Tentang codelab ini
1. Ringkasan
Di lab ini, Anda akan mempelajari cara menggunakan Vertex AI - platform ML terkelola Google Cloud yang baru saja diumumkan - untuk membangun alur kerja ML end-to-end. Anda akan belajar cara beralih dari data mentah ke model yang di-deploy, dan meninggalkan workshop ini sebagai persiapan untuk mengembangkan dan memproduksi project ML Anda sendiri dengan Vertex AI. Di lab ini, kami menggunakan Cloud Shell untuk membangun image Docker kustom guna mendemonstrasikan container kustom untuk pelatihan dengan Vertex AI.
Meskipun kita menggunakan TensorFlow untuk kode model di sini, Anda dapat dengan mudah menggantinya dengan framework lain.
Yang Anda pelajari
Anda akan mempelajari cara:
- Membuat dan memasukkan kode pelatihan model ke dalam container menggunakan Cloud Shell
- Mengirim tugas pelatihan model kustom ke Vertex AI
- Deploy model yang telah Anda latih ke endpoint, dan gunakan endpoint tersebut untuk mendapatkan prediksi
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $2.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI. Jika Anda memiliki masukan, harap lihat halaman dukungan.
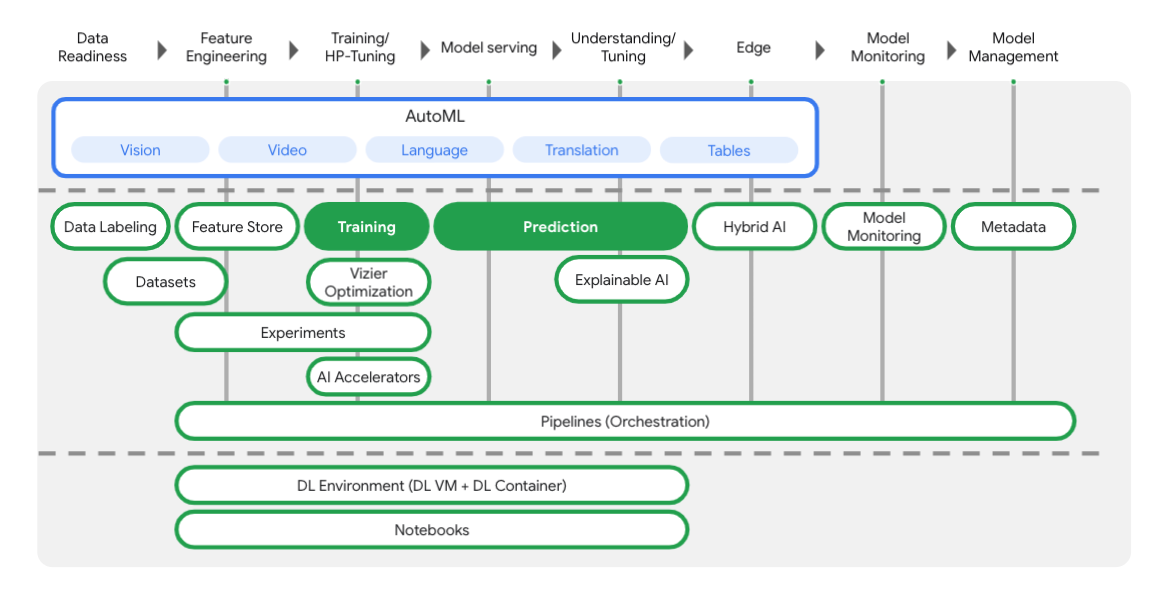
Vertex menyertakan banyak alat berbeda untuk membantu Anda di setiap tahap alur kerja ML, seperti yang dapat Anda lihat dari diagram di bawah ini. Kita akan berfokus pada penggunaan Pelatihan dan Prediksi Vertex, yang disorot di bawah ini.
3. Menyiapkan lingkungan Anda
Penyiapan lingkungan mandiri
Login ke Cloud Console lalu buat project baru atau gunakan kembali project yang sudah ada. (Jika belum memiliki akun Gmail atau Google Workspace, Anda harus membuatnya.)

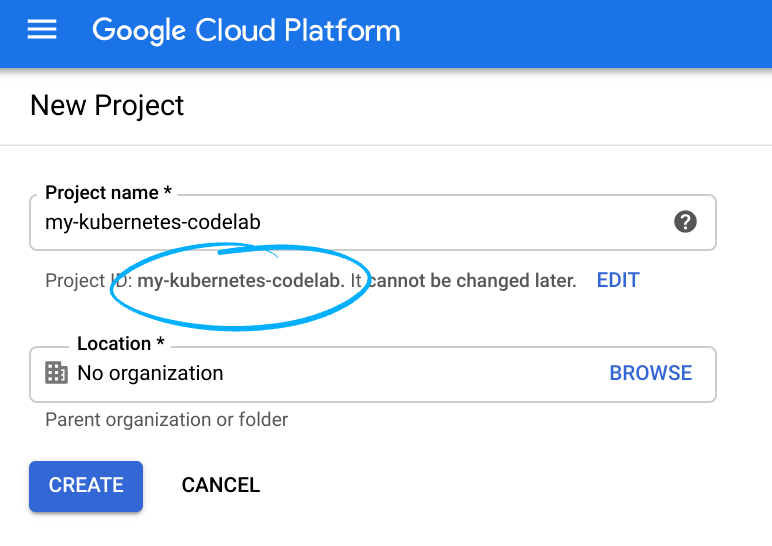
Ingat project ID, nama unik di semua project Google Cloud (maaf, nama di atas telah digunakan dan tidak akan berfungsi untuk Anda!)
Selanjutnya, Anda harus mengaktifkan penagihan di Cloud Console untuk menggunakan resource Google Cloud.
Menjalankan operasi dalam codelab ini seharusnya tidak memerlukan banyak biaya, bahkan mungkin tidak sama sekali. Pastikan untuk mengikuti petunjuk yang ada di bagian "Membersihkan" yang memberi tahu Anda cara menonaktifkan resource sehingga tidak menimbulkan penagihan di luar tutorial ini. Pengguna baru Google Cloud memenuhi syarat untuk mengikuti program Uji Coba Gratis senilai$300 USD.
Langkah 1: Mulai Cloud Shell
Di lab ini, Anda akan mengerjakan sesi Cloud Shell, yang merupakan penafsir perintah yang dihosting oleh virtual machine yang berjalan di cloud Google. Anda dapat dengan mudah menjalankan bagian ini secara lokal di komputer sendiri, tetapi menggunakan Cloud Shell akan memberi semua orang akses ke pengalaman yang dapat diproduksi ulang dalam lingkungan yang konsisten. Setelah lab ini, Anda dapat mencoba lagi bagian ini di komputer Anda sendiri.
Mengaktifkan Cloud Shell
Dari kanan atas Konsol Cloud, klik tombol di bawah untuk Activate Cloud Shell:

Jika belum pernah memulai Cloud Shell, Anda akan melihat layar perantara (di paruh bawah) yang menjelaskan apa itu Cloud Shell. Jika demikian, klik Lanjutkan (dan Anda tidak akan pernah melihatnya lagi). Berikut tampilan layar sekali-tampil tersebut:
Perlu waktu beberapa saat untuk penyediaan dan terhubung ke Cloud Shell.

Mesin virtual ini dimuat dengan semua alat pengembangan yang Anda butuhkan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Sebagian besar pekerjaan Anda dalam codelab ini dapat dilakukan hanya dengan browser atau Chromebook.
Setelah terhubung ke Cloud Shell, Anda akan melihat bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda.
Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa Anda telah diautentikasi:
gcloud auth list
Output perintah
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda:
gcloud config list project
Output perintah
[core] project = <PROJECT_ID>
Jika tidak, Anda dapat menyetelnya dengan perintah ini:
gcloud config set project <PROJECT_ID>
Output perintah
Updated property [core/project].
Cloud Shell memiliki beberapa variabel lingkungan, termasuk GOOGLE_CLOUD_PROJECT yang berisi nama project Cloud kita saat ini. Kita akan menggunakannya di berbagai tempat di lab ini. Anda dapat melihatnya dengan menjalankan:
echo $GOOGLE_CLOUD_PROJECT
Langkah 2: Aktifkan API
Pada langkah-langkah berikutnya, Anda akan melihat di mana layanan ini diperlukan (dan alasannya). Namun, untuk saat ini, jalankan perintah ini agar project Anda dapat mengakses layanan Compute Engine, Container Registry, dan Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Perintah di atas akan menampilkan pesan seperti berikut yang menandakan bahwa proses berhasil:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Langkah 3: Buat Bucket Cloud Storage
Untuk menjalankan tugas pelatihan pada Vertex AI, kita memerlukan bucket penyimpanan untuk menyimpan aset model tersimpan. Jalankan perintah berikut di terminal Cloud Shell Anda untuk membuat bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Langkah 4: Alias Python 3
Kode di lab ini menggunakan Python 3. Untuk memastikan Anda menggunakan Python 3 saat menjalankan skrip yang akan dibuat di lab ini, buat alias dengan menjalankan perintah berikut di Cloud Shell:
alias python=python3
Model yang akan kita latih dan inferensi di lab ini dibuat berdasarkan tutorial ini dari dokumen TensorFlow. Tutorial ini menggunakan set data Auto MPG dari Kaggle untuk memprediksi efisiensi bahan bakar kendaraan.
4. Menyimpan kode pelatihan dalam container
Kita akan mengirim tugas pelatihan ke Vertex dengan menempatkan kode pelatihan dalam container Docker dan mengirim container ini ke Google Container Registry. Dengan pendekatan ini, kita dapat melatih model yang dibangun dengan framework apa pun.
Langkah 1: Siapkan file
Untuk memulai, dari terminal di Cloud Shell, jalankan perintah berikut guna membuat file yang akan kita perlukan untuk Container Docker:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Sekarang Anda memiliki direktori mpg/ yang terlihat seperti berikut:
+ Dockerfile
+ trainer/
+ train.py
Untuk melihat dan mengedit file ini, kita akan menggunakan editor kode bawaan Cloud Shell. Anda dapat beralih antara editor dan terminal dengan mengklik tombol di panel menu kanan atas di Cloud Shell:

Langkah 2: Buat Dockerfile
Untuk menyimpan kode dalam container, kita akan membuat Dockerfile terlebih dahulu. Dalam Dockerfile, kita akan menyertakan semua perintah yang diperlukan untuk menjalankan image. Tindakan ini akan menginstal semua library yang kita gunakan dan menyiapkan titik entri untuk kode pelatihan.
Dari editor file Cloud Shell, buka direktori mpg/ Anda, lalu klik dua kali untuk membuka Dockerfile:
Kemudian, salin kode berikut ke file ini:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Dockerfile ini menggunakan image Docker Deep Learning Container TensorFlow Enterprise 2.3. Deep Learning Containers di Google Cloud dilengkapi dengan banyak ML umum dan framework data science yang diiinstal sebelumnya. Yang kami gunakan meliputi TF Enterprise 2.3, Pandas, Scikit-learn, dan lainnya. Setelah mendownload image tersebut, Dockerfile ini akan menyiapkan titik entri untuk kode pelatihan kita, yang akan kita tambahkan pada langkah berikutnya.
Langkah 3: Tambahkan kode pelatihan model
Dari editor Cloud Shell, selanjutnya buka file train.py dan salin kode di bawah (ini diadaptasi dari tutorial dalam dokumen TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Setelah menyalin kode di atas ke file mpg/trainer/train.py, kembali ke Terminal di Cloud Shell dan jalankan perintah berikut untuk menambahkan nama bucket Anda sendiri ke file:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Langkah 4: Bangun dan uji container secara lokal
Dari Terminal Anda, jalankan perintah berikut untuk menentukan variabel dengan URI image container Anda di Google Container Registry:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Kemudian, build container dengan menjalankan perintah berikut dari root direktori mpg Anda:
docker build ./ -t $IMAGE_URI
Setelah Anda membangun container, kirim container tersebut ke Google Container Registry:
docker push $IMAGE_URI
Untuk memverifikasi bahwa image Anda telah dikirim ke Container Registry, Anda akan melihat sesuatu seperti ini saat membuka bagian Container Registry pada konsol:
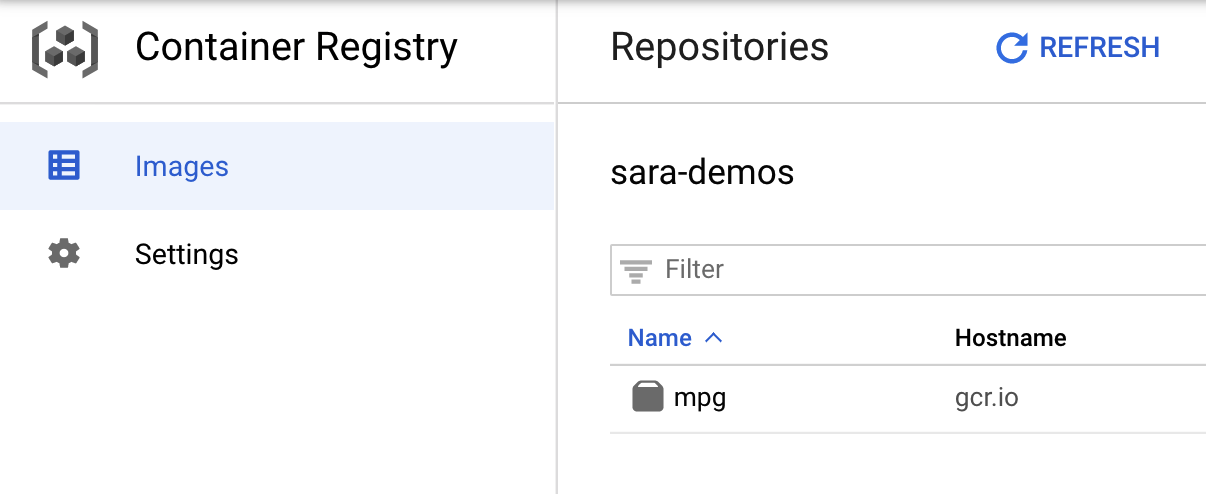
Dengan container yang dikirim ke Container Registry, sekarang kita siap untuk memulai tugas pelatihan model kustom.
5. Menjalankan tugas pelatihan pada Vertex AI
Vertex memberi Anda dua opsi untuk melatih model:
- AutoML: Latih model berkualitas tinggi dengan upaya dan keahlian ML minimal.
- Pelatihan kustom: Jalankan aplikasi pelatihan kustom Anda di cloud menggunakan salah satu container bawaan Google Cloud atau gunakan container Anda sendiri.
Dalam lab ini, kita menggunakan pelatihan kustom melalui container kustom kami sendiri di Google Container Registry. Untuk memulai, buka bagian Pelatihan di bagian Vertex pada Konsol Cloud Anda:
Langkah 1: Memulai tugas pelatihan
Klik Buat guna memasukkan parameter untuk tugas pelatihan dan model yang di-deploy:
- Di bagian Set data, pilih Tidak ada set data terkelola
- Lalu, pilih Pelatihan kustom (lanjutan) sebagai metode pelatihan Anda dan klik Lanjutkan.
- Masukkan
mpg(atau nama model yang Anda inginkan) untuk Nama model - Klik Lanjutkan
Dalam langkah setelan Container, pilih Container kustom:

Di kotak pertama (Container image), klik Browse dan temukan container yang baru saja Anda kirim ke Container Registry. Ini akan terlihat seperti berikut:
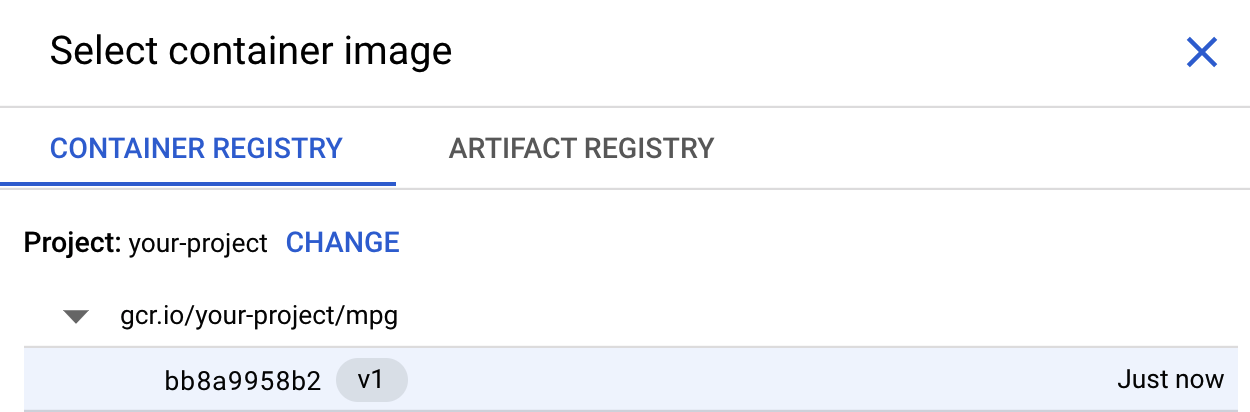
Biarkan kolom lainnya kosong dan klik Lanjutkan.
Kita tidak akan menggunakan penyesuaian hyperparameter dalam tutorial ini, jadi biarkan kotak penyesuaian Aktifkan hyperparameter tidak dicentang lalu klik Lanjutkan.
Di bagian Compute and Pricing, biarkan region yang dipilih apa adanya dan pilih n1-standard-4 sebagai jenis mesin Anda:
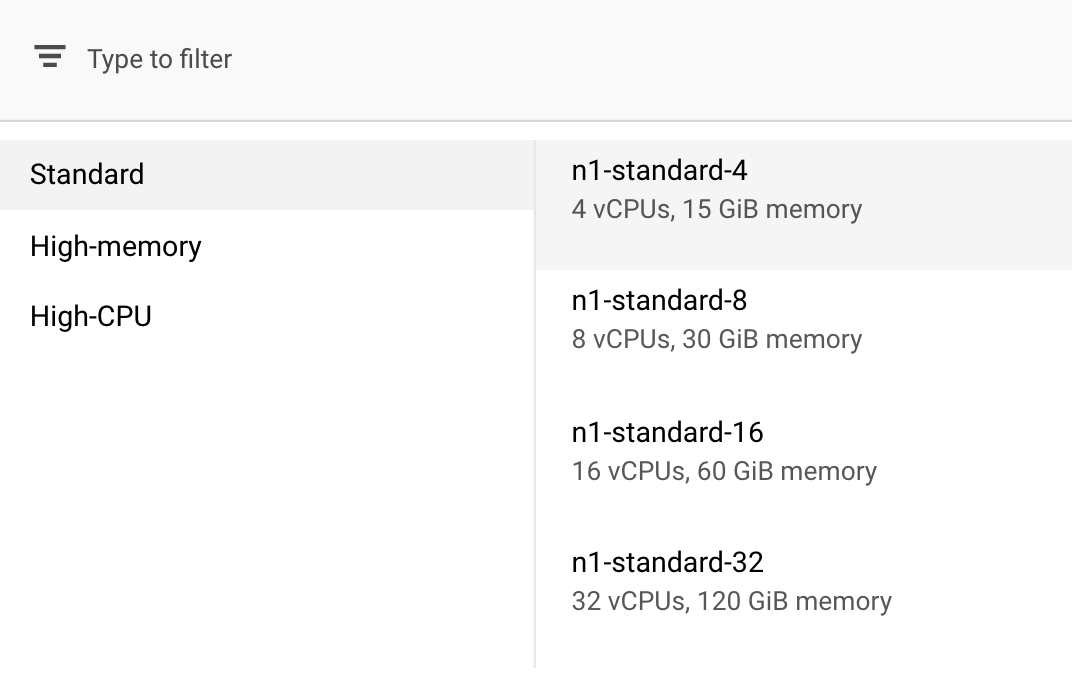
Karena model dalam demo ini berlatih dengan cepat, kita menggunakan jenis mesin yang lebih kecil.
Di bawah langkah Container prediksi, pilih Tidak ada container prediksi:
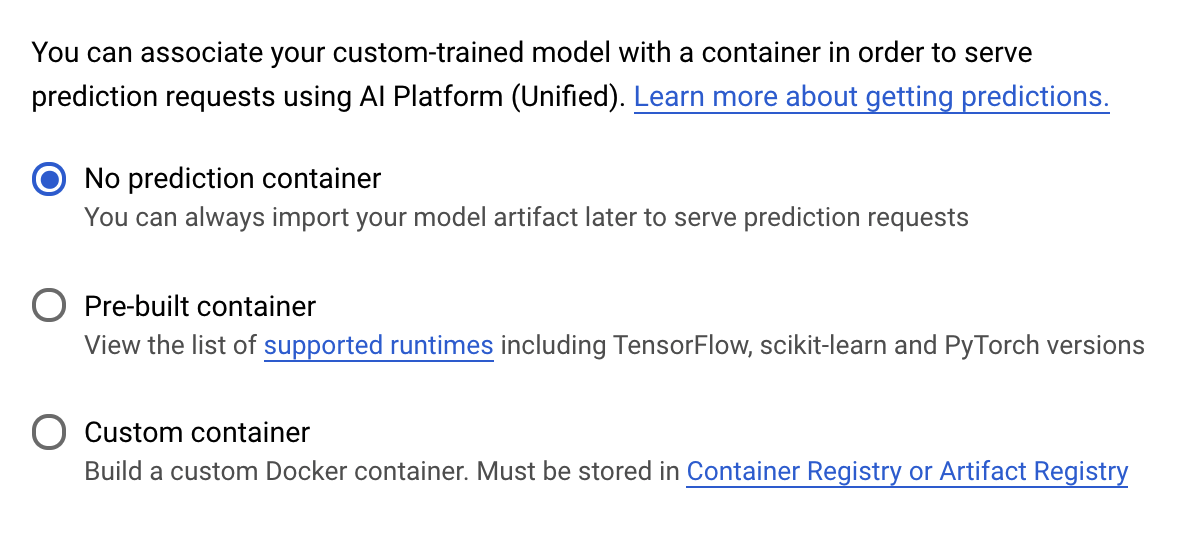
6. Men-deploy endpoint model
Pada langkah ini, kita akan membuat endpoint untuk model yang telah dilatih. Kita dapat menggunakan ini untuk mendapatkan prediksi pada model melalui Vertex AI API. Untuk melakukannya, kami telah menyediakan versi aset model terlatih yang diekspor dan tersedia di bucket GCS publik.
Dalam suatu organisasi, biasanya ada satu tim atau individu yang bertanggung jawab untuk membangun model, dan tim lain yang bertanggung jawab untuk men-deploy model tersebut. Langkah-langkah yang akan kita lakukan di sini akan menunjukkan kepada Anda cara mengambil model yang telah dilatih dan men-deploy-nya untuk prediksi.
Di sini, kita akan menggunakan Vertex AI SDK untuk membuat model, men-deploy-nya ke endpoint, dan mendapatkan prediksi.
Langkah 1: Instal Vertex SDK
Dari terminal Cloud Shell Anda, jalankan perintah berikut untuk menginstal Vertex AI SDK:
pip3 install google-cloud-aiplatform --upgrade --user
Kita dapat menggunakan SDK ini untuk berinteraksi dengan berbagai bagian Vertex.
Langkah 2: Buat model dan deploy endpoint
Berikutnya, kita akan membuat file Python dan menggunakan SDK untuk membuat resource model serta men-deploy-nya ke endpoint. Dari Editor file di Cloud Shell, pilih File lalu File Baru:
Beri nama file deploy.py. Buka file ini di editor Anda dan salin kode berikut:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Selanjutnya, kembali ke Terminal di Cloud Shell, cd kembali ke direktori root Anda, lalu jalankan skrip Python ini yang baru saja Anda buat:
cd ..
python3 deploy.py | tee deploy-output.txt
Anda akan melihat update yang dicatat ke terminal Anda saat resource sedang dibuat. Proses ini akan membutuhkan waktu 10-15 menit. Untuk memastikannya berfungsi dengan benar, buka bagian Model pada konsol Anda di Vertex AI:
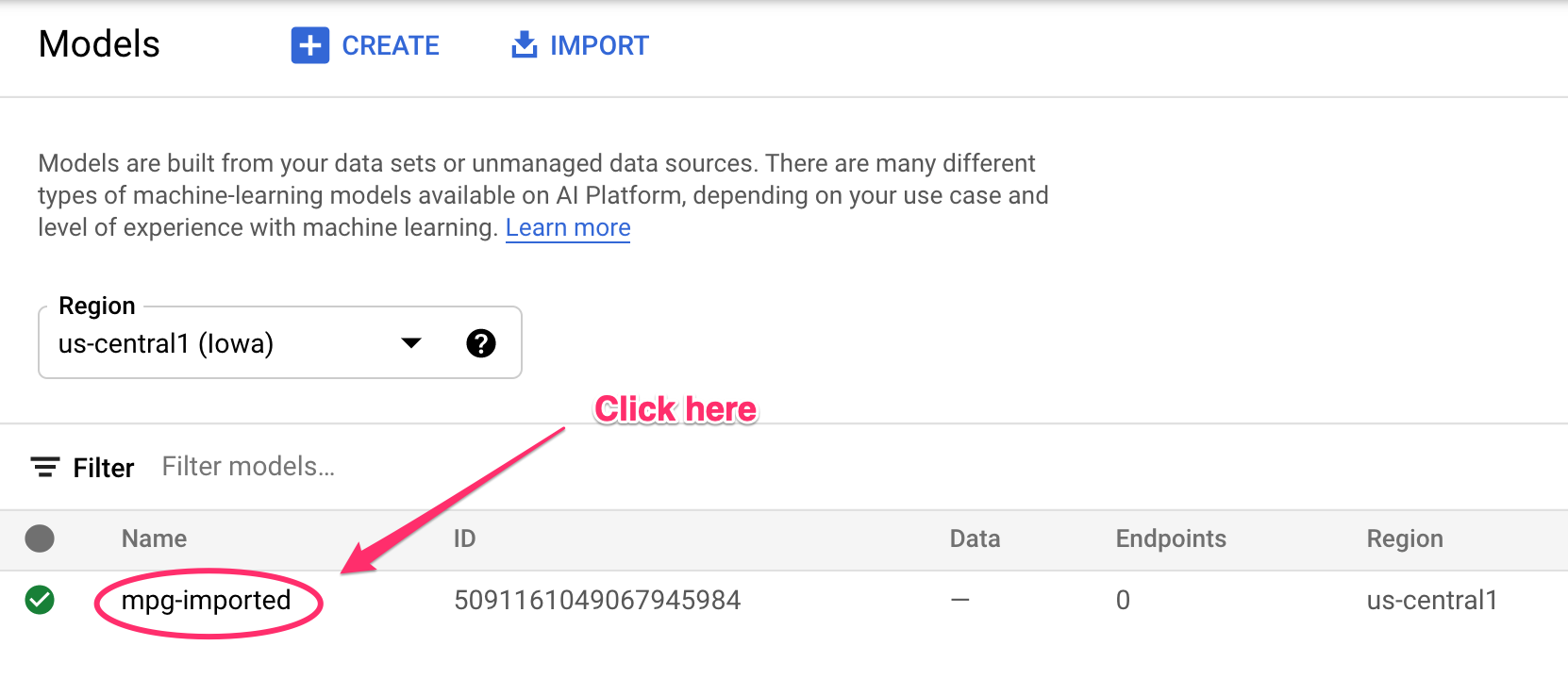
Klik mgp-imported dan Anda akan melihat endpoint untuk model tersebut yang sedang dibuat:
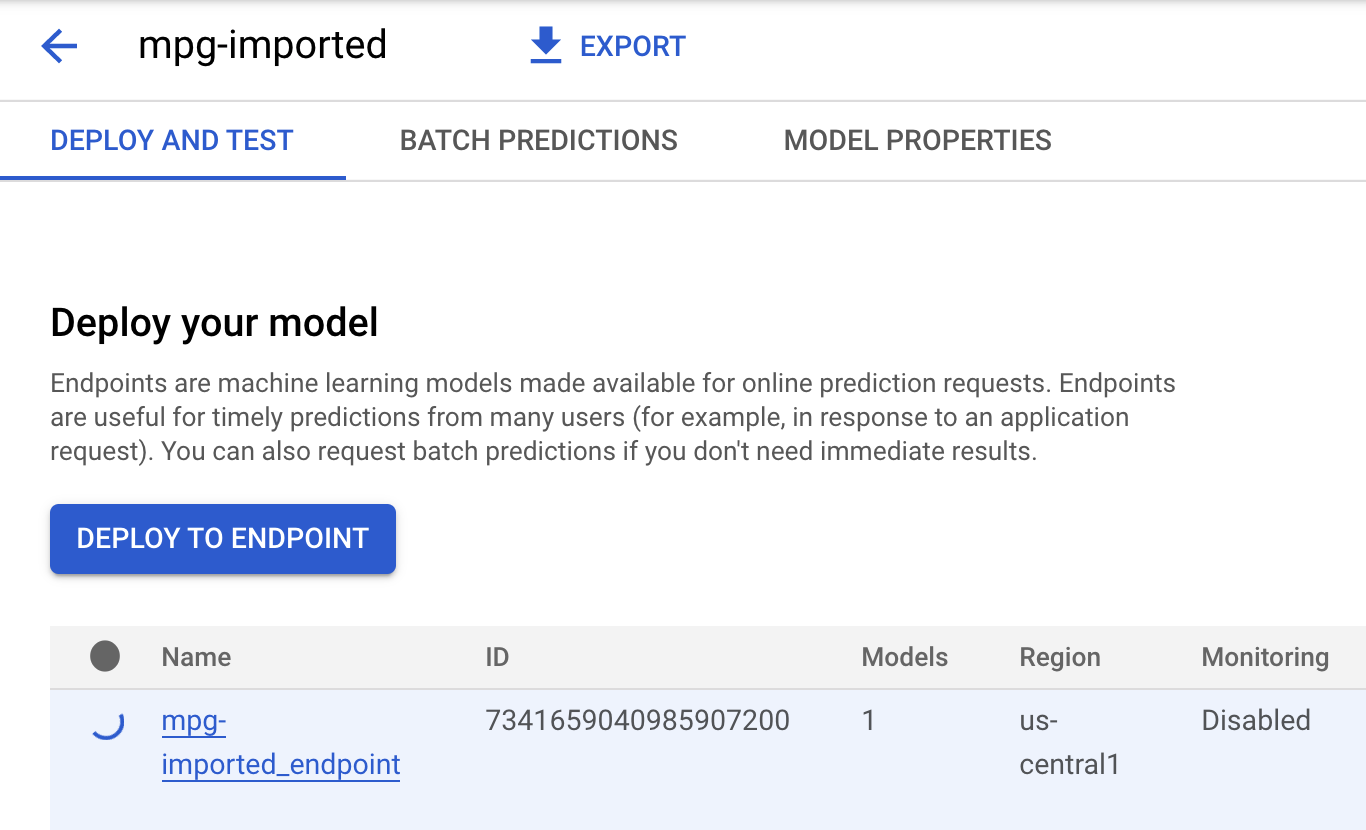
Di Terminal Cloud Shell, Anda akan melihat log berikut saat deployment endpoint selesai:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
Anda akan menggunakannya di langkah berikutnya untuk mendapatkan prediksi tentang endopint yang telah di-deploy.
Langkah 3: Dapatkan prediksi di endpoint yang di-deploy
Di editor Cloud Shell, buat file baru bernama predict.py:
Buka predict.py dan tempelkan kode berikut ke dalamnya:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Selanjutnya, kembali ke Terminal Anda dan masukkan kode berikut untuk mengganti ENDPOINT_STRING dalam file prediksi dengan endpoint Anda sendiri:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Sekarang saatnya menjalankan file predict.py untuk mendapatkan prediksi dari endpoint model yang telah di-deploy:
python3 predict.py
Anda akan melihat respons API dicatat, beserta prediksi efisiensi bahan bakar untuk prediksi pengujian kita.
🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI untuk:
- Latih model dengan menyediakan kode pelatihan dalam container kustom. Anda telah menggunakan model TensorFlow dalam contoh ini, tetapi Anda dapat melatih model yang dibangun dengan framework apa pun menggunakan container kustom.
- Deploy model TensorFlow menggunakan container yang telah dibangun sebelumnya sebagai bagian dari alur kerja yang sama yang Anda gunakan untuk pelatihan.
- Membuat endpoint model dan menghasilkan prediksi.
Untuk mempelajari lebih lanjut berbagai bagian Vertex AI, lihat dokumentasinya. Jika ingin melihat hasil tugas pelatihan yang Anda mulai pada Langkah 5, buka bagian pelatihan di konsol Vertex.
7. Pembersihan
Untuk menghapus endpoint yang di-deploy, buka bagian Endpoint di konsol Vertex dan klik ikon hapus:

Untuk menghapus Bucket Penyimpanan menggunakan menu Navigasi di Cloud Console, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus: