
১. ভূমিকা
BigQuery হলো অ্যানালিটিক্সের জন্য একটি সম্পূর্ণভাবে পরিচালিত, পেটাবাইট-স্কেল ও স্বল্প খরচের এন্টারপ্রাইজ ডেটা ওয়্যারহাউস। BigQuery সার্ভারবিহীন। এর জন্য আপনাকে ক্লাস্টার সেট আপ এবং পরিচালনা করতে হবে না।
একটি BigQuery ডেটাসেট একটি GCP প্রজেক্টে থাকে এবং এতে এক বা একাধিক টেবিল থাকে। আপনি SQL ব্যবহার করে এই ডেটাসেটগুলো কোয়েরি করতে পারেন।
এই কোডল্যাবে, আপনি BigQuery-এর পার্টিশনিং এবং ক্লাস্টারিং বোঝার জন্য GCP কনসোলে BigQuery ওয়েব UI ব্যবহার করবেন। BigQuery-এর টেবিল পার্টিশনিং এবং ক্লাস্টারিং সাধারণ ডেটা অ্যাক্সেস প্যাটার্নের সাথে মিলিয়ে আপনার ডেটাকে কাঠামোবদ্ধ করতে সাহায্য করে। একটি নির্দিষ্ট ডেটা রেঞ্জের উপর কোয়েরি করার সময় BigQuery-এর পারফরম্যান্স এবং খরচ সম্পূর্ণরূপে সর্বোচ্চ করতে পার্টিশন এবং ক্লাস্টারিং অত্যন্ত গুরুত্বপূর্ণ। এর ফলে প্রতি কোয়েরিতে কম ডেটা স্ক্যান করা হয় এবং কোয়েরি শুরু হওয়ার আগেই প্রুনিং নির্ধারণ করা হয়।
BigQuery সম্পর্কে আরও তথ্যের জন্য, BigQuery ডকুমেন্টেশন দেখুন।
আপনি যা শিখবেন
- পার্টিশন করা এবং ক্লাস্টার করা টেবিল কীভাবে তৈরি ও কোয়েরি করতে হয়
- পার্টিশন করা এবং ক্লাস্টার করা টেবিলের সাথে কোয়েরির পারফরম্যান্স তুলনা করুন
আপনার যা যা লাগবে
এই ল্যাবটি সম্পন্ন করতে আপনার প্রয়োজন:
- গুগল ক্রোমের সর্বশেষ সংস্করণ
- একটি গুগল ক্লাউড প্ল্যাটফর্ম বিলিং অ্যাকাউন্ট
২. প্রস্তুতি গ্রহণ
BigQuery নিয়ে কাজ করার জন্য, আপনাকে একটি GCP প্রজেক্ট তৈরি করতে হবে অথবা একটি বিদ্যমান প্রজেক্ট নির্বাচন করতে হবে।
একটি প্রকল্প তৈরি করুন
নতুন প্রজেক্ট তৈরি করতে, এই ধাপগুলো অনুসরণ করুন:
- আপনার যদি আগে থেকে কোনো গুগল অ্যাকাউন্ট (জিমেইল বা গুগল অ্যাপস) না থাকে, তাহলে একটি তৈরি করে নিন ।
- গুগল ক্লাউড প্ল্যাটফর্ম কনসোলে ( console.cloud.google.com ) সাইন-ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন।
- আপনার যদি কোনো প্রজেক্ট না থাকে, তাহলে 'ক্রিয়েট প্রজেক্ট' বাটনে ক্লিক করুন:
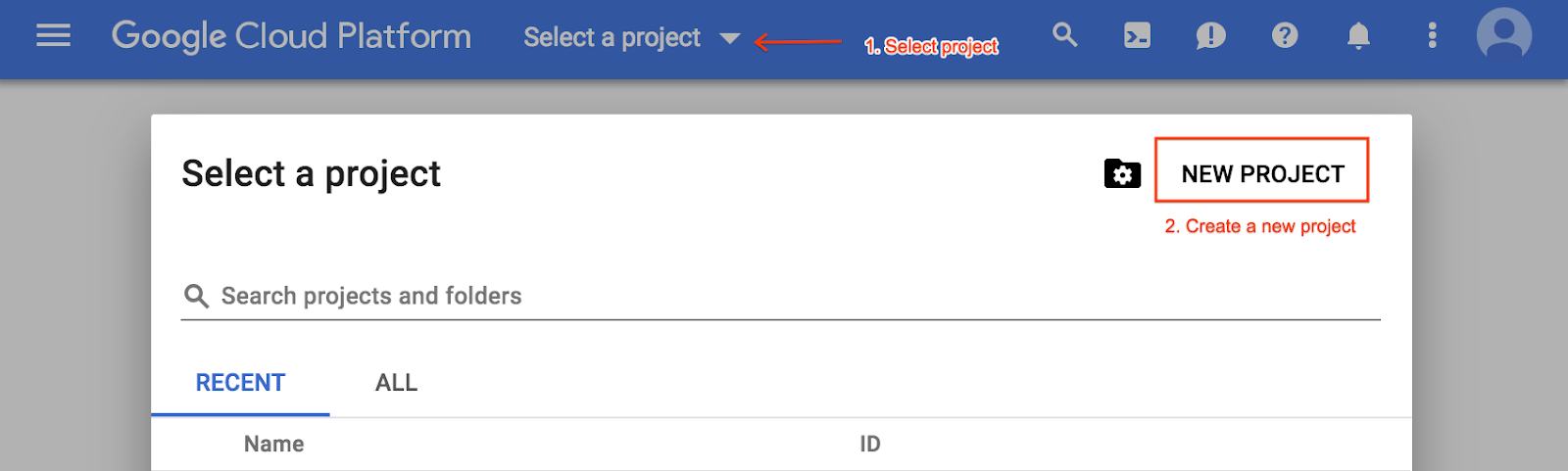
অন্যথায়, প্রজেক্ট সিলেকশন মেনু থেকে একটি নতুন প্রজেক্ট তৈরি করুন:
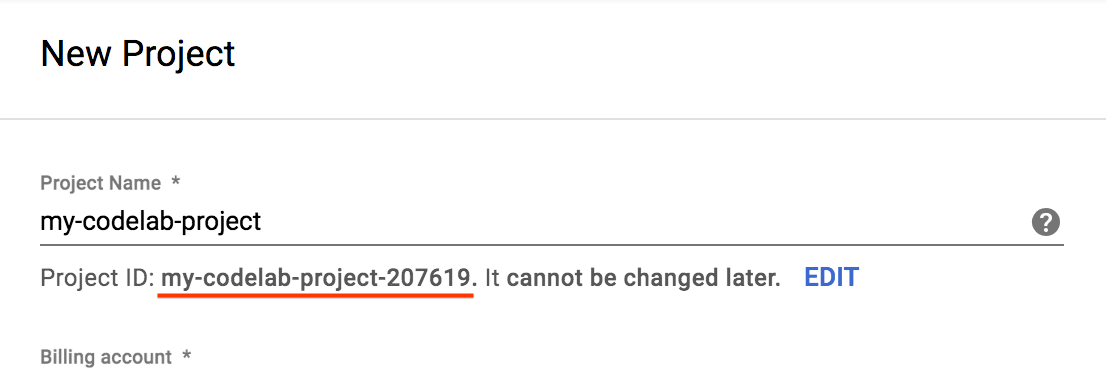
- একটি প্রজেক্টের নাম লিখুন এবং 'তৈরি করুন' নির্বাচন করুন। মনে রাখবেন, প্রজেক্ট আইডি হলো সমস্ত গুগল ক্লাউড প্রজেক্টের মধ্যে একটি অনন্য নাম।
৩. পাবলিক ডেটাসেট নিয়ে কাজ করা
BigQuery আপনাকে পাবলিক ডেটাসেট নিয়ে কাজ করার সুযোগ দেয়, যার মধ্যে রয়েছে বিবিসি নিউজ, গিটহাব রিপো, স্ট্যাক ওভারফ্লো এবং মার্কিন যুক্তরাষ্ট্রের ন্যাশনাল ওশেনিক অ্যান্ড অ্যাটমোস্ফেরিক অ্যাডমিনিস্ট্রেশন (NOAA)-এর ডেটাসেট। এই ডেটাসেটগুলো BigQuery-তে লোড করার কোনো প্রয়োজন নেই। BigQuery-তে ডেটাসেটগুলো ব্রাউজ ও কোয়েরি করার জন্য শুধু সেগুলো খুলতে হয়। এই কোডল্যাবে, আপনি স্ট্যাক ওভারফ্লো পাবলিক ডেটাসেটটি নিয়ে কাজ করবেন।
স্ট্যাক ওভারফ্লো ডেটাসেট ব্রাউজ করুন
স্ট্যাক ওভারফ্লো ডেটাসেটে পোস্ট, ট্যাগ, ব্যাজ, মন্তব্য, ব্যবহারকারী এবং আরও অনেক কিছুর তথ্য রয়েছে। BigQuery ওয়েব UI-তে স্ট্যাক ওভারফ্লো ডেটাসেট ব্রাউজ করতে, এই ধাপগুলো অনুসরণ করুন:
- স্ট্যাক ওভারফ্লো ডেটাসেটটি খুলুন। GCP কনসোলে BigQuery ওয়েব UI খুলবে এবং স্ট্যাকওভারফ্লো ডেটাসেট সম্পর্কিত তথ্য প্রদর্শন করবে।
- নেভিগেশন প্যানেলে, bigquery-public-data নির্বাচন করুন। মেনুটি প্রসারিত হয়ে পাবলিক ডেটাসেটগুলোর তালিকা দেখাবে। প্রতিটি ডেটাসেটে এক বা একাধিক টেবিল থাকে।
- নিচে স্ক্রল করুন এবং stackoverflow নির্বাচন করুন। মেনুটি প্রসারিত হয়ে Stack Overflow ডেটাসেটের টেবিলগুলোর তালিকা দেখাবে।
- ব্যাজ টেবিলের স্কিমা দেখতে ব্যাজগুলো নির্বাচন করুন। টেবিলের ফিল্ডগুলোর নামগুলো নোট করুন।
- ফিল্ডের নামগুলোর উপরে, ব্যাজ টেবিলের নমুনা ডেটা দেখতে প্রিভিউ-তে ক্লিক করুন।
BigQuery-তে উপলব্ধ সমস্ত পাবলিক ডেটাসেট সম্পর্কে আরও তথ্যের জন্য, Google BigQuery Public Datasets দেখুন।
স্ট্যাকওভারফ্লো ডেটাসেটে কোয়েরি করুন
আপনি যে ডেটা নিয়ে কাজ করছেন তা বোঝার জন্য ডেটাসেট ব্রাউজ করা একটি ভালো উপায়, কিন্তু ডেটাসেট কোয়েরি করার ক্ষেত্রেই BigQuery তার আসল দক্ষতা দেখায়। এই বিভাগে আপনাকে শেখানো হবে কীভাবে BigQuery কোয়েরি চালাতে হয়। এই পর্যায়ে আপনার কোনো SQL জানার প্রয়োজন নেই। আপনি নিচের কোয়েরিগুলো কপি ও পেস্ট করতে পারেন।
কোয়েরি চালানোর জন্য, নিম্নলিখিত ধাপগুলো সম্পন্ন করুন:
- GCP কনসোলের উপরের ডানদিকে, Compose new query নির্বাচন করুন।
- কোয়েরি এডিটর টেক্সট এরিয়াতে, নিচের SQL কোয়েরিটি কপি করে পেস্ট করুন। BigQuery কোয়েরিটি যাচাই করে এবং সিনট্যাক্সটি যে বৈধ, তা বোঝাতে ওয়েব UI টেক্সট এরিয়ার নিচে একটি সবুজ টিক চিহ্ন প্রদর্শন করে।
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- রান নির্বাচন করুন। এই কোয়েরিটি প্রতি বছর স্ট্যাক ওভারফ্লোতে পোস্ট করা পোস্ট বা প্রশ্নের সংখ্যা ফেরত দেয়।
৪. একটি নতুন টেবিল তৈরি করা
পূর্ববর্তী অংশে, আপনি BigQuery-এর দেওয়া পাবলিক ডেটাসেটগুলো কোয়েরি করেছেন। এই অংশে, আপনি BigQuery-তে একটি বিদ্যমান টেবিল থেকে একটি নতুন টেবিল তৈরি করবেন। আপনি Stack Overflow-এর পাবলিক ডেটাসেট posts_questions টেবিল থেকে ডেটা নিয়ে একটি নতুন টেবিল তৈরি করবেন এবং তারপর সেই টেবিলটি কোয়েরি করবেন।
একটি নতুন ডেটাসেট তৈরি করুন
BigQuery-তে টেবিলের ডেটা তৈরি ও লোড করার জন্য, প্রথমে নিম্নলিখিত ধাপগুলি সম্পন্ন করে ডেটা সংরক্ষণের জন্য একটি BigQuery ডেটাসেট তৈরি করুন:
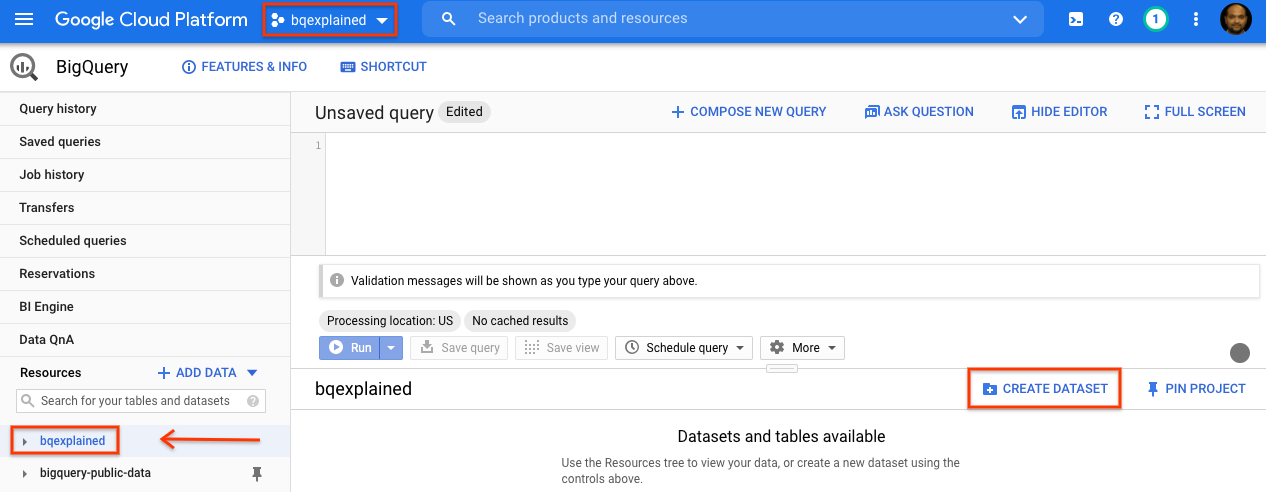
- GCP কনসোল নেভিগেশন প্যানেলে, সেটআপের অংশ হিসেবে তৈরি করা প্রজেক্টের নামটি নির্বাচন করুন।
- ডানদিকে, ডিটেইলস প্যানেলে, 'Create dataset' নির্বাচন করুন।
- ডেটা সেট তৈরি করার ডায়ালগ বক্সে, ডেটা সেট আইডি (Dataset ID) -এর জায়গায়
stackoverflowটাইপ করুন। বাকি সব ডিফল্ট সেটিংস অপরিবর্তিত রেখে ‘OK’ ক্লিক করুন।

২০১৮ সালের স্ট্যাকওভারফ্লো পোস্টগুলো দিয়ে একটি নতুন টেবিল তৈরি করুন
এখন যেহেতু আপনি একটি BigQuery ডেটাসেট তৈরি করেছেন, আপনি BigQuery-তে একটি নতুন টেবিল তৈরি করতে পারেন। বিদ্যমান কোনো টেবিলের ডেটা দিয়ে একটি নতুন টেবিল তৈরি করতে, আপনাকে 2018 Stack Overflow posts ডেটাসেটটি কোয়েরি করতে হবে এবং নিম্নলিখিত ধাপগুলো সম্পন্ন করে ফলাফলগুলো একটি নতুন টেবিলে লিখতে হবে:
- GCP কনসোলের উপরের ডানদিকে, Compose new query নির্বাচন করুন।

- কোয়েরি এডিটর টেক্সট এরিয়াতে একটি নতুন টেবিল তৈরি করার জন্য নিম্নলিখিত SQL কোয়েরিটি কপি ও পেস্ট করুন, যা একটি DDL স্টেটমেন্ট ।
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- রান নির্বাচন করুন। এই কোয়েরিটি আপনার প্রোজেক্টের
stackoverflowডেটাসেটেquestions_2018একটি নতুন টেবিল তৈরি করে, যেখানে BigQuery Stack Overflow ডেটাসেটbigquery-public-data.stackoverflow.posts_questionsএর উপর কোয়েরি চালানোর ফলে প্রাপ্ত ডেটা থাকে।
২০১৮ সালের স্ট্যাক ওভারফ্লো পোস্ট দিয়ে নতুন টেবিলটি কোয়েরি করুন
এখন যেহেতু আপনি একটি BigQuery টেবিল তৈরি করেছেন, চলুন প্রশ্ন ও শিরোনামসহ Stack Overflow পোস্টগুলো এবং সেই সাথে উত্তর, মন্তব্য, ভিউ ও ফেভারিটের সংখ্যার মতো আরও কিছু পরিসংখ্যান ফেরত আনার জন্য একটি কোয়েরি চালাই। নিচের ধাপগুলো সম্পন্ন করুন:
- GCP কনসোলের উপরের ডানদিকে, Compose new query নির্বাচন করুন।
- কোয়েরি এডিটর টেক্সট এরিয়াতে নিম্নলিখিত SQL কোয়েরিটি কপি করে পেস্ট করুন।
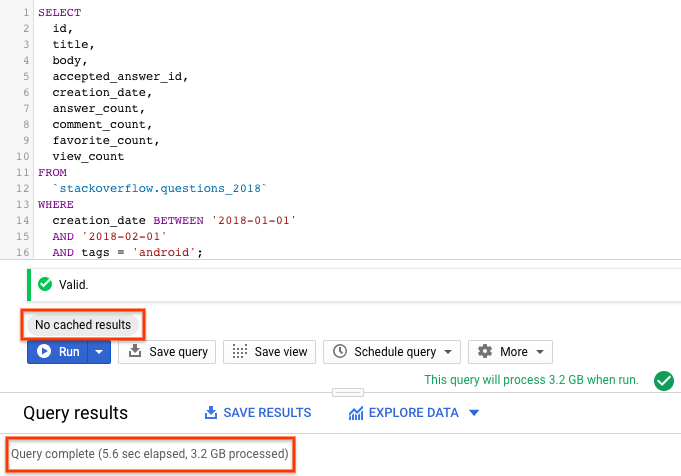
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- রান নির্বাচন করুন। এই কোয়েরিটি ২০১৮ সালের জানুয়ারী মাসে তৈরি হওয়া এবং
androidহিসেবে ট্যাগ করা স্ট্যাক ওভারফ্লো প্রশ্নগুলো, প্রশ্ন এবং আরও কিছু পরিসংখ্যান ফেরত দেয়। - ডিফল্টরূপে, BigQuery কোয়েরির ফলাফল ক্যাশ করে রাখে । একই কোয়েরিটি চালালে আপনি দেখতে পাবেন যে BigQuery ফলাফল ফেরত দিতে অনেক কম সময় নিচ্ছে, কারণ এটি ক্যাশ থেকে ফলাফল প্রদান করে।
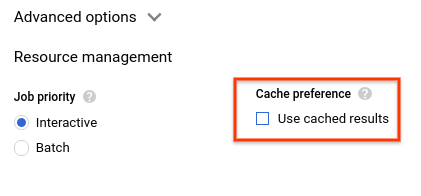
- একই কোয়েরিটি আবার চালান, তবে এবার BigQuery ক্যাশিং নিষ্ক্রিয় করে। পার্টিশন করা এবং ক্লাস্টার করা টেবিলের সাথে পারফরম্যান্সের ন্যায্য তুলনার জন্য আমরা এই ল্যাবের বাকি অংশের জন্য ক্যাশে নিষ্ক্রিয় রাখব, যা পরবর্তী বিভাগগুলিতে চালানো হবে। কোয়েরি এডিটরে, 'More'-এ ক্লিক করুন এবং 'Query settings' নির্বাচন করুন।

- ক্যাশ প্রেফারেন্সের অধীনে, ‘Use cached results’ থেকে টিক চিহ্ন তুলে দিন।
- কোয়েরির ফলাফলে, কোয়েরিটি সম্পন্ন হতে কত সময় লেগেছে এবং ফলাফল পেতে কী পরিমাণ ডেটা প্রসেস করা হয়েছে, তা আপনি দেখতে পাবেন।
৫. পার্টিশন করা টেবিল তৈরি এবং কোয়েরি করা
পূর্ববর্তী অংশে, আপনি স্ট্যাক ওভারফ্লো পাবলিক ডেটাসেট ব্যবহার করে posts_questions টেবিলের ডেটা দিয়ে BigQuery-তে একটি নতুন টেবিল তৈরি করেছিলেন। আমরা ক্যাশিং নিষ্ক্রিয় রেখে এই ডেটাসেটটি কোয়েরি করেছিলাম এবং কোয়েরির পারফরম্যান্স পর্যবেক্ষণ করেছিলাম। এই অংশে, আপনি একই স্ট্যাক ওভারফ্লো পাবলিক ডেটাসেটের posts_questions টেবিল থেকে একটি নতুন পার্টিশনড টেবিল তৈরি করবেন এবং কোয়েরির পারফরম্যান্স পর্যবেক্ষণ করবেন।
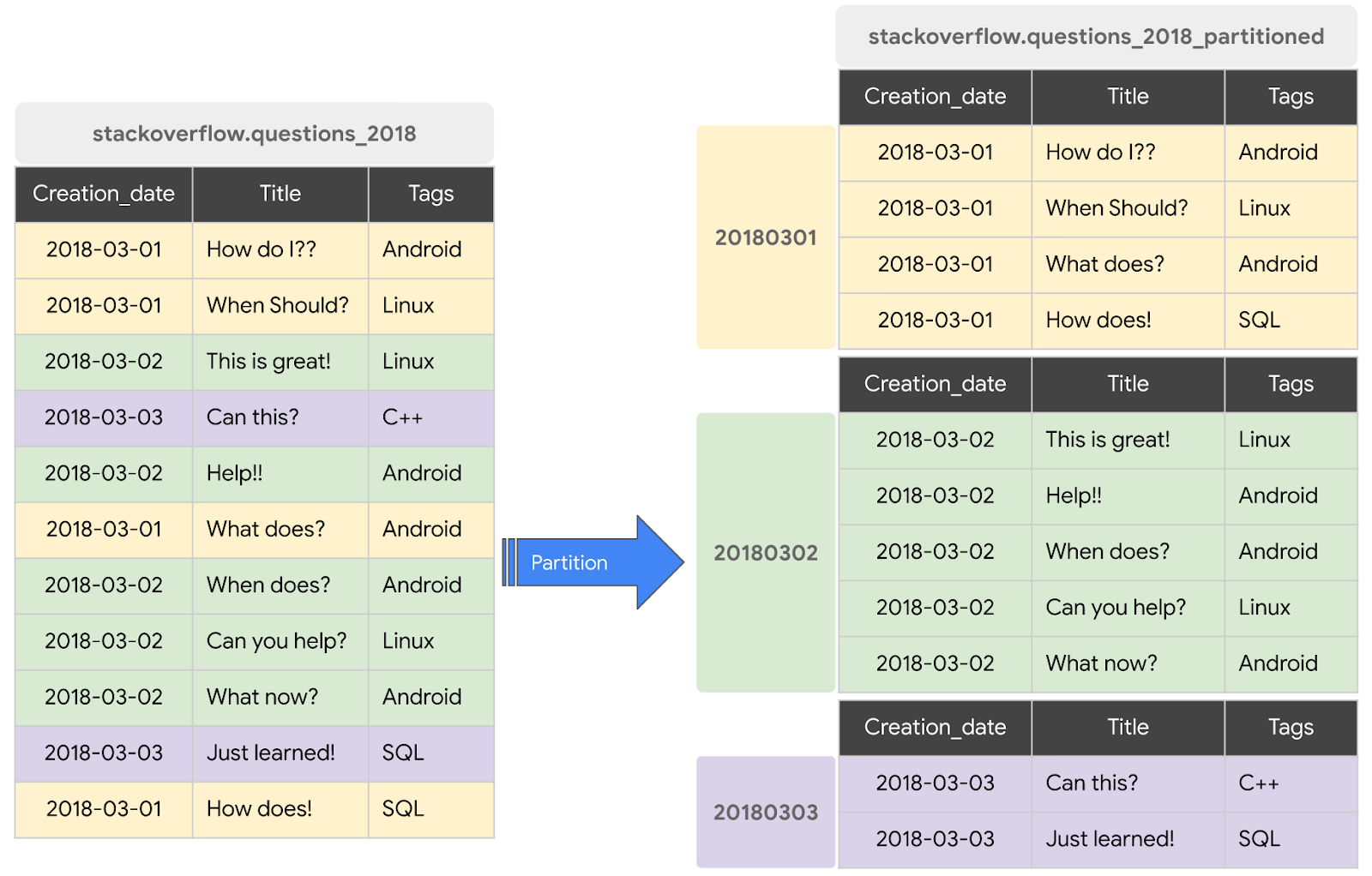
পার্টিশন করা টেবিল হলো একটি বিশেষ ধরনের টেবিল যা পার্টিশন নামক বিভিন্ন অংশে বিভক্ত থাকে, যা আপনার ডেটা পরিচালনা এবং কোয়েরি করা সহজ করে তোলে। সাধারণত ডেটা ইনজেশনের সময়, TIMESTAMP/DATE কলাম অথবা একটি INTEGER কলাম ব্যবহার করে বড় টেবিলগুলোকে অনেকগুলো ছোট ছোট পার্টিশনে ভাগ করা যায়। আমরা একটি DATE পার্টিশন করা টেবিল তৈরি করব।
পার্টিশন করা টেবিল সম্পর্কে এখানে আরও জানুন।
২০১৮ সালের স্ট্যাকওভারফ্লো পোস্ট দিয়ে একটি নতুন পার্টিশন করা টেবিল তৈরি করুন
বিদ্যমান কোনো টেবিল বা কোয়েরির ডেটা দিয়ে একটি পার্টিশন করা টেবিল তৈরি করতে, আপনাকে 2018 Stackoverflow posts ডেটাসেটটি কোয়েরি করতে হবে এবং ফলাফল একটি নতুন টেবিলে লিখতে হবে। এর জন্য নিম্নলিখিত ধাপগুলো সম্পন্ন করুন:
- GCP কনসোলের উপরের ডানদিকে, Compose new query নির্বাচন করুন।
- কোয়েরি এডিটর টেক্সট এরিয়াতে একটি নতুন টেবিল তৈরি করার জন্য নিম্নলিখিত SQL কোয়েরিটি কপি ও পেস্ট করুন, যা একটি DDL স্টেটমেন্ট ।
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- রান নির্বাচন করুন। এই কোয়েরিটি আপনার প্রোজেক্টের
stackoverflowডেটাসেটেquestions_2018_partitionedএকটি নতুন টেবিল তৈরি করে, যেখানে BigQuery Stack Overflow ডেটাসেটbigquery-public-data.stackoverflow.posts_questionsএর উপর কোয়েরি চালানোর ফলে প্রাপ্ত ডেটা থাকে।
২০১৮ সালের স্ট্যাক ওভারফ্লো পোস্ট ব্যবহার করে পার্টিশন করা টেবিলটি কোয়েরি করুন
এখন যেহেতু আপনি একটি BigQuery পার্টিশনড টেবিল তৈরি করেছেন, চলুন এবার পার্টিশনড টেবিলটির উপর একই কোয়েরিটি চালাই। এর মাধ্যমে প্রশ্ন ও শিরোনামসহ স্ট্যাক ওভারফ্লো পোস্টগুলোর পাশাপাশি উত্তর, মন্তব্য, ভিউ এবং ফেভারিটের সংখ্যার মতো আরও কিছু পরিসংখ্যান রিটার্ন করা হবে। নিচের ধাপগুলো সম্পন্ন করুন:
- GCP কনসোলের উপরের ডানদিকে, Compose new query নির্বাচন করুন।
- কোয়েরি এডিটর টেক্সট এরিয়াতে নিম্নলিখিত SQL কোয়েরিটি কপি করে পেস্ট করুন।
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery ক্যাশিং নিষ্ক্রিয় করে রান নির্বাচন করুন (BigQuery ক্যাশে নিষ্ক্রিয় করার জন্য পূর্ববর্তী বিভাগটি দেখুন)। কোয়েরিটি ২০১৮ সালের জানুয়ারী মাসে তৈরি হওয়া এবং
androidহিসাবে ট্যাগ করা স্ট্যাক ওভারফ্লো প্রশ্নগুলির সাথে প্রশ্ন এবং আরও কিছু পরিসংখ্যান ফেরত দেয়। - কোয়েরির ফলাফলে, কোয়েরিটি সম্পন্ন হতে কত সময় লেগেছে এবং ফলাফল পেতে কী পরিমাণ ডেটা প্রসেস করা হয়েছে, তা আপনি দেখতে পাবেন।
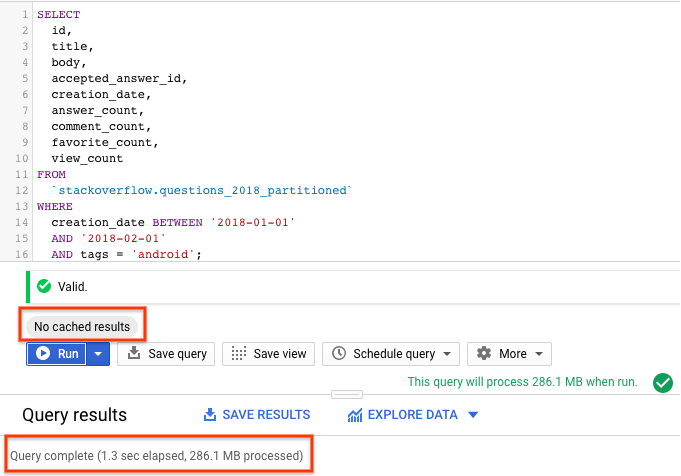
আপনি দেখবেন যে পার্টিশন করা টেবিলের ক্ষেত্রে কোয়েরির পারফরম্যান্স পার্টিশনবিহীন টেবিলের চেয়ে ভালো হয়, কারণ BigQuery পার্টিশনগুলোকে ছেঁটে ফেলে, অর্থাৎ এটি শুধু প্রয়োজনীয় পার্টিশনগুলো স্ক্যান করে কম ডেটা প্রসেস করে এবং দ্রুত চলে। এটি কোয়েরির খরচ এবং পারফরম্যান্সকে অপ্টিমাইজ করে।
৬. ক্লাস্টারড টেবিল তৈরি এবং কোয়েরি করা
পূর্ববর্তী অংশে, আপনি স্ট্যাক ওভারফ্লো পাবলিক ডেটাসেটের posts_questions টেবিলের ডেটা ব্যবহার করে BigQuery-তে একটি পার্টিশনড টেবিল তৈরি করেছিলেন। আমরা ক্যাশিং নিষ্ক্রিয় রেখে এই টেবিলটি কোয়েরি করেছিলাম এবং নন-পার্টিশনড ও পার্টিশনড উভয় টেবিলের ক্ষেত্রেই কোয়েরির পারফরম্যান্স পর্যবেক্ষণ করেছিলাম। এই অংশে, আপনি একই স্ট্যাক ওভারফ্লো পাবলিক ডেটাসেটের posts_questions টেবিল থেকে একটি নতুন ক্লাস্টারড টেবিল তৈরি করবেন এবং কোয়েরির পারফরম্যান্স পর্যবেক্ষণ করবেন।
BigQuery-তে যখন কোনো টেবিল ক্লাস্টার করা হয়, তখন টেবিলের স্কিমার এক বা একাধিক কলামের বিষয়বস্তুর উপর ভিত্তি করে টেবিলের ডেটা স্বয়ংক্রিয়ভাবে সাজানো হয়। আপনার নির্দিষ্ট করা কলামগুলো সম্পর্কিত ডেটাকে একই স্থানে রাখার জন্য ব্যবহৃত হয়। যখন কোনো ক্লাস্টার করা টেবিলে ডেটা লেখা হয়, BigQuery ক্লাস্টারিং কলামগুলোর মান ব্যবহার করে ডেটা সাজিয়ে নেয়। এই মানগুলো BigQuery স্টোরেজে ডেটাকে একাধিক ব্লকে সাজানোর জন্য ব্যবহৃত হয়। ক্লাস্টার করা কলামগুলোর ক্রম ডেটার সাজানোর ক্রম নির্ধারণ করে। যখন কোনো টেবিল বা নির্দিষ্ট পার্টিশনে নতুন ডেটা যোগ করা হয়, তখন BigQuery টেবিল বা পার্টিশনের সাজানোর বৈশিষ্ট্য পুনরুদ্ধার করার জন্য ব্যাকগ্রাউন্ডে স্বয়ংক্রিয়ভাবে পুনরায় ক্লাস্টারিং করে।
ক্লাস্টারড টেবিল নিয়ে কাজ করার বিষয়ে এখানে আরও জানুন।
২০১৮ সালের স্ট্যাক ওভারফ্লো পোস্ট দিয়ে একটি নতুন ক্লাস্টারড টেবিল তৈরি করুন
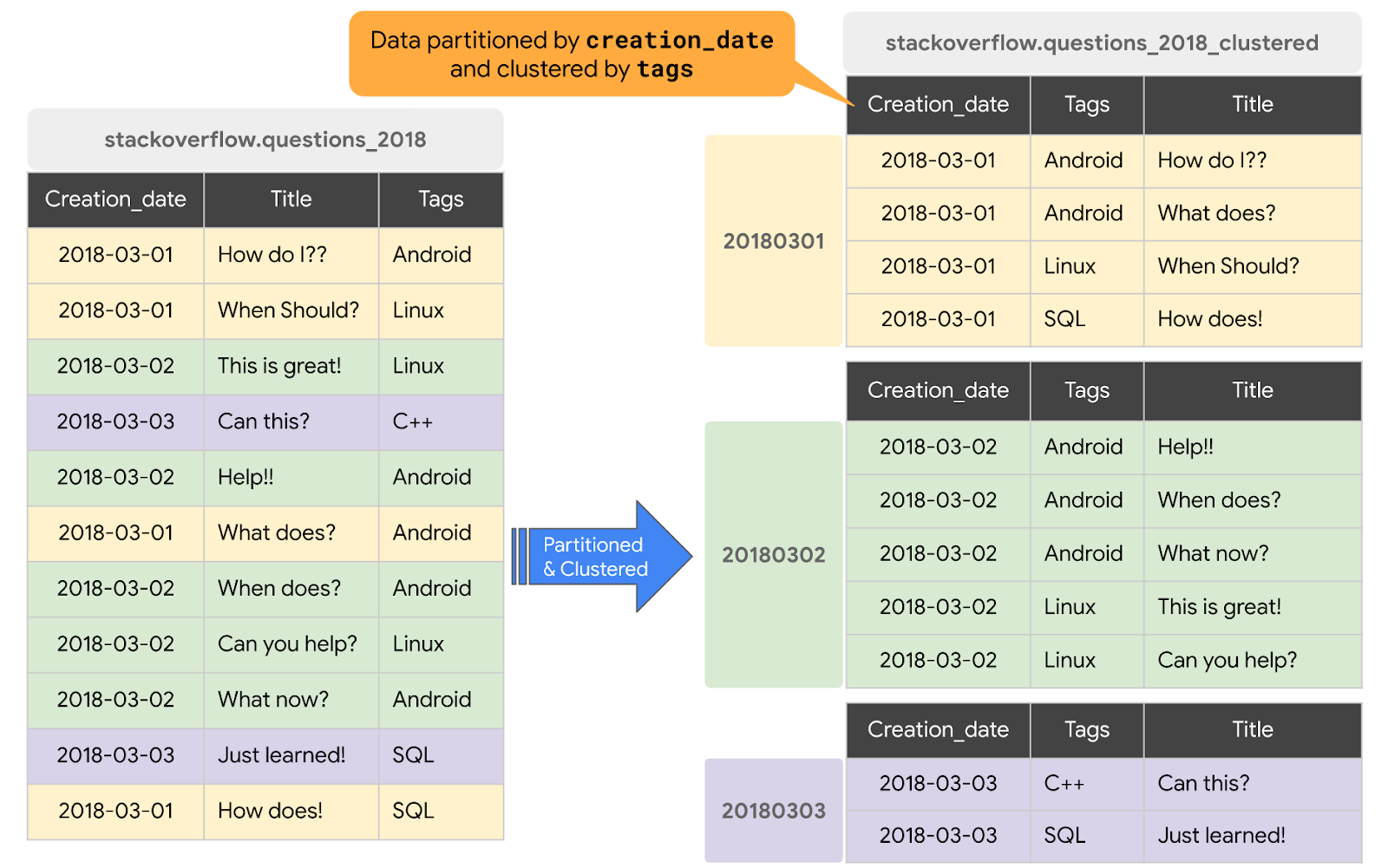
এই অংশে, আপনি query access pattern-এর উপর ভিত্তি করে creation_date দ্বারা পার্টিশন করা এবং tags কলামে ক্লাস্টার করা একটি নতুন টেবিল তৈরি করবেন। বিদ্যমান কোনো টেবিল বা কোয়েরির ডেটা দিয়ে একটি ক্লাস্টারড টেবিল তৈরি করতে, আপনি 2018 Stack Overflow posts টেবিলটি কোয়েরি করবেন এবং নিম্নলিখিত ধাপগুলি সম্পন্ন করে ফলাফলগুলি একটি নতুন টেবিলে লিখবেন:
- GCP কনসোলের উপরের ডানদিকে, Compose new query নির্বাচন করুন।
- কোয়েরি এডিটর টেক্সট এরিয়াতে একটি নতুন টেবিল তৈরি করার জন্য নিম্নলিখিত SQL কোয়েরিটি কপি ও পেস্ট করুন, যা একটি DDL স্টেটমেন্ট ।
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- রান নির্বাচন করুন। এই কোয়েরিটি আপনার প্রোজেক্টের
stackoverflowডেটাসেটেquestions_2018_clusteredএকটি নতুন টেবিল তৈরি করে, যেখানে BigQuery Stack Overflow টেবিলbigquery-public-data.stackoverflow.posts_questionsউপর কোয়েরি চালানোর ফলে প্রাপ্ত ডেটা থাকে। নতুন টেবিলটি creation_date-এর উপর পার্টিশন করা এবং tags কলামের উপর ক্লাস্টার করা হয়।
২০১৮ সালের স্ট্যাক ওভারফ্লো পোস্ট ব্যবহার করে ক্লাস্টারড টেবিলটি কোয়েরি করুন
এখন যেহেতু আপনি একটি BigQuery ক্লাস্টারড টেবিল তৈরি করেছেন, চলুন একই কোয়েরিটি আবার চালাই, এবার পার্টিশনড এবং ক্লাস্টারড টেবিলটির উপর, যাতে প্রশ্ন ও শিরোনামসহ স্ট্যাক ওভারফ্লো পোস্টগুলোর পাশাপাশি উত্তর, মন্তব্য, ভিউ এবং ফেভারিটের সংখ্যার মতো আরও কিছু পরিসংখ্যান রিটার্ন করা যায়। নিম্নলিখিত ধাপগুলো সম্পন্ন করুন:
- GCP কনসোলের উপরের ডানদিকে, Compose new query নির্বাচন করুন।
- কোয়েরি এডিটর টেক্সট এরিয়াতে নিম্নলিখিত SQL কোয়েরিটি কপি করে পেস্ট করুন।
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery ক্যাশিং নিষ্ক্রিয় করে রান নির্বাচন করুন (BigQuery ক্যাশে নিষ্ক্রিয় করার জন্য পূর্ববর্তী বিভাগটি দেখুন)। কোয়েরিটি ২০১৮ সালের জানুয়ারী মাসে তৈরি হওয়া এবং
androidহিসাবে ট্যাগ করা স্ট্যাক ওভারফ্লো প্রশ্নগুলির সাথে প্রশ্ন এবং আরও কিছু পরিসংখ্যান ফেরত দেয়। - কোয়েরির ফলাফলে, কোয়েরিটি সম্পন্ন হতে কত সময় লেগেছে এবং ফলাফল পেতে কী পরিমাণ ডেটা প্রসেস করা হয়েছে, তা আপনি দেখতে পাবেন।
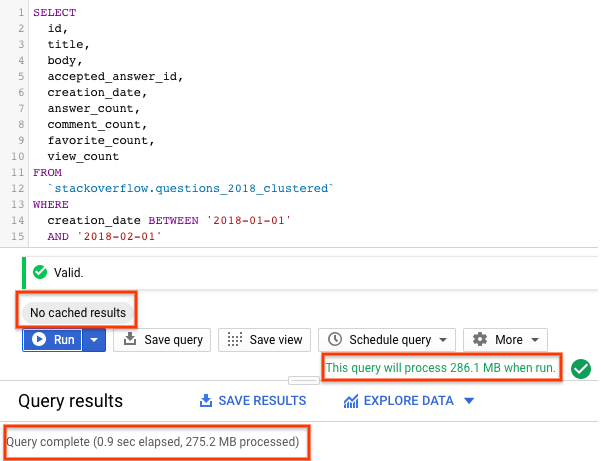
পার্টিশন করা এবং ক্লাস্টার করা টেবিলের ক্ষেত্রে, কোয়েরিটি একটি পার্টিশন করা বা পার্টিশন না করা টেবিলের চেয়ে কম ডেটা স্ক্যান করে। পার্টিশনিং এবং ক্লাস্টারিংয়ের মাধ্যমে ডেটা যেভাবে সাজানো হয়, তা স্লট ওয়ার্কারদের দ্বারা স্ক্যান করা ডেটার পরিমাণ কমিয়ে দেয়, যার ফলে কোয়েরির পারফরম্যান্স উন্নত হয় এবং খরচ অপ্টিমাইজ হয়।
৭. পরিষ্কার করা
যদি আপনি আপনার স্ট্যাকওভারফ্লো ডেটাসেট নিয়ে কাজ চালিয়ে যাওয়ার পরিকল্পনা না করেন, তবে আপনার এটি এবং এই কোডল্যাবের জন্য তৈরি করা প্রজেক্টটি ডিলিট করে দেওয়া উচিত।
BigQuery ডেটাসেটটি মুছে ফেলুন
BigQuery ডেটাসেটটি ডিলিট করতে, নিম্নলিখিত ধাপগুলো অনুসরণ করুন:
- BigQuery-এর বাম দিকের নেভিগেশন প্যানেল থেকে স্ট্যাকওভারফ্লো ডেটাসেটটি নির্বাচন করুন।
- ডিটেইলস প্যানেলে, ডিলিট ডেটাসেট নির্বাচন করুন।
- ডেটাসেট মুছুন ডায়ালগ বক্সে, stackoverflow লিখুন এবং ডেটাসেটটি মুছে ফেলার বিষয়টি নিশ্চিত করতে Delete নির্বাচন করুন।
প্রকল্পটি মুছে ফেলুন
এই কোডল্যাবের জন্য আপনার তৈরি করা GCP প্রজেক্টটি ডিলিট করতে, নিম্নলিখিত ধাপগুলো অনুসরণ করুন:
- GCP নেভিগেশন মেনুতে, IAM & Admin নির্বাচন করুন।
- ন্যাভিগেশন প্যানেলে, সেটিংস নির্বাচন করুন।
- ডিটেইলস প্যানেলে, নিশ্চিত করুন যে আপনার বর্তমান প্রজেক্টটিই এই কোডল্যাবের জন্য আপনার তৈরি করা প্রজেক্ট এবং 'শাট ডাউন' নির্বাচন করুন।
- প্রজেক্ট শাট ডাউন ডায়ালগ বক্সে, আপনার প্রজেক্টের প্রজেক্ট আইডি (প্রজেক্টের নাম নয়) লিখুন এবং নিশ্চিত করতে শাট ডাউন নির্বাচন করুন।
অভিনন্দন! আপনি এখন শিখেছেন
- বিদ্যমান টেবিল থেকে নতুন টেবিল তৈরি করতে BigQuery ওয়েব UI কীভাবে ব্যবহার করবেন
- পার্টিশন করা এবং ক্লাস্টার করা টেবিল কীভাবে তৈরি ও কোয়েরি করতে হয়
- পার্টিশনিং এবং ক্লাস্টারিং কীভাবে কোয়েরির পারফরম্যান্স এবং খরচ অপ্টিমাইজ করে
উল্লেখ্য যে, ডেটাসেট নিয়ে কাজ করার জন্য আপনাকে ক্লাস্টার সেট আপ বা পরিচালনা করতে হয়নি।