1. Panoramica
In questo lab imparerai a utilizzare Vertex AI, la piattaforma ML gestita di Google Cloud annunciata di recente, per creare flussi di lavoro ML end-to-end. Imparerai a passare dai dati non elaborati al modello di cui è stato eseguito il deployment e, al termine di questo workshop, sarai pronto a sviluppare e mettere in produzione i tuoi progetti ML con Vertex AI. In questo lab utilizzeremo Cloud Shell per creare un'immagine Docker personalizzata per dimostrare i container personalizzati per l'addestramento con Vertex AI.
Sebbene qui utilizziamo TensorFlow per il codice del modello, potresti facilmente sostituirlo con un altro framework.
Cosa imparerai
Al termine del corso sarai in grado di:
- Creare e containerizzare il codice di addestramento del modello utilizzando Cloud Shell
- Inviare un job di addestramento di modelli personalizzati a Vertex AI
- Eseguire il deployment del modello addestrato in un endpoint e utilizzare questo endpoint per ottenere previsioni
Il costo totale per eseguire questo lab su Google Cloud è di circa 2$.
2. Introduzione a Vertex AI
Questo lab utilizza la più recente offerta di prodotti AI disponibile su Google Cloud. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. La nuova offerta combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Puoi anche migrare progetti esistenti su Vertex AI. In caso di feedback, consulta la pagina di supporto.
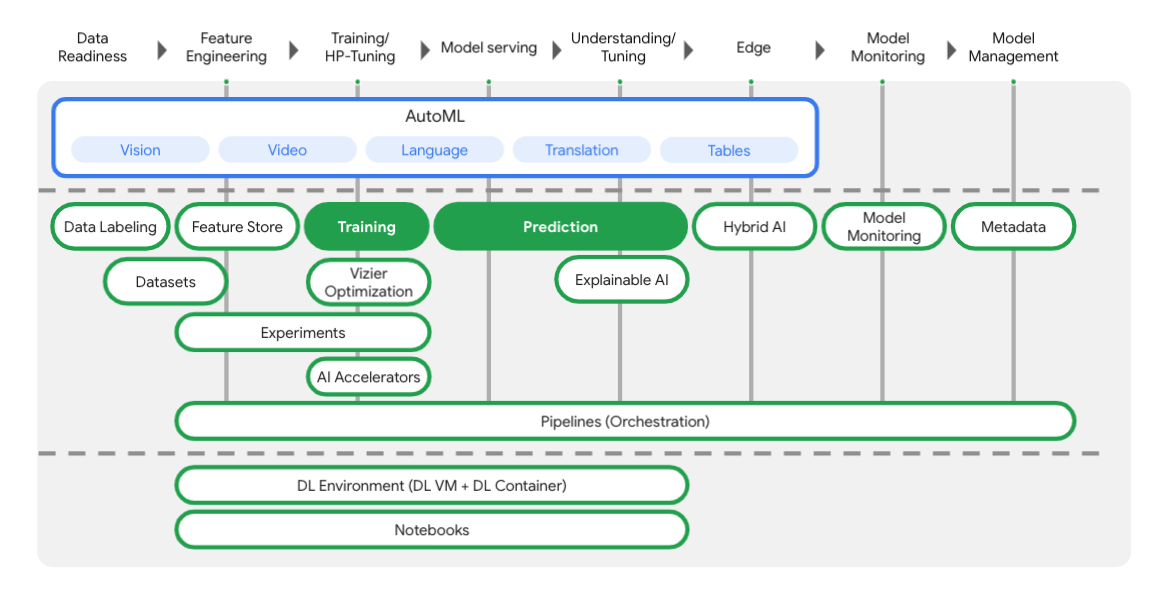
Come puoi vedere nel diagramma riportato di seguito, Vertex include molti strumenti diversi per aiutarti in ogni fase del workflow ML. Ci concentreremo sull'utilizzo di Vertex Addestramento e Previsione, evidenziati di seguito.
3. Configura l'ambiente
Configurazione dell'ambiente autonomo
Accedi a Cloud Console e crea un nuovo progetto o riutilizzane uno esistente. (Se non hai già un account Gmail o Google Workspace, devi crearne uno.)

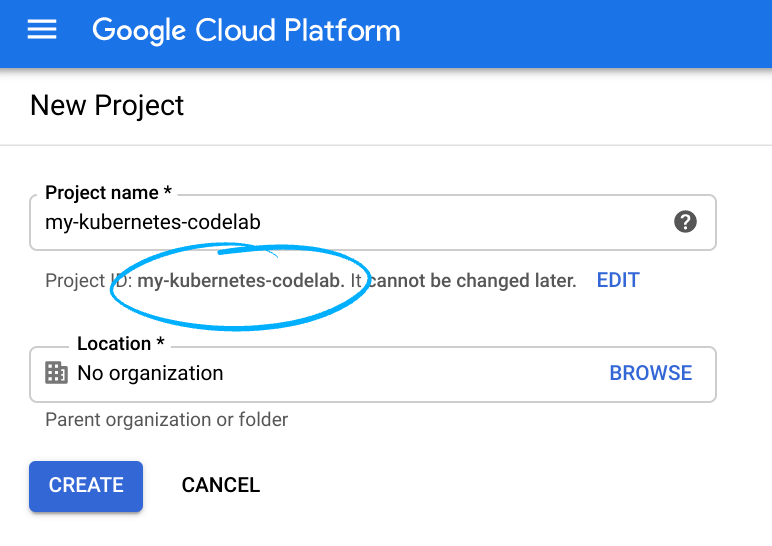
Ricorda l'ID progetto, un nome univoco tra tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, ci dispiace!).
Dopodiché, dovrai attivare la fatturazione nella console Cloud per utilizzare le risorse Google Cloud.
Completare questo codelab non dovrebbe costare molto, se non nulla. Assicurati di seguire le istruzioni nella sezione "Esegui la pulizia" che ti consigliano come arrestare le risorse in modo da non incorrere in addebiti oltre questo tutorial. I nuovi utenti di Google Cloud hanno diritto al programma di prova senza costi di 300$.
Passaggio 1: avvia Cloud Shell
In questo lab lavorerai in una sessione di Cloud Shell, un interprete di comandi ospitato da una macchina virtuale in esecuzione nel cloud di Google. Potresti eseguire facilmente questa sezione in locale sul tuo computer, ma l'utilizzo di Cloud Shell offre a chiunque l'accesso a un'esperienza riproducibile in un ambiente coerente. Dopo il lab, puoi riprovare questa sezione sul tuo computer.
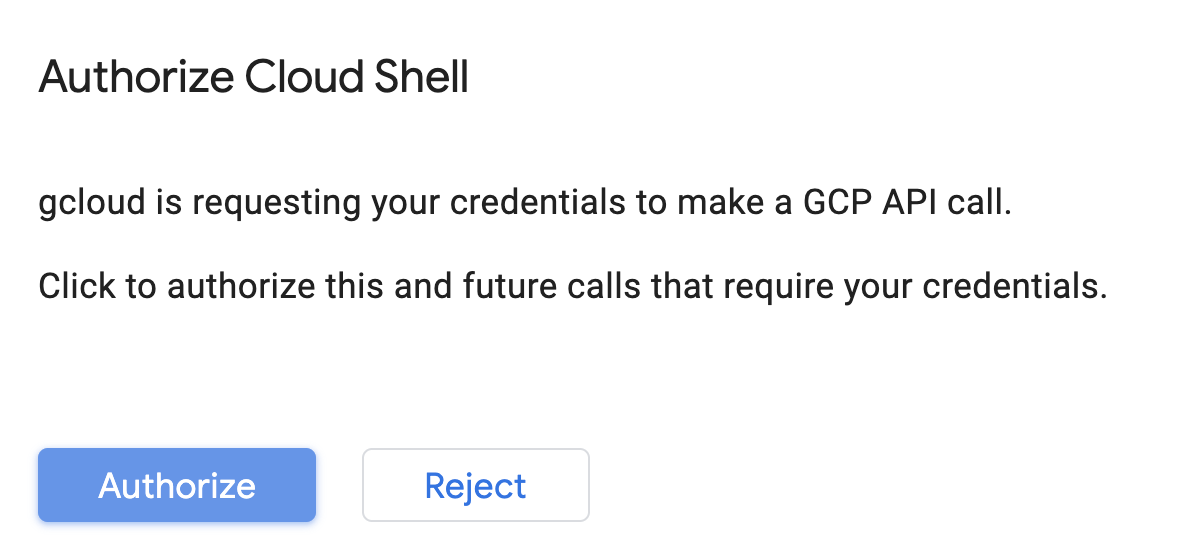
Attiva Cloud Shell
In alto a destra nella console Cloud, fai clic sul pulsante riportato di seguito per attivare Cloud Shell:

Se non hai mai avviato Cloud Shell, viene visualizzata una schermata intermedia (sotto la piega) che ne descrive le funzionalità. In questo caso, fai clic su Continua e non comparirà più. Ecco come si presenta la schermata intermedia:
Bastano pochi istanti per eseguire il provisioning e connettersi a Cloud Shell.

Questa macchina virtuale include tutti gli strumenti per sviluppatori di cui hai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Gran parte del lavoro per questo codelab, se non tutto, può essere svolto semplicemente con un browser o un Chromebook.
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo ID progetto.
Esegui questo comando in Cloud Shell per verificare che l'account sia autenticato:
gcloud auth list
Output comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto:
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
In caso contrario, puoi impostarlo con questo comando:
gcloud config set project <PROJECT_ID>
Output comando
Updated property [core/project].
Cloud Shell include alcune variabili di ambiente, tra cui GOOGLE_CLOUD_PROJECT che contiene il nome del nostro progetto Cloud corrente. La utilizzeremo in vari punti di questo lab. Puoi visualizzarla eseguendo questo comando:
echo $GOOGLE_CLOUD_PROJECT
Passaggio 2: attiva le API
Nei passaggi successivi vedrai dove (e perché) sono necessari questi servizi, ma per il momento esegui questo comando per concedere al tuo progetto l'accesso ai servizi Compute Engine, Container Registry e Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Dovrebbe essere visualizzato un messaggio di operazione riuscita simile a questo:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Passaggio 3: crea un bucket Cloud Storage
Per eseguire un job di addestramento su Vertex AI, abbiamo bisogno di un bucket di archiviazione in cui archiviare gli asset salvati nel modello. Esegui questi comandi nel terminale Cloud Shell per creare un bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Passaggio 4: crea un alias per Python 3
Il codice in questo lab utilizza Python 3. Per assicurarti di utilizzare Python 3 quando esegui gli script che creerai in questo lab, crea un alias eseguendo il comando seguente in Cloud Shell:
alias python=python3
Il modello che addestreremo e pubblicheremo in questo lab si basa su questo tutorial della documentazione di TensorFlow. Il tutorial utilizza il set di dati Auto MPG di Kaggle per prevedere il consumo di carburante di un veicolo.
4. Containerizza il codice di addestramento
Invieremo questo job di addestramento a Vertex inserendo il codice di addestramento in un container Docker ed eseguendo il push di questo container a Google Container Registry. Utilizzando questo approccio, possiamo addestrare un modello creato con qualsiasi framework.
Passaggio 1: configura i file
Per iniziare, dal terminale in Cloud Shell, esegui i seguenti comandi per creare i file di cui avremo bisogno per il nostro container Docker:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Ora dovresti avere una directory mpg/ simile alla seguente:
+ Dockerfile
+ trainer/
+ train.py
Per visualizzare e modificare questi file, utilizzeremo l'editor di codice integrato di Cloud Shell. Puoi spostarti tra l'editor e il terminale facendo clic sul pulsante nella barra dei menu in alto a destra in Cloud Shell:

Passaggio 2: crea un Dockerfile
Per containerizzare il codice, creiamo prima un Dockerfile. Nel Dockerfile includeremo tutti i comandi necessari per eseguire la nostra immagine. Installerà tutte le librerie che utilizziamo e configurerà il punto di accesso per il codice di addestramento.
Nell'editor di file di Cloud Shell, apri la directory mpg/ e poi fai doppio clic per aprire il Dockerfile:
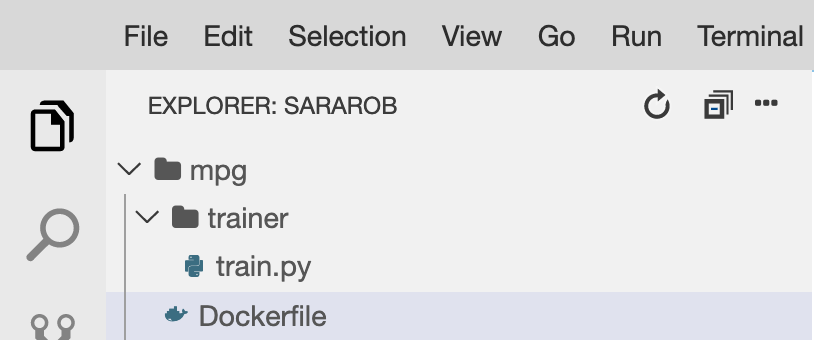
Quindi copia quanto segue in questo file:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Questo Dockerfile utilizza l'immagine Docker TensorFlow Enterprise 2.3 del container di deep learning . Deep Learning Containers su Google Cloud è dotato di molti framework comuni di ML e data science preinstallati. Quello che utilizziamo include TF Enterprise 2.3, Pandas, Scikit-learn e altri. Dopo aver scaricato l'immagine, questo Dockerfile configura il punto di accesso per il codice di addestramento, che aggiungeremo nel passaggio successivo.
Passaggio 3: aggiungi il codice di addestramento del modello
Nell'editor di Cloud Shell, apri il file train.py e copia il codice riportato di seguito (è adattato dal tutorial nella documentazione di TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Dopo aver copiato il codice riportato sopra nel file mpg/trainer/train.py, torna al terminale in Cloud Shell ed esegui il comando seguente per aggiungere il nome del tuo bucket al file:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Passaggio 4: crea e testa il container in locale
Dal terminale, esegui il comando seguente per definire una variabile con l'URI dell'immagine container in Google Container Registry:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Quindi, crea il container eseguendo il comando seguente dalla directory principale di mpg:
docker build ./ -t $IMAGE_URI
Una volta creato il container, eseguine il push in Google Container Registry:
docker push $IMAGE_URI
Per verificare che l'immagine sia stata inviata a Container Registry, dovresti vedere qualcosa di simile a questo quando vai alla sezione Container Registry della console:
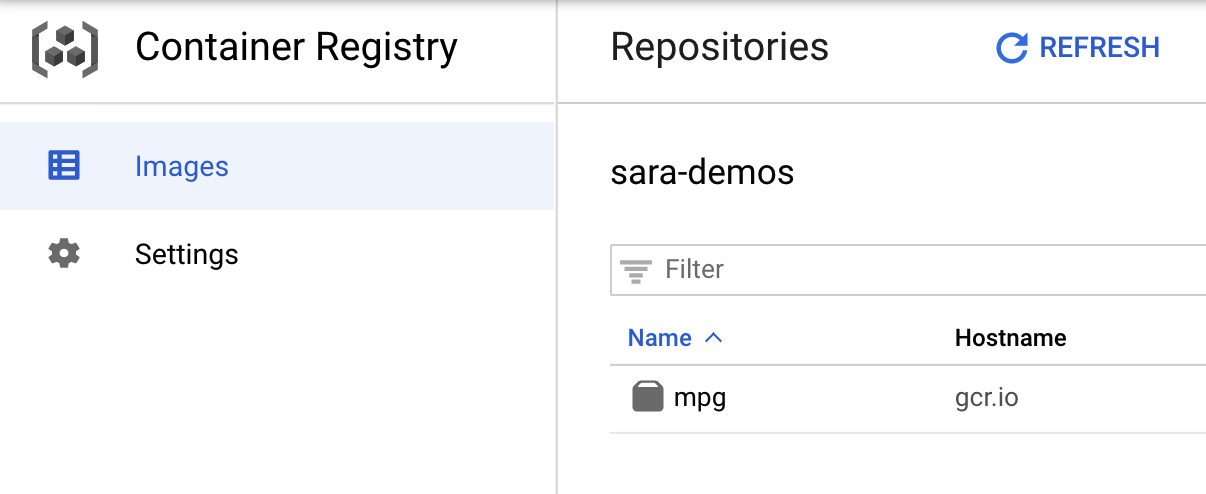
Dopo aver eseguito il push del container in Container Registry, ora puoi avviare un job di addestramento di modelli personalizzati.
5. Esegui un job di addestramento su Vertex AI
Vertex offre due opzioni per l'addestramento dei modelli:
- AutoML: addestra modelli di alta qualità con il minimo sforzo e senza dover avere esperienza nel machine learning.
- Addestramento personalizzato: esegui le tue applicazioni di addestramento personalizzate nel cloud utilizzando uno dei container predefiniti di Google Cloud o utilizzane uno tuo.
In questo lab utilizzeremo l'addestramento personalizzato tramite il nostro container personalizzato su Google Container Registry. Per iniziare, vai alla sezione Addestramento nella sezione Vertex della console Cloud:
Passaggio 1: avvia il job di addestramento
Fai clic su Crea per inserire i parametri per il job di addestramento e il modello di cui è stato eseguito il deployment:
- In Set di dati, seleziona Nessun set di dati gestito.
- Quindi seleziona Addestramento personalizzato (avanzato) come metodo di addestramento e fai clic su Continua.
- Inserisci
mpg(o come preferisci chiamare il tuo modello) in Nome modello. - Fai clic su Continua.
Nel passaggio Impostazioni container, seleziona Container personalizzato:

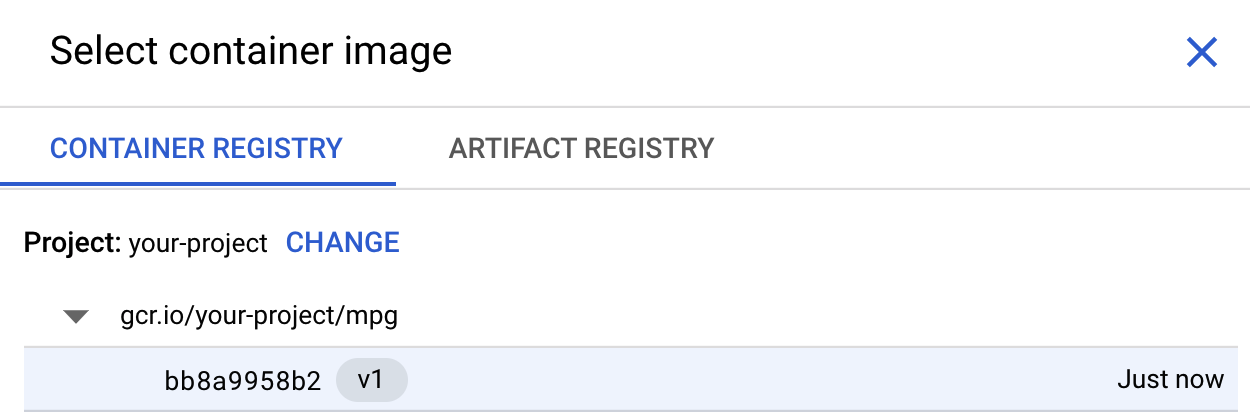
Nella prima casella (Immagine container), fai clic su Sfoglia e trova il container di cui hai appena eseguito il push in Container Registry. Il sito dovrebbe avere il seguente aspetto:
Lascia vuoti gli altri campi e fai clic su Continua.
In questo tutorial non utilizzeremo l'ottimizzazione degli iperparametri, quindi lascia la casella Abilita ottimizzazione degli iperparametri deselezionata e fai clic su Continua.
In Compute e prezzi, lascia la regione selezionata così com'è e seleziona n1-standard-4 come tipo di macchina:
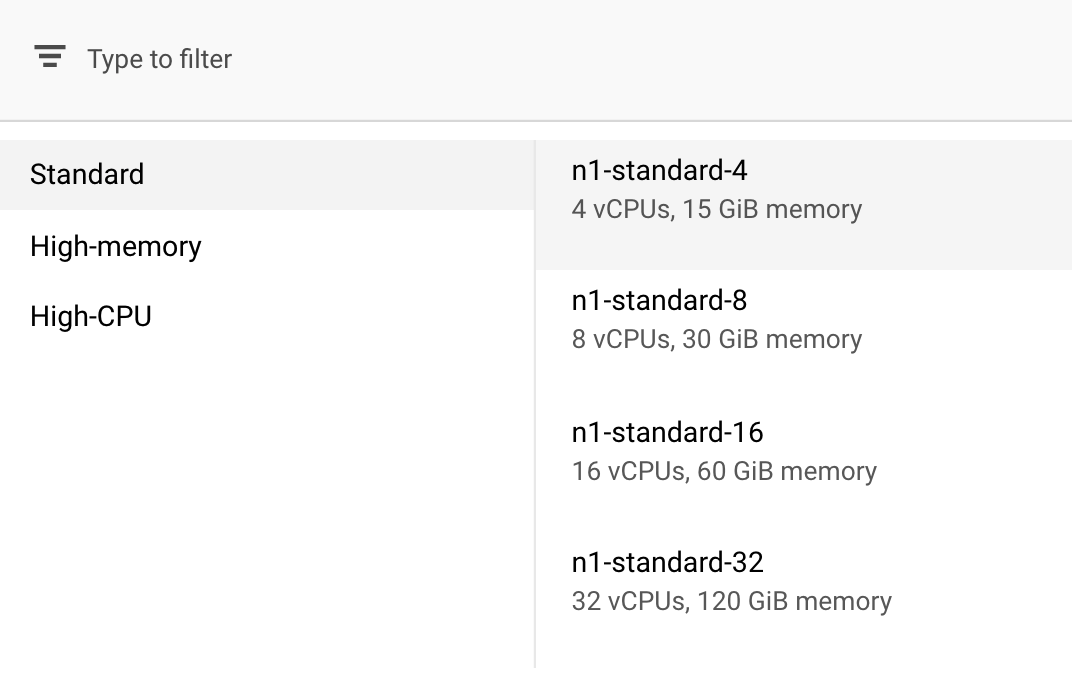
Poiché il modello in questa demo si addestra rapidamente, utilizziamo un tipo di macchina più piccolo.
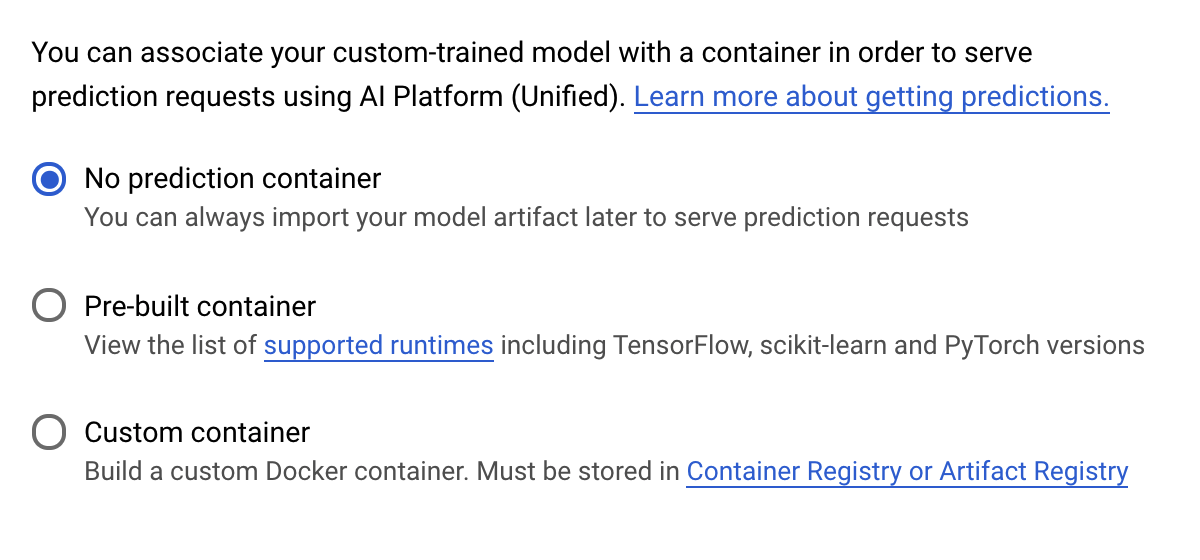
Nel passaggio Container di previsione, seleziona Nessun container di previsione:
6. Esegui il deployment di un endpoint del modello
In questo passaggio creeremo un endpoint per il nostro modello addestrato. Possiamo utilizzarlo per ottenere previsioni sul nostro modello tramite l'API Vertex AI. A questo scopo, abbiamo reso disponibile una versione degli asset del modello addestrato esportato in un bucket GCS pubblico.
In un'organizzazione, è normale che un team o una persona sia responsabile della creazione del modello e un team diverso sia responsabile del deployment. I passaggi che eseguiremo qui ti mostreranno come prendere un modello già addestrato ed eseguirne il deployment per la previsione.
Qui utilizzeremo l'SDK Vertex AI per creare un modello, eseguirne il deployment in un endpoint e ottenere una previsione.
Passaggio 1: installa l'SDK Vertex
Dal terminale Cloud Shell, esegui il comando seguente per installare l'SDK Vertex AI:
pip3 install google-cloud-aiplatform --upgrade --user
Possiamo utilizzare questo SDK per interagire con molte parti diverse di Vertex.
Passaggio 2: crea il modello ed esegui il deployment dell'endpoint
Il passaggio successivo prevede la creazione di un file Python e l'utilizzo dell'SDK per creare una risorsa modello ed eseguirne il deployment in un endpoint. Nell'editor di file di Cloud Shell, seleziona File e poi Nuovo file:
Assegna al file il nome deploy.py. Apri questo file nell'editor e copia il codice seguente:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Quindi, torna al terminale in Cloud Shell, esegui di nuovo cd nella directory principale ed esegui lo script Python che hai appena creato:
cd ..
python3 deploy.py | tee deploy-output.txt
Vedrai gli aggiornamenti registrati nel terminale man mano che le risorse vengono create. L'esecuzione richiederà 10-15 minuti. Per assicurarti che funzioni correttamente, vai alla sezione Modelli della console in Vertex AI:
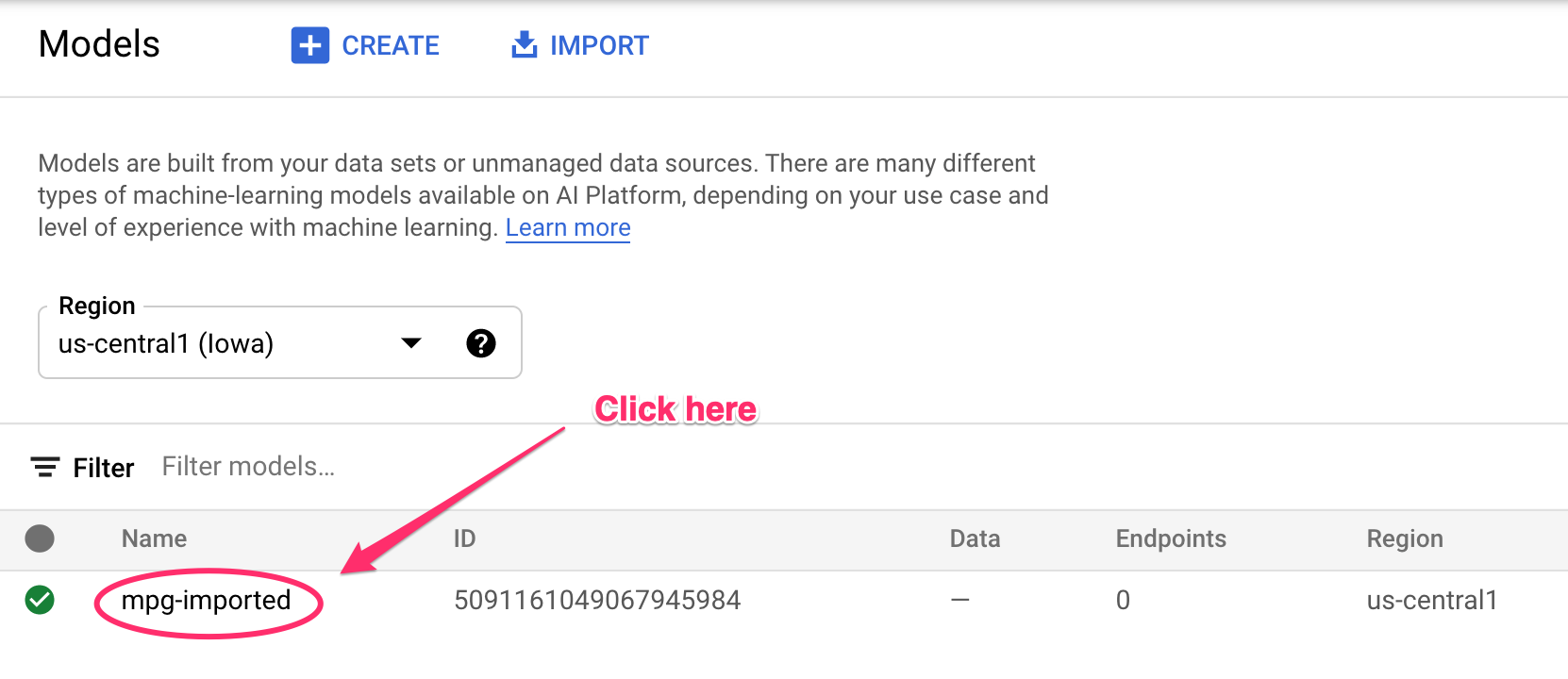
Fai clic su mgp-imported e dovresti vedere la creazione dell'endpoint per questo modello:
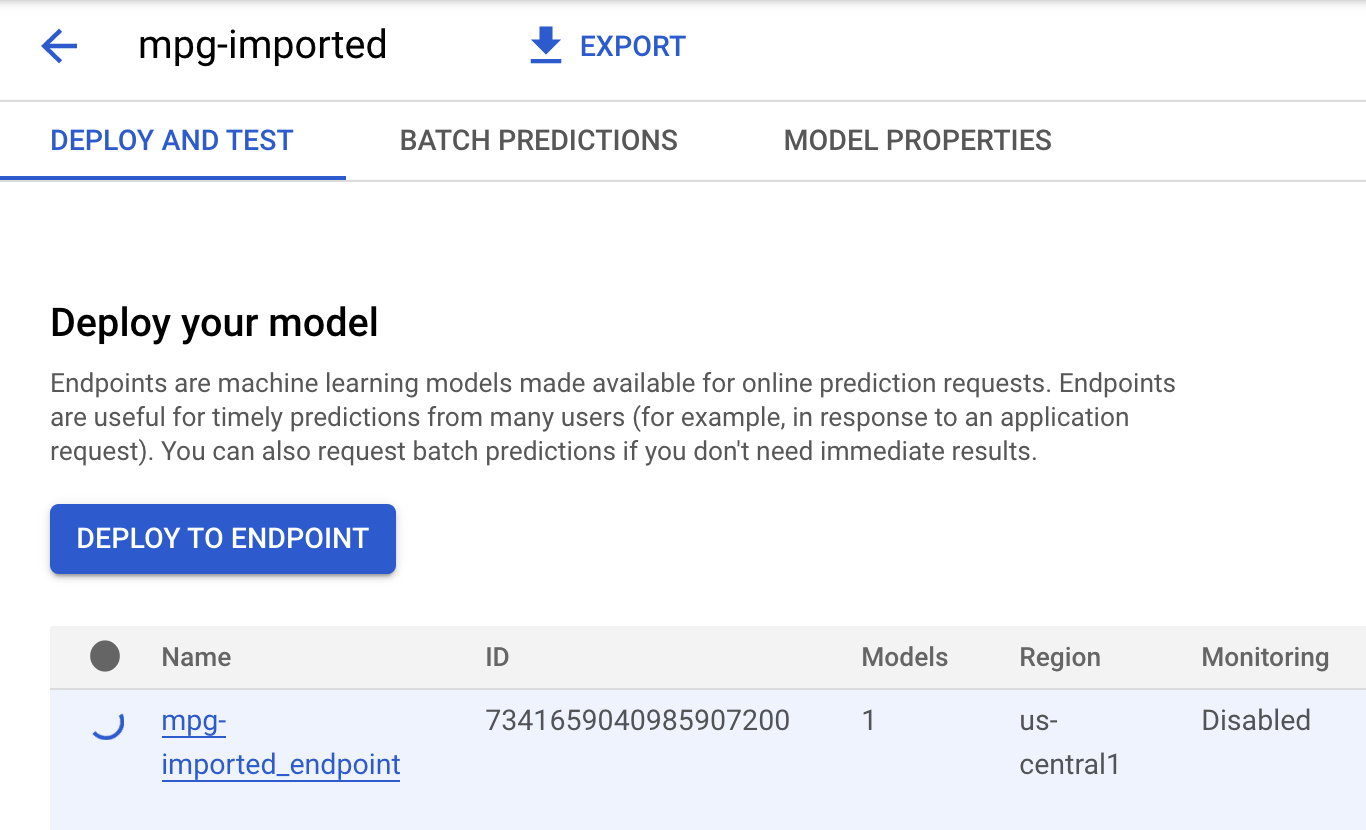
Nel terminale Cloud Shell, vedrai un log simile al seguente al termine del deployment dell'endpoint:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
Lo utilizzerai nel passaggio successivo per ottenere una previsione sull'endpoint di cui è stato eseguito il deployment.
Passaggio 3: ottieni previsioni sull'endpoint di cui è stato eseguito il deployment
Nell'editor di Cloud Shell, crea un nuovo file denominato predict.py:
Apri predict.py e incolla il codice seguente:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Quindi, torna al terminale e inserisci quanto segue per sostituire ENDPOINT_STRING nel file di previsione con il tuo endpoint:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Ora è il momento di eseguire il file predict.py per ottenere una previsione dall'endpoint del modello di cui è stato eseguito il deployment:
python3 predict.py
Dovresti vedere la risposta dell'API registrata, insieme al consumo di carburante previsto per la nostra previsione di test.
🎉 Congratulazioni! 🎉
Hai imparato come utilizzare Vertex AI per:
- Addestrare un modello fornendo il codice di addestramento in un container personalizzato. In questo esempio hai utilizzato un modello TensorFlow, ma puoi addestrare un modello creato con qualsiasi framework utilizzando container personalizzati.
- Eseguire il deployment di un modello TensorFlow utilizzando un container predefinito come parte dello stesso flusso di lavoro utilizzato per l'addestramento.
- Creare un endpoint del modello e generare una previsione.
Per saperne di più sulle diverse parti di Vertex AI, consulta la documentazione. Se vuoi visualizzare i risultati del job di addestramento avviato nel passaggio 5, vai alla sezione di addestramento della console Vertex.
7. Esegui la pulizia
Per eliminare l'endpoint di cui hai eseguito il deployment, vai alla sezione Endpoint della console Vertex e fai clic sull'icona Elimina:

Per eliminare il bucket di archiviazione, utilizza il menu di navigazione nella console Cloud, vai a Storage, seleziona il bucket e fai clic su Elimina: