
۱. مقدمه
بیگکوئری یک انبار داده سازمانی کمهزینه، با مدیریت کامل و در مقیاس پتابایت برای تجزیه و تحلیل است. بیگکوئری بدون سرور است. نیازی به راهاندازی و مدیریت کلاسترها ندارید.
یک مجموعه داده BigQuery در یک پروژه GCP قرار دارد و شامل یک یا چند جدول است. میتوانید با استفاده از SQL از این مجموعه دادهها پرسوجو کنید.
در این آزمایشگاه کد، شما از رابط کاربری وب BigQuery در کنسول GCP برای درک پارتیشنبندی و خوشهبندی در BigQuery استفاده خواهید کرد. پارتیشنبندی و خوشهبندی جداول BigQuery به ساختاردهی دادههای شما برای مطابقت با الگوهای رایج دسترسی به دادهها کمک میکند. پارتیشنبندی و خوشهبندی کلید به حداکثر رساندن عملکرد و هزینه BigQuery هنگام پرسوجو در یک محدوده داده خاص است. این امر منجر به اسکن دادههای کمتر در هر پرسوجو میشود و هرس قبل از زمان شروع پرسوجو تعیین میشود.
برای اطلاعات بیشتر در مورد BigQuery، به مستندات BigQuery مراجعه کنید.
آنچه یاد خواهید گرفت
- نحوه ایجاد و پرس و جو از جداول پارتیشن بندی شده و خوشه بندی شده
- مقایسه عملکرد پرس و جو با جداول پارتیشن بندی شده و خوشه بندی شده
آنچه نیاز دارید
برای تکمیل این آزمایشگاه، به موارد زیر نیاز دارید:
- آخرین نسخه گوگل کروم
- یک حساب پرداخت پلتفرم ابری گوگل
۲. راهاندازی
برای کار با BigQuery، باید یک پروژه GCP ایجاد کنید یا یک پروژه موجود را انتخاب کنید.
ایجاد یک پروژه
برای ایجاد یک پروژه جدید، مراحل زیر را دنبال کنید:
- اگر از قبل حساب گوگل (جیمیل یا گوگل اپس) ندارید، یکی ایجاد کنید .
- وارد کنسول پلتفرم ابری گوگل ( console.cloud.google.com ) شوید و یک پروژه جدید ایجاد کنید.
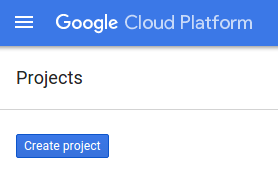
- اگر هیچ پروژهای ندارید، روی دکمهی ایجاد پروژه کلیک کنید:
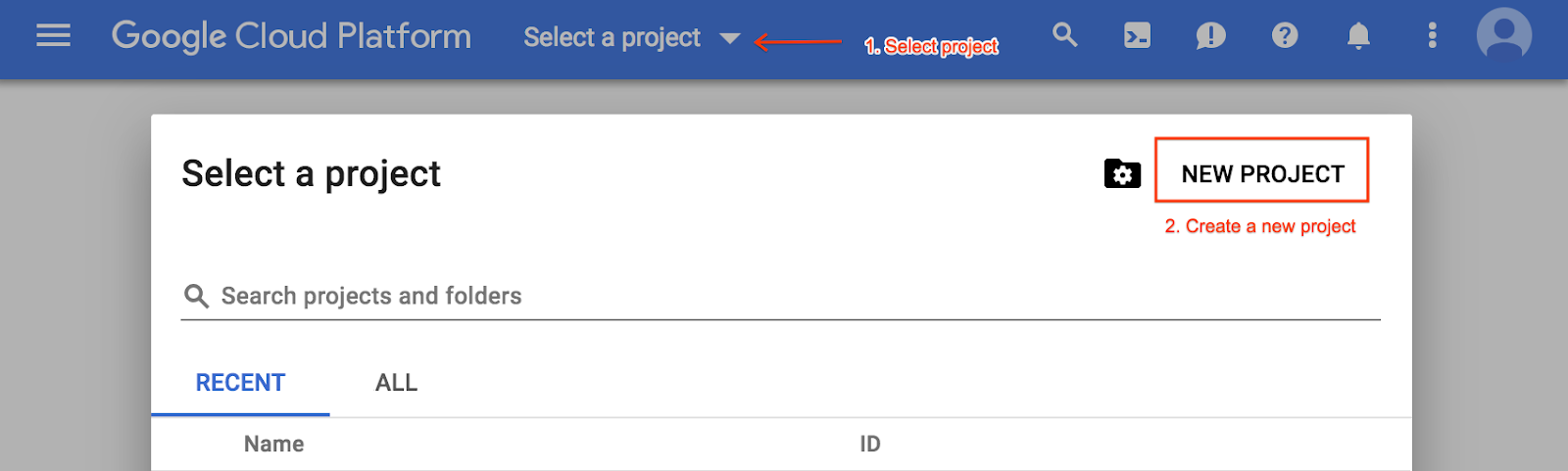
در غیر این صورت، از منوی انتخاب پروژه، یک پروژه جدید ایجاد کنید:
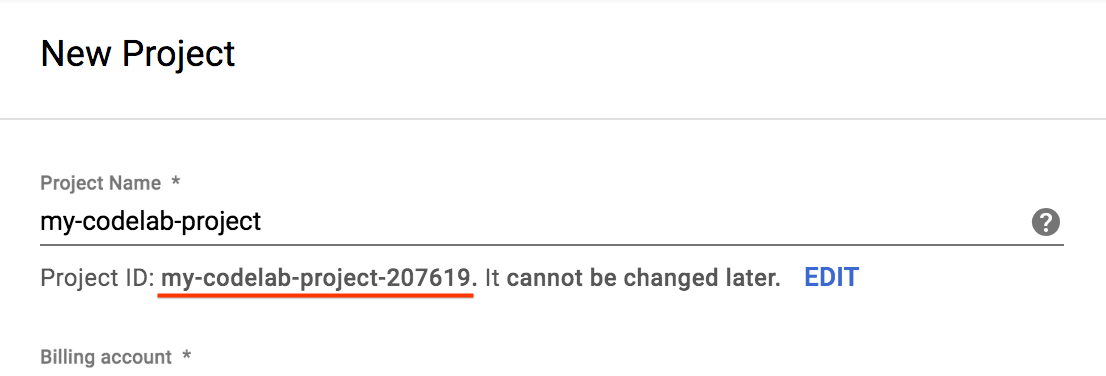
- نام پروژه را وارد کنید و ایجاد را انتخاب کنید. توجه داشته باشید که شناسه پروژه، نامی منحصر به فرد در تمام پروژههای Google Cloud است.
۳. کار با مجموعه دادههای عمومی
BigQuery به شما امکان میدهد با مجموعه دادههای عمومی، از جمله BBC News، مخازن GitHub، Stack Overflow و مجموعه دادههای اداره ملی اقیانوسی و جوی ایالات متحده (NOAA) کار کنید. نیازی به بارگذاری این مجموعه دادهها در BigQuery ندارید. فقط کافی است مجموعه دادهها را باز کنید تا آنها را در BigQuery مرور و پرسوجو کنید. در این آزمایشگاه کد، با مجموعه دادههای عمومی Stack Overflow کار خواهید کرد.
مجموعه دادههای Stack Overflow را مرور کنید
مجموعه دادههای Stack Overflow شامل اطلاعاتی در مورد پستها، برچسبها، نشانها، نظرات، کاربران و موارد دیگر است. برای مرور مجموعه دادههای Stack Overflow در رابط کاربری وب BigQuery، این مراحل را دنبال کنید:
- مجموعه داده Stack Overflow را باز کنید. رابط کاربری وب BigQuery در کنسول GCP باز میشود و اطلاعات مربوط به مجموعه داده Stackoverflow را نمایش میدهد.
- در پنل ناوبری، bigquery-public-data را انتخاب کنید. منو برای فهرست کردن مجموعه دادههای عمومی باز میشود. هر مجموعه داده شامل یک یا چند جدول است.
- به پایین اسکرول کنید و stackoverflow را انتخاب کنید. منو باز میشود و جداول موجود در مجموعه دادههای Stack Overflow را فهرست میکند.
- برای مشاهدهی طرح جدول مدالها، badges را انتخاب کنید. به نام فیلدهای جدول توجه کنید.
- بالای نام فیلدها، روی پیشنمایش کلیک کنید تا دادههای نمونه برای جدول مدالها را ببینید.
برای اطلاعات بیشتر در مورد تمام مجموعه دادههای عمومی موجود در BigQuery، به مجموعه دادههای عمومی Google BigQuery مراجعه کنید.
پرس و جو در مجموعه داده Stackoverflow
مرور یک مجموعه داده روش خوبی برای درک دادههایی است که با آنها کار میکنید، اما پرسوجو از مجموعه دادهها جایی است که BigQuery واقعاً میدرخشد. این بخش به شما نحوه اجرای پرسوجوهای BigQuery را آموزش میدهد. در این مرحله نیازی به دانستن هیچ SQL ندارید. میتوانید پرسوجوهای زیر را کپی و جایگذاری کنید.
برای اجرای یک پرس و جو، مراحل زیر را انجام دهید:
- در نزدیکی سمت راست بالای کنسول GCP، گزینه «ایجاد پرسوجوی جدید» (Compose new query) را انتخاب کنید.
- در قسمت متن ویرایشگر کوئری ، کوئری SQL زیر را کپی و جایگذاری کنید. BigQuery کوئری را اعتبارسنجی میکند و رابط کاربری وب یک علامت تیک سبز در زیر قسمت متن نمایش میدهد تا نشان دهد که سینتکس معتبر است.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- اجرا را انتخاب کنید. کوئری تعداد پستها یا سوالات ارسال شده در Stack Overflow را هر ساله برمیگرداند.
۴. ایجاد یک جدول جدید
در بخش قبلی، شما از مجموعه دادههای عمومی که BigQuery در اختیار شما قرار میدهد، پرسوجو کردید. در این بخش، شما یک جدول جدید در BigQuery از یک جدول موجود ایجاد خواهید کرد. شما یک جدول جدید با دادههای نمونهبرداری شده از جدول posts_questions مجموعه دادههای عمومی Stack Overflow ایجاد خواهید کرد و سپس از جدول پرسوجو خواهید کرد.
ایجاد یک مجموعه داده جدید
برای ایجاد و بارگذاری دادههای جدول در BigQuery، ابتدا با انجام مراحل زیر، یک مجموعه داده BigQuery برای نگهداری دادهها ایجاد کنید:
- در پنل ناوبری کنسول GCP، نام پروژه ایجاد شده به عنوان بخشی از تنظیمات را انتخاب کنید.
- در سمت راست، در پنل جزئیات، گزینهی «ایجاد مجموعه داده» (Create dataset) را انتخاب کنید.
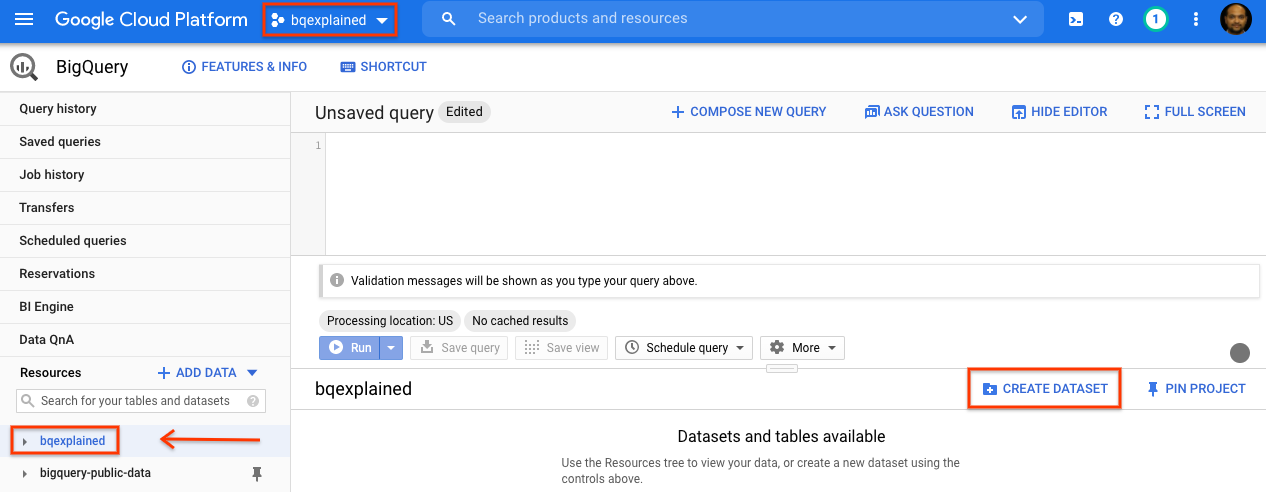
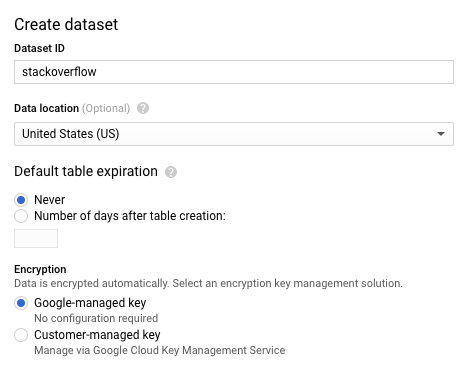
- در پنجرهی Create dataset ، برای Dataset ID ، عبارت
stackoverflowرا تایپ کنید. سایر تنظیمات پیشفرض را به حال خود رها کنید و روی OK کلیک کنید.
ایجاد یک جدول جدید با پستهای StackOverflow 2018
اکنون که یک مجموعه داده BigQuery ایجاد کردهاید، میتوانید یک جدول جدید در BigQuery ایجاد کنید. برای ایجاد یک جدول با دادههای یک جدول موجود، با انجام مراحل زیر، از مجموعه دادههای Stack Overflow 2018 پرسوجو خواهید کرد و نتایج را در یک جدول جدید خواهید نوشت:
- در نزدیکی سمت راست بالای کنسول GCP، گزینه «ایجاد پرسوجوی جدید» (Compose new query) را انتخاب کنید.

- در قسمت متن ویرایشگر کوئری ، کوئری SQL زیر را کپی و جایگذاری کنید تا یک جدول جدید ایجاد شود، که یک دستور DDL است.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- گزینه Run را انتخاب کنید. کوئری یک جدول جدید به
questions_2018در مجموعه دادهstackoverflowدر پروژه شما ایجاد میکند که دادههای آن از اجرای یک کوئری روی مجموعه داده BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questionsحاصل شده است.
پرس و جو در جدول جدید با پستهای Stack Overflow در سال ۲۰۱۸
حالا که یک جدول BigQuery ایجاد کردهاید، بیایید یک کوئری اجرا کنیم تا پستهای Stack Overflow را به همراه سوالات و عناوین به همراه چند آمار دیگر مانند تعداد پاسخها، نظرات، بازدیدها و موارد دلخواه، برگرداند. مراحل زیر را انجام دهید:
- در نزدیکی سمت راست بالای کنسول GCP، گزینه «ایجاد پرسوجوی جدید» (Compose new query) را انتخاب کنید.
- در قسمت متن ویرایشگر کوئری ، کوئری SQL زیر را کپی و جایگذاری کنید
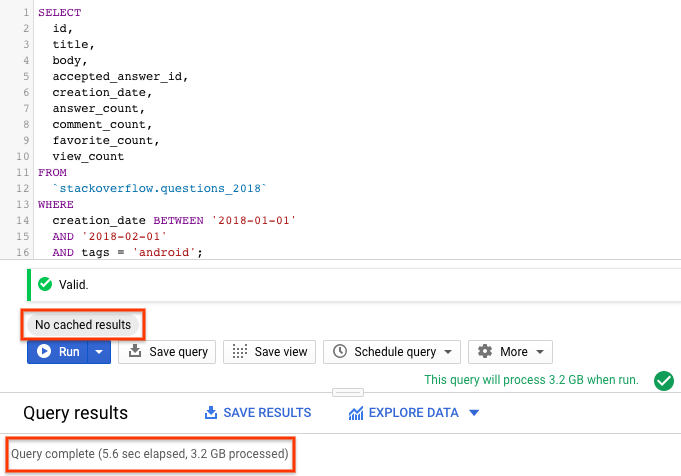
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- اجرای (Run) را انتخاب کنید. کوئری، سوالات Stack Overflow ایجاد شده در ماه ژانویه ۲۰۱۸ را که به همراه خود سوال و چند آمار دیگر با برچسب
androidمشخص شدهاند، برمیگرداند. - به طور پیشفرض، BigQuery نتایج کوئری را ذخیره میکند . همان کوئری را اجرا کنید و خواهید دید که BigQuery زمان بسیار کمتری برای بازگرداندن نتایج صرف میکند، زیرا نتایج را از حافظه پنهان برمیگرداند.
- دوباره همان کوئری را اجرا کنید، اما این بار با غیرفعال بودن قابلیت ذخیرهسازی BigQuery. برای اینکه مقایسه عملکرد در مقایسه با جداول پارتیشنبندی شده و خوشهای که در بخشهای بعدی اجرا خواهند شد، منصفانه باشد، کش را برای بقیه مراحل غیرفعال خواهیم کرد. در ویرایشگر کوئری، روی «بیشتر» کلیک کنید و «تنظیمات کوئری» را انتخاب کنید.
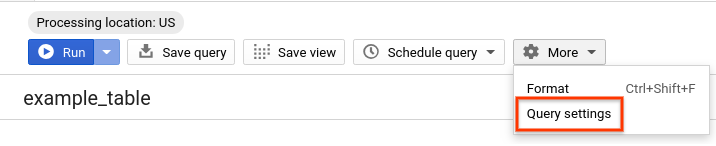
- در بخش تنظیمات حافظه پنهان (Cache preferences )، تیک گزینه «استفاده از نتایج ذخیره شده» (Use cached results) را بردارید.
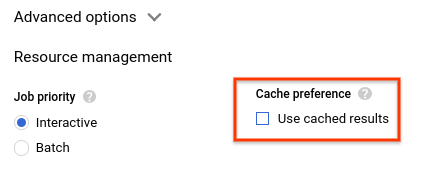
- در نتایج پرسوجو، باید مدت زمان لازم برای تکمیل پرسوجو و حجم دادههای پردازششده برای دریافت نتایج را مشاهده کنید.
۵. ایجاد و پرسوجو از یک جدول پارتیشنبندیشده
در بخش قبلی، شما یک جدول جدید در BigQuery با دادههای جدول posts_questions با استفاده از مجموعه داده عمومی Stack Overflow ایجاد کردید. ما این مجموعه داده را با غیرفعال کردن قابلیت ذخیرهسازی (caching) پرسوجو کردیم و عملکرد پرسوجو را مشاهده کردیم. در این بخش، شما یک جدول پارتیشنبندی شده جدید از همان جدول posts_questions مجموعه داده عمومی Stack Overflow ایجاد خواهید کرد و عملکرد پرسوجو را مشاهده خواهید کرد.
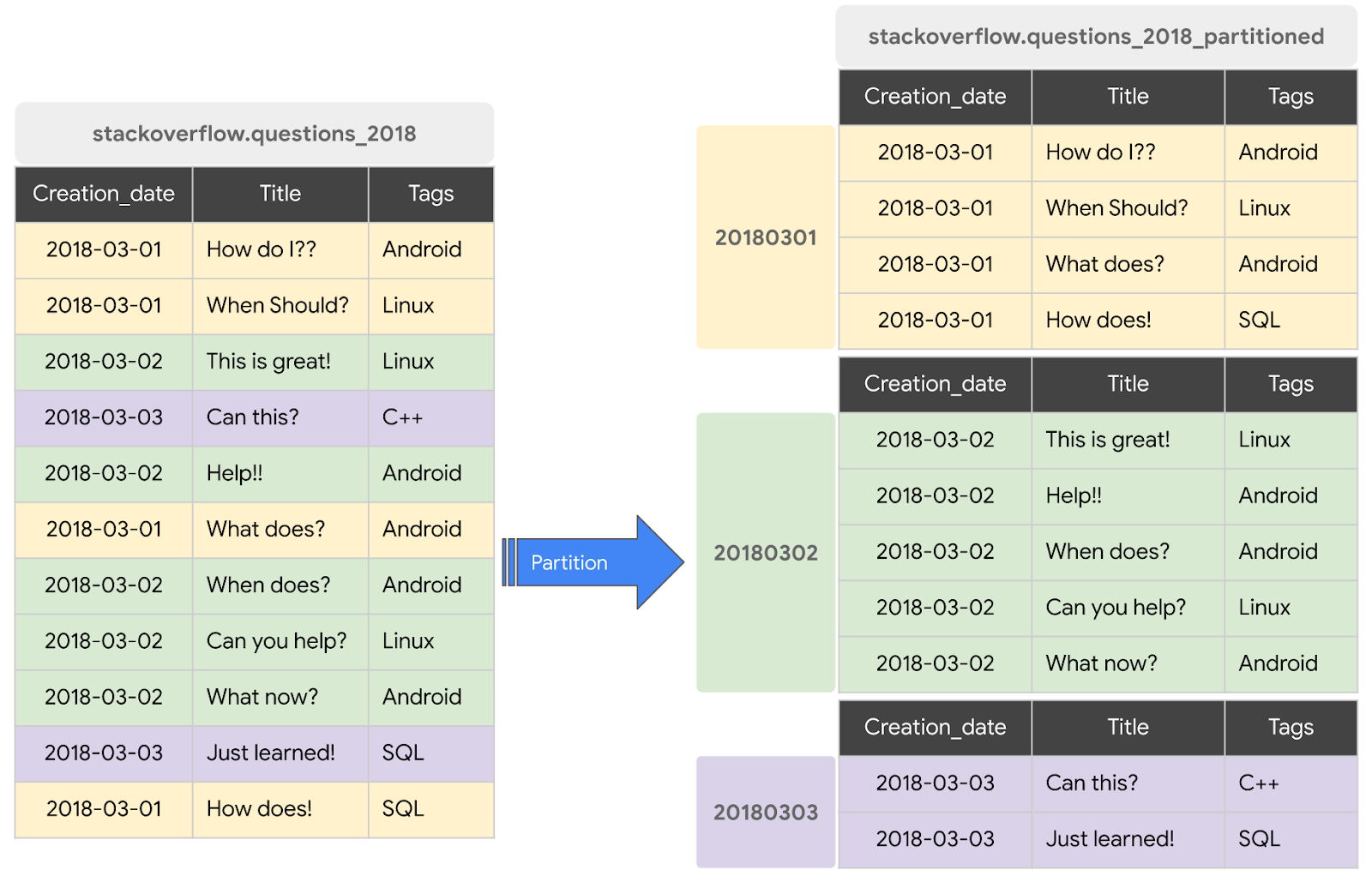
یک جدول پارتیشنبندی شده، جدول خاصی است که به بخشهایی به نام پارتیشن تقسیم میشود و مدیریت و پرسوجو از دادهها را آسانتر میکند. معمولاً میتوانید جداول بزرگ را با استفاده از زمان مصرف داده یا ستون TIMESTAMP/DATE یا یک ستون INTEGER به پارتیشنهای کوچکتری تقسیم کنید. ما یک جدول پارتیشنبندی شده از نوع DATE ایجاد خواهیم کرد.
درباره جداول پارتیشنبندی شده اینجا بیشتر بدانید.
ایجاد یک جدول پارتیشنبندی شده جدید با پستهای StackOverflow 2018
برای ایجاد یک جدول پارتیشنبندی شده با دادههای یک جدول یا پرسوجوی موجود، باید از مجموعه دادههای پستهای Stackoverflow 2018 پرسوجو کنید و نتایج را در یک جدول جدید بنویسید، مراحل زیر را انجام دهید:
- در نزدیکی سمت راست بالای کنسول GCP، گزینه «ایجاد پرسوجوی جدید» (Compose new query) را انتخاب کنید.
- در قسمت متن ویرایشگر کوئری ، کوئری SQL زیر را کپی و جایگذاری کنید تا یک جدول جدید ایجاد شود، که یک دستور DDL است.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- گزینه Run را انتخاب کنید. کوئری یک جدول جدید
questions_2018_partitionedدر مجموعه دادهstackoverflowپروژه شما ایجاد میکند که دادههای آن حاصل اجرای یک کوئری روی مجموعه داده BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions
پرس و جو در جدول پارتیشن بندی شده با پست های Stack Overflow 2018
حالا که یک جدول پارتیشنبندیشده در BigQuery ایجاد کردهاید، بیایید همان کوئری را این بار روی جدول پارتیشنبندیشده اجرا کنیم تا پستهای Stack Overflow را به همراه سوالات و عناوین به همراه چند آمار دیگر مانند تعداد پاسخها، نظرات، بازدیدها و موارد دلخواه، نمایش دهیم. مراحل زیر را انجام دهید:
- در نزدیکی سمت راست بالای کنسول GCP، گزینه «ایجاد پرسوجوی جدید» (Compose new query) را انتخاب کنید.
- در قسمت متن ویرایشگر کوئری ، کوئری SQL زیر را کپی و جایگذاری کنید
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- گزینه Run with BigQuery caching disabled را انتخاب کنید (برای غیرفعال کردن BigQuery cache به بخش قبلی مراجعه کنید). کوئری، سوالات Stack Overflow که در ماه ژانویه ۲۰۱۸ ایجاد شدهاند و به همراه خود سوال و چند آمار دیگر، با برچسب
androidمشخص شدهاند را برمیگرداند. - در نتایج پرسوجو، باید مدت زمان لازم برای تکمیل پرسوجو و حجم دادههای پردازششده برای دریافت نتایج را مشاهده کنید.
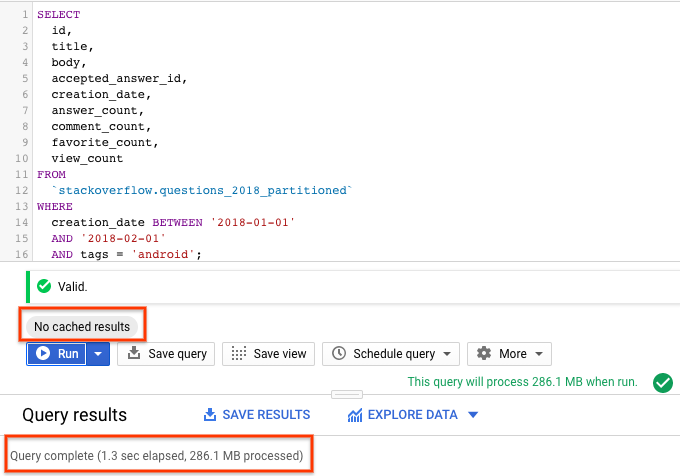
باید ببینید که عملکرد پرسوجو با جدول پارتیشنبندیشده بهتر از جدول بدون پارتیشن است، زیرا BigQuery پارتیشنها را هرس میکند، یعنی فقط پارتیشنهای مورد نیاز را اسکن میکند، دادههای کمتری پردازش میکند و سریعتر اجرا میشود. این کار هزینههای پرسوجو و عملکرد پرسوجو را بهینه میکند.
۶. ایجاد و پرسوجو از یک جدول خوشهای
در بخش قبلی، شما یک جدول پارتیشنبندی شده در BigQuery با دادههایی از جدول posts_questions در مجموعه داده عمومی Stack Overflow ایجاد کردید. ما این جدول را با غیرفعال بودن قابلیت ذخیرهسازی (caching) پرسوجو کردیم و عملکرد پرسوجو را با جداول پارتیشنبندی نشده و پارتیشنبندی شده مشاهده کردیم. در این بخش، شما یک جدول خوشهای جدید از همان جدول posts_questions مجموعه داده عمومی Stack Overflow ایجاد خواهید کرد و عملکرد پرسوجو را مشاهده خواهید کرد.
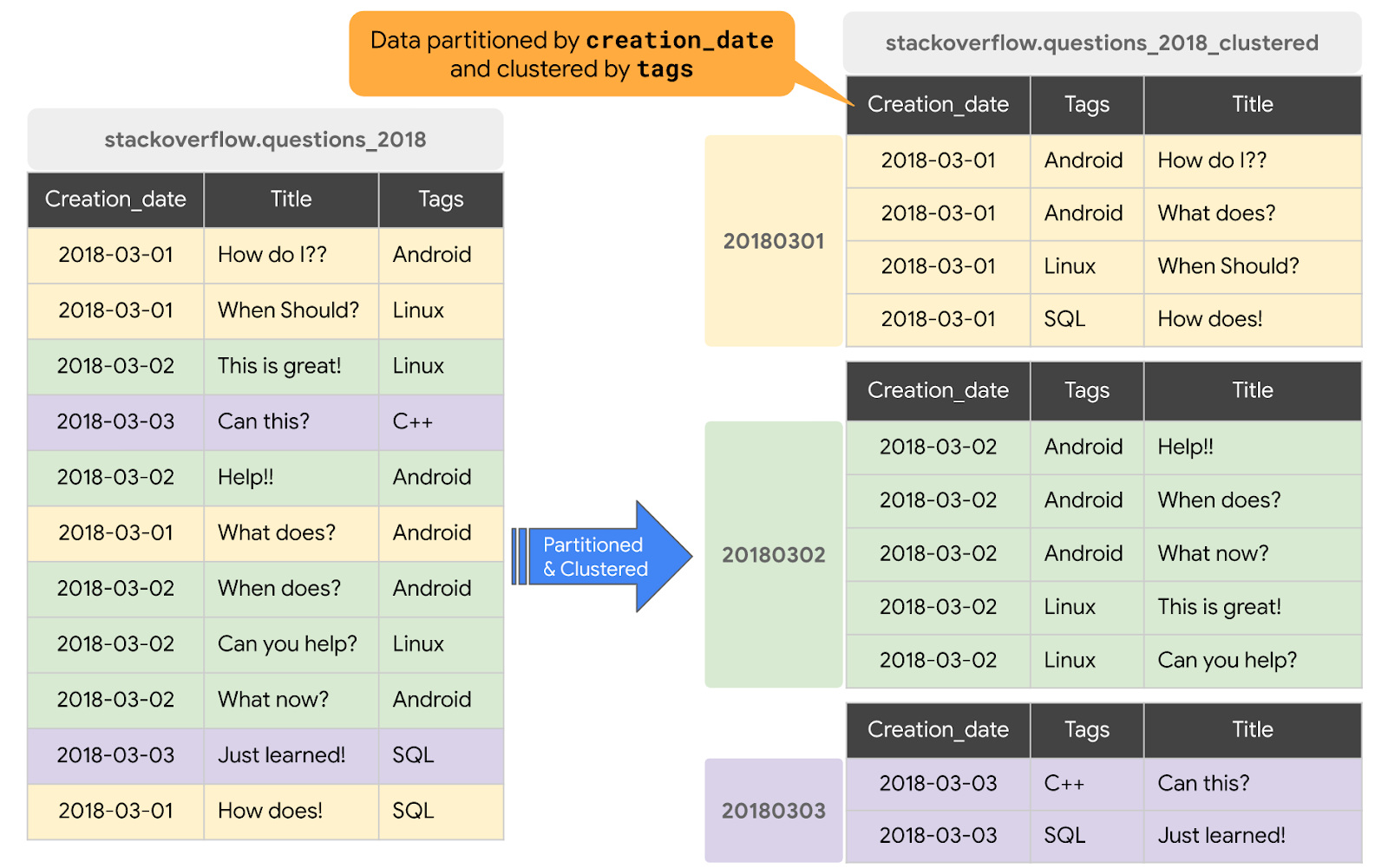
وقتی یک جدول در BigQuery خوشهبندی میشود، دادههای جدول به طور خودکار بر اساس محتویات یک یا چند ستون در طرح جدول سازماندهی میشوند. ستونهایی که شما مشخص میکنید برای کنار هم قرار دادن دادههای مرتبط استفاده میشوند. وقتی دادهها در یک جدول خوشهبندی شده نوشته میشوند، BigQuery دادهها را با استفاده از مقادیر موجود در ستونهای خوشهبندی مرتب میکند. این مقادیر برای سازماندهی دادهها در چندین بلوک در ذخیرهسازی BigQuery استفاده میشوند. ترتیب ستونهای خوشهبندی شده، ترتیب مرتبسازی دادهها را تعیین میکند. وقتی دادههای جدید به یک جدول یا یک پارتیشن خاص اضافه میشوند، BigQuery خوشهبندی مجدد خودکار را در پسزمینه انجام میدهد تا ویژگی مرتبسازی جدول یا پارتیشن را بازیابی کند.
درباره کار با جداول خوشهای اینجا بیشتر بیاموزید.
ایجاد یک جدول خوشهای جدید با پستهای Stack Overflow سال ۲۰۱۸
در این بخش، شما یک جدول جدید ایجاد خواهید کرد که بر اساس الگوی دسترسی به کوئری، در creation_date پارتیشنبندی شده و بر اساس ستون tags خوشهبندی شده است. برای ایجاد یک جدول خوشهبندی شده با دادههای یک جدول یا کوئری موجود، با انجام مراحل زیر، از جدول posts Stack Overflow 2018 کوئری خواهید گرفت و نتایج را در یک جدول جدید خواهید نوشت:
- در نزدیکی سمت راست بالای کنسول GCP، گزینه «ایجاد پرسوجوی جدید» (Compose new query) را انتخاب کنید.
- در قسمت متن ویرایشگر کوئری ، کوئری SQL زیر را کپی و جایگذاری کنید تا یک جدول جدید ایجاد شود، که یک دستور DDL است.
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- گزینه Run را انتخاب کنید. کوئری یک جدول جدید
questions_2018_clusteredدر مجموعه دادههایstackoverflowپروژه شما ایجاد میکند که شامل دادههای حاصل از اجرای یک کوئری روی جدولbigquery-public-data.stackoverflow.posts_questionsدر BigQuery Stack Overflow است. جدول جدید در تاریخ creation_date پارتیشنبندی و در ستون tags کلاستربندی میشود.
پرس و جو در جدول خوشهبندی شده با پستهای Stack Overflow سال ۲۰۱۸
حالا که یک جدول خوشهای BigQuery ایجاد کردهاید، بیایید دوباره همان پرسوجو را اجرا کنیم، این بار روی جدول پارتیشنبندی شده و خوشهای، تا پستهای Stack Overflow را به همراه سوالات و عناوین به همراه چند آمار دیگر مانند تعداد پاسخها، نظرات، بازدیدها و موارد دلخواه، برگردانیم. مراحل زیر را انجام دهید:
- در نزدیکی سمت راست بالای کنسول GCP، گزینه «ایجاد پرسوجوی جدید» (Compose new query) را انتخاب کنید.
- در قسمت متن ویرایشگر کوئری ، کوئری SQL زیر را کپی و جایگذاری کنید
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- گزینه Run with BigQuery caching disabled را انتخاب کنید (برای غیرفعال کردن BigQuery cache به بخش قبلی مراجعه کنید). کوئری، سوالات Stack Overflow که در ماه ژانویه ۲۰۱۸ ایجاد شدهاند و به همراه خود سوال و چند آمار دیگر، با برچسب
androidمشخص شدهاند را برمیگرداند. - در نتایج پرسوجو، باید مدت زمان لازم برای تکمیل پرسوجو و حجم دادههای پردازششده برای دریافت نتایج را مشاهده کنید.
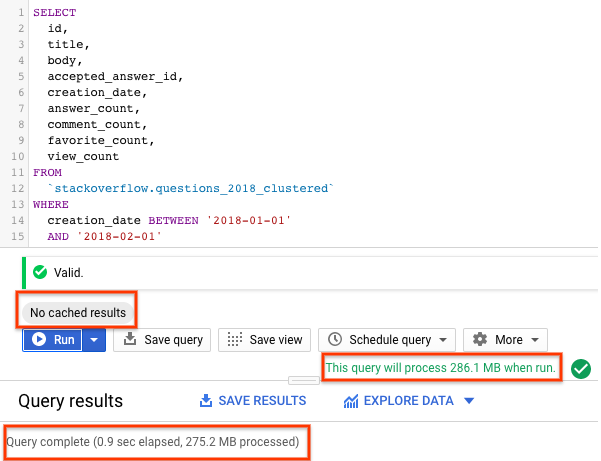
با یک جدول پارتیشنبندی شده و خوشهای، پرسوجو دادههای کمتری را نسبت به یک جدول پارتیشنبندی شده یا یک جدول پارتیشنبندی نشده اسکن میکند. نحوه سازماندهی دادهها با پارتیشنبندی و خوشهبندی، میزان دادههای اسکن شده توسط کارگران حافظه را به حداقل میرساند و در نتیجه عملکرد پرسوجو را بهبود میبخشد و هزینهها را بهینه میکند.
۷. تمیز کردن
مگر اینکه قصد ادامه کار با مجموعه دادههای stackoverflow خود را داشته باشید، باید آن را حذف کنید و پروژهای را که برای این codelab ایجاد کردهاید، حذف کنید.
مجموعه داده BigQuery را حذف کنید
برای حذف مجموعه داده BigQuery، مراحل زیر را انجام دهید:
- مجموعه داده stackoverflow را از پنل ناوبری سمت چپ در BigQuery انتخاب کنید.
- در پنل جزئیات، گزینهی «حذف مجموعه داده» را انتخاب کنید.
- در کادر محاورهای حذف مجموعه داده ، عبارت stackoverflow را وارد کرده و برای تأیید حذف مجموعه داده، گزینه Delete را انتخاب کنید.
پروژه را حذف کنید
برای حذف پروژه GCP که برای این آزمایشگاه کد ایجاد کردهاید، مراحل زیر را انجام دهید:
- در منوی پیمایش GCP، گزینه IAM & Admin را انتخاب کنید.
- در پنل ناوبری، تنظیمات (Settings) را انتخاب کنید.
- در پنل جزئیات، تأیید کنید که پروژه فعلی شما همان پروژهای است که برای این آزمایشگاه کد ایجاد کردهاید و گزینه «خاموش کردن» را انتخاب کنید.
- در پنجرهی «خاموش کردن پروژه» ، شناسهی پروژه (نه نام پروژه) را برای پروژهی خود وارد کنید و برای تأیید، «خاموش کردن» را انتخاب کنید.
تبریک میگویم! حالا یاد گرفتهاید
- نحوه استفاده از رابط کاربری وب BigQuery برای ایجاد جدول جدید از جداول موجود
- نحوه ایجاد و پرس و جو از جداول پارتیشن بندی شده و خوشه بندی شده
- چگونه پارتیشنبندی و خوشهبندی، عملکرد و هزینههای پرسوجو را بهینه میکنند
توجه داشته باشید که برای کار با مجموعه دادهها نیازی به تنظیم یا مدیریت خوشهها نداشتید.