
১. সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি ফিনান্সিয়াল ডেটার উপর প্রশিক্ষিত এবং ক্লাউড এআই প্ল্যাটফর্মে ডেপ্লয় করা একটি XGBoost মডেল বিশ্লেষণ করতে What-if Tool ব্যবহার করবেন।
আপনি যা শিখবেন
আপনি শিখবেন কীভাবে:
- এআই প্ল্যাটফর্ম নোটবুকস-এ একটি পাবলিক মর্টগেজ ডেটাসেটের উপর একটি XGBoost মডেলকে প্রশিক্ষণ দিন
- এআই প্ল্যাটফর্মে XGBoost মডেলটি স্থাপন করুন
- What-if Tool ব্যবহার করে মডেলটি বিশ্লেষণ করুন।
গুগল ক্লাউডে এই ল্যাবটি চালানোর মোট খরচ প্রায় ১ ডলার ।
২. XGBoost-এর একটি সংক্ষিপ্ত পরিচিতি
XGBoost হলো একটি মেশিন লার্নিং ফ্রেমওয়ার্ক যা ভবিষ্যদ্বাণীমূলক মডেল তৈরি করতে ডিসিশন ট্রি এবং গ্রেডিয়েন্ট বুস্টিং ব্যবহার করে। এটি একটি ট্রির বিভিন্ন লিফ নোডের সাথে যুক্ত স্কোরের উপর ভিত্তি করে একাধিক ডিসিশন ট্রিকে একত্রিত করে কাজ করে।
নিচের ডায়াগ্রামটি একটি সাধারণ ডিসিশন ট্রি মডেলের চিত্রায়ন , যা আবহাওয়ার পূর্বাভাসের উপর ভিত্তি করে কোনো ক্রীড়া প্রতিযোগিতা অনুষ্ঠিত হওয়া উচিত কিনা তা মূল্যায়ন করে:

আমরা এই মডেলের জন্য XGBoost কেন ব্যবহার করছি? যদিও প্রচলিত নিউরাল নেটওয়ার্কগুলো ছবি এবং টেক্সটের মতো অসংগঠিত ডেটার উপর সবচেয়ে ভালো কাজ করে বলে দেখা গেছে, ডিসিশন ট্রি প্রায়শই মর্টগেজ ডেটাসেটের মতো সংগঠিত ডেটার উপর অত্যন্ত ভালো পারফর্ম করে, যা আমরা এই কোডল্যাবে ব্যবহার করব।
৩. আপনার পরিবেশ প্রস্তুত করুন
এই কোডল্যাবটি চালানোর জন্য আপনার বিলিং চালু করা একটি গুগল ক্লাউড প্ল্যাটফর্ম প্রজেক্ট প্রয়োজন হবে। প্রজেক্ট তৈরি করতে, এখানের নির্দেশাবলী অনুসরণ করুন।
ধাপ ১: ক্লাউড এআই প্ল্যাটফর্ম মডেলস এপিআই সক্রিয় করুন
আপনার ক্লাউড কনসোলের AI প্ল্যাটফর্ম মডেল বিভাগে যান এবং যদি এটি আগে থেকে সক্রিয় না থাকে তবে 'সক্রিয় করুন' (Enable) বোতামে ক্লিক করুন।
ধাপ ২: কম্পিউট ইঞ্জিন এপিআই সক্রিয় করুন
Compute Engine- এ যান এবং যদি আগে থেকে সক্রিয় করা না থাকে তবে 'Enable' নির্বাচন করুন। আপনার নোটবুক ইনস্ট্যান্স তৈরি করার জন্য এটি প্রয়োজন হবে।
ধাপ ৩: একটি এআই প্ল্যাটফর্ম নোটবুক ইনস্ট্যান্স তৈরি করুন
আপনার ক্লাউড কনসোলের এআই প্ল্যাটফর্ম নোটবুকস বিভাগে যান এবং নিউ ইনস্ট্যান্স-এ ক্লিক করুন। তারপর জিপিইউ ছাড়া সর্বশেষ টিএফ এন্টারপ্রাইজ ২.এক্স ইনস্ট্যান্স টাইপটি নির্বাচন করুন:

ডিফল্ট অপশনগুলো ব্যবহার করুন এবং তারপর 'Create'-এ ক্লিক করুন। ইনস্ট্যান্সটি তৈরি হয়ে গেলে, 'Open JupyterLab' নির্বাচন করুন:

ধাপ ৪: XGBoost ইনস্টল করুন
আপনার JupyterLab ইনস্ট্যান্সটি চালু হয়ে গেলে, আপনাকে XGBoost প্যাকেজটি যোগ করতে হবে।
এটি করার জন্য, লঞ্চার থেকে টার্মিনাল নির্বাচন করুন:

এরপর ক্লাউড এআই প্ল্যাটফর্ম দ্বারা সমর্থিত XGBoost-এর সর্বশেষ সংস্করণ ইনস্টল করতে নিম্নলিখিতটি চালান:
pip3 install xgboost==0.90
এটি সম্পন্ন হলে, লঞ্চার থেকে একটি পাইথন ৩ নোটবুক ইনস্ট্যান্স খুলুন। আপনি আপনার নোটবুকে কাজ শুরু করার জন্য প্রস্তুত!
ধাপ ৫: পাইথন প্যাকেজগুলো ইম্পোর্ট করুন
আপনার নোটবুকের প্রথম সেলে, নিম্নলিখিত ইম্পোর্টগুলো যোগ করুন এবং সেলটি রান করুন। আপনি উপরের মেনুতে থাকা ডান তীর বোতামটি চেপে অথবা কমান্ড-এন্টার চেপে এটি রান করতে পারেন:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
৪. ডেটা ডাউনলোড এবং প্রক্রিয়াকরণ করুন
আমরা একটি XGBoost মডেলকে প্রশিক্ষণ দেওয়ার জন্য ffiec.gov থেকে একটি মর্টগেজ ডেটাসেট ব্যবহার করব। আমরা মূল ডেটাসেটটির উপর কিছু প্রিপ্রসেসিং করেছি এবং মডেলটিকে প্রশিক্ষণ দেওয়ার জন্য আপনার ব্যবহারের সুবিধার্থে এর একটি ছোট সংস্করণ তৈরি করেছি। মডেলটি ভবিষ্যদ্বাণী করবে যে একটি নির্দিষ্ট মর্টগেজ আবেদন অনুমোদিত হবে কি না ।
ধাপ ১: প্রাক-প্রক্রিয়াজাত ডেটাসেটটি ডাউনলোড করুন।
আমরা ডেটাসেটটির একটি সংস্করণ আপনার জন্য গুগল ক্লাউড স্টোরেজে উপলব্ধ করেছি। আপনি আপনার জুপিটার নোটবুকে নিম্নলিখিত gsutil কমান্ডটি চালিয়ে এটি ডাউনলোড করতে পারেন:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
ধাপ ২: Pandas দিয়ে ডেটাসেটটি পড়ুন
আমাদের Pandas DataFrame তৈরি করার আগে, আমরা প্রতিটি কলামের ডেটা টাইপের একটি ডিক্ট তৈরি করব, যাতে Pandas আমাদের ডেটাসেটটি সঠিকভাবে পড়তে পারে:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
এরপর আমরা উপরে উল্লেখিত ডেটা টাইপগুলো পাস করে একটি ডেটাফ্রেম তৈরি করব। আমাদের ডেটা শাফেল করা জরুরি, কারণ মূল ডেটাসেটটি একটি নির্দিষ্ট ক্রমে সাজানো থাকতে পারে। এই কাজটি করার জন্য আমরা ' shuffle নামক একটি sklearn ইউটিলিটি ব্যবহার করি, যেটি আমরা প্রথম সেলে ইম্পোর্ট করেছিলাম:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
Pandas-এ data.head() ব্যবহার করে আমরা আমাদের ডেটাসেটের প্রথম পাঁচটি সারি প্রিভিউ করতে পারি। উপরের সেলটি রান করার পর আপনি এইরকম কিছু দেখতে পাবেন:

এই বৈশিষ্ট্যগুলোই আমরা আমাদের মডেলকে প্রশিক্ষণ দিতে ব্যবহার করব। আপনি যদি একদম শেষে স্ক্রল করেন, তাহলে শেষ কলাম approved দেখতে পাবেন, যা আমরা ভবিষ্যদ্বাণী করছি। 1 মানটি নির্দেশ করে যে একটি নির্দিষ্ট আবেদন অনুমোদিত হয়েছে, এবং 0 মানটি নির্দেশ করে যে এটি প্রত্যাখ্যাত হয়েছে।
ডেটা সেটে অনুমোদিত / প্রত্যাখ্যাত মানগুলির বিন্যাস দেখতে এবং লেবেলগুলির একটি নাম্পাই অ্যারে তৈরি করতে, নিম্নলিখিতটি চালান:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
ডেটাসেটের প্রায় ৬৬% অনুমোদিত আবেদনপত্র নিয়ে গঠিত।
ধাপ ৩: ক্যাটাগরিক্যাল ভ্যালুগুলোর জন্য ডামি কলাম তৈরি করা
এই ডেটাসেটে ক্যাটাগরিক্যাল এবং নিউমেরিক্যাল মানের মিশ্রণ রয়েছে, কিন্তু XGBoost-এর জন্য সমস্ত ফিচার নিউমেরিক্যাল হতে হয়। ওয়ান-হট এনকোডিং ব্যবহার করে ক্যাটাগরিক্যাল মানগুলো উপস্থাপন করার পরিবর্তে, আমাদের XGBoost মডেলের জন্য আমরা Pandas-এর get_dummies ফাংশনটি ব্যবহার করব।
get_dummies একাধিক সম্ভাব্য মান সহ একটি কলামকে এমন একাধিক কলামে রূপান্তরিত করে, যার প্রতিটিতে কেবল ০ এবং ১ থাকবে। উদাহরণস্বরূপ, যদি আমাদের "color" নামে একটি কলাম থাকে যার সম্ভাব্য মান "blue" এবং "red", তাহলে get_dummies এটিকে "color_blue" এবং "color_red" নামে দুটি কলামে রূপান্তরিত করবে, যেগুলোর সব মান হবে বুলিয়ান ০ এবং ১।
আমাদের ক্যাটাগরিক্যাল ফিচারগুলোর জন্য ডামি কলাম তৈরি করতে, নিম্নলিখিত কোডটি চালান:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
এবার ডেটা প্রিভিউ করার সময়, আপনি দেখবেন যে একক ফিচারগুলো (যেমন নিচে দেখানো purchaser_type ) একাধিক কলামে বিভক্ত হয়ে আছে:

ধাপ ৪: ডেটাকে ট্রেন এবং টেস্ট সেটে বিভক্ত করা
মেশিন লার্নিং-এর একটি গুরুত্বপূর্ণ ধারণা হলো ট্রেন/টেস্ট স্প্লিট। আমরা আমাদের ডেটার বেশিরভাগ অংশ মডেলকে প্রশিক্ষণ দিতে ব্যবহার করব এবং বাকি অংশ এমন ডেটার উপর মডেল পরীক্ষা করার জন্য আলাদা করে রাখব যা এটি আগে কখনও দেখেনি।
আপনার নোটবুকে নিম্নলিখিত কোডটি যোগ করুন, যা আমাদের ডেটা বিভক্ত করতে Scikit Learn-এর train_test_split ফাংশনটি ব্যবহার করে:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
এখন আপনি আপনার মডেল তৈরি ও প্রশিক্ষণ দেওয়ার জন্য প্রস্তুত!
৫. একটি XGBoost মডেল তৈরি, প্রশিক্ষণ এবং মূল্যায়ন করুন।
ধাপ ১: XGBoost মডেলটি সংজ্ঞায়িত ও প্রশিক্ষণ দিন
XGBoost-এ একটি মডেল তৈরি করা সহজ। আমরা মডেলটি তৈরি করতে XGBClassifier ক্লাসটি ব্যবহার করব এবং আমাদের নির্দিষ্ট ক্লাসিফিকেশন টাস্কের জন্য শুধু সঠিক objective প্যারামিটারটি পাস করতে হবে। এই ক্ষেত্রে আমরা reg:logistic ব্যবহার করছি, কারণ আমাদের একটি বাইনারি ক্লাসিফিকেশন সমস্যা রয়েছে এবং আমরা চাই মডেলটি (0,1) রেঞ্জের মধ্যে একটি একক মান আউটপুট করুক: 0 অনুমোদিত নয় এবং 1 অনুমোদিত।
নিম্নলিখিত কোডটি একটি XGBoost মডেল তৈরি করবে:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
আপনি fit() মেথডটি কল করে এবং ট্রেনিং ডেটা ও লেবেলগুলো পাস করে এক লাইনের কোডেই মডেলটিকে প্রশিক্ষণ দিতে পারেন।
model.fit(x_train, y_train)
ধাপ ২: আপনার মডেলের নির্ভুলতা মূল্যায়ন করুন।
এখন আমরা আমাদের প্রশিক্ষিত মডেলটি ব্যবহার করে predict() ফাংশনের সাহায্যে টেস্ট ডেটার উপর প্রেডিকশন তৈরি করতে পারি।
এরপর আমরা আমাদের টেস্ট ডেটার উপর মডেলটির পারফরম্যান্সের উপর ভিত্তি করে এর নির্ভুলতা গণনা করতে Scikit Learn-এর accuracy_score ফাংশনটি ব্যবহার করব। আমরা আমাদের টেস্ট সেটের প্রতিটি উদাহরণের জন্য মডেলের পূর্বাভাসিত মানগুলোর সাথে গ্রাউন্ড ট্রুথ মানগুলোও এতে পাস করব:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
আপনার নির্ভুলতা প্রায় ৮৭% হওয়া উচিত, কিন্তু আপনার ক্ষেত্রে এটি কিছুটা ভিন্ন হতে পারে, কারণ মেশিন লার্নিং-এ সবসময়ই কিছুটা দৈবচয়নের ব্যাপার থাকে।
ধাপ ৩: আপনার মডেলটি সংরক্ষণ করুন।
মডেলটি ডেপ্লয় করার জন্য, এটিকে একটি লোকাল ফাইলে সেভ করতে নিম্নলিখিত কোডটি রান করুন:
model.save_model('model.bst')
৬. ক্লাউড এআই প্ল্যাটফর্মে মডেলটি স্থাপন করুন
আমরা আমাদের মডেলটি স্থানীয়ভাবে চালু করতে পেরেছি, কিন্তু যেকোনো জায়গা থেকে (শুধু এই নোটবুক থেকে নয়!) এর ওপর ভিত্তি করে পূর্বাভাস দেওয়া গেলে ভালো হতো। এই ধাপে আমরা এটিকে ক্লাউডে ডেপ্লয় করব।
ধাপ ১: আমাদের মডেলের জন্য একটি ক্লাউড স্টোরেজ বাকেট তৈরি করুন।
চলুন প্রথমে কিছু এনভায়রনমেন্ট ভেরিয়েবল নির্ধারণ করে নিই, যেগুলো আমরা এই কোডল্যাবের বাকি অংশে ব্যবহার করব। নিচের ভ্যালুগুলোতে আপনার গুগল ক্লাউড প্রজেক্টের নাম, আপনি যে ক্লাউড স্টোরেজ বাকেটটি তৈরি করতে চান তার নাম (যা অবশ্যই গ্লোবালি ইউনিক হতে হবে), এবং আপনার মডেলের প্রথম ভার্সনের ভার্সন নেম পূরণ করুন:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
এখন আমরা আমাদের XGBoost মডেল ফাইলটি সংরক্ষণের জন্য একটি স্টোরেজ বাকেট তৈরি করতে প্রস্তুত। ডিপ্লয় করার সময় আমরা ক্লাউড এআই প্ল্যাটফর্মকে এই ফাইলটির দিকে নির্দেশ করব।
একটি বাকেট তৈরি করতে আপনার নোটবুকের ভেতর থেকে এই gsutil কমান্ডটি চালান:
!gsutil mb $MODEL_BUCKET
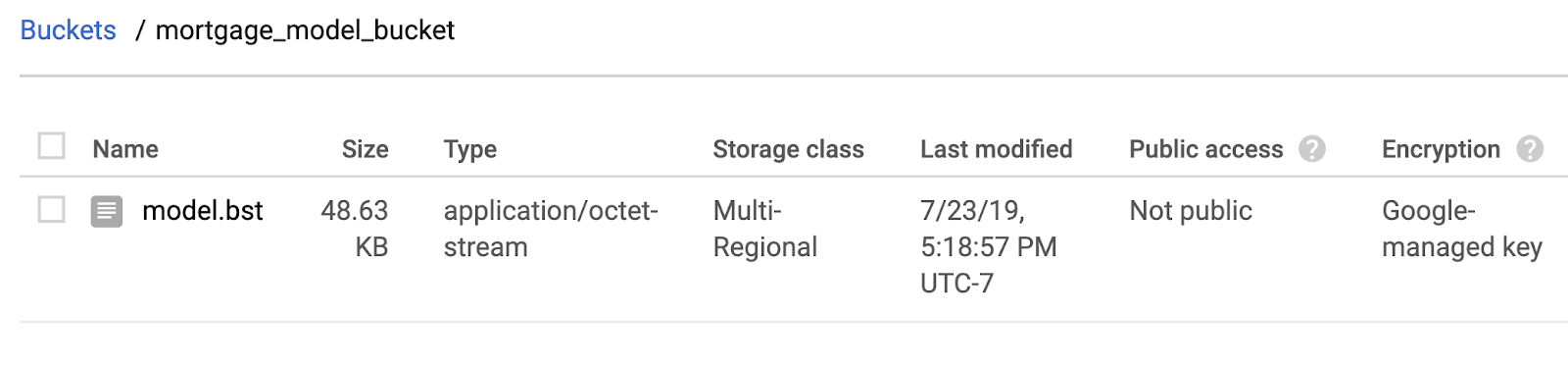
ধাপ ২: মডেল ফাইলটি ক্লাউড স্টোরেজে কপি করুন।
এরপর, আমরা আমাদের XGBoost-এ সেভ করা মডেল ফাইলটি ক্লাউড স্টোরেজে কপি করব। নিচের gsutil কমান্ডটি চালান:
!gsutil cp ./model.bst $MODEL_BUCKET
ফাইলটি কপি হয়েছে কিনা তা নিশ্চিত করতে আপনার ক্লাউড কনসোলের স্টোরেজ ব্রাউজারে যান:
ধাপ ৩: মডেলটি তৈরি এবং স্থাপন করুন
আমরা মডেলটি ডেপ্লয় করার জন্য প্রায় প্রস্তুত! নিচের ai-platform gcloud কমান্ডটি আপনার প্রোজেক্টে একটি নতুন মডেল তৈরি করবে। আমরা এটির নাম দেব xgb_mortgage :
!gcloud ai-platform models create $MODEL_NAME --region='global'
এখন মডেলটি ডেপ্লয় করার সময়। আমরা এই gcloud কমান্ডটি দিয়ে তা করতে পারি:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
এটি চলার সময়, আপনার এআই প্ল্যাটফর্ম কনসোলের মডেল বিভাগটি দেখুন। সেখানে আপনার নতুন সংস্করণটি ডেপ্লয় হতে দেখবেন:

ডিপ্লয় সফলভাবে সম্পন্ন হলে, লোডিং স্পিনারের জায়গায় আপনি একটি সবুজ টিক চিহ্ন দেখতে পাবেন। ডিপ্লয় হতে ২-৩ মিনিট সময় লাগতে পারে।
ধাপ ৪: স্থাপন করা মডেলটি পরীক্ষা করুন
আপনার ডেপ্লয় করা মডেলটি ঠিকমতো কাজ করছে কিনা তা নিশ্চিত করতে, gcloud ব্যবহার করে একটি প্রেডিকশন করে এটি পরীক্ষা করুন। প্রথমে, আমাদের টেস্ট সেটের প্রথম উদাহরণটি দিয়ে একটি JSON ফাইল সেভ করুন:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
এই কোডটি চালিয়ে আপনার মডেলটি পরীক্ষা করুন:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
আউটপুটে আপনি আপনার মডেলের পূর্বাভাস দেখতে পাবেন। এই নির্দিষ্ট উদাহরণটি অনুমোদিত হয়েছে, তাই আপনি ১-এর কাছাকাছি একটি মান দেখতে পাবেন।
৭. আপনার মডেলটি ব্যাখ্যা করতে ‘হোয়াট-ইফ টুল’ ব্যবহার করুন।
ধাপ ১: হোয়াট-ইফ টুল ভিজ্যুয়ালাইজেশন তৈরি করুন
আপনার এআই প্ল্যাটফর্ম মডেলগুলোর সাথে হোয়াট-ইফ টুলটি সংযোগ করতে, আপনাকে আপনার টেস্ট উদাহরণগুলোর একটি উপসেট এবং সেই উদাহরণগুলোর গ্রাউন্ড ট্রুথ ভ্যালুগুলো এতে পাস করতে হবে। চলুন, আমাদের ৫০০টি টেস্ট উদাহরণ এবং তাদের গ্রাউন্ড ট্রুথ লেবেলগুলো দিয়ে একটি নাম্পাই অ্যারে তৈরি করি:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
একটি WitConfigBuilder অবজেক্ট তৈরি করে এবং আমরা যে এআই প্ল্যাটফর্ম মডেলটি বিশ্লেষণ করতে চাই তা পাস করার মাধ্যমেই হোয়াট-ইফ টুলটি ইনস্ট্যানশিয়েট করা যায়।
আমরা এখানে ঐচ্ছিক adjust_prediction প্যারামিটারটি ব্যবহার করি, কারণ What-if টুলটি আমাদের মডেলের প্রতিটি ক্লাসের (এই ক্ষেত্রে ২টি) জন্য স্কোরের একটি তালিকা আশা করে। যেহেতু আমাদের মডেলটি শুধুমাত্র ০ থেকে ১ এর মধ্যে একটি একক মান রিটার্ন করে, তাই আমরা এই ফাংশনে এটিকে সঠিক ফরম্যাটে রূপান্তর করি:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
মনে রাখবেন, ভিজ্যুয়ালাইজেশনটি লোড হতে এক মিনিট সময় লাগবে। লোড হয়ে গেলে, আপনি নিম্নলিখিতটি দেখতে পাবেন:

y-অক্ষটি আমাদের মডেলের পূর্বাভাস দেখায়, যেখানে 1 হলো একটি উচ্চ আত্মবিশ্বাসের approved পূর্বাভাস এবং 0 হলো একটি উচ্চ আত্মবিশ্বাসের denied পূর্বাভাস। x-অক্ষটি হলো লোড করা সমস্ত ডেটা পয়েন্টের বিস্তার।
ধাপ ২: স্বতন্ত্র ডেটা পয়েন্টগুলো অন্বেষণ করুন
হোয়াট-ইফ টুলের ডিফল্ট ভিউ হলো ডেটাপয়েন্ট এডিটর ট্যাব। এখানে আপনি যেকোনো ডেটা পয়েন্টে ক্লিক করে তার ফিচারগুলো দেখতে, ফিচারের মান পরিবর্তন করতে এবং সেই পরিবর্তনটি একটি নির্দিষ্ট ডেটা পয়েন্টের ওপর মডেলের প্রেডিকশনকে কীভাবে প্রভাবিত করে, তা দেখতে পারেন।
নীচের উদাহরণে আমরা .5 থ্রেশহোল্ডের কাছাকাছি একটি ডেটা পয়েন্ট বেছে নিয়েছি। এই নির্দিষ্ট ডেটা পয়েন্টের সাথে যুক্ত মর্টগেজ আবেদনটি CFPB থেকে এসেছিল। আমরা সেই ফিচারটিকে 0-তে পরিবর্তন করেছি এবং agency_code_Department of Housing and Urban Development (HUD) এর মানও 1-এ পরিবর্তন করেছি, এটা দেখার জন্য যে এই ঋণটি যদি HUD থেকে আসত তাহলে মডেলের পূর্বাভাসের কী হতো:
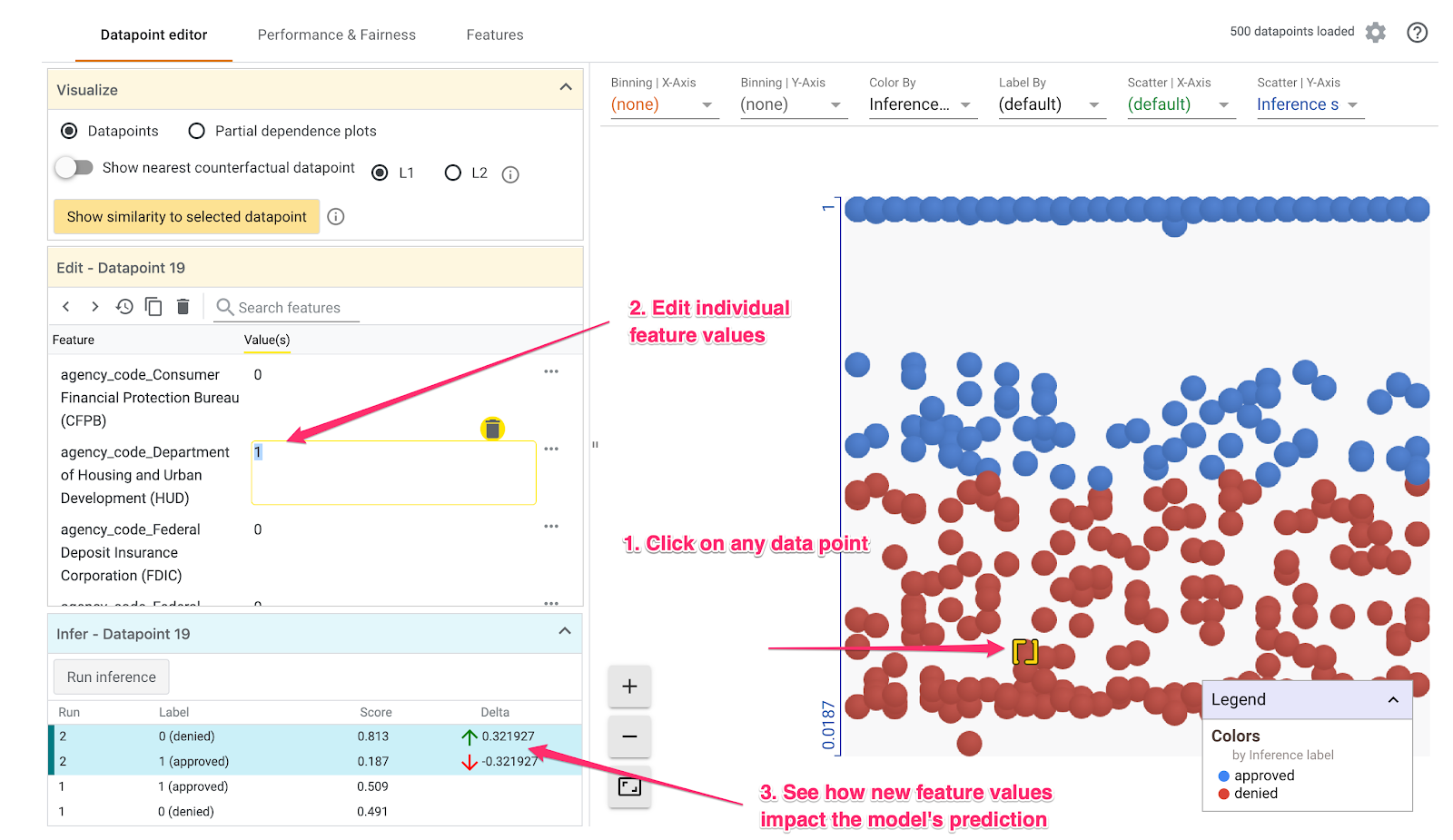
হোয়াট-ইফ টুলের নিচের বাম দিকের অংশে যেমনটা দেখা যাচ্ছে, এই ফিচারটি পরিবর্তন করার ফলে মডেলের approved পূর্বাভাস ৩২% উল্লেখযোগ্যভাবে কমে গেছে। এটি থেকে বোঝা যেতে পারে যে, ঋণটি যে সংস্থা থেকে এসেছে, তা মডেলের আউটপুটের উপর একটি শক্তিশালী প্রভাব ফেলে, কিন্তু নিশ্চিত হওয়ার জন্য আমাদের আরও বিশ্লেষণ করতে হবে।
UI-এর নিচের বাম অংশে, আমরা প্রতিটি ডেটা পয়েন্টের প্রকৃত মানও দেখতে পারি এবং সেটিকে মডেলের পূর্বাভাসের সাথে তুলনা করতে পারি:

ধাপ ৩: প্রতিবাস্তব বিশ্লেষণ
এরপর, যেকোনো ডেটাপয়েন্টে ক্লিক করুন এবং 'Show nearest counterfactual datapoint' স্লাইডারটি ডানদিকে সরান:

এটি নির্বাচন করলে আপনাকে সেই ডেটা পয়েন্টটি দেখানো হবে, যার ফিচার ভ্যালুগুলো আপনার নির্বাচিত মূল ডেটা পয়েন্টটির সাথে সবচেয়ে বেশি সাদৃশ্যপূর্ণ , কিন্তু প্রেডিকশনটি বিপরীত। এরপর আপনি ফিচার ভ্যালুগুলো স্ক্রল করে দেখতে পারবেন ডেটা পয়েন্ট দুটির মধ্যে পার্থক্যগুলো কোথায় ছিল (পার্থক্যগুলো সবুজ এবং বোল্ড অক্ষরে হাইলাইট করা থাকে)।
ধাপ ৪: আংশিক নির্ভরশীলতার প্লটগুলো দেখুন
প্রতিটি ফিচার মডেলের প্রেডিকশনকে সামগ্রিকভাবে কীভাবে প্রভাবিত করে তা দেখতে, 'Partial dependence plots' বক্সটি চেক করুন এবং নিশ্চিত করুন যে 'Global partial dependence plots' সিলেক্ট করা আছে:

এখানে আমরা দেখতে পাচ্ছি যে, HUD থেকে আসা ঋণ প্রত্যাখ্যাত হওয়ার সম্ভাবনা কিছুটা বেশি। গ্রাফটির আকৃতি এমন, কারণ এজেন্সি কোড একটি বুলিয়ান বৈশিষ্ট্য, তাই এর মান কেবল ঠিক ০ বা ১ হতে পারে।
applicant_income_thousands হলো একটি সংখ্যাসূচক বৈশিষ্ট্য, এবং আংশিক নির্ভরশীলতার প্লটে আমরা দেখতে পাই যে উচ্চ আয় একটি আবেদন অনুমোদিত হওয়ার সম্ভাবনা সামান্য বাড়িয়ে দেয়, কিন্তু তা কেবল প্রায় $200k পর্যন্ত। $200k-এর পরে, এই বৈশিষ্ট্যটি মডেলের পূর্বাভাসকে প্রভাবিত করে না।
ধাপ ৫: সামগ্রিক কর্মক্ষমতা এবং ন্যায্যতা অন্বেষণ করুন
এরপর, পারফরম্যান্স ও ফেয়ারনেস ট্যাবে যান। এখানে প্রদত্ত ডেটাসেটের উপর মডেলের ফলাফলের সামগ্রিক পারফরম্যান্স পরিসংখ্যান দেখানো হয়, যার মধ্যে কনফিউশন ম্যাট্রিক্স, পিআর কার্ভ এবং আরওসি কার্ভ অন্তর্ভুক্ত থাকে।
কনফিউশন ম্যাট্রিক্স দেখতে, গ্রাউন্ড ট্রুথ ফিচার হিসেবে mortgage_status নির্বাচন করুন:

এই কনফিউশন ম্যাট্রিক্সটি আমাদের মডেলের সঠিক এবং ভুল ভবিষ্যদ্বাণীগুলোকে মোট সংখ্যার শতাংশ হিসাবে দেখায়। আপনি যদি ' প্রকৃত হ্যাঁ / ভবিষ্যদ্বাণীকৃত হ্যাঁ' এবং 'প্রকৃত না / ভবিষ্যদ্বাণীকৃত না'-এর বর্গগুলো যোগ করেন, তাহলে এর যোগফল আপনার মডেলের সমান (প্রায় ৮৭%) হওয়া উচিত।
আপনি থ্রেশহোল্ড স্লাইডারটি নিয়েও পরীক্ষা করতে পারেন। লোনটি approved বলে ভবিষ্যদ্বাণী করার আগে মডেলটির যে পজিটিভ ক্লাসিফিকেশন স্কোরটি প্রয়োজন, সেটি বাড়িয়ে বা কমিয়ে দেখতে পারেন যে এর ফলে অ্যাকুরেসি, ফলস পজিটিভ এবং ফলস নেগেটিভ কীভাবে পরিবর্তিত হয়। এক্ষেত্রে, .৫৫ -এর থ্রেশহোল্ডের কাছাকাছি অ্যাকুরেসি সর্বোচ্চ থাকে।
এরপর, বাম দিকের 'Slice by ' ড্রপডাউন থেকে loan_purpose_Home_purchase নির্বাচন করুন:
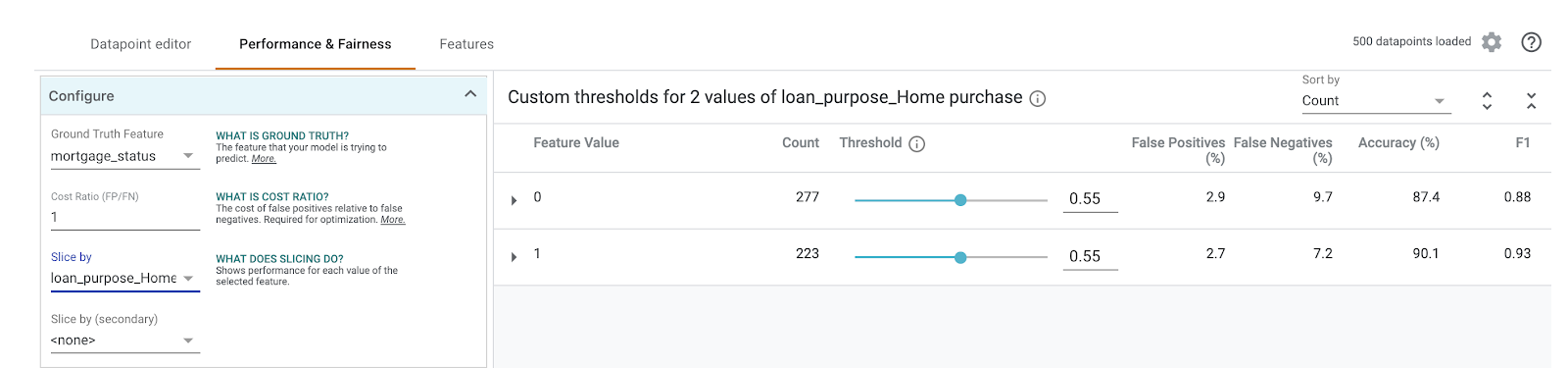
এখন আপনি আপনার ডেটার দুটি উপসেটের পারফরম্যান্স দেখতে পাবেন: "0" স্লাইসটি দেখায় যখন ঋণটি বাড়ি কেনার জন্য নয়, এবং "1" স্লাইসটি দেখায় যখন ঋণটি বাড়ি কেনার জন্য। পারফরম্যান্সের পার্থক্য খুঁজে বের করতে দুটি স্লাইসের মধ্যে অ্যাকুরেসি, ফলস পজিটিভ এবং ফলস নেগেটিভ রেট পরীক্ষা করে দেখুন।
আপনি যদি কনফিউশন ম্যাট্রিক্সগুলো দেখার জন্য সারিগুলো প্রসারিত করেন, তাহলে দেখতে পাবেন যে মডেলটি বাড়ি কেনার জন্য প্রায় ৭০% ঋণ আবেদনের ক্ষেত্রে এবং বাড়ি কেনা ছাড়া অন্য ঋণের ক্ষেত্রে মাত্র ৪৬%-এর জন্য "অনুমোদিত" পূর্বাভাস দেয় (আপনার মডেলের উপর নির্ভর করে সঠিক শতাংশ ভিন্ন হতে পারে):

আপনি যদি বাম দিকের রেডিও বাটনগুলো থেকে ‘ডেমোগ্রাফিক প্যারিটি’ নির্বাচন করেন, তাহলে দুটি থ্রেশহোল্ড এমনভাবে সমন্বয় করা হবে যাতে মডেলটি উভয় স্লাইসের প্রায় সমান শতাংশ আবেদনকারীর জন্য approved পূর্বাভাস দেয়। এর ফলে প্রতিটি স্লাইসের নির্ভুলতা, ফলস পজিটিভ এবং ফলস নেগেটিভের উপর কী প্রভাব পড়ে?
ধাপ ৬: বৈশিষ্ট্য বিতরণ অন্বেষণ করুন
অবশেষে, What-if টুলের Features ট্যাবে যান। এটি আপনাকে আপনার ডেটাসেটের প্রতিটি ফিচারের মানগুলোর বিন্যাস দেখাবে:

আপনার ডেটাসেটটি ভারসাম্যপূর্ণ কিনা তা নিশ্চিত করতে আপনি এই ট্যাবটি ব্যবহার করতে পারেন। উদাহরণস্বরূপ, দেখা যাচ্ছে যে ডেটাসেটের খুব কম সংখ্যক ঋণ ফার্ম সার্ভিস এজেন্সি থেকে এসেছে। মডেলের নির্ভুলতা উন্নত করার জন্য, ডেটা উপলব্ধ থাকলে আমরা সেই এজেন্সি থেকে আরও ঋণ যোগ করার কথা বিবেচনা করতে পারি।
আমরা এখানে What-if Tool নিয়ে অনুসন্ধানের কয়েকটি ধারণা বর্ণনা করেছি। আপনি নির্দ্বিধায় টুলটি নিয়ে আরও পরীক্ষা-নিরীক্ষা চালিয়ে যেতে পারেন, অন্বেষণের জন্য আরও অনেক ক্ষেত্র রয়েছে!
৮. পরিচ্ছন্নতা
আপনি যদি এই নোটবুকটি ব্যবহার করা চালিয়ে যেতে চান, তবে ব্যবহার না করার সময় এটি বন্ধ করে রাখার পরামর্শ দেওয়া হচ্ছে। আপনার ক্লাউড কনসোলের নোটবুকস UI থেকে, নোটবুকটি নির্বাচন করুন এবং তারপরে স্টপ (Stop ) নির্বাচন করুন।

আপনি যদি এই ল্যাবে তৈরি করা সমস্ত রিসোর্স মুছে ফেলতে চান, তাহলে নোটবুক ইনস্ট্যান্সটি বন্ধ করার পরিবর্তে সরাসরি ডিলিট করে দিন।
আপনার ক্লাউড কনসোলের নেভিগেশন মেনু ব্যবহার করে স্টোরেজ-এ যান এবং আপনার মডেল অ্যাসেটগুলো সংরক্ষণের জন্য তৈরি করা উভয় বাকেট মুছে ফেলুন।