۱. مرور کلی
در این آزمایشگاه، شما یاد خواهید گرفت که چگونه از Vertex AI - پلتفرم مدیریتشدهی یادگیری ماشینی که به تازگی توسط گوگل کلود معرفی شده است - برای ساخت گردشهای کاری یادگیری ماشینی سرتاسری استفاده کنید. شما یاد خواهید گرفت که چگونه از دادههای خام به مدل پیادهسازی شده تبدیل شوید و این کارگاه را آماده برای توسعه و تولید پروژههای یادگیری ماشینی خود با Vertex AI ترک خواهید کرد. در این آزمایشگاه، ما از Cloud Shell برای ساخت یک تصویر Docker سفارشی استفاده میکنیم تا کانتینرهای سفارشی را برای آموزش با Vertex AI نشان دهیم.
اگرچه ما در اینجا از TensorFlow برای کد مدل استفاده میکنیم، اما شما میتوانید به راحتی آن را با یک چارچوب دیگر جایگزین کنید.
آنچه یاد میگیرید
شما یاد خواهید گرفت که چگونه:
- ساخت و کانتینرایز کردن کد آموزش مدل با استفاده از Cloud Shell
- یک کار آموزش مدل سفارشی را به Vertex AI ارسال کنید
- مدل آموزشدیده خود را در یک نقطه پایانی مستقر کنید و از آن نقطه پایانی برای دریافت پیشبینیها استفاده کنید.
هزینه کل اجرای این آزمایشگاه در گوگل کلود حدود ۲ دلار است.
۲. مقدمهای بر هوش مصنوعی ورتکس
این آزمایشگاه از جدیدترین محصول هوش مصنوعی موجود در Google Cloud استفاده میکند. Vertex AI، محصولات یادگیری ماشین را در Google Cloud ادغام میکند تا یک تجربه توسعه یکپارچه را فراهم کند. پیش از این، مدلهای آموزشدیده با AutoML و مدلهای سفارشی از طریق سرویسهای جداگانه قابل دسترسی بودند. این محصول جدید، هر دو را در یک API واحد، به همراه سایر محصولات جدید، ترکیب میکند. همچنین میتوانید پروژههای موجود را به Vertex AI منتقل کنید. در صورت داشتن هرگونه بازخورد، لطفاً به صفحه پشتیبانی مراجعه کنید.
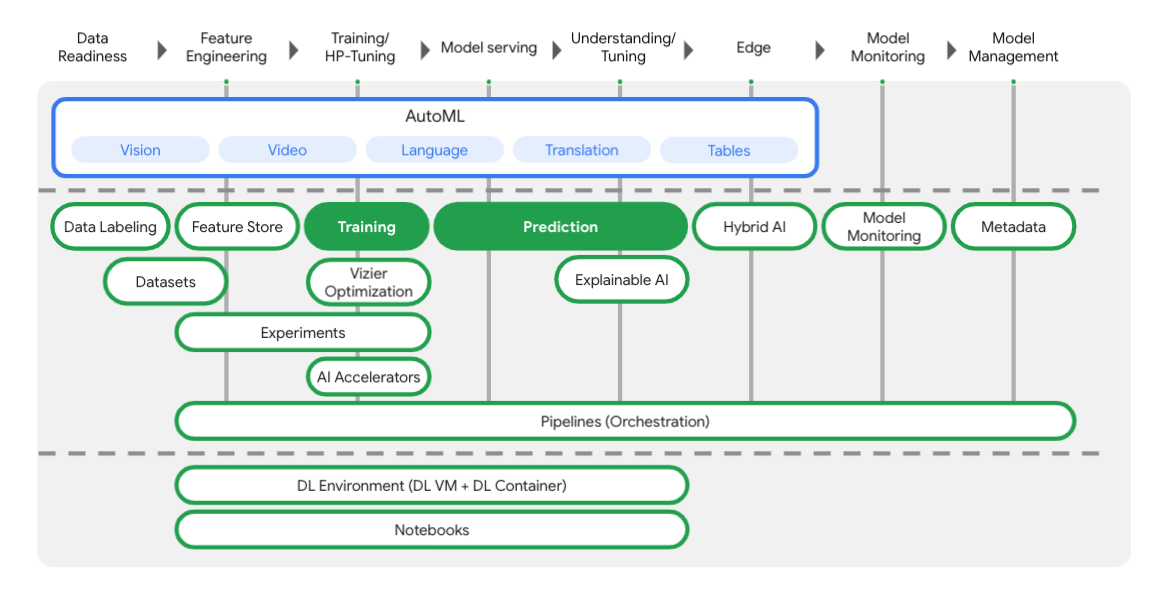
همانطور که در نمودار زیر مشاهده میکنید، ورتکس (Vertex) شامل ابزارهای مختلفی است که به شما در هر مرحله از گردش کار یادگیری ماشینی کمک میکند. ما بر استفاده از آموزش و پیشبینی ورتکس (Vertex Training and Prediction) که در زیر برجسته شده است، تمرکز خواهیم کرد.
۳. محیط خود را راهاندازی کنید
تنظیم محیط خودتنظیم
وارد Cloud Console شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. (اگر از قبل حساب Gmail یا Google Workspace ندارید، باید یکی ایجاد کنید .)

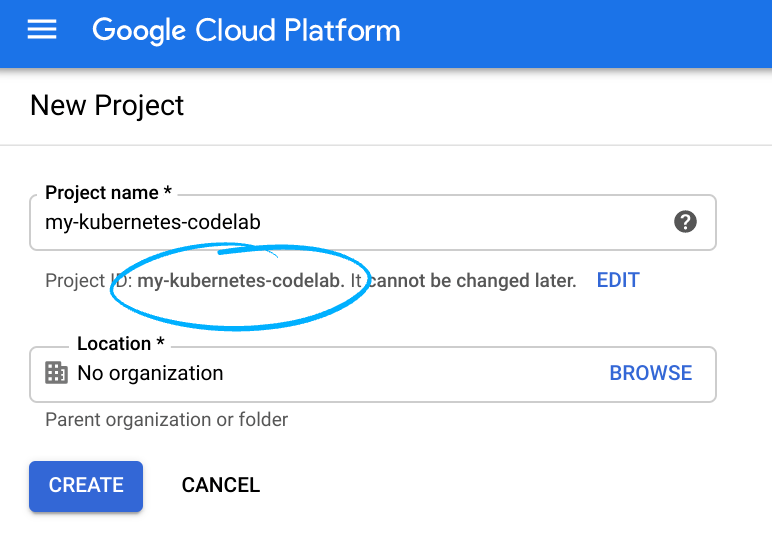
شناسه پروژه، یک نام منحصر به فرد در تمام پروژههای Google Cloud، را به خاطر بسپارید (نام بالا قبلاً گرفته شده و برای شما کار نخواهد کرد، متاسفیم!).
در مرحله بعد، برای استفاده از منابع گوگل کلود، باید پرداخت را در Cloud Console فعال کنید .
اجرای این آزمایشگاه کدنویسی نباید هزینه زیادی داشته باشد، اگر اصلاً هزینهای داشته باشد. حتماً دستورالعملهای بخش «پاکسازی» را که به شما نحوه خاموش کردن منابع را توصیه میکند، دنبال کنید تا پس از این آموزش، متحمل هزینه نشوید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
مرحله ۱: شروع Cloud Shell
در این آزمایش، شما در یک جلسه Cloud Shell کار خواهید کرد، که یک مفسر فرمان است که توسط یک ماشین مجازی که در فضای ابری گوگل اجرا میشود، میزبانی میشود. شما میتوانید به راحتی این بخش را به صورت محلی روی رایانه خود اجرا کنید، اما استفاده از Cloud Shell به همه امکان دسترسی به یک تجربه قابل تکرار در یک محیط سازگار را میدهد. پس از آزمایش، میتوانید این بخش را دوباره روی رایانه خود امتحان کنید.
فعال کردن پوسته ابری
از بالا سمت راست کنسول ابری، روی دکمه زیر کلیک کنید تا Cloud Shell فعال شود :

اگر قبلاً Cloud Shell را شروع نکردهاید، یک صفحه میانی (در پایین صفحه) به شما نمایش داده میشود که توضیح میدهد چیست. در این صورت، روی ادامه کلیک کنید (و دیگر هرگز آن را نخواهید دید). آن صفحه یکبار مصرف به این شکل است:
آمادهسازی و اتصال به Cloud Shell فقط چند لحظه طول میکشد.

این ماشین مجازی با تمام ابزارهای توسعه مورد نیاز شما پر شده است. این ماشین یک دایرکتوری خانگی ۵ گیگابایتی دائمی ارائه میدهد و در فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. بخش عمدهای از کار شما در این آزمایشگاه کد، اگر نگوییم همه، را میتوان به سادگی با یک مرورگر یا کرومبوک انجام داد.
پس از اتصال به Cloud Shell، باید ببینید که از قبل احراز هویت شدهاید و پروژه از قبل روی شناسه پروژه شما تنظیم شده است.
برای تأیید احراز هویت، دستور زیر را در Cloud Shell اجرا کنید:
gcloud auth list
خروجی دستور
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
دستور زیر را در Cloud Shell اجرا کنید تا تأیید کنید که دستور gcloud از پروژه شما اطلاع دارد:
gcloud config list project
خروجی دستور
[core] project = <PROJECT_ID>
اگر اینطور نیست، میتوانید با این دستور آن را تنظیم کنید:
gcloud config set project <PROJECT_ID>
خروجی دستور
Updated property [core/project].
Cloud Shell چند متغیر محیطی دارد، از جمله GOOGLE_CLOUD_PROJECT که شامل نام پروژه ابری فعلی ما است. ما از این در جاهای مختلف این تمرین استفاده خواهیم کرد. میتوانید با اجرای دستور زیر آن را مشاهده کنید:
echo $GOOGLE_CLOUD_PROJECT
مرحله ۲: فعال کردن APIها
در مراحل بعدی، خواهید دید که این سرویسها کجا مورد نیاز هستند (و چرا)، اما فعلاً این دستور را اجرا کنید تا به پروژه خود دسترسی به سرویسهای Compute Engine، Container Registry و Vertex AI بدهید:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
این باید یک پیام موفقیتآمیز مشابه این ایجاد کند:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
مرحله ۳: ایجاد یک فضای ذخیرهسازی ابری
برای اجرای یک کار آموزشی در Vertex AI، به یک مخزن ذخیرهسازی برای ذخیره داراییهای مدل ذخیره شده خود نیاز داریم. دستورات زیر را در ترمینال Cloud Shell خود اجرا کنید تا یک مخزن ایجاد شود:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
مرحله ۴: نام مستعار پایتون ۳
کد این آزمایش از پایتون ۳ استفاده میکند. برای اطمینان از اینکه هنگام اجرای اسکریپتهایی که در این آزمایش ایجاد خواهید کرد از پایتون ۳ استفاده میکنید، با اجرای دستور زیر در Cloud Shell یک نام مستعار ایجاد کنید:
alias python=python3
مدلی که در این آزمایشگاه آموزش داده و ارائه خواهیم داد، بر اساس این آموزش از مستندات TensorFlow ساخته شده است. این آموزش از مجموعه دادههای Auto MPG از Kaggle برای پیشبینی راندمان سوخت یک وسیله نقلیه استفاده میکند.
۴. کد آموزشی را کانتینریزه کنید
ما این کار آموزشی را با قرار دادن کد آموزشی خود در یک کانتینر Docker و ارسال این کانتینر به Google Container Registry به Vertex ارسال خواهیم کرد. با استفاده از این رویکرد، میتوانیم مدلی را که با هر چارچوبی ساخته شده است، آموزش دهیم.
مرحله ۱: تنظیم فایلها
برای شروع، از ترمینال در Cloud Shell، دستورات زیر را اجرا کنید تا فایلهایی که برای کانتینر داکر خود نیاز داریم ایجاد شوند:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
حالا باید یک دایرکتوری mpg/ داشته باشید که شبیه به زیر باشد:
+ Dockerfile
+ trainer/
+ train.py
برای مشاهده و ویرایش این فایلها، از ویرایشگر کد داخلی Cloud Shell استفاده خواهیم کرد. میتوانید با کلیک بر روی دکمهی موجود در نوار منوی بالا سمت راست در Cloud Shell، بین ویرایشگر و ترمینال جابجا شوید:

مرحله ۲: ایجاد یک داکرفایل
برای کانتینرایز کردن کدمان، ابتدا یک Dockerfile ایجاد میکنیم. در Dockerfile تمام دستورات مورد نیاز برای اجرای ایمیج را قرار میدهیم. این فایل تمام کتابخانههایی که استفاده میکنیم را نصب کرده و نقطه ورود کد آموزشی ما را تنظیم میکند.
از ویرایشگر فایل Cloud Shell، پوشه mpg/ خود را باز کنید و سپس برای باز کردن Dockerfile دوبار کلیک کنید:
سپس موارد زیر را در این فایل کپی کنید:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
این داکرفایل از ایمیج داکر کانتینر یادگیری عمیق TensorFlow Enterprise 2.3 استفاده میکند. کانتینرهای یادگیری عمیق در Google Cloud با بسیاری از چارچوبهای رایج یادگیری ماشین و علم داده از پیش نصب شده ارائه میشوند. چارچوبی که ما استفاده میکنیم شامل TF Enterprise 2.3، Pandas، Scikit-learn و موارد دیگر است. پس از دانلود آن ایمیج، این داکرفایل نقطه ورود کد آموزشی ما را تنظیم میکند که در مرحله بعدی اضافه خواهیم کرد.
مرحله ۳: کد آموزشی مدل را اضافه کنید
از ویرایشگر Cloud Shell، فایل train.py را باز کنید و کد زیر را کپی کنید (این کد از آموزش موجود در مستندات TensorFlow اقتباس شده است).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
پس از کپی کردن کد بالا در فایل mpg/trainer/train.py ، به ترمینال در Cloud Shell خود برگردید و دستور زیر را اجرا کنید تا نام bucket خود را به فایل اضافه کنید:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
مرحله ۴: ساخت و آزمایش کانتینر به صورت محلی
از ترمینال خود، دستور زیر را برای تعریف یک متغیر با URI تصویر کانتینر خود در رجیستری کانتینر گوگل اجرا کنید:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
سپس، با اجرای دستور زیر از ریشه دایرکتوری mpg خود، کانتینر را بسازید:
docker build ./ -t $IMAGE_URI
پس از ساخت کانتینر، آن را به Google Container Registry ارسال کنید:
docker push $IMAGE_URI
برای تأیید اینکه تصویر شما به Container Registry منتقل شده است، هنگام رفتن به بخش Container Registry کنسول خود، باید چیزی شبیه به این را ببینید:
با قرار دادن کانتینر در رجیستری کانتینر، اکنون آمادهایم تا یک کار آموزش مدل سفارشی را شروع کنیم.
۵. یک کار آموزشی روی Vertex AI اجرا کنید
ورتکس دو گزینه برای آموزش مدلها در اختیار شما قرار میدهد:
- AutoML : آموزش مدلهای با کیفیت بالا با حداقل تلاش و تخصص در یادگیری ماشین.
- آموزش سفارشی : برنامههای آموزشی سفارشی خود را با استفاده از یکی از کانتینرهای از پیش ساخته شده Google Cloud یا از کانتینرهای خودتان در فضای ابری اجرا کنید.
در این آزمایش، ما از آموزش سفارشی از طریق کانتینر سفارشی خودمان در Google Container Registry استفاده میکنیم. برای شروع، به بخش آموزش در بخش Vertex کنسول Cloud خود بروید:
مرحله ۱: شروع کار آموزشی
برای وارد کردن پارامترهای مربوط به کار آموزشی و مدل مستقر شده، روی «ایجاد» کلیک کنید:
- در قسمت مجموعه داده ، گزینه «بدون مجموعه داده مدیریتشده» را انتخاب کنید.
- سپس آموزش سفارشی (پیشرفته) را به عنوان روش آموزش خود انتخاب کرده و روی ادامه کلیک کنید.
- برای نام مدل،
mpg(یا هر نامی که برای مدل خود انتخاب میکنید) را وارد کنید. - روی ادامه کلیک کنید
در مرحله تنظیمات کانتینر، کانتینر سفارشی را انتخاب کنید:

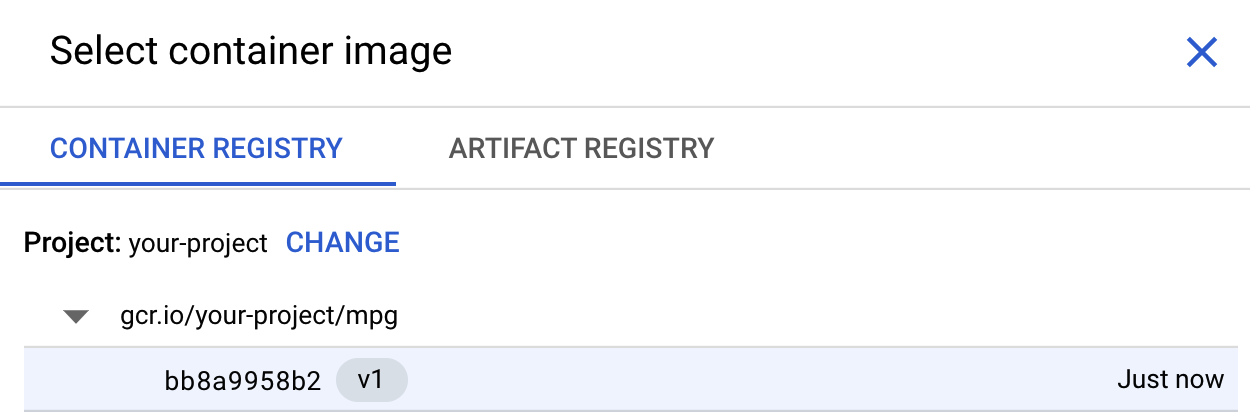
در کادر اول (تصویر کانتینر)، روی مرور کلیک کنید و کانتینری را که به رجیستری کانتینرها اضافه کردهاید، پیدا کنید. باید چیزی شبیه به این باشد:
بقیه فیلدها را خالی بگذارید و روی ادامه کلیک کنید.
ما در این آموزش از تنظیم هایپرپارامتر استفاده نخواهیم کرد، بنابراین کادر «فعال کردن تنظیم هایپرپارامتر» را علامت نزده و روی «ادامه» کلیک کنید.
در بخش محاسبه و قیمتگذاری ، منطقه انتخابشده را به همان صورت باقی بگذارید و نوع دستگاه خود را n1-standard-4 انتخاب کنید:
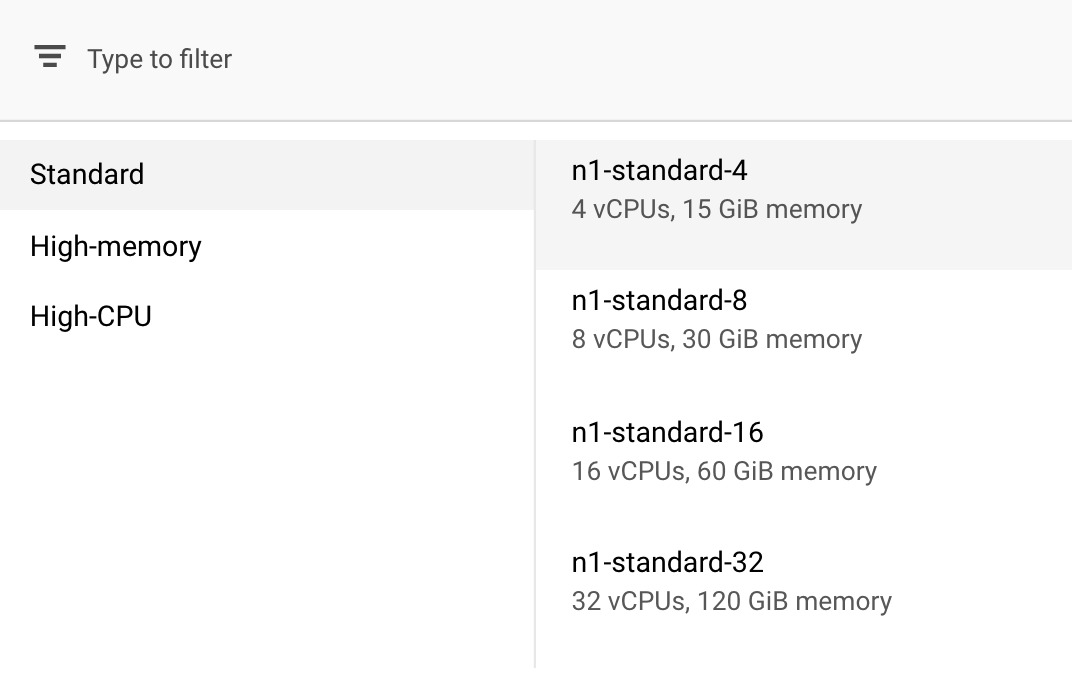
از آنجا که مدل موجود در این نسخه آزمایشی به سرعت آموزش میبیند، ما از نوع ماشین کوچکتری استفاده میکنیم.
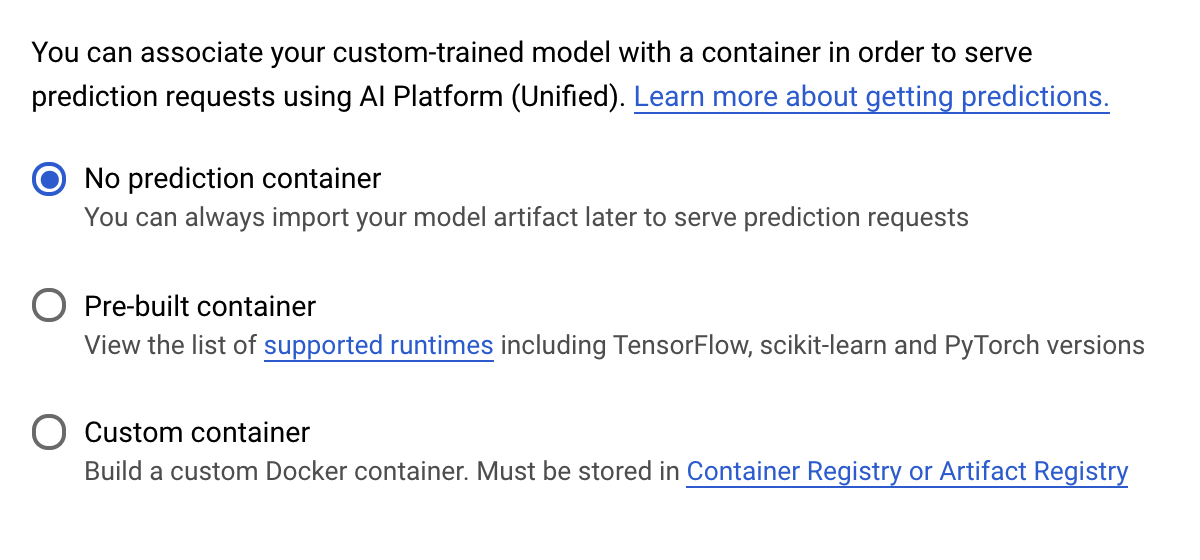
در مرحلهی «ظرف پیشبینی» ، «بدون ظرف پیشبینی» را انتخاب کنید:
۶. یک نقطه پایانی مدل را مستقر کنید
در این مرحله، یک نقطه پایانی برای مدل آموزشدیده خود ایجاد خواهیم کرد. میتوانیم از این برای دریافت پیشبینیها روی مدل خود از طریق API هوش مصنوعی Vertex استفاده کنیم. برای انجام این کار، نسخهای از دادههای مدل آموزشدیده صادر شده را در یک سطل عمومی GCS در دسترس قرار دادهایم .
در یک سازمان، معمولاً یک تیم یا فرد مسئول ساخت مدل و یک تیم دیگر مسئول استقرار آن هستند. مراحلی که در اینجا بررسی خواهیم کرد به شما نشان میدهد که چگونه مدلی را که قبلاً آموزش دیده است، بردارید و آن را برای پیشبینی مستقر کنید.
در اینجا ما از Vertex AI SDK برای ایجاد یک مدل، استقرار آن در یک نقطه پایانی و دریافت پیشبینی استفاده خواهیم کرد.
مرحله 1: نصب SDK ورتکس
از ترمینال Cloud Shell خود، دستور زیر را برای نصب Vertex AI SDK اجرا کنید:
pip3 install google-cloud-aiplatform --upgrade --user
ما میتوانیم از این SDK برای تعامل با بخشهای مختلف Vertex استفاده کنیم.
مرحله ۲: ایجاد مدل و استقرار نقطه پایانی
در مرحله بعد، یک فایل پایتون ایجاد میکنیم و از SDK برای ایجاد یک منبع مدل و استقرار آن در یک نقطه پایانی استفاده میکنیم. از ویرایشگر فایل در Cloud Shell، گزینه File و سپس New File را انتخاب کنید:
نام فایل را deploy.py . این فایل را در ویرایشگر خود باز کنید و کد زیر را در آن کپی کنید:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
در مرحله بعد، به ترمینال در Cloud Shell برگردید، cd به دایرکتوری ریشه خود برگردید و این اسکریپت پایتون را که تازه ایجاد کردهاید، اجرا کنید:
cd ..
python3 deploy.py | tee deploy-output.txt
همزمان با ایجاد منابع، بهروزرسانیهایی را که در ترمینال شما ثبت شدهاند، مشاهده خواهید کرد. اجرای این کار ۱۰ تا ۱۵ دقیقه طول خواهد کشید. برای اطمینان از عملکرد صحیح آن، به بخش Models کنسول خود در Vertex AI بروید:
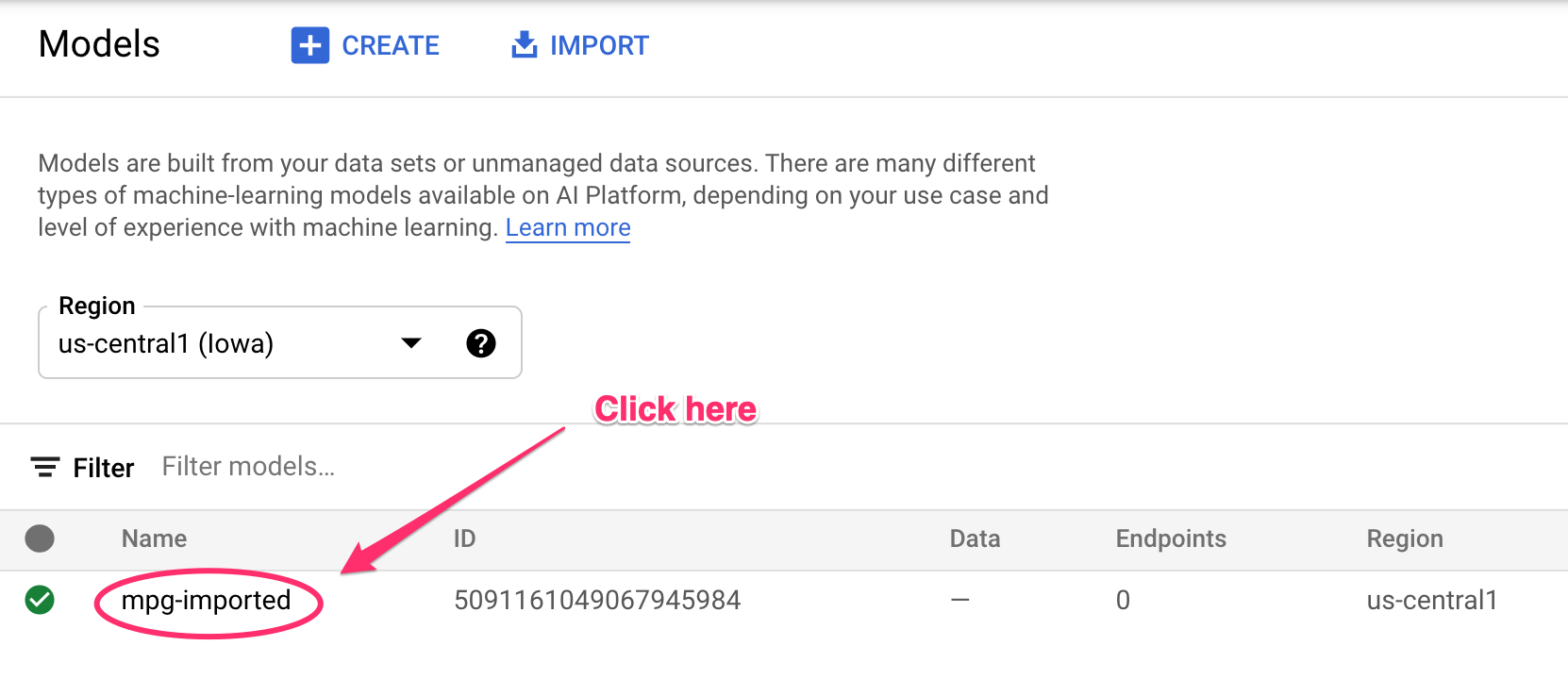
روی mgp-imported کلیک کنید تا نقطه پایانی (endpoint) مدل ایجاد شده را مشاهده کنید:
در ترمینال Cloud Shell خود، وقتی استقرار نقطه پایانی شما تکمیل شد، چیزی شبیه به گزارش زیر را مشاهده خواهید کرد:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
شما در مرحله بعدی از این برای دریافت پیشبینی در مورد endopint مستقر شده خود استفاده خواهید کرد.
مرحله ۳: دریافت پیشبینیها در مورد نقطه پایانی مستقر شده
در ویرایشگر Cloud Shell خود، یک فایل جدید به نام predict.py ایجاد کنید:
predict.py باز کنید و کد زیر را در آن قرار دهید:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
در مرحله بعد، به ترمینال خود برگردید و دستور زیر را برای جایگزینی ENDPOINT_STRING در فایل predict با نقطه پایانی خود وارد کنید:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
اکنون زمان آن رسیده است که فایل predict.py را اجرا کنیم تا پیشبینی را از نقطه پایانی مدل مستقر شده خود دریافت کنیم:
python3 predict.py
شما باید پاسخ API را به همراه میزان مصرف سوخت پیشبینیشده برای پیشبینی آزمایش ما، ثبتشده ببینید.
🎉 تبریک میگویم! 🎉
شما یاد گرفتید که چگونه از Vertex AI برای موارد زیر استفاده کنید:
- با ارائه کد آموزشی در یک کانتینر سفارشی، یک مدل را آموزش دهید. در این مثال از یک مدل TensorFlow استفاده کردید، اما میتوانید مدلی را که با هر چارچوبی ساخته شده است، با استفاده از کانتینرهای سفارشی آموزش دهید.
- یک مدل TensorFlow را با استفاده از یک کانتینر از پیش ساخته شده به عنوان بخشی از همان گردش کاری که برای آموزش استفاده کردهاید، مستقر کنید.
- یک نقطه پایانی مدل ایجاد کنید و یک پیشبینی تولید کنید.
برای کسب اطلاعات بیشتر در مورد بخشهای مختلف Vertex AI، مستندات را بررسی کنید. اگر میخواهید نتایج کار آموزشی که در مرحله 5 شروع کردهاید را ببینید، به بخش آموزش کنسول Vertex خود بروید.
۷. پاکسازی
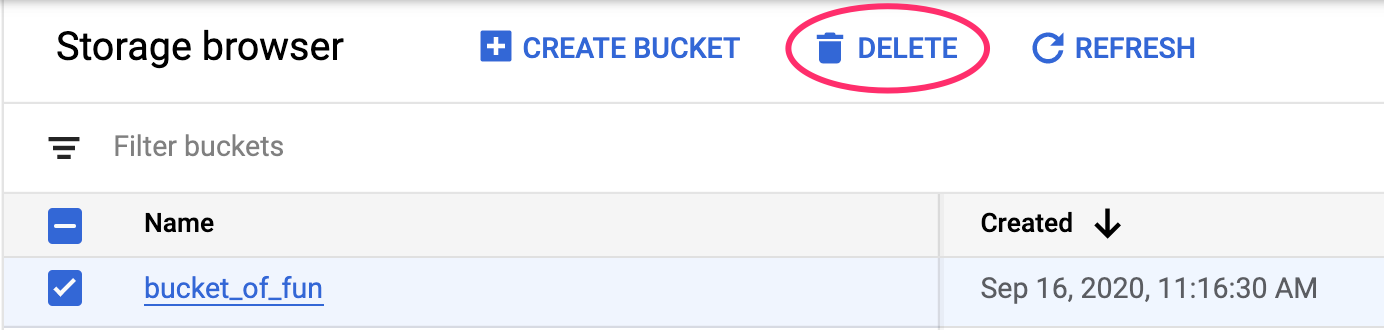
برای حذف نقطه پایانی که مستقر کردهاید، به بخش نقاط پایانی کنسول Vertex خود بروید و روی نماد حذف کلیک کنید:

برای حذف Storage Bucket، با استفاده از منوی ناوبری در Cloud Console خود، به Storage بروید، Bucket خود را انتخاب کنید و روی Delete کلیک کنید: