
1. परिचय
BigQuery, पूरी तरह से मैनेज किया जाने वाला, पेटाबाइट-स्केल का, कम लागत वाला एंटरप्राइज़ डेटा वेयरहाउस है. इसका इस्तेमाल डेटा के विश्लेषण के लिए किया जाता है. BigQuery, बिना सर्वर वाला है. आपको क्लस्टर सेट अप और मैनेज करने की ज़रूरत नहीं है.
BigQuery डेटासेट, GCP प्रोजेक्ट में होता है. इसमें एक या उससे ज़्यादा टेबल होती हैं. इन डेटासेट के लिए, एसक्यूएल क्वेरी की जा सकती हैं.
इस कोडलैब में, BigQuery में पार्टिशनिंग और क्लस्टरिंग को समझने के लिए, GCP Console में BigQuery वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल किया जाएगा. BigQuery की टेबल पार्टिशनिंग और क्लस्टरिंग की सुविधा की मदद से, डेटा को इस तरह से स्ट्रक्चर किया जा सकता है कि वह डेटा ऐक्सेस करने के सामान्य पैटर्न से मेल खाए. किसी खास डेटा रेंज पर क्वेरी करते समय, BigQuery की परफ़ॉर्मेंस और लागत को पूरी तरह से बढ़ाने के लिए, पार्टीशन और क्लस्टरिंग ज़रूरी है. इससे हर क्वेरी के लिए कम डेटा स्कैन किया जाता है. साथ ही, क्वेरी शुरू होने से पहले ही डेटा को काटा-छांटा जाता है.
BigQuery के बारे में ज़्यादा जानने के लिए, BigQuery का दस्तावेज़ पढ़ें.
आपको क्या सीखने को मिलेगा
- पार्टिशन की गई और क्लस्टर की गई टेबल बनाने और क्वेरी करने का तरीका
- पार्टिशन की गई और क्लस्टर की गई टेबल की मदद से, क्वेरी की परफ़ॉर्मेंस की तुलना करना
आपको इन चीज़ों की ज़रूरत होगी
इस लैब को पूरा करने के लिए, आपके पास ये चीज़ें होनी चाहिए:
- Google Chrome का नया वर्शन
- Google Cloud Platform का बिलिंग खाता
2. सेट अप करना
BigQuery का इस्तेमाल करने के लिए, आपको एक GCP प्रोजेक्ट बनाना होगा या कोई मौजूदा प्रोजेक्ट चुनना होगा.
प्रोजेक्ट बनाना
नया प्रोजेक्ट बनाने के लिए, यह तरीका अपनाएं:
- अगर आपके पास पहले से कोई Google खाता (Gmail या Google Apps) नहीं है, तो एक खाता बनाएं.
- Google Cloud Platform Console ( console.cloud.google.com) में साइन इन करें और एक नया प्रोजेक्ट बनाएं.
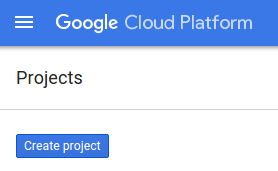
- अगर आपके पास कोई प्रोजेक्ट नहीं है, तो प्रोजेक्ट बनाएं बटन पर क्लिक करें:
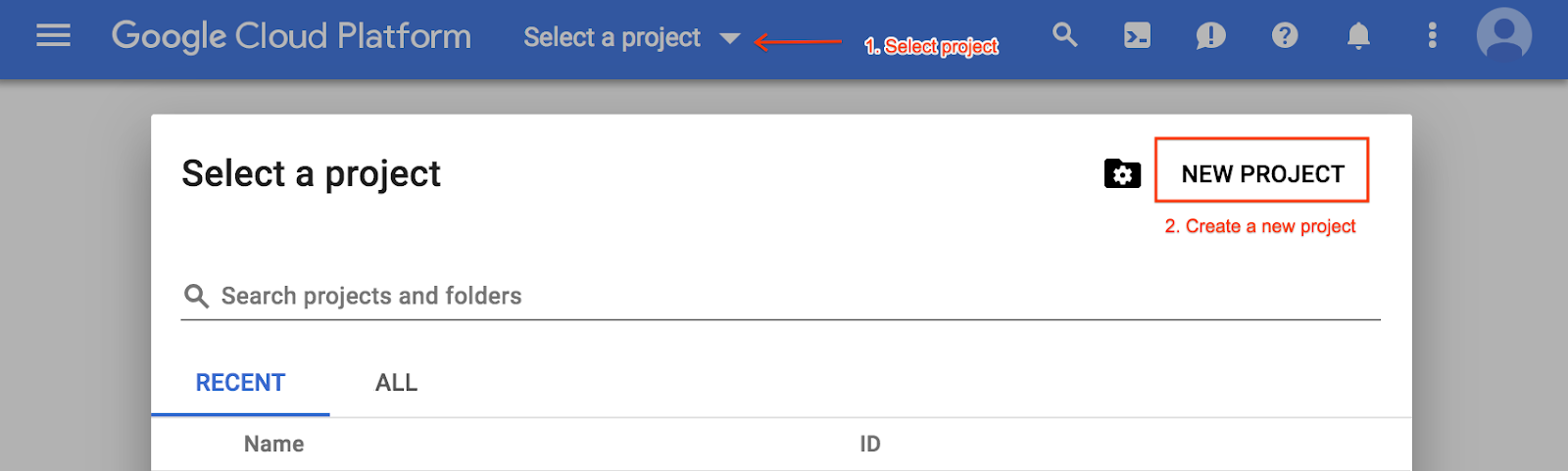
इसके अलावा, प्रोजेक्ट चुनने वाले मेन्यू से नया प्रोजेक्ट बनाएं:
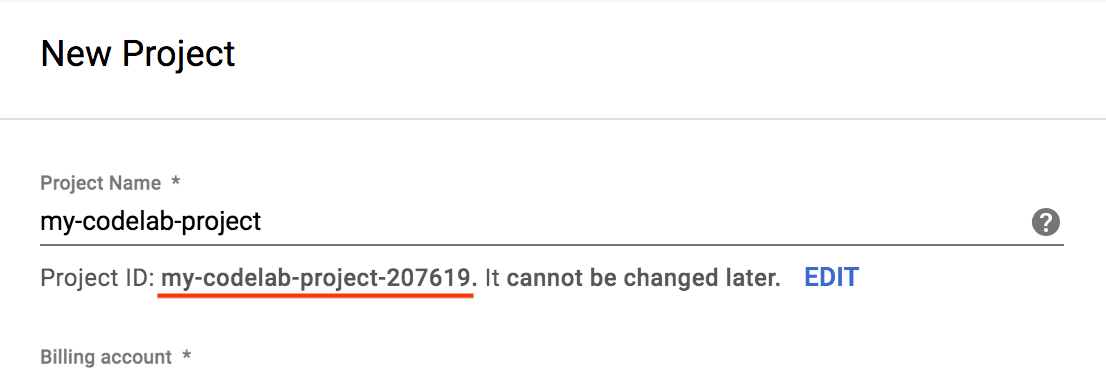
- प्रोजेक्ट का नाम डालें और बनाएं को चुनें. प्रोजेक्ट आईडी को नोट कर लें. यह सभी Google Cloud प्रोजेक्ट के लिए यूनीक नाम होता है.
3. सार्वजनिक डेटासेट के साथ काम करना
BigQuery की मदद से, सार्वजनिक डेटासेट का इस्तेमाल किया जा सकता है. जैसे, बीबीसी न्यूज़, GitHub रिपॉज़िटरी, स्टैक ओवरफ़्लो, और अमेरिका के नैशनल ओशिऐनिक ऐंड एट्मॉस्फ़ियरिक एडमिनिस्ट्रेशन (एनओएए) के डेटासेट. आपको इन डेटासेट को BigQuery में लोड करने की ज़रूरत नहीं है. आपको सिर्फ़ डेटासेट खोलने हैं, ताकि उन्हें BigQuery में ब्राउज़ और क्वेरी किया जा सके. इस कोडलैब में, Stack Overflow के सार्वजनिक डेटासेट का इस्तेमाल किया जाएगा.
Stack Overflow डेटासेट ब्राउज़ करना
Stack Overflow डेटासेट में पोस्ट, टैग, बैज, टिप्पणियां, उपयोगकर्ताओं वगैरह के बारे में जानकारी होती है. BigQuery वेब यूज़र इंटरफ़ेस (यूआई) में Stack Overflow डेटासेट ब्राउज़ करने के लिए, यह तरीका अपनाएं:
- Stack Overflow डेटासेट खोलें. GCP Console में BigQuery का वेब यूज़र इंटरफ़ेस (यूआई) खुलता है. इसमें Stackoverflow डेटासेट के बारे में जानकारी दिखती है.
- नेविगेशन पैनल में जाकर , bigquery-public-data चुनें. मेन्यू को बड़ा करके, सार्वजनिक डेटासेट की सूची दिखाई जाती है. हर डेटासेट में एक या उससे ज़्यादा टेबल होती हैं.
- नीचे की ओर स्क्रोल करें और stackoverflow को चुनें. मेन्यू को बड़ा करने पर, Stack Overflow डेटासेट में मौजूद टेबल की सूची दिखती है.
- बैज टेबल का स्कीमा देखने के लिए, बैज चुनें. टेबल में मौजूद फ़ील्ड के नाम नोट करें.
- बैज टेबल के लिए सैंपल डेटा देखने के लिए, फ़ील्ड के नामों के ऊपर मौजूद झलक देखें पर क्लिक करें.
BigQuery में उपलब्ध सभी सार्वजनिक डेटासेट के बारे में ज़्यादा जानने के लिए, Google BigQuery के सार्वजनिक डेटासेट लेख पढ़ें.
Stackoverflow डेटासेट से क्वेरी करना
डेटासेट ब्राउज़ करने से, आपको उस डेटा को समझने में मदद मिलती है जिस पर आपको काम करना है. हालांकि, BigQuery की असली ताकत डेटासेट को क्वेरी करने में है. इस सेक्शन में, BigQuery क्वेरी चलाने का तरीका बताया गया है. इस समय, आपको एसक्यूएल के बारे में कोई जानकारी होने की ज़रूरत नहीं है. यहां दी गई क्वेरी को कॉपी करके चिपकाया जा सकता है.
क्वेरी चलाने के लिए, यह तरीका अपनाएं:
- GCP Console में सबसे ऊपर दाईं ओर, नई क्वेरी लिखें को चुनें.
- क्वेरी एडिटर के टेक्स्ट एरिया में, यह एसक्यूएल क्वेरी कॉपी करके चिपकाएं. BigQuery, क्वेरी की पुष्टि करता है. इसके बाद, वेब यूज़र इंटरफ़ेस (यूआई) में टेक्स्ट एरिया के नीचे हरे रंग का सही का निशान दिखता है. इससे पता चलता है कि सिंटैक्स मान्य है.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- चलाएं को चुनें. इस क्वेरी से, हर साल पोस्ट किए गए Stack Overflow के पोस्ट या सवालों की संख्या मिलती है.
4. नई टेबल बनाना
पिछले सेक्शन में, आपने उन सार्वजनिक डेटासेट के बारे में क्वेरी की थी जिन्हें BigQuery आपके लिए उपलब्ध कराता है. इस सेक्शन में, किसी मौजूदा टेबल से BigQuery में नई टेबल बनाई जाएगी. आपको Stack Overflow के सार्वजनिक डेटासेट posts_questions टेबल से सैंपल किए गए डेटा की मदद से एक नई टेबल बनानी होगी. इसके बाद, टेबल को क्वेरी करना होगा.
नया डेटासेट बनाना
BigQuery में टेबल डेटा बनाने और लोड करने के लिए, सबसे पहले डेटा को सेव करने के लिए BigQuery डेटासेट बनाएं. इसके लिए, यह तरीका अपनाएं:
- GCP Console के नेविगेशन पैनल में, सेटअप के दौरान बनाया गया प्रोजेक्ट का नाम चुनें.
- दाईं ओर मौजूद, ज़्यादा जानकारी वाले पैनल में जाकर डेटासेट बनाएं को चुनें.
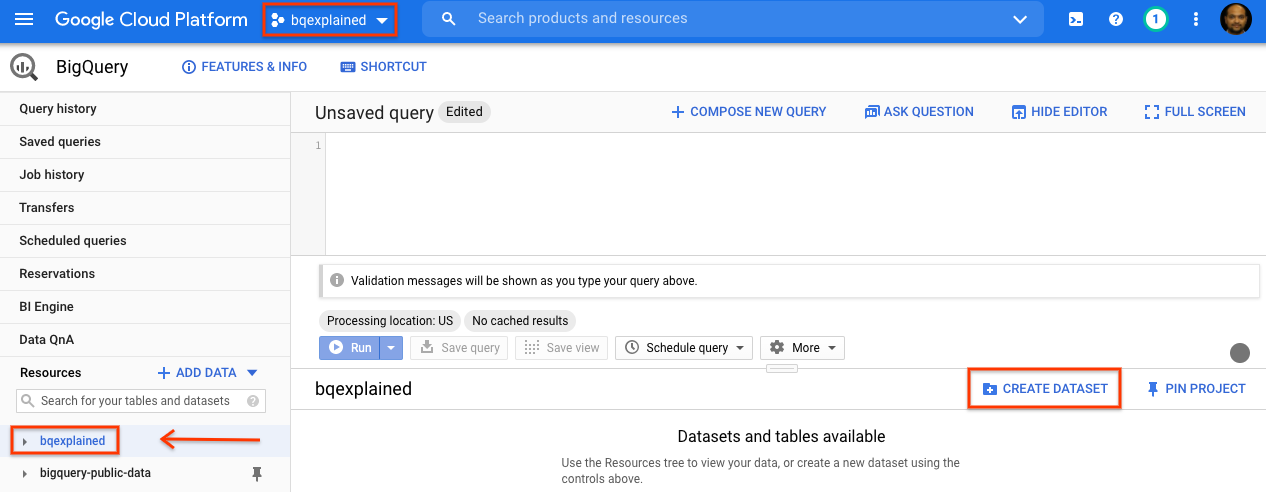
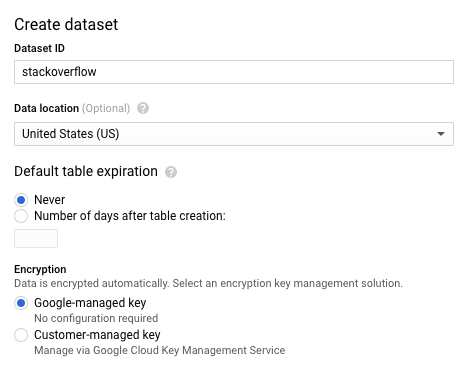
- डेटासेट बनाएं डायलॉग में, डेटासेट आईडी के लिए
stackoverflowटाइप करें. अन्य सभी डिफ़ॉल्ट सेटिंग को वैसे ही रहने दें और ठीक है पर क्लिक करें.
2018 की StackOverflow पोस्ट वाली नई टेबल बनाना
BigQuery डेटासेट बनाने के बाद, अब BigQuery में नई टेबल बनाई जा सकती है. किसी मौजूदा टेबल के डेटा से टेबल बनाने के लिए, आपको 2018 के Stack Overflow पोस्ट के डेटासेट को क्वेरी करना होगा. साथ ही, इन चरणों को पूरा करके, नतीजों को नई टेबल में लिखना होगा:
- GCP Console में सबसे ऊपर दाईं ओर, नई क्वेरी लिखें को चुनें.

- क्वेरी एडिटर के टेक्स्ट एरिया में, नई टेबल बनाने के लिए यहां दी गई एसक्यूएल क्वेरी को कॉपी करके चिपकाएं. यह एक डीडीएल स्टेटमेंट है.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- चलाएं को चुनें. क्वेरी, आपके प्रोजेक्ट के
stackoverflowडेटासेट में एक नई टेबलquestions_2018बनाती है. इसमें BigQuery Stack Overflow डेटासेटbigquery-public-data.stackoverflow.posts_questionsपर क्वेरी चलाने से मिला डेटा होता है.
2018 की Stack Overflow पोस्ट वाली नई टेबल के लिए क्वेरी करना
अब आपने BigQuery टेबल बना ली है. इसलिए, आइए एक क्वेरी चलाकर Stack Overflow की उन पोस्ट को वापस लाते हैं जिनमें सवाल और टाइटल शामिल हैं. साथ ही, कुछ अन्य आंकड़े भी शामिल हैं, जैसे कि जवाबों, टिप्पणियों, व्यू, और पसंदीदा पोस्ट की संख्या. यहां दिया गया तरीका अपनाएं:
- GCP Console में सबसे ऊपर दाईं ओर, नई क्वेरी लिखें को चुनें.
- क्वेरी एडिटर टेक्स्ट एरिया में, यह एसक्यूएल क्वेरी कॉपी करके चिपकाएं
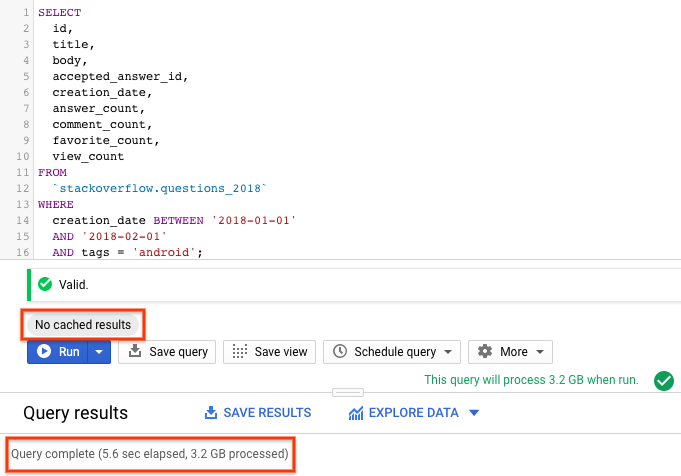
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- चलाएं को चुनें. इस क्वेरी से, जनवरी 2018 में Stack Overflow पर पूछे गए ऐसे सवाल दिखते हैं जिन्हें
androidके तौर पर टैग किया गया है. साथ ही, सवाल और कुछ अन्य आंकड़े भी दिखते हैं. - BigQuery डिफ़ॉल्ट रूप से, क्वेरी के नतीजों को कैश मेमोरी में सेव करता है. उसी क्वेरी को फिर से चलाएं. आपको दिखेगा कि BigQuery ने नतीजे दिखाने में बहुत कम समय लिया है, क्योंकि यह कैश मेमोरी से नतीजे दिखाता है.
- उसी क्वेरी को फिर से चलाएं. हालांकि, इस बार BigQuery की कैश मेमोरी की सुविधा बंद कर दें. हम बाकी लैब के लिए कैश मेमोरी को बंद कर देंगे, ताकि पार्टिशन की गई और क्लस्टर की गई टेबल की परफ़ॉर्मेंस की तुलना निष्पक्ष तरीके से की जा सके. यह तुलना अगले सेक्शन में की जाएगी. क्वेरी एडिटर में, ज़्यादा पर क्लिक करें और क्वेरी सेटिंग चुनें.
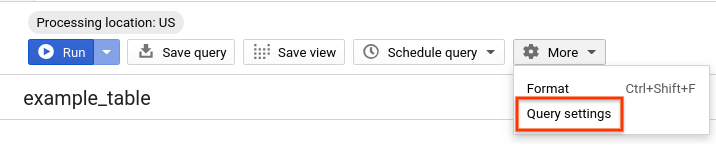
- कैश मेमोरी से जुड़े विकल्प में जाकर, कैश मेमोरी में सेव किए गए नतीजों का इस्तेमाल करें से चुने हुए का निशान हटाएं.
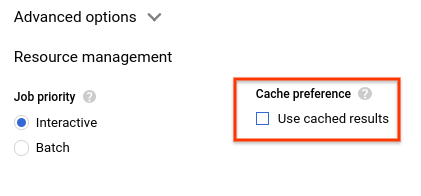
- क्वेरी के नतीजों में, आपको क्वेरी पूरी होने में लगा समय और नतीजे पाने के लिए प्रोसेस किए गए डेटा का वॉल्यूम दिखना चाहिए.
5. सेगमेंट में बांटी गई टेबल बनाना और उसे क्वेरी करना
पिछले सेक्शन में, आपने Stack Overflow के सार्वजनिक डेटासेट का इस्तेमाल करके, posts_questions टेबल से मिले डेटा की मदद से BigQuery में एक नई टेबल बनाई थी. हमने इस डेटासेट की क्वेरी की. इस दौरान, कैश मेमोरी की सुविधा बंद थी. साथ ही, हमने क्वेरी की परफ़ॉर्मेंस पर नज़र रखी. इस सेक्शन में, आपको Stack Overflow के उसी सार्वजनिक डेटासेट की posts_questions टेबल से एक नई पार्टिशन की गई टेबल बनानी होगी. साथ ही, क्वेरी की परफ़ॉर्मेंस देखनी होगी.
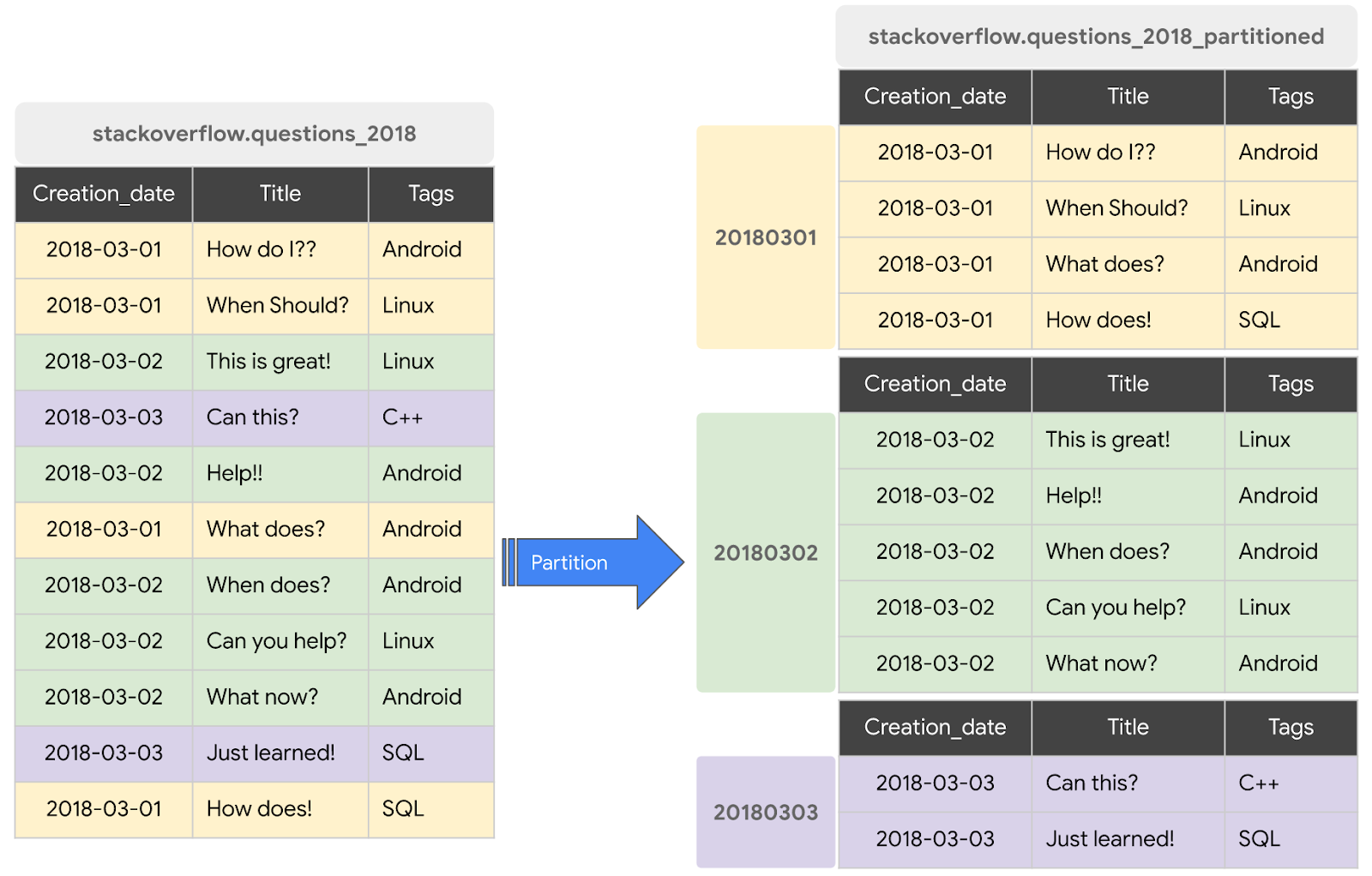
पार्टिशन की गई टेबल एक खास टेबल होती है. इसे सेगमेंट में बांटा जाता है. इन सेगमेंट को पार्टिशन कहा जाता है. इनकी मदद से, डेटा को मैनेज करना और क्वेरी करना आसान हो जाता है. आम तौर पर, बड़ी टेबल को कई छोटे-छोटे पार्टीशन में बांटा जा सकता है. इसके लिए, डेटा इंटेक का समय, TIMESTAMP/DATE कॉलम या INTEGER कॉलम का इस्तेमाल किया जाता है. हम DATE के हिसाब से सेगमेंट में बांटी गई टेबल बनाएंगे.
पार्टिशन की गई टेबल के बारे में ज़्यादा जानने के लिए, यहां जाएं.
साल 2018 की StackOverflow पोस्ट के साथ नई पार्टिशन की गई टेबल बनाना
किसी मौजूदा टेबल या क्वेरी के डेटा से पार्टिशन की गई टेबल बनाने के लिए, आपको 2018 की Stackoverflow पोस्ट के डेटासेट से क्वेरी करनी होगी. साथ ही, नतीजों को नई टेबल में लिखना होगा. इसके लिए, यह तरीका अपनाएं:
- GCP Console में सबसे ऊपर दाईं ओर, नई क्वेरी लिखें को चुनें.
- क्वेरी एडिटर के टेक्स्ट एरिया में, नई टेबल बनाने के लिए यहां दी गई एसक्यूएल क्वेरी को कॉपी करके चिपकाएं. यह एक डीडीएल स्टेटमेंट है.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- चलाएं को चुनें. क्वेरी, आपके प्रोजेक्ट के
stackoverflowडेटासेट में एक नई टेबलquestions_2018_partitionedबनाती है. इसमें BigQuery Stack Overflow डेटासेटbigquery-public-data.stackoverflow.posts_questionsपर क्वेरी चलाने से मिला डेटा होता है
साल 2018 की Stack Overflow पोस्ट वाली, पार्टिशन की गई टेबल के लिए क्वेरी करना
आपने BigQuery की पार्टिशन की गई टेबल बना ली है. अब हम उसी क्वेरी को पार्टिशन की गई टेबल पर चलाएंगे. इससे हमें Stack Overflow की ऐसी पोस्ट मिलेंगी जिनमें सवाल और टाइटल के साथ-साथ कुछ अन्य आंकड़े भी शामिल होंगे. जैसे, जवाबों की संख्या, टिप्पणियां, व्यू, और पसंदीदा पोस्ट. यहां दिया गया तरीका अपनाएं:
- GCP Console में सबसे ऊपर दाईं ओर, नई क्वेरी लिखें को चुनें.
- क्वेरी एडिटर टेक्स्ट एरिया में, यह एसक्यूएल क्वेरी कॉपी करके चिपकाएं
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery की कैश मेमोरी की सुविधा बंद करके, चलाएं को चुनें. BigQuery की कैश मेमोरी की सुविधा बंद करने के लिए, पिछला सेक्शन देखें. इस क्वेरी से, जनवरी 2018 में Stack Overflow पर पूछे गए ऐसे सवाल दिखते हैं जिन्हें
androidके तौर पर टैग किया गया है. साथ ही, सवाल और कुछ अन्य आंकड़े भी दिखते हैं. - क्वेरी के नतीजों में, आपको क्वेरी पूरी होने में लगा समय और नतीजे पाने के लिए प्रोसेस किए गए डेटा का वॉल्यूम दिखना चाहिए.
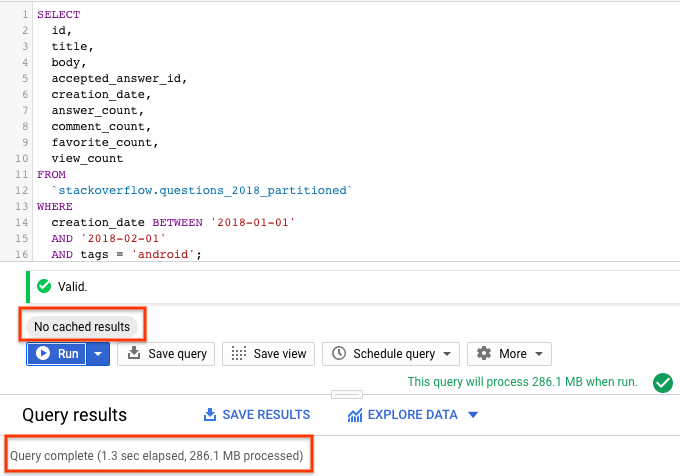
आपको दिखेगा कि सेगमेंट की गई टेबल के साथ क्वेरी की परफ़ॉर्मेंस, सेगमेंट नहीं की गई टेबल की तुलना में बेहतर है. ऐसा इसलिए है, क्योंकि BigQuery सेगमेंट को ट्रिम करता है. इसका मतलब है कि वह सिर्फ़ ज़रूरी सेगमेंट को स्कैन करता है. इससे कम डेटा प्रोसेस होता है और क्वेरी तेज़ी से चलती है. इससे क्वेरी की लागत और परफ़ॉर्मेंस को ऑप्टिमाइज़ किया जाता है.
6. क्लस्टर की गई टेबल बनाना और क्वेरी करना
पिछले सेक्शन में, आपने Stack Overflow के सार्वजनिक डेटासेट में मौजूद posts_questions टेबल के डेटा का इस्तेमाल करके, BigQuery में एक पार्टिशन की गई टेबल बनाई थी. हमने इस टेबल की क्वेरी की. इस दौरान, कैश मेमोरी की सुविधा बंद थी. साथ ही, हमने सेगमेंट में नहीं बांटी गई और सेगमेंट में बांटी गई, दोनों तरह की टेबल के लिए क्वेरी की परफ़ॉर्मेंस देखी. इस सेक्शन में, आपको Stack Overflow के उसी सार्वजनिक डेटासेट की posts_questions टेबल से एक नई क्लस्टर की गई टेबल बनानी होगी. साथ ही, क्वेरी की परफ़ॉर्मेंस देखनी होगी.
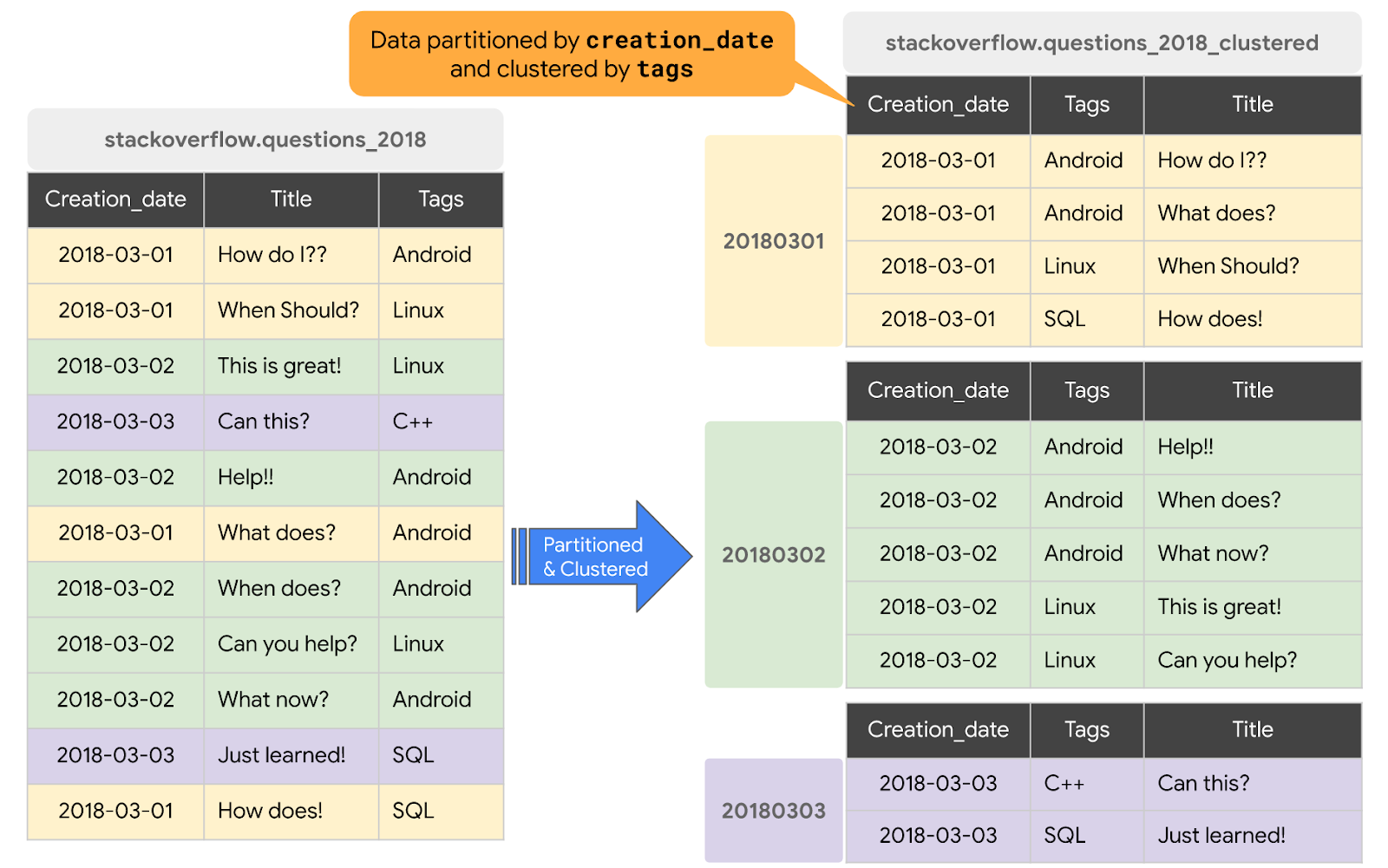
BigQuery में किसी टेबल को क्लस्टर करने पर, टेबल का डेटा अपने-आप व्यवस्थित हो जाता है. यह डेटा, टेबल के स्कीमा में मौजूद एक या उससे ज़्यादा कॉलम के कॉन्टेंट के आधार पर व्यवस्थित होता है. आपके चुने गए कॉलम का इस्तेमाल, मिलते-जुलते डेटा को एक साथ रखने के लिए किया जाता है. जब डेटा को क्लस्टर की गई टेबल में लिखा जाता है, तो BigQuery, क्लस्टरिंग कॉलम में मौजूद वैल्यू का इस्तेमाल करके डेटा को क्रम से लगाता है. इन वैल्यू का इस्तेमाल, BigQuery स्टोरेज में डेटा को कई ब्लॉक में व्यवस्थित करने के लिए किया जाता है. क्लस्टर किए गए कॉलम के क्रम से, डेटा को क्रम से लगाने का तरीका तय होता है. जब किसी टेबल या किसी खास पार्टीशन में नया डेटा जोड़ा जाता है, तो BigQuery बैकग्राउंड में अपने-आप फिर से क्लस्टरिंग करता है, ताकि टेबल या पार्टीशन की क्रम से लगाने की प्रॉपर्टी को वापस लाया जा सके.
क्लस्टर की गई टेबल के साथ काम करने के बारे में ज़्यादा जानने के लिए, यहां जाएं.
साल 2018 की Stack Overflow पोस्ट का इस्तेमाल करके, क्लस्टर की गई नई टेबल बनाना
इस सेक्शन में, क्वेरी ऐक्सेस पैटर्न के आधार पर, creation_date पर नई टेबल को बांटा जाएगा और tags कॉलम पर क्लस्टर किया जाएगा. किसी मौजूदा टेबल या क्वेरी के डेटा से क्लस्टर की गई टेबल बनाने के लिए, आपको 2018 की Stack Overflow पोस्ट वाली टेबल को क्वेरी करना होगा. इसके बाद, इन चरणों को पूरा करके, नतीजों को नई टेबल में लिखना होगा:
- GCP Console में सबसे ऊपर दाईं ओर, नई क्वेरी लिखें को चुनें.
- क्वेरी एडिटर के टेक्स्ट एरिया में, नई टेबल बनाने के लिए यहां दी गई एसक्यूएल क्वेरी को कॉपी करके चिपकाएं. यह एक डीडीएल स्टेटमेंट है.
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- 'चलाएं' को चुनें. क्वेरी, आपके प्रोजेक्ट के
stackoverflowडेटासेट में एक नई टेबलquestions_2018_clusteredबनाती है. इसमें BigQuery Stack Overflow टेबलbigquery-public-data.stackoverflow.posts_questionsपर क्वेरी चलाने से मिला डेटा होता है. नई टेबल को creation_date के हिसाब से बांटा गया है और tags कॉलम के हिसाब से क्लस्टर किया गया है.
2018 की Stack Overflow पोस्ट वाली क्लस्टर्ड टेबल के लिए क्वेरी करना
अब आपने BigQuery क्लस्टर की गई टेबल बना ली है. इसलिए, आइए उसी क्वेरी को फिर से चलाते हैं. इस बार, यह क्वेरी पार्टीशन की गई और क्लस्टर की गई टेबल पर चलाई जाएगी. इससे हमें Stack Overflow की पोस्ट मिलेंगी, जिनमें सवाल और टाइटल के साथ-साथ कुछ अन्य आंकड़े भी शामिल होंगे. जैसे, जवाबों, टिप्पणियों, व्यू, और पसंदीदा पोस्ट की संख्या. यहां दिया गया तरीका अपनाएं:
- GCP Console में सबसे ऊपर दाईं ओर, नई क्वेरी लिखें को चुनें.
- क्वेरी एडिटर टेक्स्ट एरिया में, यह एसक्यूएल क्वेरी कॉपी करके चिपकाएं
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery की कैश मेमोरी की सुविधा बंद करके, चलाएं को चुनें. BigQuery की कैश मेमोरी की सुविधा बंद करने के लिए, पिछला सेक्शन देखें. इस क्वेरी से, जनवरी 2018 में Stack Overflow पर पूछे गए ऐसे सवाल दिखते हैं जिन्हें
androidके तौर पर टैग किया गया है. साथ ही, सवाल और कुछ अन्य आंकड़े भी दिखते हैं. - क्वेरी के नतीजों में, आपको क्वेरी पूरी होने में लगा समय और नतीजे पाने के लिए प्रोसेस किए गए डेटा का वॉल्यूम दिखना चाहिए.
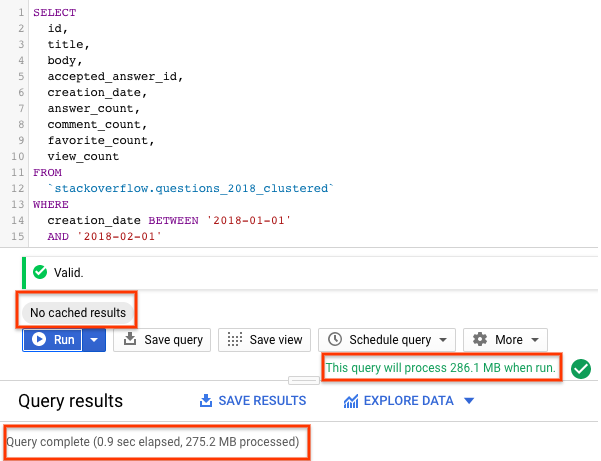
सेगमेंट में बांटी गई और क्लस्टर की गई टेबल की मदद से, क्वेरी ने सेगमेंट में बांटी गई टेबल या सेगमेंट में नहीं बांटी गई टेबल की तुलना में कम डेटा स्कैन किया. डेटा को पार्टिशन और क्लस्टर में व्यवस्थित करने से, स्लॉट वर्कर के ज़रिए स्कैन किए गए डेटा की मात्रा कम हो जाती है. इससे क्वेरी की परफ़ॉर्मेंस बेहतर होती है और लागत ऑप्टिमाइज़ होती है.
7. स्टोरेज खाली करना
अगर आपको stackoverflow डेटासेट का इस्तेमाल जारी नहीं रखना है, तो आपको इसे मिटा देना चाहिए. साथ ही, इस कोडलैब के लिए बनाया गया प्रोजेक्ट भी मिटा देना चाहिए.
BigQuery डेटासेट मिटाना
BigQuery डेटासेट मिटाने के लिए, यह तरीका अपनाएं:
- BigQuery में, बाईं ओर मौजूद नेविगेशन पैनल से stackoverflow डेटासेट चुनें .
- जानकारी वाले पैनल में, डेटासेट मिटाएं को चुनें.
- डेटासेट मिटाएं डायलॉग में, stackoverflow डालें. इसके बाद, मिटाएं को चुनें. इससे पुष्टि होगी कि आपको डेटासेट मिटाना है.
प्रोजेक्ट मिटाना
इस कोडलैब के लिए बनाया गया GCP प्रोजेक्ट मिटाने के लिए, यह तरीका अपनाएं:
- GCP के नेविगेशन मेन्यू में, IAM और एडमिन को चुनें.
- नेविगेशन पैनल में, सेटिंग चुनें.
- जानकारी वाले पैनल में, पुष्टि करें कि आपका मौजूदा प्रोजेक्ट वही है जिसे आपने इस कोडलैब के लिए बनाया था. इसके बाद, बंद करें को चुनें.
- प्रोजेक्ट बंद करें डायलॉग बॉक्स में, अपने प्रोजेक्ट का प्रोजेक्ट आईडी (प्रोजेक्ट का नाम नहीं) डालें. इसके बाद, पुष्टि करने के लिए बंद करें को चुनें.
बधाई हो! अब आपने जान लिया है
- मौजूदा टेबल से नई टेबल बनाने के लिए, BigQuery वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करने का तरीका
- पार्टिशन की गई और क्लस्टर की गई टेबल बनाने और क्वेरी करने का तरीका
- क्वेरी की परफ़ॉर्मेंस और लागत को ऑप्टिमाइज़ करने के लिए, डेटा को अलग-अलग हिस्सों में बांटने और क्लस्टर करने का तरीका
ध्यान दें कि डेटासेट के साथ काम करने के लिए, आपको क्लस्टर सेट अप या मैनेज करने की ज़रूरत नहीं है.