1. Genel Bakış
Bu laboratuvarda, uçtan uca makine öğrenimi iş akışları oluşturmak için Google Cloud'un yeni duyurulan yönetilen makine öğrenimi platformu Vertex AI'ı nasıl kullanacağınızı öğreneceksiniz. Ham verilerden dağıtılmış modele nasıl geçeceğinizi öğrenecek ve bu atölyeden Vertex AI ile kendi makine öğrenimi projelerinizi geliştirmeye ve üretime hazır hale getirmeye hazır olarak ayrılacaksınız. Bu laboratuvarda, Vertex AI ile eğitim için özel container'ları göstermek amacıyla özel bir Docker görüntüsü oluşturmak üzere Cloud Shell'i kullanıyoruz.
Burada model kodu için TensorFlow'u kullanıyoruz ancak bunu kolayca başka bir çerçeveyle değiştirebilirsiniz.
Öğrenecekleriniz
Öğrenecekleriniz:
- Cloud Shell'i kullanarak model eğitimi kodu oluşturma ve container'a dönüştürme
- Vertex AI'a özel model eğitimi işi gönderme
- Eğitilen modelinizi bir uç noktaya dağıtma ve bu uç noktayı kullanarak tahminler alma
Bu laboratuvarı Google Cloud'da çalıştırmanın toplam maliyeti yaklaşık 2 ABD dolarıdır.
2. Vertex AI'a giriş
Bu laboratuvarda, Google Cloud'da sunulan en yeni yapay zeka ürünü kullanılmaktadır. Vertex AI, Google Cloud'daki makine öğrenimi tekliflerini sorunsuz bir geliştirme deneyimi için entegre eder. Daha önce, AutoML ile eğitilmiş modeller ve özel modeller ayrı hizmetler üzerinden erişilebiliyordu. Yeni teklif, diğer yeni ürünlerle birlikte bu iki ürünü tek bir API'de birleştirir. Mevcut projeleri de Vertex AI'a taşıyabilirsiniz. Geri bildiriminiz varsa lütfen destek sayfasına göz atın.
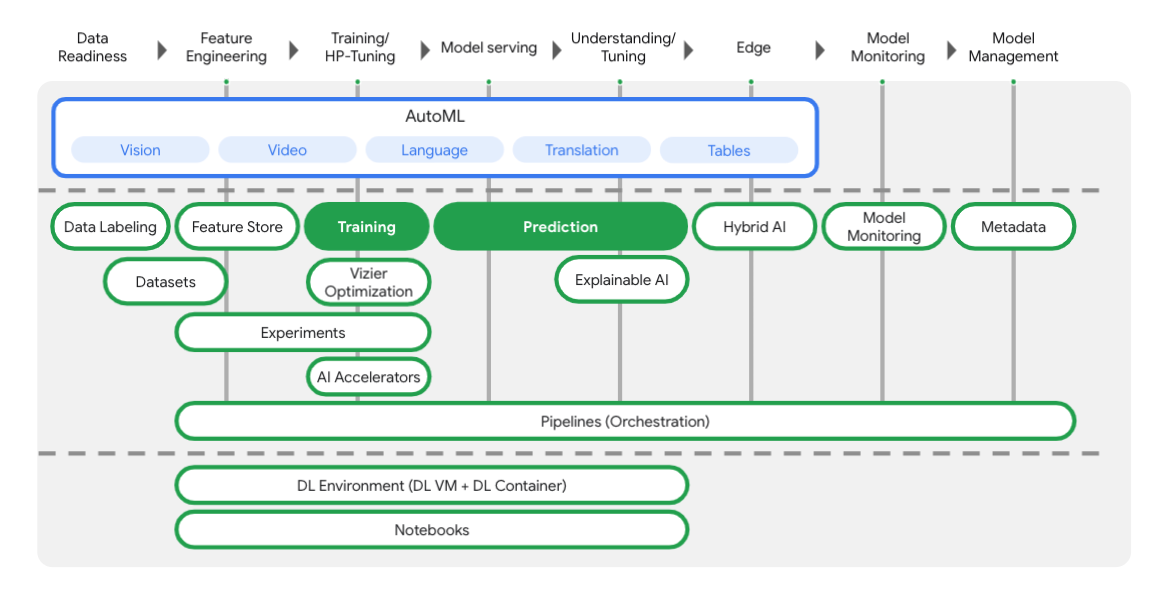
Aşağıdaki diyagramdan da görebileceğiniz gibi Vertex, makine öğrenimi iş akışının her aşamasında size yardımcı olacak birçok farklı araç içerir. Aşağıda vurgulanan Vertex Training ve Prediction'ı kullanmaya odaklanacağız.
3. Ortamınızı ayarlama
Yönlendirmesiz ortam kurulumu
Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. (Gmail veya Google Workspace hesabınız yoksa oluşturmanız gerekir.)

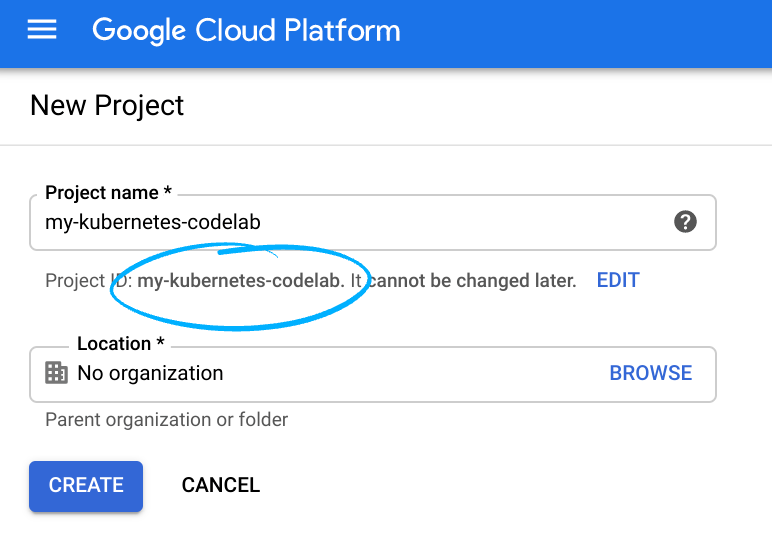
Proje kimliğini unutmayın. Bu kimlik, tüm Google Cloud projelerinde benzersiz bir addır (Yukarıdaki ad zaten alınmış olduğundan sizin için çalışmayacaktır).
Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i tamamlamak neredeyse hiç maliyetli değildir. Bu eğitimin ötesinde faturalandırma ücreti alınmaması için kaynakları nasıl kapatacağınız konusunda size tavsiyelerde bulunan "Temizleme" bölümündeki talimatları uyguladığınızdan emin olun. Google Cloud'un yeni kullanıcıları 300 ABD doları değerinde ücretsiz deneme programından yararlanabilir.
1. adım: Cloud Shell'i başlatın
Bu laboratuvarda, Google'ın bulutunda çalışan bir sanal makine tarafından barındırılan bir komut yorumlayıcı olan Cloud Shell oturumunda çalışacaksınız. Bu bölümü kendi bilgisayarınızda yerel olarak da kolayca çalıştırabilirsiniz ancak Cloud Shell'i kullanmak, herkesin tutarlı bir ortamda tekrarlanabilir bir deneyime erişmesini sağlar. Laboratuvarın ardından bu bölümü kendi bilgisayarınızda tekrar deneyebilirsiniz.
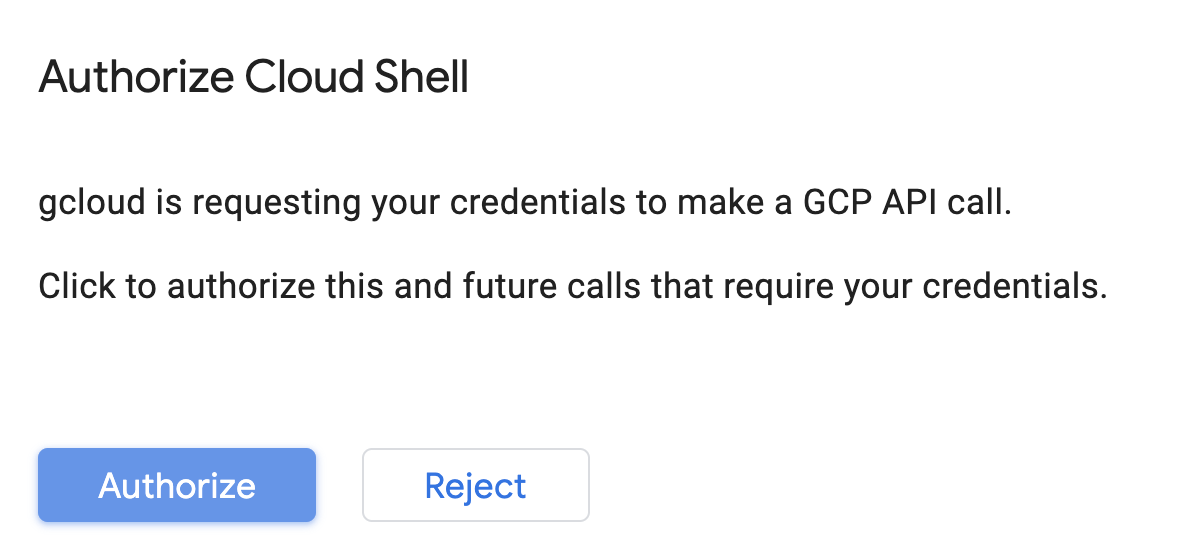
Cloud Shell'i etkinleştirme
Cloud Console'un sağ üst kısmından aşağıdaki düğmeyi tıklayarak Cloud Shell'i etkinleştirin:

Cloud Shell'i daha önce hiç başlatmadıysanız ne olduğunu açıklayan bir ara ekran (ekranın alt kısmı) gösterilir. Bu durumda Devam'ı tıkladığınızda bu ekranı bir daha görmezsiniz. Bu tek seferlik ekran aşağıdaki gibi görünür:
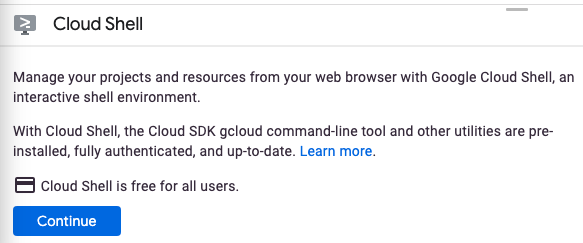
Cloud Shell'in temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır.

Bu sanal makine, ihtiyaç duyduğunuz tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin bulunur ve Google Cloud'da çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki çalışmalarınızın neredeyse tamamını yalnızca bir tarayıcı veya Chromebook'unuzla yapabilirsiniz.
Cloud Shell'e bağlandıktan sonra kimliğinizin doğrulandığını ve projenin, proje kimliğinize ayarlandığını görürsünüz.
Kimliğinizin doğrulandığını onaylamak için Cloud Shell'de şu komutu çalıştırın:
gcloud auth list
Komut çıkışı
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın:
gcloud config list project
Komut çıkışı
[core] project = <PROJECT_ID>
Değilse şu komutla ayarlayabilirsiniz:
gcloud config set project <PROJECT_ID>
Komut çıkışı
Updated property [core/project].
Cloud Shell'de, mevcut Cloud projemizin adını içeren GOOGLE_CLOUD_PROJECT dahil olmak üzere birkaç ortam değişkeni bulunur. Bu değeri laboratuvarın çeşitli yerlerinde kullanacağız. Bu durumu şu komutu çalıştırarak görebilirsiniz:
echo $GOOGLE_CLOUD_PROJECT
2. Adım: API'leri etkinleştirme
Bu hizmetlerin nerede (ve neden) gerekli olduğunu sonraki adımlarda göreceksiniz. Ancak şimdilik projenizin Compute Engine, Container Registry ve Vertex AI hizmetlerine erişmesini sağlamak için bu komutu çalıştırın:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Bu işlem, aşağıdakine benzer bir başarı mesajı oluşturur:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
3. adım: Cloud Storage paketi oluşturma
Vertex AI'da eğitim işi çalıştırmak için kayıtlı model öğelerimizi depolayacak bir depolama paketine ihtiyacımız var. Bir paket oluşturmak için Cloud Shell terminalinizde aşağıdaki komutları çalıştırın:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
4. adım: Python 3'e takma ad verme
Bu laboratuvardaki kodda Python 3 kullanılır. Bu laboratuvarda oluşturacağınız komut dosyalarını çalıştırırken Python 3'ü kullandığınızdan emin olmak için Cloud Shell'de aşağıdaki komutu çalıştırarak bir takma ad oluşturun:
alias python=python3
Bu laboratuvarda eğiteceğimiz ve sunacağımız model, TensorFlow belgelerindeki bu eğitime dayanmaktadır. Eğitimde, bir aracın yakıt verimliliğini tahmin etmek için Kaggle'daki Auto MPG veri kümesi kullanılır.
4. Eğitim kodunu kapsayıcıya alma
Eğitim kodumuzu bir Docker container'ına yerleştirip bu container'ı Google Container Registry'ye aktararak bu eğitim işini Vertex'e göndeririz. Bu yaklaşımı kullanarak herhangi bir çerçeveyle oluşturulmuş bir modeli eğitebiliriz.
1. adım: Dosyaları ayarlayın
Başlamak için Cloud Shell'deki terminalden aşağıdaki komutları çalıştırarak Docker kapsayıcımız için gereken dosyaları oluşturun:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Aşağıdaki gibi bir mpg/ dizininiz olmalıdır:
+ Dockerfile
+ trainer/
+ train.py
Bu dosyaları görüntülemek ve düzenlemek için Cloud Shell'in yerleşik kod düzenleyicisini kullanacağız. Cloud Shell'deki sağ üst menü çubuğunda bulunan düğmeyi tıklayarak düzenleyici ile terminal arasında geçiş yapabilirsiniz:

2. adım: Dockerfile oluşturun
Kodumuzu kapsüllemek için önce bir Dockerfile oluşturacağız. Dockerfile'ımıza, görüntümüzü çalıştırmak için gereken tüm komutları ekleyeceğiz. Bu işlem, kullandığımız tüm kitaplıkları yükler ve eğitim kodumuz için giriş noktasını ayarlar.
Cloud Shell dosya düzenleyicisinde mpg/ dizininizi açın ve Dockerfile'ı açmak için çift tıklayın:
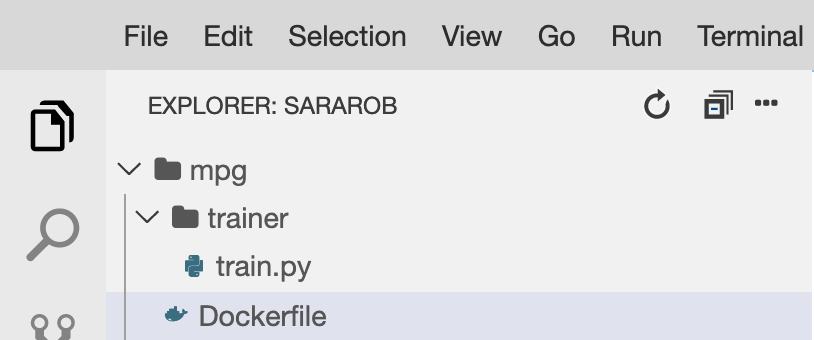
Ardından, aşağıdaki kodu bu dosyaya kopyalayın:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Bu Dockerfile, Deep Learning Container TensorFlow Enterprise 2.3 Docker görüntüsünü kullanır. Google Cloud'daki Deep Learning Containers'da birçok yaygın makine öğrenimi ve veri bilimi çerçevesi önceden yüklenmiş olarak gelir. Kullandığımız sürümde TF Enterprise 2.3, Pandas, Scikit-learn ve diğerleri yer alıyor. Bu görüntüyü indirdikten sonra bu Dockerfile, bir sonraki adımda ekleyeceğimiz eğitim kodumuzun giriş noktasını ayarlar.
3. adım: Model eğitimi kodu ekleyin
Cloud Shell düzenleyicide train.py dosyasını açın ve aşağıdaki kodu kopyalayın (bu kod, TensorFlow belgelerindeki eğitimden alınmıştır).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Yukarıdaki kodu mpg/trainer/train.py dosyasına kopyaladıktan sonra Cloud Shell'deki terminale dönün ve aşağıdaki komutu çalıştırarak kendi paket adınızı dosyaya ekleyin:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
4. adım: Kapsayıcıyı yerel olarak oluşturun ve test edin
Terminalinizden, Google Container Registry'deki container görüntünüzün URI'siyle bir değişken tanımlamak için aşağıdakileri çalıştırın:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Ardından, mpg dizininizin kökünden aşağıdaki komutu çalıştırarak kapsayıcıyı oluşturun:
docker build ./ -t $IMAGE_URI
Container'ı oluşturduktan sonra Google Container Registry'ye aktarın:
docker push $IMAGE_URI
Resminizin Container Registry'ye gönderildiğini doğrulamak için konsolunuzun Container Registry bölümüne gittiğinizde aşağıdakine benzer bir ekranla karşılaşmanız gerekir:
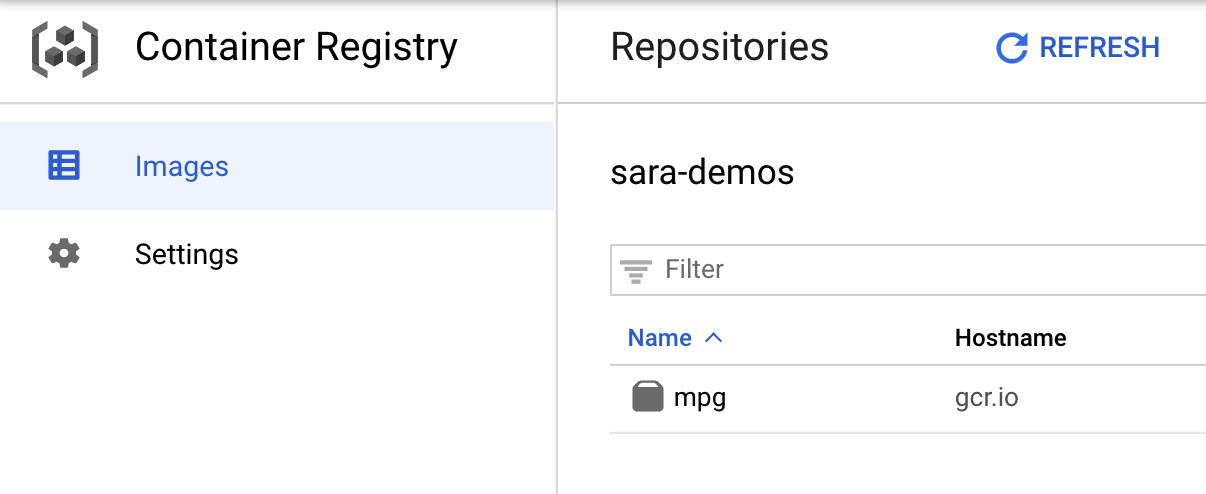
Container'ımız Container Registry'ye aktarıldığına göre artık özel model eğitim işini başlatmaya hazırız.
5. Vertex AI'da eğitim işi çalıştırma
Vertex, modelleri eğitmek için iki seçenek sunar:
- AutoML: Minimum düzeyde çaba ve makine öğrenimi uzmanlığı ile yüksek kaliteli modeller eğitin.
- Özel eğitim: Google Cloud'un önceden oluşturulmuş container'larından birini kullanarak veya kendi container'ınızı kullanarak özel eğitim uygulamalarınızı bulutta çalıştırın.
Bu laboratuvarda, Google Container Registry'deki kendi özel container'ımız aracılığıyla özel eğitim kullanıyoruz. Başlamak için Cloud Console'unuzun Vertex bölümündeki Eğitim bölümüne gidin:
1. adım: Eğitim işini başlatın
Eğitim işinizin ve dağıtılan modelinizin parametrelerini girmek için Oluştur'u tıklayın:
- Veri kümesi bölümünde Yönetilen veri kümesi yok'u seçin.
- Ardından eğitim yönteminiz olarak Özel eğitim (gelişmiş)'i seçip Devam'ı tıklayın.
- Model adı için
mpg(veya modelinize vermek istediğiniz adı) girin. - Devam et'i tıklayın.
Kapsayıcı ayarları adımında Özel kapsayıcı'yı seçin:

İlk kutuda (Container image), Browse'u (Gözat) tıklayın ve Container Registry'ye yeni aktardığınız kapsayıcıyı bulun. Şuna benzer bir görünümde olacaktır:
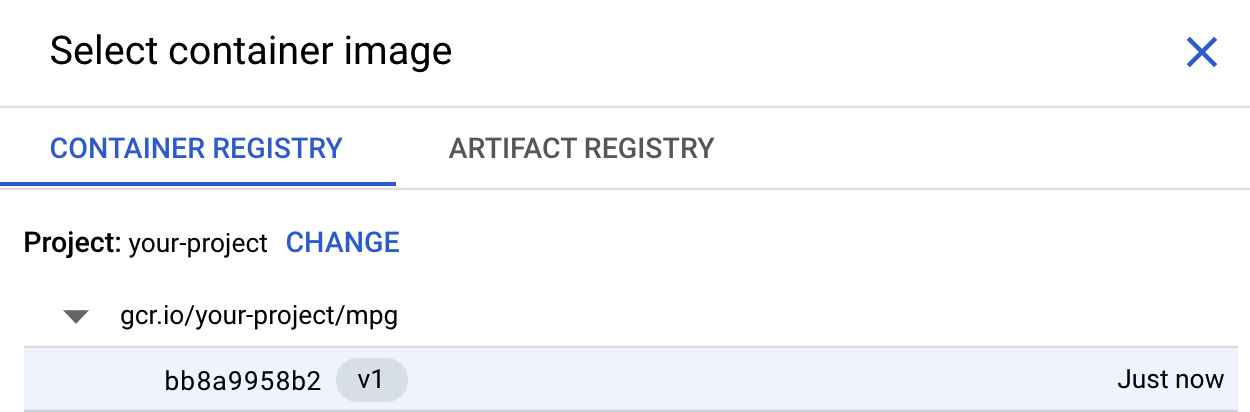
Diğer alanları boş bırakıp Devam'ı tıklayın.
Bu eğitimde hiperparametre ayarını kullanmayacağız. Bu nedenle, Hiperparametre ayarını etkinleştir kutusunu işaretsiz bırakın ve Devam'ı tıklayın.
Compute and pricing (İşlem ve fiyatlandırma) bölümünde, seçili bölgeyi olduğu gibi bırakın ve makine türünüz olarak n1-standard-4'ü seçin:
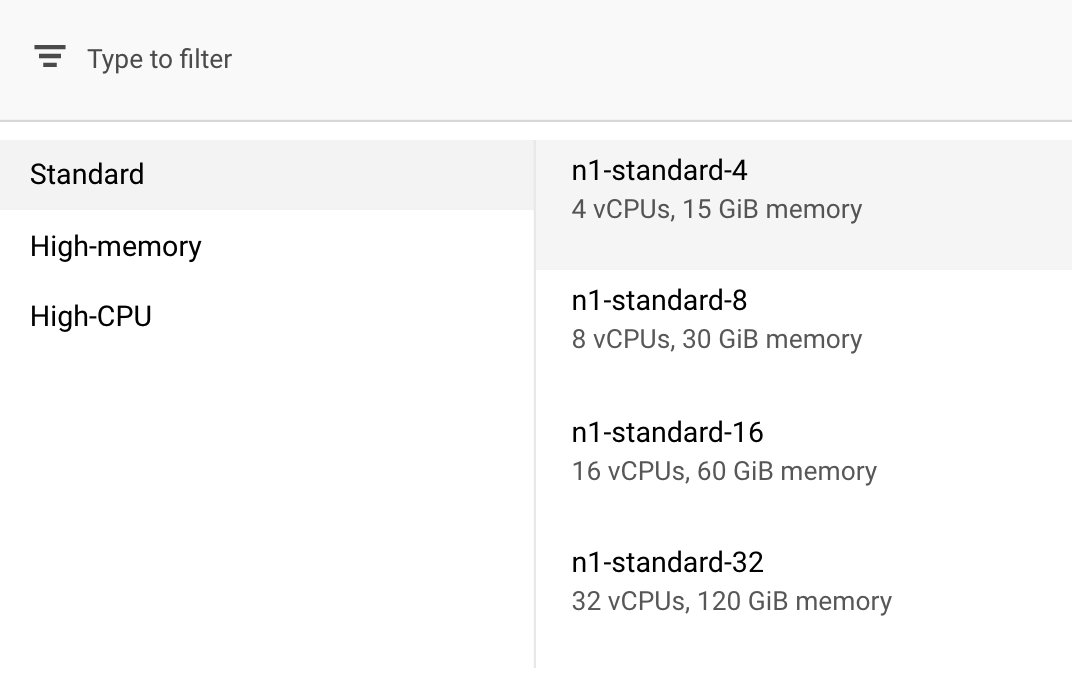
Bu demoda model hızlı bir şekilde eğitildiğinden daha küçük bir makine türü kullanıyoruz.
Tahmin kapsayıcısı adımında Tahmin kapsayıcısı yok'u seçin:
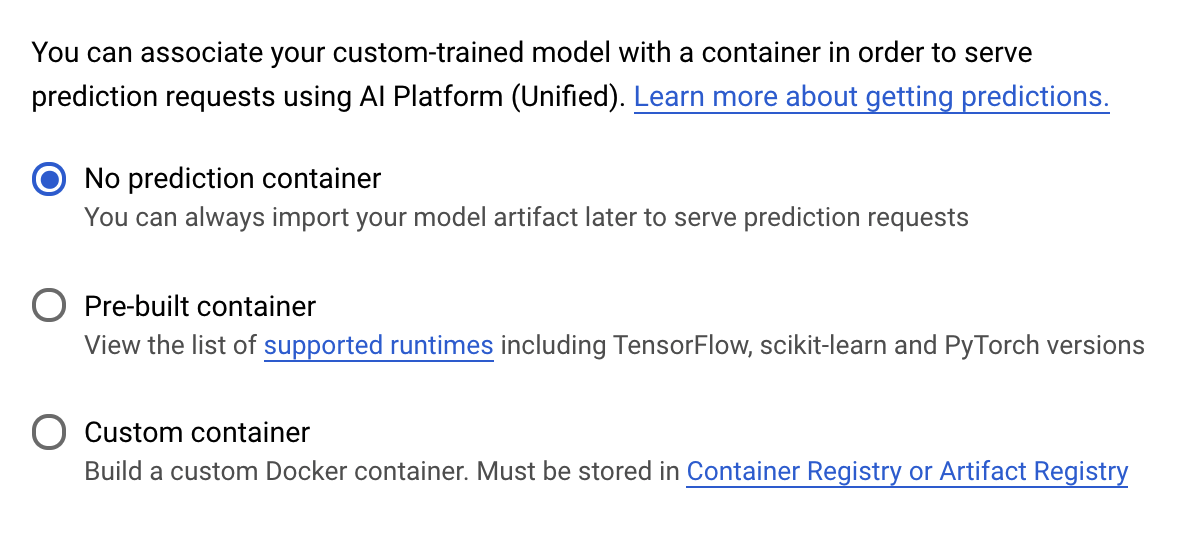
6. Model uç noktası dağıtma
Bu adımda, eğitilmiş modelimiz için bir uç nokta oluşturacağız. Bunu, Vertex AI API aracılığıyla modelimizle ilgili tahminler almak için kullanabiliriz. Bunu yapmak için eğitilmiş modelin dışa aktarılan öğelerinin bir sürümünü herkese açık bir GCS paketinde kullanıma sunduk.
Bir kuruluşta, modeli oluşturmaktan sorumlu bir ekip veya kişi, modeli dağıtmaktan sorumlu ise farklı bir ekip olması yaygın bir durumdur. Burada ele alacağımız adımlar, önceden eğitilmiş bir modeli nasıl alıp tahmin için dağıtacağınızı gösterecek.
Burada, model oluşturmak, uç noktaya dağıtmak ve tahmin almak için Vertex AI SDK'sını kullanacağız.
1. adım: Vertex SDK'yı yükleyin
Vertex AI SDK'yı yüklemek için Cloud Shell terminalinizde aşağıdaki komutu çalıştırın:
pip3 install google-cloud-aiplatform --upgrade --user
Bu SDK'yı Vertex'in birçok farklı bölümüyle etkileşim kurmak için kullanabiliriz.
2. adım: Model oluşturma ve uç nokta dağıtma
Ardından, bir Python dosyası oluşturup SDK'yı kullanarak bir model kaynağı oluşturacak ve bunu bir uç noktaya dağıtacağız. Cloud Shell'deki Dosya düzenleyiciden Dosya'yı ve ardından Yeni Dosya'yı seçin:
Dosyayı adlandırın deploy.py. Bu dosyayı düzenleyicinizde açın ve aşağıdaki kodu kopyalayın:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Ardından, Cloud Shell'deki Terminal'e geri dönün, cd ile kök dizininize geri gidin ve yeni oluşturduğunuz bu Python komut dosyasını çalıştırın:
cd ..
python3 deploy.py | tee deploy-output.txt
Kaynaklar oluşturulurken terminalinizde güncellemelerin kaydedildiğini görürsünüz. Bu işlem 10-15 dakika sürer. Doğru şekilde çalıştığından emin olmak için Vertex AI'daki konsolunuzun Modeller bölümüne gidin:
mgp-imported seçeneğini tıkladığınızda, ilgili model için uç noktanızın oluşturulduğunu görürsünüz:
Cloud Shell terminalinizde, uç nokta dağıtımınız tamamlandığında aşağıdakine benzer bir günlük görürsünüz:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
Bunu, dağıtılan uç noktanızla ilgili tahmin almak için sonraki adımda kullanacaksınız.
3. adım: Dağıtılan uç noktada tahminler alın
Cloud Shell düzenleyicinizde predict.py adlı yeni bir dosya oluşturun:
predict.py bağlantısını açın ve aşağıdaki kodu yapıştırın:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Ardından, terminalinize geri dönün ve tahmin dosyasındaki ENDPOINT_STRING yerine kendi uç noktanızı girmek için aşağıdakileri girin:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Şimdi, dağıtılan model uç noktamızdan tahmin almak için predict.py dosyasını çalıştırma zamanı:
python3 predict.py
API'nin yanıtının, test tahminimiz için tahmini yakıt verimliliğiyle birlikte kaydedildiğini görmeniz gerekir.
🎉 Tebrikler! 🎉
Vertex AI'ı kullanarak şunları yapmayı öğrendiniz:
- Özel bir kapsayıcıda eğitim kodu sağlayarak modeli eğitin. Bu örnekte TensorFlow modeli kullanılmıştır ancak özel container'lar kullanarak herhangi bir çerçeveyle oluşturulmuş bir modeli eğitebilirsiniz.
- Eğitim için kullandığınız iş akışının bir parçası olarak önceden oluşturulmuş bir container kullanarak TensorFlow modeli dağıtın.
- Model uç noktası oluşturun ve tahmin oluşturun.
Vertex AI'ın farklı bölümleri hakkında daha fazla bilgi edinmek için belgelere göz atın. 5. adımda başlattığınız eğitim işinin sonuçlarını görmek istiyorsanız Vertex konsolunuzun eğitim bölümüne gidin.
7. Temizleme
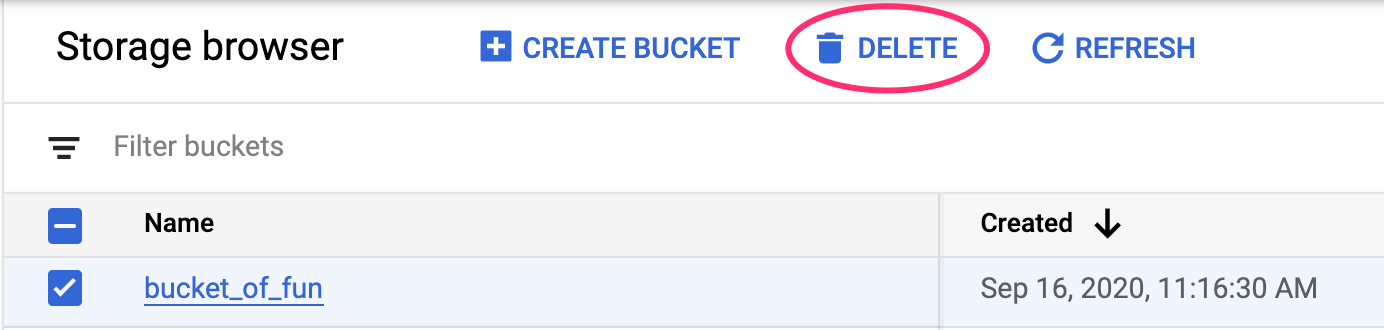
Dağıttığınız uç noktayı silmek için Vertex konsolunuzun Uç Noktalar bölümüne gidin ve silme simgesini tıklayın:

Cloud Console'unuzdaki gezinme menüsünü kullanarak depolama paketini silmek için Storage'a gidin, paketinizi seçin ve Sil'i tıklayın: