
1. Giới thiệu
Cloud Spanner là một dịch vụ cơ sở dữ liệu quan hệ được quản lý hoàn toàn, có thể mở rộng theo chiều ngang, phân phối trên toàn cầu, cung cấp các giao dịch ACID và ngữ nghĩa SQL mà không làm giảm hiệu suất và khả năng đáp ứng cao.
GKE Autopilot là một chế độ hoạt động trong GKE, trong đó Google quản lý cấu hình cụm của bạn, bao gồm cả các nút, khả năng mở rộng, tính bảo mật và các chế độ cài đặt được định cấu hình sẵn khác để tuân theo các phương pháp hay nhất. Ví dụ: GKE Autopilot cho phép Workload Identity quản lý các quyền đối với dịch vụ.
Mục tiêu của lớp học này là hướng dẫn bạn quy trình kết nối một số dịch vụ phụ trợ đang chạy trên GKE Autopilot với cơ sở dữ liệu Cloud Spanner.
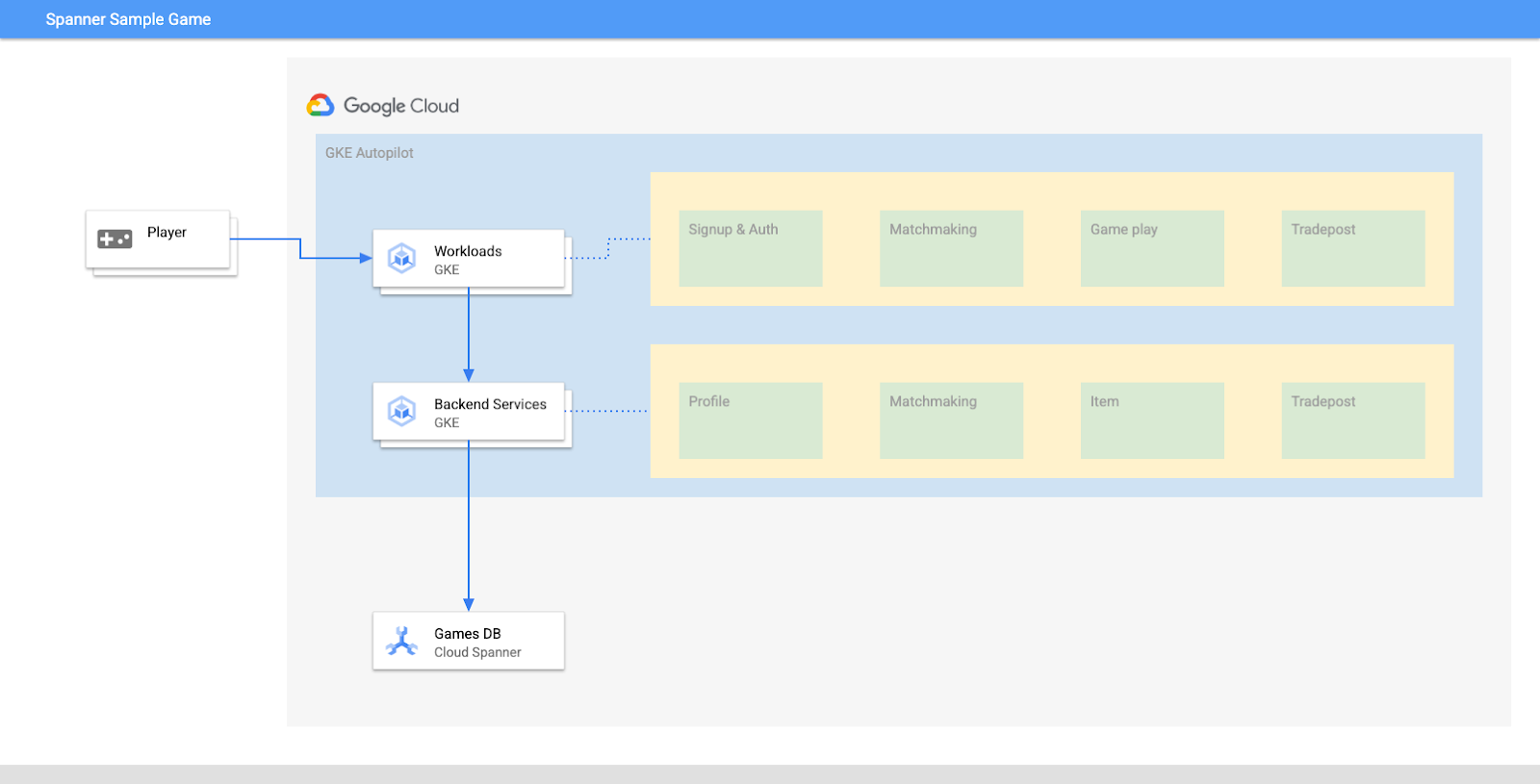
Trong phòng thí nghiệm này, trước tiên, bạn sẽ thiết lập một dự án và khởi chạy Cloud Shell. Sau đó, bạn sẽ triển khai cơ sở hạ tầng bằng Terraform.
Khi quá trình này hoàn tất, bạn sẽ tương tác với Cloud Build và Cloud Deploy để thực hiện quá trình di chuyển giản đồ ban đầu cho cơ sở dữ liệu Trò chơi, triển khai các dịch vụ phụ trợ rồi triển khai khối lượng công việc.
Các dịch vụ trong lớp học lập trình này cũng giống như trong lớp học lập trình Cloud Spanner: Bắt đầu phát triển trò chơi. Bạn không bắt buộc phải thực hiện lớp học lập trình đó để chạy các dịch vụ trên GKE và kết nối với Spanner. Nhưng nếu bạn quan tâm đến thông tin chi tiết cụ thể về những dịch vụ hoạt động trên Spanner, hãy xem thông tin đó.
Khi các dịch vụ phụ trợ và khối lượng công việc đang chạy, bạn có thể bắt đầu tạo tải và quan sát cách các dịch vụ phối hợp với nhau.
Cuối cùng, bạn sẽ dọn dẹp các tài nguyên đã được tạo trong phòng thí nghiệm này.
Sản phẩm bạn sẽ tạo ra
Trong phần này, bạn sẽ:
- Cung cấp cơ sở hạ tầng bằng Terraform
- Tạo giản đồ cơ sở dữ liệu bằng quy trình Di chuyển giản đồ trong Cloud Build
- Triển khai 4 dịch vụ phụ trợ Golang tận dụng Workload Identity để kết nối với Cloud Spanner
- Triển khai 4 dịch vụ khối lượng công việc được dùng để mô phỏng tải cho các dịch vụ phụ trợ.
Kiến thức bạn sẽ học được
- Cách cung cấp các quy trình GKE Autopilot, Cloud Spanner và Cloud Deploy bằng Terraform
- Cách Workload Identity cho phép các dịch vụ trên GKE mạo danh tài khoản dịch vụ để truy cập vào các quyền IAM nhằm làm việc với Cloud Spanner
- Cách tạo tải giống như tải thực tế trên GKE và Cloud Spanner bằng Locust.io
Bạn cần có
2. Thiết lập và yêu cầu
Tạo dự án
Nếu chưa có Tài khoản Google (Gmail hoặc Google Apps), bạn phải tạo một tài khoản. Đăng nhập vào bảng điều khiển Google Cloud Platform ( console.cloud.google.com) rồi tạo một dự án mới.
Nếu bạn đã có dự án, hãy nhấp vào trình đơn thả xuống chọn dự án ở phía trên bên trái của bảng điều khiển:

rồi nhấp vào nút "DỰ ÁN MỚI" trong hộp thoại xuất hiện để tạo một dự án mới:
Nếu chưa có dự án, bạn sẽ thấy một hộp thoại như thế này để tạo dự án đầu tiên:

Hộp thoại tạo dự án tiếp theo cho phép bạn nhập thông tin chi tiết về dự án mới:

Hãy nhớ mã dự án. Đây là tên duy nhất trên tất cả các dự án Google Cloud (tên ở trên đã được sử dụng và sẽ không hoạt động đối với bạn, xin lỗi!). Sau này trong lớp học lập trình này, chúng ta sẽ gọi nó là PROJECT_ID.
Tiếp theo, nếu chưa làm, bạn cần phải bật tính năng thanh toán trong Play Console để sử dụng các tài nguyên của Google Cloud và bật Cloud Spanner API.

Việc thực hiện lớp học lập trình này sẽ không tốn của bạn quá vài đô la, nhưng có thể tốn nhiều hơn nếu bạn quyết định sử dụng nhiều tài nguyên hơn hoặc nếu bạn để các tài nguyên đó chạy (xem phần "dọn dẹp" ở cuối tài liệu này). Giá của Google Cloud Spanner được ghi lại tại đây và giá của chế độ Tự động điều khiển GKE được ghi lại tại đây.
Người dùng mới của Google Cloud Platform đủ điều kiện dùng thử miễn phí trị giá 300 USD. Nhờ đó, bạn có thể hoàn toàn miễn phí tham gia lớp học lập trình này.
Thiết lập Cloud Shell
Mặc dù bạn có thể vận hành Google Cloud và Spanner từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, chúng ta sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên đám mây.
Máy ảo dựa trên Debian này được trang bị tất cả các công cụ phát triển mà bạn cần. Nền tảng này cung cấp một thư mục chính có dung lượng 5 GB và chạy trong Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Điều này có nghĩa là bạn chỉ cần một trình duyệt (có, trình duyệt này hoạt động trên Chromebook) cho lớp học lập trình này.
- Để kích hoạt Cloud Shell từ Bảng điều khiển Cloud, bạn chỉ cần nhấp vào biểu tượng Kích hoạt Cloud Shell
 (mất vài phút để cung cấp và kết nối với môi trường).
(mất vài phút để cung cấp và kết nối với môi trường).
Sau khi kết nối với Cloud Shell, bạn sẽ thấy rằng mình đã được xác thực và dự án đã được đặt thành PROJECT_ID.
gcloud auth list
Đầu ra của lệnh
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Đầu ra của lệnh
[core]
project = <PROJECT_ID>
Nếu vì lý do nào đó mà dự án chưa được thiết lập, bạn chỉ cần đưa ra lệnh sau:
gcloud config set project <PROJECT_ID>
Bạn đang tìm PROJECT_ID? Kiểm tra mã nhận dạng bạn đã dùng trong các bước thiết lập hoặc tìm mã nhận dạng đó trong trang tổng quan của Cloud Console:
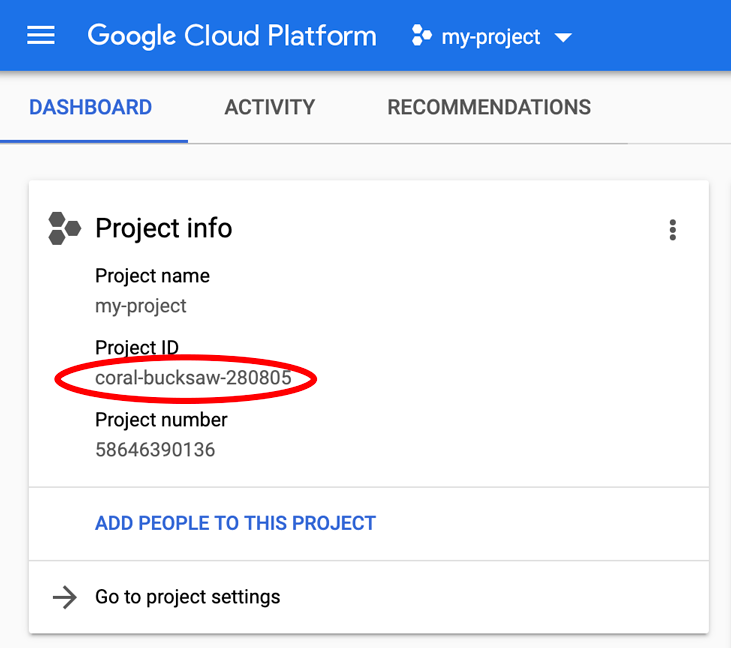
Cloud Shell cũng đặt một số biến môi trường theo mặc định, có thể hữu ích khi bạn chạy các lệnh trong tương lai.
echo $GOOGLE_CLOUD_PROJECT
Đầu ra của lệnh
<PROJECT_ID>
Tải mã xuống
Trong Cloud Shell, bạn có thể tải mã xuống cho bài tập này:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
Đầu ra của lệnh
Cloning into 'spanner-gaming-sample'...
*snip*
Lớp học lập trình này dựa trên bản phát hành v0.1.3, vì vậy, hãy kiểm tra thẻ đó:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
Đầu ra của lệnh
Switched to a new branch 'v0.1.3-branch'
Bây giờ, hãy đặt thư mục đang hoạt động hiện tại làm biến môi trường DEMO_HOME. Điều này sẽ giúp bạn dễ dàng điều hướng hơn khi thực hiện các phần khác nhau của lớp học lập trình.
export DEMO_HOME=$(pwd)
Tóm tắt
Trong bước này, bạn đã thiết lập một dự án mới, kích hoạt Cloud Shell và tải mã xuống cho phòng thí nghiệm này.
Tiếp theo
Tiếp theo, bạn sẽ cung cấp cơ sở hạ tầng bằng Terraform.
3. Cung cấp cơ sở hạ tầng
Tổng quan
Khi dự án đã sẵn sàng, bạn cần chạy cơ sở hạ tầng. Trong đó có mạng VPC, Cloud Spanner, GKE Autopilot, Artifact Registry để lưu trữ những hình ảnh sẽ chạy trên GKE, các quy trình Cloud Deploy cho các dịch vụ và khối lượng công việc phụ trợ, và cuối cùng là các tài khoản dịch vụ và đặc quyền IAM để có thể sử dụng những dịch vụ đó.
Nhiều lắm. Nhưng may mắn thay, Terraform có thể đơn giản hoá quá trình thiết lập này. Terraform là một công cụ "Cơ sở hạ tầng dưới dạng mã" cho phép chúng ta chỉ định những gì cần thiết cho dự án này trong một loạt tệp ".tf". Điều này giúp việc cung cấp cơ sở hạ tầng trở nên đơn giản.
Bạn không cần phải quen thuộc với Terraform để hoàn tất lớp học lập trình này. Nhưng nếu muốn xem vài bước tiếp theo sẽ làm gì, bạn có thể xem tất cả những gì được tạo trong các tệp này nằm trong thư mục infrastructure:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Định cấu hình Terraform
Trong Cloud Shell, bạn sẽ chuyển sang thư mục infrastructure và khởi động Terraform:
cd $DEMO_HOME/infrastructure
terraform init
Đầu ra của lệnh
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Tiếp theo, hãy định cấu hình Terraform bằng cách sao chép terraform.tfvars.sample và sửa đổi giá trị dự án. Bạn cũng có thể thay đổi các biến khác, nhưng dự án là biến duy nhất mà bạn phải thay đổi để hoạt động với môi trường của mình.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Cung cấp cơ sở hạ tầng
Giờ là lúc cung cấp cơ sở hạ tầng!
terraform apply
# review the list of things to be created
# type 'yes' when asked
Đầu ra của lệnh
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Kiểm tra nội dung đã được tạo
Để xác minh những gì đã tạo, bạn cần kiểm tra các sản phẩm trong Cloud Console.
Cloud Spanner
Trước tiên, hãy kiểm tra Cloud Spanner bằng cách chuyển đến trình đơn ba đường kẻ rồi nhấp vào Spanner. Bạn có thể phải nhấp vào "Xem các sản phẩm khác" để tìm thấy sản phẩm đó trong danh sách.
Thao tác này sẽ đưa bạn đến danh sách các phiên bản Spanner. Nhấp vào phiên bản này, bạn sẽ thấy các cơ sở dữ liệu. Đoạn mã sẽ trông giống như sau:

GKE Autopilot
Tiếp theo, hãy kiểm tra GKE bằng cách chuyển đến trình đơn ba đường kẻ rồi nhấp vào Kubernetes Engine => Clusters. Tại đây, bạn sẽ thấy cụm sample-games-gke đang chạy ở chế độ Autopilot.

Artifact Registry
Bây giờ, bạn sẽ muốn xem nơi lưu trữ hình ảnh. Vì vậy, hãy nhấp vào trình đơn có biểu tượng ba dấu gạch ngang rồi tìm biểu tượng Artifact Registry=>Repositories. Artifact Registry nằm trong phần CI/CD của trình đơn.
Tại đây, bạn sẽ thấy một sổ đăng ký Docker có tên là spanner-game-images. Hiện tại, phần này sẽ trống.

Cloud Deploy
Cloud Deploy là nơi các quy trình được tạo để Cloud Build có thể cung cấp các bước để tạo hình ảnh rồi triển khai chúng vào cụm GKE của chúng tôi.
Di chuyển đến trình đơn có biểu tượng hình chiếc bánh hamburger rồi tìm Cloud Deploy. Biểu tượng này cũng nằm trong phần CI/CD của trình đơn.
Tại đây, bạn sẽ thấy 2 quy trình: một cho các dịch vụ phụ trợ và một cho các khối lượng công việc. Cả hai đều triển khai hình ảnh vào cùng một cụm GKE, nhưng điều này cho phép tách các hoạt động triển khai của chúng ta.

IAM
Cuối cùng, hãy kiểm tra trang IAM trong Cloud Console để xác minh các tài khoản dịch vụ đã được tạo. Chuyển đến trình đơn có biểu tượng ba dấu gạch ngang rồi tìm IAM and Admin=>Service accounts. Đoạn mã sẽ trông giống như sau:

Terraform tạo tổng cộng 6 tài khoản dịch vụ:
- Tài khoản dịch vụ máy tính mặc định. Lớp học lập trình này không dùng đến.
- Tài khoản cloudbuild-cicd được dùng cho các bước Cloud Build và Cloud Deploy.
- 4 tài khoản "ứng dụng" được các dịch vụ phụ trợ của chúng tôi dùng để tương tác với Cloud Spanner.
Tiếp theo, bạn sẽ muốn định cấu hình kubectl để tương tác với cụm GKE.
Định cấu hình kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
Đầu ra của lệnh
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Tóm tắt
Tuyệt vời! Bạn có thể cung cấp một phiên bản Cloud Spanner, một cụm GKE Autopilot, tất cả trong một VPC để tạo mạng riêng tư.
Ngoài ra, 2 quy trình Cloud Deploy đã được tạo cho các dịch vụ phụ trợ và khối lượng công việc, cũng như một kho lưu trữ Artifact Registry để lưu trữ các hình ảnh đã tạo.
Cuối cùng, các tài khoản dịch vụ đã được tạo và định cấu hình để hoạt động với Workload Identity, nhờ đó các dịch vụ phụ trợ có thể sử dụng Cloud Spanner.
Bạn cũng đã định cấu hình kubectl để tương tác với cụm GKE trong Cloud Shell sau khi triển khai các dịch vụ và tải công việc phụ trợ.
Tiếp theo
Trước khi bạn có thể sử dụng các dịch vụ này, bạn cần xác định giản đồ cơ sở dữ liệu. Bạn sẽ thiết lập chế độ này ở bước tiếp theo.
4. Tạo giản đồ cơ sở dữ liệu
Tổng quan
Trước khi có thể chạy các dịch vụ phụ trợ, bạn cần đảm bảo rằng lược đồ cơ sở dữ liệu đã được thiết lập.
Nếu xem các tệp trong thư mục $DEMO_HOME/schema/migrations của kho lưu trữ bản minh hoạ, bạn sẽ thấy một loạt tệp .sql xác định giản đồ của chúng ta. Điều này mô phỏng một chu kỳ phát triển trong đó các thay đổi về giản đồ được theo dõi trong chính kho lưu trữ và có thể được liên kết với một số tính năng nhất định của ứng dụng.
Đối với môi trường mẫu này, wrench là công cụ sẽ áp dụng các hoạt động di chuyển giản đồ bằng Cloud Build.
Cloud Build
Tệp $DEMO_HOME/schema/cloudbuild.yaml mô tả các bước sẽ được thực hiện:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
Về cơ bản, có hai bước:
- tải cờ lê xuống không gian làm việc Cloud Build
- chạy quy trình di chuyển bằng cờ lê
Bạn cần có các biến môi trường dự án, phiên bản và cơ sở dữ liệu Spanner để wrench kết nối với điểm cuối ghi.
Cloud Build có thể thực hiện những thay đổi này vì đang chạy dưới dạng tài khoản dịch vụ cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
Và tài khoản dịch vụ này có vai trò spanner.databaseUser do Terraform thêm vào, cho phép tài khoản dịch vụ cập nhật DDL.
Di chuyển giản đồ
Có 5 bước di chuyển được thực hiện dựa trên các tệp trong thư mục $DEMO_HOME/schema/migrations. Sau đây là ví dụ về tệp 000001.sql tạo bảng và chỉ mục players:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Gửi quá trình di chuyển giản đồ
Để gửi bản dựng nhằm thực hiện quá trình di chuyển giản đồ, hãy chuyển sang thư mục schema rồi chạy lệnh gcloud sau:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
Đầu ra của lệnh
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
Trong đầu ra ở trên, bạn sẽ thấy một đường liên kết đến quy trình xây dựng đám mây Created. Nếu bạn nhấp vào đó, bạn sẽ được chuyển đến bản dựng trong Cloud Console để có thể theo dõi tiến trình của bản dựng và xem bản dựng đang làm gì.
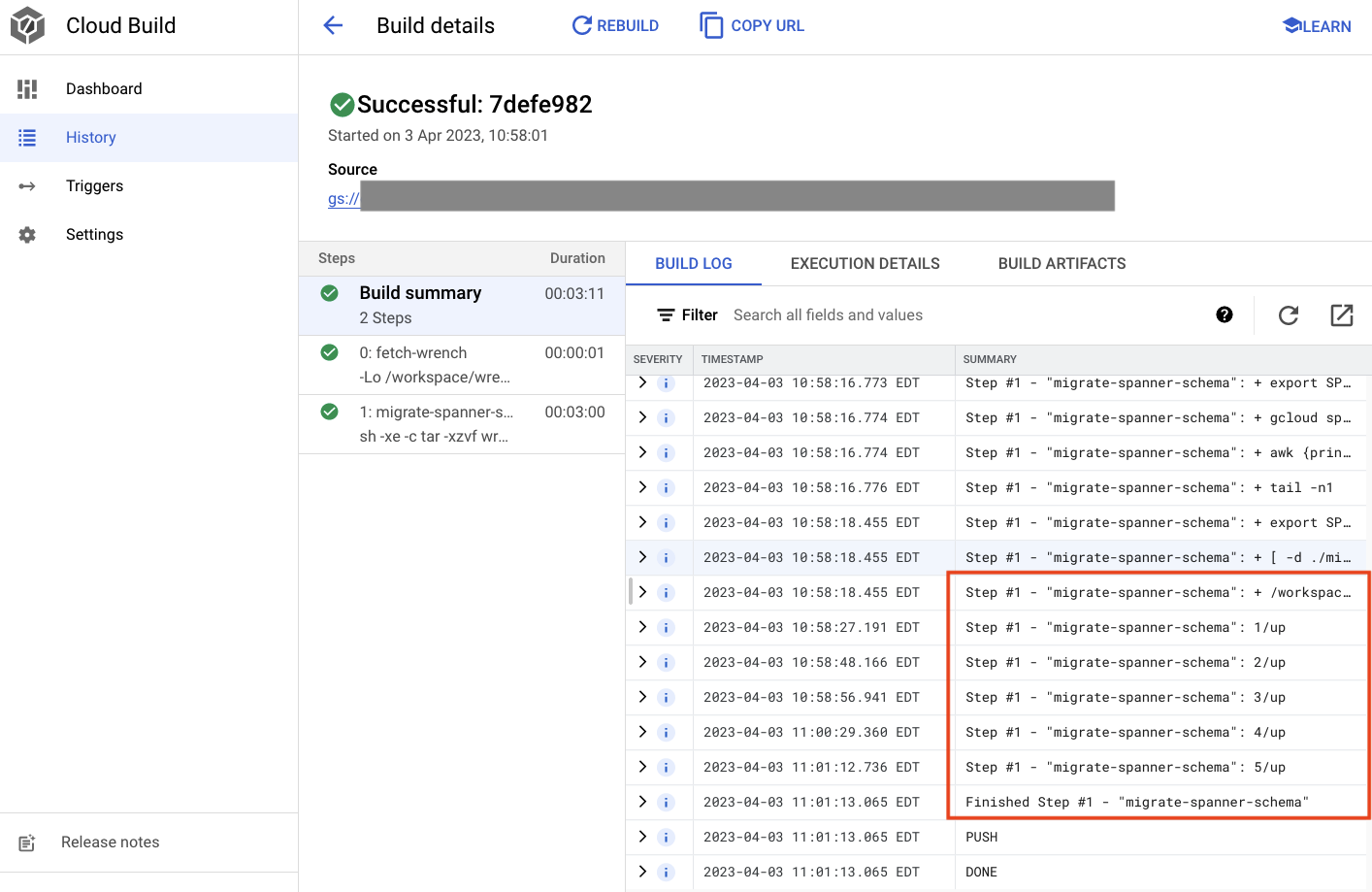
Tóm tắt
Trong bước này, bạn đã sử dụng Cloud Build để gửi quá trình di chuyển giản đồ ban đầu áp dụng 5 thao tác DDL khác nhau. Các thao tác này thể hiện thời điểm các tính năng được thêm vào cần thay đổi giản đồ cơ sở dữ liệu.
Trong trường hợp phát triển bình thường, bạn nên thực hiện các thay đổi về giản đồ tương thích ngược với ứng dụng hiện tại để tránh bị gián đoạn.
Đối với những thay đổi không tương thích ngược, bạn nên triển khai các thay đổi cho ứng dụng và giản đồ theo từng giai đoạn để đảm bảo không xảy ra tình trạng ngừng hoạt động.
Tiếp theo
Sau khi có giản đồ, bước tiếp theo là triển khai các dịch vụ phụ trợ!
5. Triển khai các dịch vụ phụ trợ
Tổng quan
Các dịch vụ phụ trợ cho lớp học lập trình này là các API REST golang đại diện cho 4 dịch vụ khác nhau:
- Hồ sơ: cho phép người chơi đăng ký và xác thực với "trò chơi" mẫu của chúng tôi.
- Ghép trận đấu: tương tác với dữ liệu người chơi để hỗ trợ chức năng ghép trận đấu, theo dõi thông tin về các trận đấu đã tạo và cập nhật số liệu thống kê về người chơi khi trận đấu kết thúc.
- Vật phẩm: cho phép người chơi nhận được vật phẩm và tiền trong trò chơi trong quá trình chơi.
- Trạm giao dịch: cho phép người chơi mua và bán vật phẩm tại trạm giao dịch
Bạn có thể tìm hiểu thêm về các dịch vụ này trong lớp học lập trình Cloud Spanner: Bắt đầu phát triển trò chơi. Đối với mục đích của chúng ta, chúng ta muốn các dịch vụ này chạy trên cụm GKE Autopilot.
Các dịch vụ này phải có khả năng sửa đổi dữ liệu Spanner. Để làm việc đó, mỗi dịch vụ đều có một tài khoản dịch vụ được tạo để cấp cho dịch vụ đó vai trò "databaseUser".
Workload Identity cho phép tài khoản dịch vụ kubernetes mạo danh tài khoản dịch vụ Google Cloud của các dịch vụ theo các bước sau trong Terraform của chúng tôi:
- Tạo tài nguyên tài khoản dịch vụ Google Cloud của dịch vụ (
GSA) - Chỉ định vai trò databaseUser cho tài khoản dịch vụ đó
- Chỉ định vai trò workloadIdentityUser cho tài khoản dịch vụ đó
- Tạo một tài khoản dịch vụ Kubernetes (
KSA) tham chiếu đến GSA
Sơ đồ phác thảo sẽ có dạng như sau:
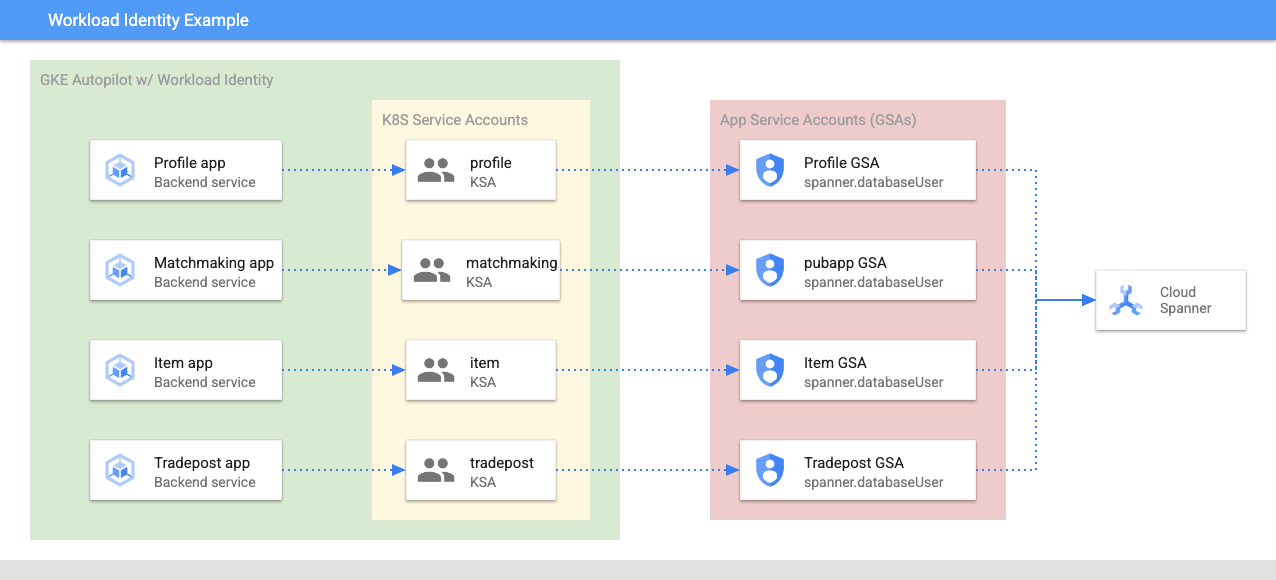
Terraform đã tạo tài khoản dịch vụ và tài khoản dịch vụ Kubernetes cho bạn. Bạn có thể kiểm tra tài khoản dịch vụ Kubernetes bằng cách sử dụng kubectl:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Cách hoạt động của bản dựng như sau:
- Terraform đã tạo một tệp
$DEMO_HOME/backend_services/cloudbuild.yamlcó dạng như sau:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Lệnh Cloud Build sẽ đọc tệp này và làm theo các bước được liệt kê. Trước tiên, nó sẽ tạo hình ảnh dịch vụ. Sau đó, nó sẽ thực thi lệnh
gcloud deploy create. Thao tác này sẽ đọc tệp$DEMO_HOME/backend_services/skaffold.yaml. Tệp này xác định vị trí của từng tệp triển khai:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy sẽ tuân theo các định nghĩa trong tệp
deployment.yamlcủa từng dịch vụ. Tệp triển khai của dịch vụ chứa thông tin để tạo một dịch vụ. Trong trường hợp này, đó là một clusterIP chạy trên cổng 80.
Loại " ClusterIP" ngăn các nhóm dịch vụ phụ trợ có IP bên ngoài, do đó, chỉ những thực thể có thể kết nối với mạng GKE nội bộ mới có thể truy cập vào các dịch vụ phụ trợ. Người chơi không được phép truy cập trực tiếp vào các dịch vụ này vì chúng truy cập và sửa đổi dữ liệu Spanner.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Ngoài việc tạo một dịch vụ Kubernetes, Cloud Deploy cũng tạo một hoạt động triển khai Kubernetes. Hãy xem xét phần triển khai dịch vụ profile:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Phần trên cùng cung cấp một số siêu dữ liệu về dịch vụ. Phần quan trọng nhất trong số này là xác định số lượng bản sao sẽ được tạo bởi quy trình triển khai này.
replicas: 2 # EDIT: Number of instances of deployment
Tiếp theo, chúng ta xem tài khoản dịch vụ nào sẽ chạy ứng dụng và ứng dụng đó sẽ sử dụng hình ảnh nào. Các tài khoản này khớp với tài khoản dịch vụ Kubernetes được tạo từ Terraform và hình ảnh được tạo trong bước Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
Sau đó, chúng ta sẽ chỉ định một số thông tin về mạng và các biến môi trường.
spanner_config là một Kubernetes ConfigMap chỉ định thông tin về dự án, phiên bản và cơ sở dữ liệu cần thiết để ứng dụng kết nối với Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST và SERVICE_PORT là các biến môi trường bổ sung mà dịch vụ cần để biết vị trí liên kết.
Phần cuối cùng cho GKE biết số lượng tài nguyên cần cho phép cho mỗi bản sao trong quá trình triển khai này. Đây cũng là những gì GKE Autopilot dùng để mở rộng quy mô cụm khi cần.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Với thông tin này, đã đến lúc triển khai các dịch vụ phụ trợ.
Triển khai các dịch vụ phụ trợ
Như đã đề cập, việc triển khai các dịch vụ phụ trợ sẽ sử dụng Cloud Build. Giống như với các hoạt động di chuyển giản đồ, bạn có thể gửi yêu cầu bản dựng bằng dòng lệnh gcloud:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
Đầu ra của lệnh
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
Không giống như đầu ra của bước schema migration, đầu ra của bản dựng này cho biết có một số hình ảnh được tạo. Các tệp đó sẽ được lưu trữ trong kho lưu trữ Artifact Registry.
Kết quả của bước gcloud build sẽ có một đường liên kết đến Cloud Console. Hãy xem những ví dụ đó.
Sau khi bạn nhận được thông báo thành công từ Cloud Build, hãy chuyển đến Cloud Deploy rồi đến quy trình sample-game-services để theo dõi tiến trình triển khai.

Sau khi triển khai các dịch vụ, bạn có thể kiểm tra kubectl để xem trạng thái của các nhóm:
kubectl get pods
Đầu ra của lệnh
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Sau đó, hãy kiểm tra các dịch vụ để xem ClusterIP đang hoạt động:
kubectl get services
Đầu ra của lệnh
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
Bạn cũng có thể chuyển đến giao diện người dùng GKE trong Cloud Console để xem Workloads, Services và ConfigMaps.
Tải

Dịch vụ

ConfigMaps
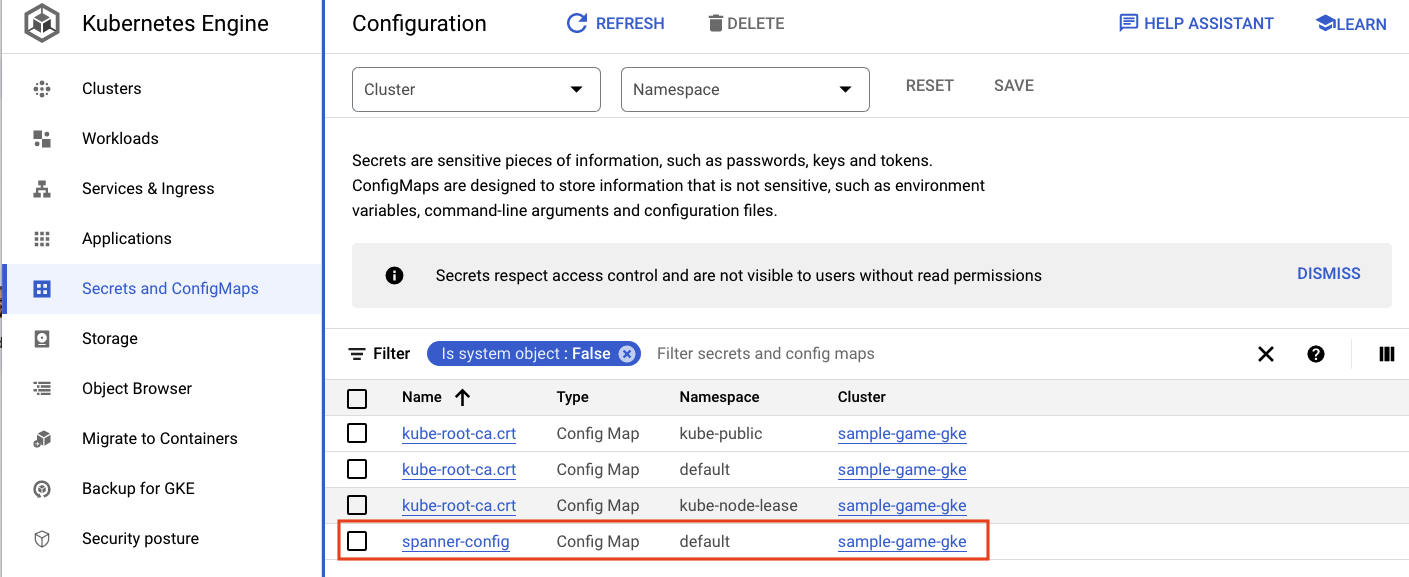

Tóm tắt
Ở bước này, bạn đã triển khai 4 dịch vụ phụ trợ cho GKE Autopilot. Bạn có thể chạy bước Cloud Build và kiểm tra tiến trình trong Cloud Deploy và trên Kubernetes trong Cloud Console.
Bạn cũng đã tìm hiểu cách các dịch vụ này sử dụng Workload Identity để mạo danh một tài khoản dịch vụ có quyền đọc và ghi dữ liệu vào cơ sở dữ liệu Spanner.
Các bước tiếp theo
Trong phần tiếp theo, bạn sẽ triển khai các tải.
6. Triển khai khối lượng công việc
Tổng quan
Giờ đây, khi các dịch vụ phụ trợ đang chạy trên cụm, bạn sẽ triển khai các khối lượng công việc.

Các tải này có thể truy cập từ bên ngoài và có một tải cho mỗi dịch vụ phụ trợ cho mục đích của lớp học lập trình này.
Đây là các tập lệnh tạo tải dựa trên Locust, mô phỏng các mẫu truy cập thực tế mà các dịch vụ mẫu này mong đợi.
Có các tệp cho quy trình xây dựng Cloud Build:
$DEMO_HOME/workloads/cloudbuild.yaml(do Terraform tạo)$DEMO_HOME/workloads/skaffold.yaml- một tệp
deployment.yamlcho mỗi khối lượng công việc
Các tệp deployment.yaml của khối lượng công việc trông hơi khác so với các tệp triển khai dịch vụ phụ trợ.
Sau đây là một ví dụ về matchmaking-workload:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
Phần trên cùng của tệp xác định dịch vụ. Trong trường hợp này, một LoadBalancer sẽ được tạo và tải sẽ chạy trên cổng 8089.
LoadBalancer sẽ cung cấp một IP ngoài có thể dùng để kết nối với khối lượng công việc.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
Đầu phần triển khai là siêu dữ liệu về khối lượng công việc. Trong trường hợp này, chỉ có một bản sao đang được triển khai:
replicas: 1
Tuy nhiên, thông số kỹ thuật của vùng chứa lại khác. Một trong những lý do là chúng ta đang sử dụng tài khoản dịch vụ Kubernetes default. Tài khoản này không có đặc quyền nào vì tải không cần kết nối với bất kỳ tài nguyên nào trên Google Cloud, ngoại trừ các dịch vụ phụ trợ đang chạy trên cụm GKE.
Điểm khác biệt khác là bạn không cần bất kỳ biến môi trường nào cho các khối lượng công việc này. Kết quả là một quy cách triển khai ngắn hơn.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
Các chế độ cài đặt tài nguyên tương tự như các dịch vụ phụ trợ. Hãy nhớ rằng đây là cách GKE Autopilot biết cần bao nhiêu tài nguyên để đáp ứng các yêu cầu của tất cả các pod đang chạy trên cụm.
Hãy triển khai các khối lượng công việc!
Triển khai khối lượng công việc
Giống như trước đây, bạn có thể gửi yêu cầu bản dựng bằng dòng lệnh gcloud:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
Đầu ra của lệnh
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Hãy nhớ kiểm tra nhật ký Cloud Build và quy trình Cloud Deploy trong Bảng điều khiển Cloud để kiểm tra trạng thái. Đối với các tải công việc, quy trình Cloud Deploy là sample-game-workloads:
Sau khi triển khai xong, hãy kiểm tra trạng thái bằng kubectl trong Cloud Shell:
kubectl get pods
Đầu ra của lệnh
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Sau đó, hãy kiểm tra các dịch vụ khối lượng công việc để xem LoadBalancer đang hoạt động:
kubectl get services
Đầu ra của lệnh
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Tóm tắt
Giờ đây, bạn đã triển khai các tải công việc vào cụm GKE. Các tải này không yêu cầu thêm quyền IAM và có thể truy cập từ bên ngoài trên cổng 8089 bằng dịch vụ LoadBalancer.
Các bước tiếp theo
Khi các dịch vụ và khối lượng công việc phụ trợ đang chạy, đã đến lúc "chơi" trò chơi!
7. Bắt đầu chơi trò chơi
Tổng quan
Các dịch vụ phụ trợ cho "trò chơi" mẫu của bạn hiện đang chạy và bạn cũng có thể tạo "người chơi" tương tác với các dịch vụ đó bằng cách sử dụng khối lượng công việc.
Mỗi khối lượng công việc sử dụng Locust để mô phỏng tải thực tế đối với các API dịch vụ của chúng tôi. Trong bước này, bạn sẽ chạy một số tải công việc để tạo tải trên cụm GKE và trên Spanner, cũng như lưu trữ dữ liệu trên Spanner.
Sau đây là nội dung mô tả về từng khối lượng công việc:
- Tải
item-generatorlà một tải nhanh để tạo danh sách game_items mà người chơi có thể nhận được trong quá trình "chơi" trò chơi. profile-workloadmô phỏng người chơi đăng ký và đăng nhập.matchmaking-workloadmô phỏng người chơi xếp hàng để được chỉ định vào các trận đấu.game-workloadmô phỏng việc người chơi mua game_item và tiền trong quá trình chơi trò chơi.tradepost-workloadmô phỏng việc người chơi có thể bán và mua vật phẩm trên trạm giao dịch.
Lớp học lập trình này sẽ đặc biệt làm nổi bật việc chạy item-generator và profile-workload.
Chạy trình tạo mục
item-generator sử dụng điểm cuối dịch vụ phụ trợ item để thêm game_items vào Spanner. Bạn phải có những mục này để game-workload và tradepost-workload hoạt động đúng cách.
Bước đầu tiên là lấy IP ngoài của dịch vụ item-generator. Trong Cloud Shell, hãy chạy lệnh sau:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
Đầu ra của lệnh
{ITEMGENERATOR_EXTERNAL_IP}
Bây giờ, hãy mở một thẻ trình duyệt mới và chuyển đến http://{ITEMGENERATOR_EXTERNAL_IP}:8089. Bạn sẽ thấy một trang như sau:
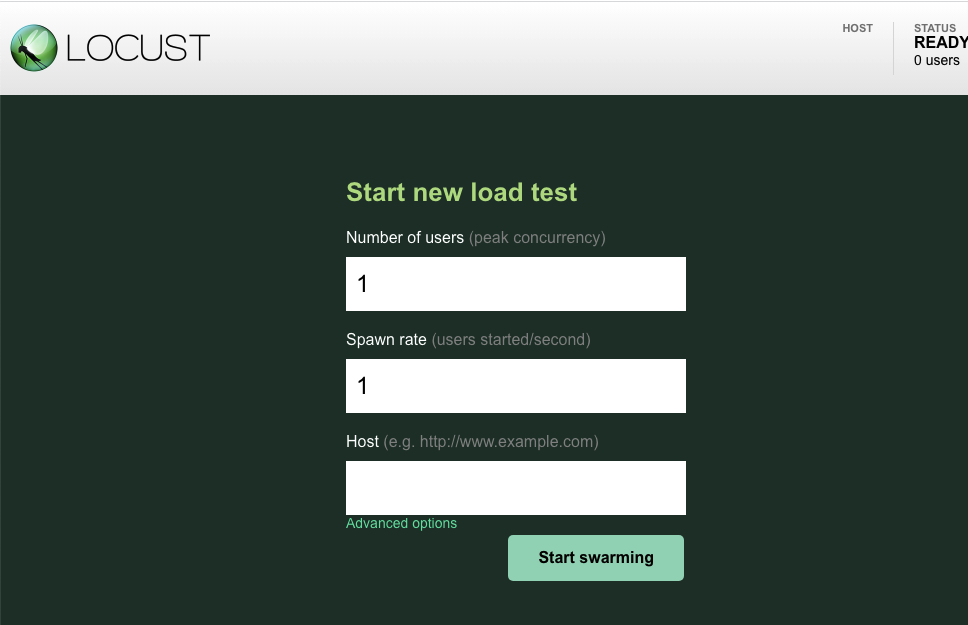
Bạn sẽ giữ nguyên users và spawn ở mức mặc định là 1. Đối với host,, hãy nhập http://item. Nhấp vào các lựa chọn nâng cao rồi nhập 10s cho thời gian chạy.
Cấu hình sẽ có dạng như sau:
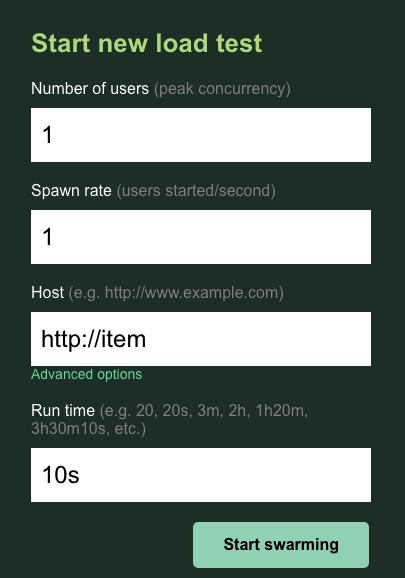
Nhấp vào "Bắt đầu kết nối"!
Số liệu thống kê sẽ bắt đầu xuất hiện cho các yêu cầu được phát hành trên điểm cuối POST /items. Sau 10 giây, quá trình tải sẽ dừng.
Nhấp vào Charts, bạn sẽ thấy một số biểu đồ về hiệu suất của các yêu cầu này.

Bây giờ, bạn muốn kiểm tra xem dữ liệu đã được nhập vào cơ sở dữ liệu Spanner hay chưa.
Để làm việc đó, hãy nhấp vào trình đơn ba đường kẻ rồi chuyển đến "Spanner". Trên trang này, hãy chuyển đến sample-instance và sample-database. Sau đó, hãy nhấp vào "Query".
Chúng ta muốn chọn số lượng game_items:
SELECT COUNT(*) FROM game_items;
Ở dưới cùng, bạn sẽ nhận được kết quả.
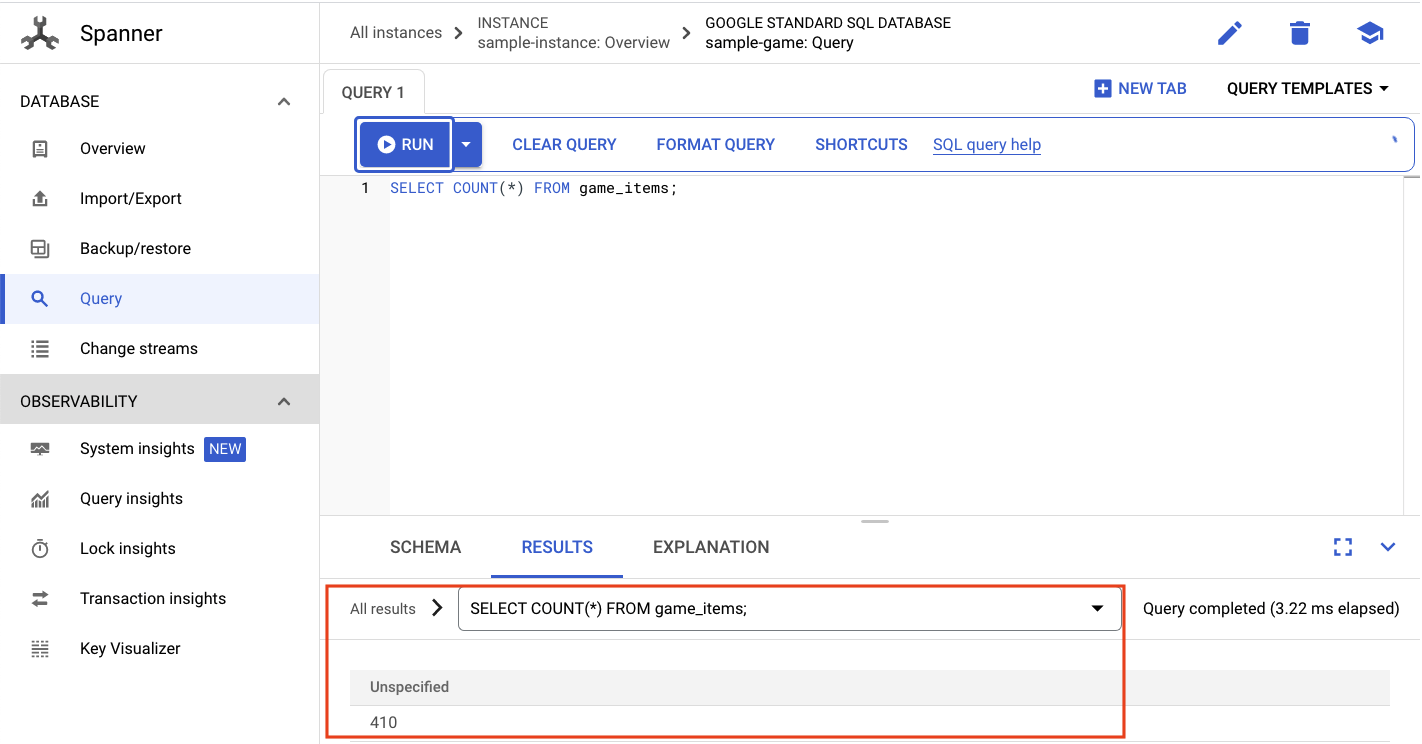
Chúng ta không cần nhiều game_items được gieo mầm. Nhưng giờ đây, người chơi có thể nhận được những vật phẩm này!
Chạy khối lượng công việc hồ sơ
Sau khi bạn gieo game_items, bước tiếp theo là yêu cầu người chơi đăng ký để có thể chơi trò chơi.
profile-workload sẽ dùng Locust để mô phỏng người chơi tạo tài khoản, đăng nhập, truy xuất thông tin hồ sơ và đăng xuất. Tất cả các kiểm thử này đều kiểm thử các điểm cuối của dịch vụ phụ trợ profile trong một khối lượng công việc điển hình giống như khối lượng công việc sản xuất.
Để chạy lệnh này, hãy lấy IP ngoài profile-workload:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
Đầu ra của lệnh
{PROFILEWORKLOAD_EXTERNAL_IP}
Bây giờ, hãy mở một thẻ trình duyệt mới và chuyển đến http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089. Bạn sẽ nhận được một trang Locust tương tự như trang trước.
Trong trường hợp này, bạn sẽ sử dụng http://profile cho máy chủ lưu trữ. Bạn sẽ không chỉ định thời gian chạy trong các lựa chọn nâng cao. Ngoài ra, hãy chỉ định users là 4 để mô phỏng 4 yêu cầu của người dùng cùng một lúc.
Bài kiểm thử profile-workload sẽ có dạng như sau:

Nhấp vào "Bắt đầu kết nối"!
Giống như trước đây, số liệu thống kê cho nhiều điểm cuối REST profile sẽ bắt đầu xuất hiện. Nhấp vào biểu đồ để xem hiệu suất của mọi thứ.
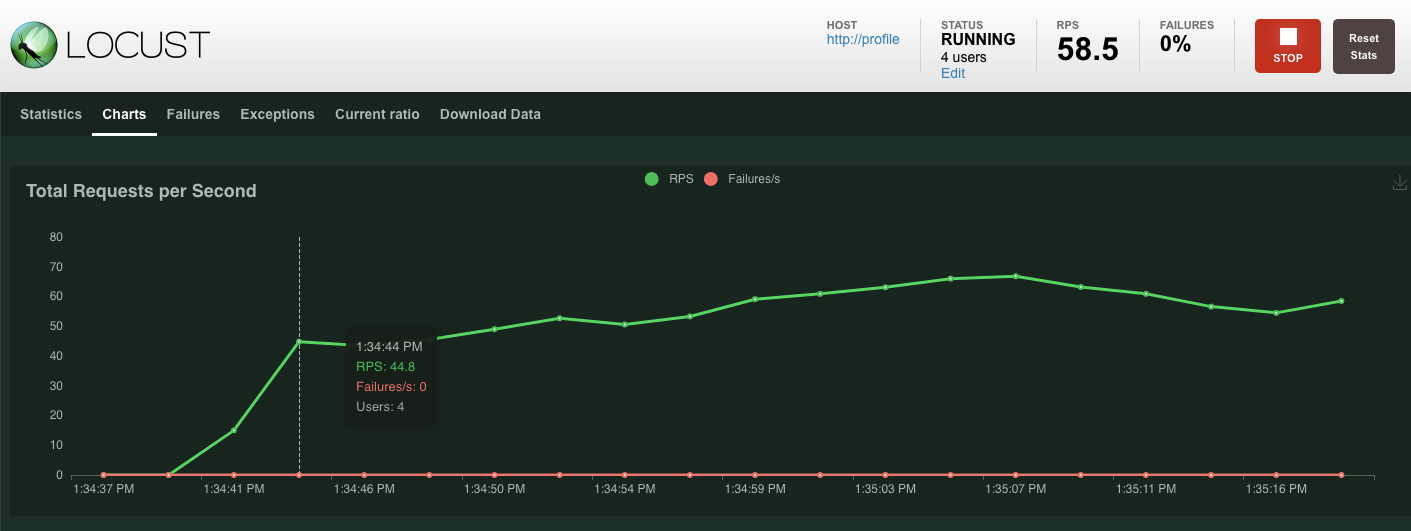
Tóm tắt
Trong bước này, bạn đã tạo một số game_items, sau đó truy vấn bảng game_items bằng Giao diện người dùng truy vấn Spanner trong Cloud Console.
Bạn cũng cho phép người chơi đăng ký trò chơi của bạn và xem cách Locust có thể tạo khối lượng công việc giống như khối lượng công việc phát hành công khai đối với các dịch vụ phụ trợ của bạn.
Các bước tiếp theo
Sau khi chạy các tải, bạn sẽ muốn kiểm tra xem cụm GKE và phiên bản Spanner đang hoạt động như thế nào.
8. Xem xét mức sử dụng GKE và Spanner
Khi dịch vụ hồ sơ đang chạy, bạn có thể tận dụng cơ hội này để xem cụm GKE Autopilot và Cloud Spanner của mình đang hoạt động như thế nào.
Kiểm tra cụm GKE
Chuyển đến cụm Kubernetes. Xin lưu ý rằng vì bạn đã triển khai các khối lượng công việc và dịch vụ, nên giờ đây, cụm đã có thêm một số thông tin về tổng số vCPU và bộ nhớ. Thông tin này không có sẵn khi không có khối lượng công việc nào trên cụm.
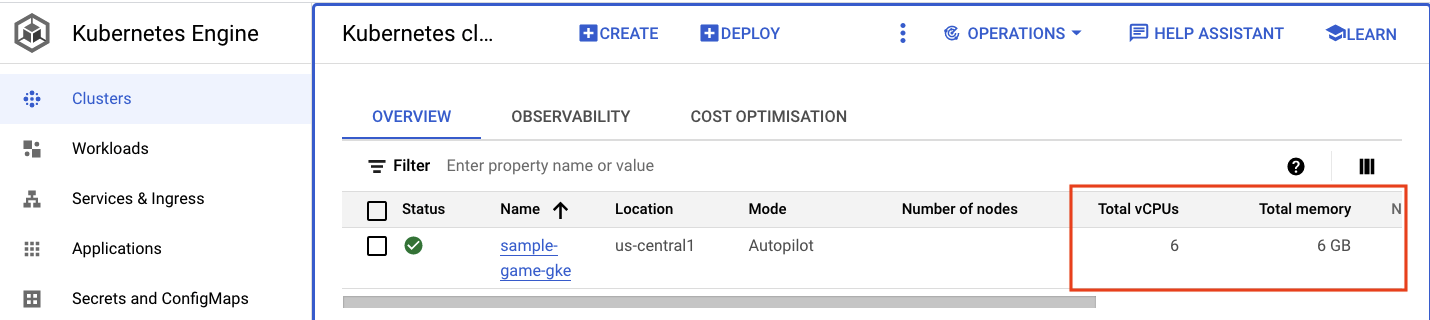
Bây giờ, hãy nhấp vào cụm sample-game-gke rồi chuyển sang thẻ observability (khả năng quan sát):

Không gian tên default kubernetes phải vượt quá không gian tên kube-system về mức sử dụng CPU vì các dịch vụ phụ trợ và khối lượng công việc của chúng tôi chạy trên default. Nếu chưa, hãy đảm bảo profile workload vẫn đang chạy và đợi vài phút để biểu đồ cập nhật.
Để xem những tải nào đang chiếm nhiều tài nguyên nhất, hãy chuyển đến trang tổng quan Workloads.
Thay vì đi vào từng khối lượng công việc riêng lẻ, hãy chuyển thẳng đến thẻ Khả năng quan sát của trang tổng quan. Bạn sẽ thấy CPU của profile và profile-workload tăng lên.

Bây giờ, hãy kiểm tra Cloud Spanner.
Kiểm tra phiên bản Cloud Spanner
Để kiểm tra hiệu suất của Cloud Spanner, hãy chuyển đến Spanner rồi nhấp vào phiên bản sample-instance và cơ sở dữ liệu sample-game.
Từ đó, bạn sẽ thấy thẻ Thông tin chi tiết về hệ thống trên trình đơn bên trái:
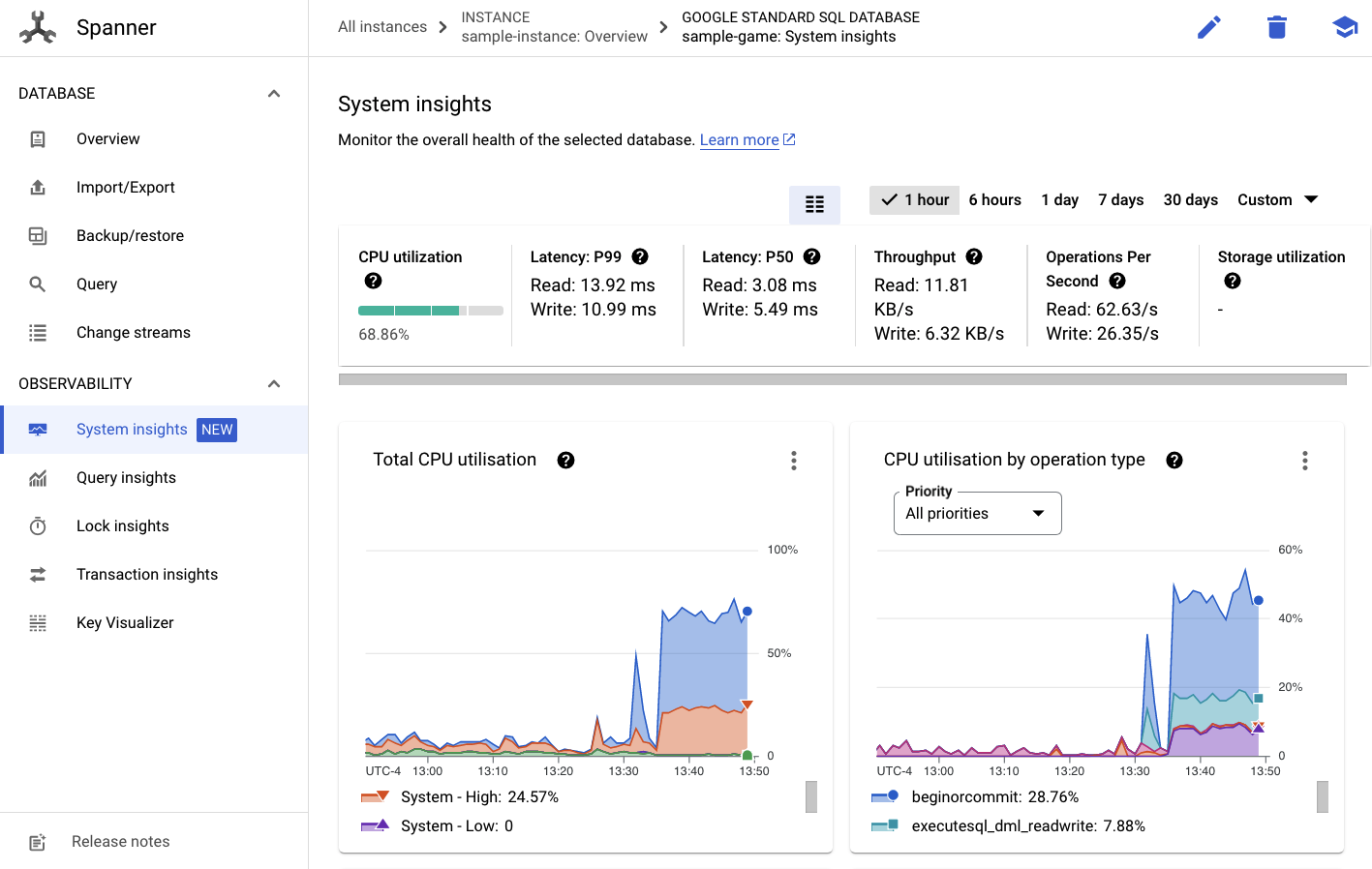
Có nhiều biểu đồ ở đây để giúp bạn hiểu được hiệu suất chung của phiên bản Spanner, bao gồm CPU utilization, transaction latency and locking và query throughput.
Ngoài System Insights, bạn có thể xem thông tin chi tiết hơn về khối lượng công việc truy vấn bằng cách xem các đường liên kết khác trong phần Observability (Khả năng quan sát):
- Thông tin chi tiết về cụm từ tìm kiếm giúp xác định N cụm từ tìm kiếm hàng đầu đang sử dụng tài nguyên trên Spanner.
- Thông tin chi tiết về Giao dịch và khoá giúp xác định các giao dịch có độ trễ cao.
- Key Visualizer giúp trực quan hoá các mẫu truy cập và có thể giúp theo dõi các điểm truy cập trong dữ liệu.
Tóm tắt
Trong bước này, bạn đã tìm hiểu cách kiểm tra một số chỉ số hiệu suất cơ bản cho cả chế độ Tự vận hành của GKE và Spanner.
Ví dụ: khi tải hồ sơ đang chạy, hãy truy vấn bảng players để biết thêm thông tin về dữ liệu đang được lưu trữ ở đó.
Các bước tiếp theo
Tiếp theo, đã đến lúc dọn dẹp!
9. Dọn dẹp
Trước khi dọn dẹp, bạn có thể khám phá các khối lượng công việc khác chưa được đề cập. Cụ thể là matchmaking-workload, game-workload và tradepost-workload.
Khi "chơi" xong trò chơi, bạn có thể dọn dẹp sân chơi. May mắn là việc này khá dễ dàng.
Trước tiên, nếu profile-workload vẫn đang chạy trong trình duyệt, hãy chuyển đến và dừng profile-workload:

Làm tương tự cho từng khối lượng công việc mà bạn có thể đã thử nghiệm.
Sau đó, trong Cloud Shell, hãy chuyển đến thư mục cơ sở hạ tầng. Bạn sẽ destroy cơ sở hạ tầng bằng cách sử dụng terraform:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
Đầu ra của lệnh
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
Trong Cloud Console, hãy chuyển đến Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy và IAM để xác thực rằng tất cả tài nguyên đã được xoá.
10. Xin chúc mừng!
Chúc mừng bạn đã triển khai thành công các ứng dụng golang mẫu trên GKE Autopilot và kết nối chúng với Cloud Spanner bằng Workload Identity!
Ngoài ra, cơ sở hạ tầng này còn dễ dàng thiết lập và xoá theo cách có thể lặp lại bằng Terraform.
Bạn có thể đọc thêm về các dịch vụ của Google Cloud mà bạn đã tương tác trong lớp học lập trình này:
- Chế độ Tự vận hành của GKE và Workload Identity
- Cloud Spanner
- Artifact Registry
- Cloud Build và Cloud Deploy
Tiếp theo là gì?
Giờ đây, khi đã hiểu cơ bản về cách chế độ Tự vận hành của GKE và Cloud Spanner có thể phối hợp với nhau, tại sao bạn không thực hiện bước tiếp theo và bắt đầu xây dựng ứng dụng của riêng mình để hoạt động với các dịch vụ này?