
1. Обзор
В этом практическом занятии вы создадите интеллектуального чат-бота для рекомендаций фильмов, объединив возможности Neo4j, Google Vertex AI и Gemini. В основе этой системы лежит граф знаний Neo4j, который моделирует фильмы, актеров, режиссеров, жанры и многое другое с помощью разветвленной сети взаимосвязанных узлов и отношений.
Для улучшения пользовательского опыта за счет семантического понимания вы будете генерировать векторные представления на основе описаний сюжетов фильмов, используя модель text-embedding-004 (или более новую версию) от Vertex AI. Эти представления индексируются в Neo4j для быстрого поиска на основе сходства.
Наконец, вы интегрируете Gemini для создания разговорного интерфейса, в котором пользователи смогут задавать вопросы на естественном языке, например: «Что мне посмотреть, если мне понравился фильм «Интерстеллар»?», и получать персонализированные рекомендации фильмов на основе семантического сходства и контекста, основанного на графах.
В ходе выполнения практического задания вы будете использовать следующий пошаговый подход:
- Создайте граф знаний Neo4j с сущностями и связями, связанными с фильмами.
- Генерация/загрузка текстовых встраиваний для обзоров фильмов с помощью Vertex AI.
- Реализуйте интерфейс чат-бота Gradio на базе Gemini, который сочетает векторный поиск с выполнением шифров на основе графов.
- (Необязательно) Разверните приложение в Cloud Run как автономное веб-приложение.
Что вы узнаете
- Как создать и заполнить граф знаний о фильмах с помощью Cypher и Neo4j
- Как использовать Vertex AI для генерации и работы с семантическими векторными представлениями текста.
- Как объединить LLM-модели и графы знаний для интеллектуального поиска с помощью GraphRAG
- Как создать удобный интерфейс чата с помощью Gradio
- Как выполнить развертывание в Google Cloud Run (при необходимости).
Что вам понадобится
- Веб-браузер Chrome
- Аккаунт Gmail
- Проект Google Cloud с включенной функцией выставления счетов.
- Бесплатный аккаунт Neo4j Aura DB
- Базовые навыки работы с командами терминала и языком Python (желательно, но не обязательно).
Этот практический урок, разработанный для разработчиков всех уровней (включая начинающих), использует Python и Neo4j в качестве примера приложения. Хотя базовое знакомство с Python и графовыми базами данных может быть полезным, для понимания концепций и выполнения заданий не требуется никакого предварительного опыта.
2. Настройка Neo4j AuraDB
Neo4j — это ведущая нативная графовая база данных, которая хранит данные в виде сети узлов (сущностей) и отношений (связей между сущностями), что делает её идеальной для задач, где понимание связей имеет ключевое значение — например, для рекомендаций, обнаружения мошенничества, построения графов знаний и многого другого. В отличие от реляционных или документоориентированных баз данных, которые полагаются на жёсткие таблицы или иерархические структуры, гибкая графовая модель Neo4j позволяет интуитивно и эффективно представлять сложные, взаимосвязанные данные.
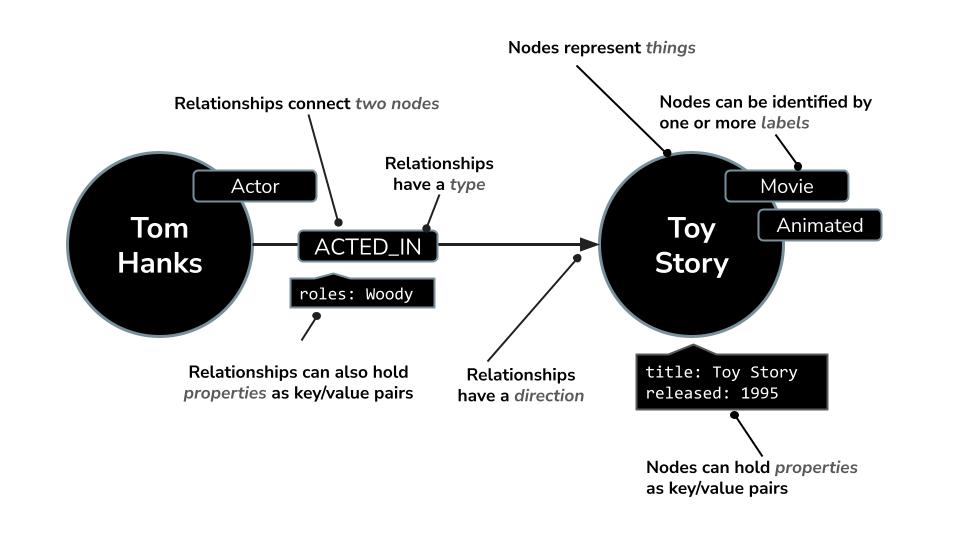
Вместо организации данных в строках и таблицах, как в реляционных базах данных, Neo4j использует графовую модель , где информация представлена в виде узлов (сущностей) и отношений (связей между этими сущностями). Эта модель делает ее исключительно интуитивно понятной для работы с данными, которые по своей природе связаны между собой — такими как люди, места, товары или, в нашем случае, фильмы, актеры и жанры.
Например, в наборе данных о фильмах:
- Узел может представлять собой
Movie,ActorилиDirector - Отношения могут быть
ACTED_INилиDIRECTED
Такая структура позволяет легко задавать вопросы, например:
- В каких фильмах снимался этот актёр?
- Кто работал с Кристофером Ноланом?
- Какие фильмы похожи по актерскому составу или жанру?
Neo4j поставляется с мощным языком запросов Cypher , разработанным специально для запросов к графам. Cypher позволяет выражать сложные шаблоны и связи в лаконичной и читаемой форме. Например: этот запрос Cypher использует MERGE для обеспечения уникального создания актера, фильма и их связи с деталями роли, избегая дубликатов.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j предлагает несколько вариантов развертывания в зависимости от ваших потребностей:
- Самостоятельное управление : запускайте Neo4j на собственной инфраструктуре, используя Neo4j Desktop или образ Docker (в локальной среде или в собственном облаке).
- Облачное управление : Развертывайте Neo4j на популярных облачных провайдерах, используя предложения из маркетплейса.
- Полностью управляемая база данных : используйте Neo4j AuraDB , полностью управляемую облачную базу данных как услугу от Neo4j, которая берет на себя выделение ресурсов, масштабирование, резервное копирование и обеспечение безопасности.
В этом практическом занятии мы будем использовать Neo4j AuraDB Free , бесплатный тарифный план AuraDB. Он предоставляет полностью управляемый экземпляр графовой базы данных с достаточным объемом хранилища и функциями для прототипирования, обучения и создания небольших приложений — идеально подходящий для нашей цели — создания чат-бота для рекомендаций фильмов на основе искусственного интеллекта.
В ходе этой лабораторной работы вы создадите бесплатный экземпляр AuraDB, подключите его к своему приложению, используя учетные данные, и будете использовать его для хранения и запроса данных из вашего графа знаний о фильмах.
Почему именно графики?
В традиционных реляционных базах данных ответы на вопросы типа «Какие фильмы похожи на «Начало» по общему актерскому составу или жанру?» потребовали бы сложных операций объединения (JOIN) между несколькими таблицами . По мере увеличения глубины связей производительность и читаемость ухудшаются.
Однако графовые базы данных, такие как Neo4j, созданы для эффективного перемещения по связям , что делает их идеальным решением для рекомендательных систем, семантического поиска и интеллектуальных помощников. Они помогают улавливать контекст реального мира — например, сети сотрудничества, сюжетные линии или предпочтения зрителей — который трудно представить с помощью традиционных моделей данных.
Объединив эти взаимосвязанные данные с LLM-системами, такими как Gemini, и векторными представлениями от Vertex AI , мы можем значительно улучшить работу чат-бота, позволив ему рассуждать, извлекать информацию и отвечать более персонализированным и релевантным образом.
Создание Neo4j AuraDB бесплатно
- Посетите https://console.neo4j.io
- Войдите в систему, используя свою учетную запись Google или адрес электронной почты.
- Нажмите «Создать бесплатный экземпляр».
- В процессе создания экземпляра базы данных появится всплывающее окно с учетными данными для подключения к ней.
Обязательно загрузите и надежно сохраните следующие данные из всплывающего окна — они необходимы для подключения вашего приложения к Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Эти значения вы будете использовать для настройки файла .env в вашем проекте для аутентификации с помощью Neo4j на следующем шаге.

Бесплатная версия Neo4j AuraDB отлично подходит для разработки, экспериментов и небольших приложений, таких как этот учебный курс. Она предлагает щедрые лимиты использования, поддерживая до 200 000 узлов и 400 000 связей . Хотя она предоставляет все необходимые функции для построения и запроса графа знаний, она не поддерживает расширенные конфигурации, такие как пользовательские плагины или увеличение объема хранилища. Для производственных нагрузок или больших наборов данных можно перейти на более высокий тарифный план AuraDB, который предлагает большую емкость, производительность и функции корпоративного уровня.
На этом завершается раздел по настройке бэкенда Neo4j AuraDB. На следующем шаге мы создадим проект в Google Cloud, клонируем репозиторий и настроим необходимые переменные среды, чтобы подготовить среду разработки перед началом работы над практическим заданием.
3. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud и поставляемую с предустановленным bq. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его настройки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API с помощью команды, указанной ниже. Это может занять несколько минут, поэтому, пожалуйста, наберитесь терпения.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
После успешного выполнения команды вы должны увидеть сообщение: « Операция .... успешно завершена».
Альтернативой команде gcloud является поиск каждого продукта в консоли или использование этой ссылки .
Если какой-либо API отсутствует, вы всегда можете включить его в процессе реализации.
Для получения информации о командах gcloud и их использовании обратитесь к документации .
Клонируйте репозиторий и настройте параметры среды.
Следующий шаг — клонирование репозитория с примерами кода, на который мы будем ссылаться в остальной части практического занятия. Предполагая, что вы находитесь в Cloud Shell, выполните следующую команду из своей домашней директории:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Чтобы запустить редактор, нажмите «Открыть редактор» на панели инструментов окна Cloud Shell. Щелкните строку меню в верхнем левом углу и выберите «Файл» → «Открыть папку», как показано ниже:

Выберите папку neo4j-vertexai-codelab , и вы увидите, что она открылась, и её структура будет примерно такой же, как показано ниже:

Далее нам нужно настроить переменные окружения, которые будут использоваться на протяжении всего практического занятия. Щелкните по файлу example.env , и вы увидите его содержимое, как показано ниже:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Теперь создайте новый файл с именем .env в той же папке, что и файл example.env , и скопируйте в него содержимое существующего файла example.env. Затем обновите следующие переменные:
-
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDиNEO4J_DATABASE: - Введите эти значения, используя учетные данные, предоставленные при создании бесплатного экземпляра Neo4j AuraDB на предыдущем шаге.
- В бесплатной версии AuraDB
NEO4J_DATABASEобычно устанавливается в значение neo4j. -
PROJECT_IDиLOCATION: - Если вы запускаете практическое занятие из Google Cloud Shell, вы можете оставить эти поля пустыми, поскольку они будут автоматически определены на основе конфигурации вашего активного проекта.
- Если вы работаете локально или вне Cloud Shell, обновите
PROJECT_ID, указав идентификатор проекта Google Cloud, созданного ранее, и установитеLOCATIONв регион, выбранный для этого проекта (например, us-central1).
После заполнения этих полей сохраните файл .env . Эта конфигурация позволит вашему приложению подключаться к сервисам Neo4j и Vertex AI.
Последний шаг в настройке среды разработки — создание виртуальной среды Python и установка всех необходимых зависимостей, перечисленных в файле requirements.txt . Эти зависимости включают библиотеки, необходимые для работы с Neo4j, Vertex AI, Gradio и другими.
Сначала создайте виртуальное окружение с именем .venv, выполнив следующую команду:
python -m venv .venv
После создания среды нам потребуется активировать её с помощью следующей команды.
source .venv/bin/activate
Теперь в начале командной строки терминала должно отображаться (.venv), указывающее на то, что среда активна. Например: (.venv) yourusername@cloudshell:
Теперь установите необходимые зависимости, выполнив команду:
pip install -r requirements.txt
Вот краткий обзор основных зависимостей, перечисленных в файле:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
После успешной установки всех зависимостей ваша локальная среда Python будет полностью настроена для запуска скриптов и чат-бота из этого практического задания.
Отлично! Теперь мы готовы перейти к следующему шагу — изучению набора данных и подготовке его к созданию графа и семантическому обогащению.
4. Подготовка набора данных «Фильмы»
Наша первая задача — подготовить набор данных о фильмах, который мы будем использовать для построения графа знаний и работы нашего чат-бота с рекомендациями. Вместо того чтобы начинать с нуля, мы воспользуемся существующим открытым набором данных и будем развивать его.
Мы используем набор данных The Movies Dataset от Рунака Баника, известный общедоступный набор данных, размещенный на Kaggle. Он включает метаданные для более чем 45 000 фильмов из TMDB, в том числе информацию об актерах, съемочной группе, ключевых словах, рейтингах и многом другом.

Для создания надежного и эффективного чат-бота для рекомендаций фильмов крайне важно начать с чистых, согласованных и структурированных данных. Хотя набор данных The Movies Dataset от Kaggle является богатым ресурсом, содержащим более 45 000 записей о фильмах и подробные метаданные, включая жанры, актерский состав, съемочную группу и многое другое, он также содержит шум, несоответствия и вложенные структуры данных, которые не идеально подходят для графового моделирования или семантического встраивания.
Для решения этой проблемы мы предварительно обработали и нормализовали набор данных , чтобы обеспечить его пригодность для построения графа знаний Neo4j и генерации высококачественных эмбеддингов. Этот процесс включал в себя:
- Удаление дубликатов и неполных записей.
- Стандартизация ключевых полей (например, названия жанров, имена людей).
- Преобразование сложных вложенных структур (например, актерский состав и съемочная группа) в структурированные CSV-файлы.
- Выбор репрезентативного подмножества из ~12 000 фильмов для соблюдения лимитов бесплатной версии Neo4j AuraDB.
Высококачественные, нормализованные данные помогают обеспечить:
- Качество данных : минимизирует ошибки и несоответствия для более точных рекомендаций.
- Производительность запросов : оптимизированная структура повышает скорость извлечения данных и уменьшает избыточность.
- Точность встраивания : Чистые входные данные приводят к более осмысленным и контекстуальным векторным представлениям.
Очищенный и нормализованный набор данных доступен в папке normalized_data/ этого репозитория GitHub. Этот набор данных также зеркалирован в хранилище Google Cloud Storage для удобного доступа в будущих скриптах Python.
После очистки и подготовки данных мы готовы загрузить их в Neo4j и начать построение графа знаний о фильмах.
5. Создайте граф знаний о фильмах.
Для работы нашего чат-бота по рекомендациям фильмов с поддержкой GenAI нам необходимо структурировать наш набор данных о фильмах таким образом, чтобы он отражал богатую сеть связей между фильмами, актерами, режиссерами, жанрами и другими метаданными. В этом разделе мы построим граф знаний о фильмах в Neo4j, используя очищенный и нормализованный набор данных, который вы подготовили ранее.
Мы воспользуемся функцией LOAD CSV в Neo4j для загрузки CSV-файлов, размещенных в общедоступном хранилище Google Cloud Storage (GCS). Эти файлы представляют различные компоненты набора данных о фильмах, такие как фильмы, жанры, актеры, съемочная группа, производственные компании и пользовательские рейтинги.
Шаг 1: Создание ограничений и индексов
Перед импортом данных рекомендуется создать ограничения и индексы для обеспечения целостности данных и оптимизации производительности запросов.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Шаг 2: Импорт метаданных и связей между фильмами
Давайте посмотрим, как импортировать метаданные фильмов с помощью команды LOAD CSV. В этом примере создаются узлы Movie с ключевыми атрибутами, такими как название, описание, язык и продолжительность:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Аналогичным образом, вы можете импортировать и связывать другие объекты, такие как жанры , производственные компании , языки вещания , страны , актерский состав , съемочная группа и пользовательские рейтинги, используя соответствующие CSV-файлы и запросы Cypher.
Загрузите полный график с помощью Python.
Вместо того чтобы вручную запускать множество запросов Cypher, мы рекомендуем использовать автоматизированный скрипт на Python, предоставленный в этом практическом задании.
Скрипт graph_build.py загружает весь набор данных из GCS в ваш экземпляр Neo4j AuraDB, используя учетные данные из вашего файла .env .
python graph_build.py
Скрипт последовательно загрузит все необходимые CSV-файлы, создаст узлы и связи, а также структурирует полный граф знаний о вашем фильме.
|
|

.png")
Проверьте свой график
После загрузки вы можете проверить свой график, запустив следующий скрипт:
python validate_graph.py
Это позволит вам быстро получить сводку о том, что находится на вашем графике: сколько фильмов, актеров, жанров и связей, таких как ACTED_IN, DIRECTED и т. д., присутствует — это подтвердит успешность импорта.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Теперь на вашем графике должны отобразиться фильмы, люди, жанры и многое другое — всё готово к семантическому обогащению на следующем шаге!
6. Сгенерируйте и загрузите векторные представления для выполнения поиска векторного сходства.
Для реализации семантического поиска в нашем чат-боте нам необходимо сгенерировать векторные представления для описаний фильмов. Эти представления преобразуют текстовые данные в числовые векторы, которые можно сравнивать на предмет сходства, что позволяет чат-боту находить релевантные фильмы, даже если запрос не соответствует точному названию или описанию.

Вариант 1: Загрузка предварительно вычисленных эмбеддингов с помощью Cypher.
Для быстрого добавления эмбеддингов к соответствующим узлам Movie в Neo4j выполните следующую команду Cypher в браузере Neo4j:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Эта команда считывает векторы встраивания из CSV-файла и добавляет их в качестве свойства ( m.embedding ) к каждому узлу Movie .
Вариант 2: Загрузка эмбеддингов с помощью Python
Вы также можете загрузить эмбеддинги программно, используя предоставленный скрипт на Python. Этот подход полезен, если вы работаете в своей собственной среде или хотите автоматизировать процесс:
python load_embeddings.py
Этот скрипт считывает тот же CSV-файл из GCS и записывает эмбеддинги в Neo4j, используя драйвер Neo4j на Python.
[Необязательно] Создайте собственные векторные представления (для исследования)
Если вам интересно понять, как генерируются эмбеддинги, вы можете изучить логику в самом скрипте generate_embeddings.py . Он использует Vertex AI для встраивания каждого текста обзора фильма с помощью модели text-embedding-004 .
Чтобы попробовать это самостоятельно, откройте и запустите раздел кода, отвечающий за генерацию встраивания. Если вы работаете в Cloud Shell, вы можете закомментировать следующую строку, поскольку Cloud Shell уже авторизован через вашу активную учетную запись:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
После загрузки векторных представлений в Neo4j ваш граф знаний о фильмах становится семантически корректным и готовым поддерживать мощный поиск на естественном языке с использованием векторного сходства!
7. Чат-бот для рекомендаций фильмов
Имея на руках граф знаний и векторные представления, пришло время объединить все это в полноценный разговорный интерфейс — ваш чат-бот для рекомендаций фильмов на основе искусственного интеллекта .
Этот чат-бот реализован на Python с использованием Gradio , легковесного веб-фреймворка для создания интуитивно понятных пользовательских интерфейсов. Основная логика находится в app.py , который подключается к вашему экземпляру Neo4j AuraDB и использует Google Vertex AI и Gemini для обработки и ответа на запросы на естественном языке.
Как это работает
- Пользователь вводит запрос на естественном языке, например: «Порекомендуйте мне научно-фантастические триллеры, похожие на «Интерстеллар»».
- Сгенерируйте векторное представление для запроса, используя модель
text-embedding-004от Vertex AI. - Выполните векторный поиск в Neo4j, чтобы найти семантически похожие фильмы.
- Используйте Gemini для:
- Интерпретируйте запрос в контексте.
- Сгенерируйте пользовательский запрос Cypher на основе результатов векторного поиска и схемы Neo4j.
- Выполните запрос для извлечения связанных данных графа (например, актеров, режиссеров, жанров).
- Кратко изложите результаты в разговорной форме для пользователя.
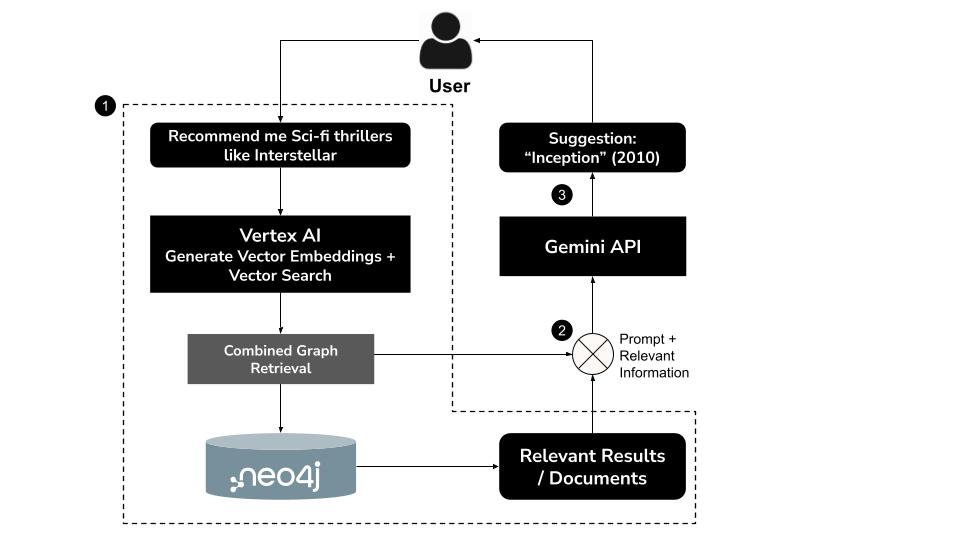
Этот гибридный подход, известный как GraphRAG (Graph Retrieval-Augmented Generation) , сочетает семантический поиск и структурированное рассуждение для получения более точных, контекстуальных и объяснимых рекомендаций.
Запустите чат-бота локально.
Активируйте свою виртуальную среду (если она еще не активирована), затем запустите чат-бота с помощью следующей команды:
python app.py
В результате вы должны увидеть сообщение, похожее на следующее:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Чтобы поделиться чат-ботом с внешними пользователями, установите share=True в функции launch() в app.py
Взаимодействуйте с чат-ботом.
Чтобы получить доступ к интерфейсу чат-бота, откройте локальный URL-адрес, отображаемый в вашем терминале (обычно 👉 http://0.0.0.0:8080 ).
Попробуйте задать такие вопросы:
- «Что мне посмотреть, если мне понравился фильм «Интерстеллар»?»
- «Предложите романтический фильм режиссера Норы Эфрон»
- «Я хочу посмотреть семейный фильм с Томом Хэнксом».
- «Найдите триллеры с участием искусственного интеллекта»
Чат-бот будет:
✅ Разберитесь в запросе
✅ Находите семантически похожие сюжеты фильмов с помощью векторных представлений.
✅ Сгенерируйте и выполните запрос Cypher для получения контекста связанного графа.
✅ Отправьте дружелюбную, персонализированную рекомендацию — всего за несколько секунд.
То, что у вас есть сейчас
Вы только что создали чат-бота для просмотра фильмов на базе GraphRAG , который объединяет в себе:
- Векторный поиск семантической релевантности
- Рассуждения на основе графа знаний с использованием Neo4j
- Возможности получения степени магистра права (LLM) через компанию Gemini.
- Удобный интерфейс чата с Gradio.
Эта архитектура закладывает основу для дальнейшего развития систем поиска, рекомендаций или логического мышления на базе искусственного интеллекта.
8. (Необязательно) Развертывание в Google Cloud Run
Если вы хотите сделать свой чат-бот для рекомендаций фильмов общедоступным, вы можете развернуть его на Google Cloud Run — полностью управляемой бессерверной платформе, которая автоматически масштабирует ваше приложение и абстрагирует от всех проблем, связанных с инфраструктурой.
В данной конфигурации используется:
-
requirements.txt— для определения зависимостей Python (Neo4j, Vertex AI, Gradio и т. д.) -
Dockerfile— для упаковки приложения. -
.env.yaml— для безопасной передачи переменных окружения во время выполнения.
Шаг 1: Подготовьте файл .env.yaml
Создайте в корневом каталоге файл с именем .env.yaml , содержащий следующее:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Этот формат предпочтительнее, чем --set-env-vars поскольку он более масштабируем, позволяет контролировать версии и лучше читается.
Шаг 2: Настройка переменных среды
В терминале установите следующие переменные среды (замените значения-заполнители фактическими настройками вашего проекта):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Шаг 2: Создайте реестр артефактов и соберите контейнер.
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Эта команда упаковывает ваше приложение с помощью Dockerfile и загружает образ контейнера в реестр артефактов Google Cloud.
Шаг 3: Развертывание в Cloud Run
Теперь разверните приложение, используя файл .env.yaml для настройки во время выполнения:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Воспользуйтесь чат-ботом
После развертывания Cloud Run предоставит общедоступный URL-адрес, например:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Откройте этот URL-адрес в браузере, чтобы получить доступ к развернутому интерфейсу чат-бота Gradio, готовому к предоставлению рекомендаций фильмов с использованием GraphRAG, Gemini и Neo4j!
Примечания и советы
- Убедитесь, что в вашем
Dockerfileво время сборки выполняетсяpip install -r requirements.txt. - Если вы не используете Cloud Shell , вам потребуется аутентифицировать свою среду, используя учетную запись службы с правами доступа к Vertex AI и реестру артефактов.
- Отслеживать журналы развертывания и метрики можно в консоли Google Cloud > Cloud Run .
Вы также можете перейти в Cloud Run из консоли Google Cloud и увидеть список сервисов в Cloud Run. Сервис movies-chatbot должен быть одним из перечисленных (если не единственным).

Вы можете просмотреть подробную информацию о сервисе, такую как URL-адрес, конфигурации, журналы и многое другое, щелкнув по названию конкретного сервиса (в нашем случае movies-chatbot ).

Таким образом, ваш чат-бот для рекомендаций фильмов теперь развернут, масштабируем и доступен для совместного использования . 🎉
9. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой статье, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
10. Поздравляем!
Вы успешно создали и развернули чат-бот для рекомендаций фильмов на базе GraphRAG с поддержкой GenAI, используя Neo4j , Vertex AI и Gemini . Объединив возможности моделирования графов Neo4j с семантическим поиском с помощью Vertex AI и рассуждениями на естественном языке с помощью Gemini, вы создали интеллектуальную систему, которая выходит за рамки базового поиска — она понимает намерения пользователя , рассуждает на основе связанных данных и отвечает в разговорном стиле .
В этом практическом задании вы выполнили следующие действия:
✅ Создал в Neo4j граф знаний о реальных фильмах для моделирования киноиндустрии, актеров, жанров и взаимосвязей.
✅ Созданы векторные представления для описания сюжетов фильмов с использованием моделей векторного представления текста от Vertex AI.
✅ Реализована технология GraphRAG , объединяющая векторный поиск и запросы Cypher, сгенерированные LLM, для более глубокого многошагового анализа.
✅ Интегрированная система Gemini для интерпретации вопросов пользователей, генерации запросов Cypher и обобщения результатов графов на естественном языке.
✅ Создан интуитивно понятный интерфейс чата с использованием Gradio.
✅ При желании вы можете развернуть своего чат-бота в Google Cloud Run для масштабируемого бессерверного хостинга.
Что дальше?
Данная архитектура не ограничивается рекомендациями фильмов — её можно расширить следующим образом:
- Платформы для поиска книг и музыки
- Научные сотрудники
- Системы рекомендаций товаров
- Помощники в области здравоохранения, финансов и права.
Везде, где присутствуют сложные взаимосвязи и богатые текстовые данные , это сочетание графов знаний, LLM-моделей и семантических вложений может стать основой для интеллектуальных приложений нового поколения.
По мере развития мультимодальных моделей искусственного интеллекта, таких как Gemini, вы сможете включать в них еще более богатый контекст, изображения, речь и персонализацию для создания по-настоящему человекоцентричных систем.
Продолжайте исследовать, продолжайте создавать — и не забывайте быть в курсе последних новостей от Neo4j , Vertex AI и Google Cloud , чтобы вывести ваши интеллектуальные приложения на новый уровень! Больше практических руководств по графам знаний вы найдете на Neo4j GraphAcademy .