट किए गए JSON का इस्तेमाल, Vertex AI Studio में जनरेटिव एआई टेक्स्ट मॉडल को प्रॉम्प्ट के तौर पर देने के लिए कर सकते हैं
Cloud Console में Vertex AI Studio Prompt खोलें.
यह आपसे कुछ और एपीआई चालू करने के लिए कह सकता है. हालांकि, इस अनुरोध को अनदेखा किया जा सकता है. हमें लैब को पूरा करने के लिए, किसी अन्य एपीआई की ज़रूरत नहीं है.
Studio में कोई प्रॉम्प्ट डालें.
हम इस प्रॉम्प्ट का इस्तेमाल करने वाले हैं:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
यहां बताया गया है कि क्वेरी के रिस्पॉन्स से JSON प्लेसहोल्डर को बदलने पर, यह कैसा दिखता है:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
यहां JSON वैल्यू के साथ प्रॉम्प्ट चलाने और gemini-2.5-flash मॉडल का इस्तेमाल करने पर मिला नतीजा दिया गया है:
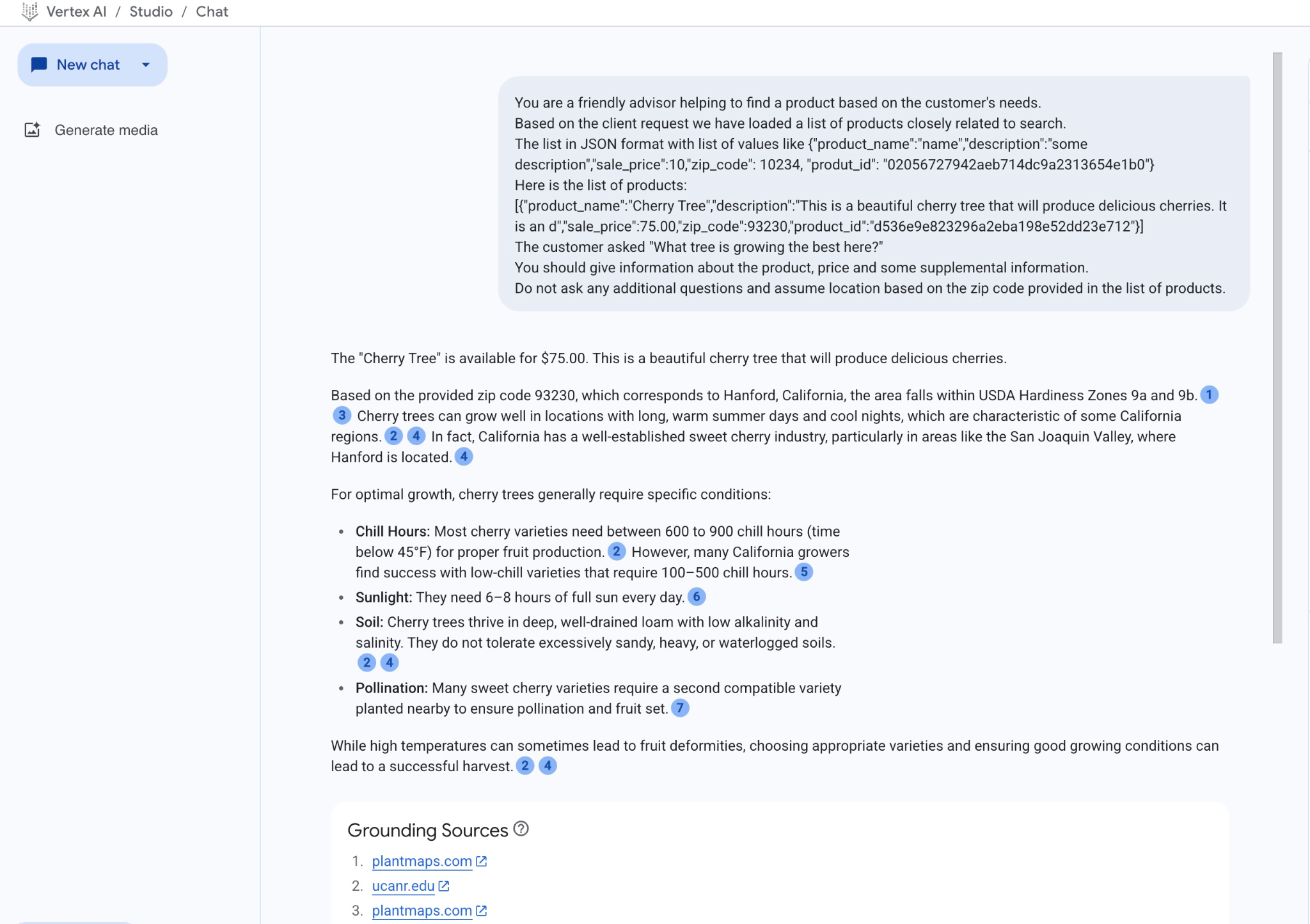
इस उदाहरण में, मॉडल से मिला जवाब, सिमैंटिक सर्च के नतीजों और बताए गए पिन कोड में उपलब्ध सबसे मिलते-जुलते प्रॉडक्ट का इस्तेमाल करके दिया गया है.
एसक्यूएल में प्रॉम्प्ट चलाएं
हम Cloud SQL के साथ Vertex AI के एआई इंटिग्रेशन का इस्तेमाल करके भी, जनरेटिव मॉडल से ऐसा ही जवाब पा सकते हैं. इसके लिए, डेटाबेस में सीधे तौर पर एसक्यूएल का इस्तेमाल करें.
अब हम जनरेट किए गए टेक्स्ट का इस्तेमाल, JSON फ़ॉर्मैट में मिले नतीजों के साथ सबक्वेरी में कर सकते हैं. ऐसा इसलिए, ताकि SQL का इस्तेमाल करके, जनरेटिव एआई टेक्स्ट मॉडल को प्रॉम्प्ट के हिस्से के तौर पर टेक्स्ट दिया जा सके.
डेटाबेस में क्वेरी चलाने के लिए, mysql या Cloud SQL Studio सेशन में जाएं
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1),
prompt AS (
SELECT
CONCAT( 'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:', json_arrayagg(json_object('product_name',trees.product_name,'description',trees.description,'sale_price',trees.sale_price,'zip_code',trees.zip_code,'product_id',trees.product_id)) , 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information') AS prompt_text
FROM
trees),
response AS (
SELECT
mysql.ML_PREDICT_ROW('publishers/google/models/gemini-2.0-flash-001:generateContent',
json_object('contents',
json_object('role',
'user',
'parts',
json_array(
json_object('text',
prompt_text))))) AS resp
FROM
prompt)
SELECT
JSON_EXTRACT(resp, '$.candidates[0].content.parts[0].text')
FROM
response;
यहां सैंपल आउटपुट दिया गया है. मॉडल के वर्शन और पैरामीटर के आधार पर, आपका आउटपुट अलग हो सकता है.:
"Okay, I see you're looking for fruit trees that grow well in your area. Based on the available product, the **Malus Domestica** (Apple Tree) is a great option to consider!\n\n* **Product:** Malus Domestica (Apple Tree)\n* **Description:** This classic apple tree grows to about 30 feet tall and provides beautiful seasonal color with green leaves in summer and fiery colors in the fall. It's known for its strength and provides good shade. Most importantly, it produces delicious apples!\n* **Price:** \\$100.00\n* **Growing Zones:** This particular apple tree is well-suited for USDA zones 4-8. Since your zip code is 93230, you are likely in USDA zone 9a or 9b. While this specific tree is rated for zones 4-8, with proper care and variety selection, apple trees can still thrive in slightly warmer climates. You may need to provide extra care during heat waves.\n\n**Recommendation:** I would recommend investigating varieties of Malus Domestica suited to slightly warmer climates or contacting a local nursery/arborist to verify if it is a good fit for your local climate conditions.\n"
आउटपुट, मार्कडाउन फ़ॉर्मैट में दिया जाता है.
10. सबसे नज़दीकी पड़ोसी इंडेक्स बनाना
हमारा डेटासेट काफ़ी छोटा है. जवाब मिलने में लगने वाला समय, मुख्य रूप से एआई मॉडल के साथ इंटरैक्शन पर निर्भर करता है. हालांकि, लाखों वेक्टर होने पर, वेक्टर सर्च में जवाब देने में लगने वाले समय का ज़्यादातर हिस्सा लग सकता है. साथ ही, इससे सिस्टम पर ज़्यादा लोड पड़ सकता है. इससे हम अपने वेक्टर के आधार पर इंडेक्स बना सकते हैं.
ScANN इंडेक्स बनाना
हम अपने टेस्ट के लिए, ScANN इंडेक्स टाइप का इस्तेमाल करेंगे.
एम्बेडिंग कॉलम के लिए इंडेक्स बनाने के लिए, हमें एम्बेडिंग कॉलम के लिए दूरी का मेज़रमेंट तय करना होगा. दस्तावेज़ में जाकर, पैरामीटर के बारे में ज़्यादा जानकारी पाएं.
CREATE VECTOR INDEX cymbal_products_embedding_idx ON cymbal_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE;
जवाब की तुलना करें
अब हम वेक्टर सर्च क्वेरी को फिर से चला सकते हैं और नतीजे देख सकते हैं
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
अनुमानित आउटपुट:
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | product_name | description | sale_price | zip_code | distance | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 | | Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 | | Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 | | Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 | | Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ 5 rows in set (0.08 sec)
हम देख सकते हैं कि एक्ज़ीक्यूशन का समय थोड़ा ही अलग था. हालांकि, इतने छोटे डेटासेट के लिए ऐसा होना सामान्य है. लाखों वेक्टर वाले बड़े डेटासेट के लिए, यह बदलाव ज़्यादा ध्यान देने वाला होना चाहिए.
EXPLAIN कमांड का इस्तेमाल करके, एक्ज़ीक्यूशन प्लान देखा जा सकता है:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
EXPLAIN ANALYZE SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
एक्ज़ीक्यूशन प्लान (उद्धरण):
...
-> Nested loop inner join (cost=443 rows=5) (actual time=1.14..1.18 rows=5 loops=1)
-> Vector index scan on cp (cost=441 rows=5) (actual time=1.1..1.1 rows=5 loops=1)
-> Single-row index lookup on cp using PRIMARY (uniq_id=cp.uniq_id) (cost=0.25 rows=1) (actual time=0.0152..0.0152 rows=1 loops=5)
...
हम देख सकते हैं कि यह cp (cymbal_products टेबल का उपनाम) पर वेक्टर इंडेक्स स्कैन का इस्तेमाल कर रहा था.
अपने डेटा के साथ एक्सपेरिमेंट किया जा सकता है. इसके अलावा, अलग-अलग सर्च क्वेरी की जांच करके देखा जा सकता है कि MySQL में सिमैंटिक सर्च कैसे काम करती है.
11. पर्यावरण को साफ़-सुथरा रखना
Cloud SQL इंस्टेंस मिटाना
लैब का काम पूरा होने के बाद, Cloud SQL इंस्टेंस को मिटा दें
अगर आपका कनेक्शन बंद हो गया है और पिछली सभी सेटिंग मिट गई हैं, तो क्लाउड शेल में प्रोजेक्ट और एनवायरमेंट वैरिएबल तय करें:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
इंस्टेंस मिटाएं:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
अनुमानित कंसोल आउटपुट:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. बधाई हो
कोड लैब पूरा करने के लिए बधाई.
Google Cloud का लर्निंग पाथ
यह लैब, Google Cloud के साथ प्रोडक्शन-रेडी एआई के लर्निंग पाथ का हिस्सा है.
- प्रोटोटाइप से प्रोडक्शन तक के अंतर को कम करने के लिए, पूरा पाठ्यक्रम देखें.
- अपनी प्रोग्रेस को
#ProductionReadyAIहैशटैग के साथ शेयर करें.
हमने क्या-क्या बताया
- PostgreSQL के लिए Cloud SQL इंस्टेंस को डिप्लॉय करने का तरीका
- डेटाबेस बनाने और Cloud SQL AI इंटिग्रेशन को चालू करने का तरीका
- डेटाबेस में डेटा लोड करने का तरीका
- Cloud SQL Studio का इस्तेमाल कैसे करें
- Cloud SQL में Vertex AI एम्बेडिंग मॉडल का इस्तेमाल कैसे करें
- Vertex AI Studio का इस्तेमाल कैसे करें
- Vertex AI जनरेटिव मॉडल का इस्तेमाल करके, नतीजे को बेहतर बनाने का तरीका
- वेक्टर इंडेक्स का इस्तेमाल करके परफ़ॉर्मेंस को बेहतर बनाने का तरीका
AlloyDB के लिए इसी तरह का कोडलैब या Cloud SQL for Postgres के लिए कोडलैब आज़माएं
13. सर्वे
आउटपुट: