
1. Introduzione
BigQuery è un data warehouse aziendale completamente gestito, su scala petabyte e dai costi contenuti, progettato per le attività di analisi. BigQuery è serverless, Non è necessario configurare e gestire i cluster.
Un set di dati BigQuery si trova in un progetto Google Cloud e contiene una o più tabelle. Puoi eseguire query su questi set di dati con SQL.
In questo codelab utilizzerai la UI web di BigQuery nella console di GCP per comprendere il partizionamento e il clustering in BigQuery. Il partizionamento e il clustering delle tabelle di BigQuery aiutano a strutturare i dati in modo che corrispondano ai modelli di accesso ai dati comuni. Il partizionamento e il clustering sono fondamentali per massimizzare completamente le prestazioni e i costi di BigQuery durante l'esecuzione di query su un intervallo di dati specifico. Consente di analizzare meno dati per query e l'eliminazione viene determinata prima dell'ora di inizio della query.
Per saperne di più su BigQuery, consulta la documentazione di BigQuery.
Obiettivi didattici
- Come creare ed eseguire query su tabelle partizionate e in cluster
- Confrontare il rendimento delle query con tabelle partizionate e in cluster
Che cosa ti serve
Per completare il lab, avrai bisogno di:
- L'ultima versione di Google Chrome
- Un account di fatturazione Google Cloud Platform
2. Preparazione
Per utilizzare BigQuery, devi creare un progetto Google Cloud o selezionarne uno esistente.
Creare un progetto
Per creare un nuovo progetto:
- Se non hai ancora un Account Google (Gmail o Google Apps), creane uno.
- Accedi alla console di Google Cloud Platform ( console.cloud.google.com) e crea un nuovo progetto.
- Se non hai progetti, fai clic sul pulsante Crea progetto:
In caso contrario, crea un nuovo progetto dal menu di selezione dei progetti:
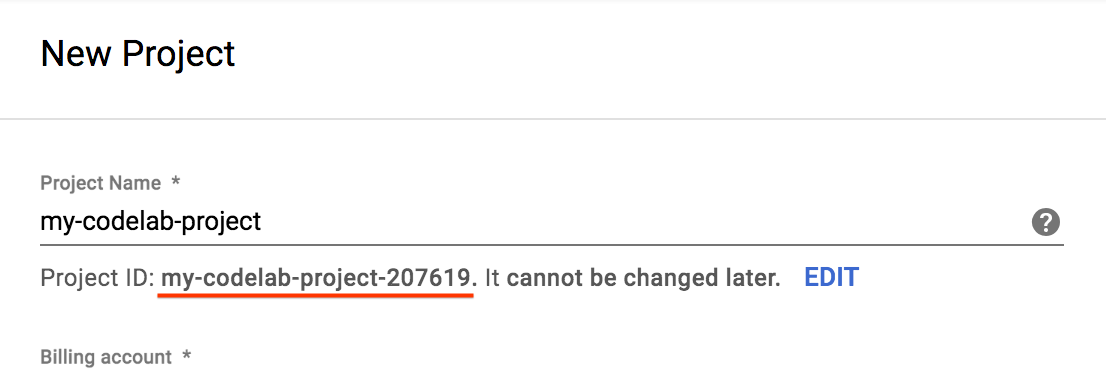
- Inserisci un nome per il progetto e seleziona Crea. Prendi nota dell'ID progetto, che è un nome univoco tra tutti i progetti Google Cloud.
3. Utilizzo dei set di dati pubblici
BigQuery ti consente di lavorare con set di dati pubblici, tra cui BBC News, repository GitHub, Stack Overflow e i set di dati della National Oceanic and Atmospheric Administration (NOAA) degli Stati Uniti. Non è necessario caricare questi set di dati in BigQuery. Devi solo aprire i set di dati per sfogliarli ed eseguire query su di essi in BigQuery. In questo codelab utilizzerai il set di dati pubblico di Stack Overflow.
Sfogliare il set di dati di Stack Overflow
Il set di dati Stack Overflow contiene informazioni su post, tag, badge, commenti, utenti e altro ancora. Per sfogliare il set di dati di Stack Overflow nell'interfaccia utente web di BigQuery:
- Apri il set di dati Stack Overflow. La UI web di BigQuery si apre nella console di GCP e mostra informazioni sul set di dati Stack Overflow.
- Nel pannello di navigazione , seleziona bigquery-public-data. Il menu si espande per elencare i set di dati pubblici. Ogni set di dati è composto da una o più tabelle.
- Scorri verso il basso e seleziona stackoverflow. Il menu si espande per elencare le tabelle nel set di dati Stack Overflow.
- Seleziona badge per visualizzare lo schema della tabella dei badge. Prendi nota dei nomi dei campi nella tabella.
- Sopra i nomi dei campi, fai clic su Anteprima per visualizzare i dati di esempio per la tabella dei badge.
Per saperne di più su tutti i set di dati pubblici disponibili in BigQuery, consulta Set di dati pubblici di Google BigQuery.
Esegui una query sul set di dati Stack Overflow
Sfogliare un set di dati è un buon modo per comprendere i dati con cui stai lavorando, ma l'esecuzione di query sui set di dati è il punto di forza di BigQuery. Questa sezione ti insegna a eseguire query BigQuery. A questo punto non è necessario conoscere SQL. Puoi copiare e incollare le query riportate di seguito.
Per eseguire una query, completa i seguenti passaggi:
- In alto a destra nella console GCP, seleziona Crea nuova query.
- Nell'area di testo Editor query, copia e incolla la seguente query SQL. BigQuery convalida la query e la UI web mostra un segno di spunta verde sotto l'area di testo per indicare che la sintassi è valida.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- Seleziona Esegui. La query restituisce il numero di post o domande di Stack Overflow pubblicati ogni anno.
4. Creare una nuova tabella
Nella sezione precedente, hai eseguito query sui set di dati pubblici che BigQuery mette a tua disposizione. In questa sezione, creerai una nuova tabella in BigQuery da una tabella esistente. Creerai una nuova tabella con i dati campionati dalla tabella posts_questions del set di dati pubblico Stack Overflow e poi eseguirai una query sulla tabella.
Crea un nuovo set di dati
Per creare e caricare i dati della tabella in BigQuery, crea prima un set di dati BigQuery per contenere i dati completando i seguenti passaggi:
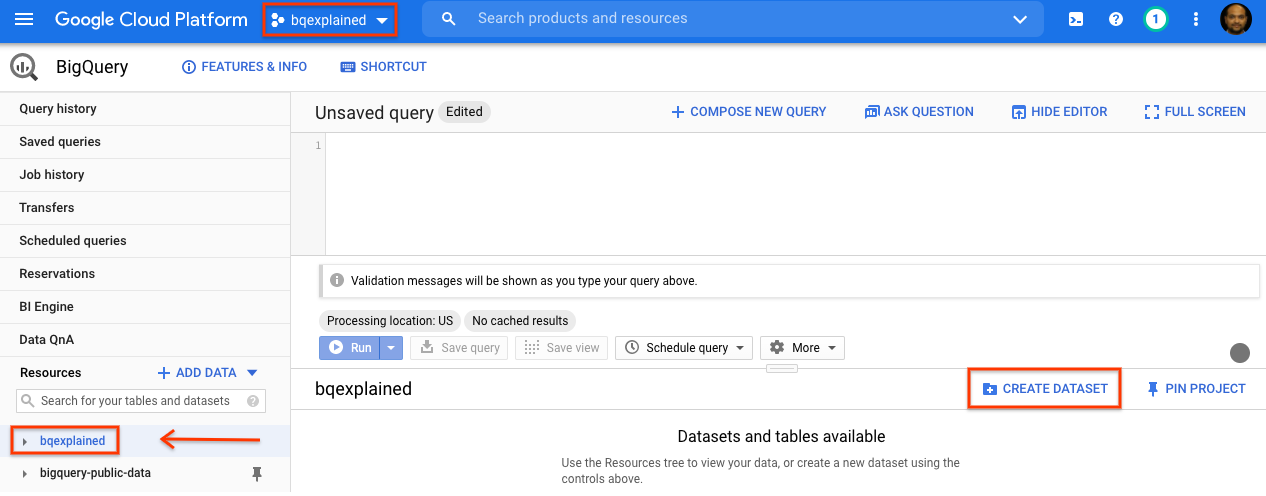
- Nel pannello di navigazione della console GCP, seleziona il nome del progetto creato durante la configurazione.
- Sul lato destro, nel riquadro dei dettagli, seleziona Crea set di dati.
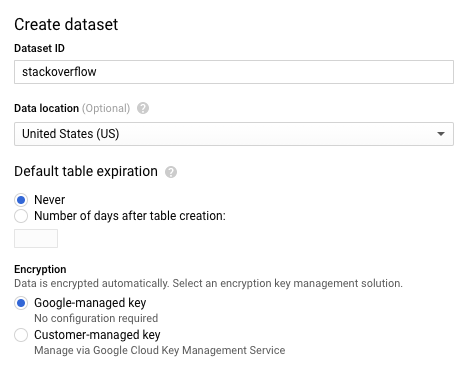
- Nella finestra di dialogo Crea set di dati, digita
stackoverflowin corrispondenza di ID set di dati. Lascia invariate tutte le altre impostazioni predefinite e fai clic su Ok.
Crea una nuova tabella con i post di Stack Overflow del 2018
Ora che hai creato un set di dati BigQuery, puoi creare una nuova tabella in BigQuery. Per creare una tabella con i dati di una tabella esistente, esegui una query sul set di dati dei post di Stack Overflow del 2018 e scrivi i risultati in una nuova tabella completando i seguenti passaggi:
- In alto a destra nella console GCP, seleziona Crea nuova query.

- Nell'area di testo Editor query, copia e incolla la seguente query SQL per creare una nuova tabella, che è un'istruzione DDL.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Seleziona Esegui. La query crea una nuova tabella
questions_2018nel set di datistackoverflowdel tuo progetto con i dati risultanti dall'esecuzione di una query sul set di dati BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions.
Esegui una query sulla nuova tabella con i post di Stack Overflow del 2018
Ora che hai creato una tabella BigQuery, eseguiamo una query per restituire i post di Stack Overflow con domande e titoli, insieme ad alcune altre statistiche, come il numero di risposte, commenti, visualizzazioni e preferiti. Completa i seguenti passaggi:
- In alto a destra nella console GCP, seleziona Crea nuova query.
- Nell'area di testo Editor query, copia e incolla la seguente query SQL
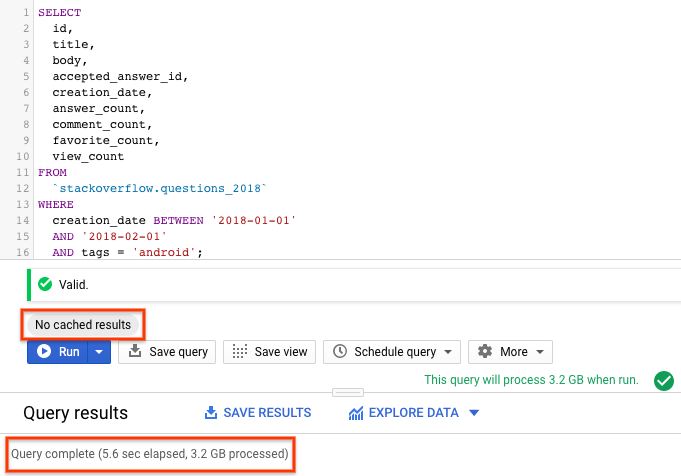
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Seleziona Esegui. La query restituisce le domande di Stack Overflow create nel mese di gennaio 2018 con il tag
android, insieme alla domanda e ad alcune altre statistiche. - Per impostazione predefinita, BigQuery memorizza nella cache i risultati delle query. Esegui la stessa query e vedrai che BigQuery ha impiegato molto meno tempo per restituire i risultati perché li restituisce dalla cache.
- Esegui di nuovo la stessa query, ma questa volta con la memorizzazione nella cache di BigQuery disattivata. Disattiveremo la cache per il resto del lab per garantire un confronto equo del rendimento con le tabelle partizionate e in cluster, che verranno eseguite nelle sezioni successive. Nell'editor delle query, fai clic su Altro e seleziona Impostazioni query.
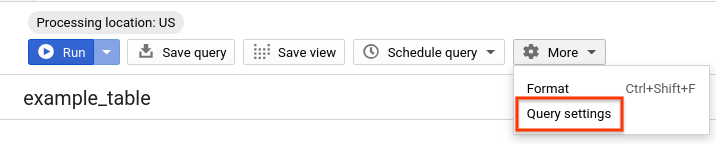
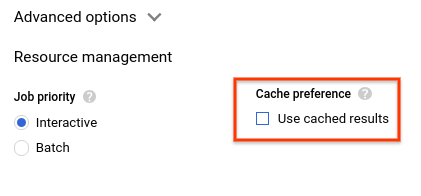
- Nella sezione Preferenza cache, deseleziona Utilizza risultati memorizzati nella cache.
- Nei risultati della query, dovresti vedere il tempo impiegato per il completamento della query e il volume di dati elaborati per ottenere i risultati.
5. Creazione ed esecuzione di query su una tabella partizionata
Nella sezione precedente, hai creato una nuova tabella in BigQuery con i dati della tabella posts_questions utilizzando il set di dati pubblico Stack Overflow. Abbiamo eseguito query su questo set di dati con la memorizzazione nella cache disattivata e abbiamo osservato il rendimento della query. In questa sezione creerai una nuova tabella partizionata dalla stessa tabella posts_questions del set di dati pubblico Stack Overflow e osserverai il rendimento della query.
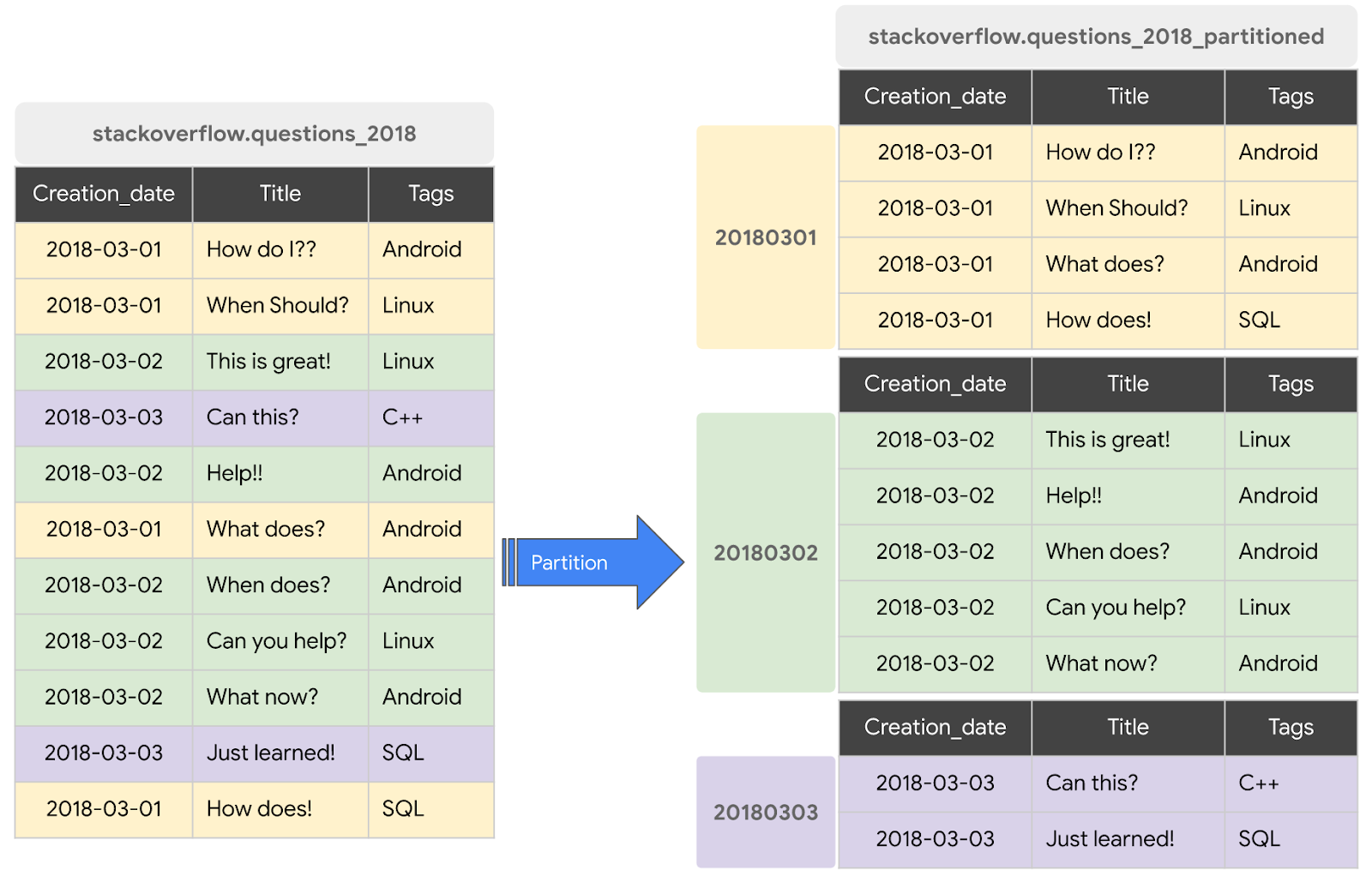
Una tabella partizionata è una tabella speciale divisa in segmenti, denominati partizioni, che semplificano la gestione e l'esecuzione di query sui dati. In genere puoi dividere le tabelle di grandi dimensioni in molte partizioni più piccole utilizzando la data di importazione o la colonna TIMESTAMP/DATE oppure una colonna INTEGER. Creeremo una tabella partizionata per data.
Scopri di più sulle tabelle partizionate qui.
Crea una nuova tabella partizionata con i post di Stack Overflow del 2018
Per creare una tabella partizionata con i dati di una tabella o query esistente, esegui una query sul set di dati dei post di Stack Overflow del 2018 e scrivi i risultati in una nuova tabella. Per farlo:
- In alto a destra nella console GCP, seleziona Crea nuova query.
- Nell'area di testo Editor query, copia e incolla la seguente query SQL per creare una nuova tabella, che è un'istruzione DDL.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Seleziona Esegui. La query crea una nuova tabella
questions_2018_partitionednel set di datistackoverflowdel tuo progetto con i dati risultanti dall'esecuzione di una query sul set di dati BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions.
Esegui query sulla tabella partizionata con i post di Stack Overflow del 2018
Ora che hai creato una tabella partizionata BigQuery, eseguiamo la stessa query, questa volta sulla tabella partizionata, per restituire i post di Stack Overflow con domande e titoli, oltre ad alcune altre statistiche come il numero di risposte, commenti, visualizzazioni e preferiti. Completa i seguenti passaggi:
- In alto a destra nella console GCP, seleziona Crea nuova query.
- Nell'area di testo Editor query, copia e incolla la seguente query SQL
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Seleziona Esegui con la memorizzazione nella cache di BigQuery disattivata (consulta la sezione precedente per disattivare la cache di BigQuery). La query restituisce le domande di Stack Overflow create nel mese di gennaio 2018 con il tag
android, insieme alla domanda e ad alcune altre statistiche. - Nei risultati della query, dovresti vedere il tempo impiegato per il completamento della query e il volume di dati elaborati per ottenere i risultati.
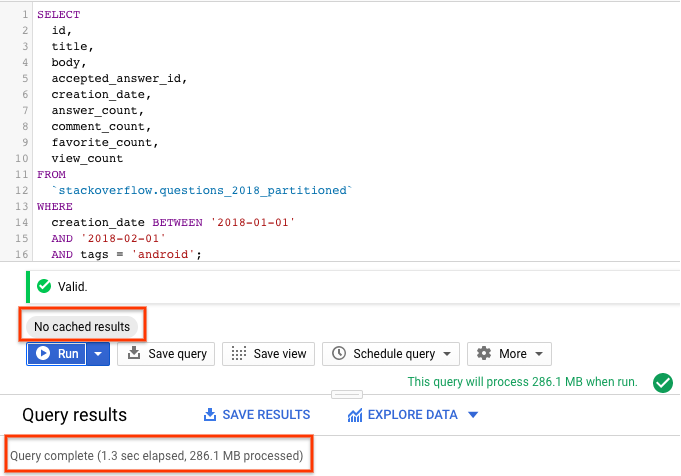
Dovresti notare che le prestazioni della query con la tabella partizionata sono migliori rispetto a quelle della tabella non partizionata, poiché BigQuery esegue il pruning delle partizioni, ovvero esegue la scansione solo delle partizioni richieste, elaborando meno dati ed eseguendo più velocemente. In questo modo, i costi e le prestazioni delle query vengono ottimizzati.
6. Creazione ed esecuzione di query su una tabella in cluster
Nella sezione precedente hai creato una tabella partizionata in BigQuery con i dati della tabella posts_questions nel set di dati pubblico di Stack Overflow. Abbiamo eseguito una query su questa tabella con la memorizzazione nella cache disattivata e abbiamo osservato il rendimento della query con tabelle partizionate e non partizionate. In questa sezione creerai una nuova tabella in cluster dalla stessa tabella posts_questions del set di dati pubblico Stack Overflow e osserverai il rendimento della query.
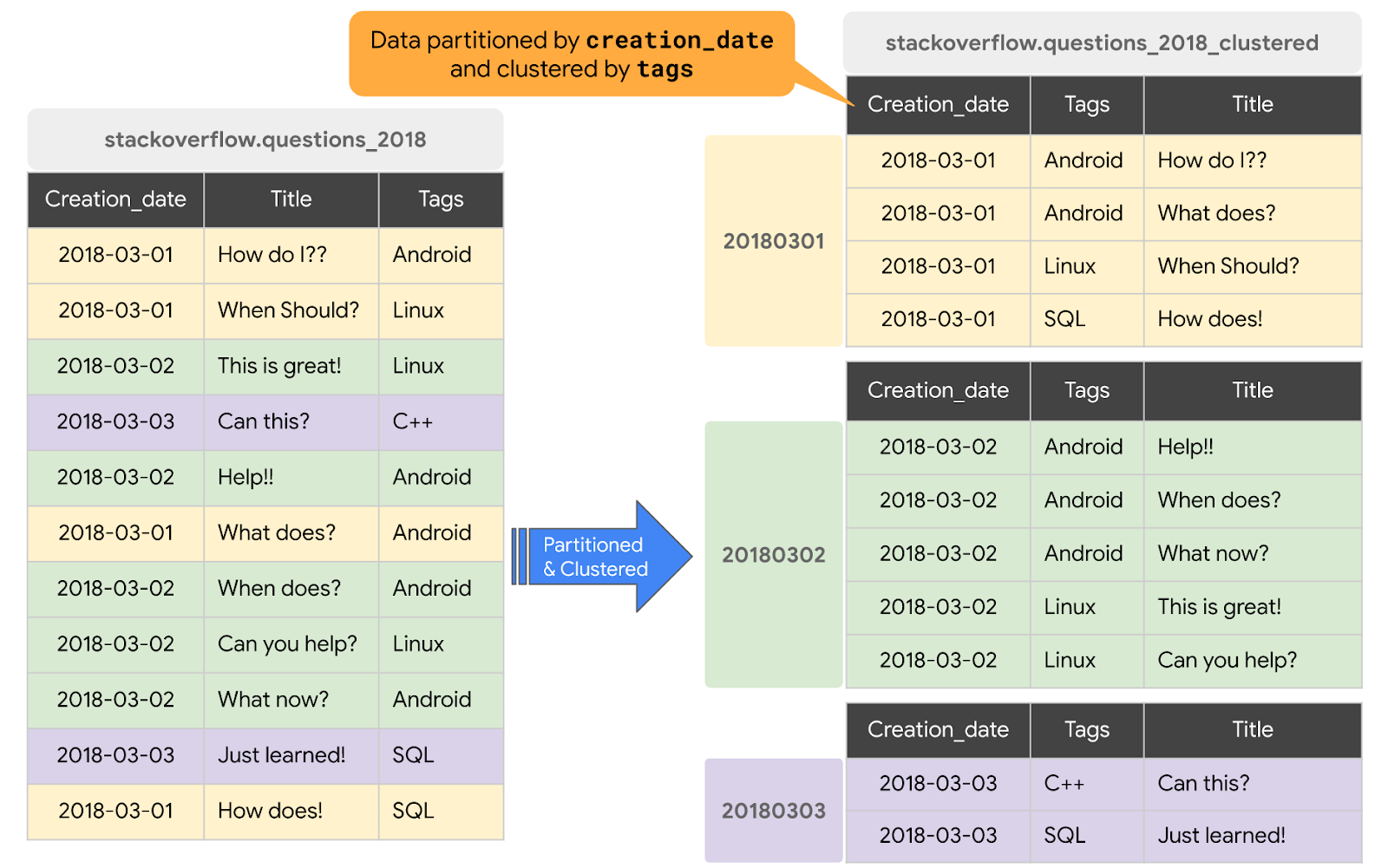
Quando una tabella è in cluster in BigQuery, i dati della tabella vengono organizzati automaticamente in base ai contenuti di una o più colonne nello schema della tabella. Le colonne specificate vengono usate per collocare vicini i dati correlati. Quando i dati vengono scritti in una tabella in cluster, BigQuery li ordina usando i valori delle colonne di clustering. Questi valori aiutano a organizzare i dati in più blocchi nello spazio di archiviazione BigQuery. L'ordine delle colonne sottoposte a clustering determina l'ordinamento dei dati. Quando vengono aggiunti nuovi dati a una tabella o a una partizione specifica, BigQuery esegue automaticamente il nuovo clustering in background per ripristinare la proprietà di ordinamento della tabella o della partizione.
Scopri di più sull'utilizzo delle tabelle in cluster qui.
Crea una nuova tabella in cluster con i post di Stack Overflow del 2018
In questa sezione creerai una nuova tabella partizionata in base a creation_date e raggruppata in cluster in base alla colonna tags in base al pattern di accesso alle query. Per creare una tabella in cluster con i dati di una tabella o query esistente, esegui una query sulla tabella dei post di Stack Overflow del 2018 e scrivi i risultati in una nuova tabella completando i seguenti passaggi:
- In alto a destra nella console GCP, seleziona Crea nuova query.
- Nell'area di testo Editor query, copia e incolla la seguente query SQL per creare una nuova tabella, che è un'istruzione DDL.
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Seleziona Esegui. La query crea una nuova tabella
questions_2018_clusterednel set di datistackoverflowdel tuo progetto con i dati risultanti dall'esecuzione di una query sulla tabella BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions. La nuova tabella è partizionata in base a creation_date e raggruppata in cluster in base alla colonna dei tag.
Esegui query sulla tabella in cluster con i post di Stack Overflow del 2018
Ora che hai creato una tabella BigQuery in cluster, esegui di nuovo la stessa query, questa volta sulla tabella partizionata e in cluster, per restituire i post di Stack Overflow con domande e titoli, oltre ad alcune altre statistiche come il numero di risposte, commenti, visualizzazioni e preferiti. Completa i seguenti passaggi:
- In alto a destra nella console GCP, seleziona Crea nuova query.
- Nell'area di testo Editor query, copia e incolla la seguente query SQL
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Seleziona Esegui con la memorizzazione nella cache di BigQuery disattivata (consulta la sezione precedente per disattivare la cache di BigQuery). La query restituisce le domande di Stack Overflow create nel mese di gennaio 2018 con il tag
android, insieme alla domanda e ad alcune altre statistiche. - Nei risultati della query, dovresti vedere il tempo impiegato per il completamento della query e il volume di dati elaborati per ottenere i risultati.
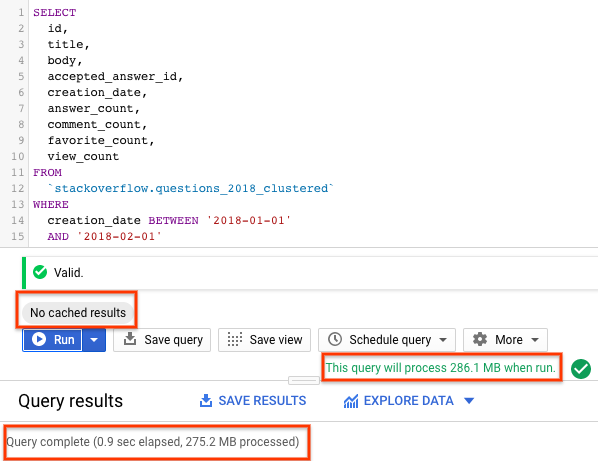
Con una tabella partizionata e in cluster, la query ha analizzato meno dati rispetto a una tabella partizionata o non partizionata. Il modo in cui i dati vengono organizzati mediante il partizionamento e il clustering riduce al minimo la quantità di dati scansionati dai worker degli slot, migliorando così le prestazioni delle query e ottimizzando i costi.
7. Pulizia
A meno che tu non preveda di continuare a lavorare con il set di dati Stack Overflow, devi eliminarlo ed eliminare il progetto che hai creato per questo codelab.
Elimina il set di dati BigQuery
Per eliminare il set di dati di BigQuery, procedi come segue:
- Seleziona il set di dati stackoverflow dal pannello di navigazione a sinistra in BigQuery .
- Nel riquadro dei dettagli, seleziona Elimina set di dati.
- Nella finestra di dialogo Elimina set di dati, inserisci stackoverflow e seleziona Elimina per confermare che vuoi eliminare il set di dati.
Elimina il progetto
Per eliminare il progetto GCP che hai creato per questo codelab, segui questi passaggi:
- Nel menu di navigazione di Google Cloud, seleziona IAM e amministrazione.
- Nel pannello di navigazione, seleziona Impostazioni.
- Nel riquadro dei dettagli, verifica che il progetto attuale sia quello che hai creato per questo codelab e seleziona Arresta.
- Nella finestra di dialogo Chiudi progetto, inserisci l'ID progetto (non il nome del progetto) e seleziona Chiudi per confermare.
Complimenti! Ora hai imparato
- Come utilizzare l'interfaccia utente web di BigQuery per creare una nuova tabella da tabelle esistenti
- Come creare ed eseguire query su tabelle partizionate e in cluster
- In che modo il partizionamento e il clustering ottimizzano le prestazioni e i costi delle query
Tieni presente che non è necessario configurare o gestire cluster per lavorare con i set di dati.