
1. はじめに
BigQuery は、データ分析のためのペタバイト規模の低料金フルマネージド エンタープライズ データ ウェアハウスです。BigQueryはサーバーレスなのでクラスタを設定して管理する必要はありません。
BigQuery データセットは GCP プロジェクトに存在し、1 つ以上のテーブルが含まれています。これらのデータセットに対して SQL でクエリを実行できます。
この Codelab では、GCP Console の BigQuery ウェブ UI を使用して、BigQuery のパーティショニングとクラスタリングについて説明します。BigQuery のテーブル パーティショニングとテーブル クラスタリングは、一般的なデータアクセス パターンに合わせてデータを構造化するのに役立ちます。パーティショニングとクラスタリングは、特定のデータ範囲でクエリを実行する場合、BigQuery のパフォーマンスと費用を完全に最適化するための重要な要因といえます。クエリごとにスキャンするデータ量を減らせるだけでなく、クエリの開始前にプルーニングを決定できます。
BigQuery の詳細については、BigQuery のドキュメントをご覧ください。
学習内容
- パーティション分割テーブルとクラスタ化テーブルを作成してクエリを実行する方法
- パーティション分割テーブルとクラスタ化テーブルを使用してクエリのパフォーマンスを比較する
必要なもの
このラボを完了するためには、下記が必要です。
- 最新バージョンの Google Chrome
- Google Cloud Platform 請求先アカウント
2. 設定方法
BigQuery を使用するには、GCP プロジェクトを作成するか、既存のプロジェクトを選択する必要があります。
プロジェクトの作成
新しいプロジェクトを作成する手順は、次のとおりです。
- Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成してください。
- Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。
- プロジェクトがない場合は、[プロジェクトを作成] ボタンをクリックします。
そうでない場合は、プロジェクト選択メニューから新しいプロジェクトを作成します。
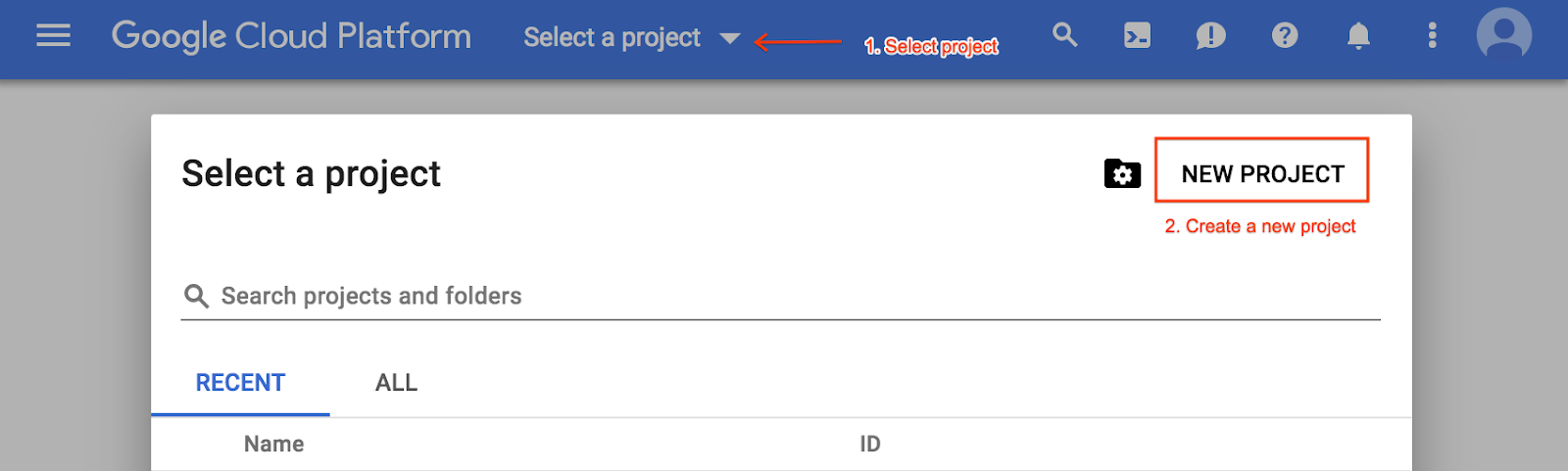
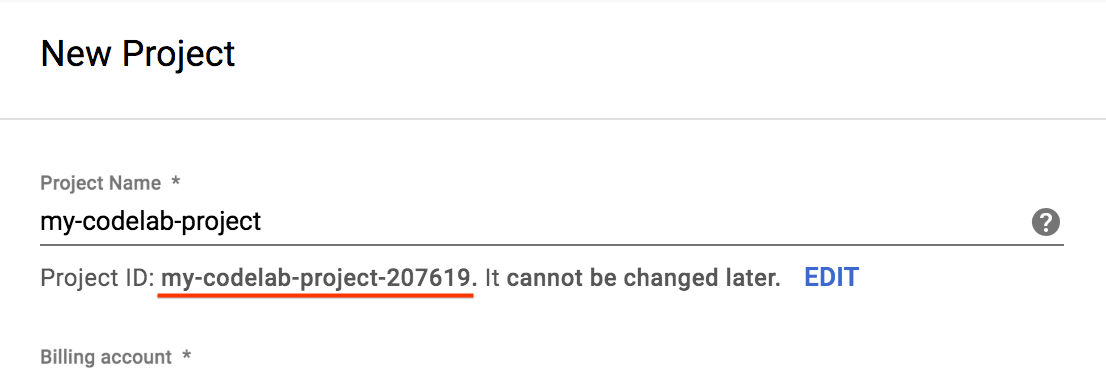
- プロジェクト名を入力して [作成] を選択します。プロジェクト ID は、すべての Google Cloud プロジェクトを通じて一意の名前にする必要があります。
3. 一般公開データセットの操作
BigQuery では、BBC News、GitHub リポジトリ、Stack Overflow、米国海洋大気庁(NOAA)のデータセットなどの一般公開データセットを操作できます。これらのデータセットを BigQuery に読み込む必要はありません。BigQuery でデータセットを開いて、ブラウジングとクエリを行うだけです。この Codelab では、Stack Overflow の一般公開データセットを使用します。
Stack Overflow データセットを閲覧する
Stack Overflow データセットには、投稿、タグ、バッジ、コメント、ユーザーなどに関する情報が含まれています。BigQuery ウェブ UI で Stack Overflow データセットを閲覧する手順は次のとおりです。
- Stack Overflow データセットを開きます。GCP Console で BigQuery ウェブ UI が開き、Stackoverflow データセットに関する情報が表示されます。
- ナビゲーション パネルで、[bigquery-public-data] を選択します。メニューが展開され、一般公開データセットが一覧表示されます。各データセットは 1 つ以上のテーブルで構成されます。
- 下にスクロールして [stackoverflow] を選択します。メニューが展開され、Stack Overflow データセット内のテーブルが一覧表示されます。
- [バッジ] を選択して、バッジ テーブルのスキーマを表示します。テーブル内のフィールドの名前をメモします。
- [フィールド名] の上にある [プレビュー] をクリックして、badges テーブルのサンプルデータを表示します。
BigQuery で利用可能なすべての一般公開データセットの詳細については、Google BigQuery 一般公開データセットをご覧ください。
Stackoverflow データセットに対してクエリを実行する
データセットの閲覧は、使用するデータを理解するうえで有効な方法ですが、BigQuery の真価が発揮されるのはデータセットのクエリです。このセクションでは、BigQuery クエリを実行する方法について説明します。この時点では SQL の知識は必要ありません。以下のクエリをコピーして貼り付けることができます。
クエリを実行する手順は次のとおりです。
- GCP コンソールの右上にある [クエリを新規作成] を選択します。
- [クエリエディタ] テキスト領域に、次の SQL クエリをコピーして貼り付けます。BigQuery がクエリを検証し、構文が有効であることを示す緑色のチェックマークがテキスト ボックスの下に表示されます。
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- [実行] を選択します。このクエリは、毎年投稿された Stack Overflow の投稿または質問の数を返します。
4. 新しいテーブルの作成
前のセクションでは、BigQuery が提供する一般公開データセットに対してクエリを実行しました。このセクションでは、既存のテーブルから BigQuery に新しいテーブルを作成します。Stack Overflow の一般公開データセットの posts_questions テーブルからサンプリングされたデータを使用して新しいテーブルを作成し、そのテーブルに対してクエリを実行します。
新しいデータセットを作成する
テーブル データを作成して BigQuery に読み込むには、まず次の手順でデータを保持する BigQuery データセットを作成します。
- GCP Console のナビゲーション パネルで、設定の一部として作成されたプロジェクト名を選択します。
- 右側の詳細パネルで、[データセットを作成] を選択します。
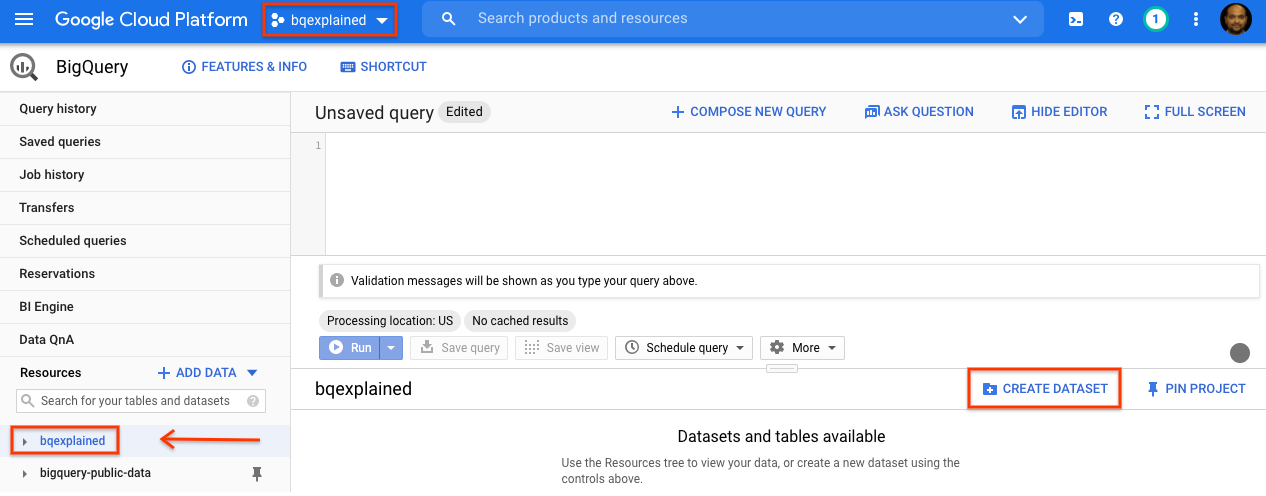
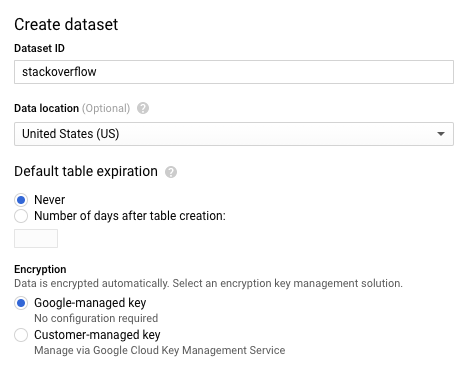
- [データセットを作成] ダイアログで、[データセット ID] に「
stackoverflow」と入力します。その他のデフォルト設定はすべてそのままにし、[OK] をクリックします。
2018 年の Stack Overflow の投稿を含む新しいテーブルを作成する
BigQuery データセットを作成したので、BigQuery に新しいテーブルを作成できます。既存のテーブルのデータを使用してテーブルを作成するには、次の手順で 2018 年の Stack Overflow 投稿データセットをクエリし、結果を新しいテーブルに書き込みます。
- GCP コンソールの右上にある [クエリを新規作成] を選択します。

- [クエリエディタ] テキスト領域で、次の SQL クエリをコピーして貼り付け、新しいテーブル(DDL ステートメント)を作成します。
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- [実行] を選択します。このクエリは、BigQuery Stack Overflow データセット
bigquery-public-data.stackoverflow.posts_questionsでクエリを実行した結果のデータを使用して、プロジェクトのstackoverflowデータセットに新しいテーブルquestions_2018を作成します。
2018 年の Stack Overflow の投稿を含む新しいテーブルに対してクエリを実行する
BigQuery テーブルを作成したので、クエリを実行して、質問とタイトルを含む Stack Overflow の投稿と、回答数、コメント数、閲覧数、お気に入り数などの他の統計情報を返します。次の手順を行います。
- GCP コンソールの右上にある [クエリを新規作成] を選択します。
- [クエリエディタ] テキスト領域に、次の SQL クエリをコピーして貼り付けます。
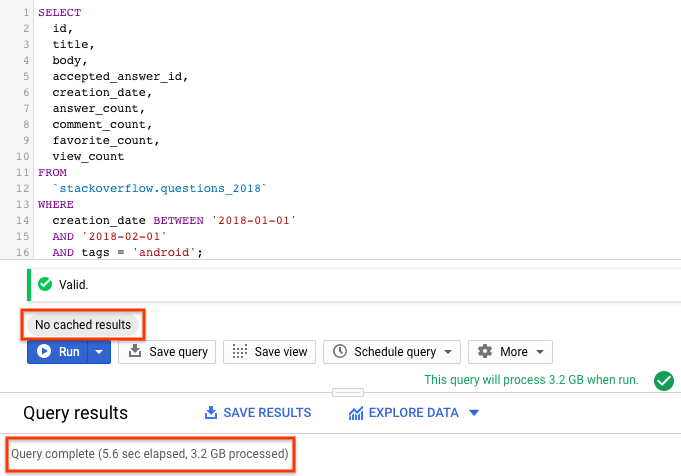
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- [実行] を選択します。このクエリは、2018 年 1 月に作成され、
androidとしてタグ付けされた Stack Overflow の質問と、その質問およびその他の統計情報を返します。 - デフォルトでは、BigQuery はクエリ結果をキャッシュに保存します。同じクエリを実行すると、BigQuery がキャッシュから結果を返すため、結果を返すまでの時間が大幅に短縮されます。
- 同じクエリをもう一度実行しますが、今回は BigQuery キャッシュを無効にします。次のセクションで実行するパーティション分割テーブルとクラスタ化テーブルのパフォーマンス比較を公平に行うため、このラボの残りの部分ではキャッシュを無効にします。クエリエディタで、[その他] をクリックして [クエリの設定] を選択します。
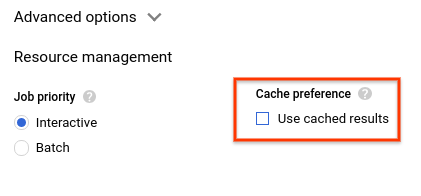
- [キャッシュの設定] の [キャッシュに保存された結果を使用] をオフにします。
- クエリ結果には、クエリの完了にかかった時間と、結果を取得するために処理されたデータ量が表示されます。
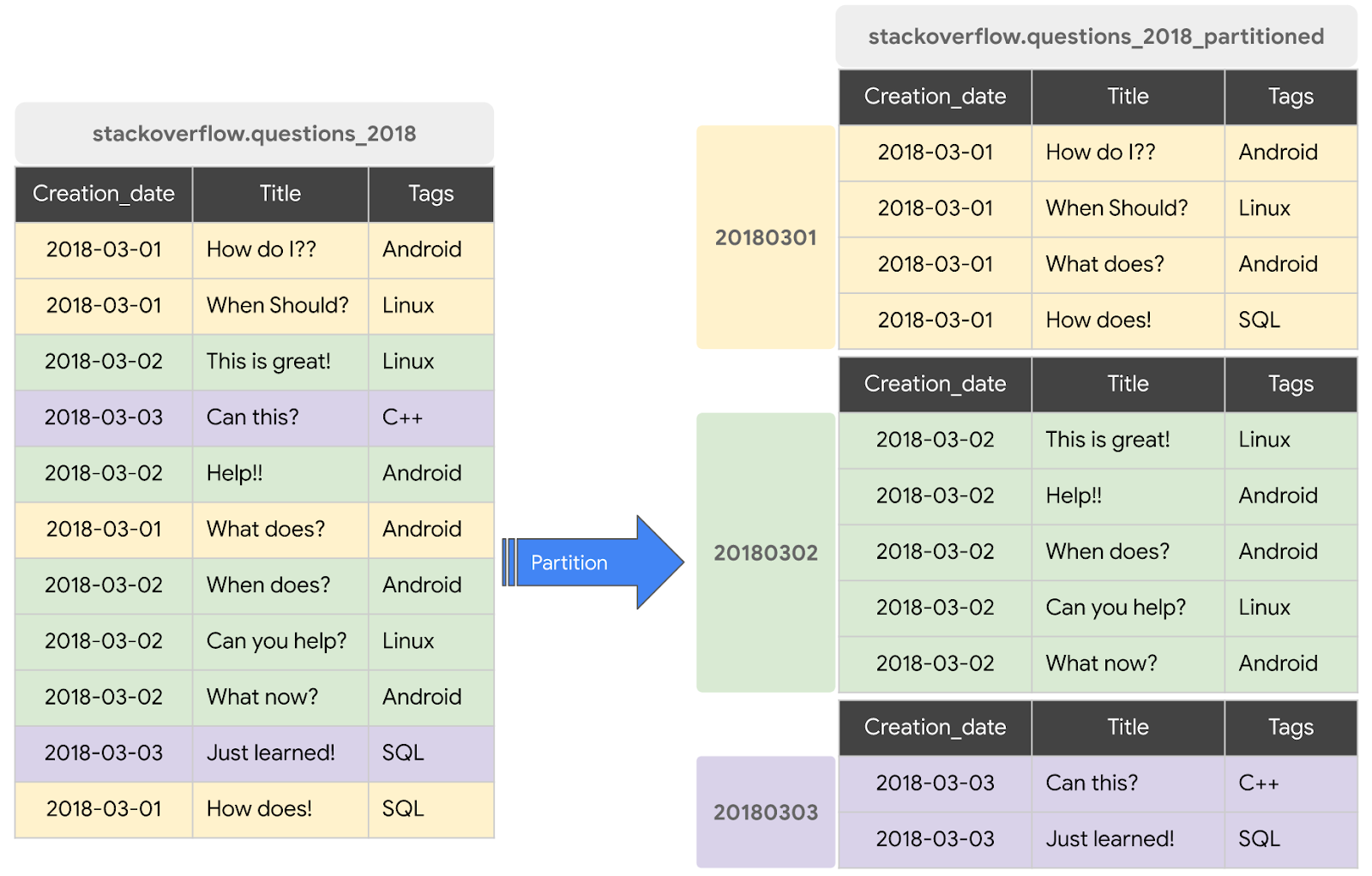
5. パーティション分割テーブルを作成してクエリを実行する
前のセクションでは、Stack Overflow の一般公開データセットを使用して、posts_questions テーブルのデータを含む新しいテーブルを BigQuery に作成しました。キャッシュ保存を無効にしてこのデータセットをクエリし、クエリのパフォーマンスを観察しました。このセクションでは、同じ Stack Overflow 一般公開データセットの posts_questions テーブルから新しいパーティション分割テーブルを作成し、クエリのパフォーマンスを確認します。
パーティション分割テーブルとは、パーティションと呼ばれるセグメントに分割された特殊なテーブルです。このテーブルを使用すると、データの管理や照会をより簡単に行うことができます。通常、データの取り込み時間、TIMESTAMP/DATE 列、INTEGER 列を使用して、大きなテーブルを多数の小さなパーティションに分割できます。DATE パーティション分割テーブルを作成します。
パーティション分割テーブルの詳細については、こちらをご覧ください。
2018 年の Stack Overflow の投稿を含む新しいパーティション分割テーブルを作成する
既存のテーブルまたはクエリのデータを使用してパーティション分割テーブルを作成するには、2018 年の Stack Overflow の投稿データセットをクエリして、結果を新しいテーブルに書き込みます。次の手順を行います。
- GCP コンソールの右上にある [クエリを新規作成] を選択します。
- [クエリエディタ] テキスト領域で、次の SQL クエリをコピーして貼り付け、新しいテーブル(DDL ステートメント)を作成します。
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- [実行] を選択します。このクエリは、BigQuery Stack Overflow データセット
bigquery-public-data.stackoverflow.posts_questionsでクエリを実行した結果のデータを使用して、プロジェクトのstackoverflowデータセットに新しいテーブルquestions_2018_partitionedを作成します。
2018 年の Stack Overflow 投稿を含むパーティション分割テーブルに対してクエリを実行する
BigQuery パーティション分割テーブルを作成したので、今度はパーティション分割テーブルに対して同じクエリを実行し、質問とタイトルを含む Stack Overflow の投稿と、回答数、コメント数、閲覧数、お気に入り数などの統計情報を返します。次の手順を行います。
- GCP コンソールの右上にある [クエリを新規作成] を選択します。
- [クエリエディタ] テキスト領域に、次の SQL クエリをコピーして貼り付けます。
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery キャッシュを無効にして [実行] を選択します(BigQuery キャッシュを無効にする方法については、前のセクションをご覧ください)。このクエリは、2018 年 1 月に作成され、
androidとしてタグ付けされた Stack Overflow の質問と、その質問およびその他の統計情報を返します。 - クエリ結果には、クエリの完了にかかった時間と、結果を取得するために処理されたデータ量が表示されます。
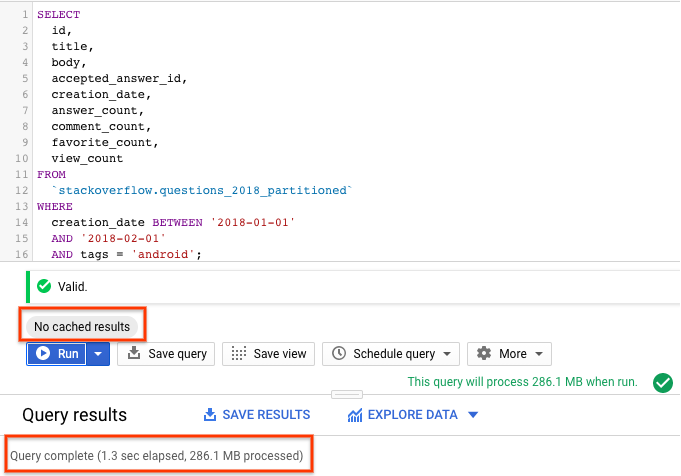
BigQuery はパーティションをプルーニングします。つまり、必要なパーティションのみをスキャンして処理するデータ量を減らし、高速で実行するため、パーティション分割テーブルを使用するクエリのパフォーマンスは、パーティション分割されていないテーブルを使用するクエリのパフォーマンスよりも優れています。これにより、クエリの費用とクエリのパフォーマンスが最適化されます。
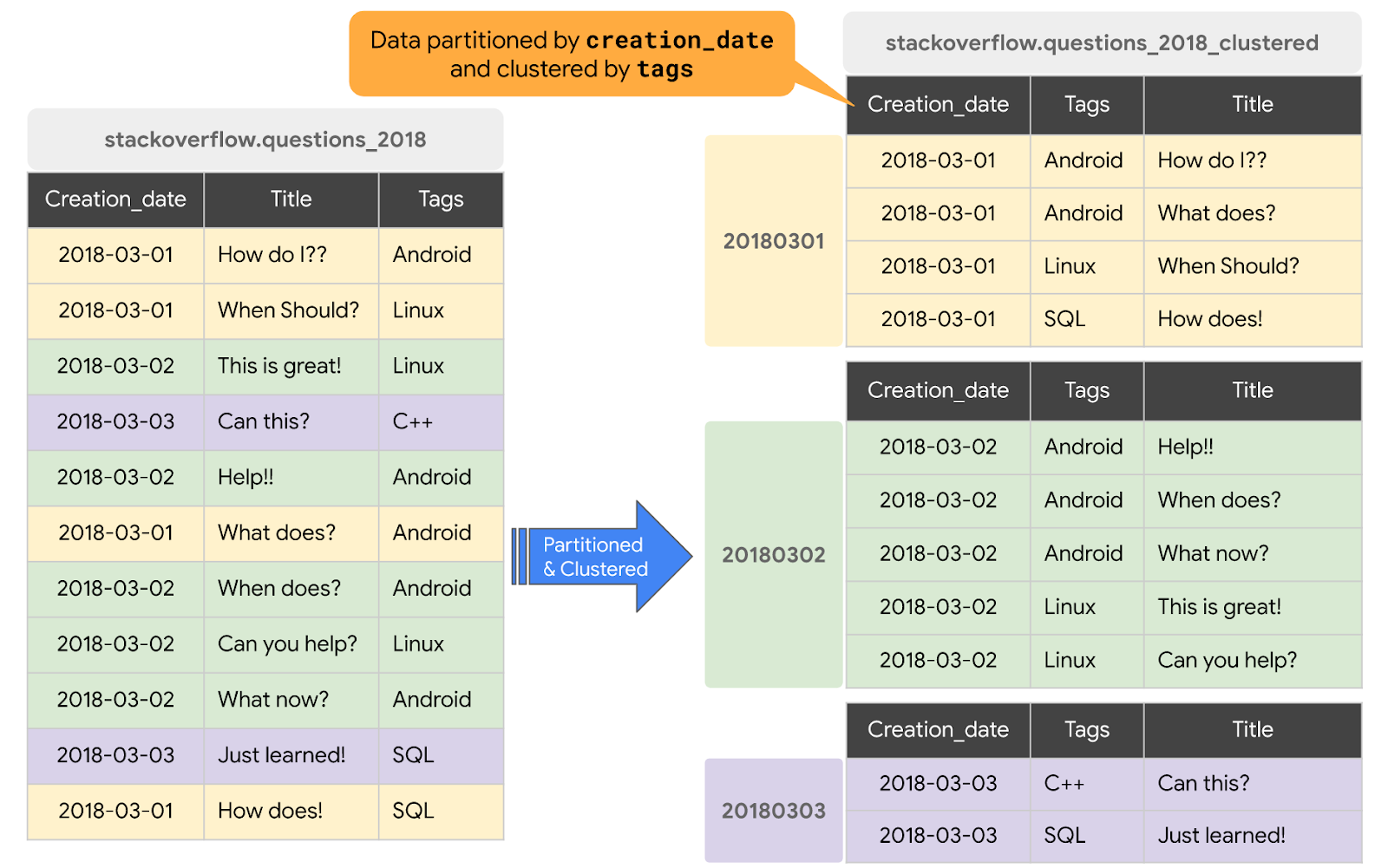
6. クラスタ化テーブルの作成とクエリ
前のセクションでは、Stack Overflow の一般公開データセットの posts_questions テーブルのデータを使用して、BigQuery にパーティション分割テーブルを作成しました。このテーブルに対してキャッシュ保存を無効にしてクエリを実行し、パーティション分割されていないテーブルとパーティション分割されたテーブルの両方でクエリのパフォーマンスを測定しました。このセクションでは、同じ Stack Overflow 一般公開データセットの posts_questions テーブルから新しいクラスタ化テーブルを作成し、クエリのパフォーマンスを確認します。
BigQuery でテーブルがクラスタ化されると、テーブルのスキーマ内の 1 つ以上の列のコンテンツに基づいて、テーブルデータが自動的に編成されます。指定した列は、関連するデータを並置するために使用されます。データがクラスタ化テーブルに書き込まれると、BigQuery はクラスタリング列の値を使用してデータを並べ替えます。これらの値は、BigQuery ストレージ内の複数のブロックにデータを整理するために使用されます。クラスタ化列の順序によって、データの並べ替え順序が決まります。新しいデータがテーブルまたは特定のパーティションに追加されると、BigQuery はバック グラウンドで自動再クラスタリングを行い、テーブルまたはパーティションのソート プロパティを復元します。
クラスタ化テーブルの操作について詳しくは、こちらをご覧ください。
2018 年の Stack Overflow の投稿を含む新しいクラスタ化テーブルを作成する
このセクションでは、クエリ アクセス パターンに基づいて、creation_date でパーティション分割され、tags 列でクラスタ化された新しいテーブルを作成します。既存のテーブルまたはクエリのデータを使用してクラスタ化テーブルを作成するには、次の手順で 2018 年の Stack Overflow 投稿テーブルをクエリし、結果を新しいテーブルに書き込みます。
- GCP コンソールの右上にある [クエリを新規作成] を選択します。
- [クエリエディタ] テキスト領域で、次の SQL クエリをコピーして貼り付け、新しいテーブル(DDL ステートメント)を作成します。
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- [実行] を選択します。このクエリは、プロジェクトの
stackoverflowデータセットに新しいテーブルquestions_2018_clusteredを作成し、BigQuery Stack Overflow テーブルbigquery-public-data.stackoverflow.posts_questionsでクエリを実行した結果のデータを格納します。新しいテーブルは creation_date でパーティション分割され、tags 列でクラスタ化されます。
2018 年の Stack Overflow 投稿を含むクラスタ化テーブルに対してクエリを実行する
BigQuery クラスタ テーブルを作成したので、今度はパーティショニングされたクラスタ テーブルに対して同じクエリを再度実行し、質問とタイトルを含む Stack Overflow の投稿と、回答数、コメント数、ビュー数、お気に入り数などの統計情報を返します。次の手順を行います。
- GCP コンソールの右上にある [クエリを新規作成] を選択します。
- [クエリエディタ] テキスト領域に、次の SQL クエリをコピーして貼り付けます。
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery キャッシュを無効にして [実行] を選択します(BigQuery キャッシュを無効にする方法については、前のセクションをご覧ください)。このクエリは、2018 年 1 月に作成され、
androidとしてタグ付けされた Stack Overflow の質問と、その質問およびその他の統計情報を返します。 - クエリ結果には、クエリの完了にかかった時間と、結果を取得するために処理されたデータ量が表示されます。
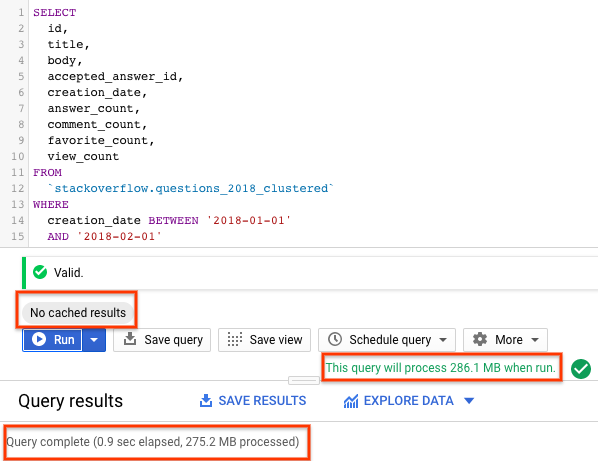
パーティション分割テーブルとクラスタ化テーブルに対するクエリの実行は、パーティション分割テーブルまたはパーティション分割されていないテーブルよりも少ないデータをスキャンしました。パーティショニングとクラスタリングによるデータの編成では、スロット ワーカーがスキャンするデータ量を最小限に抑えられるため、クエリのパフォーマンスが向上し、費用が最適化されます。
7. クリーンアップ
stackoverflow データセットの操作を続行する予定がない場合は、データセットと、この Codelab で作成したプロジェクトを削除する必要があります。
BigQuery データセットの削除
BigQuery データセットを削除するには、以下の手順を実行します。
- BigQuery の左側のナビゲーション パネルから stackoverflow データセットを選択します。
- 詳細パネルで [データセットを削除] を選択します。
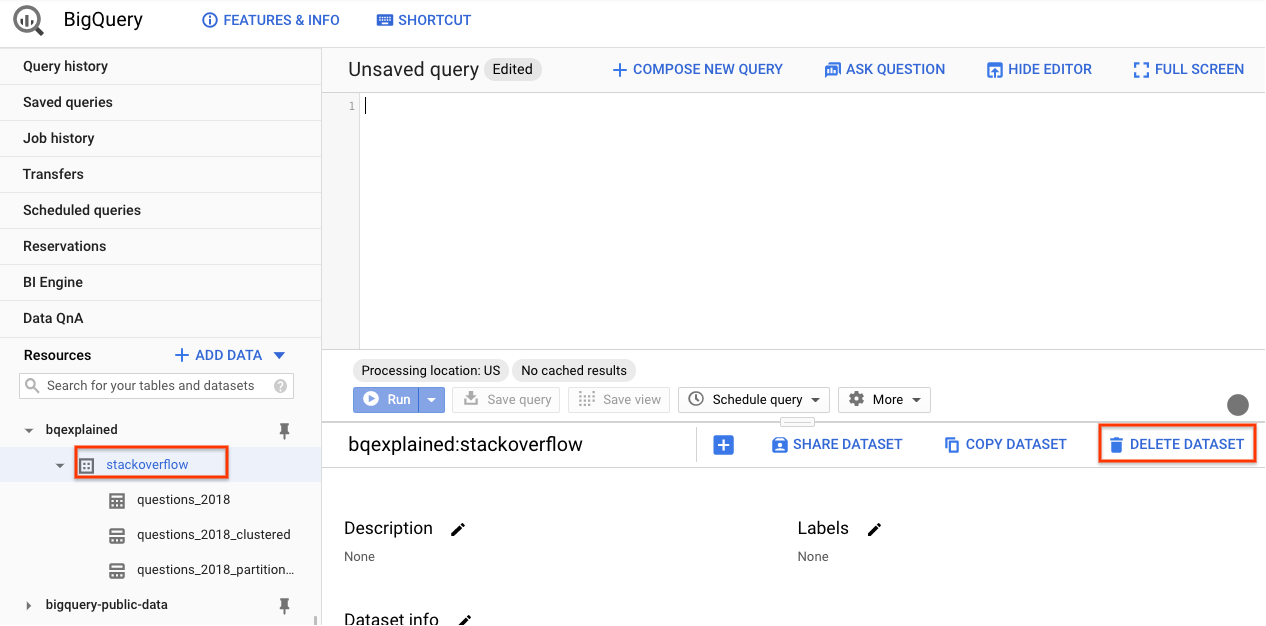
- [データセットの削除] ダイアログで、「stackoverflow」と入力し、[削除] を選択してデータセットの削除を確定します。
プロジェクトを削除する
この Codelab で作成した GCP プロジェクトを削除する手順は次のとおりです。
- GCP のナビゲーション メニューで [IAM と管理] を選択します。
- ナビゲーション パネルで [設定] を選択します。
- 詳細パネルで、現在のプロジェクトがこの Codelab のために作成したプロジェクトであることを確認し、[シャットダウン] を選択します。
- [プロジェクトをシャットダウン] ダイアログで、プロジェクトの(プロジェクト名ではなく)プロジェクト ID を入力し、[シャットダウン] を選択して確定します。
おめでとうございます!これで、
- BigQuery ウェブ UI を使用して既存のテーブルから新しいテーブルを作成する方法
- パーティション分割テーブルとクラスタ化テーブルを作成してクエリを実行する方法
- パーティショニングとクラスタリングによってクエリのパフォーマンスと費用が最適化される仕組み
データセットを操作するためにクラスタを設定または管理する必要はありません。