1. Обзор
В этой лабораторной работе вы научитесь использовать Vertex AI — недавно анонсированную Google Cloud управляемую платформу машинного обучения — для создания комплексных рабочих процессов машинного обучения. Вы узнаете, как перейти от необработанных данных к развернутой модели, и по окончании семинара будете готовы разрабатывать и внедрять собственные проекты машинного обучения с помощью Vertex AI. В этой лабораторной работе мы используем Cloud Shell для создания пользовательского образа Docker, чтобы продемонстрировать использование пользовательских контейнеров для обучения с помощью Vertex AI.
Хотя в данном случае для кода модели мы используем TensorFlow, вы легко можете заменить его другим фреймворком.
Чему вы научитесь
Вы научитесь:
- Создание и контейнеризация кода для обучения модели с использованием Cloud Shell.
- Отправьте пользовательское задание на обучение модели в Vertex AI.
- Разверните обученную модель на конечной точке и используйте эту конечную точку для получения прогнозов.
Общая стоимость запуска этой лабораторной работы в Google Cloud составляет около 2 долларов .
2. Введение в Vertex AI
В этой лабораторной работе используется новейший продукт для искусственного интеллекта, доступный в Google Cloud. Vertex AI интегрирует предложения машинного обучения в Google Cloud в единый процесс разработки. Ранее модели, обученные с помощью AutoML, и пользовательские модели были доступны через отдельные сервисы. Новое предложение объединяет оба варианта в единый API, а также включает другие новые продукты. Вы также можете перенести существующие проекты в Vertex AI. Если у вас есть какие-либо замечания, пожалуйста, посетите страницу поддержки .
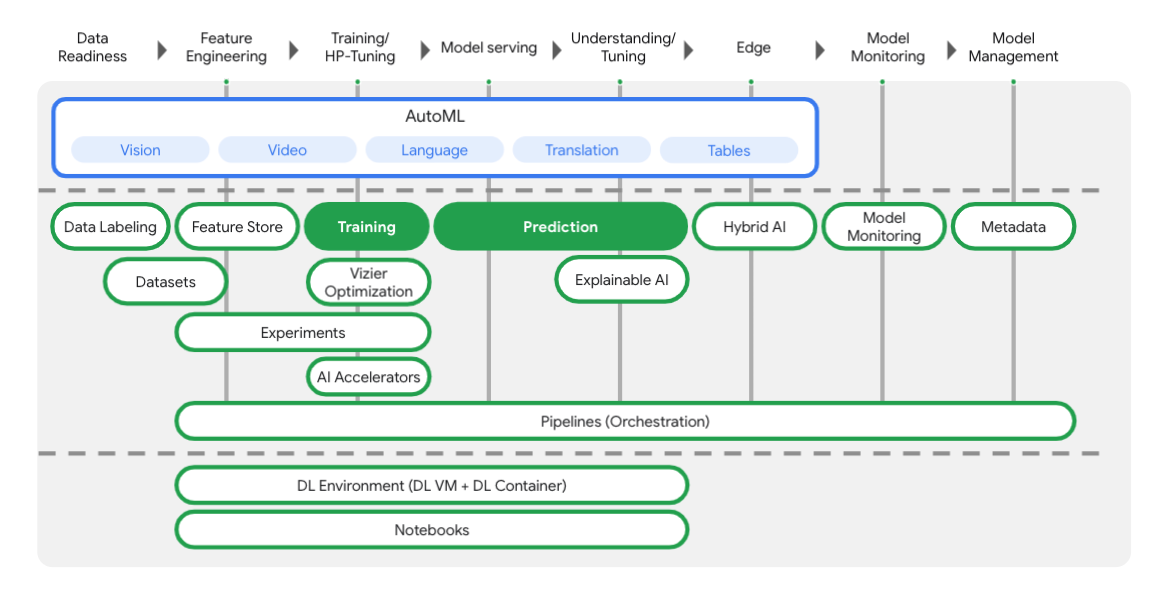
Vertex включает в себя множество различных инструментов, которые помогут вам на каждом этапе рабочего процесса машинного обучения, как вы можете видеть на диаграмме ниже. Мы сосредоточимся на использовании Vertex Training and Prediction , выделенных ниже.
3. Настройте свою среду.
Настройка среды для самостоятельного обучения
Войдите в Cloud Console и создайте новый проект или используйте существующий. (Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .)

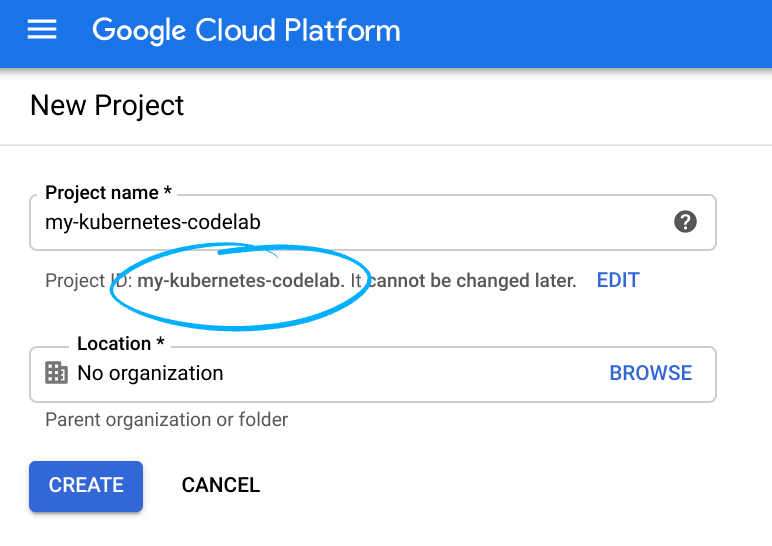
Запомните идентификатор проекта — уникальное имя для всех проектов Google Cloud (указанное выше имя уже занято и вам не подойдёт, извините!).
Далее вам потребуется включить оплату в Cloud Console, чтобы использовать ресурсы Google Cloud.
Выполнение этого практического задания не должно стоить дорого, если вообще что-либо. Обязательно следуйте инструкциям в разделе «Очистка», где указано, как отключить ресурсы, чтобы избежать дополнительных расходов после завершения этого урока. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Шаг 1: Запустите Cloud Shell
В этой лабораторной работе вы будете работать в сеансе Cloud Shell , который представляет собой интерпретатор команд, размещенный на виртуальной машине, работающей в облаке Google. Вы с таким же успехом могли бы выполнить этот раздел локально на своем компьютере, но использование Cloud Shell обеспечивает всем доступ к воспроизводимому опыту в согласованной среде. После завершения лабораторной работы вы можете повторить этот раздел на своем компьютере.
Активировать Cloud Shell
В правом верхнем углу консоли Cloud Console нажмите кнопку ниже, чтобы активировать Cloud Shell :

Если вы никогда раньше не запускали Cloud Shell, вам будет показан промежуточный экран (внизу), описывающий его назначение. В этом случае нажмите «Продолжить» (и вы больше никогда его не увидите). Вот как выглядит этот одноразовый экран:
Подготовка и подключение к Cloud Shell займут всего несколько минут.

Эта виртуальная машина оснащена всеми необходимыми инструментами разработки. Она предоставляет постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Большая часть, если не вся, работа в этом практическом задании может быть выполнена с помощью обычного браузера или вашего Chromebook.
После подключения к Cloud Shell вы увидите, что ваша аутентификация пройдена и что проект уже настроен на ваш идентификатор проекта.
Выполните следующую команду в Cloud Shell, чтобы подтвердить свою аутентификацию:
gcloud auth list
вывод команды
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте:
gcloud config list project
вывод команды
[core] project = <PROJECT_ID>
Если это не так, вы можете установить это с помощью следующей команды:
gcloud config set project <PROJECT_ID>
вывод команды
Updated property [core/project].
В Cloud Shell есть несколько переменных окружения, в том числе GOOGLE_CLOUD_PROJECT , которая содержит имя нашего текущего проекта Cloud. Мы будем использовать её в различных местах на протяжении этой лабораторной работы. Вы можете увидеть её, выполнив команду:
echo $GOOGLE_CLOUD_PROJECT
Шаг 2: Включение API
На следующих этапах вы увидите, где эти сервисы необходимы (и почему), а пока выполните эту команду, чтобы предоставить вашему проекту доступ к сервисам Compute Engine, Container Registry и Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
В результате должно появиться сообщение об успешном завершении, похожее на это:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Шаг 3: Создайте корзину облачного хранилища.
Для запуска задачи обучения на Vertex AI нам потребуется хранилище (storage bucket) для хранения сохраненных ресурсов модели. Выполните следующие команды в терминале Cloud Shell, чтобы создать хранилище:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Шаг 4: Создайте псевдоним для Python 3.
В этом лабораторном задании используется код на Python 3. Чтобы гарантировать использование Python 3 при запуске скриптов, которые вы создадите в этом задании, создайте псевдоним, выполнив следующую команду в Cloud Shell:
alias python=python3
Модель, которую мы будем обучать и использовать в этой лабораторной работе, построена на основе этого руководства из документации TensorFlow. В руководстве используется набор данных Auto MPG с Kaggle для прогнозирования топливной экономичности автомобиля.
4. Контейнеризация кода обучения
Мы отправим это задание на обучение в Vertex, поместив наш код обучения в контейнер Docker и загрузив этот контейнер в Google Container Registry . Используя этот подход, мы можем обучить модель, созданную с помощью любой платформы.
Шаг 1: Настройка файлов
Для начала, в терминале Cloud Shell выполните следующие команды, чтобы создать файлы, необходимые для нашего контейнера Docker:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Теперь у вас должна быть папка mpg/ , которая выглядит следующим образом:
+ Dockerfile
+ trainer/
+ train.py
Для просмотра и редактирования этих файлов мы будем использовать встроенный редактор кода Cloud Shell. Вы можете переключаться между редактором и терминалом, нажав на кнопку в правом верхнем углу панели меню Cloud Shell:

Шаг 2: Создайте Dockerfile.
Для контейнеризации нашего кода мы сначала создадим Dockerfile. В нашем Dockerfile мы укажем все команды, необходимые для запуска образа. Он установит все используемые нами библиотеки и настроит точку входа для нашего кода обучения.
В редакторе файлов Cloud Shell откройте каталог mpg/ и дважды щелкните по нему, чтобы открыть файл Dockerfile:
Затем скопируйте следующее в этот файл:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
В этом Dockerfile используется образ Docker для контейнеров глубокого обучения TensorFlow Enterprise 2.3 . Контейнеры глубокого обучения в Google Cloud поставляются со множеством распространенных фреймворков для машинного обучения и анализа данных, предварительно установленных в них. Мы используем TF Enterprise 2.3, Pandas, Scikit-learn и другие. После загрузки этого образа данный Dockerfile настраивает точку входа для нашего кода обучения, которую мы добавим на следующем шаге.
Шаг 3: Добавьте код для обучения модели.
В редакторе Cloud Shell откройте файл train.py и скопируйте приведенный ниже код (он адаптирован из руководства в документации TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
После того, как вы скопировали приведенный выше код в файл mpg/trainer/train.py , вернитесь в терминал в вашей оболочке Cloud Shell и выполните следующую команду, чтобы добавить имя вашего собственного сегмента в файл:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Шаг 4: Соберите и протестируйте контейнер локально.
В терминале выполните следующую команду, чтобы определить переменную с URI образа вашего контейнера в реестре контейнеров Google:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Затем соберите контейнер, выполнив следующую команду из корневой директории вашего каталога mpg :
docker build ./ -t $IMAGE_URI
После создания контейнера загрузите его в реестр контейнеров Google:
docker push $IMAGE_URI
Чтобы убедиться, что ваш образ был загружен в Container Registry, при переходе в раздел Container Registry в консоли вы должны увидеть что-то подобное:
После загрузки нашего контейнера в Container Registry мы готовы запустить задачу обучения пользовательской модели.
5. Запустите обучающую задачу на Vertex AI.
Vertex предоставляет два варианта обучения моделей:
- AutoML : Обучение высококачественных моделей с минимальными усилиями и без специальных знаний в области машинного обучения.
- Обучение на заказ : запускайте свои собственные обучающие приложения в облаке, используя один из предварительно созданных контейнеров Google Cloud, или используйте свой собственный.
В этой лабораторной работе мы используем собственное обучение с помощью нашего пользовательского контейнера в Google Container Registry. Для начала перейдите в раздел «Обучение» в разделе Vertex вашей облачной консоли:
Шаг 1: Начните обучение.
Нажмите «Создать» , чтобы ввести параметры для задания обучения и развернутой модели:
- В разделе «Набор данных» выберите «Нет управляемого набора данных» .
- Затем выберите в качестве метода обучения «Пользовательское обучение (расширенное)» и нажмите «Продолжить» .
- В поле «Название модели» введите
mpg(или как вы хотите назвать свою модель). - Нажмите «Продолжить»
На этапе настройки контейнера выберите «Пользовательский контейнер» :

В первом поле (изображение контейнера) нажмите «Обзор» и найдите контейнер, который вы только что загрузили в реестр контейнеров. Он должен выглядеть примерно так:
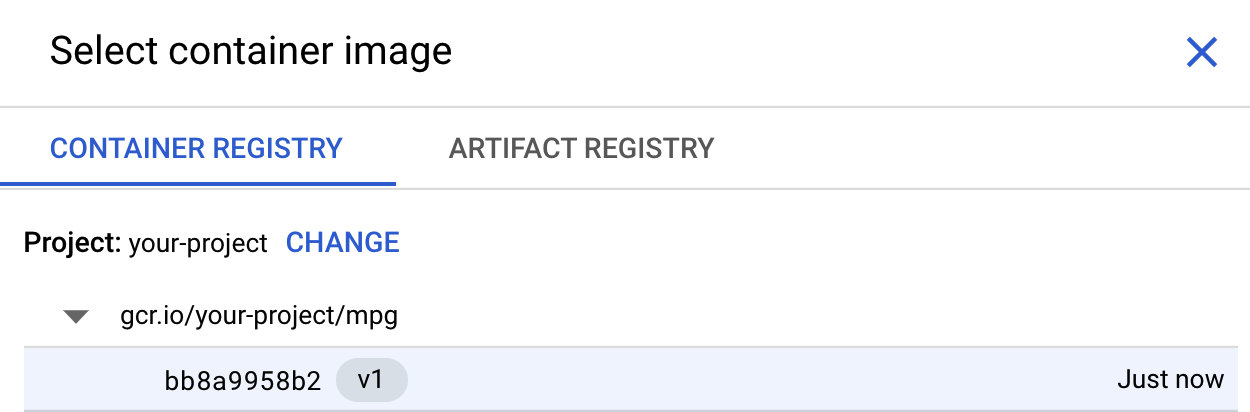
Оставьте остальные поля пустыми и нажмите «Продолжить» .
В этом руководстве мы не будем использовать настройку гиперпараметров, поэтому оставьте флажок «Включить настройку гиперпараметров» снятым и нажмите «Продолжить» .
В разделе «Вычисления и цены» оставьте выбранный регион без изменений и выберите n1-standard-4 в качестве типа машины:
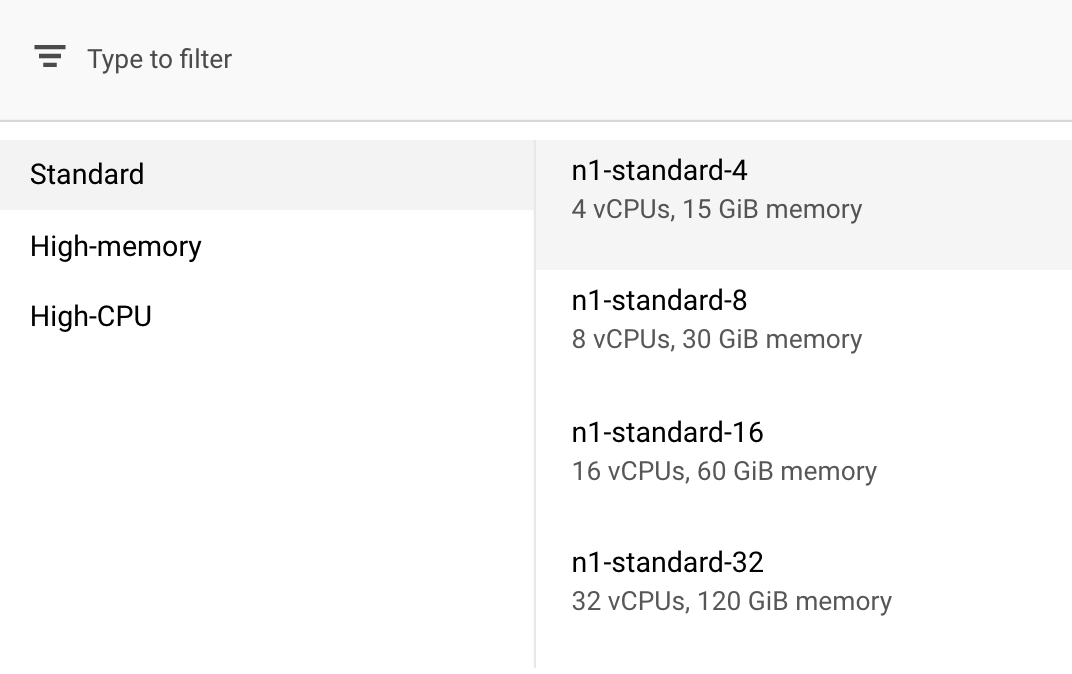
Поскольку модель в этой демонстрации обучается быстро, мы используем машину меньшего размера.
На этапе «Контейнер прогнозирования» выберите «Без контейнера прогнозирования» :
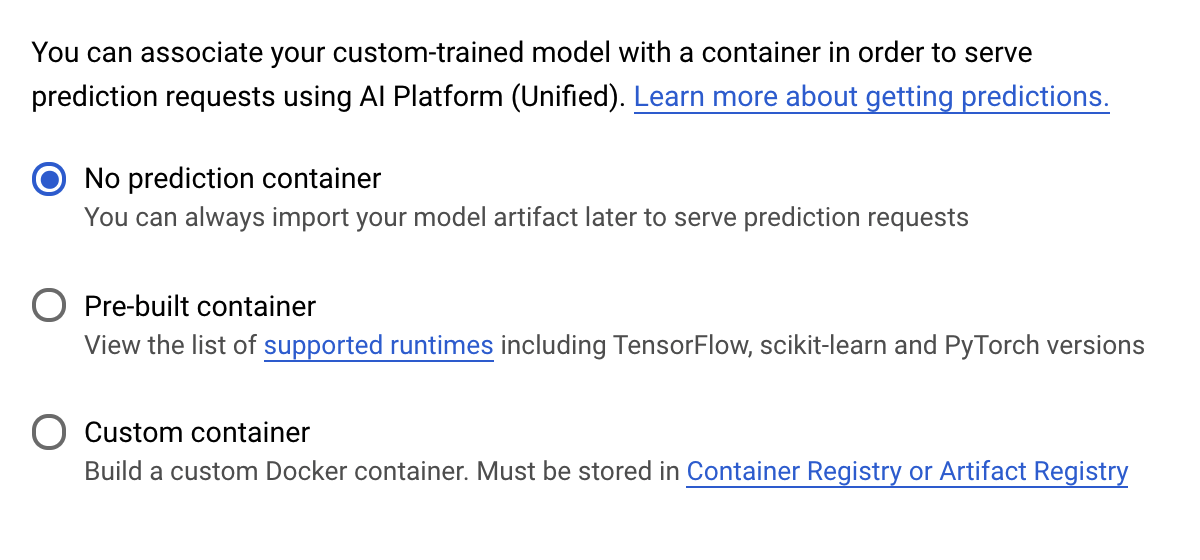
6. Разверните конечную точку модели.
На этом этапе мы создадим конечную точку для нашей обученной модели. Мы сможем использовать её для получения прогнозов от нашей модели через API Vertex AI. Для этого мы разместили версию экспортированных ресурсов обученной модели в общедоступном хранилище GCS .
В организации часто бывает так, что одна команда или отдельный человек отвечает за создание модели, а другая — за её развертывание. В этой статье мы рассмотрим шаги, которые покажут вам, как взять уже обученную модель и развернуть её для прогнозирования.
Здесь мы будем использовать SDK Vertex AI для создания модели, её развертывания на конечной точке и получения прогноза.
Шаг 1: Установите Vertex SDK
Для установки SDK Vertex AI в терминале Cloud Shell выполните следующие действия:
pip3 install google-cloud-aiplatform --upgrade --user
Мы можем использовать этот SDK для взаимодействия со многими различными частями Vertex.
Шаг 2: Создайте модель и разверните конечную точку.
Далее мы создадим файл Python и используем SDK для создания ресурса модели и его развертывания на конечной точке. В редакторе файлов в Cloud Shell выберите «Файл» , а затем «Новый файл» :
Назовите файл deploy.py . Откройте этот файл в редакторе и скопируйте следующий код:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Далее вернитесь в Терминал в Cloud Shell, cd обратно в корневую директорию и запустите созданный вами скрипт на Python:
cd ..
python3 deploy.py | tee deploy-output.txt
По мере создания ресурсов вы будете видеть обновления в своем терминале. Этот процесс займет 10-15 минут. Чтобы убедиться в его корректной работе, перейдите в раздел «Модели» в консоли Vertex AI:
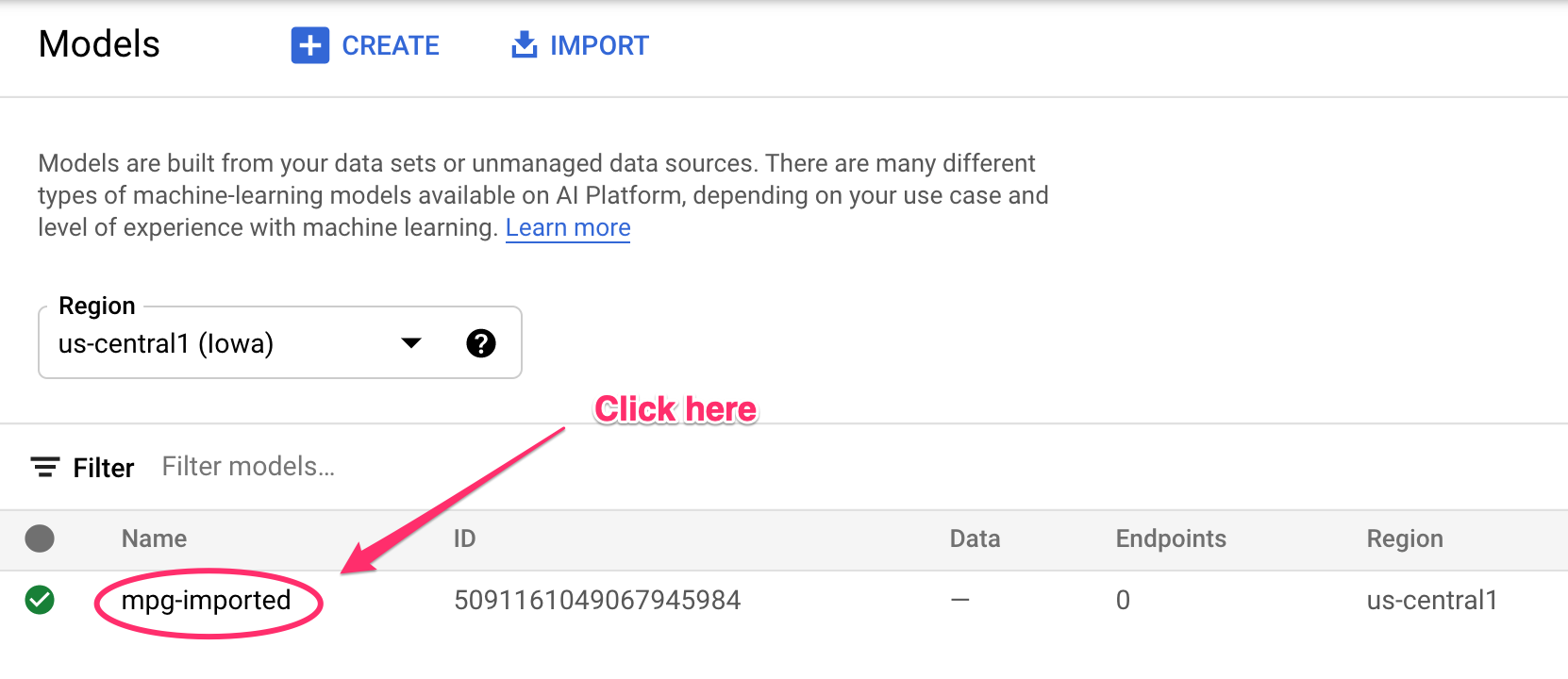
Нажмите на кнопку mgp-imported , и вы увидите, как создается конечная точка для этой модели:
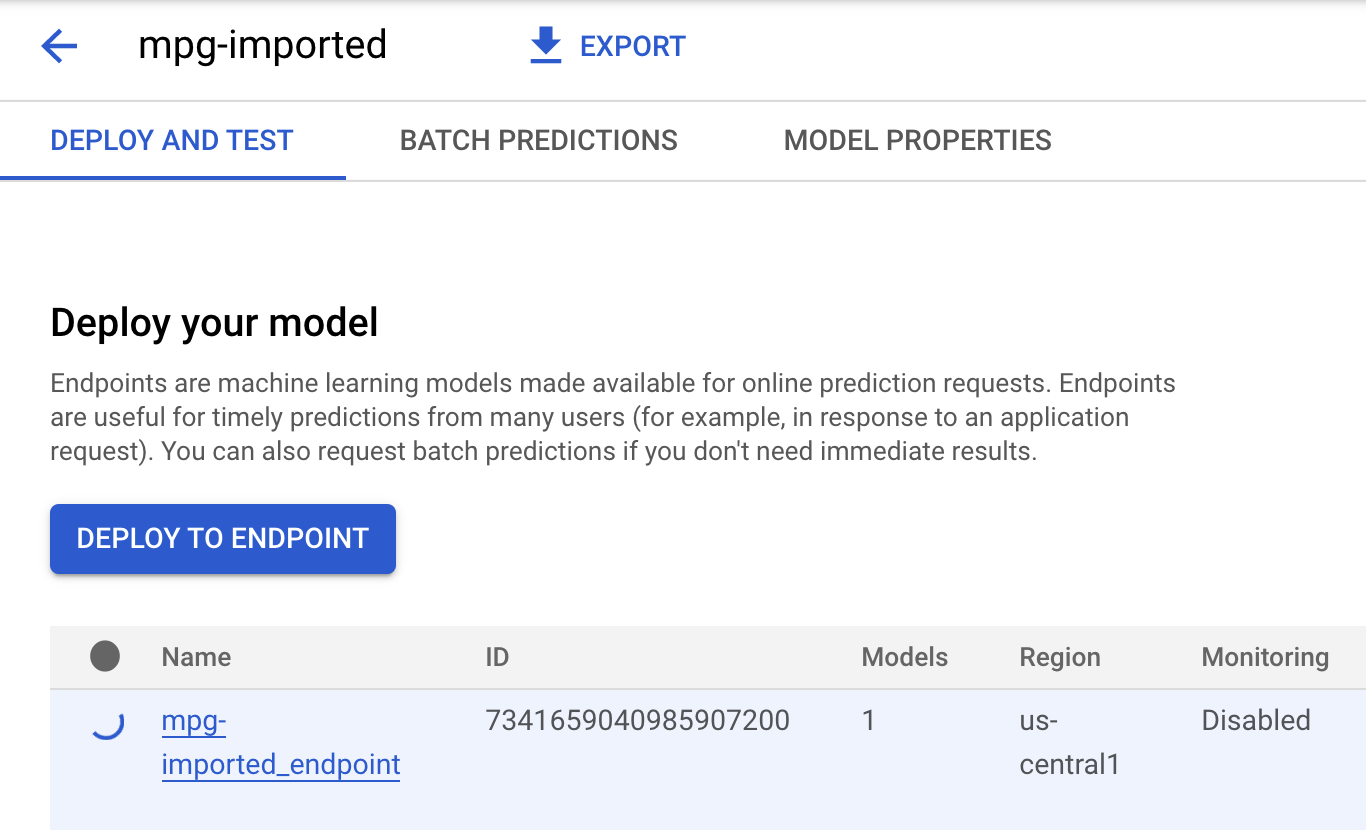
В терминале Cloud Shell после завершения развертывания конечной точки вы увидите примерно следующий лог:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
На следующем шаге вы используете это для получения прогноза для развернутой конечной точки.
Шаг 3: Получите прогнозы на развернутой конечной точке
В редакторе Cloud Shell создайте новый файл с именем predict.py :
Откройте predict.py и вставьте в него следующий код:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Далее вернитесь в терминал и введите следующее, чтобы заменить ENDPOINT_STRING в файле predict на вашу собственную конечную точку:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Теперь пришло время запустить файл predict.py , чтобы получить прогноз от конечной точки нашей развернутой модели:
python3 predict.py
В логе должен отображаться ответ API, а также прогнозируемый расход топлива, рассчитанный на основе наших тестовых данных.
🎉 Поздравляем! 🎉
Вы научились использовать Vertex AI для:
- Обучите модель, предоставив код обучения в пользовательском контейнере. В этом примере вы использовали модель TensorFlow, но вы можете обучить модель, созданную с помощью любой платформы, используя пользовательские контейнеры.
- Разверните модель TensorFlow, используя предварительно созданный контейнер, в рамках того же рабочего процесса, который вы использовали для обучения.
- Создайте конечную точку модели и сгенерируйте прогноз.
Чтобы узнать больше о различных компонентах Vertex AI, ознакомьтесь с документацией . Если вы хотите увидеть результаты обучения, начатого на шаге 5, перейдите в раздел обучения в консоли Vertex.
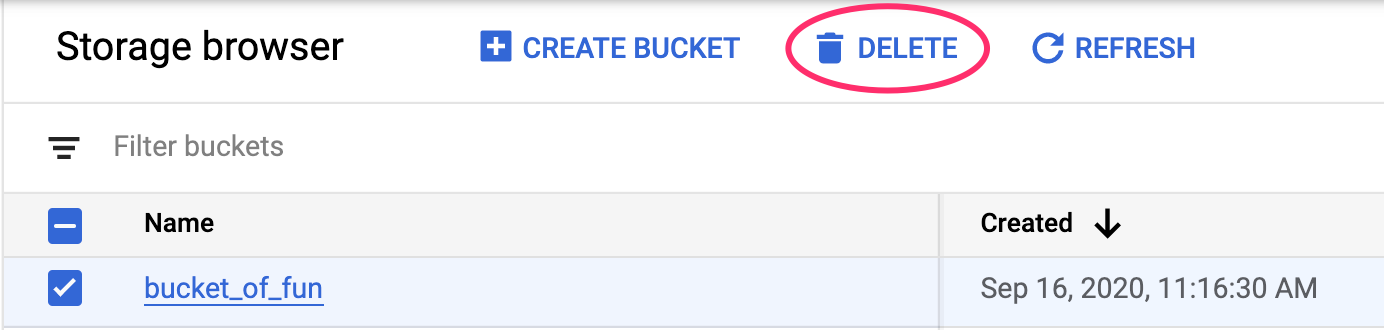
7. Уборка
Чтобы удалить развернутую конечную точку, перейдите в раздел «Конечные точки» в консоли Vertex и нажмите значок удаления:

Чтобы удалить сегмент хранилища, воспользуйтесь меню навигации в облачной консоли, перейдите в раздел «Хранилище», выберите свой сегмент и нажмите «Удалить».