
1. Tổng quan
Trong lớp học lập trình này, bạn sẽ tạo một chatbot đề xuất phim thông minh bằng cách kết hợp sức mạnh của Neo4j, Google Vertex AI và Gemini. Trọng tâm của hệ thống này là Sơ đồ tri thức Neo4j, mô hình hoá phim, diễn viên, đạo diễn, thể loại và nhiều nội dung khác thông qua một mạng lưới phong phú gồm các mối quan hệ và nút được kết nối với nhau.
Để nâng cao trải nghiệm người dùng bằng cách hiểu ngữ nghĩa, bạn sẽ tạo các giá trị nhúng vectơ từ thông tin tổng quan về cốt truyện phim bằng mô hình text-embedding-004 (hoặc mô hình mới hơn) của Vertex AI. Các vectơ nhúng này được lập chỉ mục trong Neo4j để truy xuất nhanh dựa trên độ tương tự.
Cuối cùng, bạn sẽ tích hợp Gemini để hỗ trợ một giao diện đàm thoại, nơi người dùng có thể đặt câu hỏi bằng ngôn ngữ tự nhiên như "Tôi nên xem phim gì nếu tôi thích phim Interstellar?" và nhận được các đề xuất phim phù hợp với từng người dùng dựa trên mức độ tương đồng về ngữ nghĩa và bối cảnh dựa trên biểu đồ.
Trong lớp học lập trình này, bạn sẽ sử dụng phương pháp từng bước như sau:
- Xây dựng Sơ đồ tri thức Neo4j bằng các thực thể và mối quan hệ liên quan đến phim
- Tạo/Tải các giá trị nhúng văn bản cho thông tin tổng quan về phim bằng Vertex AI
- Triển khai giao diện chatbot Gradio do Gemini cung cấp, kết hợp tính năng tìm kiếm vectơ với việc thực thi Cypher dựa trên biểu đồ
- (Không bắt buộc) Triển khai ứng dụng vào Cloud Run dưới dạng một ứng dụng web độc lập
Kiến thức bạn sẽ học được
- Cách tạo và điền thông tin vào biểu đồ tri thức về phim bằng Cypher và Neo4j
- Cách sử dụng Vertex AI để tạo và xử lý các giá trị nhúng văn bản ngữ nghĩa
- Cách kết hợp LLM và Sơ đồ tri thức để truy xuất thông tin một cách thông minh bằng GraphRAG
- Cách xây dựng giao diện trò chuyện thân thiện với người dùng bằng Gradio
- Cách triển khai (không bắt buộc) trên Google Cloud Run
Bạn cần có
- Trình duyệt web Chrome
- Tài khoản Gmail
- Một Dự án trên Google Cloud đã bật tính năng thanh toán
- Tài khoản Neo4j Aura DB miễn phí
- Quen thuộc cơ bản với các lệnh trên thiết bị đầu cuối và Python (hữu ích nhưng không bắt buộc)
Lớp học lập trình này được thiết kế cho nhà phát triển ở mọi cấp độ (kể cả người mới bắt đầu), sử dụng Python và Neo4j trong ứng dụng mẫu. Mặc dù việc có kiến thức cơ bản về Python và cơ sở dữ liệu đồ thị có thể hữu ích, nhưng bạn không cần có kinh nghiệm trước đó để hiểu các khái niệm hoặc theo dõi.
2. Thiết lập Neo4j AuraDB
Neo4j là một cơ sở dữ liệu đồ thị gốc hàng đầu, lưu trữ dữ liệu dưới dạng một mạng lưới các nút (thực thể) và mối quan hệ (kết nối giữa các thực thể), khiến cơ sở dữ liệu này trở nên lý tưởng cho các trường hợp sử dụng mà việc hiểu rõ các mối kết nối là yếu tố then chốt – chẳng hạn như đề xuất, phát hiện hành vi gian lận, biểu đồ tri thức, v.v. Không giống như cơ sở dữ liệu quan hệ hoặc dựa trên tài liệu dựa vào các bảng hoặc cấu trúc phân cấp cứng nhắc, mô hình biểu đồ linh hoạt của Neo4j cho phép biểu diễn dữ liệu phức tạp, có mối liên kết với nhau một cách trực quan và hiệu quả.
Thay vì sắp xếp dữ liệu thành các hàng và bảng như cơ sở dữ liệu quan hệ, Neo4j sử dụng một mô hình đồ thị, trong đó thông tin được biểu thị dưới dạng nút (thực thể) và mối quan hệ (kết nối giữa các thực thể đó). Mô hình này giúp bạn làm việc với dữ liệu được liên kết một cách tự nhiên (chẳng hạn như con người, địa điểm, sản phẩm hoặc trong trường hợp của chúng tôi là phim, diễn viên và thể loại) một cách cực kỳ trực quan.
Ví dụ: trong một tập dữ liệu về phim:
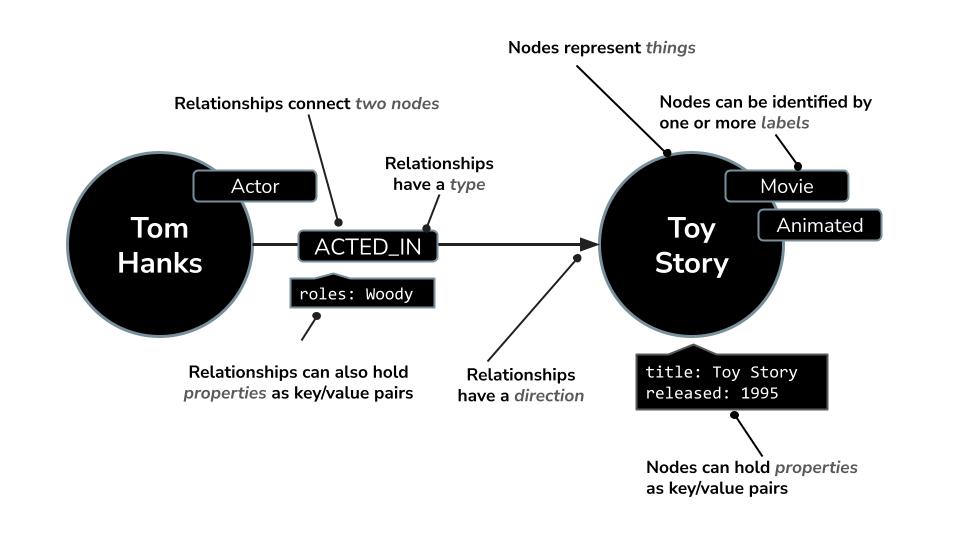
- Một nút có thể biểu thị
Movie,ActorhoặcDirector - Mối quan hệ có thể là
ACTED_INhoặcDIRECTED
Cấu trúc này giúp bạn dễ dàng đặt các câu hỏi như:
- Diễn viên này đã xuất hiện trong những bộ phim nào?
- Những diễn viên nào từng làm việc với Christopher Nolan?
- Những bộ phim tương tự dựa trên diễn viên hoặc thể loại chung là gì?
Neo4j có một ngôn ngữ truy vấn mạnh mẽ có tên là Cypher, được thiết kế riêng để truy vấn các biểu đồ. Cypher cho phép bạn thể hiện các mẫu và mối kết nối phức tạp theo cách ngắn gọn và dễ đọc. Ví dụ: truy vấn Cypher này sử dụng MERGE để đảm bảo việc tạo diễn viên, phim và mối quan hệ của họ với thông tin chi tiết về vai trò là duy nhất, tránh trùng lặp.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j cung cấp nhiều lựa chọn triển khai tuỳ theo nhu cầu của bạn:
- Tự quản lý: Chạy Neo4j trên cơ sở hạ tầng của riêng bạn bằng Neo4j Desktop hoặc dưới dạng một hình ảnh Docker (tại chỗ hoặc trong đám mây của riêng bạn).
- Được quản lý trên đám mây: Triển khai Neo4j trên các nhà cung cấp dịch vụ đám mây phổ biến bằng cách sử dụng các sản phẩm trên marketplace.
- Được quản lý toàn diện: Sử dụng Neo4j AuraDB, cơ sở dữ liệu đám mây được quản lý toàn diện dưới dạng dịch vụ của Neo4j, giúp bạn xử lý việc cấp phép, mở rộng quy mô, sao lưu và bảo mật.
Trong lớp học lập trình này, chúng ta sẽ sử dụng Neo4j AuraDB Free, cấp miễn phí của AuraDB. Đây là một thực thể cơ sở dữ liệu đồ thị được quản lý hoàn toàn, có đủ bộ nhớ và tính năng để tạo mẫu, học tập và xây dựng các ứng dụng nhỏ – rất phù hợp với mục tiêu của chúng tôi là xây dựng một chatbot đề xuất phim dựa trên AI tạo sinh.
Bạn sẽ tạo một thực thể AuraDB miễn phí, kết nối thực thể đó với ứng dụng bằng thông tin xác thực kết nối và sử dụng thực thể đó để lưu trữ và truy vấn biểu đồ tri thức về phim trong suốt phòng thí nghiệm này.
Vì sao nên dùng biểu đồ?
Trong các cơ sở dữ liệu quan hệ truyền thống, việc trả lời những câu hỏi như "Những bộ phim nào tương tự như Inception dựa trên dàn diễn viên hoặc thể loại được chia sẻ?" sẽ liên quan đến các thao tác JOIN phức tạp trên nhiều bảng. Khi độ sâu của mối quan hệ tăng lên, hiệu suất và khả năng đọc sẽ giảm.
Tuy nhiên, các cơ sở dữ liệu đồ thị như Neo4j được xây dựng để duyệt qua các mối quan hệ một cách hiệu quả, khiến chúng phù hợp một cách tự nhiên với các hệ thống đề xuất, tìm kiếm ngữ nghĩa và trợ lý thông minh. Chúng giúp nắm bắt bối cảnh thực tế (chẳng hạn như mạng lưới cộng tác, cốt truyện hoặc lựa chọn ưu tiên của người xem) mà các mô hình dữ liệu truyền thống khó có thể thể hiện được.
Bằng cách kết hợp dữ liệu được kết nối này với các LLM như Gemini và các giá trị nhúng vectơ từ Vertex AI, chúng ta có thể nâng cao trải nghiệm với chatbot, cho phép chatbot suy luận, truy xuất và phản hồi theo cách phù hợp và đáp ứng nhu cầu của từng người dùng hơn.
Tạo Neo4j AuraDB miễn phí
- Truy cập vào https://console.neo4j.io
- Đăng nhập bằng Tài khoản Google hoặc email của bạn.
- Nhấp vào "Tạo phiên bản miễn phí".
- Trong khi thực thể đang được cung cấp, một cửa sổ bật lên sẽ xuất hiện cho biết thông tin đăng nhập kết nối cho cơ sở dữ liệu của bạn.
Hãy nhớ tải xuống và lưu an toàn các thông tin sau trong cửa sổ bật lên. Đây là những thông tin cần thiết để kết nối ứng dụng của bạn với Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Bạn sẽ dùng những giá trị này để định cấu hình tệp .env trong dự án của mình nhằm xác thực với Neo4j ở bước tiếp theo.

Neo4j AuraDB Free phù hợp với việc phát triển, thử nghiệm và các ứng dụng quy mô nhỏ như lớp học lập trình này. Dịch vụ này cung cấp hạn mức sử dụng lớn, hỗ trợ tối đa 200.000 nút và 400.000 mối quan hệ. Mặc dù cung cấp tất cả các tính năng cần thiết để tạo và truy vấn Sơ đồ tri thức, nhưng phiên bản này không hỗ trợ các cấu hình nâng cao như các trình bổ trợ tuỳ chỉnh hoặc tăng bộ nhớ. Đối với khối lượng công việc sản xuất hoặc tập dữ liệu lớn hơn, bạn có thể nâng cấp lên gói AuraDB cấp cao hơn để có dung lượng, hiệu suất và các tính năng cấp doanh nghiệp cao hơn.
Như vậy là bạn đã hoàn tất phần thiết lập phụ trợ Neo4j AuraDB. Trong bước tiếp theo, chúng ta sẽ tạo một dự án trên đám mây của Google, sao chép kho lưu trữ và định cấu hình các biến môi trường cần thiết để chuẩn bị sẵn sàng môi trường phát triển trước khi bắt đầu lớp học lập trình.
3. Trước khi bắt đầu
Tạo dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trong một dự án hay không .
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud và được tải sẵn bq. Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.

- Sau khi kết nối với Cloud Shell, bạn có thể kiểm tra để đảm bảo rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt:
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc thông qua lệnh bên dưới. Quá trình này có thể mất vài phút, vì vậy, vui lòng kiên nhẫn chờ đợi.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Khi thực thi lệnh thành công, bạn sẽ thấy thông báo: "Operation .... finished successfully" (Thao tác .... đã hoàn tất thành công).
Bạn có thể thay thế lệnh gcloud bằng cách tìm kiếm từng sản phẩm trên bảng điều khiển hoặc sử dụng đường liên kết này.
Nếu bỏ lỡ API nào, bạn luôn có thể bật API đó trong quá trình triển khai.
Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
Sao chép kho lưu trữ và thiết lập chế độ cài đặt môi trường
Bước tiếp theo là sao chép kho lưu trữ mẫu mà chúng ta sẽ tham chiếu trong phần còn lại của lớp học lập trình. Giả sử bạn đang ở trong Cloud Shell, hãy đưa ra lệnh sau từ thư mục chính của bạn:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Để khởi chạy trình chỉnh sửa, hãy nhấp vào Open Editor (Mở trình chỉnh sửa) trên thanh công cụ của cửa sổ Cloud Shell. Nhấp vào thanh trình đơn ở góc trên cùng bên trái rồi chọn Tệp → Mở thư mục như minh hoạ dưới đây:
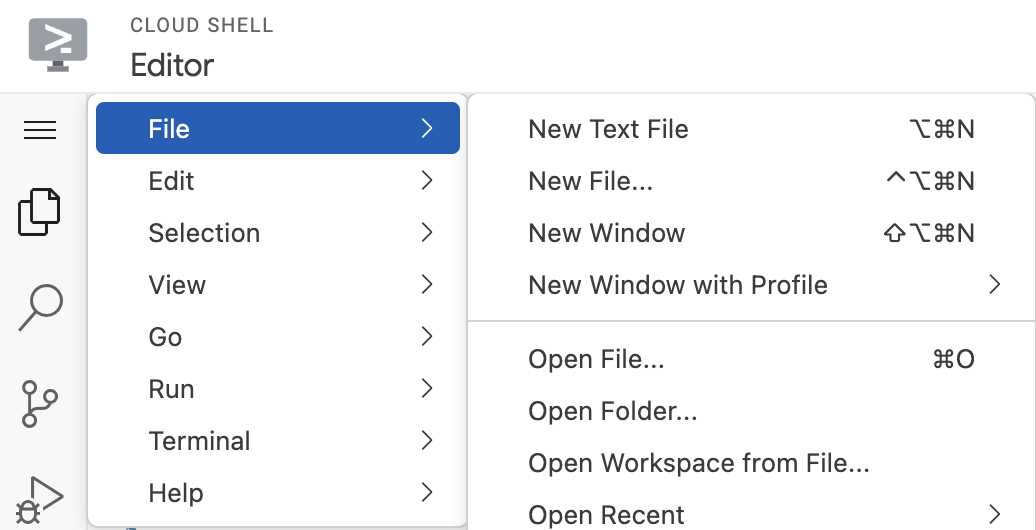
Chọn thư mục neo4j-vertexai-codelab. Bạn sẽ thấy thư mục này mở ra với cấu trúc tương tự như hình bên dưới:

Tiếp theo, chúng ta cần thiết lập các biến môi trường sẽ được dùng trong suốt lớp học lập trình. Nhấp vào tệp example.env, bạn sẽ thấy nội dung như hình bên dưới:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Bây giờ, hãy tạo một tệp mới có tên .env trong cùng thư mục với tệp example.env và sao chép nội dung của tệp example.env hiện có. Bây giờ, hãy cập nhật các biến sau:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDvàNEO4J_DATABASE:- Điền các giá trị này bằng thông tin đăng nhập được cung cấp trong quá trình tạo phiên bản Neo4j AuraDB Free ở bước trước.
NEO4J_DATABASEthường được đặt thành neo4j cho AuraDB Free.PROJECT_IDvàLOCATION:- Nếu đang chạy lớp học lập trình từ Google Cloud Shell, bạn có thể để trống các trường này vì chúng sẽ tự động được suy luận từ cấu hình dự án đang hoạt động của bạn.
- Nếu bạn đang chạy cục bộ hoặc bên ngoài Cloud Shell, hãy cập nhật
PROJECT_IDbằng mã nhận dạng của dự án trên đám mây trên Google Cloud mà bạn đã tạo trước đó và đặtLOCATIONthành vùng bạn đã chọn cho dự án đó (ví dụ: us-central1).
Sau khi bạn điền các giá trị này, hãy lưu tệp .env. Cấu hình này sẽ cho phép ứng dụng của bạn kết nối với cả dịch vụ Neo4j và Vertex AI.
Bước cuối cùng trong việc thiết lập môi trường phát triển là tạo một môi trường ảo Python và cài đặt tất cả các phần phụ thuộc bắt buộc có trong tệp requirements.txt. Các phần phụ thuộc này bao gồm những thư viện cần thiết để làm việc với Neo4j, Vertex AI, Gradio và nhiều thư viện khác.
Trước tiên, hãy tạo một môi trường ảo có tên là .venv bằng cách chạy lệnh sau:
python -m venv .venv
Sau khi tạo môi trường, chúng ta sẽ cần kích hoạt môi trường đã tạo bằng lệnh sau
source .venv/bin/activate
Bây giờ, bạn sẽ thấy (.venv) ở đầu dấu nhắc của thiết bị đầu cuối, cho biết môi trường đang hoạt động. Ví dụ: (.venv) yourusername@cloudshell:
Bây giờ, hãy cài đặt các phần phụ thuộc bắt buộc bằng cách chạy:
pip install -r requirements.txt
Sau đây là thông tin tổng quan nhanh về các phần phụ thuộc chính được liệt kê trong tệp:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Sau khi bạn cài đặt thành công tất cả các phần phụ thuộc, môi trường Python cục bộ sẽ được định cấu hình đầy đủ để chạy các tập lệnh và chatbot trong lớp học lập trình này.
Tuyệt vời! Giờ đây, chúng ta đã sẵn sàng chuyển sang bước tiếp theo – tìm hiểu tập dữ liệu và chuẩn bị tập dữ liệu đó để tạo biểu đồ và làm phong phú ngữ nghĩa.
4. Chuẩn bị tập dữ liệu Phim
Nhiệm vụ đầu tiên của chúng ta là chuẩn bị tập dữ liệu Phim mà chúng ta sẽ dùng để xây dựng biểu đồ tri thức và hỗ trợ chatbot đề xuất. Thay vì bắt đầu từ đầu, chúng ta sẽ sử dụng một tập dữ liệu công khai hiện có và xây dựng dựa trên tập dữ liệu đó.
Chúng ta sẽ sử dụng Tập dữ liệu về phim của Rounak Banik, một tập dữ liệu công khai nổi tiếng có trên Kaggle. API này bao gồm siêu dữ liệu của hơn 45.000 bộ phim trên TMDB, bao gồm dàn diễn viên, ê-kíp, từ khoá, mức phân loại và nhiều thông tin khác.

Để xây dựng một Chatbot đề xuất phim đáng tin cậy và hiệu quả, bạn cần bắt đầu bằng dữ liệu sạch, nhất quán và dữ liệu có cấu trúc. Mặc dù The Movies Dataset (Tập dữ liệu về phim) của Kaggle là một nguồn tài nguyên phong phú với hơn 45.000 bản ghi phim và siêu dữ liệu chi tiết (bao gồm cả thể loại, dàn diễn viên, đoàn làm phim, v.v.), nhưng tập dữ liệu này cũng chứa nhiều dữ liệu nhiễu, dữ liệu không nhất quán và cấu trúc dữ liệu lồng nhau không phù hợp để mô hình hoá biểu đồ hoặc nhúng ngữ nghĩa.
Để giải quyết vấn đề này, chúng tôi đã xử lý trước và chuẩn hoá tập dữ liệu để đảm bảo tập dữ liệu phù hợp với việc xây dựng biểu đồ tri thức Neo4j và tạo các vectơ nhúng chất lượng cao. Quá trình này bao gồm:
- Xoá các bản ghi trùng lặp và không đầy đủ
- Chuẩn hoá các trường khoá (ví dụ: tên thể loại, tên người)
- Đơn giản hoá các cấu trúc lồng ghép phức tạp (ví dụ: dàn diễn viên và nhân viên) thành các tệp CSV có cấu trúc
- Chọn một nhóm nhỏ tiêu biểu gồm khoảng 12.000 bộ phim để nằm trong giới hạn của Neo4j AuraDB Free
Dữ liệu chất lượng cao và được chuẩn hoá giúp đảm bảo:
- Chất lượng dữ liệu: Giảm thiểu lỗi và sự không nhất quán để đưa ra đề xuất chính xác hơn
- Hiệu suất truy vấn: Cấu trúc tinh giản giúp cải thiện tốc độ truy xuất và giảm sự dư thừa
- Độ chính xác của embeddings: Thông tin đầu vào rõ ràng sẽ dẫn đến các vectơ embeddings theo ngữ cảnh và có ý nghĩa hơn
Bạn có thể truy cập vào tập dữ liệu đã được làm sạch và chuẩn hoá trong thư mục normalized_data/ của kho lưu trữ GitHub này. Tập dữ liệu này cũng được sao chép vào một bộ chứa Google Cloud Storage để dễ dàng truy cập trong các tập lệnh Python sắp tới.
Sau khi dữ liệu được làm sạch và sẵn sàng, chúng ta sẽ chuẩn bị tải dữ liệu đó vào Neo4j và bắt đầu xây dựng biểu đồ tri thức về phim.
5. Xây dựng Sơ đồ tri thức về phim
Để hỗ trợ chatbot đề xuất phim dựa trên AI tạo sinh, chúng ta cần cấu trúc tập dữ liệu phim theo cách nắm bắt được mạng lưới kết nối phong phú giữa các bộ phim, diễn viên, đạo diễn, thể loại và siêu dữ liệu khác. Trong phần này, chúng ta sẽ tạo Sơ đồ tri thức về phim trong Neo4j bằng cách sử dụng tập dữ liệu đã được làm sạch và chuẩn hoá mà bạn đã chuẩn bị trước đó.
Chúng ta sẽ sử dụng khả năng LOAD CSV của Neo4j để nhập các tệp CSV được lưu trữ trong một bộ chứa Google Cloud Storage (GCS) công khai. Các tệp này thể hiện nhiều thành phần của tập dữ liệu phim, chẳng hạn như phim, thể loại, dàn diễn viên, đoàn làm phim, công ty sản xuất và điểm xếp hạng của người dùng.
Bước 1: Tạo các ràng buộc và chỉ mục
Trước khi nhập dữ liệu, bạn nên tạo các ràng buộc và chỉ mục để thực thi tính toàn vẹn của dữ liệu và tối ưu hoá hiệu suất truy vấn.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Bước 2: Nhập siêu dữ liệu và mối quan hệ của phim
Hãy xem cách nhập siêu dữ liệu phim bằng lệnh LOAD CSV. Ví dụ này tạo các nút Phim có các thuộc tính chính như tiêu đề, nội dung tổng quan, ngôn ngữ và thời lượng:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Tương tự, bạn có thể nhập và liên kết các thực thể khác như Thể loại, Công ty sản xuất, Ngôn ngữ nói, Quốc gia, Dàn diễn viên, Đội ngũ sản xuất và Đánh giá của người dùng bằng cách sử dụng các tệp CSV và truy vấn Cypher tương ứng.
Tải toàn bộ biểu đồ thông qua Python
Thay vì chạy nhiều truy vấn Cypher theo cách thủ công, bạn nên sử dụng tập lệnh Python tự động được cung cấp trong lớp học lập trình này.
Tập lệnh graph_build.py tải toàn bộ tập dữ liệu từ GCS vào phiên bản Neo4j AuraDB của bạn bằng thông tin xác thực trong tệp .env.
python graph_build.py
Tập lệnh này sẽ tuần tự tải tất cả các tệp CSV cần thiết, tạo các nút và mối quan hệ, đồng thời cấu trúc biểu đồ tri thức hoàn chỉnh về phim.
|
|

.png")
Xác thực biểu đồ
Sau khi tải, bạn có thể xác thực biểu đồ bằng cách chạy tập lệnh sau:
python validate_graph.py
Thao tác này sẽ cung cấp cho bạn thông tin tóm tắt nhanh về nội dung trong biểu đồ: số lượng phim, diễn viên, thể loại và mối quan hệ như ACTED_IN, DIRECTED, v.v. có trong biểu đồ, đảm bảo quá trình nhập diễn ra thành công.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Giờ đây, bạn sẽ thấy biểu đồ của mình có đầy đủ phim, người, thể loại và nhiều nội dung khác – sẵn sàng được làm phong phú về mặt ngữ nghĩa ở bước tiếp theo!
6. Tạo và tải các mục nhúng để thực hiện Tìm kiếm tương tự theo vectơ
Để bật tính năng tìm kiếm ngữ nghĩa trong chatbot, chúng ta cần tạo các vectơ nhúng cho phần tổng quan về phim. Các vectơ nhúng này chuyển đổi dữ liệu dạng văn bản thành vectơ số có thể so sánh về độ tương đồng, giúp chatbot có thể truy xuất các bộ phim có liên quan ngay cả khi truy vấn không khớp chính xác với tiêu đề hoặc nội dung mô tả.

Cách 1: Tải các vectơ nhúng được tính toán trước thông qua Cypher
Để nhanh chóng đính kèm các mục nhúng vào các nút Movie tương ứng trong Neo4j, hãy chạy lệnh Cypher sau trong Neo4j Browser:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Lệnh này đọc các vectơ nhúng từ CSV và đính kèm các vectơ đó dưới dạng một thuộc tính (m.embedding) trên mỗi nút Movie.
Cách 2: Tải các mục nhúng bằng Python
Bạn cũng có thể tải các mục nhúng theo phương thức lập trình bằng tập lệnh Python được cung cấp. Phương pháp này hữu ích nếu bạn đang làm việc trong môi trường của riêng mình hoặc muốn tự động hoá quy trình:
python load_embeddings.py
Tập lệnh này đọc cùng một tệp CSV từ GCS và ghi các vectơ nhúng vào Neo4j bằng trình điều khiển Neo4j của Python.
[Không bắt buộc] Tự tạo các vectơ nhúng (để khám phá)
Nếu muốn tìm hiểu cách tạo các mục nhúng, bạn có thể khám phá logic trong chính tập lệnh generate_embeddings.py. Ứng dụng này sử dụng Vertex AI để nhúng từng văn bản tổng quan về phim bằng mô hình text-embedding-004.
Để tự thử, hãy mở và chạy phần tạo mục nhúng của mã. Nếu đang chạy trong Cloud Shell, bạn có thể nhận xét dòng sau vì Cloud Shell đã được xác thực thông qua tài khoản đang hoạt động của bạn:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Sau khi được tải vào Neo4j, biểu đồ tri thức về phim của bạn sẽ trở thành biểu đồ có nhận thức ngữ nghĩa – sẵn sàng hỗ trợ tính năng tìm kiếm mạnh mẽ bằng ngôn ngữ tự nhiên thông qua độ tương đồng của vectơ!
7. Chatbot đề xuất phim
Sau khi đã có biểu đồ tri thức và các vectơ nhúng, giờ là lúc bạn kết hợp mọi thứ vào một giao diện đàm thoại hoạt động đầy đủ – Trợ lý trò chuyện đề xuất phim dựa trên AI tạo sinh.
Chatbot này được triển khai bằng Python thông qua Gradio, một khung web gọn nhẹ để xây dựng giao diện người dùng trực quan. Logic cốt lõi nằm trong app.py, kết nối với phiên bản Neo4j AuraDB và sử dụng Google Vertex AI và Gemini để xử lý và phản hồi các truy vấn bằng ngôn ngữ tự nhiên.
Cách tính năng hoạt động
- Người dùng nhập một truy vấn bằng ngôn ngữ tự nhiênví dụ: "Recommend me sci-fi thrillers like Interstellar" (Đề xuất cho tôi phim khoa học viễn tưởng ly kỳ như Interstellar)
- Tạo vectơ nhúng cho truy vấn bằng mô hình
text-embedding-004của Vertex AI - Thực hiện tìm kiếm vectơ trong Neo4j để truy xuất các bộ phim tương tự về mặt ngữ nghĩa
- Sử dụng Gemini để:
- Diễn giải truy vấn theo ngữ cảnh
- Tạo một câu hỏi Cypher tuỳ chỉnh dựa trên kết quả tìm kiếm vectơ và giản đồ Neo4j
- Thực thi truy vấn để trích xuất dữ liệu biểu đồ có liên quan (ví dụ: diễn viên, đạo diễn, thể loại)
- Tóm tắt kết quả theo cách trò chuyện cho người dùng
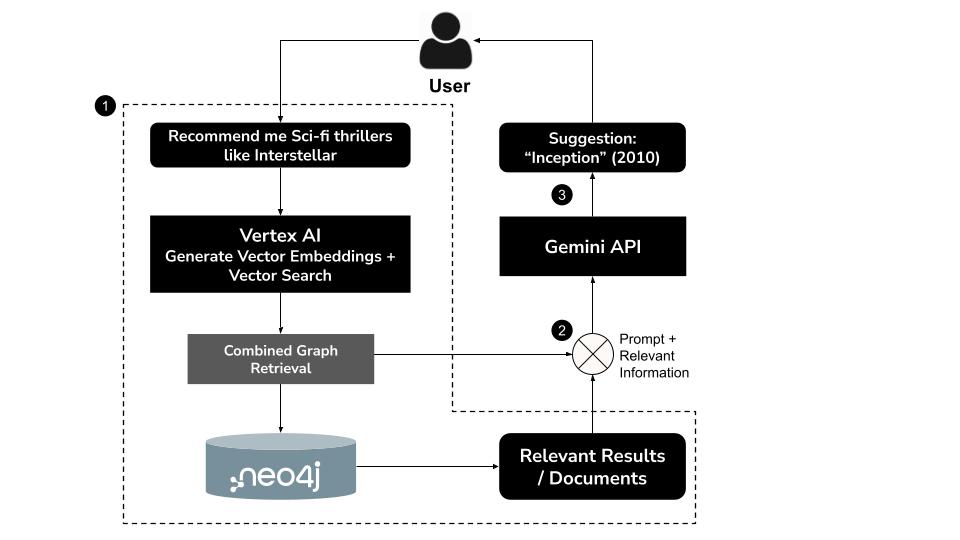
Phương pháp kết hợp này, còn được gọi là GraphRAG (Graph Retrieval-Augmented Generation), kết hợp khả năng truy xuất ngữ nghĩa và suy luận có cấu trúc để đưa ra các đề xuất chính xác, theo ngữ cảnh và dễ giải thích hơn.
Chạy Chatbot trên thiết bị
Kích hoạt môi trường ảo (nếu chưa kích hoạt), sau đó khởi chạy chatbot bằng cách:
python app.py
Bạn sẽ thấy kết quả tương tự như sau:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Để chia sẻ chatbot ra bên ngoài, hãy đặt share=True trong hàm launch() trong app.py.
Tương tác với Chatbot
Mở URL cục bộ xuất hiện trong thiết bị đầu cuối (thường là 👉 http://0.0.0.0:8080) để truy cập vào giao diện của chatbot.
Hãy thử đặt những câu hỏi như:
- "Tôi nên xem gì nếu thích phim Interstellar?"
- "Đề xuất một bộ phim lãng mạn do Nora Ephron làm đạo diễn"
- "Tôi muốn xem một bộ phim gia đình có sự tham gia của Tom Hanks"
- "Tìm phim giật gân có liên quan đến trí tuệ nhân tạo"
Chatbot sẽ:
✅ Hiểu rõ câu hỏi
✅ Tìm cốt truyện phim tương tự về mặt ngữ nghĩa bằng cách sử dụng các vectơ nhúng
✅ Tạo và chạy một truy vấn Cypher để tìm nạp ngữ cảnh biểu đồ có liên quan
✅ Đưa ra đề xuất thân thiện, phù hợp với từng người dùng – tất cả chỉ trong vài giây
Các chức năng hiện có
Bạn vừa tạo một chatbot về phim dựa trên GraphRAG, kết hợp:
- Tìm kiếm vectơ để có mức độ liên quan về ngữ nghĩa
- Lập luận dựa trên sơ đồ tri thức bằng Neo4j
- Các tính năng của LLM thông qua Gemini
- Một giao diện trò chuyện mượt mà với Gradio
Cấu trúc này tạo thành một nền tảng mà bạn có thể mở rộng thành các hệ thống tìm kiếm, đề xuất hoặc suy luận nâng cao hơn dựa trên AI tạo sinh.
8. (Không bắt buộc) Triển khai lên Google Cloud Run
Nếu muốn cung cấp công khai Chatbot đề xuất phim, bạn có thể triển khai chatbot này trên Google Cloud Run – một nền tảng không máy chủ, được quản lý hoàn toàn, có khả năng tự động mở rộng quy mô ứng dụng và loại bỏ mọi mối lo ngại về cơ sở hạ tầng.
Quy trình triển khai này sử dụng:
requirements.txt– để xác định các phần phụ thuộc Python (Neo4j, Vertex AI, Gradio, v.v.)Dockerfile– để đóng gói ứng dụng.env.yaml– để truyền các biến môi trường một cách an toàn trong thời gian chạy
Bước 1: Chuẩn bị .env.yaml
Tạo một tệp có tên là .env.yaml trong thư mục gốc có nội dung như sau:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Định dạng này được ưu tiên hơn --set-env-vars vì có khả năng mở rộng, kiểm soát phiên bản và dễ đọc hơn.
Bước 2: Thiết lập biến môi trường
Trong thiết bị đầu cuối, hãy đặt các biến môi trường sau (thay thế các giá trị trình giữ chỗ bằng chế độ cài đặt dự án thực tế của bạn):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Bước 2: Tạo Artifact Registry và tạo vùng chứa
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Lệnh này đóng gói ứng dụng của bạn bằng Dockerfile và tải hình ảnh vùng chứa lên Google Cloud Artifact Registry.
Bước 3: Triển khai lên Cloud Run
Giờ đây, hãy triển khai ứng dụng của bạn bằng tệp .env.yaml để định cấu hình thời gian chạy:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Truy cập vào Chatbot
Sau khi triển khai, Cloud Run sẽ cung cấp một URL công khai như:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Mở URL này trong trình duyệt để truy cập vào giao diện chatbot Gradio mà bạn đã triển khai – sẵn sàng xử lý các đề xuất về phim bằng GraphRAG, Gemini và Neo4j!
Lưu ý và mẹo
- Đảm bảo
Dockerfilechạypip install -r requirements.txttrong quá trình tạo bản dựng. - Nếu không sử dụng Cloud Shell, bạn sẽ cần xác thực môi trường của mình bằng Tài khoản dịch vụ có quyền đối với Vertex AI và Artifact Registry.
- Bạn có thể theo dõi nhật ký và chỉ số triển khai trên Google Cloud Console > Cloud Run.
Bạn cũng có thể truy cập vào Cloud Run từ bảng điều khiển Cloud và bạn sẽ thấy danh sách các dịch vụ trong Cloud Run. Dịch vụ movies-chatbot phải là một trong các dịch vụ (nếu không phải là dịch vụ duy nhất) được liệt kê ở đó.

Bạn có thể xem thông tin chi tiết về dịch vụ như URL, cấu hình, nhật ký và nhiều thông tin khác bằng cách nhấp vào tên dịch vụ cụ thể (movies-chatbot trong trường hợp này).

Nhờ đó, Giờ đây, Chatbot đề xuất phim của bạn đã được triển khai, có khả năng mở rộng và chia sẻ. 🎉
9. Dọn dẹp
Để tránh bị tính phí vào tài khoản Google Cloud của bạn cho các tài nguyên được dùng trong bài đăng này, hãy làm theo các bước sau:
- Trong bảng điều khiển Cloud, hãy chuyển đến trang Quản lý tài nguyên.
- Trong danh sách dự án, hãy chọn dự án mà bạn muốn xoá, rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.
10. Xin chúc mừng
Bạn đã tạo và triển khai thành công một chatbot đề xuất phim dựa trên GraphRAG và được GenAI cải tiến bằng Neo4j, Vertex AI và Gemini. Bằng cách kết hợp khả năng mô hình hoá gốc đồ thị của Neo4j với tính năng tìm kiếm ngữ nghĩa thông qua Vertex AI và tính năng suy luận bằng ngôn ngữ tự nhiên thông qua Gemini, bạn đã tạo ra một hệ thống thông minh vượt xa khả năng tìm kiếm cơ bản – hệ thống này hiểu được ý định của người dùng, suy luận dựa trên dữ liệu được kết nối và trả lời theo cách đàm thoại.
Trong lớp học lập trình này, bạn đã hoàn thành những việc sau:
✅ Xây dựng một Sơ đồ tri thức về phim trong thế giới thực trong Neo4j để mô hình hoá phim, diễn viên, thể loại và mối quan hệ
✅ Giá trị nhúng vectơ được tạo cho thông tin tổng quan về cốt truyện phim bằng các mô hình nhúng văn bản của Vertex AI
✅ Triển khai GraphRAG, kết hợp tính năng tìm kiếm vectơ và các truy vấn Cypher do LLM tạo để suy luận sâu hơn, nhiều bước
✅ Tích hợp Gemini để diễn giải câu hỏi của người dùng, tạo truy vấn Cypher và tóm tắt kết quả biểu đồ bằng ngôn ngữ tự nhiên
✅ Tạo giao diện trò chuyện trực quan bằng Gradio
✅ Triển khai chatbot của bạn (không bắt buộc) trên Google Cloud Run để có dịch vụ lưu trữ không máy chủ, có khả năng mở rộng
Tiếp theo là gì?
Cấu trúc này không chỉ giới hạn ở đề xuất phim mà còn có thể mở rộng sang:
- Nền tảng khám phá sách và nhạc
- Trợ lý nghiên cứu học thuật
- Công cụ đề xuất sản phẩm
- Trợ lý kiến thức về chăm sóc sức khoẻ, tài chính và pháp lý
Bất cứ nơi nào bạn có mối quan hệ phức tạp + dữ liệu văn bản phong phú, sự kết hợp giữa Biểu đồ tri thức + LLM + vectơ nhúng ngữ nghĩa này có thể hỗ trợ thế hệ tiếp theo của các ứng dụng thông minh.
Khi các mô hình AI tạo sinh đa phương thức như Gemini phát triển, bạn sẽ có thể kết hợp bối cảnh, hình ảnh, lời nói và khả năng cá nhân hoá phong phú hơn nữa để xây dựng các hệ thống thực sự lấy con người làm trung tâm.
Hãy tiếp tục khám phá, tiếp tục xây dựng và đừng quên cập nhật những thông tin mới nhất từ Neo4j, Vertex AI và Google Cloud để đưa các ứng dụng thông minh của bạn lên một tầm cao mới! Khám phá thêm các hướng dẫn thực hành về sơ đồ tri thức tại Neo4j GraphAcademy.