
1. Introdução
Neste codelab, listei as etapas para resumir o código-fonte de repositórios do GitHub e identificar a linguagem de programação usada neles com o modelo de linguagem grande da Vertex AI para geração de texto ( text-bison) como uma função remota hospedada no BigQuery. Graças ao Projeto de arquivo do GitHub, agora temos um snapshot completo de mais de 2,8 milhões de repositórios de código aberto do GitHub nos conjuntos de dados públicos do Google BigQuery. Os serviços usados são:
- BigQuery ML
- API PaLM da Vertex AI
O que você vai criar
Você vai criar
- Um conjunto de dados do BigQuery para conter o modelo
- Um modelo do BigQuery que hospeda a API PaLM da Vertex AI como uma função remota
- Uma conexão externa para estabelecer a conexão entre o BigQuery e a Vertex AI
2. Requisitos
3. Antes de começar
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Verifique se todas as APIs necessárias (API BigQuery, API Vertex AI e API BigQuery Connection) estão ativadas.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com bq. Consulte a documentação para ver o uso e os comandos gcloud.
No console do Cloud, clique em "Ativar o Cloud Shell" no canto superior direito:

Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Acesse o console do BigQuery diretamente inserindo o seguinte URL no navegador: https://console.cloud.google.com/bigquery
4. Preparando os dados
Neste caso de uso, estamos usando o conteúdo do código-fonte do conjunto de dados github_repos nos conjuntos de dados públicos do Google BigQuery. Para usar isso, no console do BigQuery, pesquise "github_repos" e pressione Enter. Clique na estrela ao lado do conjunto de dados listado como resultado da pesquisa. Em seguida, clique na opção "MOSTRAR SOMENTE OS MARCADOS COM ESTRELA" para ver esse conjunto de dados apenas nos conjuntos de dados públicos.

Expanda as tabelas no conjunto de dados para ver o esquema e a prévia dos dados. Vamos usar o sample_contents, que contém apenas uma amostra (10%) dos dados completos na tabela de conteúdo. Confira uma prévia dos dados:

5. Como criar o conjunto de dados do BigQuery
Um conjunto de dados do BigQuery é uma coleção de tabelas. Todas as tabelas em um conjunto de dados são armazenadas no mesmo local de dados. Também é possível anexar controles de acesso personalizados para limitar o acesso a um conjunto de dados e às tabelas dele.
Crie um conjunto de dados na região "US" (ou qualquer região de sua preferência) chamado bq_llm.
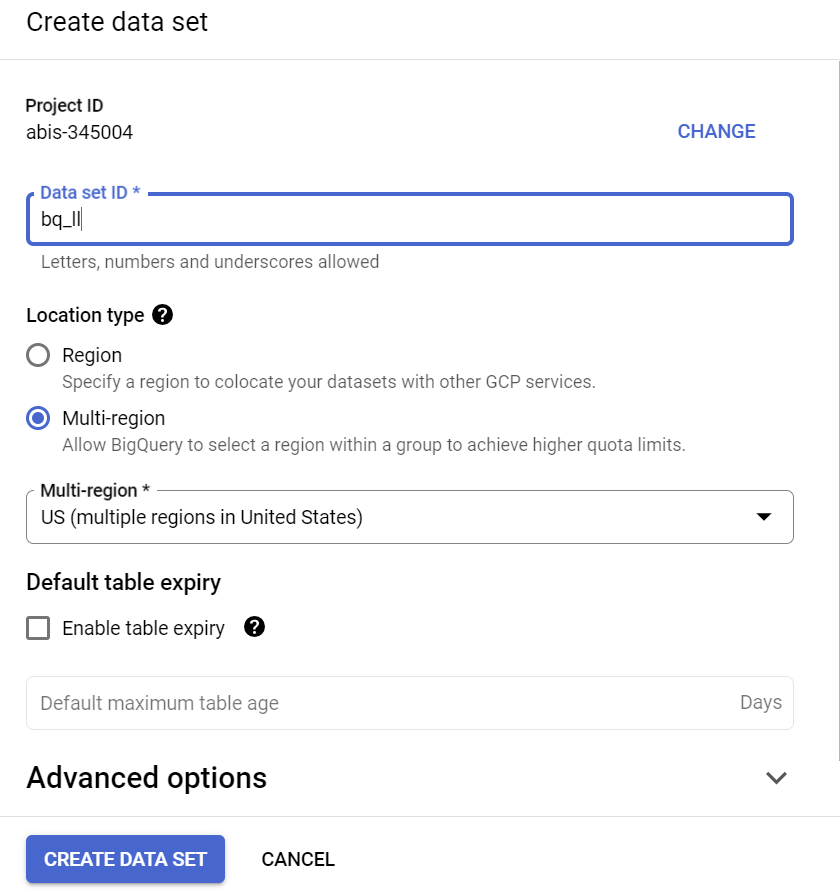
Esse conjunto de dados vai hospedar o modelo de ML que vamos criar nas próximas etapas. Normalmente, também armazenamos os dados que usamos no aplicativo de ML em uma tabela no próprio conjunto de dados. No entanto, no nosso caso de uso, os dados já estão em um conjunto de dados público do BigQuery. Vamos fazer referência a eles diretamente do conjunto de dados recém-criado, conforme necessário. Se você quiser fazer este projeto no seu próprio conjunto de dados em um arquivo CSV (ou qualquer outro arquivo), carregue os dados em uma tabela de um conjunto de dados do BigQuery executando o comando abaixo no terminal do Cloud Shell:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. Criando conexão externa
Crie uma conexão externa (ative a API BigQuery Connection, se ainda não tiver feito isso) e anote o ID da conta de serviço nos detalhes da configuração da conexão:
- Clique no botão +ADICIONAR no painel do BigQuery Explorer (à esquerda do console do BigQuery) e clique em "Conexão com fontes de dados externas" nas fontes mais usadas listadas.
- Selecione o tipo de conexão como "BigLake e funções remotas" e forneça "llm-conn" como o ID da conexão.
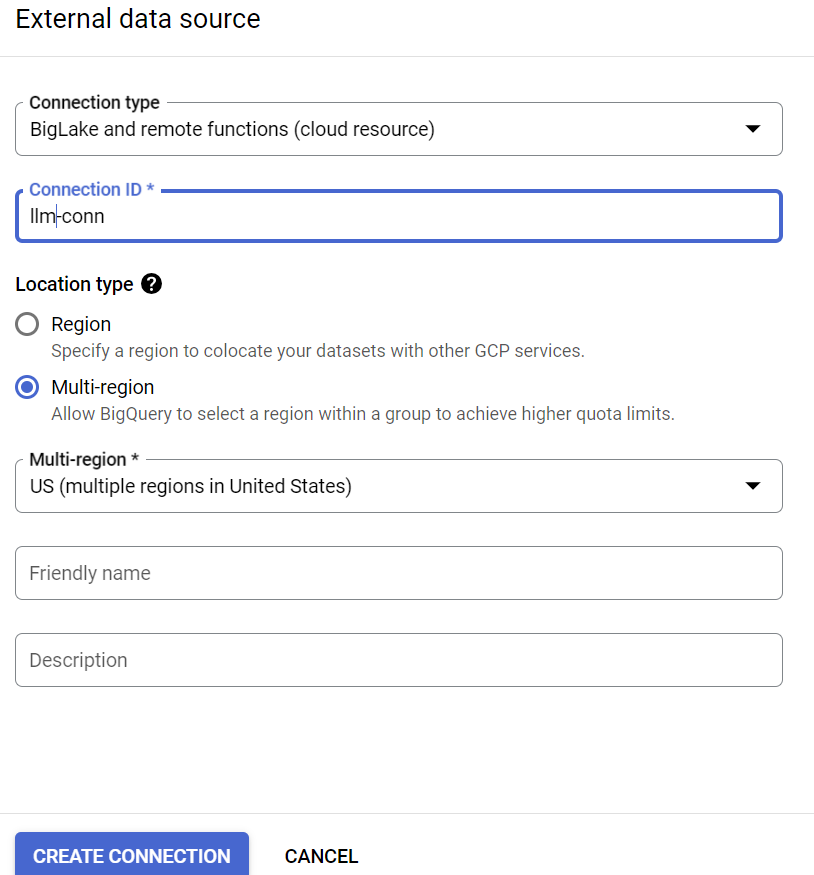
- Depois que a conexão for criada, anote a conta de serviço gerada nos detalhes da configuração da conexão.
7. Conceder permissões
Nesta etapa, vamos conceder permissões à conta de serviço para acessar o serviço da Vertex AI:
Abra o IAM e adicione a conta de serviço que você copiou depois de criar a conexão externa como principal e selecione o papel "Usuário da Vertex AI".

8. Criar um modelo de ML remoto
Crie o modelo remoto que representa um modelo de linguagem grande hospedado da Vertex AI:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
Ele cria um modelo chamado llm_model no conjunto de dados bq_llm, que usa a API CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 da Vertex AI como uma função remota. O processo vai levar vários segundos para ser concluído.
9. Gerar texto usando o modelo de ML
Depois de criar o modelo, use-o para gerar, resumir ou categorizar textos.
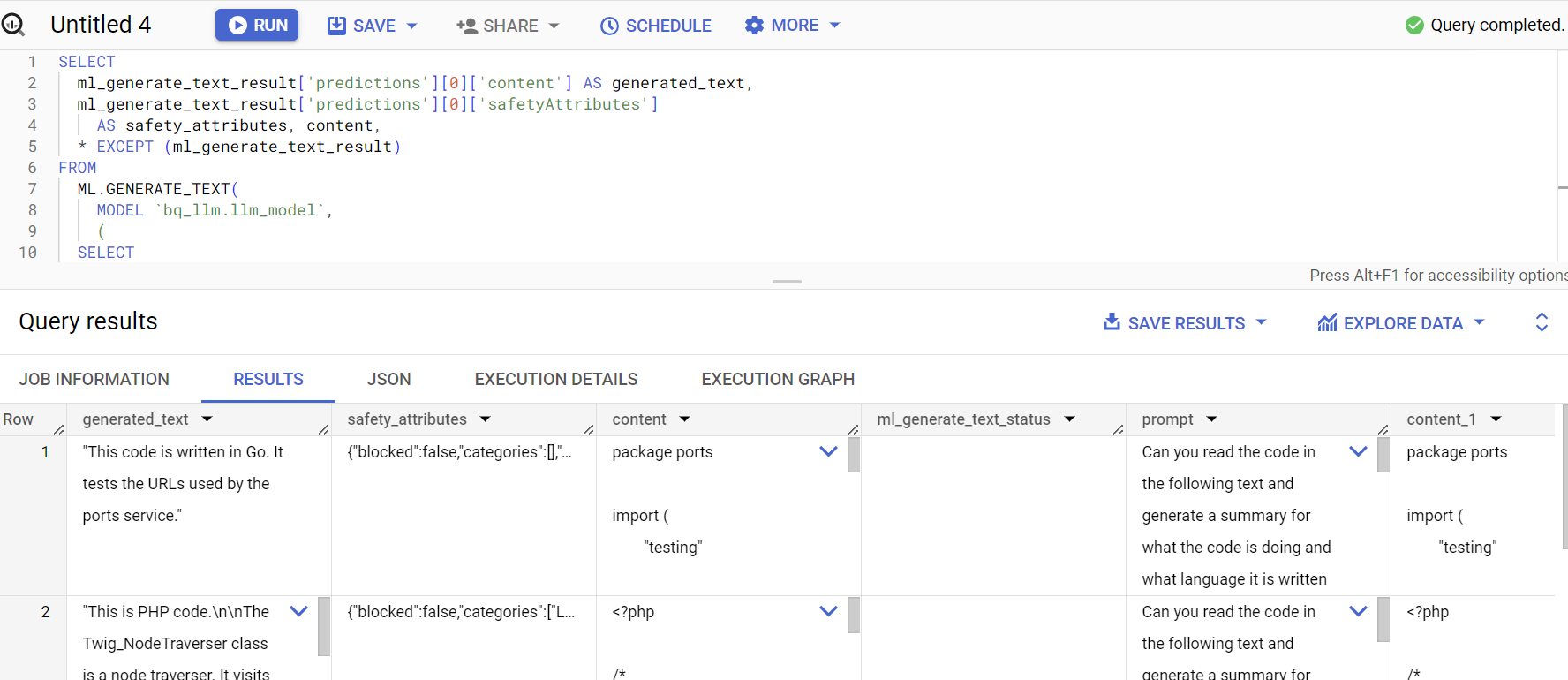
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**Explicação:
ml_generate_text_result** é a resposta do modelo de geração de texto no formato JSON que contém atributos de conteúdo e segurança: a. O conteúdo representa o resultado do texto gerado b. Os atributos de segurança representam o filtro de conteúdo integrado com um limite ajustável ativado na API PaLM da Vertex AI para evitar respostas não intencionais ou imprevistas do modelo de linguagem grande. A resposta é bloqueada se violar o limite de segurança.
ML.GENERATE_TEXT é o constructo usado no BigQuery para acessar o LLM da Vertex AI e realizar tarefas de geração de texto.
CONCAT anexa sua instrução PROMPT e o registro do banco de dados
github_repos é o nome do conjunto de dados e sample_contents é o nome da tabela que contém os dados que vamos usar no design do comando.
Temperatura é o parâmetro do comando para controlar a aleatoriedade da resposta. Quanto menor, melhor a relevância.
Max_output_tokens é o número de palavras que você quer na resposta.
A resposta da consulta é semelhante a esta:
10. Aplanar o resultado da consulta
Vamos achatar o resultado para não precisar decodificar o JSON explicitamente na consulta:
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**Explicação:
**Flatten_json_output** representa o booleano que, se definido como verdadeiro, retorna um texto simples e compreensível extraído da resposta JSON.
A resposta da consulta é semelhante a esta:

11. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
12. Parabéns
Parabéns! Você usou um LLM de geração de texto da Vertex AI de forma programática para realizar análises de texto nos seus dados usando apenas consultas SQL. Confira a documentação do produto LLM da Vertex AI para saber mais sobre os modelos disponíveis.