
1. Ringkasan
Tutorial ini telah diupdate untuk Tensorflow 2.2.

Dalam codelab ini, Anda akan mempelajari cara membuat dan melatih jaringan neural yang mengenali angka dari tulisan tangan. Selama proses ini, saat Anda meningkatkan kualitas jaringan saraf untuk mencapai akurasi 99%, Anda juga akan menemukan alat yang digunakan oleh profesional deep learning untuk melatih model mereka secara efisien.
Codelab ini menggunakan set data MNIST, kumpulan 60.000 digit berlabel yang telah membuat banyak mahasiswa PhD sibuk selama hampir dua dekade. Anda akan memecahkan masalah dengan kurang dari 100 baris kode Python / TensorFlow.
Yang akan Anda pelajari
- Apa itu jaringan neural dan cara melatihnya
- Cara membuat jaringan neural 1 lapis dasar menggunakan tf.keras
- Cara menambahkan lapisan lainnya
- Cara menyiapkan jadwal laju pembelajaran
- Cara membuat jaringan neural konvolusional
- Cara menggunakan teknik regularisasi: dropout, normalisasi batch
- Apa yang dimaksud dengan overfitting
Yang Anda butuhkan
Cukup browser. Workshop ini dapat dijalankan sepenuhnya dengan Google Colaboratory.
Masukan
Beri tahu kami jika Anda melihat sesuatu yang tidak beres di lab ini atau jika menurut Anda lab ini harus ditingkatkan. Kami menangani masukan melalui masalah GitHub [ link masukan].
2. Mulai cepat Google Colaboratory
Lab ini menggunakan Google Colaboratory dan tidak memerlukan penyiapan di pihak Anda. Anda dapat menjalankannya dari Chromebook. Buka file di bawah, dan jalankan sel untuk mempelajari notebook Colab.

Petunjuk tambahan di bawah ini:
Pilih backend GPU

Di menu Colab, pilih Runtime > Ubah jenis runtime, lalu pilih GPU. Koneksi ke runtime akan terjadi secara otomatis pada eksekusi pertama, atau Anda dapat menggunakan tombol "Hubungkan" di sudut kanan atas.
Eksekusi notebook
Jalankan sel satu per satu dengan mengklik sel dan menggunakan Shift-ENTER. Anda juga dapat menjalankan seluruh notebook dengan Runtime > Run all
Daftar isi

Semua notebook memiliki daftar isi. Anda dapat membukanya menggunakan panah hitam di sebelah kiri.
Sel tersembunyi

Beberapa sel hanya akan menampilkan judulnya. Ini adalah fitur notebook khusus Colab. Anda dapat mengklik dua kali untuk melihat kode di dalamnya, tetapi biasanya tidak terlalu menarik. Biasanya mendukung fungsi atau visualisasi. Anda tetap perlu menjalankan sel ini agar fungsi di dalamnya dapat ditentukan.
3. Melatih jaringan neural
Pertama-tama, kita akan menyaksikan pelatihan jaringan neural. Buka notebook di bawah dan jalankan semua sel. Jangan perhatikan kode dulu, kita akan mulai menjelaskannya nanti.
Saat Anda menjalankan notebook, fokuslah pada visualisasi. Lihat penjelasan di bawah.
Data pelatihan
Kita memiliki dataset digit tulisan tangan yang telah diberi label sehingga kita tahu apa yang direpresentasikan oleh setiap gambar, yaitu angka antara 0 dan 9. Di notebook, Anda akan melihat kutipan:

Jaringan neural yang akan kita buat mengklasifikasikan digit tulisan tangan dalam 10 kelasnya (0, .., 9). Hal ini dilakukan berdasarkan parameter internal yang harus memiliki nilai yang benar agar klasifikasi berfungsi dengan baik. "Nilai yang benar" ini dipelajari melalui proses pelatihan yang memerlukan "set data berlabel" dengan gambar dan jawaban benar yang terkait.
Bagaimana cara mengetahui apakah jaringan neural yang dilatih berperforma baik atau tidak? Menggunakan set data pelatihan untuk menguji jaringan akan dianggap sebagai kecurangan. Model ini telah melihat set data tersebut beberapa kali selama pelatihan dan performanya pasti sangat baik. Kita memerlukan set data berlabel lain, yang tidak pernah dilihat selama pelatihan, untuk mengevaluasi performa "dunia nyata" jaringan. Set data ini disebut "set data validasi"
Pelatihan
Seiring berjalannya pelatihan, satu batch data pelatihan pada satu waktu, parameter model internal akan diperbarui dan model akan semakin baik dalam mengenali digit tulisan tangan. Anda dapat melihatnya di grafik pelatihan:

Di sebelah kanan, "akurasi" hanyalah persentase digit yang dikenali dengan benar. Nilainya akan meningkat seiring berjalannya pelatihan, yang merupakan hal yang baik.
Di sebelah kiri, kita dapat melihat "loss". Untuk mendorong pelatihan, kita akan menentukan fungsi "loss", yang menunjukkan seberapa buruk sistem mengenali digit, dan mencoba meminimalkannya. Yang Anda lihat di sini adalah kerugian menurun pada data pelatihan dan validasi seiring berjalannya pelatihan: itu bagus. Artinya, jaringan neural sedang belajar.
Sumbu X menunjukkan jumlah "epoch" atau iterasi melalui seluruh set data.
Prediksi
Setelah model dilatih, kita dapat menggunakannya untuk mengenali angka dari tulisan tangan. Visualisasi berikutnya menunjukkan seberapa baik performanya pada beberapa digit yang dirender dari font lokal (baris pertama), lalu pada 10.000 digit set data validasi. Class yang diprediksi muncul di bawah setiap digit, berwarna merah jika salah.

Seperti yang dapat Anda lihat, model awal ini tidak terlalu bagus, tetapi masih mengenali beberapa digit dengan benar. Akurasi validasi akhirnya sekitar 90%, yang tidak terlalu buruk untuk model sederhana yang kita mulai,tetapi masih berarti bahwa model tersebut melewatkan 1.000 digit validasi dari 10.000 digit. Jumlah tersebut jauh lebih banyak daripada yang dapat ditampilkan, itulah sebabnya semua jawaban terlihat salah (merah).
Tensor
Data disimpan dalam matriks. Gambar hitam putih berukuran 28x28 piksel cocok dengan matriks dua dimensi berukuran 28x28. Namun, untuk gambar berwarna, kita memerlukan lebih banyak dimensi. Ada 3 nilai warna per piksel (Merah, Hijau, Biru), sehingga diperlukan tabel tiga dimensi dengan dimensi [28, 28, 3]. Untuk menyimpan batch 128 gambar berwarna, diperlukan tabel empat dimensi dengan dimensi [128, 28, 28, 3].
Tabel multidimensi ini disebut "tensor" dan daftar dimensinya adalah "bentuk".
4. [INFO]: Jaringan neural 101
Singkatnya
Jika semua istilah yang dicetak tebal di paragraf berikutnya sudah Anda ketahui, Anda dapat melanjutkan ke latihan berikutnya. Jika Anda baru memulai deep learning, selamat datang, dan silakan baca terus.

Untuk model yang dibuat sebagai urutan lapisan, Keras menawarkan Sequential API. Misalnya, pengklasifikasi gambar yang menggunakan tiga lapisan padat dapat ditulis di Keras sebagai:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )

Satu lapisan padat
Digit tulisan tangan dalam set data MNIST adalah gambar hitam putih berukuran 28x28 piksel. Pendekatan paling sederhana untuk mengklasifikasikannya adalah dengan menggunakan 28x28=784 piksel sebagai input untuk jaringan neural 1 lapis.

Setiap "neuron" dalam jaringan neural melakukan jumlah berbobot dari semua inputnya, menambahkan konstanta yang disebut "bias", lalu memasukkan hasilnya melalui "fungsi aktivasi" non-linear. "Bobot" dan "bias" adalah parameter yang akan ditentukan melalui pelatihan. Awalnya, variabel ini diinisialisasi dengan nilai acak.
Gambar di atas merepresentasikan jaringan neural 1 lapis dengan 10 neuron output karena kita ingin mengklasifikasikan digit ke dalam 10 kelas (0 hingga 9).
Dengan perkalian matriks
Berikut cara lapisan jaringan neural, yang memproses kumpulan gambar, dapat direpresentasikan oleh perkalian matriks:

Dengan menggunakan kolom bobot pertama dalam matriks bobot W, kita menghitung jumlah berbobot dari semua piksel gambar pertama. Jumlah ini sesuai dengan neuron pertama. Dengan menggunakan kolom bobot kedua, kita melakukan hal yang sama untuk neuron kedua dan seterusnya hingga neuron ke-10. Kemudian, kita dapat mengulangi operasi untuk 99 gambar yang tersisa. Jika kita menyebut X sebagai matriks yang berisi 100 gambar kita, semua jumlah berbobot untuk 10 neuron kita, yang dihitung pada 100 gambar, hanyalah X.W, perkalian matriks.
Setiap neuron kini harus menambahkan biasnya (konstanta). Karena kita memiliki 10 neuron, kita memiliki 10 konstanta bias. Kita akan menyebut vektor 10 nilai ini sebagai b. Nilai ini harus ditambahkan ke setiap baris matriks yang sebelumnya dihitung. Dengan menggunakan sedikit keajaiban yang disebut "penyiaran", kita akan menulisnya dengan tanda plus sederhana.
Terakhir, kita menerapkan fungsi aktivasi, misalnya "softmax" (dijelaskan di bawah) dan mendapatkan formula yang menjelaskan jaringan neural 1 lapis, yang diterapkan ke 100 gambar:

Di Keras
Dengan library jaringan saraf tingkat tinggi seperti Keras, kita tidak perlu menerapkan formula ini. Namun, penting untuk dipahami bahwa lapisan jaringan neural hanyalah sekumpulan perkalian dan penambahan. Di Keras, lapisan padat akan ditulis sebagai:
tf.keras.layers.Dense(10, activation='softmax')
Pelajari lebih dalam
Menggabungkan lapisan jaringan neural sangatlah mudah. Lapisan pertama menghitung jumlah terbobot piksel. Lapisan berikutnya menghitung jumlah terbobot dari output lapisan sebelumnya.

Satu-satunya perbedaan, selain jumlah neuron, adalah pilihan fungsi aktivasi.
Fungsi aktivasi: relu, softmax, dan sigmoid
Biasanya, Anda akan menggunakan fungsi aktivasi "relu" untuk semua lapisan kecuali yang terakhir. Lapisan terakhir, dalam pengklasifikasi, akan menggunakan aktivasi "softmax".

Sekali lagi, "neuron" menghitung jumlah bobot dari semua inputnya, menambahkan nilai yang disebut "bias", dan meneruskan hasilnya melalui fungsi aktivasi.
Fungsi aktivasi yang paling populer disebut "RELU" untuk Rectified Linear Unit. Ini adalah fungsi yang sangat sederhana seperti yang dapat Anda lihat pada grafik di atas.
Fungsi aktivasi tradisional dalam jaringan saraf adalah "sigmoid", tetapi "relu" terbukti memiliki properti konvergensi yang lebih baik di hampir semua tempat dan kini lebih disukai.

Aktivasi softmax untuk klasifikasi
Lapisan terakhir jaringan saraf kita memiliki 10 neuron karena kita ingin mengklasifikasikan digit tulisan tangan ke dalam 10 kelas (0,..9). Model ini akan menghasilkan 10 angka antara 0 dan 1 yang merepresentasikan probabilitas digit ini adalah 0, 1, 2, dan seterusnya. Untuk itu, di lapisan terakhir, kita akan menggunakan fungsi aktivasi yang disebut "softmax".
Penerapan softmax pada vektor dilakukan dengan mengambil eksponensial setiap elemen, lalu menormalisasi vektor, biasanya dengan membaginya dengan norma "L1" (yaitu jumlah nilai absolut), sehingga nilai yang dinormalisasi berjumlah 1 dan dapat ditafsirkan sebagai probabilitas.
Output lapisan terakhir, sebelum aktivasi, terkadang disebut "logits". Jika vektor ini adalah L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9], maka:


Kerugian entropi silang
Setelah jaringan neural kita menghasilkan prediksi dari gambar input, kita perlu mengukur seberapa baik prediksi tersebut, yaitu jarak antara yang disampaikan jaringan dan jawaban yang benar, yang sering disebut "label". Ingatlah bahwa kita memiliki label yang benar untuk semua gambar dalam set data.
Jarak apa pun akan berfungsi, tetapi untuk masalah klasifikasi, yang disebut "jarak entropi silang" adalah yang paling efektif. Kita akan menyebutnya sebagai fungsi error atau "loss":

Penurunan gradien
"Melatih" jaringan neural sebenarnya berarti menggunakan gambar dan label pelatihan untuk menyesuaikan bobot dan bias sehingga dapat meminimalkan fungsi loss cross-entropy. Berikut cara kerjanya.
Cross-entropy adalah fungsi bobot, bias, piksel gambar pelatihan, dan kelasnya yang diketahui.
Jika kita menghitung turunan parsial cross-entropy relatif terhadap semua bobot dan semua bias, kita akan mendapatkan "gradien", yang dihitung untuk gambar, label, dan nilai bobot dan bias saat ini. Ingatlah bahwa kita dapat memiliki jutaan bobot dan bias, sehingga menghitung gradien akan membutuhkan banyak pekerjaan. Untungnya, TensorFlow melakukannya untuk kita. Properti matematika gradien adalah bahwa gradien mengarah "ke atas". Karena kita ingin menuju tempat dengan entropi silang yang rendah, kita bergerak ke arah yang berlawanan. Kita memperbarui bobot dan bias dengan sebagian kecil gradien. Kemudian, kita melakukan hal yang sama berulang kali menggunakan batch berikutnya dari gambar dan label pelatihan, dalam loop pelatihan. Semoga, proses ini akan mencapai titik di mana entropi silang minimal, meskipun tidak ada jaminan bahwa minimum ini unik.
Mini-batching dan momentum
Anda dapat menghitung gradien hanya pada satu contoh gambar dan langsung memperbarui bobot dan bias, tetapi melakukannya pada batch, misalnya, 128 gambar akan memberikan gradien yang lebih baik dalam merepresentasikan batasan yang diberlakukan oleh contoh gambar yang berbeda dan oleh karena itu cenderung lebih cepat mencapai solusi. Ukuran tumpukan mini adalah parameter yang dapat disesuaikan.
Teknik ini, yang terkadang disebut "stochastic gradient descent", memiliki manfaat lain yang lebih pragmatis: bekerja dengan batch juga berarti bekerja dengan matriks yang lebih besar dan biasanya lebih mudah dioptimalkan di GPU dan TPU.
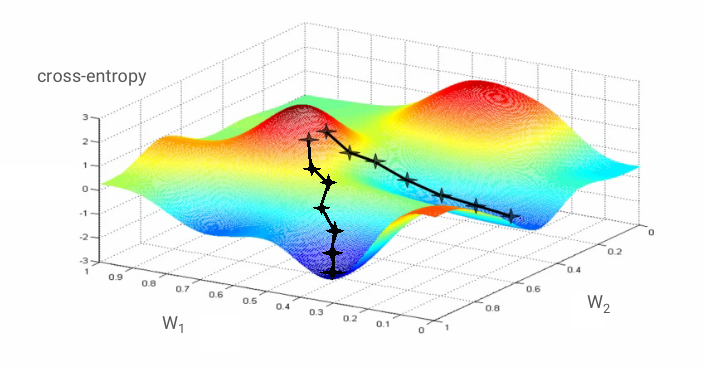
Konvergensi masih bisa sedikit kacau dan bahkan dapat berhenti jika vektor gradien semuanya nol. Apakah itu berarti kita telah menemukan nilai minimum? Tidak selalu. Komponen gradien dapat bernilai nol pada minimum atau maksimum. Dengan vektor gradien yang memiliki jutaan elemen, jika semuanya adalah nol, probabilitas bahwa setiap nol sesuai dengan titik minimum dan tidak ada yang sesuai dengan titik maksimum cukup kecil. Dalam ruang dengan banyak dimensi, titik pelana cukup umum dan kita tidak ingin berhenti di titik tersebut.

Ilustrasi: titik pelana. Gradiennya adalah 0, tetapi bukan minimum di semua arah. (Atribusi gambar Wikimedia: By Nicoguaro - Own work, CC BY 3.0)
Solusinya adalah menambahkan beberapa momentum ke algoritma pengoptimalan sehingga dapat melewati titik pelana tanpa berhenti.
Glosarium
batch atau tumpukan mini: pelatihan selalu dilakukan pada batch data dan label pelatihan. Dengan demikian, algoritma dapat melakukan konvergensi. Dimensi "batch" biasanya merupakan dimensi pertama tensor data. Misalnya, tensor dengan bentuk [100, 192, 192, 3] berisi 100 gambar berukuran 192x192 piksel dengan tiga nilai per piksel (RGB).
Kerugian entropi silang: fungsi kerugian khusus yang sering digunakan dalam pengklasifikasi.
lapisan padat: lapisan neuron di mana setiap neuron terhubung ke semua neuron di lapisan sebelumnya.
fitur: input jaringan saraf terkadang disebut "fitur". Seni mencari tahu bagian mana dari set data (atau kombinasi bagian) yang akan dimasukkan ke jaringan neural untuk mendapatkan prediksi yang baik disebut "rekayasa fitur".
label: nama lain untuk "kelas" atau jawaban yang benar dalam masalah klasifikasi terawasi
kecepatan pembelajaran: fraksi gradien yang digunakan untuk memperbarui bobot dan bias pada setiap iterasi loop pelatihan.
logits: output lapisan neuron sebelum fungsi aktivasi diterapkan disebut "logits". Istilah ini berasal dari "fungsi logistik" alias "fungsi sigmoid" yang dulunya merupakan fungsi aktivasi paling populer. "Neuron outputs before logistic function" disingkat menjadi "logits".
loss: fungsi error yang membandingkan output jaringan neural dengan jawaban yang benar
neuron: menghitung jumlah input yang diberi bobot, menambahkan bias, dan meneruskan hasilnya melalui fungsi aktivasi.
enkode one-hot: kelas 3 dari 5 dienkode sebagai vektor 5 elemen, semua nol kecuali yang ke-3 yaitu 1.
relu: unit linear yang diperbaiki. Fungsi aktivasi yang populer untuk neuron.
sigmoid: fungsi aktivasi lain yang dulu populer dan masih berguna dalam kasus khusus.
softmax: fungsi aktivasi khusus yang bekerja pada vektor, meningkatkan perbedaan antara komponen terbesar dan semua komponen lainnya, serta menormalisasi vektor agar memiliki jumlah 1 sehingga dapat ditafsirkan sebagai vektor probabilitas. Digunakan sebagai langkah terakhir dalam pengklasifikasi.
tensor: "Tensor" seperti matriks, tetapi dengan jumlah dimensi yang berubah-ubah. Tensor 1 dimensi adalah vektor. Tensor 2 dimensi adalah matriks. Kemudian, Anda dapat memiliki tensor dengan 3, 4, 5, atau lebih dimensi.
5. Mari kita mulai membuat kode
Kembali ke notebook studi dan kali ini, mari kita baca kodenya.
Mari kita pelajari semua sel di notebook ini.
Sel "Parameter"
Ukuran batch, jumlah iterasi pelatihan, dan lokasi file data ditentukan di sini. File data di-hosting di bucket Google Cloud Storage (GCS), sehingga alamatnya dimulai dengan gs://
Sel "Impor"
Semua library Python yang diperlukan diimpor di sini, termasuk TensorFlow dan juga matplotlib untuk visualisasi.
Sel "utilitas visualisasi [JALANKAN SAYA]****"
Sel ini berisi kode visualisasi yang tidak menarik. Secara default, panel ini diciutkan, tetapi Anda dapat membukanya dan melihat kodenya saat ada waktu dengan mengkliknya dua kali.
Sel "tf.data.Dataset: parse files and prepare training and validation datasets"
Sel ini menggunakan tf.data.Dataset API untuk memuat set data MNIST dari file data. Anda tidak perlu menghabiskan terlalu banyak waktu untuk sel ini. Jika Anda tertarik dengan tf.data.Dataset API, berikut tutorial yang menjelaskannya: Pipeline data berkecepatan TPU. Untuk saat ini, dasar-dasarnya adalah:
Gambar dan label (jawaban yang benar) dari set data MNIST disimpan dalam rekaman panjang tetap dalam 4 file. File dapat dimuat dengan fungsi catatan tetap khusus:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)
Sekarang kita memiliki set data byte gambar. Data ini perlu didekode menjadi gambar. Kita akan menentukan fungsi untuk melakukannya. Gambar tidak dikompresi sehingga fungsi tidak perlu mendekode apa pun (decode_raw pada dasarnya tidak melakukan apa pun). Gambar kemudian dikonversi menjadi nilai floating point antara 0 dan 1. Kita dapat mengubah bentuknya di sini sebagai gambar 2D, tetapi sebenarnya kita mempertahankannya sebagai array piksel datar berukuran 28*28 karena itulah yang diharapkan oleh lapisan padat awal kita.
def read_image(tf_bytestring):
image = tf.io.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image
Kita menerapkan fungsi ini ke set data menggunakan .map dan mendapatkan set data gambar:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)
Kita melakukan pembacaan dan decoding yang sama untuk label dan kita .zip gambar dan label bersama-sama:
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))
Sekarang kita memiliki set data pasangan (gambar, label). Inilah yang diharapkan model kami. Kita belum siap menggunakannya dalam fungsi pelatihan:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
tf.data.Dataset API memiliki semua fungsi utilitas yang diperlukan untuk menyiapkan set data:
.cache menyimpan cache set data dalam RAM. Ini adalah dataset kecil sehingga akan berfungsi. .shuffle mengacaknya dengan buffer 5.000 elemen. Penting agar data pelatihan diacak dengan baik. .repeat mengulang set data. Kita akan melatihnya beberapa kali (beberapa epoch). .batch menarik beberapa gambar dan label bersama-sama ke dalam mini-batch. Terakhir, .prefetch dapat menggunakan CPU untuk menyiapkan batch berikutnya saat batch saat ini sedang dilatih di GPU.
Set data validasi disiapkan dengan cara yang serupa. Sekarang kita siap menentukan model dan menggunakan set data ini untuk melatihnya.
Sel "Model Keras"
Semua model kita akan berupa urutan lapisan langsung sehingga kita dapat menggunakan gaya tf.keras.Sequential untuk membuatnya. Awalnya di sini, ada satu lapisan padat. Lapisan ini memiliki 10 neuron karena kita mengklasifikasikan digit tulisan tangan ke dalam 10 kelas. Lapisan ini menggunakan aktivasi "softmax" karena merupakan lapisan terakhir dalam pengklasifikasi.
Model Keras juga perlu mengetahui bentuk inputnya. tf.keras.layers.Input dapat digunakan untuk menentukannya. Di sini, vektor input adalah vektor datar nilai piksel dengan panjang 28*28.
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)
Konfigurasi model dilakukan di Keras menggunakan fungsi model.compile. Di sini kita menggunakan pengoptimal dasar 'sgd' (Stochastic Gradient Descent). Model klasifikasi memerlukan fungsi kerugian entropi silang, yang disebut 'categorical_crossentropy' di Keras. Terakhir, kita meminta model untuk menghitung metrik 'accuracy', yaitu persentase gambar yang diklasifikasikan dengan benar.
Keras menawarkan utilitas model.summary() yang sangat bagus untuk mencetak detail model yang telah Anda buat. Instruktur Anda yang baik telah menambahkan utilitas PlotTraining (ditetapkan dalam sel "utilitas visualisasi") yang akan menampilkan berbagai kurva pelatihan selama pelatihan.
Sel "Latih dan validasi model"
Di sinilah pelatihan terjadi, dengan memanggil model.fit dan meneruskan set data pelatihan dan validasi. Secara default, Keras menjalankan validasi di akhir setiap epoch.
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])
Di Keras, Anda dapat menambahkan perilaku kustom selama pelatihan menggunakan callback. Begitulah cara plot pelatihan yang diperbarui secara dinamis diterapkan untuk workshop ini.
Sel "Visualisasikan prediksi"
Setelah model dilatih, kita bisa mendapatkan prediksi darinya dengan memanggil model.predict():
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)
Di sini kami telah menyiapkan serangkaian digit cetak yang dirender dari font lokal, sebagai pengujian. Ingatlah bahwa jaringan neural menampilkan vektor 10 probabilitas dari "softmax" terakhirnya. Untuk mendapatkan label, kita harus mengetahui probabilitas mana yang paling tinggi. np.argmax dari library numpy akan melakukannya.
Untuk memahami alasan parameter axis=1 diperlukan, ingatlah bahwa kita telah memproses batch 128 gambar dan oleh karena itu, model menampilkan 128 vektor probabilitas. Bentuk tensor output adalah [128, 10]. Kita menghitung argmax di seluruh 10 probabilitas yang ditampilkan untuk setiap gambar, sehingga axis=1 (sumbu pertama adalah 0).
Model sederhana ini sudah mengenali 90% digit. Tidak buruk, tetapi sekarang Anda akan meningkatkannya secara signifikan.

6. Menambahkan lapisan

Untuk meningkatkan akurasi pengenalan, kami akan menambahkan lebih banyak lapisan ke jaringan saraf.

Kita tetap menggunakan softmax sebagai fungsi aktivasi di lapisan terakhir karena itulah yang paling cocok untuk klasifikasi. Namun, pada lapisan perantara, kita akan menggunakan fungsi aktivasi paling klasik: sigmoid:
Misalnya, model Anda dapat terlihat seperti ini (jangan lupakan koma, tf.keras.Sequential menggunakan daftar lapisan yang dipisahkan koma):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
Lihat "ringkasan" model Anda. Model ini sekarang memiliki setidaknya 10 kali lebih banyak parameter. Performa harus 10x lebih baik. Namun, entah kenapa, tidak ...

Kerugiannya juga tampaknya sangat besar. Terjadi error.
7. Perawatan khusus untuk jaringan dalam
Anda baru saja mengalami jaringan neural, seperti yang digunakan orang untuk mendesainnya pada tahun 80-an dan 90-an. Tidak heran jika mereka mengurungkan niatnya, sehingga memicu apa yang disebut "musim dingin AI". Memang, saat Anda menambahkan lapisan, jaringan neural akan semakin sulit untuk melakukan konvergensi.
Ternyata, jaringan neural dalam dengan banyak lapisan (20, 50, bahkan 100 saat ini) dapat berfungsi dengan sangat baik, asalkan ada beberapa trik kotor matematika untuk membuatnya konvergen. Penemuan trik sederhana ini adalah salah satu alasan kebangkitan deep learning pada tahun 2010-an.
Aktivasi RELU

Fungsi aktivasi sigmoid sebenarnya cukup bermasalah dalam jaringan dalam. Fungsi ini akan memadatkan semua nilai antara 0 dan 1, dan jika Anda melakukannya berulang kali, output neuron dan gradiennya dapat hilang sepenuhnya. Disebutkan karena alasan historis, tetapi jaringan modern menggunakan RELU (Rectified Linear Unit) yang terlihat seperti ini:

Di sisi lain, relu memiliki turunan 1, setidaknya di sisi kanannya. Dengan aktivasi RELU, meskipun gradien yang berasal dari beberapa neuron bisa nol, akan selalu ada neuron lain yang memberikan gradien non-nol yang jelas dan pelatihan dapat berlanjut dengan kecepatan yang baik.
Pengoptimal yang lebih baik
Dalam ruang berdimensi sangat tinggi seperti di sini — kita memiliki sekitar 10 ribu bobot dan bias — "titik pelana" sering terjadi. Ini adalah titik yang bukan minimum lokal, tetapi gradiennya nol dan pengoptimal penurunan gradien tetap macet di sana. TensorFlow memiliki serangkaian pengoptimal yang tersedia, termasuk beberapa pengoptimal yang bekerja dengan jumlah inersia dan akan melewati titik pelana dengan aman.
Inisialisasi acak
Seni menginisialisasi bias bobot sebelum pelatihan adalah bidang penelitian tersendiri, dengan banyak makalah yang dipublikasikan tentang topik ini. Anda dapat melihat semua penginisialisasi yang tersedia di Keras di sini. Untungnya, Keras melakukan hal yang benar secara default dan menggunakan inisialisasi 'glorot_uniform' yang terbaik dalam hampir semua kasus.
Anda tidak perlu melakukan apa pun, karena Keras sudah melakukan hal yang benar.
NaN ???
Formula cross-entropy melibatkan logaritma dan log(0) adalah Not a Number (NaN, error numerik jika Anda mau). Dapatkah input entropi silang bernilai 0? Input berasal dari softmax yang pada dasarnya adalah eksponensial dan eksponensial tidak pernah nol. Jadi, kita aman!
Serius? Dalam dunia matematika yang indah, kita akan aman, tetapi dalam dunia komputer, exp(-150), yang direpresentasikan dalam format float32, adalah NOL dan cross-entropy akan error.
Untungnya, Anda juga tidak perlu melakukan apa pun di sini, karena Keras akan menangani hal ini dan menghitung softmax yang diikuti dengan cross-entropy secara sangat hati-hati untuk memastikan stabilitas numerik dan menghindari NaN yang ditakuti.
Berhasil?

Sekarang Anda akan mendapatkan akurasi 97%. Tujuan dalam workshop ini adalah untuk mendapatkan skor di atas 99%, jadi mari kita lanjutkan.
Jika Anda mengalami kesulitan, berikut solusinya saat ini:
8. Peluruhan kecepatan pembelajaran
Mungkin kita bisa mencoba melatihnya lebih cepat? Kecepatan pemelajaran default di pengoptimal Adam adalah 0,001. Mari kita coba tingkatkan.
Bergerak lebih cepat tampaknya tidak banyak membantu dan suara apa ini?

Kurva pelatihan sangat berisik dan lihat kedua kurva validasi: kurva naik dan turun. Artinya, kita bergerak terlalu cepat. Kita bisa kembali ke kecepatan sebelumnya, tetapi ada cara yang lebih baik.

Solusi yang baik adalah memulai dengan cepat dan mengurangi laju pembelajaran secara eksponensial. Di Keras, Anda dapat melakukannya dengan callback tf.keras.callbacks.LearningRateScheduler.
Kode berguna untuk disalin dan ditempel:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)
Jangan lupa untuk menggunakan lr_decay_callback yang telah Anda buat. Tambahkan ke daftar callback di model.fit:
model.fit(..., callbacks=[plot_training, lr_decay_callback])
Dampak dari perubahan kecil ini sangat luar biasa. Anda melihat bahwa sebagian besar derau telah hilang dan akurasi pengujian kini di atas 98% secara berkelanjutan.

9. Dropout, overfitting
Model tampaknya berkonvergensi dengan baik sekarang. Mari kita coba bahas lebih dalam.
Apakah itu membantu?

Tidak juga, akurasinya masih stuck di 98% dan lihat kerugian validasi. Sudah naik! Algoritma pembelajaran hanya berfungsi pada data pelatihan dan mengoptimalkan kerugian pelatihan yang sesuai. Model ini tidak pernah melihat data validasi, jadi tidak mengherankan jika setelah beberapa saat, pekerjaannya tidak lagi memengaruhi kerugian validasi yang berhenti menurun dan terkadang bahkan naik kembali.
Hal ini tidak langsung memengaruhi kemampuan pengenalan dunia nyata model Anda, tetapi akan mencegah Anda menjalankan banyak iterasi dan umumnya merupakan tanda bahwa pelatihan tidak lagi memberikan efek positif.

Perbedaan ini biasanya disebut "overfitting" dan saat Anda melihatnya, Anda dapat mencoba menerapkan teknik regularisasi yang disebut "dropout". Teknik dropout menonaktifkan neuron acak pada setiap iterasi pelatihan.
Apa itu berhasil?

Noise muncul kembali (tidak mengherankan mengingat cara kerja dropout). Kerugian validasi tampaknya tidak meningkat lagi, tetapi secara keseluruhan lebih tinggi daripada tanpa dropout. Akurasi validasi juga sedikit menurun. Hasil ini cukup mengecewakan.
Sepertinya dropout bukan solusi yang tepat, atau mungkin "overfitting" adalah konsep yang lebih kompleks dan beberapa penyebabnya tidak dapat diselesaikan dengan "dropout"?
Apa yang dimaksud dengan "overfitting"? Overfitting terjadi saat jaringan neural belajar dengan "buruk", dengan cara yang berfungsi untuk contoh pelatihan, tetapi tidak terlalu baik pada data dunia nyata. Ada teknik regularisasi seperti dropout yang dapat memaksanya belajar dengan cara yang lebih baik, tetapi overfitting juga memiliki akar yang lebih dalam.

Overfitting dasar terjadi saat jaringan neural memiliki terlalu banyak derajat kebebasan untuk masalah yang sedang dihadapi. Bayangkan kita memiliki begitu banyak neuron sehingga jaringan dapat menyimpan semua gambar pelatihan kita di dalamnya dan kemudian mengenalinya dengan pencocokan pola. Model ini akan gagal sepenuhnya pada data dunia nyata. Jaringan neural harus dibatasi agar dipaksa untuk menggeneralisasi apa yang dipelajarinya selama pelatihan.
Jika Anda memiliki data pelatihan yang sangat sedikit, bahkan jaringan kecil dapat menghafalnya dan Anda akan melihat "overfitting". Secara umum, Anda selalu memerlukan banyak data untuk melatih jaringan neural.
Terakhir, jika Anda telah melakukan semuanya sesuai prosedur, bereksperimen dengan berbagai ukuran jaringan untuk memastikan derajat kebebasannya dibatasi, menerapkan dropout, dan melatih banyak data, Anda mungkin masih terjebak pada tingkat performa yang tampaknya tidak dapat ditingkatkan. Artinya, jaringan saraf Anda, dalam bentuknya saat ini, tidak dapat mengekstrak lebih banyak informasi dari data Anda, seperti dalam kasus kita di sini.
Ingat bagaimana kita menggunakan gambar kita, yang diratakan menjadi satu vektor? Itu ide yang sangat buruk. Digit tulisan tangan terdiri dari bentuk dan kita membuang informasi bentuk saat meratakan piksel. Namun, ada jenis jaringan neural yang dapat memanfaatkan informasi bentuk: jaringan konvolusional. Mari kita coba.
Jika Anda mengalami kesulitan, berikut solusinya saat ini:
10. [INFO] jaringan konvolusional
Singkatnya
Jika semua istilah yang dicetak tebal di paragraf berikutnya sudah Anda ketahui, Anda dapat melanjutkan ke latihan berikutnya. Jika Anda baru memulai jaringan neural konvolusional, silakan baca terus.

Ilustrasi: memfilter gambar dengan dua filter berurutan yang masing-masing terdiri dari 48 bobot yang dapat dipelajari (4x4x3=48).
Berikut tampilan jaringan neural konvolusional sederhana di Keras:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
Dalam lapisan jaringan konvolusional, satu "neuron" melakukan jumlah berbobot piksel tepat di atasnya, hanya di seluruh area kecil gambar. Lapisan ini menambahkan bias dan memasukkan jumlah melalui fungsi aktivasi, seperti halnya neuron di lapisan padat biasa. Operasi ini kemudian diulangi di seluruh gambar menggunakan bobot yang sama. Ingatlah bahwa di lapisan padat, setiap neuron memiliki bobotnya sendiri. Di sini, satu "patch" bobot meluncur di seluruh gambar ke kedua arah (sebuah "konvolusi"). Output memiliki nilai sebanyak jumlah piksel dalam gambar (meskipun beberapa padding diperlukan di tepi). Ini adalah operasi pemfilteran. Dalam ilustrasi di atas, filter ini menggunakan 4x4x3=48 bobot.
Namun, 48 bobot tidak akan cukup. Untuk menambahkan lebih banyak derajat kebebasan, kita mengulangi operasi yang sama dengan kumpulan bobot baru. Tindakan ini akan menghasilkan serangkaian output filter baru. Mari kita sebut sebagai "saluran" output berdasarkan analogi dengan saluran R,G,B dalam gambar input.

Dua (atau lebih) set bobot dapat dijumlahkan sebagai satu tensor dengan menambahkan dimensi baru. Hal ini memberi kita bentuk umum tensor bobot untuk lapisan konvolusional. Karena jumlah saluran input dan output adalah parameter, kita dapat mulai menumpuk dan merangkai lapisan konvolusional.

Ilustrasi: jaringan neural konvolusional mengubah "kubus" data menjadi "kubus" data lainnya.
Konvolusi berirama, penggabungan maks
Dengan melakukan konvolusi dengan langkah 2 atau 3, kita juga dapat mengecilkan kubus data yang dihasilkan dalam dimensi horizontalnya. Ada dua cara umum untuk melakukannya:
- Konvolusi berirama: filter geser seperti di atas, tetapi dengan irama >1
- Penggabungan maks: jendela geser yang menerapkan operasi MAX (biasanya pada patch 2x2, diulang setiap 2 piksel)

Ilustrasi: menggeser jendela komputasi sebesar 3 piksel akan menghasilkan lebih sedikit nilai output. Konvolusi berirama atau penggabungan maks (maks pada jendela 2x2 yang bergeser dengan irama 2) adalah cara untuk mengecilkan kubus data dalam dimensi horizontal.
Lapisan akhir
Setelah lapisan konvolusional terakhir, data berbentuk "kubus". Ada dua cara untuk memasukkannya melalui lapisan padat akhir.
Yang pertama adalah meratakan kubus data menjadi vektor, lalu memasukkannya ke lapisan softmax. Terkadang, Anda bahkan dapat menambahkan lapisan padat sebelum lapisan softmax. Hal ini cenderung mahal dalam hal jumlah bobot. Lapisan padat di akhir jaringan konvolusional dapat berisi lebih dari setengah bobot seluruh jaringan neural.
Daripada menggunakan lapisan padat yang mahal, kita juga dapat membagi "kubus" data yang masuk menjadi sebanyak bagian yang kita miliki kelas, menghitung rata-rata nilainya, dan memasukkannya melalui fungsi aktivasi softmax. Cara membangun head klasifikasi ini tidak memerlukan bobot. Di Keras, ada lapisan untuk hal ini: tf.keras.layers.GlobalAveragePooling2D().

Lanjutkan ke bagian berikutnya untuk membangun jaringan konvolusional untuk masalah yang sedang dihadapi.
11. Jaringan konvolusional
Mari kita buat jaringan konvolusional untuk pengenalan digit tulisan tangan. Kita akan menggunakan tiga lapisan konvolusional di bagian atas, lapisan pembacaan softmax tradisional di bagian bawah, dan menghubungkannya dengan satu lapisan terhubung sepenuhnya:

Perhatikan bahwa lapisan konvolusional kedua dan ketiga memiliki langkah dua yang menjelaskan mengapa jumlah nilai outputnya berkurang dari 28x28 menjadi 14x14, lalu 7x7.
Mari kita tulis kode Keras.
Perhatian khusus diperlukan sebelum lapisan konvolusional pertama. Memang, model ini mengharapkan ‘kubus' data 3D, tetapi set data kita sejauh ini telah disiapkan untuk lapisan padat dan semua piksel gambar diratakan menjadi vektor. Kita perlu mengubah bentuknya kembali menjadi gambar 28x28x1 (1 saluran untuk gambar hitam putih):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))
Anda dapat menggunakan baris ini, bukan lapisan tf.keras.layers.Input yang Anda miliki hingga saat ini.
Di Keras, sintaksis untuk lapisan konvolusional yang diaktifkan 'relu' adalah:
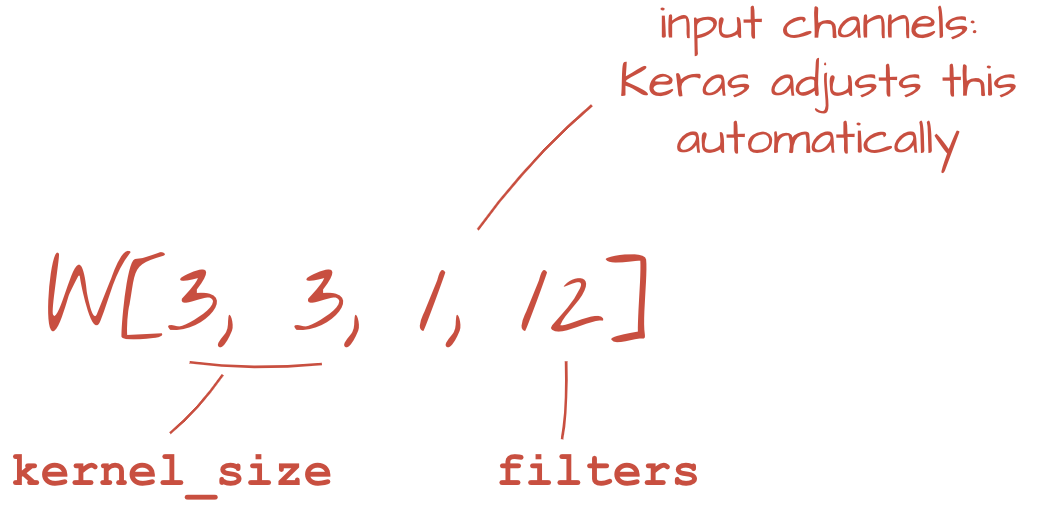
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')
Untuk konvolusi ber-stride, Anda akan menulis:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)
Untuk meratakan kubus data menjadi vektor agar dapat digunakan oleh lapisan padat:
tf.keras.layers.Flatten()
Untuk lapisan padat, sintaksisnya tidak berubah:
tf.keras.layers.Dense(200, activation='relu')
Apakah model Anda melampaui batas akurasi 99%? Hampir benar... tetapi lihat kurva kerugian validasi. Apakah Anda pernah mendengarnya?

Lihat juga prediksi. Untuk pertama kalinya, Anda akan melihat bahwa sebagian besar dari 10.000 digit pengujian kini dikenali dengan benar. Hanya sekitar 4½ baris kesalahan deteksi yang tersisa (sekitar 110 digit dari 10.000)

Jika Anda mengalami kesulitan, berikut solusinya saat ini:
12. Keluar lagi
Pelatihan sebelumnya menunjukkan tanda-tanda overfitting yang jelas (dan masih belum mencapai akurasi 99%). Haruskah kita mencoba dropout lagi?
Bagaimana hasilnya kali ini?
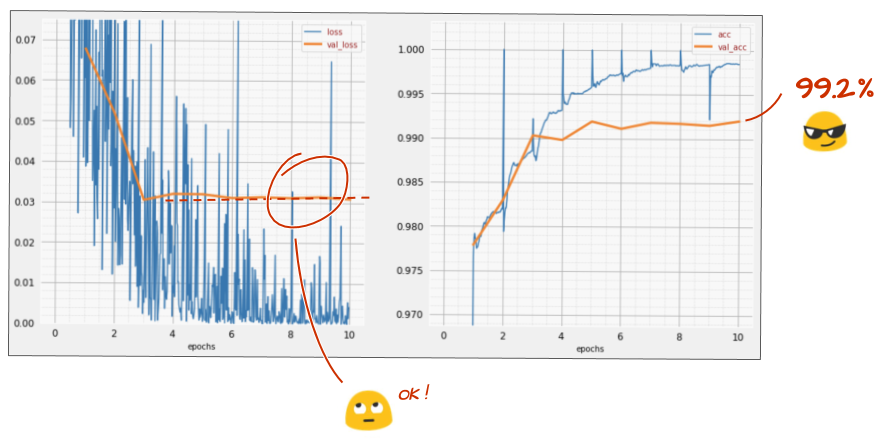
Sepertinya kali ini fitur pelepasan berfungsi. Kerugian validasi tidak meningkat lagi dan akurasi akhir harus jauh di atas 99%. Selamat!
Saat pertama kali mencoba menerapkan dropout, kami mengira ada masalah overfitting, padahal masalahnya ada pada arsitektur jaringan saraf tiruan. Kita tidak dapat melangkah lebih jauh tanpa lapisan konvolusional dan tidak ada yang dapat dilakukan dropout untuk itu.
Kali ini, sepertinya overfitting adalah penyebab masalahnya dan dropout benar-benar membantu. Ingat, ada banyak hal yang dapat menyebabkan perbedaan antara kurva kerugian pelatihan dan validasi, dengan kerugian validasi yang meningkat. Overfitting (terlalu banyak derajat kebebasan, digunakan secara buruk oleh jaringan) hanyalah salah satunya. Jika set data Anda terlalu kecil atau arsitektur jaringan saraf Anda tidak memadai, Anda mungkin melihat perilaku serupa pada kurva kerugian, tetapi dropout tidak akan membantu.
13. Normalisasi batch

Terakhir, mari kita coba menambahkan normalisasi batch.
Itulah teorinya, dalam praktiknya, cukup ingat beberapa aturan:
Untuk saat ini, mari kita ikuti aturan dan menambahkan lapisan normalisasi batch di setiap lapisan jaringan saraf kecuali yang terakhir. Jangan menambahkannya ke lapisan "softmax" terakhir. Hal ini tidak akan berguna di sana.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),
Bagaimana akurasinya sekarang?

Dengan sedikit penyesuaian (BATCH_SIZE=64, parameter peluruhan kecepatan pembelajaran 0,666, rasio dropout pada lapisan padat 0,3) dan sedikit keberuntungan, Anda dapat mencapai 99,5%. Penyesuaian laju pembelajaran dan dropout dilakukan dengan mengikuti "praktik terbaik" untuk menggunakan batch norm:
- Normalisasi batch membantu jaringan neural berkonvergensi dan biasanya memungkinkan Anda melakukan pelatihan lebih cepat.
- Batch norm adalah regularizer. Anda biasanya dapat mengurangi jumlah dropout yang Anda gunakan, atau bahkan tidak menggunakan dropout sama sekali.
Notebook solusi memiliki sesi pelatihan 99,5%:
14. Latih di cloud dengan hardware yang andal: AI Platform

Anda akan menemukan versi kode yang siap untuk cloud di folder mlengine di GitHub, beserta petunjuk untuk menjalankannya di Google Cloud AI Platform. Sebelum dapat menjalankan bagian ini, Anda harus membuat akun Google Cloud dan mengaktifkan penagihan. Resource yang diperlukan untuk menyelesaikan lab ini seharusnya kurang dari beberapa dolar (dengan asumsi waktu pelatihan 1 jam di satu GPU). Untuk menyiapkan akun Anda:
- Buat project Google Cloud Platform ( http://cloud.google.com/console).
- Aktifkan penagihan.
- Instal alat command line GCP ( GCP SDK di sini).
- Buat bucket Google Cloud Storage (di region
us-central1). Bucket ini akan digunakan untuk menyiapkan kode pelatihan dan menyimpan model terlatih Anda. - Aktifkan API yang diperlukan dan minta kuota yang diperlukan (jalankan perintah pelatihan satu kali dan Anda akan mendapatkan pesan error yang memberi tahu Anda API yang perlu diaktifkan).
15. Selamat!
Anda telah membangun jaringan neural pertama dan melatihnya hingga akurasi 99%. Teknik yang dipelajari selama proses ini tidak khusus untuk set data MNIST, tetapi sebenarnya banyak digunakan saat bekerja dengan jaringan neural. Sebagai hadiah perpisahan, berikut kartu "catatan singkat" untuk lab, dalam versi kartun. Anda dapat menggunakannya untuk mengingat apa yang telah Anda pelajari:

Langkah berikutnya
- Setelah jaringan yang terhubung sepenuhnya dan jaringan konvolusional, Anda harus melihat jaringan neural berulang.
- Untuk menjalankan pelatihan atau inferensi di cloud pada infrastruktur terdistribusi, Google Cloud menyediakan AI Platform.
- Terakhir, kami menyambut masukan dengan tangan terbuka. Beri tahu kami jika Anda melihat sesuatu yang tidak beres di lab ini atau jika menurut Anda lab ini harus ditingkatkan. Kami menangani masukan melalui masalah GitHub [ link masukan].

|
|
 Penulis: Martin GörnerTwitter:
Penulis: Martin GörnerTwitter: 
Semua gambar kartun dalam lab ini memiliki hak cipta: alexpokusay / 123RF stock photos