
1. Pengantar
Dalam codelab ini, saya telah mencantumkan langkah-langkah untuk melakukan peringkasan kode sumber dari repositori GitHub dan mengidentifikasi bahasa pemrograman dalam repositori, menggunakan Model Bahasa Besar Vertex AI untuk pembuatan teks ( text-bison) sebagai fungsi jarak jauh yang dihosting di BigQuery. Berkat Archive Project GitHub, kini kami memiliki snapshot lengkap lebih dari 2,8 juta repositori GitHub open source di Set Data Publik Google BigQuery. Daftar layanan yang digunakan adalah:
- BigQuery ML
- Vertex AI PaLM API
Yang akan Anda build
Anda akan membuat
- Set Data BigQuery untuk menampung model
- Model BigQuery yang menghosting Vertex AI PaLM API sebagai fungsi jarak jauh
- Koneksi eksternal untuk membuat koneksi antara BigQuery dan Vertex AI
2. Persyaratan
3. Sebelum memulai
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
- Pastikan semua API yang diperlukan (BigQuery API, Vertex AI API, BigQuery Connection API) telah diaktifkan
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan bq. Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya
Dari Cloud Console, klik Activate Cloud Shell di pojok kanan atas:
Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Buka konsol BigQuery secara langsung dengan memasukkan URL berikut di browser Anda: https://console.cloud.google.com/bigquery
4. Menyiapkan data
Dalam kasus penggunaan ini, kita menggunakan konten kode sumber dari set data github_repos di Set Data Publik Google BigQuery. Untuk menggunakannya, di konsol BigQuery, telusuri "github_repos" lalu tekan enter. Klik bintang di samping set data yang tercantum sebagai hasil penelusuran. Kemudian, klik opsi "SHOW STARRED ONLY" untuk melihat set data tersebut saja dari set data publik.
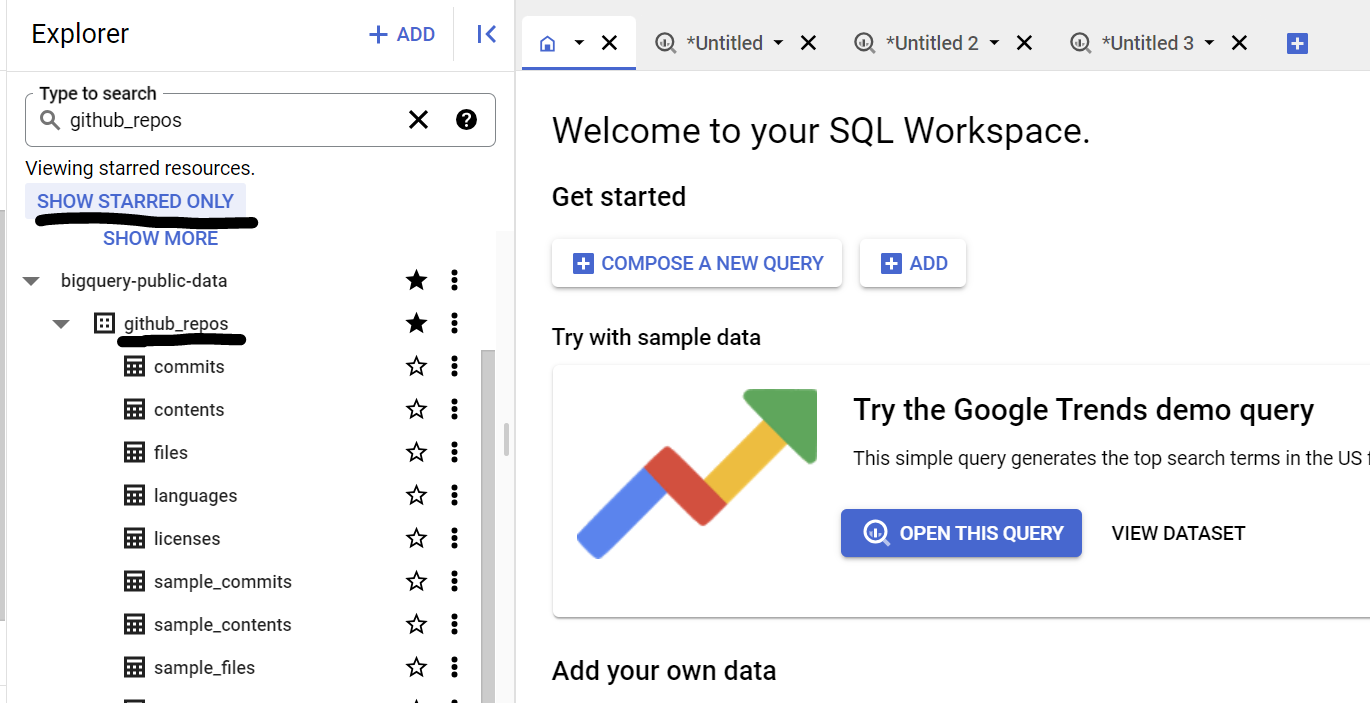
Luaskan tabel dalam set data untuk melihat skema dan pratinjau data. Kita akan menggunakan sample_contents, yang hanya berisi sampel (10%) dari data lengkap dalam tabel contents. Berikut pratinjau datanya:

5. Membuat set data BigQuery
Set data BigQuery adalah kumpulan tabel. Semua tabel dalam set data disimpan di lokasi data yang sama. Anda juga dapat melampirkan kontrol akses kustom untuk membatasi akses ke set data dan tabelnya.
Buat set data di region "US" (atau region pilihan kita) bernama bq_llm
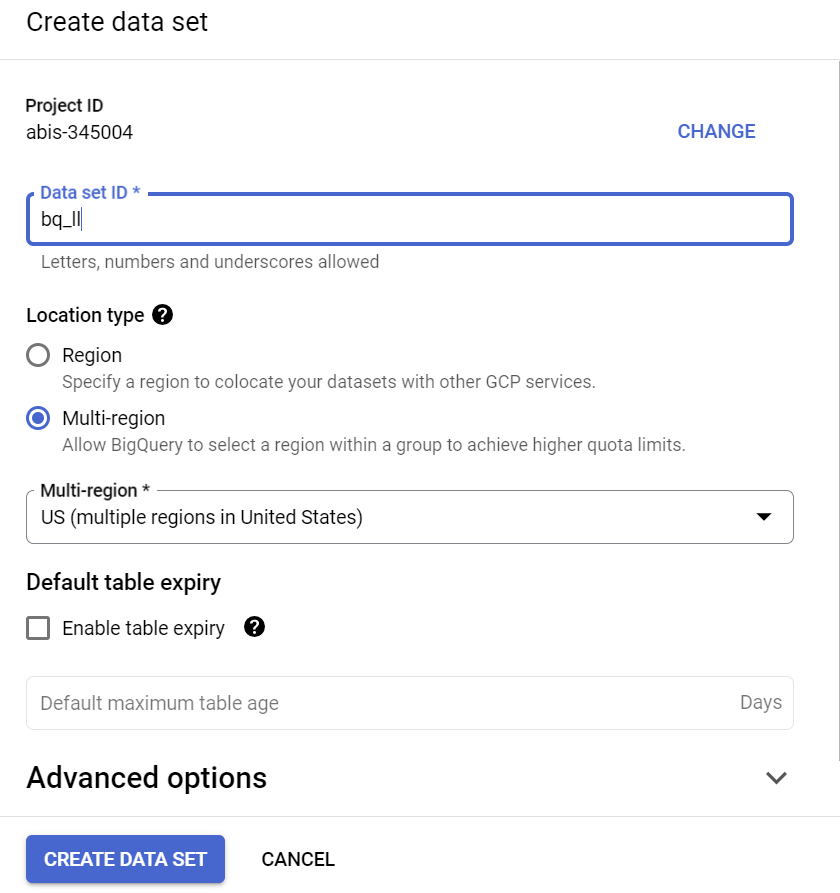
Set data ini akan menampung model ML yang akan kita buat pada langkah-langkah berikutnya. Biasanya, kita juga akan menyimpan data yang kita gunakan dalam aplikasi ML di tabel dalam set data ini sendiri. Namun, dalam kasus penggunaan kita, data sudah ada di set data publik BigQuery. Kita akan mereferensikannya langsung dari set data yang baru dibuat sesuai kebutuhan. Jika ingin mengerjakan project ini dengan set data Anda sendiri yang ada dalam CSV (atau file lainnya), Anda dapat memuat data ke dalam tabel set data BigQuery dengan menjalankan perintah di bawah dari terminal Cloud Shell:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. Membuat koneksi eksternal
Buat Koneksi Eksternal (Aktifkan BQ Connection API jika belum dilakukan) dan catat ID Akun Layanan dari detail konfigurasi koneksi:
- Klik tombol +ADD di panel BigQuery Explorer (di sebelah kiri konsol BigQuery) dan klik "Connection to external data sources" di sumber populer yang tercantum
- Pilih Connection type sebagai "BigLake and remote functions" dan berikan "llm-conn" sebagai Connection ID

- Setelah koneksi dibuat, catat Akun Layanan yang dihasilkan dari detail konfigurasi koneksi
7. Berikan izin
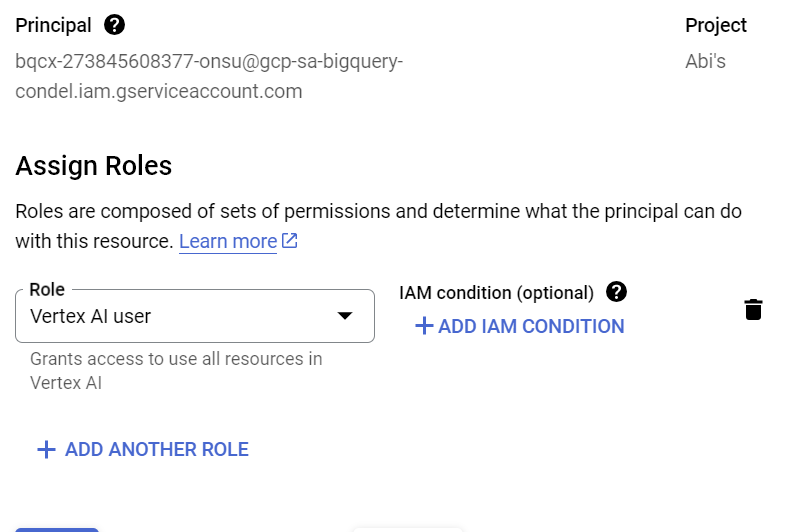
Pada langkah ini, kita akan memberikan izin ke Akun Layanan untuk mengakses layanan Vertex AI:
Buka IAM dan tambahkan Akun Layanan yang Anda salin setelah membuat koneksi eksternal sebagai Principal dan pilih Peran "Vertex AI User"
8. Membuat model ML jarak jauh
Buat model jarak jauh yang merepresentasikan model bahasa besar Vertex AI yang dihosting:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
Tindakan ini akan membuat model bernama llm_model di set data bq_llm yang memanfaatkan CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 API Vertex AI sebagai fungsi jarak jauh. Proses ini akan memerlukan waktu beberapa detik hingga selesai.
9. Membuat teks menggunakan model ML
Setelah model dibuat, gunakan model tersebut untuk membuat, meringkas, atau mengategorikan teks.
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**Penjelasan:
ml_generate_text_result** adalah respons dari model pembuatan teks dalam format JSON yang berisi atribut konten dan keamanan: a. Content merepresentasikan hasil teks yang dihasilkan b. Atribut Keamanan merepresentasikan filter konten bawaan dengan batas yang dapat disesuaikan yang diaktifkan di Vertex AI PaLM API untuk menghindari respons yang tidak diinginkan atau tidak terduga dari model bahasa besar - respons diblokir jika melanggar batas keamanan
ML.GENERATE_TEXT adalah konstruksi yang Anda gunakan di BigQuery untuk mengakses LLM Vertex AI guna melakukan tugas pembuatan teks
CONCAT menambahkan pernyataan PROMPT Anda dan catatan database
github_repos adalah nama set data dan sample_contents adalah nama tabel yang menyimpan data yang akan kita gunakan dalam desain perintah
Temperatur adalah parameter perintah untuk mengontrol keacakan respons - makin rendah makin baik dalam hal relevansi
Max_output_tokens adalah jumlah kata yang Anda inginkan dalam respons
Respons kueri akan terlihat seperti ini:

10. Meratakan hasil kueri
Mari kita ratakan hasilnya agar kita tidak perlu mendekode JSON secara eksplisit dalam kueri:
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**Penjelasan:
Flatten_json_output** merepresentasikan boolean, yang jika disetel ke benar akan menampilkan teks datar yang mudah dipahami dan diekstrak dari respons JSON.
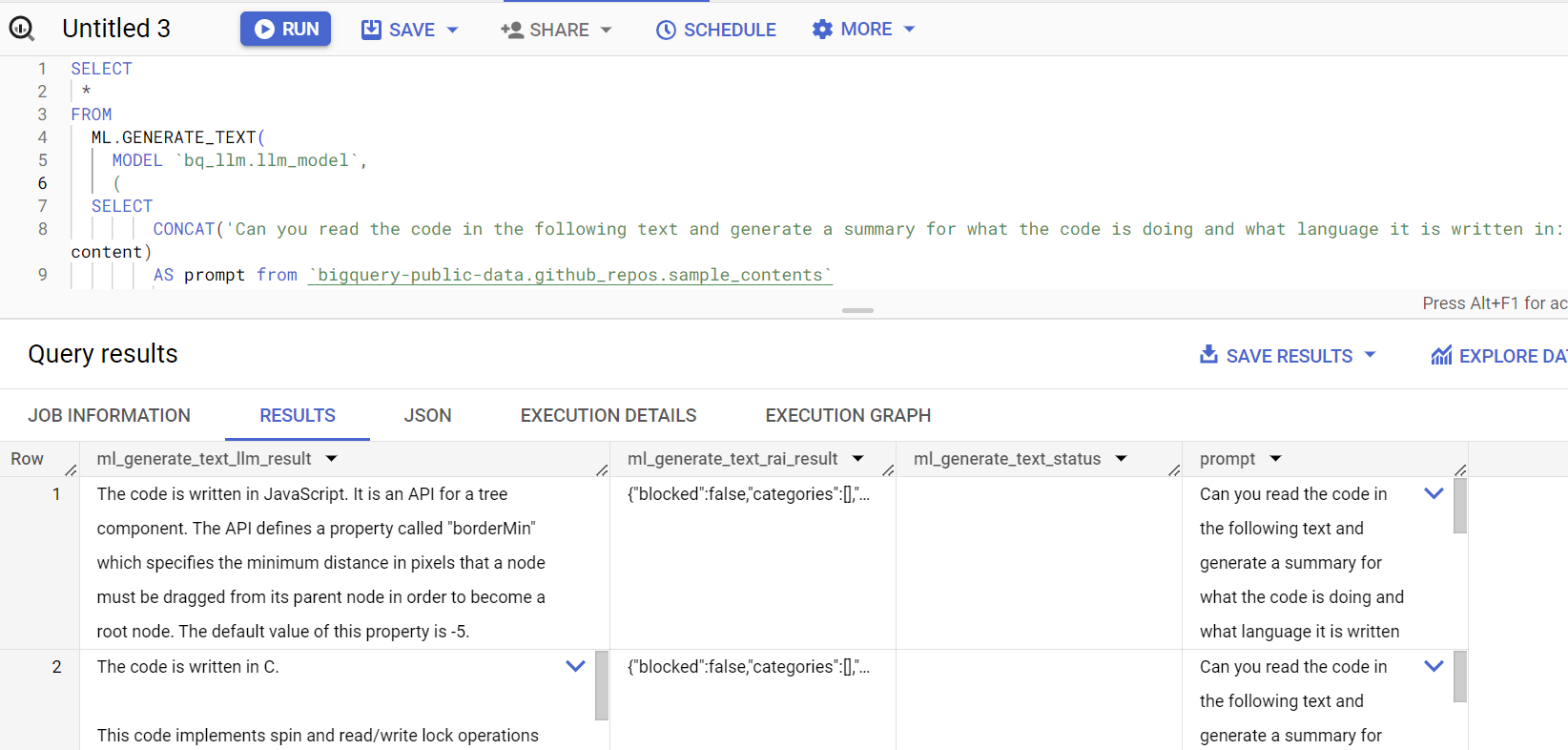
Respons kueri akan terlihat seperti ini:
11. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam posting ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman Manage resources
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project
12. Selamat
Selamat! Anda telah berhasil menggunakan LLM Pembuatan Teks Vertex AI secara terprogram untuk melakukan analisis teks pada data Anda hanya menggunakan kueri SQL. Lihat dokumentasi produk LLM Vertex AI untuk mempelajari lebih lanjut model yang tersedia.