
1. 概览
Cloud Dataproc 是一项托管式 Spark 和 Hadoop 服务,可让您充分利用开源数据工具来执行批处理、查询、流式传输和机器学习。Cloud Dataproc 自动化功能可帮助您快速创建集群并轻松管理,以及在不需要集群时将其关闭以节省费用。由于花在管理上的时间和费用减少,您可以将精力集中在实际的工作和数据上。
本教程改编自 https://cloud.google.com/dataproc/overview
学习内容
- 如何创建托管式 Cloud Dataproc 集群(预安装 Apache Spark)。
- 如何提交 Spark 作业
- 如何调整集群大小
- 如何通过 SSH 连接到 Dataproc 集群的主节点
- 如何使用 gcloud 检查集群、作业和防火墙规则
- 如何关闭集群
所需条件
您将如何使用本教程?
您如何评价自己在使用 Google Cloud Platform 服务方面的经验水平?
2. 设置和要求
自定进度的环境设置



请记住项目 ID,它在所有 Google Cloud 项目中都是唯一的名称(上述名称已被占用,您无法使用,抱歉!)。它稍后将在此 Codelab 中被称为 PROJECT_ID。
- 接下来,您需要在 Cloud 控制台中启用结算功能,才能使用 Google Cloud 资源。
运行此 Codelab 应该不会产生太多的费用(如果有费用的话)。请务必按照“清理”部分中的所有说明操作,该部分介绍了如何关停资源,以免产生超出本教程范围的结算费用。Google Cloud 的新用户符合参与 $300 USD 免费试用计划的条件。
3. 启用 Cloud Dataproc 和 Google Compute Engine API
点击屏幕左上角的菜单图标。

从下拉菜单中选择“API 管理器”。

点击启用 API 和服务。

在搜索框中搜索“Compute Engine”。在显示的搜索结果列表中,点击“Google Compute Engine API”。

在 Google Compute Engine 页面上,点击启用

启用后,点击指向左侧的箭头返回。
现在,搜索“Google Cloud Dataproc API”,然后也启用它。

4. 启动 Cloud Shell
基于 Debian 的这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证。这意味着在本 Codelab 中,您只需要一个浏览器(没错,它适用于 Chromebook)。
- 如需从 Cloud Console 激活 Cloud Shell,只需点击激活 Cloud Shell
(预配和连接到环境仅需花费一些时间)。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的 PROJECT_ID。
gcloud auth list
命令输出
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
如果出于某种原因未设置项目,只需发出以下命令即可:
gcloud config set project <PROJECT_ID>
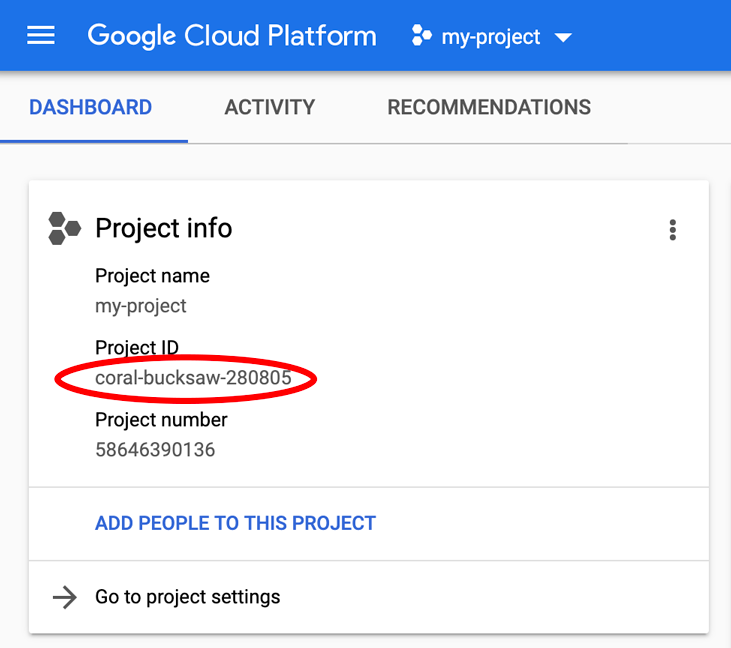
正在查找您的 PROJECT_ID?检查您在设置步骤中使用的 ID,或在 Cloud Console 信息中心查找该 ID:
默认情况下,Cloud Shell 还会设置一些环境变量,这对您日后运行命令可能会很有用。
echo $GOOGLE_CLOUD_PROJECT
命令输出
<PROJECT_ID>
- 最后,设置默认可用区和项目配置。
gcloud config set compute/zone us-central1-f
您可以选择各种不同的可用区。如需了解详情,请参阅区域和可用区。
5. 创建 Cloud Dataproc 集群
启动 Cloud Shell 后,您可以使用命令行来调用 Cloud SDK gcloud 命令或该虚拟机实例上提供的其他工具。
选择要在本实验中使用的集群名称:
$ CLUSTERNAME=${USER}-dplab
我们先创建一个新集群:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
包含两个工作器节点的默认集群设置应足以满足本教程的需求。上述命令包含 --zone 选项,用于指定将创建集群的地理可用区;还包含两个高级选项 --scopes 和 --tags,下面将介绍使用这两个选项启用的功能。如需了解如何使用命令行标志自定义集群设置,请参阅 Cloud SDK gcloud dataproc clusters create 命令。
6. 将 Spark 作业提交到集群
您可以通过 Cloud Dataproc API jobs.submit 请求、使用 gcloud 命令行工具或通过 Google Cloud Platform Console 提交作业。您还可以使用 SSH 连接到集群中的机器实例,然后从该实例运行作业。
我们来使用 Cloud Shell 命令行中的 gcloud 工具提交作业:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
作业运行时,您会在 Cloud Shell 窗口中看到输出。
输入 Control-C 以中断输出。这会停止 gcloud 命令,但作业仍会在 Dataproc 集群上运行。
7. 列出作业并重新连接
打印作业列表:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
最近提交的作业位于列表顶部。复制作业 ID,并将其粘贴到以下命令中的“jobId”位置。该命令将重新连接到指定作业并显示其输出:
$ gcloud dataproc jobs wait jobId
作业完成后,输出将包含 Pi 值的近似值。

8. 调整集群大小
如需运行更大型的计算任务,您可能需要向集群添加更多节点以加快速度。Dataproc 可让您随时向集群添加节点或从中移除节点。
检查集群配置:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
通过添加一些可抢占节点来扩大集群规模:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
再次检查集群:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
请注意,除了原始集群说明中的 workerConfig 之外,现在还有一个 secondaryWorkerConfig,其中包含两个抢占式工作器的 instanceNames。在启动新节点时,Dataproc 会将集群状态显示为“就绪”。
由于您最初使用了两个节点,现在使用了四个节点,因此 Spark 作业的运行速度应该会快一倍左右。
9. 通过 SSH 连接到集群
通过 SSH 连接到主节点,其实例名称始终是集群名称,后跟 -m:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
您首次在 Cloud Shell 上运行 ssh 命令时,系统会为您的账号生成 SSH 密钥。您可以选择口令,也可以暂时使用空白口令,日后如果需要,可以使用 ssh-keygen 更改口令。
在实例上,检查主机名:
$ hostname
由于您在创建集群时指定了 --scopes=cloud-platform,因此可以在集群上运行 gcloud 命令。列出项目中的集群:
$ gcloud dataproc clusters list
完成后,退出 SSH 连接:
$ logout
10. 检查代码
您在创建集群时添加了 --tags 选项,以便为集群中的每个节点添加标记。标记用于将防火墙规则附加到每个节点。您在本 Codelab 中未创建任何匹配的防火墙规则,但仍可以检查节点上的标记和网络上的防火墙规则。
打印主节点的说明:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
在输出的末尾附近查找 tags:,并查看其中是否包含 codelab。
打印防火墙规则:
$ gcloud compute firewall-rules list
请注意 SRC_TAGS 和 TARGET_TAGS 列。通过将标记附加到防火墙规则,您可以指定该规则应应用于具有该标记的所有节点。
11. 关闭集群
您可以通过 Cloud Dataproc API clusters.delete 请求、从命令行使用 gcloud dataproc clusters delete 可执行文件或通过 Google Cloud Platform Console 关闭集群。
我们来使用 Cloud Shell 命令行关停集群:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. 恭喜!
您学习了如何创建 Dataproc 集群、提交 Spark 作业、调整集群大小、使用 SSH 登录到主节点、使用 gcloud 检查集群、作业和防火墙规则,以及使用 gcloud 关闭集群!
了解详情
- Dataproc 文档:https://cloud.google.com/dataproc/overview
- 使用控制台开始使用 Dataproc Codelab
许可
此作品已获得 知识共享署名 3.0 通用许可和 Apache 2.0 许可授权。