
1. Einführung
In diesem Codelab habe ich die Schritte zum Zusammenfassen von Quellcode aus GitHub-Repositories und zum Identifizieren der Programmiersprache im Repository mithilfe des Vertex AI Large Language Model zur Textgenerierung ( text-bison) als gehostete Remote-Funktion in BigQuery aufgeführt. Dank des Archive Project von GitHub haben wir jetzt einen vollständigen Snapshot von über 2, 8 Millionen Open-Source-GitHub-Repositories in den öffentlichen Google BigQuery-Datasets. Folgende Dienste werden verwendet:
- BigQuery ML
- Vertex AI PaLM API
Aufgaben
Sie erstellen
- Ein BigQuery-Dataset, das das Modell enthält
- Ein BigQuery-Modell, das die Vertex AI PaLM API als Remote-Funktion hostet
- Eine externe Verbindung, um die Verbindung zwischen BigQuery und Vertex AI herzustellen
2. Voraussetzungen
3. Hinweis
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist
- Achten Sie darauf, dass alle erforderlichen APIs (BigQuery API, Vertex AI API, BigQuery Connection API) aktiviert sind.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der bq vorinstalliert ist. Dokumentation zu gcloud-Befehlen und deren Verwendung
Klicken Sie in der Cloud Console rechts oben auf „Cloud Shell aktivieren“:

Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Rufen Sie die BigQuery-Konsole direkt auf, indem Sie die folgende URL in Ihren Browser eingeben: https://console.cloud.google.com/bigquery
4. Daten vorbereiten
In diesem Anwendungsfall verwenden wir den Quellcodeinhalt aus dem Dataset „github_repos“ in den öffentlichen BigQuery-Datasets. Suchen Sie dazu in der BigQuery-Konsole nach „github_repos“ und drücken Sie die Eingabetaste. Klicken Sie auf den Stern neben dem Dataset, das als Suchergebnis aufgeführt ist. Klicken Sie dann auf die Option „SHOW STARRED ONLY“ (NUR MIT STERNCHEN MARKIERTE ANZEIGEN), um nur dieses Dataset aus den öffentlichen Datasets aufzurufen.

Maximieren Sie die Tabellen im Dataset, um das Schema und die Datenvorschau aufzurufen. Wir verwenden „sample_contents“, die nur eine Stichprobe (10%) der vollständigen Daten in der Tabelle „contents“ enthält. Hier sehen Sie eine Vorschau der Daten:

5. BigQuery-Dataset erstellen
Ein BigQuery-Dataset ist eine Sammlung von Tabellen. Alle Tabellen in einem Dataset werden am selben Datenspeicherort gespeichert. Sie können auch benutzerdefinierte Zugriffssteuerungen anhängen, um den Zugriff auf ein Dataset und seine Tabellen einzuschränken.
Erstellen Sie ein Dataset in der Region „USA“ (oder einer beliebigen Region Ihrer Wahl) mit dem Namen bq_llm.
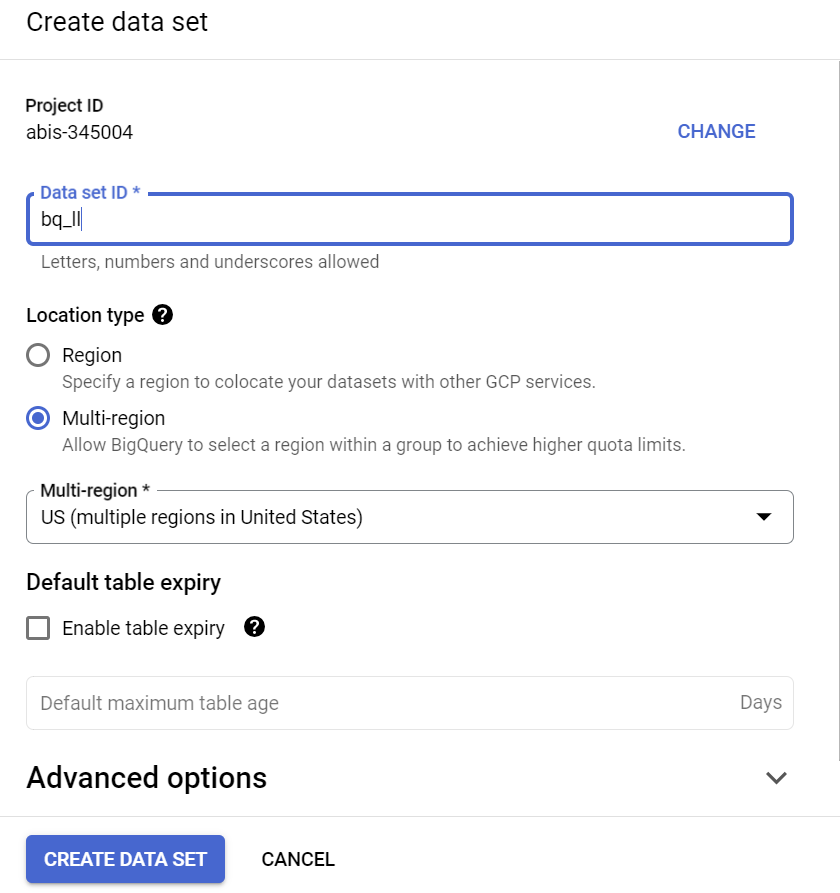
In diesem Dataset wird das ML-Modell gespeichert, das wir in den nächsten Schritten erstellen. Normalerweise würden wir die Daten, die wir in der ML-Anwendung verwenden, auch in einer Tabelle in diesem Dataset speichern. In unserem Anwendungsfall sind die Daten jedoch bereits in einem öffentlichen BigQuery-Dataset vorhanden. Wir werden bei Bedarf direkt darauf verweisen. Wenn Sie dieses Projekt mit Ihrem eigenen Dataset durchführen möchten, das in einer CSV-Datei (oder einer anderen Datei) enthalten ist, können Sie Ihre Daten in ein BigQuery-Dataset in eine Tabelle laden. Führen Sie dazu den folgenden Befehl im Cloud Shell-Terminal aus:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. Externe Verbindung wird erstellt
Erstellen Sie eine externe Verbindung (aktivieren Sie die BQ Connection API, falls noch nicht geschehen) und notieren Sie sich die Dienstkonto-ID aus den Verbindungsdetails:
- Klicken Sie im Bereich „BigQuery Explorer“ (links in der BigQuery Console) auf die Schaltfläche „+ HINZUFÜGEN“ und dann in der Liste der beliebten Quellen auf „Verbindung zu externen Datenquellen“.
- Wählen Sie „BigLake und Remote-Funktionen“ als Verbindungstyp aus und geben Sie „llm-conn“ als Verbindungs-ID an.
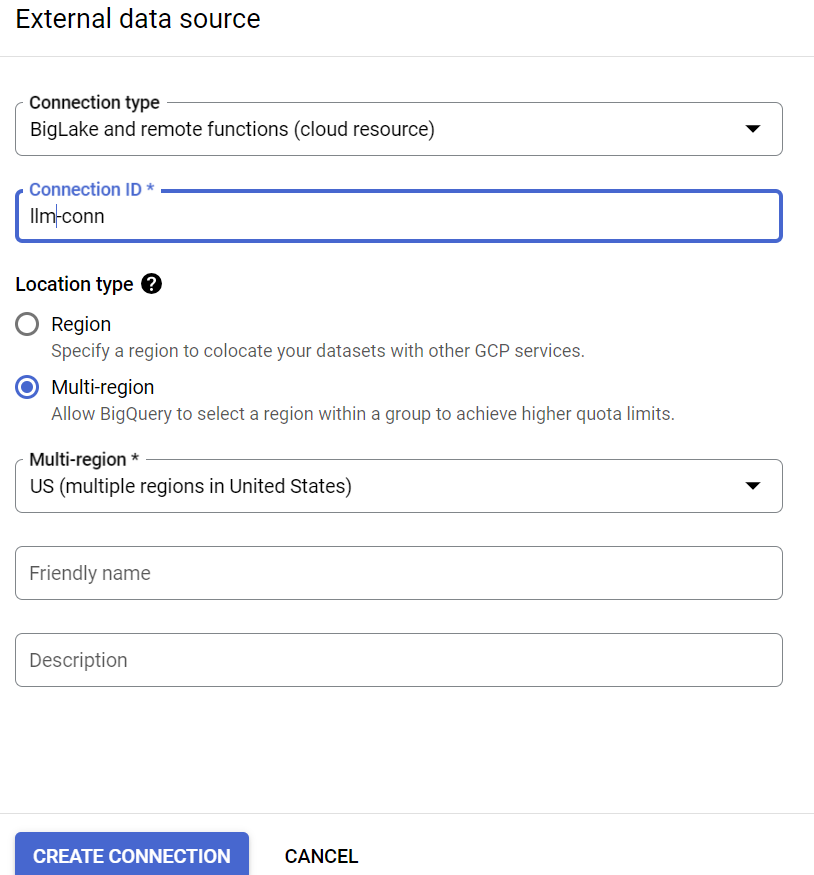
- Notieren Sie sich nach dem Erstellen der Verbindung das Dienstkonto, das aus den Details der Verbindungskonfiguration generiert wurde.
7. Berechtigungen erteilen
In diesem Schritt gewähren wir dem Dienstkonto Berechtigungen für den Zugriff auf den Vertex AI-Dienst:
Öffnen Sie IAM, fügen Sie das Dienstkonto, das Sie nach dem Erstellen der externen Verbindung kopiert haben, als Hauptkonto hinzu und wählen Sie die Rolle „Vertex AI-Nutzer“ aus.

8. Remote-ML-Modell erstellen
Erstellen Sie das Remote-Modell, das ein gehostetes Vertex AI-LLM darstellt:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
Dadurch wird ein Modell namens llm_model im Dataset „bq_llm“ erstellt, das die CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 API von Vertex AI als Remote-Funktion nutzt. Dieser Vorgang kann einige Sekunden dauern.
9. Text mit dem ML-Modell generieren
Nachdem Sie das Modell erstellt haben, können Sie es verwenden, um Text zu generieren, zusammenzufassen oder zu kategorisieren.
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**Erläuterung:
**ml_generate_text_result** ist die Antwort des Modells zur Textgenerierung im JSON-Format, die sowohl Inhalts- als auch Sicherheitsattribute enthält: a. „Content“ steht für das generierte Textergebnis b. Sicherheitsattribute stellen den integrierten Inhaltsfilter mit einem anpassbaren Grenzwert dar, der in der Vertex AI Palm API aktiviert ist, um unbeabsichtigte oder unvorhergesehene Antworten des Large Language Model zu vermeiden. Die Antwort wird blockiert, wenn sie den Sicherheitsgrenzwert überschreitet.
ML.GENERATE_TEXT ist das Konstrukt, das Sie in BigQuery verwenden, um auf das Vertex AI LLM zuzugreifen und Aufgaben zur Textgenerierung auszuführen.
CONCAT hängt Ihre PROMPT-Anweisung und den Datenbankdatensatz an.
github_repos ist der Name des Datasets und „sample_contents“ der Name der Tabelle, die die Daten enthält, die wir für das Prompt-Design verwenden.
Die Temperatur ist der Prompt-Parameter, mit dem die Zufälligkeit der Antwort gesteuert wird. Je niedriger, desto besser in Bezug auf die Relevanz.
Max_output_tokens ist die Anzahl der Wörter, die Sie in der Antwort wünschen.
Die Antwort auf die Anfrage sieht so aus:

10. Abfrageergebnis zusammenführen
Wir vereinfachen das Ergebnis, damit wir das JSON nicht explizit in der Abfrage decodieren müssen:
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**Erläuterung:
„flatten_json_output“** stellt den booleschen Wert dar, der, wenn er auf „true“ gesetzt ist, einen einfachen, verständlichen Text zurückgibt, der aus der JSON-Antwort extrahiert wurde.
Die Antwort auf die Anfrage sieht so aus:

11. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf „Löschen“.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf „Beenden“, um das Projekt zu löschen.
12. Glückwunsch
Glückwunsch! Sie haben ein Vertex AI Text Generation-LLM erfolgreich programmatisch verwendet, um Textanalysen für Ihre Daten durchzuführen, wobei Sie ausschließlich SQL-Abfragen genutzt haben. Weitere Informationen zu den verfügbaren Modellen finden Sie in der Produktdokumentation zu Vertex AI LLM.