
1. Introduction
BigQuery est un entrepôt de données d'entreprise entièrement géré, à l'échelle du pétaoctet et à faible coût, destiné à l'analyse. BigQuery fonctionne sans serveur. Vous n'avez pas besoin de configurer ni de gérer des clusters.
Un ensemble de données BigQuery réside dans un projet GCP et contient une ou plusieurs tables. Vous pouvez interroger ces ensembles de données avec SQL.
Dans cet atelier de programmation, vous allez utiliser l'interface utilisateur Web de BigQuery dans la console GCP pour comprendre le partitionnement et le clustering dans BigQuery. Le partitionnement et le clustering des tables BigQuery vous aident à structurer vos données pour qu'elles correspondent aux modèles d'accès aux données courants. Le partitionnement et le clustering sont essentiels pour maximiser pleinement les performances et le coût de BigQuery lors de l'interrogation d'une plage de données spécifique. Cela permet d'analyser moins de données par requête. L'élagage est déterminé avant l'heure de début de la requête.
Pour en savoir plus sur BigQuery, consultez la documentation BigQuery.
Points abordés
- Créer et interroger des tables partitionnées et en cluster
- Comparer les performances des requêtes avec des tables partitionnées et en cluster
Prérequis
Pour réaliser cet atelier :
- La dernière version de Google Chrome
- Un compte de facturation Google Cloud Platform
2. Configuration
Pour utiliser BigQuery, vous devez créer un projet GCP ou en sélectionner un existant.
Créer un projet
Pour créer un projet :
- Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), créez-en un.
- Connectez-vous à la console Google Cloud Platform ( console.cloud.google.com) et créez un projet.
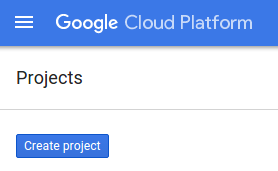
- Si vous n'avez aucun projet, cliquez sur le bouton "Créer un projet" :
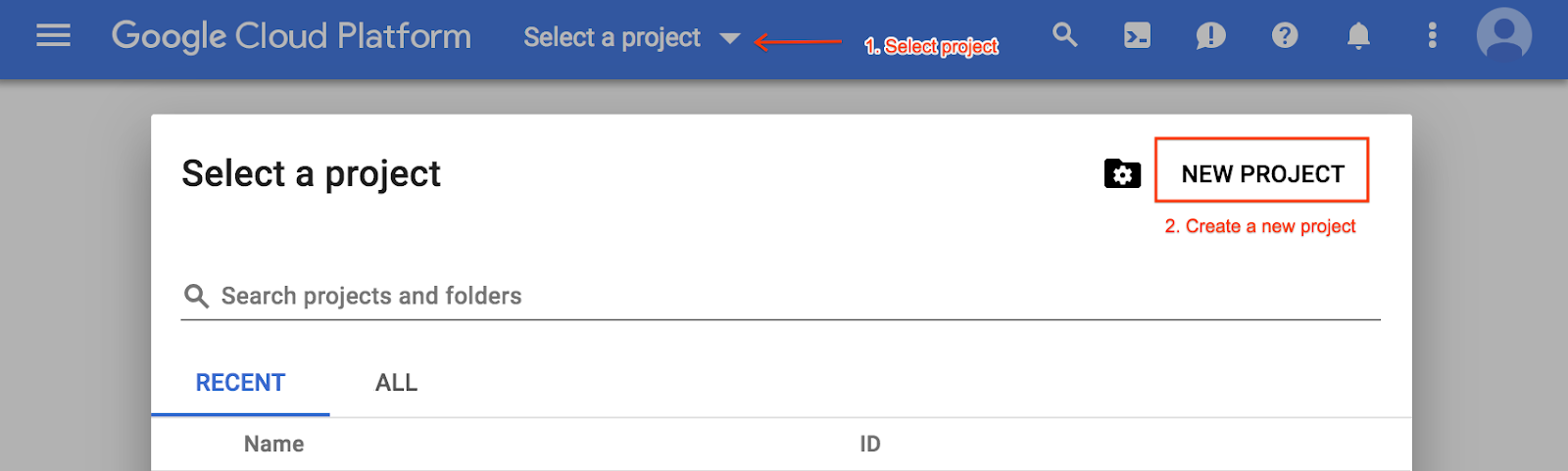
Sinon, créez un projet dans le menu de sélection des projets :
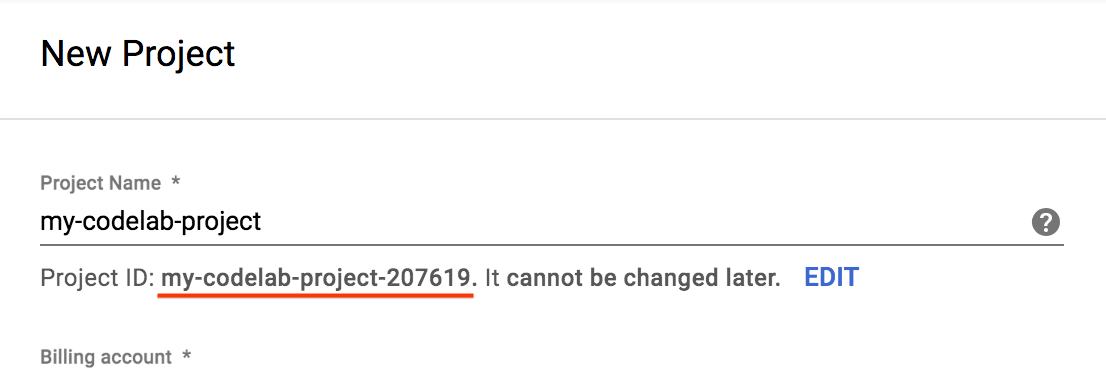
- Saisissez un nom de projet, puis sélectionnez Créer. Notez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud.
3. Utiliser des ensembles de données publics
BigQuery vous permet de travailler avec des ensembles de données publics, y compris les ensembles de données BBC News, les dépôts GitHub, Stack Overflow et ceux de la National Oceanic and Atmospheric Administration (NOAA) des États-Unis. Vous n'avez pas besoin de charger ces ensembles de données dans BigQuery. Il vous suffit d'ouvrir les ensembles de données pour les parcourir et les interroger dans BigQuery. Dans cet atelier de programmation, vous allez utiliser l'ensemble de données public Stack Overflow.
Parcourir l'ensemble de données Stack Overflow
L'ensemble de données Stack Overflow contient des informations sur les posts, les tags, les badges, les commentaires, les utilisateurs et plus encore. Pour parcourir l'ensemble de données Stack Overflow dans l'interface utilisateur Web de BigQuery, procédez comme suit :
- Ouvrez l'ensemble de données Stack Overflow. L'UI Web de BigQuery s'ouvre dans la console GCP et affiche des informations sur l'ensemble de données Stackoverflow.
- Dans le panneau de navigation , sélectionnez bigquery-public-data. Le menu se développe pour lister les ensembles de données publics. Chaque ensemble de données comprend une ou plusieurs tables.
- Faites défiler la page vers le bas, puis sélectionnez stackoverflow. Le menu se développe pour lister les tables de l'ensemble de données Stack Overflow.
- Sélectionnez badges pour afficher le schéma de la table "badges". Notez les noms des champs dans le tableau.
- Au-dessus des noms de champs, cliquez sur Aperçu pour afficher des exemples de données pour la table "badges".
Pour en savoir plus sur tous les ensembles de données publics disponibles dans BigQuery, consultez Ensembles de données publics Google BigQuery.
Interroger l'ensemble de données Stack Overflow
Parcourir un ensemble de données est un bon moyen de comprendre les données avec lesquelles vous travaillez, mais c'est en interrogeant les ensembles de données que BigQuery révèle tout son potentiel. Cette section vous explique comment exécuter des requêtes BigQuery. Vous n'avez pas besoin de connaître le langage SQL pour le moment. Vous pouvez copier et coller les requêtes ci-dessous.
Pour exécuter une requête, procédez comme suit :
- En haut à droite de la console GCP, sélectionnez Saisir une nouvelle requête.
- Dans la zone de texte de l'éditeur de requête, copiez et collez la requête SQL suivante. BigQuery valide la requête et l'UI Web affiche une coche verte sous la zone de texte pour indiquer que la syntaxe est valide.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- Sélectionnez Exécuter. La requête renvoie le nombre de posts ou de questions Stack Overflow publiés chaque année.
4. Créer une table
Dans la section précédente, vous avez interrogé des ensembles de données publics que BigQuery met à votre disposition. Dans cette section, vous allez créer une table dans BigQuery à partir d'une table existante. Vous allez créer une table avec des données échantillonnées à partir de la table posts_questions de l'ensemble de données public Stack Overflow, puis interroger cette table.
Créer un ensemble de données
Pour créer des données de table et les charger dans BigQuery, commencez par créer un ensemble de données BigQuery pour les stocker. Pour ce faire, procédez comme suit :
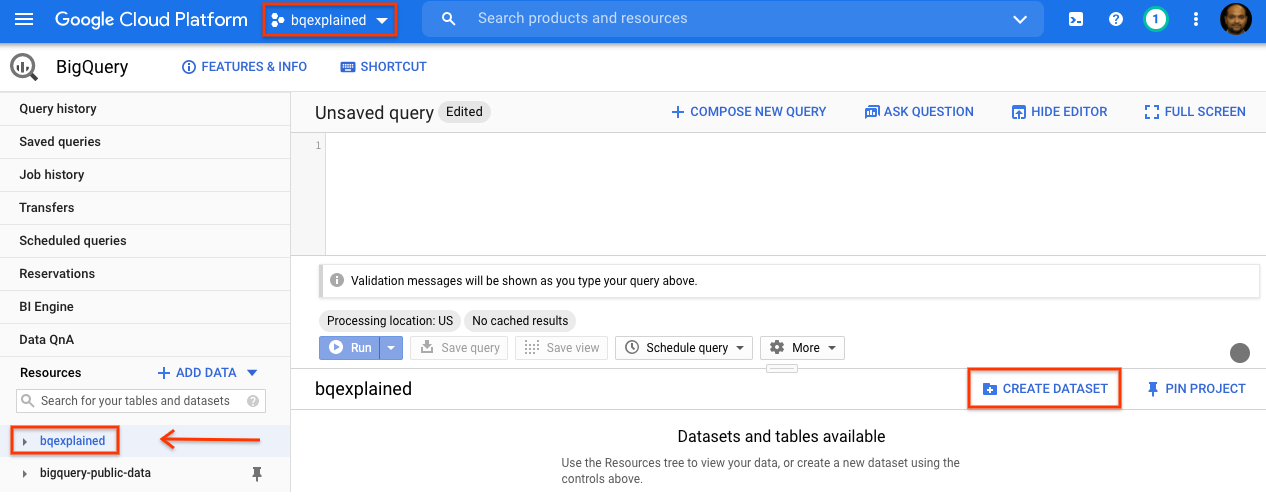
- Dans le panneau de navigation de la console GCP, sélectionnez le nom du projet créé lors de la configuration.
- Dans le panneau "Détails" situé à droite, sélectionnez Créer un ensemble de données.
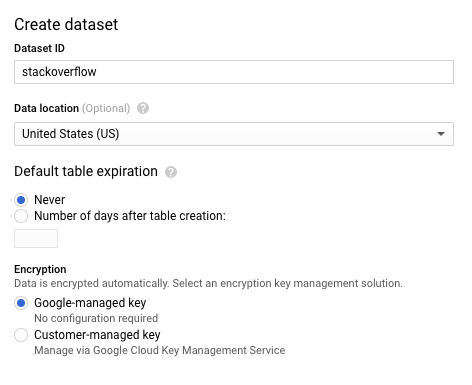
- Dans la boîte de dialogue Créer un ensemble de données, saisissez
stackoverflowdans le champ ID de l'ensemble de données. Ne modifiez aucun autre paramètre par défaut et cliquez sur OK.
Créer un tableau avec les posts Stack Overflow de 2018
Maintenant que vous avez créé un ensemble de données BigQuery, vous pouvez créer une table dans BigQuery. Pour créer une table avec des données provenant d'une table existante, vous allez interroger l'ensemble de données "Posts Stack Overflow 2018" et écrire les résultats dans une nouvelle table. Pour ce faire, procédez comme suit :
- En haut à droite de la console GCP, sélectionnez Saisir une nouvelle requête.

- Dans la zone de texte de l'éditeur de requête, copiez et collez la requête SQL suivante pour créer une table (il s'agit d'une instruction DDL).
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Sélectionnez Exécuter. La requête crée une table
questions_2018dans l'ensemble de donnéesstackoverflowde votre projet, avec les données résultant de l'exécution d'une requête sur l'ensemble de données BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions.
Interroger la nouvelle table avec les posts Stack Overflow de 2018
Maintenant que vous avez créé une table BigQuery, exécutons une requête pour renvoyer les posts Stack Overflow contenant des questions et des titres, ainsi que quelques autres statistiques telles que le nombre de réponses, de commentaires, de vues et de favoris. Procédez comme suit :
- En haut à droite de la console GCP, sélectionnez Saisir une nouvelle requête.
- Dans la zone de texte de l'éditeur de requête, copiez et collez la requête SQL suivante.
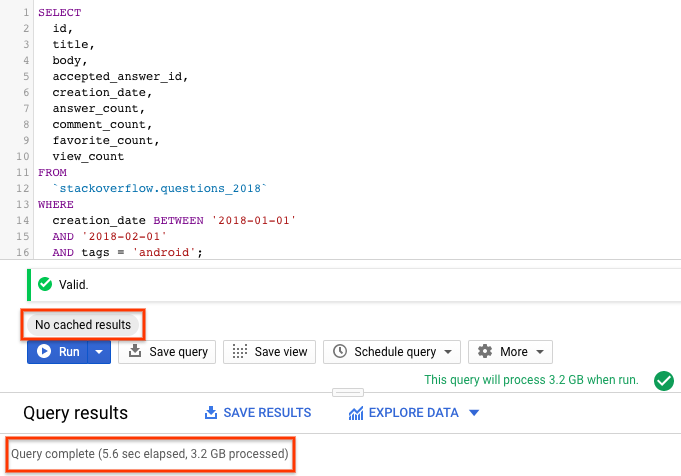
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Sélectionnez Exécuter. La requête renvoie les questions Stack Overflow créées en janvier 2018 et taguées
android, ainsi que la question et quelques autres statistiques. - Par défaut, BigQuery met en cache les résultats des requêtes. Exécutez la même requête. Vous constaterez que BigQuery a mis beaucoup moins de temps à renvoyer les résultats, car il les a récupérés à partir du cache.
- Exécutez à nouveau la même requête, mais cette fois avec la mise en cache BigQuery désactivée. Nous allons désactiver le cache pour le reste de l'atelier afin de comparer équitablement les performances des tables partitionnées et groupées qui seront exécutées dans les sections suivantes. Dans l'éditeur de requête, cliquez sur Plus et sélectionnez Paramètres de requête.
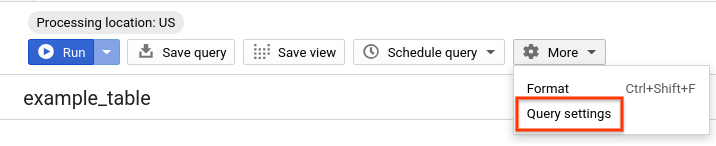
- Sous Préférence en matière de cache, décochez l'option Utiliser les résultats mis en cache.
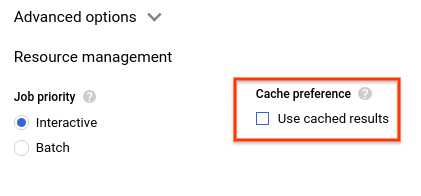
- Dans les résultats de la requête, vous devriez voir le temps nécessaire à l'exécution de la requête et le volume de données traitées pour obtenir les résultats.
5. Créer et interroger une table partitionnée
Dans la section précédente, vous avez créé une table dans BigQuery avec les données de la table posts_questions à l'aide de l'ensemble de données public Stack Overflow. Nous avons interrogé cet ensemble de données avec la mise en cache désactivée et observé les performances des requêtes. Dans cette section, vous allez créer une table partitionnée à partir de la table posts_questions du même ensemble de données public Stack Overflow et observer les performances des requêtes.
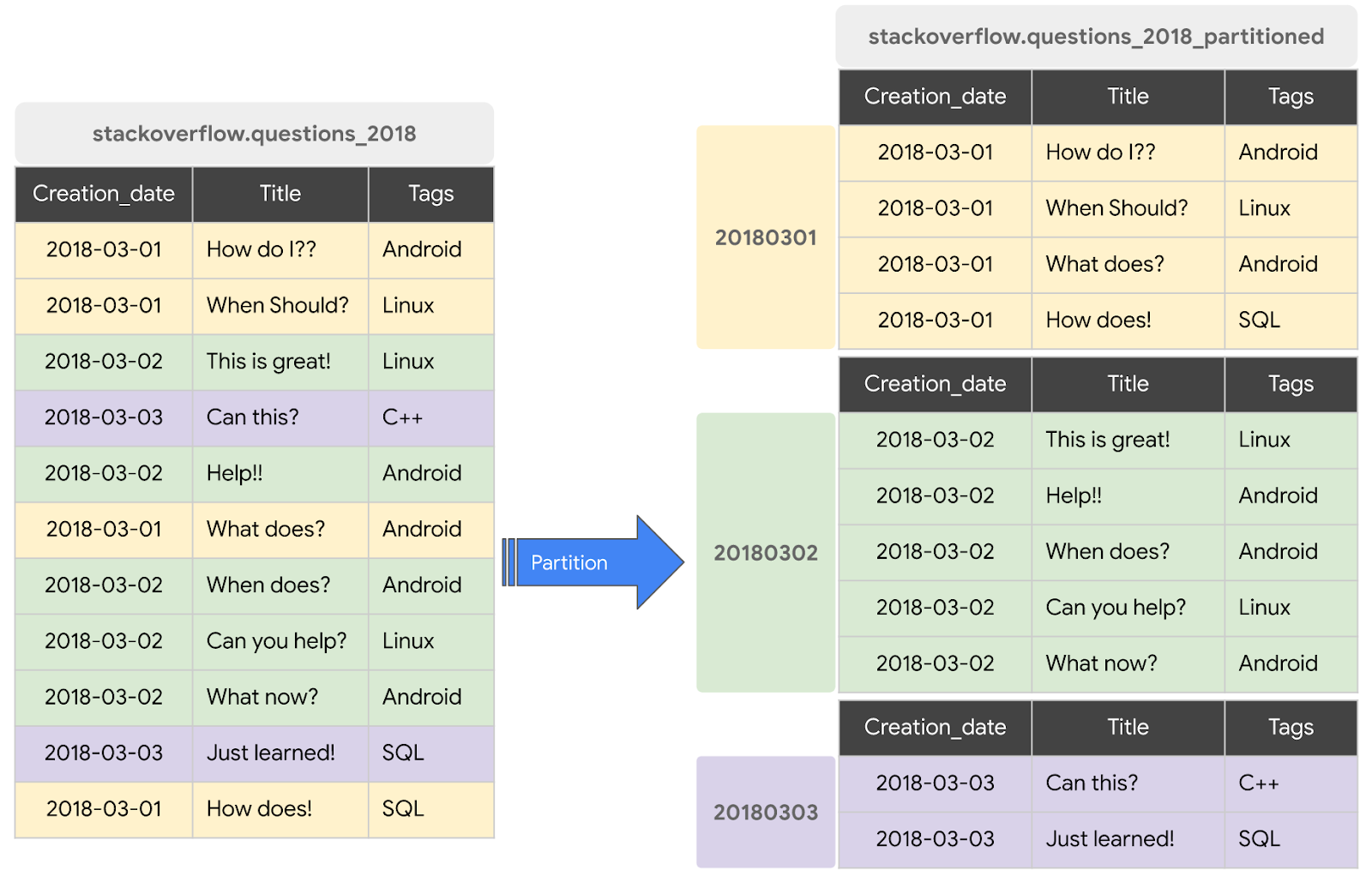
Une table partitionnée est une table spéciale divisée en segments, appelés partitions, qui permettent de gérer et d'interroger facilement les données. Vous pouvez généralement diviser les grandes tables en plusieurs partitions plus petites à l'aide de la date d'ingestion des données, d'une colonne TIMESTAMP/DATE ou d'une colonne INTEGER. Nous allons créer une table partitionnée par DATE.
Pour en savoir plus sur les tables partitionnées, cliquez ici.
Créer une table partitionnée avec les posts Stack Overflow de 2018
Pour créer une table partitionnée avec des données provenant d'une table ou d'une requête existantes, interrogez l'ensemble de données "Posts Stackoverflow 2018" et écrivez les résultats dans une nouvelle table. Pour ce faire, procédez comme suit :
- En haut à droite de la console GCP, sélectionnez Saisir une nouvelle requête.
- Dans la zone de texte de l'éditeur de requête, copiez et collez la requête SQL suivante pour créer une table (il s'agit d'une instruction DDL).
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Sélectionnez Exécuter. La requête crée une table
questions_2018_partitioneddans l'ensemble de donnéesstackoverflowde votre projet, avec les données résultant de l'exécution d'une requête sur l'ensemble de données BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions.
Interroger la table partitionnée avec les posts Stack Overflow de 2018
Maintenant que vous avez créé une table partitionnée BigQuery, exécutons la même requête, cette fois sur la table partitionnée, pour renvoyer les posts Stack Overflow avec des questions et des titres, ainsi que quelques autres statistiques telles que le nombre de réponses, de commentaires, de vues et de favoris. Procédez comme suit :
- En haut à droite de la console GCP, sélectionnez Saisir une nouvelle requête.
- Dans la zone de texte de l'éditeur de requête, copiez et collez la requête SQL suivante.
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Sélectionnez Exécuter avec la mise en cache BigQuery désactivée (consultez la section précédente pour savoir comment désactiver le cache BigQuery). La requête renvoie les questions Stack Overflow créées en janvier 2018 et taguées
android, ainsi que la question et quelques autres statistiques. - Dans les résultats de la requête, vous devriez voir le temps nécessaire à l'exécution de la requête et le volume de données traitées pour obtenir les résultats.
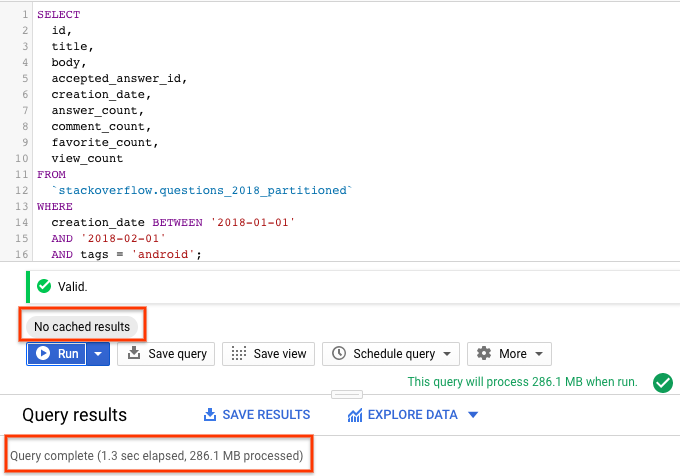
Vous devriez constater que les performances de la requête avec la table partitionnée sont meilleures que celles de la table non partitionnée, car BigQuery élague les partitions, c'est-à-dire qu'il n'analyse que les partitions requises, traite moins de données et s'exécute plus rapidement. Cela permet d'optimiser les coûts et les performances des requêtes.
6. Créer et interroger une table en cluster
Dans la section précédente, vous avez créé une table partitionnée dans BigQuery avec les données de la table posts_questions de l'ensemble de données public Stack Overflow. Nous avons interrogé cette table avec la mise en cache désactivée et observé les performances des requêtes avec des tables partitionnées et non partitionnées. Dans cette section, vous allez créer une table groupée à partir de la table posts_questions du même ensemble de données public Stack Overflow et observer les performances des requêtes.
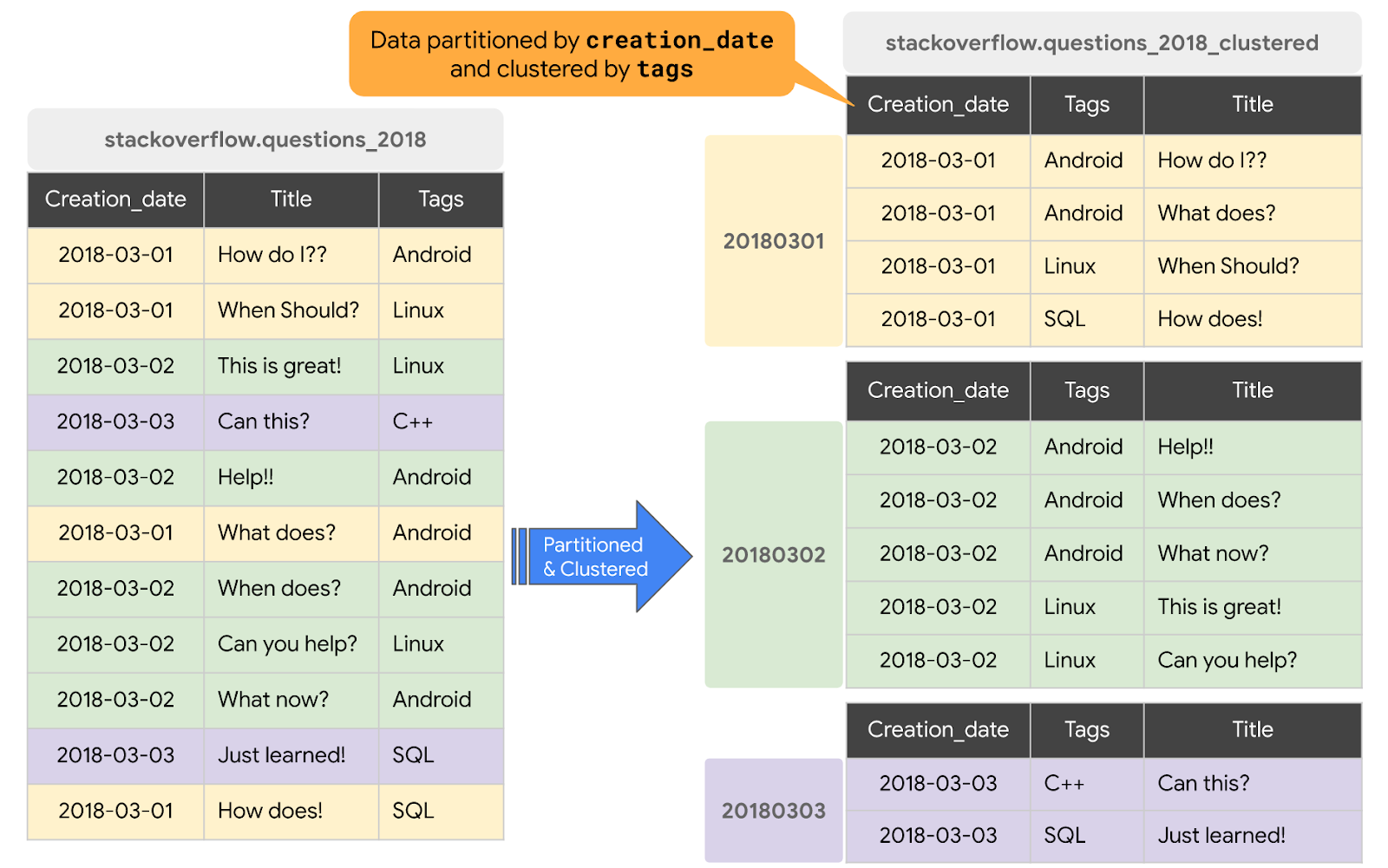
Lorsqu'une table est mise en cluster dans BigQuery, les données de la table sont automatiquement organisées en fonction du contenu d'une ou plusieurs colonnes du schéma de la table. Les colonnes que vous spécifiez sont utilisées pour rapprocher les données associées. Lorsque des données sont écrites dans une table en cluster, BigQuery les trie à l'aide des valeurs des colonnes de clustering. Ces valeurs permettent d'organiser les données en plusieurs blocs dans le stockage BigQuery. L'ordre des colonnes groupées détermine l'ordre de tri des données. Lorsque de nouvelles données sont ajoutées à une table ou à une partition spécifique, BigQuery effectue un reclustering automatique en arrière-plan pour restaurer la propriété de tri de la table ou de la partition.
Pour en savoir plus sur l'utilisation des tables en cluster, cliquez ici.
Créer une table en cluster avec les posts Stack Overflow de 2018
Dans cette section, vous allez créer une table partitionnée sur creation_date et mise en cluster sur la colonne tags en fonction du modèle d'accès aux requêtes. Pour créer une table en cluster avec des données provenant d'une table ou d'une requête existantes, vous devez interroger la table des posts Stack Overflow de 2018 et écrire les résultats dans une nouvelle table. Pour ce faire, procédez comme suit :
- En haut à droite de la console GCP, sélectionnez Saisir une nouvelle requête.
- Dans la zone de texte de l'éditeur de requête, copiez et collez la requête SQL suivante pour créer une table (il s'agit d'une instruction DDL).
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Sélectionnez "Run" (Exécuter). La requête crée une table
questions_2018_clustereddans l'ensemble de donnéesstackoverflowde votre projet, avec les données résultant de l'exécution d'une requête sur la table BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions. La nouvelle table est partitionnée sur la colonne "creation_date" et mise en cluster sur la colonne "tags".
Interroger la table en cluster avec les posts Stack Overflow de 2018
Maintenant que vous avez créé une table BigQuery en cluster, réexécutons la même requête, cette fois sur la table partitionnée et en cluster, pour renvoyer les posts Stack Overflow avec des questions et des titres, ainsi que quelques autres statistiques telles que le nombre de réponses, de commentaires, de vues et de favoris. Procédez comme suit :
- En haut à droite de la console GCP, sélectionnez Saisir une nouvelle requête.
- Dans la zone de texte de l'éditeur de requête, copiez et collez la requête SQL suivante.
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Sélectionnez Exécuter avec la mise en cache BigQuery désactivée (consultez la section précédente pour savoir comment désactiver le cache BigQuery). La requête renvoie les questions Stack Overflow créées en janvier 2018 et taguées
android, ainsi que la question et quelques autres statistiques. - Dans les résultats de la requête, vous devriez voir le temps nécessaire à l'exécution de la requête et le volume de données traitées pour obtenir les résultats.
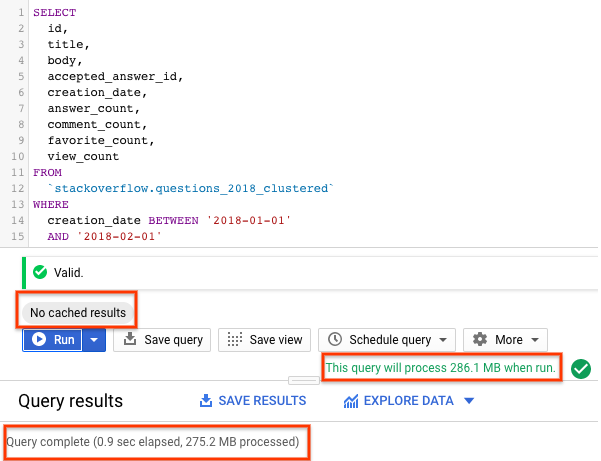
Avec une table partitionnée et en cluster, la requête a analysé moins de données qu'avec une table partitionnée ou une table non partitionnée. La façon dont les données sont organisées par partitionnement et clustering minimise la quantité de données analysées par les nœuds de calcul, ce qui améliore les performances des requêtes et optimise les coûts.
7. Nettoyer
À moins que vous ne prévoyiez de continuer à travailler avec votre ensemble de données Stack Overflow, vous devez le supprimer, ainsi que le projet que vous avez créé pour cet atelier de programmation.
Supprimer l'ensemble de données BigQuery
Pour supprimer l'ensemble de données BigQuery, procédez comme suit :
- Sélectionnez l'ensemble de données stackoverflow dans le panneau de navigation de gauche de BigQuery .
- Dans le panneau de détails, sélectionnez Supprimer l'ensemble de données.
- Dans la boîte de dialogue Supprimer l'ensemble de données, saisissez stackoverflow et cliquez sur Supprimer pour confirmer que vous voulez supprimer l'ensemble de données.
Supprimer le projet
Pour supprimer le projet GCP que vous avez créé pour cet atelier de programmation, procédez comme suit :
- Dans le menu de navigation de GCP, sélectionnez IAM et administration.
- Dans le panneau de navigation, sélectionnez Paramètres.
- Dans le panneau de détails, vérifiez que votre projet actuel est bien celui que vous avez créé pour cet atelier de programmation, puis cliquez sur Arrêter.
- Dans la boîte de dialogue Arrêter le projet, saisissez l'ID de votre projet (et non son nom), puis cliquez sur Arrêter pour confirmer votre choix.
Félicitations ! Vous avez maintenant appris
- Utiliser l'UI Web de BigQuery pour créer une table à partir de tables existantes
- Créer et interroger des tables partitionnées et en cluster
- Comment le partitionnement et le clustering optimisent les performances et les coûts des requêtes
Notez que vous n'avez pas eu à configurer ni à gérer de clusters pour travailler avec des ensembles de données.