1. Visão geral
Neste laboratório, você vai aprender a usar a Vertex AI, a plataforma de ML gerenciada recém-anunciada do Google Cloud, para criar fluxos de trabalho de ML completos. Você vai aprender a transformar dados brutos em modelos implantados e vai sair deste workshop pronto para desenvolver e produzir seus próprios projetos de ML com a Vertex AI. Neste laboratório, estamos usando o Cloud Shell para criar uma imagem Docker personalizada para demonstrar contêineres personalizados para treinamento com a Vertex AI.
Ainda que você esteja usando o TensorFlow para o código do modelo agora, ele pode ser facilmente substituído por outro framework.
Conteúdo do laboratório
Você vai aprender a:
- Criar e conteinerizar o código de treinamento de modelo usando o Cloud Shell
- Enviar um job de treinamento de modelo personalizado para a Vertex AI
- Implantar seu modelo treinado em um endpoint e usar esse endpoint para coletar previsões
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$2.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos existentes para a Vertex AI. Se você tiver algum feedback, consulte a página de suporte.
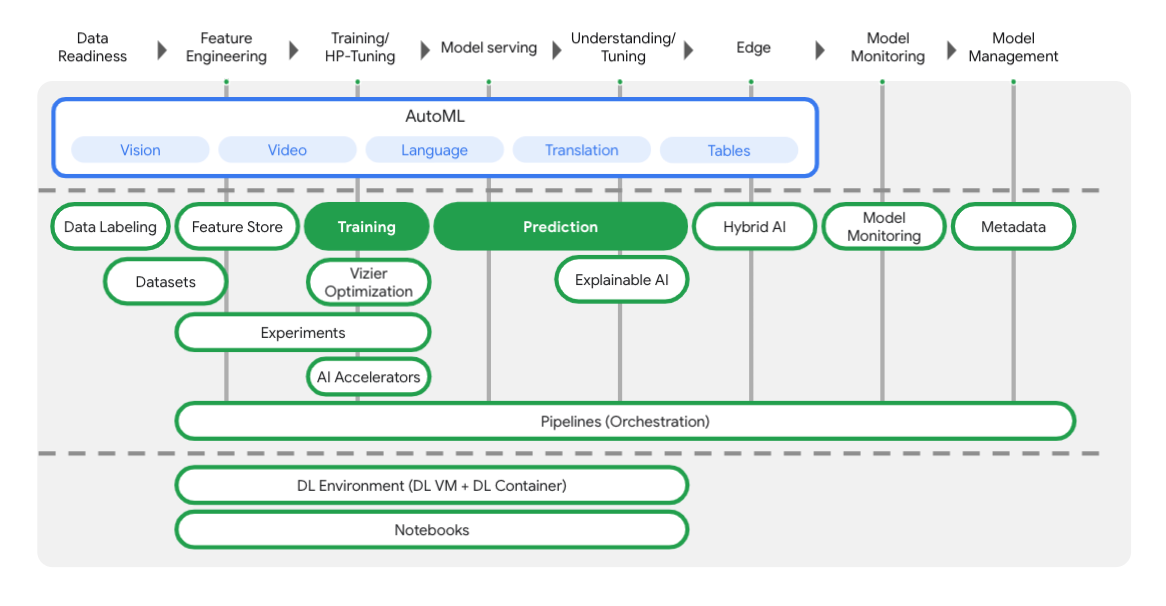
A Vertex inclui várias ferramentas diferentes para ajudar você em cada estágio do fluxo de trabalho de ML, como mostrado no diagrama abaixo. Vamos nos concentrar no uso do Vertex Training e da Prediction, destacados abaixo.
3. Configurar o ambiente
Configuração de ambiente personalizada
Faça login no console do Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma create one.

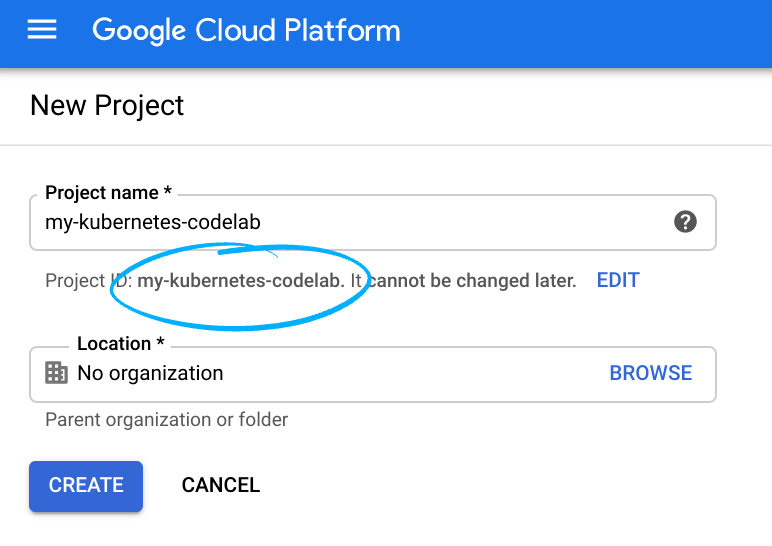
Lembre-se do ID do projeto, um nome exclusivo em todos os projetos do Google Cloud (o nome acima já foi escolhido e não servirá para você, desculpe!).
Em seguida, será necessário ativar o faturamento no console do Cloud para usar os recursos do Google Cloud.
A execução deste codelab não será muito cara, se for o caso. Siga todas as instruções na seção "Limpeza", que orienta você sobre como desligar recursos para não incorrer em cobranças além deste tutorial. Os novos usuários do Google Cloud se qualificam para o programa de teste sem custo financeiro de US$300.
Etapa 1: iniciar o Cloud Shell
Neste laboratório, você vai trabalhar em uma sessão do Cloud Shell, que é um interpretador de comandos hospedado por uma máquina virtual em execução na nuvem do Google. A sessão também pode ser executada localmente no seu computador, mas se você usar o Cloud Shell, todas as pessoas vão ter acesso a uma experiência reproduzível em um ambiente consistente. Após concluir o laboratório, é uma boa ideia testar a sessão no seu computador.
Ativar o Cloud Shell
No canto superior direito do console do Cloud, clique no botão abaixo para ativar o Cloud Shell:

Se você nunca iniciou o Cloud Shell, vai ver uma tela intermediária (abaixo da dobra) com a descrição dele. Se esse for o caso, clique em Continuar e você não a verá novamente. Esta é a aparência dessa tela única:
Leva apenas alguns instantes para provisionar e se conectar ao Cloud Shell.

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Praticamente todo o seu trabalho neste codelab pode ser feito em um navegador ou no seu Chromebook.
Depois de se conectar ao Cloud Shell, você já estará autenticado e o projeto já estará configurado com seu ID do projeto.
Execute o seguinte comando no Cloud Shell para confirmar que você está autenticado:
gcloud auth list
Resposta ao comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto:
gcloud config list project
Resposta ao comando
[core] project = <PROJECT_ID>
Se o projeto não estiver configurado, faça a configuração usando este comando:
gcloud config set project <PROJECT_ID>
Resposta ao comando
Updated property [core/project].
O Cloud Shell tem algumas variáveis de ambiente, incluindo a GOOGLE_CLOUD_PROJECT que contém o nome do nosso projeto na nuvem atual. Vamos usar isso em vários lugares neste laboratório. É possível ver essa variável ao executar:
echo $GOOGLE_CLOUD_PROJECT
Etapa 2: ativar as APIs
Nas próximas etapas, você vai entender onde e por que esses serviços são necessários. Por enquanto, apenas execute este comando para conceder ao seu projeto acesso aos serviços do Compute Engine, Container Registry e Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Uma mensagem semelhante a esta vai aparecer:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Etapa 3: criar um bucket do Cloud Storage
Para executar um job de treinamento na Vertex AI, precisamos de um bucket de armazenamento para armazenar nossos recursos de modelo salvos. Execute os comandos a seguir no terminal do Cloud Shell para criar um bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Etapa 4: criar um alias do Python 3
O código neste laboratório usa o Python 3. Para garantir que você use o Python 3 ao executar os scripts que serão criados neste laboratório, crie um alias executando o seguinte no Cloud Shell:
alias python=python3
O modelo que vamos treinar e disponibilizar neste laboratório é baseado neste tutorial da documentação do TensorFlow. O tutorial usa o conjunto de dados Auto MPG do Kaggle para prever a eficiência de combustível de um veículo.
4. Conteinerizar o código de treinamento
Vamos enviar este job de treinamento para a Vertex adicionando o código do treinamento a um contêiner do Docker e enviando esse contêiner por push para o Google Container Registry. Com essa abordagem, é possível treinar um modelo criado com qualquer framework.
Etapa 1: configurar arquivos
Para começar, no terminal do Cloud Shell, execute os comandos a seguir para criar os arquivos necessários para o contêiner do Docker:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Agora você terá um diretório mpg/ semelhante a este:
+ Dockerfile
+ trainer/
+ train.py
Para visualizar e editar esses arquivos, vamos usar o editor de código integrado do Cloud Shell. É possível alternar entre o editor e o terminal clicando no botão na barra de menus no canto superior direito do Cloud Shell:

Etapa 2: criar um Dockerfile
Para conteinerizar nosso código, primeiro vamos criar um Dockerfile. No Dockerfile, vamos incluir todos os comandos necessários para executar nossa imagem. Isso vai resultar na instalação de todas as bibliotecas que você estiver usando e na configuração do ponto de entrada do seu código de treinamento.
No editor de arquivos do Cloud Shell, abra o diretório mpg/ e clique duas vezes para abrir o Dockerfile:
Em seguida, copie o seguinte para esse arquivo:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Este Dockerfile usa a imagem Docker do Deep Learning Container TensorFlow Enterprise 2.3. O Deep Learning Containers no Google Cloud vem com muitas estruturas comuns de ML e ciência de dados pré-instaladas. O que estamos usando inclui TF Enterprise 2.3, Pandas, Scikit-learn e outros. Depois de fazer o download dessa imagem, este Dockerfile configura o ponto de entrada para nosso código de treinamento, que vamos adicionar na próxima etapa.
Etapa 3: adicionar código de treinamento de modelo
No editor do Cloud Shell, abra o arquivo train.py e copie o código abaixo (isso é adaptado do tutorial na documentação do TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Depois de copiar o código acima para o arquivo mpg/trainer/train.py, volte ao terminal no Cloud Shell e execute o comando a seguir para adicionar seu próprio nome de bucket ao arquivo:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Etapa 4: criar e testar o contêiner de forma local
No seu terminal, execute o comando a seguir para definir uma variável com o URI da imagem do contêiner no Google Container Registry:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Em seguida, crie o contêiner executando o seguinte comando na raiz do diretório mpg:
docker build ./ -t $IMAGE_URI
Depois de criar o contêiner, envie-o para o Google Container Registry:
docker push $IMAGE_URI
Para verificar se a imagem foi enviada para o Container Registry, você verá algo como isto ao navegar até a seção Container Registry do console:
Depois que nosso contêiner for enviado para o Container Registry, estará tudo pronto para iniciar um job de treinamento de modelo personalizado.
5. execute um job de treinamento na Vertex AI
Há duas opções de modelos de treinamento na Vertex:
- AutoML: treine modelos de alta qualidade com esforço mínimo e experiência em ML.
- Treinamento personalizado: execute seus aplicativos de treinamento personalizados na nuvem usando um dos contêineres pré-criados do Google Cloud ou seus próprios.
Neste laboratório, estamos usando o treinamento exclusivo do nosso próprio contêiner personalizado no Google Container Registry. Para começar, navegue até a seção Treinamento na seção da Vertex do console do Cloud:
Etapa 1: iniciar o job de treinamento
Clique em Criar para inserir os parâmetros do seu job de treinamento e modelo implantado:
- Em Conjunto de dados, selecione Sem conjunto de dados gerenciado.
- Selecione Treinamento personalizado (avançado) como seu método de treinamento e clique em Continuar.
- Insira
mpg(ou como quiser nomear seu modelo) em Nome do modelo. - Clique em Continuar.
Na etapa "Configurações do contêiner", selecione Container personalizado:

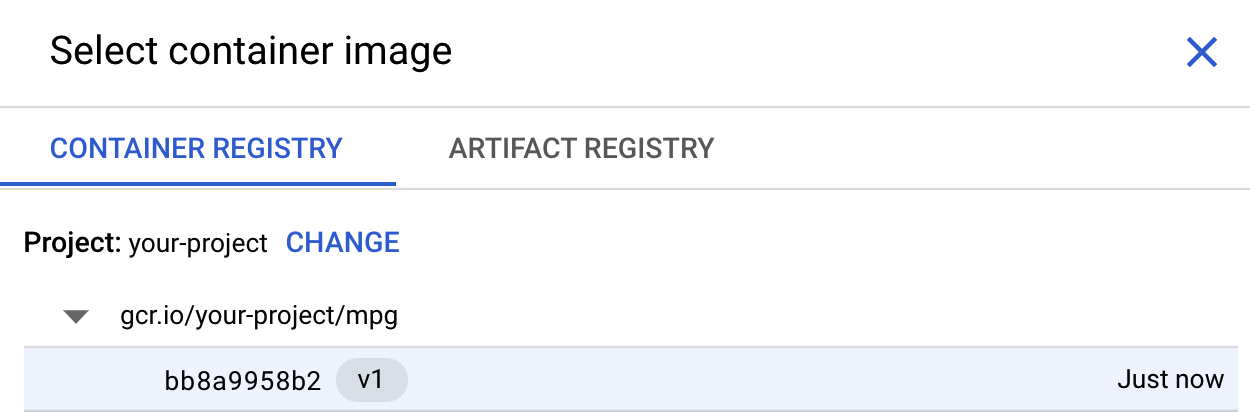
Na primeira caixa (imagem do contêiner), clique em Procurar e encontre o contêiner que você acabou de enviar para o Container Registry. O código será semelhante a este:
Deixe os demais campos em branco e clique em Continuar.
Você não vai usar o ajuste de hiperparâmetros neste tutorial, então pode deixar a caixa Ativar o ajuste de hiperparâmetros desmarcada e clicar em Continuar.
Em Computação e preços, deixe a região selecionada como está e selecione n1-standard-4 como o tipo de máquina:
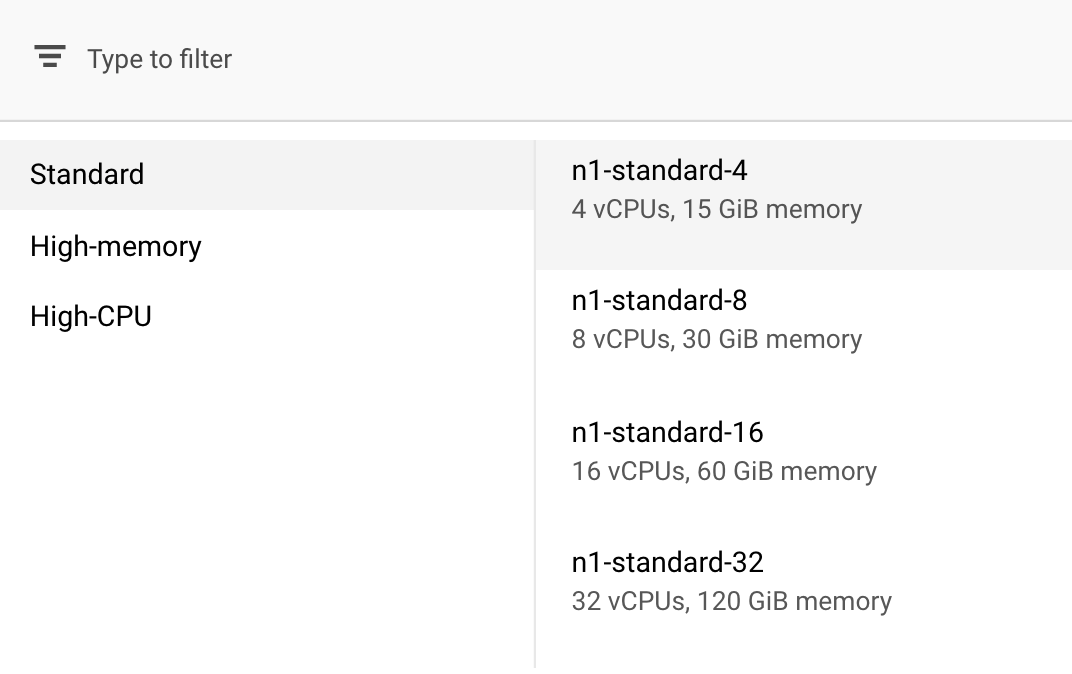
Como o modelo desta demonstração treina rapidamente, estamos usando um tipo de máquina menor.
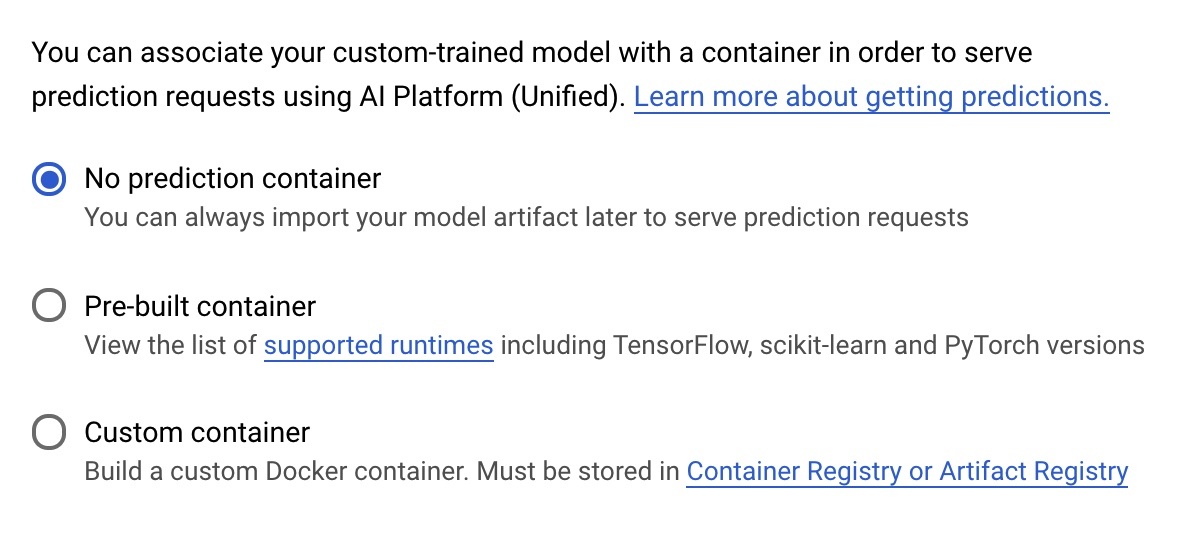
Na etapa Contêiner de previsão, selecione Nenhum contêiner de previsão:
6. Implantar um endpoint de modelo
Nesta etapa, vamos criar um endpoint para o modelo treinado. Ele pode ser usado para gerar previsões sobre nosso modelo pela API Vertex AI. Para fazer isso, disponibilizamos uma versão dos recursos de modelo treinado exportados em um bucket público do GCS.
Em uma organização, é comum ter uma equipe ou pessoa responsável pela criação do modelo e outra equipe responsável pela implantação. As etapas que vamos seguir aqui mostram como usar um modelo que já foi treinado e implantá-lo para previsão.
Aqui, vamos usar o SDK da Vertex AI para criar um modelo, implantá-lo em um endpoint e receber uma previsão.
Etapa 1: instalar o SDK Vertex
No terminal do Cloud Shell, execute o comando a seguir para instalar o SDK da Vertex AI:
pip3 install google-cloud-aiplatform --upgrade --user
Podemos usar esse SDK para interagir com muitas partes diferentes da Vertex.
Etapa 2: criar o modelo e implantar o endpoint
Em seguida, vamos criar um arquivo Python e usar o SDK para criar um recurso de modelo e implantá-lo em um endpoint. No editor de arquivos do Cloud Shell, selecione Arquivo e Novo arquivo:
Nomeie o arquivo deploy.py. Abra esse arquivo no editor e copie o código a seguir:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Em seguida, volte ao terminal no Cloud Shell, cd de volta ao diretório raiz e execute o script Python que você acabou de criar:
cd ..
python3 deploy.py | tee deploy-output.txt
Você verá as atualizações registradas no terminal à medida que os recursos forem criados. Esse processo leva de 10 a 15 minutos. Para garantir que ele esteja funcionando corretamente, navegue até a seção "Modelos" do console na Vertex AI:
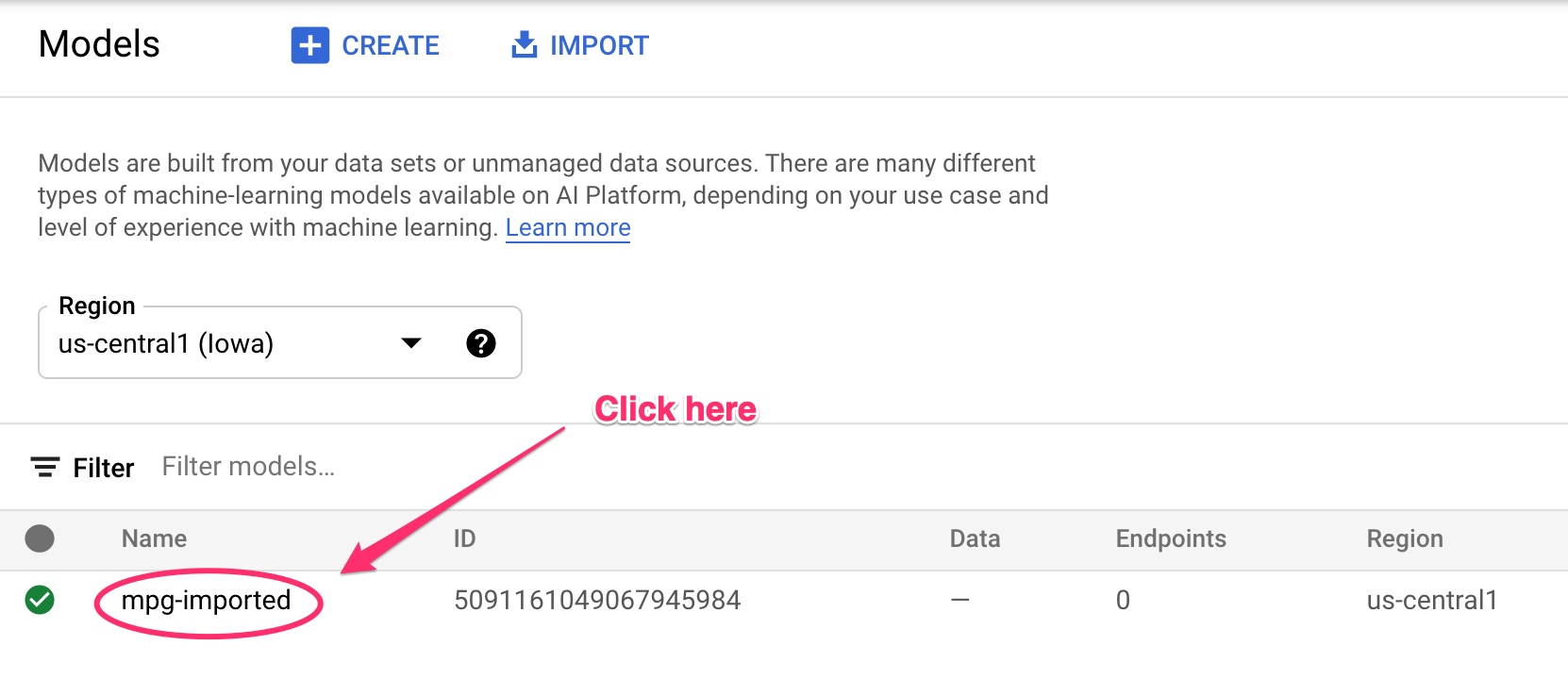
Clique em mgp-imported e você verá o endpoint desse modelo sendo criado:
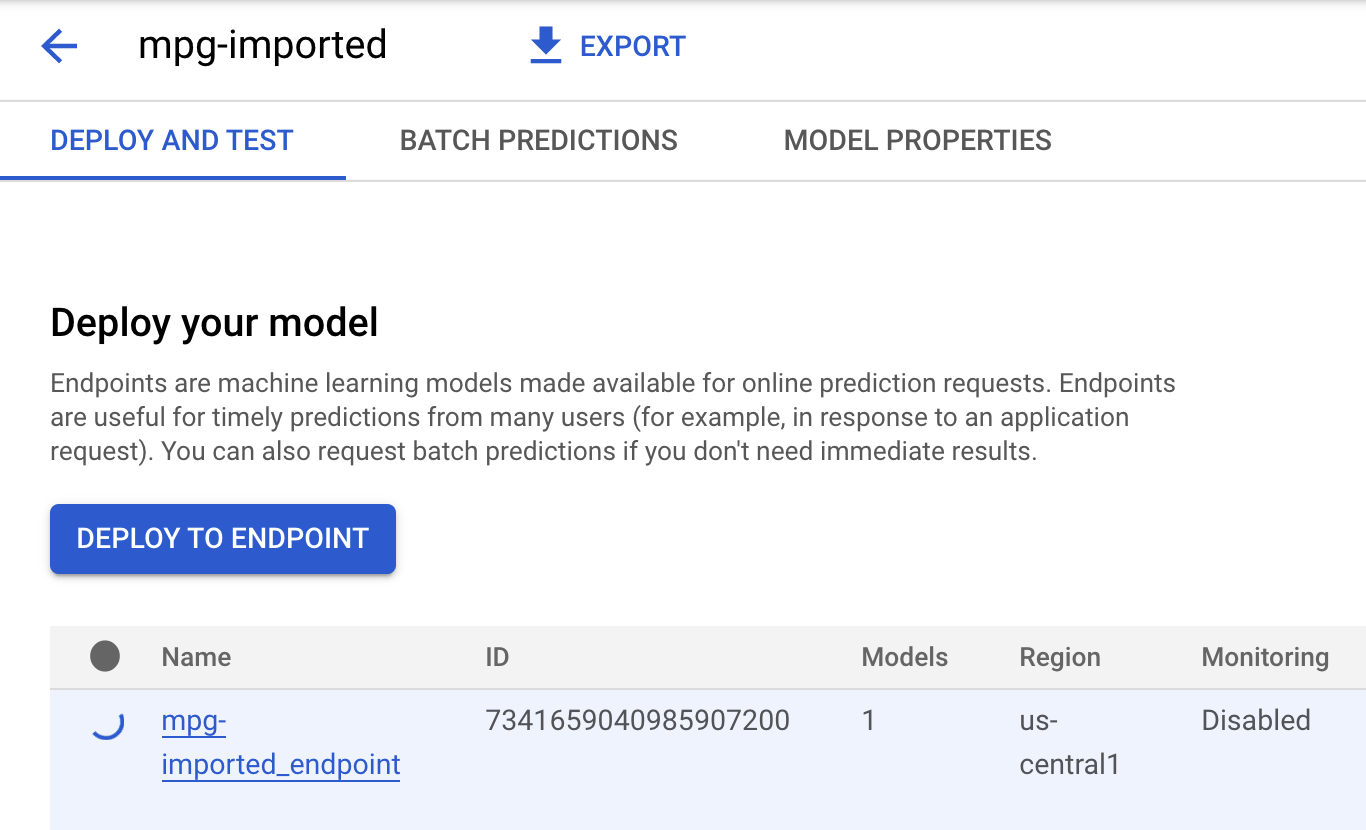
No terminal do Cloud Shell, você verá algo como o registro a seguir quando a implantação do endpoint for concluída:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
Você vai usar isso na próxima etapa para receber uma previsão no endpoint implantado.
Etapa 3: receber previsões no endpoint implantado
No editor do Cloud Shell, crie um novo arquivo chamado predict.py:
Abra predict.py e cole o código a seguir nele:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Em seguida, volte ao terminal e insira o seguinte para substituir ENDPOINT_STRING no arquivo de previsão pelo seu próprio endpoint:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Agora é hora de executar o arquivo predict.py para receber uma previsão do endpoint do modelo implantado:
python3 predict.py
Você verá a resposta da API registrada, juntamente com a eficiência de combustível prevista para nossa previsão de teste.
Parabéns! 🎉
Você aprendeu a usar a Vertex AI para:
- Treinar um modelo fornecendo o código de treinamento em um contêiner personalizado. Neste exemplo, você usou um modelo do TensorFlow, mas é possível treinar um modelo criado com qualquer framework usando contêineres personalizados.
- Implantar um modelo do TensorFlow usando um contêiner predefinido como parte do mesmo fluxo de trabalho usado no treinamento.
- Criar um endpoint de modelo e gerar uma previsão.
Para saber mais sobre partes diferentes da Vertex AI, acesse a documentação. Se você quiser conferir os resultados do job de treinamento iniciado na etapa 5, navegue até a seção de treinamento do console da Vertex.
7. Revisão dos dados
Para excluir o endpoint implantado, navegue até a seção Endpoints do console da Vertex e clique no ícone de exclusão:

Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em "Excluir":