
1. Обзор
Данный учебный материал обновлен для TensorFlow 2.2!

В этом практическом занятии вы научитесь создавать и обучать нейронную сеть, распознающую рукописные цифры. Попутно, улучшая свою нейронную сеть до 99% точности, вы также познакомитесь с инструментами, которые используют профессионалы в области глубокого обучения для эффективного обучения своих моделей.
В этом практическом задании используется набор данных MNIST , содержащий 60 000 размеченных цифр, который почти два десятилетия занимал умы многих ученых. Вы решите задачу, используя менее 100 строк кода на Python/TensorFlow.
Что вы узнаете
- Что такое нейронная сеть и как её обучать?
- Как построить простую однослойную нейронную сеть с использованием tf.keras
- Как добавить больше слоев
- Как составить график темпов обучения
- Как построить сверточные нейронные сети
- Как использовать методы регуляризации: дропаут, пакетная нормализация
- Что такое переобучение?
Что вам понадобится
Достаточно простого браузера. Этот мастер-класс можно провести полностью с помощью Google Colaboratory.
Обратная связь
Пожалуйста, сообщите нам, если вы заметите какие-либо ошибки в этой лабораторной работе или если считаете, что её следует улучшить. Мы обрабатываем отзывы через систему отслеживания проблем GitHub [ ссылка для обратной связи ].
2. Быстрый старт в Google Colaboratory
Эта лабораторная работа использует Google Colaboratory и не требует от вас никакой дополнительной настройки. Вы можете запустить её на Chromebook. Пожалуйста, откройте файл ниже и выполните ячейки, чтобы ознакомиться с блокнотами Colab.

Дополнительные инструкции ниже:
Выберите графический процессор (GPU) в качестве бэкэнда

В меню Colab выберите Runtime > Change runtime type , а затем выберите GPU. Подключение к среде выполнения произойдет автоматически при первом запуске, или вы можете использовать кнопку "Подключиться" в правом верхнем углу.
Выполнение блокнота
Выполняйте ячейки по одной, щелкнув по ячейке и нажав Shift-ENTER. Вы также можете запустить весь блокнот, выбрав Runtime > Run all.
Оглавление

Во всех блокнотах есть оглавление. Открыть его можно с помощью черной стрелки слева.
Скрытые клетки

В некоторых ячейках отображается только заголовок. Это особенность блокнотов Colab. Вы можете дважды щелкнуть по ним, чтобы увидеть код внутри, но обычно он не очень интересен. Как правило, это вспомогательные или визуализационные функции. Вам все равно нужно запустить эти ячейки, чтобы функции внутри них были определены.
3. Обучение нейронной сети
Сначала мы посмотрим, как обучается нейронная сеть. Пожалуйста, откройте приведенный ниже блокнот и пройдитесь по всем ячейкам. Пока не обращайте внимания на код, мы начнем его объяснять позже.
При работе с блокнотом сосредоточьтесь на визуализациях. Пояснения см. ниже.
обучающие данные
У нас есть набор данных рукописных цифр, помеченных таким образом, чтобы мы знали, что обозначает каждое изображение, то есть число от 0 до 9. В блокноте вы увидите фрагмент:

Создаваемая нами нейронная сеть классифицирует рукописные цифры по 10 классам (0, ..., 9). Она делает это на основе внутренних параметров, которые должны иметь правильное значение для эффективной классификации. Это «правильное значение» определяется в процессе обучения, для которого требуется «размеченный набор данных», содержащий изображения и соответствующие им правильные ответы.
Как узнать, насколько хорошо работает обученная нейронная сеть? Использование обучающего набора данных для тестирования сети было бы нечестным. Она уже многократно проходила обучение на этом наборе данных и, безусловно, демонстрирует на нем высокую производительность. Для оценки «реальной» производительности сети нам нужен другой размеченный набор данных, который никогда не использовался во время обучения. Он называется « валидационным набором данных ».
Обучение
По мере обучения, с каждой последующей порцией обучающих данных, внутренние параметры модели обновляются, и модель всё лучше и лучше распознаёт рукописные цифры. Это можно увидеть на графике обучения:

Справа «точность» — это просто процент правильно распознанных цифр. Она увеличивается по мере обучения, что хорошо.
Слева мы видим «потери» . Для управления процессом обучения мы определим функцию «потерь», которая отражает, насколько плохо система распознает цифры, и попытаемся ее минимизировать. Как вы видите, потери уменьшаются как на обучающих, так и на проверочных данных по мере обучения: это хорошо. Это означает, что нейронная сеть обучается.
По оси X отложено количество «эпох» или итераций по всему набору данных.
Прогнозы
После обучения модели мы можем использовать её для распознавания рукописных цифр. На следующей визуализации показано, насколько хорошо она работает на нескольких цифрах, созданных с помощью локальных шрифтов (первая строка), а затем на 10 000 цифрах из проверочного набора данных. Предсказанный класс отображается под каждой цифрой, красным цветом выделены ошибки.

Как видите, эта начальная модель не очень хороша, но всё же правильно распознаёт некоторые цифры. Её окончательная точность проверки составляет около 90%, что не так уж плохо для упрощённой модели, с которой мы начинаем, но это всё же означает, что она пропускает 1000 цифр из 10 000. Это гораздо больше, чем можно отобразить, поэтому кажется, что все ответы неверны (красным цветом).
Тензоры
Данные хранятся в матрицах. Изображение в оттенках серого размером 28x28 пикселей помещается в двумерную матрицу 28x28. Но для цветного изображения требуется больше измерений. В каждом пикселе содержится 3 цветовых значения (красный, зеленый, синий), поэтому потребуется трехмерная таблица с размерами [28, 28, 3]. А для хранения пакета из 128 цветных изображений потребуется четырехмерная таблица с размерами [128, 28, 28, 3].
Эти многомерные таблицы называются «тензорами» , а список их измерений — их «формой» .
4. [ИНФО]: нейронные сети 101
В двух словах
Если все выделенные жирным шрифтом термины в следующем абзаце вам уже знакомы, можете перейти к следующему упражнению. Если же вы только начинаете изучать глубокое обучение, добро пожаловать, и читайте дальше.

Для моделей, построенных в виде последовательности слоев, Keras предлагает API Sequential. Например, классификатор изображений, использующий три полносвязных слоя, можно записать в Keras следующим образом:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )

Один плотный слой
Рукописные цифры в наборе данных MNIST представляют собой изображения в оттенках серого размером 28x28 пикселей. Простейший подход к их классификации заключается в использовании этих 28x28=784 пикселей в качестве входных данных для однослойной нейронной сети.

Каждый «нейрон» в нейронной сети выполняет взвешенное суммирование всех своих входных сигналов, добавляет константу, называемую «смещением», а затем пропускает результат через некоторую нелинейную «функцию активации» . «Весы» и «смещения» — это параметры, которые будут определяться в процессе обучения. Первоначально они инициализируются случайными значениями.
На рисунке выше представлена однослойная нейронная сеть с 10 выходными нейронами, поскольку нам нужно классифицировать цифры по 10 классам (от 0 до 9).
При матричном умножении
Вот как слой нейронной сети, обрабатывающий набор изображений, может быть представлен матричным умножением:

Используя первый столбец весов в матрице весов W, мы вычисляем взвешенную сумму всех пикселей первого изображения. Эта сумма соответствует первому нейрону. Используя второй столбец весов, мы делаем то же самое для второго нейрона и так далее до 10-го нейрона. Затем мы можем повторить операцию для оставшихся 99 изображений. Если обозначить X матрицу, содержащую наши 100 изображений, то все взвешенные суммы для наших 10 нейронов, вычисленные на 100 изображениях, представляют собой просто XW, матричное умножение.
Теперь каждый нейрон должен добавить свое смещение (константу). Поскольку у нас 10 нейронов, у нас есть 10 констант смещения. Назовем этот вектор из 10 значений b. Его необходимо добавить к каждой строке ранее вычисленной матрицы. Используя небольшую магию, называемую «широковещанием», мы запишем это простым знаком плюс.
В заключение мы применяем функцию активации, например, «softmax» (подробнее см. ниже), и получаем формулу, описывающую однослойную нейронную сеть, примененную к 100 изображениям:

В Керасе
С помощью высокоуровневых библиотек для работы с нейронными сетями, таких как Keras, нам не потребуется реализовывать эту формулу. Однако важно понимать, что слой нейронной сети — это всего лишь набор умножений и сложений. В Keras полносвязный слой будет записан следующим образом:
tf.keras.layers.Dense(10, activation='softmax')
Углубиться
Последовательное соединение слоев нейронной сети — задача тривиальная. Первый слой вычисляет взвешенные суммы пикселей. Последующие слои вычисляют взвешенные суммы выходных данных предыдущих слоев.

Единственное различие, помимо количества нейронов, будет заключаться в выборе функции активации.
Функции активации: relu, softmax и sigmoid.
Обычно для всех слоев, кроме последнего, используется функция активации "relu". В классификаторе для последнего слоя используется функция активации "softmax".

Повторюсь, «нейрон» вычисляет взвешенную сумму всех своих входных сигналов, добавляет значение, называемое «смещением», и пропускает результат через функцию активации.
Наиболее популярная функция активации называется "RELU" (Rectified Linear Unit — выпрямленный линейный блок). Это очень простая функция, как видно на графике выше.
Традиционной функцией активации в нейронных сетях была «сигмоидная функция» , но было показано, что «реле-функция активации» обладает лучшими свойствами сходимости почти повсеместно, и теперь ей отдается предпочтение.

Функция активации Softmax для классификации
Последний слой нашей нейронной сети содержит 10 нейронов, поскольку мы хотим классифицировать рукописные цифры на 10 классов (0, ..., 9). Он должен выдавать 10 чисел от 0 до 1, представляющих вероятность того, что эта цифра будет 0, 1, 2 и так далее. Для этого на последнем слое мы будем использовать функцию активации под названием "softmax" .
Применение функции softmax к вектору осуществляется путем экспоненциального вычисления каждого элемента и последующей нормализации вектора, обычно путем деления его на норму "L1" (т. е. сумму абсолютных значений), так что нормализованные значения в сумме дают 1 и могут быть интерпретированы как вероятности.
Выходные данные последнего слоя, перед активацией, иногда называют «логитами» . Если этот вектор L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9], то:
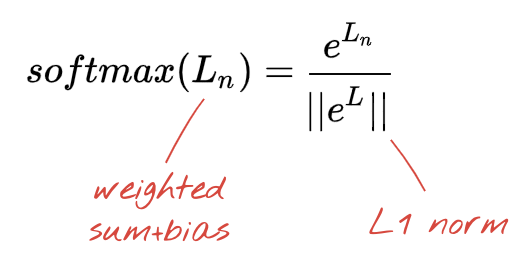

Потери перекрестной энтропии
Теперь, когда наша нейронная сеть выдает предсказания на основе входных изображений, нам нужно измерить, насколько они точны, то есть расстояние между тем, что говорит нам сеть, и правильными ответами, часто называемыми «метками». Помните, что у нас есть правильные метки для всех изображений в наборе данных.
Подойдет любое расстояние, но для задач классификации наиболее эффективным является так называемое «расстояние кросс-энтропии». Мы назовем это нашей функцией ошибки или «функцией потерь»:

Градиентный спуск
«Обучение» нейронной сети на самом деле означает использование обучающих изображений и меток для корректировки весов и смещений с целью минимизации функции потерь кросс-энтропии. Вот как это работает.
Кросс-энтропия является функцией весов, смещений, пикселей обучающего изображения и его известного класса.
Если мы вычислим частные производные кросс-энтропии относительно всех весов и всех смещений, мы получим «градиент», вычисленный для заданного изображения, метки и текущего значения весов и смещений. Следует помнить, что у нас могут быть миллионы весов и смещений, поэтому вычисление градиента кажется сложной задачей. К счастью, TensorFlow делает это за нас. Математическое свойство градиента заключается в том, что он направлен «вверх». Поскольку мы хотим двигаться туда, где кросс-энтропия низка, мы движемся в противоположном направлении. Мы обновляем веса и смещения на долю градиента. Затем мы повторяем то же самое снова и снова, используя следующие пакеты обучающих изображений и меток, в цикле обучения. Надеемся, это приведет к сходимости к точке, где кросс-энтропия минимальна, хотя ничто не гарантирует, что этот минимум является единственным.

Мини-пакетирование и импульс
Вы можете вычислить градиент на одном примере изображения и немедленно обновить веса и смещения, но если сделать это на пакете, например, из 128 изображений, градиент будет лучше отражать ограничения, накладываемые различными примерами изображений, и, следовательно, с большей вероятностью быстрее сойдется к решению. Размер мини-пакета является регулируемым параметром.
Этот метод, иногда называемый «стохастическим градиентным спуском», имеет еще одно, более прагматичное преимущество: работа с пакетами данных также означает работу с большими матрицами, которые обычно проще оптимизировать на графических и тензорных процессорах.
Однако сходимость может быть несколько хаотичной и даже остановиться, если вектор градиента состоит из одних нулей. Означает ли это, что мы нашли минимум? Не всегда. Компонент градиента может быть равен нулю как в точке минимума, так и в точке максимума. В векторе градиента, содержащем миллионы элементов, если все они равны нулю, вероятность того, что каждый ноль соответствует минимуму, а ни один из них — максимуму, довольно мала. В многомерном пространстве седловые точки встречаются довольно часто, и мы не хотим останавливаться на них.

Иллюстрация: седловая точка. Градиент равен 0, но точка не является минимумом во всех направлениях. (Источник изображения: Wikimedia: Nicoguaro - собственная работа, CC BY 3.0 )
Решение состоит в том, чтобы добавить алгоритму оптимизации некоторый импульс, чтобы он мог проходить седловые точки, не останавливаясь.
Глоссарий
Пакетная обработка или мини-пакетная обработка : обучение всегда выполняется на пакетах обучающих данных и меток. Это помогает алгоритму сойтись. Размерность «пакета» обычно представляет собой первую размерность тензоров данных. Например, тензор формы [100, 192, 192, 3] содержит 100 изображений размером 192x192 пикселя с тремя значениями на пиксель (RGB).
Функция потерь кросс-энтропии : специальная функция потерь, часто используемая в классификаторах.
Плотный слой : слой нейронов, в котором каждый нейрон соединен со всеми нейронами предыдущего слоя.
Признаки : входные данные нейронной сети иногда называют «признаками». Искусство определения того, какие части набора данных (или комбинации частей) следует подавать в нейронную сеть для получения хороших прогнозов, называется «инженерией признаков».
метки : другое название для «классов» или правильных ответов в задаче классификации с учителем.
Скорость обучения : доля градиента, на которую обновляются веса и смещения на каждой итерации цикла обучения.
Логиты : выходные сигналы слоя нейронов до применения функции активации называются «логитами». Термин происходит от «логистической функции», также известной как «сигмоидная функция», которая раньше была наиболее популярной функцией активации. Выражение «выходные сигналы нейронов до применения логистической функции» было сокращено до «логиты».
Функция потерь : функция ошибки, сравнивающая выходные данные нейронной сети с правильными ответами.
Нейрон : вычисляет взвешенную сумму своих входных сигналов, добавляет смещение и пропускает результат через функцию активации.
one-hot кодирование : класс 3 из 5 кодируется как вектор из 5 элементов, все из которых равны нулю, кроме третьего, который равен 1.
relu : выпрямленная линейная единица. Популярная функция активации для нейронов.
Сигмоидная функция : еще одна функция активации, которая когда-то была популярна и до сих пор полезна в особых случаях.
softmax : специальная функция активации, которая действует на вектор, увеличивая разницу между наибольшей компонентой и всеми остальными, а также нормализует вектор так, чтобы его сумма равнялась 1, что позволяет интерпретировать его как вектор вероятностей. Используется в качестве последнего шага в классификаторах.
Тензор : «Тензор» — это как матрица, но с произвольным числом измерений. Одномерный тензор — это вектор. Двумерный тензор — это матрица. И, наконец, могут существовать тензоры с 3, 4, 5 или более измерениями.
5. Давайте перейдём к коду.
Вернемся к учебной тетради, и на этот раз давайте прочтем код.
Давайте пройдемся по всем ячейкам в этом блокноте.
Параметры ячейки
Здесь задаются размер пакета, количество эпох обучения и местоположение файлов данных. Файлы данных размещаются в хранилище Google Cloud Storage (GCS), поэтому их адрес начинается с gs://
Клетки "Импорт"
Здесь импортированы все необходимые библиотеки Python, включая TensorFlow, а также matplotlib для визуализации.
« Утилиты визуализации ячеек [ЗАПУСТИТЕ МЕНЯ]****»
В этой ячейке содержится неинтересный код визуализации. По умолчанию она свернута, но вы можете открыть ее и посмотреть код, когда у вас будет время, дважды щелкнув по ней.
Ячейка " tf.data.Dataset: анализ файлов и подготовка обучающих и проверочных наборов данных "
В этой ячейке для загрузки набора данных MNIST из файлов данных использовался API tf.data.Dataset. Не стоит тратить на эту ячейку много времени. Если вас интересует API tf.data.Dataset, вот руководство, которое его объясняет: Конвейеры обработки данных на скорости TPU . А пока рассмотрим основные моменты:
Изображения и метки (правильные ответы) из набора данных MNIST хранятся в записях фиксированной длины в 4 файлах. Файлы можно загрузить с помощью специальной функции для файлов фиксированной длины:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)
Теперь у нас есть набор данных байтов изображений. Их необходимо декодировать в изображения. Для этого мы определяем функцию. Изображение не сжато, поэтому функции не нужно ничего декодировать ( decode_raw практически ничего не делает). Затем изображение преобразуется в значения с плавающей запятой от 0 до 1. Мы могли бы преобразовать его в двумерное изображение, но на самом деле мы сохраняем его в виде плоского массива пикселей размером 28*28, потому что именно этого ожидает наш начальный полносвязный слой.
def read_image(tf_bytestring):
image = tf.io.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image
Мы применяем эту функцию к набору данных с помощью .map и получаем набор изображений:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)
Мы выполняем аналогичное чтение и декодирование для меток, и мы объединяем изображения и метки в архивы .zip :
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))
Теперь у нас есть набор пар данных (изображение, метка). Это то, что ожидает наша модель. Мы пока не совсем готовы использовать его в функции обучения:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
API tf.data.Dataset содержит все необходимые вспомогательные функции для подготовки наборов данных:
.cache кэширует набор данных в оперативной памяти. Это очень небольшой набор данных, поэтому он подойдет. .shuffle перемешивает его с буфером из 5000 элементов. Важно, чтобы обучающие данные были хорошо перемешаны. .repeat зацикливает набор данных. Мы будем обучать на нем несколько раз (несколько эпох). .batch объединяет несколько изображений и меток в мини-пакет. Наконец, метод .prefetch может использовать ЦП для подготовки следующего пакета, пока текущий пакет обучается на графическом процессоре.
Проверочный набор данных подготавливается аналогичным образом. Теперь мы готовы определить модель и использовать этот набор данных для ее обучения.
Клеточная "модель Кераса"
Все наши модели будут представлять собой прямые последовательности слоев, поэтому мы можем использовать стиль tf.keras.Sequential для их создания. Изначально здесь используется один полносвязный слой. Он имеет 10 нейронов, поскольку мы классифицируем рукописные цифры по 10 классам. Он использует активацию "softmax", поскольку это последний слой в классификаторе.
Модель Keras также должна знать форму своих входных данных. Для этого можно использовать tf.keras.layers.Input . В данном случае входные векторы представляют собой плоские векторы значений пикселей длиной 28*28.
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)
Настройка модели выполняется в Keras с помощью функции model.compile . Здесь мы используем базовый оптимизатор 'sgd' (стохастический градиентный спуск). Для модели классификации требуется функция потерь кросс-энтропии, которая в Keras называется 'categorical_crossentropy' . Наконец, мы просим модель вычислить метрику 'accuracy' , которая представляет собой процент правильно классифицированных изображений.
Keras предлагает очень удобную утилиту model.summary() , которая выводит подробную информацию о созданной вами модели. Ваш любезный преподаватель добавил утилиту PlotTraining (определенную в ячейке "утилиты визуализации"), которая будет отображать различные кривые обучения во время процесса обучения.
Ячейка «Обучение и проверка модели»
Здесь происходит обучение: вызывается model.fit и передаются обучающий и проверочный наборы данных. По умолчанию Keras выполняет раунд проверки в конце каждой эпохи.
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])
В Keras можно добавлять пользовательские функции во время обучения, используя колбэки. Именно так был реализован динамически обновляемый график обучения для этого семинара.
Ячейка «Визуализация прогнозов»
После обучения модели мы можем получить от неё прогнозы, вызвав model.predict() :
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)
Здесь мы подготовили набор печатных цифр, созданных с помощью локальных шрифтов, в качестве теста. Напомним, что нейронная сеть возвращает вектор из 10 вероятностей из своей итоговой функции «softmax». Чтобы получить метку, нам нужно выяснить, какая вероятность является наибольшей. Для этого используется np.argmax из библиотеки numpy.
Чтобы понять, почему необходим параметр axis=1 , вспомните, что мы обработали пакет из 128 изображений, и поэтому модель возвращает 128 векторов вероятностей. Форма выходного тензора — [128, 10]. Мы вычисляем argmax по 10 вероятностям, возвращаемым для каждого изображения, поэтому axis=1 (первая ось равна 0).
Эта простая модель уже распознает 90% цифр. Неплохо, но теперь вы значительно улучшите этот показатель.

6. Добавление слоев

Для повышения точности распознавания мы добавим в нейронную сеть больше слоев.

В качестве функции активации на последнем слое мы используем softmax, поскольку она лучше всего подходит для классификации. Однако на промежуточных слоях мы будем использовать наиболее классическую функцию активации: сигмоидную.
Например, ваша модель может выглядеть так (не забудьте про запятые, tf.keras.Sequential принимает список слоев, разделенных запятыми):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
Посмотрите на "сводку" вашей модели. Теперь у неё как минимум в 10 раз больше параметров. Она должна быть в 10 раз лучше! Но по какой-то причине это не так...

Похоже, потери тоже резко возросли. Что-то не так.
7. Особое внимание уделяется глубоким нейронным сетям.
Вы только что познакомились с нейронными сетями в том виде, в котором их проектировали в 80-х и 90-х годах. Неудивительно, что от этой идеи отказались, положив начало так называемой «зиме ИИ». Действительно, с увеличением количества слоев нейронным сетям становится все сложнее сходиться.
Оказывается, глубокие нейронные сети с большим количеством слоев (сегодня это 20, 50, даже 100) могут работать действительно хорошо, если использовать пару математических ухищрений для обеспечения их сходимости. Открытие этих простых приемов — одна из причин возрождения глубокого обучения в 2010-х годах.
активация RELU

Сигмоидная функция активации на самом деле довольно проблематична в глубоких нейронных сетях. Она сжимает все значения от 0 до 1, и при многократном повторении этого действия выходные сигналы нейронов и их градиенты могут полностью исчезнуть. Это упоминалось по историческим причинам, но современные сети используют RELU (Rectified Linear Unit), которая выглядит следующим образом:

С другой стороны, функция RELU имеет производную, равную 1, по крайней мере, в правой части. При активации RELU, даже если градиенты от некоторых нейронов могут быть равны нулю, всегда найдутся другие, дающие явно ненулевой градиент, и обучение может продолжаться в хорошем темпе.
Более совершенный оптимизатор
В очень многомерных пространствах, подобных этому — где у нас порядка 10 000 весов и смещений — часто встречаются «седловые точки». Это точки, которые не являются локальными минимумами, но где градиент, тем не менее, равен нулю, и оптимизатор градиентного спуска застревает в этом месте. TensorFlow предлагает полный набор оптимизаторов, включая некоторые, которые работают с определенной инерцией и могут безопасно пройти мимо седловых точек.
Случайные инициализации
Искусство инициализации смещений весов перед обучением — это отдельная область исследований, по которой опубликовано множество работ. Вы можете ознакомиться со всеми доступными в Keras инициализаторами здесь . К счастью, Keras по умолчанию поступает правильно и использует инициализатор 'glorot_uniform' , который является наилучшим практически во всех случаях.
Вам ничего не нужно делать, поскольку Keras уже всё делает правильно.
NaN ???
Формула кросс-энтропии включает логарифм, а log(0) — это не число (NaN, если хотите, это числовая ошибка). Может ли входной параметр кросс-энтропии быть равен 0? Входной параметр поступает от функции softmax, которая по сути является экспоненциальной функцией, а экспоненциальная функция никогда не равна нулю. Так что мы в безопасности!
Неужели? В прекрасном мире математики мы были бы в безопасности, но в мире компьютеров exp(-150), представленное в формате float32, равно нулю, и перекрестная энтропия дает сбой.
К счастью, вам здесь тоже ничего не нужно делать, поскольку Keras позаботится об этом и вычислит функцию softmax, а затем кросс-энтропию, особенно тщательно, чтобы обеспечить численную стабильность и избежать появления пресловутых значений NaN.
Успех?

Теперь ваша точность должна достигать 97%. Цель этого мастер-класса — значительно превысить 99%, так что давайте продолжим.
Если вы застряли, вот решение на данном этапе:
8. Снижение скорости обучения
Может, попробуем ускорить обучение? В оптимизаторе Adam скорость обучения по умолчанию составляет 0,001. Давайте попробуем её увеличить.
Увеличение скорости, похоже, не сильно помогает, и что это за шум?

Тренировочные кривые очень шумные, и если посмотреть на обе валидационные кривые, они скачут вверх и вниз. Это означает, что мы движемся слишком быстро. Мы могли бы вернуться к прежнему темпу, но есть более эффективный способ.

Наилучшее решение — начать быстро и экспоненциально уменьшать скорость обучения. В Keras это можно сделать с помощью функции обратного вызова tf.keras.callbacks.LearningRateScheduler .
Полезный код для копирования и вставки:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)
Не забудьте использовать созданный вами lr_decay_callback . Добавьте его в список обратных вызовов в model.fit :
model.fit(..., callbacks=[plot_training, lr_decay_callback])
Результаты этого небольшого изменения впечатляют. Вы видите, что большая часть шума исчезла, и точность тестирования теперь стабильно превышает 98%.

9. Отсеивание (дропаут), переобучение
Модель, похоже, хорошо сходится. Давайте попробуем углубиться в проблему.
Это помогает?

Not really, the accuracy is still stuck at 98% and look at the validation loss. It is going up! The learning algorithm works on training data only and optimises the training loss accordingly. It never sees validation data so it is not surprising that after a while its work no longer has an effect on the validation loss which stops dropping and sometimes even bounces back up.
This does not immediately affect the real-world recognition capabilities of your model, but it will prevent you from running many iterations and is generally a sign that the training is no longer having a positive effect.

This disconnect is usually called "overfitting" and when you see it, you can try to apply a regularisation technique called "dropout". The dropout technique shoots random neurons at each training iteration.
Это сработало?

Noise reappears (unsurprisingly given how dropout works). The validation loss does not seem to be creeping up anymore, but it is higher overall than without dropout. And the validation accuracy went down a bit. This is a fairly disappointing result.
It looks like dropout was not the correct solution, or maybe "overfitting" is a more complex concept and some of its causes are not amenable to a "dropout" fix?
What is "overfitting"? Overfitting happens when a neural network learns "badly", in a way that works for the training examples but not so well on real-world data. There are regularisation techniques like dropout that can force it to learn in a better way but overfitting also has deeper roots.

Basic overfitting happens when a neural network has too many degrees of freedom for the problem at hand. Imagine we have so many neurons that the network can store all of our training images in them and then recognise them by pattern matching. It would fail on real-world data completely. A neural network must be somewhat constrained so that it is forced to generalise what it learns during training.
If you have very little training data, even a small network can learn it by heart and you will see "overfitting". Generally speaking, you always need lots of data to train neural networks.
Finally, if you have done everything by the book, experimented with different sizes of network to make sure its degrees of freedom are constrained, applied dropout, and trained on lots of data you might still be stuck at a performance level that nothing seems to be able to improve. This means that your neural network, in its present shape, is not capable of extracting more information from your data, as in our case here.
Remember how we are using our images, flattened into a single vector? That was a really bad idea. Handwritten digits are made of shapes and we discarded the shape information when we flattened the pixels. However, there is a type of neural network that can take advantage of shape information: convolutional networks. Let us try them.
If you are stuck, here is the solution at this point:
10. [INFO] convolutional networks
В двух словах
If all the terms in bold in the next paragraph are already known to you, you can move to the next exercise. If your are just starting out with convolutional neural networks, please read on.

Illustration: filtering an image with two successive filters made of 4x4x3=48 learnable weights each.
This is how a simple convolutional neural network looks in Keras:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
In a layer of a convolutional network, one "neuron" does a weighted sum of the pixels just above it, across a small region of the image only. It adds a bias and feeds the sum through an activation function, just as a neuron in a regular dense layer would. This operation is then repeated across the entire image using the same weights. Remember that in dense layers, each neuron had its own weights. Here, a single "patch" of weights slides across the image in both directions (a "convolution"). The output has as many values as there are pixels in the image (some padding is necessary at the edges though). It is a filtering operation. In the illustration above, it uses a filter of 4x4x3=48 weights.
However, 48 weights will not be enough. To add more degrees of freedom, we repeat the same operation with a new set of weights. This produces a new set of filter outputs. Let's call it a "channel" of outputs by analogy with the R,G,B channels in the input image.
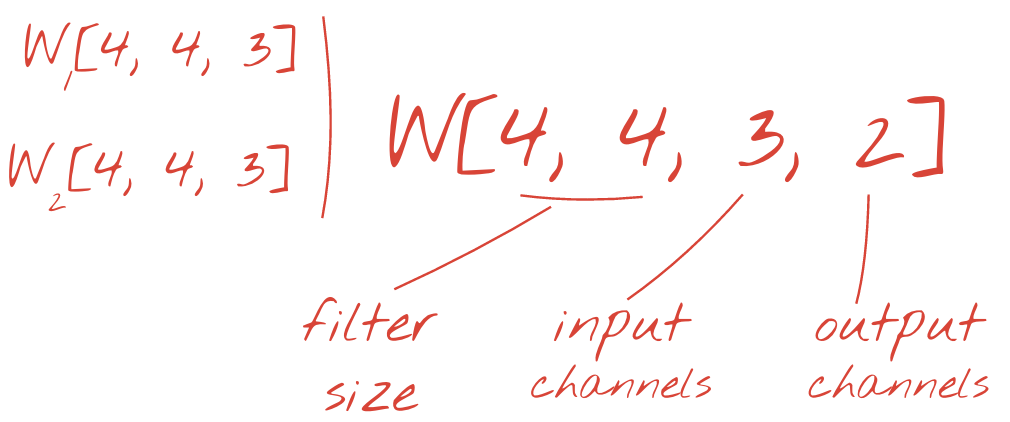
The two (or more) sets of weights can be summed up as one tensor by adding a new dimension. This gives us the generic shape of the weights tensor for a convolutional layer. Since the number of input and output channels are parameters, we can start stacking and chaining convolutional layers.

Illustration: a convolutional neural network transforms "cubes" of data into other "cubes" of data.
Strided convolutions, max pooling
By performing the convolutions with a stride of 2 or 3, we can also shrink the resulting data cube in its horizontal dimensions. There are two common ways of doing this:
- Strided convolution: a sliding filter as above but with a stride >1
- Max pooling: a sliding window applying the MAX operation (typically on 2x2 patches, repeated every 2 pixels)

Illustration: sliding the computing window by 3 pixels results in fewer output values. Strided convolutions or max pooling (max on a 2x2 window sliding by a stride of 2) are a way of shrinking the data cube in the horizontal dimensions.
The final layer
After the last convolutional layer, the data is in the form of a "cube". There are two ways of feeding it through the final dense layer.
The first one is to flatten the cube of data into a vector and then feed it to the softmax layer. Sometimes, you can even add a dense layer before the softmax layer. This tends to be expensive in terms of the number of weights. A dense layer at the end of a convolutional network can contain more than half the weights of the whole neural network.
Instead of using an expensive dense layer, we can also split the incoming data "cube" into as many parts as we have classes, average their values and feed these through a softmax activation function. This way of building the classification head costs 0 weights. In Keras, there is a layer for this: tf.keras.layers.GlobalAveragePooling2D() .

Jump to the next section to build a convolutional network for the problem at hand.
11. A convolutional network
Let us build a convolutional network for handwritten digit recognition. We will use three convolutional layers at the top, our traditional softmax readout layer at the bottom and connect them with one fully-connected layer:

Notice that the second and third convolutional layers have a stride of two which explains why they bring the number of output values down from 28x28 to 14x14 and then 7x7.
Let's write the Keras code.
Special attention is needed before the first convolutional layer. Indeed, it expects a 3D 'cube' of data but our dataset has so far been set up for dense layers and all the pixels of the images are flattened into a vector. We need to reshape them back into 28x28x1 images (1 channel for grayscale images):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))
You can use this line instead of the tf.keras.layers.Input layer you had up to now.
In Keras, the syntax for a 'relu'-activated convolutional layer is:

tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')
For a strided convolution, you would write:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)
To flatten a cube of data into a vector so that it can be consumed by a dense layer:
tf.keras.layers.Flatten()
And for dense layer, the syntax has not changed:
tf.keras.layers.Dense(200, activation='relu')
Did your model break the 99% accuracy barrier? Pretty close... but look at the validation loss curve. Does this ring a bell?

Also look at the predictions. For the first time, you should see that most of the 10,000 test digits are now correctly recognized. Only about 4½ rows of misdetections remain (about 110 digits out of 10,000)

If you are stuck, here is the solution at this point:
12. Dropout again
The previous training exhibits clear signs of overfitting (and still falls short of 99% accuracy). Should we try dropout again?
Как всё прошло на этот раз?

It looks like dropout has worked this time. The validation loss is not creeping up anymore and the final accuracy should be way above 99%. Congratulations!
The first time we tried to apply dropout, we thought we had an overfitting problem, when in fact the problem was in the architecture of the neural network. We could not go further without convolutional layers and there is nothing dropout could do about that.
This time, it does look like overfitting was the cause of the problem and dropout actually helped. Remember, there are many things that can cause a disconnect between the training and validation loss curves, with the validation loss creeping up. Overfitting (too many degrees of freedom, used badly by the network) is only one of them. If your dataset is too small or the architecture of your neural network is not adequate, you might see a similar behavior on the loss curves, but dropout will not help.
13. Batch normalization

Finally, let's try to add batch normalization.
That's the theory, in practice, just remember a couple of rules:
Let's play by the book for now and add a batch norm layer on each neural network layer but the last. Do not add it to the last "softmax" layer. It would not be useful there.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),
How is the accuracy now?

With a little bit of tweaking (BATCH_SIZE=64, learning rate decay parameter 0.666, dropout rate on dense layer 0.3) and a bit of luck, you can get to 99.5%. The learning rate and dropout adjustments were done following the "best practices" for using batch norm:
- Batch norm helps neural networks converge and usually allows you to train faster.
- Batch norm is a regularizer. You can usually decrease the amount of dropout you use, or even not use dropout at all.
The solution notebook has a 99.5% training run:
14. Train in the cloud on powerful hardware: AI Platform

You will find a cloud-ready version of the code in the mlengine folder on GitHub , along with instructions for running it on Google Cloud AI Platform . Before you can run this part, you will have to create a Google Cloud account and enable billing. The resources necessary to complete the lab should be less than a couple of dollars (assuming 1h of training time on one GPU). To prepare your account:
- Create a Google Cloud Platform project ( http://cloud.google.com/console ).
- Enable billing.
- Install the GCP command line tools ( GCP SDK here ).
- Create a Google Cloud Storage bucket (put in the region
us-central1). It will be used to stage the training code and store your trained model. - Enable the necessary APIs and request the necessary quotas (run the training command once and you should get error messages telling you what to enable).
15. Поздравляем!
You have built your first neural network and trained it all the way to 99% accuracy. The techniques learned along the way are not specific to the MNIST dataset, actually they are widely used when working with neural networks. As a parting gift, here is the "cliff's notes" card for the lab, in cartoon version. You can use it to remember what you have learned:

Следующие шаги
- After fully-connected and convolutional networks, you should have a look at recurrent neural networks .
- To run your training or inference in the cloud on a distributed infrastructure, Google Cloud provides AI Platform .
- Finally, we love feedback. Please tell us if you see something amiss in this lab or if you think it should be improved. We handle feedback through GitHub issues [ feedback link ].

|
|
 The author: Martin GörnerTwitter:
The author: Martin GörnerTwitter: 
All cartoon images in this lab copyright: alexpokusay / 123RF stock photos