১. সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি একটি TensorFlow মডেলের হাইপারপ্যারামিটার টিউনিং করার জন্য Vertex AI ব্যবহার করবেন। যদিও এই ল্যাবে মডেল কোডের জন্য TensorFlow ব্যবহার করা হয়েছে, এর ধারণাগুলো অন্যান্য ML ফ্রেমওয়ার্কের ক্ষেত্রেও প্রযোজ্য।
আপনি যা শিখবেন
আপনি শিখবেন কীভাবে:
- স্বয়ংক্রিয় হাইপারপ্যারামিটার টিউনিংয়ের জন্য প্রশিক্ষণ অ্যাপ্লিকেশন কোড পরিবর্তন করুন
- Vertex AI UI থেকে একটি হাইপারপ্যারামিটার টিউনিং জব কনফিগার ও চালু করুন।
- Vertex AI Python SDK ব্যবহার করে একটি হাইপারপ্যারামিটার টিউনিং জব কনফিগার ও চালু করুন।
গুগল ক্লাউডে এই ল্যাবটি চালানোর মোট খরচ প্রায় ৩ মার্কিন ডলার।
২. ভার্টেক্স এআই-এর পরিচিতি
এই ল্যাবটি গুগল ক্লাউডে উপলব্ধ সর্বাধুনিক এআই প্রোডাক্টটি ব্যবহার করে। ভার্টেক্স এআই গুগল ক্লাউডের এমএল (ML) অফারিংগুলোকে একটি নির্বিঘ্ন ডেভেলপমেন্ট অভিজ্ঞতায় একীভূত করে। পূর্বে, অটোএমএল (AutoML) দিয়ে প্রশিক্ষিত মডেল এবং কাস্টম মডেলগুলো আলাদা আলাদা সার্ভিসের মাধ্যমে অ্যাক্সেস করা যেত। নতুন অফারিংটি অন্যান্য নতুন প্রোডাক্টের সাথে উভয়কে একটিমাত্র এপিআই (API)-তে একত্রিত করেছে। আপনি আপনার বিদ্যমান প্রোজেক্টগুলোও ভার্টেক্স এআই-তে মাইগ্রেট করতে পারেন। আপনার কোনো মতামত থাকলে, অনুগ্রহ করে সাপোর্ট পেজটি দেখুন।
ভার্টেক্স এআই-এর এন্ড-টু-এন্ড এমএল ওয়ার্কফ্লো সমর্থন করার জন্য বিভিন্ন পণ্য রয়েছে। এই ল্যাবটি নিচে উল্লেখিত পণ্যগুলোর উপর আলোকপাত করবে: ট্রেনিং এবং ওয়ার্কবেঞ্চ ।
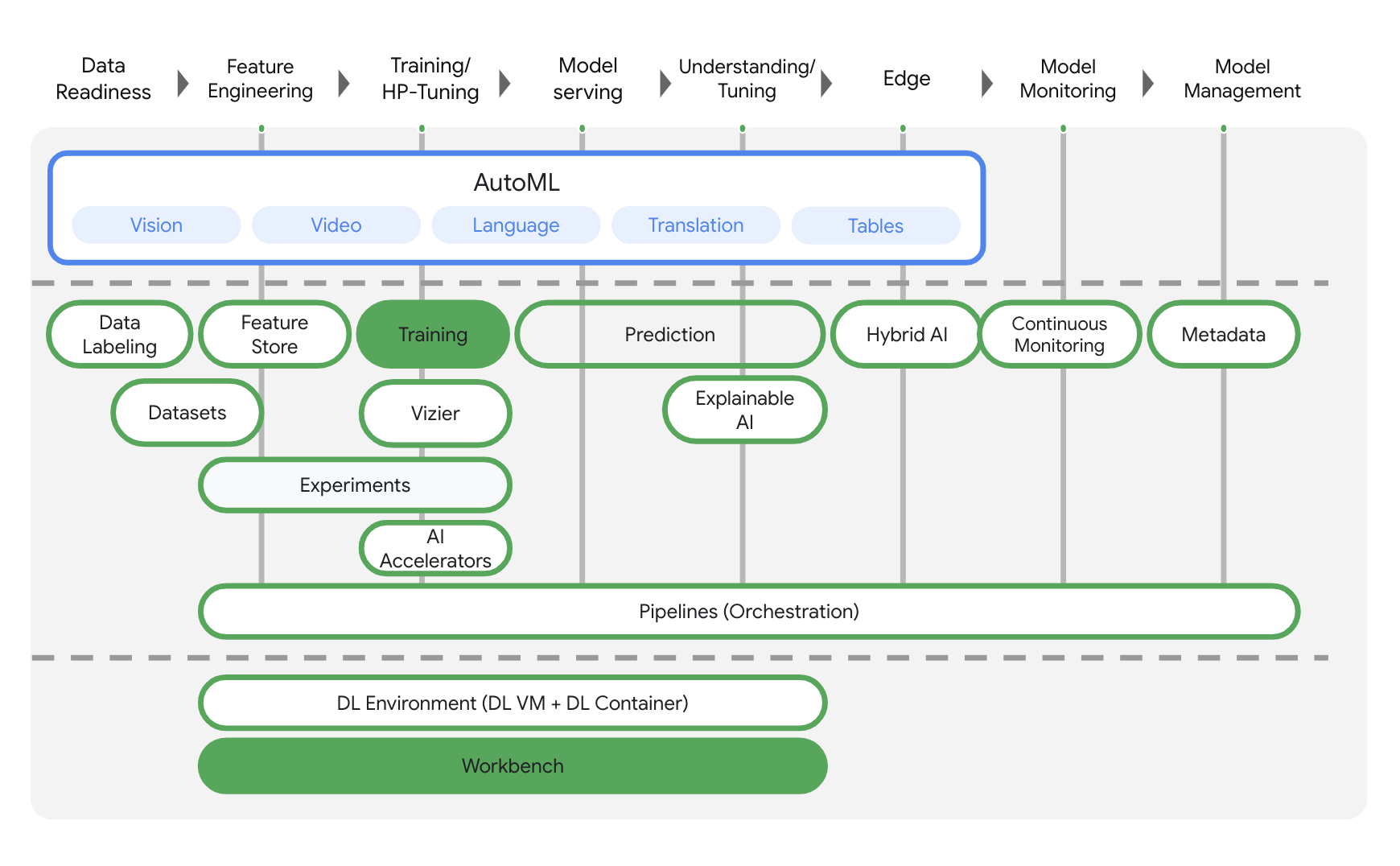
৩. আপনার পরিবেশ প্রস্তুত করুন
এই কোডল্যাবটি চালানোর জন্য আপনার বিলিং চালু করা একটি গুগল ক্লাউড প্ল্যাটফর্ম প্রজেক্ট প্রয়োজন হবে। প্রজেক্ট তৈরি করতে, এখানের নির্দেশাবলী অনুসরণ করুন।
ধাপ ১: কম্পিউট ইঞ্জিন এপিআই সক্রিয় করুন
Compute Engine- এ যান এবং যদি আগে থেকে সক্রিয় করা না থাকে তবে 'Enable' নির্বাচন করুন। আপনার নোটবুক ইনস্ট্যান্স তৈরি করার জন্য এটি প্রয়োজন হবে।
ধাপ ২: কন্টেইনার রেজিস্ট্রি এপিআই সক্রিয় করুন
কন্টেইনার রেজিস্ট্রি- তে যান এবং যদি আগে থেকে সক্ষম করা না থাকে তবে তা নির্বাচন করুন। আপনার কাস্টম ট্রেনিং জবের জন্য একটি কন্টেইনার তৈরি করতে আপনি এটি ব্যবহার করবেন।
ধাপ ৩: Vertex AI API সক্রিয় করুন
আপনার ক্লাউড কনসোলের Vertex AI বিভাগে যান এবং Enable Vertex AI API-তে ক্লিক করুন।
ধাপ ৪: একটি Vertex AI Workbench ইনস্ট্যান্স তৈরি করুন
আপনার ক্লাউড কনসোলের Vertex AI সেকশন থেকে Workbench-এ ক্লিক করুন:
নোটবুকস এপিআই (Notebooks API) সক্রিয় করুন, যদি আগে থেকে সক্রিয় করা না থাকে।
একবার চালু হয়ে গেলে, ম্যানেজড নোটবুকস-এ ক্লিক করুন:

তারপর নতুন নোটবুক নির্বাচন করুন।
আপনার নোটবুকটির একটি নাম দিন, এবং তারপর অ্যাডভান্সড সেটিংস-এ ক্লিক করুন।

অ্যাডভান্সড সেটিংস-এর অধীনে, আইডল শাটডাউন চালু করুন এবং মিনিটের সংখ্যা ৬০-এ সেট করুন। এর মানে হলো, আপনার নোটবুকটি ব্যবহার না করা হলে স্বয়ংক্রিয়ভাবে বন্ধ হয়ে যাবে, ফলে আপনার অপ্রয়োজনীয় খরচ হবে না।

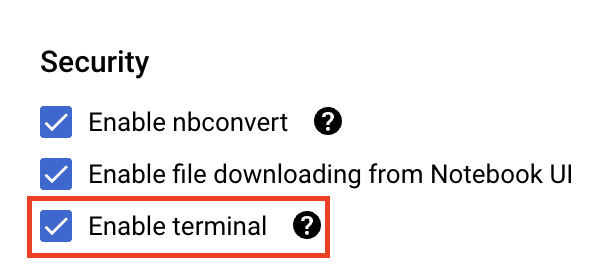
সিকিউরিটি-এর অধীনে, 'Enable terminal' নির্বাচন করুন, যদি এটি আগে থেকে সক্রিয় করা না থাকে।
আপনি অন্যান্য সমস্ত উন্নত সেটিংস অপরিবর্তিত রাখতে পারেন।
এরপর, Create-এ ক্লিক করুন। ইনস্ট্যান্সটি প্রোভিশন হতে কয়েক মিনিট সময় লাগবে।
ইনস্ট্যান্সটি তৈরি হয়ে গেলে, Open JupyterLab নির্বাচন করুন।

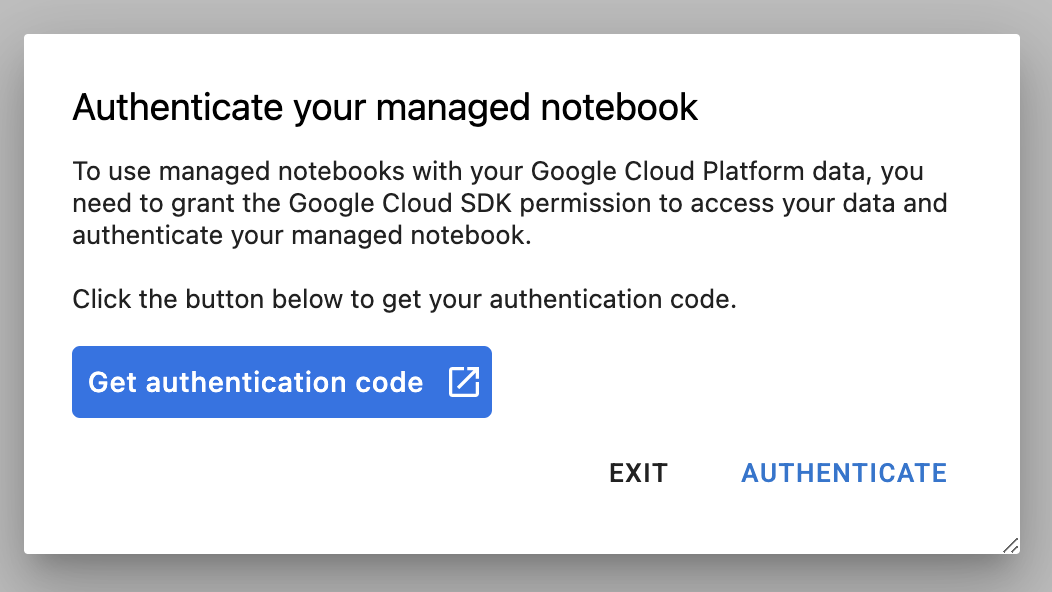
আপনি যখন প্রথমবার একটি নতুন ইনস্ট্যান্স ব্যবহার করবেন, তখন আপনাকে প্রমাণীকরণের জন্য বলা হবে। এটি করার জন্য UI-তে দেওয়া ধাপগুলো অনুসরণ করুন।
৪. প্রশিক্ষণ অ্যাপ্লিকেশন কোডকে কন্টেইনারাইজ করুন
এই ল্যাবে আপনি যে মডেলটি প্রশিক্ষণ ও টিউনিং করবেন, সেটি হলো TensorFlow Datasets- এর ঘোড়া বা মানুষের ডেটাসেটের উপর প্রশিক্ষিত একটি ইমেজ ক্লাসিফিকেশন মডেল।
আপনার ট্রেনিং অ্যাপ্লিকেশন কোড একটি ডকার কন্টেইনারে রেখে এবং সেই কন্টেইনারটিকে গুগল কন্টেইনার রেজিস্ট্রি- তে পুশ করার মাধ্যমে আপনি এই হাইপারপ্যারামিটার টিউনিং কাজটি ভার্টেক্স এআই-এর কাছে জমা দেবেন। এই পদ্ধতি ব্যবহার করে, আপনি যেকোনো ফ্রেমওয়ার্ক দিয়ে তৈরি মডেলের হাইপারপ্যারামিটার টিউন করতে পারবেন।
শুরু করতে, লঞ্চার মেনু থেকে আপনার নোটবুক ইনস্ট্যান্সে একটি টার্মিনাল উইন্ডো খুলুন:

horses_or_humans নামে একটি নতুন ডিরেক্টরি তৈরি করুন এবং এর ভেতরে যান:
mkdir horses_or_humans
cd horses_or_humans
ধাপ ১: একটি ডকারফাইল তৈরি করুন
আপনার কোডকে কন্টেইনারাইজ করার প্রথম ধাপ হলো একটি ডকারফাইল (Dockerfile) তৈরি করা। ডকারফাইলটিতে আপনি ইমেজটি চালানোর জন্য প্রয়োজনীয় সমস্ত কমান্ড অন্তর্ভুক্ত করবেন। এটি ক্লাউডএমএল হাইপারটিউন (CloudML Hypertune) লাইব্রেরিসহ সমস্ত প্রয়োজনীয় লাইব্রেরি ইনস্টল করবে এবং ট্রেনিং কোডের জন্য এন্ট্রি পয়েন্ট সেট আপ করবে।
আপনার টার্মিনাল থেকে, একটি খালি Dockerfile তৈরি করুন:
touch Dockerfile
Dockerfile-টি খুলুন এবং এর মধ্যে নিম্নলিখিত বিষয়গুলো কপি করুন:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
এই ডকারফাইলটি Deep Learning Container TensorFlow Enterprise 2.7 GPU ডকার ইমেজ ব্যবহার করে। গুগল ক্লাউডের ডিপ লার্নিং কন্টেইনারগুলোতে অনেক প্রচলিত এমএল (ML) এবং ডেটা সায়েন্স ফ্রেমওয়ার্ক আগে থেকেই ইনস্টল করা থাকে। সেই ইমেজটি ডাউনলোড করার পর, এই ডকারফাইলটি ট্রেনিং কোডের জন্য এন্ট্রি পয়েন্ট সেট আপ করে। আপনি এখনও এই ফাইলগুলো তৈরি করেননি – পরবর্তী ধাপে, আপনি মডেলটিকে ট্রেনিং ও টিউনিং করার জন্য কোড যোগ করবেন।
ধাপ ২: মডেল প্রশিক্ষণ কোড যোগ করুন
আপনার টার্মিনাল থেকে, ট্রেনিং কোডের জন্য একটি ডিরেক্টরি এবং কোড যোগ করার জন্য একটি পাইথন ফাইল তৈরি করতে নিম্নলিখিত কমান্ডটি চালান:
mkdir trainer
touch trainer/task.py
আপনার horses_or_humans/ ডিরেক্টরিতে এখন নিম্নলিখিত বিষয়গুলো থাকা উচিত:
+ Dockerfile
+ trainer/
+ task.py
এরপর, আপনার তৈরি করা task.py ফাইলটি খুলুন এবং নিচের কোডটি কপি করুন।
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
কন্টেইনারটি বিল্ড করার আগে, চলুন কোডটি আরও ভালোভাবে দেখে নেওয়া যাক। এখানে কয়েকটি কম্পোনেন্ট রয়েছে যা হাইপারপ্যারামিটার টিউনিং সার্ভিস ব্যবহারের জন্য নির্দিষ্ট।
- স্ক্রিপ্টটি
hypertuneলাইব্রেরি ইম্পোর্ট করে। উল্লেখ্য যে, ধাপ ১-এর ডকারফাইলটিতে এই লাইব্রেরিটি পিপ ইনস্টল করার নির্দেশনা অন্তর্ভুক্ত ছিল। -
get_args()ফাংশনটি আপনার টিউন করতে চাওয়া প্রতিটি হাইপারপ্যারামিটারের জন্য একটি কমান্ড-লাইন আর্গুমেন্ট নির্ধারণ করে। এই উদাহরণে, যে হাইপারপ্যারামিটারগুলো টিউন করা হবে সেগুলো হলো লার্নিং রেট, অপটিমাইজারের মোমেন্টাম ভ্যালু এবং মডেলের শেষ হিডেন লেয়ারের ইউনিটের সংখ্যা, তবে আপনি চাইলে অন্যগুলো নিয়েও পরীক্ষা করতে পারেন। এরপর, ওই আর্গুমেন্টগুলোতে পাস করা মানটি কোডে সংশ্লিষ্ট হাইপারপ্যারামিটার সেট করার জন্য ব্যবহৃত হয়। -
main()ফাংশনের শেষে, আপনি যে মেট্রিকটি অপ্টিমাইজ করতে চান তা নির্ধারণ করার জন্যhypertuneলাইব্রেরি ব্যবহার করা হয়। TensorFlow-তে, keras-এরmodel.fitমেথড একটিHistoryঅবজেক্ট রিটার্ন করে।History.historyঅ্যাট্রিবিউটটি হলো ধারাবাহিক ইপকগুলোতে ট্রেনিং লস ভ্যালু এবং মেট্রিক ভ্যালুর একটি রেকর্ড। আপনি যদিmodel.fitএ ভ্যালিডেশন ডেটা পাস করেন, তাহলেHistory.historyঅ্যাট্রিবিউটে ভ্যালিডেশন লস এবং মেট্রিক ভ্যালুও অন্তর্ভুক্ত থাকবে। উদাহরণস্বরূপ, যদি আপনি ভ্যালিডেশন ডেটা দিয়ে তিনটি ইপকের জন্য একটি মডেলকে ট্রেইন করেন এবং মেট্রিক হিসেবেaccuracyপ্রদান করেন, তাহলেHistory.historyঅ্যাট্রিবিউটটি নিম্নলিখিত ডিকশনারির মতো দেখাবে।
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
আপনি যদি চান যে হাইপারপ্যারামিটার টিউনিং সার্ভিসটি মডেলের ভ্যালিডেশন অ্যাকুরেসি সর্বাধিক করে এমন মানগুলো খুঁজে বের করুক, তাহলে মেট্রিকটিকে val_accuracy তালিকার শেষ এন্ট্রি (অথবা NUM_EPOCS - 1 ) হিসেবে সংজ্ঞায়িত করুন। এরপর, এই মেট্রিকটি HyperTune এর একটি ইনস্ট্যান্সে পাস করুন। আপনি hyperparameter_metric_tag এর জন্য আপনার পছন্দমতো যেকোনো স্ট্রিং বেছে নিতে পারেন, কিন্তু পরে যখন আপনি হাইপারপ্যারামিটার টিউনিং কাজটি শুরু করবেন, তখন আপনাকে আবার সেই স্ট্রিংটি ব্যবহার করতে হবে।
ধাপ ৩: কন্টেইনারটি তৈরি করুন
আপনার প্রোজেক্টের জন্য একটি এনভ ভ্যারিয়েবল নির্ধারণ করতে, আপনার টার্মিনাল থেকে নিম্নলিখিত কমান্ডটি চালান এবং অবশ্যই your-cloud-project এর জায়গায় আপনার প্রোজেক্টের আইডি বসাবেন:
PROJECT_ID='your-cloud-project'
গুগল কন্টেইনার রেজিস্ট্রি-তে আপনার কন্টেইনার ইমেজের URI দিয়ে একটি ভেরিয়েবল নির্ধারণ করুন:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
ডকার কনফিগার করুন
gcloud auth configure-docker
এরপর, আপনার horses_or_humans ডিরেক্টরির রুট থেকে নিম্নলিখিত কমান্ডটি চালিয়ে কন্টেইনারটি বিল্ড করুন:
docker build ./ -t $IMAGE_URI
সবশেষে, এটিকে গুগল কন্টেইনার রেজিস্ট্রি-তে পুশ করুন:
docker push $IMAGE_URI
কন্টেইনারটি কন্টেইনার রেজিস্ট্রি-তে পুশ করা হয়ে গেলে, আপনি এখন একটি কাস্টম মডেল হাইপারপ্যারামিটার টিউনিংয়ের কাজ শুরু করার জন্য প্রস্তুত।
৫. Vertex AI-তে একটি হাইপারপ্যারামিটার টিউনিং জব চালান।
এই ল্যাবে গুগল কন্টেইনার রেজিস্ট্রি-তে একটি কাস্টম কন্টেইনারের মাধ্যমে কাস্টম ট্রেনিং ব্যবহার করা হয়, কিন্তু আপনি ভার্টেক্স এআই-এর একটি প্রি-বিল্ট কন্টেইনার দিয়েও হাইপারপ্যারামিটার টিউনিং জব চালাতে পারেন।
শুরু করতে, আপনার ক্লাউড কনসোলের Vertex বিভাগের Training সেকশনে যান:
ধাপ ১: প্রশিক্ষণ কাজটি কনফিগার করুন
আপনার হাইপারপ্যারামিটার টিউনিং কাজের জন্য প্যারামিটারগুলো প্রবেশ করাতে ক্রিয়েট-এ ক্লিক করুন।
- ডেটাসেট-এর অধীনে, কোনো পরিচালিত ডেটাসেট নয় নির্বাচন করুন।
- তারপর আপনার প্রশিক্ষণ পদ্ধতি হিসেবে কাস্টম প্রশিক্ষণ (উন্নত) নির্বাচন করুন এবং চালিয়ে যান-এ ক্লিক করুন।
- মডেলের নামের জায়গায়
horses-humans-hyptertune(অথবা আপনি আপনার মডেলের যে নাম দিতে চান) লিখুন। - চালিয়ে যান ক্লিক করুন
কন্টেইনার সেটিংস ধাপে, কাস্টম কন্টেইনার নির্বাচন করুন:

প্রথম বক্সে ( কন্টেইনার ইমেজ ), পূর্ববর্তী বিভাগ থেকে আপনার IMAGE_URI ভেরিয়েবলের মান লিখুন। এটি হবে: gcr.io/your-cloud-project/horse-human:hypertune , যেখানে আপনার নিজের প্রজেক্টের নাম থাকবে। বাকি ফিল্ডগুলো খালি রেখে ' Continue' বাটনে ক্লিক করুন।
ধাপ ২: হাইপারপ্যারামিটার টিউনিং জব কনফিগার করুন
হাইপারপ্যারামিটার টিউনিং সক্ষম করুন নির্বাচন করুন।
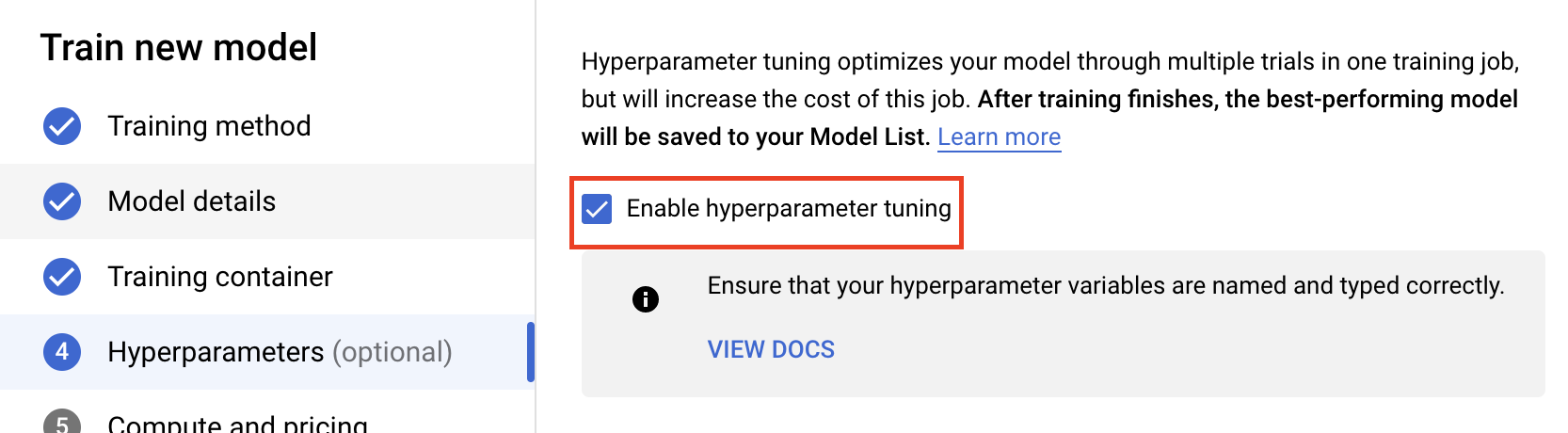
হাইপারপ্যারামিটার কনফিগার করুন
এরপরে, ট্রেনিং অ্যাপ্লিকেশন কোডে আপনাকে কমান্ড লাইন আর্গুমেন্ট হিসেবে সেট করা হাইপারপ্যারামিটারগুলো যোগ করতে হবে। একটি হাইপারপ্যারামিটার যোগ করার সময়, আপনাকে প্রথমে এর নাম দিতে হবে। এই নামটি অবশ্যই argparse এ দেওয়া আর্গুমেন্টের নামের সাথে মিলতে হবে।

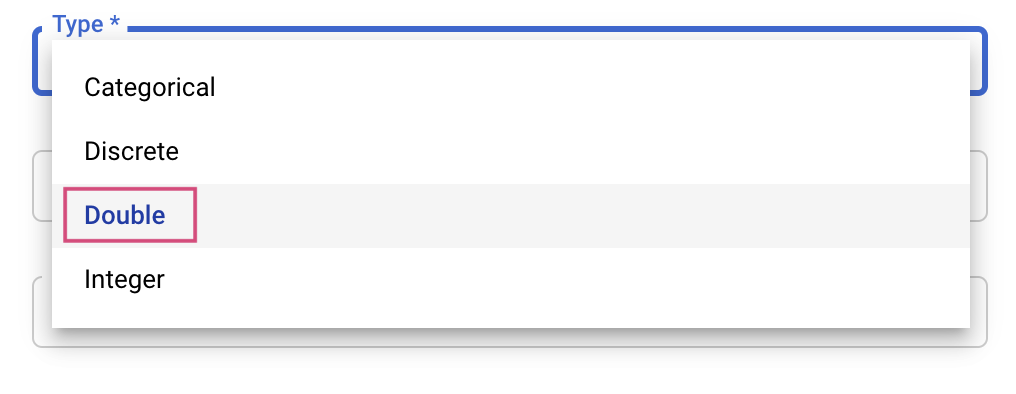
এরপর, আপনি টাইপ এবং সেইসাথে সেই মানগুলোর সীমা নির্বাচন করবেন যা টিউনিং সার্ভিসটি চেষ্টা করবে। আপনি যদি ডাবল বা ইন্টিজার টাইপ নির্বাচন করেন, তাহলে আপনাকে একটি সর্বনিম্ন এবং সর্বোচ্চ মান প্রদান করতে হবে। আর যদি আপনি ক্যাটেগরিক্যাল বা ডিসক্রিট নির্বাচন করেন, তাহলে আপনাকে মানগুলো প্রদান করতে হবে।

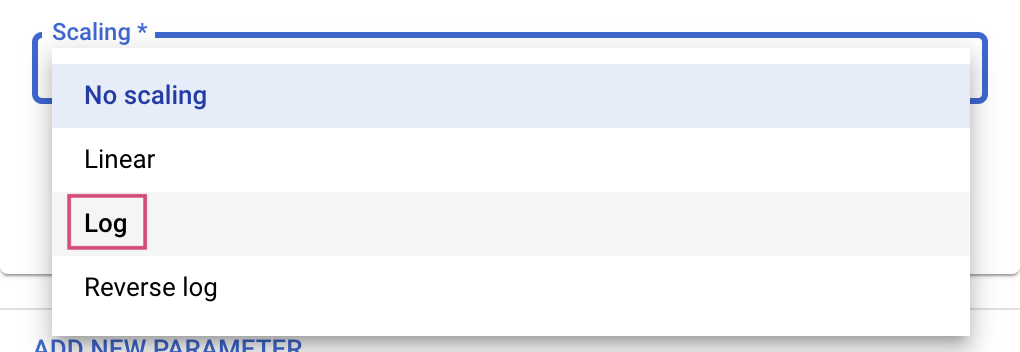
Double এবং Integer টাইপের জন্য আপনাকে Scaling ভ্যালুটিও প্রদান করতে হবে।
learning_rate হাইপারপ্যারামিটারটি যোগ করার পর, momentum এবং num_units এর জন্য প্যারামিটারগুলো যোগ করুন।


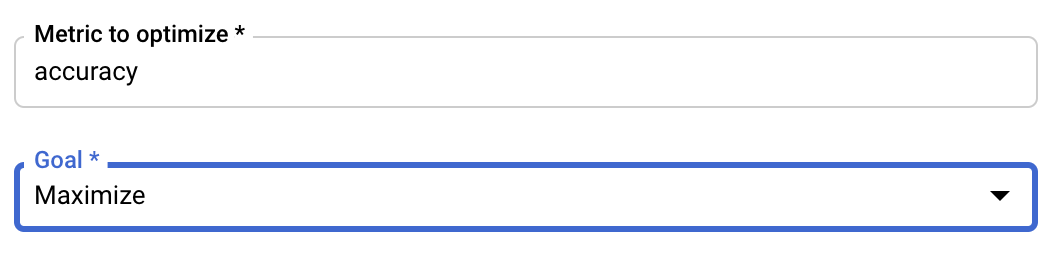
মেট্রিক কনফিগার করুন
হাইপারপ্যারামিটারগুলো যোগ করার পর, আপনাকে অপটিমাইজ করতে চাওয়া মেট্রিক এবং তার লক্ষ্য প্রদান করতে হবে। এটি আপনার ট্রেনিং অ্যাপ্লিকেশনে সেট করা hyperparameter_metric_tag এর মতোই হওয়া উচিত।
ভার্টেক্স এআই হাইপারপ্যারামিটার টিউনিং সার্ভিসটি পূর্ববর্তী ধাপগুলিতে কনফিগার করা মানগুলি ব্যবহার করে আপনার ট্রেনিং অ্যাপ্লিকেশনের একাধিক ট্রায়াল চালাবে। সার্ভিসটি কতগুলো ট্রায়াল চালাবে, তার একটি ঊর্ধ্বসীমা আপনাকে নির্ধারণ করে দিতে হবে। সাধারণত, বেশি ট্রায়াল চালালে ভালো ফলাফল পাওয়া যায়, কিন্তু এমন একটি পর্যায় আসবে যার পরে অতিরিক্ত ট্রায়ালগুলো আপনার অপটিমাইজ করতে চাওয়া মেট্রিকটির উপর সামান্য বা কোনো প্রভাবই ফেলবে না। তাই, বেশি সংখ্যক ট্রায়ালে যাওয়ার আগে অল্প সংখ্যক ট্রায়াল দিয়ে শুরু করা এবং আপনার নির্বাচিত হাইপারপ্যারামিটারগুলো কতটা কার্যকর তা বুঝে নেওয়া একটি উত্তম অভ্যাস।
আপনাকে সমান্তরাল ট্রায়ালের সংখ্যার উপর একটি ঊর্ধ্বসীমাও নির্ধারণ করতে হবে। সমান্তরাল ট্রায়ালের সংখ্যা বাড়ালে হাইপারপ্যারামিটার টিউনিং কাজটি সম্পন্ন হতে যে সময় লাগে তা কমে যাবে; তবে, এটি সামগ্রিকভাবে কাজটি কতটা কার্যকর তা কমিয়ে দিতে পারে। এর কারণ হলো, ডিফল্ট টিউনিং কৌশলটি পরবর্তী ট্রায়ালগুলোতে মান নির্ধারণের জন্য পূর্ববর্তী ট্রায়ালগুলোর ফলাফল ব্যবহার করে। আপনি যদি সমান্তরালভাবে অনেক বেশি ট্রায়াল চালান, তাহলে এমন কিছু ট্রায়াল শুরু হবে যেগুলো তখনও চলমান ট্রায়ালগুলোর ফলাফল থেকে কোনো সুবিধা পাবে না।
প্রদর্শনের উদ্দেশ্যে, আপনি ট্রায়ালের সংখ্যা ১৫ এবং সমান্তরাল ট্রায়ালের সর্বোচ্চ সংখ্যা ৩ নির্ধারণ করতে পারেন। আপনি ভিন্ন ভিন্ন সংখ্যা নিয়ে পরীক্ষা করতে পারেন, কিন্তু এর ফলে টিউনিং-এর জন্য বেশি সময় লাগতে পারে এবং খরচও বেশি হতে পারে।

শেষ ধাপটি হলো সার্চ অ্যালগরিদম হিসেবে ডিফল্ট (Default) নির্বাচন করা, যা হাইপারপ্যারামিটার টিউনিংয়ের জন্য বেসিয়ান অপটিমাইজেশন করতে গুগল ভিজিয়ার (Google Vizier) ব্যবহার করবে। আপনি এই অ্যালগরিদম সম্পর্কে এখানে আরও জানতে পারবেন।
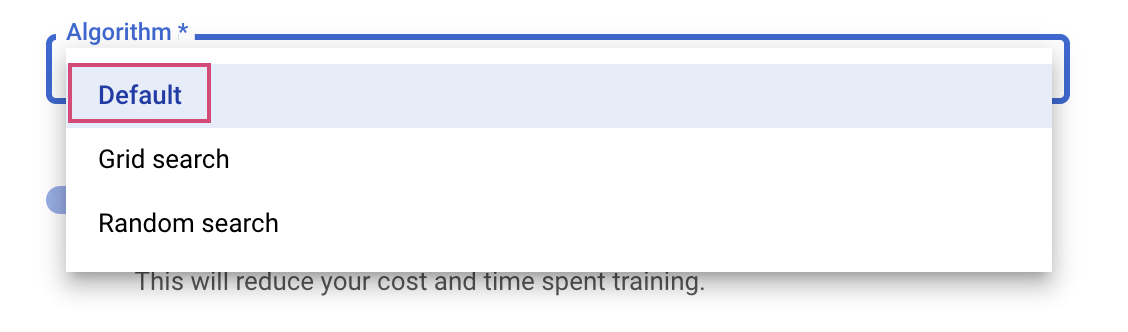
চালিয়ে যান-এ ক্লিক করুন।
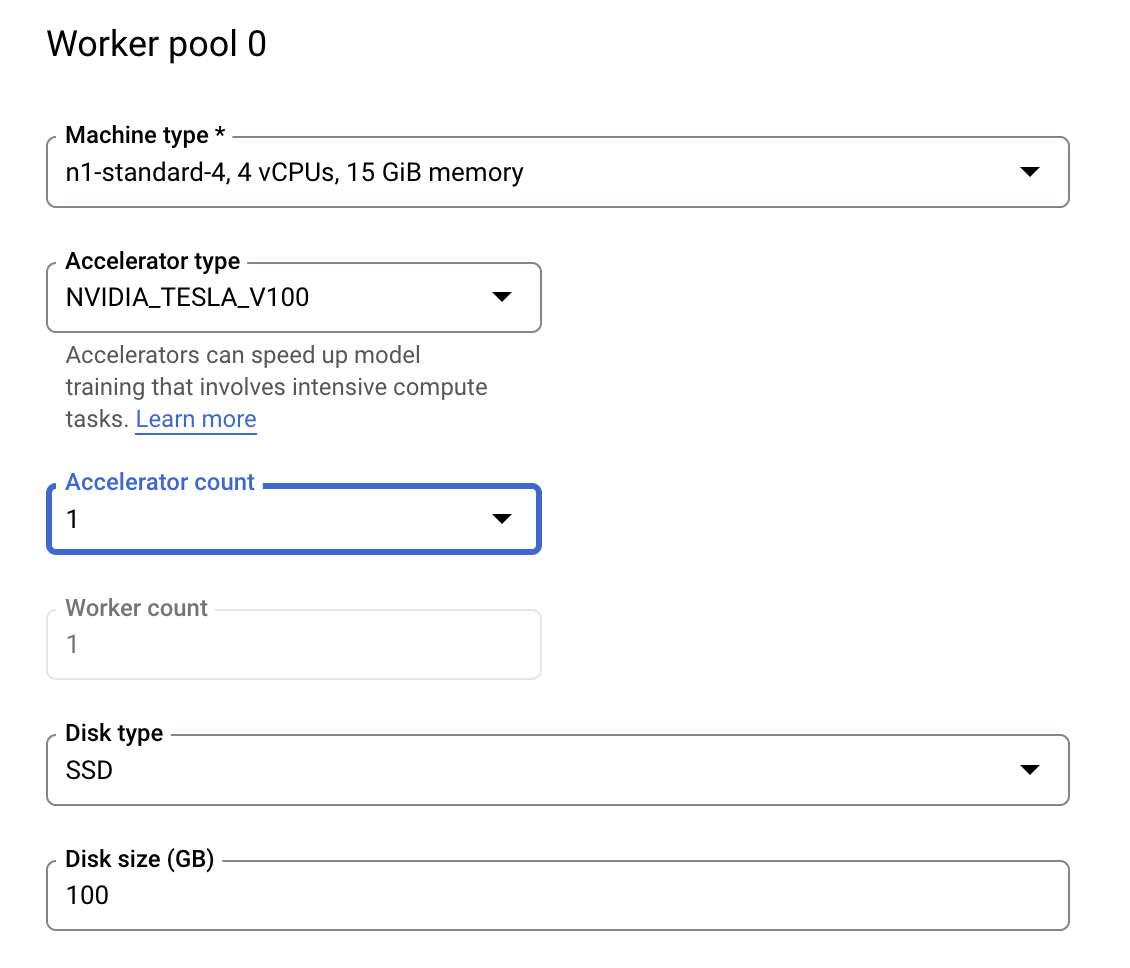
ধাপ ৩: কম্পিউট কনফিগার করুন
Compute and pricing- এ, নির্বাচিত অঞ্চলটি অপরিবর্তিত রাখুন এবং Worker pool 0 নিম্নরূপভাবে কনফিগার করুন।
হাইপারপ্যারামিটার টিউনিং কাজটি শুরু করতে ' স্টার্ট ট্রেনিং'- এ ক্লিক করুন। আপনার কনসোলের 'ট্রেনিং' বিভাগে 'হাইপারপ্যারামিটার টিউনিং জবস' ট্যাবের অধীনে আপনি এইরকম কিছু দেখতে পাবেন:
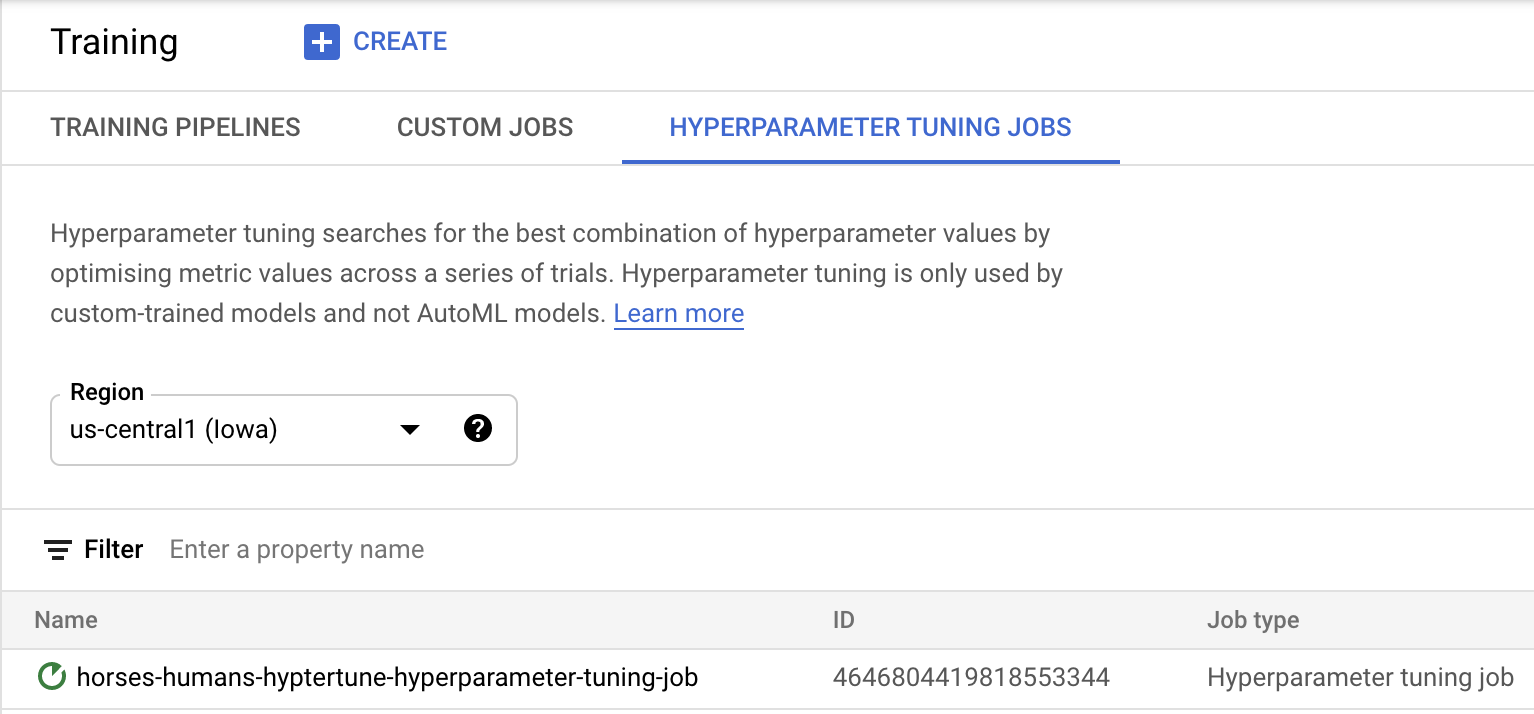
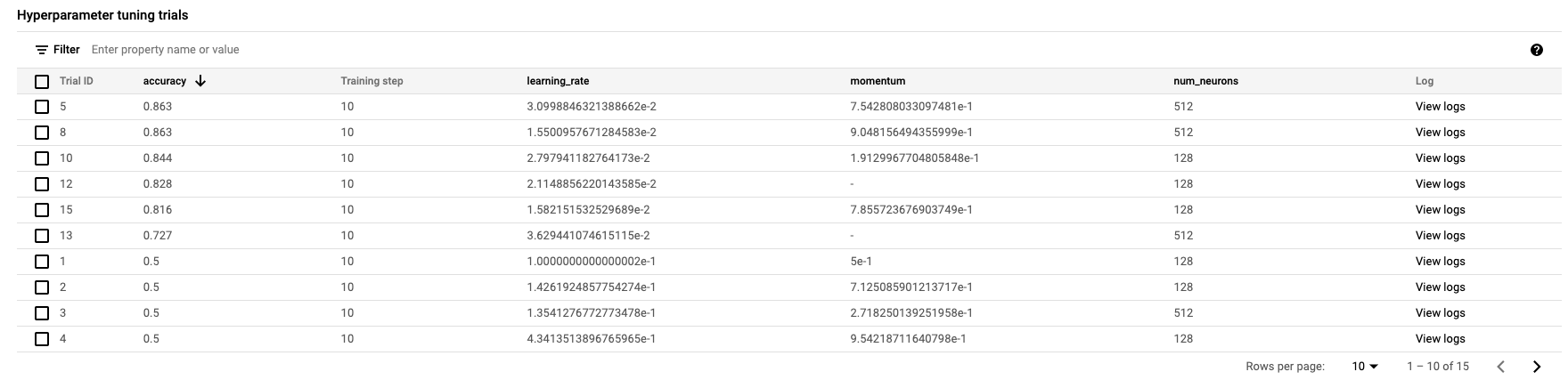
এটি শেষ হলে, আপনি কাজের নামে ক্লিক করে টিউনিং ট্রায়ালগুলোর ফলাফল দেখতে পারবেন।
🎉 অভিনন্দন! 🎉
আপনি শিখেছেন কীভাবে ভার্টেক্স এআই ব্যবহার করে:
- কাস্টম কন্টেইনারে দেওয়া ট্রেনিং কোডের জন্য একটি হাইপারপ্যারামিটার টিউনিং জব চালু করুন। এই উদাহরণে আপনি একটি TensorFlow মডেল ব্যবহার করেছেন, কিন্তু কাস্টম কন্টেইনার ব্যবহার করে যেকোনো ফ্রেমওয়ার্ক দিয়ে তৈরি মডেলকে ট্রেইন করতে পারেন।
Vertex-এর বিভিন্ন অংশ সম্পর্কে আরও জানতে ডকুমেন্টেশন দেখুন।
৬. [ঐচ্ছিক] ভার্টেক্স এসডিকে ব্যবহার করুন
পূর্ববর্তী অংশে দেখানো হয়েছে কিভাবে UI-এর মাধ্যমে হাইপারপ্যারামিটার টিউনিং জব চালু করতে হয়। এই অংশে, আপনি Vertex Python API ব্যবহার করে হাইপারপ্যারামিটার টিউনিং জব জমা দেওয়ার একটি বিকল্প উপায় দেখতে পাবেন।
লঞ্চার থেকে একটি TensorFlow 2 নোটবুক তৈরি করুন।

Vertex AI SDK ইম্পোর্ট করুন।
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
হাইপারপ্যারামিটার টিউনিং জবটি চালু করতে, আপনাকে প্রথমে নিম্নলিখিত স্পেকসগুলো সংজ্ঞায়িত করতে হবে। আপনাকে image_uri তে থাকা {PROJECT_ID} এর জায়গায় আপনার প্রজেক্টটি বসাতে হবে।
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
এরপর, একটি CustomJob তৈরি করুন। স্টেজিংয়ের জন্য আপনাকে {YOUR_BUCKET} এর জায়গায় আপনার প্রোজেক্টের একটি বাকেট বসাতে হবে।
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
এরপর, HyperparameterTuningJob টি তৈরি করে চালান।
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
৭. পরিচ্ছন্নতা
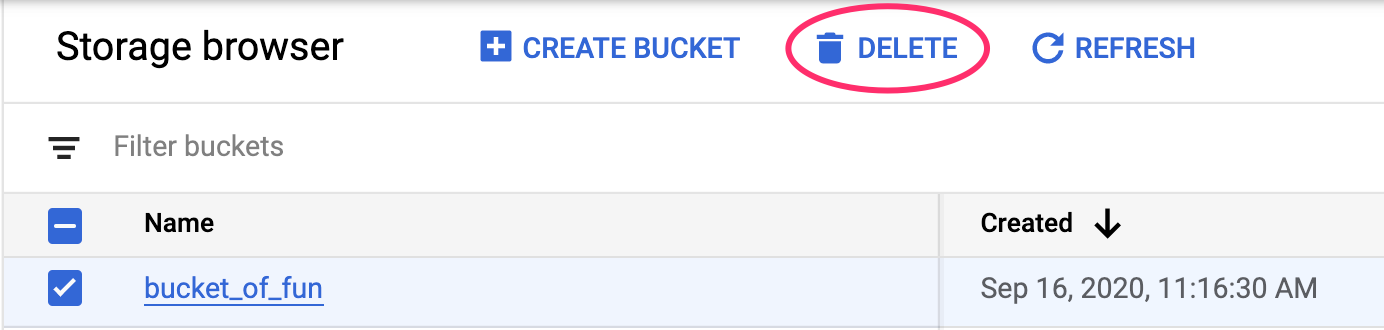
যেহেতু আমরা নোটবুকটিকে ৬০ মিনিট নিষ্ক্রিয় থাকার পর টাইম আউট হওয়ার জন্য কনফিগার করেছি, তাই ইনস্ট্যান্সটি শাট ডাউন করার বিষয়ে আমাদের চিন্তা করার দরকার নেই। আপনি যদি ইনস্ট্যান্সটি ম্যানুয়ালি শাট ডাউন করতে চান, তাহলে কনসোলের Vertex AI Workbench সেকশনে থাকা Stop বাটনে ক্লিক করুন। আর যদি নোটবুকটি পুরোপুরি মুছে ফেলতে চান, তাহলে Delete বাটনে ক্লিক করুন।

স্টোরেজ বাকেটটি ডিলিট করতে, আপনার ক্লাউড কনসোলের নেভিগেশন মেনু ব্যবহার করে স্টোরেজ-এ যান, আপনার বাকেটটি সিলেক্ট করুন এবং ডিলিট-এ ক্লিক করুন: