
1. Présentation
Cloud Dataproc est un service géré Spark et Hadoop qui vous permet de bénéficier d'outils de données Open Source pour le traitement par lot, l'émission de requêtes, le streaming et le machine learning. L'automatisation Cloud Dataproc vous permet de créer des clusters rapidement, de les gérer facilement et de faire des économies en désactivant ceux que vous n'utilisez plus. Vous consacrez moins de temps et d'argent aux fonctions d'administration, ce qui vous permet de vous concentrer sur les tâches et les données.
Ce tutoriel est adapté de https://cloud.google.com/dataproc/overview.
Points abordés
- Créer un cluster Cloud Dataproc géré (avec Apache Spark préinstallé)
- Envoyer une tâche Spark
- Redimensionner un cluster
- Se connecter en SSH au nœud maître d'un cluster Dataproc
- Utiliser gcloud pour examiner les clusters, les jobs et les règles de pare-feu
- Arrêter votre cluster
Prérequis
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec les services Google Cloud Platform ?
2. Préparation
Configuration de l'environnement d'auto-formation
- Connectez-vous à Cloud Console, puis créez un projet ou réutilisez un projet existant. (Si vous n'avez pas encore de compte Gmail ou G Suite, vous devez en créer un.)



Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
- Vous devez ensuite activer la facturation dans Cloud Console pour pouvoir utiliser les ressources Google Cloud.
L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Veillez à suivre les instructions de la section "Nettoyer" qui indique comment désactiver les ressources afin d'éviter les frais une fois ce tutoriel terminé. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
3. Activer les API Cloud Dataproc et Google Compute Engine
Cliquez sur l'icône de menu en haut à gauche de l'écran.

Sélectionnez "API Manager" dans le menu déroulant.

Cliquez sur Activer les API et les services.

Saisissez "Compute Engine" dans le champ de recherche. Cliquez sur "API Google Compute Engine" dans la liste des résultats qui s'affiche.

Sur la page Google Compute Engine, cliquez sur Activer.

Une fois l'option activée, cliquez sur la flèche pointant vers la gauche pour revenir en arrière.
Recherchez ensuite "API Google Cloud Dataproc" et activez-la également.

4. Démarrer Cloud Shell
Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Cela signifie que tout ce dont vous avez besoin pour cet atelier de programmation est un navigateur (oui, tout fonctionne sur un Chromebook).
- Pour activer Cloud Shell à partir de Cloud Console, cliquez simplement sur Activer Cloud Shell
(l'opération de provisionnement et la connexion à l'environnement ne devraient prendre que quelques minutes).
Une fois connecté à Cloud Shell, vous êtes normalement déjà authentifié et le projet PROJECT_ID est sélectionné :
gcloud auth list
Résultat de la commande
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si, pour une raison quelconque, le projet n'est pas défini, exécutez simplement la commande suivante :
gcloud config set project <PROJECT_ID>
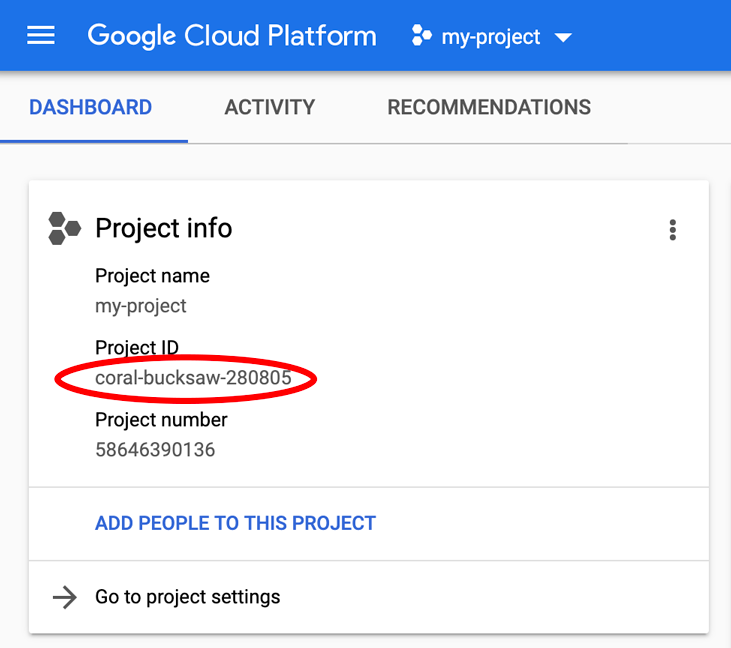
Vous recherchez votre PROJECT_ID ? Vérifiez l'ID que vous avez utilisé pendant les étapes de configuration ou recherchez-le dans le tableau de bord Cloud Console :
Par défaut, Cloud Shell définit certaines variables d'environnement qui pourront s'avérer utiles pour exécuter certaines commandes dans le futur.
echo $GOOGLE_CLOUD_PROJECT
Résultat de la commande
<PROJECT_ID>
- Pour finir, définissez la configuration du projet et de la zone par défaut :
gcloud config set compute/zone us-central1-f
Vous pouvez choisir parmi différentes zones. Pour en savoir plus, consultez la page Régions et zones.
5. Créer un cluster Cloud Dataproc
Une fois Cloud Shell lancé, vous pouvez utiliser la ligne de commande pour appeler la commande gcloud du SDK Cloud ou d'autres outils disponibles sur l'instance de machine virtuelle.
Choisissez un nom de cluster à utiliser dans cet atelier :
$ CLUSTERNAME=${USER}-dplab
Commençons par créer un cluster :
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
Les paramètres de cluster par défaut prévoient deux nœuds de calcul, ce qui devrait suffire pour ce tutoriel. La commande ci-dessus inclut l'option --zone pour spécifier la zone géographique dans laquelle le cluster sera créé, ainsi que deux options avancées, --scopes et --tags, qui sont expliquées ci-dessous lorsque vous utilisez les fonctionnalités qu'elles activent. Consultez la commande gcloud dataproc clusters create du SDK Cloud pour en savoir plus sur l'utilisation des indicateurs de ligne de commande pour personnaliser les paramètres de cluster.
6. Envoyer un job Spark à votre cluster
Vous pouvez envoyer un job via une requête jobs.submit de l'API Cloud Dataproc, à l'aide de l'outil de ligne de commande gcloud ou à partir de la console Google Cloud Platform. Vous pouvez également vous connecter à une instance de machine de votre cluster à l'aide de SSH, puis exécuter un job à partir de l'instance.
Envoyons un job à l'aide de l'outil gcloud depuis la ligne de commande Cloud Shell :
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
Au fur et à mesure de l'exécution du job, vous verrez le résultat dans la fenêtre Cloud Shell.
Interrompez la sortie en saisissant Ctrl+C. La commande gcloud sera alors arrêtée, mais le job continuera de s'exécuter sur le cluster Dataproc.
7. Lister les jobs et se reconnecter
Imprimer une liste de tâches :
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
La tâche la plus récemment envoyée figure en haut de la liste. Copiez l'ID du job et collez-le à la place de jobId dans la commande ci-dessous. La commande se reconnecte au job spécifié et affiche son résultat :
$ gcloud dataproc jobs wait jobId
Une fois le job terminé, le résultat inclut une approximation de la valeur de Pi.

8. Redimensionner le cluster
Pour exécuter des calculs plus importants, vous pouvez ajouter des nœuds à votre cluster afin de l'accélérer. Dataproc vous permet d'ajouter ou de supprimer des nœuds de votre cluster à tout moment.
Examinez la configuration du cluster :
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Agrandissez le cluster en ajoutant des nœuds préemptifs :
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Examinez à nouveau le cluster :
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Notez qu'en plus de workerConfig provenant de la description du cluster d'origine, il existe désormais un secondaryWorkerConfig qui inclut deux instanceNames pour les nœuds de calcul préemptifs. Dataproc indique que l'état du cluster est "Prêt" pendant le démarrage des nouveaux nœuds.
Comme vous avez commencé avec deux nœuds et que vous en avez maintenant quatre, vos jobs Spark devraient s'exécuter environ deux fois plus vite.
9. Se connecter en SSH au cluster
Connectez-vous via SSH au nœud maître, dont le nom d'instance est toujours le nom du cluster avec -m ajouté :
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
La première fois que vous exécutez une commande ssh sur Cloud Shell, des clés ssh sont générées pour votre compte. Vous pouvez choisir une phrase secrète ou utiliser une phrase secrète vide pour le moment et la modifier ultérieurement à l'aide de ssh-keygen, si vous le souhaitez.
Sur l'instance, vérifiez le nom d'hôte :
$ hostname
Comme vous avez spécifié --scopes=cloud-platform lorsque vous avez créé le cluster, vous pouvez exécuter des commandes gcloud sur votre cluster. Affichez la liste des clusters de votre projet :
$ gcloud dataproc clusters list
Déconnectez-vous de la connexion SSH lorsque vous avez terminé :
$ logout
10. Examiner les balises
Lorsque vous avez créé votre cluster, vous avez inclus une option --tags pour ajouter un tag à chaque nœud du cluster. Les tags permettent d'associer des règles de pare-feu à chaque nœud. Vous n'avez créé aucune règle de pare-feu correspondante dans cet atelier de programmation, mais vous pouvez toujours examiner les tags sur un nœud et les règles de pare-feu sur le réseau.
Imprimez la description du nœud maître :
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Recherchez tags: vers la fin du résultat et vérifiez qu'il inclut codelab.
Imprimez les règles de pare-feu :
$ gcloud compute firewall-rules list
Notez les colonnes SRC_TAGS et TARGET_TAGS. En associant un tag à une règle de pare-feu, vous pouvez spécifier qu'elle doit être utilisée sur tous les nœuds qui possèdent ce tag.
11. Arrêter votre cluster
Vous pouvez arrêter un cluster via une requête clusters.delete de l'API Cloud Dataproc, à partir de la ligne de commande à l'aide de l'exécutable gcloud dataproc clusters delete ou à partir de la console Google Cloud Platform.
Arrêtons le cluster à l'aide de la ligne de commande Cloud Shell :
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. Félicitations !
Vous avez appris à créer un cluster Dataproc, à envoyer un job Spark, à redimensionner un cluster, à utiliser SSH pour vous connecter à votre nœud maître, à utiliser gcloud pour examiner les clusters, les jobs et les règles de pare-feu, et à arrêter votre cluster à l'aide de gcloud.
En savoir plus
- Documentation Dataproc : https://cloud.google.com/dataproc/overview
- Atelier de programmation Premiers pas avec Dataproc à l'aide de la console
Licence
Ce contenu est concédé sous licence Creative Commons Attribution 3.0 Generic et Apache 2.0.