
1. Visão geral
Neste codelab, você vai criar um chatbot inteligente de recomendação de filmes combinando o poder do Neo4j, da Vertex AI do Google e do Gemini. No centro desse sistema está um Mapa de informações do Neo4j que modela filmes, atores, diretores, gêneros e muito mais em uma rede rica de nós e relacionamentos interconectados.
Para melhorar a experiência do usuário com o entendimento semântico, você vai gerar embeddings de vetor de visões gerais de enredos de filmes usando o modelo text-embedding-004 (ou mais recente) da Vertex AI. Esses embeddings são indexados no Neo4j para recuperação rápida baseada em similaridade.
Por fim, você vai integrar o Gemini para criar uma interface de conversa em que os usuários podem fazer perguntas em linguagem natural, como "O que devo assistir se gostei de Interestelar?", e receber sugestões de filmes personalizadas com base na similaridade semântica e no contexto baseado em gráficos.
Durante o codelab, você vai usar uma abordagem gradual da seguinte forma:
- Criar um mapa de informações do Neo4j com entidades e relacionamentos relacionados a filmes
- Gerar/carregar embeddings de texto para sinopses de filmes usando a Vertex AI
- Implementar uma interface de chatbot do Gradio com tecnologia do Gemini que combina a pesquisa de vetores com a execução do Cypher baseada em gráficos
- (Opcional) Implante o app no Cloud Run como um aplicativo da Web independente
O que você vai aprender
- Como criar e preencher um gráfico de conhecimento de filmes usando Cypher e Neo4j
- Como usar a Vertex AI para gerar e trabalhar com embeddings de texto semânticos
- Como combinar LLMs e mapas de informações para recuperação inteligente usando o GraphRAG
- Como criar uma interface de chat fácil de usar com o Gradio
- Como implantar opcionalmente no Google Cloud Run
O que é necessário
- Navegador da Web Google Chrome
- Uma conta do Gmail
- Ter um projeto do Google Cloud com o faturamento ativado
- Uma conta sem custo financeiro do banco de dados Neo4j Aura
- Conhecimento básico de comandos de terminal e Python (útil, mas não obrigatório)
Este codelab, criado para desenvolvedores de todos os níveis (inclusive iniciantes), usa Python e Neo4j no aplicativo de exemplo. Embora seja útil ter um conhecimento básico de Python e bancos de dados de grafos, não é necessário ter experiência prévia para entender os conceitos ou acompanhar.
2. Configurar o Neo4j AuraDB
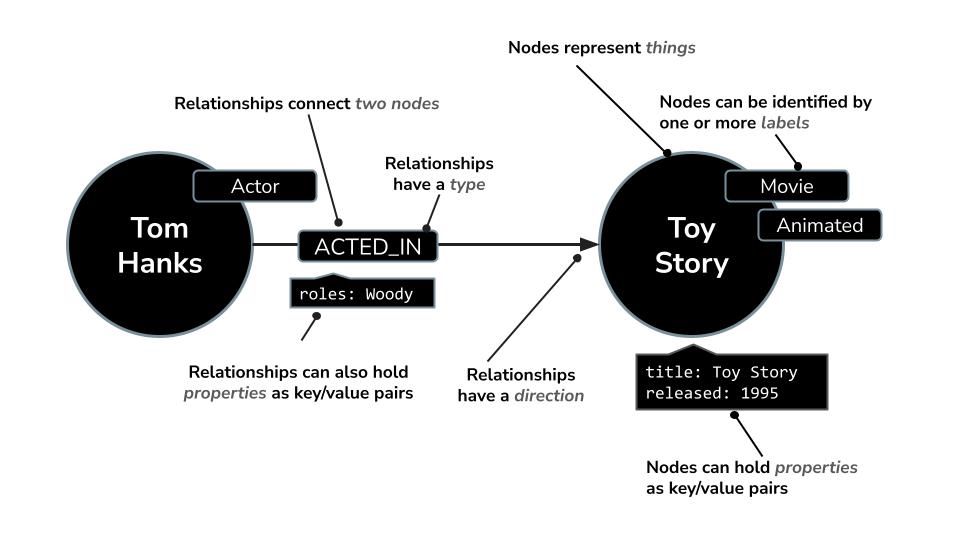
O Neo4j é um banco de dados de grafos nativo líder que armazena dados como uma rede de nós (entidades) e relações (conexões entre entidades), o que o torna ideal para casos de uso em que entender as conexões é fundamental, como recomendações, detecção de fraudes, mapas de informações e muito mais. Ao contrário dos bancos de dados relacionais ou baseados em documentos que dependem de tabelas rígidas ou estruturas hierárquicas, o modelo de grafo flexível do Neo4j permite uma representação intuitiva e eficiente de dados complexos e interconectados.
Em vez de organizar dados em linhas e tabelas como bancos de dados relacionais, o Neo4j usa um modelo de grafo, em que as informações são representadas como nós (entidades) e relações (conexões entre essas entidades). Esse modelo torna excepcionalmente intuitivo o trabalho com dados inerentemente vinculados, como pessoas, lugares, produtos ou, no nosso caso, filmes, atores e gêneros.
Por exemplo, em um conjunto de dados de filmes:
- Um nó pode representar um
Movie,ActorouDirector. - Uma relação pode ser
ACTED_INouDIRECTED
Essa estrutura permite que você faça perguntas com facilidade, como:
- Em quais filmes esse ator apareceu?
- Quem já trabalhou com Christopher Nolan?
- Quais filmes são semelhantes com base em atores ou gêneros compartilhados?
O Neo4j vem com uma linguagem de consulta avançada chamada Cypher, projetada especificamente para consultar gráficos. Com o Cypher, é possível expressar padrões e conexões complexos de maneira concisa e legível. Por exemplo, esta consulta Cypher usa MERGE para garantir a criação exclusiva do ator, do filme e da relação deles com detalhes de função, evitando duplicatas.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
O Neo4j oferece várias opções de implantação, dependendo das suas necessidades:
- Autogerenciado: execute o Neo4j na sua própria infraestrutura usando o Neo4j Desktop ou como uma imagem Docker (no local ou na sua própria nuvem).
- Gerenciado na nuvem: implante o Neo4j em provedores de nuvem conhecidos usando ofertas do marketplace.
- Totalmente gerenciado: use o Neo4j AuraDB, o banco de dados como serviço de nuvem totalmente gerenciado do Neo4j, que cuida do provisionamento, escalonamento, backups e segurança para você.
Neste codelab, vamos usar o Neo4j AuraDB Free, o nível sem custo financeiro do AuraDB. Ele oferece uma instância de banco de dados de grafo totalmente gerenciada com armazenamento e recursos suficientes para prototipagem, aprendizado e criação de pequenos aplicativos, o que é perfeito para nosso objetivo de criar um chatbot de recomendação de filmes com tecnologia de IA generativa.
Você vai criar uma instância sem custo financeiro do AuraDB, conectá-la ao seu aplicativo usando credenciais de conexão e usá-la para armazenar e consultar seu mapa de informações de filmes ao longo deste laboratório.
Por que usar gráficos?
Em bancos de dados relacionais tradicionais, responder a perguntas como "Quais filmes são semelhantes a A Origem com base no elenco ou gênero em comum?" envolveria operações JOIN complexas em várias tabelas. À medida que a profundidade dos relacionamentos aumenta, a performance e a legibilidade diminuem.
No entanto, os bancos de dados de grafos, como o Neo4j, são criados para percorrer relações com eficiência, o que os torna uma opção natural para sistemas de recomendação, pesquisa semântica e assistentes inteligentes. Eles ajudam a capturar o contexto do mundo real, como redes de colaboração, histórias ou preferências do espectador, que podem ser difíceis de representar usando modelos de dados tradicionais.
Ao combinar esses dados conectados com LLMs como o Gemini e embeddings de vetores da Vertex AI, podemos turbinar a experiência do chatbot, permitindo que ele raciocine, recupere e responda de uma maneira mais personalizada e relevante.
Criação sem custo financeiro do Neo4j AuraDB
- Acesse https://console.neo4j.io.
- Faça login com sua Conta do Google ou e-mail.
- Clique em "Criar instância sem custo financeiro".
- Enquanto a instância está sendo provisionada, uma janela pop-up aparece mostrando as credenciais de conexão do seu banco de dados.
Faça o download e salve com segurança os seguintes detalhes do pop-up. Eles são essenciais para conectar seu aplicativo ao Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Você vai usar esses valores para configurar o arquivo .env no seu projeto e fazer a autenticação com o Neo4j na próxima etapa.

O Neo4j AuraDB Free é adequado para desenvolvimento, experimentação e aplicativos de pequena escala, como este codelab. Ela oferece limites de uso generosos, com suporte para até 200.000 nós e 400.000 relacionamentos. Embora ofereça todos os recursos essenciais necessários para criar e consultar um grafo de conhecimento, ele não é compatível com configurações avançadas, como plug-ins personalizados ou aumento do armazenamento. Para cargas de trabalho de produção ou conjuntos de dados maiores, faça upgrade para um plano do AuraDB de nível superior que oferece maior capacidade, desempenho e recursos de nível empresarial.
Isso conclui a seção de configuração do back-end do Neo4j AuraDB. Na próxima etapa, vamos criar um projeto na nuvem do Google, clonar o repositório e configurar as variáveis de ambiente necessárias para preparar seu ambiente de desenvolvimento antes de começar o codelab.
3. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto .
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com bq. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias com o comando mostrado abaixo. Isso pode levar alguns minutos.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Se o comando for executado com sucesso, você vai ver a mensagem: A operação .... foi concluída com sucesso.
A alternativa ao comando gcloud é usar o console. Para isso, pesquise cada produto ou use este link.
Se alguma API for esquecida, você sempre poderá ativá-la durante a implementação.
Consulte a documentação para ver o uso e os comandos gcloud.
Clonar o repositório e configurar as definições de ambiente
A próxima etapa é clonar o repositório de amostra que vamos referenciar no restante do codelab. Supondo que você esteja no Cloud Shell, execute o seguinte comando no diretório principal:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Para iniciar o editor, clique em Abrir editor na barra de ferramentas da janela do Cloud Shell. Clique na barra de menu no canto superior esquerdo e selecione Arquivo → Abrir pasta, conforme mostrado abaixo:

Selecione a pasta neo4j-vertexai-codelab. Ela vai abrir com uma estrutura semelhante à mostrada abaixo:

Em seguida, precisamos configurar as variáveis de ambiente que serão usadas em todo o codelab. Clique no arquivo example.env. O conteúdo vai aparecer como mostrado abaixo:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Agora crie um arquivo chamado .env na mesma pasta do arquivo example.env e copie o conteúdo do arquivo example.env. Agora, atualize as seguintes variáveis:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDeNEO4J_DATABASE:- Preencha esses valores usando as credenciais fornecidas durante a criação da instância sem custo financeiro do Neo4j AuraDB na etapa anterior.
- Normalmente,
NEO4J_DATABASEé definido como "neo4j" para o AuraDB Free. PROJECT_IDeLOCATION:- Se você estiver executando o codelab no Google Cloud Shell, deixe esses campos em branco, porque eles serão inferidos automaticamente da configuração do projeto ativo.
- Se você estiver executando localmente ou fora do Cloud Shell, atualize
PROJECT_IDcom o ID do projeto na nuvem do Google que você criou anteriormente e definaLOCATIONcomo a região selecionada para esse projeto (por exemplo, us-central1).
Depois de preencher esses valores, salve o arquivo .env. Essa configuração permite que seu aplicativo se conecte aos serviços do Neo4j e da Vertex AI.
A etapa final na configuração do ambiente de desenvolvimento é criar um ambiente virtual do Python e instalar todas as dependências necessárias listadas no arquivo requirements.txt. Essas dependências incluem bibliotecas necessárias para trabalhar com Neo4j, Vertex AI, Gradio e muito mais.
Primeiro, crie um ambiente virtual chamado .venv executando o seguinte comando:
python -m venv .venv
Depois que o ambiente for criado, será necessário ativá-lo com o seguinte comando:
source .venv/bin/activate
Agora você vai ver (.venv) no início do prompt do terminal, indicando que o ambiente está ativo. Por exemplo: (.venv) yourusername@cloudshell:
Agora, instale as dependências necessárias executando:
pip install -r requirements.txt
Confira um resumo das principais dependências listadas no arquivo:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Depois que todas as dependências forem instaladas, seu ambiente Python local estará totalmente configurado para executar os scripts e o chatbot neste codelab.
Ótimo! Agora estamos prontos para passar para a próxima etapa: entender o conjunto de dados e prepará-lo para a criação de gráficos e o enriquecimento semântico.
4. Preparar o conjunto de dados de filmes
Nossa primeira tarefa é preparar o conjunto de dados de filmes que vamos usar para criar o grafo de conhecimento e alimentar nosso chatbot de recomendações. Em vez de começar do zero, vamos usar um conjunto de dados aberto e criar com base nele.
Estamos usando o The Movies Dataset (link em inglês) de Rounak Banik, um conjunto de dados público conhecido disponível no Kaggle. Ele inclui metadados de mais de 45.000 filmes do TMDB, incluindo elenco, equipe, palavras-chave, classificações e muito mais.

Para criar um chatbot de recomendação de filmes confiável e eficaz, é essencial começar com dados limpos, consistentes e estruturados. Embora The Movies Dataset do Kaggle seja um recurso rico com mais de 45.000 registros de filmes e metadados detalhados, incluindo gêneros, elenco, equipe e muito mais, ele também contém ruído, inconsistências e estruturas de dados aninhadas que não são ideais para modelagem de gráficos ou incorporação semântica.
Para resolver isso, pré-processamos e normalizamos o conjunto de dados para garantir que ele seja adequado para criar um Mapa de informações do Neo4j e gerar embeddings de alta qualidade. Esse processo envolveu:
- Remover duplicatas e registros incompletos
- Padronizar campos principais (por exemplo, nomes de gênero, nomes de pessoas)
- Transformar estruturas aninhadas complexas (por exemplo, elenco e equipe) em CSVs estruturados
- Selecionar um subconjunto representativo de aproximadamente 12.000 filmes para ficar dentro dos limites do Neo4j AuraDB Free
Dados normalizados e de alta qualidade ajudam a garantir:
- Qualidade de dados: minimiza erros e inconsistências para recomendações mais precisas.
- Desempenho da consulta: a estrutura simplificada melhora a velocidade de recuperação e reduz a redundância.
- Precisão do embedding: entradas limpas levam a embeddings de vetores mais significativos e contextuais.
Acesse o conjunto de dados limpo e normalizado na pasta normalized_data/ deste repositório do GitHub. Esse conjunto de dados também é espelhado em um bucket do Cloud Storage para facilitar o acesso nos próximos scripts Python.
Com os dados limpos e prontos, agora podemos carregá-los no Neo4j e começar a construir nosso mapa de informações de filmes.
5. Criar o Mapa de informações de filmes
Para alimentar nosso chatbot de recomendação de filmes com tecnologia de IA generativa, precisamos estruturar nosso conjunto de dados de filmes de forma a capturar a rica rede de conexões entre filmes, atores, diretores, gêneros e outros metadados. Nesta seção, vamos criar um Mapa de informações de filmes no Neo4j usando o conjunto de dados limpo e normalizado que você preparou antes.
Vamos usar a capacidade LOAD CSV do Neo4j para ingerir arquivos CSV hospedados em um bucket público do Google Cloud Storage (GCS). Esses arquivos representam diferentes componentes do conjunto de dados de filmes, como filmes, gêneros, elenco, equipe, empresas de produção e classificações dos usuários.
Etapa 1: criar restrições e índices
Antes de importar dados, é recomendável criar restrições e índices para garantir a integridade de dados e otimizar o desempenho da consulta.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Etapa 2: importar metadados e relacionamentos de filmes
Vamos ver como importar metadados de filmes usando o comando LOAD CSV. Este exemplo cria nós de filme com atributos principais, como título, visão geral, idioma e duração:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Da mesma forma, é possível importar e vincular outras entidades, como Gêneros, Empresas de produção, Idiomas falados, Países, Elenco, Equipe e Avaliações dos usuários, usando os respectivos CSVs e consultas Cypher.
Carregar o gráfico completo usando Python
Em vez de executar manualmente várias consultas Cypher, recomendamos usar o script Python automatizado fornecido neste codelab.
O script graph_build.py carrega todo o conjunto de dados do GCS na sua instância do Neo4j AuraDB usando as credenciais no arquivo .env.
python graph_build.py
O script vai carregar sequencialmente todos os arquivos CSV necessários, criar nós e relacionamentos e estruturar seu grafo de conhecimento completo de filmes.
|
|

.png")
Validar seu gráfico
Depois de carregar, valide o gráfico executando o seguinte script:
python validate_graph.py
Isso vai dar um resumo rápido do que está no seu gráfico: quantos filmes, atores, gêneros e relacionamentos como ACTED_IN, DIRECTED etc. estão presentes, garantindo que a importação foi bem-sucedida.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Agora você vai ver seu gráfico preenchido com filmes, pessoas, gêneros e muito mais, pronto para ser enriquecido semanticamente na próxima etapa.
6. Gerar e carregar embeddings para realizar a pesquisa de similaridade vetorial
Para ativar a pesquisa semântica no nosso chatbot, precisamos gerar embeddings de vetores para as sinopses de filmes. Esses embeddings transformam dados textuais em vetores numéricos que podem ser comparados para verificar a similaridade. Assim, o chatbot consegue recuperar filmes relevantes mesmo que a consulta não corresponda exatamente ao título ou à descrição.

Opção 1: carregar incorporações pré-calculadas usando Cypher
Para anexar rapidamente os embeddings aos nós Movie correspondentes no Neo4j, execute o seguinte comando Cypher no navegador Neo4j:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Esse comando lê os vetores de incorporação do CSV e os anexa como uma propriedade (m.embedding) em cada nó Movie.
Opção 2: carregar incorporações usando Python
Também é possível carregar os embeddings de forma programática usando o script Python fornecido. Essa abordagem é útil se você estiver trabalhando no seu próprio ambiente ou quiser automatizar o processo:
python load_embeddings.py
Esse script lê o mesmo CSV do GCS e grava os embeddings no Neo4j usando o driver Python Neo4j.
[Opcional] Gerar incorporações por conta própria (para análise detalhada)
Se quiser entender como as embeddings são geradas, confira a lógica no próprio script generate_embeddings.py. Ele usa a Vertex AI para incorporar cada texto de visão geral do filme usando o modelo text-embedding-004.
Para testar, abra e execute a seção de geração de incorporação do código. Se você estiver executando no Cloud Shell, comente a seguinte linha, já que o Cloud Shell já está autenticado pela sua conta ativa:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Depois que os embeddings são carregados no Neo4j, o gráfico de conhecimento de filmes se torna semântico, pronto para oferecer suporte a uma pesquisa avançada em linguagem natural usando a similaridade de vetores.
7. O chatbot de recomendação de filmes
Com o mapa de informações e as incorporações de vetores no lugar, é hora de juntar tudo em uma interface de conversa totalmente funcional: o chatbot de recomendação de filmes com tecnologia de IA generativa.
Esse chatbot é implementado em Python usando o Gradio, um framework da Web leve para criar interfaces de usuário intuitivas. A lógica principal está em app.py, que se conecta à sua instância do Neo4j AuraDB e usa a Vertex AI do Google e o Gemini para processar e responder a consultas em linguagem natural.
Como funciona
- O usuário digita uma consulta em linguagem natural, por exemplo, "Recomende filmes de suspense de ficção científica como Interestelar"
- Gere um embedding de vetor para a consulta usando o modelo
text-embedding-004da Vertex AI. - Realizar uma pesquisa vetorial no Neo4j para recuperar filmes semanticamente semelhantes
- Use o Gemini para:
- Interpretar a consulta no contexto
- Gerar uma consulta Cypher personalizada com base nos resultados da pesquisa vetorial e no esquema do Neo4j
- Execute a consulta para extrair dados de gráficos relacionados (por exemplo, atores, diretores, gêneros)
- Resumir os resultados de forma conversacional para o usuário
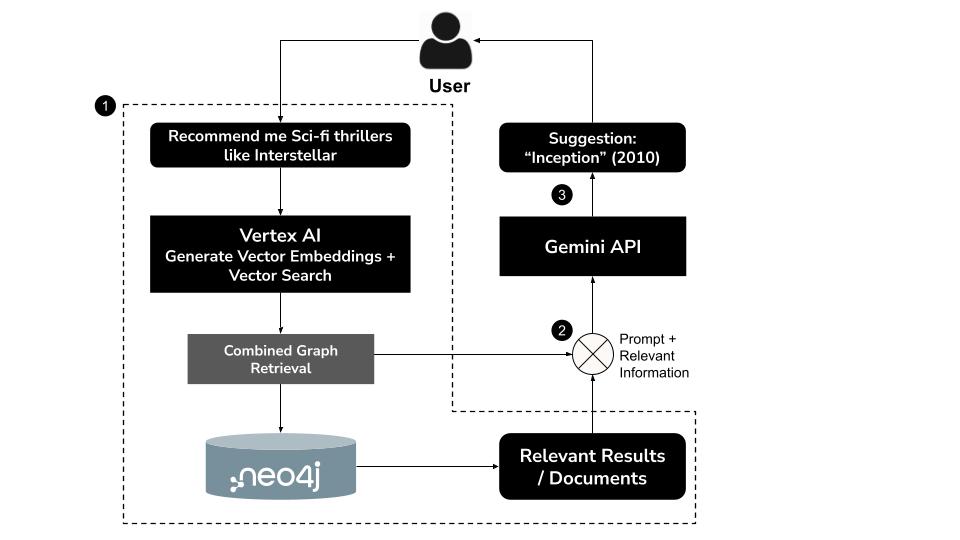
Essa abordagem híbrida, conhecida como GraphRAG (geração aumentada por recuperação de grafos), combina recuperação semântica e raciocínio estruturado para produzir recomendações mais precisas, contextuais e explicáveis.
Executar o chatbot localmente
Ative o ambiente virtual (se ainda não estiver ativo) e inicie o chatbot com:
python app.py
O resultado será semelhante a este:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Para compartilhar o chatbot externamente, defina share=True na função launch() em app.py.
Interagir com o chatbot
Abra o URL local exibido no terminal (geralmente 👉 http://0.0.0.0:8080) para acessar a interface do chatbot.
Tente fazer perguntas como:
- "O que devo assistir se gostei de Interestelar?"
- "Sugira um filme romântico dirigido por Nora Ephron"
- "Quero assistir um filme em família com Tom Hanks"
- "Encontrar filmes de suspense sobre inteligência artificial"
O chatbot vai:
✅ Entenda a consulta
✅ Encontrar enredos de filmes semanticamente semelhantes usando embeddings
✅ Gerar e executar uma consulta Cypher para buscar o contexto do gráfico relacionado
✅ Retorne uma recomendação personalizada e amigável em segundos
O que você tem agora
Você acabou de criar um chatbot de filmes com tecnologia GraphRAG que combina:
- Pesquisa de vetor para relevância semântica
- Raciocínio do mapa de informações com o Neo4j
- Recursos de LLM com o Gemini
- Uma interface de chat suave com o Gradio
Essa arquitetura forma uma base que pode ser estendida para sistemas mais avançados de pesquisa, recomendação ou raciocínio com tecnologia de IA generativa.
8. (Opcional) Como implantar no Google Cloud Run
Se você quiser tornar seu chatbot de recomendação de filmes acessível ao público, implante-o no Google Cloud Run, uma plataforma sem servidor totalmente gerenciada que dimensiona automaticamente seu app e simplifica todas as questões de infraestrutura.
Esta implantação usa:
requirements.txt: para definir dependências do Python (Neo4j, Vertex AI, Gradio etc.)Dockerfile— para empacotar o aplicativo.env.yaml: para transmitir variáveis de ambiente com segurança no ambiente de execução
Etapa 1: preparar .env.yaml
Crie um arquivo chamado .env.yaml no diretório raiz com conteúdo como:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Esse formato é preferível ao --set-env-vars porque é mais escalonável, controlável por versão e legível.
Etapa 2: configurar variáveis de ambiente
No terminal, defina as seguintes variáveis de ambiente (substitua os valores de marcador de posição pelas configurações do projeto reais):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Etapa 2: criar o Artifact Registry e criar o contêiner
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Esse comando empacota seu app usando o Dockerfile e faz upload da imagem do contêiner para o Artifact Registry do Google Cloud.
Etapa 3: implantar no Cloud Run
Agora implante o app usando o arquivo .env.yaml para configuração de tempo de execução:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Acessar o chatbot
Depois da implantação, o Cloud Run vai fornecer um URL público como:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Abra este URL no navegador para acessar a interface do chatbot do Gradio implantada, pronta para lidar com recomendações de filmes usando GraphRAG, Gemini e Neo4j.
Observações e dicas
- Verifique se o
Dockerfileexecutapip install -r requirements.txtdurante o build. - Se você não estiver usando o Cloud Shell, autentique seu ambiente usando uma conta de serviço com permissões da Vertex AI e do Artifact Registry.
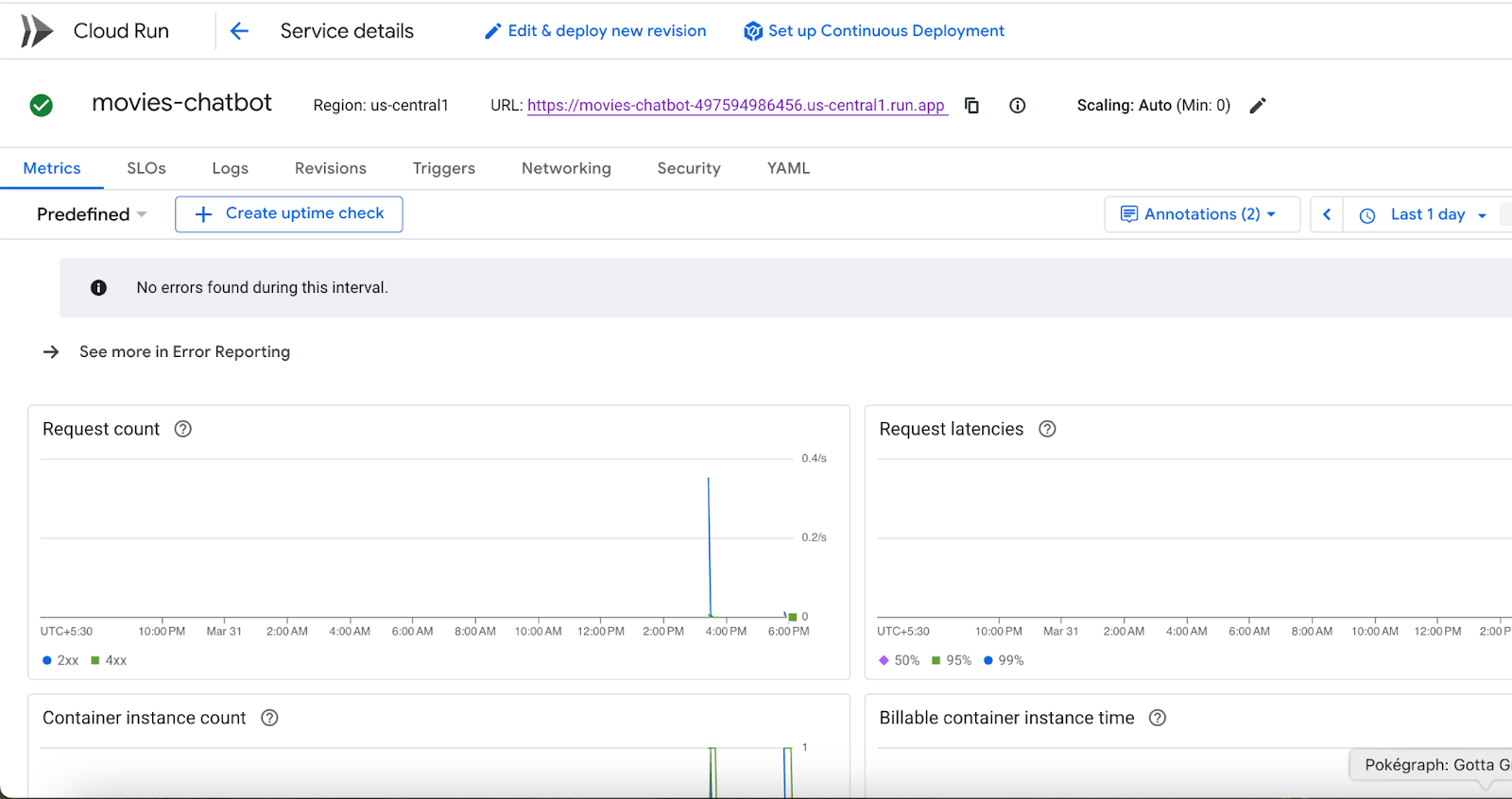
- É possível monitorar registros e métricas de implantação em Console do Google Cloud > Cloud Run.
Também é possível acessar o Cloud Run no console do Google Cloud para ver a lista de serviços no Cloud Run. O serviço movies-chatbot precisa ser um dos serviços (se não o único) listados ali.

Para conferir os detalhes do serviço, como URL, configurações, registros e muito mais, clique no nome específico (movies-chatbot, no nosso caso).
Assim, seu chatbot de recomendação de filmes agora está implantado, escalonável e compartilhável. 🎉
9. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
10. Parabéns
Você criou e implantou com sucesso um chatbot de recomendação de filmes com tecnologia GraphRAG e IA generativa usando Neo4j, Vertex AI e Gemini. Ao combinar os recursos de modelagem nativa de gráficos do Neo4j com a pesquisa semântica via Vertex AI e o raciocínio em linguagem natural pelo Gemini, você criou um sistema inteligente que vai além da pesquisa básica: ele entende a intenção do usuário, raciocina sobre dados conectados e responde de forma conversacional.
Neste codelab, você fez o seguinte:
✅ Criou um mapa de informações de filmes do mundo real no Neo4j para modelar filmes, atores, gêneros e relacionamentos
✅ Embeddings de vetor gerados para visões gerais de enredos de filmes usando os modelos de embedding de texto da Vertex AI
✅ Implementamos o GraphRAG, combinando pesquisa vetorial e consultas Cypher geradas por LLM para um raciocínio mais profundo e de várias etapas.
✅ Integração do Gemini para interpretar perguntas dos usuários, gerar consultas Cypher e resumir resultados de gráficos em linguagem natural
✅ Criamos uma interface de chat intuitiva usando o Gradio
✅ Implantou seu chatbot no Google Cloud Run (opcional) para hospedagem escalonável e sem servidor
A seguir
Essa arquitetura não se limita a recomendações de filmes. Ela pode ser estendida para:
- Plataformas de descoberta de livros e músicas
- Assistentes de pesquisa acadêmica
- Mecanismos de recomendação de produtos
- Assistentes de conhecimento para saúde, finanças e direito
Em qualquer lugar em que você tenha relações complexas e dados textuais avançados, essa combinação de grafos de conhecimento, LLMs e incorporações semânticas pode impulsionar a próxima geração de aplicativos inteligentes.
À medida que os modelos multimodais de IA generativa, como o Gemini, evoluem, você poderá incorporar um contexto, imagens, fala e personalização ainda mais avançados para criar sistemas verdadeiramente centrados no ser humano.
Continue explorando e criando. Não se esqueça de ficar por dentro das novidades do Neo4j, da Vertex AI e do Google Cloud para levar seus aplicativos inteligentes a um novo nível. Confira mais tutoriais práticos sobre mapas de informações na Neo4j GraphAcademy (em inglês).