
۱. مرور کلی
در این آزمایشگاه کد، شما با ترکیب قدرت Neo4j، هوش مصنوعی Google Vertex و Gemini، یک چتبات هوشمند پیشنهاد فیلم خواهید ساخت. در قلب این سیستم، یک گراف دانش Neo4j وجود دارد که فیلمها، بازیگران، کارگردانان، ژانرها و موارد دیگر را از طریق یک شبکه غنی از گرهها و روابط به هم پیوسته مدلسازی میکند.
برای بهبود تجربه کاربری با درک معنایی، شما با استفاده از مدل text-embedding-004 (یا جدیدتر) در Vertex AI، جاسازیهای برداری را از نمای کلی طرح فیلم ایجاد خواهید کرد. این جاسازیها برای بازیابی سریع و مبتنی بر شباهت، در Neo4j فهرستبندی میشوند.
در نهایت، شما Gemini را برای تقویت یک رابط مکالمهای ادغام خواهید کرد که در آن کاربران میتوانند سوالات زبان طبیعی مانند «اگر Interstellar را دوست داشتم، چه چیزی را باید تماشا کنم؟» بپرسند و پیشنهادات فیلم شخصیسازیشده را بر اساس شباهت معنایی و زمینه مبتنی بر نمودار دریافت کنند.
از طریق codelab، شما یک رویکرد گام به گام به شرح زیر را به کار خواهید گرفت:
- ساخت نمودار دانش Neo4j با موجودیتها و روابط مرتبط با فیلم
- با استفاده از Vertex AI، جاسازیهای متنی را برای نمای کلی فیلم ایجاد/بارگذاری کنید
- یک رابط چتبات Gradio با پشتیبانی Gemini پیادهسازی کنید که جستجوی برداری را با اجرای Cypher مبتنی بر گراف ترکیب میکند.
- (اختیاری) برنامه را به عنوان یک برنامه وب مستقل در Cloud Run مستقر کنید
آنچه یاد خواهید گرفت
- نحوه ایجاد و پر کردن نمودار دانش فیلم با استفاده از Cypher و Neo4j
- نحوه استفاده از Vertex AI برای تولید و کار با جاسازیهای متن معنایی
- نحوه ترکیب LLMها و نمودارهای دانش برای بازیابی هوشمند با استفاده از GraphRAG
- نحوه ساخت یک رابط چت کاربرپسند با استفاده از Gradio
- نحوهی استقرار اختیاری در Google Cloud Run
آنچه نیاز دارید
- مرورگر وب کروم
- یک حساب جیمیل
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- یک حساب کاربری رایگان Neo4j Aura DB
- آشنایی اولیه با دستورات ترمینال و پایتون (مفید است اما الزامی نیست)
این آزمایشگاه کد که برای توسعهدهندگان در تمام سطوح (از جمله مبتدیان) طراحی شده است، در برنامه نمونه خود از پایتون و Neo4j استفاده میکند. اگرچه آشنایی اولیه با پایتون و پایگاههای داده گراف میتواند مفید باشد، اما برای درک مفاهیم یا دنبال کردن آن نیازی به تجربه قبلی نیست.
۲. راهاندازی Neo4j AuraDB
Neo4j یک پایگاه داده گراف بومی پیشرو است که دادهها را به صورت شبکهای از گرهها (موجودیتها) و روابط (ارتباطات بین موجودیتها) ذخیره میکند و آن را برای مواردی که درک ارتباطات کلیدی است - مانند توصیهها، تشخیص تقلب، گرافهای دانش و موارد دیگر - ایدهآل میکند. برخلاف پایگاههای داده رابطهای یا مبتنی بر سند که به جداول سفت و سخت یا ساختارهای سلسله مراتبی متکی هستند، مدل گراف انعطافپذیر Neo4j امکان نمایش شهودی و کارآمد دادههای پیچیده و به هم پیوسته را فراهم میکند.
به جای سازماندهی دادهها در ردیفها و جداول مانند پایگاههای داده رابطهای، Neo4j از یک مدل گراف استفاده میکند که در آن اطلاعات به صورت گرهها (موجودیتها) و روابط (ارتباطات بین آن موجودیتها) نمایش داده میشوند. این مدل، کار با دادههایی که ذاتاً به هم مرتبط هستند - مانند افراد، مکانها، محصولات یا در مورد ما، فیلمها، بازیگران و ژانرها - را فوقالعاده شهودی میکند.
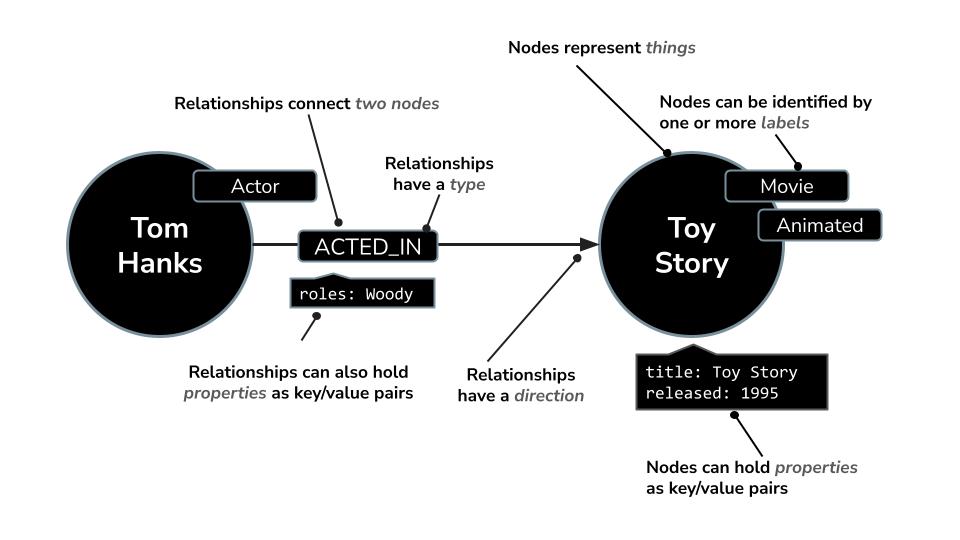
برای مثال، در یک مجموعه داده فیلم:
- یک گره میتواند نمایانگر یک
Movie،ActorیاDirectorباشد - یک رابطه میتواند
ACTED_INیاDIRECTEDباشد.
این ساختار به شما امکان میدهد به راحتی سوالاتی مانند موارد زیر را بپرسید:
- این بازیگر در کدام فیلمها بازی کرده است؟
- چه کسانی با کریستوفر نولان همکاری داشتهاند؟
- فیلمهای مشابه بر اساس بازیگران یا ژانرهای مشترک کدامند؟
Neo4j با یک زبان پرسوجوی قدرتمند به نام Cypher ارائه میشود که بهطور خاص برای پرسوجوی گرافها طراحی شده است. Cypher به شما امکان میدهد الگوها و ارتباطات پیچیده را به روشی مختصر و خوانا بیان کنید. برای مثال: این پرسوجوی Cypher از MERGE برای اطمینان از ایجاد منحصر به فرد بازیگر، فیلم و ارتباط آنها با جزئیات نقش استفاده میکند و از تکرار جلوگیری میکند.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j بسته به نیازهای شما گزینههای استقرار متعددی ارائه میدهد:
- خودمدیریتی : Neo4j را روی زیرساخت خودتان با استفاده از Neo4j Desktop یا به عنوان یک تصویر Docker (در محل یا در فضای ابری خودتان) اجرا کنید.
- مدیریتشده توسط ابر : Neo4j را با استفاده از پیشنهادات بازار، روی ارائهدهندگان ابری محبوب مستقر کنید.
- کاملاً مدیریتشده : از Neo4j AuraDB ، پایگاه داده ابری Neo4j که به عنوان سرویس کاملاً مدیریتشده است، استفاده کنید که تأمین، مقیاسپذیری، پشتیبانگیری و امنیت را برای شما مدیریت میکند.
در این آزمایشگاه کد، ما از Neo4j AuraDB Free ، لایه بدون هزینه AuraDB، استفاده خواهیم کرد. این نسخه، یک نمونه پایگاه داده گراف کاملاً مدیریتشده با فضای ذخیرهسازی و ویژگیهای کافی برای نمونهسازی اولیه، یادگیری و ساخت برنامههای کوچک را فراهم میکند - که برای هدف ما که ساخت یک چتبات پیشنهاد فیلم مبتنی بر GenAI است، ایدهآل است.
شما یک نمونه رایگان از AuraDB ایجاد خواهید کرد، آن را با استفاده از اعتبارنامههای اتصال به برنامه خود متصل خواهید کرد و از آن برای ذخیره و پرسوجو در نمودار دانش فیلم خود در طول این تمرین استفاده خواهید کرد.
چرا گرافها؟
در پایگاههای داده رابطهای سنتی، پاسخ به سوالاتی مانند «کدام فیلمها بر اساس بازیگران یا ژانر مشترک به Inception شباهت دارند؟» مستلزم عملیات پیچیده JOIN در چندین جدول است. با افزایش عمق روابط، عملکرد و خوانایی کاهش مییابد.
با این حال، پایگاههای داده گراف مانند Neo4j برای پیمایش کارآمد روابط ساخته شدهاند و همین امر آنها را به گزینهای طبیعی برای سیستمهای توصیهگر، جستجوی معنایی و دستیاران هوشمند تبدیل میکند. آنها به ثبت زمینههای دنیای واقعی - مانند شبکههای همکاری، خطوط داستانی یا ترجیحات بیننده - کمک میکنند که نمایش آنها با استفاده از مدلهای داده سنتی میتواند دشوار باشد.
با ترکیب این دادههای متصل با LLMهایی مانند Gemini و تعبیههای برداری از Vertex AI ، میتوانیم تجربه چتبات را فوقالعاده تقویت کنیم - به آن اجازه میدهیم تا به روشی شخصیتر و مرتبطتر استدلال، بازیابی و پاسخ دهد.
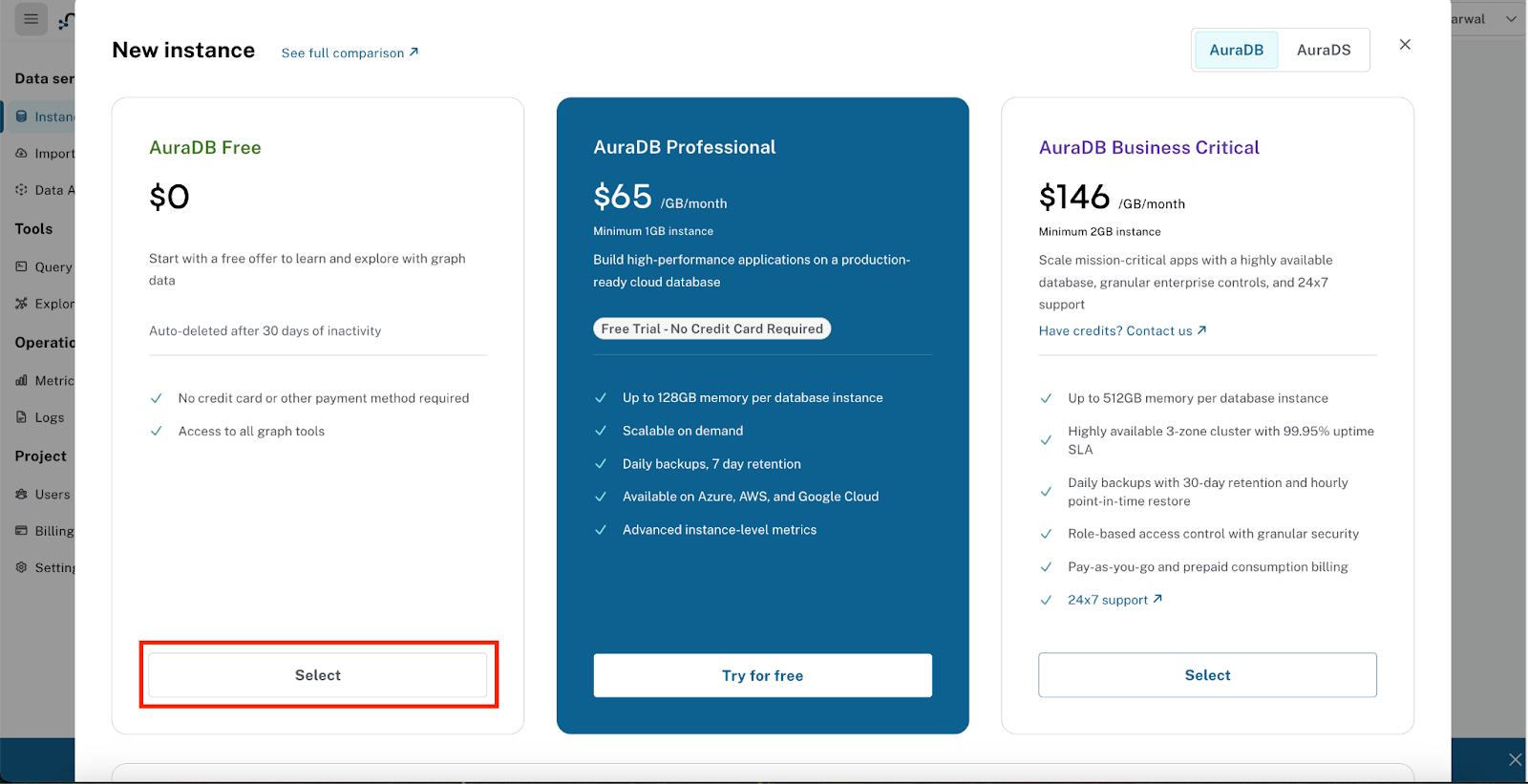
ایجاد رایگان Neo4j AuraDB
- به آدرس https://console.neo4j.io مراجعه کنید.
- با حساب گوگل یا ایمیل خود وارد شوید.
- روی «ایجاد نمونه رایگان» کلیک کنید.
- در حین آمادهسازی نمونه، یک پنجره بازشو ظاهر میشود که اعتبارنامههای اتصال به پایگاه داده شما را نشان میدهد.
حتماً جزئیات زیر را از پنجره بازشو دانلود و ذخیره کنید - این موارد برای اتصال برنامه شما به Neo4j ضروری هستند:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
شما از این مقادیر برای پیکربندی فایل .env در پروژه خود برای احراز هویت با Neo4j در مرحله بعدی استفاده خواهید کرد.
Neo4j AuraDB Free برای توسعه، آزمایش و برنامههای کاربردی در مقیاس کوچک مانند این codelab بسیار مناسب است. این برنامه محدودیتهای استفادهی زیادی را ارائه میدهد و تا ۲۰۰۰۰۰ گره و ۴۰۰۰۰۰ رابطه را پشتیبانی میکند. در حالی که تمام ویژگیهای ضروری مورد نیاز برای ساخت و پرسوجوی یک نمودار دانش را فراهم میکند، از پیکربندیهای پیشرفته مانند افزونههای سفارشی یا افزایش فضای ذخیرهسازی پشتیبانی نمیکند. برای حجم کار تولیدی یا مجموعه دادههای بزرگتر، میتوانید به یک طرح AuraDB سطح بالاتر ارتقا دهید که ظرفیت، عملکرد و ویژگیهای سطح سازمانی بیشتری را ارائه میدهد.
این بخش مربوط به راهاندازی بکاند Neo4j AuraDB شما را تکمیل میکند. در مرحله بعدی، یک پروژه Google Cloud ایجاد میکنیم، مخزن را کلون میکنیم و متغیرهای محیطی لازم را پیکربندی میکنیم تا محیط توسعه شما قبل از شروع codelab آماده شود.
۳. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود و bq از قبل روی آن بارگذاری شده است، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- API های مورد نیاز را از طریق دستور زیر فعال کنید. این کار ممکن است چند دقیقه طول بکشد، پس لطفاً صبور باشید.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
پس از اجرای موفقیتآمیز دستور، باید پیامی با مضمون « عملیات .... با موفقیت به پایان رسید» (Operation .... finished successfully) مشاهده کنید.
جایگزین دستور gcloud از طریق کنسول با جستجوی هر محصول یا استفاده از این لینک است.
اگر هر API از قلم افتاده باشد، میتوانید همیشه آن را در طول پیادهسازی فعال کنید.
برای دستورات و نحوهی استفاده از gcloud به مستندات مراجعه کنید.
مخزن کلون و تنظیمات محیط راهاندازی
مرحله بعدی، کپی کردن مخزن نمونهای است که در ادامهی کد به آن ارجاع خواهیم داد. با فرض اینکه در Cloud Shell هستید، دستور زیر را از دایرکتوری خانگی خود اجرا کنید:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
برای اجرای ویرایشگر، روی گزینه Open Editor در نوار ابزار پنجره Cloud Shell کلیک کنید. روی نوار منو در گوشه بالا سمت چپ کلیک کنید و مطابق شکل زیر، File → Open Folder را انتخاب کنید:
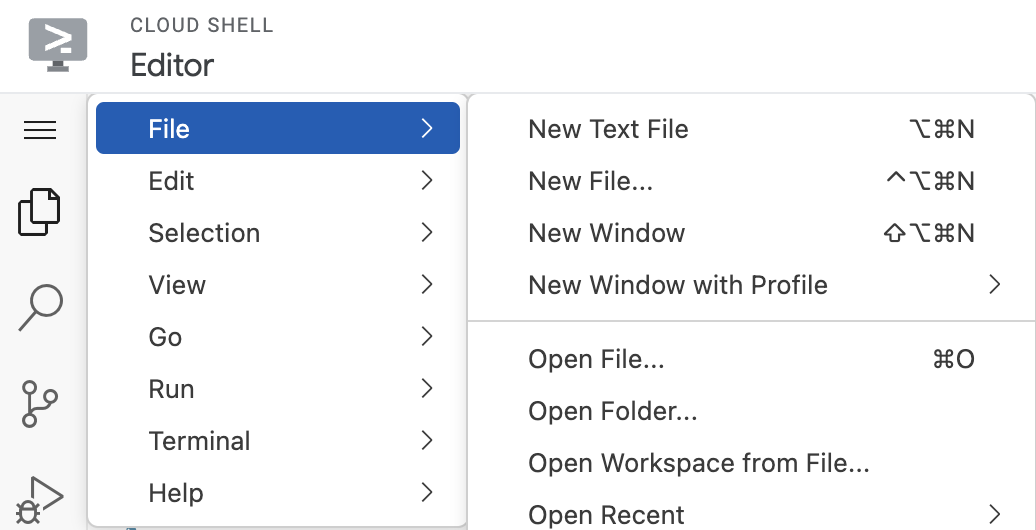
پوشه neo4j-vertexai-codelab را انتخاب کنید. باید پوشه را با ساختاری تقریباً مشابه شکل زیر باز شده ببینید:
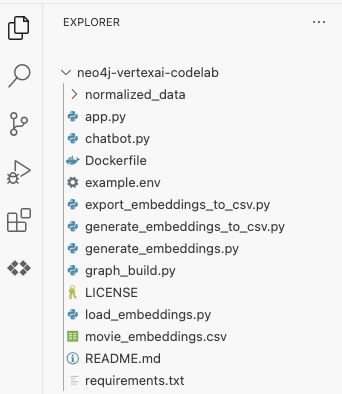
در مرحله بعد، باید متغیرهای محیطی را که در سراسر codelab استفاده خواهند شد، تنظیم کنیم. روی فایل example.env کلیک کنید تا محتویات آن را مانند تصویر زیر ببینید:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
حالا یک فایل جدید با نام .env در همان پوشهای که فایل example.env قرار دارد ایجاد کنید و محتویات فایل example.env موجود را در آن کپی کنید. حالا متغیرهای زیر را بهروزرسانی کنید:
-
NEO4J_URI،NEO4J_USER،NEO4J_PASSWORDوNEO4J_DATABASE: - این مقادیر را با استفاده از اطلاعات احراز هویت ارائه شده در طول ایجاد نمونه Neo4j AuraDB Free در مرحله قبل، پر کنید.
-
NEO4J_DATABASEمعمولاً برای AuraDB Free روی neo4j تنظیم شده است. -
PROJECT_IDوLOCATION: - اگر codelab را از Google Cloud Shell اجرا میکنید، میتوانید این فیلدها را خالی بگذارید، زیرا آنها به طور خودکار از پیکربندی پروژه فعال شما استنباط میشوند.
- اگر به صورت محلی یا خارج از Cloud Shell در حال اجرا هستید،
PROJECT_IDبا شناسه پروژه Google Cloud که قبلاً ایجاد کردهاید، بهروزرسانی کنید وLOCATIONروی منطقهای که برای آن پروژه انتخاب کردهاید (مثلاً us-central1) تنظیم کنید.
پس از پر کردن این مقادیر، فایل .env را ذخیره کنید. این پیکربندی به برنامه شما اجازه میدهد تا به سرویسهای Neo4j و Vertex AI متصل شود.
مرحله آخر در راهاندازی محیط توسعه، ایجاد یک محیط مجازی پایتون و نصب تمام وابستگیهای مورد نیاز ذکر شده در فایل requirements.txt است. این وابستگیها شامل کتابخانههای مورد نیاز برای کار با Neo4j، Vertex AI، Gradio و موارد دیگر میشود.
ابتدا، با اجرای دستور زیر، یک محیط مجازی با نام .venv ایجاد کنید:
python -m venv .venv
پس از ایجاد محیط، باید محیط ایجاد شده را با دستور زیر فعال کنیم.
source .venv/bin/activate
اکنون باید در ابتدای اعلان ترمینال خود (.venv) را ببینید که نشان میدهد محیط فعال است. برای مثال: (.venv) yourusername@cloudshell:
اکنون، با اجرای دستور زیر، وابستگیهای مورد نیاز را نصب کنید:
pip install -r requirements.txt
در اینجا خلاصهای از وابستگیهای کلیدی ذکر شده در فایل آمده است:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
زمانی که تمام وابستگیها با موفقیت نصب شدند، محیط پایتون محلی شما به طور کامل پیکربندی میشود تا اسکریپتها و ربات چت را در این codelab اجرا کند.
عالی! اکنون آمادهایم تا به مرحله بعدی برویم - درک مجموعه دادهها و آمادهسازی آن برای ایجاد نمودار و غنیسازی معنایی.
۴. مجموعه دادههای فیلمها را آماده کنید
اولین وظیفه ما آمادهسازی مجموعه دادههای Movies است که برای ساخت نمودار دانش و تقویت ربات چت پیشنهاد دهنده خود از آن استفاده خواهیم کرد. به جای شروع از ابتدا، از یک مجموعه داده باز موجود استفاده خواهیم کرد و بر اساس آن، کار را پیش خواهیم برد.
ما از مجموعه دادهی فیلمها (The Movies Dataset) نوشتهی روناک بانیک (Rounak Banik)، یک مجموعه دادهی عمومی شناختهشده که در کاگل (Kaggle) موجود است، استفاده میکنیم. این مجموعه شامل فرادادههای بیش از ۴۵۰۰۰ فیلم از TMDB، از جمله بازیگران، عوامل تولید، کلمات کلیدی، رتبهبندیها و موارد دیگر است.
برای ساخت یک چتبات پیشنهاد فیلم قابل اعتماد و مؤثر، شروع با دادههای تمیز، منسجم و ساختاریافته ضروری است. اگرچه مجموعه دادههای Movies از Kaggle منبعی غنی با بیش از ۴۵۰۰۰ رکورد فیلم و فرادادههای دقیق - از جمله ژانرها، بازیگران، عوامل و موارد دیگر - است، اما حاوی نویز، ناسازگاریها و ساختارهای داده تو در تو نیز هست که برای مدلسازی گراف یا جاسازی معنایی ایدهآل نیستند.
برای پرداختن به این موضوع، ما مجموعه دادهها را پیشپردازش و نرمالسازی کردهایم تا اطمینان حاصل کنیم که برای ساخت گراف دانش Neo4j و تولید جاسازیهای با کیفیت بالا مناسب است. این فرآیند شامل موارد زیر است:
- حذف رکوردهای تکراری و ناقص
- استانداردسازی فیلدهای کلیدی (مثلاً نام ژانر، نام اشخاص)
- مسطحسازی ساختارهای پیچیده تودرتو (مثلاً بازیگران و خدمه) به CSVهای ساختاریافته
- انتخاب زیرمجموعهای نماینده از حدود ۱۲۰۰۰ فیلم برای ماندن در محدوده Neo4j AuraDB Free
دادههای نرمالشده و با کیفیت بالا به تضمین موارد زیر کمک میکنند:
- کیفیت دادهها : خطاها و ناسازگاریها را برای توصیههای دقیقتر به حداقل میرساند.
- عملکرد پرسوجو : ساختار سادهشده، سرعت بازیابی را بهبود میبخشد و افزونگی را کاهش میدهد.
- دقت جاسازی : ورودیهای تمیز منجر به جاسازیهای برداری معنادارتر و زمینهایتر میشوند.
شما میتوانید به مجموعه دادههای پاکسازی و نرمالسازی شده در پوشه normalized_data/ در این مخزن گیتهاب دسترسی داشته باشید. این مجموعه داده همچنین در یک مخزن ذخیرهسازی ابری گوگل (Google Cloud Storage) نیز کپی شده است تا دسترسی به آن در اسکریپتهای پایتون آینده آسان باشد.
با پاکسازی و آمادهسازی دادهها، اکنون آمادهایم تا آنها را در Neo4j بارگذاری کنیم و ساخت نمودار دانش فیلم خود را آغاز کنیم.
۵. ساخت نمودار دانش فیلمها
برای فعال کردن چتبات پیشنهاد فیلم مجهز به GenAI، باید مجموعه دادههای فیلم خود را به گونهای ساختاربندی کنیم که شبکه غنی ارتباطات بین فیلمها، بازیگران، کارگردانان، ژانرها و سایر فرادادهها را در بر بگیرد. در این بخش، با استفاده از مجموعه دادههای تمیز و نرمالسازی شدهای که قبلاً آماده کردهاید، یک نمودار دانش فیلمها در Neo4j خواهیم ساخت.
ما از قابلیت LOAD CSV در Neo4j برای دریافت فایلهای CSV میزبانی شده در یک مخزن عمومی Google Cloud Storage (GCS) استفاده خواهیم کرد. این فایلها اجزای مختلف مجموعه دادههای فیلم، مانند فیلمها، ژانرها، بازیگران، عوامل، شرکتهای تولیدی و رتبهبندی کاربران را نشان میدهند.
مرحله ۱: ایجاد محدودیتها و شاخصها
قبل از وارد کردن دادهها، بهتر است محدودیتها و شاخصهایی ایجاد کنید تا یکپارچگی دادهها حفظ شود و عملکرد پرسوجو بهینه شود.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
مرحله 2: وارد کردن فراداده و روابط فیلم
بیایید نگاهی به نحوه وارد کردن ابرداده فیلم با استفاده از دستور LOAD CSV بیندازیم. این مثال گرههای فیلم را با ویژگیهای کلیدی مانند عنوان، نمای کلی، زبان و زمان اجرا ایجاد میکند:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
به طور مشابه، میتوانید موجودیتهای دیگری مانند ژانرها ، شرکتهای تولید ، زبانهای گفتاری ، کشورها ، بازیگران ، عوامل و رتبهبندیهای کاربران را با استفاده از پرسوجوهای CSV و Cypher مربوطه وارد و پیوند دهید.
بارگذاری کل گراف از طریق پایتون
به جای اجرای دستی چندین کوئری Cypher، توصیه میکنیم از اسکریپت خودکار پایتون ارائه شده در این codelab استفاده کنید.
اسکریپت graph_build.py با استفاده از اعتبارنامههای موجود در فایل .env شما، کل مجموعه دادهها را از GCS در نمونه Neo4j AuraDB شما بارگذاری میکند.
python graph_build.py
این اسکریپت به ترتیب تمام CSV های لازم را بارگذاری میکند، گرهها و روابط را ایجاد میکند و نمودار دانش کامل فیلم شما را ساختار میدهد.
|
|

.png")
نمودار خود را اعتبارسنجی کنید
پس از بارگذاری، میتوانید نمودار خود را با اجرای اسکریپت زیر اعتبارسنجی کنید:
python validate_graph.py
این به شما خلاصهای سریع از آنچه در نمودار شما وجود دارد را میدهد: چند فیلم، بازیگر، ژانر و روابطی مانند ACTED_IN، DIRECTED و غیره وجود دارد - و تضمین میکند که وارد کردن شما موفقیتآمیز بوده است.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
اکنون باید نمودار خود را پر از فیلمها، افراد، ژانرها و موارد دیگر ببینید - آماده برای غنیسازی معنایی در مرحله بعدی!
۶. تولید و بارگذاری جاسازیها برای انجام جستجوی شباهت برداری
برای فعال کردن جستجوی معنایی در چتبات خود، باید برای نمای کلی فیلمها، جاسازیهای برداری ایجاد کنیم. این جاسازیها دادههای متنی را به بردارهای عددی تبدیل میکنند که میتوانند از نظر شباهت مقایسه شوند - و این امکان را برای چتبات فراهم میکنند که فیلمهای مرتبط را بازیابی کند، حتی اگر عبارت جستجو دقیقاً با عنوان یا توضیحات مطابقت نداشته باشد.

گزینه ۱: بارگذاری جاسازیهای از پیش محاسبهشده از طریق Cypher
برای اتصال سریع جاسازیها به گرههای Movie مربوطه در Neo4j، دستور Cypher زیر را در مرورگر Neo4j اجرا کنید:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
این دستور بردارهای جاسازی را از CSV میخواند و آنها را به عنوان یک ویژگی ( m.embedding ) به هر گره Movie الصاق میکند.
گزینه ۲: بارگذاری جاسازیها با استفاده از پایتون
همچنین میتوانید جاسازیها را به صورت برنامهنویسی شده با استفاده از اسکریپت پایتون ارائه شده بارگذاری کنید. این رویکرد در صورتی مفید است که در محیط خودتان کار میکنید یا میخواهید این فرآیند را خودکار کنید:
python load_embeddings.py
این اسکریپت همان CSV را از GCS میخواند و جاسازیها را با استفاده از درایور پایتون Neo4j در Neo4j مینویسد.
[اختیاری] خودتان جاسازیها را ایجاد کنید (برای کاوش)
اگر کنجکاو هستید که بدانید جاسازیها چگونه ایجاد میشوند، میتوانید منطق موجود در خود اسکریپت generate_embeddings.py را بررسی کنید. این اسکریپت از Vertex AI برای جاسازی هر متن نمای کلی فیلم با استفاده از مدل text-embedding-004 استفاده میکند.
برای اینکه خودتان آن را امتحان کنید، بخش تولید جاسازی کد را باز کرده و اجرا کنید. اگر در Cloud Shell اجرا میکنید، میتوانید خط زیر را کامنت کنید، زیرا Cloud Shell از طریق حساب فعال شما از قبل احراز هویت شده است:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
به محض اینکه جاسازیها در Neo4j بارگذاری شوند، نمودار دانش فیلم شما از نظر معنایی آگاه میشود - آماده پشتیبانی از جستجوی قدرتمند زبان طبیعی با استفاده از شباهت برداری!
۷. چتبات پیشنهاد فیلم
با قرار دادن گراف دانش و جاسازیهای برداری، وقت آن رسیده است که همه چیز را در یک رابط مکالمهای کاملاً کاربردی - چتبات پیشنهاد فیلم مبتنی بر GenAI - گرد هم آورید.
این چتبات با استفاده از Gradio ، یک چارچوب وب سبک برای ساخت رابطهای کاربری بصری، در پایتون پیادهسازی شده است. منطق اصلی در app.py قرار دارد که به نمونه Neo4j AuraDB شما متصل میشود و از Google Vertex AI و Gemini برای پردازش و پاسخ به پرسوجوهای زبان طبیعی استفاده میکند.
چگونه کار میکند؟
- کاربر یک عبارت جستجو به زبان طبیعی تایپ میکند ، مثلاً «فیلمهای علمی تخیلی هیجانانگیز مثل «میانستارهای» را به من پیشنهاد دهید»
- با استفاده از مدل
text-embedding-004در Vertex AI ، یک جاسازی برداری برای پرسوجو ایجاد کنید. - انجام جستجوی برداری در Neo4j برای بازیابی فیلمهای مشابه از نظر معنایی
- از Gemini برای موارد زیر استفاده کنید :
- پرس و جو را در متن تفسیر کنید
- یک کوئری Cypher سفارشی بر اساس نتایج جستجوی برداری و طرح Neo4j ایجاد کنید
- اجرای پرسوجو برای استخراج دادههای نمودار مرتبط (مثلاً بازیگران، کارگردانان، ژانرها)
- نتایج را به صورت مکالمهای برای کاربر خلاصه کنید
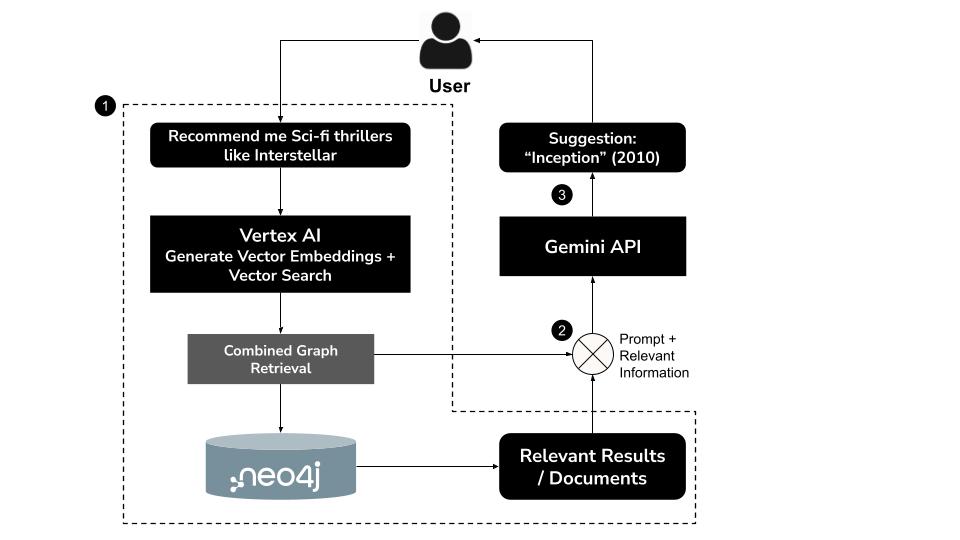
این رویکرد ترکیبی که با نام GraphRAG (بازیابی گراف-تولید افزوده) شناخته میشود، بازیابی معنایی و استدلال ساختاریافته را برای تولید توصیههای دقیقتر، زمینهایتر و قابل توضیحتر ترکیب میکند.
چتبات را به صورت محلی اجرا کنید
محیط مجازی خود را فعال کنید (اگر از قبل فعال نیست)، سپس چتبات را با دستور زیر اجرا کنید:
python app.py
شما باید خروجی مشابه زیر را ببینید:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 برای اشتراکگذاری خارجی ربات چت، در تابع launch() در app.py ، share=True را تنظیم کنید.
تعامل با چتبات
برای دسترسی به رابط چتبات، آدرس محلی نمایش داده شده در ترمینال خود (معمولاً 👉 http://0.0.0.0:8080 ) را باز کنید.
سعی کنید سوالاتی مانند موارد زیر بپرسید:
- «اگر فیلم «میانستارهای» را دوست داشته باشم، چه چیزی باید تماشا کنم؟»
- «یک فیلم عاشقانه به کارگردانی نورا افرون پیشنهاد دهید»
- «میخواهم یک فیلم خانوادگی با تام هنکس تماشا کنم»
- «فیلمهای هیجانانگیزی با موضوع هوش مصنوعی پیدا کنید»
این چتبات:
✅ مفهوم سوال را بفهمید
✅ با استفاده از جاسازیها، طرحهای فیلم از نظر معنایی مشابه را پیدا کنید
✅ ایجاد و اجرای یک کوئری Cypher برای دریافت زمینه گراف مرتبط
✅ یک توصیه دوستانه و شخصی ارائه دهید - همه اینها در عرض چند ثانیه
چیزی که الان داری
شما به تازگی یک چتبات فیلم مبتنی بر GraphRAG ساختهاید که موارد زیر را با هم ترکیب میکند:
- جستجوی برداری برای ارتباط معنایی
- استدلال گراف دانش با Neo4j
- قابلیتهای LLM از طریق Gemini
- رابط چت روان با Gradio
این معماری، پایهای را تشکیل میدهد که میتوانید آن را به سیستمهای جستجوی پیشرفتهتر، پیشنهاد یا استدلال مبتنی بر GenAI گسترش دهید.
۸. (اختیاری) استقرار در Google Cloud Run
اگر میخواهید چتبات پیشنهاد فیلم خود را در دسترس عموم قرار دهید، میتوانید آن را در Google Cloud Run مستقر کنید - یک پلتفرم کاملاً مدیریتشده و بدون سرور که به طور خودکار برنامه شما را مقیاسبندی میکند و تمام نگرانیهای زیرساختی را از بین میبرد.
این استقرار از موارد زیر استفاده میکند:
-
requirements.txt— برای تعریف وابستگیهای پایتون (Neo4j، Vertex AI، Gradio و غیره) -
Dockerfile- برای بستهبندی برنامه -
.env.yaml— برای ارسال ایمن متغیرهای محیطی در زمان اجرا
مرحله ۱: آمادهسازی .env.yaml
فایلی با نام .env.yaml در دایرکتوری ریشه خود با محتویاتی مانند زیر ایجاد کنید:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 این قالب نسبت به --set-env-vars ترجیح داده میشود زیرا مقیاسپذیرتر، قابل کنترلتر از نظر نسخه و خواناتر است.
مرحله 2: تنظیم متغیرهای محیطی
در ترمینال خود، متغیرهای محیطی زیر را تنظیم کنید (مقادیر جایگزین را با تنظیمات واقعی پروژه خود جایگزین کنید):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
مرحله 2: ایجاد رجیستری مصنوعات و ساخت کانتینر
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
این دستور برنامه شما را با استفاده از Dockerfile بستهبندی میکند و تصویر کانتینر را در Google Cloud Artifact Registry بارگذاری میکند.
مرحله ۳: استقرار در Cloud Run
اکنون برنامه خود را با استفاده از فایل .env.yaml برای پیکربندی زمان اجرا مستقر کنید:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
دسترسی به چتبات
پس از استقرار، Cloud Run یک URL عمومی مانند زیر ارائه میدهد:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
برای دسترسی به رابط چتبات Gradio مستقر شده، این URL را در مرورگر خود باز کنید - آماده برای مدیریت پیشنهادهای فیلم با استفاده از GraphRAG، Gemini و Neo4j!
یادداشتها و نکات
- مطمئن شوید که
Dockerfileشما در حین ساخت،pip install -r requirements.txtرا اجرا میکند. - اگر از Cloud Shell استفاده نمیکنید ، باید محیط خود را با استفاده از یک حساب کاربری سرویس با مجوزهای Vertex AI و Artifact Registry تأیید اعتبار کنید.
- شما میتوانید گزارشها و معیارهای استقرار را از Google Cloud Console > Cloud Run رصد کنید.
همچنین میتوانید از کنسول Google Cloud به Cloud Run مراجعه کنید و لیست سرویسها را در Cloud Run مشاهده خواهید کرد. سرویس movies-chatbot باید یکی از سرویسهایی باشد که در آنجا فهرست شده است (اگر نگوییم تنها سرویس).
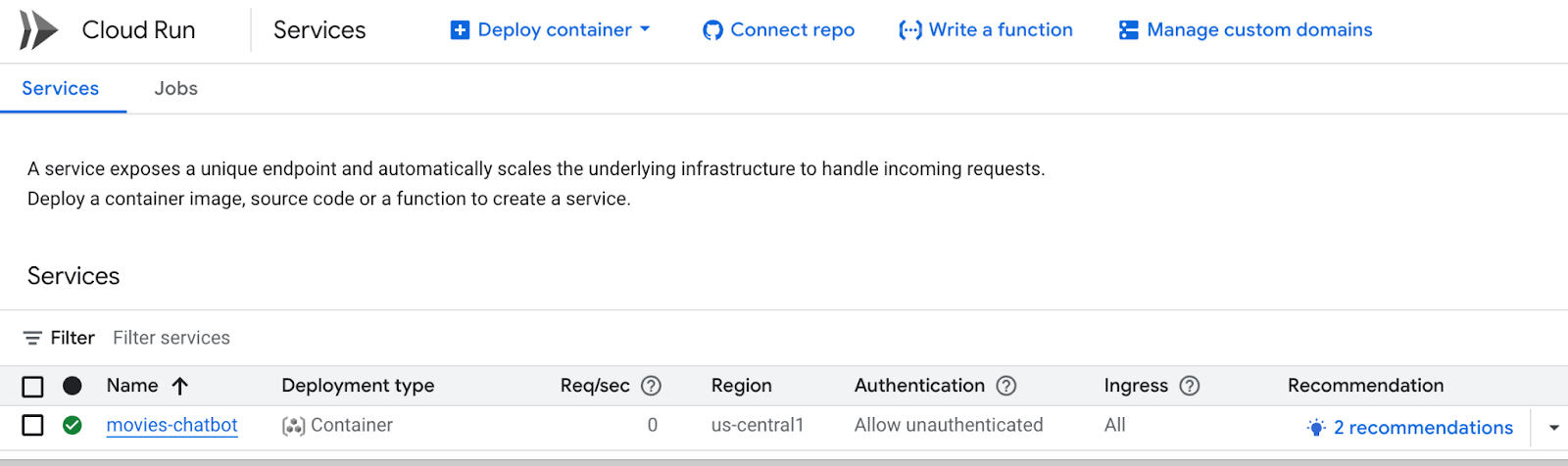
شما میتوانید جزئیات سرویس مانند URL، پیکربندیها، گزارشها و موارد دیگر را با کلیک روی نام سرویس خاص (در مورد ما movies-chatbot ) مشاهده کنید.

با این کار، چتبات پیشنهاد فیلم شما اکنون مستقر، مقیاسپذیر و قابل اشتراکگذاری است. 🎉
۹. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
۱۰. تبریک
شما با موفقیت یک چتبات پیشنهاد فیلم مبتنی بر GraphRAG و بهبود یافته توسط GenAI را با استفاده از Neo4j ، Vertex AI و Gemini ساخته و مستقر کردهاید. با ترکیب قابلیتهای مدلسازی مبتنی بر گراف Neo4j با جستجوی معنایی از طریق Vertex AI و استدلال زبان طبیعی از طریق Gemini، شما یک سیستم هوشمند ایجاد کردهاید که فراتر از جستجوی اولیه عمل میکند - این سیستم قصد کاربر را درک میکند ، دلایل را از طریق دادههای متصل بررسی میکند و به صورت مکالمهای پاسخ میدهد .
در این آزمایشگاه کد، شما موارد زیر را انجام دادید:
✅ ساخت یک نمودار دانش فیلم دنیای واقعی در Neo4j برای مدلسازی فیلمها، بازیگران، ژانرها و روابط
✅ با استفاده از مدلهای تعبیه متن Vertex AI، تعبیههای برداری برای مرور کلی طرح فیلم ایجاد شد
✅ پیادهسازی GraphRAG ، با ترکیب جستجوی برداری و پرسوجوهای Cypher تولید شده توسط LLM برای استدلال عمیقتر و چندگامی
✅ یکپارچهسازی Gemini برای تفسیر سوالات کاربر، تولید کوئریهای Cypher و خلاصهسازی نتایج نمودار به زبان طبیعی
✅ با استفاده از Gradio یک رابط چت بصری ایجاد کرد
✅ به صورت اختیاری، چتبات خود را برای میزبانی مقیاسپذیر و بدون سرور، در Google Cloud Run مستقر کنید
قدم بعدی چیست؟
این معماری محدود به پیشنهاد فیلم نیست - میتواند به موارد زیر نیز گسترش یابد:
- پلتفرمهای کشف کتاب و موسیقی
- دستیاران پژوهشی دانشگاهی
- موتورهای توصیه محصول
- دستیاران دانش مراقبتهای بهداشتی، مالی و حقوقی
هر جایی که روابط پیچیده + دادههای متنی غنی داشته باشید، این ترکیب از نمودارهای دانش + LLMها + تعبیههای معنایی میتواند نسل بعدی برنامههای هوشمند را تقویت کند.
با تکامل مدلهای چندوجهی GenAI مانند Gemini، شما قادر خواهید بود زمینه، تصاویر، گفتار و شخصیسازی غنیتری را برای ساخت سیستمهای واقعاً انسانمحور در نظر بگیرید.
به کاوش ادامه دهید، به ساختن ادامه دهید - و فراموش نکنید که با جدیدترینهای Neo4j ، Vertex AI و Google Cloud بهروز باشید تا برنامههای هوشمند خود را به سطح بالاتری ببرید! آموزشهای کاربردیتر گراف دانش را در Neo4j GraphAcademy جستجو کنید.