1. Обзор
В этой лабораторной работе вы будете использовать Vertex AI для настройки гиперпараметров модели TensorFlow. Хотя в этой работе используется код модели TensorFlow, изложенные концепции применимы и к другим фреймворкам машинного обучения.
Чему вы научитесь
Вы научитесь:
- Модифицировать код обучающего приложения для автоматической настройки гиперпараметров.
- Настройте и запустите задачу настройки гиперпараметров из пользовательского интерфейса Vertex AI.
- Настройте и запустите задачу настройки гиперпараметров с помощью Python SDK от Vertex AI.
Общая стоимость запуска этой лабораторной работы в Google Cloud составляет около 3 долларов США.
2. Введение в Vertex AI
В этой лабораторной работе используется новейший продукт для искусственного интеллекта, доступный в Google Cloud. Vertex AI интегрирует предложения машинного обучения в Google Cloud в единый процесс разработки. Ранее модели, обученные с помощью AutoML, и пользовательские модели были доступны через отдельные сервисы. Новое предложение объединяет оба варианта в единый API, а также включает другие новые продукты. Вы также можете перенести существующие проекты в Vertex AI. Если у вас есть какие-либо замечания, пожалуйста, посетите страницу поддержки .
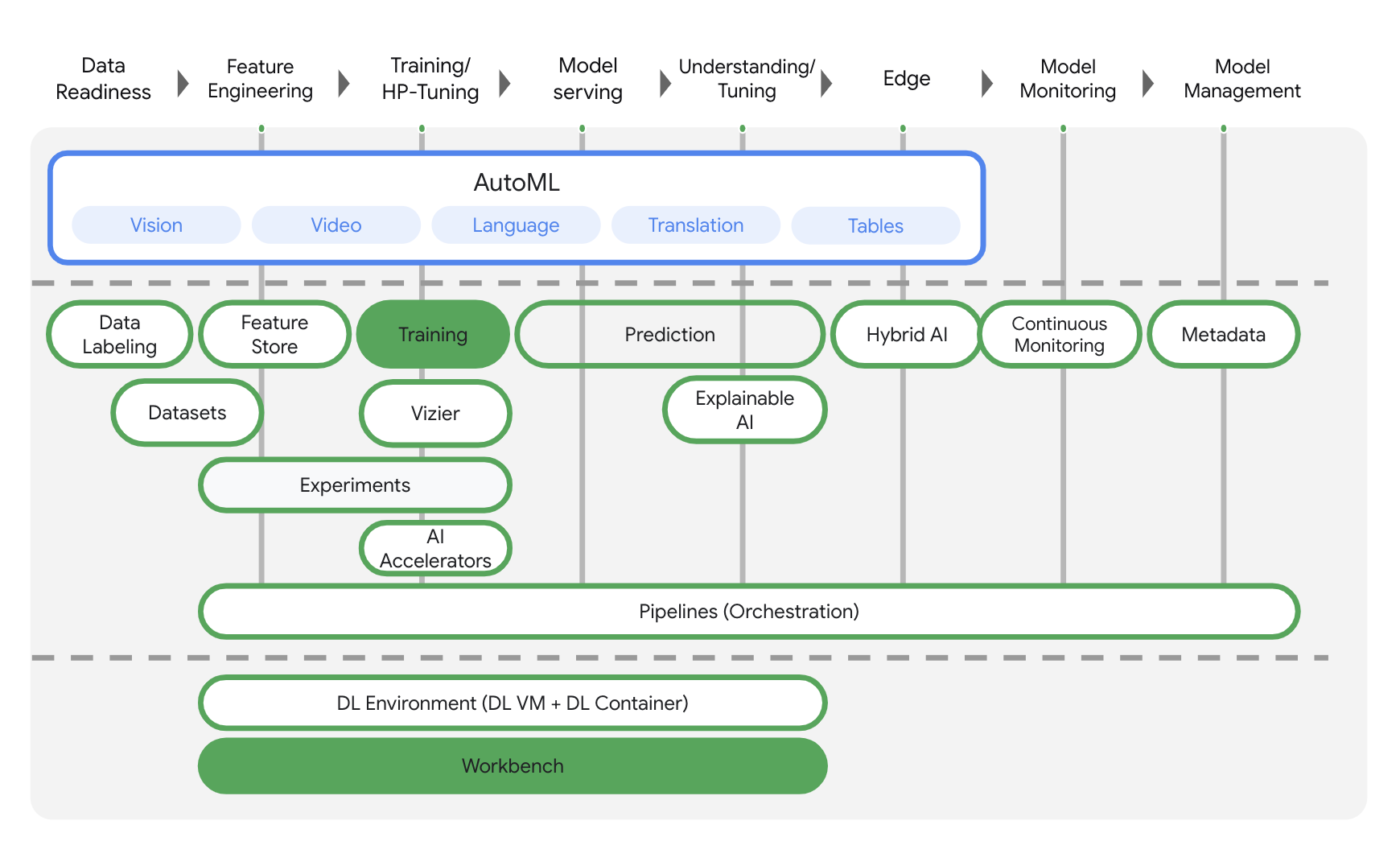
Vertex AI предлагает множество различных продуктов для поддержки комплексных рабочих процессов машинного обучения. В этой лабораторной работе мы сосредоточимся на продуктах, перечисленных ниже: Training и Workbench .
3. Настройте свою среду.
Для выполнения этого практического задания вам потребуется проект Google Cloud Platform с включенной оплатой. Чтобы создать проект, следуйте инструкциям здесь .
Шаг 1: Включите API Compute Engine.
Перейдите в Compute Engine и выберите «Включить», если эта опция еще не включена. Она понадобится для создания экземпляра ноутбука.
Шаг 2: Включите API реестра контейнеров.
Перейдите в Реестр контейнеров и выберите «Включить», если эта опция еще не включена. Это позволит создать контейнер для вашей пользовательской задачи обучения.
Шаг 3: Включите API Vertex AI
Перейдите в раздел Vertex AI в вашей облачной консоли и нажмите «Включить API Vertex AI» .
Шаг 4: Создайте экземпляр Vertex AI Workbench.
В разделе Vertex AI вашей облачной консоли нажмите на Workbench:
Включите API для блокнотов, если он еще не включен.
После включения нажмите «УПРАВЛЯЕМЫЕ ЗАПИСНЫЕ КНИЖКИ» :

Затем выберите «Создать новый блокнот» .
Присвойте своему блокноту имя, а затем нажмите «Дополнительные настройки» .

В разделе «Дополнительные настройки» включите функцию автоматического выключения в режиме ожидания и установите количество минут равным 60. Это означает, что ваш ноутбук будет автоматически выключаться, когда не используется, чтобы избежать лишних расходов.

В разделе «Безопасность» выберите «Включить терминал», если он еще не включен.
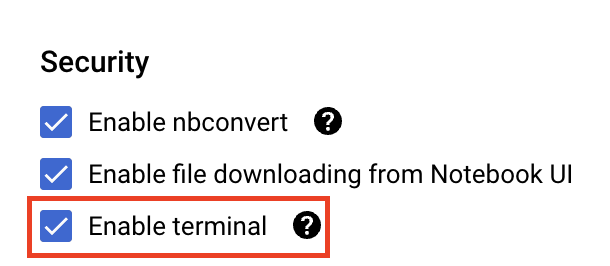
Все остальные расширенные настройки можно оставить без изменений.
Далее нажмите «Создать» . Создание экземпляра займет несколько минут.
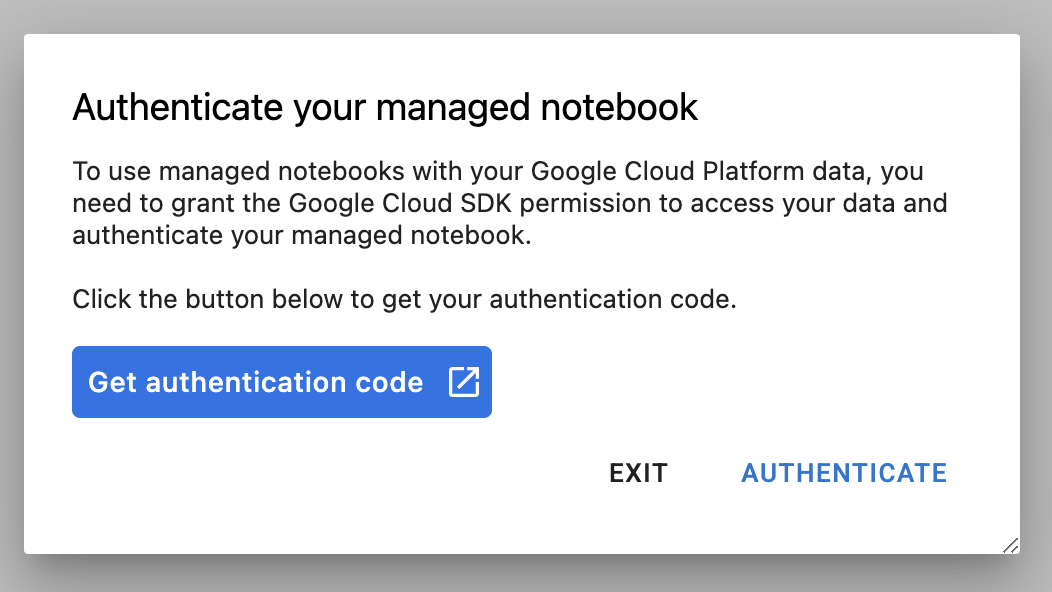
После создания экземпляра выберите «Открыть JupyterLab» .

При первом использовании нового экземпляра вам будет предложено пройти аутентификацию. Для этого следуйте инструкциям в пользовательском интерфейсе.
4. Контейнеризация кода обучающего приложения
В этой лабораторной работе вы будете обучать и настраивать модель классификации изображений, обученную на наборе данных «Лошади или люди» из TensorFlow Datasets .
Для этого вам нужно будет отправить запрос на настройку гиперпараметров в Vertex AI, поместив код вашего обучающего приложения в контейнер Docker и загрузив этот контейнер в Google Container Registry . Используя этот подход, вы можете настраивать гиперпараметры для модели, созданной с помощью любой платформы.
Для начала откройте окно Терминала в вашем ноутбуке из меню «Запуск»:

Создайте новую директорию с именем horses_or_humans и перейдите в неё с помощью команды cd:
mkdir horses_or_humans
cd horses_or_humans
Шаг 1: Создайте Dockerfile.
Первый шаг в контейнеризации вашего кода — создание Dockerfile. В Dockerfile вы укажете все команды, необходимые для запуска образа. Он установит все необходимые библиотеки, включая библиотеку CloudML Hypertune , и настроит точку входа для кода обучения.
Создайте пустой Dockerfile в терминале:
touch Dockerfile
Откройте Dockerfile и скопируйте в него следующее:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
В этом Dockerfile используется образ Docker для контейнеров глубокого обучения TensorFlow Enterprise 2.7 GPU . Контейнеры глубокого обучения в Google Cloud поставляются со множеством распространенных фреймворков для машинного обучения и анализа данных, предварительно установленных в них. После загрузки этого образа данный Dockerfile настраивает точку входа для кода обучения. Вы еще не создали эти файлы — на следующем шаге вы добавите код для обучения и настройки модели.
Шаг 2: Добавьте код для обучения модели.
В терминале выполните следующую команду, чтобы создать директорию для кода обучения и файл Python, куда вы добавите этот код:
mkdir trainer
touch trainer/task.py
Теперь в вашей директории horses_or_humans/ должны находиться следующие файлы:
+ Dockerfile
+ trainer/
+ task.py
Далее откройте только что созданный файл task.py и скопируйте приведенный ниже код.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Прежде чем создавать контейнер, давайте подробнее рассмотрим код. Некоторые компоненты специфичны для использования сервиса настройки гиперпараметров.
- Скрипт импортирует библиотеку
hypertune. Обратите внимание, что в Dockerfile из шага 1 содержались инструкции по установке этой библиотеки с помощью pip. - Функция
get_args()определяет аргумент командной строки для каждого гиперпараметра, который вы хотите настроить. В этом примере настраиваются следующие гиперпараметры: скорость обучения, значение момента в оптимизаторе и количество нейронов в последнем скрытом слое модели, но вы можете поэкспериментировать и с другими. Значение, переданное в этих аргументах, затем используется для установки соответствующего гиперпараметра в коде. - В конце функции
main()используется библиотекаhypertuneдля определения метрики, которую вы хотите оптимизировать. В TensorFlow методmodel.fitв Keras возвращает объектHistory. Атрибут `History.historyсодержит записи значений потерь и метрик на последовательных эпохах обучения. Если вы передаете данные валидации вmodel.fit, атрибут `History.historyбудет включать значения потерь и метрик валидации. Например, если вы обучали модель в течение трех эпох с использованием данных валидации и указалиaccuracyв качестве метрики, атрибут `History.historyбудет выглядеть примерно так, как показано в следующем словаре.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Если вы хотите, чтобы служба настройки гиперпараметров определила значения, которые максимизируют точность валидации модели, вы определяете метрику как последнюю запись (или NUM_EPOCS - 1 ) в списке val_accuracy . Затем передайте эту метрику экземпляру HyperTune . Вы можете выбрать любую строку для параметра hyperparameter_metric_tag , но вам потребуется использовать эту строку снова позже, когда вы запустите задачу настройки гиперпараметров.
Шаг 3: Создайте контейнер
В терминале выполните следующую команду, чтобы определить переменную окружения для вашего проекта, заменив your-cloud-project на идентификатор вашего проекта:
PROJECT_ID='your-cloud-project'
Создайте переменную с URI образа вашего контейнера в реестре Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Настройка Docker
gcloud auth configure-docker
Затем соберите контейнер, выполнив следующую команду из корневой директории каталога horses_or_humans :
docker build ./ -t $IMAGE_URI
Наконец, загрузите его в реестр контейнеров Google:
docker push $IMAGE_URI
После загрузки контейнера в Container Registry вы готовы запустить задачу настройки гиперпараметров пользовательской модели.
5. Запустите задачу настройки гиперпараметров в Vertex AI.
В этой лабораторной работе используется пользовательское обучение с помощью пользовательского контейнера в Google Container Registry, но вы также можете запустить задачу настройки гиперпараметров с помощью предварительно созданного контейнера Vertex AI .
Для начала перейдите в раздел «Обучение» в разделе Vertex вашей облачной консоли:
Шаг 1: Настройка задания обучения
Нажмите «Создать» , чтобы ввести параметры для задачи настройки гиперпараметров.
- В разделе «Набор данных» выберите «Нет управляемого набора данных» .
- Затем выберите в качестве метода обучения «Пользовательское обучение (расширенное)» и нажмите «Продолжить» .
- Введите
horses-humans-hyptertune(или как угодно назовите свою модель) в поле «Название модели» . - Нажмите «Продолжить»
На этапе настройки контейнера выберите «Пользовательский контейнер» :

В первом поле ( «Образ контейнера» ) введите значение вашей переменной IMAGE_URI из предыдущего раздела. Оно должно быть следующим: gcr.io/your-cloud-project/horse-human:hypertune , указав название вашего проекта. Оставьте остальные поля пустыми и нажмите «Продолжить» .
Шаг 2: Настройка задачи настройки гиперпараметров
Выберите «Включить настройку гиперпараметров» .
Настройка гиперпараметров
Далее вам потребуется добавить гиперпараметры, которые вы задали в качестве аргументов командной строки, в код обучающего приложения. При добавлении гиперпараметра сначала необходимо указать его имя. Оно должно совпадать с именем аргумента, переданного в argparse .

Затем вам нужно будет выбрать тип, а также границы значений, которые будет пытаться использовать служба настройки. Если вы выберете тип Double или Integer, вам потребуется указать минимальное и максимальное значение. А если вы выберете тип Categorical или Discrete, вам нужно будет указать значения.
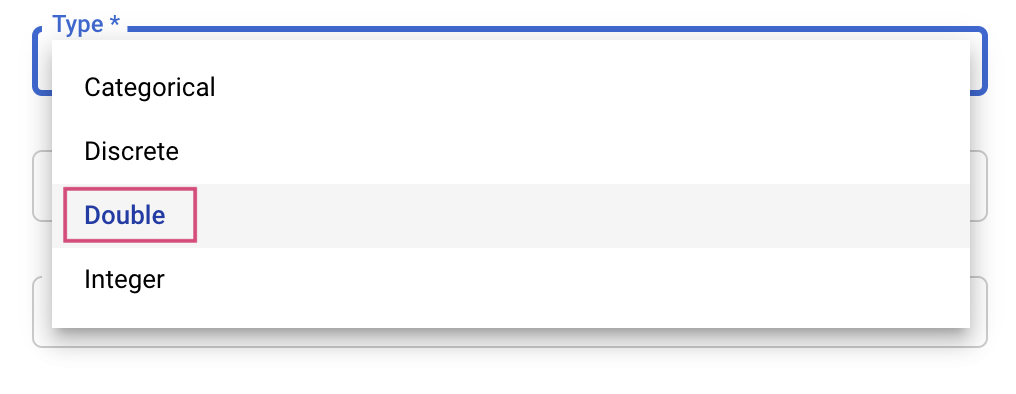

Для типов данных Double и Integer также потребуется указать значение масштабирования.
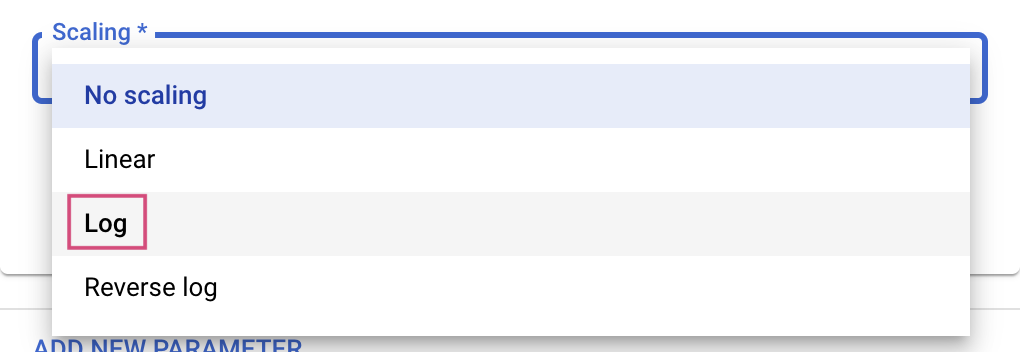
После добавления гиперпараметра learning_rate добавьте параметры momentum и num_units .


Настройка метрики
После добавления гиперпараметров вам нужно будет указать метрику, которую вы хотите оптимизировать, а также целевое значение. Оно должно совпадать с параметром hyperparameter_metric_tag который вы задали в своем приложении для обучения.
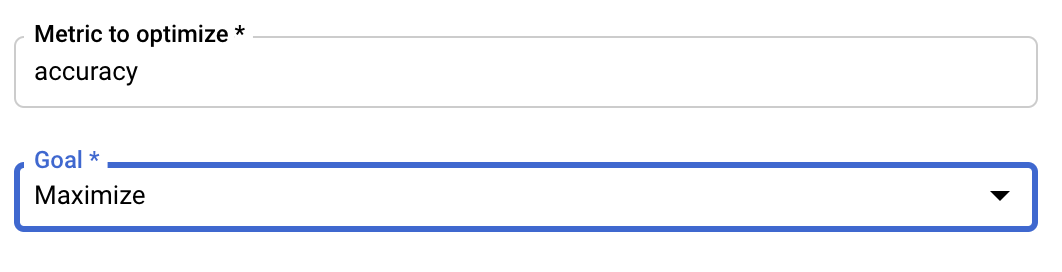
Сервис настройки гиперпараметров Vertex AI выполнит несколько итераций обучения вашего приложения со значениями, заданными на предыдущих шагах. Вам необходимо установить верхний предел количества итераций, которые будет выполнять сервис. Большее количество итераций, как правило, приводит к лучшим результатам, но существует точка убывающей отдачи, после которой дополнительные итерации практически не влияют на метрику, которую вы пытаетесь оптимизировать. Рекомендуется начинать с меньшего количества итераций, чтобы оценить влияние выбранных гиперпараметров, прежде чем увеличивать их количество.
Также необходимо установить верхнюю границу количества параллельных испытаний. Увеличение количества параллельных испытаний сократит время выполнения задачи настройки гиперпараметров; однако это может снизить общую эффективность задачи. Это связано с тем, что стратегия настройки по умолчанию использует результаты предыдущих испытаний для определения значений в последующих испытаниях. Если вы запустите слишком много испытаний параллельно, некоторые испытания начнутся без учета результатов уже выполненных испытаний.
В демонстрационных целях вы можете установить количество испытаний равным 15, а максимальное количество параллельных испытаний — 3. Вы можете поэкспериментировать с различными числами, но это может привести к увеличению времени настройки и стоимости.

Последний шаг — выбрать алгоритм поиска по умолчанию (Default), который будет использовать Google Vizier для выполнения байесовской оптимизации при настройке гиперпараметров. Подробнее об этом алгоритме можно узнать здесь.
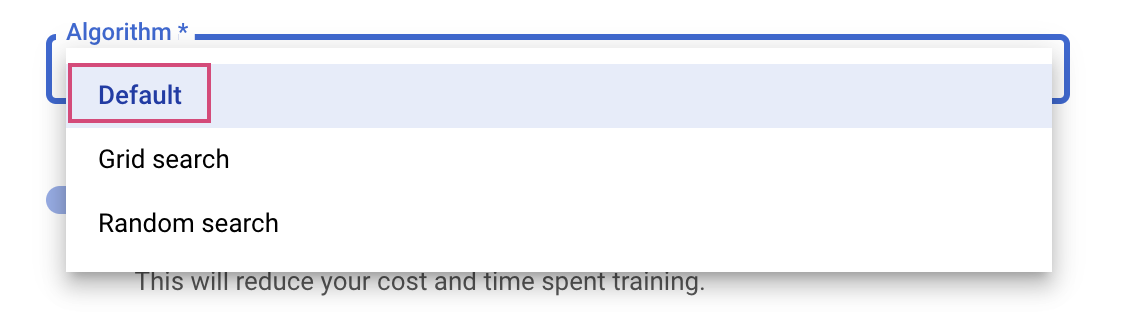
Нажмите «Продолжить» .
Шаг 3: Настройка вычислительных ресурсов
В разделе «Вычисления и ценообразование» оставьте выбранный регион без изменений и настройте пул рабочих процессов 0 следующим образом.
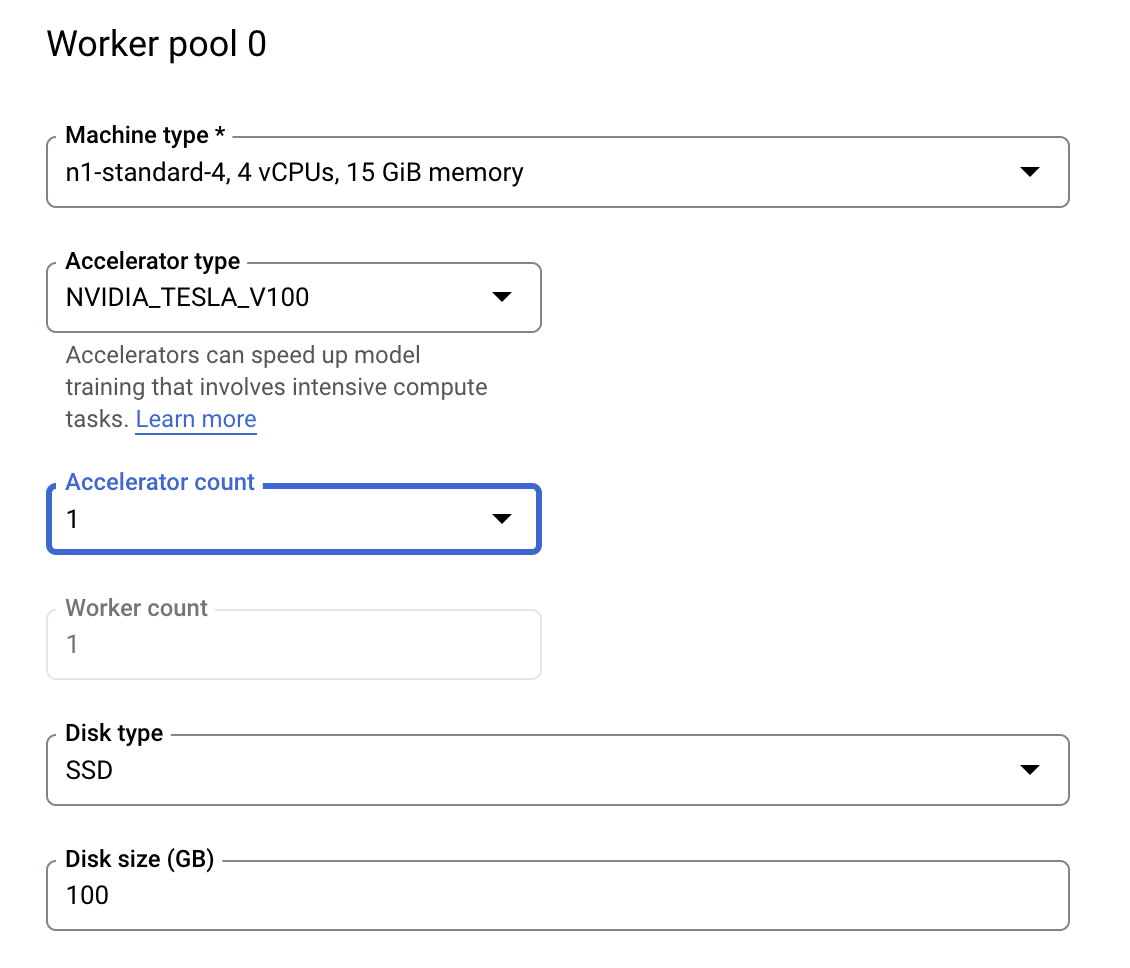
Нажмите «Начать обучение» , чтобы запустить задачу настройки гиперпараметров. В разделе «Обучение» вашей консоли на вкладке «ЗАДАЧИ НАСТРОЙКИ ГИПЕРПАРАМЕТРОВ» вы увидите что-то подобное:
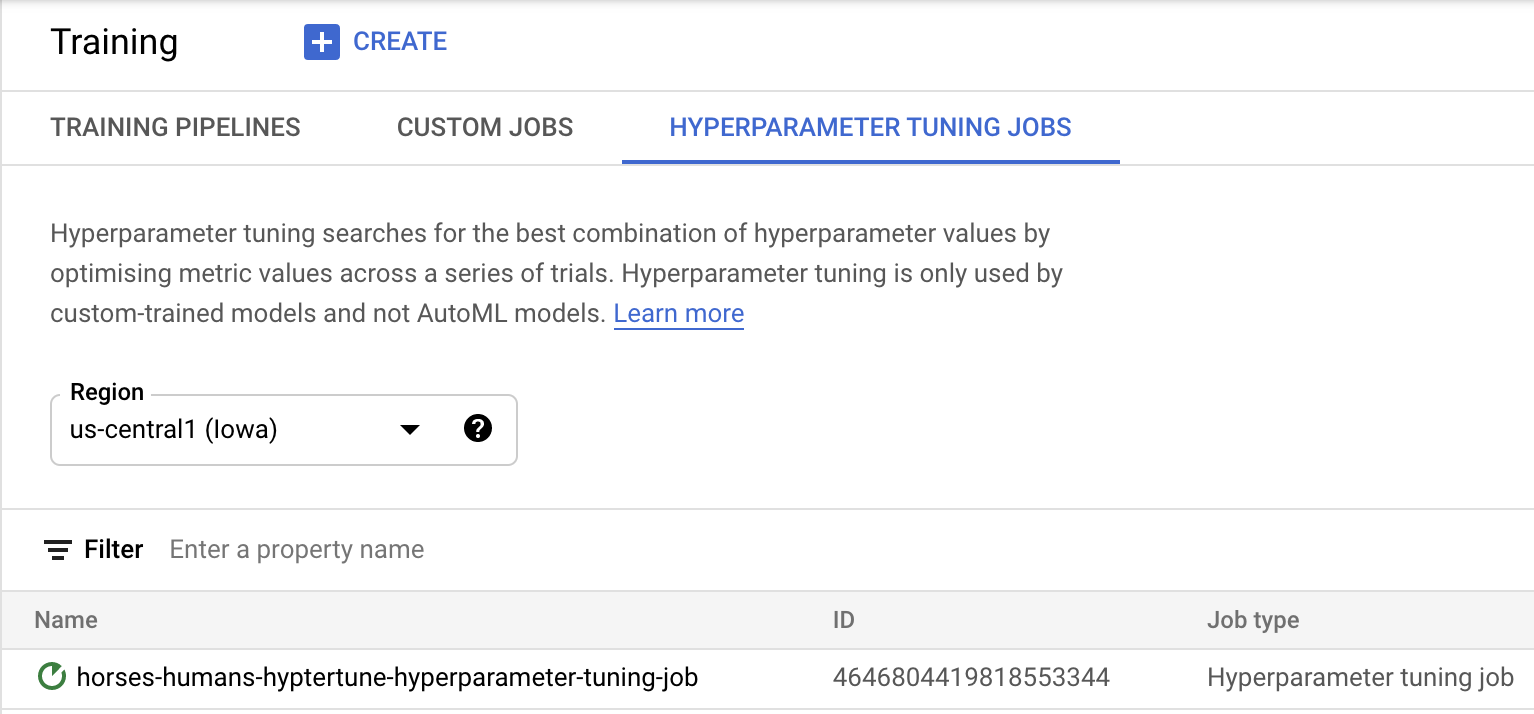
После завершения вы сможете щелкнуть по названию задания и увидеть результаты пробной настройки.
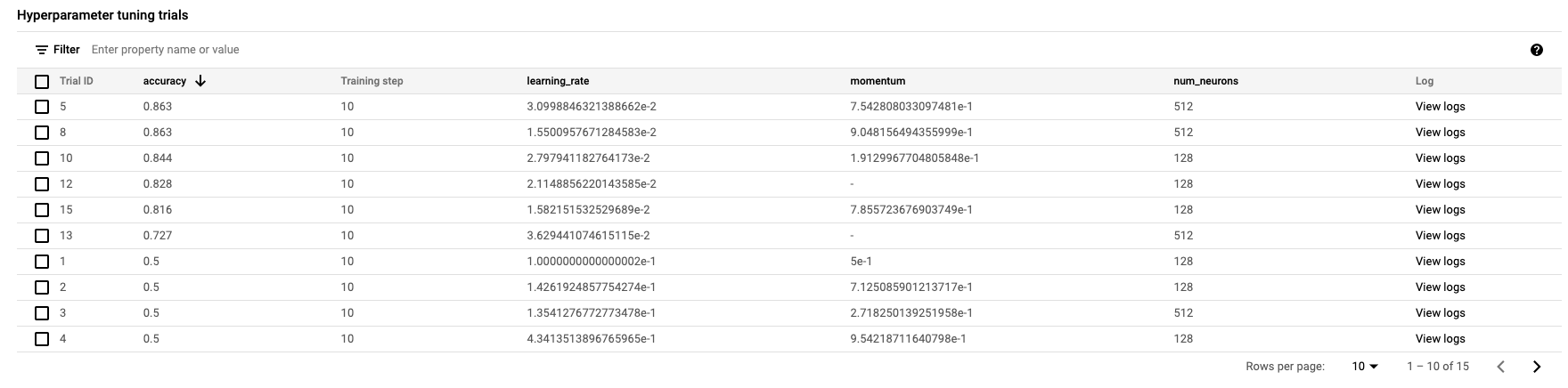
🎉 Поздравляем! 🎉
Вы научились использовать Vertex AI для:
- Запустите задачу настройки гиперпараметров для обучающего кода, предоставленного в пользовательском контейнере. В этом примере вы использовали модель TensorFlow, но вы можете обучить модель, созданную с помощью любой платформы, используя пользовательские контейнеры.
Чтобы узнать больше о различных компонентах Vertex, ознакомьтесь с документацией .
6. [Необязательно] Используйте Vertex SDK
В предыдущем разделе было показано, как запустить задачу настройки гиперпараметров через пользовательский интерфейс. В этом разделе вы увидите альтернативный способ отправки задачи настройки гиперпараметров с помощью Python API Vertex.
В панели запуска создайте блокнот TensorFlow 2.

Импортируйте Vertex AI SDK.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Для запуска задачи настройки гиперпараметров необходимо сначала определить следующие параметры. Вам потребуется заменить {PROJECT_ID} в image_uri на название вашего проекта.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Далее создайте CustomJob . Вам нужно будет заменить {YOUR_BUCKET} на название корзины в вашем проекте для размещения на тестовом сервере.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Затем создайте и запустите задание HyperparameterTuningJob .
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Уборка
Поскольку мы настроили ноутбук на автоматическое завершение работы через 60 минут простоя, нам не нужно беспокоиться о выключении экземпляра. Если вы хотите выключить экземпляр вручную, нажмите кнопку «Стоп» в разделе Vertex AI Workbench в консоли. Если вы хотите полностью удалить ноутбук, нажмите кнопку «Удалить».

Чтобы удалить сегмент хранилища, воспользуйтесь меню навигации в консоли Cloud Console, перейдите в раздел «Хранилище», выберите свой сегмент и нажмите «Удалить».