1. ภาพรวม
ในแล็บนี้ คุณจะได้ใช้ Vertex AI เพื่อเรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์สำหรับโมเดล TensorFlow แม้ว่าแล็บนี้จะใช้ TensorFlow สำหรับโค้ดโมเดล แต่แนวคิดต่างๆ ก็ใช้ได้กับเฟรมเวิร์ก ML อื่นๆ ด้วย
สิ่งที่คุณจะได้เรียนรู้
คุณจะได้เรียนรู้วิธีต่อไปนี้
- แก้ไขโค้ดของแอปพลิเคชันการฝึกสำหรับการปรับแต่งไฮเปอร์พารามิเตอร์อัตโนมัติ
- กำหนดค่าและเปิดใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์จาก UI ของ Vertex AI
- กำหนดค่าและเปิดใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ด้วย Vertex AI Python SDK
ค่าใช้จ่ายทั้งหมดในการเรียกใช้งานแล็บนี้ใน Google Cloud อยู่ที่ประมาณ $3 USD
2. ข้อมูลเบื้องต้นเกี่ยวกับ Vertex AI
แล็บนี้ใช้ผลิตภัณฑ์ AI ใหม่ล่าสุดที่พร้อมให้บริการใน Google Cloud Vertex AI ผสานรวมข้อเสนอ ML ใน Google Cloud เข้าด้วยกันเพื่อมอบประสบการณ์การพัฒนาที่ราบรื่น ก่อนหน้านี้ โมเดลที่ฝึกด้วย AutoML และโมเดลที่กำหนดเองสามารถเข้าถึงได้ผ่านบริการที่แยกกัน ข้อเสนอใหม่นี้รวมทั้ง 2 อย่างไว้ใน API เดียว พร้อมด้วยผลิตภัณฑ์ใหม่อื่นๆ นอกจากนี้ คุณยังย้ายข้อมูลโปรเจ็กต์ที่มีอยู่ไปยัง Vertex AI ได้ด้วย หากมีข้อเสนอแนะ โปรดดูที่ หน้าการสนับสนุน
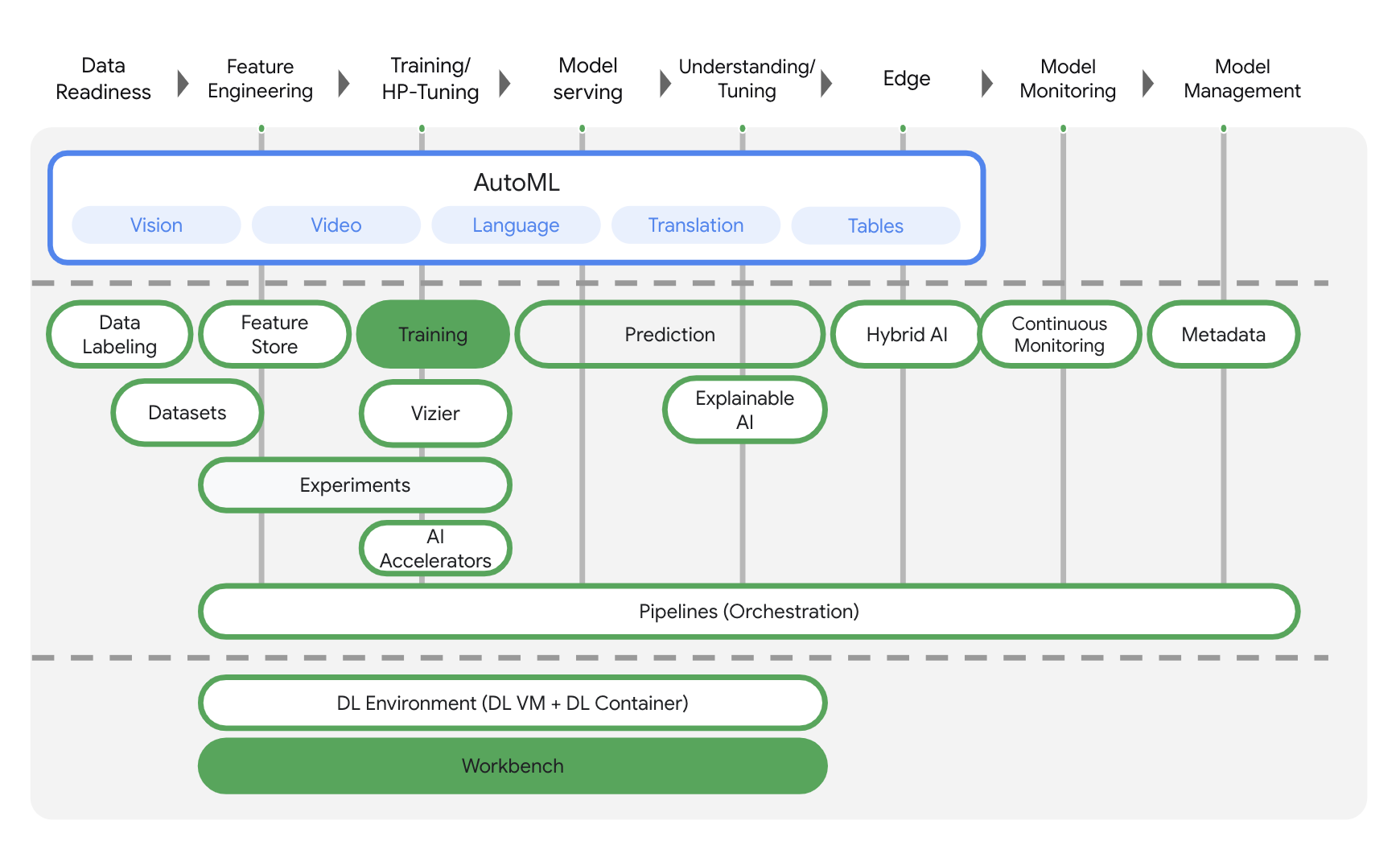
Vertex AI มีผลิตภัณฑ์มากมายที่แตกต่างกันเพื่อรองรับเวิร์กโฟลว์ ML แบบครบวงจร แล็บนี้จะเน้นที่ผลิตภัณฑ์ที่ไฮไลต์ไว้ด้านล่าง ได้แก่ Training และ Workbench
3. ตั้งค่าสภาพแวดล้อม
คุณต้องมีโปรเจ็กต์ Google Cloud Platform ที่เปิดใช้การเรียกเก็บเงินเพื่อเรียกใช้งานโค้ดแล็บนี้ หากต้องการสร้างโปรเจ็กต์ ให้ทำตาม วิธีการที่นี่
ขั้นตอนที่ 1: เปิดใช้ Compute Engine API
ไปที่ Compute Engine แล้วเลือก เปิดใช้ หากยังไม่ได้เปิดใช้ คุณจะต้องเปิดใช้ API นี้เพื่อสร้างอินสแตนซ์ Notebook
ขั้นตอนที่ 2: เปิดใช้ Container Registry API
ไปที่ Container Registry แล้วเลือก เปิดใช้ หากยังไม่ได้เปิดใช้ คุณจะใช้ API นี้เพื่อสร้างคอนเทนเนอร์สำหรับงานการฝึกที่กำหนดเอง
ขั้นตอนที่ 3: เปิดใช้ Vertex AI API
ไปที่ส่วน Vertex AI ของ Cloud Console แล้วคลิก Enable Vertex AI API
ขั้นตอนที่ 4: สร้างอินสแตนซ์ Vertex AI Workbench
จากส่วน Vertex AI ของ Cloud Console ให้คลิก Workbench
เปิดใช้ Notebooks API หากยังไม่ได้เปิดใช้
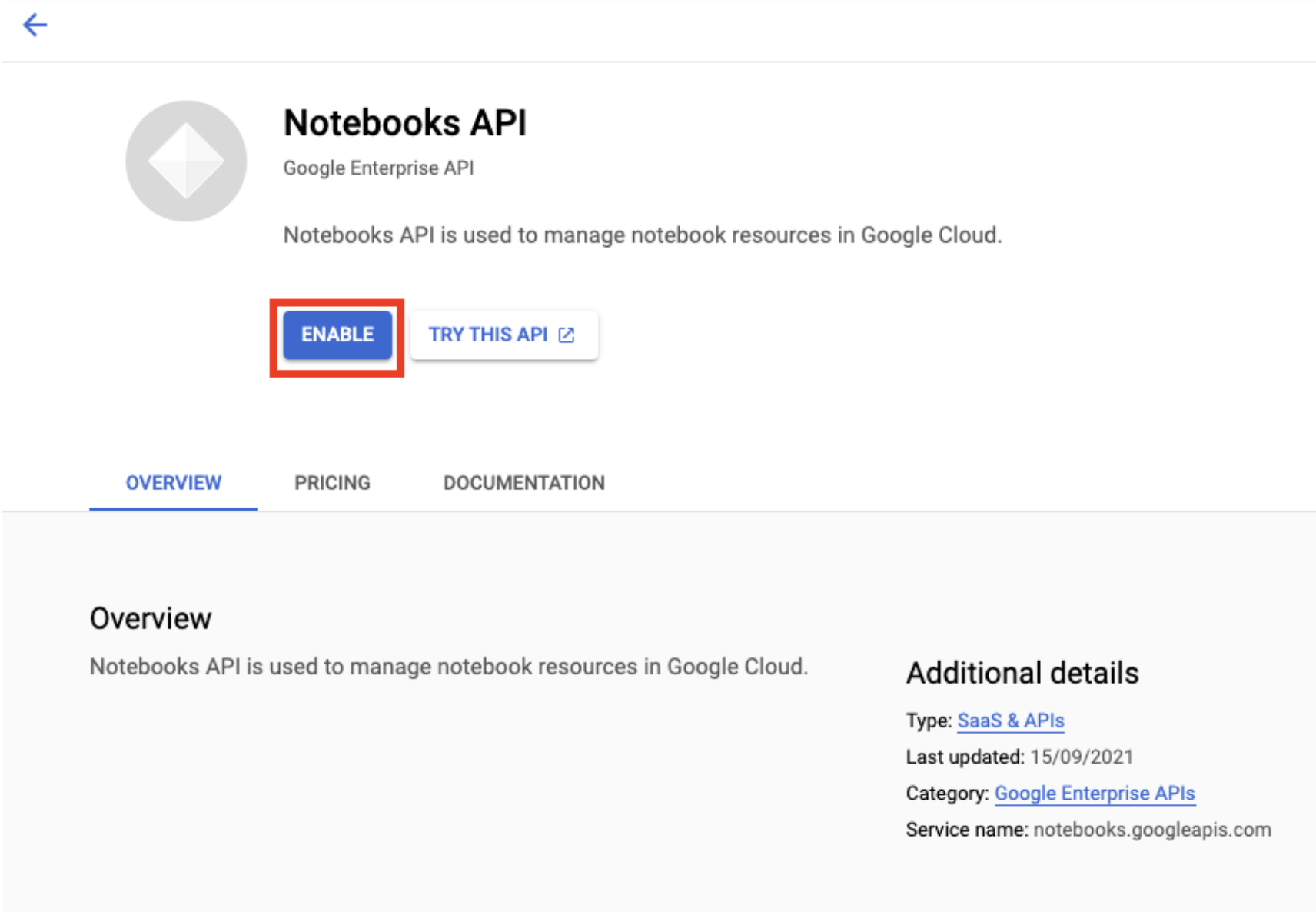
เมื่อเปิดใช้แล้ว ให้คลิก MANAGED NOTEBOOKS:

จากนั้นเลือก NEW NOTEBOOK
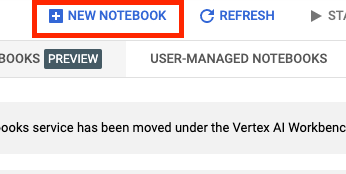
ตั้งชื่อ Notebook แล้วคลิก Advanced Settings

ในส่วน Advanced Settings ให้เปิดใช้ Idle Shutdown และตั้งค่าจำนวนนาทีเป็น 60 ซึ่งหมายความว่า Notebook จะปิดโดยอัตโนมัติเมื่อไม่ได้ใช้งาน เพื่อไม่ให้คุณต้องเสียค่าใช้จ่ายที่ไม่จำเป็น

ในส่วน Security ให้เลือก "Enable terminal" หากยังไม่ได้เปิดใช้
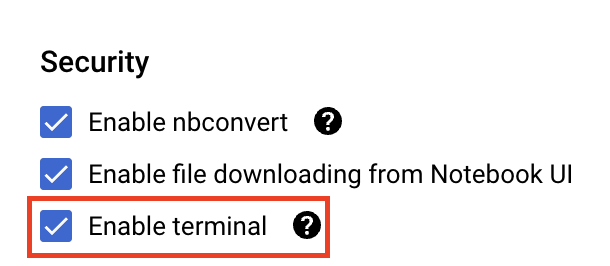
คุณสามารถปล่อยให้การตั้งค่าขั้นสูงอื่นๆ ทั้งหมดเป็นไปตามค่าเริ่มต้น
จากนั้นคลิก Create ระบบจะจัดสรรอินสแตนซ์ให้เสร็จภายใน 2-3 นาที
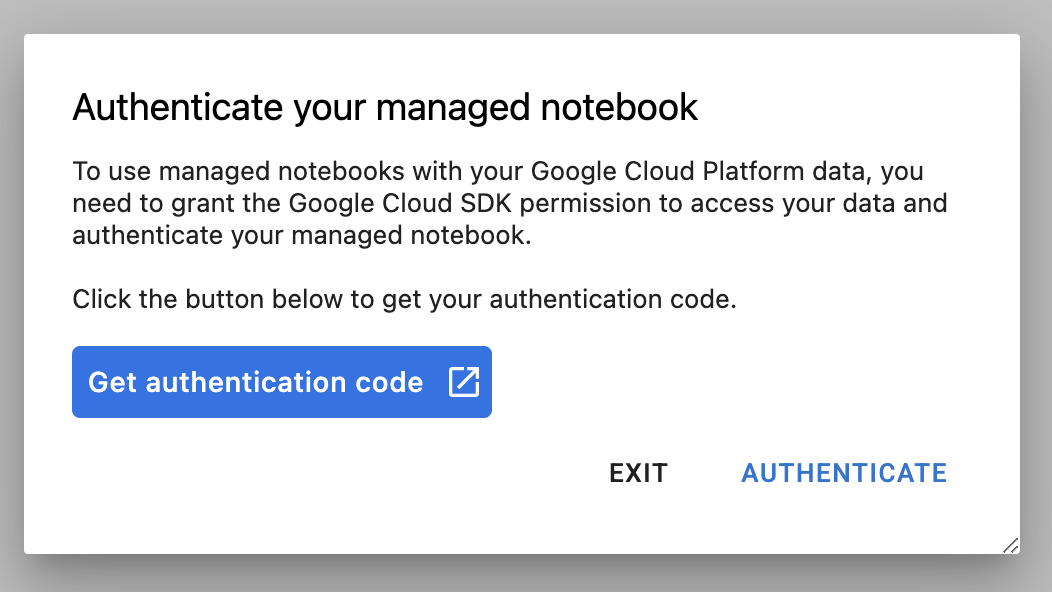
เมื่อสร้างอินสแตนซ์แล้ว ให้เลือก Open JupyterLab

เมื่อใช้อินสแตนซ์ใหม่เป็นครั้งแรก ระบบจะขอให้คุณตรวจสอบสิทธิ์ ให้ทำตามขั้นตอนใน UI
4. สร้างคอนเทนเนอร์สำหรับโค้ดของแอปพลิเคชันการฝึก
โมเดลที่คุณจะฝึกและปรับแต่งในแล็บนี้คือโมเดลการจัดประเภทรูปภาพที่ฝึกในชุดข้อมูลม้าหรือคนจากTensorFlow Datasets
คุณจะส่งงานการปรับแต่งไฮเปอร์พารามิเตอร์นี้ไปยัง Vertex AI โดยใส่โค้ดของแอปพลิเคชันการฝึกใน คอนเทนเนอร์ Docker แล้วพุชคอนเทนเนอร์นี้ไปยัง Google Container Registry การใช้แนวทางนี้จะช่วยให้คุณปรับแต่งไฮเปอร์พารามิเตอร์สำหรับโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้
หากต้องการเริ่มต้น ให้เปิดหน้าต่างเทอร์มินัลในอินสแตนซ์ Notebook จากเมนู Launcher

สร้างไดเรกทอรีใหม่ชื่อ horses_or_humans แล้วเปลี่ยนไดเรกทอรีเป็นไดเรกทอรีนี้
mkdir horses_or_humans
cd horses_or_humans
ขั้นตอนที่ 1: สร้าง Dockerfile
ขั้นตอนแรกในการสร้างคอนเทนเนอร์สำหรับโค้ดคือการสร้าง Dockerfile ใน Dockerfile คุณจะใส่คำสั่งทั้งหมดที่จำเป็นในการเรียกใช้อิมเมจ โดยจะติดตั้งไลบรารีที่จำเป็นทั้งหมด รวมถึงไลบรารี CloudML Hypertune และตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึก
สร้าง Dockerfile ว่างจากเทอร์มินัล
touch Dockerfile
เปิด Dockerfile แล้วคัดลอกโค้ดต่อไปนี้ลงใน Dockerfile
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Dockerfile นี้ใช้อิมเมจ Docker ของ Deep Learning Container TensorFlow Enterprise 2.7 GPU คอนเทนเนอร์การเรียนรู้เชิงลึกใน Google Cloud มาพร้อมกับเฟรมเวิร์ก ML และวิทยาศาสตร์ข้อมูลทั่วไปมากมายที่ติดตั้งไว้ล่วงหน้า หลังจากดาวน์โหลดอิมเมจนั้นแล้ว Dockerfile นี้จะตั้งค่าจุดเริ่มต้นสำหรับโค้ดการฝึก คุณยังไม่ได้สร้างไฟล์เหล่านี้ ในขั้นตอนถัดไป คุณจะเพิ่มโค้ดสำหรับการฝึกและปรับแต่งโมเดล
ขั้นตอนที่ 2: เพิ่มโค้ดการฝึกโมเดล
จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างไดเรกทอรีสำหรับโค้ดการฝึกและไฟล์ Python ที่คุณจะเพิ่มโค้ด
mkdir trainer
touch trainer/task.py
ตอนนี้คุณควรมีไฟล์ต่อไปนี้ในไดเรกทอรี horses_or_humans/
+ Dockerfile
+ trainer/
+ task.py
จากนั้นเปิดไฟล์ task.py ที่เพิ่งสร้างแล้วคัดลอกโค้ดด้านล่าง
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
ก่อนที่จะสร้างคอนเทนเนอร์ เรามาดูโค้ดอย่างละเอียดกันก่อน มีคอมโพเนนต์บางอย่างที่เฉพาะเจาะจงสำหรับการใช้บริการการปรับแต่งไฮเปอร์พารามิเตอร์
- สคริปต์จะนำเข้าไลบรารี
hypertuneโปรดทราบว่า Dockerfile จากขั้นตอนที่ 1 มีคำแนะนำในการติดตั้งไลบรารีนี้ด้วย pip - ฟังก์ชัน
get_args()จะกำหนดอาร์กิวเมนต์บรรทัดคำสั่งสำหรับไฮเปอร์พารามิเตอร์แต่ละรายการที่คุณต้องการปรับแต่ง ในตัวอย่างนี้ ไฮเปอร์พารามิเตอร์ที่จะปรับแต่งคืออัตราการเรียนรู้ ค่าโมเมนตัมในตัวเพิ่มประสิทธิภาพ และจำนวนหน่วยในเลเยอร์ที่ซ่อนสุดท้ายของโมเดล แต่คุณสามารถทดลองใช้ไฮเปอร์พารามิเตอร์อื่นๆ ได้ จากนั้นระบบจะใช้ค่าที่ส่งผ่านในอาร์กิวเมนต์เหล่านั้นเพื่อตั้งค่าไฮเปอร์พารามิเตอร์ที่เกี่ยวข้องในโค้ด - ที่ส่วนท้ายของฟังก์ชัน
main()ระบบจะใช้ไลบรารีhypertuneเพื่อกำหนดเมตริกที่คุณต้องการเพิ่มประสิทธิภาพ ใน TensorFlow เมธอดmodel.fitของ Keras จะแสดงผลออบเจ็กต์Historyแอตทริบิวต์History.historyคือบันทึกค่าการสูญเสียการฝึกและค่าเมตริกในยุคที่ต่อเนื่องกัน หากคุณส่งข้อมูลการตรวจสอบไปยังmodel.fitแอตทริบิวต์History.historyจะรวมค่าการสูญเสียและการตรวจสอบเมตริกด้วย ตัวอย่างเช่น หากคุณฝึกโมเดลเป็นเวลา 3 ยุคด้วยข้อมูลการตรวจสอบและระบุaccuracyเป็นเมตริก แอตทริบิวต์History.historyจะมีลักษณะคล้ายกับพจนานุกรมต่อไปนี้
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
หากต้องการให้บริการการปรับแต่งไฮเปอร์พารามิเตอร์ค้นพบค่าที่เพิ่มความแม่นยำในการตรวจสอบของโมเดลให้สูงสุด ให้กำหนดเมตริกเป็นรายการสุดท้าย (หรือ NUM_EPOCS - 1) ของรายการ val_accuracy จากนั้นส่งเมตริกนี้ไปยังอินสแตนซ์ของ HyperTune คุณเลือกสตริงใดก็ได้สำหรับ hyperparameter_metric_tag แต่คุณจะต้องใช้สตริงอีกครั้งเมื่อเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์
ขั้นตอนที่ 3: สร้างคอนเทนเนอร์
จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อกำหนดตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์ โดยอย่าลืมแทนที่ your-cloud-project ด้วยรหัสโปรเจ็กต์
PROJECT_ID='your-cloud-project'
กำหนดตัวแปรด้วย URI ของอิมเมจคอนเทนเนอร์ใน Google Container Registry
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
กำหนดค่า Docker
gcloud auth configure-docker
จากนั้นสร้างคอนเทนเนอร์โดยเรียกใช้คำสั่งต่อไปนี้จากรูทของไดเรกทอรี horses_or_humans
docker build ./ -t $IMAGE_URI
สุดท้าย ให้พุชไปยัง Google Container Registry
docker push $IMAGE_URI
เมื่อพุชคอนเทนเนอร์ไปยัง Container Registry แล้ว คุณก็พร้อมที่จะเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์ของโมเดลที่กำหนดเอง
5. เรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ใน Vertex AI
แล็บนี้ใช้การฝึกที่กำหนดเองผ่านคอนเทนเนอร์ที่กำหนดเองใน Google Container Registry แต่คุณยังเรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ด้วยคอนเทนเนอร์ที่สร้างไว้ล่วงหน้าของ Vertex AIได้ด้วย
หากต้องการเริ่มต้น ให้ไปที่ส่วน Training ในส่วน Vertex ของ Cloud Console
ขั้นตอนที่ 1: กำหนดค่างานการฝึก
คลิก Create เพื่อป้อนพารามิเตอร์สำหรับงานการปรับแต่งไฮเปอร์พารามิเตอร์
- ในส่วน Dataset ให้เลือก No managed dataset
- จากนั้นเลือก Custom training (advanced) เป็นวิธีการฝึก แล้วคลิก Continue
- ป้อน
horses-humans-hyptertune(หรือชื่อโมเดลที่ต้องการ) สำหรับชื่อโมเดล - คลิก Continue
ในขั้นตอนการตั้งค่าคอนเทนเนอร์ ให้เลือก Custom container

ในช่องแรก (Container image ) ให้ป้อนค่าของตัวแปร IMAGE_URI จากส่วนก่อนหน้า ซึ่งควรเป็น gcr.io/your-cloud-project/horse-human:hypertune โดยใช้ชื่อโปรเจ็กต์ของคุณเอง ปล่อยให้ช่องอื่นๆ ว่างไว้ แล้วคลิก Continue
ขั้นตอนที่ 2: กำหนดค่างานการปรับแต่งไฮเปอร์พารามิเตอร์
เลือก Enable hyperparameter tuning
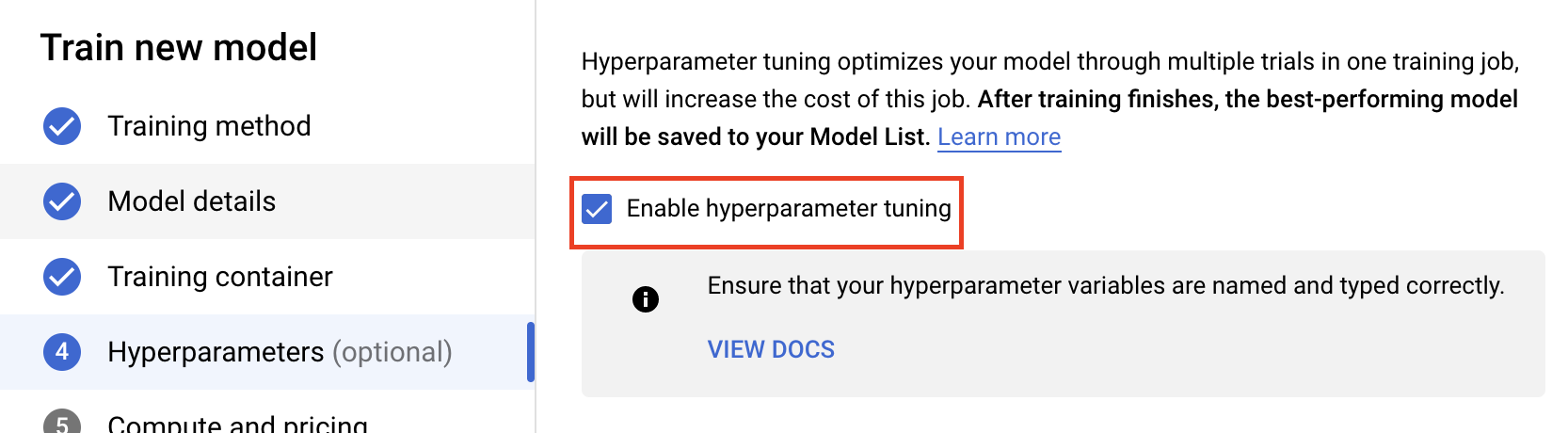
กำหนดค่าไฮเปอร์พารามิเตอร์
จากนั้นคุณจะต้องเพิ่มไฮเปอร์พารามิเตอร์ที่คุณตั้งค่าเป็นอาร์กิวเมนต์บรรทัดคำสั่งในโค้ดของแอปพลิเคชันการฝึก เมื่อเพิ่มไฮเปอร์พารามิเตอร์ คุณจะต้องระบุชื่อก่อน ซึ่งควรตรงกับชื่ออาร์กิวเมนต์ที่คุณส่งไปยัง argparse

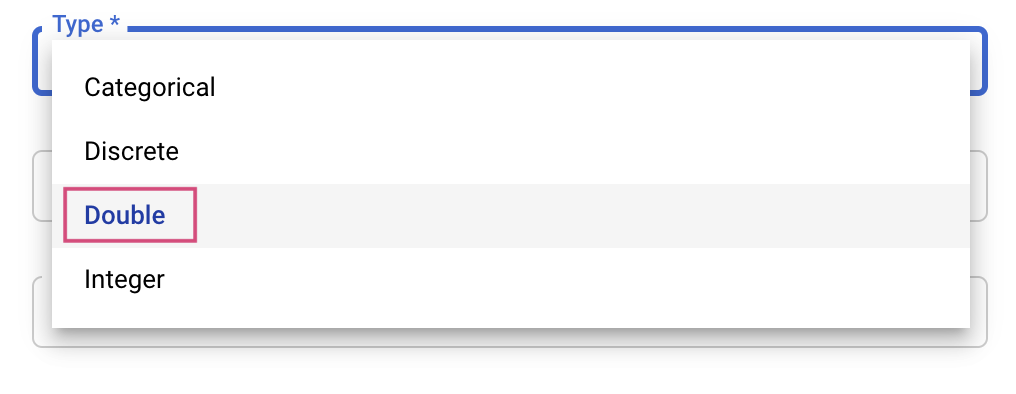
จากนั้นคุณจะเลือกประเภทและขอบเขตของค่าที่บริการการปรับแต่งจะลองใช้ หากเลือกประเภท Double หรือ Integer คุณจะต้องระบุค่าต่ำสุดและค่าสูงสุด และหากเลือก Categorical หรือ Discrete คุณจะต้องระบุค่า

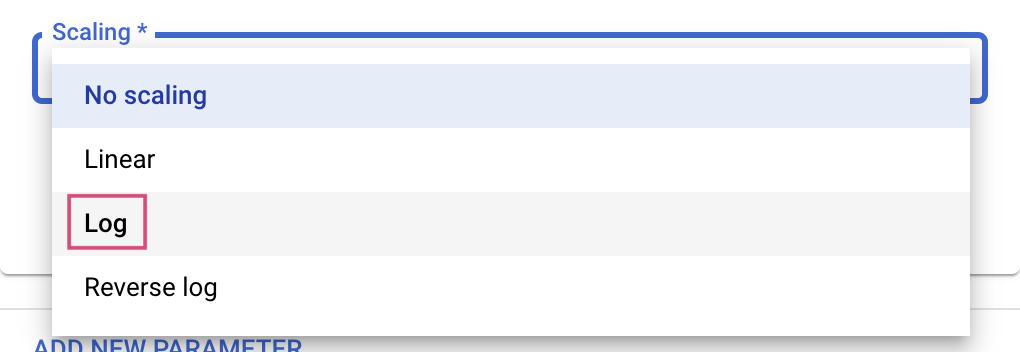
สำหรับประเภท Double และ Integer คุณจะต้องระบุค่า Scaling ด้วย
หลังจากเพิ่มไฮเปอร์พารามิเตอร์ learning_rate แล้ว ให้เพิ่มพารามิเตอร์สำหรับ momentum และ num_units


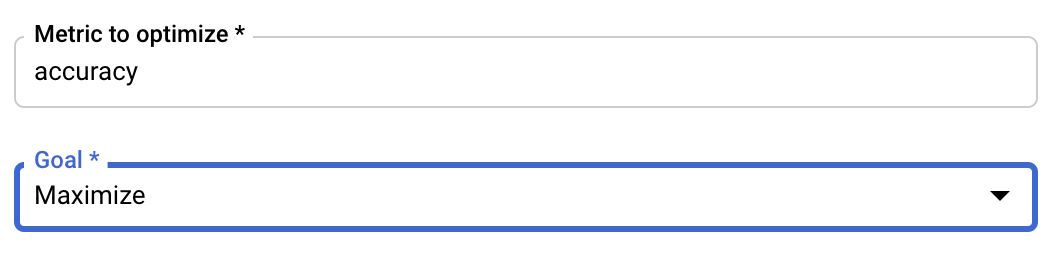
กำหนดค่าเมตริก
หลังจากเพิ่มไฮเปอร์พารามิเตอร์แล้ว ให้ระบุเมตริกที่คุณต้องการเพิ่มประสิทธิภาพและเป้าหมาย ซึ่งควรเป็น hyperparameter_metric_tag เดียวกับที่คุณตั้งค่าไว้ในแอปพลิเคชันการฝึก
บริการการปรับแต่งไฮเปอร์พารามิเตอร์ของ Vertex AI จะเรียกใช้งานแอปพลิเคชันการฝึกหลายครั้งด้วยค่าที่กำหนดค่าไว้ในขั้นตอนก่อนหน้า คุณจะต้องกำหนดขอบเขตบนสำหรับจำนวนการทดลองใช้ที่บริการจะเรียกใช้งาน โดยทั่วไปการทดลองใช้มากขึ้นจะให้ผลลัพธ์ที่ดีขึ้น แต่จะมีจุดที่ผลลัพธ์เริ่มลดลง ซึ่งหลังจากนั้นการทดลองใช้เพิ่มเติมจะส่งผลต่อเมตริกที่คุณพยายามเพิ่มประสิทธิภาพเพียงเล็กน้อยหรือไม่มีผลเลย แนวทางปฏิบัติแนะนำคือการเริ่มต้นด้วยการทดลองใช้จำนวนน้อยๆ และดูว่าไฮเปอร์พารามิเตอร์ที่คุณเลือกส่งผลมากน้อยเพียงใดก่อนที่จะเพิ่มจำนวนการทดลองใช้
นอกจากนี้ คุณยังต้องกำหนดขอบเขตบนสำหรับจำนวนการทดลองใช้แบบขนานด้วย การเพิ่มจำนวนการทดลองใช้แบบขนานจะช่วยลดระยะเวลาที่ใช้ในการเรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ แต่ก็อาจลดประสิทธิภาพของงานโดยรวมได้ เนื่องจากกลยุทธ์การปรับแต่งเริ่มต้นจะใช้ผลลัพธ์ของการทดลองใช้ก่อนหน้าเพื่อแจ้งการกำหนดค่าในครั้งต่อๆ ไป หากคุณเรียกใช้งานการทดลองใช้แบบขนานมากเกินไป จะมีการทดลองใช้ที่เริ่มต้นโดยไม่ได้รับประโยชน์จากผลลัพธ์ของการทดลองใช้ที่ยังคงทำงานอยู่
สำหรับวัตถุประสงค์ในการสาธิต คุณสามารถตั้งค่าจำนวนการทดลองใช้เป็น 15 ครั้ง และจำนวนการทดลองใช้แบบขนานสูงสุดเป็น 3 ครั้ง คุณสามารถทดลองใช้จำนวนต่างๆ ได้ แต่การทำเช่นนี้อาจทำให้เวลาในการปรับแต่งนานขึ้นและค่าใช้จ่ายสูงขึ้น

ขั้นตอนสุดท้ายคือการเลือก Default เป็นอัลกอริทึมการค้นหา ซึ่งจะใช้ Google Vizier เพื่อทำการเพิ่มประสิทธิภาพแบบเบย์สำหรับไฮเปอร์พารามิเตอร์ ดูข้อมูลเพิ่มเติมเกี่ยวกับอัลกอริทึมนี้ได้ที่นี่
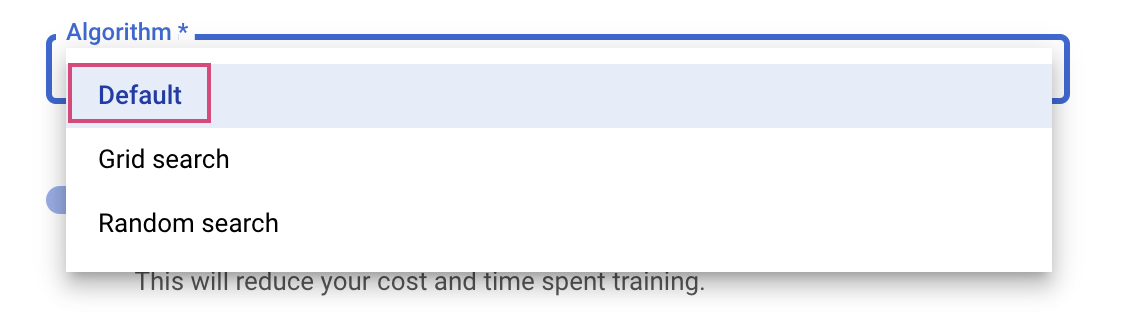
คลิก Continue
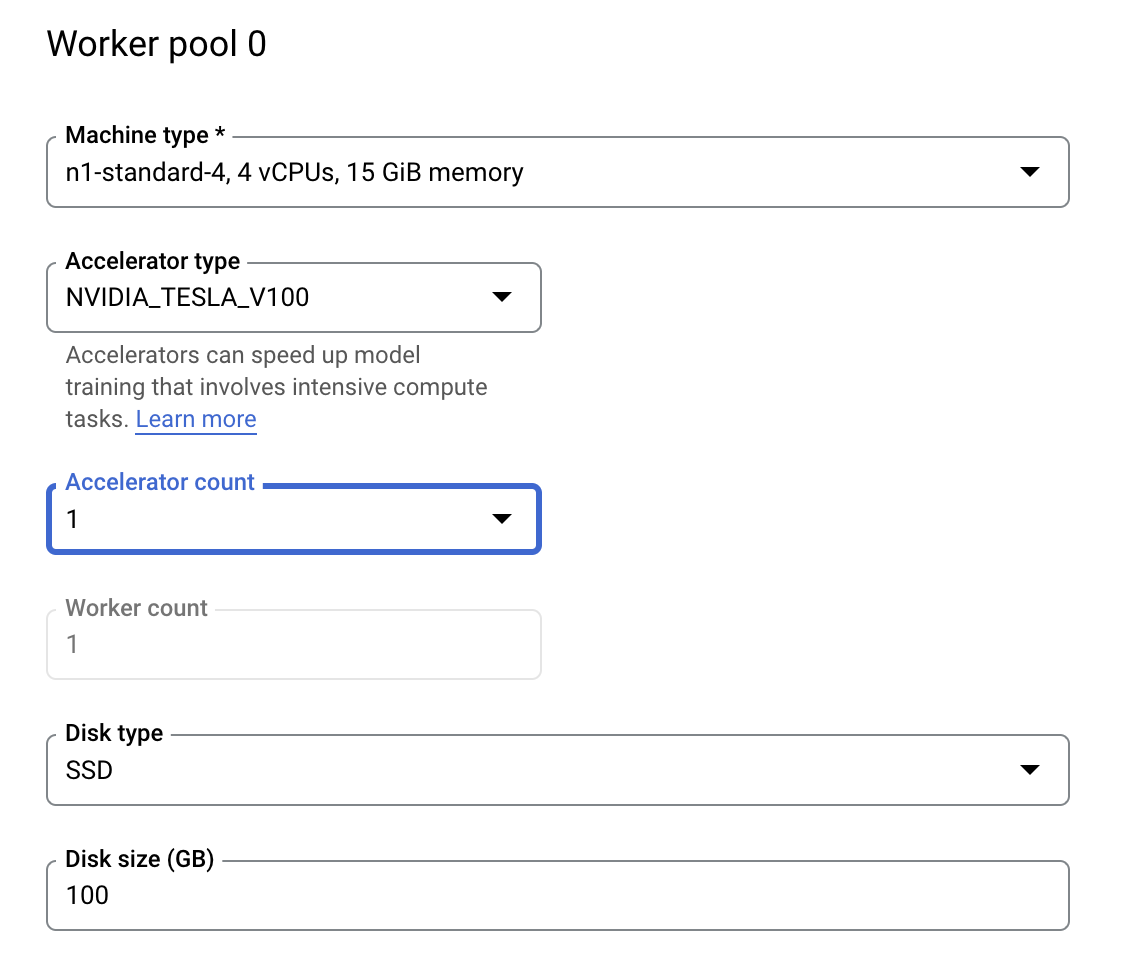
ขั้นตอนที่ 3: กำหนดค่าการประมวลผล
ในส่วน Compute and pricing ให้ปล่อยให้ภูมิภาคที่เลือกเป็นไปตามค่าเริ่มต้น และกำหนดค่า Worker pool 0 ดังนี้
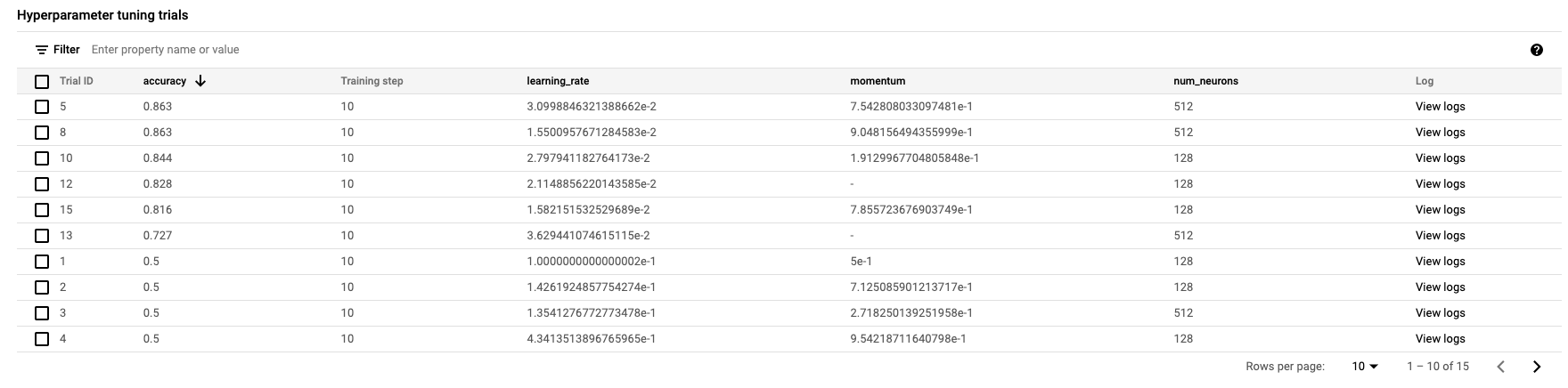
คลิก Start training เพื่อเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์ ในส่วน Training ของคอนโซลในแท็บ HYPERPARAMETER TUNING JOBS คุณจะเห็นลักษณะดังนี้
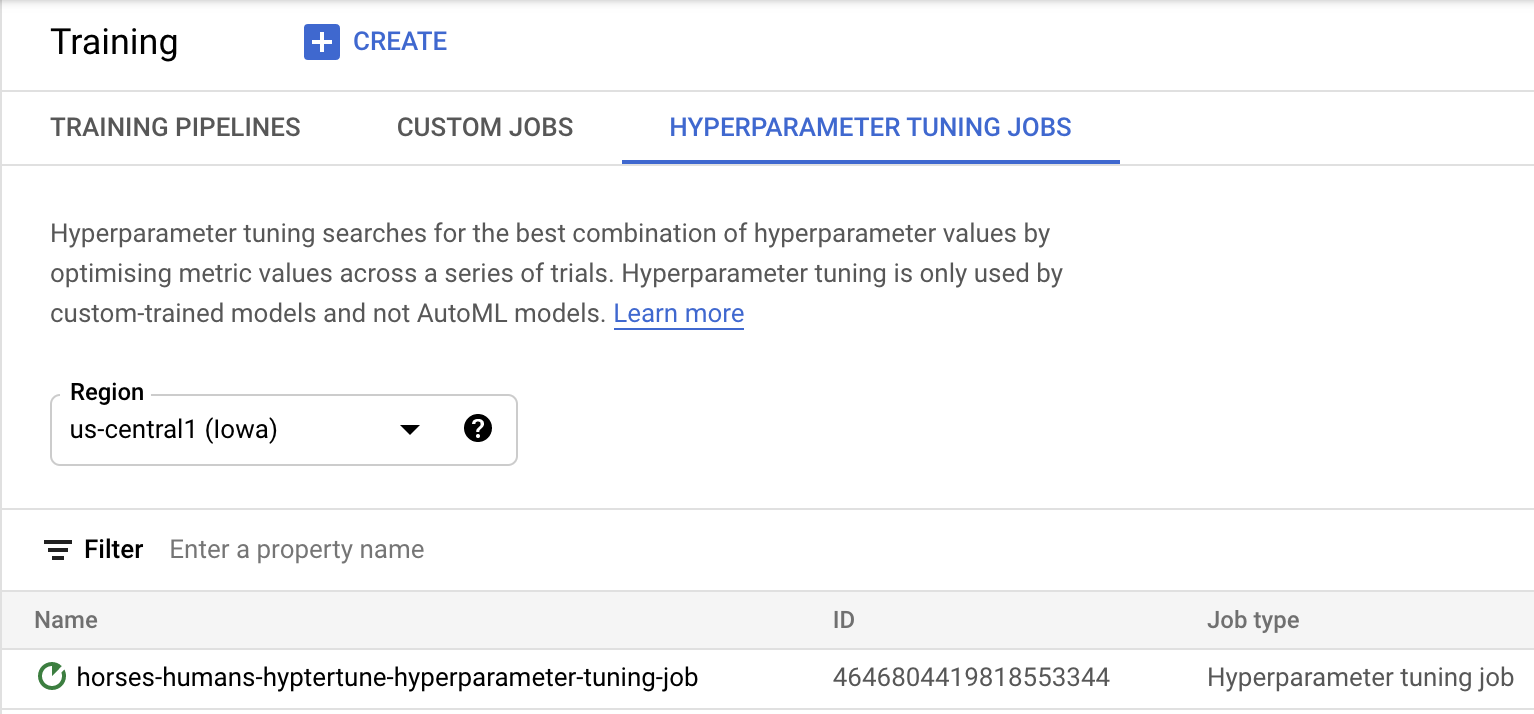
เมื่อเสร็จแล้ว คุณจะคลิกชื่องานและดูผลลัพธ์ของการทดลองใช้การปรับแต่งได้
🎉 ยินดีด้วย 🎉
คุณได้เรียนรู้วิธีใช้ Vertex AI เพื่อทำสิ่งต่อไปนี้
- เปิดใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์สำหรับโค้ดการฝึกที่ระบุไว้ในคอนเทนเนอร์ที่กำหนดเอง คุณใช้โมเดล TensorFlow ในตัวอย่างนี้ แต่คุณสามารถฝึกโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้โดยใช้คอนเทนเนอร์ที่กำหนดเอง
ดูข้อมูลเพิ่มเติมเกี่ยวกับส่วนต่างๆ ของ Vertex ได้ในเอกสารประกอบ
6. [ไม่บังคับ] ใช้ Vertex SDK
ส่วนก่อนหน้าแสดงวิธีเปิดใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ผ่าน UI ในส่วนนี้ คุณจะได้เห็นวิธีอื่นในการส่งงานการปรับแต่งไฮเปอร์พารามิเตอร์โดยใช้ Vertex Python API
สร้าง Notebook TensorFlow 2 จาก Launcher

นำเข้า Vertex AI SDK
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
หากต้องการเปิดใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ คุณต้องกำหนดข้อกำหนดต่อไปนี้ก่อน คุณจะต้องแทนที่ {PROJECT_ID} ใน image_uri ด้วยโปรเจ็กต์ของคุณ
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
จากนั้นสร้าง CustomJob คุณจะต้องแทนที่ {YOUR_BUCKET} ด้วย Bucket ในโปรเจ็กต์ของคุณสำหรับการจัดเตรียม
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
จากนั้นสร้างและเรียกใช้ HyperparameterTuningJob
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. การทำความสะอาดข้อมูล
เนื่องจากเรากำหนดค่า Notebook ให้หมดเวลาหลังจากไม่มีการใช้งานเป็นเวลา 60 นาที จึงไม่จำเป็นต้องกังวลเกี่ยวกับการปิดอินสแตนซ์ หากต้องการปิดอินสแตนซ์ด้วยตนเอง ให้คลิกปุ่ม Stop ในส่วน Vertex AI Workbench ของคอนโซล หากต้องการลบ Notebook ทั้งหมด ให้คลิกปุ่ม Delete

หากต้องการลบ Storage Bucket ให้ใช้เมนูการนำทางใน Cloud Console ไปที่ Storage เลือก Bucket แล้วคลิก Delete