
1. סקירה כללית
ב-Codelab הזה תלמדו איך ליצור צ'אט בוט חכם להמלצות על סרטים באמצעות שילוב של Neo4j, Google Vertex AI ו-Gemini. בבסיס המערכת הזו נמצא Knowledge Graph של Neo4j שמציג מודלים של סרטים, שחקנים, במאים, ז'אנרים ועוד באמצעות רשת עשירה של צמתים וקשרים מקושרים.
כדי לשפר את חוויית המשתמש באמצעות הבנה סמנטית, תיצרו הטמעות וקטורים מסיכומי עלילה של סרטים באמצעות מודל text-embedding-004 של Vertex AI (או מודל חדש יותר). ההטמעות האלה עוברות אינדוקס ב-Neo4j כדי לאפשר אחזור מהיר שמבוסס על דמיון.
לבסוף, תשלבו את Gemini כדי להפעיל ממשק שיחה שבו משתמשים יכולים לשאול שאלות בשפה טבעית, כמו "איזה סרט כדאי לי לראות אם אהבתי את 'בין כוכבים'?", ולקבל הצעות מותאמות אישית לסרטים שמבוססות על דמיון סמנטי והקשר מבוסס-גרף.
במהלך ה-codelab, תשתמשו בגישה שלב אחר שלב באופן הבא:
- יצירת Knowledge Graph ב-Neo4j עם ישויות וקשרים שקשורים לסרטים
- יצירה או טעינה של הטמעות טקסט לסיכומי סרטים באמצעות Vertex AI
- הטמעה של ממשק צ'אט בוט של Gradio שמבוסס על Gemini ומשלב חיפוש וקטורי עם הפעלה של Cypher שמבוססת על גרפים
- (אופציונלי) פריסת האפליקציה ב-Cloud Run כאפליקציית אינטרנט עצמאית
מה תלמדו
- איך יוצרים גרף ידע של סרט ומאכלסים אותו באמצעות Cypher ו-Neo4j
- איך משתמשים ב-Vertex AI כדי ליצור הטמעות סמנטיות של טקסט ולעבוד איתן
- איך משלבים בין מודלים גדולים של שפה (LLM) לבין Knowledge Graph כדי לאחזר מידע בצורה חכמה באמצעות GraphRAG
- איך יוצרים ממשק צ'אט ידידותי למשתמש באמצעות Gradio
- איך פורסים ב-Google Cloud Run (אופציונלי)
מה תצטרכו
- דפדפן האינטרנט Chrome
- חשבון Gmail
- פרויקט ב-Google Cloud שהחיוב בו מופעל
- חשבון Neo4j Aura DB בחינם
- היכרות בסיסית עם פקודות טרמינל ועם Python (מועיל אבל לא חובה)
ב-Codelab הזה, שמיועד למפתחים בכל הרמות (כולל מתחילים), נעשה שימוש ב-Python וב-Neo4j באפליקציית הדוגמה. ידע בסיסי ב-Python ובמסדי נתונים של גרפים יכול לעזור, אבל לא נדרש ניסיון קודם כדי להבין את המושגים או לעקוב אחרי ההסברים.
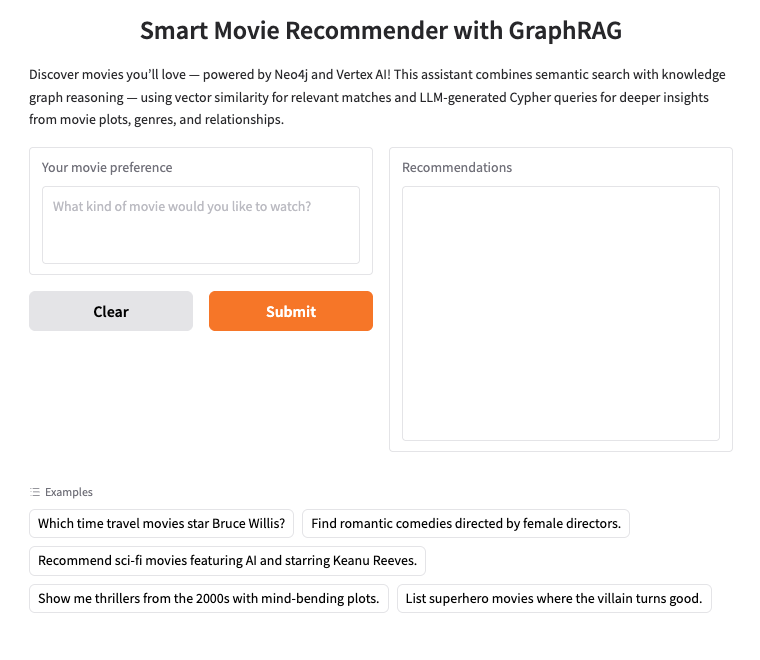
2. הגדרת Neo4j AuraDB
Neo4j הוא מסד נתונים גרפי מקורי מוביל שמאחסן נתונים כרשת של צמתים (ישויות) וקשרים (חיבורים בין ישויות). לכן הוא אידיאלי לתרחישי שימוש שבהם חשוב להבין את הקשרים – כמו המלצות, זיהוי הונאות, גרפי ידע ועוד. בניגוד למסדי נתונים יחסיים או כאלה שמבוססים על מסמכים, שמסתמכים על טבלאות נוקשות או על מבנים היררכיים, מודל הגרף הגמיש של Neo4j מאפשר הצגה אינטואיטיבית ויעילה של נתונים מורכבים ומקושרים.
במקום לארגן את הנתונים בשורות ובטבלאות כמו במסדי נתונים יחסיים, מערכת Neo4j משתמשת במודל גרף, שבו המידע מיוצג כצמתים (ישויות) וקשרים (קשרים בין הישויות האלה). המודל הזה מאפשר עבודה אינטואיטיבית במיוחד עם נתונים שמקושרים באופן מובנה – כמו אנשים, מקומות, מוצרים או, במקרה שלנו, סרטים, שחקנים וז'אנרים.
לדוגמה, בקבוצת נתונים של סרטים:
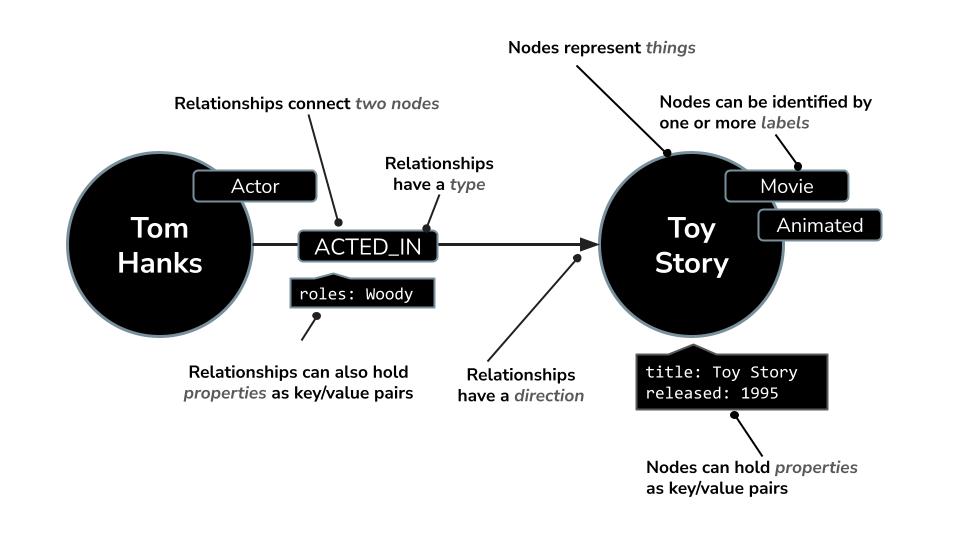
- צומת יכול לייצג
Movie,ActorאוDirector - הקשר יכול להיות
ACTED_INאוDIRECTED
המבנה הזה מאפשר לכם לשאול בקלות שאלות כמו:
- באילו סרטים השחקן הזה הופיע?
- מי עבד עם כריסטופר נולאן?
- מהם סרטים דומים שמבוססים על שחקנים או ז'אנרים משותפים?
Neo4j מגיעה עם שפת שאילתות עוצמתית בשם Cypher, שנועדה במיוחד לשאילתות בגרפים. שפת Cypher מאפשרת לכם לבטא דפוסים וקשרים מורכבים בצורה תמציתית וקריאה. לדוגמה: שאילתת Cypher הזו משתמשת ב-MERGE כדי לוודא שהשחקן, הסרט והקשר שלהם עם פרטי התפקיד נוצרים באופן ייחודי, וכך נמנעים כפילויות.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j מציעה כמה אפשרויות פריסה בהתאם לצרכים שלכם:
- בניהול עצמי: הפעלת Neo4j בתשתית שלכם באמצעות Neo4j Desktop או כקובץ אימג' של Docker (במקום או בענן שלכם).
- ניהול בענן: אפשר לפרוס את Neo4j אצל ספקי ענן פופולריים באמצעות מבצעים מ-Marketplace.
- מנוהל באופן מלא: אפשר להשתמש ב-Neo4j AuraDB, מסד נתונים מנוהל בענן כשירות של Neo4j, שמטפל בהקצאת משאבים, בהרחבה, בגיבויים ובאבטחה בשבילכם.
ב-Codelab הזה נשתמש ב-Neo4j AuraDB Free, התוכנית בחינם של AuraDB. הוא מספק מופע של מסד נתונים גרפי בניהול מלא, עם מספיק אחסון ותכונות ליצירת אב טיפוס, ללמידה ולבניית אפליקציות קטנות – מושלם למטרה שלנו לבנות צ'אטבוט להמלצות על סרטים שמבוסס על AI גנרטיבי.
במהלך הסדנה הזו, תיצרו מופע AuraDB בחינם, תקשרו אותו לאפליקציה באמצעות פרטי כניסה לחיבור ותשתמשו בו כדי לאחסן ולשאילת גרף ידע של סרטים.
למה גרפים?
במסדי נתונים רלציוניים מסורתיים, כדי לענות על שאלות כמו "אילו סרטים דומים לסרט 'ההתחלה' על סמך צוות שחקנים או ז'אנר משותפים?" צריך לבצע פעולות JOIN מורכבות בכמה טבלאות. ככל שהקשרים עמוקים יותר, הביצועים והקריאות יורדים.
לעומת זאת, מסדי נתונים של גרפים כמו Neo4j מיועדים למעבר יעיל בין קשרים, ולכן הם מתאימים באופן טבעי למערכות המלצה, לחיפוש סמנטי ולעוזרים חכמים. הם עוזרים להבין את ההקשר בעולם האמיתי – כמו רשתות שיתוף פעולה, קווי עלילה או העדפות של צופים – שקשה לייצג באמצעות מודלים מסורתיים של נתונים.
שילוב של הנתונים המקושרים האלה עם מודלים גדולים של שפה (LLM) כמו Gemini ועם הטמעות וקטורים מ-Vertex AI מאפשר לנו לשפר את חוויית השימוש בצ'אטבוט – הוא יכול להסיק מסקנות, לאחזר מידע ולהגיב בצורה מותאמת ורלוונטית יותר.
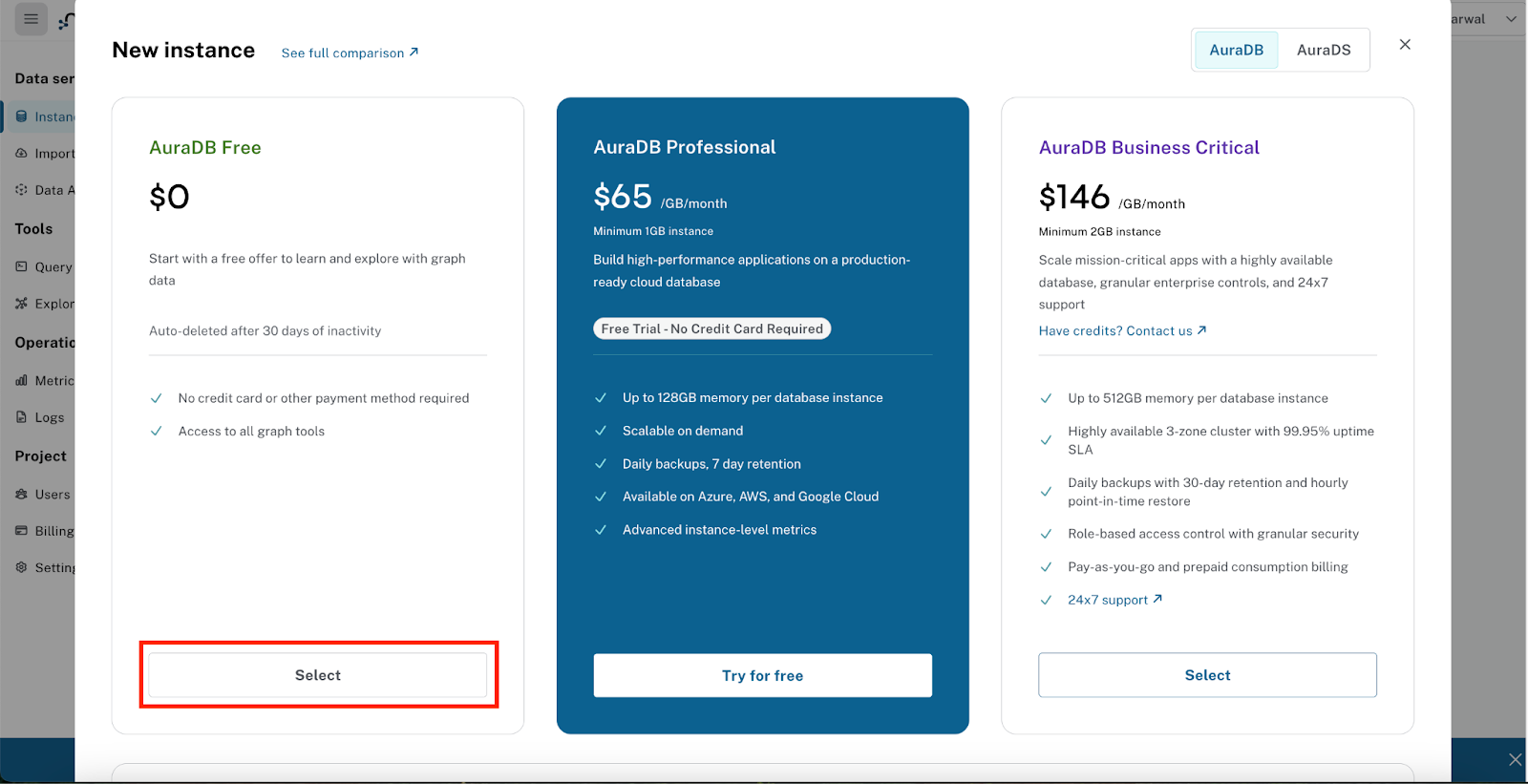
יצירה של Neo4j AuraDB Free
- נכנסים לכתובת https://console.neo4j.io
- מתחברים באמצעות חשבון Google או כתובת אימייל.
- לוחצים על 'יצירת מופע חינמי'.
- בזמן שהמופע מוקצה, יופיע חלון קופץ עם פרטי הכניסה למסד הנתונים.
חשוב להוריד ולשמור בצורה מאובטחת את הפרטים הבאים מהחלון הקופץ – הם חיוניים לחיבור האפליקציה ל-Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
בשלב הבא תשתמשו בערכים האלה כדי להגדיר את קובץ .env בפרויקט שלכם לצורך אימות ב-Neo4j.
Neo4j AuraDB Free מתאים מאוד לפיתוח, לניסויים ולאפליקציות בקנה מידה קטן כמו אלה שמופיעות ב-codelab הזה. הוא מציע מגבלות שימוש נדיבות, ותומך בעד 200,000 צמתים ו400,000 קשרים. הוא מספק את כל התכונות החיוניות שדרושות כדי לבנות גרף ידע ולשאול שאילתות לגביו, אבל הוא לא תומך בהגדרות מתקדמות כמו תוספים בהתאמה אישית או נפח אחסון מוגדל. לסביבות עבודה של ייצור או למערכי נתונים גדולים יותר, אפשר לשדרג לתוכנית AuraDB ברמה גבוהה יותר שמציעה קיבולת גדולה יותר, ביצועים טובים יותר ותכונות ברמה ארגונית.
כך מסיימים את הקטע להגדרת העורף של Neo4j AuraDB. בשלב הבא ניצור פרויקט ב-Google Cloud, נשכפל את המאגר ונגדיר את משתני הסביבה הנדרשים כדי להכין את סביבת הפיתוח לפני שנתחיל את ה-Codelab.
3. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud ומגיעה עם bq שנטען מראש. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, בודקים שכבר בוצע אימות ושהפרויקט מוגדר למזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים באמצעות הפקודה שמוצגת למטה. זה יימשך כמה דקות, אז כדאי לחכות בסבלנות.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
אם הפקודה תופעל בהצלחה, תוצג ההודעה: Operation .... finished successfully.
אפשר גם לחפש כל מוצר במסוף או להשתמש בקישור הזה במקום בפקודת gcloud.
אם פספסתם API כלשהו, תמיד תוכלו להפעיל אותו במהלך ההטמעה.
אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
שכפול מאגר והגדרת הגדרות הסביבה
השלב הבא הוא לשכפל את מאגר הדוגמאות שאליו נתייחס בהמשך ה-codelab. אם אתם נמצאים ב-Cloud Shell, מריצים את הפקודה הבאה מספריית הבית:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
כדי לפתוח את העורך, לוחצים על Open Editor בסרגל הכלים שבחלון של Cloud Shell. לוחצים על סרגל התפריטים בפינה הימנית העליונה ובוחרים באפשרות 'קובץ' ← 'פתיחת תיקייה' כמו שמוצג בהמשך:

בוחרים בתיקייה neo4j-vertexai-codelab. התיקייה אמורה להיפתח עם מבנה דומה לזה שמוצג בהמשך:

בשלב הבא צריך להגדיר את משתני הסביבה שישמשו לאורך ה-codelab. לוחצים על הקובץ example.env ורואים את התוכן כמו שמוצג בהמשך:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
עכשיו יוצרים קובץ חדש בשם .env באותה תיקייה שבה נמצא הקובץ example.env, ומעתיקים את התוכן של הקובץ הקיים example.env. עכשיו מעדכנים את המשתנים הבאים:
-
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDוגםNEO4J_DATABASE: - ממלאים את הערכים האלה באמצעות פרטי הכניסה שסופקו במהלך יצירת מופע Neo4j AuraDB Free בשלב הקודם.
- בדרך כלל הערך של
NEO4J_DATABASEהוא neo4j ב-AuraDB Free. -
PROJECT_IDו-LOCATION: - אם מריצים את ה-codelab מ-Google Cloud Shell, אפשר להשאיר את השדות האלה ריקים, כי הם יוסקו אוטומטית מההגדרה הפעילה של הפרויקט.
- אם אתם מריצים את הפקודה באופן מקומי או מחוץ ל-Cloud Shell, צריך לעדכן את
PROJECT_IDבמזהה של פרויקט בענן שיצרתם קודם, ולהגדיר אתLOCATIONלאזור שבחרתם עבור הפרויקט (לדוגמה, us-central1).
אחרי שממלאים את הערכים האלה, שומרים את הקובץ .env. ההגדרה הזו תאפשר לאפליקציה להתחבר גם ל-Neo4j וגם לשירותי Vertex AI.
השלב האחרון בהגדרת סביבת הפיתוח הוא ליצור סביבה וירטואלית של Python ולהתקין את כל הרכיבים התלויים שנדרשים ומפורטים בקובץ requirements.txt. התלויות האלה כוללות ספריות שנדרשות לעבודה עם Neo4j, Vertex AI, Gradio ועוד.
קודם יוצרים סביבה וירטואלית בשם .venv באמצעות הפקודה הבאה:
python -m venv .venv
אחרי שיוצרים את הסביבה, צריך להפעיל אותה באמצעות הפקודה הבאה
source .venv/bin/activate
עכשיו אמור להופיע (.venv) בתחילת שורת הפקודה של הטרמינל, שמציין שהסביבה פעילה. לדוגמה: (.venv) yourusername@cloudshell:
עכשיו מתקינים את יחסי התלות הנדרשים על ידי הפעלת הפקודה:
pip install -r requirements.txt
הנה תמונת מצב של התלויות העיקריות שמופיעות בקובץ:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
אחרי שכל התלויות יותקנו בהצלחה, סביבת Python המקומית תוגדר באופן מלא להרצת הסקריפטים והצ'אטבוט ב-Codelab הזה.
מעולה! עכשיו אפשר לעבור לשלב הבא – הבנת מערך הנתונים והכנתו ליצירת תרשים ולהעשרה סמנטית.
4. הכנת מערך הנתונים Movies
המשימה הראשונה שלנו היא להכין את מערך הנתונים של הסרטים שבו נשתמש כדי ליצור את גרף הידע ולהפעיל את הצ'אטבוט להמלצות. במקום להתחיל מאפס, נשתמש בקבוצת נתונים קיימת ופתוחה ונבנה עליה.
אנחנו משתמשים ב מערך הנתונים של הסרטים של Rounak Banik, מערך נתונים ציבורי מוכר שזמין ב-Kaggle. הוא כולל מטא-נתונים של יותר מ-45,000 סרטים מ-TMDB, כולל צוות השחקנים, צוות ההפקה, מילות מפתח, דירוגים ועוד.

כדי ליצור צ'אטבוט אמין ויעיל להמלצות על סרטים, חשוב להתחיל עם נתונים נקיים, עקביים ומובְנים. ערכת הנתונים של הסרטים מ-Kaggle היא מקור עשיר עם יותר מ-45,000 רשומות של סרטים ומטא-נתונים מפורטים – כולל ז'אנרים, שחקנים, צוות ועוד – אבל היא גם מכילה רעשי רקע, חוסר עקביות ומבני נתונים מקוננים שלא מתאימים במיוחד ליצירת מודלים של גרפים או להטמעה סמנטית.
כדי לפתור את הבעיה הזו, ביצענו עיבוד מוקדם של מערך הנתונים ונרמול שלו כדי לוודא שהוא מתאים ליצירת גרף ידע של Neo4j וליצירת הטמעות באיכות גבוהה. התהליך הזה כלל:
- הסרת כפילויות ורשומות לא מלאות
- סטנדרטיזציה של שדות מפתח (למשל, שמות של ז'אנרים, שמות של אנשים)
- השטחת מבנים מורכבים עם קינון (למשל, שחקנים וצוות) לקובצי CSV מובנים
- בחירת קבוצת משנה מייצגת של כ-12,000 סרטים כדי לעמוד במגבלות של Neo4j AuraDB Free
נתונים נורמליים באיכות גבוהה עוזרים להבטיח:
- איכות הנתונים: המערכת מצמצמת את השגיאות וחוסר העקביות כדי לספק המלצות מדויקות יותר
- ביצועי שאילתות: מבנה יעיל משפר את מהירות השליפה ומפחית את הכפילות
- דיוק ההטמעה: קלט נקי מוביל להטמעות וקטוריות משמעותיות יותר לפי הקשר
אפשר לגשת למערך הנתונים הנקי והמנורמל בתיקייה normalized_data/ במאגר הזה ב-GitHub. מערך הנתונים הזה משוכפל גם בקטגוריה של Cloud Storage כדי לאפשר גישה נוחה בסקריפטים עתידיים של Python.
אחרי שהנתונים נוקו והם מוכנים, אפשר לטעון אותם ל-Neo4j ולהתחיל לבנות את גרף הידע של הסרטים.
5. יצירת Knowledge Graph של סרטים
כדי להפעיל את הצ'אטבוט שלנו להמלצות על סרטים שמבוסס על AI גנרטיבי, אנחנו צריכים לבנות את מערך הנתונים של הסרטים בצורה שתתעד את רשת הקשרים העשירה בין סרטים, שחקנים, במאים, ז'אנרים ומטא-נתונים אחרים. בקטע הזה ניצור גרף ידע של סרטים ב-Neo4j באמצעות מערך הנתונים המנוקה והמנורמל שהכנתם קודם.
נשתמש ביכולת LOAD CSV של Neo4j כדי להטמיע קובצי CSV שמתארחים בקטגוריה ציבורית של Google Cloud Storage (GCS). הקבצים האלה מייצגים רכיבים שונים של קבוצת הנתונים של הסרטים, כמו סרטים, ז'אנרים, צוות שחקנים, צוות הפקה, חברות הפקה ודירוגי משתמשים.
שלב 1: יצירת אילוצים ואינדקסים
לפני ייבוא נתונים, מומלץ ליצור אילוצים ואינדקסים כדי לאכוף את תקינות הנתונים ולבצע אופטימיזציה של ביצועי השאילתות.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
שלב 2: ייבוא מטא-נתונים וקשרים של סרטים
בואו נראה איך מייבאים מטא-נתונים של סרטים באמצעות הפקודה LOAD CSV. בדוגמה הזו נוצרים צמתי Movie עם מאפיינים מרכזיים כמו title, overview, language ו-runtime:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
באופן דומה, אפשר לייבא ולקשר ישויות אחרות כמו ז'אנרים, חברות הפקה, שפות מדוברות, מדינות, צוות שחקנים, צוות הפקה ודירוגי משתמשים באמצעות קובצי ה-CSV והשאילתות המתאימות ב-Cypher.
טעינת הגרף המלא באמצעות Python
במקום להריץ באופן ידני כמה שאילתות Cypher, מומלץ להשתמש בסקריפט Python האוטומטי שמופיע ב-codelab הזה.
הסקריפט graph_build.py טוען את מערך הנתונים כולו מ-GCS למופע Neo4j AuraDB באמצעות פרטי הכניסה בקובץ .env.
python graph_build.py
הסקריפט יטען ברצף את כל קובצי ה-CSV הנדרשים, ייצור צמתים ויחסים ויבנה את גרף הידע המלא של הסרט.
|
|

.png")
אימות התרשים
אחרי הטעינה, אפשר להריץ את הסקריפט הבא כדי לאמת את הגרף:
python validate_graph.py
כך תוכלו לקבל סיכום מהיר של מה שמופיע בתרשים: כמה סרטים, שחקנים, ז'אנרים ויחסים כמו ACTED_IN, DIRECTED וכו' קיימים – כדי לוודא שהייבוא הצליח.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
עכשיו אמור להופיע הגרף עם סרטים, אנשים, ז'אנרים ועוד – מוכן להעשרה סמנטית בשלב הבא.
6. יצירה וטעינה של הטמעות כדי לבצע חיפוש דמיון וקטורי
כדי להפעיל חיפוש סמנטי בצ'אטבוט שלנו, אנחנו צריכים ליצור הטמעות וקטוריות לסקירות של סרטים. ההטמעות האלה הופכות נתונים טקסטואליים לווקטורים מספריים שאפשר להשוות ביניהם כדי למצוא דמיון – כך הצ'אטבוט יכול לאחזר סרטים רלוונטיים גם אם השאילתה לא תואמת בדיוק לכותרת או לתיאור.

אפשרות 1: טעינת הטמעות שחושבו מראש באמצעות Cypher
כדי לצרף במהירות את ההטמעות לצמתי Movie המתאימים ב-Neo4j, מריצים את פקודת Cypher הבאה בדפדפן Neo4j:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
הפקודה הזו קוראת את וקטורי ההטמעה מקובץ ה-CSV ומצרפת אותם כמאפיין (m.embedding) לכל צומת Movie.
אפשרות 2: טעינת הטמעות באמצעות Python
אפשר גם לטעון את ההטמעות באופן פרוגרמטי באמצעות סקריפט Python שסופק. הגישה הזו שימושית אם אתם עובדים בסביבה שלכם או רוצים להפוך את התהליך לאוטומטי:
python load_embeddings.py
הסקריפט הזה קורא את אותו קובץ CSV מ-GCS וכותב את ההטמעות ל-Neo4j באמצעות מנהל ההתקן של Python Neo4j.
[אופציונלי] יצירת הטמעה בעצמכם (לניתוח)
אם אתם רוצים להבין איך נוצרים ההטמעות, תוכלו לעיין בלוגיקה של סקריפט generate_embeddings.py. הוא משתמש ב-Vertex AI כדי להטמיע כל טקסט של סקירת סרט באמצעות המודל text-embedding-004.
כדי לנסות בעצמכם, פותחים ומריצים את הקטע ליצירת הטמעה בקוד. אם אתם מריצים את הפקודה ב-Cloud Shell, אתם יכולים להוסיף הערה לשורה הבאה, כי Cloud Shell כבר מאומת דרך החשבון הפעיל שלכם:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
אחרי שההטמעות נטענות ל-Neo4j, גרף הידע של הסרט הופך למודע לסמנטיקה – מוכן לתמוך בחיפוש רב עוצמה בשפה טבעית באמצעות דמיון וקטורי!
7. צ'אט בוט להמלצות על סרטים
אחרי שיצרתם את גרף הידע ואת הטמעות הווקטורים, הגיע הזמן לשלב את הכול בממשק שיחה פונקציונלי לחלוטין – צ'אטבוט להמלצות על סרטים שמבוסס על AI גנרטיבי.
הצ'אטבוט הזה מיושם ב-Python באמצעות Gradio, מסגרת אינטרנט קלה ליצירת ממשקי משתמש אינטואיטיביים. הלוגיקה המרכזית נמצאת ב-app.py, שמתחבר למופע Neo4j AuraDB ומשתמש ב-Google Vertex AI וב-Gemini כדי לעבד שאילתות בשפה טבעית ולהגיב להן.
איך זה עובד
- המשתמש מקליד שאילתה בשפה טבעיתלמשל, "Recommend me sci-fi thrillers like Interstellar"
- יצירת הטמעה וקטורית לשאילתה באמצעות מודל
text-embedding-004של Vertex AI - ביצוע חיפוש וקטורי ב-Neo4j כדי לאחזר סרטים דומים מבחינה סמנטית
- אפשר להשתמש ב-Gemini כדי:
- פירוש השאילתה בהקשר
- יצירת שאילתת Cypher בהתאמה אישית על סמך תוצאות החיפוש הווקטורי וסכימת Neo4j
- מריצים את השאילתה כדי לחלץ נתונים קשורים של הגרף (לדוגמה, שחקנים, במאים, ז'אנרים)
- לסכם את התוצאות בצורה שיחתית למשתמש
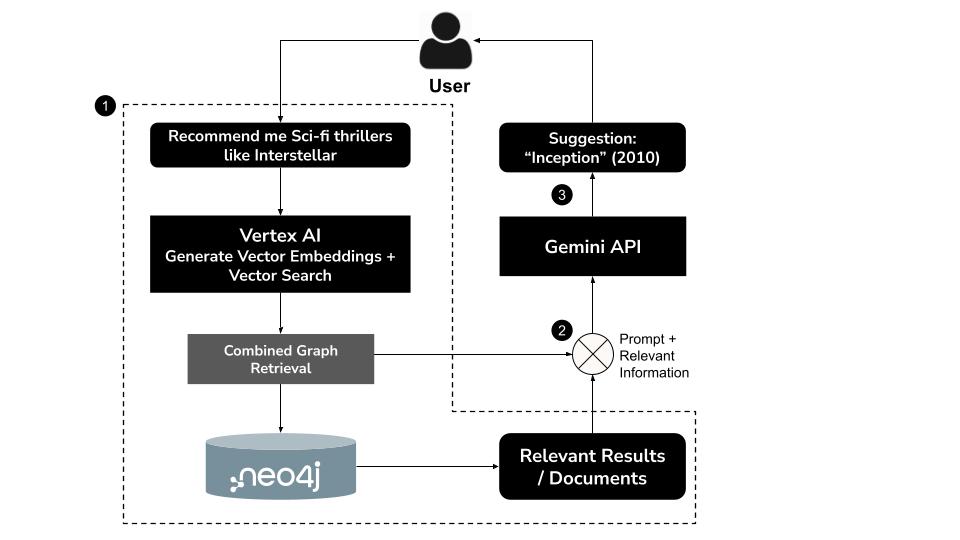
הגישה ההיברידית הזו, שנקראת GraphRAG (יצירה מוגברת באמצעות אחזור גרפים), משלבת אחזור סמנטי וחשיבה מובנית כדי להפיק המלצות מדויקות יותר, הקשריות יותר וקלות להסברה.
הפעלת הצ'אט בוט באופן מקומי
מפעילים את הסביבה הווירטואלית (אם היא לא פעילה כבר), ואז מפעילים את הצ'אטבוט באמצעות הפקודה:
python app.py
הפלט שיוצג אמור להיות דומה לזה שמופיע כאן:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 כדי לשתף את הצ'אטבוט עם אנשים מחוץ לארגון, צריך להגדיר את share=True בפונקציה launch() ב-app.py.
איך ליצור אינטראקציה עם הצ'אט בוט
פותחים את כתובת ה-URL המקומית שמוצגת בטרמינל (בדרך כלל 👉 http://0.0.0.0:8080) כדי לגשת לממשק של הצ'אטבוט.
אפשר לנסות לשאול שאלות כמו:
- "אילו סרטים כדאי לי לראות אם אהבתי את 'בין כוכבים'?"
- "תציע לי סרט רומנטי שביימה נורה אפרון"
- "אני רוצה לראות סרט משפחתי עם טום הנקס"
- "Find thriller movies involving artificial intelligence" (חיפוש סרטי מתח שקשורים לבינה מלאכותית)
הצ'אט בוט:
✅ הבנת השאילתה
✅ מציאת תקצירים של סרטים שדומים מבחינה סמנטית באמצעות הטמעות
✅ יצירה והרצה של שאילתת Cypher כדי לאחזר הקשר גרפי קשור
✅ להחזיר המלצה ידידותית ומותאמת אישית – והכול תוך שניות
מה שיש לך עכשיו
הרגע יצרתם צ'אט בוט לסרטים שמבוסס על GraphRAG ומשלב:
- חיפוש וקטורי לרלוונטיות סמנטית
- הסקת מסקנות מ-Knowledge Graph באמצעות Neo4j
- יכולות של מודלים גדולים של שפה (LLM) באמצעות Gemini
- ממשק צ'אט חלק עם Gradio
הארכיטקטורה הזו מהווה בסיס שאפשר להרחיב למערכות חיפוש מתקדם, המלצות או חשיבה רציונלית מתקדמות יותר שמבוססות על AI גנרטיבי.
8. (אופציונלי) פריסה ב-Google Cloud Run
אם רוצים להפוך את הצ'אטבוט להמלצות על סרטים לזמין לציבור, אפשר לפרוס אותו ב-Google Cloud Run – פלטפורמה ללא שרתים שמנוהלת באופן מלא, שמבצעת שינוי אוטומטי של קנה המידה של האפליקציה ומסתירה את כל בעיות התשתית.
הפריסה הזו משתמשת ב:
-
requirements.txt— כדי להגדיר יחסי תלות של Python (Neo4j, Vertex AI, Gradio וכו') -
Dockerfile– לאריזת האפליקציה -
.env.yaml— כדי להעביר משתני סביבה בצורה מאובטחת בזמן הריצה
שלב 1: הכנה .env.yaml
יוצרים קובץ בשם .env.yaml בספריית הבסיס עם תוכן כמו:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 הפורמט הזה מועדף על --set-env-vars כי הוא ניתן יותר להרחבה, קריא יותר וניתן לשליטה בגרסאות.
שלב 2: הגדרת משתני סביבה
במסוף, מגדירים את משתני הסביבה הבאים (מחליפים את ערכי שמירת המקום בהגדרות הפרויקט בפועל):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
שלב 2: יצירת Artifact Registry ובניית קונטיינר
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
הפקודה הזו אורזת את האפליקציה באמצעות Dockerfile ומעלה את קובץ האימג' של הקונטיינר אל Google Cloud Artifact Registry.
שלב 3: פריסה ב-Cloud Run
עכשיו פורסים את האפליקציה באמצעות הקובץ .env.yaml להגדרות בזמן הריצה:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
גישה לצ'אט בוט
אחרי הפריסה, Cloud Run יספק כתובת URL ציבורית כמו:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
פותחים את כתובת ה-URL הזו בדפדפן כדי לגשת לממשק הצ'אטבוט של Gradio שפרסתם – הוא מוכן לטפל בהמלצות לסרטים באמצעות GraphRAG, Gemini ו-Neo4j!
הערות וטיפים
- מוודאים ש-
Dockerfileפועלpip install -r requirements.txtבמהלך ה-build. - אם לא משתמשים ב-Cloud Shell, צריך לאמת את הסביבה באמצעות חשבון שירות עם הרשאות ל-Vertex AI ול-Artifact Registry.
- אפשר לעקוב אחרי יומני פריסה ומדדים מתוך מסוף Google Cloud > Cloud Run.
אפשר גם להיכנס אל Cloud Run דרך מסוף Google Cloud, ושם תופיע רשימת השירותים ב-Cloud Run. השירות movies-chatbot צריך להיות אחד מהשירותים (אם לא היחיד) שמופיעים שם.

כדי לראות את פרטי השירות כמו כתובת URL, הגדרות, יומנים ועוד, לוחצים על שם השירות הספציפי (movies-chatbot במקרה שלנו).

בשלב הזה, צ'אטבוט ההמלצות לסרטים מוכן לפריסה, ניתן להרחבה וניתן לשיתוף. 🎉
9. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם במאמר הזה:
- במסוף Google Cloud, עוברים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
10. מזל טוב
יצרתם ופרסתם בהצלחה צ'אטבוט להמלצות על סרטים שמבוסס על GraphRAG ומשופר על ידי AI גנרטיבי באמצעות Neo4j, Vertex AI ו-Gemini. שילוב היכולות של Neo4j ליצירת מודלים של גרפים עם חיפוש סמנטי באמצעות Vertex AI ועם חשיבה רציונלית בשפה טבעית באמצעות Gemini מאפשר ליצור מערכת חכמה שהיא יותר מחיפוש בסיסי – היא מבינה את כוונת המשתמש, מנתחת נתונים מקושרים ומגיבה בצורה שיחתית.
ב-Codelab הזה השלמתם את המשימות הבאות:
✅ בניית Knowledge Graph של סרטים מהעולם האמיתי ב-Neo4j כדי ליצור מודלים של סרטים, שחקנים, ז'אנרים ויחסים
✅ הטמעות וקטורים שנוצרו על ידי AI לסיכומי עלילה של סרטים באמצעות מודלים להטמעת טקסט של Vertex AI
✅ GraphRAG הוטמע, בשילוב של חיפוש וקטורי ושאילתות Cypher שנוצרו על ידי LLM, כדי להגיע למסקנות מעמיקות יותר שדורשות כמה שלבים
✅ Gemini משולב כדי לפרש שאלות של משתמשים, ליצור שאילתות Cypher ולסכם תוצאות של גרפים בשפה טבעית
✅ Created an intuitive chat interface using Gradio
✅ אופציונלי: פרסתם את הצ'אט בוט ב-Google Cloud Run לאירוח ניתן להרחבה בלי שרת (serverless)
מה השלב הבא?
הארכיטקטורה הזו לא מוגבלת להמלצות על סרטים – אפשר להרחיב אותה גם ל:
- פלטפורמות לגילוי ספרים ומוזיקה
- עוזרים למחקר אקדמי
- מערכות המלצות למוצרים
- עוזרים דיגיטליים עם ידע בתחומי הבריאות, הפיננסים והמשפט
בכל מקום שבו יש קשרים מורכבים + נתוני טקסט עשירים, השילוב הזה של גרפי ידע + מודלים גדולים של שפה (LLM) + הטמעות סמנטיות יכול להפעיל את הדור הבא של אפליקציות חכמות.
ככל שמודלים של AI גנרטיבי מולטי-מודאלי כמו Gemini מתפתחים, תוכלו לשלב הקשר עשיר יותר, תמונות, דיבור והתאמה אישית כדי לבנות מערכות שבאמת מתמקדות באדם.
כדאי להמשיך לחקור ולפתח, ולא לשכוח להתעדכן בחידושים האחרונים מ-Neo4j, מ-Vertex AI ומ-Google Cloud כדי לשדרג את האפליקציות החכמות שלכם! ב-Neo4j GraphAcademy יש עוד מדריכים מעשיים על תרשימי ידע.