
1. מבוא
BigQuery הוא מחסן נתונים (data warehouse) ארגוני מנוהל לניתוח נתונים, שמאפשר אחסון של נתונים בקנה מידה של פטה-בייט בעלות נמוכה. BigQuery הוא שירות ללא שרת. אין צורך להגדיר ולנהל אשכולות.
מערך נתונים ב-BigQuery נמצא בפרויקט ב-GCP ומכיל טבלה אחת או יותר. אפשר להריץ שאילתות על מערכי הנתונים האלה באמצעות SQL.
ב-codelab הזה תשתמשו בממשק המשתמש באינטרנט של BigQuery במסוף GCP כדי להבין את החלוקה למחיצות ואת האשכולות ב-BigQuery. חלוקת טבלאות למחיצות וקיבוץ שלהן ב-BigQuery עוזרים לכם לבנות את הנתונים כך שיתאימו לדפוסי גישה נפוצים לנתונים. חלוקה למחיצות וקיבוץ לאשכולות הם מרכיבים חשובים למיקסום הביצועים והעלות של BigQuery כשמריצים שאילתות על טווח נתונים ספציפי. התוצאה היא סריקה של פחות נתונים לכל שאילתה, והגיזום נקבע לפני זמן ההתחלה של השאילתה.
מידע נוסף על BigQuery זמין במאמרי העזרה של BigQuery.
מה תלמדו
- איך יוצרים טבלאות עם חלוקה למחיצות וטבלאות מקובצות ומריצים עליהן שאילתות
- השוואה בין ביצועי שאילתות לבין טבלאות מחולקות למחיצות ומקובצות לאשכולות
מה תצטרכו
כדי להשלים את שיעור ה-Lab תצטרכו:
- הגרסה העדכנית של Google Chrome
- חשבון לחיוב ב-Google Cloud Platform
2. תהליך ההגדרה
כדי לעבוד עם BigQuery, צריך ליצור פרויקט ב-GCP או לבחור פרויקט קיים.
יצירת פרויקט
כדי ליצור פרויקט חדש, פועלים לפי השלבים הבאים:
- אם עדיין אין לכם חשבון Google (Gmail או Google Apps), צריך ליצור חשבון.
- נכנסים אל Google Cloud Platform Console ( console.cloud.google.com) ויוצרים פרויקט חדש.
- אם אין לכם פרויקטים, לוחצים על לחצן יצירת הפרויקט:
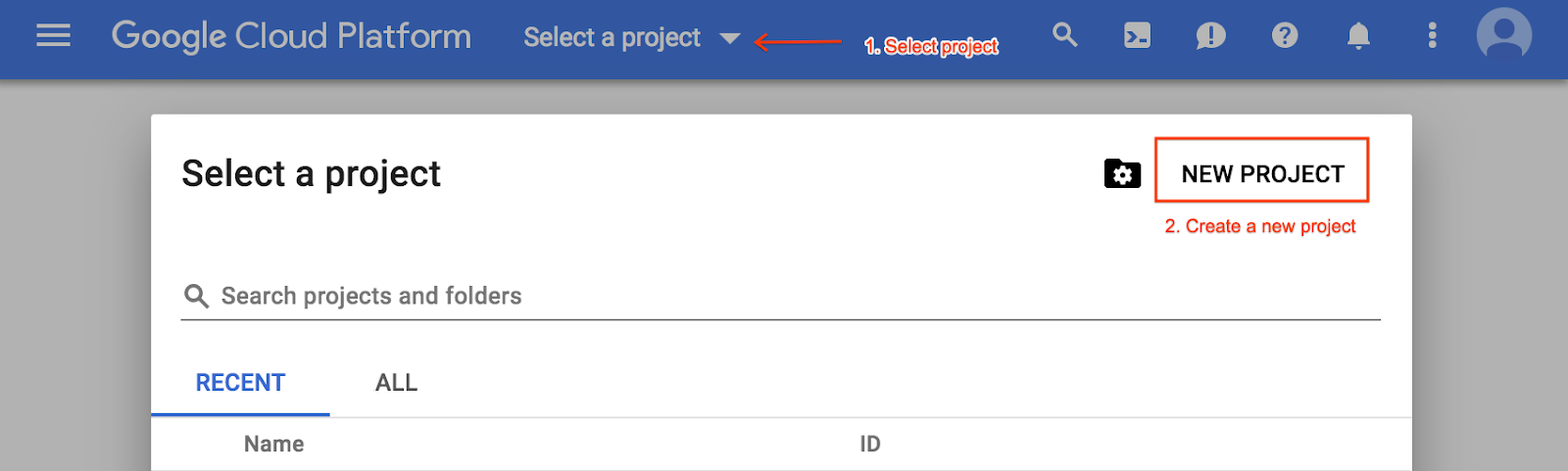
אפשר גם ליצור פרויקט חדש מתפריט בחירת הפרויקט:
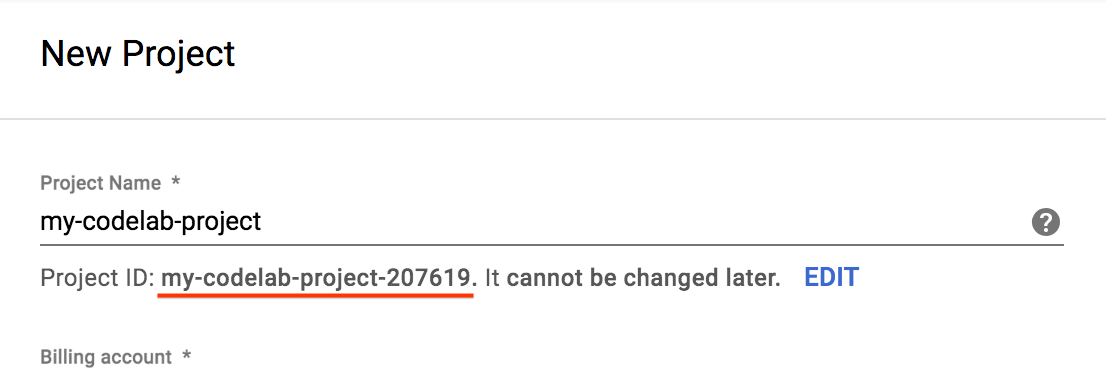
- מזינים שם לפרויקט ולוחצים על יצירה. שימו לב שמזהה הפרויקט הוא שם ייחודי בכל הפרויקטים ב-Google Cloud.
3. עבודה עם מערכי נתונים ציבוריים
BigQuery מאפשר לכם לעבוד עם מערכי נתונים ציבוריים, כולל BBC News, מאגרי GitHub, Stack Overflow ומערכי הנתונים של National Oceanic and Atmospheric Administration (NOAA, הרשות הלאומית של ארה"ב לאוקיינוסים ולאטמוספירה). אין צורך לטעון את מערכי הנתונים האלה ל-BigQuery. פשוט פותחים את מערכי הנתונים כדי לעיין בהם ולהריץ עליהם שאילתות ב-BigQuery. ב-codelab הזה תעבדו עם מערך הנתונים הציבורי של Stack Overflow.
עיון במערך הנתונים של Stack Overflow
מערך הנתונים של Stack Overflow מכיל מידע על פוסטים, תגים, תגים, תגובות, משתמשים ועוד. כדי לעיין במערך הנתונים של Stack Overflow בממשק האינטרנט של BigQuery, פועלים לפי השלבים הבאים:
- פותחים את מערך הנתונים של Stack Overflow. ממשק המשתמש של BigQuery ייפתח ב-GCP Console ויוצג בו מידע על מערך הנתונים של Stackoverflow.
- בחלונית הניווט , בוחרים באפשרות bigquery-public-data. התפריט מתרחב ומוצגת בו רשימה של מערכי נתונים ציבוריים. כל מערך נתונים מורכב מטבלה אחת או יותר.
- גוללים למטה ובוחרים באפשרות stackoverflow. התפריט יורחב ויוצגו בו הטבלאות במערך הנתונים של Stack Overflow.
- בוחרים באפשרות תגים כדי לראות את הסכימה של טבלת התגים. רושמים את שמות השדות בטבלה.
- מעל שמות השדות, לוחצים על תצוגה מקדימה כדי לראות נתוני דוגמה לטבלת התגים.
למידע נוסף על כל מערכי הנתונים הציבוריים שזמינים ב-BigQuery, אפשר לעיין במאמר מערכי נתונים ציבוריים של Google BigQuery.
הפעלת שאילתות במערך הנתונים של Stackoverflow
עיון במערך נתונים הוא דרך טובה להבין את הנתונים שאתם עובדים איתם, אבל שאילתות על מערכי נתונים הן היתרון העיקרי של BigQuery. בקטע הזה נסביר איך להריץ שאילתות ב-BigQuery. בשלב הזה לא צריך לדעת SQL. אפשר להעתיק ולהדביק את השאילתות שבהמשך.
כדי להריץ שאילתה:
- בפינה השמאלית העליונה של מסוף GCP, לוחצים על Compose new query (כתיבת שאילתה חדשה).
- באזור הטקסט של עורך השאילתות, מעתיקים ומדביקים את שאילתת ה-SQL הבאה. מערכת BigQuery מאמתת את השאילתה, ובממשק המשתמש האינטרנטי מוצג סימן וי ירוק מתחת לאזור הטקסט כדי לציין שהתחביר תקין.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- לוחצים על הפעלה. השאילתה מחזירה את מספר הפוסטים או השאלות ב-Stack Overflow שפורסמו בכל שנה.
4. יצירת טבלה חדשה
בקטע הקודם הרצתם שאילתות במערכי נתונים ציבוריים שזמינים לכם ב-BigQuery. בקטע הזה, תיצרו טבלה חדשה ב-BigQuery מטבלה קיימת. תצרו טבלה חדשה עם נתונים שנדגמו מהטבלה posts_questions של מערך הנתונים הציבורי של Stack Overflow, ואז תריצו שאילתה בטבלה.
יצירת קבוצת נתונים חדשה
כדי ליצור טבלה ולטעון לתוכה נתונים ב-BigQuery, קודם צריך ליצור מערך נתונים ב-BigQuery שיכיל את הנתונים. לשם כך, מבצעים את השלבים הבאים:
- בחלונית הניווט במסוף GCP, בוחרים את שם הפרויקט שנוצר כחלק מההגדרה.
- בצד שמאל, בחלונית הפרטים, לוחצים על יצירת מערך נתונים.
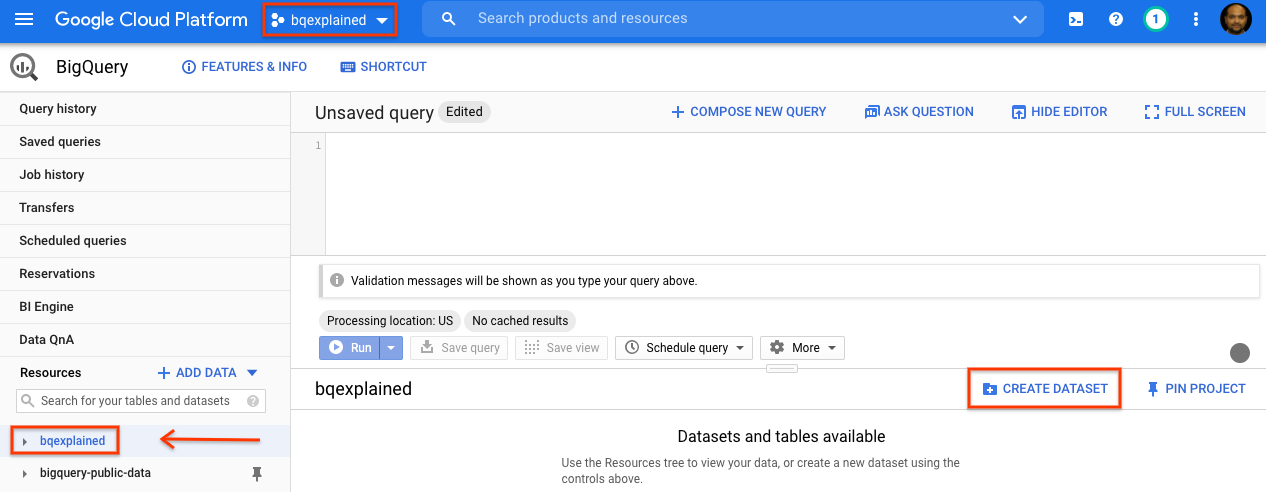
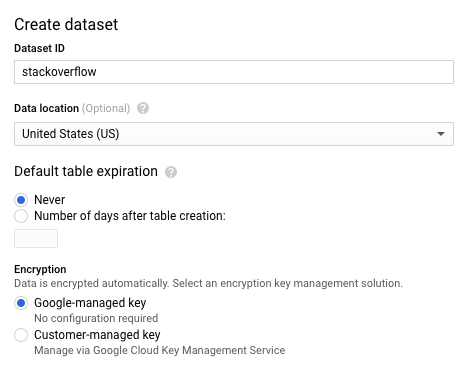
- בתיבת הדו-שיח Create dataset, בשדה Dataset ID, מקלידים
stackoverflow. משאירים את כל שאר הגדרות ברירת המחדל ולוחצים על אישור.
יצירת טבלה חדשה עם פוסטים מ-StackOverflow משנת 2018
אחרי שיצרתם מערך נתונים ב-BigQuery, אתם יכולים ליצור טבלה חדשה ב-BigQuery. כדי ליצור טבלה עם נתונים מטבלה קיימת, תשלחו שאילתה למערך הנתונים של פוסטים מ-Stack Overflow משנת 2018 ותכתבו את התוצאות לטבלה חדשה. לשם כך, תבצעו את השלבים הבאים:
- בפינה השמאלית העליונה של מסוף GCP, לוחצים על Compose new query (כתיבת שאילתה חדשה).

- באזור הטקסט של עורך השאילתות, מעתיקים ומדביקים את שאילתת ה-SQL הבאה כדי ליצור טבלה חדשה, שהיא הצהרת DDL.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- לוחצים על הפעלה. השאילתה יוצרת טבלה חדשה
questions_2018במערך הנתוניםstackoverflowבפרויקט, עם נתונים שמתקבלים מהרצת שאילתה במערך הנתונים של BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions.
הרצת שאילתה על הטבלה החדשה עם פוסטים מ-Stack Overflow משנת 2018
אחרי שיצרתם טבלה ב-BigQuery, נריץ שאילתה כדי להחזיר פוסטים עם שאלות וכותרות מ-Stack Overflow, יחד עם כמה נתונים סטטיסטיים אחרים כמו מספר התשובות, התגובות, הצפיות והמועדפים. כך עושים את זה:
- בפינה השמאלית העליונה של מסוף GCP, לוחצים על Compose new query (כתיבת שאילתה חדשה).
- באזור הטקסט של עורך השאילתות, מעתיקים ומדביקים את שאילתת ה-SQL הבאה:
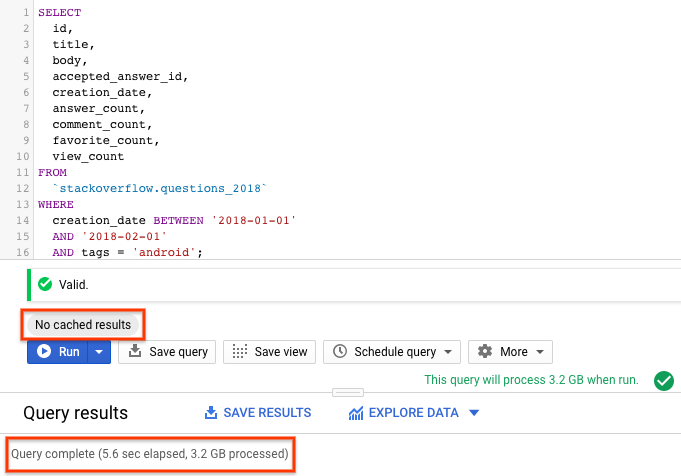
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- לוחצים על הפעלה. השאילתה מחזירה שאלות מ-Stack Overflow שנוצרו בחודש ינואר 2018 ומתויגות בתג
android, יחד עם השאלה ועוד כמה נתונים סטטיסטיים. - כברירת מחדל, BigQuery שומר במטמון את תוצאות השאילתה. מריצים את אותה שאילתה שוב, ותראו ש-BigQuery השקיע הרבה פחות זמן בהחזרת התוצאות כי הוא מחזיר תוצאות מהמטמון.
- מריצים שוב את אותה שאילתה , אבל הפעם עם השבתה של שמירת הנתונים במטמון ב-BigQuery. כדי להשוות את הביצועים בצורה הוגנת לטבלאות מחולקות ולטבלאות מקובצות, שיופעלו בסעיפים הבאים, נשבית את המטמון בשאר המעבדה. בעורך השאילתות, לוחצים על עוד ובוחרים באפשרות הגדרות השאילתה.
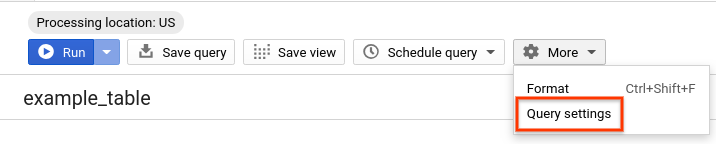
- בקטע העדפות מטמון, מבטלים את הסימון של שימוש בתוצאות שנשמרו במטמון.
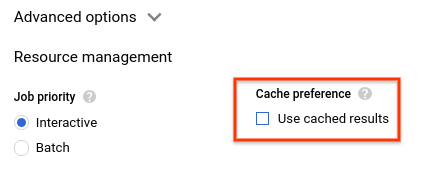
- בתוצאות השאילתה, אמור להופיע משך הזמן שנדרש להשלמת השאילתה ונפח הנתונים שעובדו כדי לקבל את התוצאות.
5. יצירה של טבלה מחולקת למחיצות והפעלת שאילתות עליה
בקטע הקודם יצרתם טבלה חדשה ב-BigQuery עם נתונים מטבלת posts_questions באמצעות מערך הנתונים הציבורי של Stack Overflow. הפעלנו שאילתה על מערך הנתונים הזה כשהאפשרות 'שמירה במטמון' מושבתת, ועקבנו אחרי ביצועי השאילתה. בקטע הזה תיצרו טבלה מחולקת למחיצות מאותה טבלה posts_questions במערך הנתונים הציבורי של Stack Overflow, ותבחנו את ביצועי השאילתה.
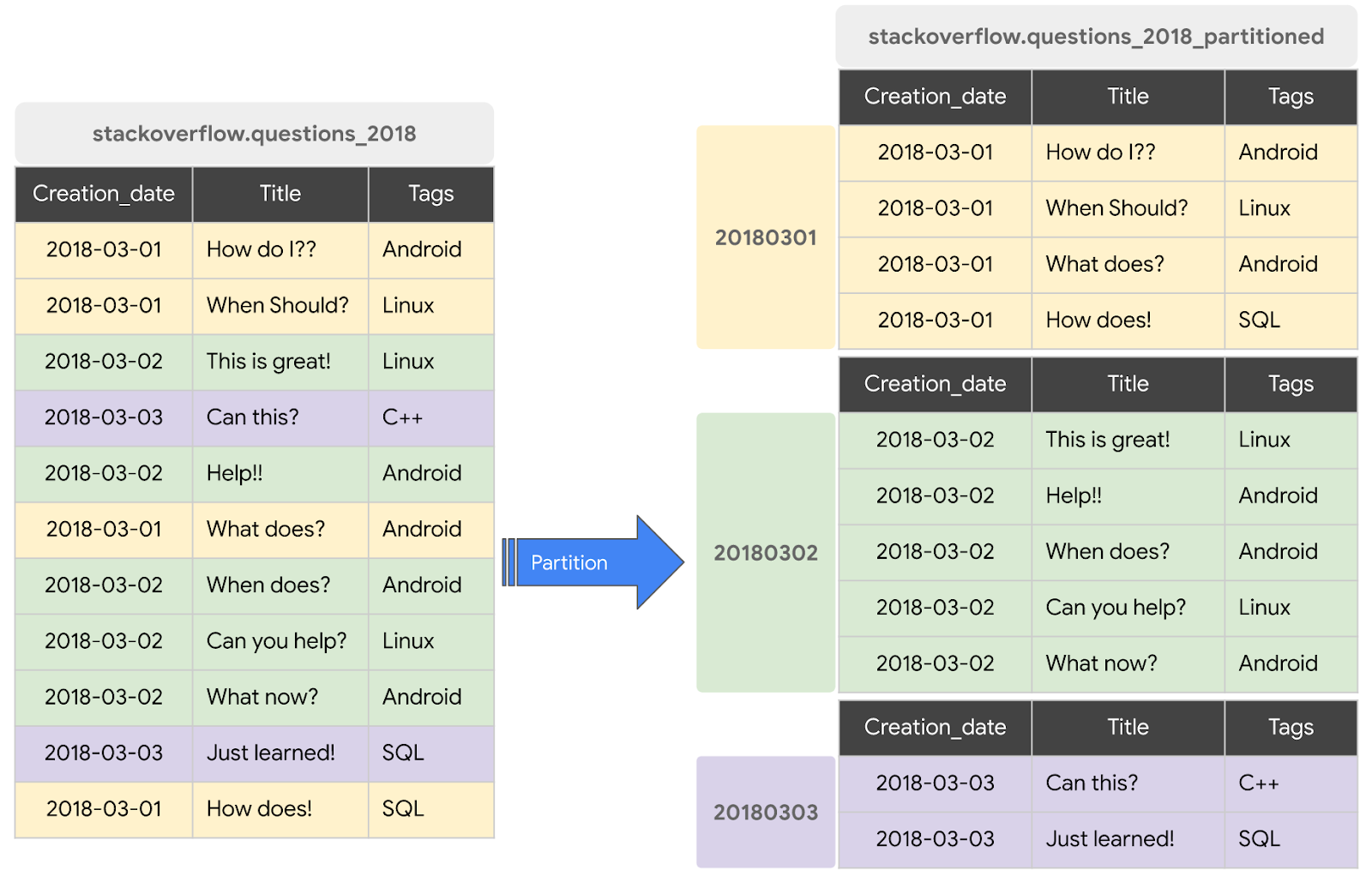
טבלה מחולקת למחיצות היא טבלה מיוחדת שמחולקת לפלחים שנקראים מחיצות. כך קל יותר לנהל את הנתונים ולשאול עליהם שאילתות. בדרך כלל אפשר לפצל טבלאות גדולות למחיצות קטנות יותר באמצעות זמן הטמעת הנתונים, עמודה של חותמת זמן או תאריך, או עמודה של מספר שלם. ניצור טבלה מחולקת למחיצות (Partitions) לפי תאריך.
יצירת טבלת מחיצות חדשה עם פוסטים מ-StackOverflow משנת 2018
כדי ליצור טבלה מחולקת למחיצות (Partitions) עם נתונים מטבלה או משאילתה קיימת, תבצעו שאילתה בקבוצת הנתונים של פוסטים מ-Stackoverflow משנת 2018 ותכתבו את התוצאות לטבלה חדשה. כדי לעשות את זה, מבצעים את השלבים הבאים:
- בפינה השמאלית העליונה של מסוף GCP, לוחצים על Compose new query (כתיבת שאילתה חדשה).
- באזור הטקסט של עורך השאילתות, מעתיקים ומדביקים את שאילתת ה-SQL הבאה כדי ליצור טבלה חדשה, שהיא הצהרת DDL.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- לוחצים על הפעלה. השאילתה יוצרת טבלה חדשה
questions_2018_partitionedבמערך הנתוניםstackoverflowבפרויקט, עם נתונים שמתקבלים מהרצת שאילתה במערך הנתונים של Stack Overflow ב-BigQuerybigquery-public-data.stackoverflow.posts_questions
הרצת שאילתה על טבלה עם מחיצות עם פוסטים מ-Stack Overflow משנת 2018
אחרי שיצרתם טבלת מחיצות ב-BigQuery, נריץ את אותה שאילתה , הפעם על טבלת המחיצות, כדי לקבל פוסטים מ-Stack Overflow עם שאלות וכותרות, וגם כמה נתונים סטטיסטיים אחרים כמו מספר התשובות, התגובות, הצפיות והמועדפים. כך עושים את זה:
- בפינה השמאלית העליונה של מסוף GCP, לוחצים על Compose new query (כתיבת שאילתה חדשה).
- באזור הטקסט של עורך השאילתות, מעתיקים ומדביקים את שאילתת ה-SQL הבאה:
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- בוחרים באפשרות הפעלה כשהשמירה במטמון של BigQuery מושבתת (הוראות להשבתת השמירה במטמון של BigQuery מופיעות בקטע הקודם). השאילתה מחזירה שאלות מ-Stack Overflow שנוצרו בחודש ינואר 2018 ומתויגות בתג
android, יחד עם השאלה ועוד כמה נתונים סטטיסטיים. - בתוצאות השאילתה, אמור להופיע משך הזמן שנדרש להשלמת השאילתה ונפח הנתונים שעובדו כדי לקבל את התוצאות.
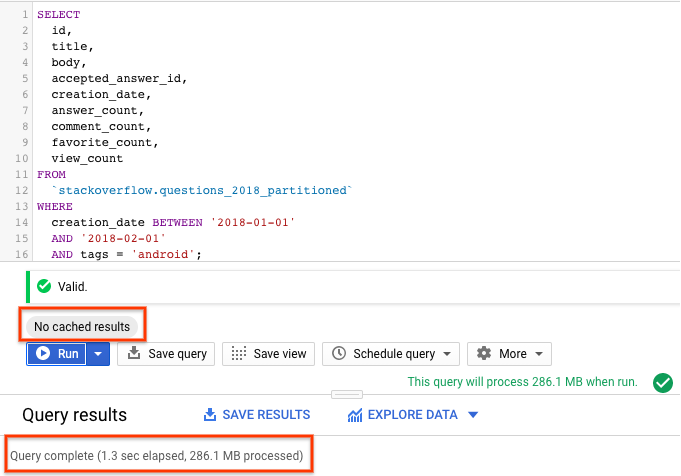
אפשר לראות שהביצועים של השאילתה עם טבלה מחולקת למחיצות טובים יותר מאשר של הטבלה שלא מחולקת למחיצות, כי BigQuery מבצע pruning של המחיצות, כלומר סורק רק את המחיצות הנדרשות, מעבד פחות נתונים ופועל מהר יותר. כך אפשר לבצע אופטימיזציה של עלויות השאילתות וביצועי השאילתות.
6. יצירה של טבלה מקובצת לאשכולות וביצוע שאילתות עליה
בקטע הקודם יצרתם טבלה מחולקת למחיצות ב-BigQuery עם נתונים מהטבלה posts_questions במערך הנתונים הציבורי של Stack Overflow. הפעלנו שאילתה על הטבלה הזו כשמטמון הנתונים מושבת, ועקבנו אחרי ביצועי השאילתה בטבלאות מחולקות למחיצות ובטבלאות שלא מחולקות למחיצות. בקטע הזה תיצרו טבלה מסודרת באשכולות חדשה מהטבלה posts_questions של אותו מערך נתונים ציבורי של Stack Overflow, ותבחנו את ביצועי השאילתה.
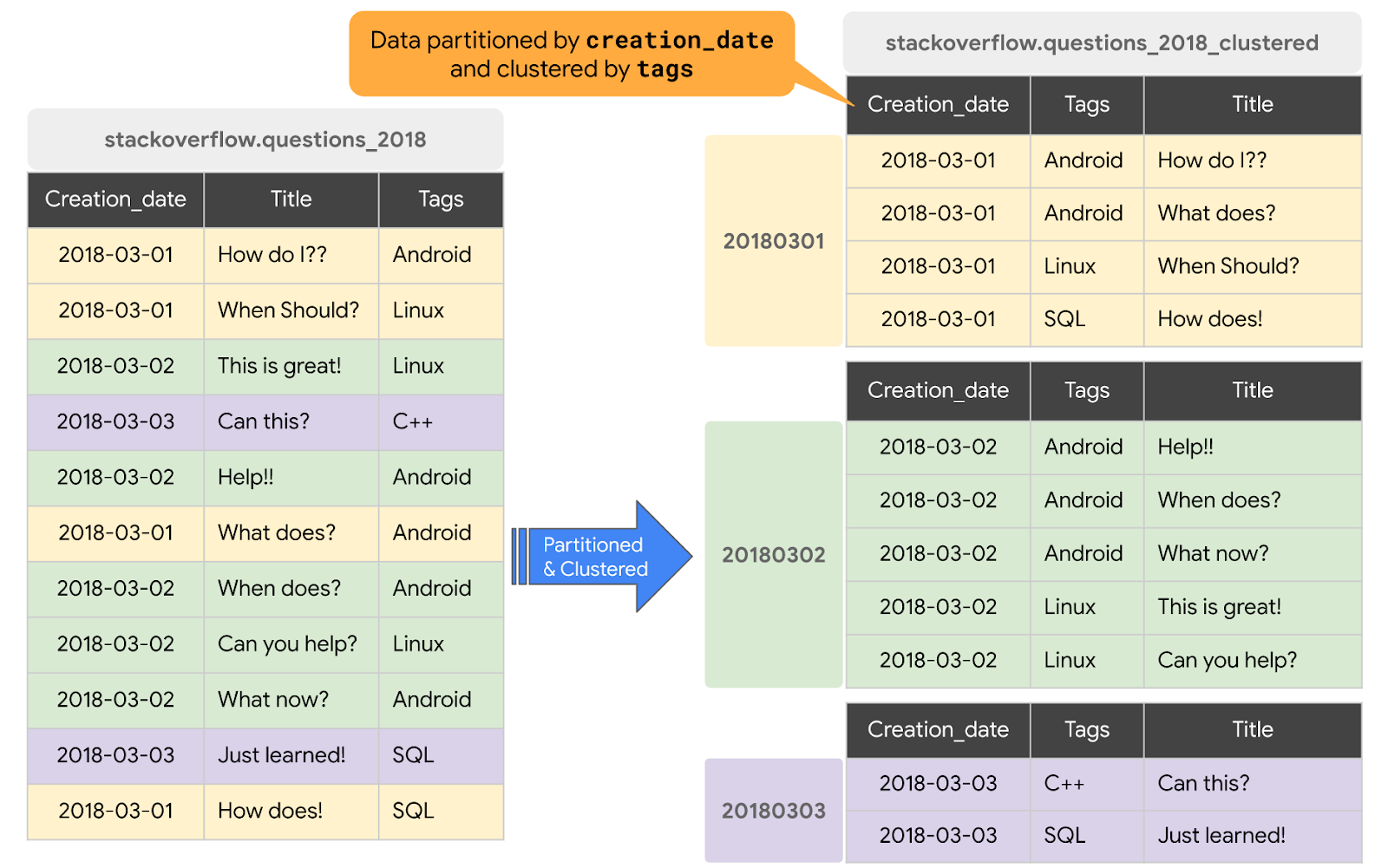
כשמבצעים אשכול בטבלה ב-BigQuery, נתוני הטבלה מאורגנים באופן אוטומטי על סמך התוכן של עמודה אחת או יותר בסכימת הטבלה. העמודות שאתם מציינים משמשות למיקום משותף של נתונים קשורים. כשנתונים נכתבים לטבלה מסודרת באשכולות, BigQuery ממיין את הנתונים באמצעות הערכים בעמודות המסודרות באשכולות. הערכים האלה משמשים לארגון הנתונים למספר בלוקים באחסון ב-BigQuery. סדר העמודות המקובצות קובע את סדר המיון של הנתונים. כשמוסיפים נתונים חדשים לטבלה או למחיצה ספציפית, מערכת BigQuery מבצעת באופן אוטומטי אשכול מחדש ברקע כדי לשחזר את מאפיין המיון של הטבלה או המחיצה.
מידע נוסף על עבודה עם טבלאות מקובצות זמין כאן.
יצירת טבלת אשכול חדשה עם פוסטים מ-Stack Overflow משנת 2018
בקטע הזה, תיצרו טבלה חדשה עם חלוקה למחיצות לפי creation_date ואשכול לפי העמודה tags על סמך דפוס הגישה לשאילתה. כדי ליצור טבלה מסודרת באשכולות עם נתונים מטבלה או משאילתה קיימות, צריך להריץ שאילתה על הטבלה posts משנת 2018 של Stack Overflow ולכתוב את התוצאות לטבלה חדשה. לשם כך, מבצעים את השלבים הבאים:
- בפינה השמאלית העליונה של מסוף GCP, לוחצים על Compose new query (כתיבת שאילתה חדשה).
- באזור הטקסט של עורך השאילתות, מעתיקים ומדביקים את שאילתת ה-SQL הבאה כדי ליצור טבלה חדשה, שהיא הצהרת DDL.
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- לוחצים על 'הפעלה'. השאילתה יוצרת טבלה חדשה
questions_2018_clusteredבמערך הנתוניםstackoverflowבפרויקט עם נתונים שמתקבלים מהרצת שאילתה בטבלת BigQuery Stack Overflowbigquery-public-data.stackoverflow.posts_questions. הטבלה החדשה מחולקת למחיצות לפי creation_date ומקובצת לפי העמודה tags.
הרצת שאילתה על טבלת האשכולות עם פוסטים מ-Stack Overflow משנת 2018
אחרי שיצרתם טבלת BigQuery עם אשכולים, נריץ שוב את אותה שאילתה, הפעם על הטבלה עם החלוקה למחיצות והאשכולות, כדי לקבל פוסטים מ-Stack Overflow עם שאלות וכותרות, וגם כמה נתונים סטטיסטיים אחרים כמו מספר התשובות, התגובות, הצפיות והמועדפים. כך עושים את זה:
- בפינה השמאלית העליונה של מסוף GCP, לוחצים על Compose new query (כתיבת שאילתה חדשה).
- באזור הטקסט של עורך השאילתות, מעתיקים ומדביקים את שאילתת ה-SQL הבאה:
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- בוחרים באפשרות הפעלה כשהשמירה במטמון של BigQuery מושבתת (הוראות להשבתת השמירה במטמון של BigQuery מופיעות בקטע הקודם). השאילתה מחזירה שאלות מ-Stack Overflow שנוצרו בחודש ינואר 2018 ומתויגות בתג
android, יחד עם השאלה ועוד כמה נתונים סטטיסטיים. - בתוצאות השאילתה, אמור להופיע משך הזמן שנדרש להשלמת השאילתה ונפח הנתונים שעובדו כדי לקבל את התוצאות.
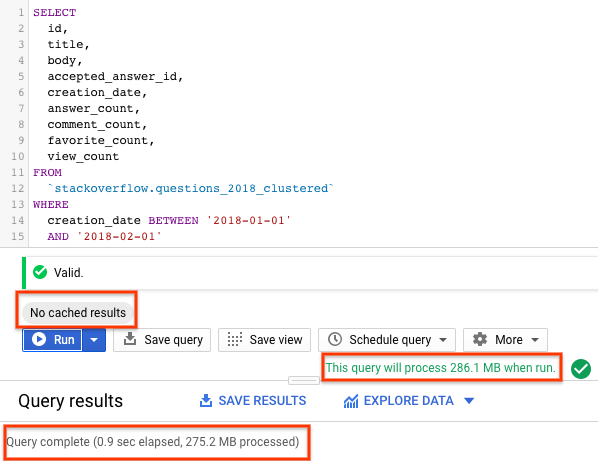
בטבלה מחולקת למחיצות ומסודרת באשכולות, השאילתה סרקה פחות נתונים מאשר בטבלה מחולקת למחיצות או בטבלה שלא מחולקת למחיצות. הדרך שבה הנתונים מאורגנים באמצעות חלוקה למחיצות וקיבוץ לאשכולות מצמצמת את כמות הנתונים שנסרקים על ידי עובדי משבצות, וכך משפרת את ביצועי השאילתות ומבצעת אופטימיזציה של העלויות.
7. סידור וארגון
אלא אם אתם מתכננים להמשיך לעבוד עם מערך הנתונים של stackoverflow, כדאי למחוק אותו ולמחוק את הפרויקט שיצרתם בשביל ה-codelab הזה.
מחיקת מערך הנתונים ב-BigQuery
כדי למחוק את מערך הנתונים ב-BigQuery:
- בחלונית הניווט הימנית ב-BigQuery, בוחרים במערך הנתונים stackoverflow .
- בחלונית הפרטים, בוחרים באפשרות מחיקת מערך נתונים.
- בתיבת הדו-שיח מחיקת מערך נתונים, מזינים stackoverflow ובוחרים באפשרות מחיקה כדי לאשר שרוצים למחוק את מערך הנתונים.
מחיקת הפרויקט
כדי למחוק את פרויקט GCP שיצרתם בשביל ה-codelab הזה, מבצעים את השלבים הבאים:
- בתפריט הניווט של GCP, בוחרים באפשרות IAM & Admin (ניהול הרשאות גישה ואדמין).
- בחלונית הניווט, בוחרים באפשרות הגדרות.
- בחלונית הפרטים, מוודאים שהפרויקט הנוכחי הוא הפרויקט שיצרתם בשביל ה-Codelab הזה ובוחרים באפשרות Shut down (כיבוי).
- בתיבת הדו-שיח Shut down project, מזינים את מזהה הפרויקט (לא את שם הפרויקט) ולוחצים על Shut down כדי לאשר.
מעולה! למדתם עכשיו
- איך משתמשים בממשק המשתמש באינטרנט של BigQuery כדי ליצור טבלה חדשה מטבלאות קיימות
- איך יוצרים טבלאות עם חלוקה למחיצות וטבלאות עם אשכולות ומריצים עליהן שאילתות
- איך חלוקה למחיצות (partitioning) וקיבוץ לאשכולות (clustering) מייעלים את הביצועים של השאילתות ומפחיתים את העלויות
שימו לב שלא הייתם צריכים להגדיר או לנהל אשכולות כדי לעבוד עם מערכי נתונים.