
1. खास जानकारी
इस लैब में, आपको What-if टूल का इस्तेमाल करके, वित्तीय डेटा पर ट्रेन किए गए XGBoost मॉडल का विश्लेषण करना होगा. इस मॉडल को Cloud AI Platform पर डिप्लॉय किया गया है.
आपको क्या सीखने को मिलेगा
आपको, इनके बारे में जानकारी मिलेगी:
- AI Platform Notebooks में, सार्वजनिक तौर पर उपलब्ध मॉर्गेज डेटासेट पर XGBoost मॉडल को ट्रेन करना
- XGBoost मॉडल को AI Platform पर डिप्लॉय करना
- व्हाट-इफ़ टूल का इस्तेमाल करके मॉडल का विश्लेषण करना
इस लैब को Google Cloud पर चलाने की कुल लागत करीब 1 डॉलर है.
2. XGBoost के बारे में खास जानकारी
XGBoost एक मशीन लर्निंग फ़्रेमवर्क है. यह अनुमान लगाने वाले मॉडल बनाने के लिए, डिसीज़न ट्री और ग्रेडिएंट बूस्टिंग का इस्तेमाल करता है. यह अलग-अलग फ़ैसले लेने वाले कई ट्री को एक साथ जोड़कर काम करता है. यह ट्री में अलग-अलग लीफ़ नोड से जुड़े स्कोर के आधार पर काम करता है.
नीचे दिए गए डायग्राम में, फ़ैसले लेने वाले एक आसान ट्री मॉडल का विज़ुअलाइज़ेशन दिखाया गया है. यह मॉडल, मौसम के पूर्वानुमान के आधार पर यह तय करता है कि कोई स्पोर्ट्स गेम खेला जाना चाहिए या नहीं:

हम इस मॉडल के लिए XGBoost का इस्तेमाल क्यों कर रहे हैं? पारंपरिक न्यूरल नेटवर्क, इमेज और टेक्स्ट जैसे बिना क्रम के डेटा पर सबसे अच्छा परफ़ॉर्म करते हैं. वहीं, फ़ैसले लेने वाले ट्री, अक्सर मॉर्गेज डेटासेट जैसे व्यवस्थित डेटा पर बहुत अच्छा परफ़ॉर्म करते हैं. हम इस कोडलैब में मॉर्गेज डेटासेट का इस्तेमाल करेंगे.
3. अपना एनवायरमेंट सेट अप करना
इस कोडलैब को चलाने के लिए, आपके पास बिलिंग की सुविधा वाला Google Cloud Platform प्रोजेक्ट होना चाहिए. प्रोजेक्ट बनाने के लिए, यहां दिए गए निर्देशों का पालन करें.
पहला चरण: Cloud AI Platform Models API चालू करना
Cloud Console के AI Platform Models सेक्शन पर जाएं. अगर यह सुविधा पहले से चालू नहीं है, तो इसे चालू करें.

दूसरा चरण: Compute Engine API चालू करना
Compute Engine पर जाएं. अगर यह पहले से चालू नहीं है, तो चालू करें को चुनें. आपको नोटबुक इंस्टेंस बनाने के लिए इसकी ज़रूरत होगी.
तीसरा चरण: AI Platform Notebooks का इंस्टेंस बनाना
Cloud Console के AI Platform Notebooks सेक्शन पर जाएं और नया इंस्टेंस पर क्लिक करें. इसके बाद, GPU के बिना TF Enterprise 2.x के सबसे नए इंस्टेंस टाइप को चुनें:

डिफ़ॉल्ट विकल्पों का इस्तेमाल करें. इसके बाद, बनाएं पर क्लिक करें. इंस्टेंस बन जाने के बाद, JupyterLab खोलें को चुनें:

चौथा चरण: XGBoost इंस्टॉल करना
JupyterLab इंस्टेंस खुलने के बाद, आपको XGBoost पैकेज जोड़ना होगा.
इसके लिए, लॉन्चर से Terminal चुनें:

इसके बाद, Cloud AI Platform के साथ काम करने वाला XGBoost का नया वर्शन इंस्टॉल करने के लिए, यह कमांड चलाएं:
pip3 install xgboost==0.90
यह प्रोसेस पूरी होने के बाद, लॉन्चर से Python 3 Notebook इंस्टेंस खोलें. अब आप अपनी नोटबुक में काम शुरू करने के लिए तैयार हैं!
पांचवां चरण: Python पैकेज इंपोर्ट करना
अपनी नोटबुक की पहली सेल में, यहां दिए गए इंपोर्ट जोड़ें और सेल को चलाएं. इसे चलाने के लिए, सबसे ऊपर मौजूद मेन्यू में जाकर राइट ऐरो बटन दबाएं या command-enter दबाएं:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
4. डेटा डाउनलोड और प्रोसेस करना
हम XGBoost मॉडल को ट्रेन करने के लिए, ffiec.gov से लिए गए मॉर्टगेज डेटासेट का इस्तेमाल करेंगे. हमने ओरिजनल डेटासेट पर कुछ प्रीप्रोसेसिंग की है. साथ ही, हमने आपके लिए एक छोटा वर्शन बनाया है, ताकि आप मॉडल को ट्रेन करने के लिए इसका इस्तेमाल कर सकें. यह मॉडल अनुमान लगाएगा कि किसी मॉर्गेज ऐप्लिकेशन को मंज़ूरी मिलेगी या नहीं.
पहला चरण: पहले से प्रोसेस किया गया डेटासेट डाउनलोड करना
हमने Google Cloud Storage में, आपके लिए डेटासेट का एक वर्शन उपलब्ध कराया है. इसे डाउनलोड करने के लिए, अपनी Jupyter नोटबुक में यह gsutil कमांड चलाएं:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
दूसरा चरण: Pandas की मदद से डेटासेट पढ़ना
Pandas DataFrame बनाने से पहले, हम हर कॉलम के डेटा टाइप का एक डिक्शनरी बनाएंगे, ताकि Pandas हमारे डेटासेट को सही तरीके से पढ़ सके:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
इसके बाद, हम एक DataFrame बनाएंगे. इसमें ऊपर बताए गए डेटा टाइप पास किए जाएंगे. अगर ओरिजनल डेटासेट को किसी खास तरीके से क्रम में लगाया गया है, तो हमारे डेटा को शफ़ल करना ज़रूरी है. इसके लिए, हम shuffle नाम की sklearn यूटिलिटी का इस्तेमाल करते हैं. इसे हमने पहली सेल में इंपोर्ट किया था:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() की मदद से, हम Pandas में अपने डेटासेट की पहली पांच लाइनों की झलक देख सकते हैं. ऊपर दी गई सेल को चलाने के बाद, आपको कुछ ऐसा दिखेगा:

हम अपने मॉडल को ट्रेनिंग देने के लिए, इन सुविधाओं का इस्तेमाल करेंगे. सबसे नीचे तक स्क्रोल करने पर, आपको आखिरी कॉलम approved दिखेगा. यह वह कॉलम है जिसके बारे में हम अनुमान लगा रहे हैं. 1 वैल्यू से पता चलता है कि किसी ऐप्लिकेशन को मंज़ूरी मिल गई है. वहीं, 0 वैल्यू से पता चलता है कि उसे अस्वीकार कर दिया गया है.
डेटासेट में स्वीकार की गई / अस्वीकार की गई वैल्यू का डिस्ट्रिब्यूशन देखने और लेबल का numpy ऐरे बनाने के लिए, यह कोड चलाएं:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
डेटासेट में मौजूद करीब 66% ऐप्लिकेशन को मंज़ूरी मिल चुकी है.
तीसरा चरण: कैटगरी के हिसाब से वैल्यू के लिए डमी कॉलम बनाना
इस डेटासेट में कैटगरी और संख्या वाली वैल्यू का मिक्सचर है. हालांकि, XGBoost के लिए ज़रूरी है कि सभी सुविधाएं संख्या वाली हों. हमारा XGBoost मॉडल, कैटगरी वाली वैल्यू को वन-हॉट एन्कोडिंग का इस्तेमाल करके दिखाने के बजाय, Pandas get_dummies फ़ंक्शन का फ़ायदा लेगा.
get_dummies फ़ंक्शन, कई संभावित वैल्यू वाले कॉलम को लेता है और उसे कॉलम की सीरीज़ में बदलता है. हर कॉलम में सिर्फ़ 0 और 1 होते हैं. उदाहरण के लिए, अगर हमारे पास "color" नाम का कोई कॉलम है और उसकी संभावित वैल्यू "blue" और "red" हैं, तो get_dummies इस कॉलम को "color_blue" और "color_red" नाम के दो कॉलम में बदल देगा. साथ ही, सभी बूलियन वैल्यू को 0 और 1 में बदल देगा.
कैटेगरी के हिसाब से तय की गई सुविधाओं के लिए डमी कॉलम बनाने के लिए, यह कोड चलाएं:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
इस बार डेटा की झलक देखने पर, आपको एक ही सुविधा (जैसे, नीचे दी गई इमेज में दिखाया गया purchaser_type) कई कॉलम में बंटी हुई दिखेगी:

चौथा चरण: डेटा को ट्रेनिंग और टेस्ट सेट में बांटना
मशीन लर्निंग में, ट्रेन / टेस्ट स्प्लिट एक अहम कॉन्सेप्ट है. हम अपने ज़्यादातर डेटा का इस्तेमाल, मॉडल को ट्रेनिंग देने के लिए करेंगे. साथ ही, बाकी डेटा को अलग रख देंगे, ताकि हम मॉडल की जांच ऐसे डेटा पर कर सकें जिसे उसने पहले कभी नहीं देखा है.
अपनी नोटबुक में यह कोड जोड़ें. इसमें Scikit Learn फ़ंक्शन train_test_split का इस्तेमाल करके, हमारे डेटा को अलग-अलग किया जाता है:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
अब आप अपना मॉडल बनाने और उसे ट्रेन करने के लिए तैयार हैं!
5. XGBoost मॉडल बनाना, उसे ट्रेन करना, और उसका आकलन करना
पहला चरण: XGBoost मॉडल को तय करना और उसे ट्रेन करना
XGBoost में मॉडल बनाना आसान है. हम मॉडल बनाने के लिए, XGBClassifier क्लास का इस्तेमाल करेंगे. साथ ही, हमें सिर्फ़ अपने खास क्लासिफ़िकेशन टास्क के लिए सही objective पैरामीटर पास करना होगा. इस मामले में, हम reg:logistic का इस्तेमाल करते हैं, क्योंकि हमें बाइनरी क्लासिफ़िकेशन की समस्या है. साथ ही, हमें मॉडल से (0,1) की रेंज में एक वैल्यू चाहिए: 0 का मतलब है कि मंज़ूरी नहीं मिली है और 1 का मतलब है कि मंज़ूरी मिल गई है.
नीचे दिया गया कोड, XGBoost मॉडल बनाएगा:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
मॉडल को कोड की एक लाइन से ट्रेन किया जा सकता है. इसके लिए, fit() तरीके को कॉल करें और उसे ट्रेनिंग डेटा और लेबल पास करें.
model.fit(x_train, y_train)
दूसरा चरण: अपने मॉडल की सटीकता का आकलन करना
अब हम अपने ट्रेन किए गए मॉडल का इस्तेमाल करके, predict() फ़ंक्शन की मदद से अपने टेस्ट डेटा के आधार पर अनुमान जनरेट कर सकते हैं.
इसके बाद, हम Scikit Learn के accuracy_score फ़ंक्शन का इस्तेमाल करेंगे. इससे हमें यह पता चलेगा कि हमारा मॉडल, टेस्ट डेटा पर कैसा परफ़ॉर्म कर रहा है. इसके आधार पर, हम अपने मॉडल की सटीकता का आकलन कर पाएंगे. हम इसे टेस्ट सेट में मौजूद हर उदाहरण के लिए, मॉडल की अनुमानित वैल्यू के साथ-साथ असल वैल्यू भी देंगे:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
आपको 87% तक सटीक नतीजे दिखेंगे. हालांकि, आपके नतीजे थोड़े अलग हो सकते हैं, क्योंकि मशीन लर्निंग में हमेशा कुछ हद तक रैंडमनेस होती है.
तीसरा चरण: मॉडल सेव करना
मॉडल को डिप्लॉय करने के लिए, इसे किसी लोकल फ़ाइल में सेव करने के लिए यह कोड चलाएं:
model.save_model('model.bst')
6. मॉडल को Cloud AI Platform पर डिप्लॉय करना
हमने अपने मॉडल को स्थानीय तौर पर काम करने के लिए सेट अप कर दिया है. हालांकि, अगर हम इस पर कहीं से भी अनुमान लगा सकें, तो यह बहुत अच्छा होगा. ऐसा सिर्फ़ इस नोटबुक से नहीं, बल्कि किसी भी जगह से किया जा सकेगा! इस चरण में, हम इसे क्लाउड पर डिप्लॉय करेंगे.
पहला चरण: हमारे मॉडल के लिए Cloud Storage बकेट बनाना
सबसे पहले, कुछ एनवायरमेंट वैरिएबल तय करते हैं. इनका इस्तेमाल हम बाकी कोडलैब में करेंगे. नीचे दी गई वैल्यू में, अपने Google Cloud प्रोजेक्ट का नाम, क्लाउड स्टोरेज बकेट का वह नाम डालें जिसे आपको बनाना है (यह नाम दुनिया भर में यूनीक होना चाहिए). साथ ही, अपने मॉडल के पहले वर्शन का नाम डालें:
# Update these to your own GCP project, model, and version names
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
VERSION_NAME = 'v1'
MODEL_NAME = 'xgb_mortgage'
अब हम XGBoost मॉडल फ़ाइल को सेव करने के लिए, स्टोरेज बकेट बनाने के लिए तैयार हैं. डप्लॉय करते समय, हम Cloud AI Platform को इस फ़ाइल के बारे में बताएंगे.
बकेट बनाने के लिए, अपनी नोटबुक में यह gsutil कमांड चलाएं:
!gsutil mb $MODEL_BUCKET
दूसरा चरण: मॉडल फ़ाइल को Cloud Storage में कॉपी करना
इसके बाद, हम XGBoost के सेव किए गए मॉडल की फ़ाइल को Cloud Storage में कॉपी करेंगे. gsutil का यह निर्देश चलाएं:
!gsutil cp ./model.bst $MODEL_BUCKET
फ़ाइल के कॉपी होने की पुष्टि करने के लिए, Cloud Console में स्टोरेज ब्राउज़र पर जाएं:

तीसरा चरण: मॉडल बनाना और उसे डिप्लॉय करना
हम मॉडल को डिप्लॉय करने के लिए करीब-करीब तैयार हैं! नीचे दिया गया ai-platform gcloud कमांड, आपके प्रोजेक्ट में एक नया मॉडल बनाएगा. हम इस नंबर पर कॉल करेंगे xgb_mortgage:
!gcloud ai-platform models create $MODEL_NAME --region='global'
अब मॉडल को डिप्लॉय करने का समय है. इस gcloud कमांड की मदद से ऐसा किया जा सकता है:
!gcloud ai-platform versions create $VERSION_NAME \
--model=$MODEL_NAME \
--framework='XGBOOST' \
--runtime-version=2.1 \
--origin=$MODEL_BUCKET \
--python-version=3.7 \
--project=$GCP_PROJECT \
--region='global'
जब यह प्रोसेस चल रही हो, तब AI Platform Console के मॉडल सेक्शन में जाकर देखें. आपको वहां नया वर्शन डिप्लॉय होता हुआ दिखेगा:

डिप्लॉयमेंट पूरा होने पर, आपको हरे रंग का सही का निशान दिखेगा. यह निशान, लोडिंग स्पिनर की जगह पर दिखेगा. डिप्लॉयमेंट में दो से तीन मिनट लगेंगे.
चौथा चरण: डिप्लॉय किए गए मॉडल की जांच करना
यह पक्का करने के लिए कि आपका डिप्लॉय किया गया मॉडल काम कर रहा है, gcloud का इस्तेमाल करके उसकी जांच करें, ताकि अनुमान लगाया जा सके. सबसे पहले, हमारे टेस्ट सेट के पहले उदाहरण के साथ एक JSON फ़ाइल सेव करें:
%%writefile predictions.json
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
इस कोड को चलाकर, अपने मॉडल को टेस्ट करें:
prediction = !gcloud ai-platform predict --model=xgb_mortgage --region='global' --json-instances=predictions.json --version=$VERSION_NAME --verbosity=none
print(prediction)
आपको आउटपुट में, अपने मॉडल का अनुमान दिखना चाहिए. इस उदाहरण को स्वीकार कर लिया गया है. इसलिए, आपको 1 के आस-पास की वैल्यू दिखेगी.
7. अपने मॉडल को समझने के लिए, 'अगर ऐसा हो, तो क्या होगा' टूल का इस्तेमाल करना
पहला चरण: 'अगर-तो' टूल का विज़ुअलाइज़ेशन बनाना
What-if टूल को अपने AI Platform मॉडल से कनेक्ट करने के लिए, आपको इसे अपने टेस्ट के उदाहरणों का सबसेट देना होगा. साथ ही, उन उदाहरणों के लिए ग्राउंड ट्रुथ वैल्यू भी देनी होंगी. आइए, अपने टेस्ट के 500 उदाहरणों का एक Numpy ऐरे बनाते हैं. साथ ही, उनके ग्राउंड ट्रुथ लेबल भी बनाते हैं:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples].values,y_test[:num_wit_examples].reshape(-1,1)))
What-if Tool को इंस्टैंशिएट करना उतना ही आसान है जितना कि WitConfigBuilder ऑब्जेक्ट बनाना. इसके बाद, हमें उस AI Platform मॉडल को पास करना होता है जिसका हमें विश्लेषण करना है.
हमने यहां adjust_prediction पैरामीटर का इस्तेमाल किया है. इसकी वजह यह है कि What-if टूल को हमारे मॉडल में मौजूद हर क्लास के लिए स्कोर की सूची चाहिए. इस मामले में, यह सूची दो क्लास के लिए है. हमारा मॉडल, 0 से 1 के बीच की सिर्फ़ एक वैल्यू दिखाता है. इसलिए, हम इस फ़ंक्शन में इसे सही फ़ॉर्मैट में बदलते हैं:
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_ai_platform_model(GCP_PROJECT, MODEL_NAME, VERSION_NAME, adjust_prediction=adjust_prediction)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
ध्यान दें कि विज़ुअलाइज़ेशन लोड होने में एक मिनट लगेगा. लोड होने के बाद, आपको यह दिखेगा:

y-ऐक्सिस पर, मॉडल का अनुमान दिखाया गया है. इसमें 1 का मतलब है कि approved के अनुमान पर मॉडल को पूरा भरोसा है. वहीं, 0 का मतलब है कि denied के अनुमान पर मॉडल को पूरा भरोसा है. x-ऐक्सिस, लोड किए गए सभी डेटा पॉइंट का स्प्रेड दिखाता है.
दूसरा चरण: अलग-अलग डेटा पॉइंट एक्सप्लोर करना
'क्या होगा अगर' टूल में डिफ़ॉल्ट व्यू के तौर पर, डेटापॉइंट एडिटर टैब सेट होता है. यहां किसी भी डेटा पॉइंट पर क्लिक करके, उसकी सुविधाएं देखी जा सकती हैं. साथ ही, सुविधाओं की वैल्यू बदली जा सकती हैं. इसके अलावा, यह भी देखा जा सकता है कि उस बदलाव से, किसी डेटा पॉइंट के लिए मॉडल के अनुमान पर क्या असर पड़ता है.
नीचे दिए गए उदाहरण में, हमने .5 थ्रेशोल्ड के आस-पास का डेटा पॉइंट चुना है. इस डेटा पॉइंट से जुड़ा मॉर्गेज ऐप्लिकेशन, CFPB से मिला है. हमने उस सुविधा को 0 पर सेट कर दिया. साथ ही, agency_code_Department of Housing and Urban Development (HUD) की वैल्यू को 1 पर सेट कर दिया, ताकि यह देखा जा सके कि अगर यह लोन HUD से मिला है, तो मॉडल के अनुमान पर क्या असर पड़ेगा:
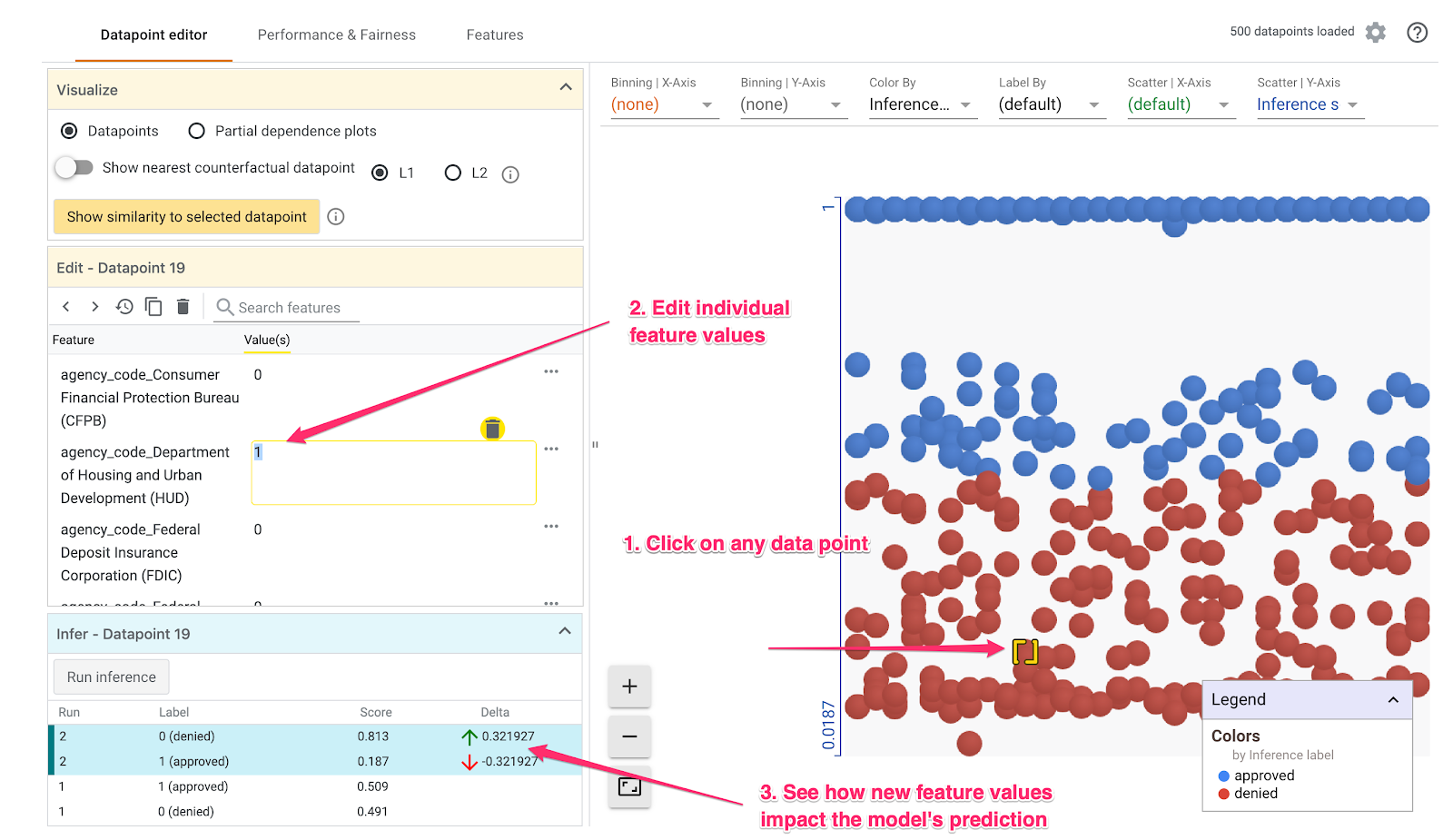
'क्या होगा अगर' टूल के सबसे नीचे बाएं सेक्शन में देखा जा सकता है कि इस सुविधा में बदलाव करने से, मॉडल की approved की संभावना 32% तक कम हो गई. इससे पता चलता है कि जिस एजेंसी से लोन लिया गया है उसका मॉडल के आउटपुट पर काफ़ी असर पड़ता है. हालांकि, इसकी पुष्टि करने के लिए हमें और विश्लेषण करना होगा.
यूज़र इंटरफ़ेस (यूआई) के सबसे नीचे बाईं ओर, हमें हर डेटा पॉइंट के लिए ग्राउंड ट्रुथ वैल्यू भी दिखती है. इसकी तुलना मॉडल के अनुमान से की जा सकती है:
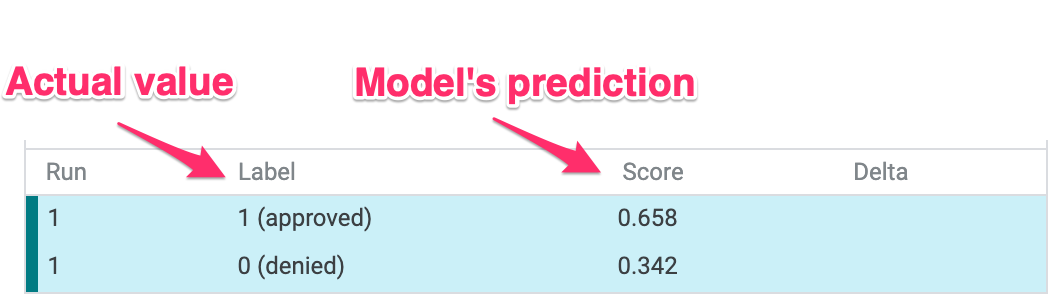
तीसरा चरण: काउंटरफ़ैक्चुअल विश्लेषण
इसके बाद, किसी भी डेटापॉइंट पर क्लिक करें और सबसे नज़दीकी काउंटरफ़ैक्चुअल डेटापॉइंट दिखाएं स्लाइडर को दाईं ओर ले जाएं:

इसे चुनने पर, आपको वह डेटा पॉइंट दिखेगा जिसमें चुनी गई ओरिजनल वैल्यू से सबसे मिलती-जुलती फ़ीचर वैल्यू हैं, लेकिन अनुमान अलग है. इसके बाद, सुविधा की वैल्यू में स्क्रोल करके देखा जा सकता है कि दो डेटा पॉइंट में क्या अंतर है. अंतर को हरे रंग में हाइलाइट किया गया है और बोल्ड किया गया है.
चौथा चरण: पार्शियल डिपेंडेंस प्लॉट देखना
यह देखने के लिए कि हर सुविधा, मॉडल के अनुमानों पर कुल मिलाकर कैसे असर डालती है, आंशिक निर्भरता वाले प्लॉट बॉक्स को चुनें. साथ ही, पक्का करें कि ग्लोबल आंशिक निर्भरता वाले प्लॉट को चुना गया हो:

यहां हम देख सकते हैं कि HUD से लिए गए कर्ज़ के आवेदन के अस्वीकार होने की संभावना थोड़ी ज़्यादा होती है. यह ग्राफ़ इस तरह का इसलिए है, क्योंकि एजेंसी कोड एक बूलियन सुविधा है. इसलिए, वैल्यू सिर्फ़ 0 या 1 हो सकती हैं.
applicant_income_thousands एक संख्यात्मक सुविधा है. आंशिक निर्भरता वाले प्लॉट में हम देख सकते हैं कि ज़्यादा आय होने पर, आवेदन के स्वीकार होने की संभावना थोड़ी बढ़ जाती है. हालांकि, यह सिर्फ़ 2 लाख डॉलर तक ही बढ़ती है. दो लाख डॉलर के बाद, इस सुविधा से मॉडल के अनुमान पर कोई असर नहीं पड़ता.
पांचवां चरण: परफ़ॉर्मेंस और निष्पक्षता के बारे में ज़्यादा जानें
इसके बाद, परफ़ॉर्मेंस और निष्पक्षता टैब पर जाएं. इससे दिए गए डेटासेट पर मॉडल के नतीजों के बारे में परफ़ॉर्मेंस के कुल आंकड़े दिखते हैं. इनमें कन्फ़्यूज़न मैट्रिक्स, पीआर कर्व, और आरओसी कर्व शामिल हैं.
कंफ़्यूज़न मैट्रिक्स देखने के लिए, mortgage_status को ग्राउंड ट्रुथ फ़ीचर के तौर पर चुनें:
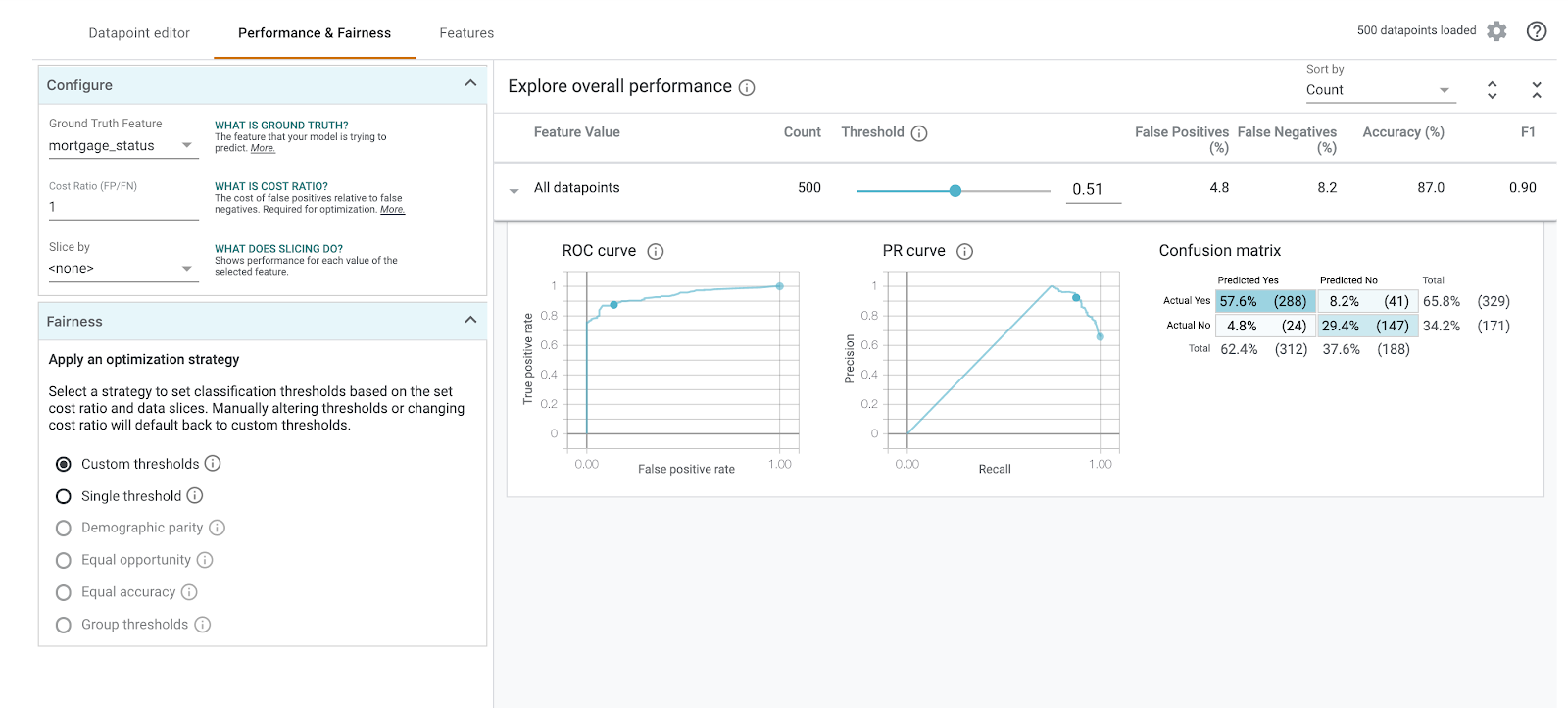
इस कन्फ़्यूज़न मैट्रिक्स में, हमारे मॉडल के सही और गलत अनुमानों को कुल प्रतिशत के तौर पर दिखाया गया है. असल में हां / अनुमानित तौर पर हां और असल में नहीं / अनुमानित तौर पर नहीं स्क्वेयर को जोड़ने पर, यह आपके मॉडल की सटीकता (लगभग 87%) के बराबर होना चाहिए.
थ्रेशोल्ड स्लाइडर का इस्तेमाल करके भी एक्सपेरिमेंट किया जा सकता है. इससे, पॉज़िटिव क्लासिफ़िकेशन स्कोर को बढ़ाया और घटाया जा सकता है. यह स्कोर, मॉडल को तब तक दिखाना होता है, जब तक वह लोन के लिए approved का अनुमान नहीं लगा लेता. इससे यह देखा जा सकता है कि स्कोर में बदलाव करने से, अनुमान की सटीकता, फ़ॉल्स पॉज़िटिव, और फ़ॉल्स नेगेटिव पर क्या असर पड़ता है. इस मामले में, .55 के थ्रेशोल्ड के आस-पास सटीकता सबसे ज़्यादा है.
इसके बाद, बाईं ओर मौजूद इसके हिसाब से स्लाइस करें ड्रॉपडाउन में जाकर, loan_purpose_Home_purchase चुनें:
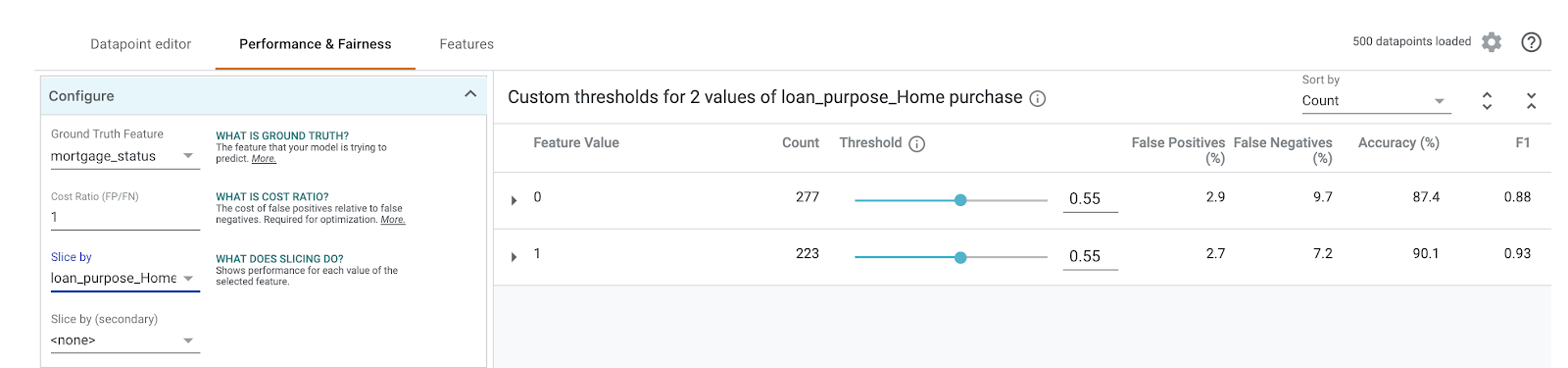
अब आपको अपने डेटा के दो सबसेट की परफ़ॉर्मेंस दिखेगी: "0" स्लाइस से पता चलता है कि होम लोन नहीं लिया गया है. वहीं, "1" स्लाइस से पता चलता है कि होम लोन लिया गया है. परफ़ॉर्मेंस में अंतर देखने के लिए, दोनों स्लाइस के बीच सटीक, फ़ॉल्स पॉज़िटिव, और फ़ॉल्स नेगेटिव रेट देखें.
अगर आपको कन्फ़्यूज़न मैट्रिक्स देखने के लिए लाइनों को बड़ा करना है, तो आपको दिखेगा कि मॉडल, घर खरीदने के लिए ~70% लोन ऐप्लिकेशन के लिए "स्वीकार किया गया" का अनुमान लगाता है. साथ ही, घर खरीदने के अलावा अन्य कामों के लिए सिर्फ़ 46% लोन के लिए ऐसा अनुमान लगाता है. सटीक प्रतिशत आपके मॉडल के हिसाब से अलग-अलग होंगे:

अगर बाईं ओर मौजूद रेडियो बटन में से डेमोग्राफ़िक पैरिटी को चुना जाता है, तो दोनों थ्रेशोल्ड को इस तरह से अडजस्ट किया जाएगा कि मॉडल, दोनों स्लाइस में आवेदकों के एक जैसे प्रतिशत के लिए approved का अनुमान लगाए. इससे हर स्लाइस के लिए, सटीक जवाब मिलने की संभावना, फ़ॉल्स पॉज़िटिव, और फ़ॉल्स नेगेटिव पर क्या असर पड़ता है?
छठा चरण: सुविधा के डिस्ट्रिब्यूशन के बारे में जानें
आखिर में, What-if टूल में सुविधाएं टैब पर जाएं. इससे आपको अपने डेटासेट में मौजूद हर सुविधा के लिए वैल्यू का डिस्ट्रिब्यूशन दिखता है:
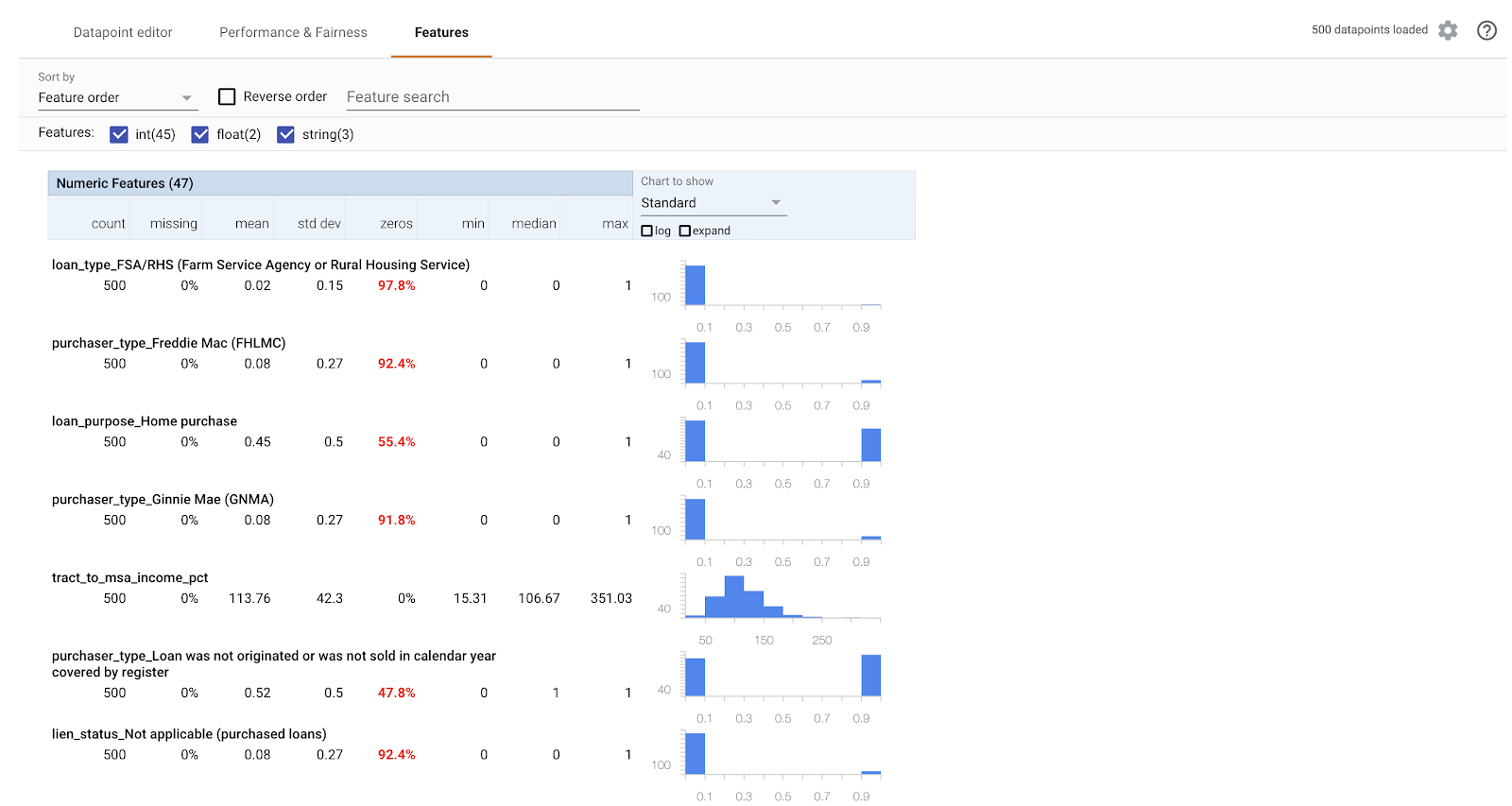
इस टैब का इस्तेमाल करके, यह पक्का किया जा सकता है कि आपका डेटासेट संतुलित है. उदाहरण के लिए, ऐसा लगता है कि डेटासेट में बहुत कम लोन, फ़ार्म सर्विस एजेंसी से मिले हैं. मॉडल की सटीकता को बेहतर बनाने के लिए, हम उस एजेंसी से ज़्यादा लोन जोड़ सकते हैं. हालांकि, ऐसा तब ही किया जाएगा, जब डेटा उपलब्ध हो.
हमने यहां What-if Tool के एक्सप्लोरेशन के कुछ आइडिया के बारे में बताया है. इस टूल का इस्तेमाल करते रहें. इसमें एक्सप्लोर करने के लिए और भी कई चीज़ें हैं!
8. साफ़-सफ़ाई सेवा
अगर आपको इस नोटबुक का इस्तेमाल जारी रखना है, तो हमारा सुझाव है कि इस्तेमाल न करने पर इसे बंद कर दें. Cloud Console में Notebooks के यूज़र इंटरफ़ेस (यूआई) में जाकर, नोटबुक चुनें. इसके बाद, बंद करें को चुनें:

अगर आपको इस लैब में बनाए गए सभी संसाधन मिटाने हैं, तो नोटबुक इंस्टेंस को बंद करने के बजाय मिटा दें.
Cloud Console में नेविगेशन मेन्यू का इस्तेमाल करके, Storage पर जाएं. इसके बाद, मॉडल ऐसेट सेव करने के लिए बनाए गए दोनों बकेट मिटाएं.