1. نظرة عامة
في هذا الدرس التطبيقي، ستستخدم Vertex AI لتنفيذ مهمة ضبط المعلَمات الفائقة لنموذج TensorFlow. على الرغم من أنّ هذا المختبر يستخدم TensorFlow لرمز النموذج، فإنّ المفاهيم تنطبق على أُطر تعلُّم الآلة الأخرى أيضًا.
ما ستتعلمه
ستتعرَّف على كيفية:
- تعديل الرمز البرمجي لتطبيق التدريب لضبط المعلَمة الفائقة تلقائيًا
- إعداد مهمة ضبط المعلَمات الفائقة وتشغيلها من واجهة مستخدم Vertex AI
- ضبط مهمة ضبط المعلَمات الفائقة وتشغيلها باستخدام حزمة تطوير البرامج (SDK) للغة Python في Vertex AI
تبلغ التكلفة الإجمالية لتنفيذ هذا الدرس التطبيقي على Google Cloud حوالي 3 دولار أمريكي.
2. مقدّمة عن Vertex AI
يستخدم هذا المختبر أحدث منتج مستند إلى الذكاء الاصطناعي متاح على Google Cloud. تدمج Vertex AI عروض تعلُّم الآلة على Google Cloud في تجربة تطوير سلسة. في السابق، كان يمكن الوصول إلى النماذج المدرَّبة باستخدام AutoML والنماذج المخصَّصة من خلال خدمات منفصلة. يجمع العرض الجديد بين كليهما في واجهة برمجة تطبيقات واحدة، بالإضافة إلى منتجات جديدة أخرى. يمكنك أيضًا نقل المشاريع الحالية إلى Vertex AI. إذا كانت لديك أي ملاحظات، يُرجى الانتقال إلى صفحة الدعم.
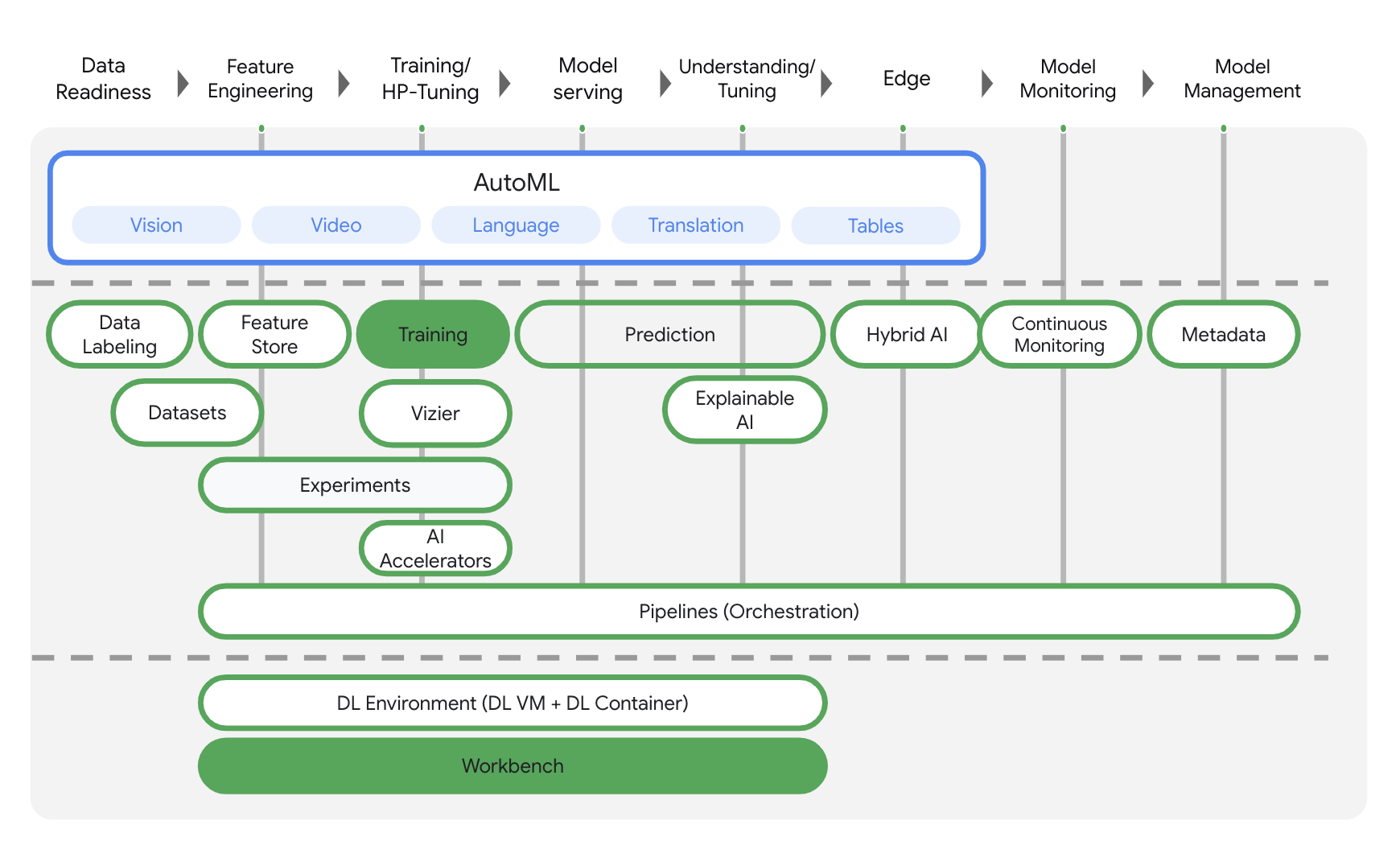
تتضمّن Vertex AI العديد من المنتجات المختلفة لدعم مهام سير العمل الشاملة لتعلُّم الآلة. سيركّز هذا الدرس التطبيقي على المنتجات الموضّحة أدناه: التدريب وWorkbench.
3- إعداد البيئة
يجب أن يكون لديك مشروع على Google Cloud Platform مع تفعيل الفوترة لتتمكّن من تنفيذ هذا الدرس العملي. لإنشاء مشروع، اتّبِع التعليمات هنا.
الخطوة 1: تفعيل Compute Engine API
انتقِل إلى Compute Engine وانقر على تفعيل إذا لم يكن مفعّلاً بعد. يجب توفير هذه المعلومات لإنشاء مثيل دفتر الملاحظات.
الخطوة 2: تفعيل واجهة برمجة التطبيقات Container Registry API
انتقِل إلى Container Registry وانقر على تفعيل إذا لم يكن مفعّلاً بعد. ستستخدم هذا المعرّف لإنشاء حاوية لمهمة التدريب المخصّصة.
الخطوة 3: تفعيل واجهة برمجة التطبيقات Vertex AI API
انتقِل إلى قسم Vertex AI في Cloud Console وانقر على تفعيل واجهة Vertex AI API.
الخطوة 4: إنشاء مثيل Vertex AI Workbench
من قسم Vertex AI في Cloud Console، انقر على Workbench:
فعِّل واجهة برمجة التطبيقات Notebooks API إذا لم تكن مفعَّلة بعد.
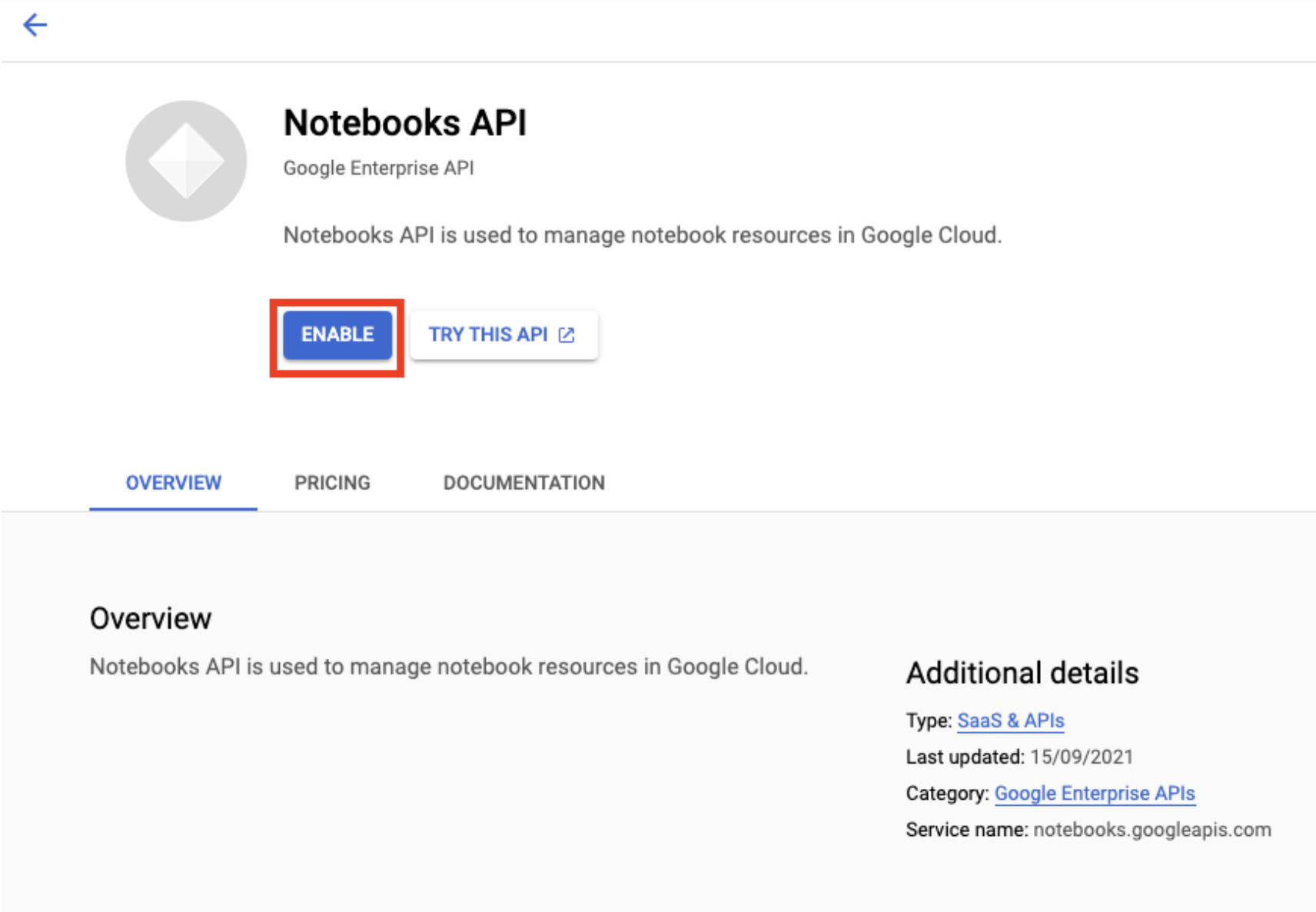
بعد التفعيل، انقر على دفاتر الملاحظات المُدارة:

بعد ذلك، انقر على دفتر ملاحظات جديد.
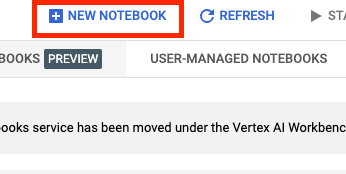
أدخِل اسمًا لدفتر الملاحظات، ثم انقر على الإعدادات المتقدّمة.

ضمن "الإعدادات المتقدّمة"، فعِّل ميزة "إيقاف التشغيل عند عدم النشاط" واضبط عدد الدقائق على 60. هذا يعني أنّه سيتم إيقاف دفتر الملاحظات تلقائيًا عند عدم استخدامه حتى لا تتكبّد تكاليف غير ضرورية.

ضمن الأمان، اختَر "تفعيل الجهاز" إذا لم يكن مفعّلاً.
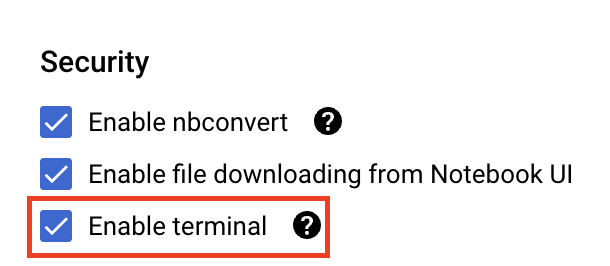
يمكنك ترك جميع الإعدادات المتقدّمة الأخرى كما هي.
بعد ذلك، انقر على إنشاء. سيستغرق توفير الجهاز الافتراضي بضع دقائق.
بعد إنشاء المثيل، انقر على فتح JupyterLab.

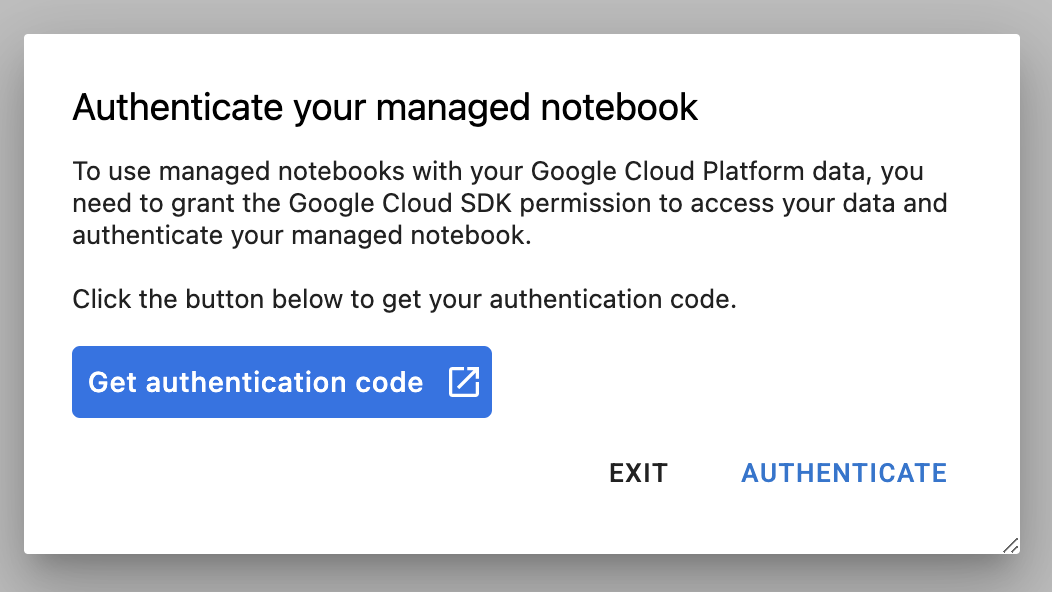
في المرة الأولى التي تستخدم فيها مثيلاً جديدًا، سيُطلب منك المصادقة. اتّبِع الخطوات الواردة في واجهة المستخدم لإجراء ذلك.
4. تضمين الرمز البرمجي لتطبيق التدريب في حاوية
النموذج الذي ستدرّبه وتعدّله في هذا المختبر هو نموذج لتصنيف الصور تم تدريبه على مجموعة بيانات الخيول أو البشر من TensorFlow Datasets.
سترسل مهمة ضبط المعلمات الفائقة هذه إلى Vertex AI من خلال وضع الرمز البرمجي لتطبيق التدريب في حاوية Docker وإرسال هذه الحاوية إلى Google Container Registry. باستخدام هذا الأسلوب، يمكنك ضبط المعلمات الفائقة لنموذج تم إنشاؤه باستخدام أي إطار عمل.
للبدء، افتح نافذة "محطة طرفية" من قائمة "مشغّل التطبيقات" في مثيل دفتر الملاحظات:

أنشئ دليلاً جديدًا باسم horses_or_humans وانتقِل إليه باستخدام الأمر cd:
mkdir horses_or_humans
cd horses_or_humans
الخطوة 1: إنشاء ملف Dockerfile
تتمثّل الخطوة الأولى في إنشاء حاوية لرمزك في إنشاء ملف Dockerfile. في Dockerfile، ستضمّن جميع الأوامر اللازمة لتشغيل الصورة. سيتم تثبيت جميع المكتبات الضرورية، بما في ذلك مكتبة CloudML Hypertune، وإعداد نقطة الدخول لرمز التدريب.
من "وحدة التحكّم"، أنشئ ملف Dockerfile فارغًا:
touch Dockerfile
افتح Dockerfile وانسخ ما يلي فيه:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
يستخدم ملف Dockerfile هذا صورة Docker لوحدة معالجة الرسومات في Deep Learning Container TensorFlow Enterprise 2.7. تتضمّن حزم Deep Learning Containers على Google Cloud العديد من أُطر عمل تعلُّم الآلة وعلم البيانات الشائعة المثبَّتة مسبقًا. بعد تنزيل هذه الصورة، يضبط ملف Dockerfile نقطة الدخول لرمز التدريب. لم يتم إنشاء هذه الملفات بعد. في الخطوة التالية، ستضيف الرمز البرمجي لتدريب النموذج وضبطه.
الخطوة 2: إضافة رمز تدريب النموذج
من "وحدة التحكّم" (Terminal)، شغِّل ما يلي لإنشاء دليل لرمز التدريب وملف Python حيث ستضيف الرمز:
mkdir trainer
touch trainer/task.py
من المفترض أن يتضمّن دليل horses_or_humans/ الآن ما يلي:
+ Dockerfile
+ trainer/
+ task.py
بعد ذلك، افتح ملف task.py الذي أنشأته للتو وانسخ الرمز أدناه.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
قبل إنشاء الحاوية، لنلقِ نظرة أعمق على الرمز. هناك بعض المكوّنات الخاصة باستخدام خدمة ضبط المعلمات الفائقة.
- يستورد النص البرمجي مكتبة
hypertune. يُرجى العِلم أنّ ملف Dockerfile من الخطوة 1 تضمّن تعليمات لتثبيت هذه المكتبة باستخدام pip. - تحدّد الدالة
get_args()وسيطة سطر أوامر لكل مَعلم فائق تريد ضبطه. في هذا المثال، ستتمّ ضبط المعلمات الفائقة، وهي معدّل التعلّم وقيمة الزخم في المحسِّن وعدد الوحدات في الطبقة المخفية الأخيرة من النموذج، ولكن يمكنك تجربة معلمات أخرى. يتم بعد ذلك استخدام القيمة التي تم تمريرها في هذه الوسيطات لضبط المعلمة الفائقة المقابلة في الرمز. - في نهاية الدالة
main()، يتم استخدام مكتبةhypertuneلتحديد المقياس الذي تريد تحسينه. في TensorFlow، يعرض الإجراءmodel.fitفي Keras عنصرHistory. السمةHistory.historyهي سجلّ لقيم خسارة التدريب وقيم المقاييس في العصور المتتالية. في حال تمرير بيانات التحقّق من الصحة إلىmodel.fit، ستتضمّن السمةHistory.historyأيضًا قيم مقاييس وفقدان التحقّق من الصحة. على سبيل المثال، إذا درّبت نموذجًا لثلاث حقب باستخدام بيانات التحقّق وقدّمتaccuracyكمقياس، سيبدو سمةHistory.historyمشابهة للقاموس التالي.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
إذا كنت تريد أن تكتشف خدمة ضبط المعلمات الفائقة القيم التي تزيد من دقة التحقّق من صحة النموذج إلى أقصى حد، عليك تحديد المقياس كآخر إدخال (أو NUM_EPOCS - 1) في قائمة val_accuracy. بعد ذلك، مرِّر هذا المقياس إلى مثيل من HyperTune. يمكنك اختيار أي سلسلة تريدها لـ hyperparameter_metric_tag، ولكن ستحتاج إلى استخدام السلسلة مرة أخرى لاحقًا عند بدء مهمة ضبط المعلمات الفائقة.
الخطوة 3: إنشاء الحاوية
من "وحدة التحكّم"، نفِّذ ما يلي لتحديد متغيّر بيئة لمشروعك، مع الحرص على استبدال your-cloud-project بمعرّف مشروعك:
PROJECT_ID='your-cloud-project'
حدِّد متغيّرًا باستخدام معرّف الموارد المنتظم (URI) لصورة الحاوية في Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
ضبط Docker
gcloud auth configure-docker
بعد ذلك، أنشئ الحاوية من خلال تنفيذ الأمر التالي من جذر دليل horses_or_humans:
docker build ./ -t $IMAGE_URI
أخيرًا، ادفعها إلى Google Container Registry:
docker push $IMAGE_URI
بعد إرسال الحاوية إلى Container Registry، يمكنك الآن بدء مهمة ضبط فائق لمَعلمات النموذج المخصّص.
5- تشغيل مهمة ضبط المَعلمات الفائقة على Vertex AI
يستخدم هذا المختبر التدريب المخصّص من خلال حاوية مخصّصة على Google Container Registry، ولكن يمكنك أيضًا تشغيل مهمة ضبط المعلَمات الفائقة باستخدام حاوية معدّة مسبقًا في Vertex AI.
للبدء، انتقِل إلى قسم التدريب في قسم Vertex في وحدة تحكّم Cloud:
الخطوة 1: ضبط مهمة التدريب
انقر على إنشاء لإدخال مَعلمات مهمة ضبط المَعلمات الفائقة.
- ضمن مجموعة البيانات، اختَر ما مِن مجموعة بيانات مُدارة.
- بعد ذلك، اختَر التدريب المخصّص (متقدّم) كطريقة التدريب وانقر على متابعة.
- أدخِل
horses-humans-hyptertune(أو أي اسم آخر تريد إطلاقه على نموذجك) في حقل اسم النموذج - انقر على متابعة.
في خطوة إعدادات الحاوية، اختَر حاوية مخصّصة:

في المربّع الأول (صورة الحاوية)، أدخِل قيمة المتغيّر IMAGE_URI من القسم السابق. يجب أن يكون: gcr.io/your-cloud-project/horse-human:hypertune، مع اسم مشروعك. اترك بقية الحقول فارغة وانقر على متابعة.
الخطوة 2: ضبط مهمة تحسين المعلمات الفائقة
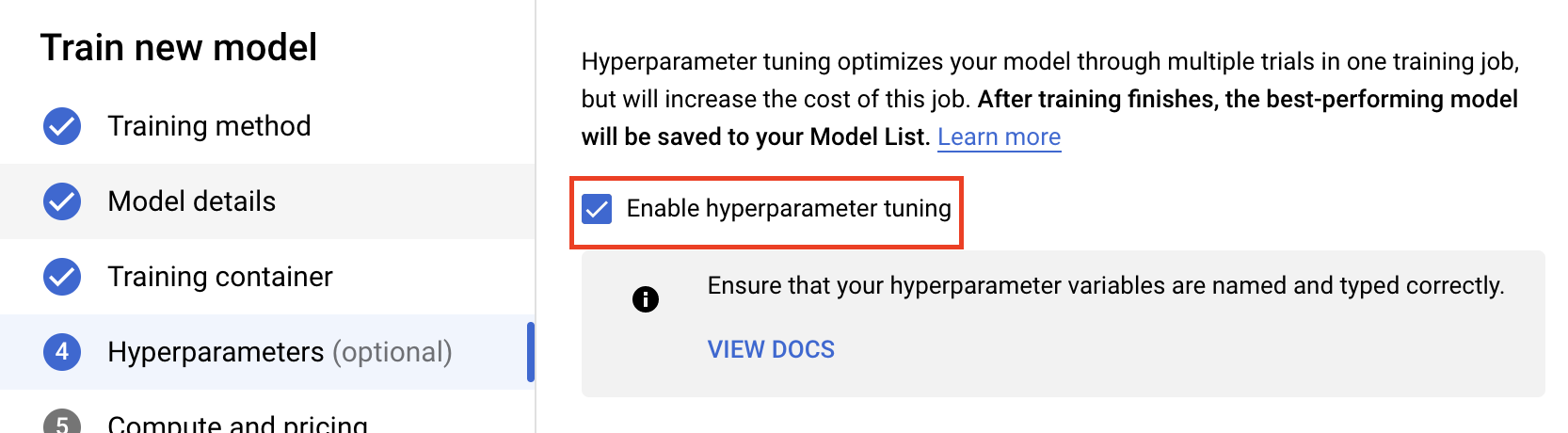
اختَر تفعيل ضبط المعلَمة الفائقة.
ضبط المَعلمات الفائقة
بعد ذلك، عليك إضافة المَعلمات الفائقة التي ضبطتها كوسيطات سطر الأوامر في الرمز البرمجي لتطبيق التدريب. عند إضافة معلَمة فائقة، عليك أولاً تقديم الاسم. يجب أن يتطابق هذا الاسم مع اسم الوسيط الذي تم تمريره إلى argparse.

بعد ذلك، ستختار النوع بالإضافة إلى حدود القيم التي ستحاول خدمة الضبط استخدامها. إذا اخترت النوع "عدد عشري" أو "عدد صحيح"، عليك تقديم حدّ أدنى وحدّ أقصى للقيمة. إذا اخترت "فئوية" أو "منفصلة"، عليك تقديم القيم.
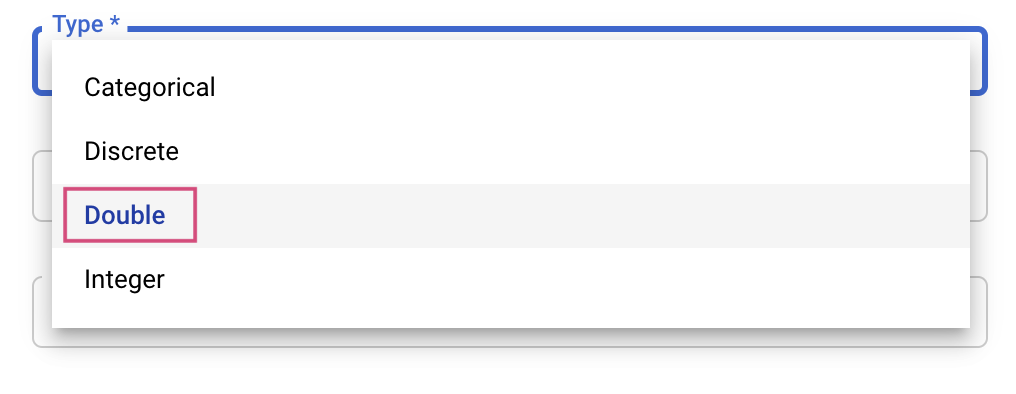

بالنسبة إلى النوعَين Double وInteger، عليك أيضًا تقديم قيمة Scaling.
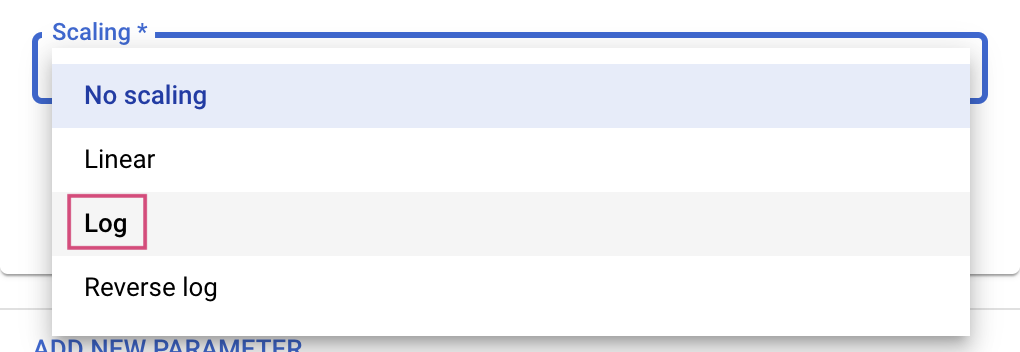
بعد إضافة المَعلمة الفائقة learning_rate، أضِف مَعلمات momentum وnum_units.


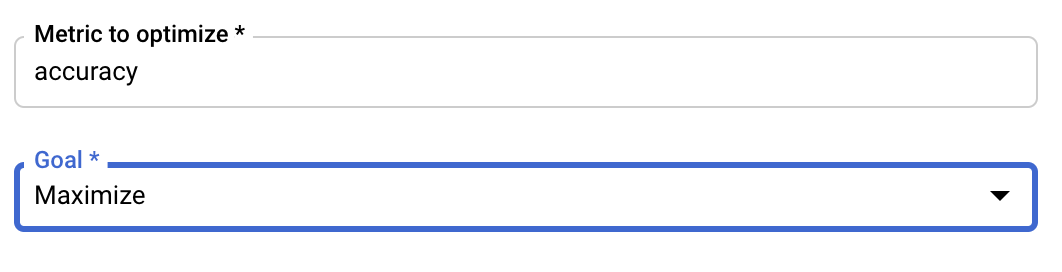
إعداد المقياس
بعد إضافة المَعلمات الفائقة، عليك تقديم المقياس الذي تريد تحسينه بالإضافة إلى الهدف. يجب أن يكون هذا المعرّف هو نفسه hyperparameter_metric_tag الذي ضبطته في تطبيق التدريب.
ستنفّذ خدمة "ضبط المَعلمات الفائقة" في Vertex AI تجارب متعدّدة لتطبيق التدريب باستخدام القيم التي تم ضبطها في الخطوات السابقة. عليك وضع حدّ أقصى لعدد المحاولات التي ستنفّذها الخدمة. تؤدي المزيد من المحاولات بشكل عام إلى نتائج أفضل، ولكن سيأتي وقت تقلّ فيه العائدات، وبعدها لن يكون للمحاولات الإضافية تأثير كبير أو لن يكون لها أي تأثير على المقياس الذي تحاول تحسينه. من أفضل الممارسات البدء بعدد أقل من التجارب والتعرّف على مدى تأثير المَعلمات الفائقة التي اخترتها قبل التوسّع إلى عدد كبير من التجارب.
عليك أيضًا ضبط حدّ أقصى لعدد المحاولات المتوازية. سيؤدي زيادة عدد التجارب المتوازية إلى تقليل مقدار الوقت الذي تستغرقه مهمة ضبط المعلمات الفائقة، ولكن يمكن أن يؤدي ذلك إلى تقليل فعالية المهمة بشكل عام. ويرجع ذلك إلى أنّ استراتيجية الضبط التلقائي تستخدم نتائج التجارب السابقة لتحديد قيم التجارب اللاحقة. إذا أجريت عددًا كبيرًا جدًا من التجارب بالتوازي، ستكون هناك تجارب تبدأ بدون الاستفادة من نتيجة التجارب التي لا تزال قيد التشغيل.
لأغراض توضيحية، يمكنك ضبط عدد المحاولات على 15 والحد الأقصى لعدد المحاولات المتوازية على 3. يمكنك تجربة أرقام مختلفة، ولكن قد يؤدي ذلك إلى إطالة مدة الضبط وزيادة التكلفة.

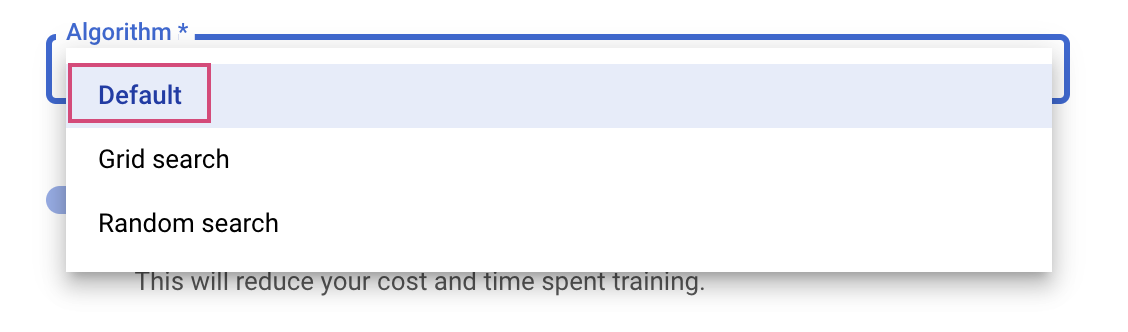
الخطوة الأخيرة هي اختيار "الخوارزمية التلقائية" كخوارزمية البحث، والتي ستستخدم Google Vizier لإجراء التحسين البايزي لضبط المعلمات الفائقة. مزيد من المعلومات حول هذه الخوارزمية
انقر على متابعة.
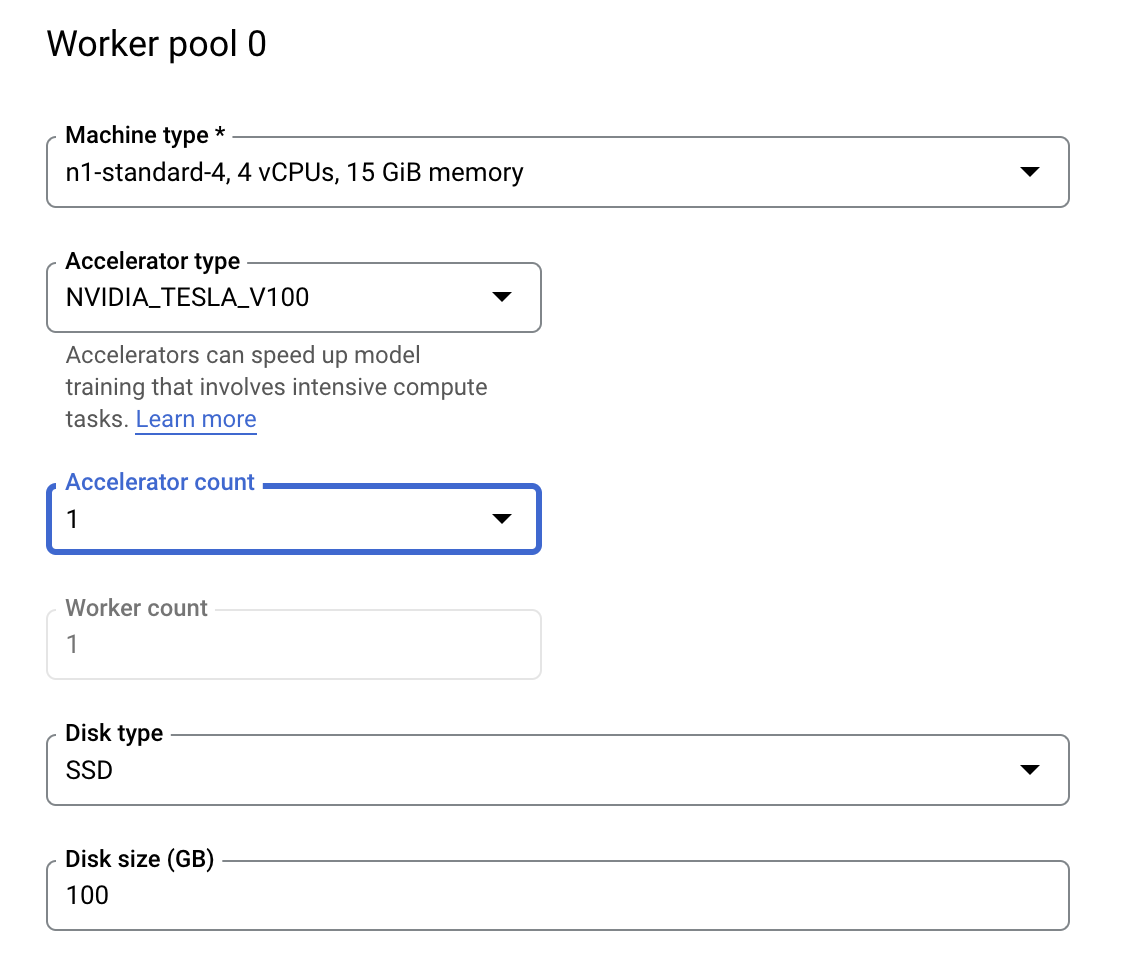
الخطوة 3: ضبط الحساب
في الحوسبة والأسعار، اترك المنطقة المحدّدة كما هي واضبط مجموعة العاملين 0 على النحو التالي.
انقر على بدء التدريب لبدء مهمة ضبط المعلمات الفائقة. في قسم "التدريب" (Training) ضمن علامة التبويب مهام ضبط المعلمات الفائقة (HYPERPARAMETER TUNING JOBS) في وحدة التحكّم، سيظهر لك ما يلي:
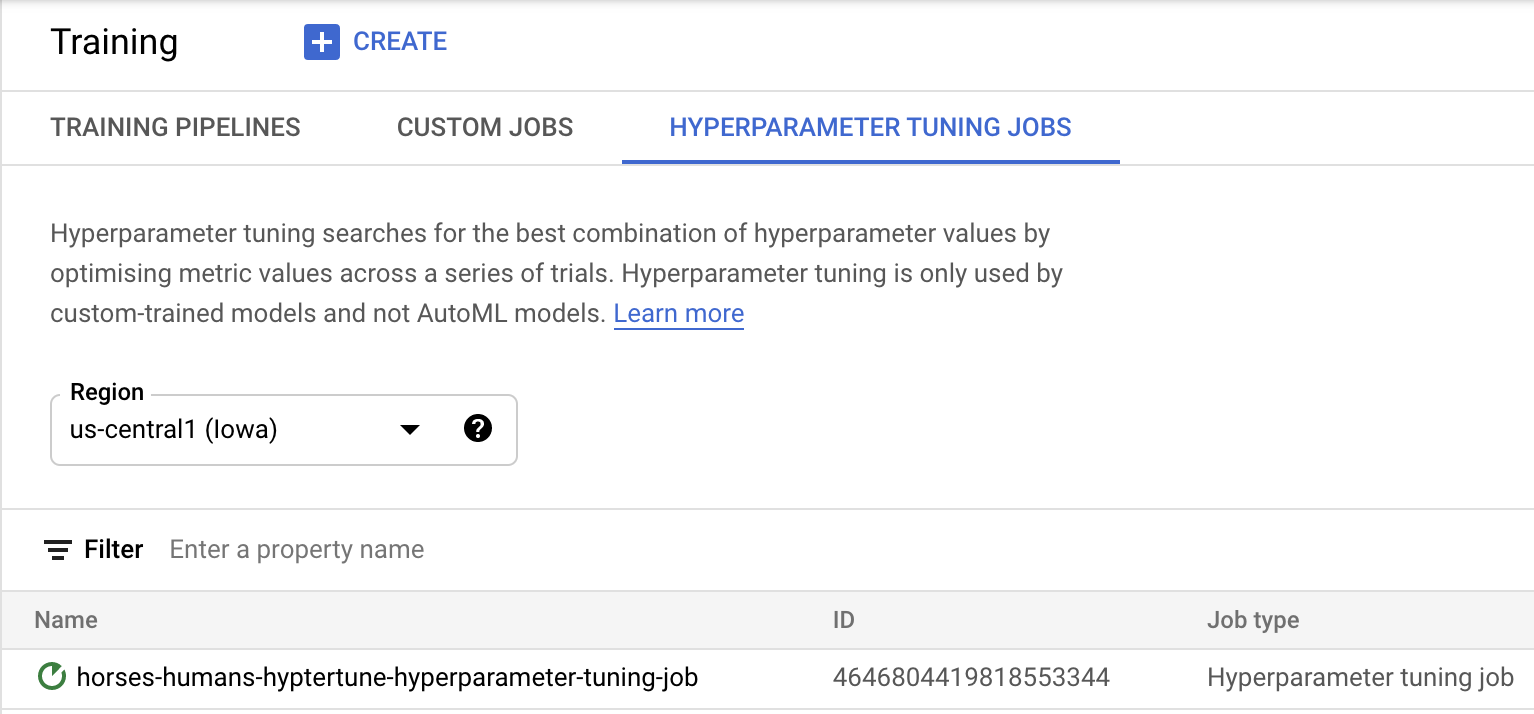
عند الانتهاء، ستتمكّن من النقر على اسم المهمة والاطّلاع على نتائج تجارب الضبط.
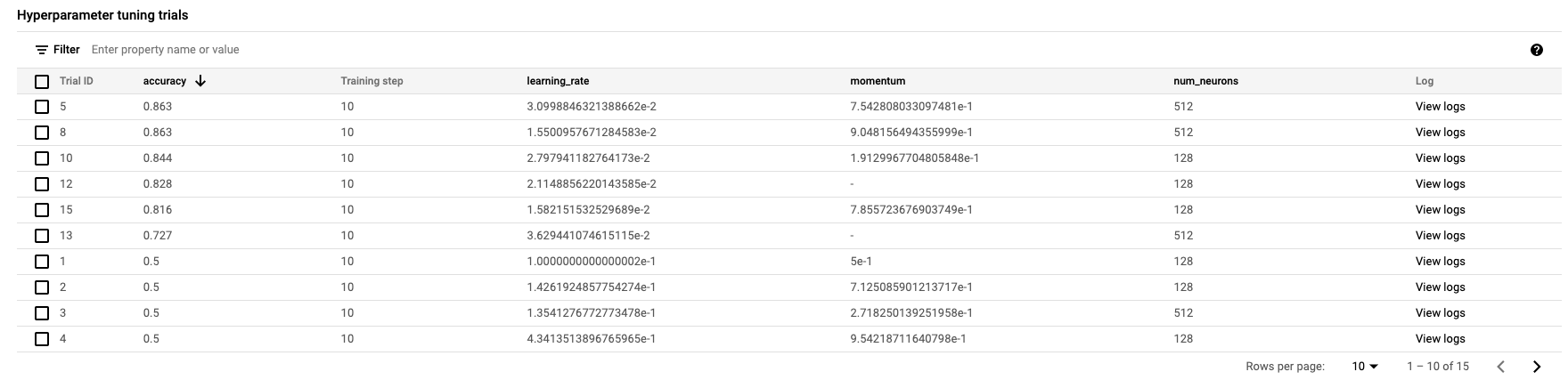
🎉 تهانينا! 🎉
تعرّفت على كيفية استخدام Vertex AI من أجل:
- ابدأ مهمة ضبط المعلَمة الفائقة لرمز التدريب المقدَّم في حاوية مخصّصة. لقد استخدمت نموذج TensorFlow في هذا المثال، ولكن يمكنك تدريب نموذج تم إنشاؤه باستخدام أي إطار عمل باستخدام حاويات مخصّصة.
لمزيد من المعلومات عن الأجزاء المختلفة من Vertex، اطّلِع على المستندات.
6. [اختياري] استخدام حزمة تطوير البرامج (SDK) الخاصة بـ Vertex
يوضّح القسم السابق كيفية تشغيل مهمة ضبط المعلمات الفائقة من خلال واجهة المستخدم. في هذا القسم، ستتعرّف على طريقة بديلة لإرسال مهمة ضبط المعلمات الفائقة باستخدام Vertex Python API.
من Launcher، أنشئ دفتر ملاحظات TensorFlow 2.

استورِد حزمة تطوير البرامج (SDK) لخدمة Vertex AI.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
لبدء مهمة ضبط المعلمات الفائقة، عليك أولاً تحديد المواصفات التالية. عليك استبدال {PROJECT_ID} في image_uri بمشروعك.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
بعد ذلك، أنشِئ CustomJob. عليك استبدال {YOUR_BUCKET} بحزمة في مشروعك لإعداد بيئة الاختبار.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
بعد ذلك، أنشئ HyperparameterTuningJob ونفِّذه.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. تنظيف
بما أنّنا ضبطنا دفتر الملاحظات على أن تنتهي مهلة عدم النشاط بعد 60 دقيقة، لسنا بحاجة إلى إيقاف الجهاز الظاهري. إذا أردت إيقاف الجهاز الافتراضي يدويًا، انقر على الزر "إيقاف" في قسم Vertex AI Workbench في وحدة التحكّم. إذا أردت حذف دفتر الملاحظات بالكامل، انقر على زر "حذف".

لحذف حزمة التخزين، استخدِم قائمة التنقّل في Cloud Console، وانتقِل إلى "مساحة التخزين"، واختَر الحزمة، ثم انقر على "حذف":