
1. Einführung
BigQuery ist ein vollständig verwaltetes, kostengünstiges Data Warehouse für Unternehmen im Petabyte-Bereich für Analysen. BigQuery ist serverlos. Sie müssen keine Cluster einrichten und verwalten.
Ein BigQuery-Dataset befindet sich in einem GCP-Projekt und enthält eine oder mehrere Tabellen. Sie können diese Datasets mit SQL abfragen.
In diesem Codelab verwenden Sie die BigQuery-Web-UI in der GCP Console, um Partitionierung und Clustering in BigQuery kennenzulernen. Mit der Tabellenpartitionierung und dem Clustering von BigQuery können Sie Ihre Daten so strukturieren, dass sie gängigen Datenzugriffsmustern entsprechen. Partitionierung und Clustering sind entscheidend, um die Leistung und Kosten von BigQuery bei Abfragen über einen bestimmten Zeitraum zu maximieren. Dadurch werden weniger Daten pro Abfrage gescannt und das Bereinigen erfolgt vor dem Startzeitpunkt der Abfrage.
Weitere Informationen zu BigQuery finden Sie in der BigQuery-Dokumentation.
Lerninhalte
- Partitionierte und geclusterte Tabellen erstellen und abfragen
- Abfrageleistung mit partitionierten und geclusterten Tabellen vergleichen
Voraussetzungen
Für dieses Lab benötigen Sie Folgendes:
- Die neueste Version von Google Chrome
- Ein Google Cloud Platform-Abrechnungskonto
2. Einrichtung
Um mit BigQuery zu arbeiten, müssen Sie ein GCP-Projekt erstellen oder ein vorhandenes Projekt auswählen.
Projekt erstellen
So erstellen Sie ein neues Projekt:
- Wenn Sie noch kein Google-Konto (Gmail oder Google Apps) haben, erstellen Sie eines.
- Melden Sie sich in der Google Cloud Console ( console.cloud.google.com) an und erstellen Sie ein neues Projekt.
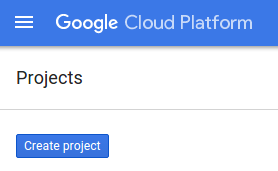
- Wenn Sie noch keine Projekte haben, klicken Sie auf die Schaltfläche „Projekt erstellen“:
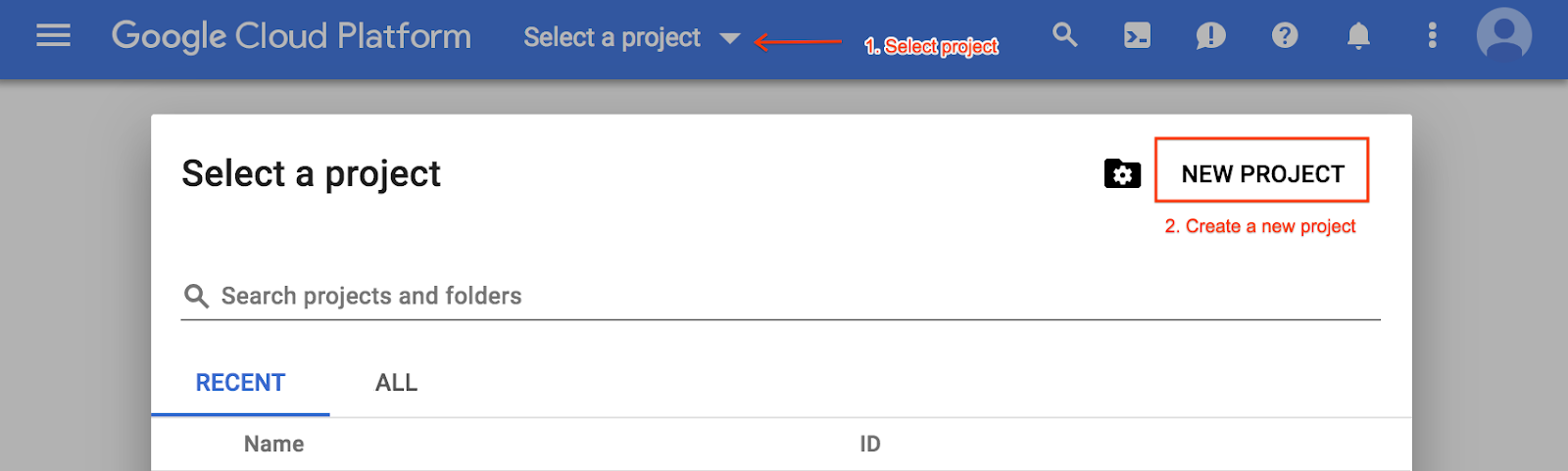
Erstellen Sie andernfalls ein neues Projekt über das Menü zur Projektauswahl:
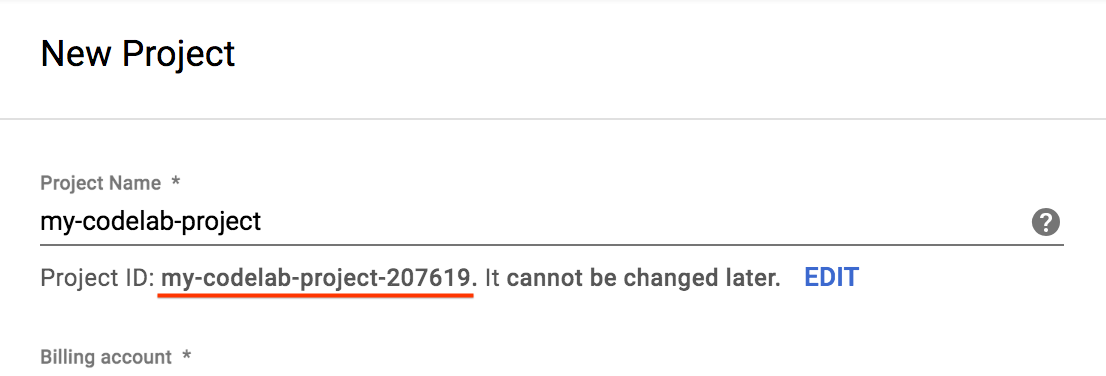
- Geben Sie einen Projektnamen ein und wählen Sie Erstellen aus. Die Projekt-ID ist für alle Google Cloud-Projekte ein eindeutiger Name.
3. Mit öffentlichen Datasets arbeiten
Mit BigQuery können Sie mit öffentlichen Datensätzen arbeiten, darunter BBC News, GitHub-Repositories, Stack Overflow und die Datensätze der US National Oceanic and Atmospheric Administration (NOAA). Sie müssen diese Datasets nicht in BigQuery laden. Sie müssen die Datasets nur öffnen, um sie in BigQuery anzusehen und abzufragen. In diesem Codelab arbeiten Sie mit dem öffentlichen Dataset von Stack Overflow.
Stack Overflow-Dataset durchsuchen
Das Stack Overflow-Dataset enthält Informationen zu Beiträgen, Tags, Badges, Kommentaren, Nutzern und mehr. So rufen Sie das Stack Overflow-Dataset in der BigQuery-Web-UI auf:
- Öffnen Sie das Stack Overflow-Dataset. Die BigQuery-Web-UI wird in der GCP Console geöffnet und zeigt Informationen zum Stackoverflow-Dataset an.
- Wählen Sie im Navigationsbereich bigquery-public-data aus. Das Menü wird erweitert und enthält eine Liste mit öffentlichen Datasets. Jedes Dataset besteht aus einer oder mehreren Tabellen.
- Scrollen Sie nach unten und wählen Sie stackoverflow aus. Das Menü wird erweitert und enthält eine Liste der Tabellen im Stack Overflow-Dataset.
- Wählen Sie Badges aus, um das Schema für die Tabelle „Badges“ aufzurufen. Notieren Sie sich die Namen der Felder in der Tabelle.
- Klicken Sie über den Feldnamen auf Vorschau, um Beispieldaten für die Tabelle „Badges“ aufzurufen.
Weitere Informationen zu allen öffentlichen Datasets, die in BigQuery verfügbar sind, finden Sie unter Öffentliche Google BigQuery-Datasets.
Stack Overflow-Dataset abfragen
Das Durchsuchen eines Datasets ist eine gute Möglichkeit, die Daten kennenzulernen, mit denen Sie arbeiten. Die Stärke von BigQuery liegt jedoch in der Abfrage von Datasets. In diesem Abschnitt erfahren Sie, wie Sie BigQuery-Abfragen ausführen. Sie benötigen zu diesem Zeitpunkt keine SQL-Kenntnisse. Sie können die folgenden Abfragen kopieren und einfügen.
Führen Sie die folgenden Schritte aus, um eine Abfrage auszuführen:
- Wählen Sie rechts oben in der GCP Console Neue Abfrage erstellen aus.
- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Textbereich des Abfrageeditors ein. BigQuery validiert die Abfrage. In der Web-UI wird unter dem Textbereich ein grünes Häkchen angezeigt, um anzugeben, dass die Syntax gültig ist.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- Wählen Sie Ausführen aus. Die Abfrage gibt die Anzahl der Stack Overflow-Beiträge oder -Fragen zurück, die jedes Jahr veröffentlicht wurden.
4. Neue Tabelle erstellen
Im vorherigen Abschnitt haben Sie öffentliche Datasets abgefragt, die BigQuery für Sie zur Verfügung stellt. In diesem Abschnitt erstellen Sie eine neue Tabelle in BigQuery aus einer vorhandenen Tabelle. Sie erstellen eine neue Tabelle mit Daten, die aus der Tabelle posts_questions des öffentlichen Datasets Stack Overflow stammen, und führen dann eine Abfrage für die Tabelle aus.
Neues Dataset erstellen
Wenn Sie Tabellendaten in BigQuery erstellen und laden möchten, müssen Sie zuerst ein BigQuery-Dataset erstellen, in dem die Daten gespeichert werden. Führen Sie dazu die folgenden Schritte aus:
- Wählen Sie in der GCP Console im Navigationsbereich den Projektnamen aus, der im Rahmen der Einrichtung erstellt wurde.
- Wählen Sie rechts im Detailbereich Dataset erstellen aus.
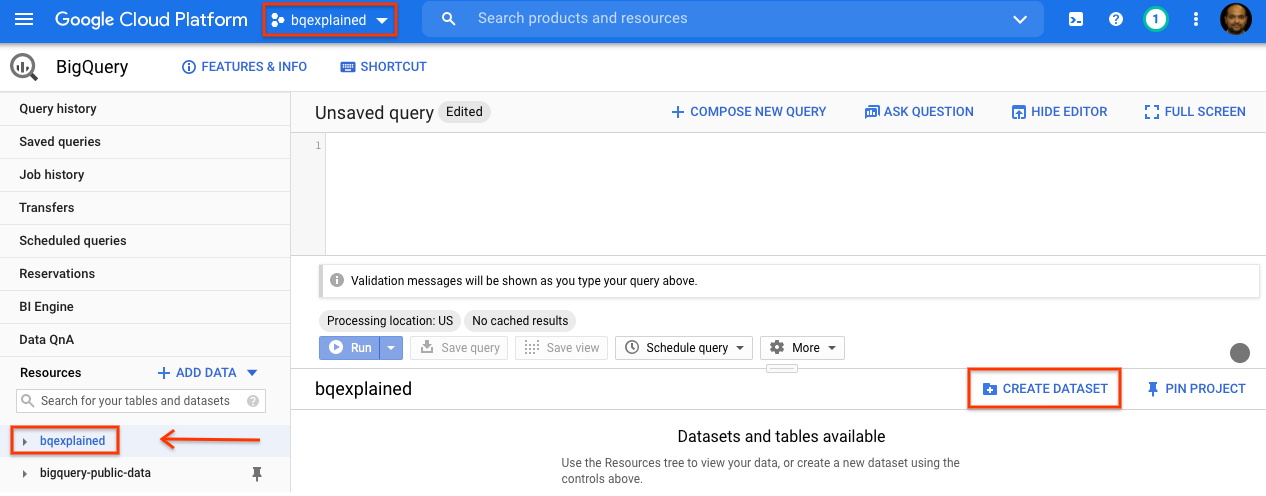
- Geben Sie im Dialogfeld Dataset erstellen als Dataset-ID
stackoverflowein. Lassen Sie alle anderen Standardeinstellungen unverändert und klicken Sie auf OK.
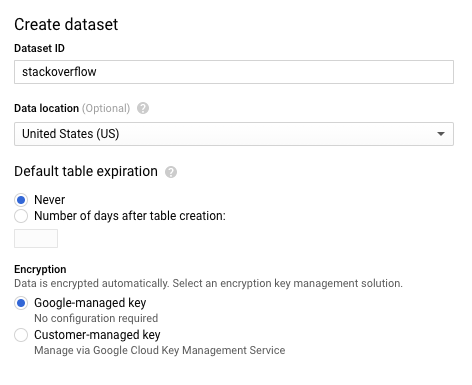
Neue Tabelle mit Stack Overflow-Beiträgen aus dem Jahr 2018 erstellen
Nachdem Sie ein BigQuery-Dataset erstellt haben, können Sie eine neue Tabelle in BigQuery erstellen. Wenn Sie eine Tabelle mit Daten aus einer vorhandenen Tabelle erstellen möchten, fragen Sie das Dataset mit Stack Overflow-Beiträgen aus dem Jahr 2018 ab und schreiben Sie die Ergebnisse in eine neue Tabelle. Gehen Sie dazu so vor:
- Wählen Sie rechts oben in der GCP Console Neue Abfrage erstellen aus.

- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Textbereich Abfrageeditor ein, um eine neue Tabelle zu erstellen. Es handelt sich dabei um eine DDL-Anweisung.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Wählen Sie Ausführen aus. Mit der Abfrage wird in Ihrem Projekt im Dataset
stackoverfloweine neue Tabellequestions_2018mit Daten erstellt, die aus der Ausführung einer Abfrage für das BigQuery Stack Overflow-Datasetbigquery-public-data.stackoverflow.posts_questionsstammen.
Neue Tabelle mit Stack Overflow-Beiträgen aus dem Jahr 2018 abfragen
Nachdem Sie eine BigQuery-Tabelle erstellt haben, führen wir eine Abfrage aus, um Stack Overflow-Beiträge mit Fragen und Titeln sowie einigen anderen Statistiken wie Anzahl der Antworten, Kommentare, Aufrufe und Favoriten zurückzugeben. Gehen Sie folgendermaßen vor:
- Wählen Sie rechts oben in der GCP Console Neue Abfrage erstellen aus.
- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Textbereich im Abfrageeditor ein.
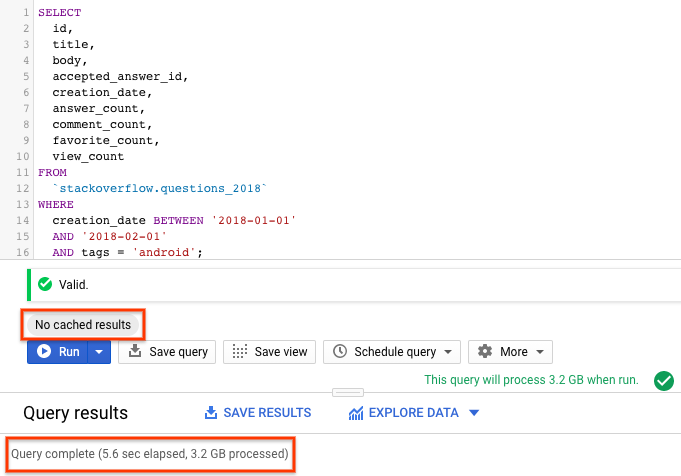
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Wählen Sie Ausführen aus. Die Abfrage gibt Stack Overflow-Fragen zurück, die im Januar 2018 erstellt und mit
androidgetaggt wurden, zusammen mit der Frage und einigen anderen Statistiken. - Standardmäßig speichert BigQuery die Abfrageergebnisse im Cache. Wenn Sie die gleiche Abfrage ausführen, sehen Sie, dass BigQuery viel weniger Zeit benötigt, um die Ergebnisse zurückzugeben, da die Ergebnisse aus dem Cache stammen.
- Führen Sie die gleiche Abfrage noch einmal aus, diesmal jedoch mit deaktiviertem BigQuery-Caching. Wir deaktivieren den Cache für den Rest des Labs, um einen fairen Leistungsvergleich mit partitionierten und geclusterten Tabellen zu ermöglichen, der in den nächsten Abschnitten durchgeführt wird. Klicken Sie im Abfrageeditor auf Mehr und wählen Sie Abfrageeinstellungen aus.
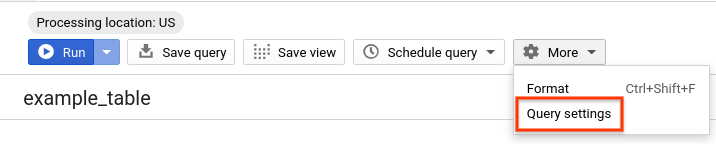
- Deaktivieren Sie unter Cache-Einstellung die Option Im Cache gespeicherte Ergebnisse verwenden.
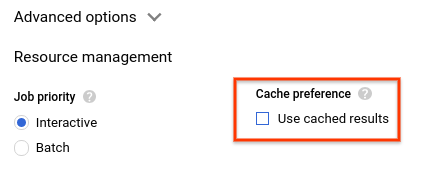
- In den Abfrageergebnissen sollten Sie die Zeit sehen, die für den Abschluss der Abfrage benötigt wurde, und das Datenvolumen, das verarbeitet wurde, um die Ergebnisse zu erhalten.
5. Partitionierte Tabelle erstellen und abfragen
Im vorherigen Abschnitt haben Sie mit dem öffentlichen Stack Overflow-Dataset eine neue Tabelle in BigQuery mit Daten aus der posts_questions-Tabelle erstellt. Wir haben diesen Datensatz ohne aktivierten Cache abgefragt und die Abfrageleistung beobachtet. In diesem Abschnitt erstellen Sie eine neue partitionierte Tabelle aus der Tabelle posts_questions des öffentlichen Datasets Stack Overflow und beobachten die Abfrageleistung.
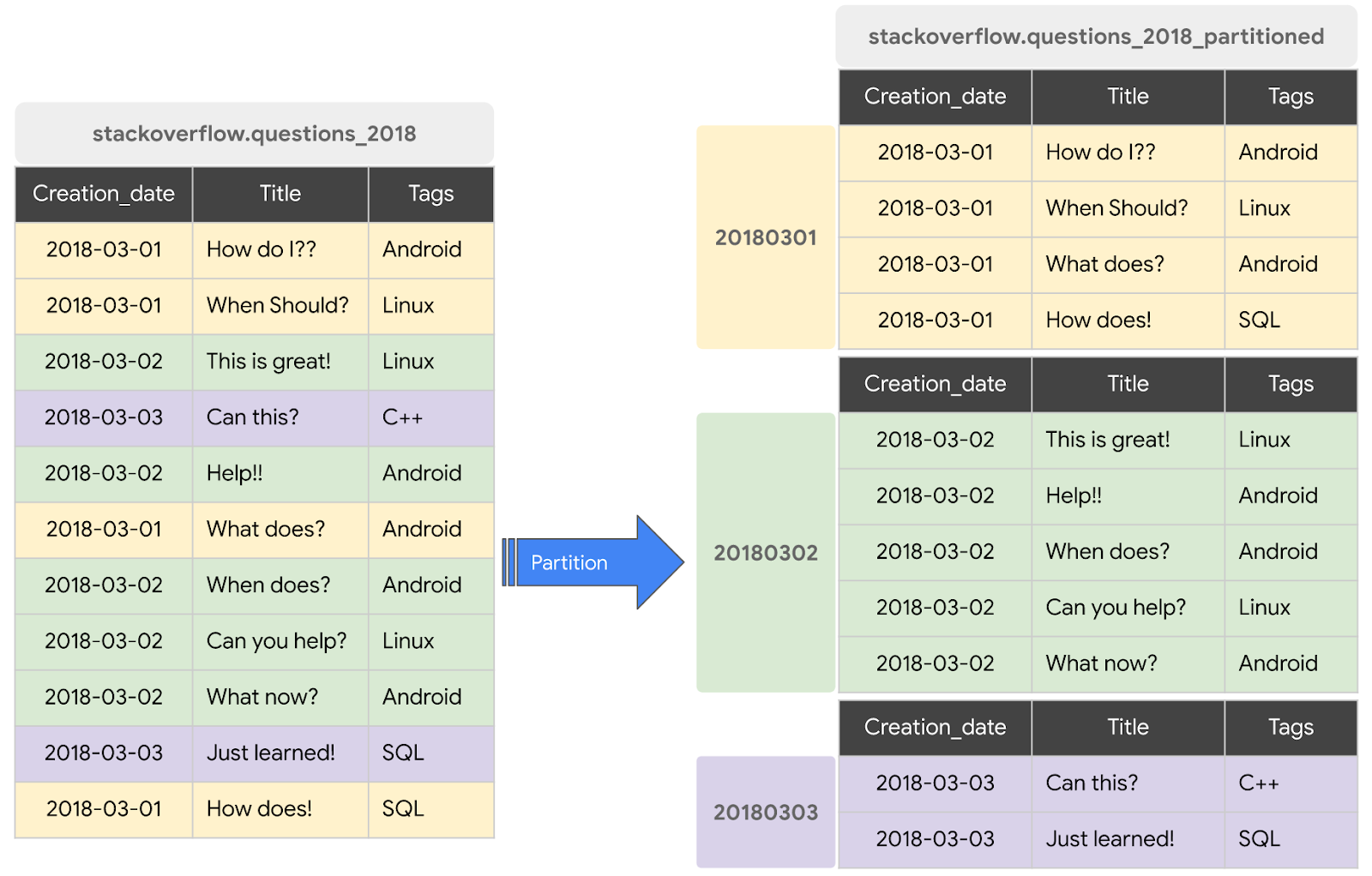
Eine partitionierte Tabelle ist eine spezielle Tabelle, die in Segmente, die als Partitionen bezeichnet werden, unterteilt ist. Damit lassen sich Daten einfacher verwalten und abfragen. Sie können große Tabellen in der Regel in viele kleinere Partitionen aufteilen, indem Sie die Aufnahmezeit von Daten, eine TIMESTAMP-/DATE-Spalte oder eine INTEGER-Spalte verwenden. Wir erstellen eine nach DATE partitionierte Tabelle.
Weitere Informationen zu partitionierten Tabellen
Neue partitionierte Tabelle mit Stack Overflow-Beiträgen aus dem Jahr 2018 erstellen
Wenn Sie eine partitionierte Tabelle mit Daten aus einer vorhandenen Tabelle oder Abfrage erstellen möchten, müssen Sie das Dataset mit Stackoverflow-Beiträgen aus dem Jahr 2018 abfragen und die Ergebnisse in eine neue Tabelle schreiben. Führen Sie dazu die folgenden Schritte aus:
- Wählen Sie rechts oben in der GCP Console Neue Abfrage erstellen aus.
- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Textbereich Abfrageeditor ein, um eine neue Tabelle zu erstellen. Es handelt sich dabei um eine DDL-Anweisung.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Wählen Sie Ausführen aus. Mit der Abfrage wird in Ihrem Projekt im Dataset
stackoverfloweine neue Tabellequestions_2018_partitionedmit Daten erstellt, die aus der Ausführung einer Abfrage für das BigQuery Stack Overflow-Datasetbigquery-public-data.stackoverflow.posts_questionsstammen.
Partitionierte Tabelle mit Stack Overflow-Beiträgen aus dem Jahr 2018 abfragen
Nachdem Sie eine partitionierte BigQuery-Tabelle erstellt haben, führen wir dieselbe Abfrage noch einmal für die partitionierte Tabelle aus, um Stack Overflow-Beiträge mit Fragen und Titeln sowie einige andere Statistiken wie die Anzahl der Antworten, Kommentare, Aufrufe und Favoriten zurückzugeben. Gehen Sie folgendermaßen vor:
- Wählen Sie rechts oben in der GCP Console Neue Abfrage erstellen aus.
- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Textbereich im Abfrageeditor ein.
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Wählen Sie Ausführen aus, wenn das BigQuery-Caching deaktiviert ist (siehe vorheriger Abschnitt). Die Abfrage gibt Stack Overflow-Fragen zurück, die im Januar 2018 erstellt und mit
androidgetaggt wurden, zusammen mit der Frage und einigen anderen Statistiken. - In den Abfrageergebnissen sollten Sie die Zeit sehen, die für den Abschluss der Abfrage benötigt wurde, und das Datenvolumen, das verarbeitet wurde, um die Ergebnisse zu erhalten.
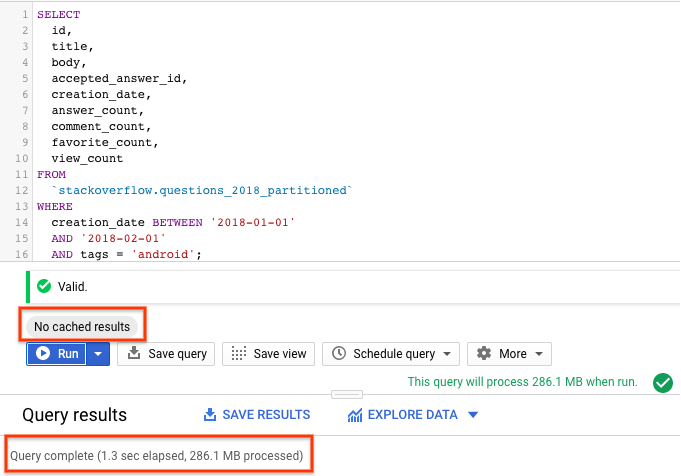
Sie sollten feststellen, dass die Leistung der Abfrage mit der partitionierten Tabelle besser ist als bei der nicht partitionierten Tabelle, da BigQuery die Partitionen bereinigt, d.h. nur die erforderlichen Partitionen durchsucht, weniger Daten verarbeitet und schneller ausgeführt wird. Dadurch werden die Abfragekosten und die Abfrageleistung optimiert.
6. Geclusterte Tabelle erstellen und abfragen
Im vorherigen Abschnitt haben Sie in BigQuery eine partitionierte Tabelle mit Daten aus der Tabelle posts_questions im öffentlichen Stack Overflow-Dataset erstellt. Wir haben diese Tabelle mit deaktiviertem Caching abgefragt und die Abfrageleistung sowohl bei nicht partitionierten als auch bei partitionierten Tabellen beobachtet. In diesem Abschnitt erstellen Sie eine neue geclusterte Tabelle aus der Tabelle posts_questions des öffentlichen Stack Overflow-Datasets und sehen sich die Abfrageleistung an.
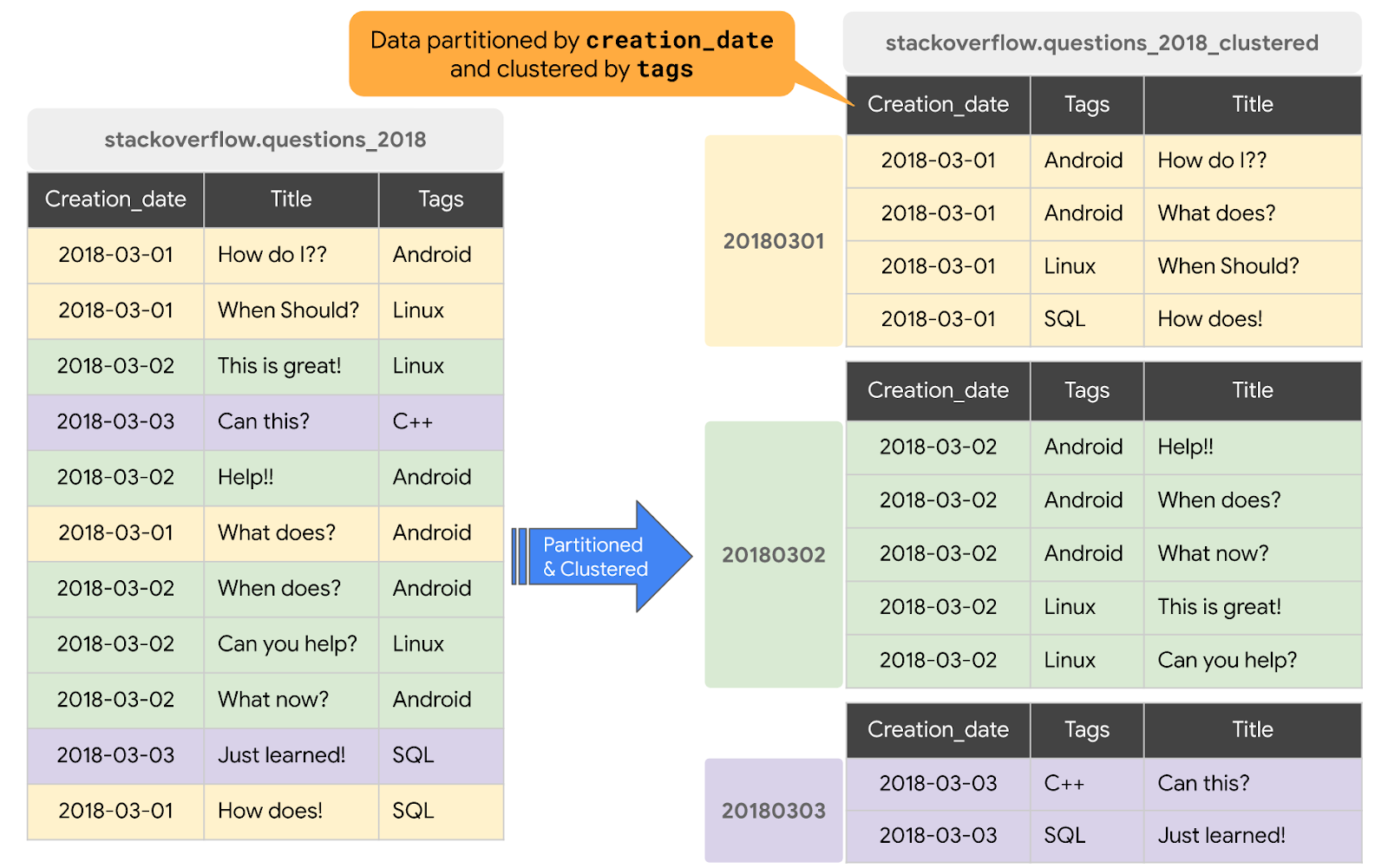
Wenn eine Tabelle in BigQuery geclustert ist, werden die Tabellendaten automatisch anhand des Inhalts einer oder mehrerer Spalten im Tabellenschema organisiert. Die von Ihnen angegebenen Spalten werden für die Zusammenstellung verwandter Daten verwendet. Wenn Daten in eine geclusterte Tabelle geschrieben werden, sortiert BigQuery die Daten anhand der Werte in den Clustering-Spalten. Mithilfe dieser Werte werden die Daten in mehreren Blöcken im BigQuery-Speicher organisiert. Die Reihenfolge der geclusterten Spalten bestimmt die Sortierreihenfolge der Daten. Wenn einer Tabelle oder einer bestimmten Partition neue Daten hinzugefügt werden, führt BigQuery automatisch ein erneutes Clustering im Hintergrund durch, um die Sortierung der Tabelle oder Partition wiederherzustellen.
Weitere Informationen zur Arbeit mit geclusterten Tabellen
Neue geclusterte Tabelle mit Stack Overflow-Beiträgen aus dem Jahr 2018 erstellen
In diesem Abschnitt erstellen Sie eine neue Tabelle, die auf creation_date partitioniert und auf der Spalte tags geclustert ist. Wenn Sie eine geclusterte Tabelle mit Daten aus einer vorhandenen Tabelle oder Abfrage erstellen möchten, fragen Sie die Tabelle mit den Stack Overflow-Beiträgen aus dem Jahr 2018 ab und schreiben Sie die Ergebnisse in eine neue Tabelle. Gehen Sie dazu so vor:
- Wählen Sie rechts oben in der GCP Console Neue Abfrage erstellen aus.
- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Textbereich Abfrageeditor ein, um eine neue Tabelle zu erstellen. Es handelt sich dabei um eine DDL-Anweisung.
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Wähle „Lauf“ aus. Mit der Abfrage wird eine neue Tabelle
questions_2018_clusteredim Datasetstackoverflowin Ihrem Projekt erstellt. Sie enthält Daten, die aus der Ausführung einer Abfrage für die BigQuery Stack Overflow-Tabellebigquery-public-data.stackoverflow.posts_questionsstammen. Die neue Tabelle wird nach „creation_date“ partitioniert und nach der Spalte „tags“ geclustert.
Geclusterte Tabelle mit Stack Overflow-Beiträgen aus dem Jahr 2018 abfragen
Nachdem Sie eine BigQuery-Tabelle mit Clustering erstellt haben, führen wir die gleiche Abfrage noch einmal aus, diesmal für die partitionierte und geclusterte Tabelle, um Stack Overflow-Beiträge mit Fragen und Titeln sowie einige andere Statistiken wie Anzahl der Antworten, Kommentare, Aufrufe und Favoriten zurückzugeben. Gehen Sie folgendermaßen vor:
- Wählen Sie rechts oben in der GCP Console Neue Abfrage erstellen aus.
- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Textbereich im Abfrageeditor ein.
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Wählen Sie Ausführen aus, wenn das BigQuery-Caching deaktiviert ist (siehe vorheriger Abschnitt). Die Abfrage gibt Stack Overflow-Fragen zurück, die im Januar 2018 erstellt und mit
androidgetaggt wurden, zusammen mit der Frage und einigen anderen Statistiken. - In den Abfrageergebnissen sollten Sie die Zeit sehen, die für den Abschluss der Abfrage benötigt wurde, und das Datenvolumen, das verarbeitet wurde, um die Ergebnisse zu erhalten.
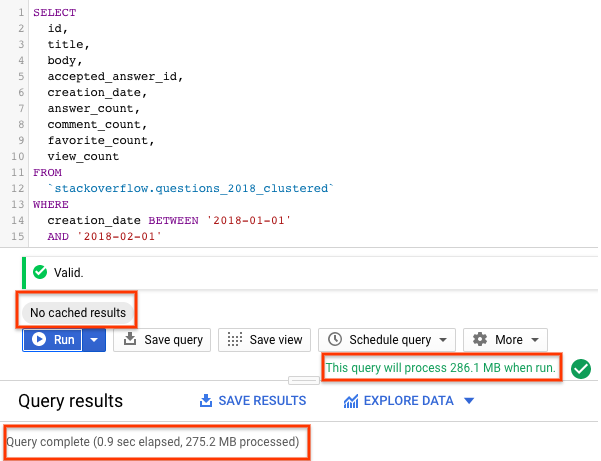
Bei einer partitionierten und geclusterten Tabelle wurden bei der Abfrage weniger Daten gescannt als bei einer partitionierten Tabelle oder einer nicht partitionierten Tabelle. Durch die Art und Weise, wie Daten durch Partitionierung und Clustering organisiert werden, wird die von Slot-Workern gescannte Datenmenge minimiert. Dadurch wird die Abfrageleistung verbessert und die Kosten werden optimiert.
7. Bereinigen
Wenn Sie nicht mit Ihrem Stack Overflow-Dataset weiterarbeiten möchten, sollten Sie es und das Projekt, das Sie für dieses Codelab erstellt haben, löschen.
BigQuery-Dataset löschen
So löschen Sie das BigQuery-Dataset:
- Wählen Sie in BigQuery in der linken Navigationsleiste das Dataset stackoverflow aus .
- Wählen Sie im Detailbereich Dataset löschen aus.
- Geben Sie im Dialogfeld Dataset löschen stackoverflow ein und wählen Sie Löschen aus, um zu bestätigen, dass Sie das Dataset löschen möchten.
Projekt löschen
So löschen Sie das GCP-Projekt, das Sie für dieses Codelab erstellt haben:
- Wählen Sie im GCP-Navigationsmenü IAM & Verwaltung aus.
- Wählen Sie im Navigationsbereich Einstellungen aus.
- Prüfen Sie im Detailbereich, ob Ihr aktuelles Projekt das Projekt ist, das Sie für dieses Codelab erstellt haben, und wählen Sie Herunterfahren aus.
- Geben Sie im Dialogfeld Projekt beenden die Projekt-ID (nicht den Projektnamen) für Ihr Projekt ein und wählen Sie zur Bestätigung Beenden aus.
Glückwunsch! Sie haben jetzt gelernt,
- Neue Tabelle aus vorhandenen Tabellen mit der BigQuery-Web-UI erstellen
- Partitionierte und geclusterte Tabellen erstellen und abfragen
- Wie Partitionierung und Clustering die Abfrageleistung und die Kosten optimieren
Sie mussten keine Cluster einrichten oder verwalten, um mit Datasets zu arbeiten.