
1. Panoramica
In questo lab utilizzerai lo strumento What-if per analizzare un modello XGBoost addestrato su dati finanziari e di cui è stato eseguito il deployment su Cloud AI Platform.
Cosa imparerai
Al termine del corso sarai in grado di:
- Addestra un modello XGBoost su un set di dati ipotecari pubblici in AI Platform Notebooks
- Esegui il deployment del modello XGBoost su AI Platform
- Analizza il modello utilizzando lo strumento What-If
Il costo totale per eseguire questo lab su Google Cloud è di circa 1$.
2. Una breve introduzione a XGBoost
XGBoost è un framework di machine learning che utilizza alberi decisionali e gradient boosting per creare modelli predittivi. Funziona combinando più alberi decisionali in base al punteggio associato a diversi nodi foglia di un albero.
Il diagramma seguente è una visualizzazione di un semplice modello di albero decisionale che valuta se una partita sportiva deve essere giocata in base alle previsioni meteo:

Perché utilizziamo XGBoost per questo modello? Sebbene le reti neurali tradizionali abbiano dimostrato di funzionare meglio con dati non strutturati come immagini e testo, gli alberi decisionali spesso funzionano molto bene con dati strutturati come il set di dati sui mutui che utilizzeremo in questo codelab.
3. Configura l'ambiente
Per eseguire questo codelab, devi avere un progetto Google Cloud Platform con la fatturazione abilitata. Per creare un progetto, segui le istruzioni riportate qui.
Passaggio 1: attiva l'API Cloud AI Platform Models
Vai alla sezione Modelli AI Platform della console Cloud e fai clic su Abilita se non è già abilitata.
Passaggio 2: abilita l'API Compute Engine
Vai a Compute Engine e seleziona Abilita se non è già abilitato. Ne avrai bisogno per creare la tua istanza di blocco note.
Passaggio 3: crea un'istanza di AI Platform Notebooks
Vai alla sezione AI Platform Notebooks della tua console Cloud e fai clic su Nuova istanza. Poi seleziona il tipo di istanza TF Enterprise 2.x più recente senza GPU:
Utilizza le opzioni predefinite e poi fai clic su Crea. Una volta creata l'istanza, seleziona Apri JupyterLab:

Passaggio 4: installa XGBoost
Una volta aperta l'istanza di JupyterLab, devi aggiungere il pacchetto XGBoost.
Per farlo, seleziona Terminale da Avvio app:
Poi esegui questo comando per installare l'ultima versione di XGBoost supportata da Cloud AI Platform:
pip3 install xgboost==0.90
Al termine, apri un'istanza di blocco note Python 3 dal launcher. Ora puoi iniziare a usare il tuo notebook.
Passaggio 5: importa i pacchetti Python
Nella prima cella del notebook, aggiungi le seguenti importazioni ed esegui la cella. Puoi eseguirlo premendo il pulsante Freccia destra nel menu in alto o premendo Comando-Invio:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. Scaricare ed elaborare i dati
Utilizzeremo un set di dati sui mutui di ffiec.gov per addestrare un modello XGBoost. Abbiamo eseguito un pre-elaborazione sul set di dati originale e creato una versione più piccola da utilizzare per addestrare il modello. Il modello prevede se una determinata richiesta di mutuo verrà approvata o meno.
Passaggio 1: scarica il set di dati pre-elaborato
Abbiamo reso disponibile una versione del set di dati in Google Cloud Storage. Puoi scaricarlo eseguendo il seguente comando gsutil nel blocco note Jupyter:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
Passaggio 2: leggi il set di dati con Pandas
Prima di creare il DataFrame Pandas, creiamo un dizionario del tipo di dati di ogni colonna in modo che Pandas legga correttamente il nostro set di dati:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
A questo punto, creeremo un DataFrame, passando i tipi di dati specificati sopra. È importante rimescolare i dati nel caso in cui il set di dati originale sia ordinato in un modo specifico. Per farlo, utilizziamo un'utilità sklearn chiamata shuffle, che abbiamo importato nella prima cella:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() ci consente di visualizzare l'anteprima delle prime cinque righe del nostro set di dati in Pandas. Dopo aver eseguito la cella precedente, dovresti visualizzare un risultato simile a questo:

Queste sono le funzionalità che utilizzeremo per addestrare il nostro modello. Se scorri fino alla fine, vedrai l'ultima colonna approved, che è ciò che stiamo prevedendo. Un valore pari a 1 indica che una determinata applicazione è stata approvata, mentre 0 indica che è stata rifiutata.
Per visualizzare la distribuzione dei valori approvati / rifiutati nel set di dati e creare un array numpy delle etichette, esegui il seguente comando:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Circa il 66% del set di dati contiene applicazioni approvate.
Passaggio 3: crea una colonna fittizia per i valori categorici
Questo set di dati contiene un mix di valori categorici e numerici, ma XGBoost richiede che tutte le funzionalità siano numeriche. Invece di rappresentare i valori categorici utilizzando la codifica one-hot, per il nostro modello XGBoost utilizzeremo la funzione get_dummies di Pandas.
get_dummies prende una colonna con più valori possibili e la converte in una serie di colonne ciascuna con solo 0 e 1. Ad esempio, se avessimo una colonna "colore" con i valori possibili "blu" e "rosso", get_dummies la trasformerebbe in due colonne chiamate "colore_blu" e "colore_rosso" con tutti i valori booleani 0 e 1.
Per creare colonne fittizie per le nostre funzionalità categoriche, esegui questo codice:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Quando visualizzi l'anteprima dei dati questa volta, vedrai le singole funzionalità (come purchaser_type nell'immagine sotto) suddivise in più colonne:

Passaggio 4: suddividi i dati in set di addestramento e test
Un concetto importante nel machine learning è la suddivisione in training e test. Prendiamo la maggior parte dei nostri dati e li utilizziamo per addestrare il modello, mentre mettiamo da parte il resto per testare il modello su dati mai visti prima.
Aggiungi il seguente codice al notebook, che utilizza la funzione Scikit-Learn train_test_split per dividere i dati:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Ora è tutto pronto per creare e addestrare il modello.
5. Crea, addestra e valuta un modello XGBoost
Passaggio 1: definisci e addestra il modello XGBoost
Creare un modello in XGBoost è semplice. Utilizzeremo la classe XGBClassifier per creare il modello e dovremo solo passare il parametro objective corretto per la nostra attività di classificazione specifica. In questo caso utilizziamo reg:logistic poiché abbiamo un problema di classificazione binaria e vogliamo che il modello restituisca un singolo valore nell'intervallo (0,1): 0 per non approvato e 1 per approvato.
Il seguente codice creerà un modello XGBoost:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
Puoi addestrare il modello con una riga di codice, chiamando il metodo fit() e passando i dati di addestramento e le etichette.
model.fit(x_train, y_train)
Passaggio 2: valuta l'accuratezza del modello
Ora possiamo utilizzare il modello addestrato per generare previsioni sui nostri dati di test con la funzione predict().
Poi utilizzeremo la funzione accuracy_score di Scikit Learn per calcolare l'accuratezza del modello in base alle sue prestazioni sui dati di test. Passeremo i valori basati su dati empirici reali insieme ai valori previsti del modello per ogni esempio nel nostro set di test:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Dovresti notare un'accuratezza di circa l'87%, ma la tua varierà leggermente poiché nel machine learning è sempre presente un elemento di casualità.
Passaggio 3: salva il modello
Per eseguire il deployment del modello, esegui questo codice per salvarlo in un file locale:
model.save_model('model.bst')
6. Esegui il deployment del modello su Cloud AI Platform
Il nostro modello funziona in locale, ma sarebbe bello poter fare previsioni ovunque (non solo in questo blocco note). In questo passaggio, eseguiremo il deployment nel cloud.
Passaggio 1: crea un bucket Cloud Storage per il modello
Definiamo innanzitutto alcune variabili di ambiente che utilizzeremo per il resto del codelab. Compila i valori riportati di seguito con il nome del tuo progetto cloud Google Cloud, il nome del bucket Cloud Storage che vuoi creare (deve essere univoco a livello globale) e il nome della versione per la prima versione del modello:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
Ora siamo pronti per creare un bucket di archiviazione per archiviare il file del modello XGBoost. Quando eseguiamo il deployment, Cloud AI Platform punterà a questo file.
Esegui questo comando gsutil dal notebook per creare un bucket:
!gsutil mb $MODEL_BUCKET
Passaggio 2: copia il file del modello in Cloud Storage
Successivamente, copieremo il file del modello salvato XGBoost in Cloud Storage. Esegui questo comando gsutil:
!gsutil cp ./model.bst $MODEL_BUCKET
Vai al browser di archiviazione nella console Cloud per verificare che il file sia stato copiato:

Passaggio 3: crea ed esegui il deployment del modello
Il modello è quasi pronto per essere implementato. Il seguente comando gcloud ai-platform creerà un nuovo modello nel tuo progetto. Lo chiameremo xgb_mortgage:
!gcloud ai-platform models create $MODEL_NAME --region='global'
Ora è il momento di eseguire il deployment del modello. Possiamo farlo con questo comando gcloud:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
Durante l'esecuzione, controlla la sezione dei modelli della console AI Platform. Dovresti visualizzare la nuova versione in fase di deployment:

Al termine del deployment, al posto della rotellina di caricamento vedrai un segno di spunta verde. Il deployment dovrebbe richiedere 2-3 minuti.
Passaggio 4: testa il modello di cui è stato eseguito il deployment
Per assicurarti che il modello di cui hai eseguito il deployment funzioni, testalo utilizzando gcloud per fare una previsione. Innanzitutto, salva un file JSON con il primo esempio del nostro set di test:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
Testa il modello eseguendo questo codice:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
Dovresti vedere la previsione del modello nell'output. Questo esempio specifico è stato approvato, quindi dovresti visualizzare un valore vicino a 1.
7. Utilizzare lo strumento What-If per interpretare il modello
Passaggio 1: crea la visualizzazione dello strumento What-if
Per connettere lo strumento What-if ai tuoi modelli AI Platform, devi trasmettergli un sottoinsieme degli esempi di test insieme ai valori di riferimento per questi esempi. Creiamo un array NumPy di 500 dei nostri esempi di test insieme alle relative etichette di verità di base:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
L'istanza dello strumento What-If è semplice come creare un oggetto WitConfigBuilder e passargli il modello AI Platform che vogliamo analizzare.
Qui utilizziamo il parametro facoltativo adjust_prediction perché lo strumento What-if prevede un elenco di punteggi per ogni classe nel nostro modello (in questo caso 2). Poiché il nostro modello restituisce un solo valore compreso tra 0 e 1, lo trasformiamo nel formato corretto in questa funzione:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
Tieni presente che il caricamento della visualizzazione richiederà un minuto. Al caricamento, dovresti visualizzare quanto segue:

L'asse y mostra la previsione del modello, con 1 che indica una previsione approved con un'affidabilità elevata e 0 che indica una previsione denied con un'affidabilità elevata. L'asse x rappresenta la distribuzione di tutti i punti dati caricati.
Passaggio 2: esplora i singoli punti dati
La visualizzazione predefinita nello strumento What-if è la scheda Editor punti dati. Qui puoi fare clic su un singolo punto dati per visualizzarne le caratteristiche, modificare i valori delle caratteristiche e vedere in che modo la modifica influisce sulla previsione del modello su un singolo punto dati.
Nell'esempio seguente abbiamo scelto un punto dati vicino alla soglia di 0,5. La richiesta di mutuo associata a questo particolare punto dati proviene dal CFPB. Abbiamo modificato questa funzionalità impostandola su 0 e abbiamo anche modificato il valore di agency_code_Department of Housing and Urban Development (HUD) impostandolo su 1 per vedere cosa sarebbe successo alla previsione del modello se questo prestito fosse stato invece originato dall'HUD:

Come possiamo vedere nella sezione in basso a sinistra dello strumento What-if, la modifica di questa funzionalità ha ridotto significativamente la previsione approved del modello del 32%. Ciò potrebbe indicare che l'agenzia da cui è stato originato un prestito ha un forte impatto sull'output del modello, ma dovremo eseguire ulteriori analisi per esserne certi.
Nella parte in basso a sinistra della UI, possiamo anche vedere il valore dei dati empirici reali per ogni punto dati e confrontarlo con la previsione del modello:

Passaggio 3: analisi controfattuale
Poi, fai clic su un punto dati e sposta il cursore Mostra il punto dati controfattuale più vicino verso destra:
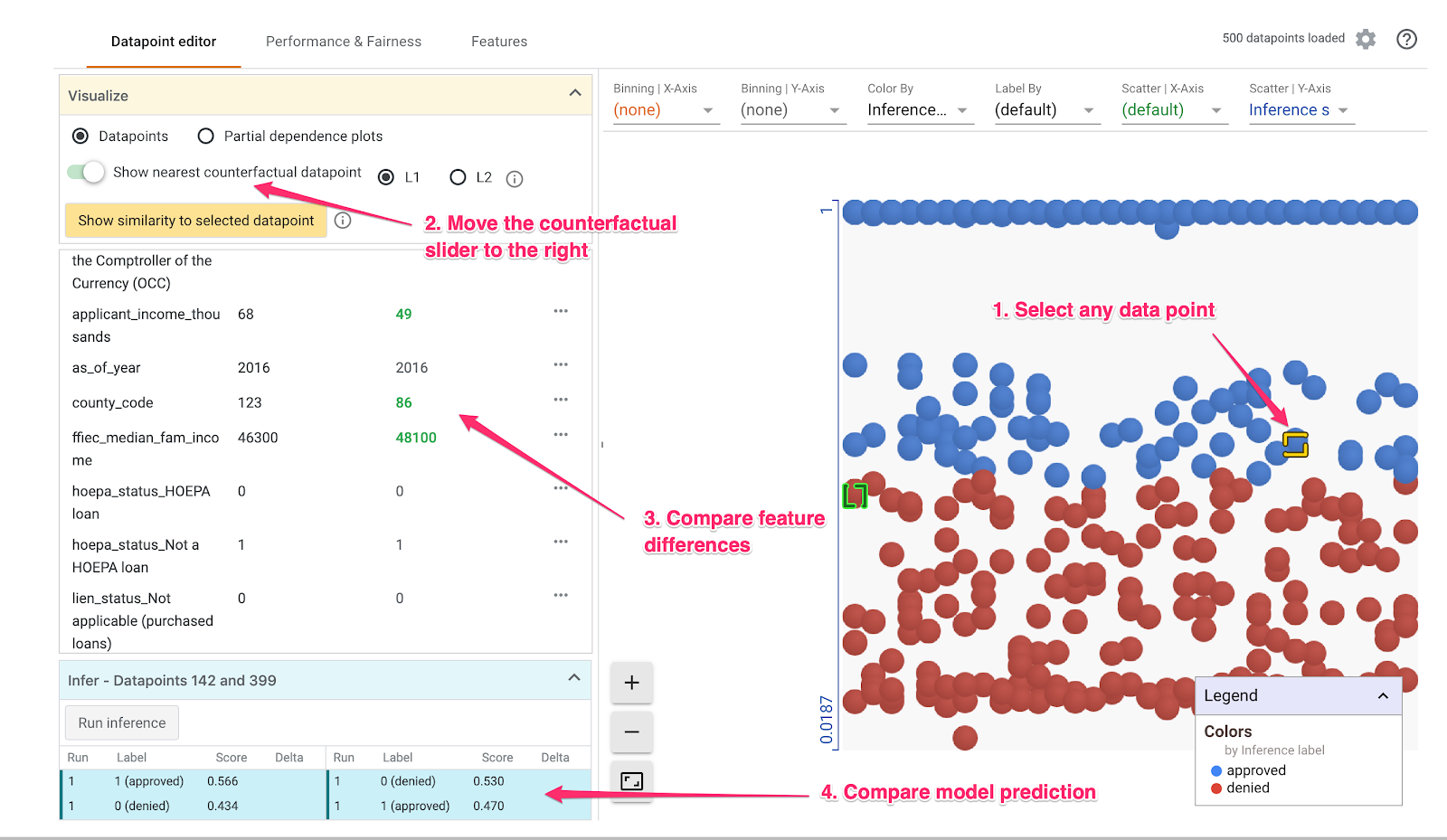
Se selezioni questa opzione, viene visualizzato il punto dati con i valori delle caratteristiche più simili a quelli originali selezionati, ma con la previsione opposta. Puoi quindi scorrere i valori delle caratteristiche per vedere dove i due punti dati differiscono (le differenze sono evidenziate in verde e in grassetto).
Passaggio 4: esamina i grafici di dipendenza parziale
Per vedere in che modo ogni funzionalità influisce sulle previsioni del modello nel complesso, seleziona la casella Grafici di dipendenza parziale e assicurati che sia selezionata l'opzione Grafici di dipendenza parziale globale:

Qui possiamo vedere che i prestiti provenienti dall'HUD hanno una probabilità leggermente maggiore di essere rifiutati. Il grafico ha questa forma perché il codice agenzia è una funzionalità booleana, quindi i valori possono essere solo esattamente 0 o 1.
applicant_income_thousands è una funzionalità numerica e nel grafico della dipendenza parziale possiamo vedere che un reddito più elevato aumenta leggermente la probabilità di approvazione di una richiesta, ma solo fino a circa 200.000 $. Dopo 200.000 $, questa funzionalità non influisce sulla previsione del modello.
Passaggio 5: esplora il rendimento complessivo e l'equità
Poi vai alla scheda Rendimento ed equità. Mostra le statistiche complessive sul rendimento dei risultati del modello nel set di dati fornito, incluse le matrici di confusione, le curve PR e le curve ROC.
Seleziona mortgage_status come funzionalità di riferimento per visualizzare una matrice di confusione:
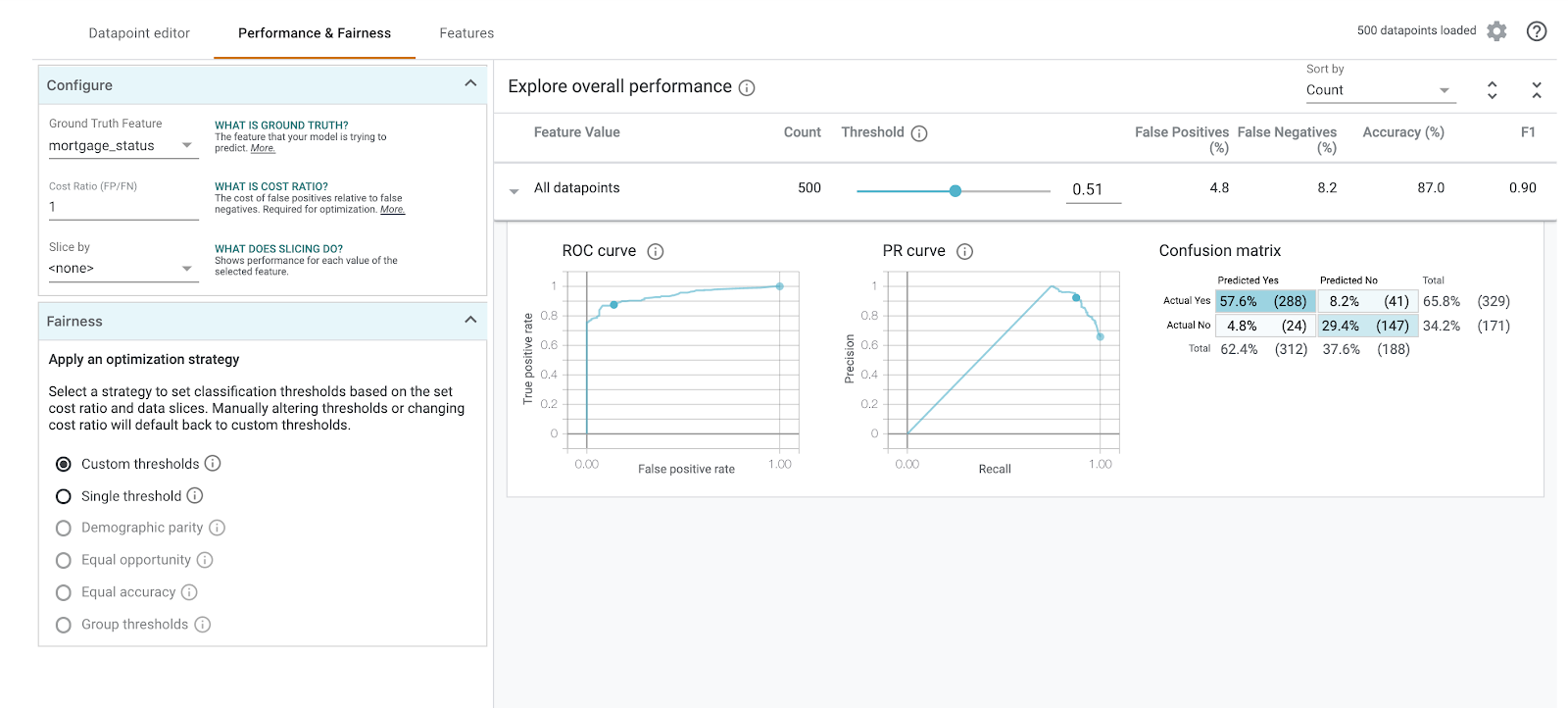
Questa matrice di confusione mostra le previsioni corrette e non corrette del nostro modello come percentuale del totale. Se sommi i quadrati Sì effettivo / Sì previsto e No effettivo / No previsto, dovresti ottenere la stessa accuratezza del modello (circa l'87%).
Puoi anche sperimentare con il cursore della soglia, alzando e abbassando il punteggio di classificazione positiva che il modello deve restituire prima di decidere di prevedere approved per il prestito e vedere come cambia l'accuratezza, i falsi positivi e i falsi negativi. In questo caso, la precisione è massima intorno a una soglia di 0,55.
Successivamente, nel menu a discesa Suddividi per a sinistra, seleziona loan_purpose_Home_purchase:
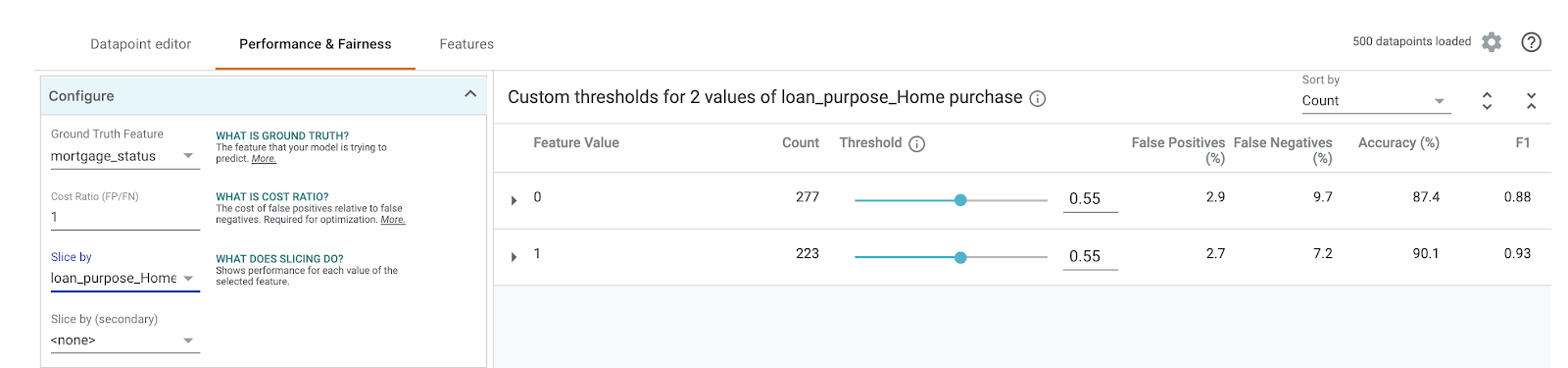
Ora vedrai il rendimento dei due sottoinsiemi dei tuoi dati: la sezione "0" mostra quando il prestito non è per l'acquisto di una casa, mentre la sezione "1" mostra quando il prestito è per l'acquisto di una casa. Controlla l'accuratezza, il tasso di falsi positivi e falsi negativi tra le due sezioni per individuare le differenze nel rendimento.
Se espandi le righe per esaminare le matrici di confusione, puoi notare che il modello prevede l'approvazione per circa il 70% delle richieste di prestito per l'acquisto di una casa e solo per il 46% dei prestiti che non riguardano l'acquisto di una casa (le percentuali esatte variano a seconda del modello):

Se selezioni Parità demografica dai pulsanti di opzione a sinistra, le due soglie verranno aggiustate in modo che il modello preveda approved per una percentuale simile di candidati in entrambe le sezioni. Qual è l'impatto su accuratezza, falsi positivi e falsi negativi per ogni segmento?
Passaggio 6: esplora la distribuzione delle funzionalità
Infine, vai alla scheda Funzionalità nello strumento What-If. Mostra la distribuzione dei valori per ogni funzionalità nel set di dati:

Puoi utilizzare questa scheda per assicurarti che il set di dati sia bilanciato. Ad esempio, sembra che pochissimi prestiti nel set di dati provengano dalla Farm Service Agency. Per migliorare l'accuratezza del modello, potremmo prendere in considerazione l'aggiunta di ulteriori prestiti di questa agenzia, se i dati sono disponibili.
Di seguito vengono descritti solo alcuni esempi di esplorazione dello strumento What-if. Continua a sperimentare con lo strumento, ci sono molte altre aree da esplorare.
8. Esegui la pulizia
Se vuoi continuare a utilizzare questo notebook, ti consigliamo di disattivarlo quando non lo usi. Dall'interfaccia utente di Notebooks nella console Cloud, seleziona il notebook, quindi seleziona Interrompi:

Se vuoi eliminare tutte le risorse che hai creato in questo lab, elimina semplicemente l'istanza del notebook anziché arrestarla.
Utilizzando il menu di navigazione della console Cloud, vai a Storage ed elimina entrambi i bucket creati per archiviare gli asset del modello.