
1. 概要
この Codelab では、Neo4j、Google Vertex AI、Gemini の機能を組み合わせて、インテリジェントな映画のおすすめ chatbot を構築します。このシステムの中心にあるのは、相互接続されたノードと関係の豊富なネットワークを通じて、映画、俳優、監督、ジャンルなどをモデル化する Neo4j ナレッジグラフです。
セマンティック理解によるユーザー エクスペリエンスを向上させるため、Vertex AI の text-embedding-004 モデル(またはそれ以降)を使用して、映画のプロットの概要からベクトル エンベディングを生成します。これらのエンベディングは、類似性に基づく高速検索のために Neo4j でインデックス登録されます。
最後に、Gemini を統合して、ユーザーが「インターステラーが好きなら、何を見たらいい?」などの自然言語の質問をすると、セマンティック類似性とグラフベースのコンテキストに基づいてパーソナライズされた映画の提案を受け取ることができる会話型インターフェースを構築します。
この Codelab では、次の手順でアプローチします。
- 映画関連のエンティティと関係を使用して Neo4j ナレッジグラフを構築する
- Vertex AI を使用して映画の概要のテキスト エンベディングを生成/読み込む
- ベクトル検索とグラフベースの Cypher 実行を組み合わせた Gemini を搭載した Gradio chatbot インターフェースを実装する
- (省略可)アプリをスタンドアロン ウェブ アプリケーションとして Cloud Run にデプロイする
学習内容
- Cypher と Neo4j を使用して映画のナレッジグラフを作成して入力する方法
- Vertex AI を使用してセマンティック テキスト エンベディングを生成し、操作する方法
- GraphRAG を使用して LLM とナレッジグラフを組み合わせてインテリジェントな検索を行う方法
- Gradio を使用してユーザー フレンドリーなチャット インターフェースを構築する方法
- 必要に応じて Google Cloud Run にデプロイする方法
必要なもの
- Chrome ウェブブラウザ
- Gmail アカウント
- 課金が有効になっている Google Cloud プロジェクト
- 無料の Neo4j Aura DB アカウント
- ターミナル コマンドと Python に関する基本的な知識(あると役立ちますが、必須ではありません)
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としており、サンプル アプリケーションで Python と Neo4j を使用します。Python とグラフ データベースの基本的な知識があると役立ちますが、コンセプトを理解したり、内容を把握したりするうえで、事前の経験は必要ありません。
2. Neo4j AuraDB を設定する
Neo4j は、データをノード(エンティティ)と関係(エンティティ間の接続)のネットワークとして保存する、代表的なネイティブ グラフ データベースです。そのため、レコメンデーション、不正行為の検出、ナレッジグラフなど、接続の理解が重要なユースケースに最適です。厳密なテーブルや階層構造に依存するリレーショナル データベースやドキュメント ベースのデータベースとは異なり、Neo4j の柔軟なグラフモデルを使用すると、複雑で相互接続されたデータを直感的かつ効率的に表現できます。
Neo4j は、リレーショナル データベースのようにデータを行とテーブルに整理するのではなく、グラフモデルを使用します。このモデルでは、情報はノード(エンティティ)と関係(エンティティ間の接続)として表されます。このモデルは、人物、場所、商品、映画、俳優、ジャンルなど、本質的にリンクされているデータを扱う場合に非常に直感的です。
たとえば、映画のデータセットでは次のようになります。
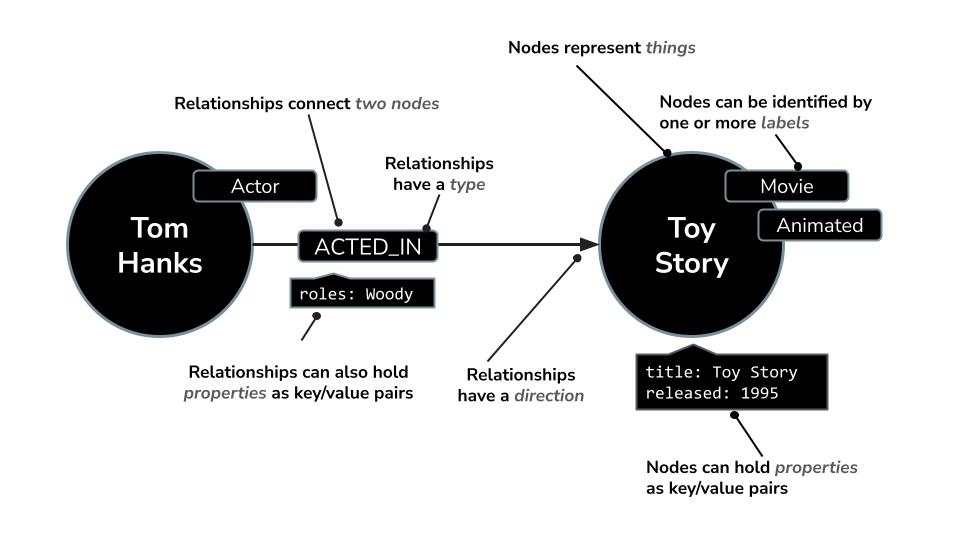
- ノードは、
Movie、Actor、またはDirectorを表すことができます。 - 関係は
ACTED_INまたはDIRECTEDのいずれかになります
この構造により、次のような質問を簡単に実行できます。
- この俳優が出演した映画を教えて。
- クリストファー ノーランと仕事をしたことがあるのは誰ですか?
- 出演者やジャンルが共通する映画はどれですか?
Neo4j には、グラフのクエリ用に特別に設計された Cypher という強力なクエリ言語が付属しています。Cypher を使用すると、複雑なパターンと接続を簡潔で読みやすい方法で表現できます。たとえば、この Cypher クエリでは、MERGE を使用して、俳優、映画、および役割の詳細との関係が一意に作成されるようにし、重複を回避しています。
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j には、ニーズに応じて複数のデプロイ オプションがあります。
- セルフマネージド: Neo4j Desktop を使用して、または Docker イメージとして(オンプレミスまたは独自のクラウドで)独自のインフラストラクチャで Neo4j を実行します。
- クラウド マネージド: Marketplace サービスを使用して、一般的なクラウド プロバイダに Neo4j をデプロイします。
- フルマネージド: Neo4j AuraDB を使用します。これは、プロビジョニング、スケーリング、バックアップ、セキュリティを処理する Neo4j のフルマネージド クラウド Database as a Service です。
この Codelab では、AuraDB の無料枠である Neo4j AuraDB Free を使用します。プロトタイピング、学習、小規模なアプリケーションの構築に十分なストレージと機能を備えたフルマネージド グラフ データベース インスタンスが提供されます。これは、生成 AI を活用した映画おすすめチャットボットの構築という目標に最適です。
このラボでは、無料の AuraDB インスタンスを作成し、接続認証情報を使用してアプリケーションに接続し、映画のナレッジグラフの保存とクエリに使用します。
グラフを使用する理由
従来のリレーショナル データベースでは、「キャストやジャンルが共通している映画で、インセプションに似た映画はどれですか?」のような質問に答えるには、複数のテーブルにわたる複雑な JOIN オペレーションが必要になります。関係の深さが増すにつれて、パフォーマンスと読みやすさが低下します。
一方、Neo4j などのグラフ データベースは、関係を効率的に走査するように構築されているため、レコメンデーション システム、セマンティック検索、インテリジェント アシスタントに最適です。グラフ データベースは、従来のデータモデルでは表現が難しいコラボレーション ネットワーク、ストーリーライン、視聴者の好みなどの現実世界のコンテキストをキャプチャするのに役立ちます。
この接続されたデータを Gemini などの LLM や Vertex AI のベクトル エンベディングと組み合わせることで、chatbot のエクスペリエンスを大幅に向上させ、よりパーソナライズされた関連性の高い方法で推論、取得、応答できるようになります。
Neo4j AuraDB Free の作成
- https://console.neo4j.io にアクセスします。
- Google アカウントまたはメールアドレスでログインします。
- [無料インスタンスを作成] をクリックします。
- インスタンスのプロビジョニング中に、データベースの接続認証情報を示すポップアップ ウィンドウが表示されます。
ポップアップから次の詳細をダウンロードして安全に保存してください。これらは、アプリケーションを Neo4j に接続するために不可欠です。
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
これらの値を使用して、次の手順で Neo4j で認証するためのプロジェクトの .env ファイルを構成します。

Neo4j AuraDB Free は、この Codelab のような開発、試験運用、小規模なアプリケーションに適しています。使用量上限が大きく、最大 200,000 個のノードと 400,000 個の関係をサポートしています。ナレッジグラフの構築とクエリに必要なすべての基本機能を提供しますが、カスタム プラグインやストレージの増加などの高度な構成はサポートしていません。本番環境のワークロードや大規模なデータセットの場合は、容量、パフォーマンス、エンタープライズ グレードの機能が強化された上位の AuraDB プランにアップグレードできます。
これで、Neo4j AuraDB バックエンドの設定セクションは完了です。次のステップでは、Google Cloud プロジェクトを作成し、リポジトリのクローンを作成して、必要な環境変数を構成し、Codelab を開始する前に開発環境を準備します。
3. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Cloud Shell(Google Cloud で動作するコマンドライン環境)を使用します。この環境には bq がプリロードされています。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/neo4j-vertexai-movie-recommender-python/img/7875ca05ca6f7cab.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 次のコマンドを使用して、必要な API を有効にします。これには数分かかることがあります。
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
コマンドが正常に実行されると、「Operation .... finished successfully」というメッセージが表示されます。
gcloud コマンドの代わりに、コンソールで各プロダクトを検索するか、こちらのリンクを使用することもできます。
API が見つからない場合は、実装中にいつでも有効にできます。
gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
リポジトリのクローンを作成して環境設定を行う
次のステップでは、Codelab の残りの部分で参照するサンプル リポジトリのクローンを作成します。Cloud Shell にいると仮定して、ホーム ディレクトリから次のコマンドを実行します。
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
エディタを起動するには、Cloud Shell ウィンドウのツールバーにある [エディタを開く] をクリックします。左上のメニューバーをクリックし、[ファイル] → [フォルダを開く] を選択します。
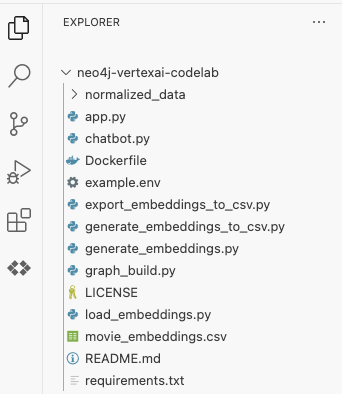
neo4j-vertexai-codelab フォルダを選択すると、次のような構造でフォルダが開きます。
次に、この Codelab 全体で使用する環境変数を設定する必要があります。example.env ファイルをクリックすると、次のような内容が表示されます。
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
次に、example.env ファイルと同じフォルダに .env という名前の新しいファイルを作成し、既存の example.env ファイルの内容をコピーします。次に、次の変数を更新します。
NEO4J_URI、NEO4J_USER、NEO4J_PASSWORD、NEO4J_DATABASE:- これらの値は、前の手順で Neo4j AuraDB Free インスタンスの作成時に指定した認証情報を使用して入力します。
- 通常、AuraDB Free の
NEO4J_DATABASEは neo4j に設定されています。 PROJECT_IDとLOCATION:- Google Cloud Shell から Codelab を実行している場合は、これらのフィールドを空白のままにできます。アクティブなプロジェクト構成から自動的に推測されます。
- ローカルで実行している場合や Cloud Shell の外部で実行している場合は、
PROJECT_IDを以前に作成した Google Cloud プロジェクトの ID で更新し、LOCATIONをそのプロジェクト用に選択したリージョン(us-central1 など)に設定します。
これらの値を入力したら、.env ファイルを保存します。この構成により、アプリケーションは Neo4j サービスと Vertex AI サービスの両方に接続できます。
開発環境の設定の最後の手順は、Python 仮想環境を作成し、requirements.txt ファイルに記載されている必要な依存関係をすべてインストールすることです。これらの依存関係には、Neo4j、Vertex AI、Gradio などの操作に必要なライブラリが含まれます。
まず、次のコマンドを実行して .venv という名前の仮想環境を作成します。
python -m venv .venv
環境が作成されたら、次のコマンドを使用して作成した環境を有効にする必要があります。
source .venv/bin/activate
ターミナル プロンプトの先頭に (.venv) と表示され、環境がアクティブになっていることが示されます。例: (.venv) yourusername@cloudshell:
次に、次のコマンドを実行して、必要な依存関係をインストールします。
pip install -r requirements.txt
ファイルに記載されている主な依存関係のスナップショットは次のとおりです。
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
すべての依存関係が正常にインストールされると、この Codelab のスクリプトと Chatbot を実行するようにローカル Python 環境が完全に構成されます。
これで準備が整いました。これで、次のステップに進む準備が整いました。データセットを理解し、グラフの作成とセマンティック エンリッチメントの準備を行います。
4. Movies データセットを準備する
最初のタスクは、ナレッジグラフの構築とレコメンデーション チャットボットの強化に使用する Movies データセットを準備することです。最初から作成するのではなく、既存のオープン データセットを使用して、それを基に構築します。
ここでは、Kaggle で公開されている有名なデータセットである Rounak Banik の The Movies Dataset を使用します。これには、TMDB の 45,000 本以上の映画のメタデータ(出演者、スタッフ、キーワード、評価など)が含まれています。

信頼性が高く効果的な映画おすすめチャットボットを構築するには、クリーンで一貫性のある構造化されたデータから始めることが不可欠です。Kaggle の The Movies Dataset は、45,000 件を超える映画のレコードと、ジャンル、キャスト、クルーなどの詳細なメタデータを含む豊富なリソースですが、グラフ モデリングやセマンティック エンベディングには適さないノイズ、不整合、ネストされたデータ構造も含まれています。
この問題に対処するため、データセットを前処理して正規化し、Neo4j ナレッジグラフの構築と高品質のエンベディングの生成に適した状態にしました。このプロセスには次の手順が含まれます。
- 重複レコードと不完全なレコードを削除する
- キーフィールドの標準化(ジャンル名、人物名など)
- 複雑なネスト構造(キャストやクルーなど)を構造化された CSV にフラット化する
- Neo4j AuraDB Free の制限内に収まるように、約 12,000 本の映画の代表的なサブセットを選択する
高品質で正規化されたデータは、次のことを保証するのに役立ちます。
- データ品質: エラーや不整合を最小限に抑え、より正確な推奨事項を提供します。
- クエリのパフォーマンス: 構造の合理化により、取得速度が向上し、冗長性が軽減されます
- エンベディングの精度: クリーンな入力により、より有意義でコンテキストに沿ったベクトル エンベディングが生成されます。
クリーンアップして正規化したデータセットは、この GitHub リポジトリの normalized_data/ フォルダで確認できます。このデータセットは、今後の Python スクリプトで簡単にアクセスできるように、Google Cloud Storage バケットにもミラーリングされています。
データがクリーンアップされ、準備が整ったので、Neo4j に読み込んで映画のナレッジグラフの構築を開始します。
5. 映画のナレッジグラフを構築する
GenAI 対応の映画おすすめ chatbot を実現するには、映画、俳優、監督、ジャンル、その他のメタデータ間の豊富なつながりを捉える方法で映画データセットを構造化する必要があります。このセクションでは、事前に準備したクリーンアップして正規化したデータセットを使用して、Neo4j に映画のナレッジグラフを構築します。
Neo4j の LOAD CSV 機能を使用して、一般公開の Google Cloud Storage(GCS)バケットでホストされている CSV ファイルを取り込みます。これらのファイルは、映画、ジャンル、キャスト、スタッフ、制作会社、ユーザー評価など、映画データセットのさまざまなコンポーネントを表しています。
ステップ 1: 制約とインデックスを作成する
データをインポートする前に、制約とインデックスを作成して、データの完全性を適用し、クエリ パフォーマンスを最適化することをおすすめします。
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
ステップ 2: 映画のメタデータとリレーションシップをインポートする
LOAD CSV コマンドを使用して映画のメタデータをインポートする方法を見てみましょう。この例では、タイトル、概要、言語、実行時間などのキー属性を持つ Movie ノードを作成します。
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
同様に、それぞれの CSV と Cypher クエリを使用して、ジャンル、制作会社、言語、国、キャスト、スタッフ、ユーザー評価などの他のエンティティをインポートしてリンクできます。
Python を使用してフルグラフを読み込む
複数の Cypher クエリを手動で実行するのではなく、この Codelab で提供されている自動 Python スクリプトを使用することをおすすめします。
スクリプト graph_build.py は、.env ファイルの認証情報を使用して、GCS から Neo4j AuraDB インスタンスにデータセット全体を読み込みます。
python graph_build.py
スクリプトは、必要なすべての CSV を順番に読み込み、ノードとリレーションシップを作成して、完全な映画ナレッジグラフを構築します。
|
|

.png")
グラフを検証する
読み込み後、次のスクリプトを実行してグラフを検証できます。
python validate_graph.py
これにより、グラフの内容の概要(映画、俳優、ジャンル、ACTED_IN、DIRECTED などの関係の数)をすばやく確認し、インポートが成功したことを確認できます。
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
グラフに映画、人物、ジャンルなどが表示されます。次のステップでセマンティック エンリッチメントを行う準備が整いました。
6. エンベディングを生成して読み込み、ベクトル類似性検索を実行する
chatbot でセマンティック検索を有効にするには、映画の概要のベクトル エンベディングを生成する必要があります。これらのエンベディングは、テキストデータを類似性を比較できる数値ベクトルに変換します。これにより、クエリがタイトルや説明と完全に一致しない場合でも、チャットボットは関連する映画を取得できます。

オプション 1: Cypher を使用して事前計算されたエンベディングを読み込む
エンベディングを Neo4j の対応する Movie ノードにすばやく関連付けるには、Neo4j ブラウザで次の Cypher コマンドを実行します。
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
このコマンドは、CSV からエンベディング ベクトルを読み取り、各 Movie ノードのプロパティ(m.embedding)として付加します。
オプション 2: Python を使用してエンベディングを読み込む
提供された Python スクリプトを使用して、エンベディングをプログラムで読み込むこともできます。この方法は、独自の環境で作業している場合や、プロセスを自動化する場合に便利です。
python load_embeddings.py
このスクリプトは、GCS から同じ CSV を読み取り、Python Neo4j ドライバを使用してエンベディングを Neo4j に書き込みます。
[省略可] エンベディングを自分で生成する(探索用)
エンベディングがどのように生成されるかを知りたい場合は、generate_embeddings.py スクリプト自体のロジックを確認してください。Vertex AI を使用して、text-embedding-004 モデルを使用して各映画の概要テキストをエンベディングします。
ご自身で試すには、コードのエンベディング生成セクションを開いて実行します。Cloud Shell で実行している場合は、Cloud Shell はアクティブなアカウントですでに認証されているため、次の行をコメントアウトできます。
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
エンベディングが Neo4j に読み込まれると、映画のナレッジグラフはセマンティック対応になり、ベクトル類似性を使用した強力な自然言語検索をサポートできるようになります。
7. 映画のおすすめ chatbot
ナレッジグラフとベクトル エンベディングが完成したら、すべてを統合して、完全に機能する会話型インターフェース(生成 AI を活用した映画のおすすめチャットボット)を作成します。
この chatbot は、直感的なユーザー インターフェースを構築するための軽量ウェブ フレームワークである Gradio を使用して Python で実装されています。コアロジックは app.py に存在します。これは Neo4j AuraDB インスタンスに接続し、Google Vertex AI と Gemini を使用して自然言語クエリを処理し、応答します。
仕組み
- ユーザーが自然言語のクエリを入力する(例: 「インターステラーのような SF スリラーをおすすめして」
- Vertex AI の
text-embedding-004モデルを使用して、クエリのベクトル エンベディングを生成します。 - Neo4j でベクトル検索を実行して、意味的に類似した映画を取得する
- Gemini を使用して、次のことができます。
- コンテキストでクエリを解釈する
- ベクトル検索結果と Neo4j スキーマに基づいてカスタム Cypher クエリを生成する
- クエリを実行して、関連するグラフデータ(俳優、監督、ジャンルなど)を抽出します。
- 結果をユーザーにわかりやすく要約する
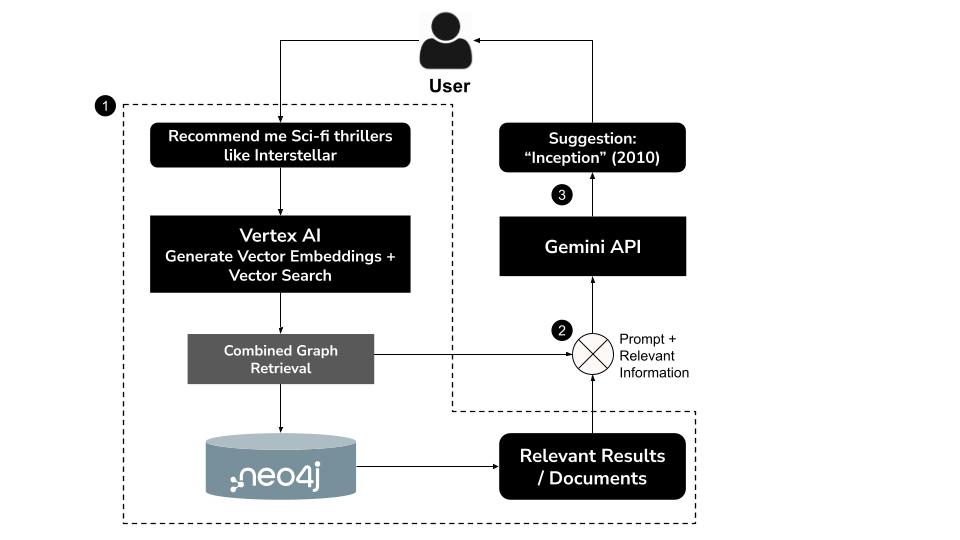
このハイブリッド アプローチは GraphRAG(グラフ検索拡張生成)と呼ばれ、セマンティック検索と構造化された推論を組み合わせて、より正確でコンテキストに沿った説明可能な推奨事項を生成します。
Chatbot をローカルで実行する
仮想環境を有効にして(まだ有効になっていない場合)、次のコマンドでチャットボットを起動します。
python app.py
出力は次のようになります。
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 チャットボットを外部に共有するには、app.py の launch() 関数で share=True を設定します。
チャットボットとやり取りする
ターミナルに表示されたローカル URL(通常は 👉 http://0.0.0.0:8080)を開いて、チャットボット インターフェースにアクセスします。
次のような質問をしてみてください。
- 「インターステラーが好きなら、何を見たらいい?」
- 「ノーラ エフロン監督のロマンティック映画をおすすめして」
- 「トム ハンクス出演の家族向け映画を見たい」
- 「人工知能がテーマのスリラー映画を探して」
chatbot は次のことを行います。
✅ クエリを理解する
✅ エンベディングを使用して意味的に類似した映画のあらすじを見つける
✅ Cypher クエリを生成して実行し、関連するグラフ コンテキストを取得する
✅ ユーザーに合わせたおすすめを数秒で返す
現在の状況
これで、次のものを組み合わせた GraphRAG を活用した映画チャットボットが構築されました。
- セマンティック関連性のためのベクトル検索
- Neo4j を使用したナレッジグラフの推論
- Gemini を介した LLM 機能
- Gradio を使用したスムーズなチャット インターフェース
このアーキテクチャは、生成 AI を活用したより高度な検索、レコメンデーション、推論システムに拡張できる基盤を形成します。
8. (省略可)Google Cloud Run へのデプロイ
映画のおすすめチャットボットを一般公開する場合は、Google Cloud Run にデプロイできます。Google Cloud Run は、アプリを自動スケーリングし、インフラストラクチャに関するすべての懸念事項を抽象化する、フルマネージドのサーバーレス プラットフォームです。
このデプロイでは、次のものを使用します。
requirements.txt- Python の依存関係(Neo4j、Vertex AI、Gradio など)を定義します。Dockerfile- アプリケーションをパッケージ化する.env.yaml- ランタイムに環境変数を安全に渡す
ステップ 1: .env.yaml を準備する
ルート ディレクトリに、次のような内容のファイルを .env.yaml という名前で作成します。
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 この形式は、スケーラビリティ、バージョン管理、可読性に優れているため、--set-env-vars よりも推奨されます。
ステップ 2: 環境変数を設定する
ターミナルで、次の環境変数を設定します(プレースホルダ値を実際のプロジェクト設定に置き換えます)。
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
ステップ 2: Artifact Registry を作成してコンテナをビルドする
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
このコマンドは、Dockerfile を使用してアプリをパッケージ化し、コンテナ イメージを Google Cloud Artifact Registry にアップロードします。
ステップ 3: Cloud Run にデプロイする
次に、ランタイム構成用の .env.yaml ファイルを使用してアプリをデプロイします。
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
chatbot にアクセスする
デプロイが完了すると、Cloud Run は次のようなパブリック URL を提供します。
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
この URL をブラウザで開いて、デプロイされた Gradio chatbot インターフェースにアクセスします。GraphRAG、Gemini、Neo4j を使用して映画のおすすめを処理する準備が整いました。
メモとヒント
Dockerfileがビルド中にpip install -r requirements.txtを実行することを確認します。- Cloud Shell を使用していない場合は、Vertex AI と Artifact Registry の権限を持つサービス アカウントを使用して環境を認証する必要があります。
- デプロイログと指標は、Google Cloud コンソール > Cloud Run でモニタリングできます。
Google Cloud コンソールから Cloud Run にアクセスして、Cloud Run のサービスリストを表示することもできます。movies-chatbot サービスは、そこにリストされているサービス(唯一のサービスではない場合)の 1 つである必要があります。
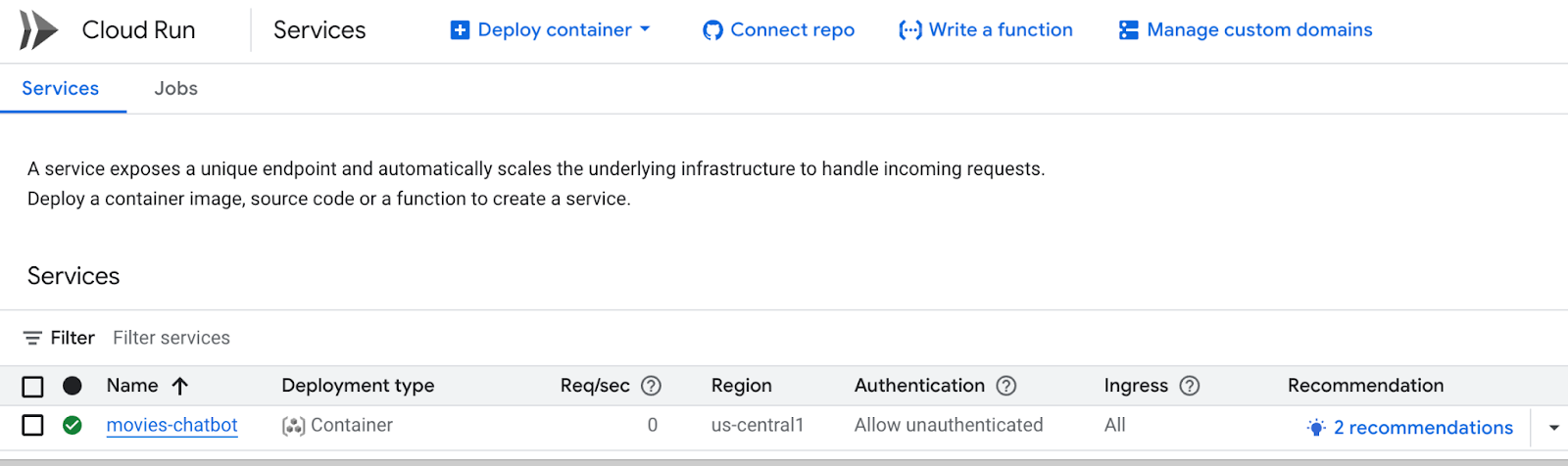
特定のサービス名(この例では movies-chatbot)をクリックすると、URL、構成、ログなどのサービスの詳細を表示できます。
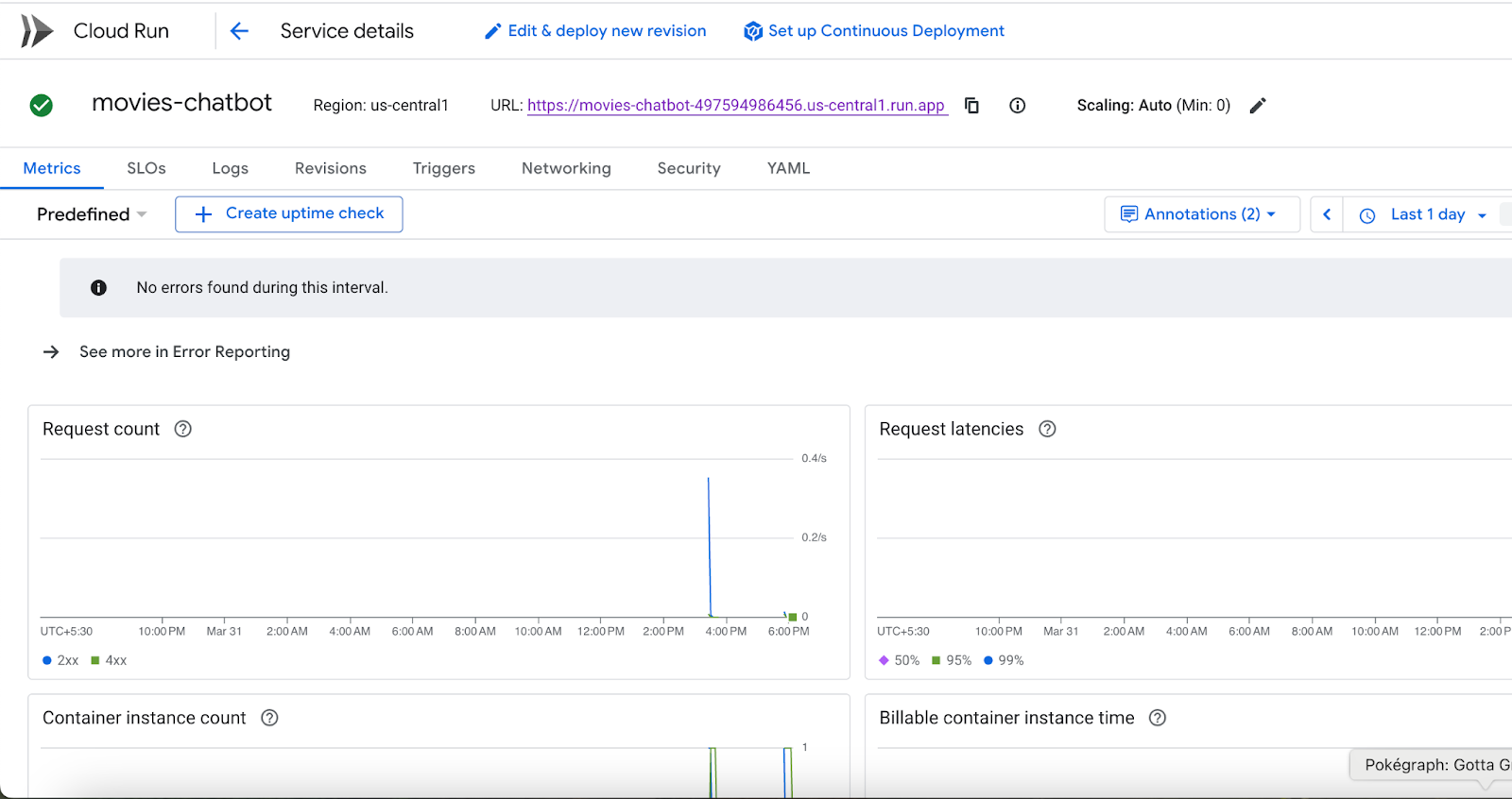
これで、映画の推奨事項チャットボットがデプロイされ、スケーラブルで共有可能になりました。🎉
9. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
10. 完了
Neo4j、Vertex AI、Gemini を使用して、GraphRAG を活用した GenAI 強化型の映画おすすめ chatbot を構築してデプロイしました。Neo4j のグラフ ネイティブ モデリング機能と、Vertex AI によるセマンティック検索、Gemini による自然言語推論を組み合わせることで、基本的な検索を超えたインテリジェントなシステムが作成されました。このシステムは、ユーザーの意図を理解し、接続されたデータについて推論し、会話形式で応答します。
この Codelab では、次のことを行いました。
✅ Neo4j で実際の映画のナレッジグラフを構築し、映画、俳優、ジャンル、関係をモデル化しました
✅ Vertex AI のテキスト エンベディング モデルを使用して映画のプロットの概要のベクトル エンベディングを生成しました
✅ GraphRAG を実装し、ベクトル検索と LLM 生成の Cypher クエリを組み合わせて、より深いマルチホップ推論を実現
✅ Gemini を統合して、ユーザーの質問を解釈し、Cypher クエリを生成し、グラフの結果を自然言語で要約します
✅ Gradio を使用して直感的なチャット インターフェースを作成しました
✅ スケーラブルなサーバーレス ホスティングのために、必要に応じてチャットボットを Google Cloud Run にデプロイした
次のステップ
このアーキテクチャは映画のおすすめに限定されず、次のように拡張できます。
- 書籍や音楽の検索プラットフォーム
- 学術研究アシスタント
- 商品レコメンデーション エンジン
- 医療、金融、法律のナレッジ アシスタント
複雑な関係と豊富なテキストデータがある場所であれば、ナレッジグラフ、LLM、セマンティック エンベディングの組み合わせにより、次世代のインテリジェント アプリケーションを強化できます。
Gemini などのマルチモーダル GenAI モデルが進化するにつれて、より豊富なコンテキスト、画像、音声、パーソナライズを組み込んで、真に人間中心のシステムを構築できるようになります。
引き続き、探索と構築を続けましょう。また、Neo4j、Vertex AI、Google Cloud の最新情報を常に把握して、インテリジェント アプリケーションを次のレベルに引き上げましょう。Neo4j GraphAcademy で、ナレッジグラフに関する実践的なチュートリアルをご覧ください。