
1. نظرة عامة
في هذا الدرس التطبيقي حول الترميز، ستنشئ روبوت دردشة ذكيًا لاقتراح الأفلام من خلال الجمع بين إمكانات Neo4j وGoogle Vertex AI وGemini. في صميم هذا النظام، هناك "رسم بياني معرفي" من Neo4j يقدّم نماذج للأفلام والممثلين والمخرجين والأنواع وغير ذلك من خلال شبكة غنية من العُقد والعلاقات المترابطة.
لتحسين تجربة المستخدم من خلال الفهم الدلالي، ستنشئ تضمينات متّجهة من نبذات عن حبكات الأفلام باستخدام نموذج text-embedding-004 (أو أحدث) من Vertex AI. يتم فهرسة هذه التضمينات في Neo4j لاسترجاعها بسرعة استنادًا إلى التشابه.
أخيرًا، يمكنك دمج Gemini لتشغيل واجهة حوارية تتيح للمستخدمين طرح أسئلة باللغة الطبيعية، مثل "ماذا يمكنني مشاهدة إذا أعجبني فيلم Interstellar؟" وتلقّي اقتراحات أفلام مخصّصة استنادًا إلى التشابه الدلالي والسياق المستند إلى الرسم البياني.
خلال هذا الدرس العملي، ستتّبع نهجًا خطوة بخطوة على النحو التالي:
- إنشاء رسم بياني معرفي في Neo4j يتضمّن كيانات وعلاقات مرتبطة بالأفلام
- إنشاء/تحميل تضمينات نصية لملخّصات الأفلام باستخدام Vertex AI
- تنفيذ واجهة روبوت دردشة Gradio مستندة إلى Gemini تجمع بين البحث المتّجه وتنفيذ Cypher المستند إلى الرسم البياني
- (اختياري) نشر التطبيق على Cloud Run كتطبيق ويب مستقل
ما ستتعلمه
- كيفية إنشاء رسم بياني معرفي للأفلام وتعبئته باستخدام Cypher وNeo4j
- كيفية استخدام Vertex AI لإنشاء تضمينات نصية دلالية والعمل بها
- كيفية الجمع بين النماذج اللغوية الكبيرة و"الرسومات البيانية المعرفية" لاسترجاع المعلومات بذكاء باستخدام GraphRAG
- كيفية إنشاء واجهة محادثة سهلة الاستخدام باستخدام Gradio
- كيفية النشر بشكل اختياري على Google Cloud Run
المتطلبات
- متصفّح الويب Chrome
- حساب Gmail
- مشروع Google Cloud تم تفعيل الفوترة فيه
- حساب مجاني على قاعدة بيانات Neo4j Aura
- معرفة أساسية بأوامر سطر الأوامر ولغة Python (مفيدة ولكنّها ليست مطلوبة)
يستخدم هذا الدرس التطبيقي حول الترميز، المصمّم للمطوّرين من جميع المستويات (بما في ذلك المبتدئين)، لغة Python وNeo4j في التطبيق النموذجي. على الرغم من أنّ الإلمام الأساسي بلغة Python وقواعد بيانات الرسوم البيانية يمكن أن يكون مفيدًا، لا يلزم وجود خبرة سابقة لفهم المفاهيم أو متابعة الدورة التدريبية.
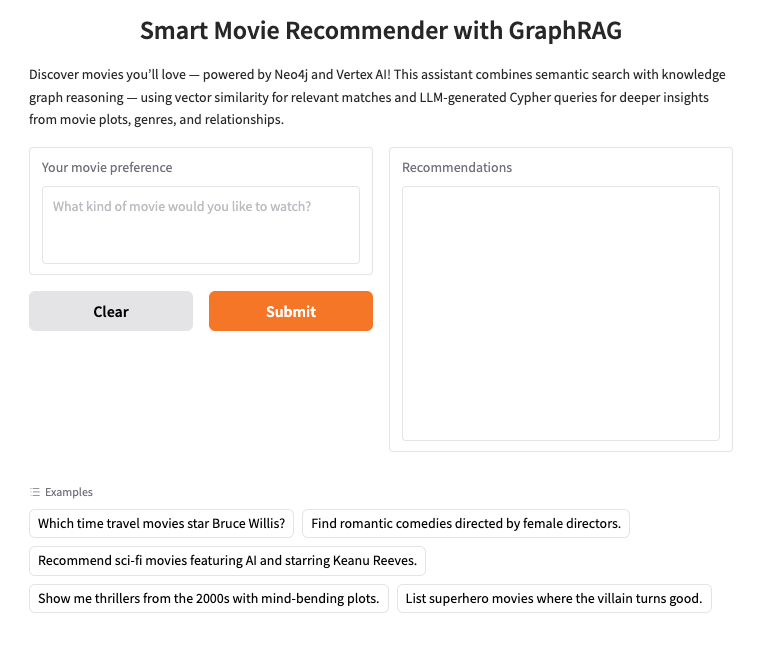
2. إعداد Neo4j AuraDB
Neo4j هي قاعدة بيانات رسومية أصلية رائدة تخزّن البيانات كشبكة من العُقد (الكيانات) والعلاقات (الروابط بين الكيانات)، ما يجعلها مثالية لحالات الاستخدام التي يكون فيها فهم الروابط أمرًا أساسيًا، مثل الاقتراحات واكتشاف الاحتيال والرسوم البيانية المعرفية وغير ذلك. على عكس قواعد البيانات العلائقية أو المستندة إلى المستندات التي تعتمد على جداول ثابتة أو بنى هرمية، يتيح نموذج الرسم البياني المرن في Neo4j تمثيلاً بديهيًا وفعّالاً للبيانات المعقّدة والمترابطة.
بدلاً من تنظيم البيانات في صفوف وجداول مثل قواعد البيانات الارتباطية، تستخدم Neo4j نموذج رسم بياني، حيث يتم تمثيل المعلومات على شكل عُقد (كيانات) وعلاقات (روابط بين هذه الكيانات). ويجعل هذا النموذج التعامل مع البيانات المرتبطة بطبيعتها أمرًا سهلًا للغاية، مثل الأشخاص أو الأماكن أو المنتجات أو الأفلام أو الممثلين أو الأنواع في حالتنا.
على سبيل المثال، في مجموعة بيانات أفلام:
- يمكن أن تمثّل العقدة
MovieأوActorأوDirector - يمكن أن تكون العلاقة
ACTED_INأوDIRECTED
يتيح لك هذا البناء طرح أسئلة بسهولة، مثل:
- ما هي الأفلام التي شارك فيها هذا الممثل؟
- مَن عمل مع "كريستوفر نولان"؟
- ما هي الأفلام المشابهة استنادًا إلى الممثلين أو الأنواع المشتركة؟
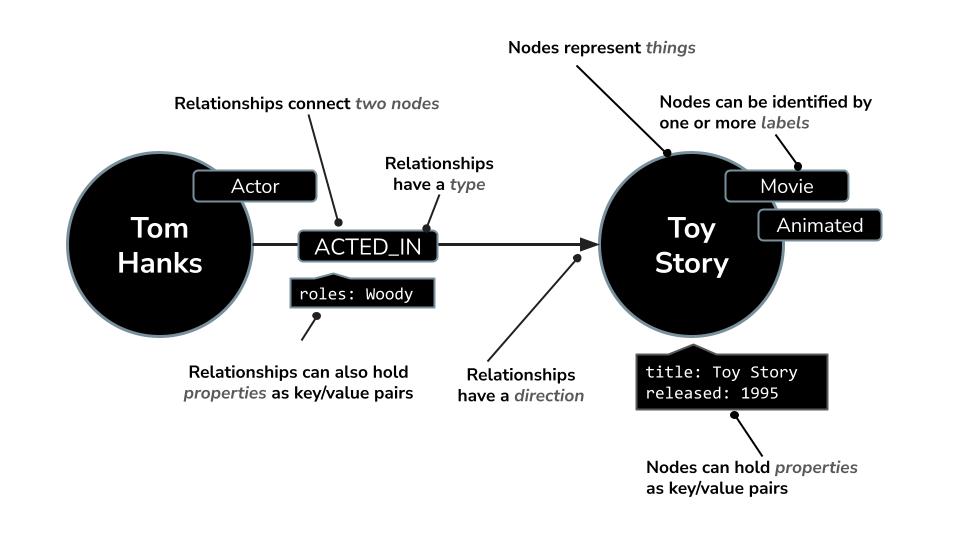
تتضمّن Neo4j لغة استعلام قوية تُعرف باسم Cypher، وهي مصمَّمة خصيصًا للاستعلام عن الرسومات البيانية. تتيح لك لغة Cypher التعبير عن الأنماط والروابط المعقّدة بطريقة موجزة وسهلة القراءة. على سبيل المثال: يستخدم طلب بحث Cypher هذا MERGE لضمان إنشاء فريد للممثل والفيلم وعلاقتهما بتفاصيل الدور، وتجنُّب التكرار.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
توفّر Neo4j خيارات نشر متعددة حسب احتياجاتك:
- الإدارة الذاتية: يمكنك تشغيل Neo4j على البنية الأساسية الخاصة بك باستخدام Neo4j Desktop أو كصورة Docker (داخل مقر الشركة أو في السحابة الإلكترونية الخاصة بك).
- إدارة السحابة الإلكترونية: يمكنك نشر Neo4j على مقدّمي الخدمات السحابية المعروفين باستخدام عروض السوق.
- مُدارة بالكامل: استخدِم Neo4j AuraDB، وهي قاعدة بيانات سحابية مُدارة بالكامل كخدمة من Neo4j، وتتولّى هذه الخدمة توفير الموارد وتوسيع النطاق والاحتفاظ بنسخ احتياطية وتوفير الأمان نيابةً عنك.
في هذا الدرس التطبيقي حول الترميز، سنستخدم Neo4j AuraDB Free، وهي فئة AuraDB بدون تكلفة. توفّر هذه الخدمة مثيلاً لقاعدة بيانات رسومية مُدارة بالكامل مع مساحة تخزين وميزات كافية لإنشاء نماذج أولية وتعلُّم كيفية استخدامها وإنشاء تطبيقات صغيرة، ما يجعلها مثالية لتحقيق هدفنا المتمثل في إنشاء برنامج دردشة آلي لاقتراح الأفلام مستند إلى الذكاء الاصطناعي التوليدي.
ستنشئ مثيلاً مجانيًا من AuraDB، وتربطه بتطبيقك باستخدام بيانات اعتماد الاتصال، وتستخدمه لتخزين مخطط معلومات الأفلام والاستعلام عنه خلال هذا التمرين العملي.
لماذا الرسوم البيانية؟
في قواعد البيانات العلائقية التقليدية، تتطلّب الإجابة عن أسئلة مثل "ما هي الأفلام المشابهة لفيلم Inception استنادًا إلى فريق التمثيل أو النوع المشترك؟" عمليات JOIN معقّدة على مستوى جداول متعددة. ومع زيادة عمق العلاقات، يتدهور الأداء وإمكانية القراءة.
في المقابل، تم تصميم قواعد بيانات الرسومات البيانية، مثل Neo4j، من أجل التنقّل بكفاءة بين العلاقات، ما يجعلها مناسبة تمامًا لأنظمة الاقتراحات والبحث الدلالي والمساعدين الأذكياء. تساعد هذه الرسومات البيانية في تسجيل السياق الواقعي، مثل شبكات التعاون أو السيناريوهات أو تفضيلات المشاهدين، والتي يصعب تمثيلها باستخدام نماذج البيانات التقليدية.
من خلال الجمع بين هذه البيانات المرتبطة والنماذج اللغوية الكبيرة، مثل Gemini وتضمينات المتّجهات من Vertex AI، يمكننا تعزيز تجربة روبوت الدردشة، ما يتيح له التفكير والاسترجاع والرد بطريقة أكثر تخصيصًا وملاءمةً.
إنشاء قاعدة بيانات مجانية في Neo4j AuraDB
- انتقِل إلى https://console.neo4j.io
- سجِّل الدخول باستخدام حسابك على Google أو بريدك الإلكتروني.
- انقر على "إنشاء آلة افتراضية مجانية".
- أثناء توفير المثيل، ستظهر نافذة منبثقة تعرض بيانات اعتماد الاتصال بقاعدة البيانات.
احرص على تنزيل التفاصيل التالية وحفظها بشكل آمن من النافذة المنبثقة، فهي ضرورية لربط تطبيقك بـ Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
ستستخدم هذه القيم لضبط ملف .env في مشروعك للمصادقة باستخدام Neo4j في الخطوة التالية.

تُعدّ Neo4j AuraDB Free مناسبة تمامًا للتطوير والتجربة والتطبيقات الصغيرة الحجم، مثل هذا الدرس التطبيقي حول الترميز. يوفّر هذا الإصدار حدود استخدام كبيرة، إذ يتيح استخدام ما يصل إلى 200,000 عقدة و400,000 علاقة. على الرغم من أنّها توفّر جميع الميزات الأساسية اللازمة لإنشاء رسم بياني معرفي وتنفيذ طلبات بحث فيه، إلا أنّها لا تتيح إعدادات متقدّمة، مثل المكوّنات الإضافية المخصّصة أو زيادة مساحة التخزين. بالنسبة إلى أحمال العمل في مرحلة الإنتاج أو مجموعات البيانات الأكبر حجمًا، يمكنك الترقية إلى خطة AuraDB ذات مستوى أعلى توفّر سعة وأداءً أكبر وميزات على مستوى المؤسسة.
بهذا تنتهي عملية إعداد الخلفية في Neo4j AuraDB. في الخطوة التالية، سننشئ مشروعًا على Google Cloud، ونستنسخ المستودع، ونضبط متغيرات البيئة اللازمة لتجهيز بيئة التطوير قبل أن نبدأ في استخدام درس تطبيقي حول الترميز.
3- قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئه.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع .
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بأداة bq. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة من خلال الأمر الموضّح أدناه. قد تستغرق هذه العملية بضع دقائق، لذا يُرجى الانتظار.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
عند تنفيذ الأمر بنجاح، من المفترض أن تظهر لك الرسالة: "تمت العملية .... بنجاح".
يمكنك بدلاً من استخدام أمر gcloud، البحث عن كل منتج في وحدة التحكّم أو استخدام هذا الرابط.
في حال عدم توفّر أي واجهة برمجة تطبيقات، يمكنك تفعيلها في أي وقت أثناء عملية التنفيذ.
راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
استنساخ المستودع وضبط إعدادات البيئة
الخطوة التالية هي استنساخ مستودع الرموز النموذجية الذي سنشير إليه في بقية الدرس العملي. بافتراض أنّك في Cloud Shell، أدخِل الأمر التالي من الدليل الرئيسي:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
لتشغيل المحرِّر، انقر على فتح المحرِّر في شريط الأدوات في نافذة Cloud Shell. انقر على شريط القوائم في أعلى يمين الصفحة واختَر "ملف" (File) → "فتح مجلد" (Open Folder) كما هو موضّح أدناه:
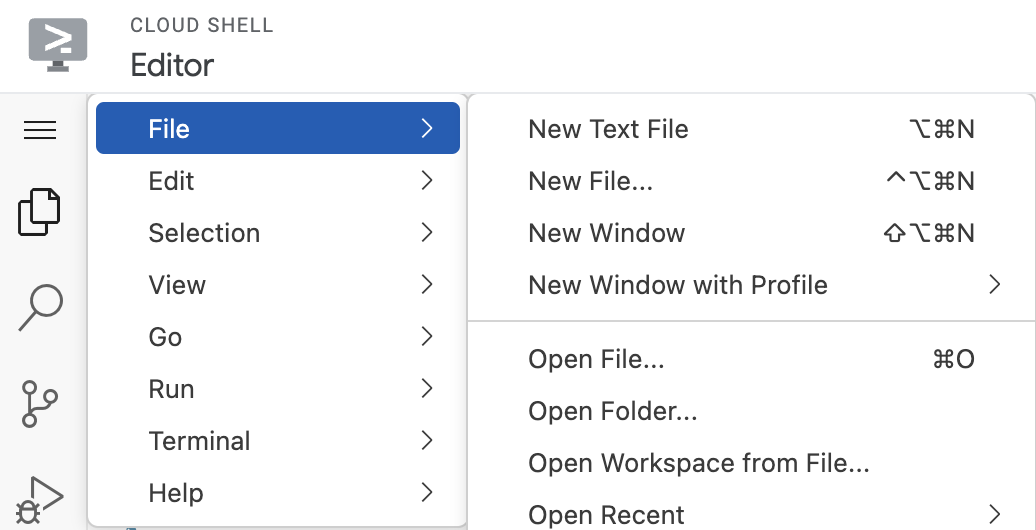
اختَر المجلد neo4j-vertexai-codelab، وسيتم فتح المجلد ببنية مشابهة إلى حد ما لما هو موضّح أدناه:

بعد ذلك، علينا إعداد متغيرات البيئة التي سيتم استخدامها في جميع مراحل هذا الدرس التطبيقي حول الترميز. انقر على ملف example.env، وسيظهر لك المحتوى كما هو موضّح أدناه:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
الآن، أنشئ ملفًا جديدًا باسم .env في المجلد نفسه الذي يحتوي على الملف example.env وانسخ محتوى ملف example.env الحالي. الآن، عدِّل المتغيّرات التالية:
-
NEO4J_URIوNEO4J_USERوNEO4J_PASSWORDوNEO4J_DATABASE: - املأ هذه القيم باستخدام بيانات الاعتماد المقدَّمة أثناء إنشاء مثيل Neo4j AuraDB Free في الخطوة السابقة.
- يتم عادةً ضبط
NEO4J_DATABASEعلى neo4j في AuraDB Free. -
PROJECT_IDوLOCATION: - إذا كنت تنفّذ درسًا تطبيقيًا حول الترميز من Google Cloud Shell، يمكنك ترك هذه الحقول فارغة، لأنّه سيتم استنتاجها تلقائيًا من إعدادات مشروعك النشط.
- إذا كنت تنفّذ الرمز برمجيًا محليًا أو خارج Cloud Shell، عدِّل
PROJECT_IDباستخدام معرّف مشروع Google Cloud الذي أنشأته سابقًا، واضبطLOCATIONعلى المنطقة التي اخترتها لهذا المشروع (مثل us-central1).
بعد ملء هذه القيم، احفظ ملف .env. سيسمح هذا الإعداد لتطبيقك بالاتصال بكلّ من Neo4j وخدمات Vertex AI.
الخطوة الأخيرة في إعداد بيئة التطوير هي إنشاء بيئة Python افتراضية وتثبيت جميع التبعيات المطلوبة المُدرَجة في ملف requirements.txt. وتشمل هذه العناصر التابعة المكتبات اللازمة للعمل مع Neo4j وVertex AI وGradio وغيرها.
أولاً، أنشئ بيئة افتراضية باسم .venv من خلال تنفيذ الأمر التالي:
python -m venv .venv
بعد إنشاء البيئة، علينا تفعيلها باستخدام الأمر التالي
source .venv/bin/activate
من المفترض أن يظهر الآن (.venv) في بداية موجّه الأوامر في الجهاز، ما يشير إلى أنّ البيئة نشطة. مثلاً: (.venv) yourusername@cloudshell:
الآن، ثبِّت التبعيات المطلوبة عن طريق تنفيذ الأمر التالي:
pip install -r requirements.txt
في ما يلي لقطة للشروط الأساسية المدرَجة في الملف:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
بعد تثبيت جميع التبعيات بنجاح، سيتم إعداد بيئة Python المحلية بالكامل لتشغيل البرامج النصية وبرنامج الدردشة الآلي في هذا الدرس التطبيقي حول الترميز.
رائع! نحن الآن جاهزون للانتقال إلى الخطوة التالية، وهي فهم مجموعة البيانات وإعدادها لإنشاء الرسوم البيانية وإثراء المعاني.
4. إعداد مجموعة بيانات الأفلام
مهمتنا الأولى هي إعداد مجموعة بيانات الأفلام التي سنستخدمها لإنشاء الرسم البياني المعرفي وتشغيل روبوت الدردشة الخاص باقتراحاتنا. بدلاً من البدء من الصفر، سنستخدم مجموعة بيانات مفتوحة حالية ونبني عليها.
نستخدم مجموعة بيانات الأفلام التي أعدّها Rounak Banik، وهي مجموعة بيانات عامة معروفة ومتاحة على Kaggle. يتضمّن بيانات وصفية لأكثر من 45,000 فيلم من TMDB، بما في ذلك الممثلون وطاقم العمل والكلمات الرئيسية والتقييمات وغير ذلك.

لإنشاء روبوت دردشة موثوق وفعّال لاقتراح الأفلام، من الضروري البدء ببيانات نظيفة ومتّسقة ومنظَّمة. على الرغم من أنّ مجموعة بيانات الأفلام من Kaggle هي مصدر غني بالمعلومات يتضمّن أكثر من 45,000 سجلّ فيلم وبيانات وصفية مفصّلة، بما في ذلك الأنواع والممثلون وطاقم العمل وغير ذلك، إلا أنّها تحتوي أيضًا على تشويش وتناقضات وبُنى بيانات متداخلة لا تُعدّ مثالية لإنشاء نماذج بيانية أو التضمين الدلالي.
ولحلّ هذه المشكلة، أجرينا معالجة مسبقة لمجموعة البيانات وتسويتها لضمان ملاءمتها لإنشاء رسم بياني معرفي في Neo4j وإنشاء تضمينات عالية الجودة. تضمّنت هذه العملية ما يلي:
- إزالة السجلات المكرّرة وغير المكتملة
- توحيد الحقول الرئيسية (مثل أسماء الأنواع وأسماء الأشخاص)
- تسوية البُنى المعقّدة المتداخلة (مثل الممثلين وطاقم العمل) في ملفات CSV منظَّمة
- اختيار مجموعة فرعية تمثيلية من حوالي 12,000 فيلم للبقاء ضمن حدود Neo4j AuraDB Free
تساعد البيانات العالية الجودة التي تمت تسويتها في ضمان ما يلي:
- جودة البيانات: تقلّل من الأخطاء والتناقضات للحصول على اقتراحات أكثر دقة
- أداء طلب البحث: تعمل البنية المبسّطة على تحسين سرعة الاسترجاع وتقليل التكرار
- دقة التضمين: تؤدي المدخلات النظيفة إلى تضمينات متّجهة أكثر فائدة وسياقية
يمكنك الوصول إلى مجموعة البيانات التي تم تنظيفها وتسويتها في المجلد normalized_data/ في مستودع GitHub هذا. يتم أيضًا نسخ مجموعة البيانات هذه في حزمة Google Cloud Storage لتسهيل الوصول إليها في نصوص Python البرمجية القادمة.
بعد تنظيف البيانات وإعدادها، أصبحنا الآن مستعدين لتحميلها إلى Neo4j والبدء في إنشاء الرسم البياني المعرفي الخاص بالأفلام.
5- إنشاء "الرسم البياني المعرفي" للأفلام
لتشغيل روبوت الدردشة الذي يقدّم اقتراحات حول الأفلام والمستند إلى الذكاء الاصطناعي التوليدي، علينا تنظيم مجموعة بيانات الأفلام بطريقة تتيح رصد شبكة واسعة من الروابط بين الأفلام والممثلين والمخرجين والأنواع وغيرها من البيانات الوصفية. في هذا القسم، سننشئ الرسم البياني المعرفي للأفلام في Neo4j باستخدام مجموعة البيانات التي تم تنظيفها وتسويتها والتي أعددتها سابقًا.
سنستخدم إمكانية LOAD CSV في Neo4j لاستيعاب ملفات CSV المستضافة في حزمة Google Cloud Storage (GCS) عامة. تمثّل هذه الملفات مكوّنات مختلفة لمجموعة بيانات الأفلام، مثل الأفلام والأنواع والممثلين وطاقم العمل وشركات الإنتاج وتقييمات المستخدمين.
الخطوة 1: إنشاء قيود وفهارس
قبل استيراد البيانات، من أفضل الممارسات إنشاء قيود وفهارس لفرض صحّة البيانات وتحسين أداء طلبات البحث.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
الخطوة 2: استيراد البيانات الوصفية للأفلام والعلاقات
لنلقِ نظرة على كيفية استيراد البيانات الوصفية للأفلام باستخدام الأمر LOAD CSV. ينشئ هذا المثال عقد Movie تتضمّن سمات رئيسية، مثل العنوان والنظرة العامة واللغة ومدة التشغيل:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
وبالمثل، يمكنك استيراد وربط كيانات أخرى، مثل الأنواع وشركات الإنتاج واللغات المنطوقة والبلدان وطاقم التمثيل وطاقم الإنتاج وتقييمات المستخدمين، باستخدام ملفات CSV واستعلامات Cypher الخاصة بها.
تحميل الرسم البياني الكامل من خلال Python
بدلاً من تنفيذ طلبات بحث Cypher متعددة يدويًا، ننصحك باستخدام نص Python البرمجي المبرمَج المقدَّم في هذا الدرس العملي.
يحمِّل النص البرمجي graph_build.py مجموعة البيانات بأكملها من "خدمة التخزين السحابي من Google" إلى مثيل Neo4j AuraDB باستخدام بيانات الاعتماد في ملف .env.
python graph_build.py
سيحمّل النص البرمجي جميع ملفات CSV اللازمة بالتسلسل، وينشئ العُقد والعلاقات، وينظّم الرسم البياني الكامل لمعرفتك بالأفلام.
|
|

.png")
التحقّق من صحة الرسم البياني
بعد التحميل، يمكنك التحقّق من صحة الرسم البياني من خلال تشغيل النص البرمجي التالي:
python validate_graph.py
سيقدّم لك هذا الإجراء ملخّصًا سريعًا للمحتوى في الرسم البياني، مثل عدد الأفلام والممثلين والأنواع والعلاقات، مثل ACTED_IN وDIRECTED وما إلى ذلك، ما يضمن نجاح عملية الاستيراد.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
من المفترض أن يظهر الرسم البياني الآن مع الأفلام والأشخاص والأنواع والمزيد، ويكون جاهزًا لإضافة المزيد من المعلومات الدلالية في الخطوة التالية.
6. إنشاء عمليات تضمين وتحميلها لإجراء بحث عن التشابه بين المتجهات
لتفعيل البحث الدلالي في برنامج الدردشة الآلي، علينا إنشاء تضمينات متجهة لملخّصات الأفلام. تحوّل هذه التضمينات البيانات النصية إلى متّجهات رقمية يمكن مقارنتها من حيث التشابه، ما يتيح لروبوت الدردشة استرداد أفلام ذات صلة حتى إذا لم يتطابق طلب البحث مع العنوان أو الوصف تمامًا.

الخيار 1: تحميل التضمينات المحسوبة مسبقًا من خلال Cypher
لإرفاق عمليات التضمين بسرعة بعُقد Movie المقابلة في Neo4j، نفِّذ أمر Cypher التالي في Neo4j Browser:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
يقرأ هذا الأمر متّجهات التضمين من ملف CSV ويربطها كسمة (m.embedding) بكل عقدة Movie.
الخيار 2: تحميل عمليات التضمين باستخدام Python
يمكنك أيضًا تحميل التضمينات آليًا باستخدام نص Python البرمجي المتوفّر. يكون هذا الأسلوب مفيدًا إذا كنت تعمل في بيئتك الخاصة أو تريد إتمام العملية تلقائيًا:
python load_embeddings.py
يقرأ هذا النص البرمجي ملف CSV نفسه من "خدمة التخزين السحابي من Google" ويكتب عمليات التضمين في Neo4j باستخدام برنامج تشغيل Python Neo4j.
[اختياري] إنشاء تضمينات بنفسك (للاستكشاف)
إذا كنت مهتمًا بمعرفة كيفية إنشاء التضمينات، يمكنك استكشاف منطقها في نص generate_embeddings.py البرمجي نفسه. يستخدم هذا التطبيق Vertex AI لتضمين نص كل نبذة عن فيلم باستخدام نموذج text-embedding-004.
لتجربة ذلك بنفسك، افتح قسم إنشاء التضمين في الرمز وشغِّله. إذا كنت تستخدم Cloud Shell، يمكنك إضافة تعليق إلى السطر التالي، لأنّ Cloud Shell يتم مصادقته تلقائيًا من خلال حسابك النشط:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
بعد تحميل التضمينات في Neo4j، يصبح الرسم البياني المعرفي للأفلام مدركًا للدلالات، ما يجعله جاهزًا لتوفير إمكانية البحث الفعّال باللغة الطبيعية باستخدام تشابه المتّجهات.
7. روبوت الدردشة لاقتراح الأفلام
بعد إعداد الرسم البياني المعرفي وعمليات التضمين المتجهة، حان الوقت لدمج كل شيء في واجهة محادثة تعمل بكامل طاقتها، وهي روبوت الدردشة لاقتراح الأفلام المستند إلى الذكاء الاصطناعي التوليدي.
تم تنفيذ روبوت الدردشة هذا في Python باستخدام Gradio، وهو إطار عمل خفيف الوزن للويب يتيح إنشاء واجهات مستخدم سهلة الاستخدام. تتوفّر المنطق الأساسي في app.py، الذي يتصل بمثيل Neo4j AuraDB ويستخدم Google Vertex AI وGemini لمعالجة طلبات البحث باللغة الطبيعية والردّ عليها.
كيفية العمل
- يكتب المستخدم طلب بحث بلغة طبيعيةمثلاً: "اقترح عليّ أفلام خيال علمي مثيرة مثل Interstellar"
- إنشاء عملية تضمين متّجه لطلب البحث باستخدام نموذج
text-embedding-004من Vertex AI - إجراء بحث متّجه في Neo4j لاسترداد أفلام متشابهة دلاليًا
- يمكنك استخدام Gemini لإجراء ما يلي:
- تفسير طلب البحث في السياق
- إنشاء طلب بحث Cypher مخصّص استنادًا إلى نتائج البحث المتّجه ومخطط Neo4j
- نفِّذ طلب البحث لاستخراج بيانات الرسم البياني ذات الصلة (مثل الممثلين والمخرجين والأنواع)
- تلخيص النتائج بطريقة حوارية للمستخدم
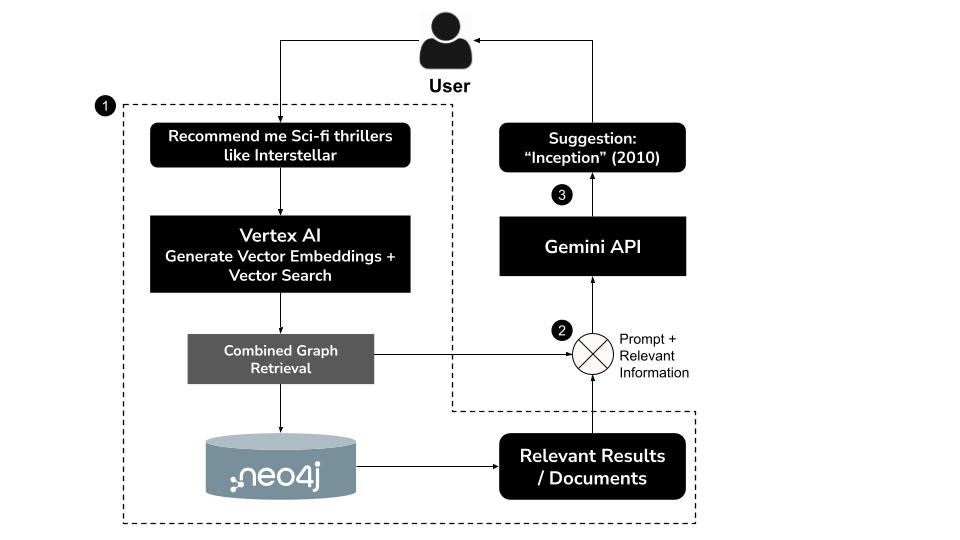
يجمع هذا النهج المختلط، المعروف باسم GraphRAG (التوليد المعزّز بالاسترجاع المستند إلى الرسم البياني)، بين الاسترجاع الدلالي والاستدلال المنطقي المنظَّم لتقديم اقتراحات أكثر دقة وسياقية وقابلة للتفسير.
تشغيل روبوت الدردشة محليًا
فعِّل بيئتك الافتراضية (إذا لم تكن مفعّلة)، ثم شغِّل برنامج الدردشة الآلي باستخدام:
python app.py
من المفترض أن تظهر لك نتيجة مشابهة لما يلي:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 لمشاركة روبوت الدردشة خارجيًا، اضبط share=True في الدالة launch() في app.py.
التفاعل مع روبوت الدردشة
افتح عنوان URL المحلي المعروض في Terminal (عادةً 👉 http://0.0.0.0:8080) للوصول إلى واجهة روبوت الدردشة.
جرِّب طرح أسئلة مثل:
- "ماذا يمكنني مشاهدته إذا أعجبني فيلم Interstellar؟"
- "اقترِح فيلمًا رومانسيًا من إخراج "نورا إفرون".
- "أريد مشاهدة فيلم عائلي من بطولة توم هانكس"
- "أريد البحث عن أفلام تشويق تتضمّن ذكاءً اصطناعيًا"
سيفعل روبوت الدردشة ما يلي:
✅ فهم طلب البحث
✅ العثور على حبكات أفلام متشابهة دلاليًا باستخدام التضمينات
✅ إنشاء طلب بحث Cypher وتنفيذه لاسترداد سياق الرسم البياني ذي الصلة
✅ تقديم اقتراح مخصّص وودّي خلال ثوانٍ معدودة
الخيارات المتاحة لك الآن
لقد أنشأت للتو روبوت دردشة للأفلام يستند إلى GraphRAG ويجمع بين:
- البحث المتّجه عن الصلة الدلالية
- الاستدلال في الرسم البياني المعرفي باستخدام Neo4j
- إمكانات النماذج اللغوية الكبيرة من خلال Gemini
- واجهة محادثة سلسة باستخدام Gradio
تشكّل هذه البنية الأساس الذي يمكنك توسيعه ليشمل أنظمة أكثر تطورًا للبحث أو الاقتراحات أو الاستدلال المستندة إلى الذكاء الاصطناعي التوليدي.
8. (اختياري) النشر على Google Cloud Run
إذا أردت إتاحة الوصول إلى روبوت الدردشة لاقتراح الأفلام بشكل علني، يمكنك تفعيلها على Google Cloud Run، وهي منصة مُدارة بالكامل للحوسبة بدون خادم تعمل على تدرّج تطبيقك تلقائيًا وتتجاهل جميع المشاكل المتعلّقة بالبنية الأساسية.
يستخدم هذا النشر ما يلي:
requirements.txt— لتحديد تبعيات Python (مثل Neo4j وVertex AI وGradio وما إلى ذلك)Dockerfile— لتعبئة التطبيق.env.yaml: لتمرير متغيرات البيئة بأمان في وقت التشغيل
الخطوة 1: إعداد .env.yaml
أنشئ ملفًا باسم .env.yaml في الدليل الجذر يتضمّن محتوًى مثل:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 يُفضّل استخدام هذا التنسيق على --set-env-vars لأنّه أكثر قابلية للتوسّع ويمكن التحكّم في إصداراته، كما أنّه أسهل في القراءة.
الخطوة 2: إعداد متغيّرات البيئة
في نافذة الأوامر، اضبط متغيرات البيئة التالية (استبدِل قيم العناصر النائبة بإعدادات مشروعك الفعلية):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
الخطوة 2: إنشاء Artifact Registry وإنشاء الحاوية
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
تُحزِّم هذه الحزمة تطبيقك باستخدام Dockerfile وتحمّل صورة الحاوية إلى Google Cloud Artifact Registry.
الخطوة 3: النشر على Cloud Run
الآن، يمكنك نشر تطبيقك باستخدام ملف .env.yaml لإعدادات وقت التشغيل:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
الوصول إلى روبوت الدردشة
بعد النشر، ستوفّر Cloud Run عنوان URL متاحًا للجميع على النحو التالي:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
افتح عنوان URL هذا في المتصفّح للوصول إلى واجهة روبوت الدردشة التي تم نشرها في Gradio، وهي جاهزة للتعامل مع اقتراحات الأفلام باستخدام GraphRAG وGemini وNeo4j.
ملاحظات ونصائح
- تأكَّد من تشغيل
Dockerfilepip install -r requirements.txtأثناء الإنشاء. - إذا كنت لا تستخدم Cloud Shell، عليك مصادقة بيئتك باستخدام حساب خدمة لديه أذونات Vertex AI وArtifact Registry.
- يمكنك مراقبة سجلّات النشر والمقاييس من Google Cloud Console > Cloud Run.
يمكنك أيضًا الانتقال إلى Cloud Run من وحدة تحكّم Google Cloud وستظهر لك قائمة الخدمات في Cloud Run. يجب أن تكون خدمة movies-chatbot إحدى الخدمات (إن لم تكن الخدمة الوحيدة) المُدرَجة هناك.
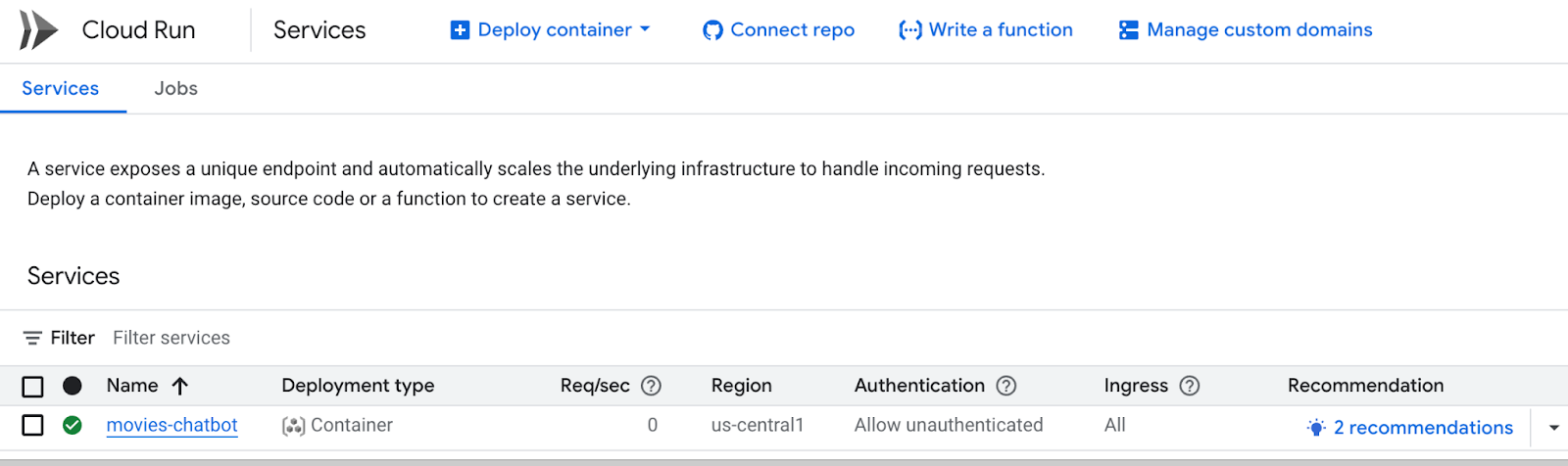
يمكنك الاطّلاع على تفاصيل الخدمة، مثل عنوان URL والإعدادات والسجلات وغير ذلك، من خلال النقر على اسم الخدمة المحدّد (movies-chatbot في حالتنا).

بهذا، يكون روبوت الدردشة لاقتراح الأفلام قد تم نشره وتوسيع نطاقه وأصبح قابلاً للمشاركة. 🎉
9- تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة إدارة الموارد.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
10. تهانينا
لقد أنشأت ونشرت بنجاح روبوت دردشة لاقتراح الأفلام مستندًا إلى GraphRAG ومحسّنًا بالذكاء الاصطناعي التوليدي باستخدام Neo4j وVertex AI وGemini. من خلال الجمع بين إمكانات تصميم الرسومات البيانية الأصلية في Neo4j والبحث الدلالي عبر Vertex AI والاستدلال باللغة الطبيعية من خلال Gemini، تمكّنت من إنشاء نظام ذكي يتجاوز البحث الأساسي، فهو يفهم نية المستخدم ويستدل على البيانات المرتبطة ويردّ بطريقة حوارية.
في هذا الدرس التطبيقي حول الترميز، أكملت ما يلي:
✅ إنشاء "الرسم البياني المعرفي" للأفلام في Neo4j لنمذجة الأفلام والممثلين والأنواع والعلاقات
✅ إنشاء تضمينات متّجهات لملخّصات حبكات الأفلام باستخدام نماذج تضمين النصوص في Vertex AI
✅ تطبيق GraphRAG، الذي يجمع بين البحث المستند إلى المتّجهات وطلبات البحث بلغة Cypher التي ينشئها النموذج اللغوي الكبير، وذلك لإجراء استدلال أعمق ومتعدد الخطوات
✅ دمج Gemini لتفسير أسئلة المستخدمين وإنشاء طلبات بحث بلغة Cypher وتلخيص نتائج الرسم البياني باللغة الطبيعية
✅ إنشاء واجهة محادثة سهلة الاستخدام باستخدام Gradio
✅ نشرت برنامج الدردشة الآلي اختياريًا على Google Cloud Run للاستضافة القابلة للتوسّع بدون خادم
الخطوات التالية:
لا يقتصر تصميم البنية هذا على اقتراحات الأفلام، بل يمكن توسيعه ليشمل ما يلي:
- منصات استكشاف الكتب والموسيقى
- مساعدو البحث الأكاديمي
- محركات اقتراحات المنتجات
- مساعدات قائمة على الذكاء الاصطناعي في مجالات الرعاية الصحية والتمويل والقانون
في أي مكان تتوفّر فيه علاقات معقّدة + بيانات نصية غنية، يمكن أن تتيح هذه المجموعة من الرسومات البيانية المعرفية + النماذج اللغوية الكبيرة + عمليات التضمين الدلالية الجيل التالي من التطبيقات الذكية.
مع تطوّر نماذج الذكاء الاصطناعي التوليدي المتعدد الوسائط، مثل Gemini، ستتمكّن من دمج سياق أكثر ثراءً وصور وكلام وتخصيص لإنشاء أنظمة تركّز على المستخدمين.
ننصحك بمواصلة الاستكشاف والبناء، ولا تنسَ متابعة آخر الأخبار من Neo4j وVertex AI وGoogle Cloud للارتقاء بتطبيقاتك الذكية إلى مستوى جديد. يمكنك الاطّلاع على المزيد من الدروس التعليمية العملية حول "الرسم البياني المعرفي" في Neo4j GraphAcademy.