
1. Panoramica
In questo codelab, creerai un chatbot intelligente per i consigli sui film combinando la potenza di Neo4j, Google Vertex AI e Gemini. Al centro di questo sistema c'è un Knowledge Graph Neo4j che modella film, attori, registi, generi e altro ancora attraverso una ricca rete di nodi e relazioni interconnessi.
Per migliorare l'esperienza utente con la comprensione semantica, genererai incorporamenti vettoriali dalle overview della trama dei film utilizzando il modello text-embedding-004 di Vertex AI (o versioni successive). Questi embedding vengono indicizzati in Neo4j per un recupero rapido basato sulla somiglianza.
Infine, integrerai Gemini per creare un'interfaccia conversazionale in cui gli utenti possono porre domande in linguaggio naturale, ad esempio "Cosa posso guardare se mi è piaciuto Interstellar?", e ricevere suggerimenti personalizzati sui film in base alla somiglianza semantica e al contesto basato su grafici.
Nel codelab, seguirai un approccio passo passo come segue:
- Crea un Knowledge Graph Neo4j con entità e relazioni correlate ai film
- Genera/carica text embedding per le panoramiche dei film utilizzando Vertex AI
- Implementa un'interfaccia chatbot Gradio basata su Gemini che combina la ricerca vettoriale con l'esecuzione di Cypher basata su grafici
- (Facoltativo) Esegui il deployment dell'app in Cloud Run come applicazione web autonoma
Cosa imparerai a fare
- Come creare e compilare un Knowledge Graph sui film utilizzando Cypher e Neo4j
- Come utilizzare Vertex AI per generare e utilizzare gli embedding semantici di testo
- Come combinare LLM e grafi di conoscenza per il recupero intelligente utilizzando GraphRAG
- Come creare un'interfaccia di chat intuitiva utilizzando Gradio
- Come eseguire il deployment facoltativo su Google Cloud Run
Che cosa ti serve
- Browser web Chrome
- Un account Gmail
- Un progetto Google Cloud con la fatturazione abilitata
- Un account DB Neo4j Aura senza costi
- Conoscenza di base dei comandi del terminale e di Python (utile ma non obbligatoria)
Questo codelab, progettato per sviluppatori di tutti i livelli (inclusi i principianti), utilizza Python e Neo4j nell'applicazione di esempio. Sebbene una conoscenza di base di Python e dei database grafici possa essere utile, non è necessaria alcuna esperienza precedente per comprendere i concetti o seguire il corso.
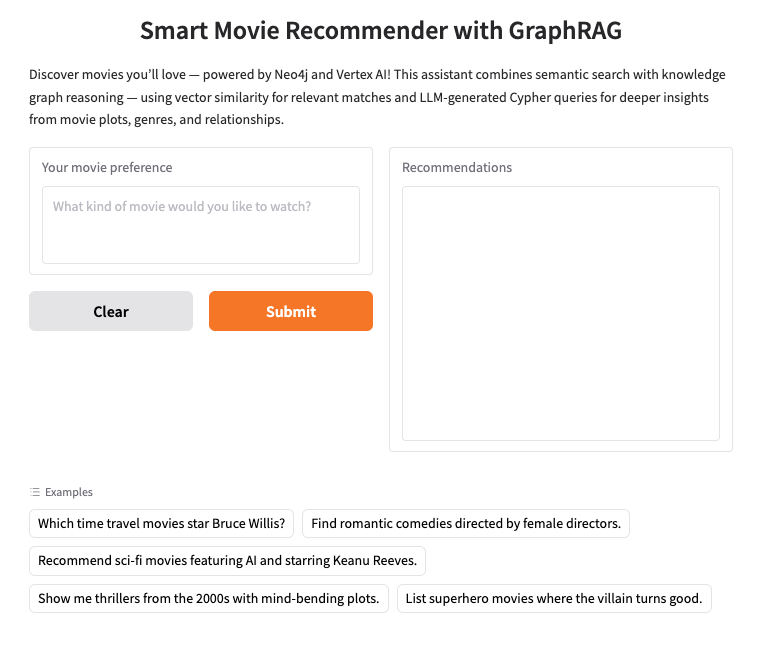
2. Configura Neo4j AuraDB
Neo4j è un database a grafo nativo leader che archivia i dati come una rete di nodi (entità) e relazioni (connessioni tra entità), il che lo rende ideale per i casi d'uso in cui la comprensione delle connessioni è fondamentale, ad esempio consigli, rilevamento delle frodi, Knowledge Graph e altro ancora. A differenza dei database relazionali o basati su documenti che si basano su tabelle rigide o strutture gerarchiche, il modello a grafo flessibile di Neo4j consente una rappresentazione intuitiva ed efficiente di dati complessi e interconnessi.
Invece di organizzare i dati in righe e tabelle come i database relazionali, Neo4j utilizza un modello a grafo, in cui le informazioni sono rappresentate come nodi (entità) e relazioni (connessioni tra queste entità). Questo modello rende eccezionalmente intuitivo l'utilizzo di dati intrinsecamente collegati, come persone, luoghi, prodotti o, nel nostro caso, film, attori e generi.
Ad esempio, in un set di dati sui film:
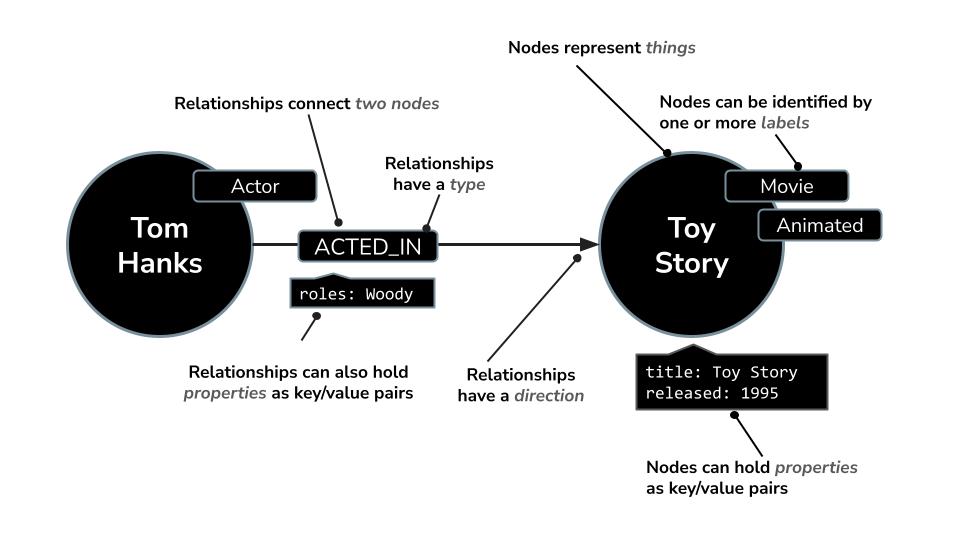
- Un nodo può rappresentare un
Movie, unActoro unDirector - Una relazione può essere
ACTED_INoDIRECTED
Questa struttura ti consente di porre facilmente domande come:
- In quali film ha recitato questo attore?
- Chi ha lavorato con Christopher Nolan?
- Quali sono i film simili basati su attori o generi condivisi?
Neo4j è dotato di un potente linguaggio di query chiamato Cypher, progettato specificamente per eseguire query sui grafici. Cypher ti consente di esprimere pattern e connessioni complessi in modo conciso e leggibile. Ad esempio, questa query Cypher utilizza MERGE per garantire la creazione univoca dell'attore, del film e della loro relazione con i dettagli del ruolo, evitando duplicati.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j offre diverse opzioni di deployment a seconda delle tue esigenze:
- Autogestito: esegui Neo4j sulla tua infrastruttura utilizzando Neo4j Desktop o come immagine Docker (on-prem o nel tuo cloud).
- Gestito dal cloud: esegui il deployment di Neo4j sui provider di servizi cloud più diffusi utilizzando le offerte del marketplace.
- Completamente gestito: utilizza Neo4j AuraDB, il servizio di database cloud completamente gestito di Neo4j, che gestisce provisioning, scalabilità, backup e sicurezza per tuo conto.
In questo codelab utilizzeremo Neo4j AuraDB Free, il livello senza costi di AuraDB. Fornisce un'istanza di database a grafo completamente gestita con spazio di archiviazione e funzionalità sufficienti per la prototipazione, l'apprendimento e la creazione di piccole applicazioni, perfetta per il nostro obiettivo di creare un chatbot di consigli sui film basato sull'AI generativa.
Creerai un'istanza AuraDB senza costi, la collegherai alla tua applicazione utilizzando le credenziali di connessione e la utilizzerai per archiviare ed eseguire query sul Knowledge Graph dei film durante questo lab.
Perché i grafici?
Nei database relazionali tradizionali, rispondere a domande come "Quali film sono simili a Inception in base al cast o al genere condivisi?" comporterebbe operazioni JOIN complesse su più tabelle. Man mano che la profondità delle relazioni aumenta, le prestazioni e la leggibilità peggiorano.
I database a grafo come Neo4j, tuttavia, sono progettati per attraversare in modo efficiente le relazioni, il che li rende adatti a sistemi di suggerimenti, ricerca semantica e assistenti intelligenti. Aiutano ad acquisire il contesto reale, come le reti di collaborazione, le trame o le preferenze degli spettatori, che può essere difficile da rappresentare utilizzando i modelli di dati tradizionali.
Combinando questi dati connessi con LLM come Gemini e incorporamenti vettoriali di Vertex AI, possiamo migliorare l'esperienza del chatbot, consentendogli di ragionare, recuperare e rispondere in modo più personalizzato e pertinente.
Creazione senza costi di Neo4j AuraDB
- Visita la pagina https://console.neo4j.io.
- Accedi con il tuo Account Google o indirizzo email.
- Fai clic su "Crea istanza senza costi".
- Mentre viene eseguito il provisioning dell'istanza, viene visualizzata una finestra popup che mostra le credenziali di connessione per il database.
Assicurati di scaricare e salvare in modo sicuro i seguenti dettagli dal popup, in quanto sono essenziali per connettere la tua applicazione a Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Utilizzerai questi valori per configurare il file .env nel tuo progetto per l'autenticazione con Neo4j nel passaggio successivo.

Neo4j AuraDB Free è ideale per lo sviluppo, la sperimentazione e le applicazioni su piccola scala come questo codelab. Offre limiti di utilizzo generosi, supportando fino a 200.000 nodi e 400.000 relazioni. Sebbene fornisca tutte le funzionalità essenziali necessarie per creare ed eseguire query su un knowledge graph, non supporta configurazioni avanzate come plug-in personalizzati o maggiore spazio di archiviazione. Per carichi di lavoro di produzione o set di dati più grandi, puoi eseguire l'upgrade a un piano AuraDB di livello superiore che offre maggiore capacità, prestazioni e funzionalità di livello aziendale.
In questo modo, la sezione per la configurazione del backend Neo4j AuraDB è completata. Nel passaggio successivo, creeremo un progetto Google Cloud, cloneremo il repository e configureremo le variabili di ambiente necessarie per preparare l'ambiente di sviluppo prima di iniziare il codelab.
3. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto .
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud precaricato con bq. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste tramite il comando mostrato di seguito. L'operazione potrebbe richiedere alcuni minuti.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Se il comando viene eseguito correttamente, viene visualizzato il messaggio: "Operazione .... terminata correttamente".
L'alternativa al comando gcloud è tramite la console, cercando ogni prodotto o utilizzando questo link.
Se manca un'API, puoi sempre abilitarla durante l'implementazione.
Consulta la documentazione per i comandi e l'utilizzo di gcloud.
Clona il repository e configura le impostazioni dell'ambiente
Il passaggio successivo consiste nel clonare il repository di esempio a cui faremo riferimento nel resto del codelab. Supponendo che tu sia in Cloud Shell, esegui questo comando dalla tua home directory:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Per avviare l'editor, fai clic su Apri editor sulla barra degli strumenti della finestra di Cloud Shell. Fai clic sulla barra dei menu nell'angolo in alto a sinistra e seleziona File → Apri cartella come mostrato di seguito:

Seleziona la cartella neo4j-vertexai-codelab e dovresti vedere la cartella aprirsi con una struttura simile a quella mostrata di seguito:

Successivamente, dobbiamo configurare le variabili di ambiente che verranno utilizzate durante il codelab. Fai clic sul file example.env e dovresti visualizzare i contenuti come mostrato di seguito:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Ora crea un nuovo file denominato .env nella stessa cartella del file example.env e copia i contenuti del file example.env esistente. Ora aggiorna le seguenti variabili:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDeNEO4J_DATABASE:- Compila questi valori utilizzando le credenziali fornite durante la creazione dell'istanza Neo4j AuraDB Free nel passaggio precedente.
NEO4J_DATABASEè in genere impostato su neo4j per AuraDB Free.PROJECT_IDeLOCATION:- Se esegui il codelab da Google Cloud Shell, puoi lasciare vuoti questi campi, in quanto verranno dedotti automaticamente dalla configurazione del progetto attivo.
- Se esegui l'operazione localmente o al di fuori di Cloud Shell, aggiorna
PROJECT_IDcon l'ID del progetto Google Cloud che hai creato in precedenza e impostaLOCATIONsulla regione selezionata per il progetto (ad es. us-central1).
Una volta compilati questi valori, salva il file .env. Questa configurazione consentirà alla tua applicazione di connettersi sia ai servizi Neo4j che a Vertex AI.
Il passaggio finale della configurazione dell'ambiente di sviluppo consiste nel creare un ambiente virtuale Python e installare tutte le dipendenze richieste elencate nel file requirements.txt. Queste dipendenze includono le librerie necessarie per lavorare con Neo4j, Vertex AI, Gradio e altro ancora.
Innanzitutto, crea un ambiente virtuale denominato .venv eseguendo questo comando:
python -m venv .venv
Una volta creato l'ambiente, dobbiamo attivarlo con il seguente comando
source .venv/bin/activate
Ora dovresti vedere (.venv) all'inizio del prompt del terminale, a indicare che l'ambiente è attivo. Ad esempio: (.venv) yourusername@cloudshell:
Ora installa le dipendenze richieste eseguendo:
pip install -r requirements.txt
Ecco un'istantanea delle dipendenze chiave elencate nel file:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Una volta installate correttamente tutte le dipendenze, l'ambiente Python locale sarà completamente configurato per eseguire gli script e il chatbot in questo codelab.
Ottimo. Ora siamo pronti per passare al passaggio successivo: comprendere il set di dati e prepararlo per la creazione del grafico e l'arricchimento semantico.
4. Prepara il set di dati Movies
Il nostro primo compito è preparare il set di dati Movies che utilizzeremo per creare il knowledge graph e potenziare il nostro chatbot di consigli. Anziché partire da zero, utilizzeremo un set di dati aperto esistente e lo amplieremo.
Utilizziamo The Movies Dataset di Rounak Banik, un noto set di dati pubblico disponibile su Kaggle. Include i metadati di oltre 45.000 film di TMDB, tra cui cast, troupe, parole chiave, valutazioni e altro ancora.

Per creare un chatbot di consigli sui film affidabile ed efficace, è essenziale iniziare con dati puliti, coerenti e strutturati. Sebbene The Movies Dataset di Kaggle sia una risorsa ricca con oltre 45.000 record di film e metadati dettagliati, tra cui generi, cast, troupe e altro ancora, contiene anche rumore, incoerenze e strutture di dati nidificate che non sono ideali per la modellazione di grafici o l'incorporamento semantico.
Per risolvere questo problema, abbiamo pre-elaborato e normalizzato il set di dati per assicurarci che sia adatto alla creazione di un Knowledge Graph Neo4j e alla generazione di incorporamenti di alta qualità. Questa procedura prevedeva:
- Rimozione di duplicati e record incompleti
- Standardizzazione dei campi chiave (ad es. nomi dei generi, nomi delle persone)
- Appiattimento di strutture nidificate complesse (ad es. cast e troupe) in file CSV strutturati
- Selezione di un sottoinsieme rappresentativo di circa 12.000 film per rimanere entro i limiti di Neo4j AuraDB Free
Dati normalizzati di alta qualità contribuiscono a garantire:
- Qualità dei dati: riduce al minimo errori e incoerenze per consigli più accurati
- Prestazioni delle query: la struttura semplificata migliora la velocità di recupero e riduce la ridondanza
- Accuratezza degli embedding: input puliti portano a embedding vettoriali più significativi e contestuali
Puoi accedere al set di dati pulito e normalizzato nella cartella normalized_data/ di questo repository GitHub. Questo set di dati viene anche sottoposto a mirroring in un bucket Cloud Storage per un facile accesso nei prossimi script Python.
Ora che i dati sono puliti e pronti, possiamo caricarli in Neo4j e iniziare a costruire il nostro Knowledge Graph sui film.
5. Crea il Knowledge Graph dei film
Per alimentare il nostro chatbot di consigli sui film basato sull'AI generativa, dobbiamo strutturare il nostro set di dati sui film in modo da acquisire la ricca rete di connessioni tra film, attori, registi, generi e altri metadati. In questa sezione creeremo un Knowledge Graph sui film in Neo4j utilizzando il set di dati pulito e normalizzato che hai preparato in precedenza.
Utilizzeremo la funzionalità LOAD CSV di Neo4j per importare i file CSV ospitati in un bucket Google Cloud Storage (GCS) pubblico. Questi file rappresentano diversi componenti del set di dati sui film, come film, generi, cast, troupe, società di produzione e valutazioni degli utenti.
Passaggio 1: crea vincoli e indici
Prima di importare i dati, è buona prassi creare vincoli e indici per garantire l'integrità dei dati e ottimizzare il rendimento delle query.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Passaggio 2: importa i metadati e le relazioni dei film
Vediamo come importare i metadati dei film utilizzando il comando LOAD CSV. Questo esempio crea nodi Movie con attributi chiave come titolo, panoramica, lingua e durata:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Allo stesso modo, puoi importare e collegare altre entità come Generi, Società di produzione, Lingue parlate, Paesi, Cast, Troupe e Valutazioni degli utenti utilizzando i rispettivi file CSV e query Cypher.
Caricare il grafico completo tramite Python
Anziché eseguire manualmente più query Cypher, ti consigliamo di utilizzare lo script Python automatizzato fornito in questo codelab.
Lo script graph_build.py carica l'intero set di dati da GCS nell'istanza Neo4j AuraDB utilizzando le credenziali nel file .env.
python graph_build.py
Lo script caricherà in sequenza tutti i file CSV necessari, creerà nodi e relazioni e strutturerà il knowledge graph completo del film.
|
|

.png")
Convalida del grafico
Dopo il caricamento, puoi convalidare il grafico eseguendo lo script seguente:
python validate_graph.py
In questo modo avrai un riepilogo rapido dei contenuti del grafico: quanti film, attori, generi e relazioni come ACTED_IN, DIRECTED e così via sono presenti, garantendo che l'importazione sia andata a buon fine.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Ora dovresti vedere il grafico popolato con film, persone, generi e altro ancora, pronto per essere arricchito semanticamente nel passaggio successivo.
6. Genera e carica gli incorporamenti per eseguire la ricerca di somiglianza vettoriale
Per attivare la ricerca semantica nel nostro chatbot, dobbiamo generare gli embedding vettoriali per le descrizioni dei film. Questi incorporamenti trasformano i dati testuali in vettori numerici che possono essere confrontati per similarità, consentendo al chatbot di recuperare film pertinenti anche se la query non corrisponde esattamente al titolo o alla descrizione.

Opzione 1: carica gli incorporamenti precalcolati tramite Cypher
Per collegare rapidamente gli incorporamenti ai nodi Movie corrispondenti in Neo4j, esegui il seguente comando Cypher in Neo4j Browser:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Questo comando legge i vettori di incorporamento dal file CSV e li allega come proprietà (m.embedding) a ogni nodo Movie.
Opzione 2: carica gli incorporamenti utilizzando Python
Puoi anche caricare gli incorporamenti in modo programmatico utilizzando lo script Python fornito. Questo approccio è utile se lavori nel tuo ambiente o vuoi automatizzare la procedura:
python load_embeddings.py
Questo script legge lo stesso file CSV da GCS e scrive gli incorporamenti in Neo4j utilizzando il driver Python Neo4j.
[Facoltativo] Genera autonomamente gli incorporamenti (per l'esplorazione)
Se vuoi capire come vengono generati gli incorporamenti, puoi esplorare la logica nello script generate_embeddings.py stesso. Utilizza Vertex AI per incorporare ogni testo di riepilogo del film utilizzando il modello text-embedding-004.
Per provarlo, apri ed esegui la sezione di generazione degli incorporamenti del codice. Se esegui l'operazione in Cloud Shell, puoi commentare la riga seguente, poiché Cloud Shell è già autenticato tramite il tuo account attivo:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Una volta caricati gli incorporamenti in Neo4j, il knowledge graph dei film diventa semanticamente consapevole, pronto a supportare una potente ricerca in linguaggio naturale utilizzando la somiglianza vettoriale.
7. Il chatbot per consigli di film
Con il grafo di conoscenza e gli incorporamenti vettoriali a posto, è il momento di riunire tutto in un'interfaccia conversazionale completamente funzionale: il tuo chatbot di consigli sui film basato sull'AI generativa.
Questo chatbot è implementato in Python utilizzando Gradio, un framework web leggero per la creazione di interfacce utente intuitive. La logica principale si trova in app.py, che si connette all'istanza Neo4j AuraDB e utilizza Google Vertex AI e Gemini per elaborare e rispondere alle query in linguaggio naturale.
Come funziona
- L'utente digita una query in linguaggio naturale, ad esempio: "Consigliami thriller di fantascienza come Interstellar"
- Genera un incorporamento vettoriale per la query utilizzando il modello
text-embedding-004di Vertex AI - Esegui una ricerca vettoriale in Neo4j per recuperare film semanticamente simili
- Usa Gemini per:
- Interpretare la query nel contesto
- Generare una query Cypher personalizzata in base ai risultati della ricerca vettoriale e allo schema Neo4j
- Esegui la query per estrarre i dati del grafico correlati (ad es. attori, registi, generi)
- Riassumere i risultati in modo colloquiale per l'utente
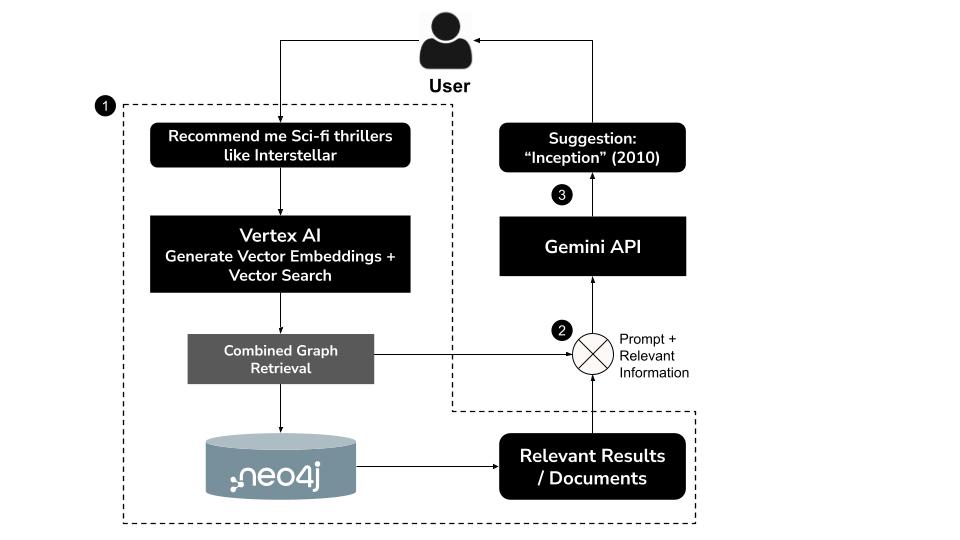
Questo approccio ibrido, noto come GraphRAG (Graph Retrieval-Augmented Generation), combina il recupero semantico e il ragionamento strutturato per produrre consigli più accurati, contestuali e spiegabili.
Esegui il chatbot localmente
Attiva l'ambiente virtuale (se non è già attivo), quindi avvia il chatbot con:
python app.py
Dovresti vedere un output simile al seguente:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Per condividere il chatbot esternamente, imposta share=True nella funzione launch() in app.py.
Interagire con il chatbot
Apri l'URL locale visualizzato nel terminale (di solito 👉 http://0.0.0.0:8080) per accedere all'interfaccia del chatbot.
Prova a porre domande come:
- "Cosa posso guardare se mi è piaciuto Interstellar?"
- "Suggeriscimi un film romantico diretto da Nora Ephron"
- "Voglio guardare un film per famiglie con Tom Hanks"
- "Trova film thriller che riguardano l'intelligenza artificiale"
Il chatbot:
✅ Comprendere la query
✅ Trovare trame di film semanticamente simili utilizzando gli incorporamenti
✅ Genera ed esegui una query Cypher per recuperare il contesto del grafico correlato
✅ Restituisci un consiglio amichevole e personalizzato in pochi secondi
Cosa hai adesso
Hai appena creato un chatbot per film basato su GraphRAG che combina:
- Ricerca vettoriale per la pertinenza semantica
- Ragionamento del Knowledge Graph con Neo4j
- Funzionalità LLM tramite Gemini
- Un'interfaccia di chat fluida con Gradio
Questa architettura costituisce una base che puoi estendere a sistemi di ricerca avanzata, suggerimenti o ragionamento più avanzati basati sull'AI generativa.
8. (Facoltativo) Eseguire il deployment in Google Cloud Run
Se vuoi rendere accessibile pubblicamente il tuo chatbot per consigli sui film, puoi eseguirne il deployment su Google Cloud Run, una piattaforma serverless completamente gestita che esegue lo scale automatico della tua app e astrae tutti i problemi relativi all'infrastruttura.
Questo deployment utilizza:
requirements.txt: per definire le dipendenze Python (Neo4j, Vertex AI, Gradio e così via)Dockerfile: per pacchettizzare l'applicazione.env.yaml: per passare le variabili di ambiente in modo sicuro in fase di runtime
Passaggio 1: prepara .env.yaml
Crea un file denominato .env.yaml nella directory radice con contenuti simili a questi:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Questo formato è preferibile a --set-env-vars perché è più scalabile, controllabile in base alla versione e leggibile.
Passaggio 2: configura le variabili di ambiente
Nel terminale, imposta le seguenti variabili di ambiente (sostituisci i valori segnaposto con le impostazioni progetto effettive):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Passaggio 2: crea Artifact Registry e crea il contenitore
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Questo comando pacchettizza l'app utilizzando Dockerfile e carica l'immagine container in Google Cloud Artifact Registry.
Passaggio 3: esegui il deployment in Cloud Run
Ora esegui il deployment della tua app utilizzando il file .env.yaml per la configurazione del runtime:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Accedere al chatbot
Una volta eseguito il deployment, Cloud Run fornirà un URL pubblico come:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Apri questo URL nel browser per accedere all'interfaccia del chatbot Gradio di cui è stato eseguito il deployment, pronto a gestire i consigli sui film utilizzando GraphRAG, Gemini e Neo4j.
Note e suggerimenti
- Assicurati che
Dockerfilevenga eseguitopip install -r requirements.txtdurante la compilazione. - Se non utilizzi Cloud Shell, devi autenticare il tuo ambiente utilizzando un service account con le autorizzazioni Vertex AI e Artifact Registry.
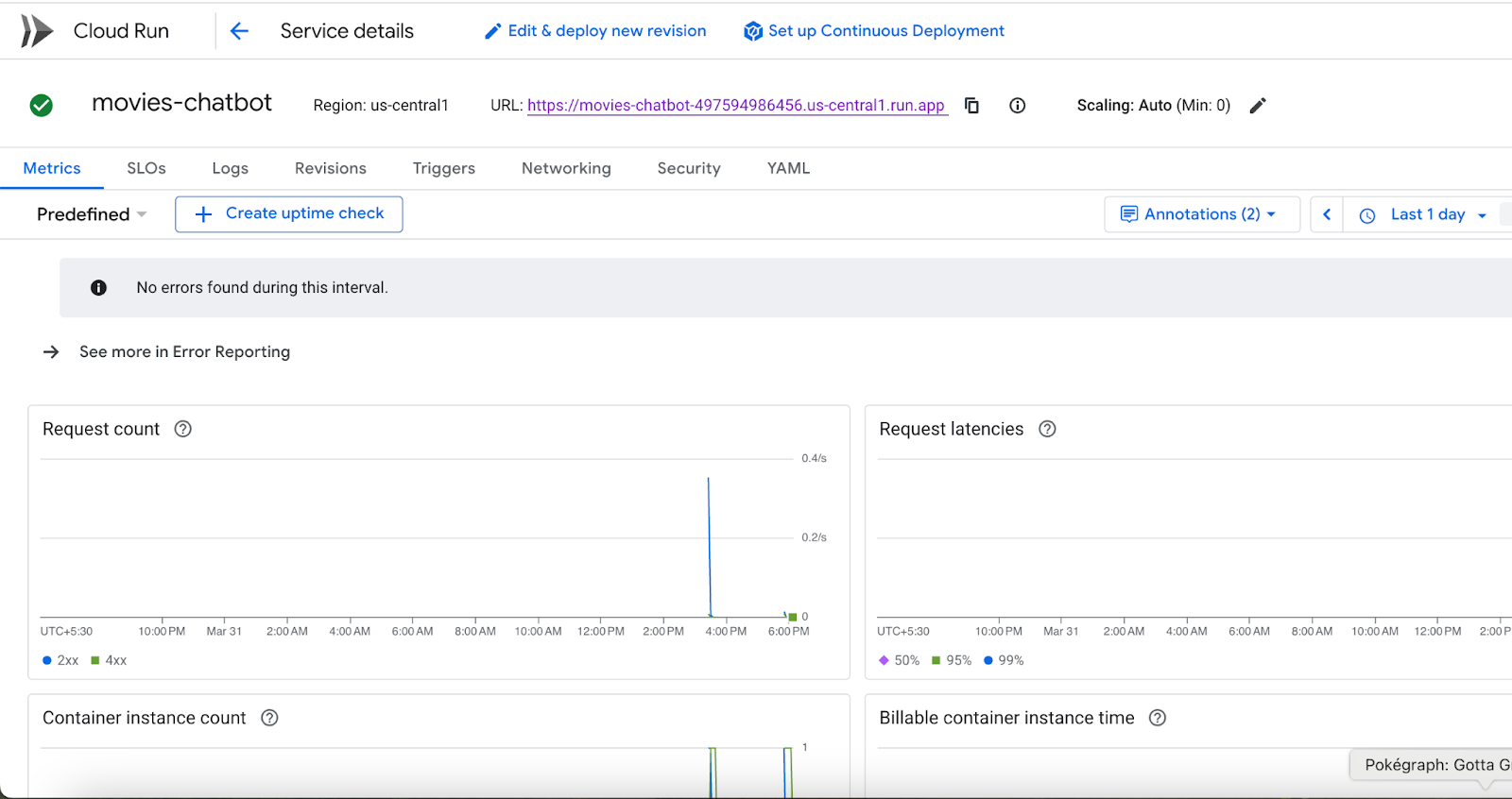
- Puoi monitorare i log e le metriche di deployment da console Google Cloud > Cloud Run.
Puoi anche visitare Cloud Run dalla console Google Cloud e visualizzare l'elenco dei servizi in Cloud Run. Il servizio movies-chatbot deve essere uno dei servizi (se non l'unico) elencati.

Puoi visualizzare i dettagli del servizio, come URL, configurazioni, log e altro ancora, facendo clic sul nome del servizio specifico (movies-chatbot nel nostro caso).
In questo modo, il tuo chatbot per i suggerimenti sui film è ora sottoposto a deployment, scalabile e condivisibile. 🎉
9. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo post, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
10. Complimenti
Hai creato e implementato correttamente un chatbot per i suggerimenti sui film basato su GraphRAG e potenziato dall'AI generativa utilizzando Neo4j, Vertex AI e Gemini. Combinando le funzionalità di modellazione native dei grafici di Neo4j con la ricerca semantica tramite Vertex AI e il ragionamento in linguaggio naturale tramite Gemini, hai creato un sistema intelligente che va oltre la ricerca di base: comprende l'intenzione dell'utente, ragiona sui dati connessi e risponde in modo conversazionale.
In questo codelab hai imparato a:
✅ Creazione di un Knowledge Graph di film reali in Neo4j per modellare film, attori, generi e relazioni
✅ Incorporamenti vettoriali generati per i riassunti delle trame dei film utilizzando i modelli di text embedding di Vertex AI
✅ Implementato GraphRAG, che combina la ricerca vettoriale e le query Cypher generate da LLM per un ragionamento più approfondito e in più passaggi
✅ Gemini integrato per interpretare le domande degli utenti, generare query Cypher e riassumere i risultati del grafico in linguaggio naturale
✅ Creata un'interfaccia di chat intuitiva utilizzando Gradio
✅ (Facoltativo) Hai eseguito il deployment del chatbot su Google Cloud Run per un hosting serverless scalabile
Passaggi successivi
Questa architettura non è limitata ai consigli sui film, ma può essere estesa a:
- Piattaforme di scoperta di libri e musica
- Assistenti di ricerca accademica
- Motori per suggerimenti sui prodotti
- Assistenti per la conoscenza di sanità, finanza e diritto
Ovunque tu abbia relazioni complesse + dati di testo avanzati, questa combinazione di grafi della conoscenza + LLM + incorporamenti semantici può alimentare la prossima generazione di applicazioni intelligenti.
Man mano che si evolvono i modelli di AI generativa multimodale come Gemini, potrai incorporare un contesto, immagini, parlato e personalizzazione ancora più ricchi per creare sistemi veramente incentrati sull'uomo.
Continua a esplorare, continua a creare e non dimenticare di rimanere aggiornato sulle ultime novità di Neo4j, Vertex AI e Google Cloud per portare le tue applicazioni intelligenti a un livello superiore. Scopri altri tutorial pratici sui Knowledge Graph su Neo4j GraphAcademy.