
1. परिचय
इस कोडलैब में, मैंने GitHub रिपॉज़िटरी से सोर्स कोड की खास जानकारी पाने और रिपॉज़िटरी में प्रोग्रामिंग की भाषा की पहचान करने के तरीके के बारे में बताया है. इसके लिए, BigQuery में होस्ट किए गए रिमोट फ़ंक्शन के तौर पर, टेक्स्ट जनरेट करने के लिए Vertex AI लार्ज लैंग्वेज मॉडल ( text-bison) का इस्तेमाल किया गया है. GitHub के Archive Project की वजह से, अब हमारे पास Google BigQuery के सार्वजनिक डेटासेट में, GitHub की 28 लाख से ज़्यादा ओपन सोर्स रिपॉज़िटरी का पूरा स्नैपशॉट है. इस्तेमाल की गई सेवाओं की सूची यहां दी गई है:
- BigQuery ML
- Vertex AI PaLM API
आपको क्या बनाना है
आपको
- मॉडल को शामिल करने के लिए BigQuery डेटासेट
- BigQuery मॉडल, जो Vertex AI PaLM API को रिमोट फ़ंक्शन के तौर पर होस्ट करता है
- BigQuery और Vertex AI के बीच कनेक्शन बनाने के लिए, बाहरी कनेक्शन
2. ज़रूरी शर्तें
3. शुरू करने से पहले
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें
- पक्का करें कि सभी ज़रूरी एपीआई (BigQuery API, Vertex AI API, BigQuery Connection API) चालू हों
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. इसमें bq पहले से लोड होता है. gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें
Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद, Cloud Shell चालू करें पर क्लिक करें:

अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- अपने ब्राउज़र में यह यूआरएल डालकर, सीधे BigQuery कंसोल पर जाएं: https://console.cloud.google.com/bigquery
4. डेटा तैयार हो रहा है
इस इस्तेमाल के उदाहरण में, हम Google BigQuery के सार्वजनिक डेटासेट में मौजूद github_repos डेटासेट के सोर्स कोड कॉन्टेंट का इस्तेमाल कर रहे हैं. इसका इस्तेमाल करने के लिए, BigQuery कंसोल में "github_repos" खोजें और Enter दबाएं. खोज के नतीजे के तौर पर दिखाए गए डेटासेट के बगल में मौजूद स्टार पर क्लिक करें. इसके बाद, "सिर्फ़ स्टार किए गए दिखाएं" विकल्प पर क्लिक करके, सिर्फ़ सार्वजनिक डेटासेट से वह डेटासेट देखें.

स्कीमा और डेटा की झलक देखने के लिए, डेटासेट में मौजूद टेबल को बड़ा करें. हम sample_contents का इस्तेमाल करने जा रहे हैं. इसमें कॉन्टेंट टेबल के पूरे डेटा का सिर्फ़ 10% हिस्सा होता है. यहां डेटा की झलक दी गई है:
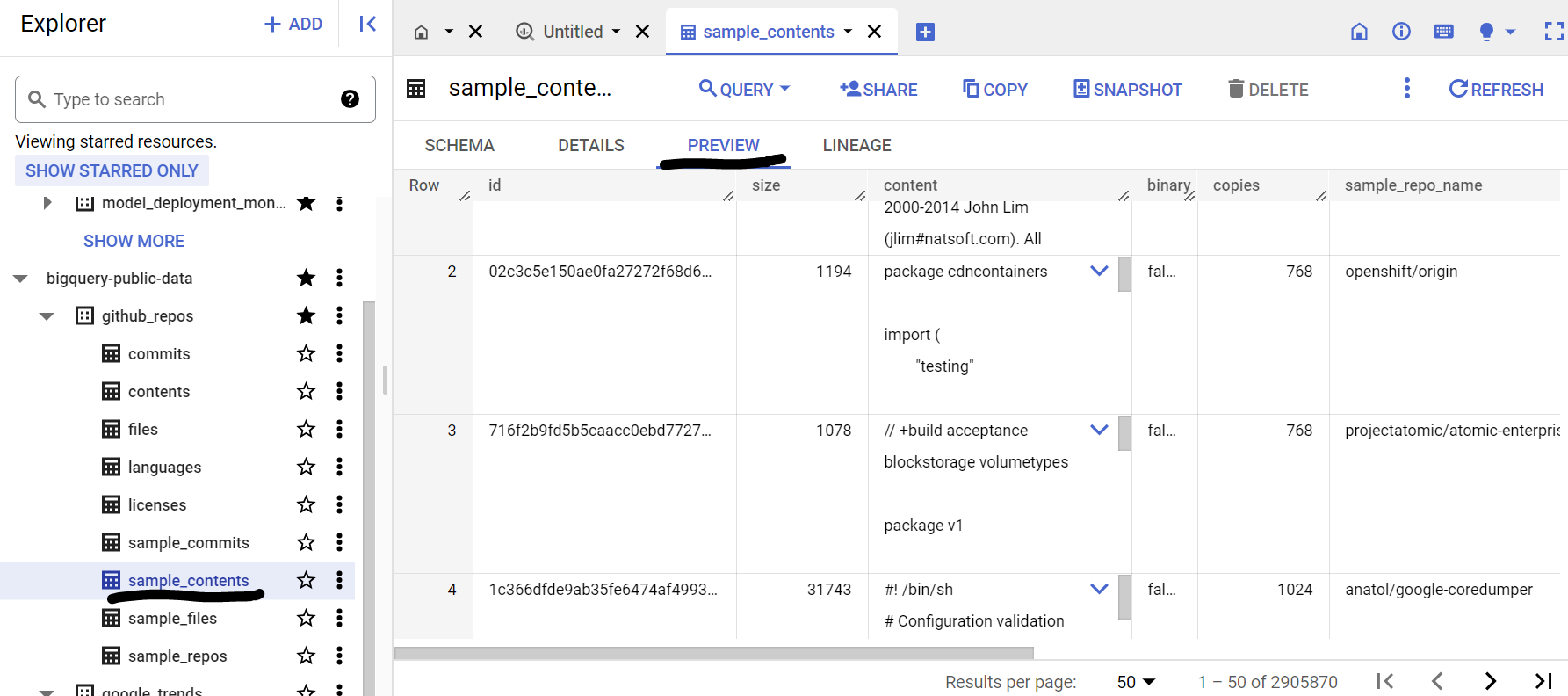
5. BigQuery डेटासेट बनाना
BigQuery डेटासेट, टेबल का कलेक्शन होता है. किसी डेटासेट की सभी टेबल, एक ही डेटा location में सेव की जाती हैं. डेटासेट और उसकी टेबल का ऐक्सेस सीमित करने के लिए, कस्टम ऐक्सेस कंट्रोल भी अटैच किए जा सकते हैं.
"US" क्षेत्र (या हमारी पसंद का कोई भी क्षेत्र) में bq_llm नाम का डेटासेट बनाएं

इस डेटासेट में, एमएल मॉडल सेव किया जाएगा. इसे हम आने वाले चरणों में बनाएंगे. आम तौर पर, हम एमएल ऐप्लिकेशन में इस्तेमाल किए जाने वाले डेटा को इसी डेटासेट की टेबल में सेव करते हैं. हालांकि, हमारे इस्तेमाल के उदाहरण में डेटा पहले से ही BigQuery के सार्वजनिक डेटासेट में मौजूद है. इसलिए, हम ज़रूरत के मुताबिक, सीधे तौर पर अपने नए डेटासेट से उस डेटा को रेफ़रंस करेंगे. अगर आपको यह प्रोजेक्ट अपने उस डेटासेट पर करना है जो CSV (या किसी अन्य फ़ाइल) में मौजूद है, तो Cloud Shell टर्मिनल से नीचे दिए गए कमांड को चलाकर, अपने डेटा को BigQuery डेटासेट में टेबल के तौर पर लोड किया जा सकता है:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. बाहरी कनेक्शन बनाया जा रहा है
बाहरी कनेक्शन बनाएं. अगर आपने पहले से BQ कनेक्शन API चालू नहीं किया है, तो उसे चालू करें. इसके बाद, कनेक्शन कॉन्फ़िगरेशन की जानकारी से सेवा खाते का आईडी नोट करें:
- BigQuery एक्सप्लोरर पैनल (BigQuery कंसोल के बाईं ओर) में, +जोड़ें बटन पर क्लिक करें. इसके बाद, सूची में दिए गए लोकप्रिय सोर्स में "बाहरी डेटा सोर्स से कनेक्शन" पर क्लिक करें
- कनेक्शन टाइप के तौर पर "BigLake और रिमोट फ़ंक्शन" को चुनें. साथ ही, कनेक्शन आईडी के तौर पर "llm-conn" डालें
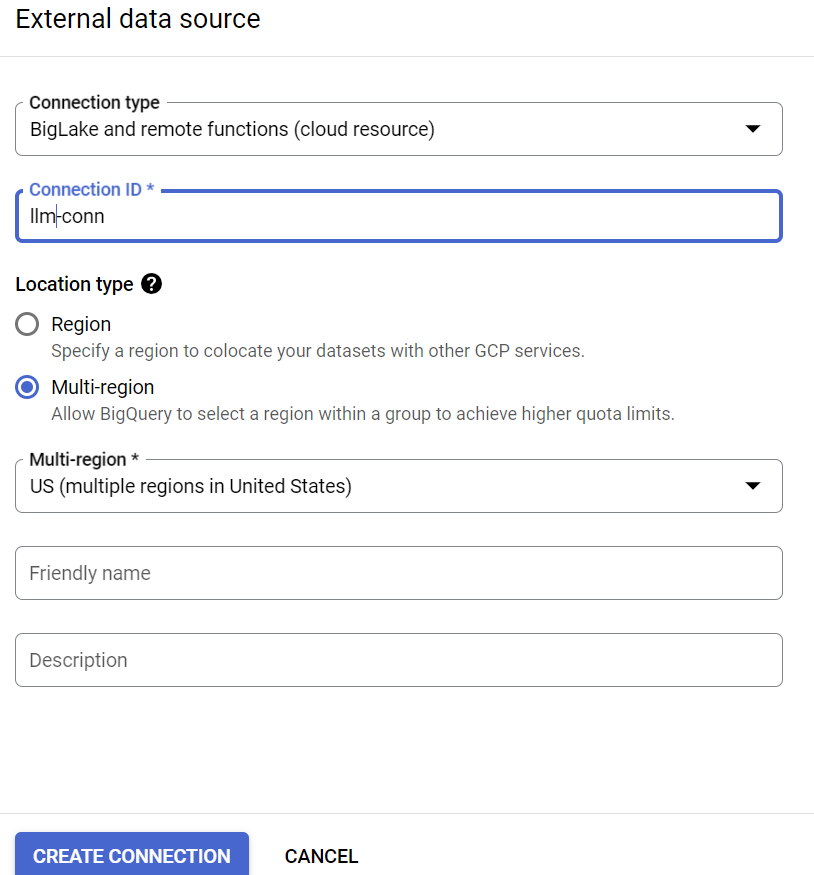
- कनेक्शन बन जाने के बाद, कनेक्शन कॉन्फ़िगरेशन की जानकारी से जनरेट हुए सेवा खाते को नोट कर लें
7. मंज़ूरी दें
इस चरण में, हम सेवा खाते को Vertex AI सेवा ऐक्सेस करने की अनुमतियां देंगे:
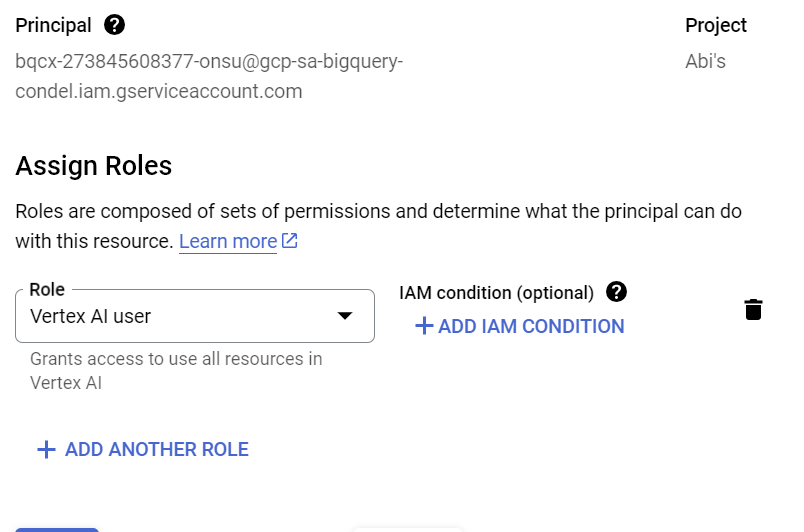
IAM खोलें और बाहरी कनेक्शन बनाने के बाद कॉपी किए गए सेवा खाते को प्रिंसिपल के तौर पर जोड़ें. इसके बाद, "Vertex AI उपयोगकर्ता" की भूमिका चुनें
8. रिमोट एमएल मॉडल बनाना
होस्ट किए गए Vertex AI लार्ज लैंग्वेज मॉडल को दिखाने वाला रिमोट मॉडल बनाएं:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
यह bq_llm डेटासेट में llm_model नाम का मॉडल बनाता है. यह रिमोट फ़ंक्शन के तौर पर, Vertex AI के CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 API का इस्तेमाल करता है. इस प्रोसेस को पूरा होने में कुछ सेकंड लगेंगे.
9. एमएल मॉडल का इस्तेमाल करके टेक्स्ट जनरेट करना
मॉडल बन जाने के बाद, इसका इस्तेमाल टेक्स्ट जनरेट करने, उसका सारांश बनाने या उसे कैटगरी में बांटने के लिए करें.
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**वजह:
ml_generate_text_result** टेक्स्ट जनरेशन मॉडल से मिला जवाब है. यह JSON फ़ॉर्मैट में होता है. इसमें कॉन्टेंट और सुरक्षा से जुड़े एट्रिब्यूट, दोनों शामिल होते हैं: a. कॉन्टेंट, जनरेट किए गए टेक्स्ट के नतीजे b को दिखाता है. सुरक्षा एट्रिब्यूट, कॉन्टेंट फ़िल्टर करने की सुविधा को दिखाते हैं. इसमें थ्रेशोल्ड को अडजस्ट किया जा सकता है. यह सुविधा, Vertex AI Palm API में चालू होती है, ताकि लार्ज लैंग्वेज मॉडल से अनचाहे या अप्रत्याशित जवाब न मिलें. अगर जवाब, सुरक्षा थ्रेशोल्ड का उल्लंघन करता है, तो उसे ब्लॉक कर दिया जाता है
ML.GENERATE_TEXT का इस्तेमाल BigQuery में किया जाता है. इससे Vertex AI LLM को ऐक्सेस किया जा सकता है, ताकि टेक्स्ट जनरेट करने से जुड़े टास्क पूरे किए जा सकें
CONCAT, आपके PROMPT स्टेटमेंट और डेटाबेस रिकॉर्ड को जोड़ता है
github_repos, डेटासेट का नाम है. साथ ही, sample_contents उस टेबल का नाम है जिसमें वह डेटा मौजूद है जिसका इस्तेमाल हम प्रॉम्प्ट डिज़ाइन में करेंगे
टेंपरेचर, प्रॉम्प्ट का एक पैरामीटर है. इससे जवाब में मौजूद रैंडमनेस को कंट्रोल किया जाता है. जवाब जितना कम रैंडम होगा, वह उतना ही ज़्यादा काम का होगा
Max_output_tokens, जवाब में आपको चाहिए शब्दों की संख्या है
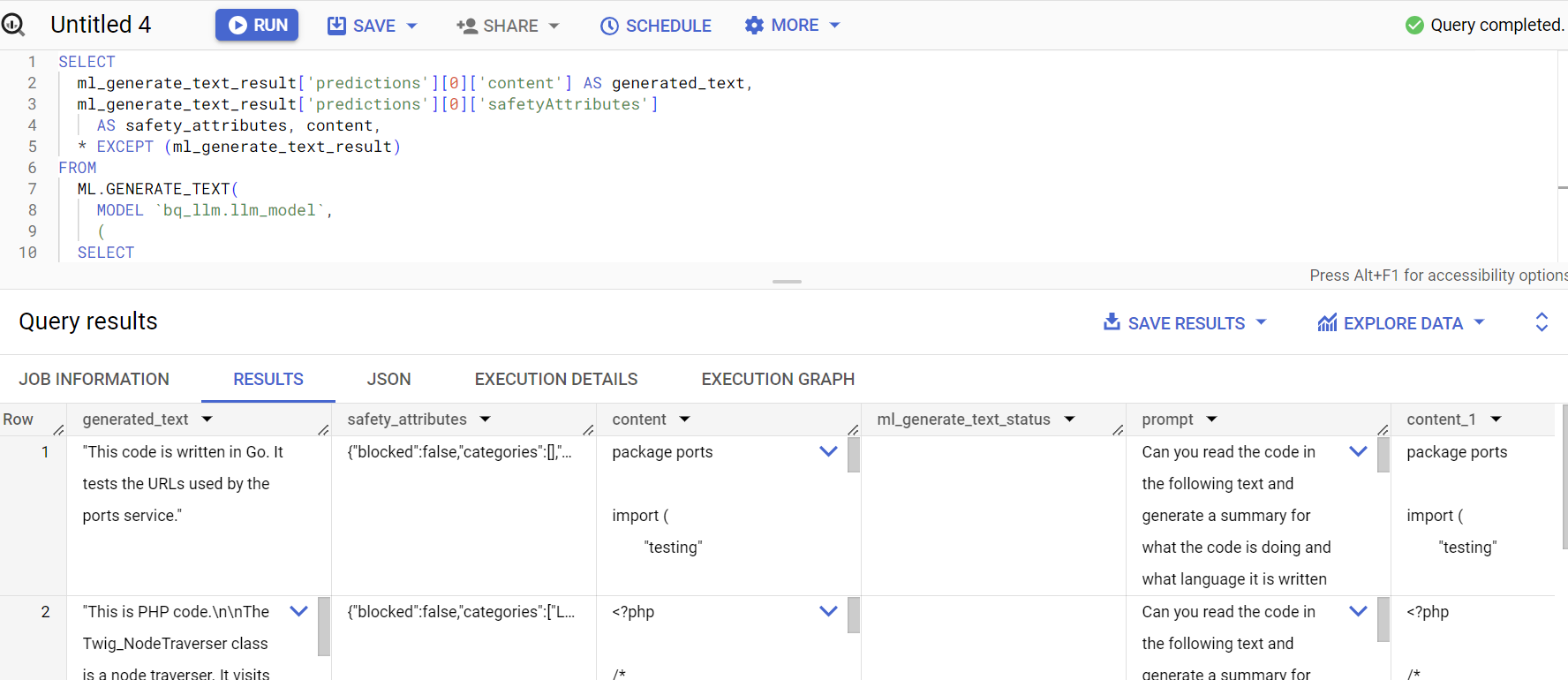
क्वेरी का जवाब ऐसा दिखता है:
10. क्वेरी के नतीजे को फ़्लैट करना
आइए, नतीजे को फ़्लैट कर देते हैं, ताकि हमें क्वेरी में JSON को साफ़ तौर पर डिकोड न करना पड़े:
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**वजह:
Flatten_json_output** बूलियन को दिखाता है. इसे सही पर सेट करने पर, JSON रिस्पॉन्स से निकाला गया ऐसा टेक्स्ट मिलता है जिसे आसानी से समझा जा सकता है.
क्वेरी का जवाब ऐसा दिखता है:

11. व्यवस्थित करें
इस पोस्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेज करें पेज पर जाएं
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी डालें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें
12. बधाई हो
बधाई हो! आपने Vertex AI के टेक्स्ट जनरेशन वाले एलएलएम का इस्तेमाल करके, अपने डेटा पर टेक्स्ट विश्लेषण किया है. इसके लिए, आपने सिर्फ़ SQL क्वेरी का इस्तेमाल किया है. उपलब्ध मॉडल के बारे में ज़्यादा जानने के लिए, Vertex AI LLM प्रॉडक्ट का दस्तावेज़ देखें.