
1. 소개
BigQuery는 분석을 위한 완전 관리형 페타바이트급 저비용 엔터프라이즈 데이터 웨어하우스입니다. BigQuery는 서버리스입니다. 클러스터를 설정하고 관리할 필요가 없습니다.
BigQuery 데이터 세트는 GCP 프로젝트에 있으며 하나 이상의 테이블을 포함합니다. SQL을 사용하여 이러한 데이터 세트를 쿼리할 수 있습니다.
이 Codelab에서는 GCP Console의 BigQuery 웹 UI를 사용하여 BigQuery의 파티셔닝과 클러스터링을 알아봅니다. BigQuery의 테이블 파티션 나누기 및 클러스터링은 일반적인 데이터 액세스 패턴에 맞게 데이터를 구조화하는 데 도움이 됩니다. 파티셔닝과 클러스터링은 특정 데이터 범위에 대해 쿼리할 때 BigQuery 성능과 비용을 최대한으로 높이는 데 중요합니다. 이렇게 하면 쿼리당 스캔되는 데이터가 줄어들고, 가지치기는 쿼리 시작 시간 전에 결정됩니다.
BigQuery에 대한 자세한 내용은 BigQuery 문서를 참고하세요.
학습할 내용
- 파티션을 나눈 테이블과 클러스터링된 테이블을 만들고 쿼리하는 방법
- 파티션을 나눈 테이블과 클러스터링된 테이블의 쿼리 성능 비교
필요한 항목
이 실습을 완료하려면 다음을 준비해야 합니다.
- 최신 버전의 Chrome
- Google Cloud Platform 결제 계정
2. 설정
BigQuery를 사용하려면 GCP 프로젝트를 만들거나 기존 프로젝트를 선택해야 합니다.
프로젝트 만들기
새 프로젝트를 만들려면 다음 단계를 따르세요.
- 아직 Google 계정 (Gmail 또는 Google Apps)이 없으면 계정을 만드세요.
- Google Cloud Platform 콘솔 ( console.cloud.google.com)에 로그인하고 새 프로젝트를 만듭니다.
- 프로젝트가 없으면 프로젝트 만들기 버튼을 클릭합니다.
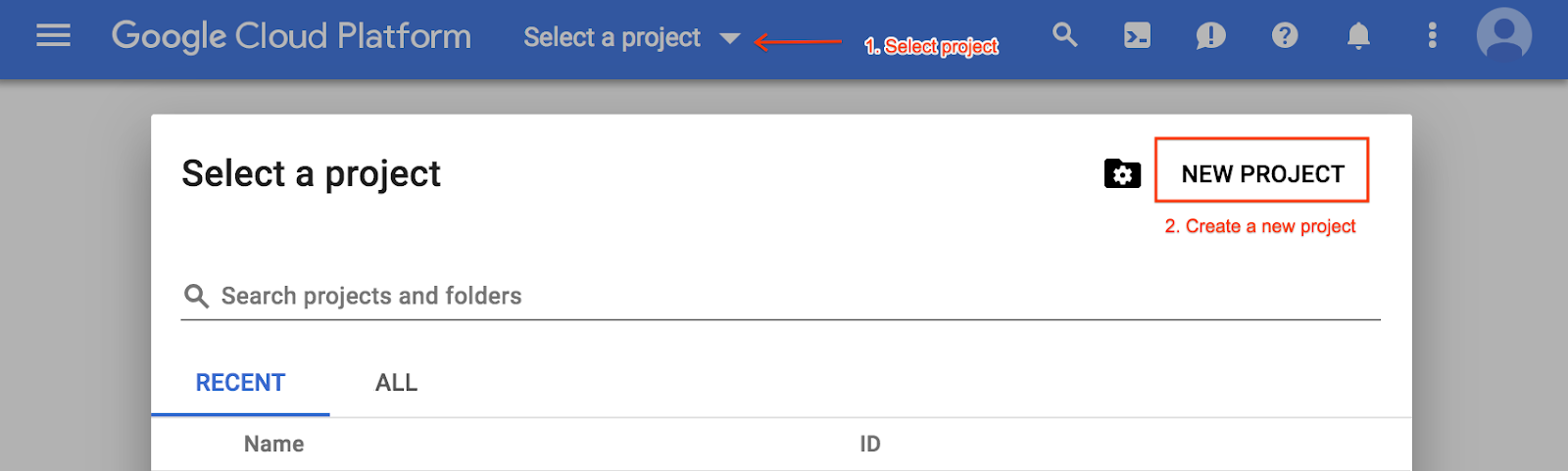
그렇지 않은 경우 프로젝트 선택 메뉴에서 새 프로젝트를 만듭니다.
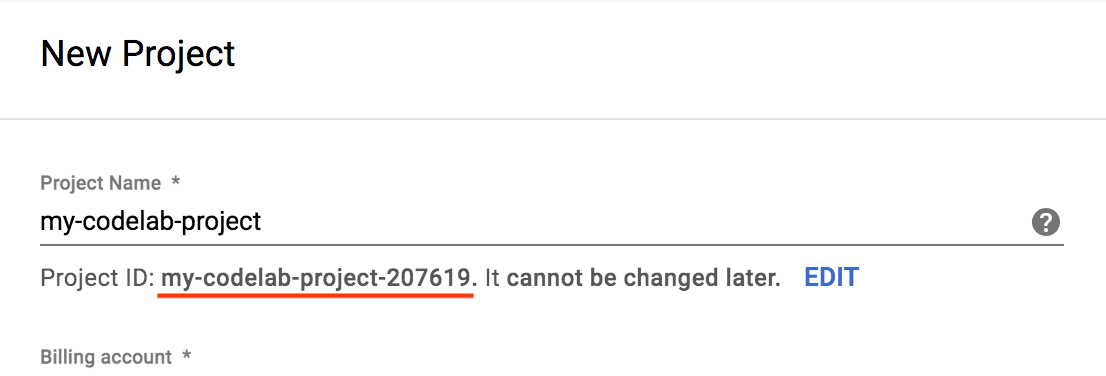
- 프로젝트 이름을 입력하고 만들기를 선택합니다. 프로젝트 ID는 모든 Google Cloud 프로젝트에서 고유한 이름입니다.
3. 공개 데이터 세트 작업
BigQuery를 사용하면 BBC News, GitHub 저장소, Stack Overflow, 미국 해양대기청 (NOAA) 데이터 세트 등 공개 데이터 세트로 작업할 수 있습니다. 이러한 데이터 세트를 BigQuery에 로드할 필요는 없습니다. BigQuery에서 데이터 세트를 열어 탐색하고 쿼리하기만 하면 됩니다. 이 Codelab에서는 Stack Overflow 공개 데이터 세트를 사용합니다.
Stack Overflow 데이터 세트 둘러보기
Stack Overflow 데이터 세트에는 게시물, 태그, 배지, 댓글, 사용자 등에 관한 정보가 포함되어 있습니다. BigQuery 웹 UI에서 Stack Overflow 데이터 세트를 탐색하려면 다음 단계를 따르세요.
- Stack Overflow 데이터 세트를 엽니다. GCP Console에서 BigQuery 웹 UI가 열리고 Stackoverflow 데이터 세트에 관한 정보가 표시됩니다.
- 탐색 패널에서 bigquery-public-data를 선택합니다. 메뉴가 펼쳐져 공개 데이터 세트가 나열됩니다. 각 데이터 세트는 하나 이상의 테이블로 구성됩니다.
- 아래로 스크롤하여 stackoverflow을 선택합니다. 메뉴가 펼쳐지면서 Stack Overflow 데이터 세트의 테이블이 나열됩니다.
- 배지를 선택하여 배지 테이블의 스키마를 확인합니다. 표에 있는 필드의 이름을 확인합니다.
- 필드 이름 위에서 미리보기를 클릭하여 배지 테이블의 샘플 데이터를 확인합니다.
BigQuery에서 사용할 수 있는 모든 공개 데이터 세트에 대한 자세한 내용은 Google BigQuery 공개 데이터 세트를 참고하세요.
Stackoverflow 데이터 세트 쿼리하기
데이터 세트를 탐색하면 작업 중인 데이터를 파악하는 데 도움이 되지만, 데이터 세트를 쿼리할 때 BigQuery의 진가가 발휘됩니다. 이 섹션에서는 BigQuery 쿼리를 실행하는 방법을 알아봅니다. 이 시점에서는 SQL을 알지 않아도 됩니다. 아래 쿼리를 복사하여 붙여넣을 수 있습니다.
쿼리를 실행하려면 다음 단계를 완료하세요.
- GCP 콘솔의 오른쪽 상단에서 새 쿼리 작성을 선택합니다.
- 쿼리 편집기 텍스트 영역에 다음 SQL 쿼리를 복사하여 붙여넣습니다. BigQuery에서 쿼리를 검증하고 웹 UI의 텍스트 영역 아래에 녹색 체크표시가 표시되어 문법이 유효함을 나타냅니다.
SELECT EXTRACT(YEAR FROM creation_date) AS creation_year, COUNT(*) AS total_posts FROM `bigquery-public-data.stackoverflow.posts_questions` GROUP BY creation_year ORDER BY total_posts DESC LIMIT 10
- Run(실행)을 선택합니다. 이 쿼리는 매년 게시된 Stack Overflow 게시물 또는 질문 수를 반환합니다.
4. 새 테이블 만들기
이전 섹션에서는 BigQuery에서 사용할 수 있는 공개 데이터 세트를 쿼리했습니다. 이 섹션에서는 기존 테이블에서 BigQuery에 새 테이블을 만듭니다. Stack Overflow 공개 데이터 세트 posts_questions 테이블에서 샘플링한 데이터로 새 테이블을 만든 다음 테이블을 쿼리합니다.
새 데이터 세트 만들기
테이블 데이터를 만들어 BigQuery에 로드하려면 먼저 다음 단계를 완료하여 데이터를 저장할 BigQuery 데이터 세트를 만드세요.
- GCP 콘솔 탐색 패널에서 설정의 일부로 생성된 프로젝트 이름을 선택합니다.
- 오른쪽의 세부정보 패널에서 데이터 세트 만들기를 선택합니다.
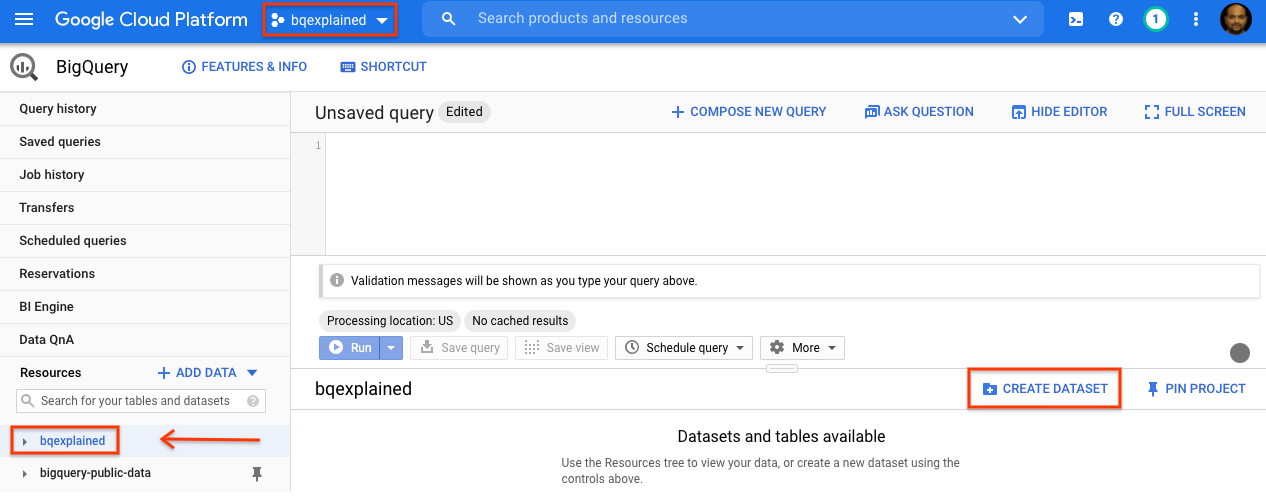
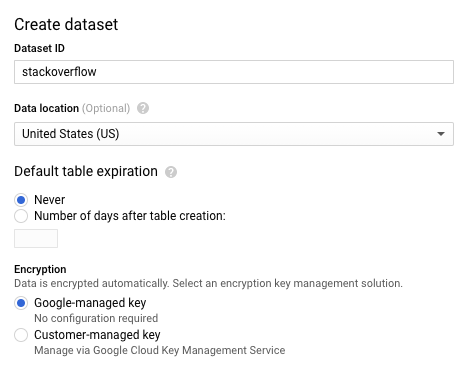
- 데이터 세트 만들기 대화상자의 데이터 세트 ID에
stackoverflow를 입력합니다. 다른 기본 설정은 모두 그대로 두고 확인을 클릭합니다.
2018년 StackOverflow 게시물로 새 테이블 만들기
BigQuery 데이터 세트를 만들었으므로 BigQuery에서 새 테이블을 만들 수 있습니다. 기존 테이블의 데이터로 테이블을 만들려면 다음 단계를 완료하여 2018년 Stack Overflow 게시물 데이터 세트를 쿼리하고 결과를 새 테이블에 작성합니다.
- GCP 콘솔의 오른쪽 상단에서 새 쿼리 작성을 선택합니다.

- 쿼리 편집기 텍스트 영역에서 다음 SQL 쿼리를 복사하여 붙여넣어 새 테이블을 만듭니다. 이는 DDL 문입니다.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Run(실행)을 선택합니다. 이 쿼리는 BigQuery Stack Overflow 데이터 세트
bigquery-public-data.stackoverflow.posts_questions에서 쿼리를 실행한 결과로 생성된 데이터가 포함된 프로젝트의stackoverflow데이터 세트에 새 테이블questions_2018를 만듭니다.
2018년 Stack Overflow 게시물로 새 테이블 쿼리하기
BigQuery 테이블을 만들었으므로 이제 쿼리를 실행하여 질문과 제목이 포함된 Stack Overflow 게시물과 답변 수, 댓글 수, 조회수, 즐겨찾기 수와 같은 몇 가지 다른 통계를 반환해 보겠습니다. 다음 단계를 완료합니다.
- GCP 콘솔의 오른쪽 상단에서 새 쿼리 작성을 선택합니다.
- 쿼리 편집기 텍스트 영역에 다음 SQL 쿼리를 복사하여 붙여넣습니다.
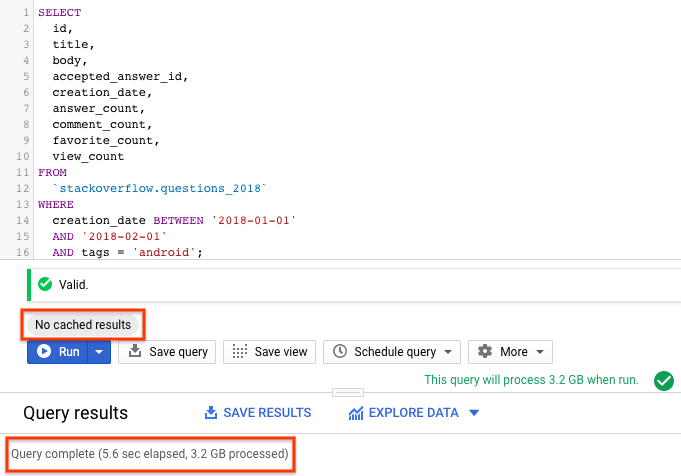
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- Run(실행)을 선택합니다. 이 쿼리는 2018년 1월에 생성되고
android태그가 지정된 Stack Overflow 질문을 질문 및 기타 통계와 함께 반환합니다. - 기본적으로 BigQuery는 쿼리 결과를 캐시합니다. 동일한 쿼리를 실행하면 BigQuery가 캐시에서 결과를 반환하므로 결과를 반환하는 데 걸리는 시간이 훨씬 짧아집니다.
- 동일한 쿼리를 다시 실행하되 이번에는 BigQuery 캐싱을 사용 중지합니다. 다음 섹션에서 실행될 파티션을 나눈 테이블과 클러스터형 테이블과의 성능 비교를 공정하게 하기 위해 실습의 나머지 부분에서는 캐시를 사용 중지합니다. 쿼리 편집기에서 더보기를 클릭하고 쿼리 설정을 선택합니다.
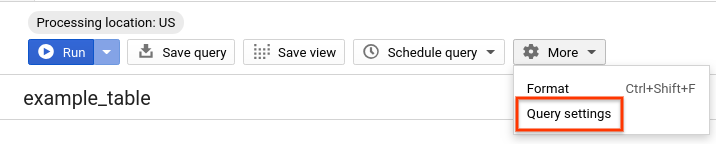
- 캐시 환경설정에서 캐시 처리된 결과 사용을 선택 해제합니다.

- 쿼리 결과에는 쿼리가 완료되는 데 걸린 시간과 결과를 얻기 위해 처리된 데이터 양이 표시됩니다.
5. 파티션을 나눈 테이블 만들기 및 쿼리하기
이전 섹션에서는 Stack Overflow 공개 데이터 세트를 사용하여 posts_questions 테이블의 데이터로 BigQuery에 새 테이블을 만들었습니다. 캐싱을 사용 중지한 상태에서 이 데이터 세트를 쿼리하고 쿼리 성능을 관찰했습니다. 이 섹션에서는 동일한 Stack Overflow 공개 데이터 세트의 posts_questions 테이블에서 새 파티션을 나눈 테이블을 만들고 쿼리 성능을 관찰합니다.
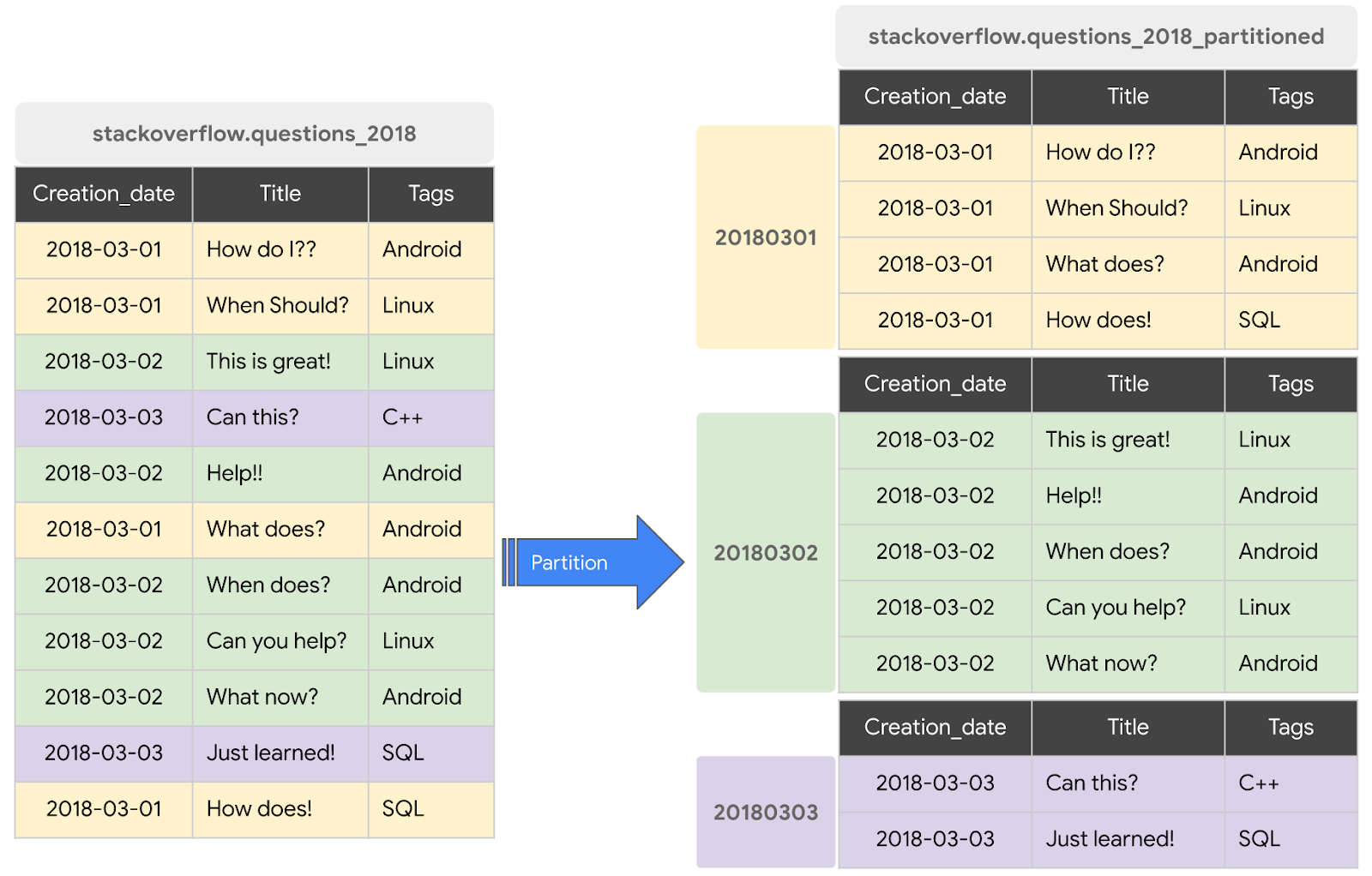
파티션을 나눈 테이블은 파티션이라고 하는 세그먼트로 분할된 특수한 테이블로, 데이터를 보다 쉽게 관리하고 쿼리할 수 있게 해줍니다. 일반적으로 데이터 수집 시간, TIMESTAMP/DATE 열 또는 INTEGER 열을 사용하여 큰 테이블을 여러 개의 작은 파티션으로 분할할 수 있습니다. DATE 파티션을 나눈 테이블을 만듭니다.
여기에서 파티션을 나눈 테이블에 대해 자세히 알아보세요.
2018년 StackOverflow 게시물이 포함된 파티션을 나눈 테이블 새로 만들기
기존 테이블 또는 쿼리의 데이터로 파티션을 나눈 테이블을 만들려면 2018 Stackoverflow 게시물 데이터 세트를 쿼리하고 결과를 새 테이블에 기록합니다. 다음 단계를 완료하세요.
- GCP 콘솔의 오른쪽 상단에서 새 쿼리 작성을 선택합니다.
- 쿼리 편집기 텍스트 영역에서 다음 SQL 쿼리를 복사하여 붙여넣어 새 테이블을 만듭니다. 이는 DDL 문입니다.
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned` PARTITION BY DATE(creation_date) AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- Run(실행)을 선택합니다. 이 쿼리는 BigQuery Stack Overflow 데이터 세트
bigquery-public-data.stackoverflow.posts_questions에서 쿼리를 실행한 결과로 생성된 데이터를 사용하여 프로젝트의stackoverflow데이터 세트에 새 테이블questions_2018_partitioned를 만듭니다.
2018년 Stack Overflow 게시물로 파티션을 나눈 테이블 쿼리
BigQuery 파티션을 나눈 테이블을 만들었으므로 이번에는 파티션을 나눈 테이블에서 동일한 쿼리를 실행하여 질문과 제목이 포함된 Stack Overflow 게시물과 답변 수, 댓글 수, 조회수, 즐겨찾기 수와 같은 몇 가지 기타 통계를 반환해 보겠습니다. 다음 단계를 완료합니다.
- GCP 콘솔의 오른쪽 상단에서 새 쿼리 작성을 선택합니다.
- 쿼리 편집기 텍스트 영역에 다음 SQL 쿼리를 복사하여 붙여넣습니다.
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_partitioned` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery 캐싱을 사용 중지한 상태에서 실행을 선택합니다 (BigQuery 캐시 사용 중지는 이전 섹션 참고). 이 쿼리는 2018년 1월에 생성되고
android태그가 지정된 Stack Overflow 질문을 질문 및 기타 통계와 함께 반환합니다. - 쿼리 결과에는 쿼리가 완료되는 데 걸린 시간과 결과를 얻기 위해 처리된 데이터 양이 표시됩니다.
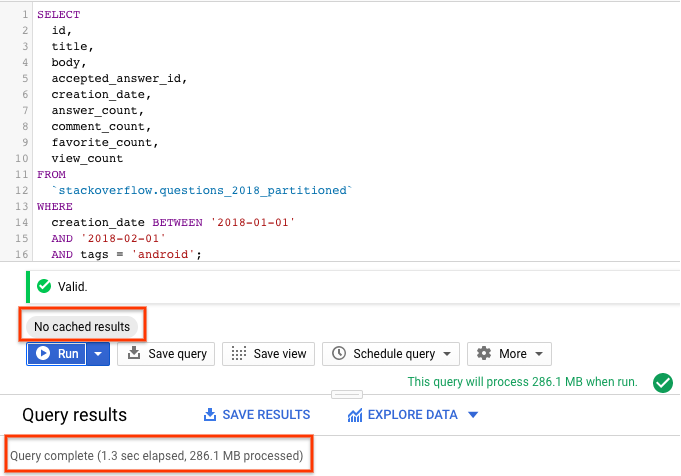
BigQuery가 파티션을 가지치기하여 필요한 파티션만 스캔하고 더 적은 데이터를 처리하며 더 빠르게 실행되므로 파티션을 나눈 테이블을 사용한 쿼리의 성능이 파티션을 나누지 않은 테이블을 사용한 쿼리보다 우수합니다. 이렇게 하면 쿼리 비용과 쿼리 성능이 최적화됩니다.
6. 클러스터링된 테이블 만들기 및 쿼리하기
이전 섹션에서는 Stack Overflow 공개 데이터 세트의 posts_questions 테이블에 있는 데이터를 사용하여 BigQuery에서 파티션을 나눈 테이블을 만들었습니다. 캐싱을 사용 중지한 상태로 이 테이블을 쿼리하고 파티션을 나누지 않은 테이블과 파티션을 나눈 테이블 모두에서 쿼리 성능을 관찰했습니다. 이 섹션에서는 동일한 Stack Overflow 공개 데이터 세트의 posts_questions 테이블에서 새 클러스터형 테이블을 만들고 쿼리 성능을 관찰합니다.
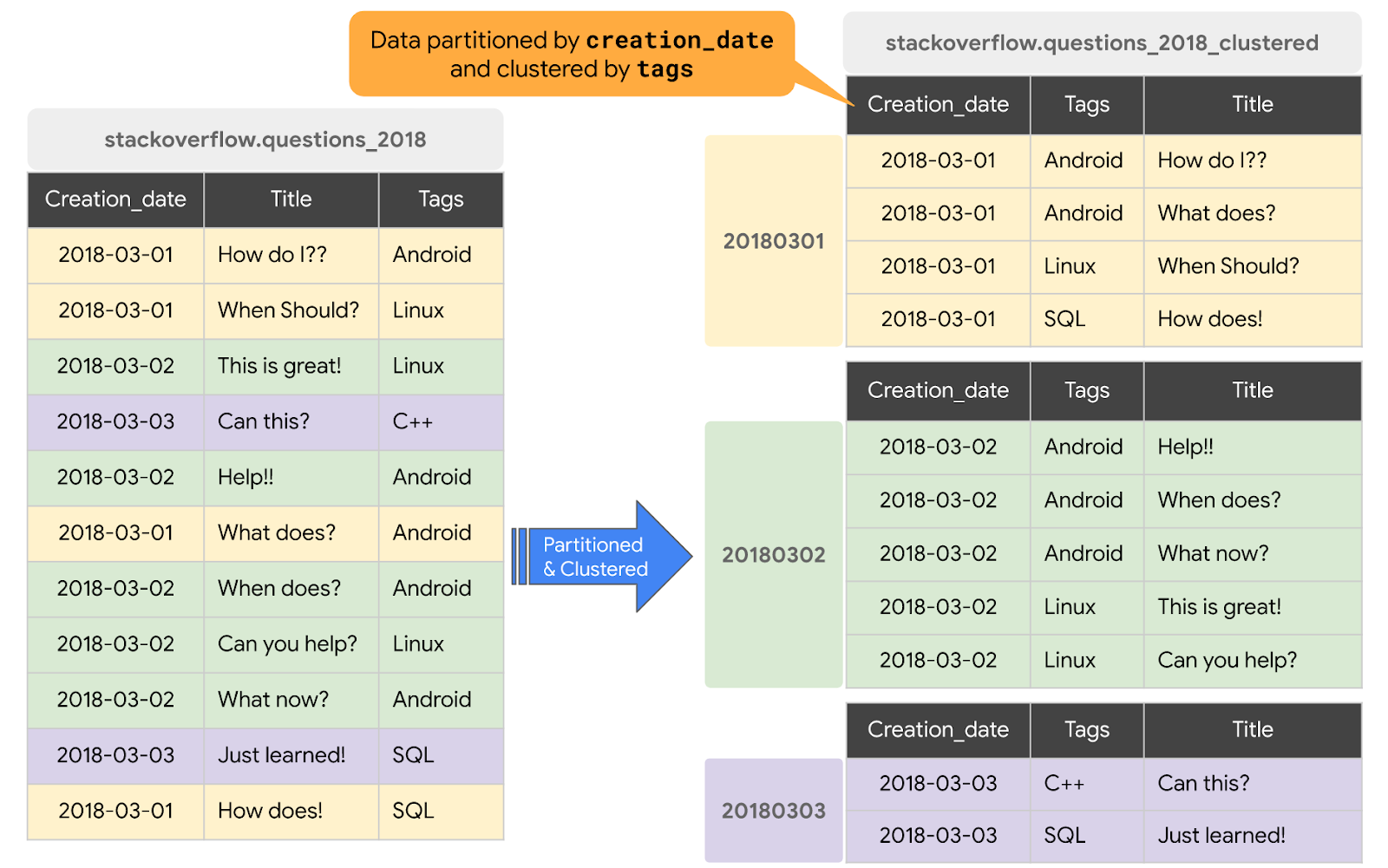
BigQuery에서 테이블이 클러스터링되면 테이블 데이터는 테이블 스키마에 있는 하나 이상의 열의 콘텐츠를 기준으로 자동 정렬됩니다. 지정하는 열은 관련 데이터를 배치하는 데 사용됩니다. 데이터가 클러스터링된 테이블에 작성될 때 BigQuery는 클러스터링 열의 값을 사용해 데이터를 정렬합니다. 이러한 값은 BigQuery 스토리지의 여러 블록에 데이터를 정리하는 데 사용됩니다. 클러스터링된 열의 순서에 따라 데이터의 정렬 순서가 결정됩니다. 테이블 또는 특정 파티션에 새 데이터가 추가되면 BigQuery는 백그라운드에서 자동 재클러스터링을 수행하여 테이블 또는 파티션의 정렬 속성을 복원합니다.
여기에서 클러스터링된 테이블 작업에 대해 자세히 알아보세요.
2018년 Stack Overflow 게시물로 새 클러스터형 테이블 만들기
이 섹션에서는 쿼리 액세스 패턴을 기반으로 creation_date에서 파티션을 나누고 tags 열에서 클러스터링된 새 테이블을 만듭니다. 기존 테이블 또는 쿼리의 데이터로 클러스터링된 테이블을 만들려면 다음 단계를 완료하여 2018년 Stack Overflow 게시물 테이블을 쿼리하고 결과를 새 테이블에 작성합니다.
- GCP 콘솔의 오른쪽 상단에서 새 쿼리 작성을 선택합니다.
- 쿼리 편집기 텍스트 영역에서 다음 SQL 쿼리를 복사하여 붙여넣어 새 테이블을 만듭니다. 이는 DDL 문입니다.
#standardSQL CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered` PARTITION BY DATE(creation_date) CLUSTER BY tags AS SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count, tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE creation_date BETWEEN '2018-01-01' AND '2019-01-01';
- '실행'을 선택합니다. 이 쿼리는 BigQuery Stack Overflow 테이블
bigquery-public-data.stackoverflow.posts_questions에서 쿼리를 실행한 결과로 생성된 데이터가 포함된 프로젝트의stackoverflow데이터 세트에 새 테이블questions_2018_clustered를 만듭니다. 새 테이블은 creation_date를 기준으로 파티션이 나누어지고 tags 열을 기준으로 클러스터링됩니다.
2018년 Stack Overflow 게시물로 클러스터링된 테이블 쿼리
이제 BigQuery 클러스터링된 테이블을 만들었으므로 이번에는 파티셔닝되고 클러스터링된 테이블에서 동일한 쿼리를 다시 실행하여 질문과 제목이 포함된 Stack Overflow 게시물과 답변 수, 댓글 수, 조회수, 즐겨찾기 수와 같은 몇 가지 다른 통계를 반환해 보겠습니다. 다음 단계를 완료합니다.
- GCP 콘솔의 오른쪽 상단에서 새 쿼리 작성을 선택합니다.
- 쿼리 편집기 텍스트 영역에 다음 SQL 쿼리를 복사하여 붙여넣습니다.
SELECT id, title, accepted_answer_id, creation_date, answer_count , comment_count , favorite_count, view_count FROM `stackoverflow.questions_2018_clustered` WHERE creation_date BETWEEN '2018-01-01' AND '2018-02-01' AND tags = 'android';
- BigQuery 캐싱을 사용 중지한 상태에서 실행을 선택합니다 (BigQuery 캐시 사용 중지는 이전 섹션 참고). 이 쿼리는 2018년 1월에 생성되고
android태그가 지정된 Stack Overflow 질문을 질문 및 기타 통계와 함께 반환합니다. - 쿼리 결과에는 쿼리가 완료되는 데 걸린 시간과 결과를 얻기 위해 처리된 데이터 양이 표시됩니다.
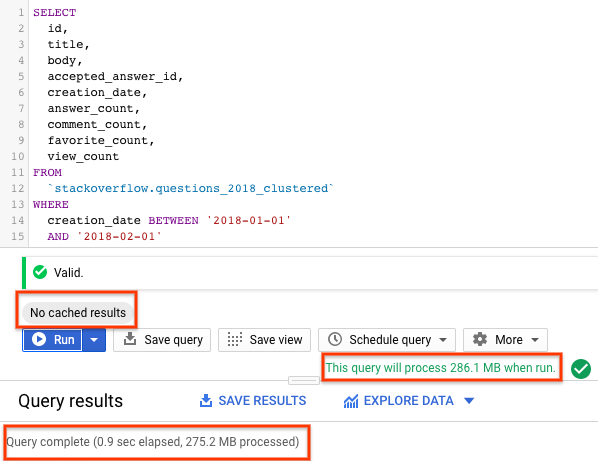
파티션을 나누고 클러스터링된 테이블을 사용하면 쿼리에서 파티션을 나눈 테이블이나 파티션을 나누지 않은 테이블보다 적은 데이터를 스캔했습니다. 파티셔닝과 클러스터링으로 데이터가 구성되는 방식은 슬롯 작업자가 스캔하는 데이터 양을 최소화하여 쿼리 성능을 개선하고 비용을 최적화합니다.
7. 삭제
stackoverflow 데이터 세트를 계속 사용하지 않을 계획이라면 데이터 세트와 이 Codelab에서 만든 프로젝트를 삭제해야 합니다.
BigQuery 데이터 세트 삭제
BigQuery 데이터 세트를 삭제하려면 다음 단계를 따르세요.
- BigQuery의 왼쪽 탐색 패널에서 stackoverflow 데이터 세트를 선택합니다 .
- 세부정보 패널에서 데이터 세트 삭제를 선택합니다.
- 데이터 세트 삭제 대화상자에서 stackoverflow를 입력하고 삭제를 선택하여 데이터 세트 삭제를 확인합니다.
프로젝트 삭제
이 Codelab에서 만든 GCP 프로젝트를 삭제하려면 다음 단계를 따르세요.
- GCP 탐색 메뉴에서 IAM 및 관리자를 선택합니다.
- 탐색 패널에서 설정을 선택합니다.
- 세부정보 패널에서 현재 프로젝트가 이 Codelab을 위해 생성한 프로젝트인지 확인하고 종료를 선택합니다.
- 프로젝트 종료 대화상자에서 프로젝트의 프로젝트 ID (프로젝트 이름 아님)를 입력하고 종료를 선택하여 확인합니다.
축하합니다. 이제 다음 내용을 학습했습니다.
- BigQuery 웹 UI를 사용하여 기존 테이블에서 새 테이블을 만드는 방법
- 파티션을 나눈 테이블과 클러스터링된 테이블을 만들고 쿼리하는 방법
- 파티셔닝과 클러스터링으로 쿼리 성능과 비용을 최적화하는 방법
데이터 세트를 사용하기 위해 클러스터를 설정하거나 관리할 필요가 없습니다.